#Mobile-app Specific Scraping
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr’s reach among the 26-to-35-year-olds in the US is 11%.
Text
Competitor Price Monitoring Services - Food Scraping Services
Competitor Price Monitoring Strategies
Price Optimization

If you want your restaurant to stay competitive, it’s crucial to analyze your competitors’ average menu prices. Foodspark offers a Competitor Price Monitoring service to help you with this task. By examining data from other restaurants and trends in menu prices, we can determine the best price for your menu. That will give you an edge in a constantly evolving industry and help you attract more customers, ultimately increasing profits.
Market Insights

Our restaurant data analytics can help you stay ahead by providing valuable insights into your competitors’ pricing trends. By collecting and analyzing data, we can give you a deep understanding of customer preferences, emerging trends, and regional variations in menu pricing. With this knowledge, you can make informed decisions and cater to evolving consumer tastes to stay ahead.
Competitive Advantage

To stay ahead in the restaurant industry, you must monitor your competitors’ charges and adjust your prices accordingly. Our solution can help you by monitoring your competitors’ pricing strategies and allowing you to adjust your expenses in real-time. That will help you find opportunities to offer special deals or menu items to make you stand out and attract more customers.
Price Gap Tracking

Knowing how your menu prices compare to your competitors is essential to improve your restaurant’s profitability. That is called price gap tracking. Using our tracking system, you can quickly identify the price differences between restaurant and your competitors for the same or similar menu items. This information can help you find opportunities to increase your prices while maintaining quality or offering lower costs. Our system allows you to keep a close eye on price gaps in your industry and identify areas where your expenses are below or above the average menu prices. By adjusting your pricing strategy accordingly, you can capture more market share and increase your profits.
Menu Mapping and SKU

Use our menu and SKU mapping features to guarantee that your products meet customer expectations. Find out which items are popular and which ones may need some changes. Stay adaptable and responsive to shifting preferences to keep your menu attractive and competitive.
Price Positioning

It’s essential to consider your target audience and desired brand image to effectively position your restaurant’s prices within the market. Competitor data can help you strategically set your prices as budget-friendly, mid-range, or premium. Foodspark Competitor Price Monitoring provides data-driven insights to optimize your pricing within your market segment. That helps you stay competitive while maximizing revenue and profit margins.
Competitor Price Index (CPI)

