#Remove duplicate values from a string in java
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
The Tumblr app for Google Glass was released on May 16, 2013.
Text
hi
Longest Substring Without Repeating Characters Problem: Find the length of the longest substring without repeating characters. Link: Longest Substring Without Repeating Characters
Median of Two Sorted Arrays Problem: Find the median of two sorted arrays. Link: Median of Two Sorted Arrays
Longest Palindromic Substring Problem: Find the longest palindromic substring in a given string. Link: Longest Palindromic Substring
Zigzag Conversion Problem: Convert a string to a zigzag pattern on a given number of rows. Link: Zigzag Conversion
Three Sum LeetCode #15: Find all unique triplets in the array which gives the sum of zero.
Container With Most Water LeetCode #11: Find two lines that together with the x-axis form a container that holds the most water.
Longest Substring Without Repeating Characters LeetCode #3: Find the length of the longest substring without repeating characters.
Product of Array Except Self LeetCode #238: Return an array such that each element is the product of all the other elements.
Valid Anagram LeetCode #242: Determine if two strings are anagrams.
Linked Lists Reverse Linked List LeetCode #206: Reverse a singly linked list.
Merge Two Sorted Lists LeetCode #21: Merge two sorted linked lists into a single sorted linked list.
Linked List Cycle LeetCode #141: Detect if a linked list has a cycle in it.
Remove Nth Node From End of List LeetCode #19: Remove the nth node from the end of a linked list.
Palindrome Linked List LeetCode #234: Check if a linked list is a palindrome.
Trees and Graphs Binary Tree Inorder Traversal LeetCode #94: Perform an inorder traversal of a binary tree.
Lowest Common Ancestor of a Binary Search Tree LeetCode #235: Find the lowest common ancestor of two nodes in a BST.
Binary Tree Level Order Traversal LeetCode #102: Traverse a binary tree level by level.
Validate Binary Search Tree LeetCode #98: Check if a binary tree is a valid BST.
Symmetric Tree LeetCode #101: Determine if a tree is symmetric.
Dynamic Programming Climbing Stairs LeetCode #70: Count the number of ways to reach the top of a staircase.
Longest Increasing Subsequence LeetCode #300: Find the length of the longest increasing subsequence.
Coin Change LeetCode #322: Given a set of coins, find the minimum number of coins to make a given amount.
Maximum Subarray LeetCode #53: Find the contiguous subarray with the maximum sum.
House Robber LeetCode #198: Maximize the amount of money you can rob without robbing two adjacent houses.
Collections and Hashing Group Anagrams LeetCode #49: Group anagrams together using Java Collections.
Top K Frequent Elements LeetCode #347: Find the k most frequent elements in an array.
Intersection of Two Arrays II LeetCode #350: Find the intersection of two arrays, allowing for duplicates.
LRU Cache LeetCode #146: Implement a Least Recently Used (LRU) cache.
Valid Parentheses LeetCode #20: Check if a string of parentheses is valid using a stack.
Sorting and Searching Merge Intervals LeetCode #56: Merge overlapping intervals.
Search in Rotated Sorted Array LeetCode #33: Search for a target value in a rotated sorted array.
Kth Largest Element in an Array LeetCode #215: Find the kth largest element in an array.
Median of Two Sorted Arrays LeetCode #4: Find the median of two sorted arrays.
0 notes
Text
Leveraging Kotlin Collections in Android Development
Kotlin has gradually replaced Java as the lingua franca of Android programming. It’s a more concise language than Java, meaning your code works harder and you can build leaner applications. And Kotlin Collections are fundamental.
These collections play a fundamental role in our work as programmers by simplifying the organization and management of data. Whether it’s a list, set, map or other data structure, they allow us to categorize and store data logically. So we can save, retrieve and manipulate information, and manage a range of tasks from simple data presentation to complex algorithm implementation.
Collections also facilitate code reusability, enabling us to utilize their existing functions and methods rather than developing individual data-handling mechanisms for every task This streamlines development, reduces errors and enhances code maintainability.
At a granular level, collections enable us to perform operations like sorting, filtering, and aggregation efficiently, improving the overall quality of our products.
Overview of Kotlin Collections
Kotlin Collections come in three primary forms: Lists, Maps, and Sets. Each is a distinct type, with its unique characteristics and use cases. Here they are:
Kotlin Lists
A Kotlin List is a sequential arrangement of elements that permit duplicate values, preserving the order in which they are added.
Elements in a list are accessed by their index, and you can have multiple elements with the same value.
Lists are a great help when storing a collection of items whose order needs to be maintained – for example, a to-do list – and storing duplicate values.
Kotlin Maps
Kotlin Maps are collections of key-value pairs. In lightweight markdown language, a method allows us to link values with distinct keys, facilitating effortless retrieval of values using their corresponding keys.
The keys are also ideal for efficient data retrieval and mapping relationships between entities.
Common use cases of Kotlin Maps include building dictionaries, storing settings, and representing relationships between objects.
Kotlin Set
A Kotlin Set is an unordered collection of distinct elements, meaning it does not allow duplicate values.
Sets are useful when you need to maintain a unique set of elements and do not require a specific order for those elements.
Common use cases of Kotlin Sets include tracking unique items, such as unique user IDs, or filtering out duplicates from a list.
The choice between lists, maps, and sets depends on your specific data requirements. Lists are suitable for ordered collections with potential duplicates, maps are ideal for key-value associations, and sets are perfect for maintaining unique, unordered elements.
Kotlin Immutable vs Mutable Collections
Kotlin provides support for both immutable and mutable collections, giving you flexibility when managing data.
Immutable Collections
Immutable collections cannot be modified once they are created. They provide both general safety and specific thread safety, making them ideal for scenarios where you want to keep the data constant. Immutable collections are created using functions like listOf() , mapOf() , and setOf() .
Mutable Collections
A mutable collection can be modified after creation. These collections are more flexible and versatile, allowing you to add, remove or modify individual elements. Mutable collections are created using functions like mutableListOf() , mutableMapOf(), and mutableSetOf().
Now that we have a foundational understanding of Kotlin collections, let’s dive deeper into each type.
Using Kotlin List
How to create a list in Kotlin
Creating a Kotlin list is straightforward. Here are two great ways to get started.
Create an immutable list
To create an immutable list we can use listOf(). Check out the following example:// Example Of listOf function fun main(args: Array<String>) { //initialize list var listA = listOf<String>("Anupam", "Singh", "Developer") //accessing elements using square brackets println(listA[0]) //accessing elements using get() println(listA.get(2)) }
In the Kotlin console, you will see the following output:[Anupam, native, android, developer]
Create a mutable list
If you want to create a mutable list, we should use the mutableListOf() method. Here is an example:// Example of mutableListOf function fun main(args: Array<String>) { //initialize a mutable list var listA = mutableListOf("Anupam", "Is", "Native") //add item to the list listA.add("Developer") //print the list println(listA) }
And this is the output :[Anupam, Is, Native, Developer]
Working with a Kotlin List
Now, we’ll look at working with list items.
Accessing elements from the List
We can reach a list item using its place or index. Here’s the first item from the cantChangeList.// get first item from list var cantChangeList = listOf<Int>(1, 2, 3) val firstItem = cantChangeList[0] println(firstItem) //Output: 1
Iterating over a list
There are multiple ways to traverse a list effectively, leveraging higher-order functions such as *forEach* or utilizing for loops. This enables you to handle the list’s elements one after the other, in sequence. For example:var MyList = listOf<Int>(1, 2, 3) // print each item from list using for loop for (element in myList) { println(element) } //output: //1 //2 //3 // print each item from list using forEach loop MyList.forEach { println(it) } // Output: // 1 // 2 // 3
Adding elements from a list
Modifying a Kotlin List is a great option for mutable lists that harness functions like *add()* , **remove()** , and set(). If we want to add an element to a list, we will simply use the add()method.// Example of add() function in list val numberAdd = mutableListOf(1, 2, 3, 4) numberAdd.add(5) println(numberAdd) //Output : [1, 2, 3, 4, 5]
Removing elements from a list
Removing elements is also a straightforward process. Here’s a coding example:// Example of remove() function in list val numberRemove = mutableListOf(1, 2, 3, 4) numberRemove.remove(3) println(numberRemove) //Output: [1, 2, 4]
Modifying List Items
Altering list items is simple. You can swap them directly with new data via their indices or by using the set commands. Here we have an example of changing an item value, either through its place marker or by using the setmethod:var myList = mutableListOf<String>("Anupam","five", "test", "change") // Changing value via index access myList[0] = "FreshValue" println(myList[0]) // Ouput: // FreshValue // Changing value using set method myList.set(0, "SetValue") println(myList[0]) // Ouput: // SetValue
Other list functions and operations
In Kotlin, list methods are essential tools when we work with collections. While there are numerous methods available, we’ll limit our focus to the most commonly used ones today.
Each of these methods brings its own unique power and utility to a Kotlin collection. Now let’s explore them in detail.
sorted() : Returns a new List with elements sorted in natural order.
sortedDescending() : Returns a new List with elements sorted in descending order.
filter() : Returns a new List containing elements that satisfy a given condition.
map() : Transforms each element of the List, based on a given predicate.
isEmpty() : Checks whether the List is empty.
Here are some key examples of these methods:
Sort a Kotlin list
This collection includes the following elements (3, 1, 7, 2, 8, 6).
Here they are in ascending order:// Ascending Sort val numbs = mutableListOf(3, 1, 7, 2, 8, 6) println(numbs) val sortedNumbs = numbs.sorted() println(sortedNumbs) //Output: // Before Sort : [3, 1, 7, 2, 8, 6] // After Sort : [1, 2, 3, 6, 7, 8]
Now, here’s an example of sorting in descending order:// Descending Sort val numbs = mutableListOf(3, 1, 7, 2, 8, 6) println(numbs) val sortedDesNumbs = numbs.sortedDescending() println(sortedDesNumbs) //Output: // Before Sort : [3, 1, 7, 2, 8, 6] // After Sort : [8, 7, 6, 3, 2, 1]
Filtering a Kotlin list
If you want to filter a Kotlin list, you can use the filter function. This allows you to specify a condition that each element of the list must satisfy in order to be included in the filtered list. Here’s an example:val listOfData = listOf("Anupam","is","native","android","developer") val longerThan5 = listOfData.filter { it.length > 5 } println(longerThan5)
In this example, we have a list of strings under the heading listOfData. We use the filter function to create a new list, longerThan5 , that contains only the strings from listOfData with a length greater than five characters.
Finally, we print the filtered list. The output will be:[Anupam, native, android, developer]
Check whether a Kotlin list is empty
Here you can use the isEmpty() function, as you can see in this example:val myList = listOf<Int>() if (myList.isEmpty()) { println("The list is empty.") } else { println("The list is not empty.") } // Output: // The list is empty.
In the following example we’ll create a list, myList , with values using the listOf() function, so the isEmpty will return false:// example of isEmpty() return false var list = listOf<String>("Anupam") if (list.isEmpty()) { println("Its empty.") } else { println("Its not empty.") } // Output: // Its not empty.
Transforming a list using map
As we mentioned earlier, the Kotlin map function is a powerful tool for transforming each element of a list into a new form. It applies a specified transformation function to each element and returns a new list with the results. This gives us a concise way to modify the elements in a list, without mutating the original collection.val numbers = listOf(1, 2, 3, 4, 5) val squaredNumbers = numbers.map { it * it } println(squaredNumbers) // Output: // [1, 4, 9, 16, 25]
In this example, we have a list called numbers, containing integers. We apply the map function to numbers and provide a lambda expression as the transformation function. The lambda expression takes each element in the numbers list and returns its square. The map function applies this transformation to each element of the list and creates a new list, squaredNumbers, with the squared values.
Searching elements in a List
Check whether element exists in the list
To search for an element in a Kotlin list, you can utilize the various methods available in the Kotlin standard library. One widely used method is the contains() function, which allows you to check whether a list contains a specific element.
Here’s an example of how you can use the contains() function in Kotlin:val myList = listOf("apple", "banana", "orange") val isElementFound = myList.contains("banana") if (isElementFound) { println("Element found!") } else { println("Element not found!") } // Output: // banana
You can also use the filter() method we mentioned earlier to filter all the elements that match a given criteria.
Search the element and get its index
Another option is to use the indexOf() method, which returns the specific position of an element in the list.val myList = listOf("apple", "banana", "orange") val index = myList.indexOf("banana") if (index != -1) { println("Element found at index $index") } else { println("Element not found in the list") } // Output: // Element found at index 1
Working with Kotlin Map
Accessing and modifying a Kotlin Map
Creating and initializing a map in Kotlin
In Kotlin, you can create and initialize a map by utilizing either the mapOf() function for immutable maps or the mutableMapOf() function for mutable maps. Here is an example of how you can create a map containing names and ages:// Immutable Map Example. Syntax is mapOf<key,value> val myImmuMap = mapOf<Int,String>(1 to "Anupam", 2 to "Singh", 3 to "Developer") for(key in myImmuMap.keys){ println(myImmuMap[key]) } // Output : // Anupam // Singh // Developer
The mapOf() function allows you to create an immutable map, ensuring that its content cannot be altered once initialized. Conversely, the **mutableMapOf()** function enables you to modify the map, transforming it into a mutable map.
In the example provided, the map contains pairs of names and ages. Each pair is created using the ‘to’ keyword, where the name is associated with its corresponding age. The map’s content is enclosed in curly brackets which look like {}.
By utilizing these functions, you can easily create and initialize maps in Kotlin according to your specific needs.
Retrieving map values
To access values in a Map, you use the associated key. For example, to get the value of “Anupam” in ‘immutable map’, you can do the:val myImmuMap = mapOf<Int,String>(1 to "Anupam", 2 to "Singh", 3 to "Developer") val valueOfAnupam = myImmuMap["Anupam"] // valueOfAnupam will be 1
Modify a map entry
You can also modify the values in a mutable Map, using keys:val myImmuMap = mapOf<Int,String>(1 to "Anupam", 2 to "Singh", 3 to "Developer") myImmuMap["Anupam"] = 5 // Update Anupam value from 1 to 5
Iterating over map entries via the map keys
You can use a for loop to iterate over a map. In this case we are iterating the map using the keys property, which contains all the keys present in the Map:val myImmuMap = mapOf<Int,String>(1 to "Anupam", 2 to "Singh", 3 to "Developer") for(key in myImmuMap.keys){ println(myImmuMap[key]) } // Output: // Anupam // Singh // Developer
Iterating over map values
We can also use a for loop to iterate over a map’s values, ignoring the map keys:val myImmuMap = mapOf<Int,String>(1 to "Anupam", 2 to "Singh", 3 to "Developer") for(value in myImmuMap.values){ println(value) } // Output: // Anupam // Singh // Developer
Other map functions and operations
Kotlin provides several useful functions and operations for working with maps. Some common ones include:
keys : This method retrieves a set, comprising all the keys present in the map.
values : The values function ensures retrieval of a collection, containing all the values stored in the map.
containsKey(key) : Determines whether a key exists in the map.
containsValue(value) : Checks whether a value exists in the map.
We have seen keys and values in the previous examples. Now let’s see the other methods in action.
Checking the existence of keys or values in the map
As we have mentioned, you can use the containsKey(key) function to check whether a specific key exists in the map, or the containsValue(value) function to determine whether a particular value is present in the map.val myImmuMap = mapOf<Int,String>(1 to "Anupam", 2 to "Singh", 3 to "Developer") // example of ***containsKey(key)*** println(myImmuMap.containsKey(2)) // exists so will print true println(myImmuMap.containsKey(4)) // not exists so will print false // Output: // true // false // example of ***containsValue(value)*** println(myImmuMap.***containsValue***("Ajay")) // not exists so print false println(myImmuMap.***containsValue***("Anupam")) // exists so print true // Output : // false // true
Working with Kotlin Set
Creating and manipulating sets in Kotlin
Creating a Kotlin Set is similar to other collections. You can use setOf() for an immutable set and mutableSetOf() for a mutable set. Here’s an example:// Immutable Set val intImmutableSet = setOf(1, 2, 3) for(element in intImmutableSet){ println(element) } // Output: // 1 // 2 // 3 // Mutable Set val intMutableSet = mutableSetOf(14, 24, 35) for(element in intMutableSet){ println(element) } // Output: // 14 // 24 // 35
Other useful Kotlin set operations and functions
Sets have unique characteristics that make them useful in certain scenarios. Common set operations include:
union() : Returns a new set that is the union of two sets.
intersect() : Returns a new set that is the intersection of two sets.
add(element) : A new element is added to enhance the set.
remove(element) : Removes an element from the set.
