#T-SQL Code Examples
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Average visit duration of Tumblr.com is 10 mins and 25 secs.
Text
Linked Server vs. Polybase: Choosing the Right Approach for SQL Server Data Integration
When it comes to pulling data from another Microsoft SQL Server, two popular options are Linked Server and Polybase. Both technologies enable you to access and query data from remote servers, but they have distinct differences in their implementation and use cases. In this article, we’ll explore the practical applications of Linked Server and Polybase, along with T-SQL code examples, to help you…
View On WordPress
0 notes
Text
Slingshots for a Spider
I recently finished (didn't take the test, I was just stumbling through the course, open mouthed and scared) the ineffable WEB-300: Advanced Web Attacks and Exploitation, from the magnanimous OffSec, which is the preparation course for the Offensive Security Web Expert certification (OSWE). The image is a very cool digital black widow spider, which makes sense, because the course is teaching you how to be an attacker on 'the web'.

As scared as I am of spiders, I am enamored by this course. Enough to stare at it for two years then finally take it and complete it over one grueling year. It covers things like: Blind SQL Injection - setting things up in a program called Burpsuite, to repeatedly try sending various things, then clicking a button, and seeing how a website answers, whether it gives us info or errors (which is more info!)


Authentication Bypass Exploitation - skirting around the steps that websites use to make sure you are who you say you are, like taking a 'reset password' click of a button, knowing some admin's email, and getting a database to spit out the token so we can get to the website to reset the password before the admin.



and Server-Side Request Forgery - making a server (someone else's computer in charge of doing real work instead of messing around with a human) ask its connections and resources to get something for you.

Now I know what you're probably thinking: Holy cow, where to even start? If you're not thinking that, congratulations. If you are, I've the answer: Tools. No spider is eating flies without sensing, lurking, biting... this metaphor to say: No one's doing it by hand with no help.
So what tools are helpful? How do you know what's good, what's useful, what's a dime a dozen, what's only going to do part of what you want versus all of it...

Luckily the fan favorites are famous for a reason. Just about anything you'd need is already downloaded into Kali Linux, which is jam packed with much, much more than the average hacker even needs!
Tools are dependent on what you need to do. For this class we need to inspect web traffic, recover source code, analyze said code of source, and debug things remotely.
Inspecting web traffic covers SSL / TLS and HTTP. SSL is Secure Sockets Layer and TLS is Transport Layer Security. These are literally just protocols (rules! internet rules that really smart people spent a lot of time figuring out) that encrypts traffic (mixes and chops and surrounds your communication, to keep it safe and secure). HTTP is the hypertext transfer protocol, which is another set of rules that figures out how information is going to travel between devices, like computers, web servers, phones, etc.

But do you always follow the rules? Exactly. Even by accident, a lot can fall through the cracks or go wrong. Being able to see *exactly* what's happening is pivotal in *taking advantage* of what's not dotting the i's and crossing the t's.
Possibly the most famous tool for web hacking, and the obvious choice for inspecting web traffic, is Burp Suite. It gathers info, can pause in the middle of talking to websites and connections that usually happen behind the scenes in milliseconds, like manipulating HTTP requests. You can easily compare changes, decode, the list goes on.


Decompiling source code is the one where you could find a million things that all do very specific things. For example dnSpy can debug and edit .NET assemblies, like .exe or .dll files that usually *run*, and don't get cracked open and checked inside. At least not by a normal user. .NET binaries are easier to convert back to something readable because it uses runtime compiling, rather than compiling during assembly. All you have to do is de-compile. It's the difference between figuring out what's in a salad and what's in a baked loaf of bread. One's pretty easy to de-compile. The other, you'd probably not be able to guess, unless you already knew, that there are eggs in it! dnSpy decompiles assemblies so you can edit code, explore, and you can even add more features via dnSpy plugins.


Another type of code objects useful to analyze are Java ARchive or JAR files. Another decompiler that's good for JAR files is JD-GUI, which lets you inspect source code and Java class files so you can figure out how things work.


Analyzing source code is another act that can come with a lot of options. Data enters an application through a source. It's then used or it acts on its own in a 'sink'. We can either start at the sink (bottom-up approach) or with the sources (top-down approach). We could do a hybrid of these or even automate code analysis to snag low-hanging fruit and really balance between time, effort and quality. But when you have to just *look* at something with your *eyes*, most people choose VSCode. VSCode can download an incredible amount of plug ins, like remote ssh or kubernetes, it can push and pull to gitlab, examine hundreds of files with ease, search, search and replace... I could go on!

Last need is remote debugging, which really shows what an application is doing during runtime (when it's running!). Debugging can go step-by-step through huge amalgamations using breakpoints, which can continue through steps, step over a step, step INTO a step (because that step has a huge amalgamation of steps inside of it too, of course it does!), step out of that step, restart from the beginning or from a breakpoint, stop, or hot code replace. And the best part? VSCode does this too!

Remote debugging lets us debug a running process. All we need is access to the source code and debugger port on whatever remote system we happen to be working in.
Easy, right? Only a few tools and all the time in the world... WEB-300 was mostly whitebox application security, research, and learning chained attack methods. For example, you'd do three or seven steps, which incorporate two or four attacks, rather than just one. It's more realistic, as just one attack usually isn't enough to fell a giant. And here there be giants. Worry not: we've got some slingshots now.
The next step is seeing if we can get them to work!

Useful links:
(PortSwigger Ltd., 2020), https://portswigger.net/burp/documentation
(DNN Corp., 2020), https://www.dnnsoftware.com/
(0xd4d, 2020), https://github.com/0xd4d/dnSpy
(ICSharpCode , 2020), https://github.com/icsharpcode/ILSpy
(MicroSoft, 2021), https://docs.microsoft.com/en-us/dotnet/csharp/language-reference/compiler-options/command-line-building-with-csc-exe
(Wikipedia, 2021), https://en.wikipedia.org/wiki/Cross-reference
(Wikipedia, 2019), https://en.wikipedia.org/wiki/Breakpoint
(Oracle, 2020), https://docs.oracle.com/javase/tutorial/deployment/jar/manifestindex.html
(Wikipedia, 2021), https://en.wikipedia.org/wiki/Integrated_development_environment
(Microsoft, 2022), https://code.visualstudio.com/(Wikipedia, 2021), https://en.wikipedia.org/wiki/False_positives_and_false_negatives
(Oracle, 2021), https://docs.oracle.com/javase/8/docs/technotes/guides/jpda/conninv.html#Invocation
0 notes
Text
How to crack the interviews: Behavioural vs. Technical Interviews in 2025
Published by Prism HRC – Empowering Job Seekers with Modern Interview Mastery
The interview process in 2025 recruitment demands candidates to show both their suitable mindset alongside their necessary competencies as well as cultural compatibility. Companies across the globe and throughout India work to develop responsive teams of tomorrow while interviews become strict, analytical, and multifaceted assessment measures.
Our position as India’s top job consulting agency based in Borivali West Mumbai at Prism HRC has proven the value of training candidates in behavioural and technical interview skills to boost job placement success. Our success has resulted in more than 10,000+ placements combined with our partnerships with leading companies Amazon, Deloitte, and Infosys which has prepared candidates from multiple industries to master both behavioural and technical interview approaches.

Understanding the Two Sides of the Interview Coin
Technical interviews focus on hard skills—your ability to do the job based on your domain knowledge, problem-solving skills, and hands-on proficiency.
Behavioural interviews explore soft skills—how you communicate, work in teams, manage conflict, handle stress, and align with company values.
Why Both Matter in 2025
T-shaped professionals who possess deep technical skills together with broad interpersonal competence have become the standard requirement for recruiters during role selections. We teach candidates to simultaneously thrive in both specialized capabilities and general abilities so they can shine during job market competitions.
The Rise of Behavioural Interviews: What They Reveal
Behavioural questions are designed to predict future performance based on past behaviour.
Common Examples:
Tell me about a time you overcame a major challenge at work.
Describe a situation where you had to collaborate with a difficult colleague.
How do you manage deadlines under pressure?
What Employers Are Looking For:
Emotional intelligence
Self-awareness and adaptability
Conflict resolution and leadership potential
Our Tip:
Use the STAR method—Situation, Task, Action, Result—to answer every behavioural question clearly and impactfully.
The Role of Technical Interviews in 2025
Especially in fields like IT, health tech, engineering, and finance, technical interviews remain a critical filter.
Key Areas Covered:
Coding and algorithmic problem solving
Case study analysis
Domain-specific tool proficiency (e.g., Excel, SQL, Python, Tableau)
Situational decision-making
Prism HRC Advantage:
We conduct mock technical rounds, aptitude tests, and real-time coding simulations for IT job seekers—making us the best IT job recruitment agency in Mumbai.
Ananya’s Journey from Confusion to Confidence
Although skilled in technical engineering, Ananya from Pune had trouble during behavioural interviews. Through the 1:1 interview simulation program, she gained skills to organize interview responses and interpret organizational values with clear achievements presentation. Ananya currently works as a project analyst at a global manufacturing firm due to Prism's interview preparation program.

Interview Trends in 2025: What You Should Expect
AI-powered screening tools that assess eye movement, tone, and speech
Case-based behavioural questions that blend soft and hard skills
Remote interviews via platforms like Zoom or MS Teams
Gamified assessments for entry-level tech and marketing roles
We keep you prepared by integrating these trends into our interview training modules.
Why Interview Coaching with Prism HRC Works
Customized feedback based on industry and role
Video recordings to review body language and communication
Industry-specific HR simulations
Access to mentors working in Amazon, Infosys, Deloitte, TCS
Whether you're applying for a software role or a brand strategy position, we have tailored solutions that elevate your interview readiness.
It’s not just an interview. It’s your moment.
You can find your future job opportunities through interviews which provide access to developmental possibilities and meaningful professional goals. Don’t walk in unprepared. Prism HRC stands as the best recruitment agency in Mumbai where we teach candidates to excel at behavioural assessments along with technical topics through comprehensive knowledge and skill development programs.
Visit www.prismhrc.com - Based in Gorai-2, Borivali West, Mumbai - Follow us on Instagram: @jobssimplified - Connect with us on LinkedIn: Prism HRC
#InterviewTips#ITJobInterview#PrismHRC#BestRecruitmentAgencyInMumbai#BestJobConsultingAgencyInIndia#InterviewSuccessStories#SoftSkillsVsHardSkills
0 notes
Text
Top Data Analysis Methods in 2025: A Complete Guide for Beginners and Professionals

