#Kubernetes For AI Model Deployment
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
28.6 is the average number of monthly visits per US mobile user.
Text
Understand how Generative AI is accelerating Kubernetes adoption, shaping industries with scalable, automated, and innovative approaches.
#AI Startups Kubernetes#Enterprise AI With Kubernetes#Generative AI#Kubernetes AI Architecture#Kubernetes For AI Model Deployment#Kubernetes For Deep Learning#Kubernetes For Machine Learning
0 notes
Text
How Is Gen AI Driving Kubernetes Demand Across Industries?
Understand how Generative AI is accelerating Kubernetes adoption, shaping industries with scalable, automated, and innovative approaches. A new breakthrough in AI, called generative AI or Gen AI, is creating incredible waves across industries and beyond. With this technology rapidly evolving there is growing pressure on the available structure to support both the deployment and scalability of…
#AI Startups Kubernetes#Enterprise AI With Kubernetes#Generative AI#Kubernetes AI Architecture#Kubernetes For AI Model Deployment#Kubernetes For Deep Learning#Kubernetes For Machine Learning
0 notes
Text
How Is Gen AI Driving Kubernetes Demand Across Industries?

Unveil how Gen AI is pushing Kubernetes to the forefront, delivering industry-specific solutions with precision and scalability.
Original Source: https://bit.ly/4cPS7G0
A new breakthrough in AI, called generative AI or Gen AI, is creating incredible waves across industries and beyond. With this technology rapidly evolving there is growing pressure on the available structure to support both the deployment and scalability of the technology. Kubernetes, an effective container orchestration platform is already indicating its ability as one of the enablers in this context. This article critically analyzes how Generative AI gives rise to the use of Kubernetes across industries with a focus of the coexistence of these two modern technological forces.
The Rise of Generative AI and Its Impact on Technology
Machine learning has grown phenomenally over the years and is now foundational in various industries including healthcare, banking, production as well as media and entertainment industries. This technology whereby an AI model is trained to write, design or even solve business problems is changing how business is done. Gen AI’s capacity to generate new data and solutions independently has opened opportunities for advancements as has never been seen before.
If companies are adopting Generative AI , then the next big issue that they are going to meet is on scalability of models and its implementation. These resource- intensive applications present a major challenge to the traditional IT architectures. It is here that Kubernetes comes into the picture, which provides solutions to automate deployment, scaling and managing the containerised applications. Kubernetes may be deployed to facilitate the ML and deep learning processing hence maximizing the efficiency of the AI pipeline to support the future growth of Gen AI applications.
The Intersection of Generative AI and Kubernetes
The integration of Generative AI and Kubernetes is probably the most significant traffic in the development of AI deployment approaches. Kubernetes is perfect for the dynamics of AI workloads in terms of scalability and flexibility. The computation of Gen AI models demands considerable resources, and Kubernetes has all the tools required to properly orchestrate those resources for deploying AI models in different setups.
Kubernetes’ infrastructure is especially beneficial for AI startups and companies that plan to use Generative AI. It enables the decentralization of workload among several nodes so that training, testing, and deployment of AI models are highly distributed. This capability is especially important for businesses that require to constantly revolve their models to adapt to competition. In addition, Kubernetes has direct support for GPU, which helps in evenly distributing computational intensity that comes with deep learning workloads thereby making it perfect for AI projects.
Key Kubernetes Features that Enable Efficient Generative AI Deployment
Scalability:
Kubernetes excels at all levels but most notably where applications are scaled horizontally. Especially for Generative AI which often needs a lot of computation, Kubernetes is capable of scaling the pods, the instances of the running processes and provide necessary resources for the workload claims without having any human intervention.
Resource Management:
Effort is required to be allocated efficiently so as to perform the AI workloads. Kubernetes assists in deploying as well as allocating resources within the cluster from where the AI models usually operate while ensuring that resource consumption and distribution is efficiently controlled.
Continuous Deployment and Integration (CI/CD):
Kubernetes allows for the execution of CI CD pipelines which facilitate contingency integration as well as contingency deployment of models. This is essential for enterprises and the AI startups that use the flexibility of launching different AI solutions depending on the current needs of their companies.
GPU Support:
Kubernetes also features the support of the GPUs for the applications in deep learning from scratch that enhances the rate of training and inference of the models of AI. It is particularly helpful for AI applications that require more data processing, such as image and speech recognition.
Multi-Cloud and Hybrid Cloud Support:
The fact that the Kubernetes can operate in several cloud environment and on-premise data centers makes it versatile as AI deployment tool. It will benefit organizations that need a half and half cloud solution and organizations that do not want to be trapped in the web of the specific company.
Challenges of Running Generative AI on Kubernetes
Complexity of Setup and Management:
That aid Kubernetes provides a great platform for AI deployments comes at the cost of operational overhead. Deploying and configuring a Kubernetes Cluster for AI based workloads therefore necessitates knowledge of both Kubernetes and the approach used to develop these models. This could be an issue for organizations that are not able to gather or hire the required expertise.
Resource Constraints:
Generative AI models require a lot of computing power and when running them in a Kubernetes environment, the computational resources can be fully utilised. AI works best when the organizational resources are well managed to ensure that there are no constraints in the delivery of the application services.
Security Concerns:
Like it is the case with any cloud-native application, security is a big issue when it comes to running artificial intelligence models on Kubernetes. Security of the data and models that AI employs needs to be protected hence comes the policies of encryption, access control and monitoring.
Data Management:
Generative AI models make use of multiple dataset samples for its learning process and is hard to deal with the concept in Kubernetes. Managing these datasets as well as accessing and processing them in a manner that does not hinder the overall performance of an organization is often a difficult task.
Conclusion: The Future of Generative AI is Powered by Kubernetes
As Generative AI advances and integrates into many sectors, the Kubernetes efficient and scalable solutions will only see a higher adoption rate. Kubernetes is a feature of AI architectures that offer resources and facilities for the development and management of AI model deployment.
If you’re an organization planning on putting Generative AI to its best use, then adopting Kubernetes is non-negotiable. Mounting the AI workloads, utilizing the resources in the best possible manner, and maintaining the neat compatibility across the multiple and different clouds are some of the key solutions provided by Kubernetes for the deployment of the AI models. With continued integration between Generative AI and Kubernetes, we have to wonder what new and exciting uses and creations are yet to come, thus strengthening Kubernetes’ position as the backbone for enterprise AI with Kubernetes. The future is bright that Kubernetes is playing leading role in this exciting technological revolution of AI.
Original Source: https://bit.ly/4cPS7G0
#AI Startups Kubernetes#Enterprise AI With Kubernetes#Generative AI#Kubernetes AI Architecture#Kubernetes For AI Model Deployment#Kubernetes For Deep Learning#Kubernetes For Machine Learning
0 notes
Text
How To Use Llama 3.1 405B FP16 LLM On Google Kubernetes

How to set up and use large open models for multi-host generation AI over GKE
Access to open models is more important than ever for developers as generative AI grows rapidly due to developments in LLMs (Large Language Models). Open models are pre-trained foundational LLMs that are accessible to the general population. Data scientists, machine learning engineers, and application developers already have easy access to open models through platforms like Hugging Face, Kaggle, and Google Cloud’s Vertex AI.
