#Open Source Parse Server
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr has 4 main sources of revenue.
Text
Why Should You Do Web Scraping for python

Web scraping is a valuable skill for Python developers, offering numerous benefits and applications. Here’s why you should consider learning and using web scraping with Python:
1. Automate Data Collection
Web scraping allows you to automate the tedious task of manually collecting data from websites. This can save significant time and effort when dealing with large amounts of data.
2. Gain Access to Real-World Data
Most real-world data exists on websites, often in formats that are not readily available for analysis (e.g., displayed in tables or charts). Web scraping helps extract this data for use in projects like:
Data analysis
Machine learning models
Business intelligence
3. Competitive Edge in Business
Businesses often need to gather insights about:
Competitor pricing
Market trends
Customer reviews Web scraping can help automate these tasks, providing timely and actionable insights.
4. Versatility and Scalability
Python’s ecosystem offers a range of tools and libraries that make web scraping highly adaptable:
BeautifulSoup: For simple HTML parsing.
Scrapy: For building scalable scraping solutions.
Selenium: For handling dynamic, JavaScript-rendered content. This versatility allows you to scrape a wide variety of websites, from static pages to complex web applications.
5. Academic and Research Applications
Researchers can use web scraping to gather datasets from online sources, such as:
Social media platforms
News websites
Scientific publications
This facilitates research in areas like sentiment analysis, trend tracking, and bibliometric studies.
6. Enhance Your Python Skills
Learning web scraping deepens your understanding of Python and related concepts:
HTML and web structures
Data cleaning and processing
API integration
Error handling and debugging
These skills are transferable to other domains, such as data engineering and backend development.
7. Open Opportunities in Data Science
Many data science and machine learning projects require datasets that are not readily available in public repositories. Web scraping empowers you to create custom datasets tailored to specific problems.
8. Real-World Problem Solving
Web scraping enables you to solve real-world problems, such as:
Aggregating product prices for an e-commerce platform.
Monitoring stock market data in real-time.
Collecting job postings to analyze industry demand.
9. Low Barrier to Entry
Python's libraries make web scraping relatively easy to learn. Even beginners can quickly build effective scrapers, making it an excellent entry point into programming or data science.
10. Cost-Effective Data Gathering
Instead of purchasing expensive data services, web scraping allows you to gather the exact data you need at little to no cost, apart from the time and computational resources.
11. Creative Use Cases
Web scraping supports creative projects like:
Building a news aggregator.
Monitoring trends on social media.
Creating a chatbot with up-to-date information.
Caution
While web scraping offers many benefits, it’s essential to use it ethically and responsibly:
Respect websites' terms of service and robots.txt.
Avoid overloading servers with excessive requests.
Ensure compliance with data privacy laws like GDPR or CCPA.
If you'd like guidance on getting started or exploring specific use cases, let me know!
2 notes
·
View notes
Text

Open-source Tools and Scripts for XMLTV Data
XMLTV is a popular format for storing TV listings. It is widely used by media centers, TV guide providers, and software applications to display program schedules. Open-source tools and scripts play a vital role in managing and manipulating XMLTV data, offering flexibility and customization options for users.
In this blog post, we will explore some of the prominent open-source tools and scripts available for working with xmltv examples.
What is XMLTV?
XMLTV is a set of software tools that helps to manage TV listings stored in the XML format. It provides a standard way to describe TV schedules, allowing for easy integration with various applications and services. XMLTV files contain information about program start times, end times, titles, descriptions, and other relevant metadata.
Open-source Tools and Scripts for XMLTV Data
1. EPG Best
EPG Best is an open-source project that provides a set of utilities to obtain, manipulate, and display TV listings. It includes tools for grabbing listings from various sources, customizing the data, and exporting it in different formats. Epg Best offers a flexible and extensible framework for managing XMLTV data.
2. TVHeadend
TVHeadend is an open-source TV streaming server and digital video recorder for Linux. It supports various TV tuner hardware and provides a web interface for managing TV listings. TVHeadend includes built-in support for importing and processing XMLTV data, making it a powerful tool for organizing and streaming TV content.
3. WebGrab+Plus
WebGrab+Plus is a popular open-source tool for grabbing electronic program guide (EPG) data from websites and converting it into XMLTV format. It supports a wide range of sources and provides extensive customization options for configuring channel mappings and data extraction rules. WebGrab+Plus is widely used in conjunction with media center software and IPTV platforms.
4. XMLTV-Perl
XMLTV-Perl is a collection of Perl modules and scripts for processing XMLTV data. It provides a rich set of APIs for parsing, manipulating, and generating XMLTV files. XMLTV-Perl is particularly useful for developers and system administrators who need to work with XMLTV data in their Perl applications or scripts.
5. XMLTV GUI
XMLTV GUI is an open-source graphical user interface for configuring and managing XMLTV grabbers. It simplifies the process of setting up grabber configurations, scheduling updates, and viewing the retrieved TV listings.
XMLTV GUI is a user-friendly tool for users who prefer a visual interface for interacting with XMLTV data.
Open-source tools and scripts for XMLTV data offer a wealth of options for managing and utilizing TV listings in XML format. Whether you are a media enthusiast, a system administrator, or a developer, these tools provide the flexibility and customization needed to work with TV schedules effectively.
By leveraging open-source solutions, users can integrate XMLTV data into their applications, media centers, and services with ease.
Stay tuned with us for more insights into open-source technologies and their applications!

Step-by-Step XMLTV Configuration for Extended Reality
Extended reality (XR) has become an increasingly popular technology, encompassing virtual reality (VR), augmented reality (AR), and mixed reality (MR).
One of the key components of creating immersive XR experiences is the use of XMLTV data for integrating live TV listings and scheduling information into XR applications. In this blog post, we will provide a step-by-step guide to configuring XMLTV for extended reality applications.
What is XMLTV?
XMLTV is a set of utilities and libraries for managing TV listings stored in the XML format. It provides a standardized format for TV scheduling information, including program start times, end times, titles, descriptions, and more. This data can be used to populate electronic program guides (EPGs) and other TV-related applications.
Why Use XMLTV for XR?
Integrating XMLTV data into XR applications allows developers to create immersive experiences that incorporate live TV scheduling information. Whether it's displaying real-time TV listings within a virtual environment or overlaying TV show schedules onto the real world in AR, XMLTV can enrich XR experiences by providing users with up-to-date programming information.
Step-by-Step XMLTV Configuration for XR
Step 1: Obtain XMLTV Data
The first step in configuring XMLTV for XR is to obtain the XMLTV data source. There are several sources for XMLTV data, including commercial providers and open-source projects. Choose a reliable source that provides the TV listings and scheduling information relevant to your target audience and region.
Step 2: Install XMLTV Utilities
Once you have obtained the XMLTV data, you will need to install the XMLTV utilities on your development environment. XMLTV provides a set of command-line tools for processing and manipulating TV listings in XML format. These tools will be essential for parsing the XMLTV data and preparing it for integration into your XR application.
Step 3: Parse XMLTV Data
Use the XMLTV utilities to parse the XMLTV data and extract the relevant scheduling information that you want to display in your XR application. This may involve filtering the data based on specific channels, dates, or genres to tailor the TV listings to the needs of your XR experience.
Step 4: Integrate XMLTV Data into XR Application
With the parsed XMLTV data in hand, you can now integrate it into your XR application. Depending on the XR platform you are developing for (e.g., VR headsets, AR glasses), you will need to leverage the platform's development tools and APIs to display the TV listings within the XR environment.
Step 5: Update XMLTV Data
Finally, it's crucial to regularly update the XMLTV data in your XR application to ensure that the TV listings remain current and accurate. Set up a process for fetching and refreshing the XMLTV data at regular intervals to reflect any changes in the TV schedule.
Incorporating XMLTV data into extended reality applications can significantly enhance the immersive and interactive nature of XR experiences. By following the step-by-step guide outlined in this blog post, developers can seamlessly configure XMLTV for XR and create compelling XR applications that seamlessly integrate live TV scheduling information.
Stay tuned for more XR development tips and tutorials!
Visit our xmltv information blog and discover how these advancements are shaping the IPTV landscape and what they mean for viewers and content creators alike. Get ready to understand the exciting innovations that are just around the corner.
youtube
4 notes
·
View notes
Text
The Best 9 Python Frameworks for App Development in 2025
Python is the most popular and high-level, general-purpose programming language that supports multiple programming models, including structured, object-oriented, and functional programming. App developers often prefer using Python frameworks for App Development.

