#Lines and Splines Annotation
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr Inc. is using 66 technologies for its website.
Text
AutoCAD Training - Edm Tech Pro
AutoCAD for Civil Architects Training & Certification Course
EDM's Autocad Civil Training Course in Jaipur is the first step towards a transforming civil engineering experience. Discover the world of AutoCAD with our extensive course, which is intended to provide you the tools you need to run an effective AutoCAD Civil program. This AutoCAD course provides a comprehensive overview of the program, covering everything from fundamental basics to sophisticated functionalities. The most widely used software for turning architectural and civil engineering concepts and specifications into blueprints, drawings, and models is AutoCAD-Civil/Architects.

What is Autodesk & auto CAD ?
Utilize AutoCAD® software's automation, collaboration, and machine learning technologies to enhance your teams' creativity. AutoCAD is used by engineers, architects, and construction specialists to Create and annotate 3D models with mesh objects, solids, and surfaces as well as 2D geometry. Automate processes like scheduling, counting objects, swapping out blocks, comparing drawings, and more. Use add-on applications and APIs to customize your workspace and increase productivity.

AutoCAD- Civil Course Syllabus
Note: More than five absent will not be allowed on the same batch due to better quality of Education.
Session 1 - Introduction to AutoCAD, History, Exploring GUI & Workspaces
File Management - New, Display Control - Zoom In, Zoom out.
Line command-Draw simple letters from line command, In the class in front of student
Session 2 - Draw commands- Circle(Radius /Diameter), File Management-Open, Save, Save as, Close
Editing commands – Trim, Extend
Session 3 - Draw Command- Rectangle(Area/ Dimension/ Rotation) Object Selection Methods and Dynamic Input
Session 4 - Editing commands – Move, Copy, Rotate,Offset ,Mirror.Difference CADD & CAD
Writing manner autoCAD
Session 5 - Draw commands- Polygon ,Ellipse
Session 6 - Draw Command- Arc, Editing commands –Erase, Undo, Redo.
Session 7 - Editing commands – Circle(2point/3 Point/TTR/TTT),Rectangle(Chamfer,Fillet Width, Thickness, Elevation Creating Detail Drawing –Revcloud.
Session 8 - Editing Command-Introduction of Array
1.Rectangular
2. Polar
3. Path
Session 9 - Join, Solid, Donut, Fill, Explode, MOCORO(Move/Copy/Rotate/Scale/Base), Break.
Session 10 - Isomectric ---i. Isometric views
ii. Isoplane
Session 11- Drafting Settings, Drawing settings – Units, Limits,Construction Line(X-Line), Ray, Polyline,Polyline Edit, Spline, Spline Edit Multiline, Multiline Style
Session 12- Dimensions- Dimension - Linear, Aligned, Radius, Diameter, Angle, Arc length, Continuous, Baseline,Dimension Break, ,Dimedit, Dimension Style Manage
Session 13- Annotations -Text,TextEdit ,Mtext, Spell, Table, Tabledit.
Session 14- "Types of lines & their uses Object Properties - Color, Linetype, Ltscale, Lineweight, Properties, Quick Properties, Matchprop."
Session 15- Layer Management-Adding / Removing Layers, How to work with layers
Session 16- Hatching utilities - Hatch, hatchedit, Superhatch
Session 17- Tracing the Product/drawing:- Importing the photo/drawing (C) , trace the image with spline or other required draw tools
Session 18- Mleader, Multileader style,region,boundary, Divide, Measure, Group, Group Edit, Block, Wblock, Insert Block, Lengthen, AutoCAD Design Centre (DC),point style
Session 19- StandardsParameters :- (standard properties of layers as per various use ie;- line type,color, linetype scale etc),(Text style, size, color, font) & (Dimension style), (Minimum room,kitechen, balcony & bathroom sizes) ,(dimension of doors, windows ,ventilators, beds,chair,sofa, tv stand etc) used by industrial experts
Session 20- Creation of Elevation, Section with the help of given plan staircase concepts. Standard sizes of stairs.
Session 21- Parametric Drawings-Workspace, Projections (First & Third angle)
Session 22- Workspace Switching & Setting Primitives-Cylinder, box, torus, wedge, cone, frustum of cone,sphere,pyramid,helix.
Session 23- Final Printing/Plotting:-Sheet sizes A0, A1, and A2…..,
Arranging/scaling the plan into Sheet Layout
Introduction to plotting, Page setup, Plot Styles
what to print, plotting scale, preview creating the pdf of final view.