In the following example we show how to use the union() function:// Example of Union function val firstNum = setOf(1, 2, 3, 4,5) val secondNum = setOf(3, 4, 5,6,7,8,9) val finalUnionNums = firstNum.union(secondNum) println(finalUnionNums) // Output : // [1, 2, 3, 4, 5, 6, 7, 8, 9]
And here we have an example of intersect()// Example of Intersect function val fArray = arrayOf(1,2,3,4,5) val sArray = arrayOf(2,5,6,7) val iArray = fArray.intersect(sArray.toList()).toIntArray() println(Arrays.toString(iArray)) // Output: // [2, 5]
Iterating over Kotlin Set elements
Iterating through a set bears resemblance to iterating through a list. You can use a ‘for’ loop, or other iterable operations, to process each element.val intImmutableSet = setOf(1, 2, 3) for(element in intImmutableSet){ println(element) } // Output: // 1 // 2 // 3
Use cases and examples of sets in Kotlin
Sets are particularly useful when you need to maintain a collection of unique elements. For example:
Keep track of unique user IDs in a chat application.
Ensure that a shopping cart contains only distinct items.
Manage tags or categories without duplicates in a content management system.
Sets also simplify the process of checking for duplicates and ensuring data integrity.
FAQs
How do I filter strings from a Kotlin list?
To extract only strings, which can contain elements of any type, utilize the filterIsInstance() method. This method should be invoked on the kist, specifying the type T as String within the filterIsInstance() function.
The appropriate syntax for filtering only string elements within a list is:var myList: List<Any> = listOf(41, false, "Anupam", 0.4 ,"five", 8, 3) var filteredList = myList.filterIsInstance<String>() println("Original List : ${myList}") println("Filtered List : ${filteredList}") // Output : // Original List : [41, false, Anupam, 0.4, five, 8, 3] // Filtered List : [Anupam,five]
Executing filterIsInstance() will yield a list consisting solely of the String elements present within the original list, if any are found.
How do I define a list of lists in Kotlin?
The Kotlin list function listOf() is employed to generate an unchangeable list of elements. This function accepts multiple arguments and promptly furnishes a fresh list incorporating the provided arguments.val listOfLists = listOf( listOf(1, 2, 3), listOf("Anupam", "Singh", "Developer") ) print(listOfLists) Output: [[1, 2, 3], [Anupam, Singh, Developer]]
How do I filter only integers from a Kotlin list?
To extract only integers, which can contain elements of any type, you should utilize the filterIsInstance() method. This method should be invoked on the list, specifying the type T as Int within the filterIsInstance() function.
The appropriate syntax for filtering solely integer elements within a list is:var myList: List<Any> = listOf(5, false, "Anupam", 0.4 ,"five", 8, 3) var filteredList = myList.filterIsInstance<Int>() println("Original List : ${myList}") println("Filtered List : ${filteredList}") // Output : // Original List : [5, false, Anupam, 0.4, five, 8, 3] // Filtered List : [5, 8, 3]
Executing filterIsInstance() will yield a list consisting solely of the Int elements present within the original list, if any are found.
What are the different types of Kotlin Collections?
Kotlin’s official docs provide an overview of collection types in the Kotlin Standard Library, including sets, lists, and maps. For each collection type, there are two interfaces available: a read-only interface that allows accessing collection elements and provides some operations and then a mutable interface collections where you can modify the items. The most common collections are:
List
Set
Map (or dictionary)
How do I find out the length a Kotlin list?
To find out the length of a Kotlin list, you can use the size property. Here is an example:val myList = listOf(1, 2, 3, 4, 5) val length = myList.size println("The length of the list is $length")
Output:The length of the list is 5
What is List<*> in Kotlin?
In Kotlin, you can create a generic list with an unspecified type. When you use a generic list, you’re essentially saying, “I want a list of something, but I don’t care what type of things are in it”. This can be useful when you are writing generic code that can work with any type of list.fun printList(list: List<*>) { for (item in list) { println(item) } } val intList = listOf(1, 2, 3) val stringList = listOf("a", "b", "c") printList(intList) // This will print 1, 2, 3 printList(stringList) // This will print a, b, c
Can we use iterators to iterate a Koltin collection?
Yes, you can use iterators in Kotlin. In the previous examples we have seen how to iterate a Kotlin collection using for or forEach. In case you want to use iterators, here you can see an example of iterating a Kotlin list with an iterator.val myList = listOf("apple", "banana", "orange") val iterator = myList.iterator() while (iterator.hasNext()) { val value = iterator.next() println(value) }
In the example, we call iterator() on the list to get the iterator for the list. The while loop then uses hasNext() to check if there is another item in the list and next() to get the value of the current item.
0 notes
Link
Data Structures and Algorithms from Zero to Hero and Crack Top Companies 100+ Interview questions (Java Coding)
What you’ll learn
Java Data Structures and Algorithms Masterclass
Learn, implement, and use different Data Structures
Learn, implement and use different Algorithms
Become a better developer by mastering computer science fundamentals
Learn everything you need to ace difficult coding interviews
Cracking the Coding Interview with 100+ questions with explanations
Time and Space Complexity of Data Structures and Algorithms
Recursion
Big O
Dynamic Programming
Divide and Conquer Algorithms
Graph Algorithms
Greedy Algorithms
Requirements
Basic Java Programming skills
Description
Welcome to the Java Data Structures and Algorithms Masterclass, the most modern, and the most complete Data Structures and Algorithms in Java course on the internet.
At 44+ hours, this is the most comprehensive course online to help you ace your coding interviews and learn about Data Structures and Algorithms in Java. You will see 100+ Interview Questions done at the top technology companies such as Apple, Amazon, Google, and Microsoft and how-to face Interviews with comprehensive visual explanatory video materials which will bring you closer to landing the tech job of your dreams!
Learning Java is one of the fastest ways to improve your career prospects as it is one of the most in-demand tech skills! This course will help you in better understanding every detail of Data Structures and how algorithms are implemented in high-level programming languages.
We’ll take you step-by-step through engaging video tutorials and teach you everything you need to succeed as a professional programmer.
After finishing this course, you will be able to:
Learn basic algorithmic techniques such as greedy algorithms, binary search, sorting, and dynamic programming to solve programming challenges.
Learn the strengths and weaknesses of a variety of data structures, so you can choose the best data structure for your data and applications
Learn many of the algorithms commonly used to sort data, so your applications will perform efficiently when sorting large datasets
Learn how to apply graph and string algorithms to solve real-world challenges: finding shortest paths on huge maps and assembling genomes from millions of pieces.
Why this course is so special and different from any other resource available online?
This course will take you from the very beginning to very complex and advanced topics in understanding Data Structures and Algorithms!
You will get video lectures explaining concepts clearly with comprehensive visual explanations throughout the course.
You will also see Interview Questions done at the top technology companies such as Apple, Amazon, Google, and Microsoft.
I cover everything you need to know about the technical interview process!
So whether you are interested in learning the top programming language in the world in-depth and interested in learning the fundamental Algorithms, Data Structures, and performance analysis that make up the core foundational skillset of every accomplished programmer/designer or software architect and is excited to ace your next technical interview this is the course for you!
And this is what you get by signing up today:
Lifetime access to 44+ hours of HD quality videos. No monthly subscription. Learn at your own pace, whenever you want
Friendly and fast support in the course Q&A whenever you have questions or get stuck
FULL money-back guarantee for 30 days!
This course is designed to help you to achieve your career goals. Whether you are looking to get more into Data Structures and Algorithms, increase your earning potential, or just want a job with more freedom, this is the right course for you!
The topics that are covered in this course.
Section 1 – Introduction
What are Data Structures?
What is an algorithm?
Why are Data Structures And Algorithms important?
Types of Data Structures
Types of Algorithms
Section 2 – Recursion
What is Recursion?
Why do we need recursion?
How does Recursion work?
Recursive vs Iterative Solutions
When to use/avoid Recursion?
How to write Recursion in 3 steps?
How to find Fibonacci numbers using Recursion?
Section 3 – Cracking Recursion Interview Questions
Question 1 – Sum of Digits
Question 2 – Power
Question 3 – Greatest Common Divisor
Question 4 – Decimal To Binary
Section 4 – Bonus CHALLENGING Recursion Problems (Exercises)
power
factorial
products array
recursiveRange
fib
reverse
palindrome
some recursive
flatten
capitalize first
nestedEvenSum
capitalize words
stringifyNumbers
collects things
Section 5 – Big O Notation
Analogy and Time Complexity
Big O, Big Theta, and Big Omega
Time complexity examples
Space Complexity
Drop the Constants and the nondominant terms
Add vs Multiply
How to measure the codes using Big O?
How to find time complexity for Recursive calls?
How to measure Recursive Algorithms that make multiple calls?
Section 6 – Top 10 Big O Interview Questions (Amazon, Facebook, Apple, and Microsoft)
Product and Sum
Print Pairs
Print Unordered Pairs
Print Unordered Pairs 2 Arrays
Print Unordered Pairs 2 Arrays 100000 Units
Reverse
O(N) Equivalents
Factorial Complexity
Fibonacci Complexity
Powers of 2
Section 7 – Arrays
What is an Array?
Types of Array
Arrays in Memory
Create an Array
Insertion Operation
Traversal Operation
Accessing an element of Array
Searching for an element in Array
Deleting an element from Array
Time and Space complexity of One Dimensional Array
One Dimensional Array Practice
Create Two Dimensional Array
Insertion – Two Dimensional Array
Accessing an element of Two Dimensional Array
Traversal – Two Dimensional Array
Searching for an element in Two Dimensional Array
Deletion – Two Dimensional Array
Time and Space complexity of Two Dimensional Array
When to use/avoid array
Section 8 – Cracking Array Interview Questions (Amazon, Facebook, Apple, and Microsoft)
Question 1 – Missing Number
Question 2 – Pairs
Question 3 – Finding a number in an Array
Question 4 – Max product of two int
Question 5 – Is Unique
Question 6 – Permutation
Question 7 – Rotate Matrix
Section 9 – CHALLENGING Array Problems (Exercises)
Middle Function
2D Lists
Best Score
Missing Number
Duplicate Number
Pairs
Section 10 – Linked List
What is a Linked List?
Linked List vs Arrays
Types of Linked List
Linked List in the Memory
Creation of Singly Linked List
Insertion in Singly Linked List in Memory
Insertion in Singly Linked List Algorithm
Insertion Method in Singly Linked List
Traversal of Singly Linked List
Search for a value in Single Linked List
Deletion of a node from Singly Linked List
Deletion Method in Singly Linked List
Deletion of entire Singly Linked List
Time and Space Complexity of Singly Linked List
Section 11 – Circular Singly Linked List
Creation of Circular Singly Linked List
Insertion in Circular Singly Linked List
Insertion Algorithm in Circular Singly Linked List
Insertion method in Circular Singly Linked List
Traversal of Circular Singly Linked List
Searching a node in Circular Singly Linked List
Deletion of a node from Circular Singly Linked List
Deletion Algorithm in Circular Singly Linked List
A method in Circular Singly Linked List
Deletion of entire Circular Singly Linked List
Time and Space Complexity of Circular Singly Linked List
Section 12 – Doubly Linked List
Creation of Doubly Linked List
Insertion in Doubly Linked List
Insertion Algorithm in Doubly Linked List
Insertion Method in Doubly Linked List
Traversal of Doubly Linked List
Reverse Traversal of Doubly Linked List
Searching for a node in Doubly Linked List
Deletion of a node in Doubly Linked List
Deletion Algorithm in Doubly Linked List
Deletion Method in Doubly Linked List
Deletion of entire Doubly Linked List
Time and Space Complexity of Doubly Linked List
Section 13 – Circular Doubly Linked List
Creation of Circular Doubly Linked List
Insertion in Circular Doubly Linked List
Insertion Algorithm in Circular Doubly Linked List
Insertion Method in Circular Doubly Linked List
Traversal of Circular Doubly Linked List
Reverse Traversal of Circular Doubly Linked List
Search for a node in Circular Doubly Linked List
Delete a node from Circular Doubly Linked List
Deletion Algorithm in Circular Doubly Linked List
Deletion Method in Circular Doubly Linked List
Entire Circular Doubly Linked List
Time and Space Complexity of Circular Doubly Linked List
Time Complexity of Linked List vs Arrays
Section 14 – Cracking Linked List Interview Questions (Amazon, Facebook, Apple, and Microsoft)
Linked List Class
Question 1 – Remove Dups
Question 2 – Return Kth to Last
Question 3 – Partition
Question 4 – Sum Linked Lists
Question 5 – Intersection
Section 15 – Stack
What is a Stack?
What and Why of Stack?
Stack Operations
Stack using Array vs Linked List
Stack Operations using Array (Create, isEmpty, isFull)
Stack Operations using Array (Push, Pop, Peek, Delete)
Time and Space Complexity of Stack using Array
Stack Operations using Linked List
Stack methods – Push, Pop, Peek, Delete, and isEmpty using Linked List
Time and Space Complexity of Stack using Linked List
When to Use/Avoid Stack
Stack Quiz
Section 16 – Queue
What is a Queue?
Linear Queue Operations using Array
Create, isFull, isEmpty, and enQueue methods using Linear Queue Array
Dequeue, Peek and Delete Methods using Linear Queue Array
Time and Space Complexity of Linear Queue using Array
Why Circular Queue?
Circular Queue Operations using Array
Create, Enqueue, isFull and isEmpty Methods in Circular Queue using Array
Dequeue, Peek and Delete Methods in Circular Queue using Array
Time and Space Complexity of Circular Queue using Array
Queue Operations using Linked List
Create, Enqueue and isEmpty Methods in Queue using Linked List
Dequeue, Peek and Delete Methods in Queue using Linked List
Time and Space Complexity of Queue using Linked List
Array vs Linked List Implementation
When to Use/Avoid Queue?
Section 17 – Cracking Stack and Queue Interview Questions (Amazon, Facebook, Apple, Microsoft)
Question 1 – Three in One
Question 2 – Stack Minimum
Question 3 – Stack of Plates
Question 4 – Queue via Stacks
Question 5 – Animal Shelter
Section 18 – Tree / Binary Tree
What is a Tree?
Why Tree?
Tree Terminology
How to create a basic tree in Java?
Binary Tree
Types of Binary Tree
Binary Tree Representation
Create Binary Tree (Linked List)
PreOrder Traversal Binary Tree (Linked List)
InOrder Traversal Binary Tree (Linked List)
PostOrder Traversal Binary Tree (Linked List)
LevelOrder Traversal Binary Tree (Linked List)
Searching for a node in Binary Tree (Linked List)
Inserting a node in Binary Tree (Linked List)
Delete a node from Binary Tree (Linked List)
Delete entire Binary Tree (Linked List)
Create Binary Tree (Array)
Insert a value Binary Tree (Array)
Search for a node in Binary Tree (Array)
PreOrder Traversal Binary Tree (Array)
InOrder Traversal Binary Tree (Array)
PostOrder Traversal Binary Tree (Array)
Level Order Traversal Binary Tree (Array)
Delete a node from Binary Tree (Array)
Entire Binary Tree (Array)
Linked List vs Python List Binary Tree
Section 19 – Binary Search Tree
What is a Binary Search Tree? Why do we need it?
Create a Binary Search Tree
Insert a node to BST
Traverse BST
Search in BST
Delete a node from BST
Delete entire BST
Time and Space complexity of BST
Section 20 – AVL Tree
What is an AVL Tree?
Why AVL Tree?
Common Operations on AVL Trees
Insert a node in AVL (Left Left Condition)
Insert a node in AVL (Left-Right Condition)
Insert a node in AVL (Right Right Condition)
Insert a node in AVL (Right Left Condition)
Insert a node in AVL (all together)
Insert a node in AVL (method)
Delete a node from AVL (LL, LR, RR, RL)
Delete a node from AVL (all together)
Delete a node from AVL (method)
Delete entire AVL
Time and Space complexity of AVL Tree
Section 21 – Binary Heap
What is Binary Heap? Why do we need it?
Common operations (Creation, Peek, sizeofheap) on Binary Heap
Insert a node in Binary Heap
Extract a node from Binary Heap
Delete entire Binary Heap
Time and space complexity of Binary Heap
Section 22 – Trie
What is a Trie? Why do we need it?
Common Operations on Trie (Creation)
Insert a string in Trie
Search for a string in Trie
Delete a string from Trie
Practical use of Trie
Section 23 – Hashing
What is Hashing? Why do we need it?
