#machine learning algorithm
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Women make up for the other 50% of Tumblr’s audience.
Text
Top 5 Innovation Management Software Of 2024

Imagine a world where communication means traveling to meet someone in person, where hunting and gathering are essential for survival, and where we dwell in caves, relying on simple tools made of wood or stone. This is a Stone Age existence, where the day ends with the setting sun.
But what if no one had ever thought of electricity, cooking gas, or the telephone? These inventions transformed our world from the Stone Age to the advanced society we live in today. We owe our gratitude to those early innovators whose ideas solved humanity's greatest challenges.
In today’s world, innovation continues at a breakneck pace, especially in areas like AI. But while individuals can jot down their ideas on a notepad, businesses need sophisticated tools to manage innovation effectively. Enter Innovation Management Software—a powerful solution that helps organizations capture, evaluate, and implement ideas seamlessly. It’s a centralized platform that allows you to document and track the most promising concepts.
So, if your business is seeking Innovation Management Software, explore our curated list of the top 5 tools for 2024. Read on to discover more!
Coming up with fresh and innovative ideas can sometimes be a challenge. That’s where Innovation Management Software steps in, helping businesses overcome creative blocks and streamline the innovation process.
According to a Markets and Markets report, the Innovation Management Software market is expected to grow from $1.3 billion in 2023 to $2.1 billion by 2028, with a CAGR of 10.8%. This impressive growth underscores the importance of such tools for businesses across various industries.
Innovation Management Software enables idea submission, voting, ranking, and collaborative discussions. AI-powered features, like sentiment analysis and topic clustering, help prioritize ideas based on their impact and relevance.
Ready to explore the best options? Here’s our updated list of the top 5 Innovation Management Software of 2024.
Top 5 Innovation Management Software of 2024
Innovation management tools empower businesses by tapping into diverse perspectives, whether from employees, customers, or partners. These tools streamline the evaluation process, ensuring that the best ideas get the attention they deserve. Ultimately, they help organizations innovate continuously, improve products, and deliver exceptional customer experiences.
Here’s our top 5 list for 2024:
Miro: Known for its virtual whiteboard platform, Miro offers real-time collaboration and integration with popular tools like Jira and Google Drive. Its AI-powered smart canvas and advanced security features make it ideal for enterprises.
Aha!: This comprehensive product roadmap and innovation platform allows teams to capture ideas, align strategic goals, and collaborate seamlessly across departments. It integrates with tools like Jira and GitHub, offering advanced portfolio management capabilities.
Brightidea: Recognized as the #1 Innovation Management Platform by G2, Brightidea offers features like idea campaigns and AI-powered evaluation tools. It’s ideal for organizations looking to foster a culture of innovation.
Ideanote: Despite its small team, Ideanote offers powerful innovation management features, including integration with project management tools like Trello and Asana. It’s perfect for businesses aiming to improve operational efficiency.
Canny: A tool that helps businesses capture customer insights, prioritize feedback, and drive product innovation. Its AI-powered sentiment analysis and topic clustering make it a valuable asset for any organization.
In conclusion, innovation is key to staying competitive. Innovation Management Software helps businesses harness the collective intelligence of their stakeholders, streamline ideation, and prioritize high-impact ideas. By adopting the right tool, companies can drive continuous improvement and deliver exceptional customer experiences.
0 notes
Text
Feature Engineering Techniques To Supercharge Your Machine Learning Algorithms

Are you ready to take your machine learning algorithms to the next level? If so, get ready because we’re about to dive into the world of feature engineering techniques that will supercharge your models like never before. Feature engineering is the secret sauce behind successful data science projects, allowing us to extract valuable insights and transform raw data into powerful predictors. In this blog post, we’ll explore some of the most effective and innovative techniques that will help you unlock hidden patterns in your datasets, boost accuracy levels, and ultimately revolutionize your machine learning game. So grab a cup of coffee and let’s embark on this exciting journey together!
Introduction to Feature Engineering
Feature engineering is the process of transforming raw data into features that can be used to train machine learning models. In this blog post, we will explore some common feature engineering techniques and how they can be used to improve the performance of machine learning algorithms.
One of the most important aspects of feature engineering is feature selection, which is the process of selecting the most relevant features from a dataset. This can be done using a variety of methods, including manual selection, statistical methods, and machine learning algorithms.
Once the relevant features have been selected, they need to be transformed into a format that can be used by machine learning algorithms. This may involve scaling numerical values, encoding categorical values as integers, or creating new features based on existing ones.
It is often necessary to split the dataset into training and test sets so that the performance of the machine learning algorithm can be properly evaluated.
What is a Feature?
A feature is a characteristic or set of characteristics that describe a data point. In machine learning, features are typically used to represent data points in a dataset. When choosing features for a machine learning algorithm, it is important to select features that are relevant to the task at hand and that can be used to distinguish between different classes of data points.
There are many different ways to engineer features, and the approach that is taken will depend on the type of data being used and the goal of the machine learning algorithm. Some common techniques for feature engineering include:
– Extracting features from text data using natural language processing (NLP) techniques – Creating new features by combining existing features (e.g., creating interaction terms) – Transforming existing features to better suit the needs of the machine learning algorithm (e.g., using logarithmic transformations for numerical data) – Using domain knowledge to create new features that capture important relationships in the data
How Does Feature Engineering Help Boost ML Algorithms?
Feature engineering is the process of using domain knowledge to extract features from raw data that can be used to improve the performance of machine learning algorithms. This process can be used to create new features that better represent the underlying data or to transform existing features so that they are more suitable for use with machine learning algorithms.
The benefits of feature engineering can be seen in both improved model accuracy and increased efficiency. By carefully crafting features, it is possible to reduce the amount of data required to train a machine learning algorithm while also increasing its accuracy. In some cases, good feature engineering can even allow a less powerful machine learning algorithm to outperform a more complex one.