How to use Llama 3.1 405B
Google is announcing today the ability to install and run open models like Llama 3.1 405B FP16 LLM over GKE (Google Kubernetes Engine), as some of these models demand robust infrastructure and deployment capabilities. With 405 billion parameters, Llama 3.1, published by Meta, shows notable gains in general knowledge, reasoning skills, and coding ability. To store and compute 405 billion parameters at FP (floating point) 16 precision, the model needs more than 750GB of GPU RAM for inference. The difficulty of deploying and serving such big models is lessened by the GKE method discussed in this article.
Customer Experience
You may locate the Llama 3.1 LLM as a Google Cloud customer by selecting the Llama 3.1 model tile in Vertex AI Model Garden.
Once the deploy button has been clicked, you can choose the Llama 3.1 405B FP16 model and select GKE.Image credit to Google Cloud
The automatically generated Kubernetes yaml and comprehensive deployment and serving instructions for Llama 3.1 405B FP16 are available on this page.
Deployment and servicing multiple hosts
Llama 3.1 405B FP16 LLM has significant deployment and service problems and demands over 750 GB of GPU memory. The total memory needs are influenced by a number of parameters, including the memory used by model weights, longer sequence length support, and KV (Key-Value) cache storage. Eight H100 Nvidia GPUs with 80 GB of HBM (High-Bandwidth Memory) apiece make up the A3 virtual machines, which are currently the most potent GPU option available on the Google Cloud platform. The only practical way to provide LLMs such as the FP16 Llama 3.1 405B model is to install and serve them across several hosts. To deploy over GKE, Google employs LeaderWorkerSet with Ray and vLLM.
LeaderWorkerSet
A deployment API called LeaderWorkerSet (LWS) was created especially to meet the workload demands of multi-host inference. It makes it easier to shard and run the model across numerous devices on numerous nodes. Built as a Kubernetes deployment API, LWS is compatible with both GPUs and TPUs and is independent of accelerators and the cloud. As shown here, LWS uses the upstream StatefulSet API as its core building piece.
A collection of pods is controlled as a single unit under the LWS architecture. Every pod in this group is given a distinct index between 0 and n-1, with the pod with number 0 being identified as the group leader. Every pod that is part of the group is created simultaneously and has the same lifecycle. At the group level, LWS makes rollout and rolling upgrades easier. For rolling updates, scaling, and mapping to a certain topology for placement, each group is treated as a single unit.
Each group’s upgrade procedure is carried out as a single, cohesive entity, guaranteeing that every pod in the group receives an update at the same time. While topology-aware placement is optional, it is acceptable for all pods in the same group to co-locate in the same topology. With optional all-or-nothing restart support, the group is also handled as a single entity when addressing failures. When enabled, if one pod in the group fails or if one container within any of the pods is restarted, all of the pods in the group will be recreated.
In the LWS framework, a group including a single leader and a group of workers is referred to as a replica. Two templates are supported by LWS: one for the workers and one for the leader. By offering a scale endpoint for HPA, LWS makes it possible to dynamically scale the number of replicas.
Deploying multiple hosts using vLLM and LWS
vLLM is a well-known open source model server that uses pipeline and tensor parallelism to provide multi-node multi-GPU inference. Using Megatron-LM’s tensor parallel technique, vLLM facilitates distributed tensor parallelism. With Ray for multi-node inferencing, vLLM controls the distributed runtime for pipeline parallelism.
By dividing the model horizontally across several GPUs, tensor parallelism makes the tensor parallel size equal to the number of GPUs at each node. It is crucial to remember that this method requires quick network connectivity between the GPUs.
However, pipeline parallelism does not require continuous connection between GPUs and divides the model vertically per layer. This usually equates to the quantity of nodes used for multi-host serving.
In order to support the complete Llama 3.1 405B FP16 paradigm, several parallelism techniques must be combined. To meet the model’s 750 GB memory requirement, two A3 nodes with eight H100 GPUs each will have a combined memory capacity of 1280 GB. Along with supporting lengthy context lengths, this setup will supply the buffer memory required for the key-value (KV) cache. The pipeline parallel size is set to two for this LWS deployment, while the tensor parallel size is set to eight.
In brief
We discussed in this blog how LWS provides you with the necessary features for multi-host serving. This method maximizes price-to-performance ratios and can also be used with smaller models, such as the Llama 3.1 405B FP8, on more affordable devices. Check out its Github to learn more and make direct contributions to LWS, which is open-sourced and has a vibrant community.
You can visit Vertex AI Model Garden to deploy and serve open models via managed Vertex AI backends or GKE DIY (Do It Yourself) clusters, as the Google Cloud Platform assists clients in embracing a gen AI workload. Multi-host deployment and serving is one example of how it aims to provide a flawless customer experience.
Read more on Govindhtech.com
#Llama3.1#Llama#LLM#GoogleKubernetes#GKE#405BFP16LLM#AI#GPU#vLLM#LWS#News#Technews#Technology#Technologynews#Technologytrends#govindhtech
2 notes
·
View notes
Text
Microsoft Azure Fundamentals AI-900 (Part 5)
Microsoft Azure AI Fundamentals: Explore visual studio tools for machine learning
What is machine learning? A technique that uses math and statistics to create models that predict unknown values
Types of Machine learning
Regression - predict a continuous value, like a price, a sales total, a measure, etc
Classification - determine a class label.
Clustering - determine labels by grouping similar information into label groups
x = features
y = label
Azure Machine Learning Studio
You can use the workspace to develop solutions with the Azure ML service on the web portal or with developer tools
Web portal for ML solutions in Sure
Capabilities for preparing data, training models, publishing and monitoring a service.
First step assign a workspace to a studio.
Compute targets are cloud-based resources which can run model training and data exploration processes
Compute Instances - Development workstations that data scientists can use to work with data and models
Compute Clusters - Scalable clusters of VMs for on demand processing of experiment code
Inference Clusters - Deployment targets for predictive services that use your trained models
Attached Compute - Links to existing Azure compute resources like VMs or Azure data brick clusters
What is Azure Automated Machine Learning
Jobs have multiple settings
Provide information needed to specify your training scripts, compute target and Azure ML environment and run a training job
Understand the AutoML Process
ML model must be trained with existing data
Data scientists spend lots of time pre-processing and selecting data
This is time consuming and often makes inefficient use of expensive compute hardware
In Azure ML data for model training and other operations are encapsulated in a data set.
You create your own dataset.
Classification (predicting categories or classes)
Regression (predicting numeric values)
Time series forecasting (predicting numeric values at a future point in time)
After part of the data is used to train a model, then the rest of the data is used to iteratively test or cross validate the model
The metric is calculated by comparing the actual known label or value with the predicted one
Difference between the actual known and predicted is known as residuals; they indicate amount of error in the model.
Root Mean Squared Error (RMSE) is a performance metric. The smaller the value, the more accurate the model’s prediction is
Normalized root mean squared error (NRMSE) standardizes the metric to be used between models which have different scales.
Shows the frequency of residual value ranges.
Residuals represents variance between predicted and true values that can’t be explained by the model, errors
Most frequently occurring residual values (errors) should be clustered around zero.