Hashing Terminology
Hash Functions
Types of Collision Resolution Techniques
Hash Table is Full
Pros and Cons of Resolution Techniques
Practical Use of Hashing
Hashing vs Other Data structures
Section 24 – Sort Algorithms
What is Sorting?
Types of Sorting
Sorting Terminologies
Bubble Sort
Selection Sort
Insertion Sort
Bucket Sort
Merge Sort
Quick Sort
Heap Sort
Comparison of Sorting Algorithms
Section 25 – Searching Algorithms
Introduction to Searching Algorithms
Linear Search
Linear Search in Python
Binary Search
Binary Search in Python
Time Complexity of Binary Search
Section 26 – Graph Algorithms
What is a Graph? Why Graph?
Graph Terminology
Types of Graph
Graph Representation
The graph in Java using Adjacency Matrix
The graph in Java using Adjacency List
Section 27 – Graph Traversal
Breadth-First Search Algorithm (BFS)
Breadth-First Search Algorithm (BFS) in Java – Adjacency Matrix
Breadth-First Search Algorithm (BFS) in Java – Adjacency List
Time Complexity of Breadth-First Search (BFS) Algorithm
Depth First Search (DFS) Algorithm
Depth First Search (DFS) Algorithm in Java – Adjacency List
Depth First Search (DFS) Algorithm in Java – Adjacency Matrix
Time Complexity of Depth First Search (DFS) Algorithm
BFS Traversal vs DFS Traversal
Section 28 – Topological Sort
What is Topological Sort?
Topological Sort Algorithm
Topological Sort using Adjacency List
Topological Sort using Adjacency Matrix
Time and Space Complexity of Topological Sort
Section 29 – Single Source Shortest Path Problem
what is Single Source Shortest Path Problem?
Breadth-First Search (BFS) for Single Source Shortest Path Problem (SSSPP)
BFS for SSSPP in Java using Adjacency List
BFS for SSSPP in Java using Adjacency Matrix
Time and Space Complexity of BFS for SSSPP
Why does BFS not work with Weighted Graph?
Why does DFS not work for SSSP?
Section 30 – Dijkstra’s Algorithm
Dijkstra’s Algorithm for SSSPP
Dijkstra’s Algorithm in Java – 1
Dijkstra’s Algorithm in Java – 2
Dijkstra’s Algorithm with Negative Cycle
Section 31 – Bellman-Ford Algorithm
Bellman-Ford Algorithm
Bellman-Ford Algorithm with negative cycle
Why does Bellman-Ford run V-1 times?
Bellman-Ford in Python
BFS vs Dijkstra vs Bellman Ford
Section 32 – All Pairs Shortest Path Problem
All pairs shortest path problem
Dry run for All pair shortest path
Section 33 – Floyd Warshall
Floyd Warshall Algorithm
Why Floyd Warshall?
Floyd Warshall with negative cycle,
Floyd Warshall in Java,
BFS vs Dijkstra vs Bellman Ford vs Floyd Warshall,
Section 34 – Minimum Spanning Tree
Minimum Spanning Tree,
Disjoint Set,
Disjoint Set in Java,
Section 35 – Kruskal’s and Prim’s Algorithms
Kruskal Algorithm,
Kruskal Algorithm in Python,
Prim’s Algorithm,
Prim’s Algorithm in Python,
Prim’s vs Kruskal
Section 36 – Cracking Graph and Tree Interview Questions (Amazon, Facebook, Apple, Microsoft)
Section 37 – Greedy Algorithms
What is a Greedy Algorithm?
Well known Greedy Algorithms
Activity Selection Problem
Activity Selection Problem in Python
Coin Change Problem
Coin Change Problem in Python
Fractional Knapsack Problem
Fractional Knapsack Problem in Python
Section 38 – Divide and Conquer Algorithms
What is a Divide and Conquer Algorithm?
Common Divide and Conquer algorithms
How to solve the Fibonacci series using the Divide and Conquer approach?
Number Factor
Number Factor in Java
House Robber
House Robber Problem in Java
Convert one string to another
Convert One String to another in Java
Zero One Knapsack problem
Zero One Knapsack problem in Java
Longest Common Sequence Problem
Longest Common Subsequence in Java
Longest Palindromic Subsequence Problem
Longest Palindromic Subsequence in Java
Minimum cost to reach the Last cell problem
Minimum Cost to reach the Last Cell in 2D array using Java
Number of Ways to reach the Last Cell with given Cost
Number of Ways to reach the Last Cell with given Cost in Java
Section 39 – Dynamic Programming
What is Dynamic Programming? (Overlapping property)
Where does the name of DC come from?
Top-Down with Memoization
Bottom-Up with Tabulation
Top-Down vs Bottom Up
Is Merge Sort Dynamic Programming?
Number Factor Problem using Dynamic Programming
Number Factor: Top-Down and Bottom-Up
House Robber Problem using Dynamic Programming
House Robber: Top-Down and Bottom-Up
Convert one string to another using Dynamic Programming
Convert String using Bottom Up
Zero One Knapsack using Dynamic Programming
Zero One Knapsack – Top Down
Zero One Knapsack – Bottom Up
Section 40 – CHALLENGING Dynamic Programming Problems
Longest repeated Subsequence Length problem
Longest Common Subsequence Length problem
Longest Common Subsequence problem
Diff Utility
Shortest Common Subsequence problem
Length of Longest Palindromic Subsequence
Subset Sum Problem
Egg Dropping Puzzle
Maximum Length Chain of Pairs
Section 41 – A Recipe for Problem Solving
Introduction
Step 1 – Understand the problem
Step 2 – Examples
Step 3 – Break it Down
Step 4 – Solve or Simplify
Step 5 – Look Back and Refactor
Section 41 – Wild West
Download
To download more paid courses for free visit course catalog where 1000+ paid courses available for free. You can get the full course into your device with just a single click. Follow the link above to download this course for free.
3 notes
·
View notes
Photo

Datatypes in python :: 1. Numeric datatypes:: Integer( for real numbers) Complex( for inputting the complex numbers) Float( for decimal numbers) 2. Dictionary:: dictionary is a collection which is unordered, changeable and indexed. In Python dictionaries are written with curly brackets, and they have keys and values Eg:: thisdict = { "brand": "Ford", "model": "Mustang", "year": 1964 } print(thisdict) 3. Boolean:: In programming you often need to know if an expression is True or False. You can evaluate any expression in Python, and get one of two answers, True or False. When you compare two values, the expression is evaluated and Python returns the Boolean answer 4. Set:: set is an unordered collection of items. Every set element is unique (no duplicates) and must be immutable (cannot be changed). However, a set itself is mutable. We can add or remove items from it. Sets can also be used to perform mathematical set operations like union, intersection, symmetric difference, etc. 5. Strings:: String literals in python are surrounded by either single quotation marks, or double quotation marks. Enjoy the post ? Drop a like and comment If you like the content Do Like comment share save 🤍 💬 📲 📁 _____________________LIKE___ ------------------COMMENT----- ------------SHARE--------- ______SAVE ____________________________ For more updates Follow us Facebook :: https://m.facebook.com/Coding_basics-109490784148247/?ref=bookmarks Instagram :: https://www.instagram.com/coding_basics/ YouTube :: https://www.youtube.com/playlist?list=PLx9JC9ithJllNRyIBuUGnurkvLZ2MHCgs ______________________________________________ ************************************************** #programming #code #c #c++ #java #javaprogramming #c_basics #python #pythonprogramming #coding #program #progress #coding_with_chakri #c_programming_language #c++_programming_language #java_programming_language #input #output #input_statements #input #LEARN_APPLY_GROW #learn #apply #grow #basics #basictraining #codingbootcamp #suray #chakri #local #global ______________________________________________ *************************************************** https://www.instagram.com/p/CDJN7OwH5Du/?igshid=xhpxjrmyccen
#programming#code#c#java#javaprogramming#c_basics#python#pythonprogramming#coding#program#progress#coding_with_chakri#c_programming_language#java_programming_language#input#output#input_statements#learn_apply_grow#learn#apply#grow#basics#basictraining#codingbootcamp#suray#chakri#local#global
1 note
·
View note
Text
Java program to remove duplicate characters from a String
Java program to remove duplicate characters from a String
In this article, we will discuss how to remove duplicate characters from a String. Here is the expected output for some given inputs : Input : topjavatutorial Output : topjavuril Input : hello Output : helo The below program that loops through each character of the String checking if it has already been encountered and ignoring it if the condition is true. package com.topjavatutorial; public…
View On WordPress
#delete duplicate characters in a string#How to remove duplicate characters from a string in java#java - function to remove duplicate characters in a string#Java - Remove duplicates from a string#java LinkedHashSet#java remove duplicate characters#java remove duplicate characters preserving order#java remove duplicate chars from String#java remove duplicates#Remove all duplicates from a given string#Remove duplicate values from a string in java#remove duplicates from String in java#Removing duplicates from a String in Java
0 notes
Text
Queue in java

Hierarchy of interfaces in Java Collection Framework: Relationship between. Next we are adding 5 strings in random order into the priority queue.
See Ĭopyright © 2000–2019, Robert Sedgewick and Kevin Wayne. Queue is a Collection that allows duplicate elements but not null elements. The first line tells us that we are creating a priority queue: Queue testStringsPQ new PriorityQueue () PriorityQueue is available in java.util package.
Chronicle Queue is a persisted low-latency messaging framework for high performance and critical. However, there's one exception that we'll touch upon later. This project covers the Java version of Chronicle Queue. Each of these methods exists in two forms: one throws an exception if the operation fails, the other returns a special value (either null or false, depending on the. Besides basic Collection operations, queues provide additional insertion, extraction, and inspection operations. In fact, most Queues we'll encounter in Java work in this first in, first out manner often abbreviated to FIFO. A collection designed for holding elements prior to processing. * * This implementation uses a singly linked list with a static nested class for * linked-list nodes. After we declare our Queue, we can add new elements to the back, and remove them from the front. Recommended Articles This is a guide to Queue in Java. We have seen examples of the most commonly used methods in queue operation. There are alternative methods available for all the methods. It supports operations like insertion, retrieval, and removal. Hence we create the instance of the LinkedList and the PriorityQueue class and assign it to the queue interface. Since the Queue is an interface, we cannot create an instance of it. ****************************************************************************** * Compilation: javac Queue.java * Execution: java Queue enqueue and dequeue * operations, along with methods for peeking at the first item, * testing if the queue is empty, and iterating through * the items in FIFO order. The Queue is a special interface in Java that is used to hold the elements in insertion order. Queue interface is a part of Java Collections that consists of two implementations: LinkedList and PriorityQueue are the two classes that implement the Queue interface. Below is the syntax highlighted version of Queue.java The Queue interface of the Java collections framework provides the functionality of the queue data structure.
0 notes
Text
android copy project
https://stackoverflow.com/a/57102685/3151712
(Not in Android Studio) Make a copy / duplicate the existing 'OldProject' directory.
(Not in Android Studio) Rename the copied directory to 'NewProject'.
Start Android Studio 3.4.
Select 'Open an existing Android Studio project'.
Navigate to the 'NewProject' directory, select it and click 'Open'.
Build -> Clean project.
File -> Sync project with gradle file.
Click the '1:Project' side tab and choose Android from the drop-down menu.
Expand the app -> java folder.
Right-click com.example.android.oldproject and select Refactor -> Rename.
Give a new name to the new project in the Rename dialog.
Select 'Search in comments and strings' and 'Search for text occurrences'. Click Refactor.
The 'Find: Refactoring Preview' pane appears, click 'Do Refactor'.
Expand the res -> values folder and double-click the strings.xml file.
Change the app_name string value to "New Project".
Check the file and sync the project with the Gradle file:
In Android Studio Project pane, expand Gradle Scripts and open build.gradle (Module: app).
In android -> defaultConfig -> applicationId check that the value of the applicationID key is "com.example.android.newproject". If the value isn't correct, change it manually.
File -> Sync project with gradle file
Make sure that the app and package names are correct in the AndroidManifest.xml file:
Expand the app -> manifests folder and double click AndroidManifest.xml.
Check that the 'package' name is correct. It should be "com.example.android.newproject". If not, change it manually.
ㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡ
위 작업후에도 firebase를 사용한 경우
https://stackoverflow.com/a/34923311/3151712
You have added the Google Play Services plugin to the project, which reads from the google-services.json found in your app module.
The google-services.json contains service configuration data, such as Google Project ID, application package name, etc..
Since the application package name is also stored in that json, it will not match anymore, so you have to create a new application in your Firebase console, and export the new configuration json.
Then replace the google-services.json in your project with the one you have generated.
위 작업을 해주어야 한다.
.
.
우선 firebase 페이지에가서 새로운 프로젝트를 만든��.
그리고 setting페이지 하단을 보면 아래와 같은에 여기서 android icon 선택
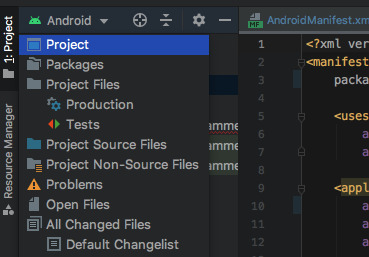
google-services.json만드는 과정


gradle화일 둘다 수정
아래) android studio 왼쪽편에 있는 화일매니저에서 android 를 project 로 바꾸고 app안에 google-services.json이 있는 것을 확인할수 있다.
새로 생성된 화일 붙여넣기
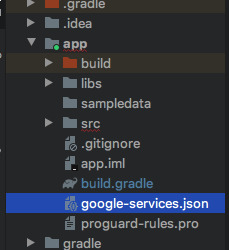

ㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡ
이렇게 하고도 navigation args관련해서 navigation화일에 들어가 각각 argument의 class를 새로 고쳐주어야 했다. 또 몇몇 에러나는 부분을 손수 수정해줘야 했다.(extension func 도 그 한예에 속한다.)
=====================================================
git을 사용하는 경우 기존의 git을 없애고 새로 시작해야한다.
https://stackoverflow.com/a/31991358
In order to drop the current git repository and create a new one you need to:
Go to the project's directory: cd PROJECT_DIRECTORY
Remove all the git specific files: rm -rf $(find . -name ".git*")
Initialize a new git repository: git init
This doesn't remove your project's files, only git configs
참고로 macos에서 숨겨진 화일도 보고 싶은경우
command + shift + . 을 하면 된다.
0 notes
Text
Python Tutorial: Nail PYTHON LIST In 10 Min, List trick.

Introduction to Python Lists.
Hola and welcome to today's Python Tutorial on "Python lists and its functions". In this, tutorial you'll learn the basics of python lists and its various function with example. Python lists are similar to an array of programming language but "Lists in Python" are more powerful in terms of functionality and are flexible in usage.
Lists in Python.
All programming language used data structure to store and manipulate data. The List data type in python is similar to array in C++ or Java or Python or Tables in COBOL. A Python Lists can be used to store, manipulate and retrieve data element as per business requirements. You can store different types (i.e. string and integer data) of data elements in the lists and lists can grow dynamically in memory. In laymen term, A list is similar to an array that consists of a group of elements or items. Just like an array, a list can store elements. But, there is one major difference between an array and a Python List. An array can store one kind of data whereas a list can store different type of the data. Thus, Python Lists are more versatile abd useful than array. List in Python are most widely used datatypes in Python program. Python Lists are easy to define and flexible to use in Python programs. In order to define a list in python, you need to enclosed data items in between square brackets. You can also use various list function to add, append, remove, update, search and delete data items from the Python Lists. Python Lists can grow dynamically in memory. But the size of any array is fixed and they cannot expand during the run time.Python Lists can store different types of data i.e. (String or Numeric), but in the array you can only store a single type of data at a time.
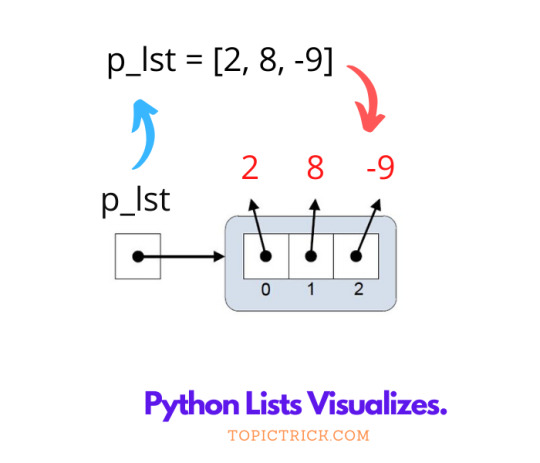
Python Lists Visualization.