The Competitor Price Index (CPI) measures how your restaurant’s prices compare to competitors. We calculate CPI for you by averaging the prices of similar menu items across multiple competitors. If your CPI is above 100, your prices are higher than your competitors. If it’s below 100, your prices are lower.
Benefits of Competitor Price Monitoring Services
Price Optimization
By continuous monitoring your competitor’s prices, you can adjust your own pricing policies, to remain competitive while maximizing your profit margins.
Dynamic Pricing
Real-time data on competitor’s prices enable to implement dynamic pricing strategies, allowing you to adjust your prices based on market demand and competitive conditions.
Market Positioning
Understanding how your prices compare to those of your competitors helps you position your brand effectively within the market.
Customer Insights
Analyzing customer pricing data can reveal customer behavior and preferences, allowing you to tailor your pricing and marketing strategies accordingly.
Brand Reputation Management
Consistently competitive pricing can enhance your brand’s reputation and make your product more appealing to customers.
Content Source: https://www.foodspark.io/competitor-price-monitoring/
#web scraping services#restaurantdataextraction#Competitor Price Monitoring#Mobile-app Specific Scraping#Real-Time API#Region - wise Restaurant Listings#Services#Food Aggregator#Food Data Scraping#Real-time Data API#Price Monitoring#Food App Scraping#Food Menu Data
0 notes
Text
Exhibitor Apps Scraping Services | Extract Event Organizers Data
Elevate your event strategy with our Exhibitor Apps Scraping Services. Extract event organizers data in the USA, UK, UAE, and Spain. Optimize your event success today!
know more: https://www.mobileappscraping.com/event-exhibitor-app-scraping-services.php
#Exhibitor Apps Scraping Services#Extract Event Organizers Data#Extracting data from event-specific mobile applications#Scraping's Event Exhibitor App Data
0 notes
Text
AI Scraping Isn't Just Art And Fanfic
Something I haven't really seen mentioned and I think people may want to bear in mind is that while artists are the most heavily impacted by AI visual medium scraping, it's not like the machine knows or cares to differentiate between original art and a photograph of your child.
AI visual media scrapers take everything, and that includes screengrabs, photographs, and memes. Selfies, pictures of your pets and children, pictures of your home, screengrabs of images posted to other sites -- all of the comic book imagery I've posted that I screengrabbed from digital comics, images of tweets (including the icons of peoples' faces in those tweets) and instas and screengrabs from tiktoks. I've posted x-ray images of my teeth. All of that will go into the machine.
That's why, at least I think, Midjourney wants Tumblr -- after Instagram we are potentially the most image-heavy social media site, and like Instagram we tag our content, which is metadata that the scraper can use.
So even if you aren't an artist, unless you want to Glaze every image of any kind that you post, you probably want to opt out of being scraped. I'm gonna go ahead and say we've probably already been scraped anyway, so I don't think there's a ton of point in taking down your tumblr or locking down specific images, but I mean...especially if it's stuff like pictures of children or say, a fundraising photo that involves your medical data, it maybe can't hurt.
If you do want to officially opt out, which may help if there's a class-action lawsuit later, you're going to want to go to the gear in the upper-right corner on the Tumblr desktop site, select each of your blogs from the list on the right-hand side, and scroll down to "Visibility". Select "Prevent third party sharing for [username]" to flip that bad boy on.
Per notes: for the app, go to your blog (the part of the app that shows what you post) and hit the gear in the upper right, then select "visibility" and it will be the last option. If you have not updated your app, it will not appear (confirmed by me, who cannot see it on my elderly version of the app).
You don't need to do it on both desktop and mobile -- either one will opt you out -- but on the app you may need to load each of your sideblogs in turn and then go back into the gear and opt out for that blog, like how you have to go into the settings for each sideblog on desktop and do it.
5K notes
·
View notes
Text
"Artists have finally had enough with Meta’s predatory AI policies, but Meta’s loss is Cara’s gain. An artist-run, anti-AI social platform, Cara has grown from 40,000 to 650,000 users within the last week, catapulting it to the top of the App Store charts.
Instagram is a necessity for many artists, who use the platform to promote their work and solicit paying clients. But Meta is using public posts to train its generative AI systems, and only European users can opt out, since they’re protected by GDPR laws. Generative AI has become so front-and-center on Meta’s apps that artists reached their breaking point.
“When you put [AI] so much in their face, and then give them the option to opt out, but then increase the friction to opt out… I think that increases their anger level — like, okay now I’ve really had enough,” Jingna Zhang, a renowned photographer and founder of Cara, told TechCrunch.
Cara, which has both a web and mobile app, is like a combination of Instagram and X, but built specifically for artists. On your profile, you can host a portfolio of work, but you can also post updates to your feed like any other microblogging site.
Zhang is perfectly positioned to helm an artist-centric social network, where they can post without the risk of becoming part of a training dataset for AI. Zhang has fought on behalf of artists, recently winning an appeal in a Luxembourg court over a painter who copied one of her photographs, which she shot for Harper’s Bazaar Vietnam.
“Using a different medium was irrelevant. My work being ‘available online’ was irrelevant. Consent was necessary,” Zhang wrote on X.
Zhang and three other artists are also suing Google for allegedly using their copyrighted work to train Imagen, an AI image generator. She’s also a plaintiff in a similar lawsuit against Stability AI, Midjourney, DeviantArt and Runway AI.
“Words can’t describe how dehumanizing it is to see my name used 20,000+ times in MidJourney,” she wrote in an Instagram post. “My life’s work and who I am—reduced to meaningless fodder for a commercial image slot machine.”
Artists are so resistant to AI because the training data behind many of these image generators includes their work without their consent. These models amass such a large swath of artwork by scraping the internet for images, without regard for whether or not those images are copyrighted. It’s a slap in the face for artists – not only are their jobs endangered by AI, but that same AI is often powered by their work.
“When it comes to art, unfortunately, we just come from a fundamentally different perspective and point of view, because on the tech side, you have this strong history of open source, and people are just thinking like, well, you put it out there, so it’s for people to use,” Zhang said. “For artists, it’s a part of our selves and our identity. I would not want my best friend to make a manipulation of my work without asking me. There’s a nuance to how we see things, but I don’t think people understand that the art we do is not a product.”
This commitment to protecting artists from copyright infringement extends to Cara, which partners with the University of Chicago’s Glaze project. By using Glaze, artists who manually apply Glaze to their work on Cara have an added layer of protection against being scraped for AI.
Other projects have also stepped up to defend artists. Spawning AI, an artist-led company, has created an API that allows artists to remove their work from popular datasets. But that opt-out only works if the companies that use those datasets honor artists’ requests. So far, HuggingFace and Stability have agreed to respect Spawning’s Do Not Train registry, but artists’ work cannot be retroactively removed from models that have already been trained.
“I think there is this clash between backgrounds and expectations on what we put on the internet,” Zhang said. “For artists, we want to share our work with the world. We put it online, and we don’t charge people to view this piece of work, but it doesn’t mean that we give up our copyright, or any ownership of our work.”"
Read the rest of the article here:
https://techcrunch.com/2024/06/06/a-social-app-for-creatives-cara-grew-from-40k-to-650k-users-in-a-week-because-artists-are-fed-up-with-metas-ai-policies/
610 notes
·
View notes
Text
The monetization creep has been evident for a while. Reddit has added a subscription ”Reddit premium”; offered “community rewards” as a paid super-vote ; embraced an NFT marketplace; changed the site's design for one with more recommended content; and started nudging users toward the official mobile app. The site has also been adding more restrictions to uploading and viewing “not safe for work” (NSFW) content. All this, while community requests for improvements to moderation tools and accessibility features have gone unaddressed on mobile, driving many users to third-party applications. Perhaps the worst development was announced on April 18th, when Reddit announced changes to its Data API would be starting on July 1st, including new “premium access” pricing for users of the API. While this wouldn’t affect projects on the free tier, such as moderator bots or tools used by researchers, the new pricing seems to be an existential threat to third-party applications for the site. It also bears a striking resemblance to a similar bad decision Twitter made this year under Elon Musk.
[...]
Details about Reddit’s API-specific costs were not shared, but it is worth noting that an API request is commonly no more burdensome to a server than an HTML request, i.e. visiting or scraping a web page. Having an API just makes it easier for developers to maintain their automated requests. It is true that most third-party apps tend to not show Reddit’s advertisements, and AI developers may make heavy use of the API for training data, but these applications could still (with more effort) access the same information over HTML. The heart of this fight is for what Reddit’s CEO calls their “valuable corpus of data,” i.e. the user-made content on the company’s servers, and for who gets live off this digital commons. While Reddit provides essential infrastructural support, these community developers and moderators make the site worth visiting, and any worthwhile content is the fruit of their volunteer labor. It’s this labor and worker solidarity which gives users unique leverage over the platform, in contrast to past backlash to other platforms.
179 notes
·
View notes
Text
Tumblr AI Update
I'm seeing a lot of knee-jerk reactions and it's making me worry, so I'm going to try and help.
Here's the announcement post by tumblr staff.
Under settings -> visibility, on desktop or mobile on mobile hitting the gear and going down to Visibility, you can change your settings to Opt Out of allowing third-party AI scrappers. (you want it to be blue).
If you can't see these options you may need to update your app or refresh your browser. I've done it on both, so it is available on mobile and desktop.
Per the update from tumblr, they already take steps to mitigate AI scraping from people they are NOT associated with. The Opt Out option is specifically for those companies they are, or are going to, partner with.
You need to change this setting on ALL your sideblogs too.
Do it if you have art, or fics or anything really. It's just best to opt out.
You can leave to another platform if you want, I just don't want to see people go because they're angry or misunderstanding what's happening.
25 notes
·
View notes
Text
Hum... Hum...
Rhythmic. What is that beautiful sound? What am I dreaming of? What makes this noise?
Hmzz... Hmzz...
It's almost like...
Buzz... Buzz...
Buzzing? What could possibly be-
Buzz, buzz, buzz ... Buzz buzz
Oh.
My hand lazily scrambled to find the source of the incessant buzzing.
That goddamn phone. Always with that phone. Buzzing. An email, a text message, an abandoned mobile game trying to suck me back in.
My eyes barely opened, I brought my phone up to my face.
3:34am
Three different contacts, desperately trying to reach me all at once? Something must be going on. Has my past come to haunt me? Has someone died? Is my boyfriend cheating on me and all our friends have come to spread their condolences before word has even reached me?
#####: hey are you awake? I need to vent
#####: on second thought nevermind im too tired
#######: can you ask ### what the plan is for next week?
##: C u d y u h ar t
By the time I had read the third notification, the irritation had already kicked it. I no longer had the energy to make out the last one, peeking out from the cutoff.
Can't you ask ### yourself? Is what I really wanted to say to #######.
And ##### could get absolutely fucked. We only talk when they "need to vent"
Do I leave it for later? Or reply now? God knows I'll forget and then repost something for everyone to see. Then they'll know I ignored them.
Let them know. Make a post about how you despise people with an inability to do things for themselves.
I giggled at the thought before a frown stretched over my mouth, guilt washing over me for even considering it.
The guilt was soon replaced by an irritation similar to the initial, but it was different. More hollow.
I swiped the notifications to the left, voiding them.
My thumb twitched, hovering over the final message preview.
"could you hear it?"
A name I recognise, but at the same time, it could be anyone.
I don't know this person.
Is it a person?
How does it know about my hearing the buzzing?
How I came to the conclusion that was what was being referenced, I was unsure. But I was decided.
It knew about the buzzing.
I swiped out of my notifications and input my password, waiting for my shitty phone to load in.
Opening the app and navigating to my inbox, my eyes frantically scanned over the name.
Before I said anything back to it, I found my way onto it's profile.
At first glance, it was so very familiar. Maybe it was in the message hidden within the follower count, or the random yet specific arrangement of letters making up the username.
And then it was nothing. I knew nothing about it. It was engimatic. Enigmatic didn't begin to cover it.
How did it know about the buzzing?
I felt something.
Something strange.
Something familiar.
Something new?
Something warm.
Something... swirly.
A magical twisting, churning, agitating, winding, spiraling heat, fermenting in the lowest pit of my stomach.
I had forgotten about the spring of my irritation.
There was danger.
It knew about the buzzing.
My eyes darted to the ceiling.
There had long been a scraping from within the ceiling. A knocking. Each night without fail. Some nights, it managed to go on for hours.
It must be the thing in the ceiling. That's the only way it could know.
FROM MY BRAIN THIS CAME FROM MY BRAIN IT CAME FROM MY BRAIN IT CAME FROM MY BRAIN. IT LIVES IN MY BRAIN.
-
Hi. I dunno what this is, really. But it was kind of fun to write. I used to write a lot. It was my ultimate joy. I don't know what constitutes good. But this is good to me, and that's good!
2 notes
·
View notes
Text
Syncing Scrivener 3 with Mega
Because Dropbox is dumb and being very glitchy lately, the sync function is no longer reliable. I spent a day trying to figure out why it wasn't syncing only to find out this is now an issue among Android and iOS users alike. Given the piddly space Dropbox gives as well as these ongoing issues, I decided to jump ship. If have Scrivener and are thinking of doing the same, here's a lil guide for you.
I opted to go with Mega. Their free account comes with 20 GB. Their website says 20, but if you download the mobile and desktop app, you get a 5 GB bonus for each. I suspect it might not be a permanent bonus, likely for a year, but I'll check again in the summer of 2025. They are also more privacy-oriented and have no AI scraping (like Google).
This walkthrough is for Android. I'd imagine the steps are similar for iOS, but I can't say for sure.
1. Make a Mega account, go through all that registration stuff.
2. Download the mobile app. Log in.
3. Download the desktop app. Log in
4. Open File Explorer and make a folder wherever you'd like your files to be synced from.
5. Once the desktop app is installed, you need to look for the icon to open the program. I found it in my task bar. The little red M icon is what you need to open.

