#Real-Time Web Scraping API Services
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Premium Tumblr themes are available from anywhere between $9 to $49.
Text
Competitor Price Monitoring Services - Food Scraping Services
Competitor Price Monitoring Strategies
Price Optimization

If you want your restaurant to stay competitive, it’s crucial to analyze your competitors’ average menu prices. Foodspark offers a Competitor Price Monitoring service to help you with this task. By examining data from other restaurants and trends in menu prices, we can determine the best price for your menu. That will give you an edge in a constantly evolving industry and help you attract more customers, ultimately increasing profits.
Market Insights

Our restaurant data analytics can help you stay ahead by providing valuable insights into your competitors’ pricing trends. By collecting and analyzing data, we can give you a deep understanding of customer preferences, emerging trends, and regional variations in menu pricing. With this knowledge, you can make informed decisions and cater to evolving consumer tastes to stay ahead.
Competitive Advantage

To stay ahead in the restaurant industry, you must monitor your competitors’ charges and adjust your prices accordingly. Our solution can help you by monitoring your competitors’ pricing strategies and allowing you to adjust your expenses in real-time. That will help you find opportunities to offer special deals or menu items to make you stand out and attract more customers.
Price Gap Tracking

Knowing how your menu prices compare to your competitors is essential to improve your restaurant’s profitability. That is called price gap tracking. Using our tracking system, you can quickly identify the price differences between restaurant and your competitors for the same or similar menu items. This information can help you find opportunities to increase your prices while maintaining quality or offering lower costs. Our system allows you to keep a close eye on price gaps in your industry and identify areas where your expenses are below or above the average menu prices. By adjusting your pricing strategy accordingly, you can capture more market share and increase your profits.
Menu Mapping and SKU

Use our menu and SKU mapping features to guarantee that your products meet customer expectations. Find out which items are popular and which ones may need some changes. Stay adaptable and responsive to shifting preferences to keep your menu attractive and competitive.
Price Positioning

It’s essential to consider your target audience and desired brand image to effectively position your restaurant’s prices within the market. Competitor data can help you strategically set your prices as budget-friendly, mid-range, or premium. Foodspark Competitor Price Monitoring provides data-driven insights to optimize your pricing within your market segment. That helps you stay competitive while maximizing revenue and profit margins.
Competitor Price Index (CPI)

The Competitor Price Index (CPI) measures how your restaurant’s prices compare to competitors. We calculate CPI for you by averaging the prices of similar menu items across multiple competitors. If your CPI is above 100, your prices are higher than your competitors. If it’s below 100, your prices are lower.
Benefits of Competitor Price Monitoring Services
Price Optimization
By continuous monitoring your competitor’s prices, you can adjust your own pricing policies, to remain competitive while maximizing your profit margins.
Dynamic Pricing
Real-time data on competitor’s prices enable to implement dynamic pricing strategies, allowing you to adjust your prices based on market demand and competitive conditions.
Market Positioning
Understanding how your prices compare to those of your competitors helps you position your brand effectively within the market.
Customer Insights
Analyzing customer pricing data can reveal customer behavior and preferences, allowing you to tailor your pricing and marketing strategies accordingly.
Brand Reputation Management
Consistently competitive pricing can enhance your brand’s reputation and make your product more appealing to customers.
Content Source: https://www.foodspark.io/competitor-price-monitoring/
#web scraping services#restaurantdataextraction#Competitor Price Monitoring#Mobile-app Specific Scraping#Real-Time API#Region - wise Restaurant Listings#Services#Food Aggregator#Food Data Scraping#Real-time Data API#Price Monitoring#Food App Scraping#Food Menu Data
0 notes
Text
Why Should You Do Web Scraping for python

Web scraping is a valuable skill for Python developers, offering numerous benefits and applications. Here’s why you should consider learning and using web scraping with Python:
1. Automate Data Collection
Web scraping allows you to automate the tedious task of manually collecting data from websites. This can save significant time and effort when dealing with large amounts of data.
2. Gain Access to Real-World Data
Most real-world data exists on websites, often in formats that are not readily available for analysis (e.g., displayed in tables or charts). Web scraping helps extract this data for use in projects like:
Data analysis
Machine learning models
Business intelligence
3. Competitive Edge in Business
Businesses often need to gather insights about:
Competitor pricing
Market trends
Customer reviews Web scraping can help automate these tasks, providing timely and actionable insights.
4. Versatility and Scalability
Python’s ecosystem offers a range of tools and libraries that make web scraping highly adaptable:
BeautifulSoup: For simple HTML parsing.
Scrapy: For building scalable scraping solutions.
Selenium: For handling dynamic, JavaScript-rendered content. This versatility allows you to scrape a wide variety of websites, from static pages to complex web applications.
5. Academic and Research Applications
Researchers can use web scraping to gather datasets from online sources, such as:
Social media platforms
News websites
Scientific publications
This facilitates research in areas like sentiment analysis, trend tracking, and bibliometric studies.
6. Enhance Your Python Skills
Learning web scraping deepens your understanding of Python and related concepts:
HTML and web structures
Data cleaning and processing
API integration
Error handling and debugging
These skills are transferable to other domains, such as data engineering and backend development.
7. Open Opportunities in Data Science
Many data science and machine learning projects require datasets that are not readily available in public repositories. Web scraping empowers you to create custom datasets tailored to specific problems.
8. Real-World Problem Solving
Web scraping enables you to solve real-world problems, such as:
Aggregating product prices for an e-commerce platform.
Monitoring stock market data in real-time.
Collecting job postings to analyze industry demand.
9. Low Barrier to Entry
Python's libraries make web scraping relatively easy to learn. Even beginners can quickly build effective scrapers, making it an excellent entry point into programming or data science.
10. Cost-Effective Data Gathering
Instead of purchasing expensive data services, web scraping allows you to gather the exact data you need at little to no cost, apart from the time and computational resources.
11. Creative Use Cases
Web scraping supports creative projects like:
Building a news aggregator.
Monitoring trends on social media.
Creating a chatbot with up-to-date information.
Caution
While web scraping offers many benefits, it’s essential to use it ethically and responsibly:
Respect websites' terms of service and robots.txt.
Avoid overloading servers with excessive requests.
Ensure compliance with data privacy laws like GDPR or CCPA.
If you'd like guidance on getting started or exploring specific use cases, let me know!
2 notes
·
View notes
Text
Unlock the Power of Python Programming: A Complete Guide
Python programming has become one of the most sought-after skills in the world of technology. Its simplicity, flexibility, and vast ecosystem of libraries make it a top choice for both beginners and experienced developers. In this guide, we will explore various aspects of Python programming, from basic concepts to advanced applications like machine learning and web development.
Python Programming: A Beginner-Friendly Language
Python programming is renowned for its readability and straightforward syntax, making it ideal for beginners. Whether you are just starting to code or transitioning from another language, Python offers a smooth learning curve. Key Python programming concepts include variables, data types, and control structures, which are essential for writing functional code.
youtube
Python Data Structures: Organizing Data Efficiently
One of the core strengths of Python programming is its rich set of data structures. Lists, dictionaries, tuples, and sets help you store and manage data effectively. Understanding Python data structures allows you to create more efficient programs by organizing and manipulating data effortlessly.
Functions in Python Programming: Building Reusable Code
Functions are a fundamental part of Python programming. They allow you to break down complex problems into smaller, reusable chunks of code. Python functions not only promote code reusability but also make your programs more organized and easier to maintain.
Loops in Python Programming: Automating Repeated Tasks
Loops are an essential feature in Python programming, allowing you to perform repeated operations efficiently. With Python loops such as for and while, you can iterate over sequences or perform tasks until a specific condition is met. Mastering loops is a key part of becoming proficient in Python.
Object-Oriented Programming in Python: Structured Development
Python programming supports object-oriented programming (OOP), a paradigm that helps you build structured and scalable software. OOP in Python allows you to work with classes and objects, making it easier to model real-world scenarios and design complex systems in a manageable way.
Python Automation Scripts: Simplify Everyday Tasks
Python programming can be used to automate repetitive tasks, saving you time and effort. Python automation scripts can help with file management, web scraping, and even interacting with APIs. With Python libraries like os and shutil, automation becomes a breeze.
Python Web Development: Creating Dynamic Websites
Python programming is also a popular choice for web development. Frameworks like Django and Flask make it easy to build robust, scalable web applications. Whether you're developing a personal blog or an enterprise-level platform, Python web development empowers you to create dynamic and responsive websites.
APIs and Python Programming: Connecting Services
Python programming allows seamless integration with external services through APIs. Using libraries like requests, you can easily interact with third-party services, retrieve data, or send requests. This makes Python an excellent choice for building applications that rely on external data or services.