How Python Lists Works?
Imagine you went to a shopping mall for shopping grocery items. Each time you pick an item from the shelf you scan it with the scanner before placing the item into your basket. The scanning machine stores the scanned item into machine memory. It also displays the list of items on the screen in the order in which item was scanned. You can visualize this scanner machine as a 'Python list' which is storing items in a sequence after being scanned on the machine. In the following example, shp_lst is a Python List which will store the name of purchase items, every time you scan an item with scanning machine, the item is added/appended to list shp_lst and index is updated. You can access these store items from shp_lst list by using python for .. loop or by other python functions and accessing list item is pretty simple and straight forward. You will learn to perform various operation on lists in later part of the Python Tutorial

How list in python works.
Python Lists and List functions.
Lists in Python are primarily used to store data in a sequence. A list is a list in itself and it can store different type of data. Lists in python are defined by square brackets and each data item is separated by ',' comma-delimited. Python list provides many in-build functions that can be used to manipulate data in the lists. Now, let's discuss all lists function in details: Example 1: How to create lists in Python? # Define an empty Lists in Python. shp_lst = # Define Lists in Python with integer items only. shp_lst = # Define Lists in Python with strings items only. shp_lst = # Define Lists in Python with mixed items. shp_lst = # Print Python Lists elements. print(shp_lst) Example 2: Python range() Function to create lists. # Python range() function. num_lst = list(range(1,10,1)) num_lst Example 3: For loop to create Python lists. # Python for loop function. a = for i in range(1,10,1): a.append(i) print ('Print List Value:' a) Example 4: Update the elements of lists. # Update first element of the lists. a = a = 2 Example 5: Concatenate two python lists. # Concatinate two Python lists. a = b = print ('Concatinate List :', (a+b)) Concatinate List : How to get individual items in a the list with Indexes and Slicing? By now you have understood that list in python is a sequence data sets. You can store a similar value of different values as per requirements and you know that each item has an associated index. You can use this index to access lists values. Python Lists start with zero and index is incremented by one every time an item is added or appended to the list. The process of creating a new python list from an existing list is termed as slicing operations. Slicing represents extracting a piece of the list by mentioning starting and ending position numbers.Syntax :: list_name list_name - Name of existing list variable. start_position - starting index position. end_position - end of index position.step size - the gap between items, the default step size is 1. Example 2: Python Lists Indexing and Slicing. # Create shp_lst shopping Lists in Python. shp_lst = # Print third element of the shp_lst list. shp_lst 'salt' # Print the second and third element of the shp_lst list. shp_lst # Create a new List from the existing shp_lst List. shp_lst_sl = shp_lst shp_lst_sl # Print last 2 items of the shp_lst List using negative indexes. shp_lst

Lists in Python with additional methods/functions.
Python Lists and Function.
As you know, Lists in Python are a powerful data set and are equally flexible to use. Python Lists provides many additional function/methods that can be used to perform many data manipulation operations on the lists. Let's discuss all these functions one by one with examples: Python List Append Method. The Python List append method is used to append items at the end of the list. In the following example, a new item would be added to the list.list.append(x)# Create shopping shp_lst Lists in Python. shp_lst = # Append jam item to the shp_lst Lists. shp_lst.append('jam') # Print the items of the lists. shp_lst Python List Extend Method. The Python List extends method is used to append all items from another list. In the following example, all items from shp_ext_lst will be added to the existing shopping list. list.extend(iterable)# Create shp_lst Lists in Python. shp_lst = # Append items from shp_ext_lst List to the shp_lst List. shp_ext_lst = shp_lst.extend(shp_ext_lst) # Print the List (shp_lst). shp_lst Python List Insert Method. The Python List insert method is used to insert an item at a specific location in the list. You need to specify the position where you want to insert value in the list. list.insert(i, x)# Create shp_lst shopping Lists in Python. shp_lst = # Insert a new item at the second position. shp_lst.insert(1,'jam') # Print the shopping list (shp_lst). shp_lst Python List Remove Method. The Python List Remove method is used to remove the item from the Python list. You need to specify the value that you want to drop from the list. Also, if your list has duplicate value then remove method will only remove first value and will retain second value. If the value is not present in the list then it will throw an error (i.e. list.remove(x): x not in list). list.remove(x)# Create Programming Language lists in Python. pgm_lst = # Remove item from the pgm_lst list. pgm_lst.remove('CICS') # Print the programming language list (pgm_lst). pgm_lst # Programming Language lists in Python. pgm_lst = # Remove an item from the list. pgm_lst.remove('JAVA') # Print the programming language list (pgm_lst). pgm_lst Python List Pop Method. The Python List POP method is to remove the specific item from the list. You are required to specify the position of the item as a parameter. list.pop()# Create programming language pgm_lst Lists in Python. pgm_lst = # Drop list last data item. pgm_lst.pop() # Print the programming list (pgm_lst). pgm_lst # Programming language lists in Python. pgm_lst = # Remove specific item from the list. pgm_lst.pop(3) # Print the programming language list (pgm_lst). pgm_lst Python List Clear Method. The Python List clear method is used to clear items from the lists. list.clear()# Programming Language lists in Python. pgm_lst = # Clear item from the list. pgm_lst.clear() # Print the programming list (pgm_lst). pgm_lst Python List Index Method. The Python List Index method is used to get the index of the item. You are required to specify the item name as a parameter. If the item is not present in the list then it will throw an error message.list.index(x])# Programming Language lists in Python. pgm_lst = # Get index of the item from the list. pgm_lst.index('CICS') 1 Python List Count Method. The Python List Count method is used to get the count of specific items in the list. You need to specify the item as an argument. list.count(x)# Programming Language lists in Python. pgm_lst = # Clear item from the list. pgm_lst.count('COBOL') 1 Python List Sort Method. The Python List Sort method is used to arrange items in the list. Python list sort has two parameters i.e. Key=None and reverse=False. list.sort(key=None, reverse=False)# Programming Language lists in Python. pgm_lst = # Sort item in the list. pgm_lst.sort() pgm_lst # Sort item in the list. pgm_lst.sort(key=None,reverse=True) pgm_lst Python List Reverse Method. The Python List Reverse method is used to reverse the order of items in the list. list.reverse()# Programming Language lists in Python. pgm_lst = # Reverse the order of items in the list. pgm_lst.reverse() pgm_lst Python List Copy Method. The Python Lists copy method is used to copy an item from one list to others.list.copy()# Programming Language lists in Python. pgm_lst = # Reverse the items sequence in the list. a = pgm_lst.copy() a Python List Sum Function. The Python Lists sum method is used to retrieve the sum of all elements of the list.list.sum()# Programming Language lists in Python. a_lst = # Get sum of all items. print('The sum of all list items :', sum(a_lst))
Lists in Python Live Coding Demo.
https://youtu.be/dyZyHaXZb-8
Conclusion.
Finally, we reach an end of today's tutorial on List in Python. By now, you have understood the basics of Lists in Python. You've also learned about various inbuilt function for performing various data manipulation operations. In our next python tutorial, you will learn more about Tuple. If you like our tutorial, please don't forget to share with your friend and family and do leave your valuable feedback. Your comments are valuable to us. Read the full article
0 notes
Text
300+ FRESHERS JAVA Interview Questions and Answers
java Interview Questions for freshers :-
1. What is Java? Java is a object-oriented programming language originally developed by Sun Micro systems and released in 1995. Java runs on a variety of platforms, such as Windows, Mac OS, and the various versions of UNIX. 2. What is serialization? Serialization converts an object to a stream of bytes for safety purposes. We can save it as a file, store in DB or send it by the network. We can also recreate the state of an item when needed. 3. What is a Java virtual machine? JVM helps the computer to run the Java program or other languages. It acts as a run-time engine. Java code is compiled into bytecode to run on any computer. 4. What is constructor? It is an instant and special method having the same name as the class. A constructor can be overloaded and a section of code to load newly created objects. If a constructor is created with a parameter then another constructor can be created without a parameter. 5. Describe variables? Name them A name for a memory location is variable. And it is called a basic unit of storage in a program. You can change the stored value during the program execution. Local variables Instant variables Static variables 6. What is the classloader? Classloader is a Java runtime environment to load Java classes into Java virtual machine. It loads class files from the network, file system, and other sources. In java, there is 3 built-in classloader. Extension System/application Bootstrap 7. What are the wrapper class? A wrapper class wraps or contains primitive data types. The Java primitives change into the reference types. It contains a field when we create an object. Primitive data types are stored in this field. Thus a primitive value is also be wrapped. 8. Define a package and its advantages? The collection of classes, sub-packages, and interfaces are bundled together is called packages. We can modularize the code and optimize its reuse. The code can also be imported by other classes and reused. It helps to remove name clashes. Provide access protection to manage the code. The classes and interfaces are easily maintained because of proper structure. It contains hidden classes to use within the packages. 9. What is the JIT compiler? JIT is a program to help in changing the Java bytecode into instructions. It improves the performance of Java applications at the run time and known as the integral parts of the Java Runtime Environment. 10. What are the special keywords in Java? Name them The special keywords in Java are access modifiers. Constructor, variable, scope of a class, data member or method is restricted. Default, private, protected and the public are four types of access modifiers.

java Interview Questions for freshers 11. What are garbage collectors? and types. It implicit memory management and destroy the unused objects to relieve the memory. It automatically removes the unreferenced objects to make the memory efficient. There are 4 types of garbage collectors. Serial garbage G1 garbage CMS garbage Parallel garbage 12. Tell the smallest piece of programmed instructions? How does it create? A thread, A scheduler executes independently. All programs having one thread is called the main thread. JVM creates the main thread when the program starts its execution. The main ( ) of the program is invoked by the main thread. Thread is created – By implementing the Runnable interface and extending the thread. 13. What executes a set of statements? Finally block always executes a set of statements. It is with a try block of any exception occurs or not. It does not execute the program by calling System.exit( ) or by a fatal error. 14. What refers to Multi-threading? Synchronization, it keeps all concurrent threads in execution. Memory consistency errors are avoided by synchronization. Execution of multiple threads accesses the same objects and fields. The thread holds the monitor when the method is considered as synchronized. 15. Tell the purpose of final, finally and finalize? Final cannot be overridden, inherited or change. For restrict the class, variable and method. Finally, is used for putting important code and executed the exception is handled or not. Finalize is for cleaning up processing before the object is collected in the garbage. 16. Where we use a different signature? In method overloading signature must be different. The same class method shares the same name. Every single method should be the indifferent number of parameters or different orders or types of parameters. For “adding” or “extending” and known as a compile-time polymorphism. 17. What is Run-time polymorphism? Method Overriding is run-time polymorphism having the same signature. Inheritance is required in Method Overriding. It is used to change existing behavior. The subclass has the same method od same number, name, parameters, return type. 18. Name the method that belongs to the class? In Java, the static method belongs to the class and access only static data. It calls only other static methods and directly accessed by the class name. To define variables, static is used. 19. Describe Object-oriented paradigm? The programming paradigm based on data and methods is called object-oriented programming. Paradigm incorporates the advantages of reusability and modularity. Objects are instances of classes to interact with one another. It designs programs and applications. 20. In Java, what is an object? A real-time entity of some behavior and state is called an object. It is an instance of a class with instance variables. The new keyword is for creating the object of the class. 21. What is an object-based programming language? JavaScript, VBScript is an object-based language and has in-built objects. All the concepts of OOPs such as polymorphism and inheritance are not followed by object-based languages. 22. Name the constructor used in Java? Default constructor – It is used to perform the task on object creation and to initialize the instance variable with default values. The constructor does not accept any value. If no constructor is defined in the class, then a default constructor is invoked implicitly by the compiler. Parameterized constructor – This constructor accepts the arguments. It initializes the instance variables with the given values. 23. How to copy the values of the item to others in Java? We can print the values by using the constructor, to allow the values of one object to other and the design of clone. In Java, there is no copy constructor. 24. Explain the Java method? The Java method is invoked explicitly and is to disclose the nature of an item, it has an entry. Its name is not the same as the class name. It is not given by the finder. 25. Describe the static variables? The static variable belongs to the class and makes the memory-efficient of the program. It refers to the common property of all objects. At the moment when class is loading, it gets the memory in the department field. 26. What is aggregation? Aggregation is described as a has-a relationship and has an entity reference. And having a relationship between two classes. The weak relationship is represented by aggregation. 27. What is a super keyword? Mention its uses. The Super keyword is a hint variable is to mention at once parent class item with the concept of inheritance, the keyword comes into the picture. It appeals soon the parent class technique and constructor. Refers directly parent class instance variable. It is used to initialize the base class variables. 28. What is method overriding? Name the rules and use them. In Java method overriding is when a subclass has the specific implementation or the same method as in the parent class. Rules : It should have the same name and signature as in the parent class. IS-A relationship should be in between two classes. Uses : For runtime polymorphism To give the specific implementation already provided by its superclass. 29. What are polymorphism and its types? Polymorphism is used in a different context and define the situations. When a single object refers to the super or sub-class depends on the reference type is polymorphism. Many forms are considered as polymorphism. 30. Explain the OOPs concepts in Java? For programmers to create the components for re-using in different ways. OOPs is known as programming style. The four concepts are Abstraction Inheritance Polymorphism Encapsulation Interface 31. What is stored in a heap memory? Java String pool is a collection of Strings are stored. If you create a new object, the string pool confirms the object is in the pool or not. The same reference is returned to the variable if it is already in the pool. 32. How to call one constructor to another to the current object? By constructor chaining. It is occurred by inheritance. The task of a subclass constructor is to call the superclass constructor. There are two ways to do constructor chaining. Within the same class using the keyword “this” ( ) From base class using the keyword “super” ( ) 33. Tell the nature of Java strings? The nature of string objects are immutable which is cached in the string pool. The state of string object cannot be modified after the creation. Java creates a new string object if you update the value of the particular object. 34. What is the interface of the Util package? It’s characteristics. Map in Java is the interface of the Util package. It is used to map a key and a value. It is different from other collection types. And it is not the subset of the main collection interface. Duplicate keys are not contained The order of a map is depending upon the specific implementation 35. Describe Java Stack memory? Stack memory is in the Last-In-First-Out order to free memory. It is used for the execution of a thread. It contains local primitives and reference to other objects. To define the stack memory, we use –Xss. The memory of the stack is considered short-lived. 36. Why Runnable Interface is used in Java? Runnable interface is used in java for implementing multi threaded applications. Java.Lang.Runnable interface is implemented by a class to support multi threading. 37. What are the two ways of implementing multi-threading in Java? Multi threaded applications can be developed in Java by using any of the following two methodologies: By using Java.Lang.Runnable Interface. Classes implement this interface to enable multi threading. There is a Run() method in this interface which is implemented. By writing a class that extend Java.Lang.Thread class. 38. When a lot of changes are required in data, which one should be a preference to be used? String or StringBuffer? Since StringBuffers are dynamic in nature and we can change the values of StringBuffer objects unlike String which is immutable, it's always a good choice to use StringBuffer when data is being changed too much. If we use String in such a case, for every data change a new String object will be created which will be an extra overhead. 39. What's the purpose of using Break in each case of Switch Statement? Break is used after each case (except the last one) in a switch so that code breaks after the valid case and doesn't flow in the proceeding cases too. If break isn't used after each case, all cases after the valid case also get executed resulting in wrong results. 40. How garbage collection is done in Java? In java, when an object is not referenced any more, garbage collection takes place and the object is destroyed automatically. For automatic garbage collection java calls either System.gc() method or Runtime.gc() method. 41. How we can execute any code even before main method? If we want to execute any statements before even creation of objects at load time of class, we can use a static block of code in the class. Any statements inside this static block of code will get executed once at the time of loading the class even before creation of objects in the main method. 42. Can a class be a super class and a sub-class at the same time? Give example. If there is a hierarchy of inheritance used, a class can be a super class for another class and a sub-class for another one at the same time. In the example below, continent class is sub-class of world class and it's super class of country class. public class world { .......... } public class continenet extends world { ............ } public class country extends continent { ...................... } 43. How objects of a class are created if no constructor is defined in the class? Even if no explicit constructor is defined in a java class, objects get created successfully as a default constructor is implicitly used for object creation. This constructor has no parameters. 44. In multi-threading how can we ensure that a resource isn't used by multiple threads simultaneously? In multi-threading, access to the resources which are shared among multiple threads can be controlled by using the concept of synchronization. Using synchronized keyword, we can ensure that only one thread can use shared resource at a time and others can get control of the resource only once it has become free from the other one using it. 45. Can we call the constructor of a class more than once for an object? Constructor is called automatically when we create an object using new keyword. It's called only once for an object at the time of object creation and hence, we can't invoke the constructor again for an object after its creation. 46. There are two classes named classA and classB. Both classes are in the same package. Can a private member of classA can be accessed by an object of classB? Private members of a class aren't accessible outside the scope of that class and any other class even in the same package can't access them. 47. Can we have two methods in a class with the same name? We can define two methods in a class with the same name but with different number/type of parameters. Which method is to get invoked will depend upon the parameters passed. For example in the class below we have two print methods with same name but different parameters. Depending upon the parameters, appropriate one will be called: public class methodExample { public void print() { system.out.println("Print method without parameters."); } public void print(String name) { system.out.println("Print method with parameter"); } public static void main(String args) { methodExample obj1 = new methodExample(); obj1.print(); obj1.print("xx"); } } 48. How can we make copy of a java object? We can use the concept of cloning to create copy of an object. Using clone, we create copies with the actual state of an object. Clone() is a method of Cloneable interface and hence, Cloneable interface needs to be implemented for making object copies. 49. What's the benefit of using inheritance? Key benefit of using inheritance is reusability of code as inheritance enables sub-classes to reuse the code of its super class. Polymorphism (Extensibility ) is another great benefit which allow new functionality to be introduced without effecting existing derived classes. 50. What's the default access specifier for variables and methods of a class? Default access specifier for variables and method is package protected i.e variables and class is available to any other class but in the same package,not outside the package. 51. Give an example of use of Pointers in Java class. There are no pointers in Java. So we can't use concept of pointers in Java. 52. How can we restrict inheritance for a class so that no class can be inherited from it? If we want a class not to be extended further by any class, we can use the keyword Final with the class name. In the following example, Stone class is Final and can't be extend public Final Class Stone { // Class methods and Variables } 53. What is Java? and how does Java enables high performance? Java is a platform-independent, object-oriented, portable, multi-thread, high-level programming language. The collection of objects is considering as Java. We use Java for developing lots of websites, games and mobile applications. For high performance, Java uses Just in time compiler. java Interview Questions and Answers for freshers Pdf free Download Read the full article
0 notes
Text
How I Made A Dysfunctional Language In The JVM
Part 1: Introduction
I remember when I first considered making my own language. I was googling how to make an abstract static variable in C#. Turns out you can't. Why? Don't know. You just can't. So this was pretty annoying. But what was even more annoying were the programmers that said not only that you couldn't but you also shouldn't.
