#Polybase
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
In 2020, 44% of users from Denmark used Tumblr daily.
Text
Unleashing the Power of PolyBase in SQL Server
Introduction Hey there, fellow data enthusiasts! Today, I want to share with you an incredible feature in SQL Server that has completely revolutionized the way we work with external data sources. It’s called PolyBase, and trust me, it’s a game-changer! In this article, we’ll dive deep into the world of PolyBase, exploring its capabilities, benefits, and how it can take your data querying to the…
View On WordPress
0 notes
Text
PolyBase – Bridging the Gap Between Relational and Non-Relational Data. We can use T-SQL queries to fetch data from external data sources, such as Hadoop or Azure Blob Storage. Let's Explore Deeply:
https://madesimplemssql.com/polybase/
Please follow us on FB: https://www.facebook.com/profile.php?id=100091338502392
OR
Join our Group: https://www.facebook.com/groups/652527240081844
2 notes
·
View notes
Text
Advanced Error Handling Techniques in Azure Data Factory
Azure Data Factory (ADF) is a powerful data integration tool, but handling errors efficiently is crucial for building robust data pipelines. This blog explores advanced error-handling techniques in ADF to ensure resilience, maintainability, and better troubleshooting.
1. Understanding Error Types in ADF
Before diving into advanced techniques, it’s essential to understand common error types in ADF:
Transient Errors — Temporary issues such as network timeouts or throttling.
Data Errors — Issues with source data integrity, format mismatches, or missing values.
Configuration Errors — Incorrect linked service credentials, dataset configurations, or pipeline settings.
System Failures — Service outages or failures in underlying compute resources.
2. Implementing Retry Policies for Transient Failures
ADF provides built-in retry mechanisms to handle transient errors. When configuring activities:
Enable Retries — Set the retry count and interval in activity settings.
Use Exponential Backoff — Adjust retry intervals dynamically to reduce repeated failures.
Leverage Polybase for SQL — If integrating with Azure Synapse, ensure the retry logic aligns with PolyBase behavior.
Example JSON snippet for retry settings in ADF:jsonCopyEdit"policy": { "concurrency": 1, "retry": { "count": 3, "intervalInSeconds": 30 } }
3. Using Error Handling Paths in Data Flows
Data Flows in ADF allow “Error Row Handling” settings per transformation. Options include:
Continue on Error — Skips problematic records and processes valid ones.
Redirect to Error Output — Routes bad data to a separate table or storage for investigation.
Fail on Error — Stops the execution on encountering issues.
Example: Redirecting bad records in a Derived Column transformation.
In Data Flow, select the Derived Column transformation.
Choose “Error Handling” → Redirect errors to an alternate sink.
Store bad records in a storage account for debugging.
4. Implementing Try-Catch Patterns in Pipelines
ADF doesn’t have a traditional try-catch block, but we can emulate it using:
Failure Paths — Use activity dependencies to handle failures.
Set Variables & Logging — Capture error messages dynamically.
Alerting Mechanisms — Integrate with Azure Monitor or Logic Apps for notifications.
Example: Using Failure Paths
Add a Web Activity after a Copy Activity.
Configure Web Activity to log errors in an Azure Function or Logic App.
Set the dependency condition to “Failure” for error handling.
5. Using Stored Procedures for Custom Error Handling
For SQL-based workflows, handling errors within stored procedures enhances control.
Example:sqlBEGIN TRY INSERT INTO target_table (col1, col2) SELECT col1, col2 FROM source_table; END TRY BEGIN CATCH INSERT INTO error_log (error_message, error_time) VALUES (ERROR_MESSAGE(), GETDATE()); END CATCH
Use RETURN codes to signal success/failure.
Log errors to an audit table for investigation.
6. Logging and Monitoring Errors with Azure Monitor
To track failures effectively, integrate ADF with Azure Monitor and Log Analytics.
Enable diagnostic logging in ADF.
Capture execution logs, activity failures, and error codes.
Set up alerts for critical failures.
Example: Query failed activities in Log AnalyticskustoADFActivityRun | where Status == "Failed" | project PipelineName, ActivityName, ErrorMessage, Start, End
7. Handling API & External System Failures
When integrating with REST APIs, handle external failures by:
Checking HTTP Status Codes — Use Web Activity to validate responses.
Implementing Circuit Breakers — Stop repeated API calls on consecutive failures.
Using Durable Functions — Store state for retrying failed requests asynchronously.
Example: Configure Web Activity to log failuresjson"dependsOn": [ { "activity": "API_Call", "dependencyConditions": ["Failed"] } ]
8. Leveraging Custom Logging with Azure Functions
For advanced logging and alerting:
Use an Azure Function to log errors to an external system (SQL DB, Blob Storage, Application Insights).
Pass activity parameters (pipeline name, error message) to the function.
Trigger alerts based on severity.
