#How to Use the Indexing API
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr.com rank in the US is 25.
Text
How to Index Webpages & Backlinks in 5 Minutes by Google Indexing API in Hindi - (Free & Very Easy)
youtube
Get Your Webpages and Backlinks Indexed Immediately by Using Google Indexing API In this video, we have explained the step-by-step process of how you can use Google’s new indexing API to get your website’s pages and backlinks crawled immediately. The process of setting this up isn’t typically very easy, but if you watch this video carefully and follow the given steps, I am sure you can save your time and the internet. You can get higher ranking in Search Engine. So, without further delay – let’s watch the full video and get indexed your backlinks and webpages. I hope that you were able to make great use of this Video to help you get up and running with Google’s Indexing API. Indexing process and Code: https://docs.google.com/document/d/10lIOtorCubWV94Pzz0juHUOG7c1-pqEit6s94qgFd6s/edit#heading=h.vyd4fqe3e5al
#API for backlinks indexing#How to index backlinks instantly?#How to index webpages instantly?#How to Use the Indexing API#Step-by-step guide to indexing backlinks by Google Indexing API#How to index backlinks with Google Indexing API?#Google Indexing API#Backlink indexing#Google Indexing API with Python#Backlink Indexing tool#How To Index Backlinks Faster In 2023?#How to Index Backlinks Faster Than Ever Before?#The Ultimate Guide To Google Indexing API#How to index backlinks quickly in Google?#Youtube
0 notes
Text
Quick Tumblr Backup Guide (Linux)
Go to www.tumblr.com/oauth/apps and click the "Register Application" button
Fill in the form. I used the following values for the required fields: Application Name - tumblr-arch Application Website - https://github.com/Cebtenzzre/tumblr-utils Application Description - tumblr archival instance based on tumblr-utils Adminstrative contact email - < my personal email > Default callback URL - https://github.com/Cebtenzzre/tumblr-utils OAuth2 redirect URLs - https://github.com/Cebtenzzre/tumblr-utils
Get the OAuth Consumer Key for your application. It should be listed right on the www.tumblr.com/oauth/apps page.
Do python things:
# check python version: python --version # I've got Python 3.9.9 # create a venv: python -m venv --prompt tumblr-bkp --upgrade-deps venv # activate the venv: source venv/bin/activate # install dependencies: pip install tumblr-backup pip install tumblr-backup[video] pip install tumblr-backup[jq] pip install tumblr-backup[bs4] # Check dependencies are all installed: pip freeze # set the api key: tumblr-backup --set-api-key <OAuth Consumer Key>
So far I have backed up two blogs using the following:
tumblr-backup --save-audio --save-video --tag-index --save-notes --incremental -j --no-post-clobber --media-list <blog name>
There have been two issues I had to deal with so far:
one of the blogs was getting a "Non-OK API repsonse: HTTP 401 Unauthorized". It further stated that "This is a dashboard-only blog, so you probably don't have the right cookies. Try --cookiefile." I resolved the issue by a) setting the "Hide from people without an account" to off and b) enabling a custom theme. I think only step a) was actually necessary though.
"Newly registered consumers are rate limited to 1,000 requests per hour, and 5,000 requests per day. If your application requires more requests for either of these periods, please use the 'Request rate limit removal' link on an app above." Depending on how big your blog is, you may need to break up the download. I suspect using the "-n COUNT" or "--count COUNT" to save only COUNT posts at a time, combined with the "--incremental" will allow you to space things out. You would have to perform multiple passes though. I will have to play with that, so I'll report back my findings.
82 notes
·
View notes
Text

(back to rec index)
F
Fa Subito by kim47
Faerie-Touched by Blind_Author
Father by NomdePlume
February 15th by prettysailorsoldier
Fifth Time’s the Charm by Eligh
Finally Home by LondonSpirit
The First and Last Trilogy by Phyona
Five Times John Talked to Mummy (and one time he didn’t) by coloredink
five times sherlock holmes lied to john watson (and one time he finally told the truth) by miss_frankenstein
Flash Bang by mydwynter
A Fold in the Universe by darkest_bird & Engazed
for all that bitter delights do sour by darcylindbergh
For The Honour Of The Division by flawedamythyst
Forever Turning Corners by DiscordantWords
A Fortuitous Oversight by scribblesinthebyline
The Four Horseman of the Apocalypse by SilentAuror
Four Times John Watson Didn’t Propose, and One Time Sherlock Did by jessevarant
Frenzy by eflo
Full Circle by cumberqueer
Full Mount by ArwaMachine
The Fundamental Things Apply by Raina_at
G
The Genetic manipulation series by TooManyChoices
Genus: Apis by TakePenAndInk
Getting On With It by StarlightAndFireflies
Ghost Stories by SwissMiss
The Gilded Cage by BeautifulFiction
Giveaway fic #1 by ConsultingPurplePants
Given In Evidence by verityburns
A Glimpse by amaruuk
Goodness Gives Extras by mydwynter
Gratitude by wearitcounts
Grey Matters by J_Baillier
The Ground Beneath Your Feet by Chryse
H
hands full of matter by simplyclockwork
Having by wearitcounts
He’s Not Paid Enough to Deal with This Shit by janonny
Hear No Evil, Speak No Evil by PipMer
The Heart In The Whole by verityburns
The Heart On Your Sleeve by flawedamythyst
Hello You by weeesi
Helpless by ivyblossom
here, our minutes grow hours by the_arc5
Here Be Dragons by Winter_of_our_Discontent
Here We Go Again by disfictional
Here With Me by bodyandsoul
here’s to love (here’s to us) by trustingno1
High and Tight, Soft and Loose by cwb
The High Tide Series by stardust_made
Hindsight by LapisLazuli
His Favourite Four-Letter F-Words by cathedral_carver
Hitting the Water at at Sixty Miles an Hour by what_alchemy
Hold You Like a Weapon by MissDavis
Holding Steady by darcylindbergh
Home by liriodendron
Home by Resonant
A Hooligans’ Game Played By Gentlemen by scullyseviltwin
HOT DOLPHIN SEX by cwb
House of Light by AlgySwinburne
How To Date Your Flatmate by EchoSilverWolf
How Will I Know? by eragon19
(back to rec index)
76 notes
·
View notes
Text

⭐️
Author: DancingFey
Group C: secret admirer; let’s get away; bees, honey
⭐️
The Bee's a Bookworm
“Snakeweed for the base, fennel for strength, garlic for protection…” Rumplestilkin hummed as he dropped each ingredient into a pot of boiling water. “Three out of four is not complete! Tell me, which ingredient do I seek?”
