#MathTools
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr has a low social media market share in South America.
Text
Did You Know the Math Simulation Software GeoGebra? 🎓🧮
In the realm of educational technology, few tools have revolutionized the way we teach and learn mathematics as profoundly as GeoGebra. This dynamic software seamlessly blends geometry, algebra, calculus, and statistics, offering a versatile platform for students and educators alike. Whether you're a teacher aiming to bring mathematical concepts to life or a student looking to explore the depths of math, GeoGebra has something to offer.
What is GeoGebra? 🤔
GeoGebra is an interactive mathematics software designed to make learning and teaching math more engaging and effective. It's a powerful tool that integrates various branches of mathematics into a single platform, providing users with a comprehensive suite of tools to explore mathematical concepts visually and interactively.
Key Features of GeoGebra 🌟
Interactive Geometry: With GeoGebra, you can create constructions and models using points, vectors, segments, lines, polygons, and conic sections. The dynamic nature of these objects allows for real-time manipulation, making abstract concepts tangible and easier to understand.
Algebraic Integration: Directly input equations and coordinates to see their graphical representations. GeoGebra links algebraic and geometric views, helping users see the relationships between different mathematical expressions.
Calculus Tools: Explore derivatives, integrals, and functions with ease. GeoGebra's calculus tools are designed to help users visualize and understand these complex concepts.
Statistics and Probability: Create graphs of statistical data, calculate probabilities, and visualize distributions. These features make it easier to teach and learn statistical concepts.
3D Graphics: GeoGebra’s 3D capabilities allow for the creation and manipulation of three-dimensional graphs and shapes, providing a deeper understanding of spatial relationships.
Spreadsheet View: Handle data efficiently with the integrated spreadsheet functionality. This feature is perfect for visualizing and analyzing large data sets.
Scripting and Custom Tools: Automate tasks and create custom tools using GeoGebra’s scripting language, GGBScript, and JavaScript. This allows for tailored solutions to specific mathematical problems.
Cross-Platform Availability: GeoGebra is accessible as a web application and on various platforms including Windows, macOS, Linux, iOS, and Android, ensuring that you can use it anywhere, anytime.
Transforming Education with GeoGebra 📚💡
GeoGebra is not just a tool for solving mathematical problems; it's a bridge that connects theoretical mathematics with practical understanding. Here’s how it’s making an impact in education:
Visualization: Complex mathematical concepts become accessible through visual representation, making it easier for students to grasp abstract ideas.
Interactive Learning: Students engage more actively with math by manipulating objects and seeing the immediate effects of changes.
Immediate Feedback: GeoGebra provides instant visual feedback, aiding in the learning process and helping students correct mistakes in real-time.
Collaborative Learning: It supports group projects and resource sharing, fostering a collaborative learning environment.
Customizable Resources: Teachers can create interactive worksheets and tailor lessons to meet the needs of their students.
Why Choose GeoGebra? 🤩
User-Friendly Interface: Designed to be intuitive and easy to use, GeoGebra is suitable for all educational levels.
Rich Community and Resources: A large community of users shares resources, tutorials, and tips, making it easier to get the most out of GeoGebra.
Cost-Effective: Free to use, GeoGebra is accessible to a wide audience, ensuring that financial barriers do not hinder learning.
Versatility: Whether you’re in elementary school, university, or working on professional research, GeoGebra has tools to meet your needs.
Real-World Applications 🌍🔍
GeoGebra’s versatility extends beyond the classroom. It’s used in academic research, professional presentations, and even in real-world problem-solving scenarios. Its ability to visualize complex data and mathematical relationships makes it an invaluable tool for a wide range of applications.
Conclusion 🎉
GeoGebra is more than just software; it's a transformative educational tool that brings mathematics to life. By combining visualization, interaction, and immediate feedback, GeoGebra helps students and teachers alike to deepen their understanding of math. Whether you're solving algebraic equations, exploring geometric constructions, or delving into calculus and statistics, GeoGebra is your go-to resource for a richer, more engaging mathematical experience. Embrace the power of GeoGebra and unlock the full potential of mathematics! 🚀🧩
3 notes
·
View notes
Text
0 notes
Text
The Essential Ounces Calculator for Home Cooks
The Essential Ounces Calculator for Home Cooks" is your reliable companion in the kitchen, designed to take the guesswork out of measurements. Perfect for both novice and experienced cooks, this tool effortlessly converts ounces into various units, helping you follow recipes with precision. Whether you're adjusting portion sizes or experimenting with new dishes, our calculator ensures consistent results every time. Embrace stress-free cooking and elevate your culinary skills with accurate measurements at your fingertips.
https://oz-to.com/
#OuncesCalculator#LiquidMeasurement#CookingMeasurements#MathTools#CookingTips#LiquidConversions#RecipeCalculator
0 notes
Text
Struggling with angle measurements?
Convert angles from degrees to radians, gradians, and more with our Angle Converter. Perfect for all you math enthusiasts and engineers out there. Simplify your calculations and get accurate results every time. 📐
0 notes
Text
Best Abacus class In saswad
#Abacus#MathSkills#NumberSense#MathEducation#LearnMath#AbacusLearning#MathTool#EducationalToys#sunbeamcomputer#sunbeamcomputerinstitute#saswad#kondhwa#pune#hadapsar#jejuri#daund#abacus#abcustraining#abacustraininginsaswad#ComputerClass#TechEd#DigitalLearning#STEMeducation#CodingClass#ComputerScience#TechSkills#EdTech#ProgrammingClass#ICTeducation
0 notes
Note
1 and 20 (👀) for the mathblr asks?
1. What is the coolest math concept you learned about this year?
Probably symmetric extensions. In the final term of the last academic year I went to the second part of a lecture series on forcing. The second half was about choiceless constructions, and I have found the idea of symmetric extensions very cool. In short, they are like forcing extensions, so you have your model V of set theory and extend it by a generic filter to V[G], but we only allow certain 'symmetrical' names, and end up with an intermediate model between V and V[G] that may not satisfy the axiom of choice.
The earliest example was Cohen's original work showing that AC is independent of ZFC. The gist is that he takes a model V of ZFC and adds a countable set of new real numbers X to it to make a new model M, but does it in such a way that M "forgets" that X is supposed to be countable. You end up with an infinite set that has no injection from the natural numbers into it, a violation of the well-ordering principle.
20. Have you discovered any cool LaTeX tricks this year?
In the last few days I have started using \DeclarePairedDelimeterX to create a \Set command that will put in curly brackets and scale them if I so choose, but also scale the middle vertical bar as well. My code for it is almost verbatim what is found on Page 27 of the MathTools package manual, https://texdoc.org/serve/mathtools/0.
6 notes
·
View notes
Text
\documentclass{article} \usepackage{amsmath, amssymb, amsthm, hyperref} \usepackage{mathtools}
\newtheorem{theorem}{Theorem}[section] \newtheorem{conjecture}[theorem]{Conjecture} \newtheorem{proposition}[theorem]{Proposition} \newtheorem{lemma}[theorem]{Lemma} \newtheorem{corollary}[theorem]{Corollary}
\title{Spectral Models, the Riemann Hypothesis, and Falsifiability: A Critical Approach} \author{Mathematical and Philosophical Research} \date{\today}
\begin{document}
\maketitle
\begin{abstract} This paper explores the relationship between spectral models and the Riemann Hypothesis (RH) under a Popperian falsifiability approach. We analyze self-adjoint differential operators, spectral statistics of the zeta function zeros, and their connection with Random Matrix Theory models. We also discuss the limitations of computational evidence and the need for rigorous proof. \end{abstract}
\section{Introduction} The Riemann Hypothesis (RH) \cite{riemann1859} postulates that all nontrivial zeros of the Riemann zeta function have real part equal to ( 1/2 ). Its validity has profound implications for number theory and the distribution of primes. The connection between RH and spectra of differential operators, suggested by the Hilbert-P\'olya Hypothesis, has motivated various spectral approaches \cite{titchmarsh1986riemann}.
The Popperian methodology emphasizes refutability as a criterion for scientific demarcation \cite{popper2002logic}. We apply this method to the investigation of RH, considering computational evidence and the limitations of existing models.
\section{Spectral Models and Differential Operators}
\begin{theorem}[Real Spectrum of Self-Adjoint Operators] Let ( H ) be a self-adjoint differential operator in a Hilbert space ( \mathcal{H} ). Then, the entire spectrum ( \sigma(H) ) is real. \end{theorem}
\begin{proof} By the Spectral Theorem for unbounded self-adjoint operators: \begin{enumerate} \item The spectrum ( \sigma(H) ) is contained in ( \mathbb{R} ). \item The spectrum can be decomposed into point ( \sigma_p(H) ), continuous ( \sigma_c(H) ), and residual ( \sigma_r(H) ) spectra. \item For self-adjoint operators, ( \sigma_r(H) = \emptyset ). \end{enumerate} For eigenvalues ( \lambda \in \sigma_p(H) ), let ( \psi \in D(H) ) be a normalized eigenvector: [ \lambda = \langle \psi, H\psi \rangle = \overline{\langle H\psi, \psi \rangle} = \overline{\lambda} \implies \lambda \in \mathbb{R}. ] For the continuous spectrum, every ( \lambda \in \sigma_c(H) ) is an accumulation point of approximate values ( \langle \phi, H\phi \rangle ) with ( |\phi|=1 ), which are necessarily real. Therefore, ( \sigma(H) \subset \mathbb{R} ). \end{proof}
\section{Statistics of the Zeta Function Zeros}
\begin{conjecture}[Pair Correlation (Montgomery, 1973)] Let ( \gamma_n ) be the nontrivial zeros of the Riemann zeta function with ( 0 < \Re(\gamma_n) < 1 ), ordered by imaginary part. The normalized pair correlation function satisfies: [ R_2(s) \approx 1 - \left( \frac{\sin(\pi s)}{\pi s} \right)^2, ] coinciding with the statistics of the GUE (Gaussian Unitary Ensemble). \end{conjecture}
\begin{proof}[Numerical Evidence] Odlyzko (1987) computed millions of zeros near ( \gamma_{10^{20}} ), verifying: \begin{itemize} \item The distribution of normalized spacings ( \tilde{S}n = (\gamma{n+1} - \gamma_n)\frac{\log\gamma_n}{2\pi} ) closely matches GUE. \item The discrepancy ( \Delta < 0.01\% ) for two- and three-level correlations. \end{itemize} The conjecture remains open but is consistent with the \textbf{Hilbert-P\'olya Hypothesis}, suggesting the existence of a self-adjoint operator ( H ) with ( \gamma_n ) as eigenvalues. \end{proof}
\section{Falsifiability in Mathematics}
\begin{theorem}[Logic of Refutation] Let ( \mathcal{P}(x) ) be a mathematical proposition with domain ( D ). If there exists ( d \in D ) such that ( \mathcal{P}(d) ) is false, then ( \mathcal{P} ) is not a universal theorem. \end{theorem}
\begin{proof} By definition, a theorem is a statement proven true for all ( x \in D ). Suppose that: [ \exists d \in D \, ( \neg \mathcal{P}(d) ) \implies \neg \forall x \in D \, ( \mathcal{P}(x) ). ] Thus, ( \mathcal{P} ) fails to be universal. In Popperian terms, ( d ) acts as a \textit{falsifying counterexample}. \end{proof}
\section{Conclusion} We have shown that the Riemann Hypothesis is strongly connected to spectral models and random matrix statistics. However, no rigorous proof has yet been established. The Popperian approach suggests that as long as RH continues to resist refutation, its validity should be considered empirically robust, though not yet definitive.
