#Online JSON Viewer
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
In 2020, 44% of users from Denmark used Tumblr daily.
Text

#free online tools#text utilities#SEO tools online#text converter#word counter tool#character counter#case converter#remove line breaks#text to csv#json viewer#keyword density checker#keyword match type#free developer tools#html to csv converter#csv to text#seo optimization tools#daily productivity tools#online calculator#free json formatter#super free tools#quick online converters#tools for bloggers#tools for students#tools for marketers#tools for developers
0 notes
Video

flickr
British Library digitised image from page 13 of "The White Cat: a story ... Illustrations by H. Ludlow" by British Library Via Flickr: Image taken from: Title: "The White Cat: a story ... Illustrations by H. Ludlow" Author(s): Warren, Ernest, author [person] ; Ludlow, Hal [person] British Library shelfmark: "Digital Store 12620.g.9" Page: 13 (scanned page number - not necessarily the actual page number in the publication) Place of publication: London (England) Date of publication: 1882 Publisher: 'Judy' Office Type of resource: Monograph Language(s): English Physical description: 118 pages (8°) Explore this item in the British Library’s catalogue: 003854908 (physical copy) and 014831718 (digitised copy) (numbers are British Library identifiers) Other links related to this image: - View this image as a scanned publication on the British Library’s online viewer (you can download the image, selected pages or the whole book) - Order a higher quality scanned version of this image from the British Library Other links related to this publication: - View all the illustrations found in this publication - View all the illustrations in publications from the same year (1882) - Download the Optical Character Recognised (OCR) derived text for this publication as JavaScript Object Notation (JSON) - Explore and experiment with the British Library’s digital collections The British Library community is able to flourish online thanks to freely available resources such as this. You can help support our mission to continue making our collection accessible to everyone, for research, inspiration and enjoyment, by donating on the British Library supporter webpage here. Thank you for supporting the British Library.
#bldigital#date:1882#pubplace:London#public_domain#sysnum:003854908#WARREN#Ernest Author of “Four Flirts.”#medium#vol:0#page:13#mechanical_curator#imagesfrombook:003854908#imagesfromvolume:003854908_0#sherlocknet:tag=young#sherlocknet:tag=office#sherlocknet:tag=street#sherlocknet:tag=beauty#sherlocknet:tag=life#sherlocknet:tag=chapter#sherlocknet:tag=girl#sherlocknet:tag=white#sherlocknet:tag=black#sherlocknet:tag=public#sherlocknet:tag=door#sherlocknet:tag=whole#sherlocknet:tag=land#sherlocknet:tag=upon#sherlocknet:tag=description#sherlocknet:tag=word#sherlocknet:category=organism
0 notes
Video

flickr
British Library digitised image from page 473 of "Eene halve Eeuw, 1848-1898. Nederland onder de regeering van Koning Willem den Derde en het Regentschap van Koningin Emma door Nederlanders beschreven onder redactie van Dr P. H. Ritter. 3e ... uitgave, et by British Library Via Flickr: Image taken from: Title: "Eene halve Eeuw, 1848-1898. Nederland onder de regeering van Koning Willem den Derde en het Regentschap van Koningin Emma door Nederlanders beschreven onder redactie van Dr P. H. Ritter. 3e ... uitgave, etc" Author(s): Ritter, Pierre Henri, the Elder [person] British Library shelfmark: "Digital Store 9406.i.5" Page: 473 (scanned page number - not necessarily the actual page number in the publication) Place of publication: Amsterdam Date of publication: 1898 Type of resource: Monograph Language(s): Dutch Physical description: 2 dl (8°) Explore this item in the British Library’s catalogue: 003111164 (physical copy) and 014919377 (digitised copy) (numbers are British Library identifiers) Other links related to this image: - View this image as a scanned publication on the British Library’s online viewer (you can download the image, selected pages or the whole book) - Order a higher quality scanned version of this image from the British Library Other links related to this publication: - View all the illustrations found in this publication - View all the illustrations in publications from the same year (1898) - Download the Optical Character Recognised (OCR) derived text for this publication as JavaScript Object Notation (JSON) - Explore and experiment with the British Library’s digital collections The British Library community is able to flourish online thanks to freely available resources such as this. You can help support our mission to continue making our collection accessible to everyone, for research, inspiration and enjoyment, by donating on the British Library supporter webpage here. Thank you for supporting the British Library.
#bldigital#date:1898#pubplace:Amsterdam#public_domain#sysnum:003111164#RITTER#Pierre Henri the Elder#medium#vol:0#page:473#books#quill#ink#scroll#skull#candlestick#book#candle#scrolls#sherlocknet:category=decorations#flickr
0 notes
Text
Why Every Developer Needs an Online JSON Viewer

