#CodeLlama
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr has 4 main sources of revenue.
Text
ROCm 6.1.3 With AMD Radeon PRO GPUs For LLM Inference

ROCm 6.1.3 Software with AMD Radeon PRO GPUs for LLM inference.
AMD Pro Radeon
Large Language Models (LLMs) are no longer limited to major businesses operating cloud-based services with specialized IT teams. New open-source LLMs like Meta’s Llama 2 and 3, including the recently released Llama 3.1, when combined with the capability of AMD hardware allow even small organizations to execute their own customized AI tools locally, on regular desktop workstations, eliminating the need to keep sensitive data online.
AMD Radeon PRO W7900
Workstation GPUs like the new AMD Radeon PRO W7900 Dual Slot offer industry-leading performance per dollar with Llama, making it affordable for small businesses to run custom chatbots, retrieve technical documentation, or create personalized sales pitches. The more specialized Code Llama models allow programmers to generate and optimize code for new digital products. These GPUs are equipped with dedicated AI accelerators and enough on-board memory to run even the larger language models.Image Credit To AMD
And now that AI tools can be operated on several Radeon PRO GPUs thanks to ROCm 6.1.3, the most recent edition of AMD’s open software stack, SMEs and developers can support more users and bigger, more complicated LLMs than ever before.
LLMs’ new applications in enterprise AI
The prospective applications of artificial intelligence (AI) are much more diverse, even if the technology is commonly used in technical domains like data analysis and computer vision and generative AI tools are being embraced by the design and entertainment industries.
With the help of specialized LLMs, such as Meta’s open-source Code Llama, web designers, programmers, and app developers can create functional code in response to straightforward text prompts or debug already-existing code bases. Meanwhile, Llama, the parent model of Code Llama, has a plethora of potential applications for “Enterprise AI,” including product personalization, customer service, and information retrieval.
Although pre-made models are designed to cater to a broad spectrum of users, small and medium-sized enterprises (SMEs) can leverage retrieval-augmented generation (RAG) to integrate their own internal data, such as product documentation or customer records, into existing AI models. This allows for further refinement of the models and produces more accurate AI-generated output that requires less manual editing.
How may LLMs be used by small businesses?
So what use may a customized Large Language Model have for a SME? Let’s examine a few instances. Through the use of an LLM tailored to its own internal data:
Even after hours, a local retailer may utilize a chatbot to respond to consumer inquiries.
Helpline employees may be able to get client information more rapidly at a bigger shop.
AI features in a sales team’s CRM system might be used to create customized customer pitches.
Complex technological items might have documentation produced by an engineering company.
Contract drafts might be first created by a solicitor.
A physician might capture information from patient calls in their medical records and summarize the conversations.
Application forms might be filled up by a mortgage broker using information from customers’ papers.
For blogs and social media postings, a marketing firm may create specialized text.
Code for new digital items might be created and optimized by an app development company.
Online standards and syntactic documentation might be consulted by a web developer.
That’s simply a small sample of the enormous potential that exists in enterprise artificial intelligence.
Why not use the cloud for running LLMs?
While there are many cloud-based choices available from the IT sector to implement AI services, small companies have many reasons to host LLMs locally.
Data safety
Predibase research indicates that the main barrier preventing businesses from using LLMs in production is their apprehension about sharing sensitive data. Using AI models locally on a workstation eliminates the need to transfer private customer information, code, or product documentation to the cloud.
Reduced latency
In use situations where rapid response is critical, such as managing a chatbot or looking up product documentation to give real-time assistance to clients phoning a helpline, running LLMs locally as opposed to on a distant server minimizes latency.
More command over actions that are vital to the purpose
Technical personnel may immediately fix issues or release upgrades by executing LLMs locally, eliminating the need to wait on a service provider situated in a different time zone.
The capacity to sandbox test instruments
IT teams may test and develop new AI technologies before implementing them widely inside a company by using a single workstation as a sandbox.Image Credit To AMD
AMD GPUs
How can small businesses use AMD GPUs to implement LLMs?
Hosting its own unique AI tools doesn’t have to be a complicated or costly enterprise for a SME since programs like LM Studio make it simple to run LLMs on desktop and laptop computers that are commonly used with Windows. Retrieval-augmented generation may be easily enabled to tailor the result, and LM Studio can use the specialized AI Accelerators in modern AMD graphics cards to increase speed since it is designed to operate on AMD GPUs via the HIP runtime API.
