#SQL Server date comparison
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr was created by web developers David Karp and Marco Arment.
Text
Finding the Maximum Value Across Multiple Columns in SQL Server
To find the maximum value across multiple columns in SQL Server 2022, you can use several approaches depending on your requirements and the structure of your data. Here are a few methods to consider: 1. Using CASE Statement or IIF You can use a CASE statement or IIF function to compare columns within a row and return the highest value. This method is straightforward but can get cumbersome with…
View On WordPress
#comparing multiple columns SQL#SQL CROSS APPLY technique#SQL Server aggregate functions#SQL Server date comparison#SQL Server maximum value
0 notes
Text
How Power BI Solutions Support Data-Driven Digital Transformation

In the era of rapid technological advancement, businesses are increasingly turning to data-driven strategies to remain competitive, agile, and customer-focused. Digital transformation has emerged as a vital objective across industries—from manufacturing to healthcare, retail to finance. A core enabler of this transformation is business intelligence (BI), and among the most effective tools available today is the Power BI solution from Microsoft.
What Is Digital Transformation?
Digital transformation refers to the strategic integration of digital technologies into all areas of a business. It goes beyond simply digitizing processes—it involves rethinking business models, customer engagement, operations, and internal workflows with a focus on innovation, efficiency, and scalability.
A Power BI solution plays a key role in this transformation by offering organizations the ability to collect, analyze, and visualize data in real time, turning raw data into actionable intelligence.
Power BI: The Catalyst for a Data-Driven Culture
1. Unified Data Access Across the Organization
One of the biggest challenges in digital transformation is breaking down data silos. Data often resides in disparate systems—CRM, ERP, cloud storage, spreadsheets, and databases—making it difficult to consolidate for analysis.
A Power BI solution seamlessly integrates with hundreds of data sources, including Microsoft Azure, SQL Server, Google Analytics, Salesforce, SAP, and more. This allows businesses to bring together scattered data into a unified view, laying the foundation for strategic decision-making.
2. Real-Time Insights for Agile Decision-Making
Digital transformation thrives on speed and responsiveness. Power BI enables real-time analytics and live dashboards that reflect the most up-to-date metrics across operations, finance, marketing, and sales. These real-time insights empower teams to respond proactively to market shifts, customer behavior changes, and internal inefficiencies.
For instance, a retailer can track live inventory levels and sales data, allowing immediate adjustments to promotions or supply chain decisions. A Power BI solution eliminates guesswork and replaces it with data-backed responsiveness.
Transforming Business Functions with Power BI
1. Finance and Operations
Power BI simplifies complex financial data into visual dashboards that highlight performance metrics like revenue trends, cost optimization, and cash flow. Finance teams gain transparency and can perform deeper analysis with predictive models and historical comparisons.
In operations, Power BI improves process visibility by tracking KPIs such as production efficiency, resource utilization, and turnaround times—enabling lean, optimized workflows.
2. Sales and Marketing
Sales teams use Power BI dashboards to monitor pipelines, lead conversions, territory performance, and customer lifetime value. Marketing teams benefit from campaign analytics, ROI tracking, and customer engagement trends.
With a Power BI solution, both departments align more closely with real-time performance indicators, leading to faster strategy pivots and higher ROI.
3. Human Resources and Employee Engagement
HR departments leverage Power BI to monitor headcount, employee satisfaction, hiring trends, and attrition rates. This data aids in workforce planning, talent management, and organizational health assessments.
Supporting Predictive and Prescriptive Analytics
True digital transformation requires organizations to move from descriptive analytics (what happened) to predictive (what will happen) and prescriptive (what should be done). Power BI integrates with advanced analytics tools such as Azure Machine Learning and R or Python scripts.
This allows companies to build and visualize predictive models directly within their dashboards, such as forecasting sales, identifying churn risks, or optimizing resource allocation. A Power BI solution turns BI from a reactive tool into a proactive strategic asset.
Enabling a Culture of Data-Driven Decision-Making
For digital transformation to be successful, data accessibility must extend beyond the executive level. Power BI promotes the democratization of data, meaning that employees across all levels can access and interact with business intelligence relevant to their role.
With user-friendly interfaces, drag-and-drop visuals, and natural language queries, a Power BI solution empowers non-technical users to explore data, generate reports, and derive their own insights, fostering a culture where decisions are based on facts, not assumptions.
Enhancing Collaboration and Communication
Power BI seamlessly integrates with Microsoft Teams, SharePoint, and other collaboration tools, allowing cross-functional teams to share dashboards, tag team members in reports, and jointly explore data. This alignment of insights promotes collaboration and accelerates collective problem-solving.
Furthermore, automated alerts and scheduled reports keep stakeholders informed without requiring manual intervention, reinforcing transparency and communication.
Scalability and Governance
As businesses grow and their data expands, maintaining governance and data security becomes essential. Power BI offers robust governance features, including role-based access control, row-level security, activity monitoring, and compliance with industry standards like GDPR and HIPAA.
Whether deployed in a small team or across a global enterprise, a Power BI solution scales with the organization while maintaining high standards of governance.
Real-World Example
A healthcare provider undergoing digital transformation adopted a Power BI solution to consolidate patient records, monitor treatment efficiency, and track hospital performance. Within months, the organization reported:
30% improvement in patient throughput
Faster identification of care bottlenecks
Enhanced reporting for regulatory compliance
This transformation not only improved operations but also elevated patient care standards.
Conclusion
Digital transformation isn’t a one-time event—it’s a continuous evolution driven by technology, data, and a commitment to innovation. Microsoft’s Power BI solution acts as a strategic enabler in this journey by providing real-time visibility, actionable insights, and predictive capabilities.
Whether you're modernizing your business model, improving customer experiences, or optimizing internal processes, Power BI is a powerful ally in turning digital aspirations into measurable outcomes. For organizations serious about data-driven transformation, investing in a Power BI solution is a forward-looking and necessary step.
0 notes
Text
Power BI Training | Power BI Online Training in Hyderabad
How to Use DAX in Power BI for Advanced Analytics

Power BI Training is a leading tool in the field of data analytics and visualization, providing businesses with the insights they need to make informed decisions. One of its most powerful features is Data Analysis Expressions (DAX), a formula language that allows users to create advanced calculations and models. This article explores how DAX can be used in Power BI for advanced analytics, unlocking its full potential for data professionals. Power BI Online Training in Hyderabad
Understanding DAX Basics
DAX is specifically designed for data modelling in Power BI, Excel, and SQL Server Analysis Services. It enables users to go beyond basic aggregations by crafting custom calculations. Some key features of DAX include:
Functions: DAX includes a wide range of functions for mathematical, statistical, and text operations.
Context Awareness: DAX formulas work within two contexts—row context and filter context—allowing calculations on both individual rows and filtered data sets.
Custom Calculations: Users can create calculated columns for static results or measures for dynamic, on-the-fly calculations.
These capabilities make DAX essential for building robust and interactive analytics in Power BI Training.
Essential DAX Functions for Advanced Analytics
To perform advanced analytics, it’s important to understand some key DAX functions that are widely used in Power BI projects.
CALCULATE Function
The CALCULATE function is incredibly versatile, enabling users to modify filter contexts dynamically. For instance, you can compute sales for specific time periods or conditions.
FILTER Function
FILTER allows users to narrow down data to meet certain criteria. This is particularly useful when working with subsets of data for detailed analysis.
Time Intelligence Functions
DAX provides built-in time intelligence functions like TOTALYTD (Year-to-Date totals), DATESBETWEEN (for custom date ranges), and PREVIOUSMONTH (to analyze historical trends). These functions make temporal data analysis more straightforward.
RANKX Function
RANKX is used to rank items, such as products or customers, based on specific metrics like sales or profitability. This is especially useful for comparisons and performance evaluations.
Applications of DAX in Advanced Analytics
With a solid understanding of DAX functions, professionals can tackle complex analytical tasks. Here are some practical applications: Power BI Online Training in Hyderabad
Customer Segmentation
DAX allows you to categorize customers into segments based on their purchasing behaviour. For example, customers can be classified as high-value, medium-value, or low-value based on their total spending. This segmentation provides actionable insights for targeted marketing campaigns.
Profitability Analysis
DAX helps businesses calculate profitability metrics dynamically. For instance, by dividing total profit by revenue, companies can monitor profit margins across products, regions, or time periods.
Trend Forecasting
Using rolling averages or moving totals, DAX enables businesses to identify trends and patterns in data. For instance, calculating a 30-day rolling average for sales can reveal performance fluctuations over time.
Best Practices for Using DAX
Understand Contexts
Context plays a critical role in DAX. Filter and row contexts impact how calculations are performed, so understanding these concepts is essential for accurate results.
Optimize Performance
Complex DAX formulas can slow down report performance. It’s best to use efficient functions and keep calculations as streamlined as possible.
Use Variables
Variables, defined using the VAR keyword, can improve formula readability and performance. By storing intermediate results, variables also make troubleshooting easier.
Test Formulas Step-by-Step
When building advanced analytics, test DAX formulas incrementally. This approach ensures accuracy and simplifies debugging.
Conclusion
Mastering DAX in Power BI is essential for unlocking advanced analytics capabilities. Whether it’s customer segmentation, profitability analysis, or trend forecasting, DAX empowers professionals to extract deeper insights and build more interactive dashboards. By learning and applying key DAX functions, understanding contexts, and following best practices, users can take their Power BI skills to the next level.
Start small with basic calculations and gradually progress to more complex scenarios. With consistent practice, you’ll be well on your way to mastering DAX and creating impactful analytics that drive decision-making.
Visualpath is the Leading and Best Institute for learning in Hyderabad. We provide Power BI Course Online. You will get the best course at an affordable cost.
Attend Free Demo
Call on – +91-9989971070
Blog: https://visualpathblogs.com/
What’s App: https://www.whatsapp.com/catalog/919989971070/
Visit: https://www.visualpath.in/powerbi-training.html
#Power BI Training#Power BI Online Training#Power BI Course Online#Power BI Training in Hyderabad#Power BI Training in Ameerpet#Power BI Training Institute in Hyderabad#Power BI Online Training Hyderabad#Power BI Course in Hyderabad
1 note
·
View note
Text
Revealing the Nature of Full-Stack Programming: Converging Frontend and Backend Development Domains
Within the dynamic field of software engineering, the phrase "full-stack development" has gained significant traction. It includes all of the extensive skill set needed to create web applications' front-end and back-end parts. Full-stack developers are the Swiss Army knives of the IT industry; they can handle every step of the development process and are skilled in a wide range of technologies.
Comprehending Full-Stack Development
The fundamental component of full-stack development is the ability to work with both frontend and backend technologies. The user-facing portion of a programme, where users interact with the interface, is referred to as the frontend. Using HTML, CSS, and JavaScript, this entails creating aesthetically pleasing and user-friendly designs. To improve functionality and user experience, frameworks and libraries like React, Angular, or Vue.js are frequently used. The backend, on the other hand, is responsible for managing business logic, data retrieval, and storage on the server-side of the programme. Working with server-side languages like Node.js, Python, Ruby, or Java in conjunction with frameworks like Express, Django, or Flask is known as backend development. Additionally, efficient data management requires familiarity with databases like SQL, MongoDB, or Firebase.
Full-Stack Developers' Role
Development teams rely heavily on full-stack engineers since they can easily switch between front-end and back-end duties. They can comprehend every aspect of the software stack, from database administration to user interface design, thanks to their adaptability. This all-encompassing method encourages teamwork and expedites the development process because full-stack engineers are able to interact with frontend and backend experts with ease. In addition, full-stack developers have a wider viewpoint that enables them to see the application as a whole instead of concentrating just on its individual parts. This all-encompassing approach is crucial for creating coherent designs and maximizing performance throughout the stack.
Benefits of Full-Stack Development
Efficiency:-Development cycles are accelerated by having a single developer that is skilled in both frontend and backend technologies. Full-stack engineers can work independently on projects at any level of the stack, removing bottlenecks and dependencies.
Flexibility:-As project requirements change, full-stack developers can easily transition between frontend and backend duties. With their limited resources, start-ups and small teams can benefit greatly from this flexibility.
Expense-effectiveness:-It may be less expensive to hire full-stack developers than to put together separate frontend and backend teams. This lowers the overhead related to interdepartmental team collaboration and communication.
Solving Problems:-Full-stack developers can identify and fix problems more quickly because they have a thorough understanding of the whole software stack. Problem-solving is sped up by their proficiency with front-end and back-end debugging and troubleshooting.
Obstacles and Things to Think About
Full-stack development has many advantages, but it also has drawbacks. Acquiring proficiency in numerous technologies necessitates commitment and continuous education to keep up with developments. Furthermore, in comparison to professionals, the depth of knowledge needed might occasionally result in a superficial grasp of particular technology. Furthermore, because technology is developing so quickly, full-stack engineers need to keep their skill set up to date in order to stay relevant. Maintaining expertise in frontend and backend development requires being up to date with new developments in the field as well as industry best practices.
The combination of frontend and backend development skills is best represented by full-stack development, which enables programmers to design comprehensive solutions that slickly combine functionality and user experience. The need for adaptable full-stack developers is expected to rise as technology advances. Adopting this diverse approach to software engineering promotes creativity, effectiveness, and adaptability in addressing the ever-changing needs of the digital world.
1 note
·
View note
Text
How to Become an SQL Developer? Essential Skills and Tips for Beginners