\bibliographystyle{plain} \bibliography{references}
\end{document}
0 notes
Text
Calculate with Ease: Babaaman’s Online Calculator
Discover a smarter way to do math with Babaaman’s new online calculator! Designed for simplicity and speed, this sleek tool handles everything from basic arithmetic to more complex calculations—right from your browser. No downloads, no hassle—just visit calculator.babaaman.com and start calculating instantly. Whether you’re a student, professional, or just a math enthusiast, this tool is your go-to for quick, accurate results.
#Calculator #OnlineCalculator #MathTools #Babaaman #Productivity #DigitalTools
0 notes
Text
🚀 Unlock the Power of Precision Calculations! 🚀
Say goodbye to manual math and hello to the Advanced Scientific Calculator! 🎉 Whether you're a student, engineer, or just need quick and accurate calculations, our free online tool has you covered.
🔢 Features Include:
Trigonometric functions, logarithms, and more
Degree and radian modes
Easy-to-use, interactive interface
No downloads required, 100% FREE!
Start solving complex problems instantly. 🔗 Click here to use the tool now: [https://freewebtoolfiesta.blogspot.com/2024/12/best-scientific-calculator_2.html]
#ScientificCalculator #MathTools #FreeTools #OnlineCalculator #TechForStudents #Engineers #MathMadeEasy #PrecisionCalculations #AdvancedCalculator #TechTools #FreeOnlineTool

0 notes
Photo

This 1-100 blacktop grid is a favorite at elementary schools. There are so many different math activities you can do with this MathTop. #outdoorlearning #outdoorlearningenvironment #mathtools https://www.instagram.com/p/Cnz1-hPv_-n/?igshid=NGJjMDIxMWI=
0 notes
Video
instagram
Animate integer division, multiplication, addition, and subtraction with the Calculator Gator 🐊➕➖✖️➗, a free digital toy available on your Chrome browser: http://piuswong.com/calculatorgator/ The #CalculatorGator is brought to you by #PiosLabs, written by Pius Wong. Learn more about Pios Labs at: http://www.pioslabs.com #math #mathtools #matheducation #stem #mathvisualization #maths #mathematics #webtools #opensource #javascript #htmlcalculator #mathteacher #prealgebra #gedmath #mathoperations #engineeringeducation #stemeducation #mathvisualisation #edtech #calculator #integerfun #fractions #decimals #negativenumbers #counting #division #multiplication
#htmlcalculator#stemeducation#javascript#gedmath#division#decimals#mathoperations#stem#integerfun#counting#mathtools#mathvisualization#engineeringeducation#mathematics#mathvisualisation#matheducation#prealgebra#opensource#math#mathteacher#pioslabs#negativenumbers#maths#webtools#calculator#edtech#calculatorgator#fractions#multiplication
1 note
·
View note
Photo

Montessori Mathematics Material Child Learning Wooden Educational Number 1 to 100 #learningaids #kidsmath #learnmath #educational #learningtools #mathtools #mathaid https://buff.ly/2xI3ujt
0 notes
Text
the mathtools package has the \coloneq and \eqcolon macros, and i create commands \ceq and \eqc for convenience. i believe that there are some other packages that provide the same behaviour in slightly different ways
last time we had the ≡ vs := discussion on a draft, i lost because i didn't have a correctly-aligned := at the time of discussion. this time, i came prepared and won. it's really much better to have a directional definition sign, since it is obvious which side of the definition has a new symbol: := ≠ =:
15 notes
·
View notes
Text
Convert Like a Pro
Introducing the 'Each to Dozen' Converter – your new best friend for quick and easy conversions. No more manual calculations, just input and go!
0 notes
Text
[ @taylorswift ]* 💜💜♾️♾️, ICML part 1, honey
There was row with 'colt2018', it will be on video
There are 10 pictures below
% Recommended, but optional, packages for figures and better typesetting:
\usepackage{wrapfig}
\usepackage{amsfonts}
\usepackage{graphicx}
\usepackage{microtype}
\usepackage{epstopdf}
\usepackage{booktabs}
\usepackage{algorithmic}
\ifpdf
\DeclareGraphicsExtensions{.eps,.pdf,.png,.jpg}
\else
\DeclareGraphicsExtensions{.eps}
\fi
\usepackage{amssymb,amsmath,amscd,amstext,bbm, enumerate, dsfont, mathtools}
\usepackage{soul}
\usepackage{array}
\usepackage{multicol}
\usepackage[]{algorithm2e}
%\usepackage{algorithm}
%\usepackage{caption}
%\usepackage{subcaption}
\usepackage{graphicx}
%\usepackage{subfig}
\usepackage{hyperref}
\usepackage{tcolorbox}
\usepackage{import}
\usepackage{tikz,pgfplots}
\usetikzlibrary{tikzmark,shapes}
\usetikzlibrary{matrix}
\usepgfplotslibrary{groupplots}
\pgfplotsset{compat=newest}
% Fonts
\usepackage{bbm}
%@Yury
\usepackage{bm}
\usepackage{bibunits}
\defaultbibliographystyle{plain}
\usepackage{filecontents}
%\usepackage{algorithm}
%\usepackage{algpseudocode}
\newcommand{\w}{\boldsymbol{\omega}}
\newcommand{\wopt}{\boldsymbol{\omega}^\star}
\newcommand{\IN}[1]{\mathcal{I}^-_{u_{#1}}}
\newcommand{\bloc}{\mathcal B}
\newcommand{\ym}[1]{\textcolor{red}{#1}}
% Attempt to make hyperref and algorithmic work together better:
\newcommand{\theHalgorithm}{\arabic{algorithm}}
\title[Sequential Optimization in Large-scale Recommender systems]{Sequential Optimization over Users Implicit Feedback \\ in Large-scale Recommender Systems}
\usepackage{times}
\usepackage{natbib}
%\newtheorem{theorem}{Theorem}
%\newtheorem{lemma}{Lemma}
%\newtheorem{proposition}{Proposition}
\newtheorem{assumption}{Assumption}
\newtheorem{ddef}{Definition}
%\usepackage{amsmath}
\usepackage{amsfonts,amstext,amssymb}
\usepackage{fancyvrb}
\usepackage{authblk}
\usepackage[]{hyperref}
%\usepackage{color, colortbl}
%\usepackage[usenames,dvipsnames]{xcolor}
\usepackage{tikz}
\usepackage{multicol}
\usepackage{multirow}
\DeclareMathOperator*{\argmax}{arg\,max}
\DeclareMathOperator*{\argmin}{arg\,min}
\usepackage{bbold}
\newcommand{\Loss}{\mathcal{L}}
\newcommand{\Trn}{\mathcal{S}}
\newcommand{\userS}{\mathcal{U}}
\newcommand{\itemS}{\mathcal{I}}
\newcommand{\vecU}{\mathbf{U}}
\newcommand{\vecI}{\mathbf{V}}
\newcommand{\prefu}{\renewcommand\arraystretch{.2} \begin{array}{c}
{\succ} \\ \mbox{{\tiny {\it u}}}
\end{array}\renewcommand\arraystretch{1ex}}
\newcommand{\posI}{\mathcal{I}^{+}}
\newcommand{\negI}{\mathcal{I}^{-}}
\newcommand{\error}{\mathcal R}
\newcommand{\MovieL}{\textsc{MovieLens}}
\newcommand{\NetF}{\textsc{Netflix}}
\newcommand{\RecS}{\textsc{RecSys 2016}}
\newcommand{\Out}{\textsc{Outbrain}}
\newcommand{\ML}{\textsc{ML}}
\newcommand{\R}{\mathbb{R}}
\newcommand{\kasandr}{\textsc{Kasandr}}
\newcommand{\commentaire}[1]{\textcolor{gray}{// #1}}
\newcommand{\RecNet}{\texttt{RecNet}}
\newcommand{\RecNetE}{{\RecNet}$_{E\!\!\backslash}$}
\newcommand{\MostPop}{\texttt{MostPop}}
\newcommand{\Random}{\texttt{Random}}
\newcommand{\MF}{\texttt{MF}}
\newcommand{\ProdVec}{\texttt{Prod2Vec}}
\newcommand{\BPR}{\texttt{BPR-MF}}
\newcommand{\CoFactor}{\texttt{Co-Factor}}
\newcommand{\LightFM}{\texttt{LightFM}}
\newcommand{\SO}{\texttt{SOLAR}}
\newcommand{\batch}{\texttt{Batch}}
\renewcommand{\w}{\boldsymbol{\omega}}
\newcommand{\N}{\mathbb{N}}
\coltauthor{\Name{Aleksandra Burashnikova} \Email{[email protected]}\\
\addr Skolkovo Institute of Science and Technology, Center for Energy Systems & Univ. Grenoble Alps
\AND
\Name{Yury Maximov} \Email{[email protected]}\\
\addr Skolkovo Institute of Science and Technology, Center for Energy Systems & Los Alamos National Laboratory
\AND
\Name{Charlotte Laclau} \Email{[email protected]}\\
\addr Univ. Grenoble Alps, LIG
}
\begin{document}
\maketitle
% this must go after the closing bracket ] following \twocolumn[ ...
% This command actually creates the footnote in the first column
% listing the affiliations and the copyright notice.
% The command takes one argument, which is text to display at the start of the footnote.
% The \icmlEqualContribution command is standard text for equal contribution.
% Remove it (just {}) if you do not need this facility.
%\printAffiliationsAndNotice{} % leave blank if no need to mention equal contribution
\begin{abstract}
In this paper we propose a sequential optimization algorithm for large-scale Recommender Systems where the user feedback is implicit, mostly in the form of clicks. Based on the assumption that users are shown a set of items sequentially, and that positive feedback convey relevant information for the problem in hand, the proposed algorithm updates the weights of a scoring function whenever an active user interacts with the system, by clicking on a shown item. Then, the update rule consists in changing the weights in order to minimize a convex surrogate ranking loss over the average number of previous unclicked items shown to the user, and that are scored higher than the clicked one. We prove that these sequential updates of the weights converge to the global minimal of the surrogate ranking loss estimated over the total set of users who interacted with the system by considering two; {\it adversarial} and {\it non-adversarial} settings where we suppose that the system which shows items to users is, or is not, instantaneously affected by the sequential learning of the weights. Experimental results on four large scale collections support our findings, and show that the proposed algorithm converges faster than when minimizing the global ranking loss in a batch mode. This is of particular interest as it meets one of the aims of online advertising which is to gradually adapt the system to the users interactions without loss of efficiency.
\end{abstract}
\section{Introduction}
With the increasing number of products available online, there is a surge of interest in the design of automatic systems --- generally referred to as Recommender Systems (RS) --- that provide personalized recommendations to users by adapting to their taste. The study of efficient RS has became an active area of research these past years, specially since the Netflix Price \citep{Bennett:07}.