Layer Management In Auto CAD Civil


0 notes
Text
Data Annotation Types to execute Autonomous Driving

Autonomous vehicles are still working towards reaching the stage of full autonomy. A fully functioning and safe autonomous vehicle must be competent in a wide range of machine learning processes before it can be trusted to drive on its own. From processing visual data in real-time to safely coordinating with other vehicles, the need for AI is essential. Self-driving cars could not do any of this without a huge volume of different types of training data, created and tagged for specific purposes.
Due to the several existing sensors and cameras, advanced automobiles generate a tremendous amount of data. We cannot use these datasets effectively unless they are correctly labeled for subsequent processing. This could range from simple 2D bounding boxes all the way to more complex annotation methods, such as semantic segmentation.
There are various image annotation types such as Polygons, bounding boxes, 3D cuboids, Semantic Segmentation, Lines, and Splines that can be incorporated into autonomous vehicles. These annotation methods help in achieving greater accuracy for autonomous driving algorithms. However, which annotation method is best suited for you must be chosen according to the requirements of your project.
Types of Annotation for Autonomous Driving
Below we have discussed all types of annotation required to make the vehicle autonomous.
2D bounding Box Annotation
The bounding box annotation technique is used to map objects in a given image/video to build datasets thereby enabling ML models to identify & localize objects.2D boxing is rectangular, and among all the annotation tools, it is the simplest data annotation type with the lowest cost. This annotation type is preferred in less complex cases and also if you are restricted by your budget. This is not trusted to be the most accurate type of annotation but saves a lot of labeling time. Common labeling objects include: Vehicles, Pedestrian, Obstacles, Road signs, Signal lights, Buildings and Parking zone.
3D Cuboid Annotation
Similar to the bounding boxes that were previously discussed, this type involves the annotator drawing boxes around the objects in an image. The bounding boxes in this sort of annotation, as the name implies, are 3D, allowing the objects to be annotated on depth, width, and length (X, Y, and Z axes). An anchor point is placed at each edge of the object after the annotator forms a box around it. Based on the characteristics of the object and the angle of the image, the annotator makes an accurate prediction as to where the edge maybe if it is missing or blocked by another object. This estimation/ annotation plays a vital role in judging the distance of the object from the car based on the depth and detecting the object’s volume and position.
Polygon Annotation
It can occasionally be challenging to add bounding boxes around specific items in an image due to their forms and sizes. In photos and movies with erratic objects, polygons provide precise object detection and localization. Due to its precision, it is one of the most popular annotation techniques. However, the accuracy comes at a price because it takes longer than other approaches. Beyond a 2D or 3D bounding box, irregular shapes like people, animals, and bicycles need to be annotated. Since polygonal annotation allows the annotator to specify additional details such as the sides of a road, a sidewalk, and obstructions, among other things, it can be a valuable tool for algorithms employed in autonomous vehicles.
Semantic Segmentation
We’ve looked at defining objects in images up to this point, but semantic segmentation is far more accurate than other methods. It deals with assigning a class to each pixel in an image. For a self-driving automobile to function well in a real-world setting, it must comprehend its surroundings. The method divides the items into groups like bicycles, people, autos, walkways, traffic signals, etc. Typically, the annotator will have a list made up of these. In conclusion, semantic segmentation locates, detects, and classifies the item for computer vision. This form of annotation demands a high degree of accuracy, where the annotation must be pixel-perfect.
Lines and Splines Annotation
In addition to object recognition, models need to be trained on boundaries and lanes. To assist in training the model, annotators drew lines in the image along the lanes and edges. These lines allow the car to identify or recognize lanes, which is essential for autonomous driving to succeed since it enables the car to move through traffic with ease while still maintaining lane discipline and preventing accidents.
Video Annotation
The purpose of video annotation is to identify and track objects over a collection of frames. The majority of them are utilized to train predictive algorithms for automated driving. Videos are divided into thousands of individual images, with annotations placed on the target object in each frame. In complicated situations, single frame annotation is always employed since it can ensure quality. At this time, machine learning-based object tracking algorithms have already helped in video annotation. The initial frame’s objects are annotated by the annotator, and the following frames’ items are tracked by the algorithm. Only when the algorithm doesn’t work properly does the annotator need to change the annotation. As labor costs decrease, clients can save a greater amount of money. In basic circumstances, streamed frame annotation is always employed.
Use Cases of Autonomous Driving
The main goal of data annotation in automotive is to classify and segment objects in an image or video. They help achieve precision, which to automotive is important, given that it is a mission-critical industry, and the accuracy, in turn, determines user experience. This process is essential because of the use cases it enables:
Object and vehicle detection: This crucial function allows an autonomous vehicle to identify obstacles and other vehicles and navigate around them. Various types of annotation are required to train the object detection model of autonomous driving so that it can detect persons, vehicles, and other obstacles coming in its way.
Environmental perception: Annotators use semantic segmentation techniques to create training data that labels every pixel in a video frame. This vital context allows the vehicle to understand its surroundings in more detail. It’s important to have a complete understanding of its location and everything surrounding it to make a safe drive.
Lane detection: Autonomous vehicles need to be able to recognize road lanes so that they can stay inside of them. This is very important to avoid any accidents. Annotators support this capability by locating road markings in video frames.
Understanding signage: The vehicle must be able to recognize all the signs and signals on the road to predict when and where to stop, take a turn, and many related objectives. Autonomous vehicles should automatically detect road signs and respond to them accordingly. Annotation services can enable this use case with careful video labeling.
Conclusion
Although it takes a lot of effort, delivering Ground Truth quality annotation for self-driving cars is crucial to the project’s overall success. Get the best solutions by using precise annotations created by TagX to train and validate your algorithms.
We are the data annotation experts for autonomous driving. We can help with any use case for your automated driving function, whether you’re validating or training your autonomous driving stack. Get in contact with our specialists to learn more about our automobile and data annotation services as well as our AI/ML knowledge.
#ObjectDetection#LaneMarkingAnnotation#SemanticSegmentation#3DAnnotation#artificial intelligence#machinelearning#dataannotation
0 notes
Text
#Outsource Image Recognition Services#Image recognition for computer vision technology refers to identifying objects and other attributes within an image. This helps in training#objects#and different variations in the pictures.#At Triyock BPO#we provide end-to-end image recognition services for your AI projects. Our team of AI experts and image annotators have rich experience and#Our Image Annotation Services Include:#2D Bounding Box Annotation#3D Bounding Boxes/ Cuboids Annotation#Online Image Annotation using Polygons#Semantic Segmentation#Image Classification#Lines and Splines Annotation#Landmark Annotation#Discuss Your Project With Us#Are you looking for a trusted outsourcing image annotation company for your image annotation needs? Contact us at [email protected] for our#Triyockbpo#bpo#outsourcingservices#bposolution
0 notes
Text
AUTOCAD commands 2
Hello, It’s me again, this week I learned how to use more commands for AUTOCAD, you already know that I’m new in this digital drawing tool and I will be showing what I learn to share my new knowledge, with anything more to say lets start
ERASE
Removes objects from a drawing.
LIST
You can use LIST to display and then copy the properties of selected objects to a text file.
The text window displays the object type, object layer, and the X,Y,Z position relative to the current user coordinate system (UCS) and whether the object is in model space or paper space.
LIST also reports the following information:
· Color, linetype, lineweight, and transparency information, if these properties are not set to BYLAYER.
· The thickness of an object, if it is nonzero.
· Elevation (Z coordinate information).
· Extrusion direction (UCS coordinates), if the extrusion direction differs from the Z axis (0,0,1) of the current UCS.
· Additional information related to the specific object type. For example, for dimensional constraint objects, LIST displays the constraint type (annotation or dynamic), reference type (yes or no), name, expression, and value.
EXTEND
Extends objects to meet the edges of other objects.
Find
To extend objects, first select the boundaries. Then press Enter and select the objects that you want to extend. To use all objects as boundaries, press Enter at the first Select Objects prompt.
The following prompts are displayed.
Current settings: Projection = current, Edge = current
Select boundary edges...
Select objects or <select all>: Select one or more objects and press Enter, or press Enter to select all displayed objects
Select object to extend or shift-select to trim or [Fence/Crossing/Project/Edge/Undo]: Select objects to extend, or hold down SHIFT and select an object to trim, or enter an option
Boundary Object Selection
Uses the selected objects to define the boundary edges to which you want to extend an object.
Object to Extend
Specifies the objects to extend. Press Enter to end the command.
Shift-Select to Trim
Trims the selected objects to the nearest boundary rather than extending them. This is an easy method to switch between trimming and extending.
Fence
Selects all objects that cross the selection fence. The selection fence is a series of temporary line segments that you specify with two or more fence points. The selection fence does not form a closed loop.
Crossing
Selects objects within and crossing a rectangular area defined by two points.
Note: Some crossing selections of objects to be extended are ambiguous. EXTEND resolves the selection by following along the rectangular crossing window in a clockwise direction from the first point to the first object encountered.
Project
Specifies the projection method used when extending objects.
None
Specifies no projection. Only objects that intersect with the boundary edge in 3D space are extended.
UCS
Specifies projection onto the XY plane of the current user coordinate system (UCS). Objects that do not intersect with the boundary objects in 3D space are extended.
View
Specifies projection along the current view direction.
Edge
Extends the object to another object's implied edge, or only to an object that actually intersects it in 3D space.
Extend
Extends the boundary object along its natural path to intersect another object or its implied edge in 3D space.
Note: Sets the EDGEMODE system variable to 1 so that extending the selected object to an imaginary extension of the boundary edge becomes the default.
No Extend
Specifies that the object is to extend only to a boundary object that actually intersects it in 3D space.
Note: Sets the EDGEMODE system variable to 0 so that using the selected boundary edge without any extensions becomes the default.
PAN
Shifts the view without changing the viewing direction or magnification.
Find
Position the cursor at the start location and press the left mouse button down. Drag the cursor to the new location. You can also press the mouse scroll wheel or middle button down and drag the cursor to pan.
JOIN
The Join command in AutoCAD is used to join the objects end to end to create a single object. The objects can be curved or linear, depending on the requirements.
It combines the series of linear and curved to create a single 2D or 3D object.
Note: The objects namely, rays, closed objects, and construction lines cannot be joined using the Join command
Steps to join any object
Select the Join command from the ribbon panel under the Modify interface. Or Type J or join on the command line and press Enter.
We need to select multiple objects to join. The selected objects are joined at once.
Press Enter.
The selected objects will be joined as a single unbreakable object.
Note: Only the collinear objects can be joined. It means that the objects lying on a straight line will be joined.
Let's consider an example.
Example:
Here, we will consider the below figure.
We are required to join the segments numbered 1, 2, 3, and 4. These segments are shown below:
The steps to join the segments markedabove are:
Type J or join on the command line or command prompt and press Enter.
Select segments 1 and 2.
Press Enter
Select segments 3 and 4.
Press Enter.
The segments will be joined, as shown in the below image:
The types of objects that can be joined using the JOIN command are listed below:
Lines The line objects can only be joined to the source line. The line can have space between them.
The endpoints of the lines should lie on the straight line. It is explained in the below image:
We can also join the series of lines in a single line.
Here, we need to specify the first and last segment of the series to join.
The above process is explained in the below image:
Arcs The arcs can only be joined to the source arc. The radius and center point of the arc must be same. The arc can have spaces between them. Let's consider an example. The image is shown below:
Polyline Here, lines, arcs, and polylines can be joined to the source arc.
Elliptical Arcs The elliptical arcs can only be joined to the specified elliptical arc. The major and minor axis of the elliptical arc must be same. The arc should be coplanar. The elliptical arcs can have space between them.
3D Polylines The linear or curved object can be joined to the specified 3D Polyline. The objects should be noncoplanar and contiguous.
Helixes The linear or curved object can be joined to the specified helix. The objects should be noncoplanar and contiguous.
Splines The linear or curved object can be joined to the specified spline. The objects should be noncoplanar and contiguous.
OFFSET
AutoCAD Offset Command