There are many different techniques that can be used for feature engineering, but some of the most common include feature selection, feature transformation, and dimensionality reduction. Feature selection involves choosing which features from the raw data should be used by the machine learning algorithm. Feature transformation involves transforming or changing the values of existing features so that they are more suitable for use with machine learning algorithms. Dimensionality reduction is a technique that can be used to reduce the number of features in the data by combining or eliminating features that are similar or redundant.
Each of these techniques has its own strengths and weaknesses, and there is no single best approach for performing feature engineering. The best approach depends on the specific dataset and machine learning algorithm being used. In general, it is important to try out different techniques and see which ones work best for your particular application.
Types of Feature Engineering Techniques
There are many different types of feature engineering techniques that can be used to improve the performance of machine learning algorithms. Some of the most popular techniques include:
1. Data preprocessing: This technique involves cleaning and preparing the data before it is fed into the machine learning algorithm. This can help to improve the accuracy of the algorithm by removing any noisy or irrelevant data.
2. Feature selection: This technique involves selecting the most relevant features from the data that will be used by the machine learning algorithm. This can help to improve the accuracy of the algorithm by reducing the amount of data that is processed and making sure that only the most important features are used.
3. Feature extraction: This technique involves extracting new features from existing data. This can help to improve the accuracy of the algorithm by providing more information for the algorithm to learn from.
4. Dimensionality reduction: This technique reduces the number of features that are used by the machine learning algorithm. This can help to improve the accuracy of the algorithm by reducing complexity and making sure that only the most important features are used.
– Data Preprocessing
Data preprocessing is a critical step in any machine learning pipeline. It is responsible for cleaning and formatting the data so that it can be fed into the model.
There are a number of techniques that can be used for data preprocessing, but some are more effective than others. Here are a few of the most popular methods:
– Standardization: This technique is used to rescale the data so that it has a mean of 0 and a standard deviation of 1. This is often done before feeding the data into a machine learning algorithm, as it can help the model converge faster.
– Normalization: This technique is used to rescale the data so that each feature is in the range [0, 1]. This is often done before feeding the data into a neural network, as it can help improve convergence.
– One-hot encoding: This technique is used to convert categorical variables into numerical ones. This is often done before feeding the data into a machine learning algorithm, as many models cannot handle categorical variables directly.
– Imputation: This technique is used to replace missing values in the data with something else (usually the mean or median of the column). This is often done before feeding the data into a machine learning algorithm, as many models cannot handle missing values directly.
– Feature Selection
There are a variety of feature selection techniques that can be used to improve the performance of machine learning algorithms. Some common methods include:
-Filter Methods: Filter methods are based on ranking features according to some criterion and then selecting a subset of the most relevant features. Common criteria used to rank features include information gain, mutual information, and chi-squared statistics.
-Wrapper Methods: Wrapper methods use a machine learning algorithm to evaluate the performance of different feature subsets and choose the best performing subset. This can be computationally expensive but is often more effective than filter methods.
-Embedded Methods: Embedded methods combine feature selection with the training of the machine learning algorithm. The most common embedded method is regularization, which penalizes certain parameters in the model if they are not relevant to the prediction task.
– Feature Transformation
Feature engineering is the process of creating new features from existing data. This can be done by combining different features, transforming features, or creating new features from scratch.
Feature engineering is a critical step in machine learning because it can help improve the performance of your algorithms. In this blog post, we will discuss some common feature engineering techniques that you can use to supercharge your machine learning algorithms.
One common technique for feature engineering is feature transformation. This involves transforming existing features to create new ones. For example, you could transform a feature such as “age” into a new feature called “age squared”. This would be useful if you were trying to predict something like life expectancy, which often increases with age but then levels off at an older age.
Another common technique is feature selection, which is the process of choosing which features to include in your model. This can be done manually or automatically using a variety of methods such as decision trees or Genetic Algorithms.
Once you have decided which features to include in your model, you may want to perform dimensionality reduction to reduce the number of features while still retaining as much information as possible. This can be done using techniques such as Principal Component Analysis (PCA) or Linear Discriminant Analysis (LDA).
You may also want to standardize your data before feeding it into your machine learning algorithm. Standardization involves rescaling the data so that it has a mean
– Generating Synthetic Features
Generating synthetic features is a great way to supercharge your machine learning algorithms. This technique can be used to create new features that are not present in the original data set. This can be done by combining existing features, or by using a variety of techniques to generate new features from scratch.
This technique is often used in conjunction with other feature engineering techniques, such as feature selection and feature extraction. When used together, these techniques can greatly improve the performance of your machine learning algorithms.
Examples of Successful Feature Engineering Projects
1. One of the most well-known examples of feature engineering is the Netflix Prize. In order to improve their movie recommendation system,Netflix released a dataset of 100 million ratings and allowed anyone to compete to find the best algorithm. The grand prize was awarded to a team that used a combination of features, including movie genres, release year, and average rating, to improve the accuracy of predictions by 10%.
2. Another example is Kaggle’s Merck Millipore Challenge, which asked participants to predict the binding affinity of small molecules to proteins. The winning team used a variety of features, including chemical structure data and protein sequence data, to achieve an accuracy of over 99%.
3. In the Google Brain Cat vs. Dog Challenge, participants were tasked with using machine learning to distinguish between pictures of cats and dogs. The winning team used a number of different features, such as color histograms and edge detection, to achieve an accuracy of over 96%.
Challenges Faced While Doing Feature Engineering
The biggest challenge when it comes to feature engineering is figuring out which features will actually be useful in predicting the target variable. There’s no easy answer to this question, and it often requires a lot of trial and error. Additionally, some features may be very time-consuming and expensive to create, so there’s a trade-off between accuracy and practicality.
Another challenge is dealing with missing data. This can be a issue when trying to create new features, especially if those features are based on other features that have missing values. One way to deal with this is to impute the missing values, but this can introduce bias if not done properly.
Sometimes the relationships between features and the target variable can be non-linear, meaning that standard linear methods of feature engineering won’t work. In these cases, it’s necessary to get creative and come up with custom transformation methods that capture the complex relationships.
