#SQL Server maximum value
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
In 2020, 27% of US Tumblr users had an annual household income of over $100,000.
Text
Finding the Maximum Value Across Multiple Columns in SQL Server
To find the maximum value across multiple columns in SQL Server 2022, you can use several approaches depending on your requirements and the structure of your data. Here are a few methods to consider: 1. Using CASE Statement or IIF You can use a CASE statement or IIF function to compare columns within a row and return the highest value. This method is straightforward but can get cumbersome with…
View On WordPress
#comparing multiple columns SQL#SQL CROSS APPLY technique#SQL Server aggregate functions#SQL Server date comparison#SQL Server maximum value
0 notes
Text
Structured Query Language (SQL): A Comprehensive Guide
Structured Query Language, popularly called SQL (reported "ess-que-ell" or sometimes "sequel"), is the same old language used for managing and manipulating relational databases. Developed in the early 1970s by using IBM researchers Donald D. Chamberlin and Raymond F. Boyce, SQL has when you consider that end up the dominant language for database structures round the world.
Structured query language commands with examples
Today, certainly every important relational database control system (RDBMS)—such as MySQL, PostgreSQL, Oracle, SQL Server, and SQLite—uses SQL as its core question language.
What is SQL?
SQL is a website-specific language used to:
Retrieve facts from a database.
Insert, replace, and delete statistics.
Create and modify database structures (tables, indexes, perspectives).
Manage get entry to permissions and security.
Perform data analytics and reporting.
In easy phrases, SQL permits customers to speak with databases to shop and retrieve structured information.
Key Characteristics of SQL
Declarative Language: SQL focuses on what to do, now not the way to do it. For instance, whilst you write SELECT * FROM users, you don’t need to inform SQL the way to fetch the facts—it figures that out.
Standardized: SQL has been standardized through agencies like ANSI and ISO, with maximum database structures enforcing the core language and including their very own extensions.
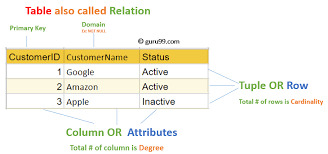
Relational Model-Based: SQL is designed to work with tables (also called members of the family) in which records is organized in rows and columns.
Core Components of SQL
SQL may be damaged down into numerous predominant categories of instructions, each with unique functions.
1. Data Definition Language (DDL)
DDL commands are used to outline or modify the shape of database gadgets like tables, schemas, indexes, and so forth.
Common DDL commands:
CREATE: To create a brand new table or database.
ALTER: To modify an present table (add or put off columns).
DROP: To delete a table or database.
TRUNCATE: To delete all rows from a table but preserve its shape.
Example:
sq.
Copy
Edit
CREATE TABLE personnel (
id INT PRIMARY KEY,
call VARCHAR(one hundred),
income DECIMAL(10,2)
);
2. Data Manipulation Language (DML)
DML commands are used for statistics operations which include inserting, updating, or deleting information.
Common DML commands:
SELECT: Retrieve data from one or more tables.
INSERT: Add new records.
UPDATE: Modify existing statistics.
DELETE: Remove information.
Example:
square
Copy
Edit
INSERT INTO employees (id, name, earnings)
VALUES (1, 'Alice Johnson', 75000.00);
three. Data Query Language (DQL)
Some specialists separate SELECT from DML and treat it as its very own category: DQL.
Example:
square
Copy
Edit
SELECT name, income FROM personnel WHERE profits > 60000;
This command retrieves names and salaries of employees earning more than 60,000.
4. Data Control Language (DCL)
DCL instructions cope with permissions and access manage.
Common DCL instructions:
GRANT: Give get right of entry to to users.
REVOKE: Remove access.
Example:
square
Copy
Edit
GRANT SELECT, INSERT ON personnel TO john_doe;
five. Transaction Control Language (TCL)
TCL commands manage transactions to ensure data integrity.
Common TCL instructions:
BEGIN: Start a transaction.
COMMIT: Save changes.
ROLLBACK: Undo changes.
SAVEPOINT: Set a savepoint inside a transaction.