During today's dynamic development environment, it is usual to handle and analyze JSON data. JSON is used everywhere, whether you're working with configuration files, websites, or APIs. For this reason, it is essential for every developer to have access to an online JSON viewer.
Without the need for extra software, you can easily prepare, visualize, and analyze your JSON data with an online JSON viewer. It is an essential asset for developers who are often on the go because it can be accessed from any device. With tools like grammar highlighting, tree view formatting, and validation, you can quickly identify mistakes and discrepancies in your JSON structure.
By decreasing complex JSON data and making it easier to read and manage, using an online JSON viewer also increases productivity. By doing this, you may save time and effort and focus on creating reliable applications.
Therefore, if you haven't already, begin using an online JSON viewer to make sure your JSON data is valid and well-structured while also simplifying your development process.
Visit Debugged Pro’s Free JSON Viewer today and see how it can improve your workflow!
1 note
·
View note
Video
youtube
How to Use JSON Viewer Online Tools for Free
0 notes
Text
Visualize Your JSON Data Like a Pro!
Tired of squinting at endless lines of code? Our JSON Viewer turns chaos into order by presenting your data in a neat, easy-to-read format. Dive into the world of structured data visualization and make your coding life simpler! Perfect for both newbies and seasoned pros.
0 notes
Text
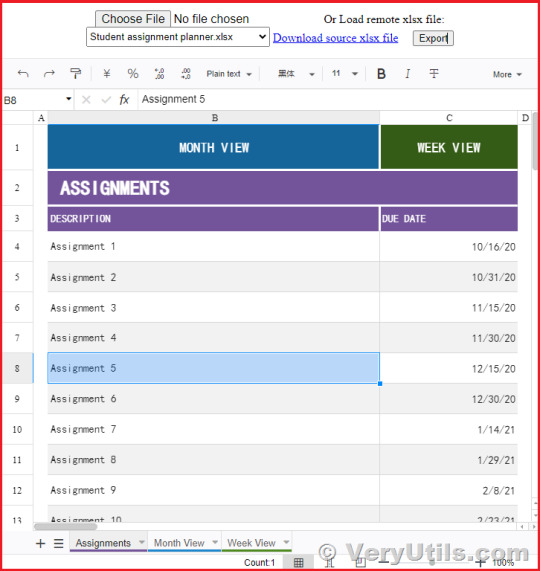
VeryUtils JavaScript Spreadsheet HTML5 Excel Viewer for Web Developers
VeryUtils JavaScript Spreadsheet HTML5 Excel Viewer for Web Developers.
In the dynamic world of web development, the need for versatile tools that can handle complex data manipulation and visualization is paramount. Enter VeryUtils JavaScript Spreadsheet HTML5 Excel Viewer—a powerful online Excel component designed to operate entirely within web applications. Written completely in JavaScript, this component replicates the full functionality of Microsoft Excel, enabling web developers to read, modify, and save Excel files seamlessly across various platforms, including Windows, Mac, Linux, iOS, and Android.
✅ What is VeryUtils JavaScript Spreadsheet HTML5 Excel Viewer?
VeryUtils JavaScript Spreadsheet HTML5 Excel Viewer is a comprehensive and flexible Excel viewer designed specifically for web developers. It allows users to perform data analysis, visualization, and management directly within a web application. The interface is highly intuitive, making it easy for users to interact with data as they would in Microsoft Excel, but without the need for standalone software installations. Whether you're handling complex spreadsheets or simple data entries, this JavaScript-based control offers all the functionality you need.
✅ Key Features of VeryUtils JavaScript Spreadsheet HTML5 Excel Viewer
Seamless Data Analysis and Visualization VeryUtils JavaScript Spreadsheet provides a full range of Excel-like features, including data binding, selection, editing, formatting, and resizing. It also supports sorting, filtering, and exporting Excel documents, making it a versatile tool for any web-based project.
Compatibility with Microsoft Excel File Formats This control is fully compatible with Microsoft Excel file formats (.xlsx, .xls, and .csv). You can load and save documents in these formats, ensuring data accuracy and retaining styles and formats.
Highly Intuitive User Interface The user interface of VeryUtils JavaScript Spreadsheet is designed to closely mimic Microsoft Excel, ensuring a familiar experience for users. This minimizes the learning curve and allows for immediate productivity.
✅ Why Choose VeryUtils JavaScript Spreadsheet HTML5 Excel Viewer?
High Performance VeryUtils JavaScript Spreadsheet is optimized for performance, capable of loading and displaying large datasets efficiently. It supports row and column virtualization, enabling smooth scrolling and fast access to data.
Seamless Data Binding The component allows seamless binding with various local and remote data sources such as JSON, OData, WCF, and RESTful web services. This flexibility makes it easier to integrate into different web applications.
Hassle-Free Formatting Formatting cells and numbers is made simple with VeryUtils JavaScript Spreadsheet. It supports conditional formatting, which allows cells to be highlighted based on specific criteria, enhancing data readability and analysis.
Transform Data into Charts With the built-in chart feature, you can transform spreadsheet data into visually appealing charts, making data interpretation more intuitive and insightful.
Wide Range of Built-In Formulas The JavaScript Spreadsheet comes with an extensive library of formulas, complete with cross-sheet reference support. This feature, combined with a built-in calculation engine, allows for complex data manipulations within your web application.
Customizable Themes VeryUtils JavaScript Spreadsheet offers attractive, customizable themes like Fluent, Tailwind CSS, Material, and Fabric. The online Theme Studio tool allows you to easily customize these themes to match your application's design.
Globalization and Localization The component supports globalization and localization, enabling users from different locales to use the spreadsheet by formatting dates, currency, and numbers according to their preferences.
✅ Additional Excel-Like Features
Excel Worksheet Management You can create, delete, rename, and customize worksheets within the JavaScript Spreadsheet. This includes adjusting headers, gridlines, and sheet visibility, providing full control over the data layout.
Excel Editing The component supports direct editing of cells, allowing users to add, modify, and remove data or formulas, just as they would in Excel.
Number and Cell Formatting With options for number formatting (currency, percentages, dates) and cell formatting (font size, color, alignment), users can easily highlight important data and ensure consistency across their documents.
Sort and Filter VeryUtils JavaScript Spreadsheet allows users to sort and filter data efficiently, supporting both simple and custom sorting options. This makes it easier to organize and analyze data according to specific criteria.
Interactive Features • Clipboard Operations: Supports cut, copy, and paste actions within the spreadsheet, maintaining formatting and formulas. • Undo and Redo: Users can easily undo or redo changes, with customizable limits. • Context Menu: A right-click context menu provides quick access to common operations, improving user interaction. • Cell Comments: Add, edit, and delete comments in cells, enhancing collaboration and data clarity. • Row and Column Resizing: The resize and autofit options allow for flexible adjustments to row heights and column widths.
Smooth Scrolling Even with a large number of cells, the JavaScript Spreadsheet offers a smooth scrolling experience, ensuring that users can navigate large datasets effortlessly.
Open and Save Excel Documents The JavaScript Spreadsheet supports Excel and CSV import and export, allowing users to open existing files or save their work with all the original styles and formats intact.
Supported Browsers VeryUtils JavaScript Spreadsheet is compatible with all modern web browsers, including Chrome, Firefox, Edge, Safari, and IE11 (with polyfills).
✅ Demo URLs:
Open a black Excel Spreadsheet online, https://veryutils.com/demo/online-excel/
Open a CSV document online, https://veryutils.com/demo/online-excel/?file=https://veryutils.com/demo/online-excel/samples/test.csv
Open an Excel XLS document online, https://veryutils.com/demo/online-excel/?file=https://veryutils.com/demo/online-excel/samples/test.xls
Open an Excel XLSX document online, https://veryutils.com/demo/online-excel/?file=https://veryutils.com/demo/online-excel/samples/test.xlsx
✅ Conclusion
VeryUtils JavaScript Spreadsheet HTML5 Excel Viewer is a must-have tool for web developers who need to integrate Excel functionality into their web applications. Its powerful features, high performance, and cross-platform compatibility make it an ideal choice for any project that requires robust spreadsheet capabilities. With its seamless data binding, rich formatting options, and interactive features, this component is designed to meet the needs of modern web development, ensuring that your applications are both powerful and user-friendly.
If you're looking to elevate your web application with advanced spreadsheet capabilities, consider integrating VeryUtils JavaScript Spreadsheet HTML5 Excel Viewer today. It's the ultimate solution for developers who demand high performance, flexibility, and an intuitive user experience.
0 notes
Text
Building Trust in the Cloud: Auditing and Reporting for Safe DICOM Viewing
DICOM images contain highly sensitive patient health information. As medical practices shift towards convenient cloud-based DICOM viewers, establishing trust around data transparency and privacy grows increasingly important.
With flexible online DICOM viewer gaining popularity, providers require assurances that sensitive imaging data stays protected when accessed remotely.
Comprehensive activity logging and routine reports enable administrators to monitor DICOM traffic while identifying abnormal usage patterns.
By upholding stringent auditing protocols and real-time visibility, medical teams can securely unlock the convenience of cloud-based workflows without compromising safety.
Why Audit Logs and Usage Reports Matter?
Track Access - Logs record viewer sessions, detailing who accessed images and when. This supports HIPAA compliance while discouraging internal data misuse.
Highlight Anomalies - Reports analyzing spikes in traffic or odd access times facilitate early anomaly detection, alerting administrators to suspicious activity.
Maintain Patient Privacy - Detailed audit trails demonstrating properly managed data help providers guarantee patient confidentiality is never broken, even off-site.
Meet Compliance Standards - Routine reports allow providers to easily produce documentation showing adherence to healthcare regulatory policies around patient privacy and information security.
Key Features That Reinforce Trust
Comprehensive Audit Logs
Logged User IDs - All viewer logins are registered to enable user-level tracking.
Timestamps - The data and time of each viewer action gets recorded for precise tracking.

IP Addresses - Systems log source IP addresses alongside session details for location-level visibility.
Granular Tracking - Individual study access, image manipulations, and more get logged to precisely track engagement.
Customizable Usage Reporting
User Breakdowns - Admins can pull reports summarizing activity across individuals, departments, sites, and more for a tailored view of usage.
Trend Analysis - Reports can highlight spikes or dips in traffic week-over-week to pinpoint abnormal patterns early.
Data Exports - Activity records can export to formats like CSV and JSON to enable further processing and oversight.
Scheduled Reports - Administrators can designate routine report deliveries to maintain continual awareness of viewer appropriation.
By centralizing DICOM access logs and distilling those raw records into digestible intelligence, medical teams can monitor cloud viewer adoption safely.
Detailed auditing paired with concise visibility reinforces provider accountability and patient confidentiality in the cloud.
Administrators gain greater awareness over how, when, and by whom data gets utilized while access permissions and protocols discourage internal misuse.
Meanwhile, patients can trust highly sensitive medical images stay protected despite remote viewing flexibility.
Real-Time Alerts Prevent Issues
In addition to retrospective tracking, real-time monitoring capabilities allow systems to automatically flag suspicious activity for intervention. Usage alerts can trigger on:
Unrecognized login attempts
Simultaneous sessions from different locations
Off-hour image access
Excessively high traffic
And more...
By setting custom rules around permissible viewer appropriation, administrators can receive system notifications the moment a potential breach occurs. This prevents unauthorized exposure instead of simply tracking it after the fact.
Maintaining Patient Trust
Medical images provide invaluable diagnostic insight for improved care, but also expose patients' most sensitive health details.
As providers adopt cloud-based DICOM workflows for enhanced convenience and collaboration, maintaining rigorous transparency protocols helps sustain patient trust that privacy stays protected.
By upholding strong accountability with comprehensive auditing and intelligent visibility into usage patterns, care teams can unlock flexible new workflows without introducing added risk.
Detailed activity tracking deters internal misuse while routine reports help consistently meet external compliance demands.
In the end, patients can rely on providers to safely manage sensitive data regardless of how modern systems evolve.
0 notes
Text
La imagen y sus propiedades

