#Feature engineering
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr Inc. has $15.1M in annual revenue.
Text
Unlocking the Power of Feature Engineering in Data Science
Discover how feature engineering enhances data science projects, ensuring better predictions and insights. Master this skill through a data science course in Kolkata!

0 notes
Text
Optimierung der KI-Modellentwicklung durch AutoML-Technologien
In der heutigen datengetriebenen Welt spielt die Entwicklung von Künstlicher Intelligenz (KI) eine zentrale Rolle in der Verbesserung von Geschäftsprozessen und Entscheidungen. AutoML-Technologien (Automated Machine Learning) bieten innovative Ansätze zur Optimierung der KI-Modellentwicklung, indem sie den manuellen Aufwand reduzieren und die Effizienz steigern. In diesem Artikel werden wir…
#Automatisierung#AutoML#Effizienzsteigerung#Feature Engineering#Geschäftsprozesse#Innovation#Innovationen#KI-Modelle#Machine Learning#Random Forests#RPA
0 notes
Text
How does feature engineering impact the performance of machine learning models?
Hi,
Here some information about How Feature Engineering Impacts Machine Learning Model Performance.
Feature engineering is all about creating and modifying features to improve the performance of your machine learning models.
1. Enhances Model Accuracy:
Impact: Well-engineered features can help the model better capture important patterns and relationships in the data.
Example: Adding a feature that represents the age of a car can help a model better predict its resale value compared to just using the car’s make and model alone.
2. Simplifies the Model:
Impact: Creating useful features can reduce the need for complex models by making the data more understandable for the model.
Example: Combining individual date components into a single “day of the week” feature can simplify the model’s task of identifying patterns related to different days.
3. Improves Feature Relevance:
Impact: Feature engineering helps in focusing the model on the most relevant aspects of the data, leading to better performance.
Example: Creating interaction terms between features (like combining income and education level) can highlight relationships that were not obvious in the original features.
4. Reduces Overfitting:
Impact: By creating meaningful features, you can reduce the complexity of the model and make it less likely to overfit the training data.
Example: Instead of using raw data with many irrelevant features, feature engineering helps in selecting the most important ones, improving the model’s generalization to new data.
5. Helps Handle Missing Data:
Impact: Feature engineering can include methods to handle missing data, improving the robustness of your model.
Example: Creating a binary feature that indicates whether data is missing can help the model make better predictions even when some values are missing.
In Summary: Feature engineering impacts model performance by improving accuracy, simplifying models, making features more relevant, reducing overfitting, and handling missing data better. By carefully designing and selecting features, you help your machine learning model work more effectively and make better predictions.
0 notes
Text
Explore What is Feature Engineering in Machine Learning
Summary: Feature engineering in Machine Learning is pivotal for refining raw data into predictive insights. Techniques like extraction, selection, transformation, and handling of missing data optimise model performance, ensuring accurate predictions. It bridges data intricacies, empowering practitioners to uncover meaningful patterns and drive informed decision-making in various domains.