Developers often use Pyjnius, a Python library that allows access to Java classes. It can either launch a new Java Virtual Machine (JVM) within the process or connect to an existing JVM, such as the one already running on Android.
According to recent research from Statista, more than 48% of developers use Python frameworks for mobile app development.
What is a Python Framework?
Python frameworks are collections of pre-built modules and packages that help developers handle common tasks efficiently.
They simplify application development by providing ready-made solutions, so developers don’t have to start from scratch.
These frameworks also take care of details like thread management, sockets, and protocols, saving time and effort.
9 Best Python Frameworks for App Development in 2025
Explore here a list of Top 10 Python App Frameworks to Use in 2025:
1-Django
Django is a leading Python framework designed for building dynamic mobile and web applications with ease. It leverages a robust Object-Relational Mapping (ORM) system and follows the Model-View-Controller (MVC) pattern, ensuring clean, reusable, and easily maintainable code.
Whether you’re creating simple apps or scaling complex projects, Django’s powerful features make development faster and more efficient.
It has built-in tools like URL routing/parsing, authentication system, form validation, template engine, and caching to ensure a swift development process.
Django follows the DRY (Don’t Repeat Yourself) concept and focuses on rapid app development with a neat design.
This framework is the first choice of developers for any Python project due to its versatility, customization, scalability, deployment speed, simplicity, and compatibility with the latest Python versions.
According to a Stack Overflow survey, Django and Flask are the most popular Python software development frameworks.
Some examples popular examples of apps built with the Django framework are Instagram and Spotify.
Key Features of Django Framework:
Enables execution of automated migrations
Robust security
Enhanced web server support
Comprehensive documentation
Vast add-ins with SEO optimization
2-Flask
Flask stands out as a top-rated, open-source Python microframework known for its simplicity and efficiency. The Flask framework comes packed with features like a built-in development server, an intuitive debugger, seamless HTTP request handling, file storage capabilities, and robust client-side session support.
It has a modular and adaptable design and added compatibility with Google App Engine.
Besides Django, Flask is another popular Python framework with the Werkzeug WSGI toolkit and Jinja2 template.
Flask operates under the BSD license, ensuring simplicity and freedom for developers.
Inspired by the popular Sinatra Ruby framework, Flask combines minimalism with powerful capabilities, making it a go-to choice for building scalable and efficient web applications.
Key Features of Flask Framework:
Jinja2 templating and WSGI compliance
Unicode-based with secure cookie support
HTTP request handling capability
RESTful request dispatch handling
Built-in server development and integrated unit-testing support
Plugs into any ORM framework
3-Web2Py
Web2Py is an open-source, full-stack, and scalable Python application framework compatible with most operating systems, both mobile-based and web-based.
It is a platform-independent framework that simplifies development through an IDE that has a code editor, debugger, and single-click deployment.
Web2Py deals with data efficiently and enables swift development with MVC design but lacks configuration files on the project level.
It has a critical feature, a ticketing system that auto-generates tickets in the event of issues and enables tracking of issues and status.
Key Features of Web2py Framework:
No configuration and installation needed
Enables use of NoSQL and relational databases
Follows MVC design with consistent API for streamlining web development
Supports internationalization and role-based access control
Enable backward compatibility
Addresses security vulnerabilities and critical dangers
4-TurboGears
TurboGears is an open-source, full-stack, data-driven popular Python web app framework based on the ObjectDispatch paradigm.
It is meant to make it possible to write both small and concise applications in Minimal mode or complex applications in Full Stack mode.
TurboGears is useful for building both simple and complex apps with its features implemented as function decorators with multi-database support.
It offers high scalability and modularity with MochiKit JavaScript library integration and ToscaWidgets for seamless coordination of server deployment and front end.
Key aspects of TurboGears Framework:
MVC-style architecture
Provides command-line tools
Extensive documentation
Validation support with Form Encode
It uses pylons as a web server
Provides PasteScript templates
5-Falcon
Falcon is a reliable and secure back-end micro Python application framework used for developing highly-performing microservices, APIs, and large-scale application backends.
It is extensible and optimized with an effective code base that promotes building cleaner designs with HTTP and REST architecture.
Falcon provides effective and accurate responses for HTTP threats, vulnerabilities, and errors, unlike other Python back-end frameworks. Large firms like RackSpace, OpenStack, and LinkedIn use Falcon.
Falcon can handle most requests with similar hardware to its contemporaries and has total code coverage.
Key Features of Falcon Framework:
Intuitive routing with URL templates
Unit testing with WSGI mocks and helpers
Native HTTP error responses
Optimized and extensible code base
Upfront exception handling support
DRY request processing
Cython support for enhanced speed
6-CherryPy
CherryPy is an object-oriented, open-source, Python micro framework for rapid development with a robust configuration system. It doesn’t require an Apache server and enables the use of technologies for Cetera templating and accessing data.
CherryPy is one of the oldest Python app development frameworks mainly for web development. Applications designed with CherryPy are self-contained and operate on multi-threaded web servers. It has built-in tools for sessions, coding, and caching.
Popular examples of CherryPy apps include Hulu and Juju.
Key features of CherryPy Framework:
Runs on Android
Flexible built-in plugin system
Support for testing, profiling, and coverage
WSGI compliant
Runs on multiple HTTP servers simultaneously
Powerful configuration system
7-Tornado
It is an open-source asynchronous networking Python framework that provides URL handling, HTML support, python database application framework support, and other crucial features of every application.
Tornado is as popular as Django and Flask because of its high-performing tools and features except that it is a threaded framework instead of being WSGI-based.
It simplifies web server coding, handles thousands of open connections with concurrent users, and strongly emphasizes non-blocking I/O activities for solving C10k difficulties.
Key features of Tornado Framework:
Web templating techniques
Extensive localization and translation support
Real-time, in-the-moment services
Allows third-party authorization, authorization methods, and user authentication
Template engine built-in
HTTP client that is not blocking
8- AIOHTTP Python Frameworks for App Development
AIOHTTP is a popular asynchronous client-side Python web development framework based on the Asyncio library. It depends on Python 3.5+ features like Async and Awaits.
AIOHTTP offers support for client and server WebSockets without the need for Callback Hell and includes request objects and routers for redirecting queries to functions.
Key Highlights of AIOHTTP Python Framework:
Provides pluggable routing
Supports HTTP servers
Supports both client and WebSockets without the callback hell.
Middleware support for web servers
Effective view building
Also, there are two main cross-platform Python mobile app frameworks
9- Kivy Python Frameworks for App Development
Kivy is a popular open-source Python framework for mobile app development that offers rapid application development of cross-platform GUI apps.
With a graphics engine designed over OpenGL, Kivy can manage GPU-bound workloads when needed.
Kivy comes with a project toolkit that allows developers to port apps to Android and has a similar one for iOS. However, porting Python apps to iOS currently is possible with Python 2.7.
Features of Kivy Framework:
Enables custom style in rendering widgets to give a native-like feel
Enhanced consistency across different platforms with a swift and straightforward approach
Well-documented, comprehensive APIs and offers multi-touch functionalities
Source of Content: Python Frameworks for App Development
#topPythonframeworks#Pythonframeworksforappdevelopment#bestPythonframeworks#Pythondevelopmentframeworks#Pythonwebframeworks#top9Pythonframeworksfordevelopers#Pythonframeworksforbuildingwebapps#Pythonframeworksformobileandwebdevelopment#fullstackPythonframeworks#microframeworksinPython#Pythonappdevelopmenttools
0 notes
Text

In the world of Industrial IoT (IIoT), the ability to efficiently monitor, store, and analyze large volumes of time-stamped data is essential. From environmental sensors in smart factories to energy meters in power systems, time-series data forms the backbone of real-time insight and historical analysis.
InfluxDB, an open-source time-series database, is designed specifically for these use cases. Combined with the industrial-grade ARMxy Edge Gateway, it creates a robust edge solution for reliable data acquisition, storage, and visualization—all without depending on cloud availability.
🧠 Why InfluxDB on ARMxy?
InfluxDB is lightweight, high-performance, and optimized for time-series workloads. It supports powerful query languages, retention policies, and integrations with monitoring tools such as Grafana. When deployed directly on an ARMxy (RK3568J/RK3568B2) gateway, it becomes a local data engine with key advantages:
Minimal latency: Store and query data at the edge
Offline reliability: Operate without cloud or internet connection
Flexible integration: Compatible with Modbus, OPC UA, MQTT, and more
🏭 Real-World Use Case Example
Imagine a factory floor with multiple PLCs controlling machinery. Each PLC sends temperature, vibration, and power consumption data every few seconds. Instead of sending that data to a remote server, it can be ingested directly into InfluxDB running on the ARMxy device.
You can then use:
Telegraf for parsing and collecting metrics
Grafana for local visualization dashboards
Node-RED to add logic and alarms
The result? A self-contained edge monitoring system capable of showing trends, detecting anomalies, and buffering data even during connectivity drops.
🔗 Integration Workflow Overview
Install InfluxDB on ARMxy via Docker or native ARM64 package
Connect data sources: Modbus devices, MQTT brokers, etc.
Configure retention policies to manage local storage
Use Grafana (also installable on ARMxy) to build dashboards
(Optional) Forward selected metrics to cloud or central server for backup
✅ Benefits of Edge Time-Series Monitoring
Faster Insights: No need to wait for data to hit the cloud
Bandwidth Optimization: Only send essential data upstream
Improved System Resilience: Data remains accessible during downtime
Security & Compliance: Sensitive data can stay on-premises
🔚 Conclusion
Deploying InfluxDB on ARMxy Edge Gateways transforms traditional data loggers into intelligent local data hubs. With flexible integration options, support for real-time applications, and a compact industrial design, ARMxy with InfluxDB is a perfect fit for smart manufacturing, energy monitoring, and any IIoT scenario that demands fast, local decision-making.
Let the data stay close—and smart.
0 notes
Text
CloudFront Now Supports gRPC Calls For Your Applications

