#Review on Biostatistics and Biometrics Journal
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
The KCSC sent more than 20K requests to delete posts related to prostitution and porn to Tumblr from January to June 2017.
Text
Lupine Publishers | On some Derivatives of Vector-Matrix Products Useful for Statistics

Lupine Publishers- Biostatistics and Biometrics Open Access Journal
Mini Review
In this brief description, we will use the numerator layout [1], and will tacitly assume that all products are conformable.
The derivative of the linear form 𝒰t𝒱 with respect to the vector 𝒱is given as
and since 𝒰t𝒱 is a scalar, we are facing a particular case of the derivative of a scalar λ with respect to a vector, e.g., ∂𝒱λ=(∂𝒱1λ ..... ∂𝒱nλ) and it must also be ∂𝒱(𝒰t𝒱)=∂𝒱(𝒱t𝒰) . Moreover, it is easy to demonstrate that using the denominator layout, the derivative would have been ∂𝒱(𝒰t𝒱)=𝒰
If both 𝒰 and 𝒱 vectors are function of a third vector 𝒵, we get
which, in the case 𝒰=𝒱=𝒲 reduces to
Dealing with a linear transform 𝒰=a𝒱, if A is 𝓂×𝓂 we have
and if 𝒱 is a function of a vector 𝒲𝒱 we get
From definition of bilinear form, we obtain, for 𝒰tA𝒱 the derivative
while, for a quadratic form 𝒰tA𝒱(where A is 𝓃 × 𝓃), we get
so that, if A is a symmetric matrix, say, for A = XtX, then
For more Lupine Publishers Open Access Journals Please visit our website:
https://lupinepublishers.us/
For more Bio statistics and Bio metrics Open Access Journal articles Please Click Here: https://lupinepublishers.com/biostatistics-biometrics-journal/
To Know More About Open Access Publishers Please Click on Lupine Publishers
#Lupinepublishers#Lupine Publishers Group#Biometrics Open Access Journal#Biostatistics and Biometrics Open Access Journal#Review on Biostatistics and Biometrics Journal
0 notes
Text
Lupine Publishers Open Access Journals



Peer Reviewed Dentistry Journals | Open Access Dental JournalsLupine Publishers Open Access Journals
Lupine Publishers is a multidisciplinary, Open Access publisher focused on Genetic, Biomedical and Remedial missions in relation with Technical Knowledge as well. We crave to select ground-breaking research based on modernism, aptness, scientific connotation, prospective spectator’s interests, etc. We endeavor to provide by far and liberally accessible belvedere to researchers and practitioners in support of their novel and valuable ideas. We already have 2000+ Editorial Board members along with 5000+ Published articles in our box. Our Journals maintain a scrupulous, methodical, fair peer review System. Besides, quality control is riveted in each step of the publication process
Agriculture Open Access Journals

Journal of Chemical Sciences

Peer Reviewed Dentistry Journals | Open Access Dental Journals

Civil Engineering Open Access Journals

Gynecology Open Access Journals

Fashion Technology Journals | Textile Engineering Journals

Biomedical Engineering Journals | Bioscience Journals

Research and Reviews Open Access Journals

Cancer Open Access Journals | Oncology Open Access Journals
Peer Reviews Journal of Forensic Science | Peer Reviews Journal of Genetic Science

journal of Drug Designing | Journal of Drug Design and Research

Petro Chemical Science Open access Journals

Medical sciences journals | Journal of Medical Sciences

Pediatric Dentistry Open Access Journal

Peer Reviewed Open Access Journals of Dairy and Veterinary Science

Journal of Neurology and Brain Disorders

Sports Medicine Open Access Journal | Orthopedics Open Access Journal

Journal of Nursing and Care | Nursing & Health Care Journal

Reproductive medicine journals | Reproductive medicine impact factor

Ophthalmology Open Access Journal | Lupine Publishers Open Access Journals

Pediatrics Open Access Journal | Pediatric Peer Reviewed Online Journal

Nanomedicine Open Access Journal | Nanomedicine research journal

Journal of Gastroenterology and Hepatology

Scholarly Journal of Psychology and Behavioral Sciences

Nutrition Science Journals Impact Factors | Open Access Nutrition Journal

Journal of Cardiology Research | Journal of Cardiology

Lupine Publishers Open Access Journals | Surgery & Case Studies Journals

Diabetes Scholarly Journals | Peer Reviewed obesity journal

Urology Journals Impact Factor List | Urology Open Access Journals

Scholarly Journal Of Otolaryngology

Open Access Journal of Environmental and Soil Sciences

Robotics & Automation Engineering Journal

journal of complementary Medicine | Journal of alternative medicine

Respiratory & Skin Diseases Open Access Journals
Journal of Clinical Research | Pharmacology Open Access Journals

Biotechnology Journal Impact Factors | Microbiology Journals
Biometrics open access journal | Biostatistics and Biometrics

Computer Science Journals | Computer Science Open Access Journals

Journal of Anesthesia and pain medicine- Open Access Journals

Material Science Journal | Open Access Material Science Journals

Open Access Immunology Journals | Open Access Journals

For more Lupine Publishers Open Access Journals Please visit our website: http://www.lupinepublishers.com/
46 notes
·
View notes
Text
Journal of Biometrics & Biostatistics
About the Journal
PubMed Abstracted NLM ID: 101558406 Research Gate Impact Factor: 0.16 Journal of Biometrics and Biostatistics broadcasts peer-reviewed articles on the development and application of mathematical & statistical theory, principles, and practices to the observation, measurement, and analysis of biological parameters and phenomena. The journal encourages reporting of studies addressing the emerging challenges in identification, security and other validation purposes and observations pertaining to the optimization and application of statistical methods to describe and interpret complex biological phenomenon.
The scholarly information disseminated by the journal is of great relevance and utility to biometric intelligence analysts, social network analysts, statistical programmers, software developers, forensic experts, biometrics engineers, biological researchers, agricultural scientists, government law enforcement agencies, judiciary, academicians, researchers, engineers, etc.
The journal operates on an open access publishing model and represents the mainstream collection of scholarly journals in this field. The journal has eminent professionals and academicians in its editorial board, who ensure that the manuscripts are processed in a timely and professional manner and oversee the publication standards. All the submitted manuscripts are subjected to the peer-review process. The journal processes the manuscripts on an online manuscript submission, review and managing systems to provide a rapid turn-around time authors can track the progress of their submission in system.
1 note
·
View note
Text
Reputed Open Access Journals
Open access journals are academic peer reviewed journals that can be accessed easily without any financial or technical restriction. Readers can read and use the information of open access journals without paying any extra fees. Some publishers are known to take fees on behalf of the author, and some are supported by their academic institutions like universities, hospitals, libraries, research center etc. There are many international journals who publish fully accessible high quality articles and journals.