Error Handling in Python Programming: Writing Resilient Code
Python programming ensures that your code can handle unexpected issues using error handling mechanisms. With try-except blocks, you can manage errors gracefully and prevent your programs from crashing. Error handling is a critical aspect of writing robust and reliable Python code.
Python for Machine Learning: Leading the AI Revolution
Python programming plays a pivotal role in machine learning, thanks to powerful libraries like scikit-learn, TensorFlow, and PyTorch. With Python, you can build predictive models, analyze data, and develop intelligent systems. Machine learning with Python opens doors to exciting opportunities in artificial intelligence and data-driven decision-making.
Python Data Science: Turning Data Into Insights
Python programming is widely used in data science for tasks such as data analysis, visualization, and statistical modeling. Libraries like pandas, NumPy, and Matplotlib provide Python programmers with powerful tools to manipulate data and extract meaningful insights. Python data science skills are highly in demand across industries.
Python Libraries Overview: Tools for Every Task
One of the greatest advantages of Python programming is its extensive library support. Whether you're working on web development, automation, data science, or machine learning, Python has a library for almost every need. Exploring Python libraries like BeautifulSoup, NumPy, and Flask can significantly boost your productivity.
Python GUI Development: Building User Interfaces
Python programming isn't just limited to back-end or web development. With tools like Tkinter and PyQt, Python programmers can develop graphical user interfaces (GUIs) for desktop applications. Python GUI development allows you to create user-friendly software with visual elements like buttons, text fields, and images.
Conclusion: Python Programming for Every Developer
Python programming is a versatile and powerful language that can be applied in various domains, from web development and automation to machine learning and data science. Its simplicity, combined with its extensive libraries, makes it a must-learn language for developers at all levels. Whether you're new to programming or looking to advance your skills, Python offers endless possibilities.
At KR Network Cloud, we provide expert-led training to help you master Python programming and unlock your potential. Start your Python programming journey today and take the first step toward a successful career in tech!
#krnetworkcloud#python#language#programming#linux#exams#coding#software engineering#coding for beginners#careers#course#training#learning#education#technology#computing#tech news#business#security#futurism#Youtube
3 notes
·
View notes
Text
Best data extraction services in USA
In today's fiercely competitive business landscape, the strategic selection of a web data extraction services provider becomes crucial. Outsource Bigdata stands out by offering access to high-quality data through a meticulously crafted automated, AI-augmented process designed to extract valuable insights from websites. Our team ensures data precision and reliability, facilitating decision-making processes.
For more details, visit: https://outsourcebigdata.com/data-automation/web-scraping-services/web-data-extraction-services/.
About AIMLEAP
Outsource Bigdata is a division of Aimleap. AIMLEAP is an ISO 9001:2015 and ISO/IEC 27001:2013 certified global technology consulting and service provider offering AI-augmented Data Solutions, Data Engineering, Automation, IT Services, and Digital Marketing Services. AIMLEAP has been recognized as a ‘Great Place to Work®’.
With a special focus on AI and automation, we built quite a few AI & ML solutions, AI-driven web scraping solutions, AI-data Labeling, AI-Data-Hub, and Self-serving BI solutions. We started in 2012 and successfully delivered IT & digital transformation projects, automation-driven data solutions, on-demand data, and digital marketing for more than 750 fast-growing companies in the USA, Europe, New Zealand, Australia, Canada; and more.
-An ISO 9001:2015 and ISO/IEC 27001:2013 certified -Served 750+ customers -11+ Years of industry experience -98% client retention -Great Place to Work® certified -Global delivery centers in the USA, Canada, India & Australia
Our Data Solutions
APISCRAPY: AI driven web scraping & workflow automation platform APISCRAPY is an AI driven web scraping and automation platform that converts any web data into ready-to-use data. The platform is capable to extract data from websites, process data, automate workflows, classify data and integrate ready to consume data into database or deliver data in any desired format.
AI-Labeler: AI augmented annotation & labeling solution AI-Labeler is an AI augmented data annotation platform that combines the power of artificial intelligence with in-person involvement to label, annotate and classify data, and allowing faster development of robust and accurate models.
AI-Data-Hub: On-demand data for building AI products & services On-demand AI data hub for curated data, pre-annotated data, pre-classified data, and allowing enterprises to obtain easily and efficiently, and exploit high-quality data for training and developing AI models.
PRICESCRAPY: AI enabled real-time pricing solution An AI and automation driven price solution that provides real time price monitoring, pricing analytics, and dynamic pricing for companies across the world.
APIKART: AI driven data API solution hub APIKART is a data API hub that allows businesses and developers to access and integrate large volume of data from various sources through APIs. It is a data solution hub for accessing data through APIs, allowing companies to leverage data, and integrate APIs into their systems and applications.
Locations: USA: 1-30235 14656 Canada: +1 4378 370 063 India: +91 810 527 1615 Australia: +61 402 576 615 Email: [email protected]
2 notes
·
View notes
Text
Scraping Hotel Listings from Yanolja & GoodChoice

Introduction
In this case study, we showcase our successful execution of Scraping Hotel Listings from Yanolja & GoodChoice to support a travel-tech client aiming to build a real-time hotel rate comparison platform for Korean users. Our team developed a robust scraping pipeline to Scrape Yanolja Hotel Listings, including essential attributes like pricing, room types, availability, user ratings, and location-based filters. By automating data extraction and scheduling daily updates, we ensured the timely and accurate delivery of hotel data feeds. The client successfully integrated this information into their frontend system, enhancing price transparency, boosting user engagement, and identifying high-demand properties during peak seasons. Our scraping infrastructure was built to handle anti-bot mechanisms and dynamically changing page structures, ensuring long-term reliability. This enabled the client to scale their platform quickly and offer rich, competitive travel data to Korean and international audiences.
Our Client
Our client, a South Korea-based travel aggregator startup, aimed to offer users a seamless hotel comparison experience by integrating listings from multiple platforms. They needed a reliable solution to Extract GoodChoice Accommodation Data and monitor competitive hotel rates in real-time. With a focus on Web Scraping Korean Travel Sites, the client aimed to provide accurate price comparisons, live availability, and detailed property information across regional destinations. Our solution enabled Real-Time Data Scraping for Hotel Prices Korea, ensuring their users received the most up-to-date information for informed decision-making. This capability enabled the client to gain a significant competitive edge, rapidly expand their property database, and enhance customer satisfaction by offering dynamic search, location filters, and real-time pricing intelligence across Korea's top booking platforms.
Challenges in the Hotel Industry

Tracking hotel prices in South Korea can be challenging without the aid of automation. Our client required reliable tools to extract real-time data from top platforms, such as Yanolja and GoodChoice, for accurate comparisons.
Fragmented Data Access: The client struggled to Scrape Hotel Deals from Yanolja and GoodChoice consistently due to differing site structures and dynamic content.
Inconsistent Pricing Information: Attempting to Extract Korean Hotel Pricing Data revealed discrepancies across listings, making it hard to maintain accuracy in hotel rate comparisons.
Lack of Scalable Infrastructure: Their internal tools were unable to support a Web Scraping API for Korean Hotel Rates, resulting in downtime and limited data refresh capacity.
Limited Market Intelligence: Without automation, gathering Real-Time Travel Pricing Insights Korea manually was slow, limiting their ability to respond to pricing fluctuations quickly.
Technical Barriers: Frequent layout changes and anti-bot measures made reliable Hotel Data Scraping difficult, impacting their platform's reliability and user trust.
Our Approach