His question was answered by his uninvited guest buzzing in his ear.
When they first arrived at the Dark Castle, he refused to break their curse without a deal. The fact that they couldn’t communicate was not his problem. He expected them to leave, but the little bug stayed even after multiple threats of shoe stomping.
He took a moment to replace his spinner’s smile with an impish smirk before turning around to face the Apis Mellifera that had been haunting his castle.
The bee hovered inches from his face.
“Well! Li’l bee, since you refuse to leave, you may as well make yourself useful.”
The honeybee flew in his face, ruffling his bangs before flying off towards his cabinet of herbs, landing on a jar.
“Testy today, dearie?” He grumbled before fluffing his hair back into place and walking over.
“Ah-ha! Thyme, of course!” He grabbed the jar and returned to the brewing potion. “How could I forget the herb for bravery in a Bravery Potion!”
Rumple extended his index finger, and the honeybee jumped from the jar onto his scaly hand without hesitation. He set the bee on his shoulder, where they would sit and observe as he worked. Not that it stopped them from flying down anytime he brought out a book.
At first, he had considered killing them, but on the fourth day, the honeybee found a passage that he had spent weeks searching for in an old botanist’s journal containing theories of how feyberry and dreamweave vines may react when dissolved with unicorn blood. Then, the bloody thing had to go and wiggle their butt high in the air, hop side to side, spin around, and perform an aerial backflip in what Bae would have called a victory dance. It reminded him so much of his son that his heart clenched at the sight.
That was the moment he knew he couldn’t kill the damn bee.
It became routine for the cursed bee to assist him in his research. They would point to paragraphs that contained the information he was looking for. And if he missed something from a previous passage, they directed him to the chapter by nestling their body between the pages, wiggling their black-striped backside to push their body underneath.
He refused to acknowledge how cute they were or that he was rapidly lowering his defenses around them.
As he finished the Bravery Potion, a white dove tapped on his window. “Dove! Good, you're back! I have a use for you.”
Rumple opened the window, and the shapeshifter transformed with a plume of grey smoke into a bald, scarred, muscular man.
“I did not expect you to take in another pet, master.”
“Ha! One pet is more than enough work for me. No, you can give me your report on your mission later. For now, I need you to translate. You see, this poor, helpless creature is cursed! And only I can break it. But alas, a deal must be struck!”
Dove stared at his master’s antics and sighed. “And what are your terms of the contract, master Rumpelstiltskin?”
“Hmm, well the little bugger has been surprisingly…helpful. I will break their curse, returning them to their human form. In return, they will stay in the Dark Castle with me, and work as my research assistant for…oh, say five years.”
A contract appeared on the table at the wave of his hand, and the bee instantly flew down to read it. Once finished, Dove translated their response.
“They will agree to your terms if you make an amendment. They want to be allowed to write home with the concession that you can read and approve the letters beforehand.”
“Fine, but remember dearie, no one breaks a deal with me.”
He swore the bee rolled their eyes at him before dipping their forelegs in ink and signing the contract.
“It’s a deal!” He giggled before black, purple-tinted magic consumed the bee, leaving a beautiful young woman sitting on his desk with chestnut curls and eyes so blue they were like the reflection of light on the ocean.
“Did it work?” She frantically patted down her blue dress, “It worked! Oh, thank you. Thank You!”
She jumped off the table and wrapped her arms around his neck. Rumple glanced at Dove for assistance, but he only raised an eyebrow and smirked—the bastard.
“Yes, yes, dearie.” He awkwardly patted her back, “We made a deal…and now…” His voice trilled, “The monster has you in its clutches!”
“You’re not a monster. You’re a scholar. The amount of knowledge you have is incredible! And your books! Some of those records have been lost for centuries. And you don’t keep them in some ostentatious display to collect dust. You use them. You’re…you’re a genius! I’ve seen you create potions and spells that no one has ever thought of!”
This woman was either a miracle or a hallucination. Rumplestiltskin was leaning more towards the drugs.
“Sounds like you have a secret admirer,” Dove nudged his shoulder. Rumple stared at him as if he’d also lost his mind, but the cretin only shrugged…and then left!
“I-Is it so hard to believe? For all your threats of squashing me, you never harmed me, and you’re so passionate about your work. How could I not admire someone so dedicated to their craft? I…I confess I have always dreamed of being a scholar. Perhaps this is not how I imagined it happening, but I am honored to be your research assistant.”
She took a deep breath and reached out her hand. “I never got the chance to introduce myself. My name is Belle.”
Rumple stared at her hand, confounded, but shook it, “I don’t believe I need any introductions, dearie?”
She laughed, “No, but now I can finally get you out of this room.”
“W-What?”
“You haven’t left this workshop at all since I got here! Not to eat, drink, or sleep. Heavens forbid, you step outside! Rumple, you need to take a break. Breathe fresh air. Feel the sun’s warmth on your skin. Come on, let’s get away from this lab.”
She grabbed his hand and led him outside. Stunned and still half convinced Belle was a hallucination, he followed. They walked until they passed through a thicket of trees that opened into a grove filled with wildflowers.
“Isn’t it beautiful?” She let go of his hand and twirled around the flowers as if she belonged among them.
Yes, you are. Rumple shook his head to stop such nonsensical thoughts.
“When I was a bee, I was drawn here by the flowers' scent. They smelled so sweet and rich, unlike anything I had ever experienced as a human, and the flowers had so many vibrant colors, some of which I had never seen before! I thought this would be a great place to get away and have a picnic.”
“Picnic?”
“Yes, you need to eat, and I haven’t had human food since my ex-fiancé’s mother cursed me.”
He would be asking her questions about that later.
“A picnic, my lady wants. A picnic she shall get.” He gave her a mock bow before a picnic blanket with various dishes appeared.
Belle looked to see what foods he had conjured, when her eyes widened, “Oh! Honey cakes…” She started laughing and looked at him expectantly, to which he only raised an eyebrow and tilted his head in a silent question. “Get it? ‘Bees, honey.’ Remember?”
His face lit up at the memory, and he sang in a high-pitched voice, “Bees, honey. Oh, how lovely! A guest has arrived! A guest has arrived! Oh, what scheme has she contrived for this bee…is surely a spy!”
“And then you caught me in a jar.”
“It’s not every day a cursed maiden flies into my workshop, honey. Odds were the Evil Queen sent you to spy on me.”