%and the organization of the RecSys conferences\footnote{\url{https://recsys.acm.org/}}.
\smallskip
\noindent\textbf{Related works.} Two main approaches have been proposed to tackle this problem. The first one, referred to as Content-Based recommendation or cognitive filtering \citep{Pazzani2007} makes use of existing contextual information about the users (e.g. demographic information) or items (e.g. textual description) for the recommendation. The second approach, referred to as Collaborative Filtering (CF) and undoubtedly the most popular one \citep{Su:2009}, relies on the past interactions and recommends items to users based on the feedback provided by other similar users. Traditionally, CF systems were designed using {\it explicit} feedback, mostly in the form of ratings \citep{DBLP:conf/kdd/Koren08}. However, rating information is non-existent on most e-commerce websites and is difficult to collect. New approaches now largely consider {\it implicit} feedback, mostly in the form of clicks, that are easier to gather but more challenging to take into account as they do not clearly depict the preference of a user over items; i.e. (no)click does not necessarily mean (dis)like \citep{Hu:2008}. As a matter of fact, recent RS systems focus now on learning scoring functions to assign higher scores to clicked items than to unclicked ones rather than to predict the clicks as it is usually the case when we are dealing with explicit feedback \citep{Pessiot:07,rendle_09,Cremonesi:2010,Volkovs2015,Zhang:16,He2016}. However, in recent publicly available collections for recommendation systems, released for competitions\footnote{\scriptsize \url{https://www.kaggle.com/c/outbrain-click-prediction}} or issued from e-commerce \citep{sidana17}\footnote{\scriptsize \url{https://archive.ics.uci.edu/ml/datasets/KASANDR}}, there is a huge unbalance between positive feedback (click) and negative feedback (no-click) in the set of items displayed to users, making the design of an efficient online RS even more challenging. Some works propose to weight the impact of positive and negative feedback directly in the objective function \citep{Hu:2008,Pan:2008} or to sample the data over a predefined buffer before learning \citep{Liu2016}, but they suppose the existence of a training set. Other approaches tackle the sequential learning problem for RS by taking into account the temporal aspect of interactions directly in the design of a dedicated model \cite{Liu:2009,Donkers:2017}, but they suffer from a lack of theoretical analysis formalizing the overall learning strategy.
\smallskip
\noindent\textbf{Contributions.} In this work, we propose a novel sequential framework for learning user preferences over implicit feedback in RS. The approach updates the weights of a scoring function user by user over blocks of items ordered by time where each block is a sequence of unclicked items (negative feedback) shown to the user followed by a last clicked one (positive feedback). At each update, the objective is to minimize a smooth convex surrogate loss over the average number of negative items scored higher than the positive one of the corresponding sequence of items. Theoretically, we provide a proof of convergence of the solution found by the algorithm to the minimal value of the surrogate of the global ranking loss estimated over the total set of users who interacted with the system by considering two cases where the system which shows items to users is, or is not, affected by the sequential learning of the weights. Experimental results on four large publicly available datasets, show that our approach is consistently faster, with a better test performance at the convergence than the full batch learning. We also analyze the conditions in which the proposed block-wise update approach is most profitable, and it turns out that the convergence speed is faster with a higher unbalance between clicked and unclicked items. This is a particularly interesting result, as it corresponds to the common situation of implicit feedback in large-scale scenarios.
\smallskip
\noindent\textbf{Organization of the paper.} The rest of this paper is organized as follows. In the next section we present the framework and the proposed sequential learning strategy for recommender systems. In Section \ref{sec:TA}, we provide a proof of convergence of the algorithm in the case where the instantaneous surrogate ranking loss is smooth and strongly convex. In Section \ref{sec:Exps}, we present the experimental results, and finally, in Section \ref{sec:Conclusion} we discuss the outcomes of this study.
\section{A Block Sequential Optimization Strategy}
\label{sec:Algorithm}
In this section, we first present definitions and our framework (Section \ref{sec:Frame}), then, the proposed block sequential learning algorithm (Section \ref{sec:Algo}).
\subsection{Framework and definitions}
\label{sec:Frame}
Throughout, we use the following notation. For any positive integer $n$, $[n]$ denotes the set $[n]\doteq \{1,\ldots,n\}$. We suppose that $\itemS\doteq [M]$ and $\userS\doteq [N]$ are two sets of indexes defined over items and users. Further, we assume that each user $u$ is distributed uniformly and independently according to a fixed yet unknown distribution ${\cal D}$, and that the system updates are performed over the interactions of an active user. At the end of the session of each active user $u\in\userS$, we suppose that $u$ has reviewed a subset of items $\itemS_u\subseteq \itemS$ composed of two sets of preferred and no-preferred items; respectively denoted by $\posI_u$ and $\negI_u$. Hence, for each pair of items $(i,i')\in\posI_u\times \negI_u$, the user $u$ prefers item $i$ over item $i'$; symbolized by the relation $i\!\prefu\! i'$. From this preference relation a desired output $y_{u,i,i'}\in\{-1,+1\}$ is defined over the pairs $(u,i)\in\userS\times\itemS$ and $(u,i')\in\userS\times\itemS$, such that $y_{u,i,i'}=+1$ iff $i\!\prefu\! i'$.
The learning objective that we address is then to find a function, in a set of scoring functions $\mathcal{F}_{\w}=\{f_{\w}:\userS\times\itemS\rightarrow \R \mid \w\}$ defined over a set of parameters $\w$, that minimizes a ranking loss defined as~:
\begin{gather}
\label{eq:RLoss}
\Loss(\w) =
{\mathbb E}_{u \sim {\cal D}} \left[\widehat{\cal L}^F_u(\w)\right],
\end{gather}
where $\widehat{\cal L}^F_u(\w)$ is the ranking loss that penalizes the misordering between the preferred and non-preferred items induced by the scoring function with parameters $\w$ measured with a surrogate instantaneous ranking loss $\ell_{\w}:(\userS\times\itemS\times\itemS )\rightarrow \mathbb{R}_+$ for user $u$~:
\begin{equation} \label{eq:TotalLoss}
\widehat{\cal L}^F_u(\w) = \frac{1}{|\posI_u||\negI_u|}\!\sum_{i\in \posI_u}\!\sum_{i'\in \negI_u} \!\ell_{\w} (u,i,i'),
\end{equation}
In the following, we suppose that $\ell_{\w}$ is a $L$-smooth, continuous, differentiable and $\mu$-strongly convex function \citep{bubeck2015convex} (Appendix A.) which is the case of the usual cross-entropy --- or the logistic ranking --- cost \citep{Burges:2005} proposed in learning-to-rank domain.
In the batch setting, this objective is achieved under the Empirical Risk Minimization principle \citep{Vapnik2000} by minimizing the empirical ranking loss estimated over the items and the final set of users who interacted with the system~:
\begin{equation}
\label{eq:RL}
\!\widehat{\Loss}(\w,\userS,\itemS)\!=\!\frac{1}{N}\sum_{u\in\userS}\frac{1}{|\posI_u||\negI_u|}\!\sum_{i\in \posI_u}\!\sum_{i'\in \negI_u} \!\ell_{\w} (u,i,i').
\end{equation}
In the online context that we consider here, the weights of the model are learned sequentially over a set of $N$ users, and during the training phase we consider a non-adversarial (resp. adversarial) setting where the predictions of the current model do not (resp. do) affect the set of items shown to the next user. In the next Section, we first present the Sequential Optimization algorithm for Large-scale Recommender systems ({\SO}) and then study its convergence properties in Section \ref{sec:TA}.
\subsection{Algorithm}
\label{sec:Algo}
In the following, we suppose that the indexes of users in $\userS$ as well as those of the items in the set $\itemS_u$, shown to the active user $u\in\userS$, are ordered by time. Although there is no evidence of the true value of interactions in implicit feedback -- clicks or no-clicks do not truly express the preference of users -- the algorithm is based on the assumption that for each user $u$, the set $\posI_u$ conveys more information than $\negI_u$ for the problem in hand, and that the updates should occur at each time when $u$ interacts positively over a shown item. The pseudo-code of {\SO} is shown in the following. The sequential
\begin{wrapfigure}[25]{r}{0.66\textwidth}
%\begin{minipage}{1.0\textwidth}
%\begin{algorithm}[H]
\tcbset{width=0.63\columnwidth,before=,after=, colframe=black,colback=white, fonttitle=\bfseries, coltitle=black, colbacktitle=white, boxrule=0.2mm,arc=1mm, left = 2pt}
\begin{tcolorbox}[title=Algorithm {\SO}\label{algo:SO}]
\KwIn{A set of User $\userS$ and Items $\itemS$;}
{\bf initialization:} Random initialization of weights $\w_0$;\\
$T \in N^*$ and $t = 0$ ;\\%\commentaire{Maximum number of epochs and the number of previously observed blocks}\\
%\KwOut{weight $\w$}
\For{$j=1,\ldots,T$}{
\For {user $u = 1,\ldots,N$} {
$\Pi_t=\emptyset$;
$N_t=\emptyset$;\\
\For {\text{item} $i=1,\ldots, |\mathcal{I}_{u}|$}{
\eIf {$u$ \mbox{ provides a negative feedback on } $i$ }{
$N_t=N_t\cup \{i\}$;
$\mathcal{I}_u^{-}=\mathcal{I}_u^{-}\cup \{i\}$;
}{
$\Pi_t=\Pi_t\cup \{i\}$;
$\mathcal{I}_u^{+}=\mathcal{I}_u^{+}\cup \{i\}$;\\
\If{$N_t \neq \emptyset$}{
% \For{$k = 1,\ldots,T$}{%$k\leftarrow k+1$
{\small
$s_t=|{N_t}||\Pi_t|$;\\
$\w_{t} = \w_{t-1}\!-\! \frac{\eta_t}{s_t}\displaystyle{\sum_{i\in\Pi_t}\sum_{i'\in N_t}} \nabla\ell_{\w_{t-1}} (u,i,i')$;\\}
$t=t+1$;\;
% }
$\Pi_t=\emptyset$;\;
$N_t=\emptyset$;\;
}
}
}
}
}
%\caption{Algorithm {\SO} to sequentially minimize the ranking loss.}
\end{tcolorbox}
%\end{algorithm}
%\end{minipage}
\end{wrapfigure}
\noindent update rule consists in updating the weights bloc by bloc, where each bloc $\bloc_t; t\ge 1$ corresponds to items shown to the active user, ending with a preferred item that follows a sequence of no-preferred ones. Note that in large-scale scenarios, as it is case in our experiments, positive feedback are rare and interactions are mostly negative so there is generally only one (last) preferred item in each bloc. Starting from initial weights $\w_0$ chosen randomly, the update rule for the active user $u$ and the current bloc $\bloc_t$ corresponds to one gradient descent step over the ranking loss estimated on the associated sets of preferred and no-preferred items, respectively denoted by $\Pi_t\subset \bloc_t$ and $N_t\subset \bloc_t$, using the current weights $\w_{t-1}$~:
\begin{gather}
\label{eq:CLoss}
{\widehat {\cal L}}^t_u(\w_{t-1}) = \frac{1}{|\Pi_t||N_t|}\sum_{i \in \Pi_t} \sum_{i'\in N_t} \ell_{{\w}_{t-1}} (u, i, i').