Example:
square
Copy
Edit
BEGIN;
UPDATE personnel SET earnings = income * 1.10;
COMMIT;
SQL Clauses and Syntax Elements
WHERE: Filters rows.
ORDER BY: Sorts effects.
GROUP BY: Groups rows sharing a assets.
HAVING: Filters companies.
JOIN: Combines rows from or greater tables.
Example with JOIN:
square
Copy
Edit
SELECT personnel.Name, departments.Name
FROM personnel
JOIN departments ON personnel.Dept_id = departments.Identity;
Types of Joins in SQL
INNER JOIN: Returns statistics with matching values in each tables.
LEFT JOIN: Returns all statistics from the left table, and matched statistics from the right.
RIGHT JOIN: Opposite of LEFT JOIN.
FULL JOIN: Returns all records while there is a in shape in either desk.
SELF JOIN: Joins a table to itself.
Subqueries and Nested Queries
A subquery is a query inside any other query.
Example:
sq.
Copy
Edit
SELECT name FROM employees
WHERE earnings > (SELECT AVG(earnings) FROM personnel);
This reveals employees who earn above common earnings.
Functions in SQL
SQL includes built-in features for acting calculations and formatting:
Aggregate Functions: SUM(), AVG(), COUNT(), MAX(), MIN()
String Functions: UPPER(), LOWER(), CONCAT()
Date Functions: NOW(), CURDATE(), DATEADD()
Conversion Functions: CAST(), CONVERT()
Indexes in SQL
An index is used to hurry up searches.
Example:
sq.
Copy
Edit
CREATE INDEX idx_name ON employees(call);
Indexes help improve the performance of queries concerning massive information.
Views in SQL
A view is a digital desk created through a question.
Example:
square
Copy
Edit
CREATE VIEW high_earners AS
SELECT call, salary FROM employees WHERE earnings > 80000;
Views are beneficial for:
Security (disguise positive columns)
Simplifying complex queries
Reusability
Normalization in SQL
Normalization is the system of organizing facts to reduce redundancy. It entails breaking a database into multiple related tables and defining overseas keys to link them.
1NF: No repeating groups.
2NF: No partial dependency.
3NF: No transitive dependency.
SQL in Real-World Applications
Web Development: Most web apps use SQL to manipulate customers, periods, orders, and content.
Data Analysis: SQL is extensively used in information analytics systems like Power BI, Tableau, and even Excel (thru Power Query).
Finance and Banking: SQL handles transaction logs, audit trails, and reporting systems.
Healthcare: Managing patient statistics, remedy records, and billing.
Retail: Inventory systems, sales analysis, and consumer statistics.
Government and Research: For storing and querying massive datasets.
Popular SQL Database Systems
MySQL: Open-supply and extensively used in internet apps.
PostgreSQL: Advanced capabilities and standards compliance.
Oracle DB: Commercial, especially scalable, agency-degree.
SQL Server: Microsoft’s relational database.
SQLite: Lightweight, file-based database used in cellular and desktop apps.
Limitations of SQL
SQL can be verbose and complicated for positive operations.
Not perfect for unstructured information (NoSQL databases like MongoDB are better acceptable).
Vendor-unique extensions can reduce portability.
Java Programming Language Tutorial
Dot Net Programming Language
C ++ Online Compliers
C Language Compliers
2 notes
·
View notes
Text
Move Ahead with Confidence: Microsoft Training Courses That Power Your Potential
Why Microsoft Skills Are a Must-Have in Modern IT
Microsoft technologies power the digital backbone of countless businesses, from small startups to global enterprises. From Microsoft Azure to Power Platform and Microsoft 365, these tools are essential for cloud computing, collaboration, security, and business intelligence. As companies adopt and scale these technologies, they need skilled professionals to configure, manage, and secure their Microsoft environments. Whether you’re in infrastructure, development, analytics, or administration, Microsoft skills are essential to remain relevant and advance your career.
The good news is that Microsoft training isn’t just for IT professionals. Business analysts, data specialists, security officers, and even non-technical managers can benefit from targeted training designed to help them work smarter, not harder.