Wait, honey?! Where did that come from?!
“Yes, you were insistent in your interrogation, even though we couldn’t communicate,” Belle smiled.
“You won’t be smiling at me for long.” He pointed a clawed finger at her, “I plan to work you to the bone.”
“I’m looking forward to it.”
Who was this woman? She wasn’t afraid of him, which already made her part of a small minority, but then she dared to not only make a demand from him but physically make him obey! Not Dove, Regina, or even Jefferson would be that bold! They would at least worry he might take revenge, but she treated him like a normal man, not a monster. She acted as if she saw him as a…friend.
Hallucination or not, Rumpelstiltskin was never letting Belle go.
He smiled back, and with a flick of his wrist, a red rose appeared in his hand.
“A flower for my li’l bee.”
Belle took the rose with a bright smile and mischief sparkling in her eyes. “I’m not a bee anymore.” She leaned across the blanket and kissed his cheek, “I’m your little bookworm.”
25 notes
·
View notes
Text
hey wanna hear about the crescent stack structure because i don't really have anyone to tell this to
YAYYYY!! THANK YOU :3
small note: threads are also referred to internally as lstates (local states) as when creating a new thread, rather than using crescent_open again, they're connected to a single gstate (global state)
the stack is the main data structure in a crescent thread, containing all of the locals and call information.
the stack is divided into frames, and each time a function is called, a new frame is created. each frame has two parts: base and top. a frame's base is where the first local object is pushed to, and the top is the total amount of stack indexes reserved after the base. also in the stack is two numbers, calls and cCalls. calls keeps track of the number of function calls in the thread, whether it's to a c or crescent function. cCalls keeps track of the number of calls to c functions. c functions, using the actual stack rather than the dynamically allocated crescent stack, could overflow the real stack and crash the program in a way crescent is unable to catch. so we want to limit the amount of these such that this (hopefully) doesn't happen.
calls also keeps track of another thing with the same number, that being the stack level. the stack level is a number starting from 0 that increments with each function call, and decrements on each return from a function. stack level 0 is the c api, where the user called crescent_open (or whatever else function that creates a new thread, that's just the only one implemented right now), and is zero because zero functions have been called before this frame.
before the next part, i should probably explain some terms:
- stack base: the address of the first object on the entire stack, also the base of frame 0
- stack top: address of the object immediately after the last object pushed onto the stack. if there are no objects on the stack, this is the stack base.
- frame base: the address of the first object in a frame, also the stack top upon calling a function (explained later) - frame top: amount of stack indexes reserved for this frame after the base address
rather than setting its base directly after the reserved space on the previous frame, we simply set it right at the stack top, such that the first object on this frame is immediately after the last object on the previous frame (except not really. it's basically that, but when pushing arguments to functions we just subtract the amount of arguments from the base, such that the top objects on the previous frame are in the new frame). this does make the stack structure a bit more complicated, and maybe a bit messy to visualize, but it uses (maybe slightly) less memory and makes some other stuff related to protected calls easier.
as we push objects onto the stack and call functions, we're eventually going to run out of space, so we need to dynamically resize the stack. though first, we need to know how much memory the stack needs. we go through all of the frames, and calculate how much that frame needs by taking the frame base offset from the stack base (framebase - stackbase) and add the frame top (or the new top if resizing the current frame in using crescent_checkTop in the c api). the largest amount a frame needs is the amount that the entire stack needs. if the needed size is less than or equal to a third of the current stack size, it shrinks. if the needed size is greater than he current stack size, it grows. when shrinking or growing, the new size is always calculated as needed * 1.5 (needed + needed / 2 in the code).
when shrinking the stack, it can only shrink to a minimum of CRESCENT_MIN_STACK (64 objects by default). even if the resizing fails, it doesn't throw an error as we still have enough memory required. when growing, if the new stack size is greater than CRESCENT_MAX_STACK, it sets it back down to just the required amount. if that still is over CRESCENT_MAX_STACK, it either returns 1 or throws a stack overflow error depending on the throw argument. if it fails to reallocate the stack, it either throws an out of memory error or returns 1 again depending on the throw argument. growing the stack can throw an error because we don't have the memory required, unlike shrinking the stack.
and also the thing about the way a frame's base is set making protected calls easier. when handling an error, we want to go back to the most recent protected call. we do this by (using a jmp_buf) saving the stack level in the handler (structure used to hold information when handling errors and returning to the protected call) and reverting the stack back to that level. but we're not keeping track of the amount of objects in a stack frame! how do we restore the stack top? because a frame's base is immediately after that last object in the previous frame, and that the stack top is immediately after the last object pushed onto the stack, we just set the top to the stack level above's base.

6 notes
·
View notes
Text
Boost Your Website Performance with URL Monitor: The Ultimate Solution for Seamless Web Management

In today's highly competitive digital landscape, maintaining a robust online presence is crucial. Whether you're a small business owner or a seasoned marketer, optimizing your website's performance can be the difference between success and stagnation.
Enter URL Monitor, an all-encompassing platform designed to revolutionize how you manage and optimize your website. By offering advanced monitoring and analytics, URL Monitor ensures that your web pages are indexed efficiently, allowing you to focus on scaling your brand with confidence.
Why Website Performance Optimization Matters
Website performance is the backbone of digital success. A well-optimized site not only enhances user experience but also improves search engine rankings, leading to increased visibility and traffic. URL Monitor empowers you to stay ahead of the curve by providing comprehensive insights into domain health and URL metrics. This tool is invaluable for anyone serious about elevating their online strategy.
Enhancing User Experience and SEO
A fast, responsive website keeps visitors engaged and satisfied. URL Monitor tracks domain-level performance, ensuring your site runs smoothly and efficiently. With the use of the Web Search Indexing API, URL Monitor facilitates faster and more effective page crawling, optimizing search visibility. This means your website can achieve higher rankings on search engines like Google and Bing, driving more organic traffic to your business.
Comprehensive Monitoring with URL Monitor
One of the standout features of URL Monitor is its ability to provide exhaustive monitoring of your website's health. Through automatic indexing updates and daily analytics tracking, this platform ensures you have real-time insights into your web traffic and performance.
Advanced URL Metrics
Understanding URL metrics is essential for identifying areas of improvement on your site. URL Monitor offers detailed tracking of these metrics, allowing you to make informed decisions that enhance your website's functionality and user engagement. By having a clear picture of how your URLs are performing, you can take proactive steps to optimize them for better results.