We designed a robust scraping engine that continuously pulled hotel listings, allowing the client to access up-to-date Hotel Price & Review data from both Yanolja and GoodChoice platforms.
Our tailored Travel Web Scraping Service ensured the extraction of structured data, adapted to site-specific HTML patterns and JavaScript-loaded content, for long-term reliability and accuracy.
We developed a dynamic analytics tool for tracking Hotel Price Intelligence , enabling the client to monitor market trends, compare competitor prices, and adjust listings in real-time.
To ensure seamless integration, we offered a high-performance Travel Scraping API that delivered clean and categorized hotel data directly into the client's system.
We expanded the solution to include Travel Aggregators Scraping , providing the client with a broader view of the Korean hospitality landscape and enhancing the value of their platform.
Results Achieved
To compete in Korea's growing travel-tech market, our client needed real-time hotel data from Yanolja and GoodChoice. We delivered an automated solution that powered faster, smarter, and scalable booking insights.
Empowered Smarter Travel Choices: Users gained access to rich, timely hotel data that supported more confident decision-making, leading to increased trust in the platform's recommendations.
Accelerated Time-to-Market: With automated data integration, the client was able to launch new city-specific hotel comparison features weeks ahead of schedule.
Enabled Dynamic Pricing Strategy: The client leveraged fresh data flows to refine their pricing benchmarks, optimizing hotel listings based on local demand and seasonal shifts.
Strengthened Competitive Advantage: By offering deeper hotel insights than rival platforms, the client positioned itself as a smarter, more responsive option in the Korean travel space.
Future-Proofed Data Pipeline: Our solution was built to adapt to ongoing site changes and scaling needs, ensuring data continuity as the platform grows.
Client's Testimonial
"Working with this team was a game-changer for our platform. We needed accurate, real-time hotel data from Yanolja and GoodChoice, and their scraping solution delivered exactly that—fast, reliable, and scalable. Their expertise helped us launch new features quickly and offer our users up-to-date hotel listings, prices, and reviews across Korea. What impressed us most was their adaptability to site changes and commitment to data accuracy. Thanks to their support, we've enhanced our competitive edge and improved user satisfaction significantly."
—Product Manager
Conclusion
Our collaboration with the client marked a significant step forward in transforming the way hotel data is sourced and delivered within the Korean travel ecosystem. By implementing a fully automated, scalable scraping infrastructure tailored to Yanolja and GoodChoice, we enabled consistent access to live hotel listings, competitive pricing, and rich content. This empowered the client to launch more innovative comparison tools, enhance user trust, and rapidly expand their service. Our adaptable solution ensured long-term sustainability and reduced operational friction. Overall, this project demonstrated the power of real-time data in reshaping digital travel platforms and driving better customer experiences across a dynamic marketplace.
Source : https://www.travelscrape.com/scraping-hotel-listings-yanolja-goodchoice.php
#ScrapingHotelListingsFromYanolja#ExtractGoodChoiceAccommodationData#WebScrapingKoreanTravelSites#RealTimeDataScrapingForHotelPricesKorea#ExtractKoreanHotelPricingData#WebScrapingAPIForKoreanHotelRates
0 notes
Text

⚡ Speed, scale, and real-time precision — all in one API.
At Actowiz Solutions, our #WebScrapingAPI Services are built for businesses that rely on #RealTimeData to stay competitive. Whether you’re in finance, eCommerce, retail, market research, or analytics, our API helps you collect #StructuredData instantly and securely.
💡 Why choose Actowiz Web Scraping APIs?
✅ Real-time data extraction
✅ Seamless integration into your systems
✅ Scalable for high-volume scraping
✅ Supports complex and dynamic websites
✅ Delivers clean, structured JSON/XML formats
Use our scraping APIs to:
Monitor product prices across #Amazon, #Walmart, #Flipkart, Target & more
Track financial data or stock trends in real time
Automate data pipelines for dashboards & BI tools
Power your competitive intelligence and analytics systems
📈 From small startups to large enterprises, we help you build smarter strategies with #AutomationReadyData.
📩 Contact: [email protected]
🌐 Explore: www.actowizsolutions.com
Make real-time data collection your competitive edge with Actowiz. 🚀
0 notes
Text
Extract Website Data with Ease Using X Scraper
In today’s fast-paced digital world, data is key to understanding trends, customer behavior, and market shifts. One of the richest sources of real-time information is Twitter. From news and opinions to product feedback and social movements — Twitter offers a public stream of valuable data.
But manually collecting tweets is slow and impractical. That’s where X Scraper comes in. It allows you to extract website data, especially from Twitter, quickly and easily — with no coding skills required.

Why Scrape Data from Twitter?
Twitter is a live source of raw, unfiltered data. Businesses and researchers use it to stay ahead of trends, gauge public sentiment, and gather content for analysis. Whether you want to monitor hashtags or track competitor tweets, Twitter scraper can help you make more informed decisions.
What is X Scraper?
X Scraper is a simple yet powerful tool that lets you scrape data from websites — especially Twitter — without the need for programming. It’s built to save you time and effort by automating the data collection process.
Here’s what you can do with X Scraper:
Collect tweets from any public Twitter account, hashtag, or keyword
Export data in structured formats like CSV, Excel, or JSON
Apply filters by date, keyword, or tweet count to target exactly what you need
Whether you're new to scraping or an experienced analyst, Scrape twitter makes the process smooth and efficient.
How to Use X Scraper for Twitter Web Scraping
Using X Scraper is simple. You launch the tool, choose the Twitter scraping option, and enter your target — a username, keyword, or hashtag. You can set filters to narrow your results. Once you click “Start,” the tool begins collecting tweets.
Real-World Use Cases
People use X Scraper for a variety of purposes, including:
Monitoring customer feedback about a product or service
Tracking viral content or trending hashtags
Collecting tweets for academic or political research
With its flexible features, X Scraper helps users scrap Twitter in a way that’s both fast and accurate.
Why Choose X Scraper?
Unlike complicated scraping tools, X Scraper is made for simplicity. It doesn’t require any setup or API keys. It just works — and works well. That’s why many users consider it the best Twitter scraper for both beginners and professionals.
FAQs
1. Is it safe to use X Scraper for scraping Twitter data?
Yes, X Scraper is designed to scrape publicly available data from Twitter in a safe and responsible way. It does not bypass Twitter's security systems or access private information, ensuring ethical data collection.
2. Do I need coding skills to use X Scraper?
Not at all. X Scraper is built for non-technical users. Its simple interface allows you to start scraping tweets with just a few clicks — no programming or API setup required.
0 notes
Text
AI-Powered Price Drop Tracking for Amazon & Walmart USA

In today’s e-commerce battleground, pricing is no longer static — it’s dynamic, competitive, and often algorithmically optimized by giants like Amazon and Walmart. For brands, sellers, and price-conscious consumers, staying ahead of these rapid-fire changes is both a challenge and an opportunity. This is where AI-powered price tracking comes in.
In this blog, we explore how Product Data Scrape enables businesses to track daily price drops from Amazon and Walmart USA using intelligent scraping, machine learning, and Web Scraping Amazon E-Commerce Product Data — offering a significant edge in strategy, margin optimization, and market positioning.
Why Price Drop Monitoring Matters
Retailers change product prices multiple times per day, especially on platforms like Amazon and Walmart. According to industry estimates:
Amazon updates prices up to 2.5 million times daily
Walmart’s algorithm reacts to competitor pricing in real time
Flash sales and limited-time deals are often unannounced
Without automated tracking, businesses miss out on:
Timely insights into competitor behavior
Opportunities for real-time repricing
Detecting underpriced inventory for reselling
Avoiding overstocking on declining-value SKUs
That’s why it’s crucial to Extract Walmart E-Commerce Product Data alongside Amazon pricing to capture these rapid changes and stay competitive in real time.
What Is AI-Based Price Tracking?