Training That Covers the Full Microsoft Ecosystem
Microsoft’s portfolio is vast, and Ascendient Learning’s training spans every major area. If your focus is cloud computing, Microsoft Azure training courses help you master topics like architecture, administration, security, and AI integration. Popular courses include Azure Fundamentals, Designing Microsoft Azure Infrastructure Solutions, and Azure AI Engineer Associate preparation.
For business professionals working with collaboration tools, Microsoft 365 training covers everything from Teams Administration to SharePoint Configuration and Microsoft Exchange Online. These tools are foundational to hybrid and remote work environments, and mastering them improves productivity across the board.
Data specialists can upskill through Power BI, Power Apps, and Power Automate training, enabling low-code development, process automation, and rich data visualization. These tools are part of the Microsoft Power Platform, and Ascendient’s courses teach how to connect them to real-time data sources and business workflows.
Security is another top concern for today’s organizations, and Microsoft’s suite of security solutions is among the most robust in the industry. Ascendient offers training in Microsoft Security, Compliance, and Identity, as well as courses on threat protection, identity management, and secure cloud deployment.
For developers and infrastructure specialists, Ascendient also offers training in Windows Server, SQL Server, PowerShell, DevOps, and programming tools. These courses provide foundational and advanced skills that support software development, automation, and enterprise system management.
Earn Certifications That Employers Trust
Microsoft certifications are globally recognized credentials that validate your expertise and commitment to professional development. Ascendient Learning’s Microsoft training courses are built to prepare learners for certifications across all levels, including Microsoft Certified: Fundamentals, Associate, and Expert tracks.
These certifications improve your job prospects and help organizations meet compliance requirements, project demands, and client expectations. Many professionals who pursue Microsoft certifications report higher salaries, faster promotions, and broader career options.
Enterprise Solutions That Scale with Your Goals
For organizations, Ascendient Learning offers end-to-end support for workforce development. Training can be customized to match project timelines, technology adoption plans, or compliance mandates. Whether you need to train a small team or launch a company-wide certification initiative, Ascendient Learning provides scalable solutions that deliver measurable results.
With Ascendient’s Customer Enrollment Portal, training coordinators can easily manage enrollments, monitor progress, and track learning outcomes in real-time. This level of insight makes it easier to align training with business strategy and get maximum value from your investment.
Get Trained. Get Certified. Get Ahead.
In today’s fast-changing tech environment, Microsoft training is a smart step toward lasting career success. Whether you are building new skills, preparing for a certification exam, or guiding a team through a technology upgrade, Ascendient Learning provides the tools, guidance, and expertise to help you move forward with confidence.
Explore Ascendient Learning’s full catalog of Microsoft training courses today and take control of your future, one course, one certification, and one success at a time.
For more information, visit: https://www.ascendientlearning.com/it-training/microsoft
0 notes
Text
How to resolve CXPACKET wait in SQL Server
CXPACKET:o Happens when a parallel query runs and some threads are slower than others.o This wait type is common in highly parallel environments. How to resolve CXPACKET wait in SQL Server Adjust the MAXDOP Setting:o The MAXDOP (Maximum Degree of Parallelism) setting controls the number ofprocessors used for parallel query execution. Reducing the MAXDOP value can helpreduce CXPACKET waits.o You…
0 notes
Text
5th Gen Intel Xeon Scalable Processors Boost SQL Server 2022

5th Gen Intel Xeon Scalable Processors
While speed and scalability have always been essential to databases, contemporary databases also need to serve AI and ML applications at higher performance levels. Real-time decision-making, which is now far more widespread, should be made possible by databases together with increasingly faster searches. Databases and the infrastructure that powers them are usually the first business goals that need to be modernized in order to support analytics. The substantial speed benefits of utilizing 5th Gen Intel Xeon Scalable Processors to run SQL Server 2022 will be demonstrated in this post.
OLTP/OLAP Performance Improvements with 5th gen Intel Xeon Scalable processors
The HammerDB benchmark uses New Orders per minute (NOPM) throughput to quantify OLTP. Figure 1 illustrates performance gains of up to 48.1% NOPM Online Analytical Processing when comparing 5th Gen Intel Xeon processors to 4th Gen Intel Xeon processors, while displays up to 50.6% faster queries.