Introduction
In today's data-driven era, Machine Learning has become pivotal across industries, revolutionising decision-making and automation. Feature Engineering in Machine Learning is at the heart of this transformative technology—an art and science that involves crafting data features to maximise model performance.
This blog explores the crucial role of Feature Engineering in Machine Learning, highlighting its significance in refining raw data into predictive insights. As businesses strive for a competitive edge through data-driven strategies, understanding how feature engineering enhances Machine Learning models becomes paramount.
Join us as we delve into techniques and strategies that empower Data Scientists to harness the full potential of their data.
What is Machine Learning?
Machine Learning is a branch of artificial intelligence (AI) that empowers systems to learn and improve from experience without explicit programming. It revolves around algorithms enabling computers to learn and automatically make decisions based on data. This section provides a concise definition and explores its core principles and the various paradigms under which Machine Learning operates.
Definition and Core Principles
Machine Learning involves algorithms that learn patterns and insights from data to make predictions or decisions. Unlike traditional programming, where rules are explicitly defined, Machine Learning models are trained using vast amounts of data, allowing them to generalise and improve their performance over time.
The core principles include data-driven learning, iterative improvement, and new data adaptation.
Common overview of learning paradigms in Machine Learning are:
Supervised Learning: In supervised learning, algorithms learn from labelled data, where each input-output pair is explicitly provided during training. The goal is to predict outputs for new, unseen data based on patterns learned from the labelled examples.
Unsupervised Learning: Unsupervised learning involves discovering patterns and structures from unlabeled data. Algorithms here aim to find inherent relationships or groupings in the data without explicit guidance.
Reinforcement Learning: This paradigm focuses on learning optimal decision-making through interaction with an environment. Algorithms learn to achieve a goal or maximise a reward by taking actions and receiving feedback or reinforcement signals.
Each paradigm serves distinct purposes in solving different types of problems, contributing to the versatility and applicability of Machine Learning across various fields.
What is Feature Engineering in Machine Learning?
Feature engineering in Machine Learning refers to selecting, transforming, and creating features (variables) from raw data most relevant to predictive modelling tasks. It involves crafting the correct set of input variables to improve model accuracy and performance.
This process aims to highlight meaningful patterns in the data and enhance the predictive power of Machine Learning algorithms.
Importance of Feature Selection and Transformation
Effective feature selection and transformation are crucial steps in the data preprocessing pipeline of Machine Learning. By selecting the most relevant features, the model becomes more focused on the essential patterns within the data, reducing noise and improving generalisation.
Transformation techniques such as normalisation or scaling ensure that features are on a comparable scale, preventing biases in model training. These processes not only streamline the learning process for Machine Learning algorithms but also contribute significantly to the interpretability and efficiency of the models.
Feature engineering bridges raw data and accurate predictions, laying the foundation for successful Machine Learning applications. By carefully curating features through selection and transformation, Data Scientists can uncover deeper insights and build robust models that perform well across diverse datasets and real-world scenarios.
Importance of Feature Engineering in Machine Learning
In Machine Learning, the quality of features—inputs used to train models—profoundly influences their predictive accuracy and performance. Practical feature engineering enhances the interpretability of models and facilitates better decision-making based on data-driven insights.
Impact on Model Performance
Quality features serve as the foundation for Machine Learning algorithms. By carefully selecting and transforming these features, practitioners can significantly improve model performance.
For instance, in a predictive model for customer churn, customer demographics, purchase history, and interaction frequency can be engineered to capture nuanced behaviours that correlate strongly with churn likelihood. This targeted feature engineering refines the model's ability to distinguish between churners and loyal customers and enhances its predictive power.
Examples of Enhanced Predictive Models
Consider a fraud detection system where features like transaction amount, location, and time are engineered to extract additional information, such as transaction frequency patterns or deviations from typical behaviour. By leveraging these engineered features, the model can more accurately identify suspicious activities, reducing false positives and improving overall detection rates.
Investing time and effort in feature engineering is crucial for building robust Machine Learning models that deliver actionable insights and drive informed decision-making across various domains.
Common Techniques in Feature Engineering in Machine Learning