Conclusion
Advanced error handling in ADF involves: ✅ Retries and Exponential Backoff for transient issues. ✅ Error Redirects in Data Flows to capture bad records. ✅ Try-Catch Patterns using failure paths. ✅ Stored Procedures for custom SQL error handling. ✅ Integration with Azure Monitor for centralized logging. ✅ API and External Failure Handling for robust external connections.
By implementing these techniques, you can enhance the reliability and maintainability of your ADF pipelines. 🚀
WEBSITE: https://www.ficusoft.in/azure-data-factory-training-in-chennai/
0 notes
Text
Azure Data Engineer Course In Bangalore | Azure Data
PolyBase in Azure SQL Data Warehouse: A Comprehensive Guide
Introduction to PolyBase
PolyBase is a technology in Microsoft SQL Server and Azure Synapse Analytics (formerly Azure SQL Data Warehouse) that enables querying data stored in external sources using T-SQL. It eliminates the need for complex ETL processes by allowing seamless data integration between relational databases and big data sources such as Hadoop, Azure Blob Storage, and external databases.
PolyBase is particularly useful in Azure SQL Data Warehouse as it enables high-performance data virtualization, allowing users to query and import large datasets efficiently without moving data manually. This makes it an essential tool for organizations dealing with vast amounts of structured and unstructured data. Microsoft Azure Data Engineer

How PolyBase Works
PolyBase operates by creating external tables that act as a bridge between Azure SQL Data Warehouse and external storage. When a query is executed on an external table, PolyBase translates it into the necessary format and fetches the required data in real-time, significantly reducing data movement and enhancing query performance.
The key components of PolyBase include:
External Data Sources – Define the external system, such as Azure Blob Storage or another database.
File Format Objects – Specify the format of external data, such as CSV, Parquet, or ORC.
External Tables – Act as an interface between Azure SQL Data Warehouse and external data sources.
Data Movement Service (DMS) – Responsible for efficient data transfer during query execution. Azure Data Engineer Course
Benefits of PolyBase in Azure SQL Data Warehouse
Seamless Integration with Big Data – PolyBase enables querying data stored in Hadoop, Azure Data Lake, and Blob Storage without additional transformation.
High-Performance Data Loading – It supports parallel data ingestion, making it faster than traditional ETL pipelines.
Cost Efficiency – By reducing data movement, PolyBase minimizes the need for additional storage and processing costs.
Simplified Data Architecture – Users can analyze external data alongside structured warehouse data using a single SQL query.
Enhanced Analytics – Supports machine learning and AI-driven analytics by integrating with external data sources for a holistic view.
Using PolyBase in Azure SQL Data Warehouse
To use PolyBase effectively, follow these key steps:
Enable PolyBase – Ensure that PolyBase is activated in Azure SQL Data Warehouse, which is typically enabled by default in Azure Synapse Analytics.
Define an External Data Source – Specify the connection details for the external system, such as Azure Blob Storage or another database.
Specify the File Format – Define the format of the external data, such as CSV or Parquet, to ensure compatibility.
Create an External Table – Establish a connection between Azure SQL Data Warehouse and the external data source by defining an external table.
Query the External Table – Data can be queried seamlessly without requiring complex ETL processes once the external table is set up. Azure Data Engineer Training
Common Use Cases of PolyBase
Data Lake Integration: Enables organizations to query raw data stored in Azure Data Lake without additional data transformation.
Hybrid Data Solutions: Facilitates seamless data integration between on-premises and cloud-based storage systems.
ETL Offloading: Reduces reliance on traditional ETL tools by allowing direct data loading into Azure SQL Data Warehouse.
IoT Data Processing: Helps analyze large volumes of sensor-generated data stored in cloud storage.
Limitations of PolyBase
Despite its advantages, PolyBase has some limitations:
It does not support direct updates or deletions on external tables.
Certain data formats, such as JSON, require additional handling.
Performance may depend on network speed and the capabilities of the external data source. Azure Data Engineering Certification
Conclusion
PolyBase is a powerful Azure SQL Data Warehouse feature that simplifies data integration, reduces data movement, and enhances query performance. By enabling direct querying of external data sources, PolyBase helps organizations optimize their big data analytics workflows without costly and complex ETL processes. For businesses leveraging Azure Synapse Analytics, mastering PolyBase can lead to better data-driven decision-making and operational efficiency.
Implementing PolyBase effectively requires understanding its components, best practices, and limitations, making it a valuable tool for modern cloud-based data engineering and analytics solutions.