Conclusion
Feature engineering is a powerful tool that can be used to optimize the performance of your machine learning algorithms. By utilizing techniques such as feature selection, dimensionality reduction and data transformation, you can drastically improve the accuracy and efficiency of your models. With these tools in hand, you will be well-equipped to tackle any machine learning challenge with confidence.
0 notes
Text
the hatred for anything labeled as “AI” is truly fucking insane 😭 just saw someone berating spotify’s “AI generated playlists” you mean the fucking recommendations? the fucking algorithm? the same brand of algorithm that recommends you new youtube videos or nextlfix shows or for you page tweets? the “you might like this” feature? that fucking AI generation?
#icarus speaks#neg#ITS JUST A BUZZWORD#IT MEANS NOTTHINNGGG#it’s just coding. it’s machine learning it’s algorithms it’s not fucking anything new#this has existed since forever GET OVER URSELF
846 notes
·
View notes
Text
The surprising truth about data-driven dictatorships

Here’s the “dictator’s dilemma”: they want to block their country’s frustrated elites from mobilizing against them, so they censor public communications; but they also want to know what their people truly believe, so they can head off simmering resentments before they boil over into regime-toppling revolutions.
These two strategies are in tension: the more you censor, the less you know about the true feelings of your citizens and the easier it will be to miss serious problems until they spill over into the streets (think: the fall of the Berlin Wall or Tunisia before the Arab Spring). Dictators try to square this circle with things like private opinion polling or petition systems, but these capture a small slice of the potentially destabiziling moods circulating in the body politic.
Enter AI: back in 2018, Yuval Harari proposed that AI would supercharge dictatorships by mining and summarizing the public mood — as captured on social media — allowing dictators to tack into serious discontent and diffuse it before it erupted into unequenchable wildfire:
https://www.theatlantic.com/magazine/archive/2018/10/yuval-noah-harari-technology-tyranny/568330/
Harari wrote that “the desire to concentrate all information and power in one place may become [dictators] decisive advantage in the 21st century.” But other political scientists sharply disagreed. Last year, Henry Farrell, Jeremy Wallace and Abraham Newman published a thoroughgoing rebuttal to Harari in Foreign Affairs:
https://www.foreignaffairs.com/world/spirals-delusion-artificial-intelligence-decision-making
They argued that — like everyone who gets excited about AI, only to have their hopes dashed — dictators seeking to use AI to understand the public mood would run into serious training data bias problems. After all, people living under dictatorships know that spouting off about their discontent and desire for change is a risky business, so they will self-censor on social media. That’s true even if a person isn’t afraid of retaliation: if you know that using certain words or phrases in a post will get it autoblocked by a censorbot, what’s the point of trying to use those words?
The phrase “Garbage In, Garbage Out” dates back to 1957. That’s how long we’ve known that a computer that operates on bad data will barf up bad conclusions. But this is a very inconvenient truth for AI weirdos: having given up on manually assembling training data based on careful human judgment with multiple review steps, the AI industry “pivoted” to mass ingestion of scraped data from the whole internet.
But adding more unreliable data to an unreliable dataset doesn’t improve its reliability. GIGO is the iron law of computing, and you can’t repeal it by shoveling more garbage into the top of the training funnel:
https://memex.craphound.com/2018/05/29/garbage-in-garbage-out-machine-learning-has-not-repealed-the-iron-law-of-computer-science/
When it comes to “AI” that’s used for decision support — that is, when an algorithm tells humans what to do and they do it — then you get something worse than Garbage In, Garbage Out — you get Garbage In, Garbage Out, Garbage Back In Again. That’s when the AI spits out something wrong, and then another AI sucks up that wrong conclusion and uses it to generate more conclusions.
To see this in action, consider the deeply flawed predictive policing systems that cities around the world rely on. These systems suck up crime data from the cops, then predict where crime is going to be, and send cops to those “hotspots” to do things like throw Black kids up against a wall and make them turn out their pockets, or pull over drivers and search their cars after pretending to have smelled cannabis.
The problem here is that “crime the police detected” isn’t the same as “crime.” You only find crime where you look for it. For example, there are far more incidents of domestic abuse reported in apartment buildings than in fully detached homes. That’s not because apartment dwellers are more likely to be wife-beaters: it’s because domestic abuse is most often reported by a neighbor who hears it through the walls.
So if your cops practice racially biased policing (I know, this is hard to imagine, but stay with me /s), then the crime they detect will already be a function of bias. If you only ever throw Black kids up against a wall and turn out their pockets, then every knife and dime-bag you find in someone’s pockets will come from some Black kid the cops decided to harass.
That’s life without AI. But now let’s throw in predictive policing: feed your “knives found in pockets” data to an algorithm and ask it to predict where there are more knives in pockets, and it will send you back to that Black neighborhood and tell you do throw even more Black kids up against a wall and search their pockets. The more you do this, the more knives you’ll find, and the more you’ll go back and do it again.
This is what Patrick Ball from the Human Rights Data Analysis Group calls “empiricism washing”: take a biased procedure and feed it to an algorithm, and then you get to go and do more biased procedures, and whenever anyone accuses you of bias, you can insist that you’re just following an empirical conclusion of a neutral algorithm, because “math can’t be racist.”
HRDAG has done excellent work on this, finding a natural experiment that makes the problem of GIGOGBI crystal clear. The National Survey On Drug Use and Health produces the gold standard snapshot of drug use in America. Kristian Lum and William Isaac took Oakland’s drug arrest data from 2010 and asked Predpol, a leading predictive policing product, to predict where Oakland’s 2011 drug use would take place.