In today’s data-driven world, SQL developers play a crucial role in managing and manipulating databases, ensuring that data is accessible, reliable, and secure. You're in the perfect place if you're thinking about a career in this exciting industry. This guide will walk you through the essential skills and tips of “how to become an SQL developer”, even if you’re a beginner.
What is SQL?
Relational database management is done with standardized computer languages like SQL (Structured Query Language). It enables users to create, read, update, and delete (CRUD) data within a database. SQL is fundamental in various applications, from business analytics to web development.
Essential Skills for SQL Developers
1. Understanding of Databases and RDBMS
Before diving into SQL, it’s essential to understand what a database is and how a Relational Database Management System (RDBMS) works. RDBMS like MySQL, PostgreSQL, SQL Server, and Oracle are the platforms where SQL operates. Familiarize yourself with the basic concepts of tables, relationships, primary keys, and foreign keys.
2. Basic SQL Commands
Begin with mastering the basic SQL commands, which form the foundation of database management:
SELECT: Extracts data from a database.
INSERT: Adds new data to a database.
UPDATE: Modifies existing data.
DELETE: Removes data.
Understanding these commands will allow you to perform fundamental data manipulation tasks.
3. Data Types and Operators
Learn about different data types (e.g., integers, strings, dates) and operators (e.g., arithmetic, comparison, logical). This knowledge is crucial for writing accurate and efficient queries.
4. Joins and Subqueries
As you progress, delve into more complex SQL concepts like joins and subqueries. Joins allow you to combine data from multiple tables, while subqueries enable you to nest queries within each other for more sophisticated data retrieval.
5. Indexes and Optimization
Understanding indexes and how to optimize queries is vital for performance tuning. Indexes improve the speed of data retrieval, and learning how to use them effectively can make a significant difference in handling large datasets.
6. SQL Functions and Procedures
SQL provides various built-in functions for performing calculations, aggregations, and other operations on data. Additionally, learning to write stored procedures and triggers can help automate and enhance database functionality.
7. Basic Programming Concepts
Having a grasp of basic programming concepts such as loops, conditionals, and error handling can be beneficial, especially when writing complex SQL scripts or integrating SQL with other programming languages.
8. Data Security and Privacy
Understanding data security and privacy is crucial for any SQL developer. Learn about user privileges, roles, and encryption techniques to ensure the data you manage is secure.
Tips for Beginners
1. Start with Online Tutorials and Courses
There are numerous online resources available for learning SQL, from free tutorials to comprehensive courses on platforms like Coursera, Udemy, and Khan Academy. Start with beginner-friendly courses and gradually move to more advanced topics.
2. Practice Regularly
SQL is a skill best learned through practice. Utilize online platforms like LeetCode, HackerRank, and SQLZoo to solve real-world problems and refine your skills. Create your own database projects to apply what you’ve learned.
3. Use Database Management Tools
Familiarize yourself with database management tools such as MySQL Workbench, pgAdmin, and SQL Server Management Studio. These tools offer user-friendly interfaces for writing and testing SQL queries, managing databases, and visualizing data.
4. Read Documentation and Books
Reading official documentation for the RDBMS you’re using can provide in-depth knowledge and best practices. Books like "SQL in 10 Minutes, Sams Teach Yourself" by Ben Forta and "SQL for Data Scientists" by Renee M. P. Teate can be excellent resources.
5. Join Communities and Forums
Engage with the SQL community through forums like Stack Overflow, Reddit’s r/SQL, and SQLServerCentral. These platforms are great for asking questions, sharing knowledge, and staying updated with the latest trends and challenges in the field.
6. Work on Real Projects
Nothing beats hands-on experience. Look for internships, freelance projects, or contribute to open-source projects. Working on real-world problems will enhance your skills and make you more attractive to potential employers.
7. Stay Updated
SQL and database technologies are continually evolving. Follow blogs, attend webinars, and participate in workshops to stay current with the latest advancements and best practices.
Conclusion
Becoming an SQL developer is a rewarding journey that requires a solid understanding of databases, continuous practice, and a willingness to learn. By mastering the essential skills and following the tips outlined above, you can set yourself on the path to a successful career in SQL development.
0 notes
Text
Creating objects on SSMS and merging with VS project
Next let's create a function in SSMS. Then we can see how to incorporate that into the SSDT project.
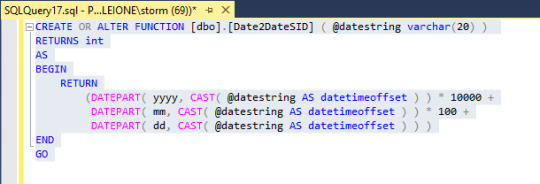
This changes a date string into the format of our DateSIDs.
To pull this into the VS project, click on Tools > SQL Server > New Schema Comparison.
We use the database on SQL server as the source, and we happen to already have that as a connection.
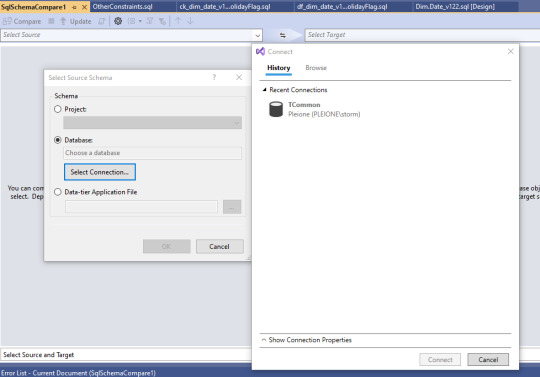
Select the connection, and click OK.
For the target, we can use the SSDT Project.
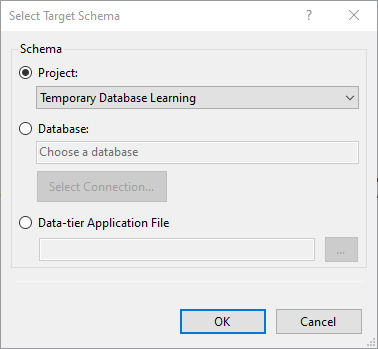
And click on OK.
Now the Compare button above the source is active. We can click that and see what happens. We can see the list of differences between the source and target. You can turn off the items to not make changes to by clearing checks from the boxes. To actually make the changes, we click on the Update button.