Reputed Open Access Journals
This is a list of some reputed open access journals. Following DOAJ and other directory of journals my recommendation is writers should consider this list and decide where they want to submit their articles.
BioMed Central: BioMed Central is publisher having a good number of peer-reviewed journals related to science, medicine and technology. BioMed published articles are easily accessible on their directory.
Co-Action Publishing: Co-Action Publishing is a publication with having multinational stuff representatives to publish quality peer reviewed journals.
SPRINGER: Springer is one of the world's most renowned STM publishers with having more than 200 Nobel Prize winners between the authors of their journals and books. The company has published more than 2900 journals and 19000o books.
Taylor & Francis Group: Taylor & Francis Group is one of the reputed open access journals for its high quality reviewing facility. The company publishes articles under the Routledge and Taylor & Francis imprints. The new part of this group is Cogent OA.
Cogent OA: Cogent OA is a part of Taylor & Francis Group. The company is reputed for publishing fully accessible peer reviewed articles.
Copernicus.org: Copernicus.org is recognized for publishing high quality peer reviewed journals. They promote scientific works. Therefore, researchers, who are dedicated to this specific subject, can review this publication.
Frontiers: Frontiers is an academic publisher who publishes peer reviewed journals based on science. The publisher was launched in 2007 and has a vision of building an open science platform. "Frontiers" is popular for combining fully accessible publishing with research networking.
Hindawi Publishing Corporation: With having 436 journals, Hindawi is a renowned academic publisher covering great disciplines and academic value. It is a reputed publishing company of scientific, technical and medical related articles.
Karger Open Access: Karger Open Access is a part of Karger Publishers. The publisher is recognized for scientific journals with maintaining high qualities. Journals are peer reviewed and publish in a high editorial standard in Karger.
Multidisciplinary Digital Publishing Institute (MDPI.): MDPI is an open access platform for publishing peer reviewed scientific journals. MDPI publishes more than 120 journals such as Molecules, the International Journal of Molecular Sciences, Marine Drugs, Viruses, Sensing, Toxins, Sensors Marine Drugs, Energies, the International Journal of Environmental Research and Public Health, Nutrients etc. Visit https://www.alduspress.com/
Journal of Biometrics & Biostatistics: A leading academic journal with having quality reviewing facility, Journal of Biometrics and Biostatistics is a well known openly readable journal.
Resource
0 notes
Video
Austin Biometrics and Biostatistics by Austin Publishing Group
Via Flickr: Austin Biometrics and Biostatistics is a peer-reviewed, open access journal published by Austin Publishers. It provides easy access to high quality Manuscripts covering wide aspects of science of biostatistics that encompasses the design of biological experiments in various related fields like medicine, pharmacy, agriculture and fishery where the collection, summarization, and analysis of data, interpretations of data and inference. This journal also focuses upon the combination of biology and statistics, commonly referred as Biometry or Biometrics. Austin Publishing Group is a successful host of more than hundred peer reviewed, open access journals in various fields of science and technology with intent to bridge the gap between academia and research access. Austin Biometrics and Biostatistics accepts original research articles, review articles, case reports, mini reviews, rapid communication, opinions and editorials on all the related aspects of biometrics and biostatistics.
6 notes
·
View notes
Text
Iris Publishers_Open access journals of Biostatistics
Authored by İlker Etikan
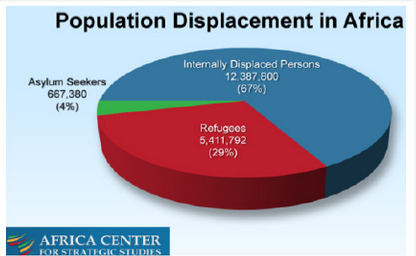
Health and Social Assessment of Internally Displaced People (IDP) in Nigeria
Introduction: The problems of Internally Displaced Peoples (IDPs) have continued to generate global debate in recent times owing to its negative implication on society organization structure and public health. The major drivers of forced human displacement have been attributed to global climate change and armed human conflicts and the developing countries are worst hit with very dearth aftermath effect of this unplanned human displacement. Nigeria as a pivotal country in the sub-Saharan region of Africa and the entire Africa continent at large have not been spared from this sordid occurrence.
Method: The article considers review of some published reports by several humanitarian organizations such as WHO, UN, IDMC and other published articles.
Result: The increasing armed conflict in the North-East Region of Nigeria is geometrically increasing the numbers of IDPs in the country. Many families are at risks of poverty, hunger and disease. And also, the dearth impact of this forced displacement has continued to lower the Nigeria rankings in global health and socio-economic indicators.
For more open access journals: https://irispublishers.com/journals.php
For more about the open access journals of Biostatistics & Biometric Applications: https://irispublishers.com/abba/
Read More: Full Text
0 notes
Text
A Review on the Assessment of the Spatial Dependence