AMD Radeon Pro
While consumer GPUs such as the Radeon RX 7900 XTX have enough memory to run smaller models, such as the 7-billion-parameter Llama-2-7B, professional GPUs such as the 32GB Radeon PRO W7800 and 48GB Radeon PRO W7900 have more on-board memory, which allows them to run larger and more accurate models, such as the 30-billion-parameter Llama-2-30B-Q8.Image Credit To AMD
Users may host their own optimized LLMs directly for more taxing activities. A Linux-based system with four Radeon PRO W7900 cards could be set up by an IT department within an organization to handle requests from multiple users at once thanks to the latest release of ROCm 6.1.3, the open-source software stack of which HIP is a part.
In testing using Llama 2, the Radeon PRO W7900’s performance-per-dollar surpassed that of the NVIDIA RTX 6000 Ada Generation, the current competitor’s top-of-the-range card, by up to 38%. AMD hardware offers unmatched AI performance for SMEs at an unbelievable price.
A new generation of AI solutions for small businesses is powered by AMD GPUs
Now that the deployment and customization of LLMs are easier than ever, even small and medium-sized businesses (SMEs) may operate their own AI tools, customized for a variety of coding and business operations.
Professional desktop GPUs like the AMD Radeon PRO W7900 are well-suited to run open-source LLMs like Llama 2 and 3 locally, eliminating the need to send sensitive data to the cloud, because of their large on-board memory capacity and specialized AI hardware. And for a fraction of the price of competing solutions, companies can now host even bigger AI models and serve more users thanks to ROCm, which enables inferencing to be shared over many Radeon PRO GPUs.
Read more on govindhtech.com
#ROCm613#AMDRadeonPRO#gpu#LLMInference#MetaLlama2#AMDRadeonPROW7900#CodeLlama#generativeAI#retrievalaugmentedgeneration#RAG#llm#artificialintelligence#chatbot#LMStudio#RadeonRX7900XTX#optimizedLLM#likeLlama#NVIDIARTX6000#technology#technews#news#govindhtech
0 notes
Text
日本語版CodeLlama
2つ前の投稿でCode Llamaを使った簡単なWebアプリケーションをモノづくり塾のサーバーにデプロイした話を書きましたが、ELYZAさんが日本語で追加学習したモデルを公開したので簡単なアプリケーションをStreamlitで作って載せ替えました。 なかなか良い感じです。 例によってGPU非搭載のサーバーなのでLlamaCppを使ってCPUで動かしています。 塾の建設が終わってひと段落ついて予算に余裕があればこのサーバーにも16GB程度のメモリーを持つGPUを載せます。推論を実行するだけならそれくらいのものが載ればそこそこ使えるはずです。

View On WordPress
0 notes
Text
I haven't seen posts about this today, but DeepSeek-Coder is the model if anyone wants to play with it. It's easily the funniest thing to happen in the ML research sphere in the last 12 months.
No time for a huge post on why but tl;dr: GPT4 is a giant fuck-off model that takes assloads of resources to run and can do decent code/formatting-related tasks. Tons of people pay for access solely for that functionality.
The previous consumer-favorite model CodeLlama laser-focuses solely on the code-formatting tasks. It can't play D&D with you or write bad poetry and will never be able to because the *only* thing it's ever seen has been code and as such it's very small, specialized and can run on consumer hardware (you can run this right now for free in about 10 minutes of setup if you've got a 2060 or above). For the last year or so anyone doing code cleanup/documenting has probably used CodeLlama a ton because it's absolutely great at cleaning things up without changing their meaning. It can write out busywork code that any programmer can type by rote from muscle memory but isn't smart enough to solve problems. Great tool, highly recommended.
But now, we've got DeepSeek which is absolutely huge and intended to be ran by college campuses and such. It's as good as GPT4 but still only cares about code, which makes it small enough that it runs on eight 80GB GPUs. This sounds like a lot but throw one instance on a college server and you've got an entire campus being served locally by a system that uses around the power draw of an average small space heater, at a cost of around 20K total investment. It kicks ass, nobody has to pay exorbitant fees to OpenAI anymore just for decent code-formatting LLM access.
There is something deliciously funny about AI getting replaced by AI.
tl;dr: China yeeted a cheaper, faster, less environmental impact making, open source LLM model onto the market and US AI companies lost nearly 600 billions in value since yesterday.
Silicone Valley is having a meltdown.
And ChatGTP just lost its job to AI~.
27K notes
·
View notes
Text
Amusing LLM Moment
I was recently playing with the Q8 32B codellama model. It turned out to be a recalcitrant and judgmental disaster that told me to take a flying leap when I asked it to write some code. The exchange was hilarious, but it makes me wonder what are they training this thing on that it would output such things?