El poder de las imágenes en la comunicación visual
En un mundo cada vez más visual, las imágenes se han convertido en un elemento fundamental de la comunicación. Su capacidad para transmitir ideas, emociones y mensajes de manera instantánea las ha convertido en una herramienta indispensable en diversos ámbitos, desde el arte y el diseño hasta la ciencia y la tecnología. En esta entrada de blog, nos embarcaremos en un viaje para comprender el fascinante mundo de las imágenes digitales. Exploraremos sus propiedades, características y aplicaciones, descubriendo cómo estas poderosas herramientas pueden ser utilizadas para crear, comunicar e impactar. Para iniciar, vamos a mencionar algunas herramientas online gratuitas que te permiten analizar en detalle las propiedades de una imagen seleccionada. A continuación, te presento algunas de las opciones más populares: 1. Exif Viewer: - URL: https://exif.tools/ - Características: - Permite visualizar información EXIF detallada, incluyendo datos sobre la cámara, la configuración de la toma, la fecha y hora, la ubicación GPS y mucho más. - Soporta una amplia variedad de formatos de imagen. - Ofrece una interfaz sencilla y fácil de usar. 2. Jeffrey's Exif Viewer: - URL: http://regex.info/blog/other-writings/online-exif-image-data-viewer - Características: - Similar a Exif Viewer, permite visualizar información EXIF detallada de imágenes. - Permite cargar imágenes desde tu ordenador o desde una URL. - Ofrece opciones para exportar los datos EXIF en formato CSV o TXT. 3. Metadato.org: - URL: https://en.wiktionary.org/wiki/metadatum - Características: - Se especializa en la extracción de metadatos de imágenes, incluyendo EXIF, IPTC y XMP. - Permite visualizar metadatos en formato de tabla o en formato JSON. - Ofrece la opción de descargar los metadatos en un archivo CSV. 4. Image Analyzer: - URL: https://developer.apple.com/documentation/visionkit/imageanalyzer - Características: - Ofrece un análisis completo de las propiedades de una imagen, incluyendo: - Tamaño y dimensiones - Tipo de imagen (JPEG, PNG, etc.) - Profundidad de color - Resolución - Histograma - Paleta de colores - Detección de rostros - Permite descargar un informe detallado en formato PDF. 5. TinEye: - URL: https://blog.tineye.com/category/image-search/ - Características: - Se especializa en la búsqueda inversa de imágenes. - Permite subir una imagen o ingresar una URL para encontrar otras copias de la misma imagen en la web. - Muestra información sobre la imagen, como el tamaño, la resolución y el formato. Recuerda que la mejor herramienta para ti dependerá de tus necesidades específicas. Te recomiendo que explores algunas de las opciones que te he presentado para encontrar la que mejor se adapte a ti. En el mundo de la captura y representación visual, las imágenes digitales y las películas son dos formatos ampliamente utilizados, cada uno con sus propias características y aplicaciones. Si bien a simple vista pueden parecer similares, existen diferencias fundamentales que las distinguen y determinan su uso en diversos contextos. 1. Definición y naturaleza: - Imágenes digitales: Son representaciones bidimensionales de una escena o un objeto, compuestas por una matriz de píxeles individuales, cada uno con un valor de color asignado. Se generan mediante sensores digitales que capturan la luz y la convierten en información digital. - Películas: Son secuencias de imágenes fijas proyectadas a una velocidad constante (generalmente 24 cuadros por segundo) para crear la ilusión de movimiento. Estas imágenes se capturan en una película fotosensible o mediante sensores digitales de alta resolución. 2. Captura y almacenamiento: - Imágenes digitales: Se capturan con cámaras digitales, dispositivos que convierten la luz en señales eléctricas que se procesan y almacenan como archivos digitales en formatos como JPEG, PNG, etc. - Películas: Se capturan con cámaras de cine, dispositivos que exponen una película fotosensible a la luz, creando una imagen latente que luego se revela y procesa para obtener la película final. En la actualidad, también se pueden capturar películas digitales con cámaras de alta resolución. 3. Edición y manipulación: - Imágenes digitales: Se editan y manipulan utilizando software de edición de imágenes, como Adobe Photoshop o GIMP. Estos programas permiten modificar propiedades como el color, el brillo, el contraste, la nitidez, entre otras, y realizar ajustes creativos como agregar filtros, texturas o elementos gráficos. - Películas: Se editan y manipulan utilizando software de edición de video, como Adobe Premiere Pro o Final Cut Pro. Estos programas permiten realizar cortes, transiciones, agregar efectos especiales, música y otros elementos audiovisuales para crear una narrativa completa. 4. Tamaño y formato: - Imágenes digitales: Generalmente tienen un tamaño menor que las películas, debido a la compresión de datos que se aplica durante el almacenamiento. El tamaño final depende de la resolución y el formato de archivo utilizado. - Películas: Pueden tener un tamaño considerable, especialmente en formatos de alta definición como 4K o 8K. Esto se debe a la gran cantidad de información que se captura en cada cuadro. 5. Calidad de imagen y sonido: - Imágenes digitales: La calidad de imagen depende de la resolución del sensor de la cámara, la profundidad de color y la compresión utilizada. Las imágenes de alta resolución y profundidad de color ofrecen una mayor calidad visual, pero también ocupan más espacio de almacenamiento. - Películas: La calidad de imagen depende de la resolución de la cámara, el tipo de película utilizada y el proceso de revelado y digitalización. Las películas de alta resolución y formato cinematográfico pueden ofrecer una calidad de imagen superior a las imágenes digitales, especialmente en términos de rango dinámico y detalle. En cuanto al sonido, las películas pueden ofrecer sonido envolvente multicanal para una experiencia auditiva más inmersiva. 6. Aplicaciones y usos: - Imágenes digitales: Se utilizan en una amplia gama de aplicaciones, incluyendo fotografía, diseño gráfico, ilustración, web, marketing, presentaciones, entre otras. Su facilidad de captura, edición y distribución las convierte en una herramienta versátil para la comunicación visual. - Películas: Se utilizan principalmente para cine, televisión, streaming y entretenimiento audiovisual. Su capacidad para crear narrativas complejas, generar emociones y ofrecer una experiencia inmersiva las convierte en un medio ideal para contar historias y transmitir mensajes. 7. Ventajas y desventajas: Imágenes digitales: - Ventajas: Fáciles de capturar, almacenar, editar y compartir. Versátiles en cuanto a aplicaciones. Relativamente económicas. - Desventajas: Pueden perder calidad al comprimirse o editarse. Limitadas en cuanto al rango dinámico y detalle. Películas: - Ventajas: Alta calidad de imagen y sonido. Experiencia inmersiva. Capacidad para crear narrativas complejas. - Desventajas: Pueden ser costosas de producir y distribuir. Requerimiento de equipos especializados para la captura y edición. En el mundo de las imágenes digitales, dos formatos predominan: las imágenes vectoriales y las imágenes ráster. Cada una posee características y aplicaciones únicas que las hacen ideales para diferentes propósitos. A continuación, se presenta una comparación detallada para comprender las diferencias clave entre ambos tipos de imágenes: 1. Definición y estructura: - Imágenes vectoriales: Se componen de líneas, formas y curvas definidas por ecuaciones matemáticas. No dependen de píxeles para su representación, sino que utilizan algoritmos para generar la imagen en función de las fórmulas matemáticas. - Imágenes ráster: Están formadas por una matriz de píxeles diminutos, cada uno con un color asignado. La imagen completa se compone de estos píxeles individuales, como si fuera un mosaico. 2. Escalabilidad: - Imágenes vectoriales: Una de las principales ventajas de las imágenes vectoriales es su escalabilidad sin pérdida de calidad. Pueden ampliarse o reducirse a cualquier tamaño sin que la imagen se pixele o pierda nitidez. Esto se debe a que las fórmulas matemáticas se ajustan automáticamente al nuevo tamaño. - Imágenes ráster: Las imágenes ráster, por el contrario, no son escalables sin pérdida de calidad. Al ampliarlas, los píxeles se vuelven visibles y la imagen se pixela. Esto sucede porque la información de cada píxel es fija y no se puede adaptar a un tamaño mayor. 3. Edición: - Imágenes vectoriales: La edición de imágenes vectoriales es relativamente sencilla y precisa. Se pueden modificar líneas, formas, colores y rellenos utilizando herramientas de dibujo y edición vectorial. Los cambios se aplican a las fórmulas matemáticas, manteniendo la nitidez y calidad de la imagen. - Imágenes ráster: La edición de imágenes ráster es más compleja y requiere herramientas de edición de imágenes como Photoshop o GIMP. Los cambios se realizan sobre los píxeles individuales, lo que puede afectar la nitidez de la imagen, especialmente al realizar modificaciones significativas. 4. Tamaño de archivo: - Imágenes vectoriales: Las imágenes vectoriales suelen tener un tamaño de archivo más pequeño que las imágenes ráster, especialmente cuando se trata de imágenes con muchos detalles o colores sólidos. Esto se debe a que las fórmulas matemáticas ocupan menos espacio de almacenamiento que la información de cada píxel. - Imágenes ráster: Las imágenes ráster, por lo general, tienen un tamaño de archivo más grande, especialmente cuando se trata de imágenes con alta resolución o muchos detalles finos. Esto se debe a que la información de cada píxel requiere más espacio de almacenamiento. 5. Aplicaciones: - Imágenes vectoriales: Son ideales para logotipos, iconos, ilustraciones, gráficos que se van a imprimir a gran escala, diseños web y cualquier imagen que requiera escalabilidad sin pérdida de calidad. - Imágenes ráster: Son perfectas para fotografías, imágenes con detalles complejos, degradados y efectos de iluminación realistas. También se utilizan en áreas como la edición fotográfica, la pintura digital y la creación de texturas. Read the full article
0 notes
Text
How to Extract Insights from OTT Media Platforms: A Guide to Data Scraping?