For More Information about Azure Data Engineer Online Training
Contact Call/WhatsApp: +91 7032290546
Visit: https://www.visualpath.in/online-azure-data-engineer-course.html
#Azure Data Engineer Course#Azure Data Engineering Certification#Azure Data Engineer Training In Hyderabad#Azure Data Engineer Training#Azure Data Engineer Training Online#Azure Data Engineer Course Online#Azure Data Engineer Online Training#Microsoft Azure Data Engineer#Azure Data Engineer Course In Bangalore#Azure Data Engineer Course In Chennai#Azure Data Engineer Training In Bangalore#Azure Data Engineer Course In Ameerpet
0 notes
Text
Understanding PolyBase and External Stages: Making Informed Decisions for Data Querying
http://securitytc.com/TC6Cxb
0 notes
Text
Oracle SQL Server: A Comprehensive Comparison and Integration Guide
Introduction:
Oracle SQL Server are two prominent relational database management systems (RDBMS) widely used in the industry. While both platforms serve the purpose of managing and storing data, they have distinct features, capabilities, and integration options. In this article, we will delve into the comparison between Oracle SQL Server and explore the possibilities of integrating these two powerful database systems.
Overview of Oracle and SQL Server:
Oracle SQL Server are industry-leading RDBMS platforms designed to handle large amounts of data efficiently. Oracle, developed by Oracle Corporation, is known for its scalability, security, and robustness. SQL Server, developed by Microsoft, is recognized for its user-friendly interface, integration with other Microsoft products, and seamless Windows compatibility.
Key Differences:
Licensing: Oracle database systems typically come with a higher upfront cost compared to SQL Server, which offers more affordable licensing options, including editions tailored for small to mid-sized businesses. However, Oracle provides extensive features and scalability, making it a preferred choice for large enterprises with complex data requirements.
Platform Compatibility: SQL Server is tightly integrated with the Windows operating system and is optimized for Windows-based environments. On the other hand, Oracle offers cross-platform compatibility, allowing it to run on various operating systems such as Windows, Linux, and Unix.
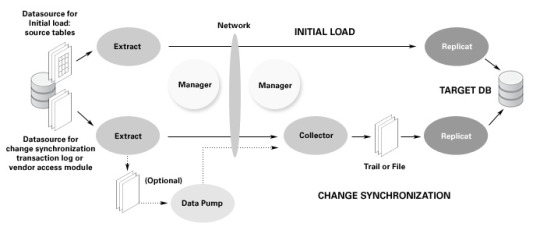
Data Replication: Oracle has a robust built-in feature called Oracle GoldenGate, which provides advanced data replication capabilities for real-time data synchronization across multiple databases. SQL Server offers similar functionality through its transactional replication feature, allowing organizations to replicate and distribute data as needed.
Performance and Scalability: Oracle is known for its exceptional performance and scalability, making it suitable for handling high-volume transactions and large databases. SQL Server also delivers good performance but may require additional tuning and optimization for specific workloads and scaling requirements.
Integration Options:
Integrating Oracle SQL Server can be beneficial for organizations that want to leverage the strengths of both platforms. Here are a few integration options:
Data Integration and ETL: Extract, Transform, Load (ETL) tools such as Oracle Data Integrator (ODI) and Microsoft SQL Server Integration Services (SSIS) facilitate seamless data movement between Oracle SQL Server databases. These tools enable data extraction, transformation, and loading operations to synchronize data across platforms.
Linked Servers: SQL Server offers a feature called Linked Servers, which allows you to establish a connection to Oracle databases from SQL Server. This enables querying Oracle data from SQL Server and performing distributed queries across both platforms.
Middleware and Integration Platforms: Middleware solutions like Oracle Fusion Middleware and Microsoft BizTalk Server provide comprehensive integration capabilities for connecting Oracle SQL Server systems. These platforms support message-based integration, data synchronization, and business process automation across heterogeneous environments.
Data Virtualization: Data virtualization tools like Denodo and SQL Server PolyBase can create a virtual layer that abstracts the underlying database systems, including Oracle SQL Server. This approach enables unified access to data from multiple sources without the need for physical data replication.
Conclusion:
Oracle SQL Server are powerful RDBMS platforms that offer distinct features and capabilities. Understanding the differences and exploring integration options between these two systems can help organizations optimize their data management strategies and leverage the strengths of each platform. Whether it's data replication, ETL processes, linked servers, middleware integration, or data virtualization, the seamless integration of Oracle SQL Server can enable organizations to achieve enhanced data interoperability and drive business success.
1 note
·
View note
Text
Microsoft has released its next data platform SQL Server 2019 for all users. Database developers can now download Developer Edition for free

#database#sql#data#sql server#sqlserver2019#sql server 2019#machine learning#polybase#data virtualization
0 notes
Text
Linked Server vs. Polybase: Choosing the Right Approach for SQL Server Data Integration
When it comes to pulling data from another Microsoft SQL Server, two popular options are Linked Server and Polybase. Both technologies enable you to access and query data from remote servers, but they have distinct differences in their implementation and use cases. In this article, we’ll explore the practical applications of Linked Server and Polybase, along with T-SQL code examples, to help you…
View On WordPress
0 notes
Text
PolyBase – Bridging the Gap Between Relational and Non-Relational Data. We can use T-SQL queries to fetch data from external data sources, such as Hadoop or Azure Blob Storage. Let's Explore Deeply:
https://madesimplemssql.com/polybase/
Please follow us on FB: https://www.facebook.com/profile.php?id=100091338502392
OR
Join our Group: https://www.facebook.com/groups/652527240081844

0 notes
Text
Building Complex Data Workflows with Azure Data Factory Mapping Data Flows

Building Complex Data Workflows with Azure Data Factory Mapping Data Flows
Azure Data Factory (ADF) Mapping Data Flows allows users to build scalable and complex data transformation workflows using a no-code or low-code approach.