6. Go to the three dots and double click to open up options.

7. Go to settings.
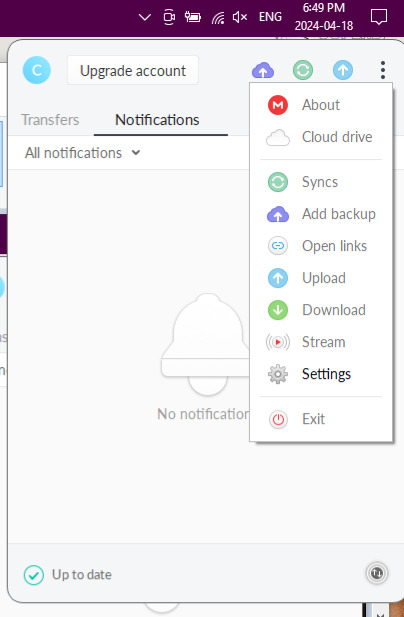
8. Go to the Sync option in the Settings menu. Select Add.

9. Another dialogue box will pop up. One the 'Local Folder' line, click 'Add'.
10. Select the folder you made specifically for sync. For this walkthrough, I'm using the 'Testing' folder.

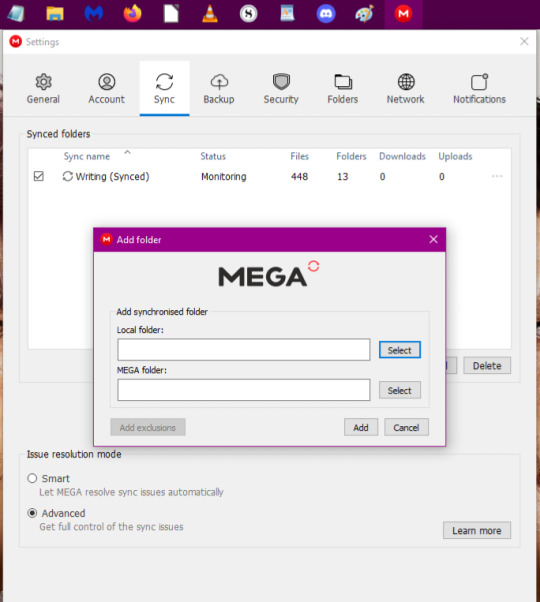
11. Once you've selected your folder, you'll be back at the previous dialogue box. Now click on 'Select' on the MEGA folder line.