The enhanced CPU efficiency of the 5th gen Intel Xeon processors, demonstrated by its 83% OLTP and 75% OLAP utilization, is another advantage. When compared to the 5th generation of Intel Xeon processors, the prior generation requires 16% more CPU resources for the OLTP workload and 13% more for the OLAP workload.
The Value of Faster Backups
Faster backups improve uptime, simplify data administration, and enhance security, among other things. Up to 2.72x and 3.42 quicker backups for idle and peak loads, respectively, are possible when running SQL Server 2022 Enterprise Edition on an Intel Xeon Platinum processor when using Intel QAT.
The reason for the longest Intel QAT values for 5th Gen Intel Xeon Scalable Processors is because the Gold version includes less backup cores than the Platinum model, which provides some perspective for the comparisons.
With an emphasis on attaining near-real-time latencies, optimizing query speed, and delivering the full potential of scalable warehouse systems, SQL Server 2022 offers a number of new features. It’s even better when it runs on 5th gen Intel Xeon Processors.
Solution snapshot for SQL Server 2022 running on 4th generation Intel Xeon Scalable CPUs. performance, security, and current data platform that lead the industry.
SQL Server 2022
The performance and dependability of 5th Gen Intel Xeon Scalable Processors, which are well known, can greatly increase your SQL Server 2022 database.
The following tutorial will examine crucial elements and tactics to maximize your setup:
Hardware Points to Consider
Choose a processor: Choose Intel Xeon with many cores and fast clock speeds. Choose models with Intel Turbo Boost and Intel Hyper-Threading Technology for greater performance.
Memory: Have enough RAM for your database size and workload. Sufficient RAM enhances query performance and lowers disk I/O.
Storage: To reduce I/O bottlenecks, choose high-performance storage options like SSDs or fast HDDs with RAID setups.
Modification of Software
Database Design: Make sure your query execution plans, indexes, and database schema are optimized. To guarantee effective data access, evaluate and improve your design on a regular basis.
Configuration Settings: Match your workload and hardware capabilities with the SQL Server 2022 configuration options, such as maximum worker threads, maximum server RAM, and I/O priority.
Query tuning: To find performance bottlenecks and improve queries, use programs like Management Studio or SQL Server Profiler. Think about methods such as parameterization, indexing, and query hints.
Features Exclusive to Intel
Use Intel Turbo Boost Technology to dynamically raise clock speeds for high-demanding tasks.
With Intel Hyper-Threading Technology, you may run many threads on a single core, which improves performance.
Intel QuickAssist Technology (QAT): Enhance database performance by speeding up encryption and compression/decompression operations.
Optimization of Workload
Workload balancing: To prevent resource congestion, divide workloads among several instances or servers.
Partitioning: To improve efficiency and management, split up huge tables into smaller sections.
Indexing: To expedite the retrieval of data, create the proper indexes. Columnstore indexes are a good option for workloads involving analysis.
Observation and Adjustment
Performance monitoring: Track key performance indicators (KPIs) and pinpoint areas for improvement with tools like SQL Server Performance Monitor.
Frequent Tuning: Keep an eye on and adjust your database on a regular basis to accommodate shifting hardware requirements and workloads.
SQL Server 2022 Pricing
SQL Server 2022 cost depends on edition and licensing model. SQL Server 2022 has three main editions:
SQL Server 2022 Standard
Description: For small to medium organizations with minimal database functions for data and application management.
Licensing
Cost per core: ~$3,586.
Server + CAL (Client Access License): ~$931 per server, ~$209 per CAL.
Basic data management, analytics, reporting, integration, and little virtualization.
SQL Server 2022 Enterprise
Designed for large companies with significant workloads, extensive features, and scalability and performance needs.
Licensing
Cost per core: ~$13,748.
High-availability, in-memory performance, business intelligence, machine learning, and infinite virtualization.
SQL Server 2022 Express
Use: Free, lightweight edition for tiny applications, learning, and testing.
License: Free.