Daily Analytics Tracking
URL Monitor's daily analytics tracking feature provides you with consistent updates on your URL indexing status and search analytics data. This continuous flow of information allows you to respond quickly to changes, ensuring your website remains at the top of its game. With this data, you can refine your strategies and maximize your site's potential.
Secure and User-Friendly Interface
In addition to its powerful monitoring capabilities, URL Monitor is also designed with user-friendliness in mind. The platform offers a seamless experience, allowing you to navigate effortlessly through its features without needing extensive technical knowledge.
Data Security and Privacy
URL Monitor prioritizes data security, offering read-only access to your Google Search Console data. This ensures that your information is protected and private, with no risk of sharing sensitive data. You can trust that your website's performance metrics are secure and reliable.
Flexible Subscription Model for Ease of Use
URL Monitor understands the importance of flexibility, which is why it offers a subscription model that caters to your needs. With monthly billing and no long-term commitments, you have complete control over your subscription. This flexibility allows you to focus on growing your business without the burden of unnecessary constraints.
Empowering Business Growth
By providing a user-friendly interface and secure data handling, URL Monitor allows you to concentrate on what truly matters—scaling your brand. The platform's robust analytics and real-time insights enable you to make data-driven decisions that drive performance and growth.
Conclusion: Elevate Your Website's Potential with URL Monitor
In conclusion, URL Monitor is the ultimate solution for anyone seeking hassle-free website management and performance optimization. Its comprehensive monitoring, automatic indexing updates, and secure analytics make it an invaluable tool for improving search visibility and driving business growth.
Don't leave your website's success to chance. Discover the power of URL Monitor and take control of your online presence today. For more information, visit URL Monitor and explore how this innovative platform can transform your digital strategy. Unlock the full potential of your website and focus on what truly matters—scaling your brand to new heights.
3 notes
·
View notes
Text
Pegasus 1.2: High-Performance Video Language Model

Pegasus 1.2 revolutionises long-form video AI with high accuracy and low latency. Scalable video querying is supported by this commercial tool.
TwelveLabs and Amazon Web Services (AWS) announced that Amazon Bedrock will soon provide Marengo and Pegasus, TwelveLabs' cutting-edge multimodal foundation models. Amazon Bedrock, a managed service, lets developers access top AI models from leading organisations via a single API. With seamless access to TwelveLabs' comprehensive video comprehension capabilities, developers and companies can revolutionise how they search for, assess, and derive insights from video content using AWS's security, privacy, and performance. TwelveLabs models were initially offered by AWS.
Introducing Pegasus 1.2
Unlike many academic contexts, real-world video applications face two challenges:
Real-world videos might be seconds or hours lengthy.
Proper temporal understanding is needed.
TwelveLabs is announcing Pegasus 1.2, a substantial industry-grade video language model upgrade, to meet commercial demands. Pegasus 1.2 interprets long films at cutting-edge levels. With low latency, low cost, and best-in-class accuracy, model can handle hour-long videos. Their embedded storage ingeniously caches movies, making it faster and cheaper to query the same film repeatedly.
Pegasus 1.2 is a cutting-edge technology that delivers corporate value through its intelligent, focused system architecture and excels in production-grade video processing pipelines.
Superior video language model for extended videos
Business requires handling long films, yet processing time and time-to-value are important concerns. As input films increase longer, a standard video processing/inference system cannot handle orders of magnitude more frames, making it unsuitable for general adoption and commercial use. A commercial system must also answer input prompts and enquiries accurately across larger time periods.
Latency
To evaluate Pegasus 1.2's speed, it compares time-to-first-token (TTFT) for 3–60-minute videos utilising frontier model APIs GPT-4o and Gemini 1.5 Pro. Pegasus 1.2 consistently displays time-to-first-token latency for films up to 15 minutes and responds faster to lengthier material because to its video-focused model design and optimised inference engine.
Performance
Pegasus 1.2 is compared to frontier model APIs using VideoMME-Long, a subset of Video-MME that contains films longer than 30 minutes. Pegasus 1.2 excels above all flagship APIs, displaying cutting-edge performance.
Pricing
Cost Pegasus 1.2 provides best-in-class commercial video processing at low cost. TwelveLabs focusses on long videos and accurate temporal information rather than everything. Its highly optimised system performs well at a competitive price with a focused approach.
Better still, system can generate many video-to-text without costing much. Pegasus 1.2 produces rich video embeddings from indexed movies and saves them in the database for future API queries, allowing clients to build continually at little cost. Google Gemini 1.5 Pro's cache cost is $4.5 per hour of storage, or 1 million tokens, which is around the token count for an hour of video. However, integrated storage costs $0.09 per video hour per month, x36,000 less. Concept benefits customers with large video archives that need to understand everything cheaply.
Model Overview & Limitations
Architecture
Pegasus 1.2's encoder-decoder architecture for video understanding includes a video encoder, tokeniser, and big language model. Though efficient, its design allows for full textual and visual data analysis.
These pieces provide a cohesive system that can understand long-term contextual information and fine-grained specifics. It architecture illustrates that tiny models may interpret video by making careful design decisions and solving fundamental multimodal processing difficulties creatively.
Restrictions
Safety and bias
Pegasus 1.2 contains safety protections, but like any AI model, it might produce objectionable or hazardous material without enough oversight and control. Video foundation model safety and ethics are being studied. It will provide a complete assessment and ethics report after more testing and input.
Hallucinations
Occasionally, Pegasus 1.2 may produce incorrect findings. Despite advances since Pegasus 1.1 to reduce hallucinations, users should be aware of this constraint, especially for precise and factual tasks.
#technology#technews#govindhtech#news#technologynews#AI#artificial intelligence#Pegasus 1.2#TwelveLabs#Amazon Bedrock#Gemini 1.5 Pro#multimodal#API
2 notes
·
View notes
Note
Maybe I’m just stupid but I downloaded Python, I downloaded the whole tumblr backup thing & extracted the files but when I opened the folder it wasn’t a system it was just a lot of other folders with like reblog on it? I tried to follow the instructions on the site but wtf does “pip-tumblr-download” mean? And then I gotta make a tumblr “app”? Sorry for bugging you w this
no worries! i've hit the same exact learning curve for this tool LMAO, so while my explanations may be more based on my own understanding of how function A leads to action B rather than real knowledge of how these things Work, I'll help where i can!
as far as i understand, pip is simply a way to install scripts through python rather than through manually downloading and installing something. it's done through the command line, so when it says "pip install tumblr-backup", that means to copy-paste that command into a command line window, press enter, and watch as python installs it directly from github. you shouldn't need to keep the file you downloaded; that's for manual installs.