We confirm we want the changes made. Then we can drill into the project in solution explorer, and see that the dbo schema now has a function.
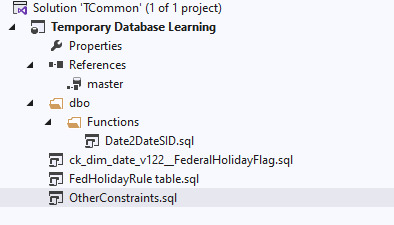
OK, now let's go the other direction and push changes to the database. We create a dapac file for our project by right-click on the solution's name, then click Build.
Then we can right-click on the solution's name, and select Publish. We need to select a target database. For now, I'm just reusing the same database, but it could go to a different SQL server for testing.
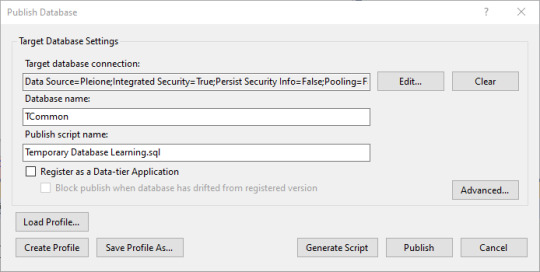
Now we can click on publish, and all the new items are placed into the SSMS database.
It's one way to keep everything in sync and stored.
0 notes
Text
Mastering OData Query Syntax in Power Automate

In today's data-driven world, efficient data retrieval is crucial for automating workflows and making informed decisions. Power Automate, a powerful workflow automation tool from Microsoft, empowers users to streamline various tasks. This blog post delves into OData Query Syntax, a valuable tool within Power Automate for filtering and retrieving specific data from various sources.
Browse More About This @ https://www.softat.co.in/odata-query-syntax-in-power-automate/
What is OData Query Syntax?
Imagine a concise language allowing you to specify the exact data you want to retrieve from a data source. OData (Open Data Protocol) Query Syntax acts like this language in Power Automate. It enables you to build precise queries to filter and retrieve data from various sources supported by Power Automate, including SharePoint lists, Microsoft Dynamics 365, and SQL Server.
Benefits of Utilizing OData Query Syntax:
Improved Efficiency: By filtering data directly at the source, OData queries significantly reduce the amount of data transferred, leading to faster processing and improved workflow performance.
Enhanced Accuracy: OData queries allow for precise filtering based on specific criteria, ensuring you retrieve only the data relevant to your needs.
Increased Flexibility: OData syntax offers various operators and functions, enabling you to create complex queries for diverse filtering and data retrieval scenarios.
Getting Started with OData Queries in Power Automate:
Identify your data source: Determine the source from which you want to retrieve data, such as a SharePoint list or a Microsoft Dynamics 365 entity.
Access the "Filter Array" action: Within your Power Automate flow, locate the "Filter Array" action, which allows you to specify the OData query.
Build your query: Utilize the OData syntax to filter the data based on your specific needs. This might involve specifying the desired fields, applying comparison operators (e.g., eq for equals, ne for not equal), and using logical operators (and, or) to combine multiple conditions.
Examples of OData Queries:
Retrieve items with a specific title: Title eq 'Important Report'
Filter items with a due date after a certain date: DueDate gt '2024-03-10'
Get items created by a specific user: CreatedBy eq '[email protected]'
Exploring Advanced OData Query Techniques in Power Automate
While the previous section provided a foundational understanding of OData Query Syntax, here's a deeper dive into advanced functionalities:
1. Filtering with Arrays and Collections:
Utilize array operators like "any" and "all" to filter based on multiple conditions within a single field.
Employ collection operators like "contains" and "notcontains" to search for specific values within text fields.
2. Sorting and Ordering Data:
Specify the order in which data should be retrieved using the "orderby" clause, including ascending and descending options.
Utilize multiple fields for sorting by combining them within the "orderby" clause.
3. Selecting Specific Fields:
Limit the retrieved data to only the relevant fields by using the "select" clause, reducing data transfer and improving performance.
4. Combining Queries and Data Sources:
Leverage the "expand" operator to retrieve related data from associated tables or entities within your query.
Combine multiple data sources using the "union" operator to create comprehensive datasets for your workflows.
5. Utilizing Advanced Functions:
Explore a range of built-in functions like "substring," "startswith," and "endswith" for complex filtering and data manipulation within your queries.
Remember, mastering OData Query Syntax in Power Automate goes beyond basic filtering. By exploring advanced techniques like those mentioned above, you can unlock its full potential for efficient and tailored data retrieval, enabling you to build sophisticated workflows and extract valuable insights from various sources.
Conclusion:
By mastering OData Query Syntax in Power Automate, you can unlock a powerful tool for efficient and accurate data retrieval. This not only streamlines your workflows but also empowers you to make informed decisions based on precise data insights.
About SoftAt PVT. LTD. :
We are a new generation IT company, focused on enterprise software implementation & Support Services.To accomplish the sustainable growth of a business, the essential factor is the industry-specific solutions that adapt to the system and its necessity. For this, SoftAt is the best place to get the Righteous solution for your business.With nearly two decades of 15 years of experience in SAP Implementation, SAP up-gradation, and SAP migration, we at SoftAt work to empower businesses with our SAP & Oracle solutions.
Contact Us: -
SoftAt Private Limited
No. A01 Second Floor Upon Bank of Baroda Kharadi,
Kharadi-Hadapsar Road, Infront of HP Petrol Pump,
Thite Vasti, Kharadi,
Pune, Maharashtra-411014
India: +91-7796611155
Email: – [email protected]
0 notes
Text
Layouteditor datatype

#Layouteditor datatype code#
#Layouteditor datatype download#
In order to evaluate the expression + ' is not a string.', SQL Server follows the rules of data type precedence to complete the implicit conversion before the result of the expression can be calculated. Msg 245, Level 16, State 1, Line 3 Conversion failed when converting the varchar value ' is not a string.' to data type int. In this case, the SELECT statement throws the following error: The following example, shows a similar script with an int variable instead: DECLARE INT The int value of 1 is converted to a varchar, so the SELECT statement returns the value 1 is a string. For comparison operators or other expressions, the resulting data type depends on the rules of data type precedence.Īs an example, the following script defines a variable of type varchar, assigns an int type value to the variable, then selects a concatenation of the variable with a string. For implicit conversions, assignment statements such as setting the value of a variable or inserting a value into a column result in the data type that was defined by the variable declaration or column definition. When SQL Server performs an explicit conversion, the statement itself determines the resulting data type. While the above chart illustrates all the explicit and implicit conversions that are allowed in SQL Server, it does not indicate the resulting data type of the conversion. There is no implicit conversion on assignment from the sql_variant data type, but there is implicit conversion to sql_variant. These include xml, bigint, and sql_variant. The following illustration shows all explicit and implicit data type conversions that are allowed for SQL Server system-supplied data types. Use CONVERT instead of CAST to take advantage of the style functionality in CONVERT.
#Layouteditor datatype code#
Use CAST instead of CONVERT if you want Transact-SQL program code to comply with ISO. For example, the following CAST function converts the numeric value of $157.27 into a character string of '157.27': CAST ( $157.27 AS VARCHAR(10) ) The CAST and CONVERT functions convert a value (a local variable, a column, or another expression) from one data type to another. SYSDATETIME() implicitly converts to date style 21.Įxplicit conversions use the CAST or CONVERT functions. GETDATE() implicitly converts to date style 0. For example, when a smallint is compared to an int, the smallint is implicitly converted to int before the comparison proceeds. SQL Server automatically converts the data from one data type to another. Implicit conversions are not visible to the user. Implicit and explicit conversionĭata types can be converted either implicitly or explicitly. When you convert between an application variable and a SQL Server result set column, return code, parameter, or parameter marker, the supported data type conversions are defined by the database API.
When data from a Transact-SQL result column, return code, or output parameter is moved into a program variable, the data must be converted from the SQL Server system data type to the data type of the variable.
When data from one object is moved to, compared with, or combined with data from another object, the data may have to be converted from the data type of one object to the data type of the other.
With the build-in photomask service you will have access to photomask production facilities around the globe for high quality photomasks of any kind.Data types can be converted in the following scenarios: The LayoutEditor will also help you in this area. Once a design is finished photomasks are required to produce the device you have designed. So even huge designs are painted with a acceptable performance. With bigger designs a lack of performance is automatically detected and scarcely visible details are omitted. Medium sized designs (up to several hundred MB of GDS file size, exact size may depend on the design) can be painted with all details in real time. Also the painting performance is excellent and can easily compete with any other tool. So for example multi Gb GDSII files can be loaded in seconds. All significant features of the LayoutEditor are optimized to handle huge designs. Via LayoutEditor python module you can embed the LayoutEditor as a off screen tool or with its graphical user interface in your own Python application.Īs designs can extend to several Gb in file size, perfomance is an important factor.
#Layouteditor datatype download#
A wide range of ready to use macros can be download at our macro market. Macros can be added in the menu structure for a perfect integration of own created extension. Macros are written in the most common language C/C++. This makes creating macros very simple and reduces the time to learn programming a lot. So, with the LayoutEditor it is possible to record macros from the user interface like some office programs can do. It can be used for different applications. As a matter of course macros or scripts are possible with the LayoutEditor.
0 notes
Text
Data is an integral part of business Nearly any kind of modern business relies on it. Data is everywhere — texts, numbers, media, all in a multitude of formats. Your name, pictures, address, age, weight, height – it’s all data. As long as data is unorganized, it’s mostly useless. In order to make it actionable, in order to analyze it and make crucial decisions, businesses organize and systematically store data in databases. What is a database? A database is a structured collection of data, stored and processed by computer systems. Databases presuppose easy access to any selection of required data, which is conveniently organized in a wide array of database objects, with tables probably being the most notable of them. Development, management and administration of databases is typically handled by dedicated specialists. If we talk about the simplest use cases, we can mention service providers that need databases to store basic information about their clients, including names, contacts, emails, service details, etc. It helps them manage billing plans, handle requests, complaints, and track the history of services pertaining to every client. There are different types of databases. Some of the best-known types are distributed databases, object-oriented databases, relational databases, open-source databases and cloud databases. The choice depends on the needs and goals of every particular business. What are database tools? There is a diversity of software tools, specifically designed to design and develop entire databases; store, change, search, extract and back up data; keep databases up-to-date with synchronization features; and much more. Let’s say all the activities can be divided into three main categories: development, management, and administration. To handle it all most effectively, software product companies develop and provide database tools, which range from simple apps for standalone tasks to integrated development environments (IDE) that perform nearly any operation and automate the routine work of a database specialist. Who uses database tools? Database tools are mostly used by three types of specialists: • Database developers use these tools to design and develop different kinds of databases. • Database analysts use these tools to retrieve data for analysis. • Database administrators use these tools to set up and manage databases and resolve any issues that stand in the way. Types of database tools The market offers a wide variety of database development and management tools, developed by software product companies. One of the well-known examples is Devart — a company that focuses on varied database-related software, ranging from simple tools to complex solutions for all major database management systems (DBMS), including SQL Server, MySQL, Oracle, and PostgreSQL. The range of Devart products is roughly similar for each DBMS. The titles mostly speak for themselves: • Studio: all-in-one IDE that covers nearly any task related to database development, management, and administration • Data Compare: a tool that helps find and eliminate data discrepancies • Schema Compare: a tool that deals with comparison and synchronization of database schemas (structures) • SQL Complete: the ultimate tool for SQL coding, delivering smart autocompletion, code formatting and refactoring, SQL debugging, data visualization, and more • Data Generator: a tool that provides any amounts of meaningful test data • Documenter: a tool that generates full database documentation in a number of formats These are the most popular tools; if you want further details, you can find the entire product lines for each DBMS on the Devart website. Benefits of database tools The value of database tools has to outweigh their price. For example, Devart provides some of the best premium tools within an affordable price range. Here are several aspects of value delivered by them: • Visual design of databases
and queries (convenient visualization tools remove the need for unnecessary coding, thus saves time) • Automation and scheduling of routine operations • Improved code writing (smart suggestions, code snippets, code formatting and refactoring make code writing a pleasure for the developer) • Fast comparison and synchronization (both database structures and data itself can be compared and synchronized in a few clicks) Besides the extended functionality, Devart tools focus on improving the productivity of every user. This winning combination has earned them a respectable place in the market.
0 notes
Text
What Is Sage X3 System?
What Is Sage X3 System?
Sage X3 is a fast to implement, flexible technology tool that adapts to your ever-changing objectives. Gain valuable insights, reduce cost, and grow your business faster with our webinars, guides, and research. "Using Sage X3, Monk Office is nimble, efficient and can deliver a superior customer experience in order to differentiate themselves from the big players." Extend the capabilities of Sage X3, grow your business, and make life easier with our powerful connected apps. Get deeper insights and visibility on your entire manufacturing operations to enhance decision making.
Sage executives say the user interface of ERP X3 V6 is a “major revamp” compared to its prior version and can also support platforms which include, SQL Server 2008, Windows 2008, RedHat 5, Internet Explorer 8 and Windows 7. Our experienced team of journalists and bloggers bring you engaging in-depth interviews, videos and content targeted to IT professionals and line-of-business executives. In the coming months to ensure a seamless transition for employees and customers." We developed the reports based on requirement templates that the client had shared. If they required any specific changes or new requests were made, we were able to provide them with new templates to deal with their evolving needs.
By comparison, NetSuite is flexible enough to support both minor modifications and more sophisticated customization based on your needs. Our ERP consulting services enable you to find the best ERP system for your business. We will help you identify the best solution, deploy it, provide training, support, and maintenance while continuing to keep you up to date with relevant new technologies. The Sage X3 ERP software amalgamates all the data and processes of an organization into a single system and database.
Effectively manage customers and sales, and improve collaboration and communication between sales reps and the office. Designed to keep up with your day-to-day challenges, today’s business management systems go above and beyond traditional ERP. Deliver an extraordinary customer experience with automated processes, streamlined workflows, and real-time insights.
Here again, QuickBooks isn’t necessarily a head-to-head ERP competitor of NetSuite. But some smaller companies do explore the option of creating a version of an ERP solution by integrating solutions like Fishbowl for inventory and warehouse management. Intacct works well in finance-centric industries, like insurance, banking and investment firms. If you have inventory, manufacturing or supply chain requirements, a more comprehensive solution like NetSuite is likely a better fit. While not a full ERP solution, Sage Intacct could come up in your search if you’re looking for more robust financial software that you can build on over time. In the NetSuite world, you’d be looking at a Financials First implementation that doesn’t include the other ERP functionality.
Sage X3 improves your compliance outcomes by delivering key product, process and inventory details on-demand. Always know exactly what’s going on inside your production facility to ensure optimal product quality while simultaneously creating an auditable trail of digital documentation to meet regulatory expectations. Reduced man hours — By streamlining administrative tasks and automating key production processes, businesses using Sage X3 can reduce total man hours spent on repetitive, error-prone activities and increase total savings. Based on a Forrester TEI framework over three years, companies reported $119,369 on average in labor savings for reporting alone. I like that X3 works really well for corporations that are made up of many different companies.
They have over 10,000 customers worldwide in a range of industries, including aerospace and defense, energy, construction, manufacturing and services. Infor is a good fit for mixed-mode manufacturers and has more robust functionality for process manufacturing when compared to NetSuite. Keep in mind that the functionality you get will be dependent on which Infor product you choose, and you won’t have as much flexibility to use multiple products.
Expanding ERP markets combined with emerging cloud technologies have created a software landscape full of potential options. Depending on your needs, cost considerations and key organizational needs, it’s possible to find a best-fit cloud solution that delivers on-demand — and keeps on you on-budget.
Key features of Sage X3 include financial management, production management, supply chain management, inventory auditing, kitting, forecasting, cost tracking, manufacturing planning, and product identification. The financial management module allows enterprises to handle expenditures, accounts payable/receivable, and general ledgers. Users can also track fixed asset stock, financing, interim statements, and more. Sage X3 comes with user-defined dashboards to help users manage configurations based on data tables, using manual or automatic sorting, joins and selections for displaying turnover, margins, KPIs, and cash forecasts.
Monitor everything happening in your business and dig deeper to reduce costs, manage risk and identify opportunities with Sage X3. With centralized data, you can check on inventory, take orders, approve expenses or pull up-to-the-minute reports to make informed decisions on the spot. Since I grew up with technology all the functions and placements, for the most part, do make sense to me and it is easy to use.
0 notes
Text
Best Windows Hosting: Unleashing its advantages and Top Service Providers