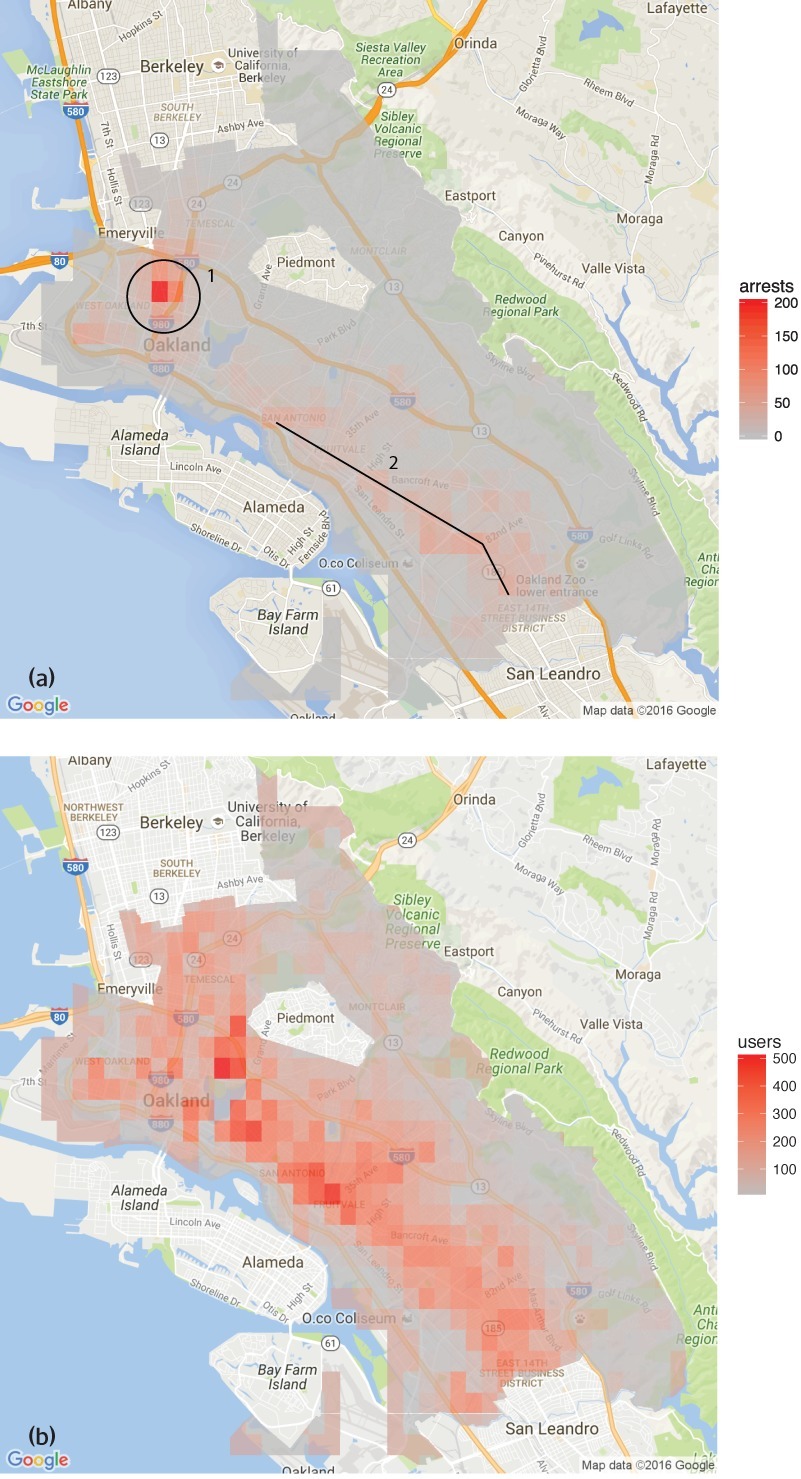
[Image ID: (a) Number of drug arrests made by Oakland police department, 2010. (1) West Oakland, (2) International Boulevard. (b) Estimated number of drug users, based on 2011 National Survey on Drug Use and Health]
Then, they compared those predictions to the outcomes of the 2011 survey, which shows where actual drug use took place. The two maps couldn’t be more different:
https://rss.onlinelibrary.wiley.com/doi/full/10.1111/j.1740-9713.2016.00960.x
Predpol told cops to go and look for drug use in a predominantly Black, working class neighborhood. Meanwhile the NSDUH survey showed the actual drug use took place all over Oakland, with a higher concentration in the Berkeley-neighboring student neighborhood.
What’s even more vivid is what happens when you simulate running Predpol on the new arrest data that would be generated by cops following its recommendations. If the cops went to that Black neighborhood and found more drugs there and told Predpol about it, the recommendation gets stronger and more confident.
In other words, GIGOGBI is a system for concentrating bias. Even trace amounts of bias in the original training data get refined and magnified when they are output though a decision support system that directs humans to go an act on that output. Algorithms are to bias what centrifuges are to radioactive ore: a way to turn minute amounts of bias into pluripotent, indestructible toxic waste.
There’s a great name for an AI that’s trained on an AI’s output, courtesy of Jathan Sadowski: “Habsburg AI.”
And that brings me back to the Dictator’s Dilemma. If your citizens are self-censoring in order to avoid retaliation or algorithmic shadowbanning, then the AI you train on their posts in order to find out what they’re really thinking will steer you in the opposite direction, so you make bad policies that make people angrier and destabilize things more.
Or at least, that was Farrell(et al)’s theory. And for many years, that’s where the debate over AI and dictatorship has stalled: theory vs theory. But now, there’s some empirical data on this, thanks to the “The Digital Dictator’s Dilemma,” a new paper from UCSD PhD candidate Eddie Yang:
https://www.eddieyang.net/research/DDD.pdf
Yang figured out a way to test these dueling hypotheses. He got 10 million Chinese social media posts from the start of the pandemic, before companies like Weibo were required to censor certain pandemic-related posts as politically sensitive. Yang treats these posts as a robust snapshot of public opinion: because there was no censorship of pandemic-related chatter, Chinese users were free to post anything they wanted without having to self-censor for fear of retaliation or deletion.
Next, Yang acquired the censorship model used by a real Chinese social media company to decide which posts should be blocked. Using this, he was able to determine which of the posts in the original set would be censored today in China.