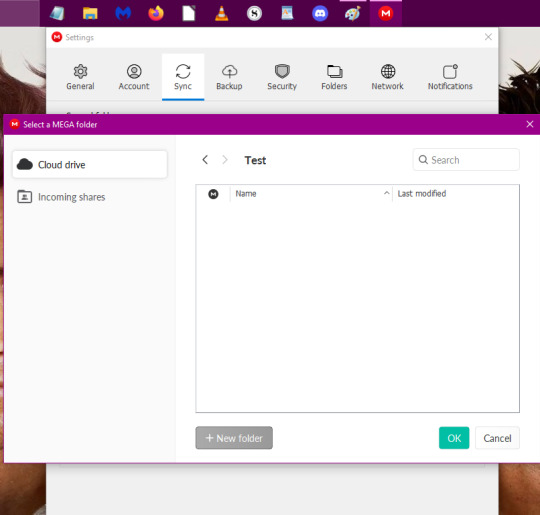
12. I forgot to take a screenshot, but you'll have a new dialogue box pop up with an empty list. Select the grey box saying 'New Folder'. You can name it whatever you want but I gave it the name 'Test'. Once done, your screen should look similar to the one below. Then click 'OK'.
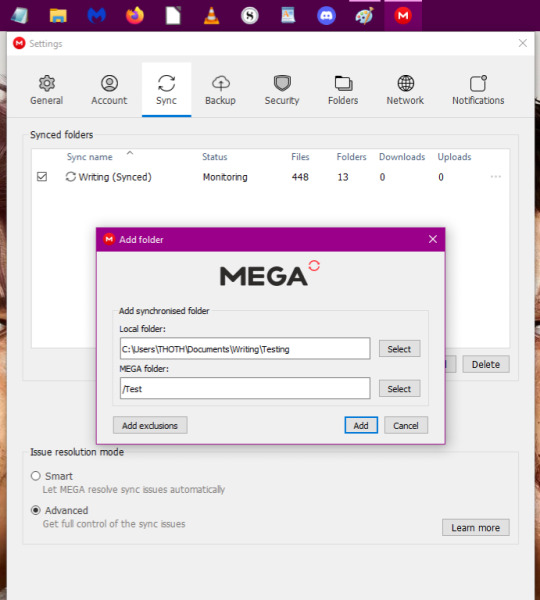
13. When done, your dialogue box should look like below. This is the crucial step as this is how the Mega program will help you sync with Scrivener. Make sure these folders are exactly where you want them to be and are named as you want. Once you're certain, click 'Add'
14. When done, you'll have a list that looks similar to this. The first step is done.
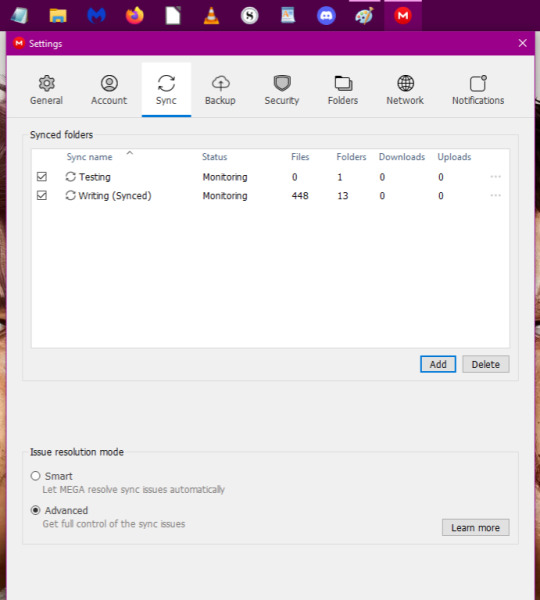
6 notes
·
View notes
Text
The way I can feel all the wind slowly pissing out of my sails as AI gets more and more engrained into social media platforms and how opting OUT of this shit is getting harder if not impossible
I've been saying it for years now, but fuck you Instagram. 1,470 posts across 3 accounts and lord fucking knows how many stories that you're scraping for your shitty AI model and you're giving me NO choice in the matter. Tumblr needing you to click a button to opt out of third party sharing was one thing, but you hiding an opt out REQUEST under a LINK under a specific SECTION of your PRIVACY POLICY under the ABOUT section of SETTINGS that doesn't even work in the US and Australia (and is reportedly being taken away in other countries) is fucking abysmal.
I don't know what to do. Almost 1.5k posts to too many to archive or delete, and they've probably already been scraped anyway. There's no Nightshade for mobile and Glaze has convoluted work-arounds. I don't want to stop creating. I don't want to stop sharing what I create. But if my creations are going to be STOLEN to create shitty little mimcries, what the fuck am I still even on your dumb shit app for anymore? You don't respect me or what I do. Is there even a point to sharing art on the internet anymore? When it's going to be inevitably stolen and exploited while I can do nothing to stop it? Can't even fight back because I can't Nightshade (at all) or (easily) Glaze traditional art?
And not even just my art. Pictures of me, castmates from high school, my friends, my family, my cats, videos I've recorded with them, concerts videos that I'm still actively posting on my irl account. You want to steal my LIKENESS, the likeness of people I care about. You want to strip away every grain of personality and humanity in the world until there's nothing left but your soulless impersonations. In the name of fucking what? I don't even know.
Fuck I wanna cry
#mj says shit#fuck ai art#didnt think id ever vent on tumblr but im just so...#tired#i dont know if ill have the motivation to post anything once i finish with the anniversary stuff#i can feel it.. i can feel the hopelessness setting it.. the depressive spiral#i might actually start crying shit
3 notes
·
View notes
Text
What happened to the cycle of renewal? Where are the regular, controlled burns?
Like the California settlers who subjugated the First Nations people and declared war on good fire, the finance sector conquered the tech sector.
It started in the 1980s, the era of personal computers — and Reaganomics. A new economic and legal orthodoxy took hold, one that celebrated monopolies as “efficient,” and counseled governments to nurture and protect corporations as they grew both too big to fail, and too big to jail.
For 40 years, we’ve been steadily reducing antitrust enforcement. That means a company like Google can create a single great product (a search engine) and use investors’ cash to buy a mobile stack, a video stack, an ad stack, a server-management stack, a collaboration stack, a maps and navigation stack — all while repeatedly failing to succeed with any of its in-house products.
It’s hard to appreciate just how many companies tech giants buy. Apple buys other companies more often than you buy groceries.
These giants buy out their rivals specifically to make sure you can’t leave their walled gardens. As Mark Zuckerberg says, “It is better to buy than to compete,” (which is why Zuckerberg bought Instagram, telling his CFO that it was imperative that they do the deal because Facebook users preferred Insta to FB, and were defecting in droves).
As these companies “merge to monopoly,” they are able to capture their regulators, ensuring that the law doesn’t interfere with their plans for literal world domination.
When a sector consists of just a handful of companies, it becomes cozy enough to agree on — and win — its lobbying priorities. That’s why America doesn’t have a federal privacy law. It’s why employees can be misclassified as “gig worker” contractors and denied basic labor protections.
It’s why companies can literally lock you out of your home — and your digital life — by terminating your access to your phone, your cloud, your apps, your thermostat, your door-locks, your family photos, and your tax records, with no appeal — not even the right to sue.
But regulatory capture isn’t merely about ensuring that tech companies can do whatever they want to you. Tech companies are even more concerned with criminalizing the things you want to do to them.
Frank Wilhoit described conservativism as “exactly one proposition”:
There must be in-groups whom the law protects but does not bind, alongside out-groups whom the law binds but does not protect.
This is likewise the project of corporatism. Tech platforms are urgently committed to ensuring that they can do anything they want on their platforms — and they’re even more dedicated to the proposition that you must not do anything they don’t want on their platforms.
They can lock you in. You can’t unlock yourself. Facebook attained network-effects growth by giving its users bots that logged into Myspace on their behalf, scraped the contents of their inboxes for the messages from the friends they left behind, and plunked them in their Facebook inboxes.
Facebook then sued a company that did the same thing to Facebook, who wanted to make it as easy for Facebook users to leave Facebook as it had been to get started there.
Apple reverse-engineered Microsoft’s crown jewels — the Office file-formats that kept users locked to its operating systems — so it could clone them and let users change OSes.
Try to do that today — say, to make a runtime so you can use your iOS apps and media on an Android device or a non-Apple desktop — and Apple will reduce you to radioactive rubble.
Big Tech has a million knobs on the back-end that they can endlessly twiddle to keep you locked in — and, just as importantly, they have convinced governments to ban any kind of twiddling back.
This is “felony contempt of business model.”
Governments hold back from passing and enforcing laws that limit the tech giants in the name of nurturing their “efficiency.”
But when states act to prevent new companies — or users, or co-ops, or nonprofits — from making it easier to leave the platforms, they do so in the name of protecting us.
Rather than passing a privacy law that would let them punish Meta, Apple, Google, Oracle, Microsoft and other spying companies, they ban scraping and reverse-engineering because someone might violate the privacy of the users of those platforms.
But a privacy law would control both scrapers and silos, banning tech giants from spying on their users, and banning startups and upstarts from spying on those users, too.
Rather than breaking up ad-tech, banning surveillance ads, and opening up app stores, which would make tech platforms stop stealing money from media companies through ad-fraud, price-gouging and deceptive practices, governments introduce laws requiring tech companies to share (some of) their ill-gotten profits with a few news companies.
This makes the news companies partners with the tech giants, rather than adversaries holding them to account, and makes the news into cheerleaders for massive tech profits, so long as they get their share. Rather than making it easier for the news to declare independence from Big Tech, we are fusing them forever.
We could make it easy for users to leave a tech platform where they are subject to abuse and harassment — but instead, governments pursue policies that require platforms to surveil and control their users in the name of protecting them from each other.
We could make it easy for users to leave a tech platform where their voices are algorithmically silenced, but instead we get laws requiring platforms to somehow “balance” different points of view.
The platforms aren’t merely combustible, they’re always on fire. Once you trap hundreds of millions — or billions — of people inside a walled fortress, where warlords who preside over have unlimited power over their captives, and those captives the are denied any right to liberate themselves, enshittification will surely and inevitably follow.
Laws that block us seizing the means of computation and moving away from Big Tech are like the heroic measures that governments undertake to keep people safe in the smouldering wildland-urban interface.
These measures prop up the lie that we can perfect the tech companies, so they will be suited to eternal rule.
Rather than building more fire debt, we should be making it easy for people to relocate away from the danger so we can have that long-overdue, “good fire” to burn away the rotten giants that have blotted out the sun.
