#Metadata Extraction Tools
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
130K people were victims of a chain letter scam that affected Tumblr in May 2011.
Note
I saw something about generative AI on JSTOR. Can you confirm whether you really are implementing it and explain why? I’m pretty sure most of your userbase hates AI.
A generative AI/machine learning research tool on JSTOR is currently in beta, meaning that it's not fully integrated into the platform. This is an opportunity to determine how this technology may be helpful in parsing through dense academic texts to make them more accessible and gauge their relevancy.
To JSTOR, this is primarily a learning experience. We're looking at how beta users are engaging with the tool and the results that the tool is producing to get a sense of its place in academia.
In order to understand what we're doing a bit more, it may help to take a look at what the tool actually does. From a recent blog post:
Content evaluation
Problem: Traditionally, researchers rely on metadata, abstracts, and the first few pages of an article to evaluate its relevance to their work. In humanities and social sciences scholarship, which makes up the majority of JSTOR’s content, many items lack abstracts, meaning scholars in these areas (who in turn are our core cohort of users) have one less option for efficient evaluation.
When using a traditional keyword search in a scholarly database, a query might return thousands of articles that a user needs significant time and considerable skill to wade through, simply to ascertain which might in fact be relevant to what they’re looking for, before beginning their search in earnest.
Solution: We’ve introduced two capabilities to help make evaluation more efficient, with the aim of opening the researcher’s time for deeper reading and analysis:
Summarize, which appears in the tool interface as “What is this text about,” provides users with concise descriptions of key document points. On the back-end, we’ve optimized the Large Language Model (LLM) prompt for a concise but thorough response, taking on the task of prompt engineering for the user by providing advanced direction to:
Extract the background, purpose, and motivations of the text provided.
Capture the intent of the author without drawing conclusions.
Limit the response to a short paragraph to provide the most important ideas presented in the text.

Search term context is automatically generated as soon as a user opens a text from search results, and provides information on how that text relates to the search terms the user has used. Whereas the summary allows the user to quickly assess what the item is about, this feature takes evaluation to the next level by automatically telling the user how the item is related to their search query, streamlining the evaluation process.

Discovering new paths for exploration
Problem: Once a researcher has discovered content of value to their work, it’s not always easy to know where to go from there. While JSTOR provides some resources, including a “Cited by” list as well as related texts and images, these pathways are limited in scope and not available for all texts. Especially for novice researchers, or those just getting started on a new project or exploring a novel area of literature, it can be needlessly difficult and frustrating to gain traction.
Solution: Two capabilities make further exploration less cumbersome, paving a smoother path for researchers to follow a line of inquiry:
Recommended topics are designed to assist users, particularly those who may be less familiar with certain concepts, by helping them identify additional search terms or refine and narrow their existing searches. This feature generates a list of up to 10 potential related search queries based on the document’s content. Researchers can simply click to run these searches.

Related content empowers users in two significant ways. First, it aids in quickly assessing the relevance of the current item by presenting a list of up to 10 conceptually similar items on JSTOR. This allows users to gauge the document’s helpfulness based on its relation to other relevant content. Second, this feature provides a pathway to more content, especially materials that may not have surfaced in the initial search. By generating a list of related items, complete with metadata and direct links, users can extend their research journey, uncovering additional sources that align with their interests and questions.

Supporting comprehension
Problem: You think you have found something that could be helpful for your work. It’s time to settle in and read the full document… working through the details, making sure they make sense, figuring out how they fit into your thesis, etc. This all takes time and can be tedious, especially when working through many items.
Solution: To help ensure that users find high quality items, the tool incorporates a conversational element that allows users to query specific points of interest. This functionality, reminiscent of CTRL+F but for concepts, offers a quicker alternative to reading through lengthy documents.
By asking questions that can be answered by the text, users receive responses only if the information is present. The conversational interface adds an accessibility layer as well, making the tool more user-friendly and tailored to the diverse needs of the JSTOR user community.
Credibility and source transparency
We knew that, for an AI-powered tool to truly address user problems, it would need to be held to extremely high standards of credibility and transparency. On the credibility side, JSTOR’s AI tool uses only the content of the item being viewed to generate answers to questions, effectively reducing hallucinations and misinformation.
On the transparency front, responses include inline references that highlight the specific snippet of text used, along with a link to the source page. This makes it clear to the user where the response came from (and that it is a credible source) and also helps them find the most relevant parts of the text.
293 notes
·
View notes
Text


this week on megumi.fm ▸ less worky more ache-y :(
aka essentially part2 of me just sitting at home and rotting away because my ankle will literally not let me do anything rip
📋 Tasks
💻 Internship mainly file redownloads and scripts for file counts, grouping and verification ↳ code to check for the redundancy in repository ✅ ↳ code to extract repository metadata ✅ ↳ code optimization ✅ ↳ learning about Superfamily tool and how to use it✅ ↳ weekly lab presentation ✅ 📝 so after a lot of edits and changes, the manuscript for our final project got accepted in Springer! so that's pretty cool
📅 Daily-s
🛌 consistent sleep [7/7] 💧 good water intake [7/7] 👟 exercise [/7] yet more ankle recovery
Fun Stuff this week
🎨 Updated my tumblr desktop themes hehe 📖 Reread Red White and Royal Blue 💗 grandma stayed over this week! I got to spend some time with her :)) then my ankle got better by the end of the week so we went to my uncle's place for lunch 📺 ongoing: Marry my Husband, Cherry Magic Th, Doctor Slump, Flex X Cop 📺 rewatch: Cherry Magic JP
📻 This week's soundtrack
Space Station No.8 by Jeff Satur -> Fade [TH/CN/EN] -> Lucid [TH/EN]
---
[Feb 5 to Feb 11 ; week 6/52 || i think all this sitting at home is getting to me. i'm losing motivation to do tasks, and my productivity is really plummeting. most of the time is spent waiting for code to run rather than actually doing anything, and my ankle has been making it's presence known so I just feel like staying in bed all day. just one more week at home. just. one more week of holding on ]
#52wktracker#studyblr#study blog#studyspo#stemblr#stem student#study goals#student life#college student#studying#stem studyblr#adhd studyblr#adhd student#study motivation#100 days of productivity#study inspo#study inspiration#gradblr#uniblr#studyinspo#sciblr#study aesthetic#study blr#study motivator#100 days of self discipline#100 days of studying#stem academia#bio student#100 dop#100dop
22 notes
·
View notes
Text
Open Deep Search (ODS)
XUẤT HIỆN ĐỐI THỦ OPEN SOURCE NGANG CƠ THẬM CHÍ HƠN PERPLEXITY SEARCH