HOWEVER! if you want to do things like saving audio/video, exif tagging, saving notes, filtering, or all of the above, you can look in the section about "optional dependencies" on the github. it lists the different pip install commands you can use for each of those, or an option to install all of them at once!
by doing it using pip, you don't have to manually tell the command line "hey, go to this folder where this script is. now run this script using these options. some of these require another script, and those are located in this other place." instead, it just goes "oh you're asking for the tumblr-backup script? i know where that is! i'll run it for you using the options you've requested! oh you're asking for this option that requires a separate script? i know where that is too!"
as for the app and oauth key, you can follow this tutorial in a doc posted on this post a while back! the actual contents of the application don't matter much; you just need the oauth consumer key provided once you've finished filling out the app information. you'll then go back to your command line and copy-paste in "tumblr-backup --set-api-key API_KEY" where API_KEY is that oauth key you got from the app page.
then you're ready to start backing up! your command line will be "tumblr-backup [options] blog-name", where blog-name is the name of the blog like it says on the tin, and the [options] are the ones listed on the github.
for example, the command i use for this blog is "tumblr-backup -i --tag-index --save-video --save-audio --skip-dns-check --no-reblog nocturne-of-illusions"... "-i" is incremental backups, the whole "i have 100 new posts, just add those to the old backup" function. "--tag-index" creates an index page with all of your tags, for easy sorting! "--save-video", "--save-audio", and "--no-reblog" are what they say they are.
⚠️ (possibly) important! there are two current main issues w backups, but the one that affected me (and therefore i know how to get around) is a dns issue. for any of multiple reasons, your backup might suddenly stall. it might not give a reason, or it might say your internet disconnected. if this happens, try adding "--skip-dns-check" to your options; if the dns check is your issue, this should theoretically solve it.
if you DO have an issue with a first backup, whether it's an error or it stalls, try closing the command window, reopening it, copy-pasting your backup command, and adding "--continue" to your list of options. it'll pick up where it left off. if it gives you any messages, follow the instructions; "--continue" doesn't work well with some commands, like "-i", so you'll want to just remove the offending option until that first backup is done. then you can remove "--continue" and add the other one back on!
there are many cool options to choose from (that i'm gonna go back through now that i have a better idea of what i'm doing ksjdkfjn), so be sure to go through to see if any of them seem useful to you!
#asks#lesbiandiegohargreeves#046txt#hope this is worded well ;; if you need clarification let me know!
2 notes
·
View notes
Text
[Profile picture transcription: An eye shape with a rainbow flag covering the whites. The iris in the middle is red, with a white d20 for a pupil. End transcription.]
Hello! This is a blog specifically dedicated to image transcriptions. My main blog is @mollymaclachlan.
For those who don't know, I used to be part of r/TranscribersOfReddit, a Reddit community dedicated to transcribing posts to improve accessibility. That project sadly had to shut down, partially as a result of the whole fiasco with Reddit's API changes. But I miss transcribing and I often see posts on Tumblr with no alt text and no transcription.
So! Here I am, making a new blog. I'll be transcribing posts that need it when I see them and I have time; likely mainly ones I see on my dashboard. I also have asks open so anyone can request posts or images.
I have plenty of experience transcribing but that doesn't mean I'm perfect. We can always learn to be better and I'm not visually impaired myself, so if you have any feedback on how I can improve my transcriptions please don't hesitate to tell me. Just be friendly about it.
The rest of this post is an FAQ, adapted from one I posted on Reddit.
1. Why do you do transcriptions?
Transcriptions help improve the accessibility of posts. Tumblr has capabilities for adding alt-text to images, but not everyone uses it, and it has a character limit that can hamper descriptions for complex images. The following is a non-exhaustive list of the ways transcriptions improve accessibility:
They help visually-impaired people. Most visually-impaired people rely on screen readers, technology that reads out what's on the screen, but this technology can't read out images.
They help people who have trouble reading any small, blurry or oddly formatted text.
In some cases they're helpful for people with colour deficiencies, particularly if there is low contrast.
They help people with bad internet connections, who might as a result not be able to load images at high quality or at all.
They can provide context or note small details many people may otherwise miss when first viewing a post.
They are useful for search engine indexing and the preservation of images.
They can provide data for improving OCR (Optical Character Recognition) technology.
2. Why don't you just use OCR or AI?
OCR (Optical Character Recoginition) is technology that detects and transcribes text in an image. However, it is currently insufficient for accessibility purposes for three reasons:
It can and does get a lot wrong. It's most accurate on simple images of plain text (e.g. screenshots of social media posts) but even there produces errors from time to time. Accessibility services have to be as close to 100% accuracy as possible. OCR just isn't reliable enough for that.
Even were OCR able to 100%-accurately describe text, there are many portions of images that don't have text, or relevant context that should be placed in transcriptions to aid understanding. OCR can't do this.
"AI" in terms of what most people mean by it - generative AI - should never be used for anything where accuracy is a requirement. Generative AI doesn't answer questions, it doesn't describe images, and it doesn't read text. It takes a prompt and it generates a statistically-likely response. No matter how well-trained it is, there's always a chance that it makes up nonsense. That simply isn't acceptable for accessibility.
3. Why do you say "image transcription" and not "image ID"?
I'm from r/TranscribersOfReddit and we called them transcriptions there. It's ingrained in my mind.
For the same reason, I follow advice and standards from our old guidelines that might not exactly match how many Tumblr transcribers do things.
3 notes
·
View notes
Text
java bootcamp ~ 2nd week (๑'ᵕ'๑)⸝
(or more like a pokedex update)
After practicing more javascript, I decided to get back to my pokedex and work on it before going into the next step on bootcamp (that would be their angular course)
I'm still having a hard time understanding API and how to use it;; but that's fine. I'll keep studying and practicing ( 。 •̀ ᴖ •́ 。)૭
Monday I finished the index page (which I want to change it later!!). and now I've been working on the profile page. I got stuck with CSS length units, couldn't understand the difference between rem/em/etc and it didn't help that my head was foggy, but today I could study more and now I get it better yey!!