The offset command in AutoCAD is used to create parallel lines, concentric circles, and parallel curves.
We can offset any object through a point or at a specified distance. We can create as many parallel lines and curves with the help of the offset command.
The offset objects can also be modified further according to the requirements. Here, modification of offset object means that we can apply trim, extend, and other methods on it.
Let's understand it with some examples.
Example 1: Offset of a circle.
The steps are listed below:
Create a circle with any specified radius. For example, 3.
Select the Offset icon on the ribbon panel. Or Type O or offset on the command line or command prompt and press Enter.
Specify the value of offset distance. It is the distance value to create a concentric circle from the original circle. For example, 1.
Press Enter.
Select the object to offset. We need to select the object with a small square cursor.
Move the cursor inside or outside to place the offset object, as shown in the below image:
Press Esc or Enter to exit from the offset command.
Example 2:
The object to offset is shown in the below image:
The steps are listed below:
Type J or join on the command line.
Select objects or multiple objects to join. Here, we will select the two lines and an arc.
Press Enter.
The distance between the object and the offset object is 1, as mentioned in step 4.
Example 2: To remove the object after the offset.
We can also remove the object after the offset. The object is shown in the below image:
The steps for such an example are listed below:
Create an object using the polyline command, as shown in above image. We can also create it using line command and can join them using Join
Select the Offset icon from the ribbon panel. Or Type O or offset on the command line or command prompt and press Enter.
Type E or erase on the command line and press Enter.
Type yes to erase the source object after offsetting. Or Click on the yes button on the command line, as shown in the below image:
Specify the value of offset distance. For example, 1.
Press Enter.
Select the object to offset with a small square cursor.
Move the cursor in the particular direction and click on that point.
Press Enter. It is shown in the below image:
Press Esc or Enter to exit from the offset command.
We can notice that the source object is erased after offsetting.
Below are the figures with their offset.
Figure 1:
Figure 2:
Figure 3:
Figure 4:
Multiple Offset
The multiple offset command in AutoCAD is used to apply the offset multiple number of times.
Let's understand it with an example.
The steps are listed below:
Select the line command from the ribbon panel and create a line of dimension 4. We can draw any object according to the requirements.
Type O or offset on the command line and press Enter.
Specify the offset distance. For example, 1.
Select the object to offset.
Type M or multiple on the command line and press Enter.
Continue clicking in the corresponding direction to place the offset objects.
With the help of the above steps, we are not required to use the offset command again and again
QSAVE
Saves the current drawing using the specified default file format.
Find
If the drawing is named, the program saves the drawing and does not request a new file name. Use the SAVEAS command if you need to save a drawing with a different name.
If the drawing is unnamed, the Save Drawing As dialog box (see SAVEAS) is displayed and the drawing is saved with the file name and format you specify.
When you save a drawing, the operation can either be an incremental save or a full save depending on the setting of the ISAVEPERCENT system variable. Incremental saves are faster, but the drawing file will be larger. Saving to a different format always results in a full save.
Note: The default file format can be specified in the Open and Save tab of the Options dialog box.
OSNAP
Sets running object snap modes.
The Object Snap tab of the Drafting Settings dialog box is displayed.
If you enter -OSNAP at the Command prompt, the following prompts are displayed.
Enter a list of object snap modes
Enter names of object snap modes separated with commas, or enter none or off.
Object Snap Modes
Specify one or more object snap modes by entering the uppercase characters of the name in the following table. If you enter more than one name, separate the names with commas.
Mode
Description
ENDpoint
Snaps to the closest endpoint or corner of a geometric object
MIDpoint
Snaps to the midpoint of a geometric object
CENter
Snaps to the center of an arc, circle, ellipse, or elliptical arc
Geometric CEnter
Snaps to the centroid of any closed polylines and splines
NODe
Snaps to a point object, dimension definition point, or dimension text origin
QUAdrant
Snaps to a quadrant point of an arc, circle, ellipse, or elliptical arc
INTersection
Snaps to the intersection of geometric objects
EXTension
Causes a temporary extension line or arc to be displayed when you pass the cursor over the endpoint of objects, so you can specify points on the extension
INSertion
Snaps to the insertion point of objects such as an attribute, a block, or text
PERpendicular
Snaps to a point perpendicular to the selected geometric object
TANgent
Snaps to the tangent of an arc, circle, ellipse, elliptical arc, polyline arc, or spline
NEArest
Snaps to the nearest point on an object such as an arc, circle, ellipse, elliptical arc, line, point, polyline, ray, spline, or xline
APParent intersection
Snaps to the visual intersection of two objects that do not intersect in 3D space but may appear to intersect in the current view
PARallel
Constrains a new line segment, polyline segment, ray or xline to be parallel to an existing linear object that you identify by hovering your cursor
NONe
Turns off object snap modes
DIM
Creates multiple dimensions and types of dimensions with a single command.
Find
You can select objects or points on objects to dimension, and then click to place the dimension line. When you hover over an object, the DIM command automatically generates a preview of a suitable dimension type to use.
Supported dimension types include the following:
· Vertical, horizontal, and aligned linear dimensions
· Ordinate dimensions
· Angular dimensions
· Radius and jogged radius dimensions
· Diameter dimensions
· Arc length dimensions
Some DIM options set a mode of operation that persists until you change it, including
· Baseline linear or baseline angular dimensioning
· Continue linear or continue angular dimensioning
· Radius, diameter, jogged radius, or arc length dimensions
Some DIM options provide methods to edit dimensions including
· Align the dimension lines of selected dimensions to a reference or base dimension
· Offset the dimension lines of selected dimensions
· Specify a different layer for subsequently created dimensions
The following prompts are displayed.
Select objects
Defaults to an applicable dimension type for the objects you select and displays the prompts corresponding to that dimension type.
Object type
Default
Arc
Radius dimensions
Circle
Diameter dimensions
Line
Linear dimensions
Polyline
Linear or radius dimensions, depending on the segment selected
First extension line origin
Creates a linear dimension when you specify two points.
Angular
Creates an angular dimension showing the angle between three points by or the angle between two lines (same as the DIMANGULAR command).
· Vertex. Specifies the point to use as the vertex of an angular dimension.
· Specify first side of angle. Specifies one of the lines that defines the angle.
· Specify second side of angle. Specifies the other line that defines the angle.
· Angular dimension location. Specifies the quadrant and location for the arc dimension line.
o Mtext. Edits the dimension text with the Text Editor contextual tab.
o Text. Edits the dimension text in the Command window.
o Text angle. Specifies the angle of the dimension text.
o Undo. Returns to the previous prompt.
· Undo. Returns to the previous prompt.
Baseline
Creates a linear, angular, or ordinate dimension from the first extension line of the previous or selected dimension (same as the DIMBASELINE command).
Note: By default, the last created dimension is used as the base dimension.
· First extension line origin. Specifies the first extension line of the base dimension as the extension line origin for the baseline dimension.
· Second extension line origin. Specifies the next edge or angle to dimension.
· Feature Location. Uses the endpoint of the base dimension (ordinate dimension) as the endpoint for the baseline dimension.
· Select. Prompts you select a linear, ordinate, or angular dimension to use as the base for the baseline dimension.
· Offset. Specifies the offset distance from which the baseline dimensions are created.
· Undo. Undoes the last baseline dimension created.
Continue
Creates a linear, angular, or ordinate dimension from the second extension line of a selected dimension (same as the DIMCONTINUE command).
· First extension line origin. Specifies the first extension line of the base dimension as the extension line origin for the continued dimension.
· Second extension line origin. Specifies the next edge or angle to dimension.
· Feature location. Uses the endpoint of the base dimension (ordinate dimension) as the endpoint for the continued dimension.
· Select. Prompts you select a linear, ordinate, or angular dimension to use as the base for the continued dimension.
· Undo. Undoes the last baseline dimension created.
Ordinate
Creates an ordinate dimension (same as DIMORDINATE command).
· Feature location. Prompts for a point on a feature such as an endpoint, intersection, or center of an object.
o Leader endpoint. Uses the difference between the feature location and the leader endpoint to determine whether it is an X or a Y ordinate dimension. If the difference in the Y ordinate is greater, the dimension measures the X ordinate. Otherwise, it measures the Y ordinate.
o Xdatum. Measures the X ordinate and determines the orientation of the leader line and dimension text.
o Ydatum. Measures the Y ordinate and determines the orientation of the leader line and dimension text.
o Mtext. Displays the Text Editor contextual tab, which you can use to edit the dimension text.
o Text. Customizes the dimension text at the Command prompt. The generated dimension is displayed within angle brackets.
o Angle. Specifies the angle of the dimension text.
o Undo. Returns to the previous prompt.
· Undo. Returns to the previous prompt.
Align
Aligns multiple parallel, concentric, or same datum dimensions to a selected base dimension.
· Base dimension. Specifies a dimension to use as basis for the dimensions alignment.
o Dimensions to align. Selects the dimensions to align to the selected base dimension.
Distribute
Specifies the method on how to distribute a group of selected isolated linear or ordinate dimensions.
· Equal. Equally distributes all selected dimensions. This method requires a minimum of three dimension lines.
· Offset. Distributes all selected dimensions at a specified offset distance.
Layer
Assigns new dimensions to the specified layer, overriding the current layer. Enter Use Current or " . " to use the current layer. (DIMLAYER system variable)
Undo
Reverses the last dimension operation.
The following options are displayed when you place a dimension in such a way that it overlaps an existing dimension.
Move away
Arranges the existing dimension and the newly inserted dimension into a baseline dimension type.
Break up
Splits up the existing dimension into two dimensions, and arranges those dimensions into a continued dimension type.
Replace
Deletes the existing dimension and replaces it with the one you insert.
None
Inserts the new dimension on top of the existing dimension.
DIMSTYLE
At the Command prompt, creates and modifies dimension styles.
You can save or restore dimensioning system variables to a selected dimension style.
List of Prompts
The following prompts are displayed.
Annotative
Creates an annotative dimension style.
Create annotative dimension style?
Specifies whether the dimension style you create are annotative. When dimensions are annotative, the process of scaling annotation objects is automated.
Name for new dimension style
Specifies a style name or enter ? to display a list of existing style names.
That name is already in use, redefine it?
Displayed if the name you entered is already in use.
If you enter y, associative dimensions that use the redefined dimension style are regenerated.
To display the differences between the dimension style name you want to save and the current style, enter a tilde (~) followed by the style name. Only settings that differ are displayed, with the current setting in the first column, and the setting of the compared style in the second column.
Save
Saves the current settings of dimensioning system variables to a dimension style. The new dimension style becomes the current one.
· Name for new dimension style.
· The name is already in use, redefine it?
Restore
Restores dimensioning system variable settings to those of a selected dimension style.
Dimension style name
Makes the dimension style you enter the current dimension style.
To display the differences between the dimension style name you want to restore and the current style, enter a tilde (~) followed by the style name at the Enter Dimension Style Name prompt. Only settings that differ are displayed, with the current setting in the first column, and the setting of the compared style in the second column. After the differences are displayed, the previous prompt returns.
?
Lists the named dimension styles in the current drawing.
Select dimension
Makes the dimension style of the selected object the current dimension style.
Status
Displays the current values of all dimension system variables in the drawing.
Variables
Lists the dimension system variable settings of a dimension style or selected dimensions without modifying the current settings.
Name
Lists the settings of dimension system variables for the dimension style name you enter.
To display the differences between a particular dimension style and the current style, enter a tilde (~) followed by the style name at the Enter Dimension Style Name prompt. Only settings that differ are displayed, with the current setting in the first column, and the setting of the compared style in the second column.
?
Lists the named dimension styles in the current drawing.
Select Dimension
Lists the dimension style and any dimension overrides for the dimension object you select.
Apply
Find
Applies the current dimensioning system variable settings to selected dimension objects, permanently overriding any existing dimension styles applied to these objects.
The dimension line spacing between existing baseline dimensions is not updated (see the DIMDLI system variable). Dimension text variable settings do not update existing leader text.
This is something I was reading this week, now I only have to put it on pratice, well, that will be all for tonight, see ya soon!
1 note
·
View note
Text
Data Annotation in Artificial Intelligence
Everything has changed dramatically since a few years ago. Additionally, artificial intelligence is blooming and perhaps essential in this fast-paced atmosphere where businesses attempt to succeed. Here are some reasons why Data Annotation is a crucial component of Artificial Intelligence.