They gave some flimsy justification about how it broke OOP or something. It was infuriating. On that day I saw the truth. These languages that were the blueprints of modern programming were just as flawed and opinionated as I was. They weren't better, they weren't worse they just were. And on that day I swore I would write my own language. One where I was in charge.
...
But you know, writing a language is hard. And C#... it's not perfect, but it's good enough. So I let my dream sit on the sidelines for several years.
But one day I saw this coding event called Code With Friends. It was one month to code whatever you want. And I was like, "Hey, you know that language you wanted to make since forever ago? Why don't you just make it?" And then I was like, "That sounds like a good idea." So I did. I entered and made a new language called Muse. And here's how I did it.
Part 2: People VS JVM
So to make a language you need to do two things. First you have to transform the code you write into what's called an abstract syntax tree. And then you have to transform that into instructions that the computer can actually understand, in my case JVM bytecode.
Step one is not too hard. I ended up using a program called ANTLR to do it.
ANTLR... let's just say if I had to do this project over I probably wouldn't use ANTLR. It's buggy. I'll be like, "What are you doing? That is obviously an addition operation!" And ANTLR will be like "No, no, no, I see an assignment operation." despite the fact that the code does not look anything like an assignment.
It is frustrating. And to top it all off the debugging tools for ANTLR are almost non-existent. The tool I used was this IntelliJ plugin. It would only tell you the raw output, not how it got there, but it was good enough. Although the plugin did occasionally crash IntelliJ.
So once you have the abstract syntax tree you have to write JVM bytecode. I used this blog post about writing hello world in the JVM to get the structure of a JVM class file. In fact I started my project by just hard coding the code from the post in my program.
So apart from the various metadata such as how many bytes your code is and the header which says 0xCAFEBABE a JVM file has basically 3 parts. The 'constant pool' part, the actual code, and attributes for the code. It's a big of a simplification. If you want to learn more go read the official JVM documentation here and here.
Anyways the constant pool as you might expect holds constant strings. In fact it's basically a grab bag of different constants. But it's most important job is to tell the code which methods/variables each class has and their type.
So then you have the code. If you've worked with assembly code at all you know what to expect here. The only difference is there are no registers, only a stack. So for example to add 1 and 2 together you'd push them both onto the stack and then use the add operation which would pop 1 and 2 and then push 3 onto the stack.
It's pretty neat. I mean, it's not the most efficient thing in the world. There is a command dup and all it does is duplicate the top value on the stack, but it does simplify things a bit.
And now lastly there's the attributes. Most of the attributes are optional. But there is one that is not. That is the Stack Map Table. This one took me forever to figure out. Basically whenever you use a jump instruction (so in an if or a while or a goto (which I really wanted in my language)) you have to use the Stack Map Table to tell Java what should be the current state (in terms of what's on the stack and what variables are defined) at that instruction address.
I mean, there's technically a flag -noverify which makes it so you don't have to have a Stack Map Table, but this pops up a scary warning about the flag being removed in a future version of Java.
So for the longest time I couldn't get the StackMapTable to work. I should probably mention the javap -v FILE_NAME command. This actually prints out the entirety of the JVM class file in a surprisingly readable way.
It was a lot easier than using a hex editor to view the files, that's for sure. In fact the strategy I was using was write a program in Java, compile it, view the JVM class file, and then copy it in my language. And this worked really well.
Until I hit the Stack Map Table. It didn't make any sense how the JVM was generating the values to put in the table. But after sleeping on it I finally got it.
The stack map entries don't hold the actual instruction numbers. They hold the instruction relative to the last instruction subtracted by 1 for whatever reason. So finally I got it working.
So that's it. You can view the project here. It's not fantastic. I mean, it doesn't support basic things like 64 bit ints and orders of operation. But for a month of work I'm pretty proud of it. And it supports things that some other languages don't support. Things like: variables that start with a number (a worryingly high number of languages don't support this), do while (not supported in python), goto statements,
)
unix directory syntax for global variables (like use ../globalVar to access something in global scope, it always bothered me how you can access a global variable identically to a local one and they can have the same name too, that's a bug just waiting to happen), named return types (it always annoyed me to no end when I had a function that returned a bool. What is it returning? If the operation succeeded? Some information about the operation?), and there are no constructors which brings me to...
Part 3: A Dysfunctional Language
This is a class in C#.
And this is a function in C#.
So this is a class.
And a function.
A class with two variables.
A function with two variables.
A class.
A function.
Class.
Function.
Are you getting it? These are not two separate things. This is one thing. And it's called a Dysfunction.
This is one of the epiphanies I had. A class and a function are fundamentally the same thing. We just use different syntax for each and under the hood they're treated a little differently.
So what if I made a language where you define a function the same way you define a class? Well, version 1 of Muse actually did just that. But I was never happy with it. Because you get a class file whether you want it or not and a random function.
So version 2 of Muse I did away with that entirely. No more functions. Only classes. But what if you actually want to use a function. Something like a square root function? Well, we can do that.
Simply instantiate a class (let's call it squareRoot), do some work in the constructor, save that work to a variable (called squareRootValue) and get that variable in the caller (which in Muse can be done on the same line we create the object). Easy.
This is what Dysfunctional Programming is. Will it take off? Well, probably not in the JVM because we have to make new objects on the heap which is much slower than on the stack.
But if I were to port this to something like LLVM and make it so dysfunctions that aren't assigned to a variable are allocated on the stack sure, why not?
Dysfunctional programming could be the next big thing.
0 notes
Text
Database Interview Questions for java
What’s the Difference between a Primary Key and a Unique Key?
Both primary key and unique key enforce uniqueness of the column on which they are defined. But by default, the primary key creates a clustered index on the column, whereas unique key creates a non-clustered index by default. Another major difference is that primary key doesn’t allow NULLs, but unique key allows one NULL only. Primary Key is the address of data and unique key may not.
What are the Different Index Configurations a Table can have?
A table can have one of the following index configurations:
No indexes A clustered index A clustered index and many non-clustered indexes A non-clustered index Many non-clustered indexes
What is Difference between DELETE and TRUNCATE Commands?
The DELETE command is used to remove rows from a table. A WHERE clause can be used to only remove some rows. If no WHERE condition is specified, all rows will be removed. After performing a DELETE operation you need to COMMIT or ROLLBACK the transaction to make the change permanent or to undo it. Note that this operation will cause all DELETE triggers on the table to fire.
TRUNCATE removes all rows from a table. The operation cannot be rolled back and no triggers will be fired. As such, TRUCATE is faster and doesn’t use as much undo space as a DELETE.
TRUNCATE
TRUNCATE is faster and uses fewer system and transaction log resources than DELETE. TRUNCATE removes the data by deallocating the data pages used to store the table’s data, and only the page deallocations are recorded in the transaction log. TRUNCATE removes all the rows from a table, but the table structure, its columns, constraints, indexes and so on remains. The counter used by an identity for new rows is reset to the seed for the column. You cannot use TRUNCATE TABLE on a table referenced by a FOREIGN KEY constraint. Using T-SQL – TRUNCATE cannot be rolled back unless it is used in TRANSACTION. OR TRUNCATE can be rolled back when used with BEGIN … END TRANSACTION using T-SQL. TRUNCATE is a DDL Command. TRUNCATE resets the identity of the table.
DELETE
DELETE removes rows one at a time and records an entry in the transaction log for each deleted row. DELETE does not reset Identity property of the table. DELETE can be used with or without a WHERE clause DELETE activates Triggers if defined on table. DELETE can be rolled back. DELETE is DML Command. DELETE does not reset the identity of the table.
What are Different Types of Locks?
Shared Locks: Used for operations that do not change or update data (read-only operations), such as a SELECT statement. Update Locks: Used on resources that can be updated. It prevents a common form of deadlock that occurs when multiple sessions are reading, locking, and potentially updating resources later. Exclusive Locks: Used for data-modification operations, such as INSERT, UPDATE, or DELETE. It ensures that multiple updates cannot be made to the same resource at the same time.
What are Pessimistic Lock and Optimistic Lock?
Optimistic Locking is a strategy where you read a record, take note of a version number and check that the version hasn’t changed before you write the record back. If the record is dirty (i.e. different version to yours), then you abort the transaction and the user can re-start it. Pessimistic Locking is when you lock the record for your exclusive use until you have finished with it. It has much better integrity than optimistic locking but requires you to be careful with your application design to avoid Deadlocks.
What is the Difference between a HAVING clause and a WHERE clause?
They specify a search condition for a group or an aggregate. But the difference is that HAVING can be used only with the SELECT statement. HAVING is typically used in a GROUP BY clause. When GROUP BY is not used, HAVING behaves like a WHERE clause. Having Clause is basically used only with the GROUP BY function in a query, whereas WHERE Clause is applied to each row before they are part of the GROUP BY function in a query.
What is NOT NULL Constraint?
A NOT NULL constraint enforces that the column will not accept null values. The not null constraints are used to enforce domain integrity, as the check constraints.
What is the difference between UNION and UNION ALL?
UNION The UNION command is used to select related information from two tables, much like the JOIN command. However, when using the UNION command all selected columns need to be of the same data type. With UNION, only distinct values are selected.
UNION ALL The UNION ALL command is equal to the UNION command, except that UNION ALL selects all values.
The difference between UNION and UNION ALL is that UNION ALL will not eliminate duplicate rows, instead it just pulls all rows from all the tables fitting your query specifics and combines them into a table.
What is B-Tree?
The database server uses a B-tree structure to organize index information. B-Tree generally has following types of index pages or nodes:
Root node: A root node contains node pointers to only one branch node.
Branch nodes: A branch node contains pointers to leaf nodes or other branch nodes, which can be two or more.
Leaf nodes: A leaf node contains index items and horizontal pointers to other leaf nodes, which can be many.
What are the Advantages of Using Stored Procedures?
Stored procedure can reduced network traffic and latency, boosting application performance. Stored procedure execution plans can be reused; they staying cached in SQL Server’s memory, reducing server overhead. Stored procedures help promote code reuse. Stored procedures can encapsulate logic. You can change stored procedure code without affecting clients. Stored procedures provide better security to your data.
What is SQL Injection? How to Protect Against SQL Injection Attack? SQL injection is an attack in which malicious code is inserted into strings that are later passed to an instance of SQL Server for parsing and execution. Any procedure that constructs SQL statements should be reviewed for injection vulnerabilities because SQL Server will execute all syntactically valid queries that it receives. Even parameterized data can be manipulated by a skilled and determined attacker. Here are few methods which can be used to protect again SQL Injection attack:
Use Type-Safe SQL Parameters Use Parameterized Input with Stored Procedures Use the Parameters Collection with Dynamic SQL Filtering Input parameters Use the escape character in LIKE clause Wrapping Parameters with QUOTENAME() and REPLACE()
What is the Correct Order of the Logical Query Processing Phases?
The correct order of the Logical Query Processing Phases is as follows: 1. FROM 2. ON 3. OUTER 4. WHERE 5. GROUP BY 6. CUBE | ROLLUP 7. HAVING 8. SELECT 9. DISTINCT 10. TOP 11. ORDER BY
What are Different Types of Join?
Cross Join : A cross join that does not have a WHERE clause produces the Cartesian product of the tables involved in the join. The size of a Cartesian product result set is the number of rows in the first table multiplied by the number of rows in the second table. The common example is when company wants to combine each product with a pricing table to analyze each product at each price. Inner Join : A join that displays only the rows that have a match in both joined tables is known as inner Join. This is the default type of join in the Query and View Designer. Outer Join : A join that includes rows even if they do not have related rows in the joined table is an Outer Join. You can create three different outer join to specify the unmatched rows to be included: Left Outer Join: In Left Outer Join, all the rows in the first-named table, i.e. “left” table, which appears leftmost in the JOIN clause, are included. Unmatched rows in the right table do not appear. Right Outer Join: In Right Outer Join, all the rows in the second-named table, i.e. “right” table, which appears rightmost in the JOIN clause are included. Unmatched rows in the left table are not included. Full Outer Join : In Full Outer Join, all the rows in all joined tables are included, whether they are matched or not. Self Join : This is a particular case when one table joins to itself with one or two aliases to avoid confusion. A self join can be of any type, as long as the joined tables are the same. A self join is rather unique in that it involves a relationship with only one table. The common example is when company has a hierarchal reporting structure whereby one member of staff reports to another. Self Join can be Outer Join or Inner Join.
What is a View?
A simple view can be thought of as a subset of a table. It can be used for retrieving data as well as updating or deleting rows. Rows updated or deleted in the view are updated or deleted in the table the view was created with. It should also be noted that as data in the original table changes, so does the data in the view as views are the way to look at parts of the original table. The results of using a view are not permanently stored in the database. The data accessed through a view is actually constructed using standard T-SQL select command and can come from one to many different base tables or even other views.
What is an Index?
An index is a physical structure containing pointers to the data. Indices are created in an existing table to locate rows more quickly and efficiently. It is possible to create an index on one or more columns of a table, and each index is given a name. The users cannot see the indexes; they are just used to speed up queries. Effective indexes are one of the best ways to improve performance in a database application. A table scan happens when there is no index available to help a query. In a table scan, the SQL Server examines every row in the table to satisfy the query results. Table scans are sometimes unavoidable, but on large tables, scans have a terrific impact on performance.
Can a view be updated/inserted/deleted? If Yes – under what conditions ?
A View can be updated/deleted/inserted if it has only one base table if the view is based on columns from one or more tables then insert, update and delete is not possible.
What is a Surrogate Key?
A surrogate key is a substitution for the natural primary key. It is just a unique identifier or number for each row that can be used for the primary key to the table. The only requirement for a surrogate primary key is that it should be unique for each row in the table. It is useful because the natural primary key can change and this makes updates more difficult. Surrogated keys are always integer or numeric.