That means that Yang knows that the “real” sentiment in the Chinese social media snapshot is, and what Chinese authorities would believe it to be if Chinese users were self-censoring all the posts that would be flagged by censorware today.
From here, Yang was able to play with the knobs, and determine how “preference-falsification” (when users lie about their feelings) and self-censorship would give a dictatorship a misleading view of public sentiment. What he finds is that the more repressive a regime is — the more people are incentivized to falsify or censor their views — the worse the system gets at uncovering the true public mood.
What’s more, adding additional (bad) data to the system doesn’t fix this “missing data” problem. GIGO remains an iron law of computing in this context, too.
But it gets better (or worse, I guess): Yang models a “crisis” scenario in which users stop self-censoring and start articulating their true views (because they’ve run out of fucks to give). This is the most dangerous moment for a dictator, and depending on the dictatorship handles it, they either get another decade or rule, or they wake up with guillotines on their lawns.
But “crisis” is where AI performs the worst. Trained on the “status quo” data where users are continuously self-censoring and preference-falsifying, AI has no clue how to handle the unvarnished truth. Both its recommendations about what to censor and its summaries of public sentiment are the least accurate when crisis erupts.
But here’s an interesting wrinkle: Yang scraped a bunch of Chinese users’ posts from Twitter — which the Chinese government doesn’t get to censor (yet) or spy on (yet) — and fed them to the model. He hypothesized that when Chinese users post to American social media, they don’t self-censor or preference-falsify, so this data should help the model improve its accuracy.
He was right — the model got significantly better once it ingested data from Twitter than when it was working solely from Weibo posts. And Yang notes that dictatorships all over the world are widely understood to be scraping western/northern social media.
But even though Twitter data improved the model’s accuracy, it was still wildly inaccurate, compared to the same model trained on a full set of un-self-censored, un-falsified data. GIGO is not an option, it’s the law (of computing).
Writing about the study on Crooked Timber, Farrell notes that as the world fills up with “garbage and noise” (he invokes Philip K Dick’s delighted coinage “gubbish”), “approximately correct knowledge becomes the scarce and valuable resource.”
https://crookedtimber.org/2023/07/25/51610/
This “probably approximately correct knowledge” comes from humans, not LLMs or AI, and so “the social applications of machine learning in non-authoritarian societies are just as parasitic on these forms of human knowledge production as authoritarian governments.”

The Clarion Science Fiction and Fantasy Writers’ Workshop summer fundraiser is almost over! I am an alum, instructor and volunteer board member for this nonprofit workshop whose alums include Octavia Butler, Kim Stanley Robinson, Bruce Sterling, Nalo Hopkinson, Kameron Hurley, Nnedi Okorafor, Lucius Shepard, and Ted Chiang! Your donations will help us subsidize tuition for students, making Clarion — and sf/f — more accessible for all kinds of writers.
Libro.fm is the indie-bookstore-friendly, DRM-free audiobook alternative to Audible, the Amazon-owned monopolist that locks every book you buy to Amazon forever. When you buy a book on Libro, they share some of the purchase price with a local indie bookstore of your choosing (Libro is the best partner I have in selling my own DRM-free audiobooks!). As of today, Libro is even better, because it’s available in five new territories and currencies: Canada, the UK, the EU, Australia and New Zealand!
[Image ID: An altered image of the Nuremberg rally, with ranked lines of soldiers facing a towering figure in a many-ribboned soldier's coat. He wears a high-peaked cap with a microchip in place of insignia. His head has been replaced with the menacing red eye of HAL9000 from Stanley Kubrick's '2001: A Space Odyssey.' The sky behind him is filled with a 'code waterfall' from 'The Matrix.']
Image: Cryteria (modified) https://commons.wikimedia.org/wiki/File:HAL9000.svg
CC BY 3.0 https://creativecommons.org/licenses/by/3.0/deed.en
—
Raimond Spekking (modified) https://commons.wikimedia.org/wiki/File:Acer_Extensa_5220_-_Columbia_MB_06236-1N_-_Intel_Celeron_M_530_-_SLA2G_-_in_Socket_479-5029.jpg
CC BY-SA 4.0 https://creativecommons.org/licenses/by-sa/4.0/deed.en
—
Russian Airborne Troops (modified) https://commons.wikimedia.org/wiki/File:Vladislav_Achalov_at_the_Airborne_Troops_Day_in_Moscow_%E2%80%93_August_2,_2008.jpg
“Soldiers of Russia” Cultural Center (modified) https://commons.wikimedia.org/wiki/File:Col._Leonid_Khabarov_in_an_everyday_service_uniform.JPG
CC BY-SA 3.0 https://creativecommons.org/licenses/by-sa/3.0/deed.en
#pluralistic#habsburg ai#self censorship#henry farrell#digital dictatorships#machine learning#dictator's dilemma#eddie yang#preference falsification#political science#training bias#scholarship#spirals of delusion#algorithmic bias#ml#Fully automated data driven authoritarianism#authoritarianism#gigo#garbage in garbage out garbage back in#gigogbi#yuval noah harari#gubbish#pkd#philip k dick#phildickian
833 notes
·
View notes
Text
I'm really not a villain enjoyer. I love anti-heroes and anti-villains. But I can't see fictional evil separate from real evil. As in not that enjoying dark fiction means you condone it, but that all fiction holds up some kind of mirror to the world as it is. Killing innocent people doesn't make you an iconic lesbian girlboss it just makes you part of the mundane and stultifying black rot of the universe.
"But characters struggling with honour and goodness and the egoism of being good are so boring." Cool well some of us actually struggle with that stuff on the daily because being a good person is complicated and harder than being an edgelord.
Sure you can use fiction to explore the darkness of human nature and learn empathy, but the world doesn't actually suffer from a deficit of empathy for powerful and privileged people who do heinous stuff. You could literally kill a thousand babies in broad daylight and they'll find a way to blame your childhood trauma for it as long as you're white, cisgender, abled and attractive, and you'll be their poor little meow meow by the end of the week. Don't act like you're advocating for Quasimodo when you're just making Elon Musk hot, smart and gay.