Summary: The article provides an overview of the advantages of selecting Windows Hosting Services. And, it also lists the best Window Hosting providers available in the market, covering each business need.
With the increasing demand for .NET and ASP.NET applications, many organizations are selecting it to develop their business applications. And for hosting them, Windows Server Hosting the most relevant mechanism.
Even hosting experts prefer Windows Hosting Service for deploying the .NET-based applications.
However, there are many companies, who are unaware of the fact, that Windows Hosting is the best for .NEt apps. Also, they get confused while selecting the best Windows Hosting for their business. But, you never face such challenges, as by reading further, you will get all the answers.
Why you should select Windows Hosting Service
Windows Server Hosting leverages the following advantages, leading to increase productivity:
The server runs on the most popular Windows Operating Systems and provides GUI for easy configuration.
It allows to utilize Windows-associated tools and efficiently make changes to the ASP.NET applications.
It is compatible with an advanced MS SQL database, automating data-related tasks.
It comes with built-in Windows security tools, protecting the data from malicious actors.
It requires less effort during configuration in comparison to Linux and leads to saving both cost and time.
Discovering the Best and Cheap Windows Hosting Providers
Cantech
Cantech is a leading hosting provider, offering up-to-date windows server hosting in budget-friendly plans. It provides you with administrator access and a Plesk panel, helping you in efficiently manage the core operations. In addition, it allows you to scale up resources at any moment for handling the extensive user load.
Moreover, its overall architecture gets based on VPS hosting technology and only contains the SSD drives for providing faster speed. If you select Cantech, you will get a fully-managed server, leading to saving additional server maintenance and upgradation cost.
Besides this, if you are hosting a website on any other platform and want to switch it to Cantech, you can flawlessly execute it. They provide 24/7 support services, which will help you to freely migrate to Cantech Windows Server hosting.
Read More
#Windows#Windows hosting services#cheap windows hosting#windows hosting providers#windows hosting companies
0 notes
Text
Revealing the Nature of Full-Stack Programming: Converging Frontend and Backend Development Domains
Within the dynamic field of software engineering, the phrase "full-stack development" has gained significant traction. It includes all of the extensive skill set needed to create web applications' front-end and back-end parts. Full-stack developers are the Swiss Army knives of the IT industry; they can handle every step of the development process and are skilled in a wide range of technologies.
Comprehending Full-Stack Development
The fundamental component of full-stack development is the ability to work with both frontend and backend technologies. The user-facing portion of a programme, where users interact with the interface, is referred to as the frontend. Using HTML, CSS, and JavaScript, this entails creating aesthetically pleasing and user-friendly designs. To improve functionality and user experience, frameworks and libraries like React, Angular, or Vue.js are frequently used. The backend, on the other hand, is responsible for managing business logic, data retrieval, and storage on the server-side of the programme. Working with server-side languages like Node.js, Python, Ruby, or Java in conjunction with frameworks like Express, Django, or Flask is known as backend development. Additionally, efficient data management requires familiarity with databases like SQL, MongoDB, or Firebase.
Full-Stack Developers' Role
Development teams rely heavily on full-stack engineers since they can easily switch between front-end and back-end duties. They can comprehend every aspect of the software stack, from database administration to user interface design, thanks to their adaptability. This all-encompassing method encourages teamwork and expedites the development process because full-stack engineers are able to interact with frontend and backend experts with ease. In addition, full-stack developers have a wider viewpoint that enables them to see the application as a whole instead of concentrating just on its individual parts. This all-encompassing approach is crucial for creating coherent designs and maximising performance throughout the stack.
Benefits of Full-Stack Development
Efficiency:-Development cycles are accelerated by having a single developer that is skilled in both frontend and backend technologies. Full-stack engineers can work independently on projects at any level of the stack, removing bottlenecks and dependencies.
Flexibility:-As project requirements change, full-stack developers can easily transition between frontend and backend duties. With their limited resources, startups and small teams can benefit greatly from this flexibility.
Expense-effectiveness:-It may be less expensive to hire full-stack developers than to put together separate frontend and backend teams. This lowers the overhead related to interdepartmental team collaboration and communication.
Solving Problems:-Full-stack developers can identify and fix problems more quickly because they have a thorough understanding of the whole software stack. Problem-solving is sped up by their proficiency with front-end and back-end debugging and troubleshooting.
Obstacles and Things to Think About
Full-stack development has many advantages, but it also has drawbacks. Acquiring proficiency in numerous technologies necessitates commitment and continuous education to keep up with developments. Furthermore, in comparison to professionals, the depth of knowledge needed might occasionally result in a superficial grasp of particular technology. Furthermore, because technology is developing so quickly, full-stack engineers need to keep their skill set up to date in order to stay relevant. Maintaining expertise in frontend and backend development requires being up to date with new developments in the field as well as industry best practices.
Conclusion
The combination of frontend and backend development skills is best represented by full-stack development, which enables programmers to design comprehensive solutions that slickly combine functionality and user experience. The need for adaptable full-stack developers is expected to rise as technology advances. Adopting this diverse approach to software engineering promotes creativity, effectiveness, and adaptability in addressing the ever-changing needs of the digital world.
0 notes
Text
300+ TOP PL/SQL Interview Questions and Answers
PL/SQL Interview Questions for freshers experienced :-
1. What is PL/SQL? It is defined as SQL having Procedural features of Programming Language i.e. Procedural Language extension of SQL. 2. Explain the structure of PL/SQL in brief. PL/SQL is a procedural language which has interactive SQL, as well as procedural programming language constructs like conditional branching and iteration. 3. Explain uses of cursor. Cursor is a named private area in SQL from which information can be accessed. They are required to process each row individually for queries which return multiple rows. 4. Show code of a cursor for loop. Cursor declares %ROWTYPE as loop index implicitly. It then opens a cursor, gets rows of values from the active set in fields of the record and shuts when all records are processed. Eg. FOR smp_rec IN C1 LOOP totalsal=totalsal+smp_recsal; ENDLOOP; 5. Explain the uses of database trigger. A PL/SQL program unit associated with a particular database table is called a database trigger. It is used for : Audit data modifications. Log events transparently. Enforce complex business rules. Maintain replica tables Derive column values Implement Complex security authorizations 6. What are the two types of exceptions. Error handling part of PL/SQL block is called Exception. They have two types : user_defined and predefined. 7. Show some predefined exceptions. DUP_VAL_ON_INDEX ZERO_DIVIDE NO_DATA_FOUND TOO_MANY_ROWS CURSOR_ALREADY_OPEN INVALID_NUMBER INVALID_CURSOR PROGRAM_ERROR TIMEOUT _ON_RESOURCE STORAGE_ERROR LOGON_DENIED VALUE_ERROR etc. 8. Explain Raise_application_error. It is a procedure of package DBMS_STANDARD that allows issuing of user_defined error messages from database trigger or stored sub-program. 9.Show how functions and procedures are called in a PL/SQL block. Function is called as a part of an expression. total:=calculate_sal(‘b644’) Procedure as a statement in PL/SQL. calculate_bonus(‘b644’); 10. Explain two virtual tables available at the time of database trigger execution. Table columns are referred as THEN.column_name and NOW.column_name. For INSERT related triggers, NOW.column_name values are available only. For DELETE related triggers, THEN.column_name values are available only. For UPDATE related triggers, both Table columns are available.