How to remove duplicates from table? ? 1 2 3 4 5 6 7 8 9
DELETE FROM TableName WHERE ID NOT IN (SELECT MAX(ID) FROM TableName GROUP BY Column1, Column2, Column3, ------ Column..n HAVING MAX(ID) IS NOT NULL)
Note : Where Combination of Column1, Column2, Column3, … Column n define the uniqueness of Record.
How to fine the N’th Maximum salary using SQL query?
Using Sub query ? 1 2 3 4 5 6
SELECT * FROM Employee E1 WHERE (N-1) = ( SELECT COUNT(DISTINCT(E2.Salary)) FROM Employee E2 WHERE E2.Salary > E1.Salary )
Another way to get 2’nd maximum salary ? 1
Select max(Salary) From Employee e where e.sal < ( select max(sal) from employee );
0 notes
Text
SOLVED:P2: Interactive PlayList Analysis Solution
In this assignment, you will develop an application that manages a user's songs in a simplified playlist. Objectives Write a class with a main method (PlayList). Use an existing, custom class (Song). Use classes from the Java standard library. Work with numeric data. Work with standard input and output. Specification Existing class that you will use: Song.java Class that you will create: PlayList.java Song (provided class) You do not need to modify this class. You will just use it in your PlayList driver class. You are given a class named Song that keeps track of the details about a song. Each song instance will keep track of the following data. Title of the song. The song title must be specified when the song is created. Artist of the song. The song artist must be specified when the song is created. The play time (in seconds) of the song. The play time must be specified when the song is created. The file path of the song. The file path must be specified when the song is created. The play count of the song (e.g. how many times has the song been played). This is set to 0 by default when the song is created. The Song class has the following methods available for you to use: public Song(String title, String artist, int playTime, String filePath) -- (The Constructor) public String getTitle() public String getArtist() public int getPlayTime() public String getFilePath() public void play() public void stop() public String toString() To find out what each method does, look at the documentation for the Song class: java docs for Song class PlayList (the driver class) You will write a class called PlayList. It is the driver class, meaning, it will contain the main method. In this class, you will gather song information from the user by prompting and reading data from the command line. Then, you will store the song information by creating song objects from the given data. You will use the methods available in the song class to extract data from the song objects, calculate statistics for song play times, and print the information to the user. Finally, you will use conditional statements to order songs by play time. The ordered "playlist" will be printed to the user. Your PlayList code should not duplicate any data or functionality that belongs to the Song objects. Make sure that you are accessing data using the Song methods. Do NOT use a loop or arrays to generate your Songs. We will discuss how to do this later, but please don't over complicate things now. If you want to do something extra, see the extra credit section below. User input Console input should be handled with a Scanner object. Create a Scanner using the standard input as follows: Scanner in = new Scanner(System.in); You should never make more than one Scanner from System.in in any program. Creating more than one Scanner from System.in crashes the script used to test the program. There is only one keyboard; there should only be one Scanner. Your program will prompt the user for the following values and read the user's input from the keyboard. A String for the song title. A String for the song artist. A String for the song play time (converted to an int later). A String for the song file path. Here is a sample input session for one song. Your program must read input in the order below. If it doesn't, it will fail our tests when grading. Enter title: Big Jet Plane Enter artist: Julia Stone Enter play time (mm:ss): 3:54 Enter file name: sounds/westernBeat.wav You can use the nextLine() method of the Scanner class to read each line of input. Creating Song objects from input As you read in the values for each song, create a new Song object using the input values. Use the following process to create each new song. Read the input values from the user into temporary variables. You will need to do some manipulation of the playing time data. The play time will be entered in the format mm:ss, where mm is the number of minutes and ss is the number of seconds. You will need to convert this string value to the total number of seconds before you can store it in your Song object. (Hint: use the String class's indexOf() method to find the index of the ':' character, then use the substring() method to get the minutes and seconds values.) All other input values are String objects, so you can store them directly in your Song object. Use the Song constructor to instantiate a new song, passing in the variables containing the title, artist, play time, and file path. Because a copy of the values will be stored in your song objects, you can re-use the same temporary variables when reading input for the next song. Before moving to the next step, print your song objects to make sure everything looks correct. To print a song, you may use the provided toString method. Look at the Song documentation for an example of how to print a song. NOTE: Each Song instance you create will store its own data, so you will use the methods of the Song class to get that data when you need it. Don't use the temporary variables that you created for reading input from the user. For example, once you create a song, you may retrieve the title using song1.getTitle(); Calculate the average play time. Use the getPlayTime() method to retrieve the play time of each song and calculate the average play time in seconds. Print the average play time formatted to two decimal places. Format the output as shown in example below. Average play time: 260.67 Use the DecimalFormat formatter to print the average. You may use this Find the song with play time closest to 4 minutes Determine which song has play time closest to 4 minutes. Print the title of the song formatted as shown in the output below. Song with play time closest to 240 secs is: Big Jet Plane Build a sorted play list Build a play list of the songs from the shortest to the longest play time and print the songs in order. To print the formatted song data, use the toString() method in the Song class. Print the play list as shown in the output below. ============================================================================== Title Artist File Name Play Time ============================================================================== Where you end Moby sounds/classical.wav 198 Big Jet Plane Julia Stone sounds/westernBeat.wav 234 Last Tango in Paris Gotan Project sounds/newAgeRhythm.wav 350 ============================================================================== Extra Credit (5 points) You may notice that you are repeating the same code to read in the song data from the user for each song (Yuck! This would get really messy if we had 10 songs). Modify your main method to use a loop to read in the songs from the user. As you read and create new songs, you will need to store your songs in an ArrayList. This can be quite challenging if you have never used ArrayLists before, so we recommend saving a backup of your original implementation before attempting the extra credit. Getting Started Create a new Eclipse project for this assignment and import Song.java into your project. Create a new Java class called PlayList and add a main method. Read the Song documentation and (if you are feeling adventurous) look through the Song.java file to familiarize yourself with what it contains and how it works before writing any code of your own. Start implementing your Song class according to the specifications. Test often! Run your program after each task so you can find and fix problems early. It is really hard for anyone to track down problems if the code was not tested along the way. Sample Input/Output Make sure you at least test all of the following inputs. Last Tango in Paris Gotan Project 05:50 sounds/newAgeRhythm.wav Where you end Moby 3:18 sounds/classical.wav Big Jet Plane Julia Stone 3:54 sounds/westernBeat.wav Where you end Moby 3:18 sounds/classical.wav Last Tango in Paris Gotan Project 05:50 sounds/newAgeRhythm.wav Big Jet Plane Julia Stone 3:54 sounds/westernBeat.wav Big Jet Plane Julia Stone 3:54 sounds/westernBeat.wav Last Tango in Paris Gotan Project 05:50 sounds/newAgeRhythm.wav Where you end Moby 3:18 sounds/classical.wav Submitting Your Project Testing Once you have completed your program in Eclipse, copy your Song.java, PlayList.java and README files into a directory on the onyx server, with no other files (if you did the project on your computer). Test that you can compile and run your program from the console in the lab to make sure that it will run properly for the grader. javac PlayList.java java PlayList Documentation If you haven't already, add a javadoc comment to your program. It should be located immediately before the class header. If you forgot how to do this, go look at the Documenting Your Program section from lab . Have a class javadoc comment before the class (as you did in the first lab) Your class comment must include the @author tag at the end of the comment. This will list you as the author of your software when you create your documentation. Include a plain-text file called README that describes your program and how to use it. Expected formatting and content are described in README_TEMPLATE. See README_EXAMPLE for an example. Submission You will follow the same process for submitting each project. Open a console and navigate to the project directory containing your source files, Remove all the .class files using the command, rm *.class. In the same directory, execute the submit command for your section as shown in the following table. Look for the success message and timestamp. If you don't see a success message and timestamp, make sure the submit command you used is EXACTLY as shown. Required Source Files Required files (be sure the names match what is here exactly): PlayList.java (main class) Song.java (provided class) README Section Instructor Submit Command 1 Luke Hindman (TuTh 1:30 - 2:45) submit lhindman cs121-1 p2 2 Greg Andersen (TuTh 9:00 - 10:15) submit gandersen cs121-2 p2 3 Luke Hindman (TuTh 10:30 - 11:45) submit lhindman cs121-3 p2 4 Marissa Schmidt (TuTh 4:30 - 5:45) submit marissa cs121-4 p2 5 Jerry Fails (TuTh 1:30 - 2:45) submit jfails cs121-5 p2 After submitting, you may check your submission using the "check" command. In the example below, replace submit -check Read the full article
0 notes
Text
Java Collections Interview Questions and Answers
Here are some Java Collections Interview Questions and Answers to prepare your interview.
Java Collections Framework is the fundamental aspect of java programming language. It’s one of the important topic for java interview questions. Here I am listing some important java collections interview questions and answers for helping you in interview.
Here is the list of mostly asked java collections interview questions with answers.
1. What is difference between ArrayList and vector?
1) Synchronization – ArrayList is not thread-safe whereas Vector is thread-safe. In Vector class each method like add(), get(int i) is surrounded with a synchronized block and thus making Vector class thread-safe.
2) Data growth – Internally, both the ArrayList and Vector hold onto their contents using an Array. When an element is inserted into an ArrayList or a Vector, the object will need to expand its internal array if it runs out of room. A Vector defaults to doubling the size of its array, while the ArrayList increases its array size by 50 percent.
2. How can Arraylist be synchronized without using Vector?
Ans) Arraylist can be synchronized using:
Collection.synchronizedList(List list)
Other collections can be synchronized:
Collection.synchronizedMap(Map map) and Collection.synchronizedCollection(Collection c)
3. If an Employee class is present and its objects are added in an arrayList. Now I want the list to be sorted on the basis of the employeeID of Employee class. What are the steps?
Ans) 1) Implement Comparable interface for the Employee class and override the compareTo(Object obj) method in which compare the employeeID
2) Now call Collections.sort() method and pass list as an argument.
Now consider that Employee class is a jar file.
1) Since Comparable interface cannot be implemented, create Comparator and override the compare(Object obj, Object obj1) method .
2) Call Collections.sort() on the list and pass comparator as an argument.
4. What is difference between HashMap and HashTable?
Both collections implements Map. Both collections store value as key-value pairs. The key differences between the two are
Hashmap is not synchronized in nature but hshtable is.
Another difference is that iterator in the HashMap is fail-safe while the enumerator for the Hashtable isn’t. Fail-safe– “if the Hashtable is structurally modified at any time after the iterator is created, in any way except through the iterator’s own remove method, the iterator will throw a ConcurrentModificationExceptionâ€?
3. HashMap permits null values and only 1 null key, while Hashtable doesn’t allow key or value as null.
5. What are the classes implementing List interface?
There are three classes that implement List interface: 1) ArrayList : It is a resizable array implementation. The size of the ArrayList can be increased dynamically also operations like add,remove and get can be formed once the object is created. It also ensures that the data is retrieved in the manner it was stored. The ArrayList is not thread-safe.
2) Vector: It is thread-safe implementation of ArrayList. The methods are wrapped around a synchronized block.
3) LinkedList: the LinkedList also implements Queue interface and provide FIFO(First In First Out) operation for add operation. It is faster if than ArrayList if it performs insertion and deletion of elements from the middle of a list.
6. Which all classes implement Set interface?
Ans) A Set is a collection that contains no duplicate elements. More formally, sets contain no pair of elements e1 and e2 such that e1.equals(e2), and at most one null element. HashSet,SortedSet and TreeSet are the commnly used class which implements Set interface.
SortedSet – It is an interface which extends Set. A the name suggest , the interface allows the data to be iterated in the ascending order or sorted on the basis of Comparator or Comparable interface. All elements inserted into the interface must implement Comparable or Comparator interface.
TreeSet – It is the implementation of SortedSet interface.This implementation provides guaranteed log(n) time cost for the basic operations (add, remove and contains). The class is not synchronized.
HashSet: This class implements the Set interface, backed by a hash table (actually a HashMap instance). It makes no guarantees as to the iteration order of the set; in particular, it does not guarantee that the order will remain constant over time. This class permits the null element. This class offers constant time performance for the basic operations (add, remove, contains and size), assuming the hash function disperses the elements properly among the buckets
7. What is difference between List and a Set?
1) List can contain duplicate values but Set doesnt allow. Set allows only to unique elements. 2) List allows retrieval of data to be in same order in the way it is inserted but Set doesnt ensures the sequence in which data can be retrieved.(Except HashSet)
8. What is difference between Arrays and ArrayList ?
Ans) Arrays are created of fix size whereas ArrayList is of not fix size. It means that once array is declared as :
int [] intArray= new int[6];
intArray[7] // will give ArraysOutOfBoundException.
Also the size of array cannot be incremented or decremented. But with arrayList the size is variable.
Once the array is created elements cannot be added or deleted from it. But with ArrayList the elements can be added and deleted at runtime.
List list = new ArrayList(); list.add(1); list.add(3); list.remove(0) // will remove the element from the 1st location.
ArrayList is one dimensional but array can be multidimensional.
int[][][] intArray= new int[3][2][1]; // 3 dimensional array
To create an array the size should be known or initalized to some value. If not initialized carefully there could me memory wastage. But arrayList is all about dynamic creation and there is no wastage of memory.
9. When to use ArrayList or LinkedList ?
Ans) Adding new elements is pretty fast for either type of list. For the ArrayList, doing random lookup using “get” is fast, but for LinkedList, it’s slow. It’s slow because there’s no efficient way to index into the middle of a linked list. When removing elements, using ArrayList is slow. This is because all remaining elements in the underlying array of Object instances must be shifted down for each remove operation. But here LinkedList is fast, because deletion can be done simply by changing a couple of links. So an ArrayList works best for cases where you’re doing random access on the list, and a LinkedList works better if you’re doing a lot of editing in the middle of the list.
10. Consider a scenario. If an ArrayList has to be iterate to read data only, what are the possible ways and which is the fastest?
Ans) It can be done in two ways, using for loop or using iterator of ArrayList. The first option is faster than using iterator. Because value stored in arraylist is indexed access. So while accessing the value is accessed directly as per the index.
11. Now another question with respect to above question is if accessing through iterator is slow then why do we need it and when to use it.
Ans) For loop does not allow the updation in the array(add or remove operation) inside the loop whereas Iterator does. Also Iterator can be used where there is no clue what type of collections will be used because all collections have iterator.
12. Which design pattern Iterator follows?
Ans) It follows Iterator design pattern. Iterator Pattern is a type of behavioral pattern. The Iterator pattern is one, which allows you to navigate through a collection of data using a common interface without knowing about the underlying implementation. Iterator should be implemented as an interface. This allows the user to implement it anyway its easier for him/her to return data. The benefits of Iterator are about their strength to provide a common interface for iterating through collections without bothering about underlying implementation.
Example of Iteration design pattern – Enumeration The class java.util.Enumeration is an example of the Iterator pattern. It represents and abstract means of iterating over a collection of elements in some sequential order without the client having to know the representation of the collection being iterated over. It can be used to provide a uniform interface for traversing collections of all kinds.
13. Is it better to have a HashMap with large number of records or n number of small hashMaps?
Ans) It depends on the different scenario one is working on: 1) If the objects in the hashMap are same then there is no point in having different hashmap as the traverse time in a hashmap is invariant to the size of the Map. 2) If the objects are of different type like one of Person class , other of Animal class etc then also one can have single hashmap but different hashmap would score over it as it would have better readability.
14. Why is it preferred to declare: List<String> list = new ArrayList<String>(); instead of ArrayList<String> = new ArrayList<String>();
Ans) It is preferred because:
If later on code needs to be changed from ArrayList to Vector then only at the declaration place we can do that.
The most important one – If a function is declared such that it takes list. E.g void showDetails(List list); When the parameter is declared as List to the function it can be called by passing any subclass of List like ArrayList,Vector,LinkedList making the function more flexible
15. What is difference between iterator access and index access?
Ans) Index based access allow access of the element directly on the basis of index. The cursor of the datastructure can directly goto the ‘n’ location and get the element. It doesnot traverse through n-1 elements.
In Iterator based access, the cursor has to traverse through each element to get the desired element.So to reach the ‘n’th element it need to traverse through n-1 elements.
Insertion,updation or deletion will be faster for iterator based access if the operations are performed on elements present in between the datastructure.
Insertion,updation or deletion will be faster for index based access if the operations are performed on elements present at last of the datastructure.
Traversal or search in index based datastructure is faster. ArrayList is index access and LinkedList is iterator access.