Authored by Pilar Garcia Soidan*
Abstract
For intrinsic random processes, an appropriate estimation of the variogram is required to derive accurate predictions, when proceeding through the kriging methodology. The resulting function must satisfy the conditionally negative definiteness condition, both to guarantee a solution for the kriging equation system and to derive a non-negative prediction error. Assessment of the resulting function is typically addressed through graphical tools, which are not necessarily conclusive, thus making it advisable to perform tests to check the adequateness of the fitted variogram.
Keywords : Intrinsic stationarity; Isotropy; Variogram
Introduction
When spatial data are collected, construction of a prediction map for the variable of interest, over the whole observation region, is typically addressed through the kriging techniques [1]. This methodology has been applied in a variety of areas (hydrology, forestry, air quality, etc.) and its practical implementation demands a previous estimation of the data correlation. The latter issue can be accomplished by approximating the variogram function [2], under the assumption that the underlying process is intrinsic, which is the least restrictive stationarity requirement.
However, estimation of the variogram is far from simple. It requires that the resulting function is valid for prediction, namely, that it fulfills the conditionally negative definiteness condition and, in practice, this problem is usually solved through a three-step procedure [3]. To start, a nonparametric method can be employed to obtain the empirical variogram or a kernel- type approach, among other options, although the functions derived in this way are not necessarily valid [4,5]. Then, in a second step, a valid parametric model is selected, so that the unknown parameters are estimated to best fit the data by any of the distinct criteria (maximum likelihood, least squares, etc.) provided in the statistics literature. Finally, the adequateness of the fitted variogram function should be checked, by using a cross-validation mechanism or goodness of fit tests. The former procedures are not always conclusive and their use is recommended for comparison of several valid models, rather than for assessment of a unique fit. Also, we could perform a test to determine the appropriateness of a variogram model, as the one introduced in Maglione & Diblasi [6], for application to random Gaussian and isotropic random processes, or a more general one suggested in Garcia-Soidan & Cotos-Yanez [7], which accounts for both the isotropic and the anisotropic scenarios.
An important shortcoming of this three-stage scheme is the choice of the parametric model. The most common options are based on the use of flexible functions, such as the Matern one, or on the selection of a model "by eye", by comparing the form of the nonparametric variogram with that derived for different valid families, typically used in practice. However this problem becomes more difficult when dealing with anisotropic variograms. Indeed, isotropy conveys that the data correlation depends only on the distance between the spatial sites and not on the direction of the lag vector, unlike the anisotropic assumption. This means that the assessment of isotropy could be a previous step, whose acceptance would simplify the selection of the model and the subsequent variogram computation. In practice, the isotropic property is typically checked through graphical methods, by plotting a nonparametric estimator in several directions, although the latter procedures are not always determinant. Formal approaches to test for isotropy have been introduced in Guan et al. [8] or in Maity & Sherman [9]. The first test was designed for its application to strictly stationary random processes, whereas the latter one works for more general settings.
Conclusion
The need to obtain an adequate variogram estimator demands a deep exploration of the available data. Firstly the isotropic condition should be checked, as this condition would simplify the characterization of the dependence structure. The graphical diagnosis for assessment of this assumption should be accompanied by the performance of some test to determine its acceptance. Then, a nonparametric estimator can be computed and used to derive a valid parametric fit, whose appropriateness can also be evaluated through any of the goodness of fit tests proposed.
To Know More About Biostatistics and Biometrics Open Access Journal Please Click on: https://juniperpublishers.com/bboaj/index.php
To Know More About Open Access Journals Publishers Please Click on: Juniper Publishers
#Juniper Publishers#open access journals#biostatistics#biometrics#kriging methodology#Variogram#spatial data
0 notes
Text
Lupine Publishers- Biostatistics and Biometrics Open Access Journal