0 notes
Text
https://uknumber.store/france-phone-data
的效能,不包括 CodeLlama 70B 或 Llama 3 70B 的數據。這限制了 Codestral 相對於其他模型的性能的比較和結論的範圍。 人類評估 HumanEval 測試透過測試模型產生透過基於函數描述的人工編寫的單元測試的程式
0 notes
Text
https://uknumber.store/france-phone-data
的效能,不包括 CodeLlama 70B 或 Llama 3 70B 的數據。這限制了 Codestral 相對於其他模型的性能的比較和結論的範圍。 人類評估 HumanEval 測試透過測試模型產生透過基於函數描述的人工編寫的單元測試的程式
0 notes
Text
https://uknumber.store/france-phone-data
的效能,不包括 CodeLlama 70B 或 Llama 3 70B 的數據。這限制了 Codestral 相對於其他模型的性能的比較和結論的範圍。 人類評估 HumanEval 測試透過測試模型產生透過基於函數描述的人工編寫的單元測試的程式
0 notes
Text
https://uknumber.store/france-phone-data
的效能,不包括 CodeLlama 70B 或 Llama 3 70B 的數據。這限制了 Codestral 相對於其他模型的性能的比較和結論的範圍。 人類評估 HumanEval 測試透過測試模型產生透過基於函數描述的人工編寫的單元測試的程式
0 notes
Text
https://uknumber.store/france-phone-data
的效能,不包括 CodeLlama 70B 或 Llama 3 70B 的數據。這限制了 Codestral 相對於其他模型的性能的比較和結論的範圍。 人類評估 HumanEval 測試透過測試模型產生透過基於函數描述的人工編寫的單元測試的程式
0 notes
Text
https://uknumber.store/france-phone-data
的效能,不包括 CodeLlama 70B 或 Llama 3 70B 的數據。這限制了 Codestral 相對於其他模型的性能的比較和結論的範圍。 人類評估 HumanEval 測試透過測試模型產生透過基於函數描述的人工編寫的單元測試的程式
0 notes
Text
https://uknumber.store/france-phone-data
的效能,不包括 CodeLlama 70B 或 Llama 3 70B 的數據。這限制了 Codestral 相對於其他模型的性能的比較和結論的範圍。 人類評估 HumanEval 測試透過測試模型產生透過基於函數描述的人工編寫的單元測試的程式
0 notes
Text
CodeLlamaをモノづくり塾サーバーで動かす
モノづくり塾のサーバーはDockerでアプリケーションを運用すると決めているので、試験的に動かすにせよアプリケーションはDockerizeしなければなりません。 今日は先日作ったCodeLlamaとGradioを使ったコード生成AIアプリをDockerizeして塾のサーバーにデプロイしました。 プログラムはこんなに短くて簡単なものです。 Dockerfileはこれ。 docker composeファイルはこれ。 モノづくり塾ではサーバーにアプリケーションをデプロイするために次の手順を踏みます。現時点ではこれが標準的なやり方です。 1.このプロジェクトを塾サーバーのGitLabにプッシュ。 2.サーバーにログインしてプロジェクトをクローンして docker compose up -d…
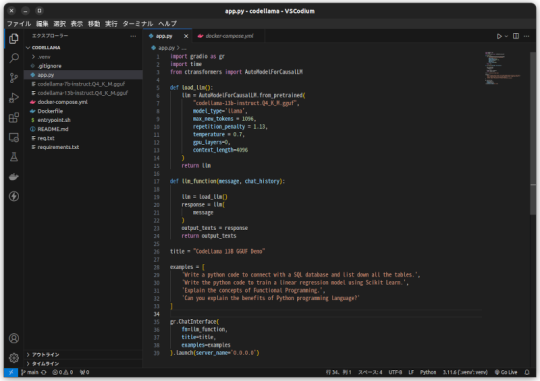
View On WordPress
0 notes
Text
https://uknumber.store/france-phone-data
的效能,不包括 CodeLlama 70B 或 Llama 3 70B 的數據。這限制了 Codestral 相對於其他模型的性能的比較和結論的範圍。 人類評估 HumanEval 測試透過測試模型產生透過基於函數描述的人工編寫的單元測試的程式
0 notes
Text
https://uknumber.store/france-phone-data
的效能,不包括 CodeLlama 70B 或 Llama 3 70B 的數據。這限制了 Codestral 相對於其他模型的性能的比較和結論的範圍。 人類評估 HumanEval 測試透過測試模型產生透過基於函數描述的人工編寫的單元測試的程式
0 notes
Text
https://uknumber.store/france-phone-data
的效能,不包括 CodeLlama 70B 或 Llama 3 70B 的數據。這限制了 Codestral 相對於其他模型的性能的比較和結論的範圍。 人類評估 HumanEval 測試透過測試模型產生透過基於函數描述的人工編寫的單元測試的程式
0 notes