Features: Basic capability, 10 GB databases, restricted memory and CPU.
Models for licensing
Per Core: Recommended for big, high-demand situations with processor core-based licensing.
Server + CAL (Client Access License): For smaller environments, each server needs a license and each connecting user/device needs a CAL.
In brief
Faster databases can help firms meet their technical and business objectives because they are the main engines for analytics and transactions. Greater business continuity may result from those databases’ faster backups.
Read more on govindhtech.com
#5thGen#IntelXeonScalableProcessors#IntelXeon#BoostSQLServer2022#IntelXeonprocessors#intel#4thGenIntelXeonprocessors#SQLServer#Software#HardwarePoints#OLTP#OLAP#technology#technews#news#govindhtech
0 notes
Text
Transitioning from Tableau to Power BI - A Comprehensive Guide
The ability to extract actionable insights from vast datasets is a game-changer. Data visualization platforms like Tableau and Power BI empower organizations to transform raw data into meaningful visualizations, enabling stakeholders to make informed decisions. However, as businesses evolve and their data needs change, they may need to migrate from Tableau to Power BI to unlock new functionalities, enhance efficiency, or align with their broader IT infrastructure.
Understanding the Importance of Switching:

Transitioning from Tableau to Power BI is not just about swapping one tool for another; it's a strategic move with far-reaching implications. Several factors underscore the importance of Tableau to Power BI migration:
Cost Considerations:
The financial aspect often plays a significant role in decision-making. Tableau's licensing model can be a considerable expense for organizations, particularly for larger deployments. Conversely, Power BI offers flexible pricing options, including free tiers for individual users and cost-effective subscription plans for enterprises, making it a financially attractive alternative.
Integration with Existing Infrastructure:
Power BI's seamless integration with Azure, Office 365, and other Microsoft products is a compelling proposition for organizations entrenched in the Microsoft ecosystem. This integration fosters interoperability, streamlines data management processes, and promotes collaboration across departments, aligning with the organization's broader IT strategy.
Enhanced Analytics and Visualization Capabilities:
While Tableau is renowned for its advanced analytics features, Power BI distinguishes itself with its user-friendly interface and robust data visualization platforms. Power BI's integration with Excel, SQL Server, and other Microsoft applications empowers users to easily create interactive dashboards, reports, and data visualizations, democratizing data access and analysis across the organization.
Simplified Setup and Maintenance:
The ease of deployment and maintenance is another crucial consideration. Power BI's intuitive interface, comprehensive documentation, and robust community support simplifies the migration process, minimizing downtime and disruption to operations. Organizations familiar with Microsoft products will find Power BI's setup process relatively straightforward, further expediting the transition.
Key Considerations for Migration from Tableau to Power BI:
Before embarking on the migration journey, organizations must carefully assess various factors to ensure a seamless transition:
Data Compatibility: Evaluate the compatibility of existing data sources with Power BI to pre-empt any compatibility issues during the migration process. Conduct thorough testing to verify data integrity and identify any potential challenges.
Training and Support: Invest in comprehensive training programs to equip users with the skills and knowledge to effectively leverage Power BI. Consider engaging external support services to address technical challenges and provide ongoing assistance during and after the migration.
Customization Needs: Assess the organization's customization requirements and ascertain whether Power BI can accommodate them effectively. Collaborate with experts to tailor Power BI to business needs and optimize its functionality to drive maximum value.
Unlocking the Benefits of Migration from Tableau to Power BI:
Migrating from Tableau to Power BI offers a multitude of benefits for organizations seeking to harness the full potential of their data:
Cost Savings: By transitioning to Power BI, organizations can realize substantial cost savings through more economical licensing options and streamlined data management processes, enabling them to reallocate resources more efficiently.
Integration with Microsoft Ecosystem: Power BI's seamless integration with other Microsoft products facilitates data sharing, collaboration, and workflow automation, fostering operational efficiency and productivity gains across the organization.
User-Friendly Interface: Power BI's intuitive interface empowers users of all skill levels to create compelling visualizations, dashboards, and reports, democratizing data access and analysis and promoting data-driven decision-making at every level of the organization.