🚀 Introduction: Why Data Analysis Methods Matter Today
We live in a world overflowing with data—from social media stats and website clicks to sales transactions and customer feedback. But raw data alone is meaningless. It’s only through the use of data analysis methods that we can extract actionable insights and make informed decisions.
Whether you’re a business owner, student, analyst, or entrepreneur, understanding data analysis methods is no longer optional—it’s essential.
In this article, we’ll explore the most widely used data analysis methods, their benefits, tools, use cases, expert opinions, and FAQs—all written in a human-friendly, easy-to-understand tone.
🔍 What Are Data Analysis Methods?
Data analysis methods are systematic approaches used to examine, transform, and interpret data to discover patterns, trends, and insights. These methods range from simple descriptive statistics to complex predictive algorithms.
By using the right method, businesses and analysts can:
📈 Identify trends
💡 Solve business problems
🔮 Forecast future outcomes
🎯 Improve performance
📘 Types of Data Analysis Methods
Here’s a detailed breakdown of the major types of data analysis methods you should know in 2025:
1. Descriptive Analysis
Goal: Summarize historical data to understand what has happened. Example: Monthly revenue report, user growth trends.
Techniques Used:
Mean, median, mode
Frequency distribution
Data visualization (charts, graphs)
Best Tools: Excel, Tableau, Google Data Studio
2. Exploratory Data Analysis (EDA)
Goal: Explore the dataset to uncover initial patterns, detect outliers, and identify relationships. Example: Discovering patterns in customer purchase history.
Techniques Used:
Box plots, scatter plots, heat maps
Correlation matrix
Data cleaning
Best Tools: Python (Pandas, Matplotlib), R, Power BI
3. Inferential Analysis
Goal: Make predictions or generalizations about a larger population based on sample data. Example: Predicting election results based on sample polling.
Techniques Used:
Hypothesis testing
Confidence intervals
T-tests, chi-square tests
Best Tools: SPSS, R, Python (SciPy)
4. Diagnostic Analysis
Goal: Determine the causes of a past event or outcome. Example: Why did the bounce rate increase last month?
Techniques Used:
Root cause analysis
Regression analysis
Data mining
Best Tools: SQL, Power BI, SAS
5. Predictive Analysis
Goal: Forecast future outcomes based on historical data. Example: Predicting next month’s sales based on seasonal trends.
Techniques Used:
Machine learning (decision trees, random forest)
Time series analysis
Neural networks
Best Tools: Python (Scikit-learn, TensorFlow), IBM Watson
6. Prescriptive Analysis
Goal: Recommend actions based on predicted outcomes. Example: Suggesting product pricing for maximum profitability.
Techniques Used:
Optimization
Simulation modeling
Decision trees
Best Tools: MATLAB, Excel Solver, Gurobi
7. Quantitative Analysis
Goal: Focus on numerical data to understand trends and measure outcomes. Example: Measuring website conversion rates.
Techniques Used:
Statistical modeling
Data aggregation
Regression
8. Qualitative Analysis
Goal: Analyze non-numerical data like text, images, or videos. Example: Analyzing customer reviews or survey responses.
Techniques Used:
Sentiment analysis
Thematic coding
Content analysis
Best Tools: NVivo, Lexalytics, Google NLP API
💼 Use Cases of Data Analysis Methods in the Real World
Here’s how businesses use these methods across industries:
🛍 Retail
Method Used: Predictive & diagnostic
Purpose: Forecast demand, understand sales dips
💳 Banking
Method Used: Inferential & prescriptive
Purpose: Detect fraud, assess risk
🏥 Healthcare
Method Used: Diagnostic & descriptive
Purpose: Patient outcome analysis, treatment optimization
📱 Tech Companies
Method Used: Exploratory & predictive
Purpose: App usage patterns, churn prediction
🛠 Best Tools for Applying Data Analysis Methods
Tool NameKey FeaturesSuitable ForExcelCharts, pivot tables, formulasBeginnersPythonML, EDA, statistical analysisIntermediate to ExpertR LanguageStatistical modeling, data visualizationIntermediateTableauVisual dashboardsBusiness analystsPower BIIntegration with Microsoft appsEnterprisesSQLQuerying large datasetsData engineers
🌟 Real Reviews From Experts
“I started with Excel for simple descriptive analysis and gradually moved to Python for predictive modeling. The transition was smoother than I expected.” – Neha D., Data Analyst at a Startup
“We used prescriptive methods in Power BI to optimize our logistics routes. Saved us 20% in transport costs within three months.” – Arjun K., Supply Chain Manager
“Using EDA methods helped us detect user drop-off points in our app, which we quickly fixed.” – Priya S., UX Designer
📌 Step-by-Step Guide to Choosing the Right Data Analysis Method
Define Your Objective: What do you want to find out?
Identify Data Type: Is it qualitative or quantitative?
Choose Your Tool: Based on your team’s skill level.
Clean the Data: Remove duplicates, null values, outliers.
Apply the Method: Use the appropriate model/technique.
Visualize & Interpret: Create charts to simplify interpretation.
Take Action: Use insights to make data-driven decisions.
❓ Frequently Asked Questions (FAQs)
🔹 Q1. What is the difference between data analysis methods and data analysis techniques?
A: Methods refer to the broad approach (e.g., descriptive, predictive), while techniques are specific tools or processes (e.g., regression, clustering).
🔹 Q2. Which data analysis method should I use as a beginner?
A: Start with descriptive and exploratory analysis. These are easy to learn and highly insightful.
🔹 Q3. Do I need coding skills to use these methods?
A: Not always. Tools like Excel, Tableau, and Power BI require minimal to no coding. For advanced analysis (e.g., machine learning), coding helps.
🔹 Q4. Can I use multiple methods in one project?
A: Absolutely! Many real-world projects use a combination of methods for deeper insights.
🔹 Q5. Which is the most powerful data analysis method?
A: That depends on your goal. For forecasting, predictive analysis is powerful. For decision-making, prescriptive analysis works best.
🧠 Tips to Master Data Analysis Methods in 2025
📝 Take online courses (Coursera, Udemy, DataCamp)
💻 Practice with real datasets (Kaggle, Google Dataset Search)
🧮 Understand the math behind techniques
📊 Visualize findings to communicate better
👥 Collaborate with other analysts and teams
✅ Conclusion: Your Data, Your Power
Data is no longer just for analysts or IT professionals. In 2025, knowing how to use data analysis methods can set you apart in virtually any profession. From optimizing marketing campaigns to launching new products, these methods empower you to make data-driven decisions with confidence.
So whether you’re just starting out or looking to level up, keep experimenting, keep analyzing, and let your data tell the story.
🌐 Read more expert data analysis content at diglip7.com 📩 Have questions? Drop a comment or connect with us for consultation.
0 notes
Text
1. Regional Technical Manager l Expression of Interest t l G4S Secure Solutions South Africa Location: North West | Salary: Market Related | Posted: 18 Mar 2025 | Closes: 25 Mar 2025 | Job Type: Full Time and Permanent | Business Unit: South Africa - Secure Solutions | Region / Division: Sub-Saharan Africa | Reference: Regional Technical Manager l North WestApply now Remuneration and benefits will be commensurate with the seniority of the role and in compliance with company remuneration policy and practice. Job Introduction: Vacancy: Regional Technical Manager: Expression of Interest We are currently seeking interest for a Regional Technical Manager based in North West, reporting to the National Operations Manager. The Regional Technical Manager is responsible for managing technology for the specified region, which includes but not limited to; ad-hoc and routine maintenance, installation projects and sales & profitability. If you have a proven track record in the above mentioned field and have the ambition and tenacity to succeed in a dynamic environment, please register your CV with us as part of our talent pipeline. Kindly note, by registering your details (for this talent pool role) you indicate your interest in a possible, future relevant role within G4S South Africa. The position requires at least 3 years management experience within a related industry; preference will be given to individuals with Electronic Security Services Management experience. Role Responsibility: Effective management of the technology contract financial performance - Manage profitability of contracts with a focus on maintenance, sustainability, cost effectiveness and labour. - Initiate cost saving model and controlsGross Margin Management - Overheads control - Contract profitability - Ensuring that claims against the Company are prevented or minimized through regular customer risk assessments. - Existing Revenue GrowthManage the contract cash flow and oversight of invoice documentation and accuracy of information. Effective management of staff - Effective Organisation - Staff turnover analysis, proper allocation of staff to work flow and job requirements. - Liaison with sub-contractors re installation requirements - Development - Succession Planning and Employment Equity - Attendance of subordinates at scheduled training interventions, meeting of employment equity goals, succession planning. - Staff motivation levels - Ensuring that performance assessments of all subordinate employees are conducted, and corrective action implemented where necessary. - Ensuring that acceptable standards of behaviour at work are maintained by all subordinate employees, as required by G4S’s code of conduct and disciplinary code. - Ensuring that all disciplinary actions are conducted in compliance with Company policies and procedures. Effective management of operations - Managing the Maintenance/Project process flow and activities that has a direct/indirect impact on the outcome and success of contract - Client retention and customer service levels - Ensuring that all required formal customer meeting are scheduled, attended and minuted. - Maintenance of positive customer relationships - Quality Management/Ops Process management – adherence to quality standard - Conduct and oversee quality controls and inspections (including sub contractors) - Shared Best Practice - Specific examples of implementation of BP from other regions Effective management of business development function - New business development - Identifying new business opportunities in the region’s sphere of operations, as well as in terms of growth of business with existing customers. - Competitors evaluations - Demonstrate a thorough understanding of the competitor environment faced by the region. The Ideal Candidate: - Electronic Security Services Management (3yrs – Management or similar) - Basic understanding and working knowlegdge of: Database implementation - Microsoft SQL and Interbase/Firebird - Extensive experience and good understanding w.r.t. implementation of the following systems: - CCTV - Access Control - Alarm Systems - Experience in Sales of Corporate (Large) Projects - Control Room Service experience - Financial Management - Software Knowledge Level - Broad knowledge of Time and Attendance - Broad knowledge of Access Control - Broad knowledge of CCTV - Strong knowledge base on communication protocols i.e. TCP/IP - Hardware Knowledge Level - Time and Attendance hardware - Access Control Hardware - CCTV - Alarms - Electric Fencing - Gate Motors - Intercoms - PA Systems - Strong knowledge base on communication protocol wiring i.e. CAT5 2. Regional Technical Manager l Expression of Interest l KwaZulu Natal l G4S Secure Solutions SA Location: KwaZulu Natal | Salary: Market Related | Posted: 18 Mar 2025 | Closes: 25 Mar 2025 | Job Type: Full Time and Permanent | Business Unit: South Africa - Secure Solutions | Region / Division: Sub-Saharan Africa | Reference: Regional Technical Manager l KwaZulu NatalApply now Remuneration and benefits will be commensurate with the seniority of the role and in compliance with company remuneration policy and practice. Job Introduction: acancy: Regional Technical Manager: Expression of Interest We are currently seeking interest for a Regional Technical Manager based in KwaZulu Natal, reporting to the National Operations Manager. The Regional Technical Manager is responsible for managing technology for the specified region, which includes but not limited to; ad-hoc and routine maintenance, installation projects and sales & profitability. If you have a proven track record in the above mentioned field and have the ambition and tenacity to succeed in a dynamic environment, please register your CV with us as part of our talent pipeline. Kindly note, by registering your details (for this talent pool role) you indicate your interest in a possible, future relevant role within G4S South Africa. The position requires at least 3 years management experience within a related industry; preference will be given to individuals with Electronic Security Services Management experience. Role Responsibility: Effective management of the technology contract financial performance - Manage profitability of contracts with a focus on maintenance, sustainability, cost effectiveness and labour. - Initiate cost saving model and controlsGross Margin Management - Overheads control - Contract profitability - Ensuring that claims against the Company are prevented or minimized through regular customer risk assessments. - Existing Revenue GrowthManage the contract cash flow and oversight of invoice documentation and accuracy of information Effective management of staff - Effective Organisation - Staff turnover analysis, proper allocation of staff to work flow and job requirements. - Liaison with sub-contractors re installation requirements - Development - Succession Planning and Employment Equity - Attendance of subordinates at scheduled training interventions, meeting of employment equity goals, succession planning. - Staff motivation levels - Ensuring that performance assessments of all subordinate employees are conducted, and corrective action implemented where necessary. - Ensuring that acceptable standards of behaviour at work are maintained by all subordinate employees, as required by G4S’s code of conduct and disciplinary code. - Ensuring that all disciplinary actions are conducted in compliance with Company policies and procedures. Effective management of operations - Managing the Maintenance/Project process flow and activities that has a direct/indirect impact on the outcome and success of contract - Client retention and customer service levels - Ensuring that all required formal customer meeting are scheduled, attended and minuted. - Maintenance of positive customer relationships - Quality Management/Ops Process management – adherence to quality standard - Conduct and oversee quality controls and inspections (including sub contractors) - Shared Best Practice - Specific examples of implementation of BP from other regions Effective management of business development function - New business development - Identifying new business opportunities in the region’s sphere of operations, as well as in terms of growth of business with existing customers. - Competitors evaluations - Demonstrate a thorough understanding of the competitor environment faced by the region. The Ideal Candidate: - Electronic Security Services Management (3yrs – Management or similar) - Basic understanding and working knowlegdge of: Database implementation - Microsoft SQL and Interbase/Firebird - Extensive experience and good understanding w.r.t. implementation of the following systems: - CCTV - Access Control - Alarm Systems - Experience in Sales of Corporate (Large) Projects - Control Room Service experience - Financial Management - Software Knowledge Level - Broad knowledge of Time and Attendance - Broad knowledge of Access Control - Broad knowledge of CCTV - Strong knowledge base on communication protocols i.e. (TCP/IP) - Hardware Knowledge Level - Time and Attendance hardware - Access Control Hardware - CCTV - Alarms - Electric Fencing - Gate Motors - Intercoms - PA Systems - Strong knowledge base on communication protocol wiring i.e. CAT5. 3. Regional Technical Manager l Expression of Interest Location: Mpumalanga | Salary: Market Related | Posted: 18 Mar 2025 | Closes: 25 Mar 2025 | Job Type: Full Time and Permanent | Business Unit: South Africa - Secure Solutions | Region / Division: Sub-Saharan Africa | Reference: Regional Technical Manager l MpumalangaApply now Remuneration and benefits will be commensurate with the seniority of the role and in compliance with company remuneration policy and practice. Job Introduction: Vacancy: Regional Technical Manager: Expression of Interest We are currently seeking interest for a Regional Technical Manager based in Mpumalanga, reporting to the National Operations Manager. The Regional Technical Manager is responsible for managing technology for the specified region, which includes but not limited to; ad-hoc and routine maintenance, installation projects and sales & profitability. If you have a proven track record in the above mentioned field and have the ambition and tenacity to succeed in a dynamic environment, please register your CV with us as part of our talent pipeline. Kindly note, by registering your details (for this talent pool role) you indicate your interest in a possible, future relevant role within G4S South Africa. The position requires at least 3 years management experience within a related industry; preference will be given to individuals with Electronic Security Services Management experience. Role Responsibility: Effective management of the technology contract financial performance - Manage profitability of contracts with a focus on maintenance, sustainability, cost effectiveness and labour. - Initiate cost saving model and controlsGross Margin Management - Overheads control - Contract profitability - Ensuring that claims against the Company are prevented or minimized through regular customer risk assessments. - Existing Revenue GrowthManage the contract cash flow and oversight of invoice documentation and accuracy of information Effective management of staff - Effective Organisation - Staff turnover analysis, proper allocation of staff to work flow and job requirements. - Liaison with sub-contractors re installation requirements - Development - Succession Planning and Employment Equity - Attendance of subordinates at scheduled training interventions, meeting of employment equity goals, succession planning. - Staff motivation levels - Ensuring that performance assessments of all subordinate employees are conducted, and corrective action implemented where necessary. - Ensuring that acceptable standards of behaviour at work are maintained by all subordinate employees, as required by G4S’s code of conduct and disciplinary code. - Ensuring that all disciplinary actions are conducted in compliance with Company policies and procedures. Effective management of operations - Managing the Maintenance/Project process flow and activities that has a direct/indirect impact on the outcome and success of contract - Client retention and customer service levels - Ensuring that all required formal customer meeting are scheduled, attended and minuted. - Maintenance of positive customer relationships - Quality Management/Ops Process management – adherence to quality standard - Conduct and oversee quality controls and inspections (including sub contractors) - Shared Best Practice - Specific examples of implementation of BP from other regions Effective management of business development function - New business development - Identifying new business opportunities in the region’s sphere of operations, as well as in terms of growth of business with existing customers. - Competitors evaluations - Demonstrate a thorough understanding of the competitor environment faced by the region. The Ideal Candidate: - Electronic Security Services Management (3yrs – Management or similar) - Basic understanding and working knowlegdge of: Database implementation - Microsoft SQL and Interbase/Firebird - Extensive experience and good understanding w.r.t. implementation of the following systems: - CCTV - Access Control - Alarm Systems - Experience in Sales of Corporate (Large) Projects - Control Room Service experience - Financial Management - Software Knowledge Level - Broad knowledge of Time and Attendance - Broad knowledge of Access Control - Broad knowledge of CCTV - Strong knowledge base on communication protocols i.e. TCP/IP) - Hardware Knowledge Level - Time and Attendance hardware - Access Control Hardware - CCTV - Alarms - Electric Fencing - Gate Motors - Intercoms - PA Systems - Strong knowledge base on communication protocol wiring i.e. CAT5 ... 