Feature engineering is a cornerstone in developing robust Machine Learning models, where the quality and relevance of features directly impact model performance and predictive accuracy. This section explores several essential techniques in feature engineering that transform raw data into meaningful insights for Machine Learning algorithms.
Feature Extraction
Feature extraction transforms raw data into a structured format that facilitates model learning and improves predictive capabilities. Text mining data is processed to extract critical features such as word frequencies or semantic meanings using natural language processing (NLP) techniques. Similarly, features like edges or textures are extracted to describe visual content in image processing.
Feature Selection
Effective feature selection enhances model performance by focusing on the most relevant features while mitigating computational complexity and overfitting risks. Methods include filter methods that assess feature relevance based on statistical measures, wrapper methods that evaluate subsets based on model performance, and embedded methods that integrate feature selection into model training.
Feature Transformation
Feature transformation techniques preprocess data to improve model interpretability and performance. Normalisation scales numerical features to a standard range, standardisation adjusts features to have a mean of zero and a standard deviation of one, and log transforms adjust skewed data distributions to improve model fit.
Handling Missing Data
Handling missing data is essential to maintain data integrity and ensure robust model performance. Techniques include imputation methods that replace missing values with substitutes like the mean or median, deletion of instances with extensive missing data, and advanced techniques such as predictive modelling to estimate missing values based on other features.
Frequently Asked Questions
What is feature engineering in Machine Learning?
Feature engineering in Machine Learning involves selecting, transforming, and creating data features to enhance model performance and accuracy.
Why is feature engineering important in Machine Learning?
Practical feature engineering refines data insights, improves model interpretability, and boosts predictive accuracy across diverse datasets.
What are standard techniques in feature engineering?
Techniques include feature extraction, selection, transformation, and handling of missing data, all crucial for optimising Machine Learning models.
Conclusion
Feature engineering is indispensable in Machine Learning, transforming raw data into meaningful features that amplify model performance. By meticulously selecting and refining data inputs, practitioners enhance predictive accuracy and ensure robustness across various applications.
The strategic crafting of features improves model efficiency. It facilitates better decision-making through actionable insights derived from comprehensive data analysis. As businesses increasingly rely on data-driven strategies, mastering feature engineering remains a pivotal skill for unlocking the full potential of Machine Learning in solving complex real-world problems.
#feature engineering#feature engineering in machine learning#machine learning#data science#engineering
0 notes
Text
Enhancing Machine Learning through Feature Engineering: A Technique by Tibil Solutions Enhancing Machine Learning Through Feature Engineering" introduces a method developed by Tibil Solutions aimed at refining machine learning models by strategically crafting and selecting features. This technique involves optimizing the input data to enhance the performance and accuracy of machine learning algorithms, ultimately leading to more robust and effective predictive models. Tibil Solutions' approach emphasizes the importance of feature engineering in maximizing the potential of machine learning systems https://tibilsolutions.com/data-solutions/feature-engineering/
0 notes
Text



tf2 7th comic makes me festive and emotional i wish my fav pyro had more screentime so i conjure my own world
#tf2#tf2 comics#tf2 comic 7 spoilers#tf2 pyro#tf2 scout#tf2 spy#tf2 engineer#i love pyro smmm#featuring all of scouts beautiful children#that he gave birth to himself
4K notes
·
View notes
Text
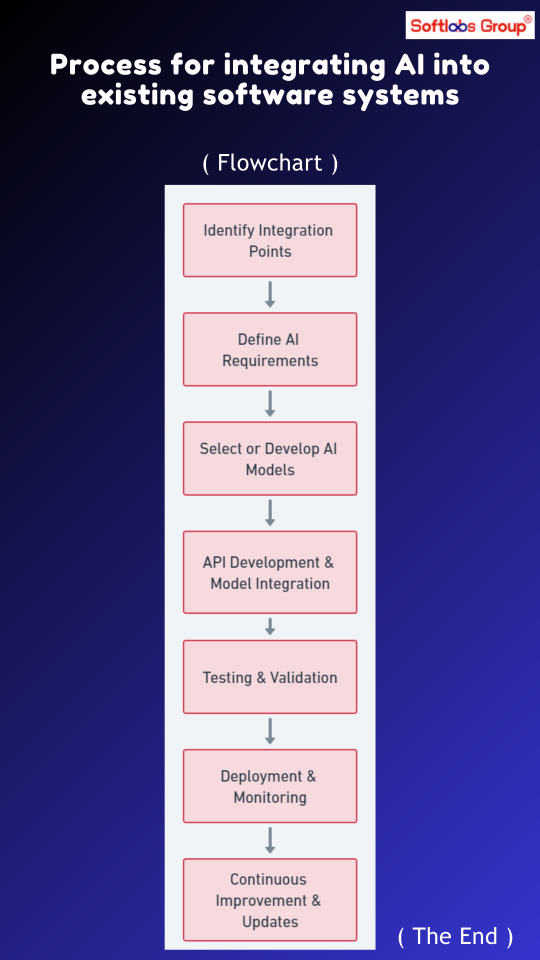
Discover the process for integrating AI into existing software systems with our simplified workflow. Follow stages including system analysis, AI model selection, integration planning, development, testing, and deployment. Simplify the integration of AI capabilities into your software for enhanced functionality. Perfect for software developers, architects, and IT professionals. Stay updated with Softlabs Group for more insights into AI integration strategies!
#System Integration#API Integration#Compatibility Assessment#Feature Engineering#Testing And Validation
0 notes
Text
Feature Engineering Techniques To Supercharge Your Machine Learning Algorithms