Your applications’ gRPC calls are now accepted by Amazon CloudFront.
You may now set up global content delivery network (CDN), Amazon CloudFront, in front of your gRPC API endpoints.
An Overview of gRPC
You may construct distributed apps and services more easily with gRPC since a client program can call a method on a server application on a separate machine as if it were a local object. The foundation of gRPC, like that of many RPC systems, is the concept of establishing a service, including the methods that may be called remotely along with their parameters and return types. This interface is implemented by the server, which also uses a gRPC server to manage client requests. The same methods as the server are provided by the client’s stub, which is sometimes referred to as just a client.
Any of the supported languages can be used to write gRPC clients and servers, which can operate and communicate with one another in a range of settings, including your desktop computer and servers within Google. For instance, a gRPC server in Java with clients in Go, Python, or Ruby can be readily created. Furthermore, the most recent Google APIs will include gRPC interfaces, making it simple to incorporate Google functionality into your apps.
Using Protocol Buffers
Although it can be used with other data formats like JSON, gRPC by default serializes structured data using Protocol Buffers, Google’s well-established open source method.
Establishing the structure for the data you wish to serialize in a proto file a regular text file with a.proto extension is the first step in dealing with protocol buffers. Protocol buffer data is organized as messages, each of which is a brief logical record of data made up of a number of fields, or name-value pairs.
After defining your data structures, you can use the protocol buffer compiler protoc to create data access classes from your proto specification in the language or languages of your choice. These offer methods to serialize and parse the entire structure to and from raw bytes, along with basic accessors for each field, such as name() and set_name(). For example, executing the compiler on the aforementioned example will produce a class named Person if you have selected C++ as your language. This class can then be used to serialize, retrieve, and populate Person protocol buffer messages in your application.
You specify RPC method parameters and return types as protocol buffer messages when defining gRPC services in standard proto files:
Protoc is used by gRPC with a specific gRPC plugin to generate code from your proto file. This includes the standard protocol buffer code for populating, serializing, and retrieving your message types, as well as generated gRPC client and server code.
Versions of protocol buffers
Although open source users have had access to protocol buffers for a while, the majority of the examples on this website use protocol buffers version 3 (proto3), which supports more languages, has a little simplified syntax, and several helpful new capabilities. In addition to a Go language generator from the golang/protobuf official package, Proto3 is presently available in Java, C++, Dart, Python, Objective-C, C#, a lite-runtime (Android Java), Ruby, and JavaScript from the protocol buffers GitHub repository. Additional languages are being developed.
Although proto2 (the current default protocol buffers version) can be used, it advises using proto3 with gRPC instead because it allows you to use all of the languages that gRPC supports and prevents incompatibilities between proto2 clients and proto3 servers.
What is gRPC?
A contemporary, open-source, high-performance Remote Procedure Call (RPC) framework that works in any setting is called gRPC. By supporting pluggable load balancing, tracing, health checking, and authentication, it may effectively connect services both within and between data centers. It can also be used to link devices, browsers, and mobile apps to backend services in the last mile of distributed computing.
A basic definition of a service
Describe your service using Protocol Buffers, a robust language and toolkit for binary serialization.
Launch swiftly and grow
Use the framework to grow to millions of RPCs per second and install the runtime and development environments with only one line.
Works on a variety of platforms and languages
For your service, automatically create idiomatic client and server stubs in several languages and platforms.
Both-way streaming and integrated authentication
Fully integrated pluggable authentication and bi-directional streaming with HTTP/2-based transport
For creating APIs, gRPC is a cutting-edge, effective, and language-neutral framework. Platform-independent service and message type design is made possible by its interface defining language (IDL), Protocol Buffers (protobuf). With gRPC, remote procedure calls (RPCs) over HTTP/2 are lightweight and highly performant, facilitating communication between services. Microservices designs benefit greatly from this since it facilitates effective and low-latency communication between services.
Features like flow control, bidirectional streaming, and automatic code generation for multiple programming languages are all provided by gRPC. When you need real-time data streaming, effective communication, and great performance, this is a good fit. gRPC may be an excellent option if your application must manage a lot of data or the client and server must communicate with low latency. However, compared to REST, it could be harder to master. Developers must specify their data structures and service methods in.proto files since gRPC uses the protobuf serialization standard.
When you put CloudFront in front of your gRPC API endpoints, we see two advantages.
Initially, it permits the decrease of latency between your API implementation and the client application. A global network of more than 600 edge locations is provided by CloudFront, with intelligent routing to the nearest edge. TLS termination and optional caching for your static content are offered by edge locations. Client application requests are sent to your gRPC origin by CloudFront via the fully managed, high-bandwidth, low-latency private AWS network.
Second, your apps gain from extra security services that are set up on edge locations, like traffic encryption, AWS Web Application Firewall’s HTTP header validation, and AWS Shield Standard defense against distributed denial of service (DDoS) assaults.
Cost and Accessibility
All of the more than 600 CloudFront edge locations offer gRPC origins at no extra cost. There are the standard requests and data transfer costs.
Read more on govindhtech.com
#CloudFront#SupportsgRPC#Applications#Google#AmazonCloudFront#distributeddenialservice#DDoS#Accessibility#ProtocolBuffers#gRPC#technology#technews#news#govindhtech
0 notes
Text
Node js V12 – What are the new features in Node js V12

Node.js has been committed about their yearly updates the new features. This year their new version — V12 named Erbium is out. Here is an honest, unbiased review. Before jumping straight into the new features of Node js V12, what Node.js is let me paint what it is and what it does. Node.js is an open source framework that runs on Chrome’s V8 JavaScript engine. It supports every OS on the market — MAC, Linux and Windows and easy on your budget.
What is Node.js?
Node.js is a platform, that supports building secure, fast and scalable network applications. Node.js is an event-driven model that doesn’t drag and is efficient for data-intensive real-time application that runs across distributed devices. Now, lets see briefly about the features in Node js V12
TLS 1.3 is now used by default Max protocol
TLS stands for Transport Layer Security, that secures communication between servers and browsers. Another notable thing about this feature is that this is the default Max protocol that offers to switch off in the CLI/NODE_OPTIONS. It is comparatively faster than TLS1.2.
Async Stack traces
Another noteworthy feature is to trace the errors of Async Stack. Previously, we won’t trace the errors in the Async await functions. Now, developers can easily do so using the asynchronous call frames of the error.stack property
Let me show you an example,
async function wait_1(x) { await wait_2(x) } async function wait_2(x) { await wait_3(x); } async function wait_3(x) { await x; throw new Error(“Oh boi”) } wait_1(1).catch(e => console.log(e.stack));