4. Warehouse Administrator- G4S Deposita - Midrand - South Africa Location: Midrand | Salary: Market related | Posted: 14 Mar 2025 | Closes: 18 Mar 2025 | Job Type: Full Time and Permanent | Business Unit: South Africa - Cash Solutions | Region / Division: Africa | Reference: G4S/TP/8008245/226678Apply now Remuneration and benefits will be commensurate with the seniority of the role and in compliance with company remuneration policy and practice. Job Introduction: Warehouse Administrator - G4S Deposita - Midrand- South Africa Deposita SA, a world renowned Cash Management Company Specializing in Smart Solutions For Banking, Retail & Wholesale Sectors has a vacancy for an Warehouse Administrator based at our Deposita operations in Midrand. Reporting to the Warehouse Manager, this role is responsible to manage and coordinate warehouse operations. The successful incumbent will be responsible for managing and coordinating stock, ensuring optimal stock levels and overseeing the supply chain Procedures including conducting audits and maintaining accurate records. Role Responsibility: 1. Maintain Stock : - Processing of Pastel on stock to Issue. - Processing of Stock to Production. - Processing of Stock to OPS. - Processing of BOM’s for device builds. - Consumable requirements. - Assist Team with ad hoc tasks. - Processing of Stock to Production. - Processing of BOM’s for device builds. - Ensuring all relevant procedures are followed. - Perform all aspects of stock handling (Ordering, receiving, matching documentation, packing, loading, offloading, maintaining, picking, issuing, capturing). - Accurate, efficient capturing and maintenance of the inventory management system. 2. Working Relationships: - Liaise with internal departments: Procurement, Production, Inception, Dispatch, OPS, Finance, & International. - Assist with Internal and External Audits. 3. Reporting: - Daily “Out of Stocks” on Dashboard. - Monthly Stocktakes.. - Feedback on production requirements or issues. 4. Legislation and Company Procedures: - Ensure adherence to ISO & Company policies & procedures. - Review standard processes and procedures and identify areas for improvement. - Initiate, coordinate and enforce optimal operational policies and procedures. - Adhere to all warehousing, handling and shipping legislation requirements. The Ideal Candidate: 1. Minimum qualification & Experience: - Diploma or relevant certificate supply chain will be an advantage. - A minimum of 3-5 years’ experience in a similar role. - Pastel Evolution. - Computer Literate, Strong people skills and problem-solving abilities. - Detail-oriented. - Ability to develop and implement standard operating procedures. 2. Skills & Attributes: - Knowledge of company policies and procedures. - Good understanding of Stock Control. - MS Office Computer skills. - Excellent communication skills. - Pastel Evolution. - Ability to work under pressure. - Attention to detail. About the Company: Deposita, a leading cash and payments management company based in South Africa. We protect lives and livelihoods from the harmful, costly effects of money. With less handling, temptation, error and waste, you can be more efficient, more profitable, save more and trust more. For over a decade, we have perfected the art of cash management using world-class innovation, product development, manufacturing and implementation of technology to collect, handle, process, safeguard and dispense cash. We provide tailored end-to-end cash, self-service, and payment management solutions for our customers in retail, wholesale and banking sectors through in-depth consultations. We ensure every security need is met and exceeded every step of the way. We draw from extensive knowledge and experience to design and implement cash management solutions for businesses operating in a range of sectors around the world. Through in-depth consultations, we customize our state-of-the-art technology to meet our customers’ unique business needs and achieve results. Our devices run on our industry-leading, international accredited operating platform. Your device and financial information are as secure as money in the bank. You can also monitor your device and its transactions from anywhere – completely automating your cash flow. We even incorporate existing systems and partner with current security services providers to create the best possible solution.To ensure you get the most out of your device and cash management solution, you and your staff will receive thorough training at a location that suits you. Plus, we’ll provide you with customized operating manuals to meet your business’s specific requirements. For more information on Deposita, please visit: www.deposita.co.za 5. Accountant | G4S Secure Solutions | Centurion Location: Centurion | Salary: Market Related | Posted: 14 Mar 2025 | Closes: 21 Mar 2025 | Job Type: Full Time and Permanent | Business Unit: South Africa - Secure Solutions | Region / Division: Africa | Reference: Accountant l Head Office CenturionApply now Remuneration and benefits will be commensurate with the seniority of the role and in compliance with company remuneration policy and practice. Job Introduction: G4S Secure Solutions (SA), a leading provider of integrated security management solutions, has a vacancy for an Accountant based at our operations in Centurion, reporting to the Finance Manager. Read the full article
0 notes
Text
Can You Master Data Science Without Coding? Let's Explore.
Data science is now one of the top-rated industries, as businesses depend on data to make decisions. However, a frequent question is asked by those who want to become a data scientist. Do you have the ability to learn data science without programming? The answer isn't a straightforward yes or no. It is contingent on the goals you have for your career, the tools you utilize, and the level of knowledge you have.
If you're considering the data science course in Jaipur, this article will be your guide to understanding the importance of coding and the alternative paths it offers within the field.
Is Coding Essential for Data Science?
Coding has always been the most essential skill in the field of data science. Languages such as Python, R, and SQL are used extensively for the analysis of data, machine learning, and building models for predictive analysis. However, advances in technology make it possible to complete a variety of jobs in data science without an extensive understanding of coding.
A variety of platforms and tools now provide low-code or no-code solutions that make data science easier to access. Examples include Microsoft Power BI, Tableau, and Google Data Studio, which enable users to study data and develop visualizations with no one line of code.
However, most data science courses in Jaipur require fundamental knowledge of programming, which can help if you are looking to further your career or participate in a complicated project. These courses include the basics of coding, and some focus on software that requires only minimal programming skills, making them perfect for beginners.
Careers in Data Science That Don't Require Coding
If you're not a coding expert, do not fret--you could still make a career in the field of data science. Several jobs require no programming skills:
1. Data Analyst
Data analysts, who interpret information to help businesses make more informed decisions, often use programs like Excel, Tableau, or Power BI, which don't require coding. This role is highly sought after, with many professionals who have completed the Data Science course in Jaipur choosing this path due to its high demand and easy entry requirements.
2. Business Intelligence (BI) Analyst
BI analysts utilize the data they collect to detect patterns and offer actionable insight. They depend on platforms like QlikView, Power BI, and Google Analytics, which provide easy-to-use interfaces that do not require programming.
3. Data Visualization Specialist
This job is focused on providing complicated data in a pleasing and easy-to-understand format. Data visualization experts use tools such as Tableau and Power BI to communicate their insights using graphs, charts, and visual dashboards.
4. Data Consultant
Data consultants help businesses develop data-driven strategies. Although some initiatives may require code, most are focused on data interpretation as well as strategy formulation and communications. The data science institute in Jaipur will equip students with the analytical and communication skills required for the job.
No-Code Tools for Data Science
Many tools enable you to complete data science-related tasks with no coding. There are a few options:
Tableau for data visualization and intelligence in business.
Microsoft Power Microsoft Power for interactive dashboards and reports.
Google Data Studio: This is used to create custom reports using Google data sources.
KNIME Data Analytics uses a visual workflow.
Orange: This is for data mining and machine learning using the drag-and-drop feature.
When you learn about these tools during a data science education at Jaipur, you can gain practical experience without needing extensive knowledge of coding.
Benefits of Learning Data Science Without Coding
Learning data science without coding can significantly accelerate your learning curve. Tools that do not require code are more straightforward to understand, making it easier to apply techniques in data science. This practical benefit can inspire you to delve deeper into the field and make the most of the opportunities available.
Accessibility: People with no technical background can get into the sector without learning programming.
Concentrate on Analysis With no coding required; it is possible to focus on understanding data and creating insight.
Multi-purpose: No-code tools are extensively used in all different industries, from the marketing sector to finance.
Should You Still Learn Coding?
Although it is possible to master data science with no programming knowledge, having at least a minimum knowledge of programming can help you enhance your job prospects. Coding lets you:
Automate repetitive tasks, as well as clean up processes for data.
Larger datasets are something that tools that do not code may be unable to manage.
Build custom machine-learning models.
Improve collaboration with engineers and data scientists.
Most data science training in Jaipur offers introductory coding classes, which makes it simple to acquire the necessary programming knowledge using non-code tools.
Real-Life Example: Data Science Success Without Coding
Take Sarah, who enrolled in a data science class, an experienced marketing professional who wanted to use information to boost her campaign. Without any programming experience, the woman enrolled in a data science course in Jaipur, which focused on instruments such as Tableau or Google Analytics. Within a short time, Sarah learned to analyze customer data, design visual reports, and improve her marketing tactics. She now leads an organization of data-driven marketers and has never had to code.
This case illustrates that coding is not always required to be successful in data science. The most important thing is to choose the best tools and programs that align with your objectives.
Finding the Right Data Science Course in Jaipur
If you're eager to begin your journey into data science, selecting the best education program is vital. Find a Data science institute in Jaipur with the following services:
Training hands-on using no-code and low-code equipment.
Case studies and practical projects taken from actual industry.
Professional instructors can help you throughout the process of learning.
Learning options are flexible, either online or in person.
Suppose you choose the best data science institute in Jaipur. In that case, you will learn the necessary skills to excel in your field without having to worry about complicated code or programming languages.
Final Thoughts
Can you master data science without programming? Absolutely! Thanks to the advent of tools that do not require code or low code, Data science has become easier to access than ever before. While programming can provide more significant opportunities, many jobs in data analysis, business intelligence, and visualization require little or no programming.
If you're planning to start a course that best suits your learning style and your journey, enrolling in a Data Science course in Jaipur will help you gain practical experience by using the most advanced tools available. Select the data science training in Jaipur that is in line with the way you learn, and then explore the numerous career opportunities. If you receive the proper training from an accredited data science institute in Jaipur, you can develop into a skilled professional in data science with no programming necessary!
0 notes
Text
Having spent time as both developer and DBA, I’ve been able to identify a few bits of advice for developers who are working closely with SQL Server. Applying these suggestions can help in several aspects of your work from writing more manageable source code to strengthening cross-functional relationships. Note, this isn’t a countdown – all of these are equally useful. Apply them as they make sense to your development efforts. 1 Review and Understand Connection Options In most cases, we connect to SQL Server using a “connection string.” The connection string tells the OLEDB framework where the server is, the database we intend to use, and how we intend to authenticate. Example connection string: Server=;Database=;User Id=;Password=; The common connection string options are all that is needed to work with the database server, but there are several additional options to consider that you can potentially have a need for later on. Designing a way to include them easily without having to recode, rebuild, and redeploy could land you on the “nice list” for your DBAs. Here are some of those options: ApplicationIntent: Used when you want to connect to an AlwaysOn Availability Group replica that is available in read-only mode for reporting and analytic purposes MultiSubnetFailover: Used when AlwaysOn Availability Groups or Failover Clusters are defined across different subnets. You’ll generally use a listener as your server address and set this to “true.” In the event of a failover, this will trigger more efficient and aggressive attempts to connect to the failover partner – greatly reducing the downtime associated with failover. Encrypt: Specifies that database communication is to be encrypted. This type of protection is very important in many applications. This can be used along with another connection string option to help in test and development environments TrustServerCertificate: When set to true, this allows certificate mismatches – don’t use this in production as it leaves you more vulnerable to attack. Use this resource from Microsoft to understand more about encrypting SQL Server connections 2 When Using an ORM – Look at the T-SQL Emitted There are lots of great options for ORM frameworks these days: Microsoft Entity Framework NHibernate AutoMapper Dapper (my current favorite) I’ve only listed a few, but they all have something in common. Besides many other things, they abstract away a lot of in-line writing of T-SQL commands as well as a lot of them, often onerous, tasks associated with ensuring the optimal path of execution for those commands. Abstracting these things away can be a great timesaver. It can also remove unintended syntax errors that often result from in-lining non-native code. At the same time, it can also create a new problem that has plagued DBAs since the first ORMs came into style. That problem is that the ORMs tend to generate commands procedurally, and they are sometimes inefficient for the specific task at hand. They can also be difficult to format and read on the database end and tend to be overly complex, which leads them to perform poorly under load and as systems experience growth over time. For these reasons, it is a great idea to learn how to review the T-SQL code ORMs generate and some techniques that will help shape it into something that performs better when tuning is needed. 3 Always be Prepared to “Undeploy” (aka Rollback) There aren’t many times I recall as terrible from when I served as a DBA. In fact, only one stands out as particularly difficult. I needed to be present for the deployment of an application update. This update contained quite a few database changes. There were changes to data, security, and schema. The deployment was going fine until changes to data had to be applied. Something had gone wrong, and the scripts were running into constraint issues. We tried to work through it, but in the end, a call was made to postpone and rollback deployment. That is when the nightmare started.
The builders involved were so confident with their work that they never provided a clean rollback procedure. Luckily, we had a copy-only full backup from just before we started (always take a backup!). Even in the current age of DevOps and DataOps, it is important to consider the full scope of deployments. If you’ve created scripts to deploy, then you should also provide a way to reverse the deployment. It will strengthen DBA/Developer relations simply by having it, even if you never have to use it. Summary These 3 tips may not be the most common, but they are directly from experiences I’ve had myself. I imagine some of you have had similar situations. I hope this will be a reminder to provide more connection string options in your applications, learn more about what is going on inside of your ORM frameworks, and put in a little extra effort to provide rollback options for deployments. Jason Hall has worked in technology for over 20 years. He joined SentryOne in 2006 having held positions in network administration, database administration, and software engineering. During his tenure at SentryOne, Jason has served as a senior software developer and founded both Client Services and Product Management. His diverse background with relevant technologies made him the perfect choice to build out both of these functions. As SentryOne experienced explosive growth, Jason returned to lead SentryOne Client Services, where he ensures that SentryOne customers receive the best possible end to end experience in the ever-changing world of database performance and productivity.
0 notes
Text
Mastering SQL Injection (SQLi) Protection for Symfony with Examples
Understanding and Preventing SQL Injection (SQLi) in Symfony Applications
SQL Injection (SQLi) remains one of the most common and damaging vulnerabilities affecting web applications. This guide will dive into what SQLi is, why Symfony developers should be aware of it, and practical, example-based strategies to prevent it in Symfony applications.