AI-based price tracking combines web scraping with machine learning models to analyze price fluctuations across large datasets. Unlike manual tools or simple scrapers, AI-based systems can:
Detect anomalies (e.g., extreme price drops)
Identify price drop patterns and sale timing
Track brand vs private label pricing
Predict the probability of future discounts
Product Data Scrape provides an AI-driven platform that extracts and analyzes millions of data points from Amazon.com and Walmart.com every day. Our Custom eCommerce Dataset Scraping service ensures clients receive tailored, high-accuracy data feeds aligned with their pricing intelligence and competitive monitoring needs.
Sample Dataset – Daily Price Drops
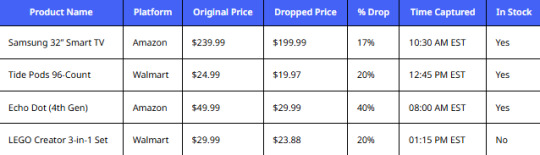
This kind of time-stamped price data allows businesses to capitalize on opportunities and respond instantly. Combined with a comprehensive Walmart Product and Review Dataset , it empowers brands to not only track price changes but also correlate them with customer sentiment and product performance — enabling smarter retail decisions.
How AI Helps Detect and Learn Price Behavior
Machine learning adds deeper layers of intelligence:
Price Trend Modeling: Predict whether a drop is part of a short-term sale or long-term markdown
Category-Level Analysis: Compare price behavior across categories like electronics, toys, and groceries
Retailer Behavior Insight: Understand when and how often Walmart reacts to Amazon’s prices (or vice versa)
This lets Product Data Scrape deliver not just the price, but also the reason and the forecast behind the change.
Why Focus on Amazon & Walmart USA?
Together, Amazon and Walmart dominate the U.S. retail landscape:
Amazon.com: 2.5 Billion+ monthly U.S. visitors, 350M+ total products
Walmart.com: 500 Million+ monthly U.S. visitors, 50M+ total products

Why monitor both?
Amazon changes prices dynamically using internal pricing AI
Walmart reacts competitively based on Amazon’s prices
Both offer exclusive discounts and loyalty pricing (e.g., Prime deals, Walmart+)
Tracking both platforms gives a 360° view of U.S. retail pricing. Using tools like the Web Scraping API for Walmart , businesses can automate the collection of real-time pricing, availability, and promotional data — ensuring they don’t miss critical shifts in market behavior.
How Product Data Scrape Tracks Price Drops
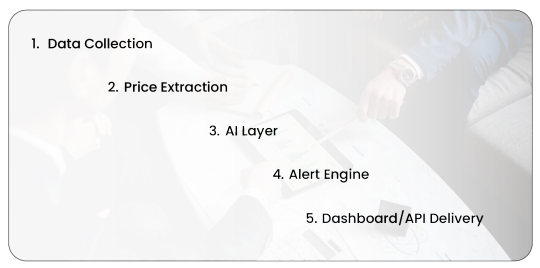
AI-Enhanced Web Scraping Pipeline
1. Data Collection – Crawlers like our Amazon Product Data Scraper visit product pages hourly or at defined intervals.
2. Price Extraction – Extract current, original, and discounted prices.
3. AI Layer – Compare historical data to detect anomalies, drops, or patterns.
4. Alert Engine – Trigger notifications for price drops beyond a defined threshold.
5. Dashboard/API Delivery – Output available in real-time or as scheduled batches.
Output Formats
CSV/Excel price reports
JSON for system integrations
Interactive dashboards
Slack/Email alert integrations
Geo-Focused Tracking (U.S. Zip Codes)
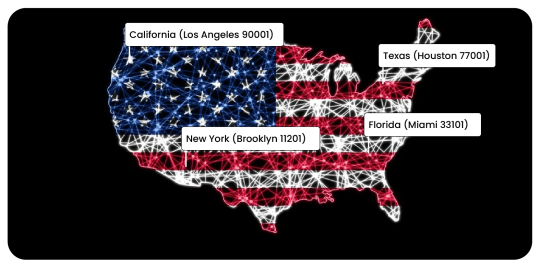
For brands with regional promotions, geo-based tracking is essential. Product Data Scrape supports U.S. regional targeting:
California (e.g., Los Angeles 90001)
New York (e.g., Brooklyn 11201)
Texas (e.g., Houston 77001)
Florida (e.g., Miami 33101)
This enables zip-code-level retail intelligence.
Use Case: Competitive Pricing for a U.S. Electronics Brand
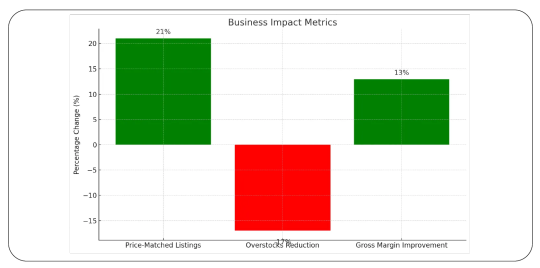
Client: A national electronics reseller selling via Amazon Seller Central and their D2C site.
Problem: They missed price drop windows on Amazon/Walmart and overstocked high-value items.
Solution:
Daily scraping of competitor product pages
AI-based pricing forecasts per product category
Real-time alert system for >10% price drops
Outcome:
+21% in price-matched listings
-17% drop in overstocks
13% improvement in gross margin within 60 days
Visualization – Example Price Drop Alert Chart
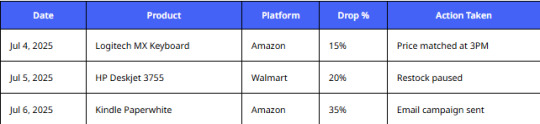
This type of actionable intelligence drives business decisions instantly.
Keywords and Categories Tracked Daily

Product Data Scrape focuses on high-volume retail categories:
Electronics price drop alerts
Home & kitchen deal monitoring
Toys & baby products tracking
Beauty and personal care
Grocery and household essentials
Targeted AI keyword models help prioritize products based on frequency of drops and discount depth.
For Whom Is This Useful?
Online Retailers
Compete with Amazon/Walmart pricing in real time
D2C Brands
Avoid being undercut by sudden price drops
Resellers & Arbitrage Sellers
Spot low-price inventory for resale quickly
Market Analysts
Understand seasonal pricing patterns, demand shifts
AI Technologies Used by Product Data Scrape
Time Series Forecasting (e.g., Prophet, ARIMA)
Anomaly Detection using Isolation Forests
Price Clustering Algorithms
NLP for Product Matching (Amazon vs Walmart SKU similarity)
All data is processed securely and can be tailored for category-specific intelligence.
Legal & Ethical Use of Price Data
Complies with Amazon’s fair use policy (via public-facing data only)
Uses ethical scraping practices (rate-limiting, proxy rotation)
Offers optional API-based ingestion if clients have Amazon PA-API or Walmart Data Exchange access
Benefits Recap
High Demand Countries for This Use Case
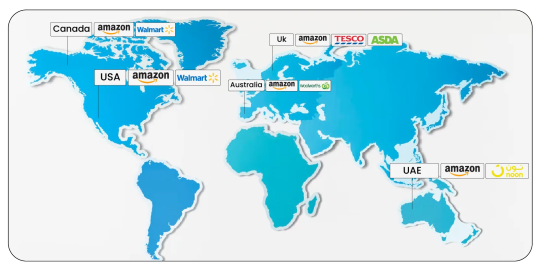
USA (Core focus: Amazon.com & Walmart.com)
Canada (Amazon.ca, Walmart.ca)
UK (Amazon UK, Tesco, ASDA)
Australia (Amazon AU, Woolworths)
UAE (Amazon.ae, Noon.com)
Product Data Scrape is seeing high traction in these markets for daily price tracking intelligence.
Final Thoughts
The U.S. e-commerce arena is ultra-competitive — and daily price drops from Amazon and Walmart are not just common, they’re strategic. Businesses that lack real-time price monitoring risk falling behind or missing opportunities.
Product Data Scrape bridges that gap with AI-powered, real-time scraping solutions that give you a daily pulse on market movements. Whether you're a seller, a brand, or a market analyst, leveraging price drop data is key to profitability and agility.
Source >>https://www.productdatascrape.com/track-daily-price-drops-amazon-walmart-usa.php
#TrackingDailyPriceDropsFromAmazonAndWalmartUSA#WebScrapingAmazonECommerceProductData#ExtractWalmartECommerceProductData#CustomEcommerceDatasetScrapingService#WalmartProductAndReviewDataset
0 notes
Text
The Truth About CAPTCHA Bypass: Is It Ethical, Legal, and Worth It?