\end{gather}
Hence for $t\ge 1$, the $t^{th}$ update performed over the bloc $\bloc_t$; conducts to new weights $\w_t$.
\section{Theoretical Analysis}
\label{sec:TA}
In our theoretical analysis, we consider two different settings of how items are shown to users. In the first one, referred to as the {\it non-adversarial setting}, we suppose that the system which shows items to users is not instantaneously affected by the sequential learning of the weights. This hypothesis corresponds to the generation of items shown to users with respect to some fixed probability distribution ${\cal D}_{\cal I}$ and constitutes the basic assumption of almost all the studies in the field. In the second setting, referred to as the {\it adversarial setting}, we suppose that the set of items shown to each user changes after the updates of the weights done over the previous active user. This setting corresponds to the realistic case of the sequential learning strategy that we propose, and it assumes the existence of a joint probability distribution ${\cal D}_{{\cal U}, {\cal I}}$ over the set of items and users, such that after each update of the weights; a new item $i$ is proposed to the active user according to the probability distribution $i \sim {\cal D}_{\cal I}(i|({\cal U}^t, {\cal I}^t))$; where $({\cal U}^t, {\cal I}^t)$ are all the pairs of users and items which previously interacted with the system.
%\ym{I would prefer to have definitions of strong convexity and lipshitsness before the theorems}
For both the {\it non-adversarial} and {\it adversarial} settings, we provide a proof of convergence of the sequence of weights $(\w_t)_{t\in\N^*}$ produced by \SO. Our analyses are based on the following assumption:
%\ym{Do we need it? It seems to be satisfied in the Algorithm}
\begin{assumption}[User Behaviour Consistency]
\label{Asmp1}
In average, active users have a consistent behaviour when interacting with the system in the sense that, for any active user $u$ and any weight vector $\w$, the gradient of the partial loss (${\widehat {\cal L}}^t_u(\w)$, Eq. \ref{eq:CLoss}) estimated over interacted items of any block $\bloc_t$; has the same expectation than the gradient of the total ranking loss $\widehat{\cal L}^F_u(\w)$ (Eq. \ref{eq:TotalLoss})~:
\begin{equation}
\label{eq:Assmp1}
\mathbb{E}_{\bloc_t} [\nabla{\widehat {\cal L}}^t_u(\w)] = \mathbb{E}_{(u,i)\sim {\cal D}_{{\cal U}, {\cal I}}}[\nabla\widehat{\cal L}^F_u(\w)].
\end{equation}
\end{assumption}
In the {\it non-adversarial} setting, our main result is the following theorem which bounds the deviation between the expected total ranking loss for any user and the minimum of the global ranking loss (Eq. \ref{eq:RLoss}).
\smallskip
\begin{theorem}\label{thm:10}
Let $\ell_{\w}$ be a $\beta$-smooth and $\mu$ strongly convex function \citep{bubeck2015convex}% (Section A) with respect to $\|\cdot\|_2$
, and $\w_{*}$ be the minimizer of the expected ranking loss in Eq.~\ref{eq:RL}. Moreover, assume that for some $M>0$, $\sup_{\w}\mathbb{E}_{{\cal D}_{{\cal U}, {\cal I}}}\, \|\nabla \ell_{\w}(u, i, i')\|_2^2 \le M^2$. Then for any $\theta>0$; and step sizes $\left(\eta_t = \theta/t\right)_{t\in\N^*}$, Algorithm~{\SO} generates a sequence $(\w_t)_{t \ge 1}$ verifying~:
\[
\forall t\in\N^*; \mathbb{E}_{(u, i)\sim {\cal D}}[{\widehat{\cal L}}_u^F(\w_{t})] - {\cal L}^\star \le \frac{\beta Q(\theta)}{2t},
\]
where $Q(\theta) =~\max \{\theta^2 M^2(2\mu\theta - 1)^{-1}, \|\w_0 - \w_*\|_2^2\}$ and ${\cal L}^\star=\min_{\w} \mathbb{E}_{u\sim {\cal D}_{\cal U}}[{\widehat{\cal L}}_u^F(\w)]$ (Eq. \ref{eq:RLoss}).
\end{theorem}
\begin{proof}
%\ym{We should explicitly cite \cite{nemirovski2009robust} to prevent impoliteness since the proofs exactly follows to their paper. ``In our proof we follow \cite{nemirovski2009robust} ... '' or smth like that}
Following the update rule, the difference in norm of the weights found by {\SO} at iteration $t$ and the minimizer of the empirical ranking loss (Eq.~\ref{eq:RL}) is~:
\begin{align}
a_{t} & \doteq \frac{1}{2}\, \|\w_{t} - \w_*\|_2^2 = \frac{1}{2} \|\w_{t-1} - \eta_t \nabla {\widehat {\cal L}}^{t}_u(\w_{t-1})- \w_*\|_2^2 \nonumber\\
& \le \frac{1}{2} \|\w_{t-1} - \w_*\|_2^2 + \frac{1}{2} \eta_t^2 \|\nabla {\widehat {\cal L}}^{t}_u(\w_{t-1})\|_2^2 - \eta_t (\w_{t-1} - \w_*)^\top \nabla {\widehat {\cal L}}^{t}_u(\w_{t-1}).\label{eq:at}
\end{align}
In the {\it non-adversarial} case, the weights $\w_t$ only depend on the user interactions in block $\bloc_t$, hence~:
%\ym{It would be more safe to say, that they are independent of the blocks 1, ... t-1. No?}
\begin{align*}
\mathbb{E}_{\bloc_1, \dots, \bloc_{t}} [(\w_{t-1} - \w_*)^\top \nabla {\widehat {\cal L}}^{t}_u(\w_{t-1})]& = \mathbb{E}_{\bloc_1, \dots, \bloc_{t-1}}\mathbb{E}_{\bloc_{t}| \bloc_1, \dots, \bloc_{t-1}} [ (\w_{t-1} - \w_*)^\top \nabla {\widehat {\cal L}}^{t}_u(\w_{t-1})] \\
& = \mathbb{E}_{\bloc_{t}} [(\w_{t-1} - \w_*)^\top \nabla {\widehat {\cal L}}^{t}_u(\w_{t-1})].%=(\w_{t-1} - \w_*)^\top \mathbb{E}_{\bloc_{t-1}} [\nabla {\widehat {\cal L}}^{t}_u(\w_{t-1})]
\end{align*}
Following Assumption \ref{Asmp1}, it comes out that~:
\[
\mathbb{E}_{\bloc_{t}} [(\w_{t-1} - \w_*)^\top \nabla {\widehat {\cal L}}^{t}_u(\w_{t-1})]= \mathbb{E}_{{\cal D}_{{\cal U}, {\cal I}}}[(\w_{t-1} - \w_*)^\top\nabla\widehat{\cal L}^F_u(\w_{t-1})].
\]
The strong convexity of the loss function $\ell_{\w}$ \citep{bubeck2015convex} implies that~:
\[
(\w - \w')^\top \left(\nabla\widehat{\cal L}^F_u(\w) - \nabla\widehat{\cal L}^F_u(\w')\right) \ge \mu \|\w - \w'\|_2^2,
\]
which for the minimizer $\w_*$ of (Eq.~\ref{eq:RLoss}), satisfying $\mathbb{E}_{{\cal D}_{{\cal U}, {\cal I}}} \nabla\widehat{\cal L}^F_u(\w_*)=0$; gives % $(\w - \w_*)^\top \nabla\widehat{\cal L}^F_u(\w) \ge \mu \|\w - \w_*\|_2^2$,and~:
\begin{equation}
\label{eq:SC}
\mathbb{E}_{{\cal D}_{{\cal U}, {\cal I}}}\, [(\w_{t-1} - \w_*)^\top \nabla\widehat{\cal L}^F_u(\w_{t-1})] \ge \mu \mathbb{E}_{{\cal D}_{{\cal U}, {\cal I}}}\, \|\w_{t-1} - \w_*\|_2^2 = 2 \mu a_{t-1}.
\end{equation}
Furthermore, we have
\begin{equation}\label{eq:Maj}
\forall \w; \mathbb{E}_{{\cal D}_{{\cal U}, {\cal I}}} \|\nabla {\widehat {\cal L}}^{t}_u(\w)\|_2^2 \le M^2.
\end{equation}
From equations \eqref{eq:at}, \eqref{eq:SC} and \eqref{eq:Maj} it then comes~:
\begin{gather}\label{eq:20}
a_{t} \le (1 - 2\mu \eta_t) a_{t-1} + \frac{1}{2} \eta_t^2 M^2.
\end{gather}
Taking $\eta_t = \theta/t$ and following \citep{nemirovski2009robust} we have by induction:
\begin{equation}
\label{eq:Q}
a_{t} \le \frac{Q(\theta)}{2t} \text{ and } \mathbb{E}_{{\cal D}_{{\cal U}, {\cal I}}} \|\w_t - \w_*\|_2^2 \le \frac{Q(\theta)}{t},
\end{equation}
where $Q(\theta) = \max \{\theta^2 M^2(2\mu\theta - 1)^{-1}, \|\w_0 - \w_*\|_2^2\}$.
Further due to the smoothness of the function $\ell_\omega$ we have:
\[
\mathbb{E}_{{\cal D}_{{\cal U}, {\cal I}}} \|\nabla{\widehat{\cal L}}_u^F(\w_t) - \nabla{\widehat{\cal L}}_u^F(\w')\|_2 \le \beta \mathbb{E}_{{\cal D}_{{\cal U}, {\cal I}}} \|\w_t - \w'\|_2,
\]
for any $\w'$ and since $\mathbb{E}_{{\cal D}_{{\cal U}, {\cal I}}} \nabla{\widehat{\cal L}}_u^F(\w_*) = 0$, we have~:
\[
\mathbb{E}_{{\cal D}_{{\cal U}, {\cal I}}} \|\nabla{\widehat{\cal L}}_u^F(\w) \|_2 \le \beta \mathbb{E}_{{\cal D}_{{\cal U} {\cal I}}}\|\w - \w_*\|_2.
\]
By integrating we finally get~:
\[
\mathbb{E}_{{\cal D}_{{\cal U}, {\cal I}}} {\widehat{\cal L}}_u^F(\w_t) - {\cal L}^* \le \frac{\beta}{2} \mathbb{E}_{{\cal D}_{{\cal U}, {\cal I}}} \|\w _t- \w_*\|_2^2.
\]
And the result follows from Eq. (\ref{eq:Q})~:
\[
\mathbb{E}_{{\cal D}_{{\cal U}, {\cal I}}} [\widehat{\cal L}_u^F(\w_t)] - {\cal L}^* \le \frac{\beta Q(\theta)}{2t}.