The practice of categorizing and identifying data for AI applications is known as data annotation. Simply enough, annotators label what they see while separating the format they view. Text, video, audio, or image can be used as the format.
Annotators identify particular things in an Image Annotation Service and name them.
Different Types of Image Annotation Exist:
Bounding Box Annotation: Annotators draw a square or a two-dimensional square around the chosen object.
Cuboid Annotation: Annotators describe the thing in the form of a cube, a three-dimensional square. The depth or distance of various objects can be determined using this form of annotation.
Landmark Annotation: Annotators place tiny dots around the target image to indicate their labels. This is frequently used to identify faces, such as when using face recognition to unlock a phone.
Bounding Box Annotation: This is a sort of annotation similar to the polygon annotation, however, the polygon annotation is more accurate since the annotators may pick and choose what they want to annotate rather than simply drawing a square all over the object. Using aerial photography calls for this kind of annotation. Annotators can label houses, trees, roads, street signs, and more using polygon annotation.
Semantic Segmentation: divides the image's items by grouping them together in various colored pixels. Multilingual Annotators divide the route into three groups, for instance, to perform this annotation on an image of a road. People are pixelated in blue in the first part, cars in red in the second, and street signs in blue in the third (pixelated in yellow).
However, "Instance Segmentation" is a different approach to semantic segmentation. The ability of Instance Segmentation to generate a segment inside of another part is the sole important distinction between these two segmentation techniques. This means that by designing an inner section with the names "person#1, person#2, and person#3," annotators can distinguish between the individuals pixelated in blue. Of course, the pixelated color of person #1 would differ from that of person #2, and so on.
Splines and Lines This type's function is to be aware of lane markings and borders.
0 notes
Text
Image Annotation Service For Computer Vision Models
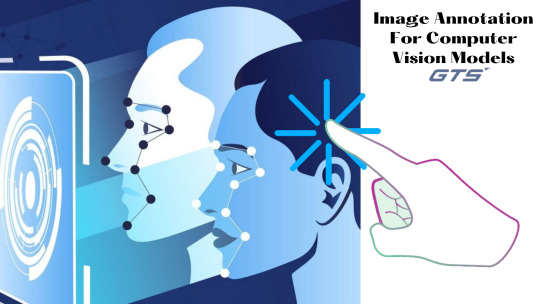
Computer vision models that are able to distinguish between objects of various shapes and environments. The location of people.
Face identification
To develop computer vision models built on the basis of differentiating points, or to recognize and read specific parts of the form and the position of an object, our Image Annotation Service based on particular problems is a great idea. Computer vision models, for instance, could make use of pictures that are precisely identified using vital points on various face features in order to develop the brain to distinguish the features that make up expressions, expressions and emotions using this service. An annotation may be conducted by placing crucial elements on an image in different places based on the categories you select.
Image Annotation
2D Bounding Boxes in Computer Vision
The computation of attributes within computer-vision models as well as the recognition of the environment around it in real-world scenarios are made easier with the aid by bounding boxes that are 2D.
3D Cuboid Annotation
In transforming 2D pictures into a 3D representation in space Cuboids can be used to determine the depth of objects like vehicles, buildings or people, as well as many other objects are.
Important Point Annotation
Critical Point annotation, often known as dots annotation, makes use of the joining of dots to signify face expressions in humans. postures of human expressions and emotions and body language, and even emotions.
Splines and Lines
With splines and lines you can add annotations to images with lines and splines that mark boundaries within certain regions. In different areas, this technique can be used to define the boundaries.
Text that has been annotated
When it comes to annotating text appropriate tags will be added as text according to various requirements in relation to the industrial or commercial use that uses the information to, for example names, sentiments and motives.
Polygons Annotation
Images that have uneven dimensions i.e. the uneven breaths and lengths, are marked with methods for AI Annotation Services of polygons like aerial and traffic photos which require exact annotation.
Semantic Segmentation
It can recognize every category and class in the image data that are used by semantic segmentation. This technique allows for the different objects contained in images to be identified and understood. It also allows for separation at an pixel level.
3D Point Cloud Annotation
3D point cloud technology finds, locates and classifies objects with greater precision and helps visualize the dimensions of objects to arrange things more efficiently.
Service for annotation of images
The process of labeling digital images, also known as image annotation, usually requires input from human beings and occasionally computers' assistance. Machine-learning (ML) engineer selects the labels in advance to provide computers with data about the objects in the image. Engineers using machine learning are able to focus on particular aspects of images that impact the accuracy and precision of their models by labeling images. This could lead to problems with categorization and labeling and the best way to show obscured objects (hidden behind other images).
The image becomes an annotation?
In the image below, an individual uses tools to mark an image using different labels, by creating bounding boxes around important objects. In this instance trucks will see those in blue; pedestrians remain in blue, taxis will mark the image in yellow, and the list goes on. There are a variety of annotations on each photo could vary according to the requirements of the project and the particular business scenario. In certain cases just one label might be enough to convey all information concerning the photograph (e.g. the classification of images). Some projects might require multiple object tags that have different brands within a single embodiment (e.g. box bounds). The purpose of programs that use the ability to tag images to make marking images in the best way feasible.
What kind of annotations for images do we have?
Researchers working in data science and ML engineers can make use of various styles of annotation they can apply to their images in order to produce a distinctive labeled data set that is able to be used as part of computer-vision research. To aid in the labels, the researchers utilize software for marking up images. For computer vision research, three of the most common types of annotations for images are:
Classification:
The purpose of classifying the entire image is to identify the objects and other elements that are present but without being able to locate them.
Recognizing objects through locating the exact position of every object within the image by using bounding boxes is just one of the main goals of the detection of objects in images.
segmenting images
The purpose in image segmentation is identify and analyze the pixel-level information that exist inside an image. Contrary to this, in the field of object recognition, where the boundaries between objects could be overlapping, each image's pixels is assigned at least one class. Semantic segmentation is another word used to explain this.
Annotating Polygons in Images for Computer Vision Models
Improve the precision of your computer's images through sophisticated image recognition technology.
Recognizing the presence of objects within space
Utilizing polygons and classification tags to distinguish objects
Generally, text labels in images are required to construct computers that make use of computer vision. In order to train models that can understand and process images that have different classifiable details and information of objects, using object marking solution's polygons as well as tags are the best choice.
We can categorize everything by the type of object. They are required to present images in various ways. When drawing with polygons, the primary focus will be the type of category you choose and that means providing these marks with the proper description and name of the object.
Identifying the regions
Semantic segmentation and segmentation of the areas of aerial photos
If a high degree of accuracy is required to prepare for a particular task and it is suggested that the Image Annotation service for segmenting images with semantic elements based on pixel size is the best option. Semantic segmentation in images provide the data needed to train algorithms for computer vision to identify images with high pixel precision.
Modells for object placement and classes training
Monitoring of traffic flow and conditional awareness
Road signs and vehicles identify themselves by the borders of boxes, which are classifiable.
To train computer vision models how to detect particular objects and individuals in pictures, you can utilize our image annotation services by using bounding boxes. Automakers often use this type of data for training to build the most precise computers that are able to detect any traffic condition and in the development of autonomous cars.
0 notes
Text
Flat file comparison tool