CAPTCHAs—short for Completely Automated Public Turing test to tell Computers and Humans Apart—are an integral part of online security. They're meant to distinguish human users from bots by presenting tasks that are easy for people but difficult for machines. However, as technology advances, so does the sophistication of CAPTCHA bypass methods.
In this article, we explore the evolving landscape of CAPTCHA bypass—how it works, who uses it, the tools and methods involved, and the ethical and legal implications surrounding its use.
What Is CAPTCHA Bypass?
CAPTCHA bypass refers to any method used to defeat or circumvent CAPTCHA verification systems, allowing bots or scripts to access content, forms, or services without human interaction. It's widely used in web scraping, automated form submissions, data harvesting, and sometimes for malicious purposes like spamming or credential stuffing.
While some use CAPTCHA bypass for legitimate business automation, others exploit it to carry out unethical or illegal activities.
Types of CAPTCHA Systems
Before discussing bypass methods, let’s review common CAPTCHA types:
Text-based CAPTCHAs – Users type distorted characters.
Image-based CAPTCHAs – Users click on specific images (e.g., "select all traffic lights").
Audio CAPTCHAs – Used for accessibility.
Invisible CAPTCHAs – Detect behavior (like mouse movement) to infer human presence.
reCAPTCHA v2 & v3 – Google’s advanced CAPTCHA versions that evaluate risk scores and behavioral patterns.
Each CAPTCHA type requires different bypass approaches.
Common CAPTCHA Bypass Techniques
1. Optical Character Recognition (OCR)
OCR engines can read distorted text from image-based CAPTCHAs. Tools like Tesseract (an open-source OCR engine) are trained to decode common fonts and noise patterns.
2. Machine Learning (ML)
ML models, especially Convolutional Neural Networks (CNNs), can be trained on thousands of CAPTCHA examples. These systems learn to identify patterns and bypass even complex image-based CAPTCHAs with high accuracy.
3. Human-in-the-Loop Services
Services like 2Captcha and Anti-Captcha outsource CAPTCHA solving to low-cost human labor, solving them in real-time via APIs. While controversial, they are legal in many jurisdictions.
4. Browser Automation (Selenium, Puppeteer)
Automating browser actions can trick behavioral-based CAPTCHAs. Combining Selenium with CAPTCHA solving APIs creates a powerful bypass system.
5. Token Reuse or Session Hijacking
Some CAPTCHAs generate session tokens. If these are stored or reused improperly, attackers can replay valid tokens to bypass the system.
CAPTCHA Bypass Tools and APIs
Here are popular tools and services in 2025:
2Captcha – Crowdsourced human solvers.
Anti-Captcha – AI-based and human-based CAPTCHA solving.
CapMonster – AI-driven CAPTCHA solver with browser emulation.
Buster – A browser extension for solving reCAPTCHAs via audio analysis.
Death by CAPTCHA – Another human-powered solving API.
Legal and Ethical Considerations
While bypassing CAPTCHA may sound clever or harmless, the legal and ethical landscape is more complex:
✅ Legitimate Use Cases
Automation for accessibility: Helping disabled users bypass complex CAPTCHAs.
Web scraping with permission: For competitive research or data aggregation.
Testing and QA: Developers use CAPTCHA bypass to test form behavior.
❌ Illegitimate Use Cases
Spam bots and credential stuffing.
Bypassing terms of service on platforms like Google or Facebook.
Data harvesting without permission.
Most websites have terms that prohibit automated bypasses. Violating them may result in legal action or IP bans. In some countries, large-scale CAPTCHA bypass for malicious use could violate cybercrime laws.
How Websites Are Fighting Back
Web developers and security professionals continuously adapt to evolving bypass techniques. New defenses include:
Fingerprinting & behavioral analysis – Tracking mouse movement, typing rhythm, etc.
Rate limiting & honeypots – Limiting requests and setting traps for bots.
Advanced bot detection services – Tools like Cloudflare Bot Management and Akamai Bot Manager.
Best Practices for Ethical CAPTCHA Use
Avoid scraping or automating tasks on sites without permission.
Use CAPTCHA-solving APIs only where legally allowed.
Inform users or clients when using bypass tools during development or testing.
Stay updated on laws in your country about bot activity and scraping.
The Future of CAPTCHA and Bypass
CAPTCHAs are evolving. In 2025, we're seeing movement toward:
Invisible CAPTCHAs with behavioral scoring.
Biometric authentication instead of traditional CAPTCHAs.
Decentralized bot protection via blockchain-like verification systems.
But as long as there's automation, there will be ways to bypass CAPTCHAs—the challenge is balancing innovation with responsibility.
Conclusion
CAPTCHA bypass is a fascinating, ever-evolving field that combines artificial intelligence, web automation, and cybersecurity. While the tools and techniques are powerful, they come with ethical and legal responsibilities.
If you're a developer, business owner, or security professional, understanding CAPTCHA bypass can help you protect your systems—or responsibly automate tasks. But always keep in mind: just because you can bypass a CAPTCHA doesn’t mean you should.
0 notes
Text
🎯 Turn Data Into Decisions – Smarter. Faster. At Scale.
In today’s fast-moving digital world, speed and precision in data extraction define competitive edge. Our advanced web scraping services empower eCommerce, retail, travel, and Q-commerce companies to make real-time decisions backed by live data.
🔍 What We Deliver:
● Real-time product & pricing intelligence ● Mobile app & website data scraping across platforms ● Review & sentiment mining from top marketplaces ● Geo-specific inventory, deals & stock status ● JSON, CSV, or API-based delivery for automation-ready workflows
💡 Whether you're benchmarking competitors, enhancing pricing strategy, or powering a smart dashboard—our scraping infrastructure has you covered.
0 notes
Text
Captcha Solver: What It Is and How It Works
CAPTCHA (Completely Automated Public Turing test to tell Computers and Humans Apart) is a common online security tool used to block bots and verify that a user is human. While useful for cybersecurity, CAPTCHAs can be frustrating and time-consuming—especially for people with disabilities, or when they appear too frequently. This is where Captcha Solver come in, offering solutions that can bypass or automate CAPTCHA challenges.
What is a Captcha Solver?
A Captcha Solver is a tool, software, or service that automatically solves CAPTCHA challenges—such as identifying objects in images, typing distorted text, or checking a box labeled “I’m not a robot.” These solvers are used for different purposes, both legitimate and illegitimate.
There are two main types:
Automated Captcha Solvers – These use AI, OCR (optical character recognition), and machine learning to analyze and solve CAPTCHAs without human intervention.
Human-Based Captcha Solvers – These services outsource CAPTCHA solving to real people (often paid workers) who solve them in real time.
How Do Captcha Solvers Work?
Captcha Solvers typically work through one of the following methods:
AI and Image Recognition: For image-based CAPTCHAs (e.g., “Click all squares with traffic lights”), AI algorithms are trained to recognize and respond correctly.
OCR for Text-Based CAPTCHAs: For CAPTCHAs that involve reading distorted text, OCR software can interpret and convert the images into readable text.
Browser Extensions and Bots: Some solvers are embedded into bots or browser extensions that automatically detect and bypass CAPTCHA fields.
API Integration: Many commercial solvers offer APIs that developers can plug into scripts or apps, allowing automated CAPTCHA resolution.
Legitimate Uses of Captcha Solvers
Not all uses of CAPTCHA solvers are unethical. Legitimate scenarios include:
Accessibility: People with visual or motor impairments may use CAPTCHA solvers to access websites and services.
Testing Automation: Developers and QA testers use solvers during automated testing of web applications that include CAPTCHA barriers.
Data Collection: Companies that collect public data (like for SEO or research) may use solvers to streamline the process while complying with terms of use.
Risks and Ethical Concerns
However, CAPTCHA solvers are also used for unethical or illegal activities, such as:
Spam Bots: Bypassing CAPTCHA to post spam on forums, social media, or comment sections.
Credential Stuffing: Automating login attempts with stolen credentials.
Web Scraping Violations: Bypassing site protections to extract large amounts of data without permission.
Using CAPTCHA solvers against a site's terms of service can lead to IP bans, legal consequences, or security breaches.
Conclusion
Captcha Solver are a double-edged sword. They offer convenience and accessibility in some cases but can also enable abuse and automation for malicious purposes. As AI continues to evolve, so will CAPTCHA and its solvers—sparking an ongoing cat-and-mouse game between cyber defense and those trying to bypass it. For ethical users, it’s crucial to use these tools responsibly and only where permitted.
0 notes
Text
Python Certification Course in 2025
Your Future-Ready Career Begins Here – Powered by APOTAC
As we step into an increasingly tech-driven future, Python stands tall as one of the most versatile, beginner-friendly, and high-demand programming languages in the world. In 2025, mastering Python is more than a skill—it's a gateway to unlocking career opportunities across data science, web development, automation, AI, and more. That’s where APOTAC’s Python Certification Course comes in—designed to equip you with real-world skills, hands-on projects, and the confidence to land your first (or next) job in tech.
✅ Why Learn Python in 2025?
Python’s popularity continues to rise in 2025 due to its simplicity and power. It is used extensively by companies like Google, Netflix, and Spotify for building scalable applications and smart algorithms.
Top Reasons to Learn Python This Year:
🚀 Essential for AI & Data Science
💼 Demand in Every Industry (Finance, Health, E-commerce, EdTech)
🛠️ Ideal for Automation and Productivity Tools
🌐 Backbone of Web Development & APIs
🧠 Simple Syntax – Perfect for Beginners
Python is no longer “optional.” It’s the language of innovation—and now is the time to learn it.
About APOTAC’s Python Certification Program
APOTAC's 100% Job-Ready Python Certification Course is built to take you from absolute beginner to confident developer. Whether you want to become a Python developer, data analyst, or automation engineer, this course gives you the knowledge, tools, and mentorship to succeed.
🌟 Course Highlights:
🧠 Beginner-Friendly Learning Path
💻 Hands-On Projects & Real-Time Coding
📊 Data Analysis Using Pandas, NumPy, Matplotlib
🔄 Automation Scripts & Web Scraping
🔌 Working with APIs and JSON
📜 Industry-Recognized Certification
🎥 Lifetime Access to Sessions
🤝 1-on-1 Mentor Support & Career Guidance
🛠️ What You'll Learn
The course is structured into easy-to-follow modules with a strong emphasis on practical implementation:
Python Fundamentals (Variables, Loops, Functions)
Data Structures & Object-Oriented Programming
File Handling & Exception Management
Data Analysis with Pandas & NumPy
Visualization with Matplotlib & Seaborn
Web Scraping with BeautifulSoup & Selenium
API Integration & Basic Automation Projects
Capstone Project for Portfolio Building
👩🎓 Who Should Join?
This course is ideal for:
Students entering the tech space
Freshers looking for a first job in IT
Working professionals upskilling or switching careers
Entrepreneurs automating business workflows
Freelancers who want to offer coding/data services
No prior coding experience? No problem! We start from scratch and guide you all the way to job readiness.
💼 Career Opportunities After Certification
Once you complete APOTAC’s Python Certification, you can confidently apply for:
Python Developer
Data Analyst
Automation Engineer
Backend Developer
Junior Data Scientist
SDET / QA Tester
AI & ML Internships (with further learning)
This certification opens the door to in-demand, high-paying, and future-proof roles in the IT and data ecosystem.
🌐 Tools & Platforms You'll Work With
Python 3.x
Jupyter Notebook / Google Colab
VS Code
Git & GitHub
Pandas, NumPy, Matplotlib
APIs & JSON
BeautifulSoup / Selenium
🏅 Certification That Matters
On completion, you’ll receive an industry-recognized certificate from APOTAC—perfect to showcase on your resume, LinkedIn, and GitHub portfolio. You'll also get interview prep, resume building, and job guidance as part of the program.
🚀 Why APOTAC?
We don’t just teach – we mentor, guide, and place. At APOTAC, we focus on outcome-based learning with a strong support system.
✅ 100% Job-Oriented Curriculum
✅ Expert Mentors from the Industry
✅ Real-Time Projects & Portfolio Building
✅ Career Guidance & Interview Preparation
✅ Peer Learning Community & Alumni Network
✅ Lifetime Access & Updates
📢 What Our Students Say
“This course gave me confidence to switch from BPO to tech. I landed a Python Developer role within 3 months of completing it!” — Prateek M., Hyderabad
“I knew nothing about coding. The mentors at APOTAC made everything simple, and now I’m working as a Data Analyst!” — Sneha R., Mumbai
📅 Enroll Today – Limited Seats!
Take the first step toward your tech career in 2025. Join APOTAC Python Certification Course and transform your future with hands-on learning, expert guidance, and job-ready skills.
Become a certified Python professional. Your journey starts now.
Home
Data Science Course
Data Analytics Course
Artificial Intelligence Course
Web Development Course
Python Course
Machine Learning Course
Digital Marketing Course
Generative AI Course
0 notes
Text