PL/SQL Interview Questions 11. What are the rules to be applied to NULLs whilst doing comparisons? NULL is never TRUE or FALSE NULL cannot be equal or unequal to other values If a value in an expression is NULL, then the expression itself evaluates to NULL except for concatenation operator (||) 12. How is a process of PL/SQL compiled? Compilation process includes syntax check, bind and p-code generation processes. Syntax checking checks the PL/SQL codes for compilation errors. When all errors are corrected, a storage address is assigned to the variables that hold data. It is called Binding. P-code is a list of instructions for the PL/SQL engine. P-code is stored in the database for named blocks and is used the next time it is executed. 13. Differentiate between Syntax and runtime errors. A syntax error can be easily detected by a PL/SQL compiler. For eg, incorrect spelling. A runtime error is handled with the help of exception-handling section in an PL/SQL block. For eg, SELECT INTO statement, which does not return any rows. 14. Explain Commit, Rollback and Savepoint. For a COMMIT statement, the following is true: Other users can see the data changes made by the transaction. The locks acquired by the transaction are released. The work done by the transaction becomes permanent. A ROLLBACK statement gets issued when the transaction ends, and the following is true. The work done in a transition is undone as if it was never issued. All locks acquired by transaction are released. It undoes all the work done by the user in a transaction. With SAVEPOINT, only part of transaction can be undone. 15. Define Implicit and Explicit Cursors. A cursor is implicit by default. The user cannot control or process the information in this cursor. If a query returns multiple rows of data, the program defines an explicit cursor. This allows the application to process each row sequentially as the cursor returns it. 16. Explain mutating table error. It occurs when a trigger tries to update a row that it is currently using. It is fixed by using views or temporary tables, so database selects one and updates the other. 17. When is a declare statement required? DECLARE statement is used by PL/SQL anonymous blocks such as with stand alone, non-stored procedures. If it is used, it must come first in a stand alone file. 18. How many triggers can be applied to a table? A maximum of 12 triggers can be applied to one table. 19. What is the importance of SQLCODE and SQLERRM? SQLCODE returns the value of the number of error for the last encountered error whereas SQLERRM returns the message for the last error. 20. If a cursor is open, how can we find in a PL/SQL Block? the %ISOPEN cursor status variable can be used. 21. Show the two PL/SQL cursor exceptions. Cursor_Already_Open Invaid_cursor 22. What operators deal with NULL? NVL converts NULL to another specified value. var:=NVL(var2,’Hi’); IS NULL and IS NOT NULL can be used to check specifically to see whether the value of a variable is NULL or not. 23. Does SQL*Plus also have a PL/SQL Engine? No, SQL*Plus does not have a PL/SQL Engine embedded in it. Thus, all PL/SQL code is sent directly to database engine. It is much more efficient as each statement is not individually stripped off. 24. What packages are available to PL/SQL developers? DBMS_ series of packages, such as, DBMS_PIPE, DBMS_DDL, DBMS_LOCK, DBMS_ALERT, DBMS_OUTPUT, DBMS_JOB, DBMS_UTILITY, DBMS_SQL, DBMS_TRANSACTION, UTL_FILE. 25. Explain 3 basic parts of a trigger. A triggering statement or event. A restriction An action 26. What are character functions? INITCAP, UPPER, SUBSTR, LOWER and LENGTH are all character functions. Group functions give results based on groups of rows, as opposed to individual rows. They are MAX, MIN, AVG, COUNT and SUM. 27. Explain TTITLE and BTITLE. TTITLE and BTITLE commands that control report headers and footers. 28. Show the cursor attributes of PL/SQL. %ISOPEN : Checks if the cursor is open or not %ROWCOUNT : The number of rows that are updated, deleted or fetched. %FOUND : Checks if the cursor has fetched any row. It is true if rows are fetched %NOT FOUND : Checks if the cursor has fetched any row. It is True if rows are not fetched. 29. What is an Intersect? Intersect is the product of two tables and it lists only matching rows. 30. What are sequences? Sequences are used to generate sequence numbers without an overhead of locking. Its drawback is that the sequence number is lost if the transaction is rolled back. 31. How would you reference column values BEFORE and AFTER you have inserted and deleted triggers? Using the keyword “new.column name”, the triggers can reference column values by new collection. By using the keyword “old.column name”, they can reference column vaues by old collection. 32. What are the uses of SYSDATE and USER keywords? SYSDATE refers to the current server system date. It is a pseudo column. USER is also a pseudo column but refers to current user logged onto the session. They are used to monitor changes happening in the table. 33. How does ROWID help in running a query faster? ROWID is the logical address of a row, it is not a physical column. It composes of data block number, file number and row number in the data block. Thus, I/O time gets minimized retrieving the row, and results in a faster query. 34. What are database links used for? Database links are created in order to form communication between various databases, or different environments like test, development and production. The database links are read-only to access other information as well. 35. What does fetching a cursor do? Fetching a cursor reads Result Set row by row. 36. What does closing a cursor do? Closing a cursor clears the private SQL area as well as de-allocates memory 37. Explain the uses of Control File. It is a binary file. It records the structure of the database. It includes locations of several log files, names and timestamps. They can be stored in different locations to help in retrieval of information if one file gets corrupted. 38. Explain Consistency Consistency shows that data will not be reflected to other users until the data is commit, so that consistency is maintained. 39. Difference between Anonymous blocks and sub-programs. Anonymous blocks are unnamed blocks that are not stored anywhere whilst sub-programs are compiled and stored in database. They are compiled at runtime. 40. Differ between DECODE and CASE. DECODE and CASE statements are very similar, but CASE is extended version of DECODE. DECODE does not allow Decision making statements in its place. select decode(totalsal=12000,’high’,10000,’medium’) as decode_tesr from smp where smpno in (10,12,14,16); This statement returns an error. CASE is directly used in PL/SQL, but DECODE is used in PL/SQL through SQL only. 41. Explain autonomous transaction. An autonomous transaction is an independent transaction of the main or parent transaction. It is not nested if it is started by another transaction. There are several situations to use autonomous transactions like event logging and auditing. 42. Differentiate between SGA and PGA. SGA stands for System Global Area whereas PGA stands for Program or Process Global Area. PGA is only allocated 10% RAM size, but SGA is given 40% RAM size. 43. What is the location of Pre_defined_functions. They are stored in the standard package called “Functions, Procedures and Packages” 44. Explain polymorphism in PL/SQL. Polymorphism is a feature of OOP. It is the ability to create a variable, an object or function with multiple forms. PL/SQL supports Polymorphism in the form of program unit overloading inside a member function or package..Unambiguous logic must be avoided whilst overloading is being done. 45. What are the uses of MERGE? MERGE is used to combine multiple DML statements into one. Syntax : merge into tablename using(query) on(join condition) when not matched then command when matched then command 46. Can 2 queries be executed simultaneously in a Distributed Database System? Yes, they can be executed simultaneously. One query is always independent of the second query in a distributed database system based on the 2 phase commit. 47. Explain Raise_application_error. It is a procedure of the package DBMS_STANDARD that allow issuing a user_defined error messages from the database trigger or stored sub-program. 48. What is out parameter used for eventhough return statement can also be used in pl/sql? Out parameters allows more than one value in the calling program. Out parameter is not recommended in functions. Procedures can be used instead of functions if multiple values are required. Thus, these procedures are used to execute Out parameters. 49. How would you convert date into Julian date format? We can use the J format string : SQL > select to_char(to_date(‘29-Mar-2013’,’dd-mon-yyyy’),’J’) as julian from dual; JULIAN 50. Explain SPOOL Spool command can print the output of sql statements in a file. spool/tmp/sql_outtxt select smp_name, smp_id from smp where dept=’accounts’; spool off; 51. What are the system privileges that are required by a schema owner (user) to create a trigger on a table? A user must be able to alter a table to create a trigger on the table. The user must own the table and either have the ALTER TABLE privilege on that table or have the ALTER ANY TABLE system privilege. In addition, the user must have the CREATE TRIGGER system privilege. User should have the CREATE ANY TRIGGER system privilege to be able to create triggers in any other user account or schema. A database-level event trigger can be created if the user has the ADMINISTER DATABASE TRIGGER system privilege. 52. What are the different types of triggers? There are following two types of triggers: Database triggers are executed implicitly whenever a Data Manipulation Language (DML) statement is carried out on a database table or a Data Definition Language (DDL) statement, such as CREATE OR ALTER, is performed on the database. They may also be executed when a user or database event occurs, such as a user logs on or a database is shutdown. Application triggers are executed implicitly whenever a DML event takes place within an application, such as WHEN_NEW_FORM_INSTANCE in the Oracle Forms application. 53. How can triggers be used for the table auditing? Triggers can be used to track values for data operations on tables. This is done using the old and new qualifiers within the trigger code. These two clauses help keep track of the data that is being inserted, updated, or deleted in the table; and therefore, facilitate in application auditing of DML statements. The audit trail can be written to a user-defined table and audit records can be generated for both row-level and statement-level triggers. 54. What are INSTEAD OF triggers? The INSTEAD OF triggers are used in association with views. The standard table-based triggers cannot be used by views. These triggers inform the database of what actions are to be performed instead of the actions that invoked the trigger. Therefore, the INSTEAD OF triggers can be used to update the underlying tables, which are part of the views. They can be used on both relational views and object views. The INSTEAD OF triggers can only be defined as row-level triggers and not as statement-level triggers. 55. What is the difference between database trigger and stored procedure? The main difference between database trigger and stored procedure is that the trigger is invoked implicitly and stored procedure is invoked explicitly. Transaction Control statements, such as COMMIT, ROLLBACK, and SAVEPOINT, are not allowed within the body of a trigger whereas, these statements can be included in a stored procedure. 56. How can the performance of a trigger be improved? The performance of a trigger can be improved by using column names along with the UPDATE clause in the trigger. This will make the trigger fire when that particular column is updated and therefore, prevents unnecessary action of trigger when other columns are being updated. 57. What are the events on which a database trigger can be based? Database triggers are based on system events and can be defined at database or schema level. The various events on which a database trigger can be based are given as follows: Data definition statement on a database or schema object Logging off or on of a specific user Database shutdown or startup On any specific error that occurs 58. What is a CALL statement? Explain with an example. A CALL statement within a trigger enables you to call a stored procedure within the trigger rather than writing the Procedural Language/Structured Query Language (PL/SQL) code in it, The procedure may be in PL/SQL, C, or Java language. Following is an example of the CALL statement: CREAT OR REPLASE TRIGGER BEFORE UPDATE OF ON FOR EACH ROW WHEN CALL 59. What is a mutating table? A mutating table is a table, which is in the state of transition. In other words, it is a table, which is being updated at the time of triggering action. If the trigger code queries this table, then a mutating table error occurs, which causes the trigger to view the inconsistent data. 60. Which data dictionary views have the information on the triggers that are available in the database? The data dictionary views that have information on database triggers are given as follows: USER_OBJECTS —Contain the name and status of a trigger as well as the date and time of trigger creation USER_ERRORS—Contain the compilation error of a trigger USER_ TRIGGERS— Contain the source code of a trigger USER_ TRIGGER_COLS—Contain the information on columns used in triggers 62. What are schema-level triggers? Schema-level triggers are created on schema-level operations, such as create table, alter table, drop table, rename, truncate, and revoke. These triggers prevent DDL statements, provide security, and monitor the DDL operations. 63. What is a database event trigger? Trigger that is executed when a database event, such as startup, shutdown, or error, occurs is called a database event trigger. It can be used to reference the attributes of the event and perform system maintenance functions immediately after the database startup. 64. In what condition is it good to disable a trigger? It is good to disable triggers during data load operations. This improves the performance of the data loading activities. The data modification and manipulation that the trigger would have performed has to be done manually after the data loading. 65. Which column of the USERJTRIGGERS data dictionary view displays the database event that will fire the trigger? The Description column of the USERJTRIGGERS view combines information from many columns to display the trigger header, which includes the database event. 66. What is the meaning of disabling a trigger? When a trigger is disabled, it does not mean that it is deleted. The code of the trigger is still stored in the data dictionary but the trigger will not have any effect on the table. 67. Can triggers stop a DML statement from executing on a table? Yes, triggers have the capability of stopping any DML statement from execution on a table. Any logical business rule can be implemented using PL/SQL to block modification on table data. 68. Can a view be mutating? If yes, then how? No, a view cannot be mutating like a table. If an UPDATE statement fires an INSTEAD OF trigger on a view, the view is not considered to be mutating. If the UPDATE statement had been executed on a table, the table would have been considered as mutating. 69. Can a COMMIT statement be executed as part of a trigger? No, A COMMIT statement cannot be executed as a part of a trigger because it is a Transaction Control statement, which cannot be executed within a trigger body. Triggers fire within transactions and cannot include any Transaction Control statement within its code. 70. What is the difference between ALTER TRIGGER and DROP TRIGGER statements? An ALTER TRIGGER statement is used to recompile, disable, or enable a trigger; whereas, the DROP TRIGGER statement is used to remove the trigger from the database. 71. Do triggers have restrictions on the usage of large datatypes, such as LONG and LONG RAW? Triggers have restrictions on the usage of large datatypes as they cannot declare or reference the LONG and LONG RAW datatypes and cannot use them even if they form part of the object with which the trigger is associated. Similarly, triggers cannot modify the CLOB and BLOB objects as well however, they can reference them for read-only access. 72. Are DDL triggers fired for DDL statements within a PL/SQL code executed using the DBMS.SQL package? No, DDL triggers are not executed for DDL statements, which are executed within the PL/SQL code using the DBMS_SQL package. 73. Does a USER_OBJECTS view have an entry for a trigger? Yes, the USER_OBJECTS view has one row entry for each trigger in the schema. 74. How can you view the errors encountered in a trigger? The USERJERRORS view can be used to show all the parsing errors that occur in a trigger during the compilation until they are resolved. 75. Does USERJTRIGGERS have entry for triggers with compilation errors? Yes, USER_TRIGGERS have entries for all triggers that are created in the schema with or without errors. 76. Is it possible to pass parameters to triggers? No, it is not possible to pass parameters to triggers. However, triggers fired by INSERT and UPDATE statements can reference new data by using the mew prefix. In addition, the triggers fired in response to UPDATE and DELETE statements can reference old, modified, or deleted data using the :old prefix. 77. Can a SELECT statement fire a trigger? No, a SELECT statement cannot fire a trigger. DML statements, such as INSERT, UPDATE, and DELETE, can cause triggers to fire. 78. Can cursors be part of a trigger body? Yes, cursors can be a part of code in trigger. 79. Is it possible to create STARTUP or SHUTDOWN trigger for ON-SCHEMA? No, It is not possible to create STARTUP or SHUTDOWN triggers for ON-SCHEMA. 80. What does the BASE_OBJECT_TYPE column shows in the USER.TRIGGERS data dictionary view? The BASE_OBJECT_TYPE column identifies the type of database object with which the trigger is associated. It shows whether the object of database is a TABLE, VIEW, SCHEMA, or DATABASE. 81. Is it possible to create the following trigger: BEFORE OR AFTER UPDATE trigger FOR EACH ROW? No, it is an invalid trigger as both BEFORE and AFTER cannot be used in the same trigger. A trigger can be either BEFORE TRIGGER or AFTER TRIGGER. 82. Can INSTEAD OF triggers be used to fire once for each statement on a view? No, INSTEAD OF triggers cannot be used for each statement however, It can only be used for each row on a view. 83. Is it possible to include an INSERT statement on the same table to which the trigger is assigned? If an INSERT statement is used on the same table to which the trigger is associated, then this will give rise to a mutating table, as it is not possible to change the same table that is already in the process of being changed. 84. What are conditional predicates? Triggers use conditional predicates, such as INSERTING, UPDATING, and DELETING, to determine which particular event will cause the trigger to fire. All the three predicates have Boolean values and are useful in triggers, such as AFTER INSERT or UPDATE. 85. Write the ALTER statement to enable all the triggers on the T.STUDENTS table. The ALTER statement is given as follows: ALTER TABLE T_STUDENTS ENABLE ALL TRIGGERS; 86. Which column in the USER.TRIGGERS data dictionary view shows that the trigger is a PL/SQL trigger? The ACTION_TYPE column of the USER_TRIGGERS data dictionary view shows that the trigger is a PL/SQL trigger. 87. Differentiate between % ROWTYPE and TYPE RECORD. % ROWTYPE is used when a query returns an entire row of a table or view. TYPE RECORD, on the other hand, is used when a query returns column of different tables or views. Eg. TYPE r_emp is RECORD (sno smp.smpno%type,sname smp sname %type) e_rec smp ROWTYPE Cursor c1 is select smpno,dept from smp; e_rec c1 %ROWTYPE PL/SQL Questions and Answers Pdf Download Read the full article
1 note
·
View note
Text
A Layman’s Guide to Data Science. Part 3: Data Science Workflow