\]
Which ends the proof.\end{proof}
\paragraph{Discussion.} The bound established in Theorem~\eqref{thm:10} suggests that it is required $t = O(\beta Q^2(\theta) / \varepsilon)$ iterations, e.g. blocks of the positive and negative items shown to users, to achieve~:
\begin{gather}\label{eq:30}\mathbb{E}_{{\cal D}_{I, U}} [\widehat{\cal L}_u^F(\w_t) - \widehat{\cal L}_u^F(\w_*)] \le \varepsilon,\end{gather}
that is the same number of users which is required to get~:
\begin{gather}\label{eq:40}
\mathbb{E}_{{\cal D}_{U}} [\widehat{\cal L}_u^F(\w_t) - \widehat{\cal L}_u^F(\w_*)] \le \varepsilon,
\end{gather}
if one computes the total pairwise loss between all pairs of positive and negative items. The difference in Eq.~\eqref{eq:30} and \eqref{eq:40} is that the expectation is taken with respect to the joint probability measure over the triplets of users and items in Eq.~\eqref{eq:30} and over the users only in Eq.~\eqref{eq:40}. It particularly shows that randomization helps to speed-up learning in average. The non-adversarial setting is the usual setup followed in almost all studies in RS; as the collections containing the sets of items shown to users as well as their interactions are collected offline.
%\ym{We probably should say that blocks corresponding to the same user are not independent. So, in spite of the fact that we have better convergence in expectation, there is a derandomization issue. Should we? }
However, the aim of sequential learning, as in real life practice of recommender systems, is to adapt the set of shown items to users with respect to past updates; that is to change the distribution of items shown to users after $t$ updates of Algorithm~\ref{algo:SO}, with respect to the sequence of $t$ blocs of interactions $(\bloc_j)_{1\le j\le t}$; ${\cal D}_{{\cal U}, {\cal I}| {\cal B}_1, \dots, {\cal B}_t}$. However if the changes in the Wasserstein 1-distance \citep{villani:09}[Section 6] between two consecutive probability distributions is not bounded, the behaviour of the learning system will become non-ergodic \citep{Gibbs02onchoosing}. In order to lessen this effect, we make the following assumption.
\begin{assumption}[$\delta$-stable probability distributions]
\label{Asmp2}
If $({\cal D}_{{\cal U}, {\cal I}| {\cal B}_1, \dots, {\cal B}_t})_{t\in\N^*}$ is the sequence of probability measures over the set of items obtained after each update of the weights, then Wasserstein 1-distance $W_1$ \citep{villani:09} between any two probability distributions is bounded by a constant $\delta>0$~:
\[
W_1(\mu^t, \mu^k) \le \delta, \quad t,k \ge 0
\]
where $\mu^t = {\cal D}_{{\cal U}, {\cal I}| {\cal B}_1, \dots, {\cal B}_{t}}$ and Wasserstein 1-distance is $W_1 = \sup_f \int_{{\cal U}, {\cal I}} f(x) d(\mu - \nu)(x)$ if the supremum is over all 1-Lipshitz functions, $|f(x) - f(y)| \le \|x - y\|_2$.
%\[\|{\cal D}_{{\cal U}, {\cal I}| {\cal B}_1, \dots, {\cal B}_{t+1}} - {\cal D}_{{\cal U}, {\cal I}| {\cal B}_1, \dots, {\cal B}_t}\|_{TV} \le \delta \quad \forall t, t \ge 1.\]
\end{assumption}
From this assumption we present our main result for the convergence of the weights produced by Algorithm {\SO} in a full adversarial setting and a mix setting where we alternate between the adversarial and the no-adversarial settings. According to Assumption \ref{Asmp2}, the result suggests that the sequence of weights found with respect to an evolving probability distribution over the items will converge to the minimizer of the ranking loss Eq.~\eqref{eq:RL}. For the sake of presentation we will denote by ${\cal D}_{\mathcal{ U,I}}^t$, in the following the distribution ${\cal D}_{\mathcal{ U,I}\mid \bloc_{1},\ldots,\bloc_t}$.
\begin{theorem}\label{thm:40}
Let $\ell_{\w}$ be a %convex and
$\beta$-smooth, %$L$-Lipshitz,
and $\mu$ strongly convex function with respect to $\|\cdot\|_2$ and $({\cal D}_{\mathcal{ U,I}}^t)_{t\ge 1}$ be a $\delta$ stable sequence of distributions (Assumption \ref{Asmp2}). We further assume that there exist $M>0$ and $W>0$ such that~:
\begin{enumerate}
\item the expected norm of the gradient is bounded from above : $\sup_{\w}\mathbb{E}_{{\cal D}^t_{{\cal U}, {\cal I}}}\, \|\nabla \ell_{\w}(u, i, i')\|_2^2 \le M^2$ for any $t\ge 1$;
\item the distance from the starting point $\w_0$ to any of the optimal points $\w_*^t$ taken with respect to the associated distribution~${\cal D}_{\mathcal{ U,I}}^t$ is bounded from above by~$W$.
\end{enumerate}
Then, for any $\theta>0$ and a step size $(\eta_t = \theta/t)_{t\in\mathbb{N}^*}$, Algorithm~{\SO} generates a sequence $(\w_t)_{t \ge 1}$ such that~:
\[
\mathbb{E}_{(u, i)\sim {\cal D}}\,[{\widehat{\cal L}}_u^F(\w_{t})] - {\cal L}^*_t \le \frac{LQ(\theta)}{2t} + Ct, %\frac{L Q(\theta)}{2j}
\]
where ${\cal L}_t^\star=\min_{\w} \mathbb{E}_{u\sim {\cal D}^t_{\cal U}}\,[ {\widehat{\cal L}}_u^F(\w)]$,$Q(\theta) = \max \{\theta^2 M^2(2\mu\theta - 1)^{-1}, \|\w_0 - \w_{*}^1\|_2^2\}$, and $C = \frac{3\beta\delta}{2\mu} \max \left\{W, \frac{\beta\delta}{\mu}\right\}$.
\end{theorem}
\begin{proof}
%The proof of this theorem is similar to the proof of Theorem~\ref{thm:10}.
%Let $({\cal D}^t_{{\cal U}, {\cal I}})_{t\ge 1}$ be a sequence of distributions over the pairs (user, item) affected by the updates of Algorithm \ref{algo:SO} and respecting the $\delta$-stability condition of Assumption \ref{Asmp2}.
By adding and subtracting $\w_*^{t-1}$ in $a_t = \frac{1}{2} \|\w_t - \w_*^{t}\|_2^2$ and from the update rule, we have~:
\begin{align*}
a_{t} \doteq \frac{1}{2} \|\w_{t} - \w_*^{t}\|_2^2 &\le \frac{1}{2} \|\w_{t} - \w_*^{t-1}\|_2^2 + \frac{1}{2} \|\w_*^{t} - \w_*^{t-1}\|_2^2 + (\w_{t} - \w_*^{t-1})^\top(\w_*^{t} - \w_*^{t-1})\\
& = \frac{1}{2}\|\w_{t-1} - \eta_t \nabla {\widehat {\cal L}}^{t}_u(\w_{t-1}) - \w_*^{t-1}\|_2^2 + \frac{1}{2} \|\w_*^{t} - \w_*^{t-1}\|_2^2 \\
& \hspace{4mm} + (\w_{t} - \w_*^{t-1})^\top(\w_*^{t} - \w_*^{t-1}).
\end{align*}
Furthermore, by the definition of $a_{t-1}$ and the update rule we have~:
\begin{equation*}
\frac{1}{2}\|\w_{t-1} - \eta_t \nabla {\widehat {\cal L}}^{t}_u(\w_{t-1}) - \w_*^{t-1}\|_2^2 \le a_{t-1} + \frac{1}{2} \eta_t^2 \|{\widehat {\cal L}}^{t}_u(\w_{t-1})\|^2_2 - \eta_t (\omega_t - \omega_*^{t-1}){\widehat {\cal L}}^{t}_u(\w_{t-1}).
\end{equation*}
By denoting~:
\[C_t = \frac{3}{2} \|\w_*^{t} - \w_*^{t-1}\|_2 \max \{\|\w_*^{t} - \w_*^{t-1}\|_2, \|\w_{t} - \w_*^{t-1}\|_2\},
\]
it then comes from the last two inequalities that~:
\begin{equation*}
a_t \le a_{t-1} + \frac{1}{2} \eta_t^2 \|\nabla {\widehat {\cal L}}^{t}_u(\w_{t-1})\|_2^2 - \eta_t (\w_{t-1} - \w_*^{t-1})^\top \nabla {\widehat {\cal L}}^{t}_u(\w_{t-1}) + C_t.
\end{equation*}
Finally using the same argument as in Theorem~\ref{thm:10}:
\begin{gather}\label{eq:main-2}
a_{t} \le (1 - 2\mu \eta_t) a_{t-1} + \frac{1}{2} \eta_t^2 M^2 + C,
\end{gather}
where $C= \sup_t C_t$. By the notion of the Wasserstein distance and the strong convexity argument, we have
\begin{align}\label{eq:010}
\mathbb{E}_{{\cal D}^t_{{\cal U}, {\cal I}}} \|\w_*^t - \w_*^{t-1}\|_2^2
& \le \frac{1}{\mu} \mathbb{E}_{{\cal D}^t_{{\cal U}, {\cal I}}} \, [(\w^{t-1}_* - \w_*^t)^\top \nabla\widehat{\cal L}^F_u(\w_*^{t-1})
] \nonumber\\
&
\le \frac{1}{\mu} \mathbb{E}_{{\cal D}^t_{{\cal U}, {\cal I}}} \, \|(\w^{t-1}_* - \w_*^t)\|_2 \mathbb{E}_{{\cal D}^t_{{\cal U}, {\cal I}}} \,\|\nabla\widehat{\cal L}^F_u(\w_*^{t-1})\|_2,
\end{align}
where the last Eq. (\ref{eq:010}) is due to the Cauchy-Scwartz inequality.
From Assumption \ref{Asmp2}, it comes~:
\begin{gather}\label{eq:020}
\mathbb{E}_{{\cal D}^t_{{\cal U}, {\cal I}}} \,\|\nabla\widehat{\cal L}^F_u(\w_*^{t-1})\|_2 = \mathbb{E}_{{\cal D}^t_{{\cal U}, {\cal I}}} \,\|\nabla\widehat{\cal L}^F_u(\w_*^{t-1})\|_2 - \mathbb{E}_{{\cal D}^{t-1}_{{\cal U}, {\cal I}}} \,
\|\nabla\widehat{\cal L}^F_u(\w_*^{t-1})\|_2 \le \beta\delta,
\end{gather}
where the last inequality is due to $\beta$-smoothness of the loss function and the conditions of the theorem. By the convexity of the square function and Jensen's inequality, we have
\begin{gather}\label{eq:030}
\mathbb{E}_{{\cal D}^t_{{\cal U}, {\cal I}}}\|\w_*^t - \w_*^{t-1}\|_2^2 \ge
\left(\mathbb{E}_{{\cal D}^t_{{\cal U}, {\cal I}}}\|\w_*^t - \w_*^{t-1}\|_2\right)^2,
\end{gather}
and finally by Inequalities \eqref{eq:010}, \eqref{eq:020}, and \eqref{eq:030} we get $\mathbb{E}_{{\cal D}^t_{{\cal U}, {\cal I}}}\|\w_*^t - \w_*^{t-1}\|_2 \le \beta\delta/\mu$ which gives
\[
C \le \frac{3\beta\delta}{2\mu} \max \left\{W, \frac{\beta\delta}{\mu}\right\} \quad \forall t \ge 0.