Life Losses and Gains in British Korean War Veterans: The Late Life Legacy by Deidre Wild
Abstract
In 2001, a survey of the veteran members of the British Korean War Veterans Association was conducted with support from the Royal British Legion. As a part of this survey, the present inquiry addresses the relationship between older combatant and noncombatant veterans’ levels of combat exposure, their losses and Gains in life and current psychological symptoms. Nine hundred and ninety-four British Korean War veterans provided data for four measurement scales: The Combat Exposure Scale (CES); the Losses from life scale and the Gains from life scale, and the Impact of Event Scale (IES). Significant positive correlation effects were found between life losses (but not life gains) with and between the CES and the IES. Combatants had an overall score on the IES that clearly exceeded its recommended cut-off level but notably the score for non-combatants was just approaching the cut-off, indicating that some of them were also experiencing psychological symptoms just from being in the war zone. Although it is now some 65 years since the cessation of fighting in 1954, the findings seem to suggest that their life losses are not positively influenced by their life gains, rather they appear to co-exist.
Introduction
Hickey (1999) states that the Korean War (KW) of 1950-54 was the first serious conflict of the Cold War and a major test of the United Nations with troops sent from 16 countries [1]. Some 100,000 personnel from the United Kingdom (UK) served in the Korean War. Two-thirds of the land-based troops were National Service men and Reservists (mandatorily recalled civilians having served in World War II [WWII]) and the remainder were Regular soldiers. Over the war’s course, there were periods of both fierce fighting and tense stalemate, conducted in an inhospitable terrain with a harsh climate of permafrost in winter and high temperatures in summer. Some 1,106 British troops were killed in action, more were injured, and 1060 were taken prisoner or were missing. Aside from military action, many witnessed the plight of large numbers of Korean refugees who had fled from North to South ahead of the advancing communist North Koreans backed by China [1].
Review of the Literature
Military service is regarded as exerting an important influence upon veterans’ lives [2] yet the potential for adverse effects from combat exposure has been described as a ‘hidden variable’ in the lives of older men [3]. These effects can lie dormant for decades, only to re-emerge later in response to other adverse changes in roles, relationships, and mental and physical health [4,5]. Much of war-based literature focusses upon adversity and/or human vulnerability as outcomes from participation in warfare and in general, combatants are shown to be those most prone to post war anxiety, depression and Post Traumatic Stress Disorder (PTSD) [3,6,7]. Participation in warfare can have positive as well as negative effects [3,7,8]. These have been referred to as: losses and gains [7], or post-traumatic or stress-related growth or benefit [3,9]. Reasons why some people show benefit from a stressful experience while others become debilitated by it has been studied through measurement of personal attributes such as: perceived optimism and pessimism [10]; locus of control [11]; self-esteem and selfefficacy [12], and increased resilience [7,13]. In a longitudinal study of college students that used a pre-tested measurement scale, stress–related growth was associated with the level of religious belief; positive coping strategies; the number of recent positive life events, and social support satisfaction [14].
Several studies have shown that combat exposure and other adverse experiences can lead to negative psychosomatic outcomes for veterans such as PTSD, that may be short term or long term [15- 17] and may continue into late life [7,18]. Increasingly the complex study of the impact of war-service upon the lives of participants includes consideration of childhood and family histories [19]; pre, during and post deployment war factors [20], and other intervening life events [21]. The role of post war social support [22] and the effects of the quality of the homecoming experience in terms of unmet expectations are also believed to be influential factors in post war mental health [23] and include not only the home-based family’s support but also that from the workplace [24]. A further consideration for this enquiry is to contribute to fleshing out the knowledge of the long-term effects on UK KW veterans as a distinct cohort. For, often researchers have often placed KW veterans in mixed samples with those of WWII on the basis that both Wars’ veterans are in their ‘late life’. Although some research shows similarity of responses between veterans of different wars, it can be argued that there is sufficient evidence for the KW veterans to stand alone. For example, when veterans of the KW, the Vietnam War (VW) and WWII were compared, although the severity of psychiatric symptoms was primarily related to severity of combat experience and independent of the theatre of war, the frequency with which the symptoms appeared differed between the wars’ cohorts [15]. Furthermore, in other research by McCranie and Hyer (2000) comparing the severity of PTSD symptoms in KW and WWII veterans, they found that the KW cohort had more pronounced symptoms, even after controlling for confounding variables such as age and different levels of combat exposure [25].
In general, returning US KW veterans were welcomed back home but as UK society was still war-weary from WWII, there was little interest in this far away war or its veterans. UK media reporting was low, particularly for returning troops who were often treated with indifference [26]. For this reason, it is often reported as ‘The Forgotten War’ and anecdotally its ‘forgotten’ veterans believe themselves to be ‘different’ from other wars’ veterans. Now well into their third age, US research with WWII and KW US veteran participants [27] shows that older combatant veterans with PTSD are associated with increased morbidity. Ikin et al. [28] similarly found an association between combatant war service, anxiety, posttraumatic stress disorder (PTSD) and depression in 7525 surviving Australian male KW veterans in comparison with a community group. In terms of life gains and losses, other authors suggest that traumatic stress poses both risks and benefits but the positive benefits from military experiences can counter the negative sense of loss that is seen to accompany combatants [8].
Combatants (unsurprisingly) are shown to be those most prone to post war anxiety, depression and PTSD [3,7]. However, whilst there is plenty of evidence supporting the argument that heavy exposure to combat is a strong predictor of psychiatric symptoms, what is less clear is if simple exposure to a war zone can in some circumstances also be stressful. Relatively little attention has been paid to the distinction between the setting where combat takes place and the combat activities themselves. Accounts of the KW certainly indicate that even for non-combatants, conditions could be very stressful indeed. For example, there was the constant apprehension even after the war entered its ‘standoff’ phase that a counter-surge might be imminent. Given the extremely labile conditions of the first stage of the war, this was a reasonable paranoia and not helped by UK troops reportedly not being adequately clothed to protect them from cold injuries in the sub-zero winter climate in the early part of the War [29].
Methodology
Sample Selection and Method
The UK KW veteran participants were recruited opportunistically through the British Korean Veteran Association. A preliminary article to explain the intended survey was published in the members’ magazine. In the subsequent issue, the questionnaires, completion instructions, and pre-paid return envelopes to the researchers were inserted in 4000 magazines with a request for anonymous completed returns to the researcher within a four-week period.
Materials and content
The questionnaire sought to establish personal and military characteristics including: age; marital status: type and length of service, rank, where service took place, role in warfare and duties; receipt of war pension if applicable; a health checklist, and current levels of social and health care support. The intensity of war experiences was measured using an adapted version of the Combat Exposure Scale (CES) [30] with 9 ordinal items with values of 1 no exposure through to 6. heavy exposure. The intensity of losses and gains from war-time experiences in post war life was measured by the 14 item losses scale (LS) and 14 item gains scale (GS) [7]. Each item had the ordinal values of 1. Not at all through to 4. A lot [7]. The final measure, the Impact of vent Scale (IES) [31] determined levels of intrusion and exclusion of thought arising from the respondent’s experiences of the KW and had 15 items with the ordinal values of 1. not at all through to 4. a lot.
The key objectives for the inquiry
For the purpose of this article, the following three objectives were set to guide the analysis:
A. To observe and compare the veterans’ levels of subscription to individual items in the life losses and gains scales.
B. To identify the significance of correlations effects between the KW veterans’ levels for combat exposure, their life Losses and Gains, and presence of psychological symptoms in the Impact of Event Scale.
C. To establish the significance of differences between the combatants with non-combatants using t test on the same four scales as above in ii].
Results
Return Rate and Data Management
The postal survey, conducted in 2001, resulted in 1009 returned questionnaires of which 15 were so poorly completed that they were discarded as unreliable. Of the remaining 994 returned questionnaires attention was drawn to the high number of missing values predominantly in the psychology-based scales (the IES and CES). For example, 76 veterans had missing values in the completion of the CES and 116 in the IES (missing could be due to non-completion of a whole scale’s items or more frequently non completion of scale’s single or multiple items). In contrast, other dichotomous more factual questions such as combat status, there were in general only 20 veterans or fewer missing values. Reasons for this are suggested later in the conclusions. The above anomalies required a pragmatic approach to reduce complexity whilst facilitating reliable statistical outputs. Hence, the scales��� data were standardized to n=994 before statistical comparisons were made, using the SPSS facility for computer-generated missing data replacement. It is of note that there were minimal differences in a pre-test using the same tests (correlation and t test) between the outputs from the original data with those manipulated to replace missing data and no difference was found in their respective levels of statistical significance.
Sample Characteristics
The 994 participating veterans represented some 1 in 4 of the total BKVA membership. Of these, their mean age in Korea was 22 years and at the time of the survey their mean age was 70. Most were: in the army; land-based; male; undertaking National Service and of other ranks. Of the 994 participants, 504 were combatants and 490 were non-combatants.
Veterans Subscription to Life Losses and Gains Scales’ Items
The responses to the 14 items in each of the two scales for losses and for gains, respectively, were reviewed to identify items that were the most frequently subscribed to or of other comparative interest between the two groups (combatants and non-combatants). In work by Aldwin et al. [3], these positive and negative life span appraisals have been related to the diagnosis of veterans with PTSD symptoms in later life. The mean scores are given for combatants and non-combatants in Table 1 for losses and in Table 2 for gains. As shown in Table 1, combatants’ mean scores for losses items were consistently higher than those for non-combatants. The most marked differences where combatants had notably higher mean scores than non-combatants were in the following 7 numbered items: Disrupted my life [2]; Memories of misery/discomfort [4]; Combat anxieties/apprehensions [7]; Death of friends [9]; Bad memories/nightmares [10] ; loss of my good health [11] and Memories death/ destruction [13].
Table 1: Mean values for life losses by combat status.
Table 2: Mean values for life gains by combat status.
In contrast, as shown in Table 2, the mean scores for life gains items for both combatants and non-combatants were higher than those for losses and the differences between the two groups’ sets of mean scores were much smaller than those for Losses. This suggests that both groups perceived that the kW contributed more gains to life than losses. Non-combatants had notably higher mean scores than combatants for the following gains numbered items: gained a greater perspective on life [2]; gained rewarding memories [8]; gained better job skills and options [14]. Conversely, combatant gains at a notably higher level than non-combatants comprised only one item: Learned to value life more [9].
Correlation Effects
The second stage of the analysis sought to determine the correlation effects between losses and gains mean scores with and between those of the CES and IES. The correlation matrix is shown as Table 3. There were no significant correlation effects between the gains score with that of the CES, the IES, or losses. However, significant positive correlation effects are shown for the losses score with the CES (p<0.01) and the IES scores (p<0.01), respectively. The observed positive effects indicate that veterans with higher scores on losses from life were significantly associated with higher scores on the CES (indicative of higher combat exposure) and on the IES (indicative of higher levels of intrusion and avoidance of thought).
Table 3: Correlation effects for Losses and Gains Scores with IES and CES scores (n=994). *Correlation is significant at the 0.01 level (2 tailed).
Independent t-test
To identify the significance of the difference between combatants’ and non-combatants’ scores on each of the four scales, first the group means were reviewed, as shown in Table 4. The mean scores for life gains were similar between the two groups but as expected the means for life losses were higher for combatants than non-combatants. It is of note, that the IES cut off score for the presence of psychological symptoms is set at 26 and above and whereas combatants clearly exceeded this with a mean score of 30.98, non-combatants were nearly approaching the cut off with a score of 25.39. This suggests that as some noncombatants must have had scores above the cut-off, just being under the combat zone’s conditions appears to have been sufficient to produce psychological symptoms later in life in them too. When independent t-tests were undertaken, the difference between the combatant and non-combatant groups’ respective mean scores was significant for life losses (t=6.706, df=918.93, p<0.01), but not for life gains (p>0.05). Furthermore, the differences between these two groups’ scores were significant for the CES (t=24.73, df=921.89, p<0.01)-and the IES (t=8.27, df=878 52, p<0.01), respectively. Thus, combatants were more likely than non-combatants to have had greater exposure to combat, higher levels of losses from life and to be experiencing psychological symptoms stemming from their KW war service.
Table 4: Group statistics for Losses and Gains: Combatants and non-combatants mean scores.
Limitations
The article provides findings based on a large participant sample of British KW veterans. Arguably as a community–based sample, it avoids some of the bias problems that may arise when sampleselection is based upon veterans as patients already presenting with clinical levels of a psychiatric disorder. Furthermore, it is recognized that at this distance in time from the KW, asking for retrospective judgements from the participants may involve bias through exaggeration or diminish memory. However, other authors in a comparative study of US military men’s present appraisals of World War II with those recorded after it, found that the former significantly predicted the latter [32]. A further issue concerns the representativeness of the participant sample. In this, it is possible that by only attracting responses from a quarter of the target KW veterans, there could be bias towards those with an ‘an axe to grind’ but there was no evidence suggesting this form of bias in the comments. Indeed. the poor level of completion of psychological scales would suggest that the survey could have underestimated rather than overestimated the extent of the psychological problems being experienced by the KW veterans and some receiving the questionnaire may have been too distressed to complete it.
Discussion
Although life gains from wartime experiences were perceived mostly at similar and higher levels than life losses by combatants and non-combatants, there were differences in emphasis in individual items. Non-combatants tended to perceive their war experiences as having offered opportunity to gain education and skills, whereas combatants perceived their life gains as growth in personal resilience and valuing life, both probably because of surviving the war. Losses on the other hand for combatants reflected the miseries of warfare in terms of death and destruction. There is no evidence to suggest combatants heightened level of current psychological symptoms have been positively influenced by their life gains, as suggested by other authors [8]. Rather, their life losses and gains seem to co-exist without interaction. (Reasons for this will be made clearer when the qualitative interview data is published later.
A sizeable number of KW veterans living in the community were found to have psychological symptoms that must (at the least be marring) their quality of life. However, what is of interest is that, psychological distress has arisen in non-combatants as well as combatants just from being in the war zone and being exposed to the extremes of the climate, appalling living conditions and loss of friends. Although some overall similarity between these present findings with earlier studies of mixed KW with WW11 veteran samples [2, 3-5], it also supports the case for KW veterans to be studied as a stand-alone sample, if such subtle differences are to be clearly identified.
The emergence of PTSD symptoms in older veterans has been noted in the US literature for some years [32] particularly when in tandem with the onset of age-related morbidities or exposure to traumatic news events triggering dormant trauma-induced syndromes [33]. From a UK perspective, in a mixed veteran sample (WWII with KW veterans), Hunt and Robbins, (2001) found that almost a fifth of the sample scored above the threshold on completion of the General Health Questionnaire and the IES [34]. Their results collectively indicate the presence of traumatic long-term effects of combat exposure in older KW veterans. However, without clinical diagnoses, PTSD could not be confirmed, as is the case with the present study. Similarly, the interesting question posed by Spiro et al (1991) as to whether PTSD in older veterans occurring after their exposure to combat is following the true course of the disorder or is it a consequence of a failure to recognize and treat the disorder [35], also cannot be addressed by the present study. However, the findings reinforce the view that although combat exposure in the KW is particularly associated with long-term psychological distress in later life, the non-combatant’s exposure to the conditions of the warzone alone also seems to produce adverse effects long after the event.
Finally, the apparent reluctance of a high number of these veterans to fully complete psychology-orientated scales perhaps uncovers a long-standing cultural dislike of inquiry that touches on war-related mental functioning. Furthermore, they may not wish to disclose or discuss their past or present psychological health and despite the potential benefits of doing so. Therefore, medical and para-medical personnel may fail to attach importance to the longterm effects of participation in the KW when undertaking older veterans’ histories and assessments.
Conclusion and Recommendations
In meeting the three objectives for this article, the use of life losses and gains scales in conjunction with the CES and IES is an efficient way of gaining insight into the extent and nature of the KW’s life-span effects and the differences between combatants’ with non-combatants’ perspectives. As participation in combat was not the sole causal agent of psychological distress in this participant sample, it is recommended that greater attention should be given to the non-combat conditions of a warzone as well as those of combat. Further research is needed to establish whether this phenomenon is peculiar to the KW (thus adding credence to its veterans’ belief that they are indeed ‘different from other wars’ veterans) or to veterans of all wars.
For more Lupine Publishers Open Access Journals Please visit our website:
https://lupinepublishers.us/
For more Bio statistics and Bio metrics Open Access Journal articles Please Click Here: https://lupinepublishers.com/biostatistics-biometrics-journal/
To Know More About Open Access Publishers Please Click on Lupine Publishers
#Biometrics Open Access Journal#Journal of Biometrics#Lupine Publishers Review on Biostatistics and Biometrics Journal#Biometrics Journal Impact Factor#Lupine Publishers LLC#Lupine Publishers#Lupine Pulbishers Group
0 notes
Text
Some Simple Mathematical Models in Epilepsy
Lupine Publishers- Biostatistics and Biometrics Open Access Journal