By now you have already gained enough knowledge and skills about Data Science and have built your first (or even your second and third) project. At this point, it is time to improve your workflow to facilitate further development process.
There is no specific template for solving any data science problem (otherwise you’d see it in the first textbook you come across). Each new dataset and each new problem will lead to a different roadmap. However, there are similar high-level steps in many different projects.
In this post, we offer a clean workflow that can be used as a basis for data science projects. Every stage and step in it, of course, can be addressed on its own and can even be implemented by different specialists in larger-scale projects.
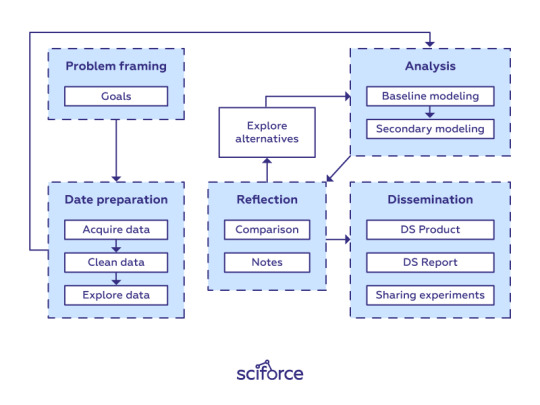
Data science workflow
Framing the problem and the goals
As you already know, at the starting point, you’re asking questions and trying to get a handle on what data you need. Therefore, think of the problem you are trying to solve. What do you want to learn more about? For now, forget about modeling, evaluation metrics, and data science-related things. Clearly stating your problem and defining goals are the first step to providing a good solution. Without it, you could lose the track in the data-science forest.
Data Preparation Phase
In any Data Science project, getting the right kind of data is critical. Before any analysis can be done, you must acquire the relevant data, reformat it into a form that is amenable to computation and clean it.