Advanced Analytics Capabilities: Leverage Power BI's advanced analytics tools, including machine learning capabilities and predictive analytics, to uncover hidden insights, identify trends, and drive innovation, enabling organizations to stay ahead of the curve in an increasingly competitive landscape.
Best Practices for a Smooth Transition:
Successfully moving from Tableau to Power BI requires careful planning, execution, and optimization. Here are some best practices to follow through the process:
Assess The Requirements: Conduct a thorough analysis of the organization's data visualization needs, technical requirements, and strategic objectives to inform migration strategy and prioritize key milestones.
Develop a Migration Plan: Create a detailed migration plan delineating key milestone, timelines, resource requirements, and stakeholder responsibilities to ensure a structured and coordinated approach to the migration process.
Test and Validate: Before migrating critical data and workflows, conduct rigorous testing and validation to identify and address potential issues, errors, or compatibility challenges, minimizing the risk of disruptions during the migration.
Provide Comprehensive Training: Invest in comprehensive training programs to equip users with the skills, knowledge, and confidence to leverage Power BI effectively and maximize its value across the organization. Offer ongoing support and resources to facilitate continuous learning and skill development.
Monitor and Optimize: Continuously monitor the migration process, user adoption rates, and performance metrics to identify areas for improvement, optimization, and ongoing support. Solicit feedback from stakeholders to address concerns and ensure alignment with business objectives.
Migrating from Tableau to Power BI represents an opportunity for organizations to unlock new capabilities, drive innovation, and gain a competitive edge in today's data-driven landscape. While the migration journey may present challenges, with proper planning, execution, and support, organizations can successfully navigate these challenges and realize Power BI's full potential. Nous specializes in helping organizations seamlessly migrate from Tableau to Power BI. The team of experts offers comprehensive migration services, including strategy development, technical implementation, user training, and ongoing support, to ensure a smooth and successful transition.
#data analytics solutions#data visualization#power bi migration#microsoft power bi#power bi services#tableau#data migration
1 note
·
View note
Text
SAP Basis Expert

The Backbone of SAP Systems: Understanding the SAP Basis Expert
SAP systems are the technological lifelines powering countless modern businesses. Behind that smooth functionality lies a crucial figure: the SAP Basis expert. These professionals hold the keys to optimizing and maintaining those complex SAP environments upon which businesses depend.
What is SAP Basis?
SAP Basis is the technical foundation of any SAP implementation. It involves the core administration and configuration of SAP systems, including:
Installation and Configuration: Setting up the SAP landscape and tailor it to business needs.
Database Management: Ensuring the SAP database (Oracle, SQL Server, etc.) is running smoothly.
System Monitoring and Performance Tuning: Keeping an eye on the system’s health and optimizing performance for peak efficiency.
User and Security Management: Securely adding new users and managing their permissions.
Transport Management: Handling the movement of changes and customizations between SAP environments (development, testing, production).
Troubleshooting: Proactively identifying and resolving technical issues.
Why Do You Need an SAP Basis Expert?
Think of the SAP Basis expert as your SAP environment’s doctor. Here’s why their expertise is vital:
Smooth Operations: They ensure seamless day-to-day operations within the SAP system keeping mission-critical applications running optimally.
Proactive Problem Solving: They prevent breakdowns and downtime by spotting potential issues early.
Performance Optimization: Constant analysis and tuning helps maintain system speed and efficiency, especially during high-load situations.
Security: They uphold a strong security posture, implementing safeguards against unauthorized access or data breaches.
Business Agility: Basis experts quickly adapt SAP environments to business needs like expansions and updates.
Essential Skills of an SAP Basis Expert
A successful SAP Basis expert usually possesses a robust mix of skills:
SAP Technical Knowledge: Deep understanding of SAP architecture, ABAP programming, and NetWeaver components.
Operating Systems: Expertise in Linux, Windows, and other platforms commonly hosting SAP systems.
Database Administration: Strong database skills (Oracle, SQL Server, HANA, etc.) to handle the underlying data structures.
Troubleshooting and Problem-Solving: The ability to analyze logs, diagnose issues, and implement rapid solutions.