This is ideal for ETL (Extract, Transform, Load) and ELT (Extract, Load, Transform) scenarios where large datasets need processing efficiently.
1. Understanding Mapping Data Flows
Mapping Data Flows in ADF provide a graphical interface for defining data transformations without writing complex code. The backend execution leverages Azure Databricks, making it highly scalable.
Key Features
✅ Drag-and-drop transformations — No need for complex scripting. ✅ Scalability with Spark — Uses Azure-managed Spark clusters for execution. ✅ Optimized data movement — Push-down optimization for SQL-based sources. ✅ Schema drift handling — Auto-adjusts to changes in source schema. ✅ Incremental data processing — Supports delta loads to process only new or changed data.
2. Designing a Complex Data Workflow
A well-structured data workflow typically involves:
📌 Step 1: Ingest Data from Multiple Sources
Connect to Azure Blob Storage, Data Lake, SQL Server, Snowflake, SAP, REST APIs, etc.
Use Self-Hosted Integration Runtime if data is on-premises.
Optimize data movement with parallel copy.
📌 Step 2: Perform Data Transformations
Join, Filter, Aggregate, and Pivot operations.
Derived columns for computed values.
Surrogate keys for primary key generation.
Flatten hierarchical data (JSON, XML).
📌 Step 3: Implement Incremental Data Processing
Use watermark columns (e.g., last updated timestamp).
Leverage Change Data Capture (CDC) for tracking updates.
Implement lookup transformations to merge new records efficiently.
📌 Step 4: Optimize Performance
Use Partitioning Strategies: Hash, Round Robin, Range-based.
Enable staging before transformations to reduce processing time.
Choose the right compute scale (low, medium, high).
Monitor debug mode to analyze execution plans.
📌 Step 5: Load Transformed Data to the Destination
Write data to Azure SQL, Synapse Analytics, Data Lake, Snowflake, Cosmos DB, etc.
Optimize data sinks by batching inserts and using PolyBase for bulk loads.
3. Best Practices for Efficient Workflows
✅ Reduce the number of transformations — Push down operations to source SQL engine when possible. ✅ Use partitioning to distribute workload across multiple nodes. ✅ Avoid unnecessary data movement — Stage data in Azure Blob instead of frequent reads/writes. ✅ Monitor with Azure Monitor — Identify bottlenecks and tune performance. ✅ Automate execution with triggers, event-driven execution, and metadata-driven pipelines.
Conclusion
Azure Data Factory Mapping Data Flows simplifies the development of complex ETL workflows with a scalable, graphical, and optimized approach.
By leveraging best practices, organizations can streamline data pipelines, reduce costs, and improve performance.
WEBSITE: https://www.ficusoft.in/azure-data-factory-training-in-chennai/
0 notes
Text
How Viruses Evolve
https://sciencespies.com/nature/how-viruses-evolve/
How Viruses Evolve

The unusual cases of pneumonia began to appear in midwinter, in China. The cause, researchers would later learn, was a coronavirus new to science. By March, the infection began to spread to other Asian countries and overseas. People were dying, and the World Health Organization issued a global health alert.
But this was 2003, not 2020, and the disease was SARS, not Covid-19. By June, the outbreak was almost gone, with just 8,098 confirmed infections and 774 deaths worldwide. No cases of SARS have been reported since 2004.
Contrast that with the closely related coronavirus that causes Covid-19 today: more than 13,600,000 confirmed cases as of July 16, and more than 585,000 deaths.
Why did SARS go away while today’s coronavirus just keeps on spreading? Why, for that matter, did both these coronaviruses spill over into people at all, from their original bat hosts?
And just as vital as those questions is another: What happens next?
As we face the current pandemic, it will be important to understand how SARS-CoV-2, the virus that causes Covid-19, is likely to evolve in the months and years ahead. It’s possible the virus could lose its lethal character and settle into an evolutionary détente with humanity. It might end up as just another cold virus, as may have happened to another coronavirus in the past. But it could also remain a serious threat or perhaps even evolve to become more lethal. The outcome depends on the complex and sometimes subtle interplay of ecological and evolutionary forces that shape how viruses and their hosts respond to one another.
“One thing you learn about evolution is never to generalize,” says Edward Holmes, an evolutionary virologist at the University of Sydney, Australia, and author of an article on the evolution of emerging viruses in the Annual Review of Ecology, Evolution, and Systematics. “It depends entirely on the biological nuance of the situation.”