16. How to sort list in reverse order?
Ans) To sort the elements of the List in the reverse natural order of the strings, get a reverse Comparator from the Collections class with reverseOrder(). Then, pass the reverse Comparator to the sort() method.
List list = new ArrayList(); Comparator comp = Collections.reverseOrder(); Collections.sort(list, comp)
17. Can a null element added to a Treeset or HashSet?
Ans) A null element can be added only if the set contains one element because when a second element is added then as per set defination a check is made to check duplicate value and comparison with null element will throw NullPointerException. HashSet is based on hashMap and can contain null element.
18. How to sort list of strings ,case insensitive?
Ans) using Collections.sort(list, String.CASE_INSENSITIVE_ORDER);
19. How to make a List (ArrayList,Vector,LinkedList) read only?
Ans) A list implemenation can be made read only using Collections.unmodifiableList(list). This method returns a new list. If a user tries to perform add operation on the new list; UnSupportedOperationException is thrown.
20. What is ConcurrentHashMap?
Ans) A concurrentHashMap is thread-safe implementation of Map interface. In this class put and remove method are synchronized but not get method. This class is different from Hashtable in terms of locking; it means that hashtable use object level lock but this class uses bucket level lock thus having better performance.
21. Which is faster to iterate LinkedHashSet or LinkedList?
Ans) LinkedList.
22. Which data structure HashSet implements?
Ans) HashSet implements hashmap internally to store the data. The data passed to hashset is stored as key in hashmap with null as value.
23. Arrange in the order of speed – HashMap,HashTable, Collections.synchronizedMap, concurrentHashmap ?
Ans) HashMap is fastest, ConcurrentHashMap,Collections.synchronizedMap,HashTable.
24. What is identityHashMap?
Ans) The IdentityHashMap uses == for equality checking instead of equals(). This can be used for both performance reasons, if you know that two different elements will never be equals and for preventing spoofing, where an object tries to imitate another.
25. What is WeakHashMap?
Ans) A hashtable-based Map implementation with weak keys. An entry in a WeakHashMap will automatically be removed when its key is no longer in ordinary use. More precisely, the presence of a mapping for a given key will not prevent the key from being discarded by the garbage collector, that is, made finalizable, finalized, and then reclaimed. When a key has been discarded its entry is effectively removed from the map, so this class behaves somewhat differently than other Map implementations.
#Java Collections Interview Questions and Answers#Java Collections Interview Questions#java interview questions#Java tutorials#india
0 notes
Text
Reasons to Use Python for Marketers
The digital marketing has become so sophisticated and data-oriented powered by numerous business intelligence tools in the present day marketing field. The modern marketing strategies are highly influenced by deeper data analytics based on the rich data, artificial intelligence, and creative marketing ideas. The main goal of a successful marketing strategy is to achieve the marketing return on investment MROI greater and faster, which is not possible without using the technologies like Python, Java or PHP for marketing automation and data analysis.
Many companies hire Python developers to support their digital marketers, but that solution is not viable due to high-cost in the fiercely competitive marketplace. The best solution to overcome all glitches in the effectiveness of digital marketing strategies is to learn coding skills of Python or other such powerful languages.
Python in Marketing Strategy
A modern marketing strategy consists of numerous components like social media, SEO, paid search, content marketing, ads, video, and others. You need technical expertise to understand the crux of all those components and analyze the data achieved by the virtue of those components. Python and R languages are the most popular languages used in the data analysis field, according to the Digital Vidya information.
To have a deeper insight in the marketing strategy, you should develop your own custom code to analyze the data collected in the digital marketing so that you can find out the fault lines, take the corrective measures, and launch the right campaign. According to the CodeAcademy information, Python is at the top of all other big programming languages like Java, PHP, and others. The enrollment to learn to programme in Python has also increased rapidly during the past few years.
Useful Tips on How to Automate Marketing in Python
The main components for automating the marketing campaigns include data mining, competitor price monitoring, SEO indexation, and such other tasks. Python is a very powerful programming language that can help you out in automating your marketing strategies with short and simple coding.
Let’s have a look at a few very useful tips on how to automate marketing in Python:
#1 Automate Data Collection
The marketers gather data from multiple sources repetitively for processing and analyzing. So, the collection of data should be fully automated to generate a big file of data. The main points in collecting data may include:
Automate SEO indexation through a python code that can trace the changes in ranking
Try to automate the price changes of the competitor products with a Python code
Gathering survey data, chat chains, and other commercial data files
Collecting email and SMS responses
Top marketing trend information gathering
#2 Automate Repetitive Data Formatting
Once the raw data is collected from the multiple sources, you need to format that data in such a way that the entire data looks in sync with the data processing requirements. The main activities of repetitive formatting tasks include:
Text string matching functions
Number matching functions
Marking/tagging data source, location, time, and other attributes of data
Encrypting PDF file repeatedly
Formatting functions for PDFs and web ads like splitting, watermarking and other such functions
#3 Automate Customized Error Checking
The software or the Python module that your company uses for data mining should accept the certain criteria and fields. Any kinds of typo or other errors in the data that is mandatory for your organization should be automated to improve efficiency and save valuable time.
#4 Automate Massive File Operations
The massive operations on the files like copying, editing or removing the files based on certain criteria such as timestamp, data strings, changes in files and other conditions should be automated through Python codes. This will improve the efficiency of data processing.
Reading the file properties and its attributes
Tracking of modifications made to the files in comparison with the timestamps
Always develop the custom code, the way you work and based on your own marketing skills
Automate the filling out of forms, naming renaming files, and formatting sheets
#5 Automate Data Mining Process
The data mining process plays a pivotal role in all types of marketing in the marketplace. The data mining components may vary from company to company. It is always a good idea to automate the major functions related to the processing of big data.
The customized code should be developed for all data mining related tasks to find out the useful information
Create a shortcode for the repetitive marketing tasks rather than doing them manually
Making information summary as an automated task
Highlighting the new trends of user behaviors
Why Use Python for Marketers?
According to the IEEE Spectrum ranking of the top programming languages in 2018 information, Python sits on the top of the list. The marketers, data scientists, big data engineers, and machine learning developers extensively use Python language in their respective fields.
There are numerous advantages of using the Python programming language in the digital marketing field. Those benefits are listed below:
It is cheaper to learn Python than using readymade data analytics tools in the market
It is very simple and easy to learn for even a novice programmer
It has a large number of libraries for data analysis
It is an open source programming language without any fee to use
It is powered by a large community to support
It is an interpreted language, which does not require compilation
Its code is cross-platform portable
It is an object-oriented language with high performance
It is widely used in the marketing so new marketing-related features are counting
Top 5 Reasons to Use Python for Marketers
Python is extensively used in automating different tasks used for digital marketing campaigns nowadays. The main objective of using Python as an automation code development is to improve the marketing efficiency and effectiveness to create a competitive advantage over the competitors.
Let’s figure out a few important reasons for using the Python for marketing in the modern digital marketing field.
#1 Large Number of Data Analytics Libraries
Python language is powered by numerous data analytics related libraries that are extensively useful for the digital marketing professionals. The examples of such tools include NumPy, Pandas, StatsModel, SciPy and others. These tools are large-scale libraries for data mining, analyzing, converting, cleaning, processing, summarizing, visualizing, and reporting. There are many other libraries that can help you get a deeper perspective on the user data that you as a marketer, are interested in. The present-day digital marketing is useless if it is not properly driven by the meaningful information behind it. That information can efficiently be achieved by using the power of the Python language.
#2 Increased Data Mining Efficiency
By using the Python programming language, the marketers achieve huge efficiency in the data mining process. The traditional data mining processes mostly used excel sheet processing, which has its own limits and performance. For instance, processing an excel sheet of about 100 MB data at a better speed and performance would be difficult.
But, Python code can just do it in a few seconds without sweating at all. Thus, Python increases the efficiency of data mining processes commonly used for getting insight into the marketing campaigns as well as launching the new campaigns.
#3 Improved Search Engine Optimization (SEO)
Search engine optimization or SEO is one of the core components to make your marketing campaign a success. A better ranking index of the website can help improve the visibility of your website and business. A large number of matters related to SEO, such as 404 errors, meta tags, descriptions, robot text file, content duplication, faulty navigation map, and others can easily be detected through a custom Python code for automating SEO process.
Once the SEO faults detected, it is easy to remove them instantly before they could damage the search engine ranking badly. It is very critical to use the best white label SEO rules recommended for a high ranking index, which can be achieved by getting a deeper perspective on the website technical and content related issues in the early stages.
#4 Efficient Use of Big Data
According to the Research and Markets predictions, the global market of big data will grow over 14% CAGR for the next three years from the present value of about $65 billion in 2018. The total volume of big data will cross 44 zettabytes by 2020. To skim the valuable information from this valuable heap of data, Python plays an important role. Developing customized Python codes to combine, process, analyze, and visualize the big data makes the big data so useful for the marketers.
#5 Effective Campaign Monitoring
One of the most critical bottlenecks in making the digital marketing campaigns successful includes the monitoring and course correction of the marketing campaigns. The use of Python custom codes can make the life so easy in monitoring the ads, effectiveness, clicks, checkouts, conversion rate, and other parameters in the real-time.
This monitoring can help the marketers make the campaigns more focused towards the desired segments by correcting the fault lines in the campaign components. A good Python code is able to monitor Facebook, Google, YouTube, and other ads in real time by using the APIs of the social websites.
Final Takeaways
After having discussed the different technical and commercial aspects of Python and digital marketing, we come to conclude that:
Programming skills are important in the modern digital marketing field
Python leads all other languages in data analytics and digital marketing
Top 5 useful tips out of the many include automation of data collection, processing, mining, and repetitive tasks that are time-consuming and less productive.
Top 5 important reasons for using Python for digital marketing include big data handling, automatic campaign monitoring, data mining efficiency, SEO automation, and powerful libraries of the platform
The post Reasons to Use Python for Marketers appeared first on Facebook Advertising Agency | Facebook Marketing Company.
from Facebook Advertising Agency | Facebook Marketing Company https://voymedia.com/reasons-to-use-python-for-marketers/
0 notes
Text
Structured JUnit 5 testing
Automated tests, in Java most commonly written with JUnit, are critical to any reasonable software project. Some even say that test code is more important than production code, because it’s easier to recreate the production code from the tests than the other way around. Anyway, they are valuable assets, so it’s necessary to keep them clean.
Adding new tests is something you’ll be doing every day, but hold yourself from getting into a write-only mode: Its overwhelmingly tempting to simply duplicate an existing test method and change just some details for the new test. But when you refactor the production code, you often have to change some test code, too. If this is spilled all over your tests, you will have a hard time; and what’s worse, you will be tempted to not do the refactoring or even stop writing tests. So also in your test code you’ll have to reduce code duplication to a minimum from the very beginning. It’s so little extra work to do now, when you’re into the subject, that it will amortize in no time.
JUnit 5 gives us some opportunities to do this even better, and I’ll show you some techniques here.
Any examples I can come up with are necessarily simplified, as they can’t have the full complexity of a real system. So bear with me while I try to contrive examples with enough complexity to show the effects; and allow me to challenge your fantasy that some things, while they are just over-engineered at this scale, will prove useful when things get bigger.
If you like, you can follow the refactorings done here by looking at the tests in this Git project. They are numbered to match the order presented here.
Example: Testing a parser with three methods for four documents
Let’s take a parser for a stream of documents (like in YAML) as an example test subject. It has three methods:
public class Parser { /** * Parse the one and only document in the input. * * @throws ParseException if there is none or more than one. */ public static Document parseSingle(String input); /** * Parse only the first document in the input. * * @throws ParseException if there is none. */ public static Document parseFirst(String input); /** Parse the list of documents in the input; may be empty, too. */ public static Stream parseAll(String input); }
We use static methods only to make the tests simpler; normally this would be a normal object with member methods.
We write tests for four input files (not to make things too complex): one is empty, one contains a document with only one space character, one contains a single document containing only a comment, and one contains two documents with each only containing a comment. That makes a total of 12 tests looking similar to this one:
class ParserTest { @Test void shouldParseSingleInDocumentOnly() { String input = "# test comment"; Document document = Parser.parseSingle(input); assertThat(document).isEqualTo(new Document().comment(new Comment().text("test comment"))); } }
Following the BDD given-when-then schema, I first have a test setup part (given), then an invocation of the system under test (when), and finally a verification of the outcome (then). These three parts are delimited with empty lines.
For the verification, I use AssertJ.
To reduce duplication, we extract the given and when parts into methods:
class ParserTest { @Test void shouldParseSingleInDocumentOnly() { String input = givenCommentOnlyDocument(); Document document = whenParseSingle(input); assertThat(document).isEqualTo(COMMENT_ONLY_DOCUMENT); } }
Or when the parser is expected to fail:
class ParserTest { @Test void shouldParseSingleInEmpty() { String input = givenEmptyDocument(); ParseException thrown = whenParseSingleThrows(input); assertThat(thrown).hasMessage("expected exactly one document, but found 0"); } }
The given... methods are called three times each, once for every parser method. The when... methods are called four times each, once for every input document, minus the cases where the tests expect exceptions. There is actually not so much reuse for the then... methods; we only extract some constants for the expected documents here, e.g. COMMENT_ONLY.
But reuse is not the most important reason to extract a method. It’s more about hiding complexity and staying at a single level of abstraction. As always, you’ll have to find the right balance: Is whenParseSingle(input) better than Parser.parseSingle(input)? It’s so simple and unlikely that you will ever have to change it by hand, that it’s probably better to not extract it. If you want to go into more detail, read the Clean Code book by Robert C. Martin, it’s worth it!
You can see that the given... methods all return an input string, while all when... methods take that string as an argument. When tests get more complex, they produce or require more than one object, so you’ll have to pass them via fields. But normally I wouldn’t do this in such a simple case. Let’s do that here anyway, as a preparation for the next step:
class ParserTest { private String input; @Test void shouldParseAllInEmptyDocument() { givenEmptyDocument(); Stream stream = whenParseAll(); assertThat(stream.documents()).isEmpty(); } private void givenEmptyDocument() { input = ""; } private Stream whenParseAll() { return Parser.parseAll(input); } }
Adding structure
It would be nice to group all tests with the same input together, so it’s easier to find them in a larger test base, and to more easily see if there are some setups missing or duplicated. To do so in JUnit 5, you can surround all tests that call, e.g., givenTwoCommentOnlyDocuments() with an inner class GivenTwoCommentOnlyDocuments. To have JUnit still recognize the nested test methods, we’ll have to add a @Nested annotation:
class ParserTest { @Nested class GivenOneCommentOnlyDocument { @Test void shouldParseAllInDocumentOnly() { givenOneCommentOnlyDocument(); Stream stream = whenParseAll(); assertThat(stream.documents()).containsExactly(COMMENT_ONLY); } } }
In contrast to having separate top-level test classes, JUnit runs these tests as nested groups, so we see the test run structured like this:
Nice, but we can go a step further. Instead of calling the respective given... method from each test method, we can call it in a @BeforeEach setup method, and as there is now only one call for each given... method, we can inline it:
@Nested class GivenTwoCommentOnlyDocuments { @BeforeEach void givenTwoCommentOnlyDocuments() { input = "# test comment\n---\n# test comment 2"; } }
We could have a little bit less code (which is generally a good thing) by using a constructor like this:
@Nested class GivenTwoCommentOnlyDocuments { GivenTwoCommentOnlyDocuments() { input = "# test comment\n---\n# test comment 2"; } }
…or even an anonymous initializer like this:
@Nested class GivenTwoCommentOnlyDocuments { { input = "# test comment\n---\n# test comment 2"; } }
But I prefer methods to have names that say what they do, and as you can see in the first variant, setup methods are no exception. I sometimes even have several @BeforeEach methods in a single class, when they do separate setup work. This gives me the advantage that I don’t have to read the method body to understand what it does, and when some setup doesn’t work as expected, I can start by looking directly at the method that is responsible for that. But I must admit that this is actually some repetition in this case; probably it’s a matter of taste.
Now the test method names still describe the setup they run in, i.e. the InDocumentOnly part in shouldParseSingleInDocumentOnly. In the code structure as well as in the output provided by the JUnit runner, this is redundant, so we should remove it: shouldParseSingle.
The JUnit runner now looks like this:
Most real world tests share only part of the setup with other tests. You can extract the common setup and simply add the specific setup in each test. I often use objects with all fields set up with reasonable dummy values, and only modify those relevant for each test, e.g. setting one field to null to test that specific outcome. Just make sure to express any additional setup steps in the name of the test, or you may overlook it.