#this is one of the reasons why#although i would kill antis in real life if i could#i also don't trust anyone who identifies as 'pro-ship'#it's just an excuse to shut down legitimate ethical questions and engaging in honest self-reflective media consumption and critique#art doesn't exist in a vacuum#it's a flat impossibility for it not to inform nor be informed by real world politics and attitudes#because that's what it means to be created by human hands#we can't even make machine learning thats not just human bias fed into an algorithm#if the way we interact with art truly didn't influence anything then there would be no value in it#just because antis have weaponized those points in the most bad faith ways possible#doesn't mean you can ignore them in good faith#anyway fandom stans villains because society loves to defend and protect abusers#it's not because you get the chance to be free and empathetic and indulge in your darkness and what not#it's just people's normal levels of attachment to shitty people with an added layer of justification for it#this blog is for boring do-gooder enjoyers only#lol#knee of huss#fandom wank#media critique#pop culture#fandom discourse
205 notes
·
View notes
Text
communist generative ai boosters on this website truly like

#generative ai#yes the cheating through school arguments can skew into personal chastisement instead of criticising the for-profit education system#that's hostile to learning in the first place#and yes the copyright defense is self-defeating and goofy#yes yeeeeeeeeeees i get it but fucking hell now the concept of art is bourgeois lmaao contrarian ass reactionary bullshit#whYYYYYYY are you fighting the alienation war on the side of alienation????#fucking unhinged cold-stream marxism really is just like -- what the fuck are you even fighting for? what even is the point of you?#sorry idk i just think that something that is actively and exponentially heightening capitalist alienation#while calcifying hyper-extractive private infrastructure to capture all energy production as we continue descending into climate chaos#and locking skills that our fucking species has cultivated through centuries of communicative learning behind an algorithmic black box#and doing it on the back of hyperexploitation of labour primarily in the neocolonial world#to try and sort and categorise the human experience into privately owned and traded bits of data capital#explicitly being used to streamline systematic emiseration and further erode human communal connection#OH I DON'T KNOW seems kind of bad!#seems kind of antithetical to and violent against the working class and our class struggle?#seems like everything - including technology - has a class character and isn't just neutral tools we can bend to our benefit#it is literally an exploitation; extraction; and alienation machine - idk maybe that isn't gonna aid the struggle#and flourishing of the full panoply of human experience that - i fucking hope - we're fighting for???#for the fullness of human creative liberation that can only come through the first step of socialist revolution???#that's what i'm fighting for anyway - idk what the fuck some of you are doing#fucking brittle economic marxists genuinely defending a technology that is demonstrably violent to the sources of all value:#the soil and the worker#but sure it'll be fine - abundance babey!#WHEW.
9 notes
·
View notes
Text
PSA:
An algorithm is simply a list of instructions used to perform a computation. They've existed for use by mathematicians long prior to the invention of computers. Nearly everything a computer does is algorithmic in some way. It is not inherently a machine-learning concept (though machine learning systems do use algorithms), and websites do not have special algorithms designed just for you. Sentences like "Youtube is making bad recommendations, I guess I messed up my algorithm" simply make no sense. No one at Youtube HQ has written a bespoke algorithm just for you.
Furthermore, people often try to distinguish between more predictable and less predictable software systems (eg tag-based searching vs data-driven search/fuzzy-finding) by referring to the less predictable version as "algorithmic". Deterministic algorithms are still algorithms. Better terms for most of these situations include:
data-driven
fuzzy
probabilistic
machine-learning/ML
Thank you.
#196#r196#r/196#algorithm#algorithmic#search#search engine#recommendation system#machine learning#ai#artificial intelligence
6 notes
·
View notes
Text

Neturbiz Enterprises - AI Innov7ions
Our mission is to provide details about AI-powered platforms across different technologies, each of which offer unique set of features. The AI industry encompasses a broad range of technologies designed to simulate human intelligence. These include machine learning, natural language processing, robotics, computer vision, and more. Companies and research institutions are continuously advancing AI capabilities, from creating sophisticated algorithms to developing powerful hardware. The AI industry, characterized by the development and deployment of artificial intelligence technologies, has a profound impact on our daily lives, reshaping various aspects of how we live, work, and interact.
#ai technology#Technology Revolution#Machine Learning#Content Generation#Complex Algorithms#Neural Networks#Human Creativity#Original Content#Healthcare#Finance#Entertainment#Medical Image Analysis#Drug Discovery#Ethical Concerns#Data Privacy#Artificial Intelligence#GANs#AudioGeneration#Creativity#Problem Solving#ai#autonomous#deepbrain#fliki#krater#podcast#stealthgpt#riverside#restream#murf
17 notes
·
View notes
Text
I desprately need someone to talk to about this
I've been working on a system to allow a genetic algorithm to create DNA code which can create self-organising organisms. Someone I know has created a very effective genetic algorithm which blows NEAT out of the water in my opinion. So, this algorithm is very good at using food values to determine which organisms to breed, how to breed them, and the multitude of different biologically inspired mutation mechanisms which allow for things like meta genes and meta-meta genes, and a whole other slew of things. I am building a translation system, basically a compiler on top of it, and designing an instruction set and genetic repair mechanisms to allow it to convert ANY hexadecimal string into a valid, operable program. I'm doing this by having an organism with, so far, 5 planned chromosomes. The first and second chromosome are the INITIAL STATE of a neural network. The number and configuration of input nodes, the number and configuration of output nodes, whatever code it needs for a fitness function, and the configuration and weights of the layers. This neural network is not used at all in the fitness evaluation of the organism, but purely something the organism itself can manage, train, and utilize how it sees fit.