The use of metal hand files depends on the requirement of the level of finish and shape of the workpiece. The metal files are designed to fulfill various tasks for cutting, shaping, surface finishing, deburring on any metal and wooden workpiece. Used for primary or initial or primary finishing and draw filing. The cut pattern of the mill files is always a single cut type. While the mill files are featured with one safe edge. Generally used to sharpen the blades and knives. It is a great tool with teeth on both sides. If the comparison has already been saved as HTML, clicking "Preview in Browser" launches a browser with the stored HTML.The design of the flat files is mostly tapered at width and thickness towards the endpoint of the file. If the "Preview in Browser" icon is clicked the user is prompted to first "Save as HTML" for launching a web browser. The "Save As HTML" button at the top left of the comparison window prompts for file destination and font selection. The results of a comparison can be saved as HTML for viewing later or for sharing with others. It is also possible to select two new files for comparison by clicking the "Browse" buttons at the top of the comparison results without having to launch the Compare Tools Menu again. Once the comparison is complete, it can be refreshed, allowing the same comparison to be run again. If a marker in the annotation bar is used to navigate to a particular difference by left clicking, a tick mark overlay shows which difference currently has focus. When differences are found, their corresponding highlight colors appear in the annotation bar on the right side of the results and can be used to quickly navigate to them. The annotation bar provides a bird's eye view of all of the differences detected in a comparison. The colors for the difference highlighting can be changed with the Options button at the top right of the comparison results. If they are not identical they are highlighted by default in pink (deleted), purple (changed) or green (added). Comparisons show the character differences in a modified line with bolding and background color highlights indicate modified blocks. The large up and down arrows at the top of the comparison results allow navigating through the differences one at a time. At the top, between the two files above the line numbering, digits separated by a / indicate the difference selected out of total number of differences discovered (i.e. Each file in a comparison takes up half of the comparison results window and each can be vertically scrolled independently of the other. The results of a comparison display as a split-pane with line numbering down the center and connecting splines for identifying where the deletions, changes and additions occur. When the comparison is being performed, it runs in a background thread so that other operations in Aqua Data Studio can be performed. The File Compare Tool keeps the last files selected when the application is restarted and the File Compare Tool is relaunched. Filters to exclude files by file size, name, directory, or file extension can be selected before the comparison is run using the "Show Differences" button. It is also possible to drag items into the application from the operating and drop them off on the File Compare Tool file selection window. If the File Compare Tool is launched from the Tools Menu, it is possible to choose files that are not listed in the Files Browser, but are available to the operating system. To compare two files, either multi-select individual files in the Files Browser from mounted directories, or launch the File Compare Tool from Tools Menu (Tools->Compare->File Compare) and browse to them. The File Compare Tool provides users a method of depicting differences in the content between two text-based files.
0 notes
Text
Accelerate AI/ML Model Implementation With Professional Image Labeling Services
Image annotation lays the foundation behind many successful Artificial Intelligence (AI) and Machine Learning (ML) applications we interact with in our daily lives—from unlocking our phones via biometric identification such as facial detection, iris recognition, or fingerprint detection to autonomous vehicles, drone photography, and so on. It is also one of the most important processes in Computer Vision (CV).
Image Annotation Process
Image annotation is the process of adding tags or metadata to the input datasets to be fed into the Machine Learning systems. These labels help the algorithm to learn and identify the characteristics of the data you want it to recognize. Further, these tagged images are used to train the Computer Vision based models to identify those characteristics when presented with raw, unlabeled data.
For instance, think of the time when you were a child. You learned what a dog was at some point in time. After seeing many dogs, you gradually understood the different breeds of dogs and how it was different from a pig or a cat. In the same way, computers need ample examples to learn how to categorize things in their environment.
Image labeling provides these examples in a way that is easily comprehensible to computers. The increased availability of visual data for companies pursuing AI has led to an exponential growth in the number of projects relying on image labeling. And, creating an efficient image annotation process has become critical for organizations working within this area.
Image Annotation Techniques
To help the Computer Vision based models learn and grow, datasets must be labeled. There are various image labeling techniques used by data annotators to prepare enhanced training sets. Some of these techniques are listed here. Take a look:
2D Bounding Boxes
Bounding boxes are one of the most used annotation techniques in Computer Vision. As the name suggests, bounding boxes are rectangular boxes drawn around the object of interest used to define its location. The annotators use the 𝑥-axis and 𝑦 axis coordinates to determine the location of the target object. This technique is generally used for object detection as well as localization tasks.
Polygonal Segmentation
You must be agreeing that objects are not always rectangular in shape. On this note, polygonal segmentation is another type of data labeling technique where rectangles are replaced by complex polygons to define the shape and location of the target object in a much more effective and precise way.
Semantic Segmentation
Also known as pixel-wise annotation, every pixel in the image is assigned a class in the semantic segmentation process—these classes could be cars, busses, pedestrians, roads, sidewalks, etc., and each pixel carries semantic meaning.
This technique is primarily used in the environmental context. For example, semantic segmentation is used in robotics and self-driving cars because it is important for the Computer Vision based models to understand the environment in, which they are operating.
3D Cuboids
3D cuboids are almost similar to 2D bounding boxes; the only difference is the additional depth information of the target object. Thus, 3D cuboids help you get a 3D representation of the object of interest, allowing Machine Learning systems to distinguish features such as position and volume in a 3D space.
A common use-case of the 3D cuboid annotation technique is seen in autonomous vehicles where it can use the additional depth information of the target object to measure its distance from the car.
Key-Point & Landmark
In the landmark and key-point annotation technique, dotted lines are drawn across the image. This is used to detect small objects and shape variations such as facial expressions, features, emotions, human body parts, poses, etc.
Lines & Splines
As the name suggests, lines and splines image annotation techniques are created using lines and are commonly used in self-driving cars for lane detection and recognition.
These were the top 6 image annotation techniques. However, adding labels to each pixel is a significant undertaking. Any errors or inaccuracies in the process might deviate from the desired outcomes. Therefore, a smarter move is to engage in professional image labeling services to get enhanced training datasets.
Final Words
You might be wondering about the outsourced image labeling services cost; however, the collaboration pays off totally. The professionals have the potential in terms of a competent pool of data annotators, the latest software, proprietary tools, a time-tested blend of manual workflows, flexible delivery models, and so on—everything that is required to label images accurately. Having the right blend of skills and experience ensures excellence in all the image labeling outcomes. Hence, you get accurately labeled datasets within the stipulated time and budget.
Read the blog here : https://writeupcafe.com/accelerate-ai-ml-model-implementation-with-professional-image-labeling-services/
0 notes
Photo