XUẤT HIỆN ĐỐI THỦ OPEN SOURCE NGANG CƠ THẬM CHÍ HƠN PERPLEXITY SEARCH
Open đang phả hơi nóng và gáy close source trên các mặt trận trong đó có search và deep search. Open Deep Search (ODS) là một giải pháp như thế.
Hiệu suất và Benchmarks của ODS:
- Cải thiện độ chính xác trên FRAMES thêm 9.7% so với GPT-4o Search Preview. Khi xài model DeepSeek-R1, ODS đạt 88.3% chính xác trên SimpleQA và 75.3% trên FRAMES.
- SimpleQA kiểu như các câu hỏi đơn giản, trả lời đúng sai hoặc ngắn gọn. ODS đạt 88.3% tức là nó trả lời đúng gần 9/10 lần.
- FRAMES thì phức tạp hơn, có thể là bài test kiểu phân tích dữ liệu hay xử lý ngữ cảnh dài. 75.3% không phải max cao nhất, nhưng cộng thêm cái vụ cải thiện 9.7% so với GPT-4o thì rõ ràng ODS không phải dạng vừa.
CÁCH HOẠT ĐỘNG
1. Context retrieval toàn diện, không bỏ sót
ODS không phải kiểu nhận query rồi search bừa. Nó nghĩ sâu hơn bằng cách tự rephrase câu hỏi của user thành nhiều phiên bản khác nhau. Ví dụ, hỏi "cách tối ưu code Python", nó sẽ tự biến tấu thành "làm sao để Python chạy nhanh hơn" hay "mẹo optimize Python hiệu quả". Nhờ vậy, dù user diễn đạt hơi lủng củng, nó vẫn moi được thông tin chuẩn từ web.
2. Retrieval và filter level pro
Không như một số commercial tool chỉ bê nguyên dữ liệu từ SERP, ODS chơi hẳn combo: lấy top kết quả, reformat, rồi xử lý lại. Nó còn extract thêm metadata như title, URL, description để chọn lọc nguồn ngon nhất. Sau đó, nó chunk nhỏ nội dung, rank lại dựa trên độ liên quan trước khi trả về cho LLM.
Kết quả: Context sạch sẽ, chất lượng, không phải đống data lộn xộn.
3. Xử lý riêng cho nguồn xịn
Con này không search kiểu generic đâu. Nó có cách xử lý riêng cho các nguồn uy tín như Wikipedia, ArXiv, PubMed. Khi scrape web, nó tự chọn đoạn nội dung chất nhất, giảm rủi ro dính fake news – đây là công đoạn mà proprietary tool ít để tâm.
4. Cơ chế search thông minh, linh hoạt
ODS không cố định số lần search. Query đơn giản thì search một phát là xong, nhưng với câu hỏi phức tạp kiểu multi-hop như "AI ảnh hưởng ngành y thế nào trong 10 năm tới", nó tự động gọi thêm search để đào sâu. Cách này vừa tiết kiệm tài nguyên, vừa đảm bảo trả lời chất. Trong khi đó, proprietary tool thường search bục mặt, tốn công mà kết quả không đã.
5. Open-source – minh bạch và cải tiến liên tục
Là tool open-source, code với thuật toán của nó ai cũng thấy, cộng đồng dev tha hồ kiểm tra, nâng cấp. Nhờ vậy, nó tiến hóa nhanh hơn các hệ thống đóng của proprietary.
Tóm lại
ODS ăn đứt proprietary nhờ: rephrase query khéo, retrieval/filter xịn, xử lý riêng cho nguồn chất, search linh hoạt, và cộng đồng open-source đẩy nhanh cải tiến.
2 notes
·
View notes
Text
Ever wondered where a photo was taken? 📸🌍
With the rise of smartphones and digital cameras, most photos are embedded with geolocation data — a hidden treasure map right in the image file! This metadata, known as EXIF, can reveal exactly where a photo was snapped, down to the coordinates. It's like a secret travel log for every picture!
Want to try it for yourself? You can extract the GPS info from any image and see it on a map. Check out this tool I found: BasicUtils Pic2Map — it’s simple, quick, and free!
Give it a go and unlock the stories behind your photos! 🌍✨
2 notes
·
View notes
Text
Must-Have Programmatic SEO Tools for Superior Rankings

Understanding Programmatic SEO
What is programmatic SEO?
Programmatic SEO uses automated tools and scripts to scale SEO efforts. In contrast to traditional SEO, where huge manual efforts were taken, programmatic SEO extracts data and uses automation for content development, on-page SEO element optimization, and large-scale link building. This is especially effective on large websites with thousands of pages, like e-commerce platforms, travel sites, and news portals.
The Power of SEO Automation
The automation within SEO tends to consume less time, with large content levels needing optimization. Using programmatic tools, therefore, makes it easier to analyze vast volumes of data, identify opportunities, and even make changes within the least period of time available. This thus keeps you ahead in the competitive SEO game and helps drive more organic traffic to your site.
Top Programmatic SEO Tools

1. Screaming Frog SEO Spider
The Screaming Frog is a multipurpose tool that crawls websites to identify SEO issues. Amongst the things it does are everything, from broken links to duplication of content and missing metadata to other on-page SEO problems within your website. Screaming Frog shortens a procedure from thousands of hours of manual work to hours of automated work.
Example: It helped an e-commerce giant fix over 10,000 broken links and increase their organic traffic by as much as 20%.
2. Ahrefs
Ahrefs is an all-in-one SEO tool that helps you understand your website performance, backlinks, and keyword research. The site audit shows technical SEO issues, whereas its keyword research and content explorer tools help one locate new content opportunities.
Example: A travel blog that used Ahrefs for sniffing out high-potential keywords and updating its existing content for those keywords grew search visibility by 30%.
3. SEMrush
SEMrush is the next well-known, full-featured SEO tool with a lot of features related to keyword research, site audit, backlink analysis, and competitor analysis. Its position tracking and content optimization tools are very helpful in programmatic SEO.
Example: A news portal leveraged SEMrush to analyze competitor strategies, thus improving their content and hoisting themselves to the first page of rankings significantly.
4. Google Data Studio
Google Data Studio allows users to build interactive dashboards from a professional and visualized perspective regarding SEO data. It is possible to integrate data from different sources like Google Analytics, Google Search Console, and third-party tools while tracking SEO performance in real-time.
Example: Google Data Studio helped a retailer stay up-to-date on all of their SEO KPIs to drive data-driven decisions that led to a 25% organic traffic improvement.
5. Python
Python, in general, is a very powerful programming language with the ability to program almost all SEO work. You can write a script in Python to scrape data, analyze huge datasets, automate content optimization, and much more.
Example: A marketing agency used Python for thousands of product meta-description automations. This saved the manual time of resources and improved search rank.
The How for Programmatic SEO
Step 1: In-Depth Site Analysis
Before diving into programmatic SEO, one has to conduct a full site audit. Such technical SEO issues, together with on-page optimization gaps and opportunities to earn backlinks, can be found with tools like Screaming Frog, Ahrefs, and SEMrush.
Step 2: Identify High-Impact Opportunities
Use the data collected to figure out the biggest bang-for-buck opportunities. Look at those pages with the potential for quite a high volume of traffic, but which are underperforming regarding the keywords focused on and content gaps that can be filled with new or updated content.
Step 3: Content Automation
This is one of the most vital parts of programmatic SEO. Scripts and tools such as the ones programmed in Python for the generation of content come quite in handy for producing significant, plentiful, and high-quality content in a short amount of time. Ensure no duplication of content, relevance, and optimization for all your target keywords.
Example: An e-commerce website generated unique product descriptions for thousands of its products with a Python script, gaining 15% more organic traffic.
Step 4: Optimize on-page elements
Tools like Screaming Frog and Ahrefs can also be leveraged to find loopholes for optimizing the on-page SEO elements. This includes meta titles, meta descriptions, headings, or even adding alt text for images. Make these changes in as effective a manner as possible.
Step 5: Build High-Quality Backlinks
Link building is one of the most vital components of SEO. Tools to be used in this regard include Ahrefs and SEMrush, which help identify opportunities for backlinks and automate outreach campaigns. Begin to acquire high-quality links from authoritative websites.
Example: A SaaS company automated its link-building outreach using SEMrush, landed some wonderful backlinks from industry-leading blogs, and considerably improved its domain authority. ### Step 6: Monitor and Analyze Performance
Regularly track your SEO performance on Google Data Studio. Analyze your data concerning your programmatic efforts and make data-driven decisions on the refinement of your strategy.
See Programmatic SEO in Action
50% Win in Organic Traffic for an E-Commerce Site
Remarkably, an e-commerce electronics website was undergoing an exercise in setting up programmatic SEO for its product pages with Python scripting to enable unique meta descriptions while fixing technical issues with the help of Screaming Frog. Within just six months, the experience had already driven a 50% rise in organic traffic.
A Travel Blog Boosts Search Visibility by 40%
Ahrefs and SEMrush were used to recognize high-potential keywords and optimize the content on their travel blog. By automating updates in content and link-building activities, it was able to set itself up to achieve 40% increased search visibility and more organic visitors.
User Engagement Improvement on a News Portal
A news portal had the option to use Google Data Studio to make some real-time dashboards to monitor their performance in SEO. Backed by insights from real-time dashboards, this helped them optimize the content strategy, leading to increased user engagement and organic traffic.
Challenges and Solutions in Programmatic SEO
Ensuring Content Quality
Quality may take a hit in the automated process of creating content. Therefore, ensure that your automated scripts can produce unique, high-quality, and relevant content. Make sure to review and fine-tune the content generation process periodically.
Handling Huge Amounts of Data
Dealing with huge amounts of data can become overwhelming. Use data visualization tools such as Google Data Studio to create dashboards that are interactive, easy to make sense of, and result in effective decision-making.
Keeping Current With Algorithm Changes
Search engine algorithms are always in a state of flux. Keep current on all the recent updates and calibrate your programmatic SEO strategies accordingly. Get ahead of the learning curve by following industry blogs, attending webinars, and taking part in SEO forums.
Future of Programmatic SEO
The future of programmatic SEO seems promising, as developing sectors in artificial intelligence and machine learning are taking this space to new heights. Developing AI-driven tools would allow much more sophisticated automation of tasks, thus making things easier and faster for marketers to optimize sites as well.
There are already AI-driven content creation tools that can make the content to be written highly relevant and engaging at scale, multiplying the potential of programmatic SEO.
Conclusion
Programmatic SEO is the next step for any digital marketer willing to scale up efforts in the competitive online landscape. The right tools and techniques put you in a position to automate key SEO tasks, thus optimizing your website for more organic traffic. The same goals can be reached more effectively and efficiently if one applies programmatic SEO to an e-commerce site, a travel blog, or even a news portal.
#Programmatic SEO#Programmatic SEO tools#SEO Tools#SEO Automation Tools#AI-Powered SEO Tools#Programmatic Content Generation#SEO Tool Integrations#AI SEO Solutions#Scalable SEO Tools#Content Automation Tools#best programmatic seo tools#programmatic seo tool#what is programmatic seo#how to do programmatic seo#seo programmatic#programmatic seo wordpress#programmatic seo guide#programmatic seo examples#learn programmatic seo#how does programmatic seo work#practical programmatic seo#programmatic seo ai
4 notes
·
View notes
Text