What would that look like?
Well, this week’s news was all about Threads, Meta’s awful Twitter replacement devoted to “brand-safe vaporposting,” where the news and controversy are not welcome, and the experience is “like watching a Powerpoint from the Brand Research team where they tell you that Pop Tarts is crushing it on social.”
Threads may be a vacuous “Twitter alternative you would order from Brookstone,” but it commanded a lot of news, because it experienced massive growth in just hours. “Two million signups in the first two hours” and “30 million signups in the first morning.”
That growth was network-effects driven. Specifically, Meta made it possible for you to automatically carry over your list of followed Instagram accounts to Threads.
Meta was able to do this because it owns both Threads and Instagram. But Meta does not own the list of people you trust and enjoy enough to follow.
That’s yours.
Your relationships belong to you. You should be able to bring them from one service to another.
Take Mastodon. One of the most common complaints about Mastodon is that it’s hard to know whom to follow there. But as a technical matter, it’s easy: you should just follow the people you used to follow on Twitter —either because they’re on Mastodon, too, or because there’s a way to use Mastodon to read their Twitter posts.
Indeed, this is already built into Mastodon. With one click, you can export the list of everyone you follow, and everyone who follows you. Then you can switch Mastodon servers, upload that file, and automatically re-establish all those relationships.
That means that if the person who runs your server decides to shut it down, or if the server ends up being run by a maniac who hates you and delights in your torment, you don’t have to petition a public prosecutor or an elected lawmaker or a regulator to make them behave better.
You can just leave.
Meta claims that Threads will someday join the “Fediverse” (the collection of apps built on top of ActivityPub, the standard that powers Mastodon).
Rather than passing laws requiring Threads to prioritize news content, or to limit the kinds of ads the platform accepts, we could order it to turn on this Fediverse gateway and operate it such that any Threads user can leave, join any other Fediverse server, and continue to see posts from the people they follow, and who will also continue to see their posts.
youtube
Rather than devoting all our energy to keep Meta’s empire of oily rags from burning, we could devote ourselves to evacuating the burn zone.
This is the thing the platforms fear the most. They know that network effects gave them explosive growth, and they know that tech’s low switching costs will enable implosive contraction.
The thing is, network effects are a double-edged sword. People join a service to be with the people they care about. But when the people they care about start to leave, everyone rushes for the exits. Here’s danah boyd, describing the last days of Myspace:
If a central node in a network disappeared and went somewhere else (like from MySpace to Facebook), that person could pull some portion of their connections with them to a new site. However, if the accounts on the site that drew emotional intensity stopped doing so, people stopped engaging as much. Watching Friendster come undone, I started to think that the fading of emotionally sticky nodes was even more problematic than the disappearance of segments of the graph. With MySpace, I was trying to identify the point where I thought the site was going to unravel. When I started seeing the disappearance of emotionally sticky nodes, I reached out to members of the MySpace team to share my concerns and they told me that their numbers looked fine. Active uniques were high, the amount of time people spent on the site was continuing to grow, and new accounts were being created at a rate faster than accounts were being closed. I shook my head; I didn’t think that was enough. A few months later, the site started to unravel.
Tech bosses know the only thing protecting them from sudden platform collapse syndrome are the laws that have been passed to stave off the inevitable fire.
They know that platforms implode “slowly, then all at once.”
They know that if we weren’t holding each other hostage, we’d all leave in a heartbeat.
But anything that can’t go on forever will eventually stop. Suppressing good fire doesn’t mean “no fires,” it means wildfires. It’s time to declare fire debt bankruptcy. It’s time to admit we can’t make these combustible, tinder-heavy forests safe.
It’s time to start moving people out of the danger zone.
It’s time to let the platforms burn.
2 notes
·
View notes
Text
Exhibitor Apps Scraping Services | Extract Event Organizers Data
Elevate your event strategy with our Exhibitor Apps Scraping Services. Extract event organizers data in the USA, UK, UAE, and Spain. Optimize your event success today!
know more: https://www.mobileappscraping.com/event-exhibitor-app-scraping-services.php
#Exhibitor Apps Scraping Services#Extract Event Organizers Data#Extracting data from event-specific mobile applications#Scraping's Event Exhibitor App Data
0 notes
Text
Boost Your Retail Strategy with Quick Commerce Data Scraping in 2025
Introduction
The retail landscape is evolving rapidly, with Quick Commerce (Q-Commerce) driving instant deliveries across groceries, FMCG, and essential products. Platforms like Blinkit, Instacart, Getir, Gorillas, Swiggy Instamart, and Zapp dominate the space, offering ultra-fast deliveries. However, for retailers to stay competitive, optimize pricing, and track inventory, real-time data insights are crucial.
Quick Commerce Data Scraping has become a game-changer in 2025, enabling retailers to extract, analyze, and act on live market data. Retail Scrape, a leader in AI-powered data extraction, helps businesses track pricing trends, stock levels, promotions, and competitor strategies.
Why Quick Commerce Data Scraping is Essential for Retailers?
Optimize Pricing Strategies – Track real-time competitor prices & adjust dynamically.
Monitor Inventory Trends – Avoid overstocking or stockouts with demand forecasting.
Analyze Promotions & Discounts – Identify top deals & seasonal price drops.
Understand Consumer Behavior – Extract insights from customer reviews & preferences.
Improve Supply Chain Management – Align logistics with real-time demand analysis.
How Quick Commerce Data Scraping Enhances Retail Strategies?
1. Real-Time Competitor Price Monitoring
2. Inventory Optimization & Demand Forecasting
3. Tracking Promotions & Discounts
4. AI-Driven Consumer Behavior Analysis
Challenges in Quick Commerce Scraping & How to Overcome Them
Frequent Website Structure Changes Use AI-driven scrapers that automatically adapt to dynamic HTML structures and website updates.
Anti-Scraping Technologies (CAPTCHAs, Bot Detection, IP Bans) Deploy rotating proxies, headless browsers, and CAPTCHA-solving techniques to bypass restrictions.
Real-Time Price & Stock Changes Implement real-time web scraping APIs to fetch updated pricing, discounts, and inventory availability.
Geo-Restricted Content & Location-Based Offers Use geo-targeted proxies and VPNs to access region-specific data and ensure accuracy.
High Request Volume Leading to Bans Optimize request intervals, use distributed scraping, and implement smart throttling to prevent getting blocked.
Unstructured Data & Parsing Complexities Utilize AI-based data parsing tools to convert raw HTML into structured formats like JSON, CSV, or databases.
Multiple Platforms with Different Data Formats Standardize data collection from apps, websites, and APIs into a unified format for seamless analysis.
Industries Benefiting from Quick Commerce Data Scraping
1. eCommerce & Online Retailers
2. FMCG & Grocery Brands
3. Market Research & Analytics Firms
4. Logistics & Supply Chain Companies
How Retail Scrape Can Help Businesses in 2025
Retail Scrape provides customized Quick Commerce Data Scraping Services to help businesses gain actionable insights. Our solutions include:
Automated Web & Mobile App Scraping for Q-Commerce Data.
Competitor Price & Inventory Tracking with AI-Powered Analysis.
Real-Time Data Extraction with API Integration.
Custom Dashboards for Data Visualization & Predictive Insights.
Conclusion
In 2025, Quick Commerce Data Scraping is an essential tool for retailers looking to optimize pricing, track inventory, and gain competitive intelligence. With platforms like Blinkit, Getir, Instacart, and Swiggy Instamart shaping the future of instant commerce, data-driven strategies are the key to success.
Retail Scrape’s AI-powered solutions help businesses extract, analyze, and leverage real-time pricing, stock, and consumer insights for maximum profitability.
Want to enhance your retail strategy with real-time Q-Commerce insights? Contact Retail Scrape today!
Read more >>https://www.retailscrape.com/fnac-data-scraping-retail-market-intelligence.php
officially published by https://www.retailscrape.com/.
#QuickCommerceDataScraping#RealTimeDataExtraction#AIPoweredDataExtraction#RealTimeCompetitorPriceMonitoring#MobileAppScraping#QCommerceData#QCommerceInsights#BlinkitDataScraping#RealTimeQCommerceInsights#RetailScrape#EcommerceAnalytics#InstantDeliveryData#OnDemandCommerceData#QuickCommerceTrends
0 notes
Text
How To Ensure Accurate Naver Blog Data Scraping On Android And iOS Devices?