Are you ready to take your machine learning algorithms to the next level? If so, get ready because we’re about to dive into the world of feature engineering techniques that will supercharge your models like never before. Feature engineering is the secret sauce behind successful data science projects, allowing us to extract valuable insights and transform raw data into powerful predictors. In this blog post, we’ll explore some of the most effective and innovative techniques that will help you unlock hidden patterns in your datasets, boost accuracy levels, and ultimately revolutionize your machine learning game. So grab a cup of coffee and let’s embark on this exciting journey together!
Introduction to Feature Engineering
Feature engineering is the process of transforming raw data into features that can be used to train machine learning models. In this blog post, we will explore some common feature engineering techniques and how they can be used to improve the performance of machine learning algorithms.
One of the most important aspects of feature engineering is feature selection, which is the process of selecting the most relevant features from a dataset. This can be done using a variety of methods, including manual selection, statistical methods, and machine learning algorithms.
Once the relevant features have been selected, they need to be transformed into a format that can be used by machine learning algorithms. This may involve scaling numerical values, encoding categorical values as integers, or creating new features based on existing ones.
It is often necessary to split the dataset into training and test sets so that the performance of the machine learning algorithm can be properly evaluated.
What is a Feature?
A feature is a characteristic or set of characteristics that describe a data point. In machine learning, features are typically used to represent data points in a dataset. When choosing features for a machine learning algorithm, it is important to select features that are relevant to the task at hand and that can be used to distinguish between different classes of data points.
There are many different ways to engineer features, and the approach that is taken will depend on the type of data being used and the goal of the machine learning algorithm. Some common techniques for feature engineering include:
– Extracting features from text data using natural language processing (NLP) techniques – Creating new features by combining existing features (e.g., creating interaction terms) – Transforming existing features to better suit the needs of the machine learning algorithm (e.g., using logarithmic transformations for numerical data) – Using domain knowledge to create new features that capture important relationships in the data
How Does Feature Engineering Help Boost ML Algorithms?
Feature engineering is the process of using domain knowledge to extract features from raw data that can be used to improve the performance of machine learning algorithms. This process can be used to create new features that better represent the underlying data or to transform existing features so that they are more suitable for use with machine learning algorithms.
The benefits of feature engineering can be seen in both improved model accuracy and increased efficiency. By carefully crafting features, it is possible to reduce the amount of data required to train a machine learning algorithm while also increasing its accuracy. In some cases, good feature engineering can even allow a less powerful machine learning algorithm to outperform a more complex one.
There are many different techniques that can be used for feature engineering, but some of the most common include feature selection, feature transformation, and dimensionality reduction. Feature selection involves choosing which features from the raw data should be used by the machine learning algorithm. Feature transformation involves transforming or changing the values of existing features so that they are more suitable for use with machine learning algorithms. Dimensionality reduction is a technique that can be used to reduce the number of features in the data by combining or eliminating features that are similar or redundant.
Each of these techniques has its own strengths and weaknesses, and there is no single best approach for performing feature engineering. The best approach depends on the specific dataset and machine learning algorithm being used. In general, it is important to try out different techniques and see which ones work best for your particular application.
Types of Feature Engineering Techniques
There are many different types of feature engineering techniques that can be used to improve the performance of machine learning algorithms. Some of the most popular techniques include:
1. Data preprocessing: This technique involves cleaning and preparing the data before it is fed into the machine learning algorithm. This can help to improve the accuracy of the algorithm by removing any noisy or irrelevant data.
2. Feature selection: This technique involves selecting the most relevant features from the data that will be used by the machine learning algorithm. This can help to improve the accuracy of the algorithm by reducing the amount of data that is processed and making sure that only the most important features are used.
3. Feature extraction: This technique involves extracting new features from existing data. This can help to improve the accuracy of the algorithm by providing more information for the algorithm to learn from.
4. Dimensionality reduction: This technique reduces the number of features that are used by the machine learning algorithm. This can help to improve the accuracy of the algorithm by reducing complexity and making sure that only the most important features are used.
– Data Preprocessing
Data preprocessing is a critical step in any machine learning pipeline. It is responsible for cleaning and formatting the data so that it can be fed into the model.
There are a number of techniques that can be used for data preprocessing, but some are more effective than others. Here are a few of the most popular methods:
– Standardization: This technique is used to rescale the data so that it has a mean of 0 and a standard deviation of 1. This is often done before feeding the data into a machine learning algorithm, as it can help the model converge faster.