Acquire data
The first step in any data science workflow is to acquire the data to analyze. Data can come from a variety of sources:
imported from CSV files from your local machine;
queried from SQL servers;
stripped from online repositories such as public websites;
streamed on-demand from online sources via an API;
automatically generated by physical apparatus, such as scientific lab equipment attached to computers;
generated by computer software, such as logs from a webserver.
In many cases, collecting data can become messy, especially if the data isn’t something people have been collecting in an organized fashion. You’ll have to work with different sources and apply a variety of tools and methods to collect a dataset.
There are several key points to remember while collecting data:
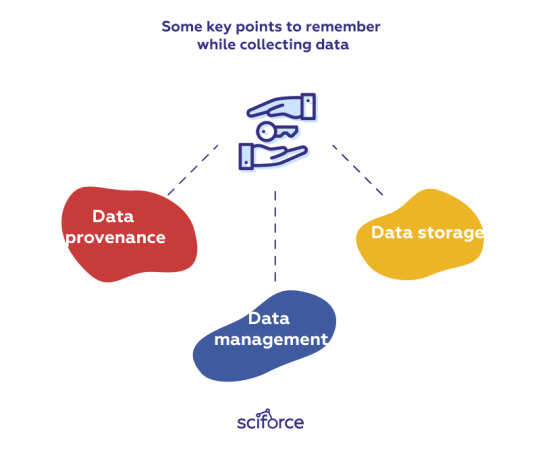
Data provenance: It is important to accurately track provenance, i.e. where each piece of data comes from and whether it is still up-to-date, since data often needs to be re-acquired later to run new experiments. Re-acquisition can be helpful if the original data sources get updated or if researchers want to test alternate hypotheses. Besides, we can use provenance to trace back downstream analysis errors to the original data sources.
Data management: To avoid data duplication and confusion between different versions, it is critical to assign proper names to data files that they create or download and then organize those files into directories. When new versions of those files are created, corresponding names should be assigned to all versions to be able to keep track of their differences. For instance, scientific lab equipment can generate hundreds or thousands of data files that scientists must name and organize before running computational analyses on them.
Data storage: With modern almost limitless access to data, it often happens that there is so much data that it cannot fit on a hard drive, so it must be stored on remote servers. While cloud services are gaining popularity, a significant amount of data analysis is still done on desktop machines with data sets that fit on modern hard drives (i.e., less than a terabyte).

Reformat and clean data
Raw data is usually not in a convenient format to run an analysis, since it was formatted by somebody else without that analysis in mind. Moreover, raw data often contains semantic errors, missing entries, or inconsistent formatting, so it needs to be “cleaned” prior to analysis.
Data wrangling (munging) is the process of cleaning data, putting everything together into one workspace, and making sure your data has no faults in it. It is possible to reformat and clean the data either manually or by writing scripts. Getting all of the values in the correct format can involve stripping characters from strings, converting integers to floats, or many other things. Afterwards, it is necessary to deal with missing values and null values that are common in sparse matrices. The process of handling them is called missing data imputation where the missing data are replaced with substituted data.
Data integration is a related challenge, since data from all sources needs to be integrated into a central MySQL relational database, which serves as the master data source for his analyses.
Usually it consumes a lot of time and cannot be fully automated, but at the same time, it can provide insights into the data structure and quality as well as the models and analyses that might be optimal to apply.

Explore the data
Here’s where you’ll start getting summary-level insights of what you’re looking at, and extracting the large trends. At this step, there are three dimensions to explore: whether the data imply supervised learning or unsupervised learning? Is this a classification problem or is it a regression problem? Is this a prediction problem or an inference problem? These three sets of questions can offer a lot of guidance when solving your data science problem.
There are many tools that help you understand your data quickly. You can start with checking out the first few rows of the data frame to get the initial impression of the data organization. Automatic tools incorporated in multiple libraries, such as Pandas’ .describe(), can quickly give you the mean, count, standard deviation and you might already see things worth diving deeper into. With this information you’ll be able to determine which variable is our target and which features we think are important.
Analysis Phase
Analysis is the core phase of data science that includes writing, executing, and refining computer programs to analyze and obtain insights from the data prepared at the previous phase. Though there are many programming languages for data science projects ranging from interpreted “scripting” languages such as Python, Perl, R, and MATLAB to compiled ones such as Java, C, C++, or even Fortran, the workflow for writing analysis software is similar across the languages.
As you can see, analysis is a repeated iteration cycle of editing scripts or programs, executing to produce output files, inspecting the output files to gain insights and discover mistakes, debugging, and re-editing.

Baseline Modeling
As a data scientist, you will build a lot of models with a variety of algorithms to perform different tasks. At the first approach to the task, it is worthwhile to avoid advanced complicated models, but to stick to simpler and more traditional linear regression for regression problems and logistic regression for classification problems as a baseline upon which you can improve.
At the model preprocessing stage you can separate out features from dependent variables, scale the data, and use a train-test-split or cross validation to prevent overfitting of the model — the problem when a model too closely tracks the training data and doesn’t perform well with new data.
With the model ready, it can be fitted on the training data and tested by having it predict y values for the X_test data. Finally, the model is evaluated with the help of metrics that are appropriate for the task, such as R-squared for regression problems and accuracy or ROC-AUC scores for classification tasks.

Secondary Modeling
Now it is time to go into a deeper analysis and, if necessary, use more advanced models, such as, for example neural networks, XGBoost, or Random Forests. It is important to remember that such models can initially render worse results than simple and easy-to-understand models due to a small dataset that cannot provide enough data or to the collinearity problem with features providing similar information.
Therefore, the key task of the secondary modeling step is parameter tuning. Each algorithm has a set of parameters you can optimize. Parameters are the variables that a machine learning technique uses to adjust to the data. Hyperparameters that are the variables that govern the training process itself, such as the number of nodes or hidden layers in a neural network, are tuned by running the whole training job, looking at the aggregate accuracy, and adjusting.
Reflection Phase
Data scientists frequently alternate between the analysis and reflection phases: whereas the analysis phase focuses on programming, the reflection phase involves thinking and communicating about the outputs of analyses. After inspecting a set of output files, a data scientist, or a group of data scientists can make comparisons between output variants and explore alternative paths by adjusting script code and/or execution parameters. Much of the data analysis process is trial-and-error: a scientist runs tests, graphs the output, reruns them, graphs the output and so on. Therefore, graphs are the central comparison tool that can be displayed side-by-side on monitors to visually compare and contrast their characteristics. A supplementary tool is taking notes, both physical and digital to keep track of the line of thought and experiments.
Communication Phase
The final phase of data science is disseminating results either in the form of a data science product or as written reports such as internal memos, slideshow presentations, business/policy white papers, or academic research publications.
A data science product implies getting your model into production. In most companies, data scientists will be working with the software engineering team to write the production code. The software can be used both to reproduce the experiments or play with the prototype systems and as an independent solution to tackle a known issue on the market, like, for example, assessing the risk of financial fraud.
Alternatively to the data product, you can create a data science report. You can showcase your results with a presentation and offer a technical overview on the process. Remember to keep your audience in mind: go into more detail if presenting to fellow data scientists or focus on the findings if you address the sales team or executives. If your company allows publishing the results, it is also a good opportunity to have feedback from other specialists. Additionally, you can write a blog post and push your code to GitHub so the data science community can learn from your success. Communicating your results is an important part of the scientific process, so this phase should not be overlooked.
0 notes
Text
ดูโปรแกรมการสอนคอร์สจาก orange ทางเลือกสำหรับคนที่ต้องการเขียนเว็บไซต์
ยุคเดี่ยวนี้หากใครรู้เรื่องเกี่ยวกับโปรแกรมแล้วหละก็จะเป็นเรื่องที่ดีเป็นอย่างมากเพราะว่าการทำเว็บไซต์นั้นเป็นสิ่งที่จำเป็นอย่างยิ่งในยุคเดียวนี้ เพราะถ้าใครรู้เรื่องเกี่ยวกับการทำเว็บไซต์แล้วจะเป็นโอกาสดีที่สามารถพัฒนาและต่อยอดการทำ ธุรกิจในอนาคต
คอร์สเรียนเขียนโปรแกรม นั่นมีคอร์สมากมายที่เราสามารถเรียนได้ อย่างคอร์สจาก orange ทีมีการกำหนดการเรียนคอร์สให้เราสามารถเรียนคอร์สจากทีมงานได้ไม่ว่าจะเป็นการเรียนคอร์สเขียนเว็บไซต์ การเรียน wordpress และอื่นอีกมากมาย ซึ่งตารางที่เราได้ไปหาในเว็บในการเรียนคอร์สได้ดังต่อไปนี้