The profile page is looking like this right now (mobile first):
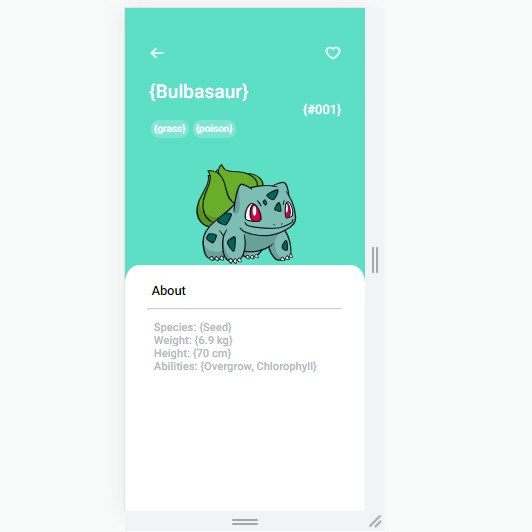
I'm still trying to figure out how I want it to be displayed on a bigger device *thinking*, but I'm pretty happy about how it turned out as it was made without tutoring ˶‘ ᵕ ‘˶
Another part that I liked is the two buttons on the top. I couldn't add an event with javascript so the arrow button works as a back page button. I kind of know how I can do it, but I don't know what I did wrong Σ(-᷅_-᷄๑) For now I did this on html:

ᶦ ʷᶦˡˡ ᶜʰᵃⁿᵍᵉ ᶦᵗ ˡᵃᵗᵉʳ or perhaps I dont need javascript?
19 notes
·
View notes
Text
obviously we don't know exactly how this is being done but from what i understand this new midjourney deal (if it even happens) is specifically about tumblr giving midjourney access to the Tumblr API, which it previously did not have. various datasets used in AI training probably already include data from Tumblr because they either scraped data from Tumblr specifically (something that is probably technically against TOS but can be done without accessing the API, also something I have personally done many times on websites like TikTok and Twitter for research) or from google (which indexes links and images posted to Tumblr that you can scrape without even going on Tumblr). The API, which I currently have access to bc of my university, specifically allows you to create a dataset from specific blogs and specific tags. This dataset for tags looks basically exactly like the tag page you or i would have access to, with only original posts showing up but with all of the metadata recorded explicitly (all info you have access to from the user interface of Tumblr itself, just not always extremely clearly). For specific blogs it does include reblogs as well, but this generally seems like a less useful way of collecting data unless you are doing research into specific users (not something i am doing). It depends on your institution what the limits of this API are of course, and it does seem a bit concerning that Tumblr internally seems to have a version that includes unanswered asks, private posts, drafts etc but through the API itself you cannot get these posts. If you choose to exclude your blog from 3rd party partners, what it seems like Tumblr is doing is just removing your original posts from being indexed in any way, so not showing up on Google, not showing up in tags, in searches etc. This means your original posts arent showing up when asking the API for all posts in a specific tag, and it probably also makes it impossible to retrieve a dataset based on your blog. This means it doesnt just exclude your posts and blog from any dataset midjourney creates (if they even take the deal), it's also excluded from the type of research i'm doing (not saying this as a guilt trip, i already have my datasets so i dont care) and it's seemingly excluded from all on-site searches by other users. it's also important to note that every single thing you can do with the Tumblr API to collect data on posts and users you could feasibly also do manually by scrolling while logged in and just writing everything down in an excel sheet.
#this isnt a Take about whether or not you should turn on that new option bc like idk which option is better personally. like im not sure#im just trying to clarify what i think is going on as someone who's used this API quite a lot
3 notes
·
View notes
Text
Process "File" Descriptors (PID FD)
Linux in recent years has fixed some of the biggest annoyances I had with the UNIX model, and I'm feeling rather happy about this. One example of this is with how you can refer to processes.
With traditional UNIX APIs, you can never signal a process without a PID reuse race condition. The problem is somewhat inherent to the model: a PID is just an integer reference to a kernel-level Thing, but crucially, that Thing is not being passed around between processes. If I tell you the PID 42, that's not qualitatively different from you randomly picking the number 42 - either way, you can try to signal whichever process currently has PID 42. You might not have permissions to signal the current resident of that PID for other reasons, but you don't need a prior relationship to signal it - you don't need to receive any capability object from anyone. I haven't given you something tied to any process, I just gave you a number, and in the traditional UNIX model there's nothing better (more intrinsically tied to a single process) to pass around.
Compare file descriptors. An FD is also "just" an integer, but having that integer is worthless unless you also have the kernel-level Thing shared with your process. Even if I give you the number 2, you can't write to my stderr - I have to share my stderr, for example by inheritance or by passing it through a UNIX domain socket.
This difference is subtle but technically crucial for eliminating race conditions: since an FD has to be shared from one process to another through the kernel, and the underlying "file" descriptor/description is managed and owned by the kernel, when you later use the FD in a system call, the kernel can always know a fully unambiguous identity of which Thing you were referring to. If you just told it 42 in some global ID space, well do you mean the thing currently at index 42? Or did you really think you were referring to a thing which existed some time ago at index 42? That information has been lost, or at least isn't being conveyed. But if you told it 42 in your file descriptor table, now that can hold more information, so it can remember precisely which thing your 42 was referring to when you last received or changed it.
So how did Linux fix this?
We now have "PID FDs", which are magic FDs referring to processes. Processes "as a file", in a more true and complete way than the older procfs stuff.
Unlike PIDs, which by design can only travel around like raw numbers divorced from the true identity information they gesture at, a PID FD can never lose track of the process it refers to: if that process dies, its PID FD will forever "know" that its dead even if the PID is reused (because when that process yields to or is preempted by the kernel for the last time, the kernel remembers that there's a PID FD for it which needs to be updated, and even if the kernel recycles the PID it knows not to update that PID FD to point to the new process).
And we now have a system calls which let us
create a new process (or thread!) and have that return a PID FD instead of a PID (or "TID" in the case of threads, but in the Linux kernel those are basically the same thing)
signal a PID FD instead of the traditional PID (or TID), and
wait on a PID FD (in fact, the FDs just plug into the normal poll, select, or epoll system calls, so waiting on process or thread status can just hook into all existing event loops).
The one crucial thing is that we must not forget that these guarantees only start once we've gotten the PID FD: in particular, if you get a PID FD from a PID instead of getting the PID FD directly, you still need to check once if the PID hasn't gotten invalidated between when you got the PID and when you got the PID FD. This is something you can only do as the direct parent or (sub)reaper of the PID in question, because then you can use the traditional "wait" system call on the PID after getting the PID FD - if getting the PID FD succeeded but then the wait reports that the PID exited, that means you could've gotten a PID reuse by the time you got the PID FD from the PID.