You want small errors with fewer errors at the extreme ends of the sale
Should show a diagonal trend where the predicted value correlates closely with the true value
Dotted line shows a perfect model’s performance
The closer to the line of your model’s average predicted value to the dotted, the better.
Services can be deployed as an Azure Container Instance (ACI) or to a Azure Kubernetes Service (AKS) cluster
For production AKS is recommended.
Identify regression machine learning scenarios
Regression is a form of ML
Understands the relationships between variables to predict a desired outcome
Predicts a numeric label or outcome base on variables (features)
Regression is an example of supervised ML
What is Azure Machine Learning designer
Allow you to organize, manage, and reuse complex ML workflows across projects and users
Pipelines start with the dataset you want to use to train the model
Each time you run a pipelines, the context(history) is stored as a pipeline job
Encapsulates one step in a machine learning pipeline.
Like a function in programming
In a pipeline project, you access data assets and components from the Asset Library tab
You can create data assets on the data tab from local files, web files, open at a sets, and a datastore
Data assets appear in the Asset Library
Azure ML job executes a task against a specified compute target.
Jobs allow systematic tracking of your ML experiments and workflows.
Understand steps for regression
To train a regression model, your data set needs to include historic features and known label values.
Use the designer’s Score Model component to generate the predicted class label value
Connect all the components that will run in the experiment
Average difference between predicted and true values
It is based on the same unit as the label
The lower the value is the better the model is predicting
The square root of the mean squared difference between predicted and true values
Metric based on the same unit as the label.
A larger difference indicates greater variance in the individual label errors
Relative metric between 0 and 1 on the square based on the square of the differences between predicted and true values
Closer to 0 means the better the model is performing.
Since the value is relative, it can compare different models with different label units
Relative metric between 0 and 1 on the square based on the absolute of the differences between predicted and true values
Closer to 0 means the better the model is performing.
Can be used to compare models where the labels are in different units
Also known as R-squared
Summarizes how much variance exists between predicted and true values
Closer to 1 means the model is performing better
Remove training components form your data and replace it with a web service inputs and outputs to handle the web requests
It does the same data transformations as the first pipeline for new data
It then uses trained model to infer/predict label values based on the features.
Create a classification model with Azure ML designer
Classification is a form of ML used to predict which category an item belongs to
Like regression this is a supervised ML technique.
Understand steps for classification
True Positive - Model predicts the label and the label is correct
False Positive - Model predicts wrong label and the data has the label
False Negative - Model predicts the wrong label, and the data does have the label
True Negative - Model predicts the label correctly and the data has the label
For multi-class classification, same approach is used. A model with 3 possible results would have a 3x3 matrix.
Diagonal lien of cells were the predicted and actual labels match
Number of cases classified as positive that are actually positive
True positives divided by (true positives + false positives)
Fraction of positive cases correctly identified
Number of true positives divided by (true positives + false negatives)
Overall metric that essentially combines precision and recall
Classification models predict probability for each possible class
For binary classification models, the probability is between 0 and 1
Setting the threshold can define when a value is interpreted as 0 or 1. If its set to 0.5 then 0.5-1.0 is 1 and 0.0-0.4 is 0
Recall also known as True Positive Rate
Has a corresponding False Positive Rate
Plotting these two metrics on a graph for all values between 0 and 1 provides information.
Receiver Operating Characteristic (ROC) is the curve.
In a perfect model, this curve would be high to the top left
Area under the curve (AUC).
Remove training components form your data and replace it with a web service inputs and outputs to handle the web requests
It does the same data transformations as the first pipeline for new data
It then uses trained model to infer/predict label values based on the features.
Create a Clustering model with Azure ML designer
Clustering is used to group similar objects together based on features.
Clustering is an example of unsupervised learning, you train a model to just separate items based on their features.
Understanding steps for clustering
Prebuilt components exist that allow you to clean the data, normalize it, join tables and more
Requires a dataset that includes multiple observations of the items you want to cluster
Requires numeric features that can be used to determine similarities between individual cases
Initializing K coordinates as randomly selected points called centroids in an n-dimensional space (n is the number of dimensions in the feature vectors)
Plotting feature vectors as points in the same space and assigns a value how close they are to the closes centroid
Moving the centroids to the middle points allocated to it (mean distance)
Reassigning to the closes centroids after the move
Repeating the last two steps until tone.
Maximum distances between each point and the centroid of that point’s cluster.
If the value is high it can mean that cluster is widely dispersed.
With the Average Distance to Closer Center, we can determine how spread out the cluster is
Remove training components form your data and replace it with a web service inputs and outputs to handle the web requests
It does the same data transformations as the first pipeline for new data
It then uses trained model to infer/predict label values based on the features.
2 notes
·
View notes
Text
Google Cloud Solution: Empowering Businesses with Scalable Innovation
In today’s fast-paced digital era, cloud computing has become the cornerstone of innovation and operational efficiency. At Izoe Solution, we harness the power of Google Cloud Platform (GCP) to deliver robust, scalable, and secure cloud solutions that drive business transformation across industries.
Why Google Cloud?
Google Cloud offers a comprehensive suite of cloud services that support a wide range of enterprise needs—from data storage and computing to advanced AI/ML capabilities. Known for its powerful infrastructure, cutting-edge tools, and strong security framework, Google Cloud is trusted by some of the world's largest organizations.
Our Core Google Cloud Services
Cloud Migration & Modernization We help businesses migrate their workloads and applications to Google Cloud with minimal disruption. Our phased approach ensures data integrity, performance tuning, and post-migration optimization.
Data Analytics & BigQuery Izoe Solution leverages Google’s powerful BigQuery platform to deliver real-time analytics, enabling data-driven decision-making. We build end-to-end data pipelines for maximum business insight.
App Development & Hosting Using Google App Engine, Kubernetes Engine, and Cloud Functions, we develop and deploy modern applications that are secure, scalable, and cost-efficient.
AI and Machine Learning From image recognition to predictive modeling, we implement Google Cloud AI/ML tools like Vertex AI to build intelligent systems that enhance customer experiences and operational efficiency.
Cloud Security & Compliance Security is at the core of every cloud solution we design. We follow best practices and leverage Google’s built-in security features to ensure data protection, access control, and compliance with industry standards.
Why Choose Izoe Solution?
Certified Google Cloud Professionals: Our team holds GCP certifications and brings hands-on expertise in architecture, development, and operations.
Tailored Solutions: We design cloud architectures that align with your unique business goals.
End-to-End Support: From planning and deployment to monitoring and optimization, we provide continuous support throughout your cloud journey.
Proven Results: Our solutions have improved performance, reduced costs, and accelerated innovation for clients across sectors.
Conclusion
Cloud adoption is no longer optional—it's essential. Partner with Izoe Solution to leverage the full potential of Google Cloud and future-proof your business with intelligent, secure, and scalable solutions.
Contact us today to learn how Izoe Solution can transform your business through Google Cloud.
0 notes
Text
Hybrid Cloud Application: The Smart Future of Business IT

Introduction
In today’s digital-first environment, businesses are constantly seeking scalable, flexible, and cost-effective solutions to stay competitive. One solution that is gaining rapid traction is the hybrid cloud application model. Combining the best of public and private cloud environments, hybrid cloud applications enable businesses to maximize performance while maintaining control and security.