Break 1 (10.00-12.00)
PHP & HTML5 & CSS เบื้องต้น
เนื้อหาของหน่วยนี้จะแนะนำให้รู้จักกับ PHP ตั้งแต่เริ่มต้นไปจนถึงการนำไปพัฒนาใช้งาน และรู้จักกับพื้นฐาน HTML5 & CSS เพื่อประยุกต์พัฒนาเว็บต่อไป
PHP คือ?
หลักการทำงานและข้อดีของPHP
พื้นฐานโครงสร้างHTML5 เบื้องต้น
พื้นฐานโครงสร้างCSS เบื้องต้น
Break 2 (13.00-16.00)
ติดตั้งซอฟต์แวร์ที่ได้ใช้งานกับ PHP
ได้แก่ โปรแกรมที่ทำหน้าเป็นเว็บเซิร์ฟเวอร์ และ PHP รวมไปถึงโปรแกรมที่ช่วยในการเขียนโค้ด
Web Server > XAMPP
Tools Editor > Sublime
(Work Shop)
ครั้งที่ 2
Break 1 (10.00-12.00)
Getting started with PHP
หน่วยนี้จะเริ่มพื้นฐานการเขียนโปรแกรมด้วย PHP
การเปิด-ปิดแท็ก, comment อธิบายโค้ด
ตัวแปร(Variable)
ประเภทของข้อมูล(Data Type)
ค่าคงที่(Constant)
โอเปอเรเตอร์ต่างๆ(Operator) ได้แก่
Arithmetic Operator, String Operator, Assignment Operator, Combination Assignment Operator, Increment and Decrement Operator, Comparison Operator, Logical Operator
Break 2 ( 13.00-16.00 )
กลุ่มคำสั่งที่ใช้ตรวจสอบเงื่อนไข
คำสั่งif / else / elseif
คำสั่งswitch
กลุ่มคำสั่งควบคุมการทำงานซ้ำๆ
คำสั่งwhile
คำสั่งfor
คำสั่งdo..while
(Work Shop)
ครั้งที่ 3
Break 1 (10.00-12.00)
อาร์เรย์ (Array)
หน่วยที่ผ่านมาได้กล่าวถึงตัวแปรที่ใช้สำหรับเก็บค่าเพียงค่าเดียว แต่การที่จะเก็บข้อมูลหลายๆ ตัวไว้ในกลุ่มเดียวกันอีกรูปแบบหนึ่ง โดยไม่ต้องใช้ตัวแปรหลายๆ ตัว เรียกว่า อาร์เรย์ ซึ่งหน่วยนี้จะแนะนำการใช้งานตัวแปรอาร์เรย์ที่มีความหลากหลาย
พื้นฐานของอาร์เรย์
การสร้างอาร์เรย์
นับจำนวนสมาชิกในอาร์เรย์
แสดงรายการสมาชิกในอาร์เรย์
ตรวจสอบข้อมูลในอาร์เรย์
แก้ไขและลบสมาชิกในอาร์เรย์
สร้างสตริงจากอาร์เรย์ด้วยimplode() และสร้างอาร์เรย์จากสตริงด้วย explode()
จัดเรียงสมาชิกในอาร์เรย์เบื้องต้น
อาร์เรย์หลายมิติ
Break 2 (13.00-16.00)
Work Shop เกี่ยวกับ Array
ครั้งที่ 4
Break 1 (10.00-12.00)
สตริง (String)
ในหน่วยนี้จะกล่าวถึงฟังก์ชันที่ใช้ จัดการกับสตริง ซึ่งจะเป็นพื้นฐานในการพัฒนาเว็บแอปพลิเคชันด้วย PHP ต่อไป
ตัดช่องว่างสตริง , จัดรูปแบบ สตริง
หาความยาวและ เปรียบเทียบ สตริง
หาสตริงย่อยและ ตำแหน่งของสตริง
ค้นหาและแทนที่ข้อมูลในสตริง
(Work Shop)
Break 2 (13.00-16.00)
Date & Time
PHP มีความสามารถในการจัดการข้อมูลวันที่และเวลาได้หลากหลายรูปแบบและการแสดงผลทางเว็บไซต์ ซึ่งวันที่และเวลา มีความสำคัญในการพัฒนาเว็บไซต์ และแสดงให้เห็นบนเว็บไซต์โดยทั่วไป เช่น การแสดงวันที่เวลาปัจจุบัน วันที่การสั่งซื้อสินค้า การบันทึกเวลาที่โพสต์ข้อมูลบนเว็บไซต์ การคำนวณวันเวลาในระบบฐานข้อมูลที่ใช้พัฒนาเว็บไซต์ เป็นต้น
แสดงวันที่ภาษาไทย
ตรวจสอบวันที่ว่าถูกต้องหรือไม่
รู้จักกับค่าtimestamp
การแสดงวันที่และเวลาในหลายๆรูปแบบ
(Work Shop)
ครั้งที่ 5
Break 1 (10.00-12.00)
ฟอร์ม (FORM) และ MySQL
การเขียน PHP เพื่อจัดการกับข้อมูลในแบบฟอร์ม การตรวจสอบข้อมูลที่รับมาจากผู้ใช้จากฟอร์ม และการใช้งาน MySQL ซึ่งเป็นระบบฐานข้อมูลที่ได้รับความนิยมเป็นจำนวนมากในช่วงที่ผ่านมา เนื่องจากเป็นฐานข้อมูลประเภทโอเพ่นซอร์ซ ทำให้ไม่มีค่าใช้จ่ายเมื่อนำมาใช้งาน อีกทั้งยังมีความสามารถ ไม่แพ้ระบบจัดการฐานข้อมูลที่ต้องเสียเงินอย่างเช่น Oracle, MS SQL เป็นต้น
ฟอร์ม=> text box, text area, hidden field
ฟอร์ม=> radio button, checkbox
ฟอร์ม=> select box
ตรวจสอบข้อมูลจากแบบฟอร์มและการประยุกต์ใช้งาน Form
การใช้งานMySQL เบื้องต้น
การสร้างฐานข้อมูล, การสร้างตาราง
ชนิดข้อมูลในMySQL เบื้องต้น เช่น ข้อมูลตัวเลข, ข้อมูลวันที่-เวลา, ข้อมูลสตริง เป็นต้น
(Work Shop)
Break 2 (13.00-16.00)
เขียน PHP ติดต่อกับ MySQL (PDO)
เนื้อหาในหน่วยนี้จะเชื่อมโยงจากหน่วยที่ผ่านมา เป็นการใช้งานร่วมกันระหว่าง PHP และ MySQL เพื่อเพิ่มข้อมูล แสดงข้อมูล แก้ไขข้อมูล ลบข้อมูล ผ่านฟอร์ม เป็นต้น รวมไปถึง Work Shop การสร้างระบบตัวอย่าง การบันทึกข้อมูล news
PHP จัดการกับMySQL => SELECT, INSERT, UPDATE, DELETE เป็นต้น
การอ่านข้อมูลจากฐานข้อมูลMySQL มาแสดงบนเว็บเพ็จ
เพิ่มเรคอร์ดลงฐานข้อมูลผ่านแบบฟอร์ม
Work Shop (INSERT, UPDATE, DELETE => NEWS)
ครั้งที่ 6
Break 1 (10.00-12.00)
Work Shop (บทความข่าวสาร & การค้นข้อมูล)
(ต่อเนื่องจากเนื้อหาครั้งที่ผ่านมา) สามารถ เขียนระบบบทความข่าวสารบนเว็บไซต์ เเละสามารถค้นหาข่าวสารต่างๆ ที่เพิ่มเข้าไปในระบบได้
สร้างเพ็จข่าวสารและมีส่วนของการเพิ่ม (Insert) การ แก้ไข (Update) และการลบ (Delete)
การค้นหาข่าวสารจากระบบ(Search)
Break 2 (13.00-16.00)
อัปโหลดไฟล์ขึ้นเว็บไซต์
การอัปโหลดไฟล์ขึ้นโฮสจริง (FTP) ด้วยโปรแกรม FileZilla
ติดตั้งโปรแกรม FileZilla
การคอนฟิกค่าต่างๆเพื่อใช้งาน FTP
การอัปโหลดไฟล์ขึ้นโฮส
(Work Shop)
คอร์สเรียนโปรแกรม สอนเรียนโปรแกรม สอนwordpress เรียนwordpress เรียนได้ที่ https://www.orange-thailand.com/workshop/
0 notes
Text
AWS Training in Noida
AWS is better or Azure?
Credit goes to public cloud services for rendering physical storage devices redundant. Two of the prominent names in cloud computing arena are AWS and Azure. AWS (Amazon web services) is amazon.com’s subsidiary that offers cloud services on paid subscription basis to governments, companies and individuals. Microsoft launched Azure cloud computing services helps in building, deploying, testing and managing applications through a global network of Microsoft managed data centers.
AWS (Amazon web services) was launched in way back in 2006 and has far more experience in cloud computing domain compared to Azure which was launched much later in 2010. AWS (Amazon web services)has successfully fulfilled the demands of enterprises regarding cloud computing. Azure has been trying hard to match AWS since its launch in 2010 but has been unsuccessful in this effort till date.
Now let us attempt point by point comparison between AWS (Amazon web services)and Microsoft Azure.
· Availability zones- AWS (Amazon web services) has significantly more availability zones compared to Microsoft Azure.
· Market share- AWS (Amazon web services) has 40% of public cloud market share while Microsoft Azure is having 30% of public cloud market share globally. AWS (Amazon web services) is ahead of Azure in fame too.
· Trust- AWS (Amazon web services) enjoys far more community support and trust among users.
· Clients- Unilever, BMW, Netflix, Airbnb, Samsung, MI, Zynga etc. are clients of AWS (Amazon web services) and Fujitsu, Honeywell, Johnson controls, Polycom, Adobe, HP etc.
· Services- Both AWS (Amazon web services) and Microsoft Azure provide 100+ services. Services of AWS include S3, AWS IAM, EC2, AWS RDS BTC, Cloud watch, Cloud9 and many more. Services of Azure include virtual network, virtual machine, SQL database, blob storage, active directory, azure monitor, visual studio, azure IoT hub and so on.
· Integration with open source tools- AWS (Amazon web services) has considerably better relations with open source communities compared to Microsoft Azure. This leads to more open source integration with AWS (Amazon web services) which includes open source tools like github, Jenkins, docker and ansible. Azure offers native integratation with windows development tools like active directory, VBS ,SQL server etc.
· Pricing- 2 virtual CPUs and 8 GB RAM will cost 0.0928 USD per hour when using AWS (Amazon web services) and same 2 virtual CPUs and 8 GB RAM will cost 0.096 USD per hour when using Azure. But Azure costs considerably more if usage is high.
· Job roles- There are three roles in AWS (Amazon web services)- AWS SysOps, AWS architect and AWS developer. Those with admin background should opt for AWS sysops role. People choosing this role have to carry out AWS admin jobs. AWS developer is a job for people from development background. AWS architect job is for people with prior know-how of AWS sysops and AWS development. In Azure roles, Application cloud services developer and cloud system administrator are very important. DevOps engineer roles are accessible to both AWS and Azure professionals.
Where to go for AWS training in Noida?
There are lot many alternatives available for AWS training in Noida. Ignited wings is one of the many choices. By virtue of its unique course updation policy and persistent placement support, Ignited wings today ranks highly among institutes competing for best AWS training institute in Noida tag. This institute also offers in-depth Azure training. In the humongous crowd of institutes contending for best Azure training institute in Noida tag, Ignited wings stands out.
0 notes