This output terminal instantly shows additional details. In this version, we can easily debug the async/wait functions.
Parser
The Node.js v12 switches default http parser to ||http that improves the llhttp-based implementation drastically.
Purpose of heap dumps
Another notable update in the Node.js V12 is the integrated heap dump capability an out of the box experience to examine the memory issues.
Heap size configuration
In V8, the max heap size was limited to 700MB and 1400MB on 32-bit and 64-bit platforms, respectively. The updated version of Node.js V12 supports automation, that ensures the heap size helps to process the large data sets.
Startup time establishment
According to the new release of Node.js V12, improves startup speed approximately 30 % for the main thread. It developed the build time for code cache in built-in libraries and embedded it as a binary. Also it improves the performance in JavaScript parsing
N-API performance in Node.js V 12
Node.js V12 supports enhanced N-API in combination with worker threads. The concept of N-API brings stable and enabled native node modules that can prevent ABI-compatibility come across various Node.js versions.
Runtime engine upgrade to 7.4
The Node.js V12 runs on V8 JavaScript engine which is upgraded to 7.4 and eventually will upgrade to 7.6. It brings the stability with the help of Application Binary Interface (ABI). Additionally, it provides high speed execution, supports ECMAScript syntax, secured memory management and so on.
Compiler
For code base, the minimum requirement of the compiler is GNU Compiler Collection (GCC) 6 and glibc 2.17 on platforms other than MAC OS and Windows. The Node.js is now fully facilitated with optimized compiler and high-level security. Nodejs.org released binaries that use a new tool-chain minimum and it provides efficient compile-time and upgraded security.
Diagnostic report
Last but not least, Node.js includes the additional feature is diagnostic report. It generates the report On-Demand that will be hit by any particular event. The user can ability to identify the abnormal termination in production such as performance, crashes, memory leaks, CPU usage, irrelevant output etc.
This article covers the noteworthy features of the Nodejs Erbium recent version.
0 notes
Text
Horse Racing Data Scraping | Scrape Horse Racing Data Daily
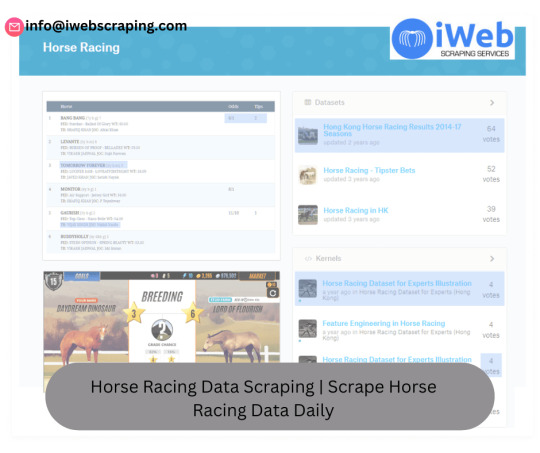
Horse racing, a sport steeped in tradition, continues to captivate audiences worldwide. Enthusiasts and bettors alike crave up-to-date information to make informed decisions. This is where horse racing data scraping comes into play. By leveraging modern technology, it's possible to scrape horse racing data daily, offering invaluable insights and a competitive edge. In this blog, we'll explore the intricacies of horse racing data scraping, its benefits, and how you can get started.
What is Horse Racing Data Scraping?
Data scraping involves extracting information from websites using automated tools. For horse racing, this means pulling data on races, horses, jockeys, track conditions, and more from various online sources. This information is then compiled into a structured format, such as a spreadsheet or database, where it can be easily analyzed.
Why Scrape Horse Racing Data?
Comprehensive Analysis: Scraping allows you to gather extensive data across multiple sources, providing a holistic view of the racing landscape. This includes historical performance, current form, and even predictive analytics.
Timeliness: Manually collecting data can be time-consuming and prone to errors. Automated scraping ensures you get the latest information daily, crucial for making timely betting decisions.
Competitive Edge: With access to detailed and up-to-date data, you can spot trends and patterns that others might miss. This can significantly improve your chances of placing successful bets.
Customization: Scraping allows you to collect data specific to your needs. Whether you're interested in particular races, horses, or statistics, you can tailor the scraping process to your preferences.
Key Data Points to Scrape
When setting up your horse racing data scraping project, focus on the following key data points:
Race Details: Date, time, location, race type, and distance.
Horse Information: Name, age, gender, breed, past performance, and current form.
Jockey Data: Name, weight, past performance, and win rates.
Trainer Statistics: Name, career statistics, recent performance, and track record.
Track Conditions: Weather, track surface, and condition ratings.
Betting Odds: Opening odds, closing odds, and fluctuations.
Tools and Techniques for Data Scraping
Python Libraries: Python offers several powerful libraries like BeautifulSoup, Scrapy, and Selenium for web scraping. BeautifulSoup is great for parsing HTML and XML documents, while Scrapy is a more robust framework for large-scale scraping projects. Selenium is useful for scraping dynamic content.
APIs: Some websites provide APIs (Application Programming Interfaces) that allow you to access their data directly. This is often a more reliable and ethical way to gather information.
Browser Extensions: Tools like Octoparse and ParseHub offer user-friendly interfaces for scraping without needing to write code. These are ideal for beginners or those who prefer a visual approach.
Database Management: Once data is scraped, tools like SQL databases or NoSQL databases (e.g., MongoDB) can help manage and analyze it effectively.
Ethical Considerations
It's important to approach data scraping ethically and legally. Here are some guidelines:
Respect Terms of Service: Always check the terms of service of the websites you plan to scrape. Some sites explicitly forbid scraping.
Rate Limiting: Avoid overwhelming a website's server with too many requests in a short period. Implement rate limiting to ensure your scraping activities don't cause disruptions.
Data Privacy: Be mindful of data privacy regulations and avoid scraping personal or sensitive information.
Getting Started
Identify Your Data Sources: Start by listing the websites and APIs that provide the data you need.
Choose Your Tools: Select the scraping tools that best fit your technical skills and project requirements.
Set Up Your Scraping Environment: Configure your development environment with the necessary libraries and tools.
Write and Test Your Scrapers: Develop your scraping scripts and test them to ensure they are extracting the correct data accurately.
Automate and Maintain: Set up automation to run your scrapers daily. Regularly monitor and update your scrapers to handle any changes in the websites' structures.
Conclusion
Horse racing data scraping offers a wealth of opportunities for enthusiasts and bettors to enhance their understanding and improve their betting strategies. By automating the data collection process, you can access timely, comprehensive, and accurate information, giving you a significant edge in the competitive world of horse racing. Whether you're a seasoned bettor or a newcomer, leveraging data scraping can take your horse racing experience to the next level.
0 notes
Note
hello! BIG HUGE FAN of your Fayde On-Air project here. I lived and died on it while I was playing the game and still regularly go back to it. I’ve been interested in potentially creating my own web-based dialogue library in a similar search-based style (not for disco, for a different game). do you have anywhere you have recounted any amount of the process, so I can know where to start and what I’m getting into (or even if this is achievable with the files I have 😭) thanks!
Sure! The FAYDE itself is open-source but with the caveat that it was kinda hacked together in the fastest way possible and much of the code it uhhhhhhnprofleshional.
So the operant questions are: what programming languages/frameworks do you know, and if none, how much Ruby of Rails are you willing to learn. And yeah, what files do you have?
Step one is to make those files into something you can parse into an SQLite database.
Step 2, for me, was the FAYDE desktop, the precursor MVP you had to actually install on a computer and run locally which I used to distribute quietly via fan discord servers. (This was partly cos I was scared of getting DMCA'd to death. Knowing how chill or unchill the company owning your target IP is is probably smart.)
1 note
·
View note
Text
Golang Project Ideas That Will Make Your Portfolio Scream "Hire Me!"

Golang, also known as Go, is an open-source programming language developed by Google. It is designed to be simple, efficient, and reliable, making it a popular choice among developers. One of the best ways to learn Golang is by building projects that allow you to apply your knowledge in a practical way.
By working on Golang projects, you can gain hands-on experience, understand different concepts, and improve your problem-solving skills. Whether you're a beginner looking to get started with Golang or an experienced developer seeking to enhance your expertise, these project ideas will provide the perfect opportunity to explore the language and push your boundaries.
Top 7 Golang Project Ideas
1. Create a Simple Web Server
Building a web server is an excellent project for beginners to get started with web development in Golang. Start by setting up a server that can handle HTTP requests and serve responses back to clients. Use the built-in "net/http" package in Golang to handle routing, HTTP methods, query parameters, and serving static files. This project will give you hands-on experience in web development and help you understand the fundamentals of building web servers.
2. Develop a To-Do List App
A To-Do List app is a classic project idea that allows you to create a simple application while learning important Golang concepts. Build features to add, delete, and track tasks, utilizing data structures and user input handling. This project will enhance your skills in developing command-line applications and give you a practical understanding of managing tasks efficiently.
3. Build a URL Shortener
Develop a web application that converts long URLs into shortened versions, making it easier to share links. This project will give you hands-on experience in web development using Golang. You'll learn how to handle HTTP requests, interact with databases, and build a useful tool that can be utilized in various contexts.
4. Create a File Encryption/Decryption Tool
Build a tool that utilizes different encryption techniques to encrypt and decrypt files. Users should be able to select the encryption technique and supply the file they want to encrypt or decrypt. This project will enhance your understanding of encryption algorithms, file handling in Golang, and command-line argument parsing.
5. Develop a CRUD API
Creating a CRUD (Create, Read, Update, Delete) API is a common project for backend developers. Build a RESTful API using Golang that can perform all CRUD operations on a database. Implement basic authentication and validation of user input to ensure data integrity. This project will give you hands-on experience in building APIs, handling HTTP methods, and JSON serialization and deserialization.
6. Build an Artificial Intelligence Chatbot
Take your Golang skills to the next level by building an AI-powered chatbot. Integrate machine learning and natural language processing technologies to create a bot that can understand and respond to user queries. Train your bot using machine learning libraries like TensorFlow or PyTorch and natural language processing libraries like NLTK or SpaCy. This project will allow you to explore the fascinating world of AI and develop a functional and responsive chatbot.
7. Create a Real-Time Messaging Application
Build a real-time messaging application using Golang and WebSockets. Users should be able to send and receive messages instantly, creating a seamless communication experience. This project will enhance your understanding of WebSockets, event-driven programming, and real-time applications.
Wrapping Up
Embarking on Golang projects is an exciting way to enhance your skills and explore the vast possibilities of the language. Whether you're a beginner or an experienced developer, these top 7 Golang project ideas will challenge your coding abilities and push you to new heights. Choose a project that aligns with your interests and start building today!
Now, it's time to unleash your creativity, dive into these Golang project ideas, and take your coding skills to new heights. Happy coding!
0 notes
Text
“Understanding Compiler Variants: An In-Depth Analysis of Various Compiler Types”
Java depends on dedicated programs to convert human-readable code into machine-understandable language. This transformation results in bytecode, a series of 0s and 1s that computers can interpret. The widely acknowledged primary Java compiler, javac, is particularly familiar to newcomers in the field. With the aid of these compilers, we can run Java programs on a variety of platforms, including Windows, Linux, and macOS. While there is flexibility in selecting a compiler, having knowledge about the availability of different compiler options can be advantageous.