This 2000-word comprehensive article on hybrid cloud applications explains what they are, why they matter, how they work, their benefits, and how businesses can use them effectively. We also include real-user reviews, expert insights, and FAQs to help guide your cloud journey.
What is a Hybrid Cloud Application?
A hybrid cloud application is a software solution that operates across both public and private cloud environments. It enables data, services, and workflows to move seamlessly between the two, offering flexibility and optimization in terms of cost, performance, and security.
For example, a business might host sensitive customer data in a private cloud while running less critical workloads on a public cloud like AWS, Azure, or Google Cloud Platform.
Key Components of Hybrid Cloud Applications
Public Cloud Services – Scalable and cost-effective compute and storage offered by providers like AWS, Azure, and GCP.
Private Cloud Infrastructure – More secure environments, either on-premises or managed by a third-party.
Middleware/Integration Tools – Platforms that ensure communication and data sharing between cloud environments.
Application Orchestration – Manages application deployment and performance across both clouds.
Why Choose a Hybrid Cloud Application Model?
1. Flexibility
Run workloads where they make the most sense, optimizing both performance and cost.
2. Security and Compliance
Sensitive data can remain in a private cloud to meet regulatory requirements.
3. Scalability
Burst into public cloud resources when private cloud capacity is reached.
4. Business Continuity
Maintain uptime and minimize downtime with distributed architecture.
5. Cost Efficiency
Avoid overprovisioning private infrastructure while still meeting demand spikes.
Real-World Use Cases of Hybrid Cloud Applications
1. Healthcare
Protect sensitive patient data in a private cloud while using public cloud resources for analytics and AI.
2. Finance
Securely handle customer transactions and compliance data, while leveraging the cloud for large-scale computations.
3. Retail and E-Commerce
Manage customer interactions and seasonal traffic spikes efficiently.
4. Manufacturing
Enable remote monitoring and IoT integrations across factory units using hybrid cloud applications.
5. Education
Store student records securely while using cloud platforms for learning management systems.
Benefits of Hybrid Cloud Applications
Enhanced Agility
Better Resource Utilization
Reduced Latency
Compliance Made Easier
Risk Mitigation
Simplified Workload Management
Tools and Platforms Supporting Hybrid Cloud
Microsoft Azure Arc – Extends Azure services and management to any infrastructure.
AWS Outposts – Run AWS infrastructure and services on-premises.
Google Anthos – Manage applications across multiple clouds.
VMware Cloud Foundation – Hybrid solution for virtual machines and containers.
Red Hat OpenShift – Kubernetes-based platform for hybrid deployment.
Best Practices for Developing Hybrid Cloud Applications
Design for Portability Use containers and microservices to enable seamless movement between clouds.
Ensure Security Implement zero-trust architectures, encryption, and access control.
Automate and Monitor Use DevOps and continuous monitoring tools to maintain performance and compliance.
Choose the Right Partner Work with experienced providers who understand hybrid cloud deployment strategies.
Regular Testing and Backup Test failover scenarios and ensure robust backup solutions are in place.
Reviews from Industry Professionals
Amrita Singh, Cloud Engineer at FinCloud Solutions:
"Implementing hybrid cloud applications helped us reduce latency by 40% and improve client satisfaction."
John Meadows, CTO at EdTechNext:
"Our LMS platform runs on a hybrid model. We’ve achieved excellent uptime and student experience during peak loads."
Rahul Varma, Data Security Specialist:
"For compliance-heavy environments like finance and healthcare, hybrid cloud is a no-brainer."
Challenges and How to Overcome Them
1. Complex Architecture
Solution: Simplify with orchestration tools and automation.
2. Integration Difficulties
Solution: Use APIs and middleware platforms for seamless data exchange.
3. Cost Overruns
Solution: Use cloud cost optimization tools like Azure Advisor, AWS Cost Explorer.
4. Security Risks
Solution: Implement multi-layered security protocols and conduct regular audits.
FAQ: Hybrid Cloud Application
Q1: What is the main advantage of a hybrid cloud application?
A: It combines the strengths of public and private clouds for flexibility, scalability, and security.
Q2: Is hybrid cloud suitable for small businesses?
A: Yes, especially those with fluctuating workloads or compliance needs.
Q3: How secure is a hybrid cloud application?
A: When properly configured, hybrid cloud applications can be as secure as traditional setups.
Q4: Can hybrid cloud reduce IT costs?
A: Yes. By only paying for public cloud usage as needed, and avoiding overprovisioning private servers.
Q5: How do you monitor a hybrid cloud application?
A: With cloud management platforms and monitoring tools like Datadog, Splunk, or Prometheus.
Q6: What are the best platforms for hybrid deployment?
A: Azure Arc, Google Anthos, AWS Outposts, and Red Hat OpenShift are top choices.
Conclusion: Hybrid Cloud is the New Normal
The hybrid cloud application model is more than a trend—it’s a strategic evolution that empowers organizations to balance innovation with control. It offers the agility of the cloud without sacrificing the oversight and security of on-premises systems.
If your organization is looking to modernize its IT infrastructure while staying compliant, resilient, and efficient, then hybrid cloud application development is the way forward.
At diglip7.com, we help businesses build scalable, secure, and agile hybrid cloud solutions tailored to their unique needs. Ready to unlock the future? Contact us today to get started.
0 notes
Text
Best Software Development Company in Chennai: Your Partner for Digital Excellence

In today’s fast-paced digital landscape, partnering with the best software development company in Chennai can be the key to transforming your business vision into reality. Chennai, a thriving IT hub, is home to numerous firms specializing in cutting-edge technologies—from AI and blockchain to cloud-native applications. Whether you’re a startup seeking an MVP or an enterprise ready for digital transformation, choosing the right Software Development Company in Chennai ensures top-tier quality, on‑time delivery, and scalable solutions.
Why Choose a Software Development Company in Chennai?
Rich IT Ecosystem Chennai boasts a vibrant ecosystem of skilled engineers, designers, and project managers. The city’s robust educational institutions and thriving tech parks cultivate talent proficient in the latest programming languages and development frameworks.
Cost-Effective Excellence Compared to Western markets, Chennai offers highly competitive rates without compromising on code quality or innovation. This cost advantage enables businesses of all sizes to access world‑class software solutions within budget.
Agile & Customer‑Centric Approach Leading firms in Chennai adopt Agile methodologies—breaking projects into sprints, facilitating continuous feedback loops, and ensuring that deliverables align precisely with client expectations.
Strong Communication & Support With English as the primary medium and overlapping work hours with Europe and parts of Asia, Chennai teams maintain clear, real‑time communication, seamless collaboration, and dependable post‑launch support.
Core Services Offered
A top Software Development Company in Chennai typically provides:
Custom Software Development: Tailor‑made applications powered by Java, .NET, Python, or Node.js to meet your unique business requirements.
Mobile App Development: Native and cross‑platform apps built with Swift, Kotlin, React Native, or Flutter for iOS and Android.
Web Application Development: Responsive, secure, and SEO‑friendly web portals using Angular, React, Vue.js, or Laravel.