Steps to viral success
Many of the scariest viruses that have caused past or current epidemics originated in other animals and then jumped to people: HIV from other primates, influenza from birds and pigs, and Ebola probably from bats. So, too, for coronaviruses: The ones behind SARS (severe acute respiratory syndrome), MERS (Middle East respiratory syndrome) and Covid-19 all probably originated in bats and arrived in people via another, stepping-stone species, likely palm civets, camels and possibly pangolins, respectively.
But making the jump from one species to another isn’t easy, because successful viruses have to be tightly adapted to their hosts. To get into a host cell, a molecule on the virus’s surface has to match a receptor on the outside of the cell, like a key fitting into a lock. Once inside the cell, the virus has to evade the cell’s immune defenses and then commandeer the appropriate parts of the host’s biochemistry to churn out new viruses. Any or all of these factors are likely to differ from one host species to another, so viruses will need to change genetically — that is, evolve — in order to set up shop in a new animal.
Pandemics — disease outbreaks of global reach — have visited humanity many times. Here are examples.
A recent mutation alters the SARS-CoV-2 spike protein to make it less fragile (the altered bits are shown as colored blobs). This added robustness appears to make the virus more infectious. Three sites are shown because the spike protein is composed of three identical subunits that bind together.
(DOE/Los Alamos National Laboratory)
Host switching actually involves two steps, though these can overlap. First, the virus has to be able to invade the new host’s cells: That’s a minimum requirement for making the host sick. But to become capable of causing epidemics, the virus also has to become infectious — that is, transmissible between individuals — in its new host. That’s what elevates a virus from an occasional nuisance to one capable of causing widespread harm.
SARS-CoV-2 shows these two stages clearly. Compared with the virus in bats, both the virus that infects people and a close relative in pangolins carry a mutation that changes the shape of the surface “ spike protein.” The alteration is right at the spot that binds to host cell receptors to let the virus in. This suggests that the mutation first arose either in pangolins or an as yet unidentified species and happened to allow the virus to jump over to people, too.
But SARS-CoV-2 carries other changes in the spike protein that appear to have arisen after it jumped to people, since they don’t occur in the bat or pangolin viruses. One is in a region called the polybasic cleavage site, which is known to make other coronaviruses and flu viruses more infectious. Another appears to make the spike protein less fragile, and in lab experiments with cell cultures, it makes the virus more infectious. The mutation has become more common as the Covid-19 pandemic goes on, which suggests — but does not prove — that it makes the virus more infectious in the real world, too. (Fortunately, though it may increase spread, it doesn’t seem to make people sicker.)
This evolutionary two-step — first spillover, then adaptation to the new host — is probably characteristic of most viruses as they shift hosts, says Daniel Streicker, a viral ecologist at the University of Glasgow. If so, emerging viruses probably pass through a “silent period” immediately after a host shift, in which the virus barely scrapes by, teetering on the brink of extinction until it acquires the mutations needed for an epidemic to bloom.
Streicker sees this in studies of rabies in bats — which is a good model for studying the evolution of emerging viruses, he says, since the rabies virus has jumped between different bat species many times. He and his colleagues looked at decades’ worth of genetic sequence data for rabies viruses that had undergone such host shifts. Since larger populations contain more genetic variants than smaller populations do, measuring genetic diversity in their samples enabled the scientists to estimate how widespread the virus was at any given time.
The team found that almost none of the 13 viral strains they studied took off immediately after switching to a new bat species. Instead, the viruses eked out a marginal existence for years to decades before they acquired the mutations — of as yet unknown function — that allowed them to burst out to epidemic levels. Not surprisingly, the viruses that emerged the fastest were those that needed the fewest genetic changes to blossom.
SARS-CoV-2 probably passed through a similar tenuous phase before it acquired the key adaptations that allowed it to flourish, perhaps the mutation to the polybasic cleavage site, perhaps others not yet identified. In any case, says Colin Parrish, a virologist at Cornell University who studies host shifts, “by the time the first person in Wuhan had been identified with coronavirus, it had probably been in people for a while.”
It was our bad luck that SARS-CoV-2 adapted successfully. Many viruses that spill over to humans never do. About 220 to 250 viruses are known to infect people, but only about half are transmissible — many only weakly — from one person to another, says Jemma Geoghegan, an evolutionary virologist at the University of Otago, New Zealand. The rest are dead-end infections. Half is a generous estimate, she adds, since many other spillover events probably fizzle out before they can even be counted.
Getting nicer — or nastier
SARS-CoV-2, of course, is well past the teetering stage. The big question now is: What happens next? One popular theory, endorsed by some experts, is that viruses often start off harming their hosts, but evolve toward a more benign coexistence. After all, many of the viruses we know of that trigger severe problems in a new host species cause mild or no disease in the host they originally came from. And from the virus’s perspective, this theory asserts, hosts that are less sick are more likely to be moving around, meeting others and spreading the infection onward.