Abstract
Epilepsy is a chronic disorder of the brain that affects people of all ages. Here epileptic seizures equations are related to the telegraph equation.
Introduction
Some Basic Facts about Epilepsy
Epilepsy is a chronic disorder of the brain that affects people of all ages. Approximately 50 million people worldwide have epilepsy, making it one of the most common neurological diseases globally. People with epilepsy respond to treatment approximately 70% of the time. About three fourths of people with epilepsy living in lowand middle- income countries do not get the treatment they need. Therefore, using different approaches to study epilepsy is useful [1].
2.2. Telegraph Equation in Epilepsy
Telegraph equation [2,3] is a generalization of diffusion equation where the standard diffusion equation depends on the continuity equation and Fick’s law
Where,
j is the diffusing object (e. g. technology, concept, etc...),
c is the distribution function of this object and
D is the diffusion constant.
The resulting standard diffusion equation is
where is the second order differentiation w. r. t. position x.
A basic weakness of this equation is that the flux j reacts simultaneously to the gradient of c and consequently an unbounded propagation speed is assumed. To solve this problem Fick’s law is replaced by
where T is a time constant which measures the memory or delay effect. Thus, one gets the telegraph equation:
Applying this equation to the case
and making the identifications
one regains equations 1-4 in [4] where t0 is small and we made the expansion
These equations are used to explain dynamical properties of epileptic seizures.
For more Lupine Publishers Open Access Journals Please visit our website:
https://lupinepublishers.us/
For more Bio statistics and Bio metrics Open Access Journal articles Please Click Here: https://lupinepublishers.com/biostatistics-biometrics-journal/
To Know More About Open Access Publishers Please Click on Lupine Publishers
#Lupinepublishers#Lupine Publishers Group#lupine publishers#Journal of Biometrics#Lupine Publishers Review on Biostatistics and Biometrics Journal
0 notes
Text
The T-R {Generalized Lambda V} Families of Distributions