What is SQL Injection (SQLi)?
SQL Injection occurs when attackers can insert malicious SQL code into a query, allowing them to access, alter, or delete database data. For Symfony apps, this can happen if inputs are not properly handled. Consider the following unsafe SQL query:
php
$query = "SELECT * FROM users WHERE username = '" . $_POST['username'] . "' AND password = '" . $_POST['password'] . "'";
Here, attackers could input SQL code as the username or password, potentially gaining unauthorized access.
How to Prevent SQL Injection in Symfony
Symfony provides tools that, when used correctly, can prevent SQL Injection vulnerabilities. Here are the best practices, with examples, to secure your Symfony app.
1. Use Prepared Statements (Example Included)
Prepared statements ensure SQL queries are safely constructed by separating SQL code from user inputs. Here’s an example using Symfony's Doctrine ORM:
php
// Safe SQL query using Doctrine $repository = $this->getDoctrine()->getRepository(User::class); $user = $repository->findOneBy([ 'username' => $_POST['username'], 'password' => $_POST['password'] ]);
Doctrine’s findOneBy() automatically prepares statements, preventing SQL Injection.
2. Validate and Sanitize Input Data
Input validation restricts the type and length of data users can input. Symfony’s Validator component makes this easy:
php
use Symfony\Component\Validator\Validation; use Symfony\Component\Validator\Constraints as Assert; $validator = Validation::createValidator(); $input = $_POST['username']; $violations = $validator->validate($input, [ new Assert\Length(['max' => 20]), new Assert\Regex(['pattern' => '/^[a-zA-Z0-9_]+$/']) ]); if (count($violations) > 0) { // Handle invalid input }
In this example, only alphanumeric characters are allowed, and the input length is limited to 20 characters, reducing SQL Injection risks.
3. Use Doctrine’s Query Builder for Safe Queries
The Symfony Query Builder simplifies creating dynamic queries while automatically escaping input data. Here’s an example:
php
$qb = $this->createQueryBuilder('u'); $qb->select('u') ->from('users', 'u') ->where('u.username = :username') ->setParameter('username', $_POST['username']); $query = $qb->getQuery(); $result = $query->getResult();
By using setParameter(), Symfony binds the input parameter safely, blocking potential injection attacks.
Using Free Tools for Vulnerability Assessment
To check your application’s security, visit our Free Tools page. Here’s a snapshot of the free tools page where you can scan your website for SQL Injection vulnerabilities:

These tools help you identify security issues and provide guidance on securing your Symfony application.
Example: Vulnerability Assessment Report
Once you’ve completed a vulnerability scan, you’ll receive a detailed report outlining detected issues and recommended fixes. Here’s an example screenshot of a vulnerability assessment report generated by our free tool:

This report gives insights into potential SQL Injection vulnerabilities and steps to improve your app’s security.
Additional Resources
For more guidance on web security and SQL Injection prevention, check out our other resources:
Pentest Testing – Get expert penetration testing services.
Cyber Rely – Access comprehensive cybersecurity resources.
Conclusion
SQL Injection vulnerabilities can be effectively mitigated with the right coding practices. Symfony’s built-in tools like Doctrine, the Query Builder, and the Validator are valuable resources for safeguarding your application. Explore our free tools and vulnerability assessments to strengthen your Symfony app’s security today!
#cybersecurity#sql#sqlserver#penetration testing#pentesting#cyber security#the security breach show#data security#security
1 note
·
View note
Text
SQL Server is quickest way to your Data Analytics journey, says expert
SQL server tools get you through the whole, end-to-end ‘data ecosystem’; where you learn data engineering, data warehousing, and business intelligence all in single platform
Microsoft SQL Server is currently leading the RDBMS market with its tremendously diverse tools and services for data analytics. Whether it’s data management, analysis or reporting, you get all in one package, that too for free.
Given that SQL server provides an end-to-end exposure to the whole data ecosystem, learning SQL server is the quickest path to your data analytics journey..
Note: This career advice is for newbies just starting their analytics journey, as well as for technical geeks who wish to opt for SQL server job roles.
Table of contents
Data Ecosystem and SQL Server Tools
How can SQL Server help me begin a Career in Data Analytics?
Career Tracks to target a job role
Learn SQL Server Tools
Watch Webinar!
Data Ecosystem and SQL Server tools
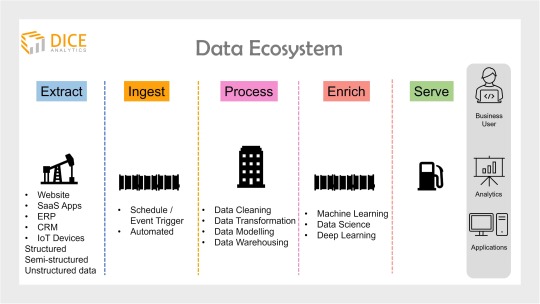
Data ecosystem is the backbone of any organization’s data analytics project.
Simply put, a data ecosystem documents and presents infrastructure and applications for data storage and processing.
Any data ecosystem portrays four to five stages of data, depending on the organization’s objectives.
Starting off, a data expert always needs to collect data from the vast sources of the organization. This includes, website data, SaaS applications, IoT devices, CRM, ERP etc.
Next, all of the data from diverse sources is gathered over a common place through a process called ingestion.
Integrated on a single database, this data needs to be cleaned, transformed and organized into a universal format (data harmonization) to avoid misalignment across the ecosystem.
This process is called data warehousing (aka data engineering).
Optional is to further enrich data using machine learning technology. One of the main data science job roles is to apply predictive analytics at this stage.
Finally, at the last stage, data is analyzed and presented to business users for value driving and decision making. A BI developer or engineer is specialized to handle data visualization at this stage.
SQL Server tools and services offer a low code environment to all of the above steps and therefore quickly and easily helps to build an end-to-end data ecosystem for an organization.
The tools and services can be broadly classified as data management and business intelligence (BI) functionalities.
For data management, SQL Server provides SQL Server Integration Services (SSIS), SQL Server Data Quality Services, and SQL Server Master Data Services.
SQL Server provides SQL Server Data tools for building a database. And for management, deployment, and monitoring the platform has SQL Server Management Studio (SSMS).
SQL Server Analysis Services (SSAS) handle data analysis.
SQL Server Reporting Services (SSRS) are used for reporting and visualization of data.
Earlier known as the R services, the Machine Learning Services came as part of SQL Server suite in 2016 and renamed afterwards.
How can SQL Server help me begin a Career in Data Analytics?
When you learn SQL Server, it exposes you to the complete data ecosystem. This helps you in your career advancement in two ways.
Access to the vast SQL Server jobs
Microsoft SQL Server currently stands at 3rd rank (after Oracle and MySQL) in the world’s most used commercial relational databases. This is because Microsoft offers an intensely feature-rich version of SQL Server for free.
This makes SQL server skills one of the most in-demand across the data analytics ecosystem.
Tip: For newbies, and those with career transitions, if you want to land on an analytics job quickly, learning SQL server tools is a smart idea since the job market is lucrative.
Further, once in, as you move along in your career we recommend growing your skill set and ascending towards more specific job roles, for example, data engineer and BI developer.
Career Tracks to target a job role
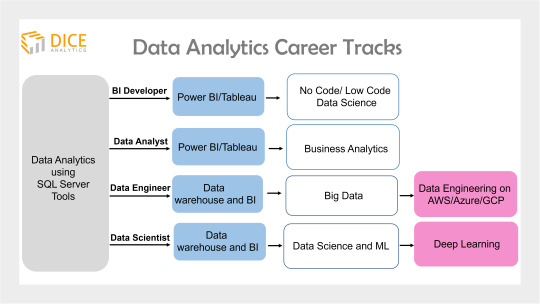
Once you get a grab of the end-to-end data analytics ecosystem, now it’s a step to move forward in your analytics journey.
But why?
Data analytics is a broad field, and carries lucrative job opportunities in the form of various job roles available in the market.
Moreover, given a myriad of job roles, you can opt for a career in the field of your interest.
What are the career tracks when I work with SQL server?
Become a Data Engineer
Once getting to know what data engineering holds, you can now opt for a vendor specific data engineering skills.
For example, Teradata is a market leader in on-premise data warehousing solutions. Learning data engineering on Teradata will offer bright career prospects in the data analytics field.
While SQL Server and Teradata RDBMS have a data architecture built for small scale data, when it comes to data volumes up to petabytes size, these solutions don’t work.
Thus a data engineer can move to learning big data technology that holds even brighter career prospects (read about the blooming big data market forecast).
Become a BI Developer/BI Engineer
This job role narrows to the data visualization, and reporting only. A BI developer is expert in BI tools such as Power BI and Tableau.
As a next step, a BI Developer can also opt for no code/low code Data Science using Knime.
Become an ML Engineer
A Machine Learning engineer uses ML technology to employ predictive analytics and finds out future trends and patterns within data.
The requirement for an ML engineer is to understand how databases and data warehousing works, and needs to build a strong foundation in that.
Next, you can opt for Deep Learning in your career journey for better positions in large enterprises.
Become a Data Analyst
After getting to work with SQL server tools, you can also opt data analyst as your career choice. This requires you to build expertise in BI tools such as Power BI and Tableau.
The next step for career advancement is to learn Business Analytics that deals with business data and marketing analytics.
You might want to view Business Analytics career prospects and salary in Pakistan.
Interested in Learning SQL Server Tools?
Dicecamp offers an 8 weeks course* on Learning SQL Server Tools.
The course covers four tools; SQL Server Integrated Services (SSIS), SQL Server Management Services (SSMS), Azure Cloud, and Power BI.
You will learn:
SQL hands-on
DWH building using SSIS
Data Management using SSMS
AZURE SQL CONFIG, DTU basics
DAX implementation in Power BI
Data visualization in Power BI
Visit complete course outline and registration details here.
*We offer flexible pricing and valuable concessions.
Straight from the Horse’s Mouth!

The instructor of this course is Mr. Abu Bakar Nisar Alvi who’s Pakistan’s celebrated engineer awarded Tamgha e Imtiaz (fourth highest civil rank) for his excellent engineering performance back in 2005.
Mr. Alvi serves as a senior IT consultant at the World Bank with key experience in enabling digital transformation as part of the village service delivery in Indonesia.
Taking two decades of experience and vast work diversity, Mr. Alvi is now associated with Dicecamp as a lead trainer Data Analytics and Visualization.
Webinar: Watch him speaking on ‘Why to Learn SQL Server Tools’ in the latest webinar (LinkedIn Webinar Link).
#dicecamp#datascience#careertest#devops#dataengineercourse#datawarehouse#devopscourse#datawarehousecourse#sqlserver#sql#mysql
1 note
·
View note
Text
Boosting SQL Server Performance with Instant File Initialization
In the fast-paced world of database administration, efficiency and speed are paramount. One often overlooked feature that can significantly enhance SQL Server performance is Instant File Initialization (IFI). This powerful capability reduces the time it takes to initialize data files, accelerating database operations such as restoring backups or adding data files to a database. Below, we explore…

View On WordPress
#database optimization#enabling instant file initialization#instant file initialization#SQL Server performance#T-SQL Code Examples
0 notes
Text
How to Crack Interviews After a Data Analytics Course in Delhi