🚀 Enterprise Web Crawling Services – Scalable, Reliable, Customizable
In the age of #DigitalTransformation, real-time access to data is a business necessity—not a luxury. At Actowiz Solutions, our #EnterpriseWebCrawlingServices are designed to empower businesses with scalable, robust, and fully customizable web data extraction from any website, at any volume.
Whether you're monitoring product prices, tracking brand mentions, gathering market intelligence, or fueling your AI/ML pipelines, our crawling infrastructure ensures:
✅ High-Volume Data Extraction — Crawl millions of pages across thousands of domains
✅ Custom Configurations — Tailored scraping logic to meet your unique business goals
✅ Structured Output Formats — JSON, CSV, Excel, APIs, and more
✅ Real-Time & Scheduled Crawls — Stay updated on fast-changing data like pricing, availability, reviews, or news
✅ Compliance-First Approach — Ethical scraping practices with respect for site integrity and data policies
🌐 From #ECommerce and #Travel to finance, healthcare, and logistics, our enterprise-grade crawling platform supports #LargeScaleDEata aggregation, automation, and business intelligence workflows across industries.
💼 Who is it for?
Retailers & Aggregators needing competitive price and inventory tracking
Market Intelligence Firms conducting ongoing research and analytics
Data Science Teams needing fresh datasets to train predictive models
Enterprises requiring massive data ingestion pipelines with enterprise SLAs
📈 Let your business make smarter, faster, and data-backed decisions—with Actowiz Solutions as your data partner.
🔗 Explore more: https://www.actowizsolutions.com
📩 Get in touch: [email protected]
0 notes
Text
Automating Restaurant Menu Data Extraction Using Web Scraping APIs
Introduction
The food and restaurant business sector is going very heavily digital with millions of restaurant menus being made available through online platforms. Companies that are into food delivery, restaurant aggregation, and market research require menu data on a real-time basis for competition analysis, pricing strategies, and enhancement of customer experience. Manually collecting and updating this information is time-consuming and a laborious endeavor. This is where web scraping APIs come into play with the automated collection of such information to scrape restaurant menu data efficiently and accurately.
This guide discusses the importance of extracting restaurant menu data, how web scraping works for this use case, some challenges to expect, the best practices in dealing with such issues, and the future direction of menu data automation.
Why Export Restaurant Menu Data?
1. Food Delivery Service
Most online food delivery services, like Uber Eats, DoorDash, and Grubhub, need real-time menu updates for accurate pricing or availability. With the extraction of restaurant menu data, at least those online platforms are kept updated and discrepancies avoidable.
2. Competitive Pricing Strategy
Restaurants and food chains make use of web scraping restaurant menu data to determine their competitors' price positions. By tracking rival menus, they will know how they should price their products to remain competitive in the marketplace.
3. Nutritional and Dietary Insights
Health and wellness platforms utilize menu data for dietary recommendations to customers. By scraping restaurant menu data, these platforms can classify foods according to calorie levels, ingredients, and allergens.
4. Market Research and Trend Analysis
This is the group of data analysts and research firms collecting restaurant menu data to analyze consumer behavior about cuisines and track price variations with time.
5. Personalized Food Recommendations
Machine learning and artificial intelligence now provide food apps with the means to recommend meals according to user preferences. With restaurant menu data web scraping, food apps can access updated menus and thus afford personalized suggestions on food.
How Web Scraping APIs Automate Restaurant Menu Data Extraction
1. Identifying Target Websites
The first step is selecting restaurant platforms such as:
Food delivery aggregators (Uber Eats, DoorDash, Grubhub)
Restaurant chains' official websites (McDonald's, Subway, Starbucks)
Review sites (Yelp, TripAdvisor)
Local restaurant directories
2. Sending HTTP Requests
Scraping APIs send HTTP requests to restaurant websites to retrieve HTML content containing menu information.
3. Parsing HTML Data
The extracted HTML is parsed using tools like BeautifulSoup, Scrapy, or Selenium to locate menu items, prices, descriptions, and images.
4. Structuring and Storing Data
Once extracted, the data is formatted into JSON, CSV, or databases for easy integration with applications.
5. Automating Data Updates
APIs can be scheduled to run periodically, ensuring restaurant menus are always up to date.
Data Fields Extracted from Restaurant Menus
1. Restaurant Information
Restaurant Name
Address & Location
Contact Details
Cuisine Type
Ratings & Reviews
2. Menu Items
Dish Name
Description
Category (e.g., Appetizers, Main Course, Desserts)
Ingredients
Nutritional Information
3. Pricing and Discounts
Item Price
Combo Offers
Special Discounts
Delivery Fees
4. Availability & Ordering Information
Available Timings
In-Stock/Out-of-Stock Status
Delivery & Pickup Options
Challenges in Restaurant Menu Data Extraction
1. Frequent Menu Updates
Restaurants frequently update their menus, making it challenging to maintain up-to-date data.
2. Anti-Scraping Mechanisms
Many restaurant websites implement CAPTCHAs, bot detection, and IP blocking to prevent automated data extraction.
3. Dynamic Content Loading
Most restaurant platforms use JavaScript to load menu data dynamically, requiring headless browsers like Selenium or Puppeteer for scraping.
4. Data Standardization Issues
Different restaurants structure their menu data in various formats, making it difficult to standardize extracted information.
5. Legal and Ethical Considerations
Extracting restaurant menu data must comply with legal guidelines, including robots.txt policies and data privacy laws.
Best Practices for Scraping Restaurant Menu Data
1. Use API-Based Scraping
Leveraging dedicated web scraping APIs ensures more efficient and reliable data extraction without worrying about website restrictions.
2. Rotate IP Addresses & Use Proxies
Avoid IP bans by using rotating proxies or VPNs to simulate different users accessing the website.
3. Implement Headless Browsers
For JavaScript-heavy pages, headless browsers like Puppeteer or Selenium can load and extract dynamic content.
4. Use AI for Data Cleaning
Machine learning algorithms help clean and normalize menu data, making it structured and consistent across different sources.
5. Schedule Automated Scraping Jobs
To maintain up-to-date menu data, set up scheduled scraping jobs that run daily or weekly.
Popular Web Scraping APIs for Restaurant Menu Data Extraction
1. Scrapy Cloud API
A powerful cloud-based API that allows automated menu data scraping at scale.
2. Apify Restaurant Scraper
Apify provides pre-built restaurant scrapers that can extract menu details from multiple platforms.
3. Octoparse
A no-code scraping tool with API integration, ideal for businesses that require frequent menu updates.
4. ParseHub
A flexible API that extracts structured restaurant menu data with minimal coding requirements.
5. CrawlXpert API
A robust and scalable solution tailored for web scraping restaurant menu data, offering real-time data extraction with advanced anti-blocking mechanisms.
Future of Restaurant Menu Data Extraction
1. AI-Powered Menu Scraping
Artificial intelligence will improve data extraction accuracy, enabling automatic menu updates without manual intervention.
2. Real-Time Menu Synchronization
Restaurants will integrate web scraping APIs to sync menu data instantly across platforms.
3. Predictive Pricing Analysis
Machine learning models will analyze scraped menu data to predict price fluctuations and customer demand trends.
4. Enhanced Personalization in Food Apps
By leveraging scraped menu data, food delivery apps will provide more personalized recommendations based on user preferences.
5. Blockchain for Menu Authentication
Blockchain technology may be used to verify menu authenticity, preventing fraudulent modifications in restaurant listings.
Conclusion
Automating the extraction of restaurant menus from the web through scraping APIs has changed the food industry by offering real-time prices, recommendations for food based on liking, and analysis of competitors. With advances in technology, more AI-driven scraping solutions will further improve the accuracy and speed of data collection.
Know More : https://www.crawlxpert.com/blog/restaurant-menu-data-extraction-using-web-scraping-apis
#RestaurantMenuDataExtraction#ScrapingRestaurantMenuData#ExtractRestaurantMenus#ScrapeRestaurantMenuData
0 notes
Text
Real-Time Grocery Price Monitoring For Zepto, Blinkit & BigBasket