\]
Taking $\eta_t = \theta/t$ similarly to the Theorem~\ref{thm:10} gives~:
\[
a_t \le \left(1 - 2\mu \frac{\theta}{t}\right) + \frac{\theta^2M^2}{2t^2} + C\sum_{i \le t} \prod_{t > k \ge i} (1 - 2\mu \eta_t).
\]
Recall that $Q(\theta) = \max \{\theta^2 M^2(2\mu\theta - 1)^{-1}, \|\w_0 - \w_*^1\|_2^2\}$. %Set $\pi \doteq \frac{3}{2} (W \delta + \delta^2)$.
Then
\[
\mathbb{E}_{{\cal D}^t_{{\cal U}, {\cal I}}} \|\w_t - \w_*\|_2^2 \le \frac{Q(\theta)}{t} + Ct.
\]
Using $\beta$-smoothness of the function $\widehat{\cal L}_u^F$ we have~:
\[
\mathbb{E}_{{\cal D}^t_{{\cal U}, {\cal I}}} [\widehat{\cal L}_u^F(\w_t)] - \mathbb{E}_{{\cal D}^t_{{\cal U}, {\cal I}}} [\widehat{\cal L}_u^F(\w_*^t)] \le \frac{\beta Q(\theta)}{2t} + Ct,
\]
which concludes the proof of the theorem.
\end{proof}
\section{Experimental evaluations}
\label{sec:Exps}
In this section, we provide an empirical evaluation of our optimization strategy on some popular benchmarks proposed for evaluating RS. All subsequently discussed components were implemented in Python3 using the TensorFlow library.\footnote{\url{https://www.tensorflow.org/}. }$^,$\footnote{For research purpose, we will make publicly available all the code as well as all pre-processed datasets.}
\subsection{Experimental setup}
First, we describe the ranking approach used in our evaluations. Then, we proceed with a presentation of the general experimental set-up, including a description of the datasets and baselines.
\paragraph{Problem Instantiation}\mbox{}\\
%In order to evaluate our Algorithm \ref{algo:SO}, we propose to use a simplified version of {\RecNet} \citep{sidana17b}, a CF ranking approach, based on a Neural-Network (NN) model that jointly learns a new representation of users and items in an embedded space as well as the preference relation of users over the pairs of items. Their objective loss relies on a linear combination of two surrogates of the logistic loss and demonstrates good results for implicit feedback, outperforming other common and recent approaches for the same task, namely Bayesian Personalized Ranking ({\BPR}) \citep{rendle_09}, {\CoFactor} \citep{liang_16}, and {\LightFM} \citep{kula_15}. Hereafter, we describe briefly the objective function that we aim to minimize.
We consider the ranking counterpart of Matrix Factorization \cite{Koren:2009} for click prediction in the implicit feedback datasets we use in our experiments. That is, each user $u$ and item $i$ are respectively represented by vectors $\vecU_u\in\R^k$ and $\vecI_i\in\R^k$ in a same latent space of dimension $k$. The set of weights $\w=(\vecU,\vecI)$ are matrices formed by the vector representations of users and items; $\vecU=(\vecU_u)_{u\in [N]}\in\R^{N\times k}$ and $\vecI=(\vecI_i)_{i\in[M]}\in\R^{M\times k}$; and we consider the regularized cross-entropy as the instantaneous ranking loss~:
%\par {\bf Y:} probably notation $\bf{I}$ instead of $\vecU$ would be much less confusing
%\par {\bf Y:} we specify the loss function as $\ell_\omega$, but there is no $\omega$ in the loss function
%Regarding the loss function, we consider the scenario that relies on the optimization of the surrogate of the logistic loss, given by
%Regarding the loss function, we consider two scenarios: the first one relies on the optimization of the surrogate of the logistic loss, given by
\[
\ell_{\w}(u,i,i')=\log\left(1+e^{-y_{i,u,i'}\vecU_u^\top(\vecI_{i}-\vecI_{i'})}\right)+\lambda (\|\vecU_u\|_2^2+\|\vecI_{i}\|_2^2 + \|\vecI_{i'}\|_2^2).
\]
%In case of the implicit feedback, suggested logistic loss matches with the cross-entropy, that is defined as follows
%The second one is based on the cross-entropy defined as follows
%\[
%\ell(u,i,i') = y_{i,u,i'} \log(\hat{y}_{i,u,i'})+(1-y_{i,u,i'}) \log(1-\hat{y}_{i,u,i'})
%\]
The objective of learning, is hence to find user and item embeddings such that the dot product between these representations in the latent space reflects the best the preference of users over items.
\paragraph{Datasets}\mbox{}\\
We report results obtained on four publicly available data\-sets, for the
task of personalized top-N recommendation: {\MovieL} 1M (\ML-1M) \citep{Harper:2015:MDH:2866565.2827872}, {\NetF}\footnote{\url{http://academictorrents.com/details/9b13183dc4d60676b773c9e2cd6de5e5542cee9a}}-- one clicks dataset, {\kasandr}-Germany\footnote{\url{https://archive.ics.uci.edu/ml/datasets/KASANDR}} \citep{sidana17} -- a recently released data set for on-line advertising and {\Out}\footnote{\url{https://www.kaggle.com/c/outbrain-click-prediction}} -- created from a recent challenge. The description of the collections is given below.
\begin{itemize}
\item \ML-1M and {\NetF} consist of user-movie ratings, on a scale of one to five, collected from a movie recommendation service and the Netflix company. The latter was released to support the Netlfix Prize competition\footnote{B. James and L. Stan, The Netflix Prize (2007).}. \ML-1M dataset gathers 1,000,000 ratings from 6040 users and 3900 movies and {\NetF} consists of 100 million ratings from 480,000 users and 17,000 movies. For both datasets, we consider ratings greater or equal to $4$ as positive feedback, and negative feedback otherwise.
\vspace{1mm}\item The original {\kasandr} dataset contains the interactions and clicks done by the users of Kelkoo, an online advertising platform, across twenty Europeans countries. In this article, we used a subset of {\kasandr} that only considers interactions from Germany. It gathers 15,844,717 interactions from 291,485 users on 2,158,859 offers belonging to 272 categories and spanning across 801 merchants.
\item
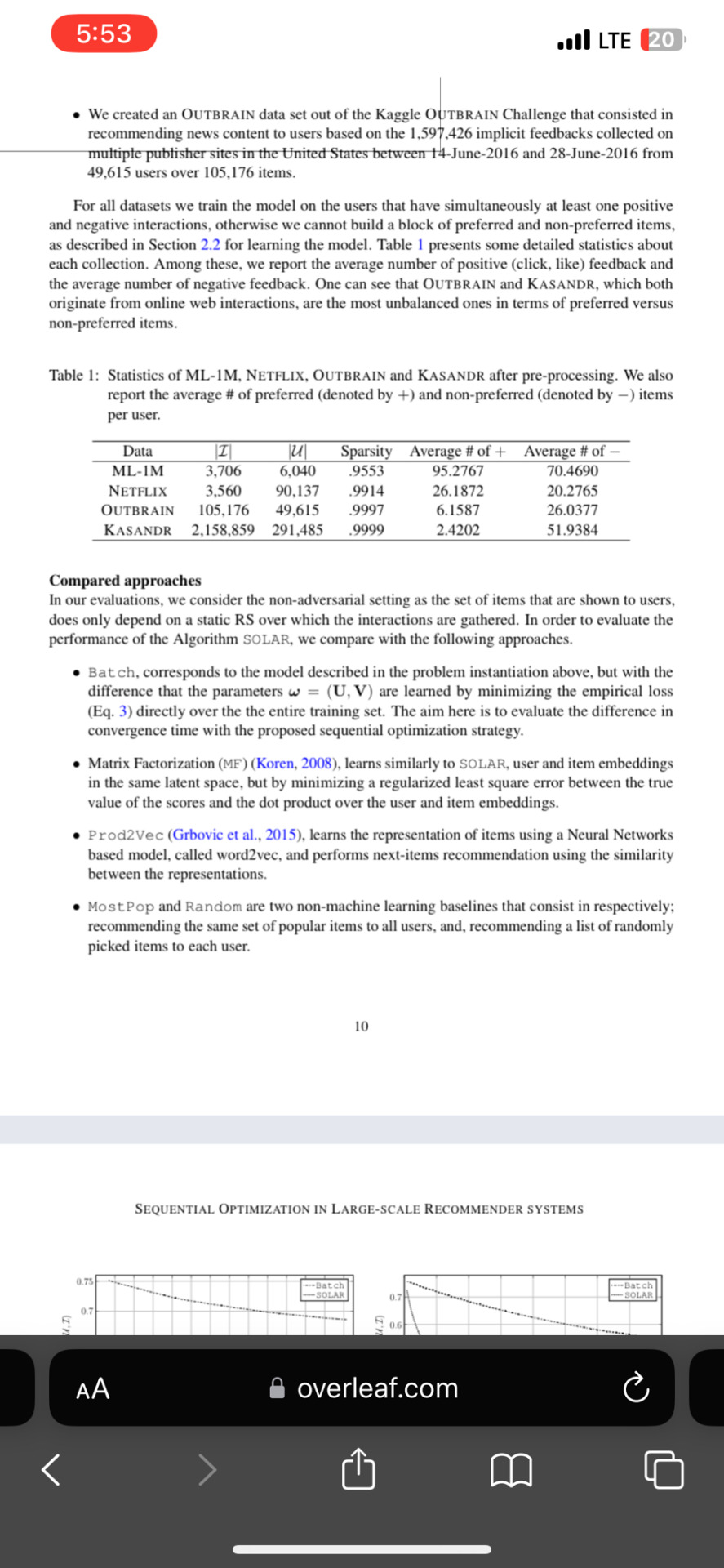
We created an {\Out} data set out of the Kaggle {\Out} Challenge that consisted in recommending news content to users based on the 1,597,426 implicit feedbacks collected on multiple publisher sites in the United States between 14-June-2016 and 28-June-2016 from 49,615 users over 105,176 items.