Enterprise Solutions: Scalable ERP, CRM, and BI tools that optimize operations and provide actionable insights.
Cloud Services & DevOps: AWS, Azure, or Google Cloud deployments paired with CI/CD pipelines—ensuring high availability, security, and rapid releases.
UI/UX Design: Intuitive interfaces and immersive user experiences guided by data‑driven design principles and user testing.
Technology Stack & Expertise
Front‑End: React, Angular, Vue.js, Svelte
Back‑End: Node.js, Django, Spring Boot, .NET Core
Databases: MySQL, PostgreSQL, MongoDB, Redis
Mobile: Flutter, React Native, Swift, Kotlin
Cloud & DevOps: Docker, Kubernetes, Jenkins, Terraform, AWS, Azure, GCP
Emerging Tech: AI/ML models in TensorFlow and PyTorch, Blockchain development, IoT integrations
Our Proven Process
Discovery & Planning
Stakeholder workshops to define scope
Requirement analysis and feasibility studies
Project roadmap with milestones and timelines
Design & Prototyping
Wireframes and interactive mockups
UI/UX validation through user feedback
Design handoff with detailed style guides
Development & Iteration
Agile sprints with regular demos
Continuous integration and code reviews
Unit, integration, and performance testing
Quality Assurance
Automated and manual testing for functionality and security
Compatibility checks across devices and browsers
Load testing to ensure scalability
Deployment & Maintenance
Staged releases: dev → staging → production
24/7 monitoring, troubleshooting, and updates
Dedicated support plans for ongoing enhancements
Success Stories
FinTech Startup: Developed a real‑time trading platform with React and Node.js, supporting over 10,000 concurrent users and reducing transaction latency by 40%. Healthcare Portal: Created a HIPAA‑compliant patient management system on Azure, improving appointment scheduling efficiency by 60%. E‑Learning Platform: Built a scalable LMS with Laravel and Vue.js, accommodating 50,000+ users and integrating interactive video lectures.
Why We Stand Out
Client‑First Culture: Transparent reporting, flexible engagement models (T&M, fixed‑price, dedicated teams), and a commitment to your success.
Certified Experts: AWS Solution Architects, Microsoft Gold Partners, and Scrum Masters drive every project.
Innovation Labs: R&D teams exploring AI, blockchain, and VR to keep you ahead of the curve.
Quality Assurance: ISO 9001 and CMMI Level 3 certifications ensure rigorous process adherence.
Conclusion & Next Steps
Selecting the best software development company in Chennai means partnering with a team that blends technical prowess, creative design, and unwavering dedication to your goals. Ready to accelerate your digital journey? Get in touch today for a free consultation and project estimate with our award‑winning Software Development Company in Chennai. Let’s build the future—together.
0 notes
Text
Creating and Configuring Production ROSA Clusters (CS220) – A Practical Guide
Introduction
Red Hat OpenShift Service on AWS (ROSA) is a powerful managed Kubernetes solution that blends the scalability of AWS with the developer-centric features of OpenShift. Whether you're modernizing applications or building cloud-native architectures, ROSA provides a production-grade container platform with integrated support from Red Hat and AWS. In this blog post, we’ll walk through the essential steps covered in CS220: Creating and Configuring Production ROSA Clusters, an instructor-led course designed for DevOps professionals and cloud architects.
What is CS220?
CS220 is a hands-on, lab-driven course developed by Red Hat that teaches IT teams how to deploy, configure, and manage ROSA clusters in a production environment. It is tailored for organizations that are serious about leveraging OpenShift at scale with the operational convenience of a fully managed service.
Why ROSA for Production?
Deploying OpenShift through ROSA offers multiple benefits:
Streamlined Deployment: Fully managed clusters provisioned in minutes.
Integrated Security: AWS IAM, STS, and OpenShift RBAC policies combined.
Scalability: Elastic and cost-efficient scaling with built-in monitoring and logging.
Support: Joint support model between AWS and Red Hat.
Key Concepts Covered in CS220
Here’s a breakdown of the main learning outcomes from the CS220 course:
1. Provisioning ROSA Clusters
Participants learn how to:
Set up required AWS permissions and networking pre-requisites.
Deploy clusters using Red Hat OpenShift Cluster Manager (OCM) or CLI tools like rosa and oc.
Use STS (Short-Term Credentials) for secure cluster access.
2. Configuring Identity Providers
Learn how to integrate Identity Providers (IdPs) such as:
GitHub, Google, LDAP, or corporate IdPs using OpenID Connect.
Configure secure, role-based access control (RBAC) for teams.
3. Networking and Security Best Practices
Implement private clusters with public or private load balancers.
Enable end-to-end encryption for APIs and services.
Use Security Context Constraints (SCCs) and network policies for workload isolation.
4. Storage and Data Management
Configure dynamic storage provisioning with AWS EBS, EFS, or external CSI drivers.
Learn persistent volume (PV) and persistent volume claim (PVC) lifecycle management.
5. Cluster Monitoring and Logging
Integrate OpenShift Monitoring Stack for health and performance insights.
Forward logs to Amazon CloudWatch, ElasticSearch, or third-party SIEM tools.
6. Cluster Scaling and Updates
Set up autoscaling for compute nodes.
Perform controlled updates and understand ROSA’s maintenance policies.
Use Cases for ROSA in Production
Modernizing Monoliths to Microservices
CI/CD Platform for Agile Development
Data Science and ML Workflows with OpenShift AI
Edge Computing with OpenShift on AWS Outposts
Getting Started with CS220
The CS220 course is ideal for:
DevOps Engineers
Cloud Architects
Platform Engineers
Prerequisites: Basic knowledge of OpenShift administration (recommended: DO280 or equivalent experience) and a working AWS account.
Course Format: Instructor-led (virtual or on-site), hands-on labs, and guided projects.
Final Thoughts
As more enterprises adopt hybrid and multi-cloud strategies, ROSA emerges as a strategic choice for running OpenShift on AWS with minimal operational overhead. CS220 equips your team with the right skills to confidently deploy, configure, and manage production-grade ROSA clusters — unlocking agility, security, and innovation in your cloud-native journey.
Want to Learn More or Book the CS220 Course? At HawkStack Technologies, we offer certified Red Hat training, including CS220, tailored for teams and enterprises. Contact us today to schedule a session or explore our Red Hat Learning Subscription packages. www.hawkstack.com
0 notes
Text
The Future of Full-Stack Web Development: Trends, Tools, and Technologies to Watch
In the ever-evolving world of tech, few areas have seen as much rapid growth and transformation as full stack web development. What used to be a clear separation between frontend and backend has now turned into a more seamless, hybrid model, where developers are expected to juggle both ends of the spectrum. But where is this all heading?
As we look into the future of full-stack web development, it's clear that exciting changes are on the horizon — from smarter tools and frameworks to revolutionary technologies that promise to redefine how we build for the web. If you're a developer, student, or tech enthusiast, it's time to pay attention.
What is Full Stack Web Development?
Before diving into future trends, let’s briefly revisit what full stack web development really means. A full stack developer works on both:
Frontend (client-side): Everything users interact with — HTML, CSS, JavaScript, and UI frameworks like React or Vue.js.