The third is the complete code of the program which runs the organism. Its basically a list of ASM opcodes and arguments written in hexadecimal. It is comprised of codons which represent the different hexadecimal characters, as well as a start and stop codon. This program will be compiled into executable machine code using LLVM IR and a custom instruction set I've designed for the organisms to give them a turing complete programming language and some helper functions to make certain processes simpler to evolve. This includes messages between the organisms, reproduction methods, and all the methods necessary for the organisms to develop sight, hearing, and recieve various other inputs, and also to output audio, video, and various outputs like mouse, keyboard, or a gamepad output. The fourth is a blank slate, which the organism can evolve whatever data it wants. The first half will be the complete contents of the organisms ROM after the important information, and the second half will be the initial state of the organisms memory. This will likely be stored as base 64 of its hash and unfolded into binary on compilation.
The 5th chromosome is one I just came up with and I am very excited about, it will be a translation dictionary. It will be 512 individual codons exactly, with each codon pair being mapped between 00 and FF hex. When evaulating the hex of the other chromosomes, this dictionary will be used to determine the equivalent instruction of any given hex pair. When evolving, each hex pair in the 5th organism will be guaranteed to be a valid opcode in the instruction set by using modulus to constrain each pair to the 55 instructions currently available. This will allow an organism to evolve its own instruction distribution, and try to prevent random instructions which might be harmful or inneficient from springing up as often, and instead more often select for efficient or safer instructions.
#ai#technology#genetic algorithm#machine learning#programming#python#ideas#discussion#open source#FOSS#linux#linuxposting#musings#word vomit#random thoughts#rant
7 notes
·
View notes
Text
I'm 4 streams and a collective 16-ish hours behind.
#Liu Yuning#OTL#i wish there were a machine i could hook up to my brain#that auto-transcribes as i watch/listen#the newest stream- douyin algorithm thinks ning-ge has no interest in girls & starts showing him boys instead. i'm dying. X'D#not beating the allegations ning-ge watches the shorts to 'learn' something
9 notes
·
View notes
Text
Did anyone else notice the unexpected shift?
In the past year, the MLearning Art community saw breakthroughs that defy expectation.
They challenge how we imagine, create, and share art
#machinelearning#artificialintelligence#art#digitalart#mlart#datascience#algorithm#ai art#machine learning
5 notes
·
View notes
Text
Machine Learning: A Comprehensive Overview
Machine Learning (ML) is a subfield of synthetic intelligence (AI) that offers structures with the capacity to robotically examine and enhance from revel in without being explicitly programmed. Instead of using a fixed set of guidelines or commands, device studying algorithms perceive styles in facts and use the ones styles to make predictions or decisions. Over the beyond decade, ML has transformed how we have interaction with generation, touching nearly each aspect of our every day lives — from personalised recommendations on streaming services to actual-time fraud detection in banking.

Machine learning algorithms
What is Machine Learning?
At its center, gadget learning entails feeding facts right into a pc algorithm that allows the gadget to adjust its parameters and improve its overall performance on a project through the years. The more statistics the machine sees, the better it usually turns into. This is corresponding to how humans study — through trial, error, and revel in.
Arthur Samuel, a pioneer within the discipline, defined gadget gaining knowledge of in 1959 as “a discipline of take a look at that offers computers the capability to study without being explicitly programmed.” Today, ML is a critical technology powering a huge array of packages in enterprise, healthcare, science, and enjoyment.
Types of Machine Learning
Machine studying can be broadly categorised into 4 major categories:
1. Supervised Learning
For example, in a spam electronic mail detection device, emails are classified as "spam" or "no longer unsolicited mail," and the algorithm learns to classify new emails for this reason.
Common algorithms include:
Linear Regression
Logistic Regression
Support Vector Machines (SVM)
Decision Trees
Random Forests
Neural Networks
2. Unsupervised Learning
Unsupervised mastering offers with unlabeled information. Clustering and association are commonplace obligations on this class.
Key strategies encompass:
K-Means Clustering
Hierarchical Clustering
Principal Component Analysis (PCA)
Autoencoders
three. Semi-Supervised Learning
It is specifically beneficial when acquiring categorised data is highly-priced or time-consuming, as in scientific diagnosis.
Four. Reinforcement Learning
Reinforcement mastering includes an agent that interacts with an surroundings and learns to make choices with the aid of receiving rewards or consequences. It is broadly utilized in areas like robotics, recreation gambling (e.G., AlphaGo), and independent vehicles.
Popular algorithms encompass:
Q-Learning
Deep Q-Networks (DQN)
Policy Gradient Methods
Key Components of Machine Learning Systems
1. Data
Data is the muse of any machine learning version. The pleasant and quantity of the facts directly effect the performance of the version. Preprocessing — consisting of cleansing, normalization, and transformation — is vital to make sure beneficial insights can be extracted.
2. Features
Feature engineering, the technique of selecting and reworking variables to enhance model accuracy, is one of the most important steps within the ML workflow.
Three. Algorithms
Algorithms define the rules and mathematical fashions that help machines study from information. Choosing the proper set of rules relies upon at the trouble, the records, and the desired accuracy and interpretability.
4. Model Evaluation
Models are evaluated the use of numerous metrics along with accuracy, precision, consider, F1-score (for class), or RMSE and R² (for regression). Cross-validation enables check how nicely a model generalizes to unseen statistics.
Applications of Machine Learning
Machine getting to know is now deeply incorporated into severa domain names, together with:
1. Healthcare
ML is used for disorder prognosis, drug discovery, customized medicinal drug, and clinical imaging. Algorithms assist locate situations like cancer and diabetes from clinical facts and scans.
2. Finance
Fraud detection, algorithmic buying and selling, credit score scoring, and client segmentation are pushed with the aid of machine gaining knowledge of within the financial area.
3. Retail and E-commerce
Recommendation engines, stock management, dynamic pricing, and sentiment evaluation assist businesses boom sales and improve patron revel in.
Four. Transportation
Self-riding motors, traffic prediction, and route optimization all rely upon real-time gadget getting to know models.
6. Cybersecurity
Anomaly detection algorithms help in identifying suspicious activities and capacity cyber threats.