Open-source Tools and Scripts for XMLTV Data
XMLTV is a popular format for storing TV listings. It is widely used by media centers, TV guide providers, and software applications to display program schedules. Open-source tools and scripts play a vital role in managing and manipulating XMLTV data, offering flexibility and customization options for users.
In this blog post, we will explore some of the prominent open-source tools and scripts available for working with xmltv examples.
What is XMLTV?
XMLTV is a set of software tools that helps to manage TV listings stored in the XML format. It provides a standard way to describe TV schedules, allowing for easy integration with various applications and services. XMLTV files contain information about program start times, end times, titles, descriptions, and other relevant metadata.
Open-source Tools and Scripts for XMLTV Data
1. EPG Best
EPG Best is an open-source project that provides a set of utilities to obtain, manipulate, and display TV listings. It includes tools for grabbing listings from various sources, customizing the data, and exporting it in different formats. Epg Best offers a flexible and extensible framework for managing XMLTV data.
2. TVHeadend
TVHeadend is an open-source TV streaming server and digital video recorder for Linux. It supports various TV tuner hardware and provides a web interface for managing TV listings. TVHeadend includes built-in support for importing and processing XMLTV data, making it a powerful tool for organizing and streaming TV content.
3. WebGrab+Plus
WebGrab+Plus is a popular open-source tool for grabbing electronic program guide (EPG) data from websites and converting it into XMLTV format. It supports a wide range of sources and provides extensive customization options for configuring channel mappings and data extraction rules. WebGrab+Plus is widely used in conjunction with media center software and IPTV platforms.
4. XMLTV-Perl
XMLTV-Perl is a collection of Perl modules and scripts for processing XMLTV data. It provides a rich set of APIs for parsing, manipulating, and generating XMLTV files. XMLTV-Perl is particularly useful for developers and system administrators who need to work with XMLTV data in their Perl applications or scripts.
5. XMLTV GUI
XMLTV GUI is an open-source graphical user interface for configuring and managing XMLTV grabbers. It simplifies the process of setting up grabber configurations, scheduling updates, and viewing the retrieved TV listings.
XMLTV GUI is a user-friendly tool for users who prefer a visual interface for interacting with XMLTV data.
Open-source tools and scripts for XMLTV data offer a wealth of options for managing and utilizing TV listings in XML format. Whether you are a media enthusiast, a system administrator, or a developer, these tools provide the flexibility and customization needed to work with TV schedules effectively.
By leveraging open-source solutions, users can integrate XMLTV data into their applications, media centers, and services with ease.
Stay tuned with us for more insights into open-source technologies and their applications!

Step-by-Step XMLTV Configuration for Extended Reality
Extended reality (XR) has become an increasingly popular technology, encompassing virtual reality (VR), augmented reality (AR), and mixed reality (MR).
One of the key components of creating immersive XR experiences is the use of XMLTV data for integrating live TV listings and scheduling information into XR applications. In this blog post, we will provide a step-by-step guide to configuring XMLTV for extended reality applications.
What is XMLTV?
XMLTV is a set of utilities and libraries for managing TV listings stored in the XML format. It provides a standardized format for TV scheduling information, including program start times, end times, titles, descriptions, and more. This data can be used to populate electronic program guides (EPGs) and other TV-related applications.
Why Use XMLTV for XR?
Integrating XMLTV data into XR applications allows developers to create immersive experiences that incorporate live TV scheduling information. Whether it's displaying real-time TV listings within a virtual environment or overlaying TV show schedules onto the real world in AR, XMLTV can enrich XR experiences by providing users with up-to-date programming information.
Step-by-Step XMLTV Configuration for XR
Step 1: Obtain XMLTV Data
The first step in configuring XMLTV for XR is to obtain the XMLTV data source. There are several sources for XMLTV data, including commercial providers and open-source projects. Choose a reliable source that provides the TV listings and scheduling information relevant to your target audience and region.
Step 2: Install XMLTV Utilities
Once you have obtained the XMLTV data, you will need to install the XMLTV utilities on your development environment. XMLTV provides a set of command-line tools for processing and manipulating TV listings in XML format. These tools will be essential for parsing the XMLTV data and preparing it for integration into your XR application.
Step 3: Parse XMLTV Data
Use the XMLTV utilities to parse the XMLTV data and extract the relevant scheduling information that you want to display in your XR application. This may involve filtering the data based on specific channels, dates, or genres to tailor the TV listings to the needs of your XR experience.
Step 4: Integrate XMLTV Data into XR Application
With the parsed XMLTV data in hand, you can now integrate it into your XR application. Depending on the XR platform you are developing for (e.g., VR headsets, AR glasses), you will need to leverage the platform's development tools and APIs to display the TV listings within the XR environment.
Step 5: Update XMLTV Data
Finally, it's crucial to regularly update the XMLTV data in your XR application to ensure that the TV listings remain current and accurate. Set up a process for fetching and refreshing the XMLTV data at regular intervals to reflect any changes in the TV schedule.
Incorporating XMLTV data into extended reality applications can significantly enhance the immersive and interactive nature of XR experiences. By following the step-by-step guide outlined in this blog post, developers can seamlessly configure XMLTV for XR and create compelling XR applications that seamlessly integrate live TV scheduling information.
Stay tuned for more XR development tips and tutorials!
Visit our xmltv information blog and discover how these advancements are shaping the IPTV landscape and what they mean for viewers and content creators alike. Get ready to understand the exciting innovations that are just around the corner.
youtube
4 notes
·
View notes
Text

Television lineups are a pivotal instrument in boosting TV shows and movie programs and skillfully leveraging them can drastically rocket the triumph of your content. In this explanation, I'll lead you on the art of exploiting TV lineups for your benefit, making sure your programs absorb the spotlight they're worthy of.
Impressively pivotal to contemplate is the employment of an XMLTV guide for IPTV. XMLTV guides are a splendid tool that offers extensive and current data about TV shows, encompassing the timetable, episode insights, and extra metadata. By integrating an XMLTV guide within your IPTV service, you can elevate the viewer's journey and ensure they have access to precise program details.
On the subject of acquiring an XMLTV guide for IPTV, options are manifold. You could either formulate your own XMLTV guide by amassing data from various sources or partake in a trustworthy xmltv iptv epg source that grants a prepared guide. The decision hinges on your available assets and needs. Nonetheless, it's imperative to validate that the XMLTV guide is trusted and routinely updated to provide viewers with genuine details.
Besides exploiting an XMLTV guide, it's critically important to play your powerful card of local television lineups to properly broadcast your programs. Local TV lineups are a priceless tool as they let you connect with a particular audience in a distinct geographical sphere. By targeting local lineups, you can surge the observability of your programs amongst potential viewers who have a higher predisposition to your content.
To extract the utmost from local TV lineups, you ought to certify that your show information is optimized for web search tools. This involves adding relevant keywords in your program titles, outlines, and metadata. In doing so, you bolster the likelihood of your programs appearing in search outcomes when viewers are hunting for specific content.
Moreover, offering an EPG Guide (Electronic Program Guide) with an xmltv subscription to users is imperative. This interactive interface tantalizes viewers with the ease of zipping through the TV schedule. Every program is accompanied by a wealth of data such as time slots, duration, genre, and an enticing precis. Facilitating an XMLTV EPG dramatically amplifies the viewing journey and makes your content discovery a breeze for the audience.