How to Extract Insights from OTT Media Platforms: A Guide to Data Scraping?
Aug 01, 2023
OTT (Over-The-Top) media platform data scraping refers to extracting relevant data from OTT media platforms. OTT platforms are streaming services that deliver media content directly to users online, bypassing old-style broadcast channels. Some examples of leading OTT media platforms include Netflix, Amazon Prime Video, Hulu, and Disney+.
Data scraping from OTT media platforms involves accessing and extracting various data types, such as user engagement metrics, viewer demographics, content catalogs, ratings and reviews, streaming performance, and more. This data can provide valuable insights for content providers, advertisers, and market researchers to understand audience preferences, track content performance, optimize marketing strategies, and make informed business decisions.
OTT media platform data scraping enables businesses to gather real-time and historical data from multiple platforms. It allows them to analyze trends, identify popular content, target specific audience segments, and enhance content strategies. By leveraging the scraped data, businesses can gain an edge in the highly competitive and rapidly evolving OTT media industry.
How Does OTT Media Platform Data Scraping Work?

OTT Media Platform Data Scraping involves systematically extracting relevant data from OTT media platforms. Here's a simplified overview of how it works:
Identification of Target Platforms: Determine the specific OTT media platforms you want to scrape data from. This could include platforms like Netflix, Hulu, Amazon Prime Video, or any other platform that hosts the content you're interested in.
Data Collection Strategy: Define the scope and parameters of the data you want to scrape. This may include user engagement metrics, content catalogs, ratings and reviews, viewer demographics, streaming performance, and other relevant data points.
Data Scraping Techniques: Employ data scraping techniques to extract the desired data from the OTT platforms. This involves automated software or scripts that navigate the platform's pages, simulate user interactions, and extract data elements based on predefined rules and patterns.
Data Extraction: Use scraping tools to extract the identified data points from the pages. This may involve capturing HTML elements, parsing JSON or XML data, or employing browser automation techniques to interact with the platform's interfaces and retrieve the desired information.
Data Processing and Analysis: Once the data is extracted, it may go through a preprocessing stage to clean and normalize the data for further analysis. This can include removing duplicates, handling missing values, and transforming the data into a structured format suitable for analysis.
Data Storage and Management: Store the scraped data securely and organized, ensuring proper data management practices. This may involve structuring the data into a database, data warehouse, or other storage systems for easy access and retrieval.
Analysis and Insights: Analyze the scraped data to gain actionable insights. This can include performing statistical analysis, visualizing trends, identifying patterns, and deriving meaningful conclusions to inform content strategies, marketing campaigns, or audience targeting.
It's important to note that OTT Media Platform Data Scraping should be conducted ethically and in compliance with the terms of service and legal regulations governing the platforms. Respect user privacy and adhere to data protection guidelines while scraping and handling the extracted data.
What Types Of Data Can Be Scraped From OTT Media Platforms?