Introduction
In today's interconnected digital landscape, accessing content from global platforms has become increasingly crucial for businesses and individuals. Naver, often called "South Korea's Google," hosts a treasure trove of valuable information through its blogging platform. Utilizing Naver Blog Data Scraping techniques effectively, especially on mobile devices, can unlock significant advantages for international businesses looking to tap into the Korean market or analyze trends
Understanding the Naver Blog Ecosystem

Naver Blog represents one of South Korea's most influential content hubs, with millions of daily active users sharing insights across countless topics. Unlike Western blogging platforms, Naver's unique structure and predominantly Korean interface present distinct challenges for international data collection efforts, particularly when attempting to Extract Naver Blog From Mobile Apps.
The platform's mobile presence differs significantly from its desktop version, with dedicated apps for both Android and iOS devices featuring proprietary rendering engines and security measures. These differences necessitate specialized approaches when developing Mobile App Web Scraping solutions targeted at Naver's ecosystem.
Technical Challenges in Mobile Naver Blog Extraction

When developing solutions for Naver App Scraping, several technical hurdles must be addressed:
Dynamic Content Loading Mechanisms
Platform-Specific Considerations
Character Encoding and Language Processing
Ethical and Legal Framework for Data Collection

Before implementing any Naver Blog Data Scraping solution, understanding the ethical and legal boundaries is essential:
Respecting Rate Limits and Server Load
Terms of Service Compliance
Data Privacy Considerations
Building Effective Mobile Scraping Solutions

Developing robust mobile scraping frameworks requires careful consideration of both technical and practical factors:
Proxy Management Systems
User-Agent Configuration
Session Management
Advanced Techniques for Enhanced Accuracy

Moving beyond basic extraction requires implementing sophisticated approaches that improve data quality and comprehensiveness:
Headless Browser Integration
Pattern Recognition for Content Identification
Adaptive Parsing Strategies
Platform-Specific Implementation Strategies

Optimizing Naver Blog Data Scraping Services by tailoring approaches to Android and iOS ecosystems to align with platform-specific capabilities and constraints.
1. Android-Focused Approaches
When deploying Android iOS Naver Blog Data Scraping Services with an Android-first strategy, the platform’s open architecture provides unique advantages for building resilient and efficient scraping tools.
Key strengths include:
Persistent Background Services: Android supports long-running background tasks, enabling sustained data collection even when the app is not in the foreground.
Enhanced System Access: Developers can utilize broader access to device resources, allowing more complex local processing and logic execution.
Simplified File Handling: Direct file system access enables seamless storage and retrieval of extracted data for further analysis.
When developing Android iOS Naver Blog Data Scraping Services with an Android focus, leverage these platform advantages to create more robust solutions.
2. iOS Implementation Considerations
Building IOS Naver Blog Scraping workflows requires a more constrained yet strategic approach due to Apple’s controlled ecosystem.
Essential factors to consider include:
Limited Background Execution: iOS imposes tight restrictions on app activity when running in the background, making timing and task management critical.
Tight Memory Management: Developers must work within stricter RAM usage limits, optimizing performance without overloading system resources.
WebKit-Specific Behaviors: iOS browsers and WebViews are built on WebKit, requiring special handling for JavaScript execution and DOM parsing.
To ensure consistency and reliability, IOS Naver Blog Scraping solutions must be carefully engineered to adapt to these platform-specific limitations.
Data Processing and Transformation

Data Processing and Transformation is the crucial next step after data extraction. In this step, raw, unstructured inputs are cleaned, enriched, and converted into structured, analyzable formats to drive actionable insights and real-time decision-making.
Structured Data Conversion
Media Content Handling
Metadata Extraction and Enhancement
Overcoming Common Challenges

Even well-designed extraction systems encounter obstacles requiring specific mitigation strategies:
Handling Authentication Requirements
Adapting to Platform Updates
Managing Extraction Failures
Future-Proofing Your Extraction Strategy

The mobile content landscape continues evolving rapidly, requiring forward-thinking approaches:
API Integration Opportunities
Hybrid Extraction Approaches
Continuous Learning Systems
Measuring Extraction Quality and Success

Implementing quality assurance mechanisms ensures your extraction systems deliver reliable results:
Completeness Verification: Comparing extracted content against manually viewed content samples helps identify extraction gaps or failures. This is particularly important when developing comprehensive Naver Blog Content Data For IOS And Android collection systems.
Accuracy Benchmarking: Regular validation of extracted content against known reference datasets helps quantify extraction accuracy and identify potential improvement areas in your IOS Naver Blog Scraping implementations.
Performance Monitoring: Tracking extraction times, success rates, and resource utilization provides insights into system efficiency, particularly valuable when scaling up Mobile App Web Scraping operations to handle large data volumes.
How Mobile App Scraping Can Help You?