Challenges in Machine Learning
Despite its rapid development, machine mastering still faces numerous demanding situations:
1. Data Quality and Quantity
Accessing fantastic, categorised statistics is often a bottleneck. Incomplete, imbalanced, or biased datasets can cause misguided fashions.
2. Overfitting and Underfitting
Overfitting occurs when the model learns the education statistics too nicely and fails to generalize.
Three. Interpretability
Many modern fashions, specifically deep neural networks, act as "black boxes," making it tough to recognize how predictions are made — a concern in excessive-stakes regions like healthcare and law.
4. Ethical and Fairness Issues
Algorithms can inadvertently study and enlarge biases gift inside the training facts. Ensuring equity, transparency, and duty in ML structures is a growing area of studies.
5. Security
Adversarial assaults — in which small changes to enter information can fool ML models — present critical dangers, especially in applications like facial reputation and autonomous riding.
Future of Machine Learning
The destiny of system studying is each interesting and complicated. Some promising instructions consist of:
1. Explainable AI (XAI)
Efforts are underway to make ML models greater obvious and understandable, allowing customers to believe and interpret decisions made through algorithms.
2. Automated Machine Learning (AutoML)
AutoML aims to automate the stop-to-cease manner of applying ML to real-world issues, making it extra reachable to non-professionals.
3. Federated Learning
This approach permits fashions to gain knowledge of across a couple of gadgets or servers with out sharing uncooked records, enhancing privateness and efficiency.
4. Edge ML
Deploying device mastering models on side devices like smartphones and IoT devices permits real-time processing with reduced latency and value.
Five. Integration with Other Technologies
ML will maintain to converge with fields like blockchain, quantum computing, and augmented fact, growing new opportunities and challenges.
2 notes
·
View notes
Text
why is everything called AI now. boy thats an algorithm
#'ubers evil AI will detect your phone battery is low and raise the prices accordingly' thats fucked up but it#doesnt need a machine learning program for that#and not algorithm like your social media feed or whatever like in the most basic sense of the definition
7 notes
·
View notes
Text
fell down the youtube rabbithole of essays about the indie internet and 90/y2k-style personal and self-made websites on neocities et al as counterculture to the modern internet and guess what ads i keep getting. fuckin. ai-powered website tools where you write a prompt and get a ready-to-use pre-made website in minutes. brb i'm gonna go kill all ai and marketing companies with hammers 💥💥💥
#add that to the list of hints that we live in the darkest timeline!#youtube person: here's why you should free yourself from algorithms and join the indie internet with your unique and self-made website!#it will take some effort and there's a learning curve and it might look a bit tacky and it's absolutely unprofitable#but it's fun uniquely your own and builds community!#ad on the same video: stop using your brain give up creativity and get a website that looks like every other website!#give us money feed us your data and use the plagiarism environment-destroying job-stealing machine!!#it's all so fucking bleak man.#x
2 notes
·
View notes
Text
KNN Algorithm | Learn About Artificial Intelligence
The k-Nearest Neighbors (KNN) algorithm is a simple, versatile, and popular machine learning method used for both classification and regression tasks, making predictions based on the proximity of data points to their nearest neighbors in a dataset.
Detect Triangle shape inside image using Java Open CV //Triangle Transform Computer Vision part one

KNN is a supervised learning algorithm, meaning it learns from labeled data to make predictions on new, unseen data. KNN relies on a distance metric.
Lazy Learning: It's considered a "lazy learner" because it doesn't have a dedicated training phase; instead, it stores the training data and uses it directly for prediction.
Proximity-Based: KNN relies on the principle that similar data points are located near each other, and it makes predictions based on the classes or values of the nearest neighbors.
Classification: In classification, KNN assigns a new data point to the class that is most common among its k nearest neighbors.
Regression: In regression, KNN predicts a value by averaging the values of the k nearest neighbors.
Parameter k: The parameter 'k' determines the number of nearest neighbors to consider when making a prediction.
#machine learning#artificial image#artificial intelligence#knn algorithm#opencv#image processing#ai image#ai image generator#animation#animation practice#animation design#3d printing#3d image producing#3d image process
5 notes
·
View notes
Text
UAITrading (Unstoppable AI Trading): AI-Powered Trading for Stocks, Forex, and Crypto
https://uaitrading.ai/ UAITrading For On trading volumes offers, many free trade analysis tools and pending bonuses | Unstoppable AI Trading (Uaitrading) is a platform that integrates advanced artificial intelligence (AI) technologies to enhance trading strategies across various financial markets, including stocks, forex, and cryptocurrencies. By leveraging AI, the platform aims to provide real-time asset monitoring, automated portfolio management, and optimized trade execution, thereby simplifying the investment process for users.

One of the innovative features of Unstoppable AI Trading is its UAI token farming, which offers users opportunities to earn additional income through decentralized finance (DeFi) mechanisms. This approach allows traders to diversify their investment strategies and potentially increase returns by participating in token farming activities.
The platform's AI-driven systems are designed to analyze vast amounts of market data, identify profitable trading opportunities, and execute trades without human intervention. This automation not only enhances efficiency but also reduces the emotional biases that often affect human traders, leading to more consistent and objective trading decisions.
By harnessing the power of AI, Unstoppable AI Trading aims to empower both novice and experienced traders to navigate the complexities of financial markets more effectively, offering tools and strategies that adapt to dynamic market conditions
#Uaitrading#AI Trading#Automated Trading#Forex Trading AI#Crypto Trading Bot#UAI Token#Token Farming#Decentralized Finance (DeFi)#AI Investment Platform#Smart Trading Algorithms#AI Stock Trading#Machine Learning in Trading#AI-Powered Portfolio Management#Algorithmic Trading#Uaitrading AI Trading#Forex AI#Smart Trading#Stock Market#AI Investing#Machine Learning Trading#Trading Bot#Crypto AI#DeFi#UAI#Crypto Investing
2 notes
·
View notes