Several data types can be scraped from OTT (Over-The-Top) media platforms. The specific data available for scraping may vary depending on the platform and its terms of service. Here are some common types of data that can be scraped from OTT media platforms:
Content Catalog: Information about the available movies, TV shows, documentaries, and other forms of media content, including titles, descriptions, genres, release dates, and duration.
User Engagement Metrics: Data related to user interactions with the platform, such as the number of views, likes, ratings, reviews, comments, and shares for specific content.
Viewer Demographics: Data on the demographic characteristics of platform users, including age, gender, location, and language preferences. This information can help understand the target audience and tailor content strategies accordingly.
Streaming Performance: Metrics related to streaming quality, buffering time, playback errors, and other performance indicators that assess the user experience on the platform.
Recommendations and Personalization: The platform provides data about user preferences, watch history, and personalized recommendations based on user behavior and content consumption patterns.
Ratings and Reviews: User-generated ratings, reviews, and comments on individual movies, TV shows, or episodes. This data can provide insights into audience sentiment and feedback on specific content.
Licensing and Availability: Information regarding content licensing agreements, availability by region, and expiration dates for specific titles. This data is particularly relevant for content acquisition and distribution strategies.
Metadata and Tags: Additional metadata associated with media content, including cast and crew information, production details, keywords, tags, and categorization.
Platform-Specific Data: Each OTT media platform may have unique data points that can be scraped, such as user playlists, recently watched content, or content-specific metrics provided by the platform's API.
By scraping these types of data from OTT media platforms, businesses can gain valuable insights into audience preferences, content performance, and market trends. This information can inform content strategies, marketing campaigns, audience targeting, and other decision-making processes in the dynamic OTT industry.
What Are The Benefits Of Mobile App Scraping's OTT Media Platform Data Scraping Services For Businesses?
Mobile App Scraping's OTT Media Platform Data Scraping Services offer several benefits for businesses in the media industry. Here are some key advantages:
Market Analysis and Audience Insights: Businesses gain valuable market analysis and audience insights by scraping data from OTT media platforms. This includes understanding viewer preferences, consumption patterns, demographic information, and engagement metrics. These insights help make informed decisions about content creation, licensing, marketing, and audience targeting.
Competitive Intelligence: Data scraping allows businesses to gather competitive intelligence by analyzing content catalogs, pricing strategies, user ratings, and reviews of competitors on OTT platforms. This information helps identify market trends, positioning strategies, and opportunities for differentiation.
Content Optimization: Scraped data provides insights into performance, user feedback, and preferences. Businesses can analyze this data to optimize their content offerings, improve user engagement, and tailor their content strategy to meet the evolving demands of their audience.
Personalization and Recommendation Systems: OTT platforms rely on personalized recommendations to enhance user experiences. Businesses can understand user behavior, preferences, and viewing habits by scraping data. This enables them to build more effective recommendation systems, providing personalized content suggestions and improving user satisfaction.
Advertising and Monetization: Data scraping helps businesses identify popular content genres, target relevant audience segments, and optimize advertising campaigns. Businesses can make data-driven decisions to maximize ad revenue and optimize monetization strategies by analyzing user engagement metrics and demographics.
Market Trends and Forecasting: Scraped data from OTT media platforms provide insights into emerging market trends, viewer preferences, and content consumption patterns. This data can be used for market forecasting, predicting future content demand, and making strategic content acquisition and production decisions.
Operational Efficiency: Data scraping automates the process of data collection, allowing businesses to gather large amounts of data from multiple platforms efficiently. This saves time and resources that would otherwise be spent on manual data gathering and analysis.
Data-Driven Decision Making: Businesses can make data-driven decisions based on accurate and up-to-date market information by leveraging scraped data. This reduces guesswork and enhances decision-making processes related to content strategies, marketing campaigns, audience targeting, and business growth.
Overall, Mobile App Scraping's OTT Media Platform Data Scraping Services provide businesses with valuable insights, enabling them to stay competitive, improve content offerings, enhance user experiences, optimize monetization strategies, and make informed decisions in the dynamic and rapidly evolving OTT media industry.
How Can OTT Media Platform Data Scraping From Mobile App Scraping Help In Market Analysis And Audience Insights?
OTT Media Platform Data Scraping from Mobile App Scraping can significantly contribute to market analysis and provide valuable audience insights. Here's how it can help:
Market Trends: By scraping data from various OTT media platforms, businesses can gain insights into market trends, including popular content genres, emerging themes, and viewer preferences. This information allows businesses to identify opportunities for content acquisition, production, and strategic partnerships.
Content Performance Analysis: Data scraping enables businesses to analyze the performance of their content and that of competitors. Metrics such as viewership, ratings, reviews, and engagement statistics provide valuable feedback on content quality, audience reception, and areas for improvement.
Audience Segmentation: Through scraped data, businesses can identify different audience segments based on demographics, viewing habits, and content preferences. This segmentation helps tailor content offerings, marketing campaigns, and personalized recommendations to specific target audiences, enhancing user satisfaction and engagement.
User Behavior Analysis: By scraping data, businesses can gain insights into user behavior, including viewing patterns, session duration, content consumption habits, and user interactions with the platform. This information aids in understanding user preferences, habits, and engagement levels, allowing for more effective content planning and curation.
Content Personalization: Scraped data provides valuable inputs for building robust recommendation systems and personalized content delivery. Businesses can offer tailored content suggestions by analyzing user preferences, watch history, and engagement metrics, improving user experiences and increasing user retention.
Competitor Analysis: OTT Media Platform Data Scraping allows businesses to gather data on competitors' content catalogs, ratings, reviews, and audience engagement. This data provides insights into competitor strategies, content gaps, and areas of potential differentiation, supporting competitive analysis and informed decision-making.
Market Positioning: Scraped data helps businesses understand their position within the market. By comparing their content offerings, performance, and audience engagement metrics with competitors, businesses can identify their strengths, weaknesses, and opportunities for differentiation, refining their market positioning.
User Feedback and Sentiment Analysis: Scraped data includes user reviews, ratings, and comments. Analyzing this feedback gives businesses insights into user sentiments, satisfaction levels, and areas for improvement. It helps address user concerns, refine content strategies, and enhance the overall user experience.
OTT Media Platform Data Scraping from Mobile App Scraping empowers businesses with comprehensive market analysis and audience insights, enabling them to make data-driven decisions, optimize content strategies, improve user experiences, and stay ahead in the competitive OTT media landscape.
What Challenges Or Limitations Are Associated With OTT Media Platform Data Scraping?
OTT Media Platform Data Scraping comes with its own set of challenges and limitations. Here are some common ones:
Platform Restrictions: OTT media platforms often have strict terms of service and may explicitly prohibit data scraping or impose limitations on the extent and frequency of data extraction. Adhering to these restrictions is essential to ensure compliance and maintain a positive relationship with the platforms.
Legal and Ethical Considerations: Data scraping must comply with applicable laws, including copyright, intellectual property, and data protection regulations. Respecting user privacy, obtaining necessary permissions, and handling scraped data responsibly and securely is crucial.
Anti-Scraping Measures: OTT platforms may implement anti-scraping measures to protect their data and prevent unauthorized access. These measures can include CAPTCHAs, IP blocking, session monitoring, or other techniques that make scraping more challenging. Overcoming these measures requires advanced scraping techniques and continuous monitoring.
Data Quality and Accuracy: The scraped data may only sometimes be accurate or consistent. Factors such as variations in data formats, incomplete information, or user-generated content can introduce data quality issues. Data cleaning and validation processes must address these challenges and ensure reliable insights.
Dynamic Data Structures: OTT platforms frequently update their interfaces and underlying technologies, leading to changes in the structure and organization of data. This dynamic nature makes it challenging to maintain scraping scripts and adapt them to new versions of the platforms. Regular monitoring and adjustments are necessary to keep the scraping process current.
Data Volume and Processing: OTT platforms generate vast amounts of data, and scraping them can result in significant data volumes. Managing and processing such large-scale data requires robust infrastructure, storage capacity, and processing capabilities. Efficient data handling and analysis methods are crucial to extract meaningful insights.
Capturing Streaming Content: Scraping video or audio content itself poses additional challenges. Unlike static pages, capturing and extracting streaming media requires specialized techniques and tools to handle media codecs, DRM protection, and streaming protocols.
Constant Monitoring and Maintenance: OTT media platforms and their data structures are subject to frequent changes. To ensure continuous and accurate data scraping, ongoing monitoring and maintenance efforts are required to identify and address any disruptions or updates that affect the scraping process.Despite these challenges, with the proper expertise, technical capabilities, and compliance with legal and ethical standards, businesses can overcome the limitations and leverage the valuable insights derived from OTT Media Platform Data Scraping to drive informed decision-making and achieve a competitive advantage in the market.
How Can Businesses Effectively Utilize The Scraped Data From OTT Media Platforms To Enhance Their Marketing And Content Strategies?
Businesses can effectively utilize the scraped data from OTT Media Platforms to enhance their marketing and content strategies in the following ways:
Audience Segmentation and Targeting: Analyze the scraped data to identify distinct audience segments based on demographics, viewing habits, preferences, and engagement metrics. This segmentation helps businesses create targeted marketing campaigns and personalized content recommendations, increasing user engagement and retention.
Content Optimization: Gain insights into content performance, user feedback, and ratings from the scraped data. Use this information to optimize existing content, identify gaps, and develop new content that aligns with audience preferences. This can lead to improved viewer satisfaction and increased viewership.
Personalized Recommendations: Leverage the scraped data to build robust recommendation systems. By understanding user preferences and viewing patterns, businesses can offer personalized content suggestions, enhancing the user experience, increasing content consumption, and driving customer loyalty.