Backend (server-side): Databases, servers, APIs, and the business logic behind the scenes using technologies like Node.js, Python, Ruby, or Java.
A full stack developer is essentially a digital Swiss Army knife — versatile, adaptable, and always in demand.
Emerging Trends in Full Stack Web Development
Here’s what’s shaping the future:
1. The Rise of Jamstack
Jamstack (JavaScript, APIs, and Markup) is becoming the preferred architecture for faster, more secure, and scalable web applications. Unlike traditional stacks, Jamstack decouples the frontend from the backend, improving performance and simplifying development.
2. AI-Powered Development Tools
Artificial Intelligence is now making its way into code editors and development platforms. Think GitHub Copilot or ChatGPT. These tools assist in writing code, identifying bugs, and even generating entire functions — speeding up the full stack workflow.
Benefits:
Faster coding with AI suggestions
Error prediction and debugging assistance
Smart documentation generation
3. Serverless and Edge Computing
Forget managing traditional servers — serverless architectures and edge computing are becoming the new standard. They allow developers to deploy applications with minimal infrastructure concerns, focusing purely on code and performance.
4. Component-Based Development
Modern frontend frameworks like React, Angular, and Vue are pushing developers towards building reusable components. This modular approach is now extending into the backend too, creating consistent development patterns across the stack.
Tools to Watch in Full Stack Development
To stay relevant, developers must keep their toolkits updated. Here are some must-watch tools shaping the future:
Frontend Tools
React (with Next.js) – For server-side rendering and static generation
Svelte – Lightweight and highly efficient for reactive apps
Tailwind CSS – Utility-first CSS framework for rapid UI development
Backend Tools
Node.js – Continues to dominate with asynchronous performance
Deno – A secure runtime from Node.js’s creator
GraphQL – Replacing REST APIs with a more flexible query language
DevOps & Hosting
Vercel & Netlify – Leading platforms for seamless frontend deployment
Docker & Kubernetes – For containerization and orchestration
Firebase & Supabase – Backend-as-a-service options for fast prototyping
Key Technologies Shaping the Future
Let’s look at the bigger innovations redefining full stack web development:
WebAssembly (WASM): Bringing languages like C++ and Rust to the web browser
Progressive Web Apps (PWAs): Combining web and native app experiences
Blockchain Integration: Decentralized apps (dApps) and smart contract backends
Real-Time Web with WebSockets & MQTT: Enabling live updates and chats
The Human Side of Full Stack Development
Beyond the code and tools, the role of a full stack developer is evolving on a human level too.
Collaborative Skills: Developers must now work more closely with designers, DevOps, and data teams.
Soft Skills Matter: Communication, problem-solving, and adaptability are becoming just as crucial as technical expertise.
Lifelong Learning: With new frameworks emerging almost monthly, continuous learning is a non-negotiable part of the job.
Final Thoughts
Full stack web development is no longer just about knowing a few languages. It’s about understanding entire ecosystems, embracing new paradigms, and building applications that are fast, scalable, and user-centric.
As we look to the future, the lines between frontend and backend will continue to blur, AI will become a coding partner, and developers will be more empowered than ever before. Staying curious, adaptable, and open to learning will be the key to thriving in this dynamic field.
In summary, here’s what to watch for in full stack web development:
Greater automation through AI tools
Continued growth of Jamstack and serverless models
Wider adoption of real-time, decentralized, and modular systems
The rise of multi-disciplinary developer roles
The future is full of possibilities — and if you’re a developer today, you’re right at the center of this exciting evolution.
0 notes
Text
Unveil how Gen AI is pushing Kubernetes to the forefront, delivering industry-specific solutions with precision and scalability.
#AI Startups Kubernetes#Enterprise AI With Kubernetes#Generative AI#Kubernetes AI Architecture#Kubernetes For AI Model Deployment#Kubernetes For Deep Learning#Kubernetes For Machine Learning
0 notes
Text
Step-by-Step Guide to Hiring an MLOps Engineer
: Steps to Hire an MLOps Engineer Make the role clear.
Decide your needs: model deployment, CI/CD for ML, monitoring, cloud infrastructure, etc.
2. Choose the level (junior, mid, senior) depending on how advanced the project is.
Create a concise job description.
Include responsibilities like:
2. ML workflow automation (CI/CD)
3. Model lifecycle management (training to deployment)
4. Model performance tracking
5. Utilizing Docker, Kubernetes, Airflow, MLflow, etc.
: Emphasize necessary experience with ML libraries (TensorFlow, PyTorch), cloud platforms (AWS, GCP, Azure), and DevOps tools.
: Source Candidates
Utilize dedicated platforms: LinkedIn, Stack Overflow, GitHub, and AI/ML forums (e.g., MLOps Community, Weights & Biases forums).
Use freelancers or agencies on a temporary or project-by-project basis.
1. Screen Resumes for Technical Skills
2. Look for experience in:
3. Building responsive machine learning pipelines
4 .Employing in a cloud-based environment
5. Managing manufacturing ML systems
: Technical Interview & Assessment
Add coding and system design rounds.
Check understanding of:
1.CI/CD for ML
2. Container management.
3. Monitoring & logging (e.g., Prometheus, Grafana)
4. Tracking experiments
Optional: hands-on exercise or take-home assignment (e.g., build a simple training-to-deployment pipeline).
1. Evaluate Soft Skills & Culture Fit
2. Collaboration with data scientists, software engineers, and product managers is necessary.
3. Assess communication, documentation style, and collaboration.
4. Make an Offer & Onboard
5. Offer thorough onboarding instructions.
6. Begin with a real project to see the impact soon.
Mlops engineer
???? Most Important Points to Remember MLOps ≠ DevOps: MLOps introduces additional complexity — model versioning, drift, data pipelines.
Infrastructure experience is a must: Hire individuals who have experience with cloud, containers, and orchestration tools.
Cross-function thinking: This is where MLOps intersect IT, software development, and machine learning—clear communications are crucial.
Knowledge tools: MLflow, Kubeflow, Airflow, DVC, Terraform, Docker, and Kubernetes are typical.
Security and scalability: Consider if the candidate has developed secure and scalable machine learning systems.
Model monitoring and feedback loops: Make sure they know how to check and keep the model’s performance good over time.
0 notes
Link
0 notes
Text
ARM Embedded Controllers ARMxy and Datadog for Machine Monitoring and Data Analytics

Case Details
ARM Embedded Controllers
ARM-based embedded controllers are low-power, high-performance microcontrollers or processors widely used in industrial automation, IoT, smart devices, and edge computing. Key features include:
High Efficiency: ARM architecture excels in energy efficiency, ideal for real-time data processing and complex computations.
Real-Time Performance: Supports Real-Time Operating Systems (RTOS) for low-latency industrial control.
Low Power Consumption: Optimized for continuous operation in sensors and monitoring nodes.
Flexibility: Compatible with industrial protocols (CAN, Modbus, MT connect).
Scalability: Cortex-M series for basic tasks to Cortex-A series for advanced edge computing.
Datadog
Datadog is a leading cloud-native monitoring and analytics platform for infrastructure, application performance, and log management. Core capabilities:
Data Aggregation: Collects metrics, logs, and traces from servers, cloud services, and IoT devices.