When scrutinizing an XMLTV EPG provider, key attributes like dependability, precision, and personalization should weigh heavily in your decision. Hunt for providers who commit to frequent updates and vouch for the authenticity of their EPG data. Also, providers who allow customization can be a boon, letting you align the EPG aesthetics with your brand’s essence.
Fundamentally, compliance with the XMLTV format for TV listings and EPG data is non-negotiable. This format has won hearts across various software applications and platforms due to its standardized structure that makes data handling a cinch for both developers and users.
Wrapping up, adept management of TV listings is instrumental in augmenting the popularity of your TV and movie programs. By tactfully harnessing an XMLTV guide for IPTV, capitalizing on local TV listings, extending an XMLTV EPG, and adhering to the XMLTV format, you can thrust your programs into the spotlight and reel in the ideal audience.
youtube
10 notes
·
View notes
Text
Facebook Policy Playbook

Preserving digital privacy and understanding the digital landscape of popular platforms like Facebook has become essential for responsible virtual citizens and tech-aware individuals. Today's discussion on Facebook's data collection practices was incredibly eye-opening. We watched an informative video that shed light on the various types of data that the platform gathers - explicit data we provide, metadata about our activity, information from third-party sources, and even off-Facebook online activity through tracking pixels and plugins on other websites.
The video provided some wise advice on limiting the platform's access to our personal data by regularly reviewing and tightening privacy settings, being cautious about sharing sensitive information publicly, and being wary of scams and phishing attempts aimed at extracting login credentials. Ultimately, the professor rightly emphasized that "privacy only comes to those who work for it" and that we must remain proactive about safeguarding our digital footprints.
I applied this learning in the creation of my social media policy, a learning evidence output that is a deliverable for this course. Mine so happens to be Facebook, and the content summarized the best practices for responsible platform use. Developing these guidelines forced me to think critically about online privacy, security, and ethical conduct.

Personally, crafting a balanced policy that protected user privacy while still enabling the core social functionality of Facebook was quite challenging. Eventually, I decided to aim to empower users with knowledge and tools to make well-informed choices that align with their personal privacy preferences. I advocated for clear, straightforward language and a fun visual layout to maximize accessibility and engagement.
Notably, I stressed the importance of the platform being transparent about its data collection practices - an issue highlighted in today's lesson that currently needs to be addressed. I also appropriately tackled on the definition of digital citizenship and respectful conduct without being overly restrictive.
Creating these guidelines hands-on brought the risks and nuances of the digital world into sharp focus and solidified my learnings from this session. I now have a deeper appreciation for thoughtfully upholding ethics as a virtual citizen and potential future tech developer. As the line between our digital and tangible realities continues blurring, thoughtfully navigating through these risks and nuances is essential for protecting our privacy and rights moving forward.
2 notes
·
View notes
Text
Amazon Product Review Data Scraping | Scrape Amazon Product Review Data

In the vast ocean of e-commerce, Amazon stands as an undisputed titan, housing millions of products and catering to the needs of countless consumers worldwide. Amidst this plethora of offerings, product reviews serve as guiding stars, illuminating the path for prospective buyers. Harnessing the insights embedded within these reviews can provide businesses with a competitive edge, offering invaluable market intelligence and consumer sentiment analysis.
In the realm of data acquisition, web scraping emerges as a potent tool, empowering businesses to extract structured data from the labyrinthine expanse of the internet. When it comes to Amazon product review data scraping, this technique becomes particularly indispensable, enabling businesses to glean actionable insights from the vast repository of customer feedback.
Understanding Amazon Product Review Data Scraping
Amazon product review data scraping involves the automated extraction of reviews, ratings, and associated metadata from Amazon product pages. This process typically entails utilizing web scraping tools or custom scripts to navigate through product listings, access review sections, and extract relevant information systematically.
The Components of Amazon Product Review Data:
Review Text: The core content of the review, containing valuable insights, opinions, and feedback from customers regarding their experience with the product.
Rating: The numerical or star-based rating provided by the reviewer, offering a quick glimpse into the overall satisfaction level associated with the product.
Reviewer Information: Details such as the reviewer's username, profile information, and sometimes demographic data, which can be leveraged for segmentation and profiling purposes.
Review Date: The timestamp indicating when the review was posted, aiding in trend analysis and temporal assessment of product performance.
The Benefits of Amazon Product Review Data Scraping
1. Market Research and Competitive Analysis:
By systematically scraping Amazon product reviews, businesses can gain profound insights into market trends, consumer preferences, and competitor performance. Analyzing the sentiment expressed in reviews can unveil strengths, weaknesses, opportunities, and threats within the market landscape, guiding strategic decision-making processes.
2. Product Enhancement and Innovation:
Customer feedback serves as a treasure trove of suggestions and improvement opportunities. By aggregating and analyzing product reviews at scale, businesses can identify recurring themes, pain points, and feature requests, thus informing product enhancement strategies and fostering innovation.
3. Reputation Management:
Proactively monitoring and addressing customer feedback on Amazon can be instrumental in maintaining a positive brand image. Through sentiment analysis and sentiment-based alerts derived from scraped reviews, businesses can swiftly identify and mitigate potential reputation risks, thereby safeguarding brand equity.
4. Pricing and Promotion Strategies:
Analyzing Amazon product reviews can provide valuable insights into perceived product value, price sensitivity, and the effectiveness of promotional campaigns. By correlating review sentiments with pricing fluctuations and promotional activities, businesses can refine their pricing strategies and promotional tactics for optimal market positioning.
Ethical Considerations and Best Practices
While Amazon product review data scraping offers immense potential, it's crucial to approach it ethically and responsibly. Adhering to Amazon's terms of service and respecting user privacy are paramount. Businesses should also exercise caution to ensure compliance with relevant data protection regulations, such as the GDPR.
Moreover, the use of scraped data should be guided by principles of transparency and accountability. Clearly communicating data collection practices and obtaining consent whenever necessary fosters trust and credibility.
Conclusion
Amazon product review data scraping unlocks a wealth of opportunities for businesses seeking to gain a competitive edge in the dynamic e-commerce landscape. By harnessing the power of automated data extraction and analysis, businesses can unearth actionable insights, drive informed decision-making, and cultivate stronger relationships with their customers. However, it's imperative to approach data scraping with integrity, prioritizing ethical considerations and compliance with regulatory frameworks. Embraced judiciously, Amazon product review data scraping can be a catalyst for innovation, growth, and sustainable business success in the digital age.
3 notes
·
View notes
Text
Not the french YouTubers going "oh but citation software is so difficult to understand uwu" when they say they struggle with putting all the sources in their script in response to a plagiarism criticism, and you recommend them tools. Worthless idiots. You use video editing software how is extracting a pdf metadata and linking it to word too hard. Next time I see a piece of shit saying "citing is hard" I'll just cite all the softwares I know of and can find in one search to get all the sources neatly organized together. I'm gonna bite.
5 notes
·
View notes
Photo
information is power !! (i HATE with a passion how the culture of seeing info on exploits as somehow endorsing their use or whatever). the idea that knowing about an exploit is equivalent to acting upon it to malicious ends ? that's literally thoughtcrime ! living in fear of the unknown and fearing knowledge itself is NOT healthy !
also i completely forgot about markers being translucent bc i tend to use boxes or the pen option, or a blur/distort filter.
the best way to prevent information being extracted from an image is to not have an image of it in the first place. the second best way to prevent information being extracted from an image is to have it fully covered by anything opaque.
also, for stuff taken on your camera, get one of those tools that deletes exif data (metadata that contains stuff like date/time, camera/phone model, and possibly even your location when taking the picture)
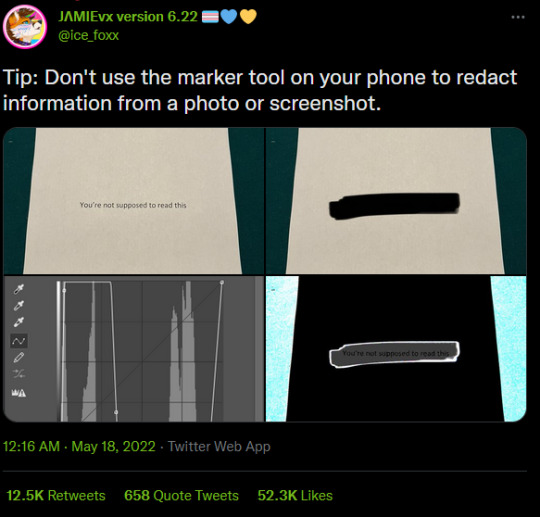
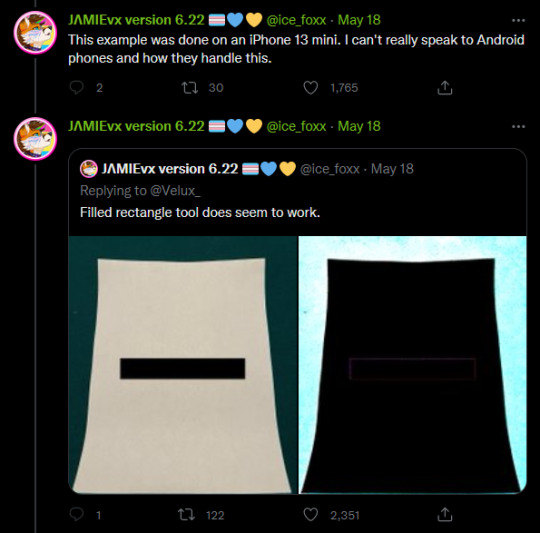
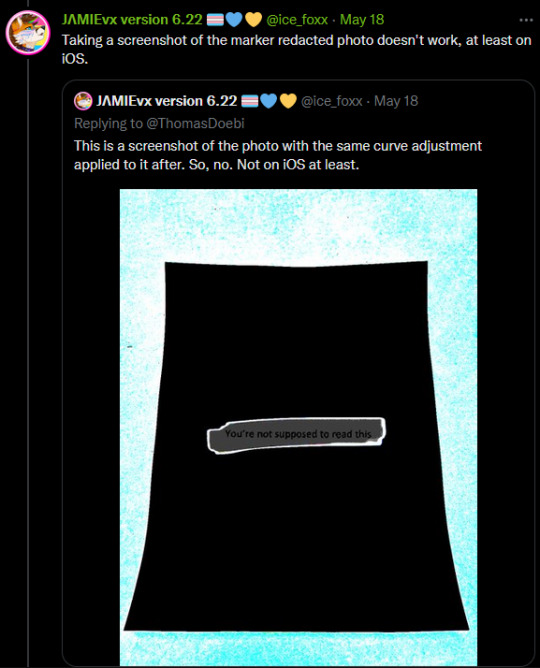