Lupine Publishers- Biostatistics and Biometrics Open Access Journal
The four-parameter generalized lambda distribution (GLD) was proposed in [1]. We say the GLD is of type V, if the quantile function corresponds to Case(v) in of [2], that is,
where u 2 (0, 1) and a, b 2 (−1, 0). In this short note, we introduce the T-R {Generalized Lambda V} Families of Distributions and show a sub-model of this class of distributions is significant in modeling real life data, in particular the Wheaton river data, [2]. We conjecture the new class of distributions can be used to fit biological and health data.
Contents
a) The T – R {Y} Family of Distributions
b) The New Distribution
c) Practical Significance
d) Open Problem
The T – R {Y} Family of Distributions
This family of distributions was proposed in [3]. In particular, let T, R, Y be random variables with CDF’s FT (x) = P (T _ x), FR(x) = P (R _ x), and FY (x) = P (Y _ x), respectively. Let the corresponding quantile functions be denoted by QT (p), QR(p), and QY (p), respectively. Also, if the densities exist, let the corresponding PDF’s be denoted by fT (x), fR(x), and fY (x), respectively. Following this notation, the, the CDF of the T – R {Y} is given by
and the PDF of the T-R{Y} family is given by
The New Distribution
Theorem: The CDF of the T-R {Generalized Lambda V} Families of Distributions is given by
where the random variable R has CDF FR(x), the random variable T with support (0,1) has CDF FT, and a, b 2 (−1, 0) Proof. Consider the integral
and let Y follow the generalized lambda class of distributions of type V, where the quantile is as stated in the abstract
Remark: the PDF can be obtained by differentiating the CDF
Practical Significance
In this section, we show a sub-model of the new distribution defined in the previous section is significant in modeling real life data. We assume T is standard exponential so that FT (t) = 1 − e−t, t > 0 and R follows the two-parameter Weibull distribution, so that
Now from Theorem 2.1, we have the following
Theorem: The CDF of the Standard Exponential-Weibull {Generalized Lambda V}
Families of Distributions is given by
where c, d > 0 and a, b 2 (−1, 0)
By differentiating the CDF, we obtain the following
Theorem: the PDF of the Standard Exponential-Weibull {Generalized Lambda V} Families of Distributions is given by
where c, d > 0 and a, b 2 (−1, 0)
Remark: If a random variable B follows the Standard Exponential-Weibull {Generalized
Lambda V} Families of Distributions write
B _ SEWGLV (a, b, c, d)
Open Problem
Conjecture: The new class of distributions can be used in forecasting and modelingn of biological and health data. Related to the above conjecture is the following
Question: Is there a sub-model of the T-R {Generalized Lambda V} Families of Distributions that can fit? [3] (Appendix 1) and (Figures 1-3).
Appendix 1:
DataQ1 = Flatten Data11; Length DataQ1 72
Min DataQ1 0.1; Max DataQ1 64.
AX1 = Empirical Distribution DataQ1
Data Distribution «Empirical», { 58}
K1 = Discrete Plot [CDF [AX1, x ], {x, 0, 65, (65-0)/58} , Plot Style c {Black, Thick} , Plot Markers c {Automatic, Small} , Filling c None,
Plot Range c All]
(Figure 1)
F1 x_, a_, b: = 1 - 1 - x ^ ab
CDF Weibull Distribution c, d, x
I. Weibull. nb
D 1 - E^ - F1 M x, c, d, a, b, x
PLK1 = Sum Log MQ DataQ1, a, b, c, di, i,1, Length DataQ1;
JK=D [PLK, a];
JK1=D [PLK, b];
JK2=D [PLK, c];
JK3=D [PLK,d];
Find Root JK, JK1, JK2, JK3, a, - 0.11 ,b, - 0.12 , c, 0.9 , d, 11.6
a c – 7.2577, b c – 0.395297, c c 0.776499, d c 657.998
RR = Plot 1 - E^ - F1 M x, 0.776499, 657. 998, - 7.2577, - 0.395297, x, 0, 65, Plot Style c Thick, Blue, Plot Range c All
(Figure 2)
II. Weibull. nb
CMU = Show K1, RR, Plot Range c All
(Figure 3)
Export “CMU.jpg”, CMU CMU.jpg
For more Lupine Publishers Open Access Journals Please visit our website: https://lupinepublishersgroup.com/
For more Bio statistics and Bio metrics Open Access Journal articles Please Click Here: https://lupinepublishers.com/biostatistics-biometrics-journal/
To Know More About Open Access Publishers Please Click on Lupine Publishers
#Lupine publishers#Lupine Publishers Group#Biometrics Open Access Journal#Biostatistics and Biometrics Open Access Journal#Lupine Publishers Review on Biostatistics
0 notes
Text
P Value and Statistical Significance