Our specialized team at Mobile App Scraping delivers comprehensive solutions for accessing and leveraging Korean market insights through our advanced Naver Blog Data Scraping services:
Custom extraction solutions tailored to your specific business requirements and use cases.
Cross-platform compatibility ensures consistent results across both Android and iOS devices.
Scalable infrastructure capable of handling extraction projects of any size while maintaining performance.
Real-time monitoring systems that detect and adapt to platform changes automatically.
Data transformation services convert raw extracted content into analytics-ready formats.
Compliance expertise ensures all extraction activities remain within legal and ethical boundaries.
Technical support provides ongoing assistance as your extraction needs evolve.
Our dedicated developers specialize in Android iOS Naver Blog Data Scraping Services that overcome the unique challenges presented by mobile platforms while delivering accurate, comprehensive results.
Conclusion
Accessing the valuable information within Naver's blogging ecosystem requires specialized knowledge and technical expertise. Whether you're researching market trends, monitoring brand perception, or gathering competitive intelligence, effective Naver Blog Data Scraping provides invaluable insights into one of Asia's most influential digital markets.
Need expert assistance with your Korean content extraction needs? Contact Mobile App Scraping today to discuss how our specialized Mobile App Web Scraping solutions can help you access and leverage Naver's content ecosystem.
Source: https://www.mobileappscraping.com/naver-blog-data-scraping-guide-android-ios-devices.php Originally Published By: https://www.mobileappscraping.com
#NaverBlogDataScraping#ExtractNaverBlogFromMobileApps#MobileAppWebScraping#NaverBlogExtraction#NaverBlogMobileAppDataExtraction#IOSNaverBlogScraping#NaverBlogContentDataForiOSAndAndroid#NaverBlogDataScrapingSolution#RealTimeDataScrapingFromNaver#AndroidiOSNaverBlogDataScrapingService#ScrapeNaverBlogPostsOnMobileApps#NaverBlogContentExtractionAPI#NaverAppScraping
0 notes
Text
How to Scrape Data from the Tuhu App: A Guide to Mobile App Scraping
In today’s data-driven economy, real-time access to mobile app data offers a significant competitive advantage to businesses across industries. Extracting data from high-value platforms such as the Tuhu app—China’s leading car service and tire e-commerce platform—presents opportunities to gain meaningful insights, optimize offerings, and improve market positioning. This comprehensive guide will walk you through the ins and outs of Tuhu app scraping, highlight the best practices for scraping data from apps, and explain how working with experienced data scraping companies or data scraping services can make a real difference.
What Is the Tuhu App?
The Tuhu app is a full-service automotive maintenance and e-commerce platform based in China. It allows users to purchase tires, batteries, and vehicle accessories, and to schedule services such as oil changes and car repairs. With detailed listings, live pricing, user-generated reviews, and geo-tagged garage information, Tuhu is a goldmine for any business wanting to understand the automotive after-sales service sector in China.