Custom Dashboards: Real-time visualization of trends and anomalies.
Smart Alerts: ML-driven anomaly detection and threshold-based notifications.
Integration Ecosystem: 600+ pre-built integrations (AWS, Kubernetes, etc.).
Predictive Analytics: Identifies patterns to forecast failures or bottlenecks.
Benefits of Combining ARM Controllers with Datadog
1. End-to-End Machine Monitoring Solution
Edge Data Collection: ARM controllers act as edge nodes, interfacing directly with sensors (e.g., temperature, vibration, current sensors).
Cloud-Based Intelligence: Data sent via MQTT/HTTP to Datadog for AI/ML-driven analysis (e.g., detecting abnormal vibration frequencies).
Use Case: Predictive maintenance for factory CNC machines by correlating sensor data with operational logs.
2. Low Latency and Real-Time Response
Edge Preprocessing: ARM controllers perform local computations (e.g., FFT analysis), reducing bandwidth usage by uploading only critical data.
Instant Alerts: Datadog triggers alerts via Slack/email for threshold breaches (e.g., overheating), minimizing downtime.
3. Remote Monitoring and Centralized Management
Global Device Oversight: Monitor distributed ARM devices worldwide via Datadog’s unified dashboard.
OTA Updates: Deploy firmware updates remotely using Datadog APIs, reducing on-site maintenance.
4. Cost and Energy Efficiency
Bandwidth Optimization: Edge computing reduces cloud storage and transmission costs.
Power-Saving Design: ARM’s low power consumption aligns with Datadog’s pay-as-you-go model for scalable deployments.
5. Scalability and Ecosystem Compatibility
Industrial Protocol Support: ARM controllers integrate with Modbus, OPC UA; Datadog ingests data via plugins or custom APIs.
Elastic Scalability: Datadog handles data from single devices to thousands of nodes without architectural overhauls.
6. Data-Driven Predictive Maintenance
Historical Insights: Datadog stores long-term data to train models predicting equipment lifespan (e.g., bearing wear trends).
Root Cause Analysis: Combine ARM controller logs with metrics to diagnose issues (e.g., power fluctuations causing downtime).
Typical Applications
Industry 4.0 Production Lines: Monitor CNC machine health with Datadog optimizing production schedules.
Wind Turbine Monitoring: ARM nodes collect gearbox vibration data; Datadog predicts failures to schedule maintenance.
Smart Buildings: ARM-based sensor networks track HVAC performance, with Datadog adjusting energy usage for sustainability.
Conclusion
The integration of ARM embedded controllers and Datadog delivers a robust machine monitoring framework, combining edge reliability with cloud-powered intelligence. The ARMxy BL410 series is equipped with 1 Tops NPU, low-power data acquisition, while Datadog enables predictive analytics and global scalability. This synergy is ideal for industrial automation, energy management, and smart manufacturing, driving efficiency and reducing operational risks.
0 notes
Text

Comparison of Ubuntu, Debian, and Yocto for IIoT and Edge Computing
In industrial IoT (IIoT) and edge computing scenarios, Ubuntu, Debian, and Yocto Project each have unique advantages. Below is a detailed comparison and recommendations for these three systems:
1. Ubuntu (ARM)
Advantages
Ready-to-use: Provides official ARM images (e.g., Ubuntu Server 22.04 LTS) supporting hardware like Raspberry Pi and NVIDIA Jetson, requiring no complex configuration.
Cloud-native support: Built-in tools like MicroK8s, Docker, and Kubernetes, ideal for edge-cloud collaboration.
Long-term support (LTS): 5 years of security updates, meeting industrial stability requirements.
Rich software ecosystem: Access to AI/ML tools (e.g., TensorFlow Lite) and databases (e.g., PostgreSQL ARM-optimized) via APT and Snap Store.
Use Cases
Rapid prototyping: Quick deployment of Python/Node.js applications on edge gateways.
AI edge inference: Running computer vision models (e.g., ROS 2 + Ubuntu) on Jetson devices.
Lightweight K8s clusters: Edge nodes managed by MicroK8s.
Limitations
Higher resource usage (minimum ~512MB RAM), unsuitable for ultra-low-power devices.
2. Debian (ARM)
Advantages
Exceptional stability: Packages undergo rigorous testing, ideal for 24/7 industrial operation.
Lightweight: Minimal installation requires only 128MB RAM; GUI-free versions available.
Long-term support: Up to 10+ years of security updates via Debian LTS (with commercial support).
Hardware compatibility: Supports older or niche ARM chips (e.g., TI Sitara series).
Use Cases
Industrial controllers: PLCs, HMIs, and other devices requiring deterministic responses.
Network edge devices: Firewalls, protocol gateways (e.g., Modbus-to-MQTT).
Critical systems (medical/transport): Compliance with IEC 62304/DO-178C certifications.
Limitations
Older software versions (e.g., default GCC version); newer features require backports.
3. Yocto Project
Advantages
Full customization: Tailor everything from kernel to user space, generating minimal images (<50MB possible).
Real-time extensions: Supports Xenomai/Preempt-RT patches for μs-level latency.
Cross-platform portability: Single recipe set adapts to multiple hardware platforms (e.g., NXP i.MX6 → i.MX8).
Security design: Built-in industrial-grade features like SELinux and dm-verity.
Use Cases
Custom industrial devices: Requires specific kernel configurations or proprietary drivers (e.g., CAN-FD bus support).
High real-time systems: Robotic motion control, CNC machines.
Resource-constrained terminals: Sensor nodes running lightweight stacks (e.g., Zephyr+FreeRTOS hybrid deployment).
Limitations
Steep learning curve (BitBake syntax required); longer development cycles.
4. Comparison Summary
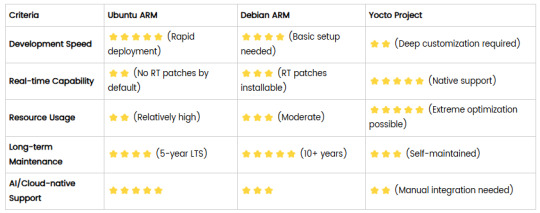
5. Selection Recommendations
Choose Ubuntu ARM: For rapid deployment of edge AI applications (e.g., vision detection on Jetson) or deep integration with public clouds (e.g., AWS IoT Greengrass).
Choose Debian ARM: For mission-critical industrial equipment (e.g., substation monitoring) where stability outweighs feature novelty.
Choose Yocto Project: For custom hardware development (e.g., proprietary industrial boards) or strict real-time/safety certification (e.g., ISO 13849) requirements.
6. Hybrid Architecture Example
Smart factory edge node:
Real-time control layer: RTOS built with Yocto (controlling robotic arms)
Data processing layer: Debian running OPC UA servers
Cloud connectivity layer: Ubuntu Server managing K8s edge clusters
Combining these systems based on specific needs can maximize the efficiency of IIoT edge computing.
0 notes
Text
Machine Learning Infrastructure: The Foundation of Scalable AI Solutions

Introduction: Why Machine Learning Infrastructure Matters
In today's digital-first world, the adoption of artificial intelligence (AI) and machine learning (ML) is revolutionizing every industry—from healthcare and finance to e-commerce and entertainment. However, while many organizations aim to leverage ML for automation and insights, few realize that success depends not just on algorithms, but also on a well-structured machine learning infrastructure.