Java Compiler:
• Compilers act as an intermediary between human-readable language and machine-interpretable code.
• When dealing with Java, the compiler processes the .java file, converting each class into a matching .class file that remains independent of any particular Operating System.
• As a result, Java is recognized as a platform-agnostic language. The javac compiler is tasked with converting our Java code into machine language, which is commonly referred to as bytecode.
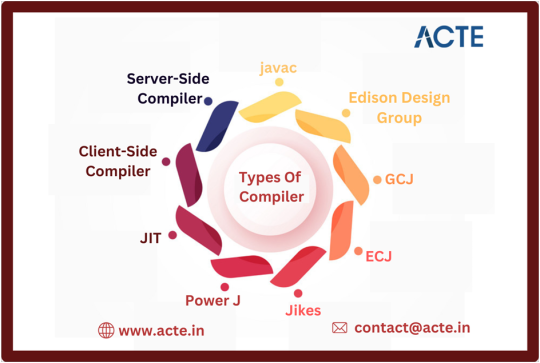
1. Javac:
· Javac stands as the standard Java compiler, primarily serving the purpose of translating Java source code into bytecode.
· It plays a pivotal role in the Java development process, enabling the execution of Java programs across various platforms.
· Javac commonly integrates with popular Integrated Development Environments (IDEs) such as Eclipse and IntelliJ IDEA.
2. Edison Design Group:
· The Edison Design Group (EDG) compiler is renowned for its preprocessing and parsing capabilities.
· It aids in optimizing code and enhancing overall software performance.
· Although it may not be as extensively integrated into IDEs as Javac, it remains a valuable tool for specific tasks related to code refinement and enhancement.
3. GCJ:
· The GNU Compiler for Java (GCJ) is a versatile compiler that not only handles Java source code but also supports other programming languages like C, C++, Fortran, and Pascal.
· While its support is confined to UNIX, GCJ serves as a useful option for developers seeking a free and multi-purpose compiler for their projects.
4. ECJ:
· The Eclipse Compiler for Java (ECJ) is seamlessly integrated with the Eclipse IDE, providing developers with a comprehensive environment for Java development.
· ECJ stands out for its distinctive approach to identifying and managing compile-time errors, allowing for quicker debugging and development cycles within the Eclipse IDE.
5. Jikes:
· Jikes, an open-source Java compiler developed at IBM, is renowned for its high-performance capabilities, especially in managing extensive projects.
· However, it lacks support for newer Java versions, making it more suitable for legacy systems operating on older versions of the Java Development Kit (JDK).
6. Power J:
· Power J is a compiler created at Sybase, now under the ownership of SAP.
· Tailored for the Windows platform, it provides developers with an efficient means to compile and execute Java code within specific development environments.
7. JIT:
· The Just-In-Time (JIT) compiler constitutes an integral component of the Java Runtime Environment (JRE), responsible for optimizing Java application performance during runtime.
· It dynamically compiles segments of bytecode into native machine code, resulting in improved execution speed and overall performance.
8. Client-Side Compilers:
· The client-side compiler (C1) concentrates on reducing the startup time of applications operating under limited resources.
· By specifically optimizing the code for client-side environments, this compiler ensures that Java applications can launch swiftly and operate efficiently, even on systems with restricted capabilities.
9. Server-Side Java Compilers:
· Server-side compilers (C2) are specifically engineered for enterprise-level applications, offering advanced optimization techniques and algorithms to enhance the performance of Java applications operating within server environments.
· These compilers facilitate the execution of intricate operations and ensure that server-side applications can effectively manage substantial workloads.
If you are looking to bolster your Java expertise, you can take advantage of the comprehensive Java learning programs offered by ACTE Technologies. Achieving mastery in Java demands consistent dedication to learning, regular practice, and unwavering commitment. ACTE Technologies provides an array of Java learning courses, complete with certifications and support for job placements, enabling you to acquire proficiency in Java. By maintaining a persistent learning routine, you can develop a strong grasp of Java and leverage its capabilities to create a wide range of applications and projects. Should you have any more questions or require further discussion on related topics, please feel free to get in touch. Your interest and support are greatly valued and inspire me to share additional valuable insights on Java.
0 notes
Text
This Week in Rust 507
Hello and welcome to another issue of This Week in Rust! Rust is a programming language empowering everyone to build reliable and efficient software. This is a weekly summary of its progress and community. Want something mentioned? Tag us at @ThisWeekInRust on Twitter or @ThisWeekinRust on mastodon.social, or send us a pull request. Want to get involved? We love contributions.
This Week in Rust is openly developed on GitHub and archives can be viewed at this-week-in-rust.org. If you find any errors in this week's issue, please submit a PR.
Updates from Rust Community
Official
2022 Annual Rust Survey Results
Security advisory for Cargo (CVE-2023-38497)
Announcing Rust 1.71.1
Rotating Rust compiler team leadership
Foundation
Announcing Speakers & Schedule for Inaugural Rust Global Event
Newsletters
This Month in Rust OSDev: July 2023
Rust Nigeria Issue 20
Project/Tooling Updates
Turbocharging Rust Code Verification
Changelog #193
This Week in Ars Militaris #5
Observations/Thoughts
No telemetry in the Rust compiler: metrics without betraying user privacy
A failed experiment with Rust static dispatch
nesting allocators
Allocator trait 1: Let’s talk about the Allocator trait
How to improve Rust compiler’s CI in 2023
Rust Pointer Metadata
Parse Prometheus Exposition format in Rust using Pest
Client-Side Server with Rust: A New Approach to UI Development
[video] Andreas Monitzer - Bevy-ECS explained - Rust Vienna June 2023
Rust Walkthroughs
Handling Rust enum variants with kinded crate
Let's Build a Cargo Compatible Build Tool - Part 1
Instrumenting Axum projects
Rust Server Components
Optimizing Rust Enum Debug-ing with Perfect Hashing
Running a Bevy game in SvelteKit
ESP32 Standard Library Embedded Rust: Timers
Miscellaneous
Shuttle Launchpad #5: Our first foray into traits!
[video] Rust API design: the curious case of Result
[video] A Tour of Iced 0.10
[video] 5 programs you can't compile with Rust
[video] Rich Terminal Interfaces with Ratatui
[video] Build a Cross Platform Mobile SDK in Rust
Crate of the Week
This week's crate is deep_causality, a hyper-geometric computational causality library.
Thanks to Marvin Hansen for the self-suggestion!
Please submit your suggestions and votes for next week!
Call for Participation
Always wanted to contribute to open-source projects but did not know where to start? Every week we highlight some tasks from the Rust community for you to pick and get started!
Some of these tasks may also have mentors available, visit the task page for more information.
zerocopy - Install OpenSSF Scorecard and consider adopting its recommendations
Ockam - Add icons to the menu items in Tauri system tray app 1
Ockam - Improve docs of ockam completion clap command to specify how to use it
Ockam - Remove unused Error enum members and avoid appearing of such members in the future 1
Hyperswitch - Add Create Merchant and Create Merchant Key Store in a DB transaction
Hyperswitch - Use proxy exclusion instead of a separate proxied client
Hyperswitch - Schedule webhook for retry
If you are a Rust project owner and are looking for contributors, please submit tasks here.
Updates from the Rust Project
417 pull requests were merged in the last week
WASI threads, implementation of wasm32-wasi-preview1-threads target
set max_atomic_width for AVR to 16
set max_atomic_width for sparc-unknown-linux-gnu to 32
re-enable atomic loads and stores for all RISC-V targets
account for Rc and Arc when suggesting to clone
account for macros when suggesting a new let binding
avoid invalid NaN lint machine-applicable suggestion in const context
avoid wrong code suggesting for attribute macro
change default panic handler message format
parser: more friendly hints for handling async move in the 2015 edition
coverage: consolidate FFI types into one module
coverage: replace ExpressionOperandId with enum Operand
detect trait upcasting through struct tail unsizing in new solver select
don't ICE on higher ranked hidden types
fix ICE failed to get layout for ReferencesError
fix invalid slice coercion suggestion reported in turbofish
fix suggestion spans for expr from macro expansions
fix the span in the suggestion of remove question mark
fix wrong span for trait selection failure error reporting
expand, rename and improve incorrect_fn_null_checks lint
improve invalid_reference_casting lint
improve diagnostic for wrong borrow on binary operations
improve spans for indexing expressions
infer type in irrefutable slice patterns with fixed length as array
interpret: fix alignment handling for Repeat expressions
make Debug representations of [Lazy, Once]*[Cell, Lock] consistent with Mutex and RwLock
make unconditional_recursion warning detect recursive drops
make lint missing-copy-implementations honor negative Copy impls
make test harness lint about unnnameable tests
only consider places with the same local in each_borrow_involving_path
only unpack tupled args in inliner if we expect args to be unpacked
const validation: point at where we found a pointer but expected an integer
optimize Iterator implementation for &mut impl Iterator + Sized
perform OpaqueCast field projection on HIR, too