Data Analytics is one of the most in-demand career paths today. With the rise of digital businesses, data is everywhere. Companies need skilled professionals to analyze that data and make smart decisions. If you’ve just completed a Data Analytics Course in Delhi from Uncodemy, congratulations! You’re now ready to take the next big step—cracking job interviews.
In this article, we will guide you through everything you need to know to prepare, practice, and confidently face data analytics interviews. Whether you're a fresher or someone switching careers, this guide is for you.
1. Understand What Interviewers Are Looking For
Before you sit for an interview, it’s important to know what the employer wants. In a data analytics role, most companies look for candidates who have:
Good problem-solving skills
Strong knowledge of Excel, SQL, Python, or R
Understanding of data visualization tools like Power BI or Tableau
Clear thinking and logical reasoning
Communication skills to explain data findings in simple terms
Employers want someone who can take raw data and turn it into useful insights. That means they need you to not just be good with tools but also think like a business person.
2. Build a Strong Resume
Your resume is the first thing an interviewer will see. A good resume increases your chances of getting shortlisted. Here’s how to make your resume stand out:
Keep it simple and clear:
Use bullet points
Highlight your skills, tools you know, and projects you’ve done
Focus on your data analytics skills:
Mention your knowledge in Excel, SQL, Python, Tableau, etc.
Add details about real projects or case studies you completed during the course
Include a summary at the top:
Example: “Certified Data Analytics Professional from Uncodemy with hands-on experience in SQL, Excel, and Tableau. Strong analytical skills with a passion for solving business problems using data.”
3. Practice Common Data Analytics Interview Questions
Here are some common questions you might be asked:
a. Technical Questions:
What is data cleaning?
How would you handle missing data?
What is the difference between clustered and non-clustered indexes in SQL?
How do you join two tables in SQL?
What is the difference between inner join and left join?
b. Scenario-Based Questions:
How would you help a sales team improve performance using data?
Imagine your dataset has 10% missing values. What will you do?
You found outliers in the data—what steps would you take?
c. Tools-Based Questions:
Show how to use a pivot table in Excel.
How would you create a dashboard in Tableau?
Write a Python code to find the average value of a column.
d. HR Questions:
Tell me about yourself.
Why did you choose data analytics?
Where do you see yourself in 5 years?
Practice these questions with a friend or in front of a mirror. Be confident, calm, and clear with your answers.
4. Work on Real-Time Projects
Employers love candidates who have done practical work. At Uncodemy, you may have worked on some real-time projects during your course. Be ready to talk about them in detail:
What was the project about?
What tools did you use?
What challenges did you face, and how did you solve them?
What insights did you discover?
Make sure you can explain your project like you’re telling a simple story. Use plain words—avoid too much technical jargon unless the interviewer asks.
5. Improve Your Communication Skills
Data analytics is not just about coding. You need to explain your findings in simple terms to people who don’t understand data—like managers, marketers, or sales teams.
Practice explaining:
What a graph shows
What a number means
Why a pattern in data is important
You can practice by explaining your projects to friends or family members who don’t come from a tech background.
6. Create a Portfolio
A portfolio is a great way to show your skills. It’s like an online resume that includes:
A short bio about you
Tools and skills you know
Links to your projects
Screenshots of dashboards or charts you’ve made
GitHub link (if you have code)
You can create a free portfolio using websites like GitHub, WordPress, or even a simple PDF.
7. Learn About the Company
Before your interview, always research the company. Visit their website, read about their products, services, and recent news. Try to understand what kind of data they might use.
If it's an e-commerce company, think about sales, customer data, and inventory. If it’s a finance company, think about transactions, risk analysis, and customer behavior.
Knowing about the company helps you give better answers and shows that you’re serious about the job.
8. Ask Smart Questions
At the end of most interviews, the interviewer will ask, “Do you have any questions for us?”
Always say yes!
Here are some good questions you can ask:
What kind of data projects does the team work on?
What tools do you use most often?
What are the biggest challenges your data team is facing?
How do you measure success in this role?
These questions show that you are curious, thoughtful, and serious about the role.
9. Stay Updated with Trends
Data analytics is a fast-changing field. New tools, techniques, and trends come up regularly.
Follow blogs, LinkedIn pages, YouTube channels, and news related to data analytics. Stay updated on topics like:
Artificial Intelligence (AI) and Machine Learning (ML)
Big Data
Data privacy laws
Business Intelligence trends
Being aware of current trends shows that you're passionate and committed to learning.
10. Join Communities and Networking Events
Sometimes, jobs don’t come from job portals—they come from people you know.
Join LinkedIn groups, attend webinars, career fairs, and workshops in Delhi. Connect with other data analysts. You might get job referrals, interview tips, or mentorship.
Uncodemy often conducts webinars and alumni meetups—don’t miss those events!
11. Practice Mock Interviews
Doing a few mock interviews will make a big difference. Ask a friend, mentor, or trainer from Uncodemy to help you with mock sessions.
You can also record yourself and check:
Are you speaking clearly?
Are you too fast or too slow?
Do you use filler words like “umm” or “like” too much?
The more you practice, the better you get.
12. Keep Learning
Even after finishing your course, continue to build your skills. Learn new tools, do mini-projects, and take free online courses on platforms like:
Coursera
edX
Kaggle
YouTube tutorials
Your learning journey doesn’t stop with a course. Keep growing.
Final Words from Uncodemy
Cracking a data analytics interview is not just about technical skills—it’s about being confident, clear, and curious. At Uncodemy, we aim to not just teach you the tools but also prepare you for the real world.
If you’ve taken our Data Analytics course in delhi, remember:
Practice interview questions
Build your resume and portfolio
Work on projects
Stay updated and keep learning
Don’t worry if you don’t get selected in your first few interviews. Every interview is a learning experience. Stay motivated, stay focused, and success will follow.
Good luck! Your dream data analytics job is waiting for you.
0 notes
Text
Quotes from the book Data Science on AWS
Data Science on AWS
Antje Barth, Chris Fregly
As input data, we leverage samples from the Amazon Customer Reviews Dataset [https://s3.amazonaws.com/amazon-reviews-pds/readme.html]. This dataset is a collection of over 150 million product reviews on Amazon.com from 1995 to 2015. Those product reviews and star ratings are a popular customer feature of Amazon.com. Star rating 5 is the best and 1 is the worst. We will describe and explore this dataset in much more detail in the next chapters.
*****
Let’s click Create Experiment and start our first Autopilot job. You can observe the progress of the job in the UI as shown in Figure 1-11.
--
Amazon AufotML experiments
*****
...When the Feature Engineering stage starts, you will see SageMaker training jobs appearing in the AWS Console as shown in Figure 1-13.
*****
Autopilot built to find the best performing model. You can select any of those training jobs to view the job status, configuration, parameters, and log files.
*****
The Model Tuning creates a SageMaker Hyperparameter tuning job as shown in Figure 1-15. Amazon SageMaker automatic model tuning, also known as hyperparameter tuning (HPT), is another functionality of the SageMaker service.
*****
You can find an overview of all AWS instance types supported by Amazon SageMaker and their performance characteristics here: https://aws.amazon.com/sagemaker/pricing/instance-types/. Note that those instances start with ml. in their name.
Optionally, you can enable data capture of all prediction requests and responses for your deployed model. We can now click on Deploy model and watch our model endpoint being created. Once the endpoint shows up as In Service
--
Once Autopilot find best hyperpharameters you can deploy them to save for later
*****
Here is a simple Python code snippet to invoke the endpoint. We pass a sample review (“I loved it!”) and see which star rating our model chooses. Remember, star rating 1 is the worst and star rating 5 is the best.
*****
If you prefer to interact with AWS services in a programmatic way, you can use the AWS SDK for Python boto3 [https://boto3.amazonaws.com/v1/documentation/api/latest/index.html], to interact with AWS services from your Python development environment.
*****
In the next section, we describe how you can run real-time predictions from within a SQL query using Amazon Athena.
*****
Amazon Comprehend. As input data, we leverage a subset of Amazon’s public customer reviews dataset. We want Amazon Comprehend to classify the sentiment of a provided review. The Comprehend UI is the easiest way to get started. You can paste in any text and Comprehend will analyze the input in real-time using the built-in model. Let’s test this with a sample product review such as “I loved it! I will recommend this to everyone.” as shown in Figure 1-23.
*****
mprehend Custom is another example of automated machine learning that enables the practitioner to fine-tune Comprehend’s built-in model to a specific datase
*****
We will introduce you to Amazon Athena and show you how to leverage Athena as an interactive query service to analyze data in S3 using standard SQL, without moving the data. In the first step, we will register the TSV data in our S3 bucket with Athena, and then run some ad-hoc queries on the dataset. We will also show how you can easily convert the TSV data into the more query-optimized, columnar file format Apache Parquet.
--
S3 deki datayı her zaman parquet e çevir
*****
One of the biggest advantages of data lakes is that you don’t need to pre-define any schemas. You can store your raw data at scale and then decide later in which ways you need to process and analyze it. Data Lakes may contain structured relational data, files, and any form of semi-structured and unstructured data. You can also ingest data in real time.
*****
Each of those steps involves a range of tools and technologies, and while you can build a data lake manually from the ground up, there are cloud services available to help you streamline this process, i.e. AWS Lake Formation.
Lake Formation helps you to collect and catalog data from databases and object storage, move the data into your Amazon S3 data lake, clean and classify your data using machine learning algorithms, and secure access to your sensitive data.
*****
From a data analysis perspective, another key benefit of storing your data in Amazon S3 is, that it shortens the “time to insight’ dramatically, as you can run ad-hoc queries directly on the data in S3, and you don’t have to go through complex ETL (Extract-Transform-Load) processes and data pipeli
*****
Amazon Athena is an interactive query service that makes it easy to analyze data in Amazon S3 using standard SQL. Athena is serverless, so you don’t need to manage any infrastructure, and you only pay for the queries you run.
*****
With Athena, you can query data wherever it is stored (S3 in our case) without needing to move the data to a relational database.
*****
Athena and Redshift Spectrum can use to locate and query data.
*****
Athena queries run in parallel over a dynamic, serverless cluster which makes Athena extremely fast -- even on large datasets. Athena will automatically scale the cluster depending on the query and dataset -- freeing the user from worrying about these details.
*****
Athena is based on Presto, an open source, distributed SQL query engine designed for fast, ad-hoc data analytics on large datasets. Similar to Apache Spark, Presto uses high RAM clusters to perform its queries. However, Presto does not require a large amount of disk as it is designed for ad-hoc queries (vs. automated, repeatable queries) and therefore does not perform the checkpointing required for fault-tolerance.
*****
Apache Spark is slower than Athena for many ad-hoc queries.
*****
For longer-running Athena jobs, you can listen for query-completion events using CloudWatch Events. When the query completes, all listeners are notified with the event details including query success status, total execution time, and total bytes scanned.
*****
With a functionality called Athena Federated Query, you can also run SQL queries across data stored in relational databases (such as Amazon RDS and Amazon Aurora), non-relational databases (such as Amazon DynamoDB), object storage (Amazon S3), and custom data sources. This gives you a unified analytics view across data stored in your data warehouse, data lake and operational databases without the need to actually move the data.
*****
You can access Athena via the AWS Management Console, an API, or an ODBC or JDBC driver for programmatic access. Let’s have a look at how to use Amazon Athena via the AWS Management Console.
*****
When using LIMIT, you can better-sample the rows by adding TABLESAMPLE BERNOULLI(10) after the FROM. Otherwise, you will always return the data in the same order that it was ingested into S3 which could be skewed towards a single product_category, for example. To reduce code clutter, we will just use LIMIT without TABLESAMPLE.
*****
In a next step, we will show you how you can easily convert that data now into the Apache Parquet columnar file format to improve the query performance. Parquet is optimized for columnar-based queries such as counts, sums, averages, and other aggregation-based summary statistics that focus on the column values vs. row information.
*****
selected for DATABASE and then choose “New Query” and run the following “CREATE TABLE AS” (short CTAS) SQL statement:
CREATE TABLE IF NOT EXISTS dsoaws.amazon_reviews_parquet
WITH (format = 'PARQUET', external_location = 's3://data-science-on-aws/amazon-reviews-pds/parquet', partitioned_by = ARRAY['product_category']) AS
SELECT marketplace,
*****
One of the fundamental differences between data lakes and data warehouses is that while you ingest and store huge amounts of raw, unprocessed data in your data lake, you normally only load some fraction of your recent data into your data warehouse. Depending on your business and analytics use case, this might be data from the past couple of months, a year, or maybe the past 2 years. Let’s assume we want to have the past 2 years of our Amazon Customer Reviews Dataset in a data warehouse to analyze year-over-year customer behavior and review trends. We will use Amazon Redshift as our data warehouse for this.
*****
Amazon Redshift is a fully managed data warehouse which allows you to run complex analytic queries against petabytes of structured data. Your queries are distributed and parallelized across multiple nodes. In contrast to relational databases which are optimized to store data in rows and mostly serve transactional applications, Redshift implements columnar data storage which is optimized for analytical applications where you are mostly interested in the data within the individual columns.