\end{itemize}
For all datasets we train the model on the users that have simultaneously at least one positive and negative interactions, otherwise we cannot build a block of preferred and non-preferred items, as described in Section \ref{sec:Algo} for learning the model. Table \ref{tab:datasets} presents some detailed statistics about each collection. Among these, we report the average number of positive (click, like) feedback and the average number of negative feedback. One can see that {\Out} and {\kasandr}, which both originate from online web interactions, are the most unbalanced ones in terms of preferred versus non-preferred items.
\begin{table}[!htpb]
\caption{Statistics of {\ML}-1M, {\NetF}, {\Out} and {\kasandr} after pre-processing. We also report the average \# of preferred (denoted by $+$) and non-preferred (denoted by $-$) items per user.}
\label{tab:datasets}
\centering
\begin{tabular}{cccccc}
\hline
Data&$|\mathcal{I}|$&$|\mathcal{U}|$&Sparsity&Average \# of $+$ & Average \# of $-$\\
\hline
{\ML}-1M&3,706&6,040&.9553&95.2767&70.4690\\
\NetF&3,560&90,137&.9914&26.1872&20.2765\\
\Out&105,176&49,615&.9997&6.1587&26.0377 \\
\kasandr&2,158,859&291,485&.9999&2.4202&51.9384\\
\hline
\end{tabular}
\end{table}
\paragraph{Compared approaches}\mbox{}\\
In our evaluations, we consider the non-adversarial setting as the set of items that are shown to users, does only depend on a static RS over which the interactions are gathered. In order to evaluate the performance of the Algorithm {\SO}, we compare with the following approaches.
\begin{itemize}
\item {\batch}, corresponds to the model described in the problem instantiation above, but with the difference that the parameters $\w=(\vecU,\vecI)$ are learned by minimizing the empirical loss (Eq.~\ref{eq:RL}) directly over the the entire training set. The aim here is to evaluate the difference in convergence time with the proposed sequential optimization strategy.
\item Matrix Factorization ({\MF}) \citep{DBLP:conf/kdd/Koren08}, learns similarly to {\SO}, user and item embeddings in the same latent space, but by minimizing a regularized least square error between the true value of the scores and the dot product over the user and item embeddings.
\item {\ProdVec} \citep{GrbovicRDBSBS15}, learns the representation of items using a Neural Networks based model, called word2vec, and performs next-items recommendation using the similarity between the representations.
\item {\MostPop} and {\Random} are two non-machine learning baselines that consist in respectively; recommending the same set of popular items to all users, and, recommending a list of randomly picked items to each user.
\end{itemize}
\smallskip
\begin{table}[b!]
\centering
\caption{Number of interactions used for train and test on each dataset, and the percentage of positive feedback among these interactions.}
\label{tab:detail_setting}
\begin{tabular}{ccccc}
\hline
Data&$|S_{train}|$&$|S_{test}|$&\% pos$_{train}$&\% pos$_{test}$\\
\hline
{\ML}-1M&797,758&202,451&58.82&52.39\\
\NetF&3,314,621&873,477&56.27&56.70\\
\Out&1,261,373&336,053&17.64&24.73\\
\kasandr&12,509,509&3,335,208&3.36&8.56\\
\hline
\end{tabular}
\end{table}
Hyper-parameters are found by cross-validation, and $\theta$ used in the Algorithm is set to $0.05$ on {\Out}, {\ML-1M}, {\kasandr}, for both {\batch} and {\SO}, and to $0.01$ on {\NetF}. For all compared approaches, we present results with the dimension of embedded space set to $k=5$, which we found as a good trade-off between complexity and performance. Further, we set the regularization parameter over the norms of the embeddings for {\SO}, {\batch} and {\MF} methods to $0.01$.
\paragraph{Evaluation protocol}\mbox{}\\
In our experiments, we first sort all interactions according by time with respect to the given time-stamps in the datasets. In order to construct the training and the test sets, we considered $80\%$ of each user's first interactions (both positive and negative) for training, and the remaining for test. The number of interactions in both sets after splitting are given in Table \ref{tab:detail_setting}. In addition we give the percentage of positive interactions during training and test. One can see that while for {\ML-1M} and {\NetF} datasets we have in average $50\%$ of positive interactions, on {\Out} and {\kasandr} this percentage is significantly lower. We compare the performance of these approaches on the basis of a common ranking metric based, the Mean Average Precision (MAP$@K$) over all users defined as $\text{MAP}@K=\frac{1}{N}\sum_{u=1}^{N}\text{AP}@K(u)$, where $\text{AP}@K(u)$ is the average precision of preferred items of user $u$ in the top $K$ ranked ones \citep[Ch. 8]{Manning:2008}.
%where the Average Precision at rank $K$, AP$@K$, is defined as :
%\begin{equation}
%\text{AP}@K=\frac{1}{K}\sum_{k=1}^K r_{k} Pr(k)
%\end{equation}
%and, $Pr(k)$ is the precision at rank $k$ of the relevant items and $r_k=1$ if the item at rank $k$ is preferred or clicked, and $0$ otherwise. In the following experiments, we consider MAP@1 and MAP@10.
\begin{figure}[t!]
\centering
\begin{tabular}{cc}
\begin{tikzpicture}[scale=0.46]
\begin{axis}[
width=1.0\columnwidth,
height=0.75\columnwidth,
xmajorgrids,
yminorticks=true,
ymajorgrids,
yminorgrids,
ylabel={Training error ~~~~$\widehat{\mathcal{L}}(\w,\userS,\itemS)$},
xlabel = {Time $(mn)$},
ymin = 0.45,
ymax= 0.76,
xmin = 0,
xmax = 135,
legend style={font=\Large},
label style={font=\Large} ,
tick label style={font=\Large}
]
\addplot [color=black,
dash pattern=on 1pt off 3pt on 3pt off 3pt,
mark=none,
mark options={solid},
smooth,
line width=1.2pt] file { ./results/ml_batch.txt};
\addlegendentry{ \batch };
\addplot [color=black,
dotted,
mark=none,
mark options={solid},
smooth,
line width=1.2pt] file { ./results/ml_online.txt };
\addlegendentry{ \SO };
\end{axis}
\end{tikzpicture}
&
\begin{tikzpicture}[scale=0.46]
\begin{axis}[
width=\columnwidth,
height=0.75\columnwidth,
xmajorgrids,
yminorticks=true,
ymajorgrids,
yminorgrids,
ylabel={Training error ~~~~$\widehat{\mathcal{L}}(\w,\userS,\itemS)$},
xlabel = {Time $(mn)$},
ymin = 0.1,
ymax=0.78,
xmin = 0,
xmax = 400,
legend style={font=\Large},
label style={font=\Large} ,
tick label style={font=\Large}
]
\addplot [color=black,
dash pattern=on 1pt off 3pt on 3pt off 3pt,
mark=none,
mark options={solid},
smooth,
line width=1.2pt] file { ./results/kassandr_batch.txt };
\addlegendentry{ \batch };
\addplot [color=black,
dotted,
mark=none,
mark options={solid},
smooth,
line width=1.2pt] file { ./results/kassandr_online.txt };
\addlegendentry{ \SO };
\end{axis}
\end{tikzpicture}\\
(a) \ML-1M & (b) \kasandr
\end{tabular}
\caption{Evolution of the loss on training sets for both {\batch} and {\SO} versions as a function of time in minutes.}
\label{fig:losses}
\end{figure}
\subsection{Results}
Figure \ref{fig:losses} presents the evolution of the training loss of {\SO} and {\batch} methods as a function of time (expressed in seconds). In order to have a fair comparison, we measured the evolution over time and not iterations; as the {\batch} approach overviews all the interacted training items of a user to do an update it takes longer time to do one iteration than {\SO} which does an update at each time a preferred item follows a sequence of negative ones. We recall that both methods produce a sequence of weights that converge to the same minimizer of the training loss (Eq. \ref{eq:RL}).
From these figures it comes out that, {\SO} converges faster and that {\batch} needs longer time to reach the minimum. We have also observed the same behaviour on the two other {\NetF} and {\Out} datasets (Appendix B.). We also compare the performance in terms of MAP@1 and MAP@10 between {\MostPop}, \Random, \ProdVec, \MF, {\batch} and {\SO} over the test sets of the different benchmarks we consider, in Table \ref{tab:online_vs_all}. Non-machine learning methods, {\MostPop} and {\Random} give results of an order of magnitude lower than learning based approaches. We stopped both {\batch} and {\SO} methods at the moment when the delta difference of empirical losses (Eq. \ref{eq:RL}) between two epochs for {\SO} drops below $10^{-3}$. The resulting test performance are in line with Figure \ref{fig:losses} and suggest that {\SO} converges faster to the minimum of the training loss by keeping a good generalization ability as we obtain an impressive boost in ranking performance with the latter. Furthermore, these results suggest that the embeddings found by {\SO} are more robust than the ones found by {\ProdVec} and that for implicit feedback learning to rank is more efficient than click prediction as compared to {\MF}. Comparisons in terms of MAP between {\SO} when the algorithm is stopped after one epoch ({\SO} 1 epoch) and {\batch} and {\SO} when they are stopped as for the experiments in Table \ref{tab:online_vs_all} are shown in Appendix C. As it can be seen, by passing once over $N$ users the algorithm reaches almost the same performance than before.
\begin{table}[!ht]
\centering
\caption{Comparison of different approaches in terms on MAP@1 and MAP@10. }
\label{tab:online_vs_all}
\resizebox{\textwidth}{!}{\begin{tabular}{c|cccccc|cccccc}
\hline
% Dataset& \multicolumn{12}{c|}{Metric}\\
\cline{2-13}
\multirow{2}{*}{Dataset}&\multicolumn{6}{c}{MAP@1}&\multicolumn{6}{c}{MAP@10}\\
\cline{2-13}
&{\MostPop}&\Random&\ProdVec&\MF&{\batch}&{\SO}&{\MostPop}&\Random&\ProdVec&\MF&{\batch}&{\SO}\\
\hline
\ML-1M &$.0359$&$.0048$&$.7187$&$.5187$&$.6043$&$\bf{.7986}$&$.0831$&$.0141$&$.7716$&$.6537$&$.6883$&$\bf{.8132}$\\
\NetF&$.0134$&$.0016$&$.6148$&$.5996$&$.6474$&$\bf{.8159}$&$.0513$&$.0044$&$.7026$&$.6912$&$.7476$&$\bf{.8488}$\\
\Out&$.0036$&$.0001$&$.2807$&$.3266$&$.2701$&$\bf{.4913}$&$.0086$&$.0002$&$.4803$&$.5132$&$.4771$&$\bf{.6301}$\\
\kasandr&$.0020$&$.0001$&$.0691$&$.1845$&$.3773$&$\bf{.5973}$&$.0020$&$.0003$&$.1096$&$.2240$&$.5099$&$\bf{.6986}$\\
\hline
\end{tabular}
}
\end{table}
%\paragraph{{\SO} vs. all} \mbox{}\\
%As for experiments presented on the figure \ref{fig:losses} and related to the convergence of the proposed online algorithm, it should be noted, that it was stopped at the point corresponding the last point where the model doesn't suffer from overfitting. Based on these results it can be seen that the sequential process of weight updates converges to global minimum of the surrogate ranking loss. Moreover it is ahead of the batch version in comparison of the convergence with respect to time. It gets approximately 10 - 30\% profit in train loss at fixed point of time. This is basically because of the update scheme where in online case we provide update step only when positive feedback comes, whereas batch weights are updated on all existing triplets at once that makes the convergence of it longer.\\
%From the obtained MAP one can observe that the online algorithm outperforms batch model that confirms the predictability of the proposed approach and the property to deal with the simulated online procedure expressed by more preferable performances in an online setting.\\
\iffalse
\begin{table}[!htpb]
\centering
\caption{Comparison between {\batch} and {\SO} on several benchmark datasets in terms on MAP. }
\label{tab:my_label}
\resizebox{0.38\textwidth}{!}{\begin{tabular}{ccccc}
\hline
Dataset& \multicolumn{4}{c}{Metric}\\
\cline{2-5}
&\multicolumn{2}{c}{MAP@1}&\multicolumn{2}{c}{MAP@10}\\
\cline{2-5}
&batch&online&batch&online\\
\hline
\ML-1M &$0.6043$&\bf{0.7986}&$0.6883$&\bf{0.8132}\\
\Out&$0.2701$&\bf{0.4913}&$0.4771$&\bf{0.6301}\\
\kasandr&$0.3773$&\bf{0.5973}&$0.5099$&\bf{0.6986}\\
\NetF&0.6474&\bf{0.8159}&0.7476&\bf{0.8488}\\
\hline
\end{tabular}
}
\end{table}
\fi
\section{Conclusion}
\label{sec:Conclusion}
In this paper, we presented an efficient learning framework for large-scale Recommender Systems, {\SO}, that sequentially updates the weights of a scoring function user by user over blocks of items ordered by time where each block is a sequence of unclicked items (negative feedback) shown to the user followed by a last clicked one (positive feedback). We considered two settings where the system showing items to users is not instantaneously affected by the sequential learning of the weights (non-adversarial setting), and where the set of items shown to each user changes after the updates of the weights done over the previous active user (adversarial setting). We provided a proof of convergence of the sequence of weights to the minimizer of an empirical ranking loss that is strongly convex in both settings. The empirical studies we conducted on four real-life implicit feedback datasets support our founding, and they show that the proposed approach converges much faster to the minimum of the ranking loss than the batch mode that minimizes the empirical loss (Eq.~\ref{eq:RL}) over the entire training set.