Data Labelling and Annotation It is an essential step in a supervised machine learning task. Data labelling is a task that requires a lot of manual work. If you can find a good open dataset for your project, that is labelled. Get done your machine learning project through Wisepl. Accurate and talented resources maintain your dataset by various annotation types. - Bounding box - Semantic Segmentation - Polygonal Segmentation - 3D Cuboids - Key-Point and Landmark - Lines and Splines The tools which we offer #LabelImg #VGG #imageannotator #LabelMe #basicai #dataloop #alegion #labelbox #imageannotation #annotationpartners #dataannotation #datalabelling #machinelearning #computervision #artificialintelligence #deeplearning #ai #ml #cv #autonomusvehicles #wisepl #lableres #annotators #annotationsupport https://www.instagram.com/p/CN-tE9ipLmJ/?igshid=svb3olprn9cs
#labelimg#vgg#imageannotator#labelme#basicai#dataloop#alegion#labelbox#imageannotation#annotationpartners#dataannotation#datalabelling#machinelearning#computervision#artificialintelligence#deeplearning#ai#ml#cv#autonomusvehicles#wisepl#lableres#annotators#annotationsupport
0 notes
Text
Autocad Commands 3
DIVIDE
Creates evenly spaced point objects or blocks along the length or perimeter of an object.
The following prompts are displayed.
Select Object to Divide
Specifies a single geometric object such as a line, polyline, arc, circle, ellipse, or spline.
Number of Segments
Places point objects at equal intervals along the selected objects. The number of point objects created is one less than the number of segments that you specify.
Use PTYPE to set the style and size of all point objects in a drawing.
Block
Places specified blocks at equal intervals along the selected object. The blocks will be inserted on the plane in which the selected object was originally created. If the block has variable attributes, these attributes are not included.
Yes
Aligns the blocks according to the curvature of the selected object. The X axes of the inserted blocks will be tangent to, or collinear with, the selected object at the dividing locations
No
Aligns the blocks according to the current orientation of the user coordinate system. The X axes of the inserted blocks will be parallel to the X axis of the UCS at the dividing locations.
The illustration shows an arc divided into five equal parts using a block consisting of a vertically oriented ellipse.
The following prompts are displayed.
Select Object to Divide
Specifies a single geometric object such as a line, polyline, arc, circle, ellipse, or spline.
Number of Segments
Places point objects at equal intervals along the selected objects. The number of point objects created is one less than the number of segments that you specify.
Use PTYPE to set the style and size of all point objects in a drawing.
Block
Places specified blocks at equal intervals along the selected object. The blocks will be inserted on the plane in which the selected object was originally created. If the block has variable attributes, these attributes are not included.
Yes
Aligns the blocks according to the curvature of the selected object. The X axes of the inserted blocks will be tangent to, or collinear with, the selected object at the dividing locations
No
Aligns the blocks according to the current orientation of the user coordinate system. The X axes of the inserted blocks will be parallel to the X axis of the UCS at the dividing locations.
The illustration shows an arc divided into five equal parts using a block consisting of a vertically oriented ellipse.
DDPTYPE: Specifies the display style and size of point objects.
The Point Style dialog box is displayed.
REGEN regenerates the drawing with the following effects: Recomputes the locations and visibility for all objects in the current viewport Reindexes the drawing database for optimum display and object selection performance Resets the overall area available for realtime panning and zooming in the current viewport
REDRAW :
Removes temporary graphics left by VSLIDE and some operations from the current viewport. To remove stray pixels, use the REGEN command.
CHPROP
Changes the lineweight of the selected objects. Lineweight values are predefined values. If you enter a value that is not a predefined value, the closest predefined lineweight is assigned to the selected objects.
Thickness
Changes the Z-direction thickness of 2D objects.
Changing the thickness of a 3D polyline, dimension, or layout viewport object has no effect.
Transparency
Changes the transparency level of selected objects.
Set the transparency to ByLayer or ByBlock, or enter a value from 0 to 90.
Material
Changes the material of the selected objects if a material is attached.
Annotative
Changes the annotative property of the selected objects.
Plotstyle
(Available only if you use named plot styles)
Changes the properties of named plot styles.
LAYER
Changes the layer of the selected objects.
Ltype
Changes the linetype of the selected objects.
If the new linetype is not loaded, the program tries to load it from the standard linetype library file, acad.linfor AutoCAD, or acadlt.lin for AutoCAD LT. If this procedure fails, use LINETYPE to load the linetype.
Ltscale
Changes the linetype scale factor of the selected objects.
Lweight
Manages layers and layer properties.
The Layer Properties Manager is displayed.
If you enter -LAYER at the Command prompt, options are displayed.
Use layers to control the visibility of objects and to assign properties such as color and linetype. Objects on a layer normally assume the properties of that layer. However, you can override any layer property of an object. For example, if an object’s color property is set to BYLAYER, the object displays the color of that layer. If the object’s color is set to Red, the object displays as red, regardless of the color assigned to that layer.
If you enter -LAYER at the Command prompt, options are displayed.
0 notes
Text
Video Data Collection And Annotation In AI And ML