– Normalization: This technique is used to rescale the data so that each feature is in the range [0, 1]. This is often done before feeding the data into a neural network, as it can help improve convergence.
– One-hot encoding: This technique is used to convert categorical variables into numerical ones. This is often done before feeding the data into a machine learning algorithm, as many models cannot handle categorical variables directly.
– Imputation: This technique is used to replace missing values in the data with something else (usually the mean or median of the column). This is often done before feeding the data into a machine learning algorithm, as many models cannot handle missing values directly.
– Feature Selection
There are a variety of feature selection techniques that can be used to improve the performance of machine learning algorithms. Some common methods include:
-Filter Methods: Filter methods are based on ranking features according to some criterion and then selecting a subset of the most relevant features. Common criteria used to rank features include information gain, mutual information, and chi-squared statistics.
-Wrapper Methods: Wrapper methods use a machine learning algorithm to evaluate the performance of different feature subsets and choose the best performing subset. This can be computationally expensive but is often more effective than filter methods.
-Embedded Methods: Embedded methods combine feature selection with the training of the machine learning algorithm. The most common embedded method is regularization, which penalizes certain parameters in the model if they are not relevant to the prediction task.
– Feature Transformation
Feature engineering is the process of creating new features from existing data. This can be done by combining different features, transforming features, or creating new features from scratch.
Feature engineering is a critical step in machine learning because it can help improve the performance of your algorithms. In this blog post, we will discuss some common feature engineering techniques that you can use to supercharge your machine learning algorithms.
One common technique for feature engineering is feature transformation. This involves transforming existing features to create new ones. For example, you could transform a feature such as “age” into a new feature called “age squared”. This would be useful if you were trying to predict something like life expectancy, which often increases with age but then levels off at an older age.
Another common technique is feature selection, which is the process of choosing which features to include in your model. This can be done manually or automatically using a variety of methods such as decision trees or Genetic Algorithms.
Once you have decided which features to include in your model, you may want to perform dimensionality reduction to reduce the number of features while still retaining as much information as possible. This can be done using techniques such as Principal Component Analysis (PCA) or Linear Discriminant Analysis (LDA).
You may also want to standardize your data before feeding it into your machine learning algorithm. Standardization involves rescaling the data so that it has a mean
– Generating Synthetic Features
Generating synthetic features is a great way to supercharge your machine learning algorithms. This technique can be used to create new features that are not present in the original data set. This can be done by combining existing features, or by using a variety of techniques to generate new features from scratch.
This technique is often used in conjunction with other feature engineering techniques, such as feature selection and feature extraction. When used together, these techniques can greatly improve the performance of your machine learning algorithms.
Examples of Successful Feature Engineering Projects
1. One of the most well-known examples of feature engineering is the Netflix Prize. In order to improve their movie recommendation system,Netflix released a dataset of 100 million ratings and allowed anyone to compete to find the best algorithm. The grand prize was awarded to a team that used a combination of features, including movie genres, release year, and average rating, to improve the accuracy of predictions by 10%.
2. Another example is Kaggle’s Merck Millipore Challenge, which asked participants to predict the binding affinity of small molecules to proteins. The winning team used a variety of features, including chemical structure data and protein sequence data, to achieve an accuracy of over 99%.
3. In the Google Brain Cat vs. Dog Challenge, participants were tasked with using machine learning to distinguish between pictures of cats and dogs. The winning team used a number of different features, such as color histograms and edge detection, to achieve an accuracy of over 96%.
Challenges Faced While Doing Feature Engineering
The biggest challenge when it comes to feature engineering is figuring out which features will actually be useful in predicting the target variable. There’s no easy answer to this question, and it often requires a lot of trial and error. Additionally, some features may be very time-consuming and expensive to create, so there’s a trade-off between accuracy and practicality.
Another challenge is dealing with missing data. This can be a issue when trying to create new features, especially if those features are based on other features that have missing values. One way to deal with this is to impute the missing values, but this can introduce bias if not done properly.
Sometimes the relationships between features and the target variable can be non-linear, meaning that standard linear methods of feature engineering won’t work. In these cases, it’s necessary to get creative and come up with custom transformation methods that capture the complex relationships.
Conclusion
Feature engineering is a powerful tool that can be used to optimize the performance of your machine learning algorithms. By utilizing techniques such as feature selection, dimensionality reduction and data transformation, you can drastically improve the accuracy and efficiency of your models. With these tools in hand, you will be well-equipped to tackle any machine learning challenge with confidence.
0 notes
Text
Data science development