Marketing Campaign Optimization: Utilize the scraped data to optimize marketing campaigns. Identify the most engaging content, determine the best time to release new content, and tailor promotional strategies based on viewer behavior and preferences. This helps maximize the reach and impact of marketing efforts.
Competitive Analysis: Compare scraped data from competitors to gain insights into their content catalogs, ratings, reviews, and viewer engagement. This analysis helps identify competitive advantages, uncover content gaps, and develop differentiation and market positioning strategies.
User Experience Enhancement: Analyze user feedback, ratings, and reviews from the scraped data to identify areas for improvement in user experience. Address user concerns, enhance platform usability, and optimize features and functionalities to increase user satisfaction and retention.
Advertising Campaign Optimization: Utilize scraped data to understand viewer demographics, preferences, and engagement metrics. This information enables businesses to target relevant audiences more precisely, optimize advertising campaigns, and maximize ad revenue.
Pricing and Monetization Strategies: Analyze pricing models, viewer engagement, and competitor data from the scraped information to optimize pricing strategies. Identify opportunities for revenue growth, determine the optimal pricing points, and make informed decisions about monetization options.
By effectively utilizing the scraped data from OTT Media Platforms, businesses can gain valuable insights into their audience, market trends, content performance, and competitive landscape. These insights empower them to make informed decisions, tailor their marketing and content strategies, and ultimately enhance viewer engagement, retention, and business growth.
OTT Media Platform Data Scraping from Mobile App Scraping offers businesses valuable insights to enhance their marketing and content strategies. By leveraging scraped data, businesses can deeply understand audience preferences, content performance, market trends, and competitor landscape. These insights enable businesses to personalize content recommendations, optimize marketing campaigns, improve user experiences, and make data-driven decisions to stay ahead in the dynamic OTT media industry. Take your business to the next level in the OTT media landscape. Contact Mobile App Scraping today to learn more about our OTT Media Platform Data Scraping services and how we can help you leverage the power of data to transform your marketing and content strategies. Let's collaborate and drive success in the ever-evolving world of OTT media.
know more: https://www.mobileappscraping.com/extract-insights-from-ott-media-platforms.php
#ExtractOttMediaApps#OttMediaAppScraper#OttMediaAppsScraping#OttMediaDataScraping#ScrapeOttMediaData
0 notes
Text
#illustration#art#artists on tumblr#character art#character design#ttrpg#indie rpg#the hidden isle#fantasy art#swashbuckling#occult#rogue#hunter#knight#cottagecore#so ethereal and gorgeous#nature#naturecore#flowers#flowercore#warmcore#photography#cozycore#cosycore#drawing#digitalart#digitaldrawing#dailydrawing#illust#illo
1 note
·
View note
Text
Db2 and AI Integration: A 40-Year Success Story

Evolution of Db2
IBM Db2, released on June 7, 1983, revolutionized data storage, management, processing, and query.
Db2 has had an exciting and transformative 40 years. In 1969, retired IBM Fellow Edgar F. Codd published “A Relational Model of Data for Large Shared Data Banks.” His paper and research inspired Donald D. Chamberlin and Raymond F. Boyce to create SQL.
IBM Db2 V1.1 launched on MVS in 1985 after its 1983 announcement. The “father of Db2,” retired IBM Fellow Don Haderle, saw 1988 as a turning point when DB2 version 2 proved it could handle online transactional processing (OLTP), the lifeblood of business computing. A single database and relational model for transactions and business intelligence were created.
Successful mainframe ports led to OS/2, AIX, Linux, Unix, Windows, and other platforms on IBM and non-IBM hardware. The 1993-born Db2 (LUW) turns 30 in 2023.
Impact of Db2 on IBM
Db2 established IBM as a hardware, software, and services provider. Its early success and IBM WebSphere in the 1990s made it the database system for the 1992 Barcelona, 1996 Atlanta, and 1998 Nagano Olympics. Performance and stability were essential to avoid failures or delays that could affect millions of viewers.
IBM Db2 protecting, performant, and resilient business applications and analytics anywhere is based on decades of data security, scalability, and availability innovation. Forrester’s 2022 Total Economic Impact Report for Data Management highlights Db2 and IBM’s data management portfolio’s impact on customers:
ROI = 241% and payback <6 months.
Benefits PV $3.43M and NPV $2.42M
Customer experience growth of $1.76M, automation-driven productivity gains of $1.20M, and data-driven operational improvements of $473K are three-year benefits.
What is LUW IBM Db2?
IBM Db2 (LUW) is a cloud-native database that powers low-latency transactions and real-time analytics at scale. It offers self-managed and SaaS options. It gives DBAs, enterprise architects, and developers a single engine to run critical apps. It stores and queries anything and speeds decision-making across organizations.
Db2 has given customers’ data management solutions stability and dependability for 30 years. Its robust architecture and proven performance have powered enterprise-level applications and provided uninterrupted data access.
Db2 v11.5 revolutionized data management, allowing organizations to maximize their data.
How Db2, AI, and hybrid cloud interact
IBM AI-infused intelligence Data management is improved by automated insights, self-tuning performance optimization, and predictive analytics in Db2 v11.5. Machine learning algorithms continuously learn and adapt to workload patterns, improving performance and reducing administrative work.
Additionally, robust tooling and integration with popular development frameworks speed up application development and deployment. REST APIs, JSON support, and SQL compatibility help developers build cloud-native apps. Db2 v11.5 is reliable, flexible, and AI-ready.
Db2 Universal Container (Db2u) is a microservices-based containerization technology. Every component is divided into services that run in one or more containers. This architecture improves fault isolation because applications are mostly unaffected by microservice failures. Overall, deployment is easier. Automatic provisioning, scaling, and redundancy. Db2 runs on Red Hat OpenShift, Kubernetes, AWS ROSA & EKS, and Azure ARO & AKS.
Fully managed IBM Db2 database and warehouse services are also available. Fully managed Db2 database SaaS for high-performance transactional workloads. Meanwhile, Db2 Warehouse SaaS is a fully managed elastic cloud data warehouse using columnar technology. Both services scale compute and storage independently, provide high availability, and automate DBA tasks.
Watsonx.data integration
IBM introduced watsonx.data, an open, hybrid, and governed data store for all data, analytics, and AI workloads, at Think. Open data lakehouse architecture integrates commodity Cloud Object Store, open data/table formats, and open-source query engines. Watsonx.data will be fully integrated with Db2 Warehouse, allowing it to access data in Db2 tables using a Db2 connector and cataloging its metastore to share data in open formats like Parquet and Apache Iceberg.
Watsonx.data scales up and down with cost-effective compute and storage and powerful query engines like Presto and Spark. This allows Db2 Warehouse customers to pair the right workload with the right engine based on price and performance to augment workloads and reduce costs. Db2 transactional data can be combined with watsonx.data data for new insights and scaled AI.
Connecting Db2 and z/OS Db2
The world’s most valuable data is still stored on mainframes. The platform can execute 110,000 million instructions per second, or 9.5 trillion per day. Cybercriminals may target the mainframe due to its high-value data, which contains sensitive financial and personal information. Fortunately, IBM Z is one of the most secure platforms. Industry’s first quantum-safe system is IBM z16.
Parallel sysplex and Db2 data sharing are landmarks in database history and technological achievements. The IBM mainframe’s deep software-hardware integration and synergy yields these benefits. Parallel sysplex and Db2 data sharing provide mission-critical workloads with maximum scalability and availability.
Exploring Db2 for z/OS Version 13 innovations
IBM Db2 for z/OS version 13, released May 2022, adds cutting-edge features to strengthen its position as a hybrid cloud foundation for enterprise computing.
In availability, scalability, performance, security, and ease of use, Db2 13 for z/OS improves all critical enterprise database success factors. Synergy with surrounding tools and technology maximizes Db2 13’s value. The latest IBM Z hardware and SQL Data Insights AI technology provide semantic SQL query support for unprecedented business value from data.
New and improved application development tooling, AI infusion for operational efficiency, and IBM Db2 Data Gate complement Db2 13’s new capabilities.
Db2 for z/OS offers enterprise-scale HTAP with its patented consistency and coherency model and heterogeneous scale-out architecture.
More applications, especially mobile computing and the Internet of Things, require the ability to ingest hundreds of thousands of rows per second. Tracking website clicks, mobile network carrier call data, “smart meter” events, and embedded devices can generate huge volumes of transactions with the IoT.
Many consider NoSQL databases necessary for high data ingestion. However, Db2 allows high insert rates without partitioning or sharding the database and queries the data using standard SQL with ACID compliance on the world’s most stable, highly available platform.
Db2 for z/OS switched to continuous delivery in 2016, delivering new features and enhancements through the service stream in weeks (and sometimes days) instead of years. This improves agility while maintaining customer quality, reliability, stability, and security.
Db2 invests in availability, performance, and scalability to handle today’s and tomorrow’s most demanding workloads with a continuous delivery model. This allows millions of inserts per second, trillions of rows per table, and more.
IBM analytics solutions like Cognos, SPSS, QMF, ML for z/OS, IBM Db2 Analytics Accelerator, Data Gate, and others use IBM Db2 for z/OS as their data server. Db2 for z/OS’s value has created “Data Gravity,” prompting organizations to co-locate their applications and analytics solutions with their data. This reduces network and infrastructure latencies, costs, and security risks.
The volume and velocity of transaction workloads, the richness of data in each transaction, and the data in log files are gold mines for machine learning and AI applications to exploit cognitive capabilities and create a more intelligent and secure solution.
The recently released IBM Watson Machine Learning for z/OS uses open-source technology and the latest innovations to make the platform’s perceived complexity transparent to data scientists through the IBM Data Science Experience interface.
0 notes
Text
JSON Viewer Tool
"Effortlessly view and format JSON data with our online JSON Viewer Tool. Paste or upload your JSON code, and instantly visualize it in a human-readable and structured format. Simplify data analysis and debugging tasks with ease."
1 note
·
View note
Text
To add to the previous part about Cat, Dream's choice to accuse her of being the burner has had insane negative impacts on her life. He genuinely, deeply harmed someone on a whim. Cat also does not want to be involved in this situation anymore, but just for clarity about Jaime's situation, I will be involving their tweets. I'd also like to add that Dream retracted his accusation against Cat of being the burner.
Also, to amend something, Jaime's situation was not reported to the police, it was reported to an agency for child exploitation.
From what I have seen of Dream's response, it's quite complicated and there are some issues worthy of noting.
Some notable things he did in the video:
He edited the video like it was a drama youtuber exposé on some fallen youtuber and not his response to multiple grooming allegations.
He compared him flirting (and possibly sexting) with his underage stans (as a 19 - 22 year old with 10 million+ subscribers to people 16/17 years old) to Phil and Kristin's relationship (a late 20s streamer with at most tens of viewers who held a platonic relationship with a viewer who was also in their late 20s for a least one year before beginning a romantic relationship). This is talked about my first post in this long post. It's a bad point.
He discussed many of his controversies, including his speedrunning, before the allegations against him (very strange to talk about how frequent of a liar he is before going on to say that he's not a liar).
*He admitted to having known Manatreed (accused domestic abuser who he added to the SMP for one day before Manatreed left when the allegations came out through doxxing) and apologized for how he reacted back then. (*I haven't seen much about this point, so take it with a grain of salt)
He talked about how several other CCs, like Ranboo and Wilbur, have had false allegations against them (which is interesting to me, as people like his close friend BBH, who has actively defended him, had false allegations as well, so I am curious why he chose Ranboo and Wilbur, but nevertheless).
He made up controversial messages between him and Pokimane, and him and XQC to show how easily you can fake messages without asking Pokimane or XQC for permission to do so or warning them about it? Essentially dragging them into the controversy for no reason, as the messages spread online, even though Dream did state they were fake (or at least implied heavily).
He included tweets against him which showed people's usernames, which reportedly lead to doxxing, in the same video where he apologizes for his previous statement about how doxxing didn't matter.
He talked about Jaime/burner22 and Amanda with a brief mention of Anastasia and no mention of Jay (even if Jay does not consider themselves a victim).
He apologized to Quackity, and reportedly admitted to the fact that he had been accusing Quackity of stealing the idea for USMP.
I would like to add that I have not watched the video in its entirety, but I believe that I have most of the key information from the portions I have seen.
When it comes to the allegations from Amanda, he showed the JSON chat logs from Snapchat. Except, he didn't show all of it. He showed snippets, specifically right before the supposed messages of him flirting with Amanda that we saw in Amanda's videos.
I don't personally use Snapchat, so here is the entire problem explained by someone who does. I've summarized it below.
Looking at the Snapchat logs he showed, they're out of order. The dates are inconsistent, when Snapchat data is chronological. Dream would have had to manually edit them to rearrange the order they're in.
There are also missing messages that exist in Amanda's videos that are not flirtatious or sexual, meaning that Amanda would have faked sending innocent, short messages with Dream when they in no way would benefit her narrative unless she was trying to build their platonic relationship? So either she added those in for that reason, or Dream removed them without realizing.
Amanda was recording her phone screen with another phone, and Dream confirmed that some of the Snapchat messages are real.
Dream's logs also fail to include any sort of reference to a media file, when it's confirmed that there are instances where pictures or other files were shared. It is very odd that these are missing.
Also, this thread showed yet another instance of Dream acting inappropriate towards Amanda that I had never seen.