Machine learning infrastructure provides the backbone needed to deploy, monitor, scale, and maintain ML models effectively. Without it, even the most promising ML solutions fail to meet their potential.
In this comprehensive guide from diglip7.com, we’ll explore what machine learning infrastructure is, why it’s crucial, and how businesses can build and manage it effectively.
What is Machine Learning Infrastructure?
Machine learning infrastructure refers to the full stack of tools, platforms, and systems that support the development, training, deployment, and monitoring of ML models. This includes:
Data storage systems
Compute resources (CPU, GPU, TPU)
Model training and validation environments
Monitoring and orchestration tools
Version control for code and models
Together, these components form the ecosystem where machine learning workflows operate efficiently and reliably.
Key Components of Machine Learning Infrastructure
To build robust ML pipelines, several foundational elements must be in place:
1. Data Infrastructure
Data is the fuel of machine learning. Key tools and technologies include:
Data Lakes & Warehouses: Store structured and unstructured data (e.g., AWS S3, Google BigQuery).
ETL Pipelines: Extract, transform, and load raw data for modeling (e.g., Apache Airflow, dbt).
Data Labeling Tools: For supervised learning (e.g., Labelbox, Amazon SageMaker Ground Truth).
2. Compute Resources
Training ML models requires high-performance computing. Options include:
On-Premise Clusters: Cost-effective for large enterprises.
Cloud Compute: Scalable resources like AWS EC2, Google Cloud AI Platform, or Azure ML.
GPUs/TPUs: Essential for deep learning and neural networks.
3. Model Training Platforms
These platforms simplify experimentation and hyperparameter tuning:
TensorFlow, PyTorch, Scikit-learn: Popular ML libraries.
MLflow: Experiment tracking and model lifecycle management.
KubeFlow: ML workflow orchestration on Kubernetes.
4. Deployment Infrastructure
Once trained, models must be deployed in real-world environments:
Containers & Microservices: Docker, Kubernetes, and serverless functions.
Model Serving Platforms: TensorFlow Serving, TorchServe, or custom REST APIs.
CI/CD Pipelines: Automate testing, integration, and deployment of ML models.
5. Monitoring & Observability
Key to ensure ongoing model performance:
Drift Detection: Spot when model predictions diverge from expected outputs.
Performance Monitoring: Track latency, accuracy, and throughput.
Logging & Alerts: Tools like Prometheus, Grafana, or Seldon Core.
Benefits of Investing in Machine Learning Infrastructure
Here’s why having a strong machine learning infrastructure matters:
Scalability: Run models on large datasets and serve thousands of requests per second.
Reproducibility: Re-run experiments with the same configuration.
Speed: Accelerate development cycles with automation and reusable pipelines.
Collaboration: Enable data scientists, ML engineers, and DevOps to work in sync.
Compliance: Keep data and models auditable and secure for regulations like GDPR or HIPAA.
Real-World Applications of Machine Learning Infrastructure
Let’s look at how industry leaders use ML infrastructure to power their services:
Netflix: Uses a robust ML pipeline to personalize content and optimize streaming.
Amazon: Trains recommendation models using massive data pipelines and custom ML platforms.
Tesla: Collects real-time driving data from vehicles and retrains autonomous driving models.
Spotify: Relies on cloud-based infrastructure for playlist generation and music discovery.
Challenges in Building ML Infrastructure
Despite its importance, developing ML infrastructure has its hurdles:
High Costs: GPU servers and cloud compute aren't cheap.
Complex Tooling: Choosing the right combination of tools can be overwhelming.
Maintenance Overhead: Regular updates, monitoring, and security patching are required.
Talent Shortage: Skilled ML engineers and MLOps professionals are in short supply.
How to Build Machine Learning Infrastructure: A Step-by-Step Guide
Here’s a simplified roadmap for setting up scalable ML infrastructure:
Step 1: Define Use Cases
Know what problem you're solving. Fraud detection? Product recommendations? Forecasting?
Step 2: Collect & Store Data
Use data lakes, warehouses, or relational databases. Ensure it’s clean, labeled, and secure.
Step 3: Choose ML Tools
Select frameworks (e.g., TensorFlow, PyTorch), orchestration tools, and compute environments.
Step 4: Set Up Compute Environment
Use cloud-based Jupyter notebooks, Colab, or on-premise GPUs for training.
Step 5: Build CI/CD Pipelines
Automate model testing and deployment with Git, Jenkins, or MLflow.
Step 6: Monitor Performance
Track accuracy, latency, and data drift. Set alerts for anomalies.
Step 7: Iterate & Improve
Collect feedback, retrain models, and scale solutions based on business needs.
Machine Learning Infrastructure Providers & Tools
Below are some popular platforms that help streamline ML infrastructure: Tool/PlatformPurposeExampleAmazon SageMakerFull ML development environmentEnd-to-end ML pipelineGoogle Vertex AICloud ML serviceTraining, deploying, managing ML modelsDatabricksBig data + MLCollaborative notebooksKubeFlowKubernetes-based ML workflowsModel orchestrationMLflowModel lifecycle trackingExperiments, models, metricsWeights & BiasesExperiment trackingVisualization and monitoring
Expert Review
Reviewed by: Rajeev Kapoor, Senior ML Engineer at DataStack AI
"Machine learning infrastructure is no longer a luxury; it's a necessity for scalable AI deployments. Companies that invest early in robust, cloud-native ML infrastructure are far more likely to deliver consistent, accurate, and responsible AI solutions."
Frequently Asked Questions (FAQs)
Q1: What is the difference between ML infrastructure and traditional IT infrastructure?
Answer: Traditional IT supports business applications, while ML infrastructure is designed for data processing, model training, and deployment at scale. It often includes specialized hardware (e.g., GPUs) and tools for data science workflows.
Q2: Can small businesses benefit from ML infrastructure?
Answer: Yes, with the rise of cloud platforms like AWS SageMaker and Google Vertex AI, even startups can leverage scalable machine learning infrastructure without heavy upfront investment.
Q3: Is Kubernetes necessary for ML infrastructure?
Answer: While not mandatory, Kubernetes helps orchestrate containerized workloads and is widely adopted for scalable ML infrastructure, especially in production environments.
Q4: What skills are needed to manage ML infrastructure?
Answer: Familiarity with Python, cloud computing, Docker/Kubernetes, CI/CD, and ML frameworks like TensorFlow or PyTorch is essential.
Q5: How often should ML models be retrained?
Answer: It depends on data volatility. In dynamic environments (e.g., fraud detection), retraining may occur weekly or daily. In stable domains, monthly or quarterly retraining suffices.
Final Thoughts
Machine learning infrastructure isn’t just about stacking technologies—it's about creating an agile, scalable, and collaborative environment that empowers data scientists and engineers to build models with real-world impact. Whether you're a startup or an enterprise, investing in the right infrastructure will directly influence the success of your AI initiatives.
By building and maintaining a robust ML infrastructure, you ensure that your models perform optimally, adapt to new data, and generate consistent business value.
For more insights and updates on AI, ML, and digital innovation, visit diglip7.com.
0 notes