remove constness from TraitPredicate
resolve before canonicalization in new solver, ICE if unresolved
resolve visibility paths as modules not as types
reword confusable_idents lint
rework upcasting confirmation to support upcasting to fewer projections in target bounds
specify macro is invalid in certain contexts
steal MIR for CTFE when possible
strip unexpected debuginfo from libLLVM.so and librustc_driver.so when not requesting any debuginfo
suggests turbofish in patterns
add allocation to SMIR
add missing rvalues to SMIR
add trait decls to SMIR
miri-script and cargo-miri cleanups
miri-script: simplify flag computation a bit
miri: fix error on dangling pointer inbounds offset
miri: add some SB and TB tests
miri: avoid infinite recursion for auto-fmt and auto-clippy
miri: tree borrows: consider some retags as writes for the purpose of data races
do not run ConstProp on mir_for_ctfe
add a new compare_bytes intrinsic instead of calling memcmp directly
some parser and AST cleanups
convert builtin "global" late lints to run per module
use parking lot's rwlock even without parallel-rustc
parent_module_from_def_id does not need to be a query
rustc_data_structures: Simplify base_n::push_str
rustc_span: Hoist lookup sorted by words out of the loop
cg_llvm: stop identifying ADTs in LLVM IR
filter out short-lived LLVM diagnostics before they reach the rustc handler
stabilize abi_thiscall
impl SliceIndex<str> for (Bound<usize>, Bound<usize>)
implement RefUnwindSafe for Backtrace
implement Option::take_if
unix/kernel_copy.rs: copy_file_range_candidate allows empty output files
regex-automata: fix incorrect offsets reported by reverse inner optimization
regex: fix memory usage regression for RegexSet with capture groups
cargo: bail out an error when using cargo: in custom build script
cargo: display crate version on timings graph
cargo: don't attempt to read a token from stdin if a cmdline token is provided
cargo: fix CVE-2023-38497 for master
cargo: fix printing multiple warning messages for unused fields in registries table
cargo: refactor: migrate to tracing
rustfmt: fix: add parenthesis around .. closure if it's a method call receiver
clippy: ptr_as_ptr: Take snippet instead of pretty printing type
clippy: redundant_type_annotations: only pass certain def kinds to type_of
clippy: unnecessary_mut_passed: don't lint in macro expansions
clippy: unwrap_used: Do not lint unwrapping on ! or never-like enums
clippy: alphabetically order arms in methods/mod.rs match
clippy: fix suspicious_xor_used_as_pow.rs performance
clippy: new lint ignored_unit_patterns
clippy: new lints: impossible_comparisons and redundant_comparisons
clippy: suppress question_mark warning if question_mark_used is not allowed
rust-analyzer: allow match to matches assist to trigger on non-literal bool arms
rust-analyzer: skip doc(hidden) default members
rust-analyzer: don't provide generate_default_from_new when impl self ty is missing
rust-analyzer: exclude non-identifier aliases from completion filtering text
rust-analyzer: added remove unused imports assist
rust-analyzer: fix unsized struct problems in mir eval
rust-analyzer: don't provide add_missing_match_arms assist when upmapping match arm list failed
rust-analyzer: remove unwraps from "Generate delegate trait"
rust-analyzer: strip unused token ids from eager macro input token maps
rust-analyzer: name change Import to Use in hir-def, add unused placeholder variants for UseId
rust-analyzer: set the default status bar action to openLogs
rust-analyzer: use the warning color when rust-analyzer is stopped
Rust Compiler Performance Triage
Overall a very positive last week, primarily due to an upgrade to LLVM 17 and some changes to lint execution. Memory usage is down 4-7% over the last week and wall times are down 3-5%.
Triage done by @simulacrum. Revision range: 828bdc2c..443c3161
2 Regressions, 7 Improvements, 2 Mixed; 2 of them in rollups 64 artifact comparisons made in total
Full report 7/22-8/1, Full report 8/1-8/8.
Approved RFCs
Changes to Rust follow the Rust RFC (request for comments) process. These are the RFCs that were approved for implementation this week:
No RFCs were approved this week.
Final Comment Period
Every week, the team announces the 'final comment period' for RFCs and key PRs which are reaching a decision. Express your opinions now.
RFCs
No RFCs entered Final Comment Period this week.
Tracking Issues & PRs
[disposition: merge] Specialize count for range iterators
[disposition: merge] Accept additional user-defined classes in fenced code blocks
[disposition: merge] Warn on inductive cycle in coherence leading to impls being considered not overlapping
[disposition: close] Named format arguments can be used as positional
[disposition: merge] Tracking Issue for const_collections_with_hasher
[disposition: merge] Document soundness of Integer -> Pointer -> Integer conversions in const contexts.
[disposition: merge] Allow explicit #[repr(Rust)]
[disposition: merge] Tracking issue for thread local Cell methods
[disposition: merge] Implement From\<OwnedFd/Handle> for ChildStdin/out/err object
New and Updated RFCs
[new] CPU feature detection in core
Call for Testing
An important step for RFC implementation is for people to experiment with the implementation and give feedback, especially before stabilization. The following RFCs would benefit from user testing before moving forward:
No RFCs issued a call for testing this week.
If you are a feature implementer and would like your RFC to appear on the above list, add the new call-for-testing label to your RFC along with a comment providing testing instructions and/or guidance on which aspect(s) of the feature need testing.
Upcoming Events
Rusty Events between 2023-08-09 - 2023-09-06 🦀
Virtual
2023-08-09 | Virtual (New York, NY, US) | Rust NYC
Helping Rust Developers See Data Dependencies in the IDE
2023-08-10 | Virtual (Berlin, DE) | Berlin.rs
Rust and Tell - August Edition
2023-08-10 | Virtual (Charlottesville, NC, US) | Charlottesville Rust Meetup
Crafting Interpreters in Rust Collaboratively
2023-08-10 | Virtual (Nuremberg, DE) | Rust Nuremberg
Rust Nürnberg online
2023-08-15 | Virtual (Berlin, DE) | OpenTechSchool Berlin
Rust Hack and Learn
2023-08-15 | Virtual (Washington, DC, US) | Rust DC
Mid-month Rustful
2023-08-16 | Virtual (Vancouver, BC, CA) | Vancouver Rust
Rust Study/Hack/Hang-out
2023-08-17 | Virtual (Linz, AT) | Rust Linz
Rust Meetup Linz - 32nd Edition
2023-08-17 | Virtual (Stuttgart, DE) | Rust Community Stuttgart
Rust Hack and Learn
2023-08-22 | Virtual (Dublin, IE) | Rust Dublin
Rust, Serverless and AWS
2023-09-05 | Virtual (Buffalo, NY, US) | Buffalo Rust Meetup
Buffalo Rust User Group, First Tuesdays
2023-09-05 | Virtual (Munich, DE) | Rust Munich
Rust Munich 2023 / 4 - hybrid
2023-09-06 | Virtual (Indianapolis, IN, US) | Indy Rust
Indy.rs - with Social Distancing
Asia
2023-08-09 | Kuala Lumpur, MY | Rust Malaysia
Rust Malaysia Meetup August 2023
2023-08-10 | Tokyo, JP | Tokyo Rust Meetup
Bring Your Laptop: The Great Oxidation Event
Europe
2023-08-17 | Reading, UK | Reading Rust Workshop
Reading Rust Meetup at Browns
2023-08-19 | Augsburg, DE | Rust Rhein-Main
Rust Frontend Workshop (Yew + WebAssembly + Axum)
2023-08-22 | Helsinki, FI | Finland Rust Meetup
Helsink Rustaceans First Gathering
2023-08-23 | London, UK | Rust London User Group
LDN Talks Aug 2023: Rust London x RNL (The next Frontier in App Development)
2023-08-24 | Aarhus, DK | Rust Aarhus
Rust Aarhus Hack and Learn at Trifork
2023-08-31 | Augsburg, DE | Rust Meetup Augsburg
Augsburg Rust Meetup #2
2023-09-05 | Munich, DE + Virtual | Rust Munich
Rust Munich 2023 / 4 - hybrid
North America
2023-08-10 | Mountain View, CA, US | Mountain View Rust Meetup
Rust Meetup at Hacker Dojo
2023-08-10 | Lehi, UT, US | Utah Rust
Building a simplified JVM in Rust
2023-08-15 | San Francisco, CA, US | San Francisco Rust Study Group
Rust Hacking in Person
2023-08-15 | Seattle, WA, US | Seattle Rust User Group Meetup
Seattle Rust User Group - August Meetup
2023-08-16 | Cambridge, MA, US | Boston Rust Meetup
Alewife Rust Lunch
2023-08-16 | Copenhagen, DK | Copenhagen Rust Community
Rust metup #39 sponsored by Fermyon
2023-08-17 | Nashville, TN, US | Seattle Rust User Group Meetup
Rust goes where it pleases. Rust on the web and embedded
2023-08-23 | Austin, TX, US | Rust ATX
Rust Lunch - Fareground
2023-08-24 | Mountain View, CA, US | Mountain View Rust Meetup
Rust Meetup at Hacker Dojo
2023-09-06 | Bellevue, WA, US | The Linux Foundation
Rust Global
Oceania
2023-08-09 | Perth, WA, AU | Rust Perth
August Meetup
2023-08-15 | Melbourne, VIC, AU | Rust Melbourne
(Hybrid - in person & online) August 2023 Rust Melbourne Meetup
If you are running a Rust event please add it to the calendar to get it mentioned here. Please remember to add a link to the event too. Email the Rust Community Team for access.
Jobs
Please see the latest Who's Hiring thread on r/rust
Quote of the Week
Claiming Rust won't help you because you're doing so many unsafe things is like claiming protective gear won't help you because you're handling so many dangerous substances.
– llogiq on twitter
llogiq feels very smug about his self-suggestion!
Please submit quotes and vote for next week!
This Week in Rust is edited by: nellshamrell, llogiq, cdmistman, ericseppanen, extrawurst, andrewpollack, U007D, kolharsam, joelmarcey, mariannegoldin, bennyvasquez.
Email list hosting is sponsored by The Rust Foundation
Discuss on r/rust
0 notes
Text
9 Top Python Frameworks for App Development (+Use Cases)
Explore here a list of Top 10 Python App Frameworks to Use in 2025:
1-Django