So ideally, we just don't deal in PIDs at all anymore. When we create a process, we can get its PID FD atomically with the creation. (If we can't do that, if we're creating the process and then getting the PID FD with a separate system call, we do the wait check described in the last paragraph after getting the PID.) Then we pass the PID FD around - this might superficially look like passing an integer around, for example if you need to use the FD number in a shell redirection or communicate it to a child process, but underneath that the actual FD would be getting passed around either by inheritance, UNIX domain sockets, or whatever other means are available.
I've been wanting this for years. I've spent a lot of mental cycles trying to figure out the most elegantly minimal and composable primitives which could work around various problems in service supervision and automatic restarts in the face of random processes dying or getting killed. Those edge cases are now much more simple to totally cover by using the PID FD stuff, at least so long as we're willing to lose compatibility with the BSDs and other Unix-y systems until they catch up. Which, honestly, is an increasingly appealing proposition as Linux has been adding good stuff like this lately.
P.S. On that note, another thing we now have, is the ability to reach into a process (if we have its PID FD and have the same relationship to it (or elevated privileges) that we'd need to hook into it with debugger system calls) and copy a file descriptor out of it. This means we no longer need a child process to have been coded to share it with us through a domain socket or by forking or exec-chaining into a process we specify. Accessing file descriptors in already-running processes enables some neat monkey-patching and composition, and it's simpler to implement than the UNIX domain socket trick. I remember being frustrated about 7 years ago by the lack of ability to do exactly this - reach down into a child process (for example into a shell script, which has no built-in ability to access the "ancillary data" of a socket) and pluck a file descriptor out of it.
6 notes
·
View notes
Text
youtube
Backlink Indexer How To Do Google Indexing Backlink Indexer How To Do Google Indexing Step by Step ! Website: https://ift.tt/WTmAkKX In this video, I'll show you how to start indexing your backlinks and your own site pages for free. I'll walk you through the process step by step and provide you with all the necessary scripts and instructions. What you will learn in this video: 1. The video explains how to start indexing backlinks and site pages for free. 2. The strategy shared results in a significant increase in indexed pages and backlinks. 3. The process involves signing up for a Google Cloud account and accessing the indexing API. 4. Users need to create a service account and make it the owner in Google Search Console. 5. Google Collaboratory account is needed to run the provided script or create a custom one. 6. Using the script inside Google Cloud account's Json key and the URLs to be indexed. 7. Running the script triggers Google to crawl and index the specified pages or backlinks. Join my channel for members only content and perks: https://www.youtube.com/channel/UC8P0dc0Zn2gf8L6tJi_k6xg/join Chris Palmer Tamaqua PA 18252 (570) 810-1080 https://www.youtube.com/watch?v=Mdod2ty8F5I https://www.youtube.com/watch/Mdod2ty8F5I
#seo#chris palmer seo#marketing#digital marketing#local seo#google maps seo#google my business#google#internet marketing#SEM#bing#Youtube
2 notes
·
View notes
Text

Are you looking to scale up your SEO efforts? Then Page SERP is the tool for you. It not only offers insights into how your website is performing in the most popular search engines such as Google, Bing, and Yahoo but also helps maximize your SEO strategies with its advanced features.
Page SERP stands as an essential tool in your SEO arsenal, offering a detailed and accurate analysis of your Search Engine Result Page. You can track everything, from rankings for specific keywords to click-through rates. By offering such analytics, Page SERP is not just a tool but a complete solution for your SEO needs.
So, how does this work? The answer lies in what makes Page SERP so effective – its advanced features. Firstly, global location targeting allows you to see how you rank across various regions. Secondly, device type filtering enables you to understand how you’re performing on different platforms and devices. Lastly, you can view different search type results, giving you insights into video searches, image searches, and more.
To ensure you get the most out of this tool, Page SERP provides detailed API documentation for reliable integrations with the platform. What’s more? With its scalable and queueless cloud infrastructure, you can make high-volume API requests with ease. Or, if you prefer, you can use the tool directly from the dashboard – here it is for everyone from beginners to pros!
Page SERP works with Google, Yandex, and Bing search engines. This means that you get SERP insights from probably the most used search engines globally. No matter what search engine you would like to optimize for, Page SERP got you covered.
Right now comes the cherry on top! Page SERP’s API goes beyond just giving you SERP insights. They provide an excellent platform with a backlink market place where you can buy and sell high-quality links. By incorporating this feature in your strategy, you will surely improve your website’s SERP ratings.
For those interested, Page SERP also offers the ability to generate PBN blogs for web 2 2.0 with ease. The tool includes a comment generator, indexer, and backlink. It also features a SERP and Automated Guest Write-up System. These features make it easy to manage your online presence and streamline your SEO efforts.
If you are keen to explore more, head over to their website [here](https://ad.page/serp). If you’re convinced and want to register, click [here](https://ad.page/app/register). By using Page SERP, you’re sure to see your SEO overall performance shine and your website traffic boost.
Unlock the full potential of your website’s SEO efforts with Page SERP today!
2 notes
·
View notes
Text
It's worse.
The glasses Meta built come with language translation features -- meaning it becomes harder for bilingual families to speak privately without being overheard.
No it's even worse.
Because someone has developed an app (I-XRAY) that scans and detects who people are in real-time.
No even worse.
Because I-XRAY accesses all kinds of public data about that person.
Wait is it so bad?
I-XRAY is not publicly usable and was only built to show what a privacy nightmare Meta is creating. Here's a 2-minute video of the creators doing a experiment how quickly people on the street's trust can be exploited. It's chilling because the interactions are kind and heartwarming but obviously the people are being tricked in the most uncomfortable way.
Yes it is so bad:
Because as satirical IT News channel Fireship demonstrated, if you combine a few easily available technologies, you can reproduce I-XRAYs results easily.
Hook up an open source vision model (for face detection). This model gives us the coordinates to a human face. Then tools like PimEyes or FaceCheck.ID -- uh, both of those are free as well... put a name to that face. Then phone book websites like fastpeoplesearch.com or Instant Checkmate let us look up lots of details about those names (date of birth, phone #, address, traffic and criminal records, social media accounts, known aliases, photos & videos, email addresses, friends and relatives, location history, assets & financial info). Now you can use webscrapers (the little programs Google uses to index the entire internet and feed it to you) or APIs (programs that let us interface with, for example, open data sets by the government) -> these scraping methods will, for many targeted people, provide the perpetrators with a bulk of information. And if that sounds impractical, well, the perpetrators can use a open source, free-to-use large language model like LLaMa (also developed by Meta, oh the irony) to get a summary (or get ChatGPT style answers) of all that data.