“I believe that viruses tend to become less pathogenic,” says Burtram Fielding, a coronavirologist at the University of the Western Cape, South Africa. “The ultimate aim of a pathogen is to reproduce, to make more of itself. Any pathogen that kills the host too fast will not give itself enough time to reproduce.” If SARS-CoV-2 can spread faster and further by killing or severely harming fewer of the people it infects, we might expect that over time, it will become less harmful — or, as virologists term it, less virulent.
This kind of evolutionary gentling may be exactly what happened more than a century ago to one of the other human coronaviruses, known as OC43, Fielding suggests. Today, OC43 is one of four coronaviruses that account for up to a third of cases of the common cold (and perhaps occasionally more severe illness). But Fielding and a few others think it could also have been the virus behind a worldwide pandemic, usually ascribed to influenza, that began in 1890 and killed more than a million people worldwide, including Queen Victoria’s grandson and heir.

After rabbits were introduced to Australia, their population exploded. “They are very plentiful here,” says the handwritten inscription on the back of this postcard from around 1930. Scientists eventually introduced the myxoma virus to control the rabbit plague.
(Photographer Paul C. Nomchong / National Museum of Australia)
Scientists can’t prove that, because no virus samples survive from that pandemic, but some circumstantial evidence makes the case plausible, Fielding says. For one thing, people who were infected in the 1890 pandemic apparently experienced nervous-system symptoms we now see as more typical of coronaviruses than of influenza. And when Belgian researchers sequenced OC43’s genome in 2005 and compared it to other known coronaviruses, they concluded that it likely originated as a cattle virus and may have jumped to people right around 1890. They speculated that it may have caused the 1890 pandemic and then settled down to a less nasty coexistence as an ordinary cold virus.
Other evolutionary biologists disagree. The pandemic certainly faded as more people became immune, but there’s no solid evidence that OC43 itself evolved from highly virulent to mostly benign over the last century, they say. Even if it did, that does not mean SARS-CoV-2 will follow the same trajectory. “You can’t just say it’s going to become nicer, that somehow a well-adapted pathogen doesn’t harm its host. Modern evolutionary biology, and a lot of data, shows that doesn’t have to be true. It can get nicer, and it can get nastier,” says Andrew Read, an evolutionary microbiologist at Penn State University. (Holmes is blunter: “Trying to predict virulence evolution is a mug’s game,” he says.)
To understand why it’s so hard to predict changes in virulence, Read says it’s important to recognize the difference between virulence — that is, how sick a virus makes its host — and its transmissibility, or how easily it passes from one host individual to another. Evolution always favors increased transmissibility, because viruses that spread more easily are evolutionarily fitter — that is, they leave more descendants. But transmissibility and virulence aren’t linked in any dependable way, Read says. Some germs do just fine even if they make you very sick. The bacteria that cause cholera spread through diarrhea, so severe disease is good for them. Malaria and yellow fever, which are transmitted by mosquitos, can spread just fine even from a person at death’s door.

Funeral for a U.S. soldier who died of influenza in Russia in 1919. The 1918-1920 pandemic killed an estimated 50 million people worldwide.
(U.S. National Archives)
Respiratory viruses, like influenza and the human coronaviruses, need hosts that move around enough to breathe on one another, so extremely high virulence might be detrimental in some cases. But there’s no obvious evolutionary advantage for SARS-CoV-2 to reduce its virulence, because it pays little price for occasionally killing people: It spreads readily from infected people who are not yet feeling sick, and even from those who may never show symptoms of illness. “To be honest, the novel coronavirus is pretty fit already,” Geoghegan says.
Nor are there many documented instances of viruses whose virulence has abated over time. The rare, classic example is the myxoma virus, which was deliberately introduced to Australia in the 1950s from South America to control invasive European rabbits. Within a few decades, the virus evolved to reduce its virulence, albeit only down to 70 to 95 percent lethality from a whopping 99.8 percent. (It has since ticked up again.)
But myxoma stands nearly alone, Parrish says. For instance, he notes, there is no evidence that recent human pathogens such as Ebola, Zika or chikungunya viruses have shown any signs of becoming less pathogenic in the relatively short time since jumping to humans.

“Everyone has influenza,” reads a headline in a French publication from January 1890.
(Wellcome Collection via CC by 4.0)
The ones that went away
The faded nightmares of our past — pandemics that terrorized, then receded, such as SARS in 2003 and flu in 1918-20 and again in 1957, 1968 and 2009 — went away not because the viruses evolved to cause milder disease, but for other reasons. In the case of SARS, the virus made people sick enough that health workers were able to contain the disease before it got out of hand. “People who got SARS got very sick, very fast and were easily identified, easily tracked and readily quarantined — and their contacts were also readily identified and quarantined,” says Mark Cameron, an immunologist at Case Western Reserve University in Cleveland, who worked in a Toronto hospital during the height of the SARS outbreak there. That was never going to be as easy to do for Covid-19 because people who don’t show symptoms can spread the virus.