Key Features of the Tuhu App
1. Detailed automotive product listings (tires, oils, batteries, accessories)
2. Service package descriptions with pricing
3. Real-time stock availability and delivery timelines
4. Location-based garage and service center data
5. Customer feedback, reviews, and star ratings
Given this wealth of data, companies across sectors, whether e-commerce, supply chain, automotive retail, or analytics, stand to benefit immensely when they scrape Tuhu app data for strategic use.
Why Scrape Data from the Tuhu App?
Tuhu app scraping provides access to actionable insights that businesses can use to stay ahead in the market. Here’s why organizations turn to app scraping:
Competitive Benchmarking: Analyze pricing, product specs, discounts, and promotions to adjust your own strategies.
Inventory Tracking: Understand stock trends and availability for popular SKUs.
Market Research: Identify trends, user demand, and emerging service categories.
Consumer Behavior Analysis: Evaluate reviews and ratings to assess customer sentiment.
Lead Generation: Extract contact information for garages and service providers listed in the app.
With targeted data scraping services, businesses can transform raw data into market intelligence.
Types of Data You Can Extract from the Tuhu App
Here’s an overview of the data categories typically available via the Tuhu app scraping:
Product details: brand, model, SKU, specifications
Real-time pricing: including promotions and discounts Stock status and delivery estimates
Customer reviews: ratings, feedback, user location
Location data: garage and service center addresses, maps, contact numbers
Service offerings: oil changes, tire replacements, brake servicing, etc.
Having structured access to this information through a reliable app scraper can help automate data collection processes and provide a strategic edge.
Is Tuhu App Scraping Legal?
Legality is one of the primary concerns in scraping data from apps. While public data (like product listings and user reviews) is typically accessible, it’s critical to operate within legal and ethical boundaries.
Legal Guidelines and Best Practices -
1. Always avoid scraping personally identifiable information (PII)
2. Respect the platform's terms of service and local data privacy laws
3. Ensure your scraping activity does not harm or overload Tuhu’s infrastructure
4. Consult legal counsel when in doubt
Partnering with professional data scraping companies ensures compliance while maintaining data quality and accuracy.
Technical Challenges in Scraping the Tuhu App
Scraping mobile apps is considerably more complex than scraping websites. The Tuhu app, like many modern applications, likely implements a range of anti-scraping techniques.
Common Technical Hurdles -
API Obfuscation: App APIs may be encrypted or hidden to prevent easy access.
Authentication: Secure login or OTP mechanisms may block automated access.
Dynamic Content: Content loaded via JavaScript or in real-time complicates extraction.
Bot Detection: Rate limiting, CAPTCHAs, and behavior analysis mechanisms can block bots.
To overcome these, you’ll need the best web scraper tools and advanced mobile scraping tactics—or collaborate with specialized data scraping services.
Step-by-Step Guide: How to Scrape Data from the Tuhu App
Here is a structured approach for successful Tuhu app scraping:
Step 1: Traffic Interception
Use proxy tools like mitmproxy or Charles Proxy to analyze traffic between the app and its server. This helps identify endpoints and parameters that carry data.
Step 2: Reverse Engineer API Calls
Once you identify API patterns, replicate requests using Python scripts (with requests or httpx). Emulate headers, tokens, and session data as needed.
Step 3: UI-Based Scraping (if APIs are not accessible)
Use tools like Appium or UIAutomator to interact with the app interface. This simulates a user browsing the app and captures screen-level data.
Step 4: Data Structuring
Parse and clean the raw data. Convert responses into structured formats like CSV, JSON, or feed it directly into a database.
Step 5: Automate the Workflow
Use schedulers (like CRON, Airflow, or cloud services) to automate scraping tasks daily or weekly to ensure up-to-date insights. Hiring an expert data scraping company can help you execute this entire workflow efficiently.
Best Tools for Tuhu App Scraping
Here are some top tools for scraping mobile applications like Tuhu -
mitmproxy – Analyze encrypted mobile traffic
Charles Proxy – Capture and modify app traffic
Postman – Test API calls and inspect responses
Python (requests, BeautifulSoup) – Build lightweight scraping scripts
Appium/UIAutomator – Automate Android or iOS interactions
Scrapy – Although primarily web-focused, Scrapy can support mobile scraping extensions
Choosing the best web scraper for your case depends on your access level, app architecture, and data complexity.
The Role of Data Scraping Services
If building in-house scraping infrastructure is not feasible, outsourcing is a smart option. Top data scraping services offer custom, scalable, and legally compliant solutions.
Why Businesses Opt for Data Scraping Services -
1. Prebuilt tools for rapid deployment
2. Scalable infrastructure and cloud storage
3. Continuous monitoring and maintenance
4. Legal compliance and robust data pipelines
5. Real-time data feeds and API integrations
Look for data scraping companies with mobile app expertise and proven results in similar industries.
How Different Businesses Use Tuhu App Data
The data extracted through the Tuhu app scraping is incredibly versatile:
E-commerce Platforms: Monitor competitor pricing, trending products, and seasonal promotions.
Automotive Suppliers: Identify popular brands and SKUs for sourcing decisions.
Market Analysts: Track consumer preferences and geographic trends.
Repair Service Aggregators: Discover high-rated garages and potential partnerships.
Digital Marketers: Analyze reviews and product feedback to refine campaigns. By integrating this data into BI tools or analytics dashboards, businesses can visualize trends, benchmark performance, and drive strategy.
Ethical Considerations and Data Governance
Even if your methods are technically sound, ethical data use is essential. Here are guidelines to follow:
1. Do not collect or store personal user data
2. Avoid aggressive scraping patterns that may slow down or block app services
3. Clearly define use cases and share responsibilities with your scraping provider
4. Regularly audit and monitor your scraping systems for compliance
Adhering to ethical standards builds long-term trust and ensures that your data operations are sustainable.
Future of App Scraping: Trends to Watch
Mobile app scraping is evolving fast. Here are some future trends businesses should be aware of:
AI-Powered Scraping: Machine learning models are being used to improve screen understanding and anomaly detection in scraped data.
Serverless Architectures: Cloud-native scraping reduces infrastructure overhead and scales seamlessly.
Real-Time Scraping APIs: On-demand data pipelines are replacing traditional batch-based scrapers.
Increased Regulation: As more countries introduce digital laws, compliance will be a key differentiator.
Staying updated with these trends will help businesses build better, faster, and more ethical scraping systems.
Conclusion
In a landscape where information equals power, scraping data from apps like Tuhu can give your business the edge it needs. From competitive intelligence to customer sentiment analysis, the Tuhu app contains valuable, public-facing data that can fuel smart decisions.
Whether you’re building your own app scraper or working with trusted data scraping services, make sure to approach the task with a well-structured plan and legal awareness. Use the best web scraper tools to handle technical challenges, and focus on extracting structured, usable, and ethically sourced data.
Need expert assistance? Get in touch with professional data scraping companies that specialize in mobile app scraping, and unlock the power of Tuhu app data for your business growth.
0 notes
Text
How to Choose the Right Proxy for Your Needs
Proxies are essential tools for privacy, security, and accessing restricted content. However, with different types available, selecting the right one can be challenging. Here’s a quick guide to help you make an informed decision.
1. Understand the Different Proxy Types
Residential Proxies – Use real IP addresses from ISPs, making them appear as regular users. Best for tasks requiring high anonymity (e.g., web scraping, ad verification).
Datacenter Proxies – Come from cloud servers, offering high speed but lower anonymity. Ideal for bulk tasks where IP bans are less likely.
Mobile Proxies – Use 4G/5G IPs, perfect for mobile-specific tasks like app testing or social media management.
SOCKS5 Proxies – Support various traffic types (TCP/UDP), useful for torrenting and gaming.
2. Consider Your Use Case
Web Scraping? → Residential or rotating proxies to avoid blocks.
SEO Monitoring? → Location-specific proxies for accurate local results.
Gaming or Streaming? → Low-latency SOCKS5 proxies.
Social Media Management? → Mobile or residential proxies to mimic real users.
3. Check Key Features
Speed & Reliability – Datacenter proxies are faster, while residential proxies are more stable for long sessions.
Geo-Targeting – Ensure the provider offers IPs in your desired locations.
Rotation Options – Rotating IPs help avoid detection in automated tasks.
Concurrent Connections – Some proxies limit simultaneous sessions; choose based on your needs.
4. Security & Privacy
Avoid Free Proxies – They often log data and may be unsafe.
Look for HTTPS Support – Ensures encrypted connections.
No-Log Policies – Critical if handling sensitive data. https://nodemaven.com/
5. Test Before Committing
Many providers offer trial periods or money-back guarantees. Test speed, uptime, and compatibility with your tools before long-term use.
0 notes
Text
Advantages of Mobile Proxies
A mobile proxy is an essential tool for businesses and individuals looking to enhance their online activities. With a mobile proxy, your internet requests are routed through real mobile devices connected to mobile networks, ensuring anonymity, flexibility, and reliability. Here's why mobile proxies, especially mobile proxy Ukraine, are gaining popularity:
Authenticity and Trust
Mobile proxies use IP addresses assigned by mobile carriers, making them appear as genuine users. This ensures higher trust scores compared to data center proxies and significantly reduces the chances of being blocked or flagged.
Enhanced Anonymity
Using a mobile proxy, your real IP address is hidden, and your online activity is routed through mobile networks. This provides an added layer of security and anonymity, making it ideal for web scraping, social media management, and bypassing geo-restrictions.
Superior Geo-Targeting
With mobile proxy Ukraine, you can access region-specific content as if you're browsing from within Ukraine. This feature is invaluable for businesses conducting local market research or running location-based ad campaigns.
Bypassing Restrictions and CAPTCHA Challenges
Mobile proxies are less likely to be blocked or flagged by websites since they replicate real user behavior. They also excel at bypassing CAPTCHA challenges, allowing seamless browsing and automation tasks.
High Success Rates
Due to the rotating IPs provided by mobile networks, mobile proxies have high success rates when accessing restricted websites, performing data scraping, or managing multiple accounts without detection.
Ideal for Social Media Management
Mobile proxies are perfect for managing multiple social media accounts simultaneously. Platforms like Instagram, Facebook, and TikTok trust mobile IPs, reducing the risk of bans or restrictions.
Access to Mobile-Only Content
Some websites or apps provide content or services exclusively for mobile users. By using a mobile proxy, you can easily access and interact with this mobile-only content.
Scalability and Flexibility
Mobile proxies offer scalability for businesses handling large volumes of requests. The rotating IP feature ensures flexibility, making them suitable for a wide range of use cases.
Why Choose Mobile Proxy Ukraine?
Localized Access: Ideal for businesses or users targeting the Ukrainian market or accessing Ukrainian-specific content.
Stable Connections: Reliable mobile networks ensure uninterrupted service.
Compliance with Local Laws: Operates within the framework of Ukrainian regulations for safe and legal usage.
Conclusion
A mobile proxy is a powerful tool for ensuring online privacy, accessing restricted content, and conducting various digital activities effectively. Whether you're managing social media, conducting market research, or bypassing geo-blocks, mobile proxy Ukraine offers an excellent solution tailored for localized and global needs.
0 notes