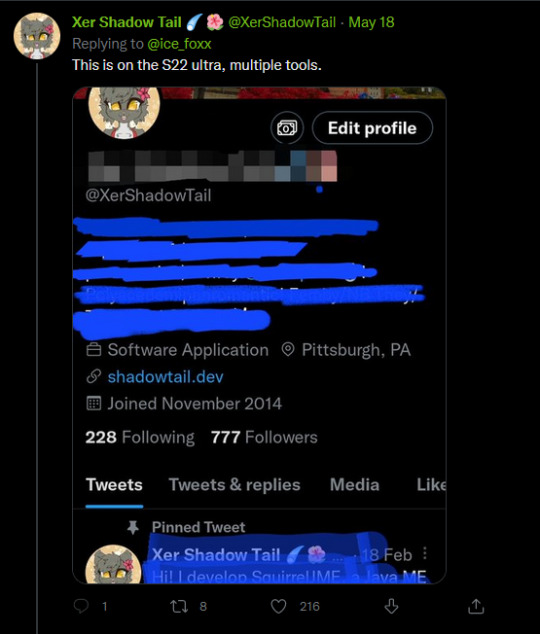
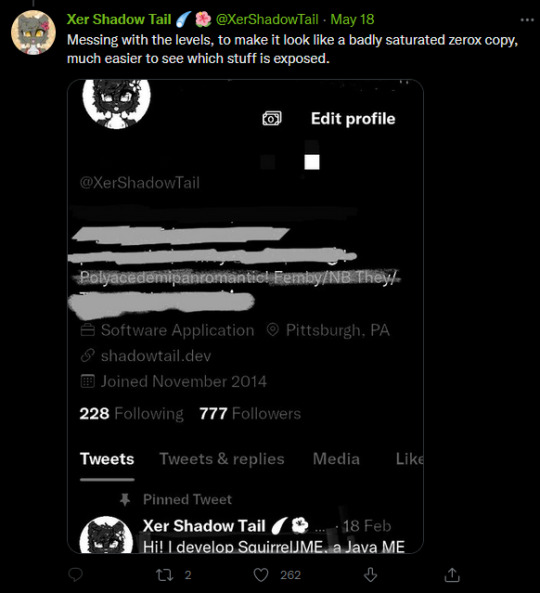
When censoring information out of pictures, do NOT use the marker tool. Block it out with a full filled in square, or use a mosiac filter. Marker tools are not fully opaque and are slightly off from black, which makes it possible to alter the levels and reveal the information underneath.
21K notes
·
View notes
Text
Leverage Real-time Beauty Product Scraping from Ulta Beauty
What Makes Real-time Beauty Product Scraping from Ulta Beauty Essential for Competitive Pricing?
Introduction
In the fast-paced digital retail world, having instant access to market data is essential for staying competitive. The beauty and cosmetics industry thrives on evolving trends, new product launches, and rapidly shifting consumer preferences. Real-time Beauty Product Scraping from Ulta Beauty offers a powerful solution for brands and retailers looking to tap into live updates on pricing, stock status, and promotional activities. Ulta Beauty, a leading U.S. beauty retailer, hosts a vast and dynamic range of products across skincare, makeup, haircare, and wellness. Businesses that Scrape Makeup and Skincare Product Listings from Ulta can gain a clear edge in assortment planning and trend analysis. Moreover, with Ulta Beauty Product Reviews Web Scraping, brands can monitor customer feedback in real-time, allowing for more responsive product development and marketing strategies. Harnessing this data-driven approach ensures faster decision-making and a more substantial presence in the competitive beauty marketplace.
Why Ulta Beauty is a Prime Target for Real-Time Scraping?
Ulta Beauty is not just a retail giant; it's an ecosystem of branded and private-label beauty products. With thousands of SKUs (Stock Keeping Units), honest customer reviews, curated collections, and loyalty-driven offers, the platform provides a panoramic view of what's trending in the beauty world. Businesses aiming to Extract Cosmetics Product Data from Ulta Beauty can access valuable insights from the platform's continuously updated product pages, which serve as a live feed for data on:
Product pricing and discounts
Customer reviews and ratings
Inventory and stock status
Product descriptions and ingredients
New arrivals and seasonal offers
When organizations Scrape Ulta Beauty Product Data in real-time, this wealth of information becomes a powerful asset for DTC (Direct-to-Consumer) brands, competitors, data aggregators, and market analysts. Furthermore, Ulta Beauty Product Price Scraping enables real-time tracking of price shifts, promotions, and discount strategies that drive consumer behavior and influence purchasing decisions.
Key Use Cases of Real-Time Ulta Beauty Data Scraping
Real-time Ulta Beauty data scraping offers valuable insights for various business strategies. From competitive price monitoring and trend forecasting to product assortment optimization and customer sentiment analysis, these key use cases help brands stay agile and ahead in the beauty market.
Competitive Price Monitoring In the beauty industry, minute-by-minute pricing updates are essential. Real-time scraping of Ulta’s listings enables:
Tracking flash sales and limited-time promotions
Detecting price drops on popular SKUs
Monitoring competitor pricing on similar products
This supports dynamic pricing algorithms and ensures competitiveness without manual oversight.
Trend Forecasting & Product Planning Ulta frequently features trending products and influencer picks. Real-time data scraping helps brands:
Identify trending ingredients like hyaluronic acid or niacinamide
Spot emerging categories such as hybrid makeup or sustainable skincare
Launch data-driven and timely marketing campaigns
Scraped metadata becomes a predictive tool for strategic planning.
Product Assortment & Catalog Optimization Analyzing Ulta’s catalog helps optimize inventory and merchandising strategies. Data reveals:
Real-time demand signals via stockout trends
Bundled product combinations for cross-selling
Top-reviewed items and seasonal promotions
This empowers smarter inventory decisions and product positioning.
Review Aggregation for Sentiment Analysis Ulta's customer reviews provide authentic feedback. Scraping reviews enables:
Sentiment detection (e.g., "too oily," "long-lasting")
Monitoring review frequency for new products
Rating aggregation for trend analysis and quality control
Real-Time Data Elements Extracted from Ulta Beauty
When scraping in real time, precision and consistency matter. The primary data points collected from Ulta Beauty include:
Product Name: Title and variant details (e.g., "Tarte Shape Tape Concealer – Light Beige")
Brand Name: Parent brand of the product
Price: Regular price, discounted price, and pricing history
Availability: In-stock or out-of-stock status
Discounts and Promotions: Percentage off, BOGO offers, gifts
Ratings: Average customer rating
Reviews Count: Number of written reviews
Review Texts: Raw review data for NLP analysis
Images: High-res product images
Ingredients and Claims: Product benefits, ingredients, and application instructions
Category Hierarchy: Category, subcategory, and tags (e.g., Skincare > Moisturizers > Night Creams)
Each of these elements offers invaluable insight for various business arms, from product teams to digital marketers.
Benefits of Real-Time Scraping Over Periodic Data Collection
While traditional scraping models focus on daily or weekly data extraction, real-time scraping offers several distinct advantages:
Instant Market Reaction: Timing is everything, whether it's a flash sale or a new product launch. Real-time scraping allows stakeholders to respond immediately to market movements.
Dynamic Dashboard Updates: For companies running BI tools and dashboards, real-time data scraping keeps visualizations and analytics continuously updated without lags, enhancing decision-making.
Live Competitor Tracking: With constant updates from Ulta, competitors can mirror promotional strategies or alter marketing messages based on real-time competitor movements.
Campaign ROI Monitoring: Are you running a campaign on Ulta Beauty? Real-time scraping of product views, reviews, and ratings helps you track campaign impact in near real-time.
Impact Across Business Units
Marketing Teams: Real-time scraped data feeds into targeted campaigns. If a particular product suddenly becomes popular or is featured in Ulta's "Best Sellers," marketers can create real-time ad content or influencer tie-ins.
Sales and Category Managers: Ulta's live pricing and inventory insights help managers determine which products are in high demand and which may be losing traction, enabling better stock management and vendor negotiations.
Product Development Teams: Formulators and designers can study which ingredients or product types are gaining traction, thanks to frequent mentions in reviews or new launches on Ulta.
E-commerce Platforms: Multi-brand beauty sellers or emerging DTC brands can benchmark their listings against Ulta's in real time, ensuring catalog parity and competitive positioning.
Applications in Third-Party Tools and AI Models
Real-time data scraping from Ulta Beauty doesn't just sit idle—it powers automation tools, AI-driven insights, and data pipelines. Examples include:
Dynamic Pricing Engines: Adjust prices automatically across platforms based on Ulta's live pricing.
Review Sentiment Analysis Models: Use NLP to extract positive/negative patterns and inform customer service or product improvements.
Recommendation Engines: Incorporate real-time trends from Ulta to offer smarter recommendations on your platform.
Product Match Engines: Identify equivalent SKUs for price comparison or bundle suggestions based on Ulta's latest inventory.
Role in Competitive Intelligence and Retail Benchmarking
Scraping Ulta Beauty in real time contributes immensely to competitive intelligence frameworks. Businesses gain clarity on the following:
Which brands Ulta is prioritizing with front-page placements
Emerging indie brands getting traction
New bundle or gifting strategies used by Ulta
This helps retailers and brand managers benchmark themselves against a beauty giant's best practices and avoid falling behind.
Unlock real-time beauty market insights—start your data scraping journey with us today!
Contact Us Today!
Future of Real-Time Beauty Product Scraping
Beauty brands can no longer rely on monthly data snapshots as consumer behavior shifts rapidly—often driven by TikTok trends, seasonal transitions, or viral moments. Real-time scraping is fast becoming a must-have, not a luxury. With advancements in AI, cloud computing, and data pipelines, real-time scraped data can be instantly cleaned, structured, and fed into real-time dashboards or alert systems. These evolving capabilities empower better decision-making and unlock future-ready applications such as integrations with augmented reality shopping tools, voice search optimization, and AI-generated campaign strategies—all fueled by rich, real-time Ulta Beauty data, including comprehensive Ecommerce Product Prices Dataset insights.
How Product Data Scrape Can Help You?
Real-Time Market Insights: We deliver up-to-the-minute data from leading platforms like Ulta Beauty, helping businesses stay ahead of trends, monitor competitor pricing, and respond instantly to market shifts.
Customized Data Solutions: Our services are tailored to your specific business needs—whether you're tracking skincare products, analyzing customer reviews, or monitoring stock levels across product categories.
High-Quality Structured Data: We ensure that all extracted data is clean, organized, and ready for integration into your analytics tools, dashboards, or machine learning models—saving you time and resources.
Scalable Infrastructure: Whether you need data from 100 products or 100,000, our robust infrastructure scales with your needs while maintaining speed and reliability.
Actionable Intelligence for Smarter Decisions: Our scraping services empower businesses with data that fuels product planning, pricing optimization, marketing campaigns, and customer sentiment analysis—turning raw data into business value.
Conclusion
Real-time beauty product scraping from Ulta Beauty redefines how businesses collect, analyze, and act on e-commerce data. It transforms raw product listings into actionable insights across pricing, marketing, product development, and competitor tracking. In a fast-moving industry like beauty, being a step ahead means having access to the freshest data at your fingertips—24/7. Companies that Extract Popular E-Commerce Website Data from platforms like Ulta can make faster, smarter decisions based on current trends and consumer behavior. The ability to tap into Ulta's data stream in real-time isn't just a technological advantage—it's a strategic imperative. Whether you aim to Extract E-commerce Data for competitive analysis or adapt your pricing in real-time, real-time scraping puts your brand on the frontline of innovation. With Web Scraping E-commerce Websites, beauty businesses—from indie startups to global giants—gain the intelligence they need to lead, adapt, and thrive in the ever-evolving cosmetics industry.
At Product Data Scrape, we strongly emphasize ethical practices across all our services, including Competitor Price Monitoring and Mobile App Data Scraping. Our commitment to transparency and integrity is at the heart of everything we do. With a global presence and a focus on personalized solutions, we aim to exceed client expectations and drive success in data analytics. Our dedication to ethical principles ensures that our operations are both responsible and effective.
#RealTimeBeautyProductScrapingFromUltaBeauty#ScrapeMakeupAndSkincareProductListingsFromUlta#ExtractCosmeticsProductDataFromUltaBeauty#ScrapeUltaBeautyProductData#UltaBeautyProductPriceScraping
0 notes
Text
Laserfiche Kuwait: Empowering Digital Transformation with Al-Hakimi United
In today's fast-paced digital landscape, organizations in Kuwait are increasingly seeking robust solutions to streamline operations, enhance efficiency, and ensure compliance. Laserfiche Kuwait, a leading enterprise content management (ECM) and business process automation platform, has emerged as a pivotal tool in this transformation journey. At the forefront of delivering these solutions in Kuwait is Al-Hakimi United, an authorized Laserfiche partner dedicated to facilitating seamless digital transitions for businesses across various sectors.
Understanding Laserfiche: A Comprehensive ECM Solution
Laserfiche offers a comprehensive suite of tools designed to manage documents, automate workflows, and provide actionable insights. Its capabilities extend beyond traditional document management, encompassing intelligent data capture, process automation, and robust analytics. By leveraging Laserfiche, organizations can centralize their information, reduce manual tasks, and make informed decisions based on real-time data.
Al-Hakimi United: Your Trusted Partner in Kuwait
Al-Hakimi United stands as a beacon of digital innovation in Kuwait, offering tailored Laserfiche solutions to meet the unique needs of local businesses. With a deep understanding of the regional market and a commitment to excellence, Al-Hakimi United provides end-to-end services, from consultation and implementation to ongoing support. Their expertise ensures that organizations can harness the full potential of Laserfiche to drive efficiency and growth.
Key Features and Benefits of Laserfiche
1. Intelligent Content Capture Laserfiche's advanced capture tools enable organizations to process high volumes of content, extract critical data, and automatically organize files. This intelligent system transforms unstructured data into valuable information, facilitating easier access and management.
2. Process Automation With low-code/no-code automation capabilities, Laserfiche allows teams to design and implement workflows that streamline operations. From approval processes to task management, automation reduces manual intervention, minimizes errors, and accelerates task completion.
3. Enhanced Collaboration Laserfiche fosters collaboration by providing a centralized platform where teams can access, edit, and share documents securely. Features like version control, annotations, and simultaneous editing ensure that everyone stays on the same page, enhancing productivity.
4. Robust Security and Compliance Security is paramount in today's digital age. Laserfiche offers fine-grained access controls, audit trails, and compliance tools to protect sensitive information. Organizations can confidently manage records, ensuring they meet regulatory requirements and maintain data integrity.
Laserfiche 12: The Latest Advancements
The release of Laserfiche 12 marks a significant milestone, introducing features that further enhance user experience and administrative capabilities. Notable enhancements include:
New Metadata Template Designer – Simplifies the creation and management of metadata templates, improving data organization.
Test Mode in Forms – Allows users to test forms before deployment, ensuring functionality and user-friendliness.
Updated Administration Console – Provides administrators with more control and visibility, streamlining system management.
These features, combined with improved usability and flexible deployment options, make Laserfiche 12 a powerful tool for organizations aiming to modernize their operations.
Industry Applications in Kuwait
Laserfiche's versatility makes it suitable for various industries in Kuwait:
Education – Institutions can digitize student records, automate admissions, and streamline administrative processes.
Healthcare – Hospitals and clinics can manage patient records securely, automate billing, and ensure compliance with health regulations.
Legal Services – Law firms can organize case files, automate client intake, and manage contracts efficiently.