Video annotation works in the same way as image annotation to help modern machines recognize objects with computer vision. Frame-to-frame identification of moving objects and entities in videos. A 60-second video clip that has a frame rate 30 fps (frames/second) contains 1800 video frames. These frames can be converted into static images. Videos are often considered Video Dataset in order to enable technological applications to make accurate and real-time analyses. Video annotation is critical because it helps to train deep-learning AI models. Annotation can be used to create AI models using deep learning.
This blog will explain video annotations. It will also discuss how they function, features that make annotating frames simpler, applications for annotations, and the best platform to use for video labelling.
What is video annotation?
Video annotation is the process of labelling, marking, tagging and evaluating video data. Video annotation refers the practice of classifying or recognising video content. It is done to prepare the dataset for training machine-learning (ML) or deep learning models (DL). Simply put, humans annotate the video and tag/label the data which can be video datasets, Speech Recognition Datasets and many more dataset according the specified categories in order create training data for machine-learning models.
What does Video Annotation look like?
Annotators have a wide range of tools and methods for video annotation. Annotating video is a tedious task due to the fact that annotation is so important. Annotating video takes more time than just annotating images. Since video can have up to 60 frames per sec, you will need to use more advanced data annotation tools. There are many options for annotation of videos.
Single-Frame design: The annotator divides the video in thousands of images, then performs individual annotations. Annotators sometimes complete the work by copying the annotation frames from one frame to the next. This can be a tedious process. If the object movement in the frames is slower, this could be a better option.
Streaming Video - This method allows the annotator to analyse a stream containing video frames by using data annotation tool tools. This method is more practical as it allows annotators to label items in frames. This makes machines more efficient. As companies improve their data annotation tool markets and expand the capabilities to their tooling platforms this method becomes more regular and accurate.
Different types of annotations for video
There are many methods of annotating. Most commonly used are 3D cuboids, 2D bounding blocks, landmarks, polylines and polygons.
Bounding Boxes 2D: Rectangular boxes are used in this method of object identification and labelling. These boxes are drawn carefully around moving objects and placed in multiple frames. The box should be drawn so that it is as close as possible the object.
Bounding Boxes 3D. The 3D bounding boxes method allows for an accurate 3D depiction and interaction between an item and its environment. This represents the object in motion's length, width, and depth. This approach is particularly useful when trying to identify items that share common characteristics.
Polygons: Polygons is used when 2D or 3D binding boxes are inadequate to accurately describe an object’s movement or form. This requires high accuracy from the labeller. Annotators need to draw lines by placing dots precisely around the outer edge of the item they wish.
Landmark: This is also known as a focal point or key-point. It's used to identify the smallest objects, postures, or forms. The dots are generated throughout the image, then linked to make a skeleton.
Splines and lines. Lines are used in order to teach robots to recognize lanes or borders, particularly in the autonomous-driving industry. Annotators only need to draw lines between the points the AI algorithm must identify across frames.
Video Annotations - How to use them
Video annotation is used in the generation of AI Training Dataset for visual perception-based AI Models. Another application of video annotation to computer vision object localisation is the localization of objects in the video. Although a video can contain many items, localization is used to help locate the most prominent and central item in the frame. The primary goal of object localization is to identify the item and its limits in a photo. Another purpose of video annotation is to train computer vision-based, machine learning models to predict human positions and track human movement. This is most commonly used in sports, to track players' movements during competitions. Another application of video annotation is to collect the object of interest and machine-read it frame by frame. The moving objects appear on the screen. They are marked with a tool to detect them precisely. Machine learning is used to train AI models that use visual perception.
Why choose GTS for video data capture and annotation?
It is important to have experience in Video Dataset Collection. AI programmes can only function with labelled data. Annotating video can be done in any format, using novel methods that help to build high-quality machine learning model at global technology solution. GTS supports all types and formats of video dataset collection and can provide high-quality annotation movies for deep learning as well as machine learning domains. Our experts can both annotate live videos using the most effective tools and procedures as well as provide data for processing.
0 notes
Text
What is data Annotation?
Data annotation is the technique of labeling the data, which is present in different formats such as images, texts, and videos. Labeling the data makes objects recognizable to computer vision, which further trains the machine. In short, the process helps the machine to understand and memorize the input patterns.
To create a data set required for machine learning, different types of data annotation methods are available. The prime aim of all these types of annotations is to help a machine to recognize text, images, and videos (objects) via computer vision.
Types of Data Annotations
• Bounding boxes
• Lines and splines
• Semantic segmentation
• 3D cuboids
• Polygonal segmentation
• Landmark and key-point
• Images and video annotations
• Entity annotation
• Content and text categorization
Aispotters helps you build data for computer vision models with our fully managed Service.
Because they provide skillful cost effective services. And their business methodology and our appetite to stay current with evolving technology and fast changing industry norms has earned us a huge number of satisfied customers across the globe.
0 notes
Text
Anolytics : Types and Use Cases of Image Annotation for Computer Vision in AI
Image annotation is the process of annotating or labeling the objects in an image to make it recognizable to computer vision for machine learning. And there are different types of image annotation services used for computer vision in machine learning and AI.
You can find here what are the image annotation types and in which industry or sector such techniques are used to annotate the images. Along with the types of annotation, the use cases is also discussed here to find in which types of machine learning model training it used to create the training data sets for visual based perception model.
Types of Image Annotation
Though, there are multiple types of image annotation techniques but few of them is used in the industry. Let’s find out the popular one and which one is suitable for different types of perception based model to make the prediction accurate.

1. Bounding Boxes
Bounding boxes are one of the most commonly used image annotation types for computer vision in machine learning. Bounding boxes owing to versatility and simplicity, enclose objects and assist the computer vision network in locating objects of interest.
Creating Bounding boxes are easy and fast due to simply specifying X and Y coordinates for the upper left and bottom right corners of the box. The bounding box can be applied to almost any conceivable object, and they can substantially improve the accuracy of an object detection process in machine learning.

2. Line Annotation
Line annotation involves the creation of lines and splines, which are used primarily to delineate boundaries between one part of an image and another. Line annotation is used when a region that needs to be annotated can be conceived of as a boundary, but it is too small or thin for a bounding box or other type of annotation to make sense.
Splines and lines are easy to create annotations for and commonly used for situations like training warehouse robots to recognize differences between parts of a conveyor belt, or for autonomous vehicles to recognize lanes.

3. Polygonal Segmentation
Another type of image annotation is polygonal segmentation, and the theory behind it is just an extension of the theory behind bounding boxes. Polygonal segmentation tells a computer vision system where to look for an object, but thanks to using complex polygons and not simply a box, the object’s location and boundaries can be determined with much greater accuracy.
The advantage of using polygonal segmentation over bounding boxes is that it cuts out much of the noise/unnecessary pixels around the object that can potentially confuse the classifier.

4. Semantic Segmentation
Semantic segmentation is method of image annotation that involves separating an image into different regions, assigning a label to every pixel in an image. This is basically used for classifying the objects needs high-accuracy.
Regions of an image that carry different semantic meanings/definitions are considered separate from other regions. For example, one portion of an image could be “sky”, while another could be “grass”.
The key idea is that regions are defined based on semantic information, and that the image classifier gives a label to every pixel that comprises that region.

5. Landmark Annotation
This is another landmark image annotation types used for creating training data for computer vision systems. Sometimes referred as dot annotation, owing to the fact that it involves the creation of dots/points across an image.
Dots are used to label objects in images containing many small objects, but it is common for many dots to be joined together to represent the outline or skeleton of an entire object in the image for precise detection.
The size of the dots can be varied, and larger dots are sometimes used to distinguish important/landmark areas from surrounding areas.