Lupine Publishers- Biostatistics and Biometrics Open Access Journal
Abstract
The practice of reporting P-values is commonplace in applied research. Presenting the result of a test only as the rejection or acceptance of the null hypothesis at a certain level of significance, does not make full use of the information available from the observed value of the test statistic. Rather P-values have been used in the place of hypothesis tests as a means of giving more information about the relationship between the data and the hypothesis. In this brief note we discuss how to obtain P-values with R codes.
Introduction
Very often in practice we are called upon to make decisions about populations on the basis of sample data. In attempting to reach decisions, it is useful to make assumptions or guesses about the populations involved. Such assumptions which may or may not be true, are called statistical hypotheses and in general are statements about the population parameters. The entire procedure of testing of hypothesis that consists of setting up what is called a ’Null hypothesis’ and testing it. R.A. Fisher quotes, ’Every experiment may be said to exist only in order to give the facts about a chance of disproving the null hypothesis’. So, what is this null hypothesis?”. For example, if we consider the measurements on weights of newborn babies, then the observations on these measurements follows Normal distribution is a null hypothesis [1]. Suppose the measurements denoted by a random variable X that is thought to have a normal distribution with mean μ and variance 1, denoted by N(μ,1). The usual types of hypotheses concerning mean μ in which one is interested include H0: μ = μ0 versus H1: μ6= μ0(two-tailed hypothesis) and H0: μ ≤ μ0 versus H1: μ > μ0 and H0: μ ≥ μ0 versus H1: μ < μ0(one-tailed hypothesis). So null hypothesis H0 is a hypothesis which is tested for possible rejection under the assumption that it is true.
In general, a procedure for the problem of testing of significance of a hypothesis is as follows: Given the sample point x = (x1, x2, . . .. ,xn), find a decision ru. le that will lead to a decision [2].
P Value and Statistical Significance
To reject or fail to reject the null hypothesis H0: θ ∈ Θ in favor of the alternative hypothesis H1: θ ∈ Θ1 = Θ-Θ. This decision rule is based on a test statistic whose probability distribution when H0 is true is known, at least approximately. Calculate the value of the test statistic for the available data [3]. If the test statistic is in the extreme of its probability distribution under the null hypothesis, there is evidence that the null hypothesis is rejected. More quantitatively, we calculate from the distribution of the test statistic, the probability P that a deviation would arise by chance as or more extreme than that actually observed, the H0 being true. This value of P is called the significance level achieved from the sample data or P-value. There are several ways to define P-values [4]. It is the probability of observing under H0 a sample outcome at least as extreme as the one observed. One could define P-value as the greatest lower bound on the set of all significance levels α such that we would reject H0 at level α. P-value is a value satisfying 0 ≤ P ≤ 1 for every sample point x. A P-value is valid if Pθ (p ≤ α) ≤ α. For fixed sample data X=x it changes for different hypotheses. Let T(X) be a test statistic such that large values of T give evidence that H1 is true. For each sample point x, P-value is defined as p-value= sup Pθ(T(X) ≥ T(x)). θ∈Θ. Fisher writes: “The value for which P-value= 0.05, or 1 in 20, is 1.96 or nearly 2; it is convenient to take this point as a limit in judging whether a deviation ought to be considered significant or not. Deviations exceeding twice the standard deviation are thus formally regarded as significant”. Thus, for a given α, we reject H0 if P-value ≤ α and do not reject H0 if P-value > α. In the two-tailed case, if the distribution of the test statistic is symmetric, one-tailed P-value is doubled to obtain P-value. If the distribution of the test statistic is not symmetric, the P-value is not well defined in twotailed case, although many authors recommend doubling the onesided P-value.
Examples: Let X1, . . . , Xn be a random sample from a N(μ,σ2) population. If we want to test H0: μ ≤ μ0 versus H1: μ > μ0 when σ unknown, test procedure is to reject H0 for large values of which has Student’s t distribution with n-1 degrees of freedom when H0 is true. Thus, the P value for this one-sided test is P-value=P (Tn-1 ≥ T(x)). Again, if we want to test H0: μ = μ0 versus H1: μ6= μ0 then and P-value=2P (Tn-1 ≥ T(x)). R codes for obtaining these P-values are ”1-pt(T(x), df)” and ”2*(1- pt(T(x), df))” respectively where df is the degrees of freedom. If we want to test these hypotheses when σ known, test procedure is to reject H0 for large values of which has standard normal distribution when H0 is true. Then P-value=P(Zα ≥ Z) where Zα is the critical value of Z for a given level of significance α. R codes for obtaining these P-values are ”1-pnorm(Z)” and ”2*(1- p norm(Z)) or 2*p norm(abs(Z))” respectively. Similarly, for testing homogeneity of variances Chi-square(χ2) test statistic.
P Value and Statistical Significance
And F test statistics will be used. R codes of P-values for these tests are ”1-pchisq (χ2, df)” and ”1-pf (F, df1, df2)” respectively where df is degrees of freedom, df1 is the degrees of freedom for numerator and df2 is the degrees of freedom for the denominator.
Conclusion
Nowadays reporting of p-values is very common in applied fields. The most important conclusion is that, for testing the hypotheses, P-values should not be used directly, because they are easily misinterpreted. From the Bayesian perspective, P-values overstate the evidence against the null hypothesis and other methods to adduce evidence (likelihood ratios) may be of more utility. Finally, in many scenarios P-values can distract or even mislead, either a nonsignificant result wrongly interpreted as a confidence statement in support of the null hypothesis or a significant P-value that is taken as proof of an effect. Thus, there would appear to be considerable virtue in reporting both P-values and confidence interval (CI), on the basis that singular statements such as P¿0.05, or P = Non-Significant, convey little useful information, although for a 100(1-α) % CI, it must be remembered that any violation of the assumptions that effect the true value of effect CI precision. From the Bayesian perspective, Lindley has summarized the position thus: significance tests, as inference procedures, are better replaced by estimation methods it is better to quote a confidence interval. Finally, p-values should be retained for a limited role as part of the statistical significance approaches.
For more Lupine Publishers Open Access Journals Please visit our website: https://lupinepublishersgroup.com/
For more Bio statistics and Bio metrics Open Access Journal articles Please Click Here: https://lupinepublishers.com/biostatistics-biometrics-journal/
To Know More About Open Access Publishers Please Click on Lupine Publishers
#Biometrics Open Access Journal#Biometrics Journal Impact Factor#Review on Biostatistics and Biometrics Journal#Biostatistics and Biometrics Open Access Journal
0 notes
Text
Lupine Publishers-Biometrics and Biostatistics Journal
Model Selection in Regression: Application to Tumours in Childhood by Annah Managa