Django is a leading Python framework designed for building dynamic mobile and web applications with ease. It leverages a robust Object-Relational Mapping (ORM) system and follows the Model-View-Controller (MVC) pattern, ensuring clean, reusable, and easily maintainable code.
Whether you’re creating simple apps or scaling complex projects, Django’s powerful features make development faster and more efficient.
It has built-in tools like URL routing/parsing, authentication system, form validation, template engine, and caching to ensure a swift development process.
Django follows the DRY (Don’t Repeat Yourself) concept and focuses on rapid app development with a neat design.
This framework is the first choice of developers for any Python project due to its versatility, customization, scalability, deployment speed, simplicity, and compatibility with the latest Python versions.
According to a Stack Overflow survey, Django and Flask are the most popular Python software development frameworks.
Some examples popular examples of apps built with the Django framework are Instagram and Spotify.
Key Features of Django Framework:
Enables execution of automated migrations
Robust security
Enhanced web server support
Comprehensive documentation
Vast add-ins with SEO optimization
2-Flask

Flask stands out as a top-rated, open-source Python microframework known for its simplicity and efficiency. The Flask framework comes packed with features like a built-in development server, an intuitive debugger, seamless HTTP request handling, file storage capabilities, and robust client-side session support.
It has a modular and adaptable design and added compatibility with Google App Engine.
Besides Django, Flask is another popular Python framework with the Werkzeug WSGI toolkit and Jinja2 template.
Flask operates under the BSD license, ensuring simplicity and freedom for developers.
Inspired by the popular Sinatra Ruby framework, Flask combines minimalism with powerful capabilities, making it a go-to choice for building scalable and efficient web applications.
Key Features of Flask Framework:
Jinja2 templating and WSGI compliance
Unicode-based with secure cookie support
HTTP request handling capability
RESTful request dispatch handling
Built-in server development and integrated unit-testing support
Plugs into any ORM framework
3-Web2Py

Web2Py is an open-source, full-stack, and scalable Python application framework compatible with most operating systems, both mobile-based and web-based.
It is a platform-independent framework that simplifies development through an IDE that has a code editor, debugger, and single-click deployment.
Web2Py deals with data efficiently and enables swift development with MVC design but lacks configuration files on the project level.
It has a critical feature, a ticketing system that auto-generates tickets in the event of issues and enables tracking of issues and status.
Key Features of Web2py Framework:
No configuration and installation needed
Enables use of NoSQL and relational databases
Follows MVC design with consistent API for streamlining web development
Supports internationalization and role-based access control
Enable backward compatibility
Addresses security vulnerabilities and critical dangers
4-TurboGears

TurboGears is an open-source, full-stack, data-driven popular Python web app framework based on the ObjectDispatch paradigm.
It is meant to make it possible to write both small and concise applications in Minimal mode or complex applications in Full Stack mode.
TurboGears is useful for building both simple and complex apps with its features implemented as function decorators with multi-database support.
It offers high scalability and modularity with MochiKit JavaScript library integration and ToscaWidgets for seamless coordination of server deployment and front end.
Key aspects of TurboGears Framework:
MVC-style architecture
Provides command-line tools
Extensive documentation
Validation support with Form Encode
It uses pylons as a web server
Provides PasteScript templates
5-Falcon

Falcon is a reliable and secure back-end micro Python application framework used for developing highly-performing microservices, APIs, and large-scale application backends.
It is extensible and optimized with an effective code base that promotes building cleaner designs with HTTP and REST architecture.
Falcon provides effective and accurate responses for HTTP threats, vulnerabilities, and errors, unlike other Python back-end frameworks. Large firms like RackSpace, OpenStack, and LinkedIn use Falcon.
Falcon can handle most requests with similar hardware to its contemporaries and has total code coverage.
Key Features of Falcon Framework:
Intuitive routing with URL templates
Unit testing with WSGI mocks and helpers
Native HTTP error responses
Optimized and extensible code base
Upfront exception handling support
DRY request processing
Cython support for enhanced speed
6-CherryPy

CherryPy is an object-oriented, open-source, Python micro framework for rapid development with a robust configuration system. It doesn’t require an Apache server and enables the use of technologies for Cetera templating and accessing data.
CherryPy is one of the oldest Python app development frameworks mainly for web development. Applications designed with CherryPy are self-contained and operate on multi-threaded web servers. It has built-in tools for sessions, coding, and caching.
Popular examples of CherryPy apps include Hulu and Juju.
Key features of CherryPy Framework:
Runs on Android
Flexible built-in plugin system
Support for testing, profiling, and coverage
WSGI compliant
Runs on multiple HTTP servers simultaneously
Powerful configuration system
7-Tornado

It is an open-source asynchronous networking Python framework that provides URL handling, HTML support, python database application framework support, and other crucial features of every application.
Tornado is as popular as Django and Flask because of its high-performing tools and features except that it is a threaded framework instead of being WSGI-based.
It simplifies web server coding, handles thousands of open connections with concurrent users, and strongly emphasizes non-blocking I/O activities for solving C10k difficulties.
Key features of Tornado Framework:
Web templating techniques
Extensive localization and translation support
Real-time, in-the-moment services
Allows third-party authorization, authorization methods, and user authentication
Template engine built-in
HTTP client that is not blocking
8-AIOHTTP

AIOHTTP is a popular asynchronous client-side Python web development framework based on the Asyncio library. It depends on Python 3.5+ features like Async and Awaits.
AIOHTTP offers support for client and server WebSockets without the need for Callback Hell and includes request objects and routers for redirecting queries to functions.
Key Highlights of AIOHTTP Python Framework:
Provides pluggable routing
Supports HTTP servers
Supports both client and WebSockets without the callback hell.
Middleware support for web servers
Effective view building
Also, there are two main cross-platform Python mobile app frameworks
9- Kivy

Kivy is a popular open-source Python framework for mobile app development that offers rapid application development of cross-platform GUI apps.
With a graphics engine designed over OpenGL, Kivy can manage GPU-bound workloads when needed.
Kivy comes with a project toolkit that allows developers to port apps to Android and has a similar one for iOS. However, porting Python apps to iOS currently is possible with Python 2.7.
Features of Kivy Framework:
Enables custom style in rendering widgets to give a native-like feel
Enhanced consistency across different platforms with a swift and straightforward approach
Well-documented, comprehensive APIs and offers multi-touch functionalities
Source of Content
#pythonframeworkformobileappdevelopment#pythonappframework#pythonmobileapplicationframework#pythonandroidappframework#pythonandroiddevelopmentframework#pythonappdevelopmentframework#pythonapplicationdevelopmentframework#pythonlibrariesforappdevelopment#pythonmobileappdevelopmentframework#pythonsoftwaredevelopmentframework
0 notes
Text
How To Scrape & Automate Job Data From Websites?