View On WordPress
0 notes
Text

The kiddos <3
#my kid Engie sketch has been plaguing me so I had to draw him again#this time featuring kiddo scrout :3#ya ik they’re different ages in canon#but may I counter that argument with my own:#I wanted to draw them 😌#tf2#team fortress 2#tf2 fanart#team fortress fanart#tf2 scout#engineer tf2#my art#digital art
3K notes
·
View notes
Text



The new race engineer has arrived and he’s … beautiful !?
Part 2
#genshin impact#alhaitham#kaveh#tighnari#cyno#genshin comic#kavetham#haikaveh#genshin kaveh#genshin tighnari#genshin cyno#genshin alhaitham#genshin impact art#racer alhaitham x engineer/mechanic kaveh#I guess???#That official art featuring mec!kaveh flipped my brain okay?#my art#sd art#artists on tumblr#manga#drawing#art#anime#my comic
3K notes
·
View notes
Text
i've been so tired of google's new legal liability bot sitting on top of the existing highlighted result, taking up page space and either parroting exactly what the highlighted result said or offering completely unrelated or incorrect results, that i actually cheered when this came up:

"oh but AI is experimental -"
the bot told people to eat glue on pizza. you can talk yourself blue in the face about the bot's learning curve and how "it'll be improved with time", but maybe a bot being touted as the latest and greatest in scouring the internet for accurate information should not come with a permanent glaring disclaimer of "it's still learning / results may not be accurate!" as the generative AI ouroboros continues to keep on chewing.
#google ai overview#and yES i know we use bots for existing search engine features#and how use ai for actually beneficial purposes such as in the medical field#but i am beyond burnt out on this ai hype trend and how every other website / company is flailing around their shiny new bot#i can't do this anymore i'm going outside
281 notes
·
View notes
Text
guys gyuys have any of you seen this if no PLEASE watch im on the verge of tears over this video
youtube
#PICKED UP SO MANY VOCAL STIMS#“WHADDYA SAY?????” “i CANT HEAR NOTHIN!!!!!”#“dustin thats you mate”#“i am... am a purse”#“FREQUENCYYYYEYEYEYEEEEY”#though dustin and flat-top are truly the highlights in here 😭😭😭#CIAO MAMA#starlight express#stex#okay and how on earth do i tag this. okay everyone who featured in the vid i guess#go my engines#pearl the observation car#dinah the dining car#buffy the buffet car#ashley the smoking car#flat top the brick truck#dustin the big hopper#the rockies#electra the electric engine#krupp the armaments truck#volta the freezer truck#joule the dynamite truck#purse the money truck#wrench the repair truck#greaseball the diesel
126 notes
·
View notes
Text
Good evening to the three people that are into stex and transformers!!!!! I bring more trainsformers food

Did some insta requests yay yayyyyy

Doodle batch no 1
#morf's art#stex#starlight express#transformers#maccadam#transformers animated#wowza character tagging time#hydra the hydrogen tanker#ruhrgold the german engine#ruhrgold#brexit the british engine#momma mccoy#electra the electric engine#caboose#cb the red caboose#featuring a jet who‘s finally met his match#starscream#trainsformers
205 notes
·
View notes
Note
I LOVE HOW YOU DRAW ENGIE SO MUCH HES SO CUUUTEEE
thank u :] have an engie

#my art#ask#tf2#tf2 engineer#team fortress 2#hes actually so difficult for me to draw for no reason#i blame his stupid goggles#also featuring the new cosmetic cuz i like it a lot
199 notes
·
View notes
Text

Feature Engineering Solutions: A comprehensive guide | Tibil Solutions
Feature engineering is the process of collecting, transforming, and creating new features using raw data through data mining techniques to increase the predictive power of machine learning models. It helps in the improvement of the quality of the features to derive accurate predictions. Automated feature engineering solutions can save time, improve feature or model development, and lead to better-performing machine learning models. Tibil Solutions use the feature generation process to create new features from one or multiple existing features, for use in statistical analysis.
0 notes