[Image ID: a screenshot of a camera role that is showing a photo of a phone. The phone is open to Snapchat and shows Dream responding to a bikini photo of Amanda. He wrote "baddd bitch", "fine as HELL", "beach day?". End ID]
When asked about this photo and response, he deflected and talked about when he called her 'gorgeous as fuck'.
I'd also like to add that he once again says that Amanda messaged him from her personal and he didn't know any fan accounts of hers, but it was obvious that she was a devoted fan, as she said so in her first message to him on Instagram.
When it comes to Jaime, the situation is very complicated. Dream apparently had Keemstar helping him behind the scenes, which I just wanted to note due to arguments about the validity of the previous time Keemstar was involved.
There's a message sent to Keemstar from Jaime on Snapchat saying that Jaime did not release the information behind shared, and that it was shared without her consent. She does not consider herself groomed or a victim in any way, and also does not want to be involved.
Regardless of this, there was a large document released that showed evidence that Jaime was 16 and a fan at the time of Dream messaging them. Whether or not Jaime was groomed, it's very inappropriate for a 20 year old to be sending sexual messages with a 16 year old fan.
However, the allegations and their validity are being called into question.
In the video, Dream includes a person by the name of Sam (the previously blurred person in Cat's discord messages), who was the person who sent Jaime's messages to the burner. In the video, they talked very differently about the messages sent to Jaime than they did in screenshots of the conversation between them and the burner.
Most of this information is coming from these threads from Cat, who does not believe Dream to be a groomer. By their own words, they're not 100% sure about Amanda and Anastasia, but they've received personal information about the situation with Jaime that they cannot share. They believe that the burner did not lie about Jaime, but they were purposefully mislead.
It's unclear why Sam has lied repeatedly, but reportedly, they left out several key details when informing the burner of the situation. After the burner responded by saying they did not understand who Sam had lied to (Dream or them), the burner deactivated their account.
Really, I think the best thing to be said about this is what Pyrocynical said, which is that this video probably will not change anyone's minds whether they're a fan of him or not. I doubt this post will either, but I am trying to document the situation for information purposes.
Remember you really don't have to have an opinion on everything, do whatever is safe for you and if this is stressing you, try to step back.
I feel that regardless of what you think of whether he groomed, sexted, or flirted with anyone underage or otherwise, his responses to this situation and the many other situations he has been in definitely show a pattern of behaviour in how he acts in his position. I still personally believe that he was acting inappropriately in messaging his fans and flirting with them (by his own words in his original response) and I still believe he should not have a platform.
I am so fucking angry about Dream stans (mostly on Twitter, though they are here) being like “can you BELIEVE people are upset that a minor 😱😱😱 was messaging with an ADULT!! LMAOO wait until they get into the real world and find out that 17 year olds can be friends with 25 year olds. Next they’re gonna call Tommy messaging Schlatt dangerous!!”
It was not that she was 17 and Dream was 20. The age gap was not the issue.
It was that Dream had a position of power over her and abused it.
He knew he had this position from the very start, as she was a fan of his and their first messages with each other was her telling him how much his content had helped her through depression.
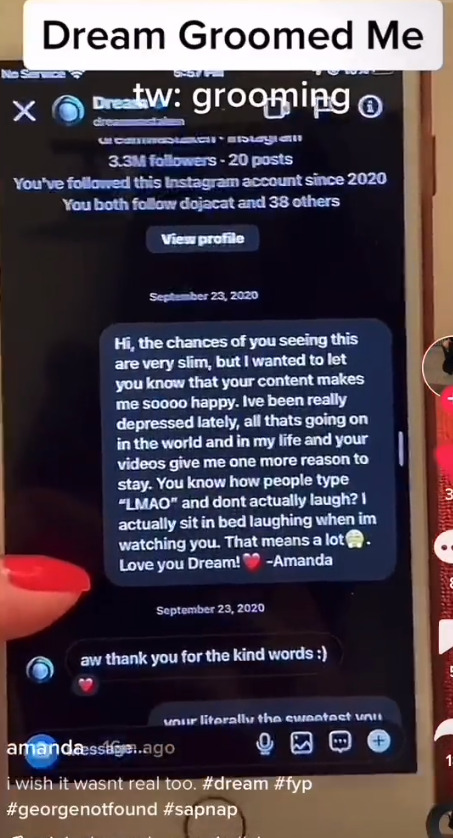
[Image ID: a screenshot of an Instagram direct message to Dream that reads “Hi, the chances of you seeing this are very slim, but I wanted to let you know that your content makes me sooo happy. Ive been really depressed lately, all thats going on in the world and in my life and your videos give me one more reason to stay. You know how people type “LMAO” and dont actually laugh? I actually sit in bed laughing when im watching you. That means a lot [Unclear emoji]. Love you Dream!❤️ -Amanda”. Dream replied and wrote “aw thank you for the kind words :)”. End ID]
This means that he knew full well that her wellbeing was somewhat dependant on his content. She says that his videos gave her one more reason to stay alive.
He confirmed that the Instagram messages are real.