We give a chronological review of the major model selection methods that have been proposed from circa 1960. These model selection procedures include Residual mean square error (MSE), coefficient of multiple determination (R2), adjusted coefficient of multiple determination (Adj R2), Estimate of Error Variance (S2), Stepwise methods, Mallow’s Cp, Akaike information criterion (AIC), Schwarz criterion (BIC). Some of these methods are applied to a problem of developing a model for predicting tumors in childhood using log-linear models. The theoretical review will discuss the problem of model selection in a general setting. The application will be applied to log-linear models in particular.
https://lupinepublishers.com/biostatistics-biometrics-journal/fulltext/model-selection-in-regression-application-to-tumours-in-childhood.ID.000101.php
For more Lupine Publishers Open Access Journals Please visit our website https://www.lupinepublishers.com/
For more Biostatistics & Biometrics Articles Please Click Here: https://lupinepublishers.com/biostatistics-biometrics-journal/
#Biometrics Open Access Journal#Biostatistics and Biometrics Open Access Journal#Biometrics Journal Reference#Journal of Biometrics
1 note
·
View note
Text
Review of Designing a Big Data Platform in Healthcare

Authored by Dillon Chrimes*
In many hospital systems, new technologies that influence patient data require extensive technical testing before implementation in to production. Therefore, to implement, an existing High Performance Computing (HPC) Linux node clusters via WestGrid were used, and simulation of patient data benchmarked and cross-referenced with current metadata profiles in operational hospital systems at the Vancouver Island Health Authority (VIHA), Victoria, Canada. Over the tested cross platform, the data were generated, indexed and stored over a Hadoop Distributed File System (HDFS) to no SQL database (HBase) that represented three billion patient records. The study objective to establish an interactive Big Data Platform (BDA) was successful in that Hadoop/Map Reduce technologies formed the framework of the platform distributed with HBase (key- value No SQL database storage) and generated desired hospital-specific metadata at very large volumes. In fact, the framework over generated HBase data files took a week or a month for one billion (10TB) and three billion (30TB), respectively. Further performance tests retrieved results from simulated patient records with Apache tools in Hadoop's ecosystem. At optimized iteration, HDFS ingestion with HBase exhibited sustained database integrity over hundreds of iterations; however, to complete the bulk loading via Map Reduce to HBase required a month. Inconsistencies of Map Reduce limited the capacity to generate/replicate data to HBase efficiently. Hospital system based on patient encounter database was very difficult and data profiles were fully representative of complex patient-to-hospital relationships. Our work is important to lead discovery of big data technologies useful across platforms of hospital systems.
For Read More... Fulltext click on: https://juniperpublishers.com/bboaj/BBOAJ.MS.ID.555666.php
For More Articles in Biostatistics and Biometrics Open Access Journal Please Click on: https://juniperpublishers.com/bboaj/index.php
For More Open Access Journals In Juniper Publishers Please Click on:
https://juniperpublishers.com/index.php
0 notes
Text
Statistical Methods for Clinical Trial Designs in the New Era of Cancer Treatment

Authored by Beibei Guo *
Recent success of immunotherapy and other targeted therapies in cancer treatment has signaled the advent of precision medicine. Unlike conventional trial designs that aim to find an optimal treatment ignoring inter-patient heterogeneity, clinical trial designs for precision medicine must take into account patients' variability in genes, environments, and lifestyle. This article provides a review of recent research development of clinical trial designs toward this trend. Traditional clinical trials aim to find an optimal treatment ignoring patient variability, which means the optimal treatment is the same for all patients of a specific disease. However, due to inter-patient heterogeneity, a treatment can be very successful for some patients but not for others. For example, some drugs may benefit only 2% of the patients and there are even drugs that are harmful to certain ethnic groups. To overcome this "one-size-fits-all" approach and to acknowledge patient heterogeneity, a new 215-million national Precision Medicine Initiative was launched by former President Barack Obama in January 2015. Precision or personalized medicine provides emerging approaches for disease treatment and prevention that target to the needs of a patient based on his/her own individual characteristics such as biomarker, environmental exposures, lifestyle, and psychosocial characteristics.
For Read More... Fulltext click on: https://juniperpublishers.com/bboaj/BBOAJ.MS.ID.555665.php
For More Articles in Biostatistics and Biometrics Open Access Journal Please Click on: https://juniperpublishers.com/bboaj/index.php
For More Open Access Journals In Juniper Publishers Please Click on: https://juniperpublishers.com/index.php
0 notes
Text
Model Selection in Regression: Application to Tumours in Childhood in #CTBB in #Lupine Publishers

We give a chronological review of the major model selection methods that have been proposed from circa 1960. These model selection procedures include Residual mean square error (MSE), coefficient of multiple determination (R2 ), adjusted coefficient of multiple determination (Adj R2 ), Estimate of Error Variance (S2 ), Stepwise methods, Mallow’s Cp , Akaike information criterion (AIC), Schwarz criterion (BIC). Some of these methods are applied to a problem of developing a model for predicting tumors in childhood using log-linear models. The theoretical review will discuss the problem of model selection in a general setting. The application will be applied to log-linear models in particular.
https://lupinepublishers.com/biostatistics-biometrics-journal/fulltext/model-selection-in-regression-application-to-tumours-in-childhood.ID.000101.php
0 notes
Text
Model Selection in Regression: Application to Tumours in Childhood by Annah Managa in CTBB-Lupine publishers

We give a chronological review of the major model selection methods that have been proposed from circa 1960. These model selection procedures include Residual mean square error (MSE), coefficient of multiple determination (R2 ), adjusted coefficient of multiple determination (Adj R2 ), Estimate of Error Variance (S2 ), Stepwise methods, Mallow’s Cp , Akaike information criterion (AIC), Schwarz criterion (BIC). Some of these methods are applied to a problem of developing a model for predicting tumors in childhood using log-linear models. The theoretical review will discuss the problem of model selection in a general setting. The application will be applied to log-linear models in particular.
https://www.lupinepublishers.com/biostatistics-biometrics-journal/pdf/CTBB.MS.ID.000101.pdf
0 notes