Flu pandemics, meanwhile, have tended to recede for another reason, one that offers more hope in our present moment: Enough of the population eventually becomes immune to slow the virus down. The H1N1 influenza virus that caused the 1918 pandemic continued as the main influenza virus until the 1950s, and its descendants still circulate in the human population. What made the virus such a threat in 1918-20 is that it was novel and people had little immunity. Once much of the population had been exposed to the virus and had developed immunity, the pandemic waned, although the virus persisted at a lower level of infections — as it does to this day. It appears less lethal now largely because older people, who are at greatest risk of dying from influenza, have usually encountered H1N1 influenza or something like it at some point in their lives and retain some degree of immunity, Read says.
With the new coronavirus, Parrish says, “we’re sort of in that 1918 period where the virus is spreading fast in a naive population.” But that will change as more people either catch Covid-19 or are vaccinated (if and when that becomes possible) and develop some level of immunity. “There’s no question that once the population is largely immune, the virus will die down,” Parrish says.
The question is how long that immunity will last: for a lifetime, like smallpox, or just a few years, like flu? In part, that will depend on whether the vaccine induces a permanent antibody response or just a temporary one. But it also depends on whether the virus can change to evade the antibodies generated by the vaccine. Although coronaviruses don’t accumulate mutations as fast as flu viruses, they do still change. And at least one, which causes bronchitis in chickens, has evolved new variants that aren’t covered by previous vaccines. But at this point, no one knows what to expect from SARS-CoV-2.
There is, at least, one encouraging aspect to all this. Even if we can’t predict how the virus will evolve or how it will respond to the coming vaccine, there is something all of us can do to reduce the risk of the virus evolving in dangerous ways. And it doesn’t involve any complicated new behaviors. “Viruses can only evolve if they’re replicating and transmitting,” Streicker says. “Anything that reduces the replication of a virus will in consequence reduce the amount of evolution that happens.” In other words, we can do our part to slow down the evolution of the Covid-19 virus by behaving exactly as we’ve been told to already to avoid catching it: Minimize contact with others, wash your hands and wear a mask.
This article originally appeared in Knowable Magazine, an independent journalistic endeavor from Annual Reviews. Sign up for the newsletter.
#Nature
3 notes
·
View notes
Text
The improvement of the polybasic furin cleavage site explained
January 17, 2025 Radagast Uncategorized 7

We’ll start at the basics. The polybasic furin cleavage site, is a region in the Spike protein of SARS-COV-2, between S1 and S2, where a bunch of basic (opposite of acidic) amino acids are found. Those amino acids encourage enzymes produced by our cells to bind there, that cut up the protein in the right way for it to perform its task.
It’s somewhat mysterious for this virus to have a polybasic furin cleavage site in the first place, because sarbeco viruses normally don’t have a polybasic furin cleavage site. It sits alone in the family tree as a black sheep, uniquely different from its relatives.
It’s not easy for a virus to just suddenly develop it either, because when it does, there will be antibodies developed against it, as it’s the sort of unusual thing associated with nasty behavior. But in case of SARS2, it’s shielded on both sides by O-linked glycans (sugar molecules), that make it difficult to develop an antibody response against it. That seems to be why its close relatives never figured out this trick in nature: Without the glycans the polybasic cleavage site is useless, without the polybasic cleavage site the glycans are pointless.
Now SARS-COV-2 is far from alone in having a polybasic cleavage site among viruses that infect us. That is in fact, how we know that polybasic cleavage sites can cause trouble. In Influenza, it has been well studied. With one basic amino acid, the viral Hemagluttinin protein that gives it entry into your cells is only going to be cleaved by an enzyme found only in your lungs (trypsin-like proteases), so it stays pretty mild.

The three basic amino acids in nature are Lysine (K), Hystidine (H) and Arginine (R). So you can just count here. We start out with just two basic amino acids apart from each other and so it’s mild. They turn threonine into Lysine and it remains mild. Another Lysine is added and now the pathogenicity increases. Finally, there is an insertion of another Arginine and now you have your five basic amino acids in a row, triggering fireworks. For another unrelated poultry virus, Newcastle disease, you see the same principle, where virulence of these viruses is reduced by removing basic amino acids from their polybasic cleavage site.
Alright, so that’s H5N1 Influenza. But do we have any reason to think it works like this in SARS-COV-2? Well, we do. The SARS-COV-2 polybasic cleavage site was known to be suboptimal and it’s a bit of a mystery why it ended up with a suboptimal variant. But when Delta emerged, its main difference was that it improved the furin cleavage site by turning 681 from Proline into Arginine. That’s what makes it more lethal. It increases its fusogenicity, its ability to spread by fusing cells together (you don’t want your cells to fuse together, unless you’re trying to have a baby). Even so, the Delta version is still considered a suboptimal cleavage site for Furin, as it needs more basic amino acids to function optimally. In H5N1 you now tend to see QRERRRKKR, so seven basic amino acids.