6. 3D Cuboid Annotation
3D cuboid is another powerful type of image annotation, similar to bounding boxes in that they distinguish where a classifier should look for objects. However, 3D cuboids have depth in addition to height and width.
Anchor points are typically placed at the edges of the item, and the space between the anchors is filled in with a line. This creates a 3D representation of the object, which means the computer vision system can learn to distinguish features like volume and position in a 3D space for accurate detection of object position.

IMAGE ANNOTATION TYPES USE CASES
Bounding Boxes – Use Cases
Bounding boxes are used to localize the objects in the images. Models that localize and classify objects benefit from bounding boxes. Common uses for bounding boxes include any situation where objects are being checked for collisions against each other.
An obvious application of bounding boxes and object detection is autonomous driving. Autonomous driving systems must be able to locate vehicles on the road, but they could also be applied to situations like tagging objects in construction sites to help analyze site safety and for robots to recognize objects in different environments.
This technique of image annotation is also used for drone footage to monitor the progress of construction projects, from the initial laying of foundation all the way through to completion when the house is ready for move in.
Recognizing food products and other items in grocery stores to automate aspects of the checkout process. Detecting exterior vehicle damage, enabling detailed analysis of vehicles when insurance claims are made.
Polygonal Segmentation – Use Cases
Polygonal segmentation is the process of annotating objects using many complex polygons, allowing the capturing of objects with irregular shapes. When precision is of importance, polygonal segmentation is used over bounding boxes.
Because polygons can capture the outline of an object, they eliminate the noise that can be found within a bounding box, something that can potentially throw off the accuracy of the model.
Polygonal segmentation is useful in autonomous driving, where it can highlight irregularly shaped objects like logos and street signs, and more precisely locate cars compared to the use of bounding boxes to locate cars.
Polygonal segmentation is also helpful for tasks where many irregularly shaped objects must be annotated with precision, such as object detection in images collected by satellites and drones. If the goal is to detect objects like water features with precision, polygonal segmentation should be used over bounding boxes.
Annotating the many irregularly shaped objects found in cityscapes like cars, trees and pools. Polygonal segmentation can also make the detection of objects easier.
For instance, Polygon-RNN, a polygon annotation tool sees significant improvement in both speed and accuracy compared to the traditional methods used to annotate irregular shapes and namely semantic segmentation.
Line Annotation – Use Cases
Because line annotation concerns itself with drawing attention to lines in an image, it is best used whenever important features are linear in appearance.
Autonomous driving is a common use case for line annotation, as it an be used to delineate lanes on the road. Similarly, line annotation can be used to instruct industrial robots where to place certain objects, designating a target zone as between two lines. Bounding boxes could theoretically be used for these purposes, but polyline annotation is a much cleaner solution, as it avoids much of the noise that comes with using bounding boxes. Notable computer vision use cases of line annotation include the automatic detection of crop rows and even the tracking of insect leg positions.
Landmark Annotation – Use Cases
Because landmark annotation/dot annotation draws small dots that represent objects, one of its primary uses is in detecting and quantifying small objects. For instance, aerial views of cities may require the use of landmark detection to find objects of interest like cars, houses, trees, or ponds.
That said, landmark annotation can have other uses as well. Combining many landmarks together can create outlines of objects, like a connect-the-dots puzzle. These dot outlines can be used to recognize facial features or analyze the motion and posture of people doing sports activities and other actions.
Face Recognition, thanks to the fact that tracking multiple landmarks can make the recognition of emotions and other facial features easier. Landmark annotation is also used in the field of biology for geometric morphometrics.
3D Cuboid Annotation – Use Cases
3D cuboids are used when a computer vision system doesn’t just need to recognize an object, it must also predict the general shape and volume of that object.
Most frequently 3D cuboids are used when a computer vision system is developed for an autonomous system capable of locomotion, as it must make predictions about objects in its surrounding environment. Uses cases for 3D cuboids annotation in computer vision include the development of computer vision systems for autonomous vehicles and locomotive robots.
Semantic Segmentation – Use Cases
A one of the precise technique of image annotation. The potentially unintuitive fact about semantic segmentation is that it’s basically a form of classification, but the classification is just being done on every pixel in a desired region rather than an object.
When this is considered, it becomes easy to use semantic segmentation for any task where sizable, discrete regions must be classified/recognized. Autonomous driving is one application of semantic segmentation, where the vehicle’s AI must distinguish between sections of road and sections of grass or sidewalk.
Additional computer vision use cases for semantic segmentation, outside of autonomous driving, include:
Analysis of crop fields to detect weeds and specific crop types.
Recognition of medical images for diagnosis, cell detection, and blood flow analysis.
Monitoring forests and jungles for deforestation and ecosystem damage to improve conservation efforts.
Summing-up
Finally, if you want to annotate the data for computer vision, selecting the right tool is very important to create the right data sets. Now you have become more acquainted with the different types of image annotation techniques with use cases of each of them. Anolytics is one of the best data annotation companies, providing the image annotation service to annotate the images with best quality and accuracy.
PH. No. : +1-516-342-5749
Email ID : [email protected]
#data annotation#Data Annotation Services#Image Annotation#Image Annotation Services#Image Annotation for Computer Vision
0 notes
Text
AutoCAD 2016 Essential Training
Scott Onstott has been using AutoCAD for 24 years and has witnessed its evolution into the most popular industry-standard computer-aided drafting and design application. This course is your detailed introduction to the 2016 version of AutoCAD. Scott begins with the basics of the user interface and leads you step-by-step to learning how to draw the kind of precise, measured 2D drawings that form the basis of design communication the world over. Along the way, you’ll learn how to create and modify geometry, layers, blocks, attributes, dimensions, layouts, and how to share your drawings with others.
Note: The course is an update to our 2015 training, including new movies on working with object snaps, writing multiline objects, making dimension objects, and more.
Topics include:
Changing workspaces Converting drawings to new units Drawing lines, circles, splines, polygons, and more Moving, copying, rotating, and scaling objects Mirroring, lengthening, trimming, and joining objects Drawing accurately with coordinates and snapping Creating gradients Making dimension objects Managing object and layer properties Reusing content Making external references (including xrefs) Adding annotations Packaging and publishing CAD data
Duration: 8h 46m Author: Scott Onstott Level: Beginner Category: CAD Subject Tags: 2D Drawing Software Tags: AutoCAD LT AutoCAD ID: dc625e9ada9293a3fff5273510a60f78
Course Content: (Please leave comment if any problem occurs)
Welcome
The post AutoCAD 2016 Essential Training appeared first on Lyndastreaming.
source https://www.lyndastreaming.com/autocad-2016-essential-training/?utm_source=rss&utm_medium=rss&utm_campaign=autocad-2016-essential-training
0 notes
Text
[Lynda] Cert Prep: AutoCAD Certified Professional
Become an AutoCAD certified professional. This training course helps you study for the Autodesk certification exam while you reinforce your CAD skills. Shaun Bryant helps you understand the two pathways available: Autodesk Certified User—for new designers who want to demonstrate basic proficiency—and Autodesk Certified Professional—for those who possess more advanced skills and can solve complex workflow and design challenges. He then walks through basic drawing skills, object manipulation techniques, and organization skills necessary to pass both certification exams. Plus, learn how to reuse content to be more efficient, annotate drawings, and set your AutoCAD designs up for printing. Note: The exam objectives are not release specific, but the course has been revised to reflect the most recent version of the software, AutoCAD 2018. Topics include: What is AutoCAD certification? Drawing shapes and lines Creating isometric drawings Modifying objects Creating and using arrays Working with polylines and splines Organizing objects and layers Reusing content with blocks Annotating drawings with text, dimensions, multileaders, and tables Creating layouts Setting printing and plotting options source https://ttorial.com/cert-prep-autocad-certified-professional
source https://ttorialcom.tumblr.com/post/178676242943
0 notes
Link

Cogito is providing Polyline annotation for lane detection through computer vision in machine learning for self-driving cars and autonomous vehicles. With line and spline annotation service, it is making the road surface marking recognizable to such autonomous cars to detect the path and drive in the right lane.
0 notes