Fireship points out that people can opt out of most of these data brokers by contacting them ("the right to be forgotten" has been successfully enforced by European courts and applies globally to people that make use of our data). Apparently the New York Times has compiled an extensive list of such sites and services.
But this is definitely dystopian. And individual opt-outs exploit that many people don't even know that this is a thing and that place the entire responsibility on the individual. And to be honest, I don't trust the New York Times and almost feel I'm drawing attention to myself if I opt out. It really leaves me personally uncertain what is the smarter move. I hope this tech is like Google's smartglasses and becomes extinct.
i hate the "meta glasses" with their invisible cameras i hate when people record strangers just-living-their-lives i hate the culture of "it's not illegal so it's fine". people deserve to walk around the city without some nameless freak recording their faces and putting them up on the internet. like dude you don't show your own face how's that for irony huh.
i hate those "testing strangers to see if they're friendly and kind! kindness wins! kindness pays!" clickbait recordings where overwhelmingly it is young, attractive people (largely women) who are being scouted for views and free advertising . they're making you model for them and they reap the benefits. they profit now off of testing you while you fucking exist. i do not want to be fucking tested. i hate the commodification of "kindness" like dude just give random people the money, not because they fucking smiled for it. none of the people recording has any idea about the origin of the term "emotional labor" and none of us could get them to even think about it. i did not apply for this job! and you know what! i actually super am a nice person! i still don't want to be fucking recorded!
& it's so normalized that the comments are always so fucking ignorant like wow the brunette is so evil so mean so twisted just because she didn't smile at a random guy in an intersection. god forbid any person is in hiding due to an abusive situation. no, we need to see if they'll say good morning to a stranger approaching them. i am trying to walk towards my job i am not "unkind" just because i didn't notice your fucked up "social experiment". you fucking weirdo. stop doing this.
19K notes
·
View notes
Text
How a Web Development Company Builds Scalable SaaS Platforms
Building a SaaS (Software as a Service) platform isn't just about writing code—it’s about designing a product that can grow with your business, serve thousands of users reliably, and continuously evolve based on market needs. Whether you're launching a CRM, learning management system, or a niche productivity tool, scalability must be part of the plan from day one.
That’s why a professional Web Development Company brings more than just technical skills to the table. They understand the architectural, design, and business logic decisions required to ensure your SaaS product is not just functional—but scalable, secure, and future-proof.
1. Laying a Solid Architectural Foundation
The first step in building a scalable SaaS product is choosing the right architecture. Most development agencies follow a modular, service-oriented approach that separates different components of the application—user management, billing, dashboards, APIs, etc.—into layers or even microservices.
This ensures:
Features can be developed and deployed independently
The system can scale horizontally (adding more servers) or vertically (upgrading resources)
Future updates or integrations won’t require rebuilding the entire platform
Development teams often choose cloud-native architectures built on platforms like AWS, Azure, or GCP for their scalability and reliability.
2. Selecting the Right Tech Stack
Choosing the right technology stack is critical. The tech must support performance under heavy loads and allow for easy development as your team grows.
Popular stacks for SaaS platforms include:
Frontend: React.js, Vue.js, or Angular
Backend: Node.js, Django, Ruby on Rails, or Laravel
Databases: PostgreSQL or MongoDB for flexibility and performance
Infrastructure: Docker, Kubernetes, CI/CD pipelines for automation
A skilled agency doesn’t just pick trendy tools—they choose frameworks aligned with your app’s use case, team skills, and scaling needs.
3. Multi-Tenancy Setup
One of the biggest differentiators in SaaS development is whether the platform is multi-tenant—where one codebase and database serve multiple customers with logical separation.
A web development company configures multi-tenancy using:
Separate schemas per tenant (isolated but efficient)
Shared databases with tenant identifiers (cost-effective)
Isolated instances for enterprise clients (maximum security)
This architecture supports onboarding multiple customers without duplicating infrastructure—making it cost-efficient and easy to manage.
4. Building Secure, Scalable User Management
SaaS platforms must support a range of users—admins, team members, clients—with different permissions. That’s why role-based access control (RBAC) is built into the system from the start.
Key features include:
Secure user registration and login (OAuth2, SSO, MFA)
Dynamic role creation and permission assignment
Audit logs and activity tracking
This layer is integrated with identity providers and third-party auth services to meet enterprise security expectations.
5. Ensuring Seamless Billing and Subscription Management
Monetization is central to SaaS success. Development companies build subscription logic that supports:
Monthly and annual billing cycles
Tiered or usage-based pricing models
Free trials and discounts
Integration with Stripe, Razorpay, or other payment gateways
They also ensure compliance with global standards (like PCI DSS for payment security and GDPR for user data privacy), especially if you're targeting international customers.
6. Performance Optimization from Day One
Scalability means staying fast even as traffic and data grow. Web developers implement:
Caching systems (like Redis or Memcached)
Load balancers and auto-scaling policies
Asynchronous task queues (e.g., Celery, RabbitMQ)
CDN integration for static asset delivery
Combined with code profiling and database indexing, these enhancements ensure your SaaS stays performant no matter how many users are active.
7. Continuous Deployment and Monitoring
SaaS products evolve quickly—new features, fixes, improvements. That’s why agencies set up:
CI/CD pipelines for automated testing and deployment
Error tracking tools like Sentry or Rollbar
Performance monitoring with tools like Datadog or New Relic
Log management for incident response and debugging
This allows for rapid iteration and minimal downtime, which are critical in SaaS environments.
8. Preparing for Scale from a Product Perspective
Scalability isn’t just technical—it’s also about UX and support. A good development company collaborates on:
Intuitive onboarding flows
Scalable navigation and UI design systems
Help center and chatbot integrations
Data export and reporting features for growing teams
These elements allow users to self-serve as the platform scales, reducing support load and improving retention.
Conclusion
SaaS platforms are complex ecosystems that require planning, flexibility, and technical excellence. From architecture and authentication to billing and performance, every layer must be built with growth in mind. That’s why startups and enterprises alike trust a Web Development Company to help them design and launch SaaS solutions that can handle scale—without sacrificing speed or security.
Whether you're building your first SaaS MVP or upgrading an existing product, the right development partner can transform your vision into a resilient, scalable reality.
0 notes