Finance – Banks and financial institutions can handle documents related to loans, compliance, and customer onboarding with greater efficiency.
Cloud Solutions for Modern Businesses
Recognizing the need for scalable and accessible solutions, Laserfiche offers cloud-based options that cater to organizations of all sizes:
Starter Plan – Ideal for small teams, offering essential document management features.
Professional Plan – Includes advanced automation and integration tools, suitable for growing businesses.
Business Plan – Designed for larger organizations, providing extensive administrative and compliance features.
These cloud solutions ensure that businesses can access their documents anytime, anywhere, while benefiting from regular updates and robust security measures.
Why Choose Al-Hakimi United?
Partnering with Al-Hakimi United means more than just implementing a software solution; it's about embarking on a journey towards digital excellence. Their team of experts works closely with clients to understand their unique challenges and tailor solutions that align with their goals. With a proven track record and a commitment to customer satisfaction, Al-Hakimi United is the go-to partner for organizations in Kuwait seeking to leverage Laserfiche for digital transformation.
Getting Started
Embarking on your digital transformation journey is just a step away. Contact Al-Hakimi United today to learn more about how Laserfiche can revolutionize your organization's operations.
Phone: +965-66331629
Email: [email protected]
Website: www.alhakimiunited.com
With Al-Hakimi United and Laserfiche, your organization is poised to achieve greater efficiency, compliance, and growth in the digital era.
0 notes
Text
Telegram Data: A Deep Dive into Usage, Privacy, and Potential
Introduction
In the age of digital communication, data is king. From simple text messages to large multimedia files, our conversations generate vast amounts of data every day. One of the platforms at the center of this data revolution is Telegram, a cloud-based instant messaging app with over 800 million active users globally. Telegram is known not only for its secure messaging but also for the unique way it handles and stores data. This article explores the concept of Telegram data, its structure, uses, privacy implications, and potential for businesses, developers, and users alike.
What is Telegram Data?
Telegram data refers to all the information transmitted, stored, and processed through the Telegram messaging platform. This includes:
User data: Profile information like phone number, username, profile picture, bio, and last seen.
Message data: Texts, voice notes, videos, documents, and multimedia shared in individual or group chats.
Bot interactions: Data generated from automated bots, including user commands, bot replies, and API calls.
Channel and group metadata: Member counts, post histories, reactions, polls, and engagement statistics.
Cloud storage data: Files saved in Telegram's cloud, including saved messages and media.
This dataset is massive and can be useful for analytics, personalization, moderation, and even machine learning applications.
Why Telegram Data Matters
1. User Communication and Experience
Telegram's data-centric approach enables features like:
Seamless multi-device synchronization.
Unlimited cloud storage for messages and files.
Advanced search across messages and media.
Easy retrieval of old conversations and documents.
2. Privacy and Security
Telegram markets itself as a secure platform. It offers:
End-to-end encryption for Secret Chats.
Self-destructing messages.
Two-factor authentication.
Anonymous group management.
While not all Telegram data is end-to-end encrypted (only Secret Chats are), it uses its proprietary MTProto protocol to encrypt and securely store data on its servers. This dual approach offers both speed and privacy.
3. Data for Developers
Telegram offers APIs for accessing data:
Telegram Bot API allows developers to create bots that interact with users and respond to messages.
Telegram API and TDLib (Telegram Database Library) are more powerful tools used to build custom Telegram clients and extract deeper data insights (with user permission).
These APIs open a world of possibilities in automation, customer service, content delivery, and data analysis.
Types of Telegram Data
1. Chat and Messaging Data
This includes:
Messages (text, images, videos, stickers, etc.)
Voice and video calls metadata
Reactions, replies, and forwarded messages
Message timestamps, edits, and deletions
2. User Metadata
Even if content is encrypted, Telegram collects metadata such as:
IP addresses
Device types
App version
Contact lists (if synced)
Telegram stores this data to improve user experience, detect abuse, and comply with regional regulations when necessary.
3. Bot and API Data
Bots can log:
Commands issued
User interactions
Poll responses
API call logs
External service data linked to bots
This makes bots powerful tools for collecting and analyzing structured user inputs.
4. Group and Channel Data
Number of users
Posting activity
Comments and reactions
Engagement levels over time
Link clicks and post views (in public channels)
Admins can export this data for marketing, community building, and strategic planning.
How Telegram Stores and Manages Data
Telegram uses a cloud-based infrastructure to store data. It splits data into multiple data centers across the world and uses the MTProto protocol for encryption. Key features of their architecture include:
Client-server/server-client encryption for normal chats.
End-to-end encryption for Secret Chats (data is not stored on Telegram’s servers).
Data localization based on local laws.
Self-destructing content with timers for extra privacy.
Telegram's architecture ensures speed and reliability while maintaining a level of privacy suitable for most users.
Telegram Data and Privacy Concerns
Despite being privacy-focused, Telegram is not immune to scrutiny. Some key concerns include:
1. Not Fully Encrypted by Default
Only Secret Chats are fully end-to-end encrypted. Normal cloud chats are encrypted between the client and the server but stored on Telegram servers.
2. Metadata Collection
Telegram collects metadata like IP address, device information, and contact lists (if synced), which can theoretically be used to build user profiles.
3. Third-Party Bots and Data Leakage
Bots are not bound by Telegram’s privacy policy. A poorly designed or malicious bot can collect sensitive user data without consent.
4. Government Requests
Telegram claims it has never handed over user data to any government. However, its privacy policy leaves room for cooperation with legal investigations, especially in cases of terrorism or child abuse.
Applications of Telegram Data
1. Marketing and Analytics
Telegram channels and groups are increasingly used for brand promotion, telegram data content distribution, and user engagement. Admins use data to:
Track engagement rates
Measure reach and retention
Understand user behavior
Tailor content strategies
2. Customer Service Automation
Businesses use Telegram bots to automate:
Order tracking
FAQs
Feedback collection
Appointment bookings All these interactions generate valuable data that can improve customer experience.
3. Research and Sentiment Analysis
Academics and analysts extract Telegram data (via APIs or web scraping) to study:
Political discourse
Misinformation
Public sentiment on global events Especially in countries with internet censorship, Telegram becomes a vital source for open discussions.
4. Machine Learning and AI Training
Developers can train chatbots, recommender systems, and NLP models using anonymized Telegram data, particularly from public groups or channels.
5. Education and E-learning
Telegram’s structure supports sharing courses, lectures, and learning materials. Educators can analyze engagement data to improve course delivery.