Introduction
India’s quick commerce boom has transformed how millions shop for groceries. To keep up with changing prices, offers, and hyperlocal stock availability, Indian startups are embracing Real-Time Grocery Price Monitoring For Zepto, Blinkit & BigBasket. Product Data Scrape helps these brands build competitive, real-time insights into grocery price shifts, discounts, and competitor tactics. By combining Scrape Real-Time Price Data from Zepto, Blinkit & BigBasket with robust tracking tools, startups now respond instantly to market moves and demand spikes. In this case study, discover how real-time price monitoring has powered smarter pricing, increased sales, and improved customer loyalty for India’s fastest-growing quick commerce brands.
The Client
An emerging grocery aggregator startup approached Product Data Scrape with one clear goal: outperform larger players by using reliable, granular price intelligence across India’s top grocery delivery apps. This client needed Real-Time Grocery Price Monitoring For Zepto, Blinkit & BigBasket to spot price drops, match competitor discounts, and adjust their own offers dynamically. With fierce local competition and daily pricing changes, it was no longer enough to rely on manual checks or outdated spreadsheets. The client also wanted to scale insights across multiple cities and store formats, covering essentials, fresh produce, and Gourmet Food Data. The need for a trusted partner who could deliver Real-Time Data Monitoring for Grocery Prices & Discounts led them to Product Data Scrape’s proven expertise. The client’s vision was clear: get real-time data or get left behind.
Key Challenges
The client faced several challenges typical for India’s quick commerce and grocery tech startups. First, manual price checks on Zepto, Blinkit, and BigBasket were time-consuming and error-prone, missing daily promotions and location-specific discounts. Second, without a system to Scrape Real-Time Price Data from Zepto, Blinkit & BigBasket, they couldn’t confidently match or beat competitor offers, which led to lost customers. Third, the team struggled to handle huge volumes of SKU-level data with variations across cities, PIN codes, and product categories. They needed Real-Time Grocery Price Tracking from Zepto, Blinkit & BigBasket to feed their pricing engines and marketing tools automatically. Additionally, they lacked robust tools for Quick Commerce Grocery & FMCG Data Scraping, which meant missing insights on emerging neighborhood-level demand. They also required clean integrations with Real-Time Indian Grocery Price Scraping APIs , so their tech stack could automatically update pricing dashboards daily. Without dependable Grocery Price Monitoring Scraper For Zepto, Blinkit & BigBasket, their strategy was reactive instead of proactive. Staying competitive demanded a scalable solution to Extract Blinkit Grocery & Gourmet Food Data , Extract Bigbasket Product Data , and launch smarter promotions instantly.
Key Solutions
Product Data Scrape built a robust solution covering every pain point. We deployed dedicated crawlers to Scrape Real-Time Price Data from Zepto, Blinkit & BigBasket with 99% accuracy. The client gained city-level price feeds that updated hourly, fueling their dynamic pricing engine with precise SKU details and store-specific offers. Our team customized Zepto Grocery Data Scraping modules to capture neighborhood differences for quick commerce. Combined with Web Scraping Grocery Price Data, they could compare pricing trends, track discounts, and identify competitors’ loss leaders. To scale, we integrated Real-Time Indian Grocery Price Scraping APIs into the client’s dashboards, giving instant visibility into price gaps and fresh offers.
Product Data Scrape also activated Grocery & Supermarket Data Scraping Services for broader market mapping, including insights from smaller grocery stores and specialty listings. The client used our Grocery Data Scraping Services to enhance supply chain forecasting and inventory planning with a high-quality Grocery Store Dataset. Our tools helped them Scrape Grocery & Gourmet Food Data to spot premium product trends, boosting margins with curated assortments. Together, this complete solution turned chaotic market signals into actionable pricing strategies. Today, the client uses Product Data Scrape for continuous Grocery Price Monitoring Scraper For Zepto, Blinkit & BigBasket, plus robust Quick Commerce Grocery & FMCG Data Scraping to stay ahead in India’s competitive grocery space.
Client’s Testimonial
"Product Data Scrape transformed how we compete. Their Real-Time Grocery Price Monitoring For Zepto, Blinkit & BigBasket helps us adjust prices daily, match discounts, and win more loyal customers. Their data scraping quality and support are unmatched."
— Head of Growth, Leading Indian Quick Commerce Startup
Conclusion
Real-time grocery price tracking is no longer optional for India’s quick commerce brands — it’s mission-critical. This case study proves that Real-Time Grocery Price Monitoring For Zepto, Blinkit & BigBasket drives competitive advantage, sharper pricing, and smarter promotions. Product Data Scrape remains the trusted partner for startups that need powerful Grocery Price Monitoring Scraper For Zepto, Blinkit & BigBasket and ready-to-use insights that fuel growth. Get started with Product Data Scrape today and unlock your edge in India’s grocery market!
Unlock More Info>>>https://www.productdatascrape.com/real-time-grocery-price-monitoring-zepto-blinkit-bigbasket.php
#RealTimeGroceryPriceMonitoringForZeptoBlinkitAndBigBasket#ScrapeRealTimePriceDataFromZeptoBlinkitAndBigBasket#RealTimeDataMonitoringForGroceryPricesAndDiscounts#RealTimeGroceryPriceTrackingFromZeptoBlinkitAndBigBasket#RealTimeIndianGroceryPriceScrapingAPIs#QuickCommerceGroceryAndFMCGDataScraping#WebScrapingGroceryPriceData
0 notes
Text
Flight Price Intelligence 2025: Real-Time Data for Travel Platforms
Introduction
In the rapidly evolving landscape of travel technology, staying ahead of the competition is no longer about just offering competitive fares or diverse destinations. In 2025, flight price data intelligence has emerged as a game-changer, empowering travel platforms with real-time insights to optimize pricing, boost conversions, and enhance user experience.
What is Flight Price Data Intelligence?