They’re both basic amino acids, but Arginine at -2 tends to work much better than Lysine for cleavageby many enzymes.
But this is not the only apparent improvement to the furin cleavage site we’re now seeing emerge on multiple lineages independently. One amino acid to the right, you have serine, which is being turned into Proline and Phenylalanine. This seems to result in loss of an o-linked glycan, which would make it easier for the protein to be cleaved. Except for the ones making the change to 679, the fastest growing lineages right now are those that change 680 to either proline or phenylalanine. So to me it’s pretty obvious: It’s improving the furin cleavage site.
The reason I think this will cause trouble, is because this is what we saw after H5N1 emerged in chickens in the late 90’s: It began steadily improving its polybasic cleavage site with new arginine and lysine amino acids over a period of a number of years and vaccination proved futile. And as it did, it grew increasingly deadly. It seems to be something respiratory viruses do to improve their systemic spread, that is, their ability to move beyond the surface layer tissues they would normally depend on.
It’s worth asking ourselves why this is happening now to SARS-COV-2. Why didn’t this change emerge before? Part of the answer seems to be that the virus is currently going through a bottleneck. There are relatively few people currently catching it, it has to compete with influenza and other viruses affecting the same respiratory tissues. This should now favor variants that spread systematically, hiding from the antibodies by fusing cells together and spreading through the body.
You can’t expect vaccination to stop the polybasic cleavage site from improving. This was tried in chickens, it didn’t work. In humans it may be worse, due to original antigenic sin: The ability to develop novel antibodies against the polybasic cleavage site would be hampered by pre-existing antibodies to overlapping epitopes. This is what I mean, when I say that through mass vaccination you prohibit the population from discriminating against virulence associated epitopes.
With a better polybasic furin cleavage site, you’re going to get a deadlier virus.
This is not a very digestible story, there is no villain identified, there’s no conspiracy uncovered, it’s not going to earn me any money, it doesn’t have anything to do with Zionism or the World Economic Forum and it doesn’t mention Anthony Fauci. Three people are going to read it.
But I explained it to the best of my ability and I show you my sources, I didn’t just make it up.
And it doesn’t take a genius to figure this stuff out either. You just have to take a look at what happened to the viruses that we began vaccinating chickens against: Those viruses did not disappear, but instead gradually grew deadlier and began to jump over into other species thanks to the new mutations favored by the antibody response the chickens developed.
This is not something that happens overnight, it’s a process that takes a number of years to unfold, if the problem we saw in chickens is to be our guide. We’re still in that process. The studies show that since the first Omicron wave, SARS-COV-2 has steadily been growing more virulent again, as it’s becoming steadily better able to fuse cells together again. The improvement of the polybasic cleavage site is part of that process.
Fusing cells together allows it to spread undetected by antibodies. And so, vaccination is a great way to encourage this path of evolution towards greater virulence. As most antibodies don’t manage to pass the blood-brain barrier, it also encourages greater neurovirulence. This is what you saw with H5N1: It evolved to become a very neurovirulent virus, it now kills cats by destroying the brain.
I understand none of this is very interesting to most of the population, but it just surprises me, that we see the same thing happening to SARS-COV-2 after vaccinating against it, that we witnessed happening to H5N1 after vaccinating poultry against it, but nobody seems to be very interested in where this is headed.
0 notes
Link
Check out this listing I just added to my Poshmark closet: Carhartt D89 Messenger Bag.
0 notes
Text
What is Polybase?
Polybase is a database for web3. There's a lot to unpack there.
Developers building decentralized applications face this kind of key tradeoff, wherein you increase decentralization, kind of the worse the user experience gets and it also gets more expensive.
So now you're trying to build on top of Ethereum instead of other smaller networks, and things like that.
Looking from a structured data perspective, a lot of developers just opt to store their data in traditional databases like Postgres, MongoDB, or Firebase.
And so they're kind of basically choosing UX over decentralization. Now, what Polybase does is actually solve this trade-off.
Now, developers no longer have to choose between better UX and cost versus decentralization, but they can get both.
They can build applications that have a really good user experience but are also cost-effective and decentralized.
The key kind of insight or a breakthrough here, and the reason we are able to do this is because of a new cryptography primitive called Zero-Knowledge proofs.
The way we use them is by storing data off-chain and then generating zero-knowledge proofs of that data and the permissions of that data, as proofs to the L1s on-chain.
So that way you inherit the security and decentralization of L1s, but you also get the better UX and cost-effectiveness of storing data off-chain.
Here is our whitepaper and docs for those who are interested in learning more about Polybase.
Feel free to hit us up on our discord server, if you would like to know more about what we do at Polybase.

1 note
·
View note
Text
Free SQL Server 2019 for database developers to try new features of the data platform tool from Microsoft like Polybase, Machine Learning services with R and Python, etc

0 notes