Legal and Ethical Considerations
Using Telegram data raises several ethical and legal issues:
Data scraping without consent may violate Telegram’s terms of service.
GDPR compliance: In the EU, users have rights over their data (access, portability, deletion). Telegram has mechanisms for data download and account deletion.
Consent and transparency: Especially in research or analytics, informing users about data usage is critical.
Bias and misinformation: Public groups can become echo chambers or spread fake news. Responsible data use includes efforts to counterbalance these issues.
Telegram Data Export
Telegram offers a Data Export Tool in its desktop app:
Accessible via Settings > Advanced > Export Telegram Data
Exports chat history, media, account info, and even stickers
Data is provided in JSON and HTML formats
This tool enhances transparency and gives users control over their digital footprint.
Future of Telegram Data
As Telegram continues to grow, the scope and significance of its data will increase. Here are some trends to watch:
1. AI Integration
Telegram bots powered by AI will create new data types (e.g., chatbot conversations, smart assistant queries).
2. Decentralized Communication
Telegram may adopt decentralized storage or blockchain technologies to further secure user data.
3. Data Monetization
Though Telegram is ad-free in private chats, it may allow channel monetization or ad-based analytics, leveraging aggregate user data.
4. Stricter Privacy Regulations
With rising global focus on privacy (e.g., India’s Data Protection Bill, U.S. AI regulation talks), Telegram may need to adapt its data practices to avoid legal issues.
0 notes
Text
Version 619
youtube
windows
zip
exe
macOS
app
linux
tar.zst
I had a good week. There's a mix of several sorts of work, and duplicates auto-resolution gets more tools.
Your client is going to clean its tags on update. If you have a lot of tags (e.g. you sync with the PTR), it will take twenty minutes or more to complete.
full changelog
Linux build
The Linux build had a problem last week at the last minute. Github retired the old runner, and I missed the news. I have rolled out a test build that uses 22.04 instead of 20.04, and several users report that the build boots, does not seem to need a clean install, and may even fix some things.
If you use the Linux build, please update as normal this week. If the build does not boot, please try doing a clean install, as here: https://hydrusnetwork.github.io/hydrus/getting_started_installing.html#clean_installs
If today's release does not work at all, not even a fresh extract to your desktop, please let me know the details. If this happens to you, you might like to consider running from source, which solves many Linux OS-compatibility problems: https://hydrusnetwork.github.io/hydrus/running_from_source.html
I've now got a job to check for runner news in future, so this sudden break shouldn't happen again.
misc work
AVIF rendering broke last week, sorry! Should be fixed now, but let me know if it sometimes still fails for you.
I updated the tag-cleaning filter to remove many weird unicode characters like 'zero-width space' that slips in usually because of a bad decode or parse or copy-paste transliteration. On update, your client will scan all of its tags for 'invalid tags', renaming anything bad that it finds. If you sync with the PTR, this will take at least twenty minutes and will likely discover 30,000+ invalid tags--don't worry too much about it. If you want to see exactly what it found, it logs everything.
If you use sidecars for export, I moved the hardcoded 'sort results before sending them out' job to the string processor that's actually in each sidecar. Every sidecar will get this new processing step on update. They work as they did before, but if you do want the results sorted in a particular different way, you can now change it.
duplicates auto-resolution
I had success adding more tools to duplicates auto-resolution. You can now do "A has at least 2x the num_pixels as B" comparisons for some basic metadata types, and also say "A and B have/do not have the same filetype".
I have enabled all the UI and added two new suggested rules for clearing out some pixel-perfect duplicates. If you have been following along, please check these out and let me know what you think. I do not recommend going crazy here, but if you are semi-automatic, I guess you can try anything for fun.
Odd bug I've just noticed while playing around: sometimes, after editing existing rules, the list stops updating numbers for that edited rule. Closing and opening a new duplicates processing page fixes it. I'll fix it properly for next week.
Next step, so we can push beyond pixel-perfect duplicates, is to figure out a rich similarity-measuring tool that lets us automatically differentiate alternates from duplicates. I'm thinking about it!
next week
I might try this 'A is > 99.7% similar to B' tech for duplicates auto-resolution. I've got some IRL that might impact my work schedule in a couple weeks, so I'll otherwise just do some small jobs.
0 notes
Text
How to Automate Tableau to Power BI Migration for Faster Results
As businesses continue to evolve, so do their analytics needs. Many organizations are moving from Tableau to Power BI to leverage Microsoft’s broader ecosystem, tighter integration with Office 365, and cost efficiency. But migrating from one powerful BI platform to another isn’t a plug-and-play operation—it requires strategy, tools, and automation to ensure speed and accuracy.
At OfficeSolution, we specialize in streamlining your analytics journey. Here’s how you can automate your Tableau to Power BI migration and accelerate results without losing data integrity or performance.
Why Consider Migration to Power BI?
While Tableau offers rich data visualization capabilities, Power BI brings a robust suite of benefits, especially for organizations already embedded in Microsoft’s ecosystem. These include:
Seamless integration with Azure, Excel, and SharePoint
Scalable data models using DAX
Lower licensing costs
Embedded AI and natural language querying
Migrating doesn’t mean starting from scratch. With the right automation approach, your dashboards, data models, and business logic can be transitioned efficiently.
Step 1: Inventory and Assessment
Before automating anything, conduct a full inventory of your Tableau assets:
Dashboards and worksheets
Data sources and connectors
Calculated fields and filters
User roles and access permissions
This phase helps prioritize which dashboards to migrate first and which ones need redesigning due to functional differences between Tableau and Power BI.
Step 2: Use Automation Tools for Conversion
There are now tools and scripts that can partially automate the migration process. While full one-to-one conversion isn’t always possible due to the structural differences, automation can significantly cut manual effort:
Tableau to Power BI Converter Tools: Emerging tools can read Tableau workbook (TWB/TWBX) files and extract metadata, data sources, and layout designs.
Custom Python Scripts: Developers can use Tableau’s REST API and Power BI’s PowerShell modules or REST API to programmatically extract data and push it into Power BI.
ETL Automation Platforms: If your Tableau dashboards use SQL-based data sources, tools like Azure Data Factory or Talend can automate data migration and transformation to match Power BI requirements.
At OfficeSolution, we’ve developed proprietary scripts that map Tableau calculations to DAX and automate the bulk of the report structure transformation.
Step 3: Validate and Optimize
After automation, a manual review is crucial. Even the best tools require human oversight to:
Rebuild advanced visualizations
Validate data integrity and filters
Optimize performance using Power BI best practices
Align with governance and compliance standards
Our team uses a rigorous QA checklist to ensure everything in Power BI mirrors the original Tableau experience—or improves upon it.
Step 4: Train and Transition Users
The success of any migration depends on end-user adoption. Power BI offers a different interface and experience. Conduct hands-on training sessions, create Power BI templates for common use cases, and provide support as users transition.
Conclusion
Automating Tableau to Power BI migration isn’t just about saving time—it’s about ensuring accuracy, scalability, and business continuity. With the right combination of tools, scripting, and expertise, you can accelerate your analytics modernization with confidence.
At OfficeSolution, we help enterprises unlock the full value of Power BI through intelligent migration and ongoing support. Ready to upgrade your analytics stack? Let’s talk.
0 notes