*****
Redshift Spectrum, which allows you to directly execute SQL queries from Redshift against exabytes of unstructured data in your Amazon S3 data lake without the need to physically move the data. Amazon Redshift Spectrum automatically scales the compute resources needed based on how much data is being received, so queries against Amazon S3 run fast, regardless of the size of your data.
*****
We will use Amazon Redshift Spectrum to access our data in S3, and then show you how you can combine data that is stored in Redshift with data that is still in S3.
This might sound similar to the approach we showed earlier with Amazon Athena, but note that in this case we show how your Business Intelligence team can enrich their queries with data that is not stored in the data warehouse itself.
*****
So with just one command, we now have access and can query our S3 data lake from Amazon Redshift without moving any data into our data warehouse. This is the power of Redshift Spectrum.
But now, let’s actually copy some data from S3 into Amazon Redshift. Let’s pull in customer reviews data from the year 2015.
*****
You might ask yourself now, when should I use Athena, and when should I use Redshift? Let’s discuss.
*****
Amazon Athena should be your preferred choice when running ad-hoc SQL queries on data that is stored in Amazon S3. It doesn’t require you to set up or manage any infrastructure resources, and you don’t need to move any data. It supports structured, unstructured, and semi-structured data. With Athena, you are defining a “schema on read” -- you basically just log in, create a table and you are good to go.
Amazon Redshift is targeted for modern data analytics on large, peta-byte scale, sets of structured data. Here, you need to have a predefined “schema on write”. Unlike serverless Athena, Redshift requires you to create a cluster (compute and storage resources), ingest the data and build tables before you can start to query, but caters to performance and scale. So for any highly-relational data with a transactional nature (data gets updated), workloads which involve complex joins, and latency requirements to be sub-second, Redshift is the right choice.
*****
But how do you know which objects to move? Imagine your S3 data lake has grown over time, and you might have billions of objects across several S3 buckets in S3 Standard storage class. Some of those objects are extremely important, while you haven’t accessed others maybe in months or even years. This is where S3 Intelligent-Tiering comes into play.
Amazon S3 Intelligent-Tiering, automatically optimizes your storage cost for data with changing access patterns by moving objects between the frequent-access tier optimized for frequent use of data, and the lower-cost infrequent-access tier optimized for less-accessed data.
*****
Amazon Athena offers ad-hoc, serverless SQL queries for data in S3 without needing to setup, scale, and manage any clusters.
Amazon Redshift provides the fastest query performance for enterprise reporting and business intelligence workloads, particularly those involving extremely complex SQL with multiple joins and subqueries across many data sources including relational databases and flat files.
*****
To interact with AWS resources from within a Python Jupyter notebook, we leverage the AWS Python SDK boto3, the Python DB client PyAthena to connect to Athena, and SQLAlchemy) as a Python SQL toolkit to connect to Redshift.
*****
easy-to-use business intelligence service to build visualizations, perform ad-hoc analysis, and build dashboards from many data sources - and across many devices.
*****
We will also introduce you to PyAthena, the Python DB Client for Amazon Athena, that enables us to run Athena queries right from our notebook.
*****
There are different cursor implementations that you can use. While the standard cursor fetches the query result row by row, the PandasCursor will first save the CSV query results in the S3 staging directory, then read the CSV from S3 in parallel down to your Pandas DataFrame. This leads to better performance than fetching data with the standard cursor implementation.
*****
We need to install SQLAlchemy, define our Redshift connection parameters, query the Redshift secret credentials from AWS Secret Manager, and obtain our Redshift Endpoint address. Finally, create the Redshift Query Engine.
# Ins
*****
Create Redshift Query Engine
from sqlalchemy import create_engine
engine = create_engine('postgresql://{}:{}@{}:{}/{}'.format(redshift_username, redshift_pw, redshift_endpoint_address, redshift_port, redshift_database))
*****
Detect Data Quality Issues with Apache Spark
*****
Data quality can halt a data processing pipeline in its tracks. If these issues are not caught early, they can lead to misleading reports (ie. double-counted revenue), biased AI/ML models (skewed towards/against a single gender or race), and other unintended data products.
To catch these data issues early, we use Deequ, an open source library from Amazon that uses Apache Spark to analyze data quality, detect anomalies, and even “notify the Data Scientist at 3am” about a data issue. Deequ continuously analyzes data throughout the complete, end-to-end lifetime of the model from feature engineering to model training to model serving in production.
*****
Learning from run to run, Deequ will suggest new rules to apply during the next pass through the dataset. Deequ learns the baseline statistics of our dataset at model training time, for example - then detects anomalies as new data arrives for model prediction. This problem is classically called “training-serving skew”. Essentially, a model is trained with one set of learned constraints, then the model sees new data that does not fit those existing constraints. This is a sign that the data has shifted - or skewed - from the original distribution.
*****
Since we have 130+ million reviews, we need to run Deequ on a cluster vs. inside our notebook. This is the trade-off of working with data at scale. Notebooks work fine for exploratory analytics on small data sets, but not suitable to process large data sets or train large models. We will use a notebook to kick off a Deequ Spark job on a cluster using SageMaker Processing Jobs.
*****
You can optimize expensive SQL COUNT queries across large datasets by using approximate counts.
*****
HyperLogLogCounting is a big deal in analytics. We always need to count users (daily active users), orders, returns, support calls, etc. Maintaining super-fast counts in an ever-growing dataset can be a critical advantage over competitors.
Both Redshift and Athena support HyperLogLog (HLL), a type of “cardinality-estimation” or COUNT DISTINCT algorithm designed to provide highly accurate counts (<2% error) in a small fraction of the time (seconds) requiring a tiny fraction of the storage (1.2KB) to store 130+ million separate counts.
*****
Existing data warehouses move data from storage nodes to compute nodes during query execution. This requires high network I/O between the nodes - and reduces query performance.
Figure 3-23 below shows a traditional data warehouse architecture with shared, centralized storage.
*****
certain “latent” features hidden in our data sets and not immediately-recognizable by a human. Netflix’s recommendation system is famous for discovering new movie genres beyond the usual drama, horror, and romantic comedy. For example, they discovered very specific genres such as “Gory Canadian Revenge Movies,” “Sentimental Movies about Horses for Ages 11-12,” “
*****
Figure 6-2 shows more “secret” genres discovered by Netflix’s Viewing History Service - code named, “VHS,” like the popular video tape format from the 80’s and 90’s.
*****
Feature creation combines existing data points into new features that help improve the predictive power of your model. For example, combining review_headline and review_body into a single feature may lead to more-accurate predictions than using them separately.
*****
Feature transformation converts data from one representation to another to facilitate machine learning. Transforming continuous values such as a timestamp into categorical “bins” such as hourly, daily, or monthly helps to reduce dimensionality. Two common statistical feature transformations are normalization and standardization. Normalization scales all values of a particular data point between 0 and 1, while standardization transforms the values to a mean of 0 and standard deviation of 1. These techniques help reduce the impact of large-valued data points such as number of reviews (represented in 1,000’s) over small-valued data points such as helpful_votes (represented in 10’s.) Without these techniques, the mod
*****
One drawback to undersampling is that your training dataset size is sampled down to the size of the smallest category. This can reduce the predictive power of your trained models. In this example, we reduced the number of reviews by 65% from approximately 100,000 to 35,000.
*****
Oversampling will artificially create new data for the under-represented class. In our case, star_rating 2 and 3 are under-represented. One common oversampling technique is called Synthetic Minority Oversampling Technique (SMOTE). Oversampling techniques use statistical methods such as interpolation to generate new data from your current data. They tend to work better when you have a larger data set, so be careful when using oversampling on small datasets with a low number of minority class examples. Figure 6-10 shows SMOTE generating new examples for the minority class to improve the imbalance.
*****
Each of the three phases should use a separate and independent dataset - otherwise “leakage” may occur. Leakage happens when data is leaked from one phase of modeling into another through the splits. Leakage can artificially inflate the accuracy of your model.
Time-series data is often prone to leakage across splits. Companies often want to validate a new model using “back-in-time” historical information before pushing the model to production. When working with time-series data, make sure your model does not peak into the future accidentally. Otherwise, these models may appear more accurate than they really are.
*****
We will use TensorFlow and a state-of-the-art Natural Language Processing (NLP) and Natural Language Understanding (NLU) neural network architecture called BERT. Unlike previous generations of NLP models such as Word2Vec, BERT captures the bi-directional (left-to-right and right-to-left) context of each word in a sentence. This allows BERT to learn different meanings of the same word across different sentences. For example, the meaning of the word “bank” is different between these two sentences: “A thief stole money from the bank vault” and “Later, he was arrested while fishing on a river bank.”
For each review_body, we use BERT to create a feature vector within a previously-learned, high-dimensional vector space of 30,000 words or “tokens.” BERT learned these tokens by training on millions of documents including Wikipedia and Google Books.
Let’s use a variant of BERT called DistilBert. DistilBert is a light-weight version of BERT that is 60% faster, 40% smaller, and preserves 97% of BERT’s language understanding capabilities. We use a popular Python library called Transformers to perform the transformation.
*****
Feature stores can cache “hot features” into memory to reduce model-training times. A feature store can provide governance and access control to regulate and audit our features. Lastly, a feature store can provide consistency between model training and model predicting by ensuring the same features for both batch training and real-time predicting.
Customers have implemented feature stores using a combination of DynamoDB, ElasticSearch, and S3. DynamoDB and ElasticSearch track metadata such as file format (ie. csv, parquet), BERT-specific data (ie. maximum sequence length), and other summary statistics (ie. min, max, standard deviation). S3 stores the underlying features such as our generated BERT embeddings. This feature store reference architecture is shown in Figure 6-22.
*****
Our training scripts almost always include pip installing Python libraries from PyPi or downloading pre-trained models from third-party model repositories (or “model zoo’s”) on the internet. By creating dependencies on external resources, your training job is now at the mercy of these third-party services. If one of these services is temporarily down, your training job may not start.
To improve availability, it is recommended that we reduce as many external dependencies as possible by copying these resources into your Docker images - or into your own S3 bucket. This has the added benefit of reducing network utilization and starting our training jobs faster.
*****
Bring Your Own Container
The most customizable option is “bring your own container” (BYOC). This option lets you build and deploy your own Docker container to SageMaker. This Docker container can contain any library or framework. While we maintain complete control over the details of the training script and its dependencies, SageMaker manages the low-level infrastructure for logging, monitoring, environment variables, S3 locations, etc. This option is targeted at more specialized or systems-focused machine learning folks.
*****
GloVe goes one step further and uses recurrent neural networks (RNNs) to encode the global co-occurrence of words vs. Word2Vec’s local co-occurence of words. An RNN is a special type of neutral network that learns and remembers longer-form inputs such as text sequences and time-series data.
FastText continues the innovation and builds word embeddings using combinations of lower-level character embeddings using character-level RNNs. This character-level focus allows FastText to learn non-English language models with relatively small amounts of data compared to other models. Amazon SageMaker offers a built-in, pay-as-you-go SageMaker algorithm called BlazingText which is an implementation of FastText optimized for AWS. This algorithm was shown in the Built-In Algorithms section above.
*****
ELMo preserves the trained model and uses two separate Long-Short Term Memory (LSTM) networks: one to learn from left-to-right and one to learn from right-to-left. Neither LSTM uses both the previous and next words at the same time, however. Therefore ELMo does not learn a true bidirectional contextual representation of the words and phrases in the corpus, but it performs very well nonetheless.
*****
Without this bi-directional attention, an algorithm would potentially create the same embedding for the word bank for the following two(2) sentences: “A thief stole money from the bank vault” and “Later, he was arrested while fishing on a river bank.” Note that the word bank has a different meaning in each sentence. This is easy for humans to distinguish because of our life-long, natural “pre-training”, but this is not easy for a machine without similar pre-training.
*****
To be more concrete, BERT is trained by forcing it to predict masked words in a sentence. For example, if we feed in the contents of this book, we can ask BERT to predict the missing word in the following sentence: “This book is called Data ____ on AWS.” Obviously, the missing word is “Science.” This is easy for a human who has been pre-trained on millions of documents since birth, but not easy fo
*****
Neural networks are designed to be re-used and continuously trained as new data arrives into the system. Since BERT has already been pre-trained on millions of public documents from Wikipedia and the Google Books Corpus, the vocabulary and learned representations are transferable to a large number of NLP and NLU tasks across a wide variety of domains.