[Image ID: a screenshot of Dream’s twitlonger regarding the allegations that reads “The second thread had instagram dms from me, again, having friendly normal conversation and nothing inappropriate. I believe these message are real as well. Once”. End ID]
Thusly, the Snapchat messages that haven’t been deleted are, without a doubt, real, because he tells her the name of his private Snapchat in the Instagram messages. They cannot be ignored.
It is incredibly inappropriate for Dream to message her on Snapchat knowing that she was 17 and a fan at the time and that messages can easily be erased. That on its own would be uncomfortable, but he was talking to her in a flirtatious manner.

[Image ID: a screenshot of a Snapchat message by Dream/Clay that is a reply to a video sent by Amanda that reads “ur gorgeous as fuck”. End ID]
This is not normal, friendly behavior. Especially with a fan who is underage and has said that she is emotionally invested in his content.
This is predatory. Several girls have come forward. This proves that Dream not only has more than once, but likely will again, use his platform and power to engage in sexual relationships with underage girls.
He cannot have a platform anymore.
Please, read this post about the Snapchat messages, this post about why Tommy messaging Schlatt and other CCs was completely different, and these two threads about his response to the situation (thread one) (thread two) and how it was manipulative and more focused on his audience rather than adressing the allegations.
This thread includes most of the information regarding the situation.
#dream situation#// dream#tw mentioned grooming#tw grooming#long post#// cmc#ask to tag#areus rambles#if there's anything inaccurate in this let me know#it's a very complicated situation and everyone is entitled to their own thoughts on the video#I have mine though#and I do not see why he needed to take over a year and include everything else that he got messed up in to respond#it feels like he's trying to cover everything#and the allegations are just one of those things he's been caught up in#instead of. allegations of grooming#and the amount of time had resulted in the situation becoming very muddied as both maliciously and accidentally false allegations#have been released#I feel that the video taking so long to be released made the situation between people who believed or did not believe the allegations worse#as victim blaming and doxxing and harassment became insanely common#and dream has responded to situations in the past year in ways that are just. like straight up unsafe in some cases. and childish in others#as for Jaime. I am neither here nor there.#It all really depends on Sam and idk what the fuck is going on there and it seems like any information coming out would doxx people so#I don't think we'll get an answer#these are just my thoughts of course
2K notes
·
View notes
Photo
Aimraj.com offer you some useful tools and services for free like photo editor online, internet speed tester, json viewer etc.
1 note
·
View note
Text
REVIVING 1990S DIGITAL DRESS-UP DOLLS WITH SMOOCH

Libby Horacek
POSITION DEVELOPMENT
@horrorcheck
What is the Kisekae Set System: It is a system to make digital dress up dolls!
Created in 1991 by MIO.H for use in a Japanese BBS. Pre-web!!! By separating the system from the assets of the dolls, you can make the systems much smaller
CEL image format. They have a transparent background and indexed colors like GIFs!
There is also the KCF Palette Format. Each GUF stores its own palette, with CELs there is a shared KCF palette file. Which is a file size cost savings. You do not have to repeat your color info per file.
Having your palette in another file makes palette swapping really easy! Just swap the KCF file!
CNF configuration files dictate layering, grouping, setting, and positions!
KiSS dolls have a lot of files, so they used LhA, the most popular compression format in Japan at the time.
In 1994, KLS (a user) created the KiSS General Specification
1995 FKiSS is born by Dov Sherman and Yav, which adds sounds, and animation!
FKiSS 2, 3, 4, two versions of FKiSS 5! So much innovation!
1995-2005 huge growth in KiSS! Increase of access, mainstreaming of anime, younger and more female audience.
2007-2012: KiSS declined due to it being much harder to make. All the old tutorials were written for older systems, English-speaking KiSS-making died out by 2010
The Sims, and other doll making was more accessible.
But, why KiSS? If I can make dolls in other places. They are great snapshots of the pre-internet world, and how play online evolved early on.
Lots of fun dolls were available, and it would be cool to save it.
Picrew is a modern thing people use to make dolls.
Tagi Academy is a tamagochi game within KiSS. Impressive!
KiSS has an open specification!!!! That is super cool! That means anyone can make your own viewer, as opposed to a closed system in The Sims.
So, why NOT make a KiSS interpreter?!!
Libby made Smooch, a KiSS renderer written in Haskell, which at the Recurse Center!
Smooch used a web framework called Fn (fnhaskell.com)
Had to make a CNF file parser using Parsec library that uses parsing combinators.
She created a data type that houses everything that can be in a CNF file, and parses it correctly in priority order.
Parsing is a great candidate for test-driven development. You can write a test with a bad CNF file, and then make sure your parser handles it.
The parser translates CNF lines into JSON. Uses the ASON library to translate into JSON.
First tried cel2pnm, coded with help from Mark Dominus at Recurse Center Made a C program that converted cels to portable bitmaps, which could be translated into PNGs.
Then JuicyPixels was created to translate palette files directly in Haskell
Now it is converted to JavaScript! No libraries, just JS!
Using PNGs in JS, thought, made it hard to click on parts of the clothing! Since it is squares.
So, you use ghost canvases! You use tow canvases, one on top of the other, to find the color of the pixel you clicked on, If you clicked on a scarf color, it will pick the scarf, and if you pick the sweater, you get the sweater!
Libby just added FKiSS 1 to Smooch! So we have animations now! The animations are basically event-based scripting the CEL files.
Smooch translates FKiSS to JSON, then the interpreter translates the JSON to JavaScript!
An action in FKiSS is translated into a function in JS. To do this you have to use bind in JS.
The events become CustomEvents in JS! So it looks like a regular event on the DOM.
What is the future of KiSS? Let's get more people making KiSS dolls!!! So why not make it easy to make dolls using PNGs.
How can we make people interested in building KiSS dolls and KiSS tooling.
Smooch need contributors!
Thank you, Libby, for the great talk!
9 notes
·
View notes