Flight price data intelligence refers to the systematic collection, analysis, and application of airfare data from multiple sources using advanced data scraping and analytics tools. It goes beyond simple price tracking and dives deep into pricing patterns, historical fare trends, competitive pricing, and dynamic market changes.
With rising consumer expectations and fluctuating airline pricing strategies, leveraging this intelligence is essential for travel aggregators, OTAs, and even airlines themselves.
Why Flight Price Intelligence Matters in 2025

Airfare pricing is more dynamic than ever before. With airlines adjusting fares based on demand, seasonality, user behavior, and competitor pricing, having access to real-time, comprehensive data is no longer optional—it’s a necessity.
Key reasons why flight price intelligence is crucial:
Real-time visibility into airfare changes
Dynamic pricing optimization for travel platforms
Competitor benchmarking for OTAs and aggregators
Enhanced customer targeting using pricing trends
Increased booking conversions through smarter fare presentation
How Data Scraping Powers Price Intelligence

Travel platforms rely heavily on web scraping airlines data to feed their pricing engines and predictive models. By extracting structured data from airline websites, GDSs, OTAs, and meta-search engines, businesses can compare flight fares across routes, airlines, and dates.
This data is then cleaned, analyzed, and visualized to inform
Fare forecasting models
Personalized pricing strategies
Competitor fare matching
Route-specific fare trend analysis
For those seeking a reliable solution, Travel Scrape’s flight price data intelligence services offer global airfare tracking from leading sources with historical trends and real-time updates.
Key Use Cases of Flight Price Intelligence
1. Revenue Management for Airlines
Airlines use dynamic pricing to maximize revenue per seat. Flight price intelligence allows them to benchmark against competitors and fine-tune pricing strategies.
2. Pricing Optimization for OTAs
Online Travel Agencies leverage flight price data scraping to present the most competitive fares to users, increasing booking rates and reducing bounce rates.
Explore Travel Scrape's flight price data scraping solutions for real-time fare tracking across global carriers.
3. Travel Aggregators and Meta Search Tools
Travel aggregators need real-time airfare intelligence to power their search and comparison engines. Having access to updated flight pricing enhances user trust and engagement.
Take a look at our tools for extracting flight ticket price data from leading travel platforms like Skyscanner.
Emerging Trends in Flight Price Intelligence

As technology advances, new trends are shaping how travel platforms utilize pricing data:
AI & machine learning for predictive fare modeling
API integration for live data feeds and automation
Mobile-first data scraping for app-based booking platforms
Customer segmentation for personalized fare offerings
The Competitive Advantage in 2025
In 2025, travel companies investing in flight price intelligence will be better positioned to:
Outprice competitors with real-time insights
Deliver personalized offers based on user behavior
Predict market shifts and prepare early
Build customer loyalty with better price transparency
This is particularly crucial in a market where consumers often abandon carts if they find cheaper options elsewhere within minutes.
Conclusion: Intelligence is the New Currency
In 2025, flight price intelligence has become essential for travel platforms aiming to compete on speed, pricing precision, and user personalization. Real-time airfare data empowers businesses to stay agile, optimize conversions, and build long-term traveler trust.
To unlock even deeper insights and automation, explore our travel web scraping services, integrate real-time data through the Travel Scraping API, or power your platform with travel aggregator data scraping.
Read More :- https://www.travelscrape.com/flight-price-intelligence-travel-platforms-2025.php
#FlightPriceIntelligence#ExtractingFlightTicketPriceData#TravelWebScrapingServices#TravelAggregatorDataScraping#TravelScrapingAPI
0 notes