In this article, we will scrape & automate job data from websites. Both of these tasks are achievable using several tools and libraries. Let’s have a look at each one of them.
Web Scraping: Web Scraping is a method that enables data extraction from websites and collecting them on spreadsheets or databases on a server. It is helpful for data analytics or developing bots for several purposes. Here, we will change it to small jobs scraper that can automatically run and fetch the data and help us see new scraped job offerings. The Job automate data scraper is the most used tool for this purpose.
Several different libraries help you achieve this task successfully:
Python: Both Scrapy and BeautifulSoup are the most popular used libraries for web scraping. The role of BeautifulSoup is to provide a simple interface for extracting data from HTML and XML documents. Scrapy, on the other hand, is a robust framework for building web spiders and crawling websites.
Node.js: Regarding web scraping in Node.js, Cheerio and Puppeteer are popular choices. Cheerio is a jQuery-like library that enables one to traverse and manipulate HTML. Puppeteer is a headless browser automation tool that is helpful for more complex scraping tasks.
Ruby: To perform web scraping in Ruby, Nokogiri is a commonly used library. It provides an easy-to-use interface for parsing HTML and XML documents and extracting data.
Android Automation: When it comes to performing automating tasks on Android devices, several tools and frameworks are helpful:
Puppeteer: a Node.js collection offers advanced API to switch Chromium over the DevTools Procedure. It possesses advance JavaScript and browser features.
Playwright: This library provides cross-browser automation via a single API.
Appium: Appium is an open-source tool for automating mobile apps on Android and iOS platforms. It supports multiple programming languages, including Java, Python, and Ruby, and allows you to write tests that interact with your Android app.
Thus, when it comes to scraping job websites, the best and most affordable option is to seek professional help from Job recruitment data scraping services. They are well equipped with the tricks and latest techniques that help obtain scraped job posting data and get the most relevant ones based on your needs.
Those, as mentioned earlier, are some of the few examples of the tools and frameworks required for web scraping job postings Python and Android automation. Depending upon your preference and specific requirements, you choose the one that best suits your requirements.
List of Data Fields
Job Title
Company name
Location
Job Summary
Description
Salary
Employee profiles
Job Postings
Company Profiles
Job Type
To scrape job recruitment data online, the site we are supposed to scrape is remoteok.io.
Installing Libraries: We use Puppeteer to scrape job data from the websites. To automate the scraping, we have to run the script every day. It is possible to use CronTab, a Linus time job scheduler utility. It is a headless browser API that offers the Chromium browser with easy control, similar to the other browsers.
We will use a framework generator to frame an project and the Pug template engine to show the scraped jobs via the Express server.
Inspecting the Site: The first and foremost step before scraping any site is to inspect every detail of the site content to know the process of building the script. However, scraping is a technique that mostly depends on understanding the website structure, like, how DOM is structured and which HTML Elements & attributes are important. We are using ChromeDev Tools or Mozilla Dev Tools for inspection.
Developing the Scraping Script
All async codes are handled using async/await. We will also export the primary function to the modules run to be used from outside and called from our server.
Next, we will look for the job and extract the Title, Company, and other details.
For more information, get in touch with iWeb Data Scraping now! You can also reach us for all your web scraping service and mobile app data scraping requirements.
#Scrape&AutomateJobDataFromWebsites#Jobrecruitmentdatascrapingservices#webscrapingjobpostingsPythonandAndroidautomation#Jobautomatedatascraper#scrapejobdatafromthewebsites#dataextractionfromwebsites
0 notes
Text
Five9 VoiceStream With Google Cloud CCAI Agent Assist
Google CCAI Agents Assist
Support for Google Cloud CCAI Agent Assist Integration with Five9 VoiceStream. Customers of cloud contact center provider Five9 may view their domain’s audio stream and call events in real time by subscribing to VoiceStream. This article will demonstrate how to use a Five9 gRPC streaming enabled solution to combine VoiceStream Service with Google CCAI Agents.
Using Dialoflow, Five9 cloud contact center may be coupled with Google Cloud’s Agent Assist to manage inquiries from customers and/or human agents in real time. This is a fantastic choice if you’re searching for a platform that can interpret natural language and power Five9 VoiceStream. With this connection, you’ll be able to listen in on your real-time audio interactions with ease and provide your human agents with AI-powered real-time advice.
You may also adjust and fine-tune your virtual agents to the unique needs of each consumer thanks to the connection. By improving the response speeds and tailored experiences of your human agents, you may increase customer happiness and introduce deep customization into your discussions in real time.
CCAI Agent Assist
Introducing an open-source method that combines Five9 VoiceStream with Dialogflow.
The goal at Google is to provide software that is accessible to all users. In light of this dedication, the ensuing solution is readily available and serves as a fundamental building block for integrating Five9’s audio channels for conversations with virtual agents and Google Agent Assist.
What Is The Five9 VoiceStream?
Businesses may record and examine live audio conversations at their contact centers using Five9 VoiceStream, a Real-Time Streaming service. It functions by providing real-time, high-quality audio data to a variety of applications, including analytics, artificial intelligence, and compliance monitoring systems. By offering insights during live contacts, such as detecting sentiment, recognizing client wants, or automating chores, this enables businesses to enhance customer experiences.
VoiceStream is compatible with the larger cloud-based contact center system called Five9 platform. By using real-time data from voice exchanges, it helps firms maintain regulatory compliance, increase agent performance, and improve customer experience.
Five9 VoiceStream: How it Works
It is possible to create middleware that uses Dialogflow to parse audio conversation input and provide real-time recommendations to a human agent speaking with a customer. This solution will manage two levels of communication. Using a VoiceStream subscription, the first one included Five9, and the second one utilized Dialogflow. An upcoming high-level architecture is shown in the figure below.Image Credit To Google Cloud
gRCP Voice Server
The middleware and gRCP Voice Server, as shown in the above diagram, may be developed, tested, and deployed on a fully managed platform like Cloud Run after completing the Five9 self service subscription procedure.
The following are the actors and roles in the solution:
A Five9 subscription is required to build the Five9 VoiceStream role, a gRPC client that connects to the gRPC Voice Server and streams audio from live conversations.
Receiving and processing audio streaming in two channels one for the customer and one for the human agent in accordance with the guidelines on the Five9 voice stream proto file is the responsibility of the gRCP Voice Server.
What middleware does is:
Overseeing the Dialogflow dialogue lifecycle.
Real-time suggestion answers to human agents, comprehending events from a participant (consumer or human agent), and processing conversation audio streams.
Example code for gRCP Server and Middleware.
Google Agent Assist with Five9 VoiceStream
It explained how to combine Google Agent Assist with Five9 VoiceStream in this blog article. Consider these alternative ideas:
Real-Time Call transcription: Record conversations in real time so that agents may refer to them during the conversation or use the transcripts for analysis afterwards.
Real-Time Sentiment Analysis: Sentiment Score is a feature that analyzes talks between a human agent and a customer in real-time to ascertain the emotional intent.
Agent Assist Summarization: This AI-driven Agent Assist function compiles client discussions into an automated summary. The productivity of supervisors and analysts is increased, and contact center agents are able to create better summaries with less work and less time spent reviewing previous talks for returning consumers.
CCAI Insights: Contact center interaction data is provided by CCAI Insights to assist choices and offer business-related answers in order to maximize efficiency.
Read more on govindhtech.com
#Five9VoiceStream#GoogleCloud#CCAIAgentAssist#GoogleCCAI#RealTimeStreaming#CloudRun#gRPC#Middleware#CCAIInsights#GoogleAgentAssist#gRCPVoiceServer#CCAI#technology#technews#news#govindhtech
0 notes
Text
CVE's are a tracking system for software vulnerabilities. They look like this:
CVE-2023-6209: Relative URLs starting with three slashes were incorrectly parsed, and a path-traversal "/../" part in the path could be used to override the specified host. This could contribute to security problems in web sites. This vulnerability affects Firefox < 120, Firefox ESR < 115.5.0, and Thunderbird < 115.5.
A common type of vulnerability/consequence of a vulnerability is arbitrary code execution, where an attacker can run any code they want on a machine. (Eg, imagine you have a minecraft server and by sending a malformed packet the server doesn't know how to handle, you can cause the server to run any code you want).
The weird thing is like, the function of a web browser basically *requires* you to run untrusted, potentially malicious code every day forever. Tumblr just *doesn't work* if you don't enable a ton of javascript written both by Automattic and a zillion other companies and open source projects.
And, to their credit, javascript engines are *very* good and generally do not let a website get arbitrary code execution on the machine--you can run a bitcoin miner in the browser, but you can't generally install and run a bitcoin miner on the desktop without convincing the user to install it themselves.
BUUUT, it's kinda like. okay well we've defined "every nightmarish thing you can do with javascript" to be not a critical vulnerability but an intended feature. In another world, 'this website can track your every move across the web and use it to sell that information to advertisers' is a critical-rated vulnerability, but we're so used to it.
(Obviously, some of this was inspired by chrome's ManifestV3, which in my view is another step down the trail of 'you don't own your computer and you you don't control what we put on your computer'. But ig the point of this post is that the 'original sin' that leads to stuff like mv3 happened a long time ago.)
CVE-1991-0326: Inappropriate implementation of The Internet allows a remote attacker to remotely execute code and display arbitrary malicious content via a crafted HTML page
141 notes
·
View notes
Link
App developers can now build, host, customize and scale their apps without infrastructure hassles and boilerplate code using a farfetched NodeJS framework known as Back4App.
#Open Source Backend#Best Backend Platform#Parse Framework#Parse Server Solution#Backend as a Service (BAAS)#Parse Server Hosting#Open Source Parse Server#Best App Scaling Option#Open Source Baas Framework#Parse Server Provider
1 note
·
View note