When things get more complex, it’s probably better to nest several layers of Given... classes, even when they have only one test, just to make all setup steps visible in one place, the class names, and not some in the class names and some in the method names.
When you start extracting your setups like this, you will find that it gets easier to concentrate on one thing at a time: within one test setup, it’s easier to see if you have covered all requirements in this context; and when you look at the setup classes, it’s easier to see if you have all variations of the setup covered.
Extracting when...
The next step gets a little bit more involved and there are some forces to balance. If it’s too difficult to grasp now, you can also simply start by just extracting Given... classes as described above. When you’re fluent with that pattern and feel the need for more, you can return here and continue to learn.
You may have noticed that the four classes not only all have the same three test method names (except for the tests that catch exceptions), these three also call exactly the same when... methods; they only differ in the checks performed. This is, too, code duplication that has a potential to become harmful when the test code base gets big. In this carefully crafted example, we have a very symmetric set of three when... methods we want to call; this not always the case, so it’s not something you’ll be doing with every test class. But it’s good to know the technique, just in case. Let’s have a look at how it works.
We can extract an abstract class WhenParseAllFirstAndSingle to contain the three test methods that delegate the actual verification to abstract verify... methods. As the when... methods are not reused any more and the test methods have the same level of abstraction, we can also inline these.
class ParserTest { private String input; abstract class WhenParseAllFirstAndSingle { @Test void whenParseAll() { Stream stream = Parser.parseAll(input); verifyParseAll(stream); } protected abstract void verifyParseAll(Stream stream); } @Nested class GivenOneCommentOnlyDocument extends WhenParseAllFirstAndSingle { @BeforeEach void givenOneCommentOnlyDocument() { input = "# test comment"; } @Override protected void verifyParseAll(Stream stream) { assertThat(stream.documents()).containsExactly(COMMENT_ONLY); } } }
The verification is done in the implementations, so we can’t say something like thenIsEmpty, we’ll need a generic name. thenParseAll would be misleading, so verify with the method called is a good name, e.g. verifyParseAll.
This extraction works fine for parseAll and the whenParseAll method is simple to understand. But, e.g., parseSingle throws an exception when there is more than one document. So the whenParseSingle test has to delegate the exception for verification, too.
Let’s introduce a second verifyParseSingleException method for that check. When we expect an exception, we don’t want to implement the verifyParseSingle method any more, and when we don’t expect an exception, we don’t want to implement the verifyParseSingleException, so we give both verify... methods a default implementation instead:
abstract class WhenParseAllFirstAndSingle { @Test void whenParseSingle() { ParseException thrown = catchThrowableOfType(() -> { Document document = Parser.parseSingle(input); verifyParseSingle(document); }, ParseException.class); if (thrown != null) verifyParseSingleException(thrown); } protected void verifyParseSingle(Document document) { fail("expected exception was not thrown. see the verifyParseSingleParseException method for details"); } protected void verifyParseSingleException(ParseException thrown) { fail("unexpected exception. see verifyParseSingle for what was expected", thrown); } }
That’s okay, but when you expect an exception, but it doesn’t throw and the verification fails instead, you’ll get a test failure that is not very helpful (stacktraces omitted):
java.lang.AssertionError: Expecting code to throw but threw instead
So we need an even smarter whenParseSingle:
abstract class WhenParseAllFirstAndSingle { @Test void whenParseSingle() { AtomicReference document = new AtomicReference<>(); ParseException thrown = catchThrowableOfType(() -> document.set(Parser.parseSingle(input)), ParseException.class); if (thrown != null) verifyParseSingleException(thrown); else verifyParseSingle(document.get()); } }
We have to pass the document from the closure back to the method level. I can’t use a simple variable, as it has to be assigned to null as a default, making it not-effectively-final, so the compiler won’t allow me to. Instead, I use an AtomicReference.
In this way, even when a test that expects a result throws an exception or vice versa, the error message is nice and helpful, e.g. when GivenEmptyDocument.whenParseSingle, which throws an exception, would expect an empty document, the exception would be:
AssertionError: unexpected exception. see verifyParseSingle for what was expected Caused by: ParseException: expected exactly one document, but found 0
All of this does add quite some complexity to the when... methods, bloating them from 2 lines to 6 with a non-trivial flow. Gladly, we can extract that to a generic whenVerify method that we can put into a test utilities class or even module.
abstract class WhenParseAllFirstAndSingle { @Test void whenParseSingle() { whenVerify(() -> Parser.parseSingle(input), ParseException.class, this::verifyParseSingle, this::verifyParseSingleException); } protected void verifyParseSingle(Document document) { fail("expected exception was not thrown. see the verifyParseSingleException method for details"); } protected void verifyParseSingleException(ParseException thrown) { fail("unexpected exception. see verifyParseSingle for what was expected", thrown); } /** * Calls the call and verifies the outcome. * If it succeeds, it calls verify. * If it fails with an exception of type exceptionClass, it calls verifyException. * * @param call The `when` part to invoke on the system under test * @param exceptionClass The type of exception that may be expected * @param verify The `then` part to check a successful outcome * @param verifyException The `then` part to check an expected exception * @param The type of the result of the `call` * @param The type of the expected exception */ public static void whenVerify( Supplier call, Class exceptionClass, Consumer verify, Consumer verifyException) { AtomicReference success = new AtomicReference<>(); E failure = catchThrowableOfType(() -> success.set(call.get()), exceptionClass); if (failure != null) verifyException.accept(failure); else verify.accept(success.get()); } }
The call to whenVerify is still far from easy to understand; it’s not clean code. I’ve added extensive JavaDoc to help the reader, but it still requires getting into. We can make the call more expressive by using a fluent builder, so it looks like this:
abstract class WhenParseAllFirstAndSingle { @Test void whenParseFirst() { when(() -> Parser.parseFirst(input)) .failsWith(ParseException.class).then(this::verifyParseFirstException) .succeeds().then(this::verifyParseFirst); } }
This makes the implementation explode, but the call is okay now.
As seen above, the tests themselves look nice, and that’s the most important part:
@Nested class GivenTwoCommentOnlyDocuments extends WhenParseAllFirstAndSingle { @BeforeEach void givenTwoCommentOnlyDocuments() { input = "# test comment\n---\n# test comment 2"; } @Override protected void verifyParseAll(Stream stream) { assertThat(stream.documents()).containsExactly(COMMENT_ONLY, COMMENT_ONLY_2); } @Override protected void verifyParseFirst(Document document) { assertThat(document).isEqualTo(COMMENT_ONLY); } @Override protected void verifyParseSingleException(ParseException thrown) { assertThat(thrown).hasMessage("expected exactly one document, but found 2"); } }
Multiple When... classes
If you have tests that only apply to a specific test setup, you can simply add them directly to that Given... class. If you have tests that apply to all test setups, you can add them to the When... super class. But there may be tests that apply to more than one setup, but not to all. In other words: you may want to have more than one When... superclass, which isn’t allowed in Java, but you can change the When... classes to interfaces with default methods. You’ll then have to change the fields used to pass test setup objects (the input String in our example) to be static, as interfaces can’t access non-static fields.
This looks like a simple change, but it can cause some nasty behavior: you’ll have to set these fields for every test, or you may accidentally inherit them from tests that ran before, i.e. your tests depend on the execution order. This will bend the time-space-continuum when you try to debug it, so be extra careful. It’s probably worth resetting everything to null in a top level @BeforeEach. Note that @BeforeEach methods from super classes are executed before those in sub classes, and the @BeforeEach of the container class is executed before everything else.
Otherwise, the change is straightforward:
class ParserTest { private static String input; @BeforeEach void resetInput() { input = null; } interface WhenParseAllFirstAndSingle { @Test default void whenParseAll() { Stream stream = Parser.parseAll(input); verifyParseAll(stream); } void verifyParseAll(Stream stream); } @Nested class GivenTwoCommentOnlyDocuments implements WhenParseAllFirstAndSingle { @BeforeEach void givenTwoCommentOnlyDocuments() { input = "# test comment\n---\n# test comment 2"; } // ... } }
Generic verifications
You may want to add generic verifications, e.g. YAML documents and streams should render toString equal to the input they where generated from. For the whenParseAll method, we add a verification line directly after the call to verifyParseAll:
interface WhenParseAllFirstAndSingle { @Test default void whenParseAll() { Stream stream = Parser.parseAll(input); verifyParseAll(stream); assertThat(stream).hasToString(input); } }
This is not so easy with the the other tests that are sometimes expected to fail (e.g. whenParseSingle). We chose an implementation using the whenVerify method (or the fluent builder) which we wanted to be generic. We could give up on that and inline it, but that would be sad.
Alternatively, we could add the verification to all overridden verifyParseFirst methods, but that would add duplication and it’d be easy to forget. What’s worse, each new verification we wanted to add, we’d have to add to every verify... method; this just doesn’t scale.
It’s better to call the generic verification directly after the abstract verification:
class ParserTest { interface WhenParseAllFirstAndSingle { @Test default void whenParseFirst() { when(() -> Parser.parseFirst(input)) .failsWith(ParseException.class).then(this::verifyParseFirstException) .succeeds().then(document -> { verifyParseFirst(document); verifyToStringEqualsInput(document); }); } default void verifyParseFirst(Document document) { fail("expected exception was not thrown. see the verifyParseFirstException method for details"); } default void verifyParseFirstException(ParseException thrown) { fail("unexpected exception. see verifyParseFirst for what was expected", thrown); } default void verifyToStringEqualsInput(Document document) { assertThat(document).hasToString(input); } } }
If you have more than one generic verification, it would be better to extract them to a verifyParseFirstGeneric method.
There is one last little nasty detail hiding in this test example: The verifyToStringEqualsInput(Document document) method has to be overridden in GivenTwoCommentOnlyDocuments, as only the first document from the stream is part of the toString, not the complete input. Make sure to briefly explain such things with a comment:
@Nested class GivenTwoCommentOnlyDocuments implements WhenParseAllFirstAndSingle { @Override public void verifyToStringEqualsInput(Document document) { assertThat(document).hasToString("# test comment"); // only first } }
tl;dr
To add structure to a long sequence of test methods in a class, group them according to their test setup in inner classes annotated as @Nested. Name these classes Given... and set them up in one or more @BeforeEach methods. Pass the objects that are set up and then used in your when... method in fields.
When there are sets of tests that should be executed in several setups (and given you prefer complexity over duplication), you may want to extract them to a super class, or (if you need more than one such set in one setup) to an interface with default methods (and make the fields you set up static). Name these classes or interfaces When... and delegate the verification to methods called verify + the name of the method invoked on the system under test.
I think grouping test setups is something you should do even in medium-sized test classes; it pays off quickly. Extracting sets of tests adds quite some complexity, so you probably should do it only when you have a significantly large set of tests to share between test setups, maybe 5 or more.
I hope this helps you reap the benefits JUnit 5 provides. I’d be glad to hear if you have any feedback from nitpicking to success stories.
Der Beitrag Structured JUnit 5 testing erschien zuerst auf codecentric AG Blog.
Structured JUnit 5 testing published first on https://medium.com/@koresol
0 notes
Text
Java executor
Interfaces. Executor is a simple standardized interface for defining custom thread-like subsystems, including thread pools, asynchronous I/O, and lightweight task frameworks. Depending on which concrete Executor class is being used, tasks may execute in a newly created thread, an existing task-execution thread, or the thread calling execute, and may execute sequentially or concurrently. ExecutorService provides a more complete asynchronous task execution framework. An ExecutorService manages queuing and scheduling of tasks, and allows controlled shutdown. The ScheduledExecutorService subinterface and associated interfaces add support for delayed and periodic task execution. ExecutorServices provide methods arranging asynchronous execution of any function expressed as Callable, the result-bearing analog of Runnable. A Future returns the results of a function, allows determination of whether execution has completed, and provides a means to cancel execution. A RunnableFuture is a Future that possesses a run method that upon execution, sets its results. How to get sublist from arraylist in java? How to sort arraylist using comparator in java? How to reverse contents of arraylist java? How to shuffle elements in an arraylist in java? How to swap two elements in an arraylist java? how to read all elements in linkedlist by using iterator in java? How to copy or clone linked list in java? How to add all elements of a list to linkedlist in java? How to remove all elements from a linked list java? How to convert linked list to array in java? How to sort linkedlist using comparator in java? How to reverse linked list in java? How to shuffle elements in linked list in java? How to swap two elements in a linked list java? How to add an element at first and last position of linked list? How to get first element in linked list in java? How to get last element in linked list in java? How to iterate through linked list in reverse order? Linked list push and pop in java How to remove element from linkedlist in java? How to iterate through hashtable in java? How to copy map content to another hashtable? How to search a key in hashtable? How to search a value in hashtable? How to get all keys from hashtable in java? How to get entry set from hashtable in java? How to remove all elements from hashtable in java? Hash table implementation with equals and hashcode example How to eliminate duplicate keys user defined objects with Hashtable? How to remove duplicate elements from arraylist in java? How to remove duplicate elements from linkedlist in java? how to iterate a hashset in java? How to copy set content to another hashset in java? How to remove all elements from hashset in java? How to convert a hashset to an array in java? How to eliminate duplicate user defined objects from hashset in java? How to iterate a linkedhashset in java? How to convert linkedhashset to array in java? How to add all elements of a set to linkedhashset in java? How to remove all elements from linkedhashset in java? How to delete specific element from linkedhashset? How to check if a particular element exists in LinkedHashSet? How to eliminate duplicate user defined objects from linkedhashset? How to create a treeset in java? How to iterate treeset in java? How to convert list to treeset in java? How to remove duplicate entries from an array in java? How to find duplicate value in an array in java? How to get least value element from a set? How to get highest value element from a set? How to avoid duplicate user defined objects in TreeSet? How to create a hashmap in java? How to iterate hashmap in java? How to copy map content to another hashmap in java? How to search a key in hashmap in java? How to search a value in hashmap in java? How to get list of keys from hashmap java? How to get entryset from hashmap in java? How to delete all elements from hashmap in java? How to eliminate duplicate user defined objects as a key from hashmap? How to create a treemap in java? How to iterate treemap in java? How to copy map content to another treemap? How to search a key in treemap in java? How to search a value in treemap in java? How to get all keys from treemap in java? How to get entry set from treemap in java? How to remove all elements from a treeMap in java? How to sort keys in treemap by using comparator? How to get first key element from treemap in java? How to get last key element from treemap in java? How to reverse sort keys in a treemap? How to create a linkedhashmap in java? How to iterate linkedhashmap in java? How to search a key in linkedhashmap in java? How to search a value in linkedhashmap in java? How to remove all entries from linkedhashmap? How to eliminate duplicate user defined objects as a key from linkedhashmap? How to find user defined objects as a key from linkedhashmap? Java 8 functional interface. Java lambda expression. Java lambda expression hello world. Java lambda expression multiple parameters. Java lambda expression foreach loop. Java lambda expression multiple statements. Java lambda expression create thread. Java lambda expression comparator. Java lambda expression filter. Java method references. Java default method. Java stream api. Java create stream. Java create stream using list. Java stream filter. Java stream map. Java stream flatmap. Java stream distinct. Java forEach. Java collectors class. Java stringjoiner class. Java optional class. Java parallel array sorting. Java Base64. Java 8 type interface improvements. Java 7 type interface. Java 8 Date Time API. Java LocalDate class. Java LocalTime class. Java LocalDateTime class. Java MonthDay class. Java OffsetTime class. Java OffsetDateTime class. Java Clock class. Java ZonedDateTime class. Java ZoneId class. Java ZoneOffset class. Java Year class. Java YearMonth class. Java Period class. Java Duration class. Java Instant class. Java DayOfWeek class. Java Month enum. Java regular expression. Regex character classes. Java Regex Quantifiers. Regex metacharacters. Regex validate alphanumeric. Regex validate 10 digit number. Regex validate number. Regex validate alphabets. Regex validate username. Regex validate email. Regex validate password. Regex validate hex code. Regex validate image file extension. Regex validate ip address. Regex validate 12 hours time format. Regex validate 24 hours time format. Regex validate date. Regex validate html tag. Java Date class example. Java DateFormat class. Java SimpleDateFormat class. Java Calendar class. Java GregorianCalendar class. Java TimeZone class. Java SQL date class. Java get current date time. Java convert calendar to date. Java compare dates. Java calculate elapsed time. Java convert date and time between timezone. Java add days to current date. Java variable arguments. Java string in switch case. Java try-with-resources. Java binary literals. Numeric literals with underscore. Java catch multiple exceptions.
0 notes