\bibliographystyle{icml2018}
\bibliography{_main}
\appendix
\section{Basic Definitions \citep{bubeck2015convex}}
We assume that we are given $\|\cdot\|$ a norm of $\R^n$
\begin{ddef}[Strongly convex]
A real-valued differentiable function ${\cal L}:\R^n\rightarrow \R$ is said to be strongly convex with parameter $\mu > 0$ if for any $x, y \in \mathbb{R}^n$ we have~:
\[
{\cal L}(y) \ge {\cal L}(x) + \nabla {\cal L}(x)^\top (y - x) + \frac{\mu}{2} \|y-x\|^2%,
\]
%where $\|\cdot\|$ is any norm.
\end{ddef}
\begin{ddef}[L-Smoothness]
A real-valued function ${\cal L}:\R^n\rightarrow \R$ is said to be $L$-smooth% with constant $L$ if for any $x, y \in \mathbb{R}^n$ we have~:
\[
\|\nabla{\cal L}(x) - \nabla{\cal L}(y)\| \le L\|x - y\|%,
\]
%where $\|\cdot\|$ is any norm.
\end{ddef}
\newpage
\section{Evolution of the train loss of {\batch} and {\SO} algorithms with respect to time on {\NetF} and {\Out} datasets. }
\begin{figure}[h!]
\centering
\begin{tabular}{cc}
\begin{tikzpicture}[scale=0.46]
\begin{axis}[
width=1.0\columnwidth,
height=0.75\columnwidth,
xmajorgrids,
yminorticks=true,
ymajorgrids,
yminorgrids,
ylabel={Training error ~~~~$\widehat{\mathcal{L}}(\w,\userS,\itemS)$},
xlabel = {Time $(mn)$},
ymin = 0.58,
ymax= 0.75,
xmin = 25,
xmax = 170,
legend style={font=\Large},
label style={font=\Large} ,
tick label style={font=\Large}
]
\addplot [color=black,
dash pattern=on 1pt off 3pt on 3pt off 3pt,
mark=none,
mark options={solid},
smooth,
line width=1.2pt] file { ./results/netflix_batch.txt};
\addlegendentry{ \batch };
\addplot [color=black,
dotted,
mark=none,
mark options={solid},
smooth,
line width=1.2pt] file { ./results/netflix_online.txt };
\addlegendentry{ \SO };
\end{axis}
\end{tikzpicture}
&
\begin{tikzpicture}[scale=0.46]
\begin{axis}[
width=\columnwidth,
height=0.75\columnwidth,
xmajorgrids,
yminorticks=true,
ymajorgrids,
yminorgrids,
ylabel={Training error ~~~~$\widehat{\mathcal{L}}(\w,\userS,\itemS)$},
xlabel = {Time $(mn)$},
ymin = 0.58,
ymax=0.72,
xmin = 2.6,
xmax = 12,
legend style={font=\Large},
label style={font=\Large} ,
tick label style={font=\Large}
]
\addplot [color=black,
dash pattern=on 1pt off 3pt on 3pt off 3pt,
mark=none,
mark options={solid},
smooth,
line width=1.2pt] file { ./results/out_batch.txt };
\addlegendentry{ \batch };
\addplot [color=black,
dotted,
mark=none,
mark options={solid},
smooth,
line width=1.2pt] file { ./results/out_online.txt };
\addlegendentry{ \SO };
\end{axis}
\end{tikzpicture}\\
(a) \NetF & (b) \Out
\end{tabular}
\caption{Evolution of the loss on training sets for both {\batch} and {\SO} versions as a function of time in minutes.}
\label{fig:losses}
\end{figure}
\section{{\SO}, {\SO} 1 epoch and {\batch}} \mbox{}\\
We compare the performance in terms of MAP between {\batch}, {\SO}, and {\SO} with only 1 epoch in Figure \ref{fig:map}. Overall, we observe that our optimization strategy, {\SO}, gives an impressive boost in ranking performance, especially on the most sparse datasets, {\kasandr} and {\Out}, and even after only one epoch outperforms the {\batch} version.
\begin{figure}[!htpb]
\centering
\subfigure[MAP@1]{
\includegraphics[width=0.48\textwidth]{hist_map1.png}
\label{sub:map_1}
}
\vspace{-3mm}
\subfigure[MAP@10]{
\includegraphics[width=0.48\textwidth]{hist_map10.png}
\label{sub:map_10}}
\caption{MAP@1 and MAP@10 of {\batch}, {\SO} and {\SO} with 1 epoch on all collections.}
\label{fig:map}
\end{figure}
\end{document}









0 notes
Text
Adobe incopy 2.0
DOWNLOAD NOW Adobe incopy 2.0
ADOBE INCOPY 2.0 PDF
ADOBE INCOPY 2.0 INSTALL
ADOBE INCOPY 2.0 UPDATE
ADOBE INCOPY 2.0 UPGRADE
ADOBE INCOPY 2.0 PC
Adobe InDesign 2022 v17.0.1. 0.0 (圆4) + UPDATED v2 Crack (FIXED) CracksNow Adobe InCopy CC 2019 - a program for the professional creation and editing of materials, closely associated with.InDesign is the successor to Adobe PageMaker, which Adobe acquired by buying. Adobe InDesign 2022 v17.2.0.20 Multilingual ( 圆4) The Adobe InCopy word processor uses the same formatting engine as InDesign.(3596468) Zoom in-Zoom out is slow and sluggish. (3650794) Panning and scrolling is slower in CC than CS6. (3596522) Rendering of pasted text frames is very slow in CC as compared to CS6. Adobe InDesign 2022 v17.4.0.51 Multilingual ( 圆4) An object or text frame drawing is slower in CC than CS.Designed to integrate with InDesign, InCopy allows writers to easily.
ADOBE INCOPY 2.0 UPGRADE
Adobe InCopy 2022 v17.0.0.96 Multilingual Adobe today announced InCopy 2.0 an upgrade to its InDesign-based editorial software.
Adobe InCopy 2022 v17.0.1.105 Multilingual Adobe InCopy 2022 v17.1.0 Multilingual (Mac OS X) Adobe Master Collection CC 2022 v Multilingual (圆4) Adobe InCopy 2022 v17.1.0.50 Multilingual (圆4) Adobe Master Collection CC 2022 v Multilingual (圆4) Adobe Master Collection CC 2022 v Multilingual (圆4) Adobe InCopy 2022 v17.0.1.
Adobe InCopy 2.0 for Windows X-XXX-XXX Adobe InCopy CS for Macintosh.
Adobe InCopy 2022 v17.2.0.20 Multilingual ( 圆4) Acrobat Reader 2.0 for Macintosh X-XXX-XXX Adobe Acrobat Reader 2.0 for Windows.
ADOBE INCOPY 2.0 PC
Monitor resolution: 1024 x 768 display (1920 X 1080 recommended), HiDPI display support Platform: PC Vendor: Adobe Systems Incorporated Verion: 2.0 and higher. Product is delivered only in electronic form.
ADOBE INCOPY 2.0 PDF
Pricing and availability 14 days tryout version of History is available for download at On the same URL you can also purchase the license. Rare Adobe InDesign 2.0 Adobe InCopy 2.0 freeload ApInDesign will prepare the document for export to PDF with advanced features using the process described in this article. MathTools V3 comes with new and improved functionality and V2 backward.
ADOBE INCOPY 2.0 INSTALL
Hard disk space: 3.6 GB of available hard-disk space for installation additional free space required during installation (cannot install on removable flash storage devices) SSD recommended History 2.0 is compatible with InDesign and InCopy CS & CS2 on both, Mac and PC. covers an Equation Editor for Adobe InDesign, InCopy and InDesign Server. Save to Cloud command lets you access files on any device MUSICFREE) Library Resources for Teachers. HiDPI and Retina display support in Windows Rare Adobe InDesign 2.0 Adobe InCopy 2.0 freeload High Quality. Color swatch folders for swatch management Footnote enhancements that respect text wrap Simple application of shading to text includes controls for offsets and more If you do anyway, it will be deleted without further notice. InCopy CC 9.2.0 Release Notes Last updated on What's New and Changed in InCopy CC What's new and changed in InCopy 9.2 (Jan 2014) Typekit Desktop fonts integration Simplified hyperlinks Font search and filter Sync Fonts What's new and changed in InCopy 9. Don't post a request if you have under 10 posts as stated in the rules. all without overwriting each other.s contributions. Request Adobe InCopy 2.0 (2002) Forum rules Please read the following rules before posting a download request in this area: 1. InCopy lets copywriters and editors style text, track changes, and make simple layout modifications to a document while designers work on the same document simultaneously in Adobe InDesign. Collaborate with copywriters and editors. 2056.Adobe InCopy 2022 v17.2.0.20 Multilingual (圆4) | 767.8 Mb iwant to find out end of life support for following adobe products: 1-Step RoboPDF 3.1. Kaspersky Internet & Total Security 2019 v19. Windows XP Professional SP3 x86 - Integral Edition 2020.5.5Īdobe Dreamweaver 2020 v20.3 (圆4) Pre-CrackedĪdobe Photoshop Lightroom Classic 2020 v9.2.0.10 (圆4)Īdobe.Premiere.
ADOBE INCOPY 2.0 UPDATE
150/= Micosoft office 2019 Windows 10 poffesonal 2020 March update Windows 10 Pro 圆4 v2004 En-US - ACTiVATED July 2020 Update Windows 7 SP1 Professional X64 OEM ESD MULTi-7 JUNE 2019
DOWNLOAD NOW Adobe incopy 2.0
0 notes