Training BERT from scratch requires a lot of data and compute, it allows BERT to learn a representation of the custom dataset using a highly-specialized vocabulary. Companies like LinkedIn have pre-trained BERT from scratch to learn language representations specific to their domain including job titles, resumes, companies, and business news. The default pre-trained BERT models were not good enough for NLP/NLU tasks. Fortunately, LinkedIn has plenty of data and compute
*****
The choice of instance type and instance count depends on your workload and budget. Fortunately AWS offers many different instance types including AI/ML-optimized instances with terabytes of RAM and gigabits of network bandwidth. In the cloud, we can easily scale our training job to tens, hundreds, or even thousands of instances with just one line of code.
Let’s select 3 instances of the powerful p3.2xlarge - each with 8 CPUs, 61GB of CPU RAM, 1 Nvidia Volta V100’s GPU processor, and 16GB of GPU RAM. Empirically, we found this combination to perform well with our specific training script and dataset - and within our budget for this task.
instance_type='ml.p3.2xlarge'
instance_count=3
*****
TIP: You can specify instance_type='local' to run the script either inside your notebook or on your local laptop. In both cases, your script will execute inside of the same open source SageMaker Docker container that runs in the managed SageMaker service. This lets you test locally before incurring any cloud cost.
*****
Also, it’s important to choose parallelizable algorithms that benefit from multiple cluster instances. If your algorithm is not parallelizable, you should not add more instances as they will not be used. And adding too many instances may actually slow down your training job by creating too much communication overhead between the instances. Most neural network-based algorithms like BERT are parallelizable and benefit from a distributed cluster.
0 notes
Text
So, I've eliminated a few paths already. One has nice examples that the author says are scripts. They're not Batch commands. If they're PowerShell, I don't have the right module (and it doesn't look right to my untrained eye). So what are they? Another was supposedly learning to use ScriptDOM, but no explanation of what to create is included. Maybe I'm too inexperienced to understand some stuff, but if you don't include at least a file type I'm fairly sure you skipped something.
So I'm trying this. It's worth a shot. First step, have a database project in VS. Uhm... I've never done that. I know why we should. But my work has a history of not requiring programmers to document what we do on production systems. Finally got the server admins doing it a while ago, but folks like me live dangerously. Grumble.
So - step 1, create a database. It's not a listed step, but apparently you don't do the creation in VS. There's no step for it in the template listing at least.
So instead I'm doing https://medium.com/hitachisolutions-braintrust/create-your-first-visual-studio-database-project-e6c22e45145b
Step one: in SSMS run the command:
CREATE DATABASE TCommon
T for temporary, and Common is a database I've already got going. It's for non-secure tools/programs/etc. that any of the other databases should be able to access.
Now to start up VS 2022. We begin a new project and search for database templates.
Clear the checkbox for putting the solution and project in the same directory, and give an overarching name to the solution. That way you can have multiple database projects worked on inside of one solution.
Next, we import the blank database so we have a test bed based off what is in production. Right click on the solution name, select Import, then Database.
The import database wizard looks like this after the connection is set.
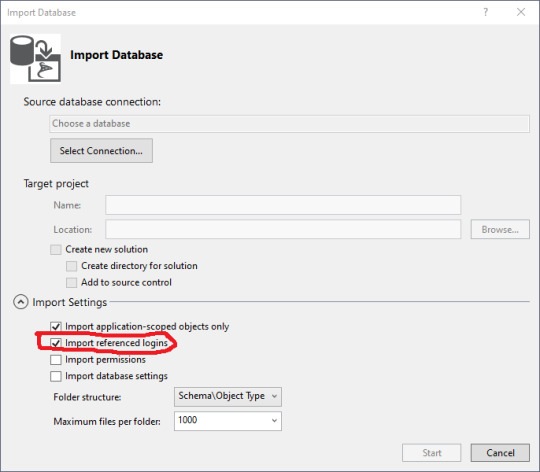
Blackburn suggests that you turn off the importation of referenced logins so you don't accidentally alter permissions. Sound strategy.
Then you can click on the "Select Connection" button.
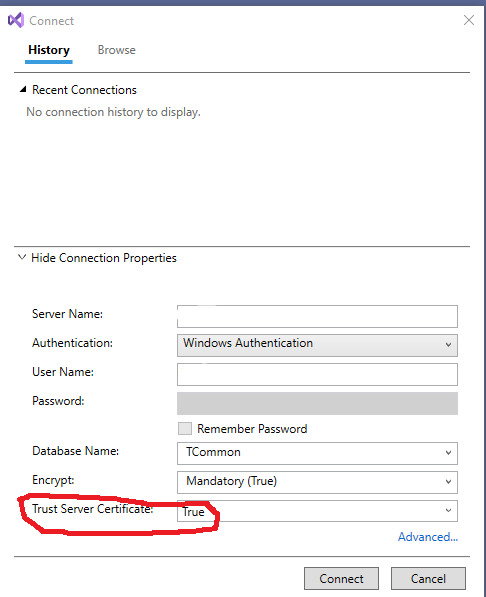
On my workstation, I have to Show Connection Properties, then change the default for Trust Server Certificate to True for it to make a connection. I'm running a test version of SQL Server and didn't set up the certificates.
Click on Connect. Then on the Import Database window, click Start.
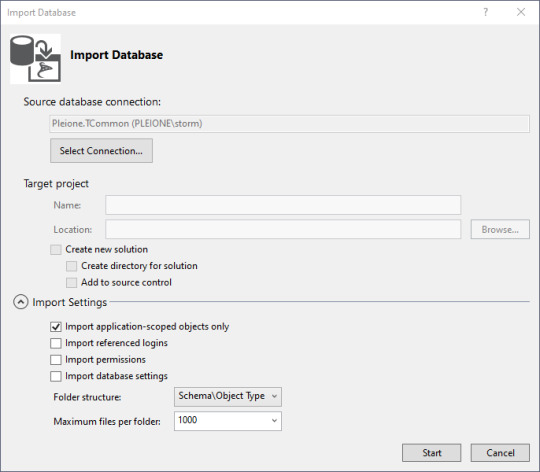
With a blank database, it's fairly anticlimactic, but there really is a connection now to the database, and the properties are copied to your work area. The summary tells you where the log is stored. Then click "Finish" to continue on.
Next, we'll add some objects in. Right click in the Solution Explorer pane, then click Add, then New Item. Lots of little goodies to play with. Since I've been trying to match a project from another site, I need to create a schema to store the objects in. Schemas are part of Security, and there's my little object. I select the schema, give it a name down below, and click Add.
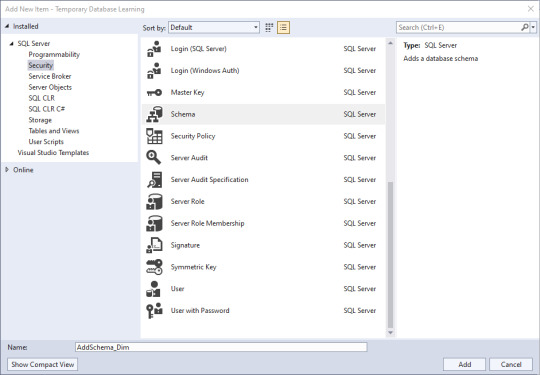
Well, not quite what I expected to happen: CREATE SCHEMA [AddSchema_Dim]
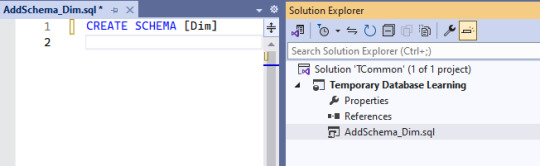
But that's changeable. And in making that change, the solution's object has the name I wanted, and the code has the actual name of the schema I want.
Now, lets add a table.
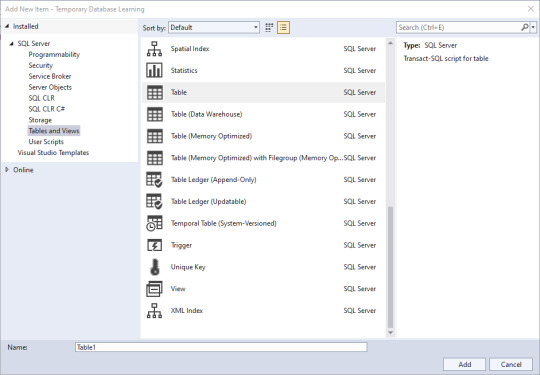
If you're like me, you've used a few of these, but not all of them. Time to do research if you're unsure, but I'm going to go with a simple table for this demonstration. Since I know the name of the solution object will take the name I put in the bottom, I'll name this one AddTable_Dim.Date, and know that I need to edit the actual code.
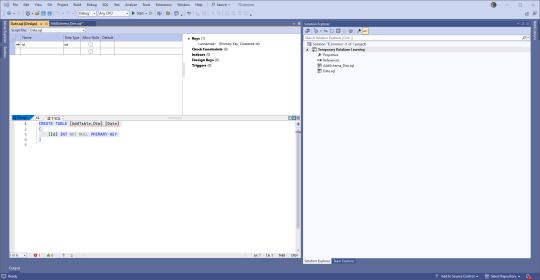
You have choices. If you're used to creating tables using the upper part of the pane where there is a GUI type of set up, go for that. If you're used to typing things out, go to the lower part. Or mix and match! VS will keep the two in sync.
Instead of 'ID' we use 'SID' for Surrogate Identifier. The intake process sets up the unique (across a table) SID values and follows rules that help us track issues backwards to the original location where the data came from.
Second, there's a version number in there. We have the same tables across various enclaves (groups of servers), and we keep the versions the same between all but our development enclave. But instead of forcing our developers and end users to keep up, we use views that are in the databases they work from to expose the data. Many times we don't need to change the views at all which is easier on people that don't need to memorize a few hundred tables and variations.
I'm going to cut this off here, and start working on the next post. Back soon!
0 notes
Text
How to Hire the Perfect Full Stack Developer for Your Project
In today's fast-paced digital landscape, having a skilled full stack developer on your team is essential for the success of your web development projects. Full stack developers possess a broad skill set, enabling them to handle both front-end and back-end development tasks efficiently. However, finding the perfect full stack developer for your project can be challenging. In this blog post, we'll guide you through the process of hiring the right full stack developer to ensure your project's success.
1. Understand What a Full Stack Developer Does:
Before you start the hiring process, it's crucial to understand what a full stack developer does. A full stack developer is proficient in both front-end and back-end technologies, including HTML, CSS, JavaScript, databases, server-side languages (e.g., Python, Ruby, Node.js), and more. They can build an entire web application from start to finish, making them valuable assets to any development team.
2. Define Your Project Needs:
The first step in hiring a full stack developer is to clearly define your project's requirements and objectives. Determine the technologies, frameworks, and languages you'll need for your project. Understanding your project's scope and goals will help you identify the specific skills and experience you require in a full stack developer.
3. Look for a Strong Technical Skill Set:
When evaluating potential candidates, prioritize technical skills. A proficient full stack developer should have expertise in:
Front-end technologies like HTML, CSS, JavaScript, and relevant frameworks (e.g., React, Angular, Vue.js).
Back-end development, including server-side languages (e.g., Python, Ruby, Java, Node.js) and frameworks (e.g., Django, Ruby on Rails, Express.js).
Database management (SQL and NoSQL databases).
Version control systems (e.g., Git).
Knowledge of web security and best practices.
4. Assess Problem-Solving and Critical Thinking Skills:
Full stack developers often encounter complex challenges during project development. Look for candidates who can demonstrate strong problem-solving and critical thinking skills. Ask them about previous projects where they had to troubleshoot and find creative solutions.
5. Evaluate Communication and Teamwork:
Effective communication and teamwork are vital in any development project. Ensure that your chosen full stack developer can work collaboratively with your existing team members, understand project requirements, and communicate progress effectively.
6. Review Past Work and Portfolio:
Ask candidates for their portfolios and examples of previous projects. Examining their work will give you insight into their coding style, attention to detail, and the quality of their previous work. It's an excellent way to assess their practical skills.
7. Conduct Technical Interviews:
Consider conducting technical interviews or coding tests to assess a candidate's coding abilities. Ask them to complete coding challenges or provide solutions to real-world problems relevant to your project. This step can help you gauge their problem-solving skills and coding proficiency.
8. Check References:
Don't skip the reference-checking process. Contact previous employers or clients to inquire about the candidate's work ethic, reliability, and overall performance. References can provide valuable insights into a candidate's professional background.
9. Assess Soft Skills:
In addition to technical skills, consider a full stack developer's soft skills, such as adaptability, willingness to learn, and the ability to handle stress. These qualities are essential for working in dynamic development environments.
10. Discuss Compensation and Terms:
Once you've identified the right full stack developer for your project, have a transparent discussion about compensation, contract terms, and project milestones. Ensure both parties are on the same page regarding expectations and deliverables.
Conclusion:
Hiring the perfect full stack developer is crucial for the success of your web development project. By defining your project needs, assessing technical and soft skills, reviewing past work, and conducting thorough interviews, you can increase your chances of finding the ideal candidate. Remember that a skilled full stack developer can significantly impact the quality and efficiency of your project, so invest time and effort in the hiring process to ensure a successful outcome.
0 notes
Text
If you are preparing for a coding interview, you might be wondering which online platform is the best choice to practice your skills and learn new concepts.
Two of the most popular options are HackerRank and LeetCode, both of which offer a large collection of coding challenges, contests, and learning resources. But which one is better for coding interviews?
In this blog post, we will compare HackerRank and LeetCode on several criteria, such as difficulty level, variety of questions and Interview preparation material. We will also give some tips on how to use both platforms effectively to ace your coding interviews.
Difficulty Level
One of the main factors to consider when choosing an online platform for coding practice is the difficulty level of the questions. You want to challenge yourself with problems that are similar to or slightly harder than the ones you will encounter in real interviews, but not so hard that you get frustrated and demotivated.
HackerRank and LeetCode both have a wide range of difficulty levels, from easy to hard, and they also label their questions according to the companies that have asked them in the past. However, there are some differences in how they categorize their questions and how they match the expectations of different companies.
HackerRank has four difficulty levels: easy, medium, hard, and expert. The easy and medium questions are usually suitable for beginners and intermediate programmers, while the hard and expert questions are more challenging and require more advanced skills and knowledge.
LeetCode has three difficulty levels: easy, medium, and hard. The easy questions are often basic and straightforward, while the medium and hard questions are more complex and require more logic and creativity.
Interview Preparation Material
HackerRank has a section called Interview Preparation Kit, which contains curated questions that cover the most common topics and skills tested in coding interviews. These questions are grouped by domains, such as arrays, strings, trees, graphs, dynamic programming, etc., and they have a difficulty rating from 1 to 5 stars. The Interview Preparation Kit is a good way to focus on the essential topics and practice the most frequently asked questions.
LeetCode also has a section called Explore, which contains curated collections of questions that cover various topics and skills, such as arrays, linked lists, binary search, backtracking, etc. These collections also include explanations, hints, solutions, and video tutorials for each question. The Explore section is a good way to learn new concepts and techniques and apply them to different problems.
In general, LeetCode tends to have harder questions than HackerRank, especially in the medium and hard categories. This is because LeetCode focuses more on algorithmic and data structure problems, which are often more abstract and require more optimization.
Variety of Questions
HackerRank has more diverse types of problems, such as database queries, regex expressions, shell commands, etc., which are more practical and relevant for certain roles and companies. Therefore, depending on your target role and company, you might want to choose the platform that matches their expectations better.
For example, if you are applying for a software engineering role at a big tech company like Google or Facebook, you might want to practice more on LeetCode, since they tend to ask more algorithmic and data structure problems. If you are applying for a data analyst or web developer role at a smaller company or startup, you might want to practice more on HackerRank, since they tend to ask more SQL or web-related problems.
Conclusion
In conclusion, both HackerRank and LeetCode are great platforms for coding interviews, and they both have their pros and cons. It really depends on your target role and company, as well as your personal preferences and learning style.
Disclaimer: This blog post is not sponsored by either HackerRank or LeetCode. The opinions expressed here are my own and do not necessarily reflect those of either company. The logos and trademarks used in this blog post belong to their respective owners.
0 notes
Text
Overcoming SQL Server Row Lock Contention
In the world of database management, efficiency and smooth operation are paramount. Particularly with SQL Server, one challenge that often arises is row lock contention. This issue can severely impact the performance of your database, leading to slower response times and, in severe cases, deadlocks. However, with the right strategies and understanding, overcoming this hurdle is entirely within…
View On WordPress
#database performance#deadlock prevention#lock contention solutions#SQL Server row lock#T-SQL Code Examples
0 notes