Communication and Collaboration: Clear documentation skills and the ability to collaborate effectively with cross-functional teams.
Finding the Right SAP Basis Expert
When seeking an SAP Basis expert, you’ve got options:
In-House: Large companies may maintain their own team of SAP Basis specialists for dedicated support.
SAP Consulting Firms: Engaging a reputable firm provides access to seasoned experts as needed.
Freelance SAP Basis Consultants: Independent specialists bring flexibility and can be cost-effective for project-based or ongoing needs.
The Takeaway
The SAP Basis expert is a quiet force that keeps complex business systems humming. Their expertise ensures your SAP investments deliver maximum value and remain a reliable engine that drives your enterprise forward. Investing in the right SAP Basis talent is an investment in your business’s overall success.
youtube
You can find more information about SAP BASIS in this SAP BASIS Link
Conclusion:
Unogeeks is the No.1 IT Training Institute for SAP BASIS Training. Anyone Disagree? Please drop in a comment
You can check out our other latest blogs on SAP BASIS here – SAP BASIS Blogs
You can check out our Best In Class SAP BASIS Details here – SAP BASIS Training
Follow & Connect with us:
———————————-
For Training inquiries:
Call/Whatsapp: +91 73960 33555
Mail us at: [email protected]
Our Website ➜ https://unogeeks.com
Follow us:
Instagram: https://www.instagram.com/unogeeks
Facebook:https://www.facebook.com/UnogeeksSoftwareTrainingInstitute
Twitter: https://twitter.com/unogeek
#Unogeeks #training #Unogeekstraining
1 note
·
View note
Text
Web Application Penetration Testing Checklist
Web-application penetration testing, or web pen testing, is a way for a business to test its own software by mimicking cyber attacks, find and fix vulnerabilities before the software is made public. As such, it involves more than simply shaking the doors and rattling the digital windows of your company's online applications. It uses a methodological approach employing known, commonly used threat attacks and tools to test web apps for potential vulnerabilities. In the process, it can also uncover programming mistakes and faults, assess the overall vulnerability of the application, which include buffer overflow, input validation, code Execution, Bypass Authentication, SQL-Injection, CSRF, XSS etc.
Penetration Types and Testing Stages
Penetration testing can be performed at various points during application development and by various parties including developers, hosts and clients. There are two essential types of web pen testing:
l Internal: Tests are done on the enterprise's network while the app is still relatively secure and can reveal LAN vulnerabilities and susceptibility to an attack by an employee.
l External: Testing is done outside via the Internet, more closely approximating how customers — and hackers — would encounter the app once it is live.
The earlier in the software development stage that web pen testing begins, the more efficient and cost effective it will be. Fixing problems as an application is being built, rather than after it's completed and online, will save time, money and potential damage to a company's reputation.
The web pen testing process typically includes five stages:
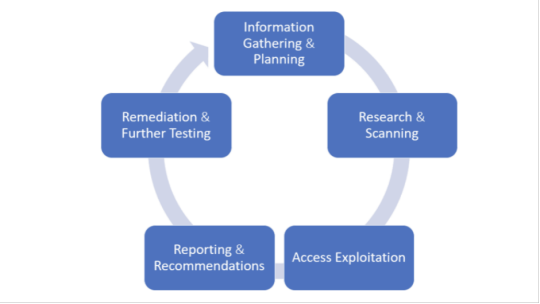
1. Information Gathering and Planning: This comprises forming goals for testing, such as what systems will be under scrutiny, and gathering further information on the systems that will be hosting the web app.
2. Research and Scanning: Before mimicking an actual attack, a lot can be learned by scanning the application's static code. This can reveal many vulnerabilities. In addition to that, a dynamic scan of the application in actual use online will reveal additional weaknesses, if it has any.
3. Access and Exploitation: Using a standard array of hacking attacks ranging from SQL injection to password cracking, this part of the test will try to exploit any vulnerabilities and use them to determine if information can be stolen from or unauthorized access can be gained to other systems.
4. Reporting and Recommendations: At this stage a thorough analysis is done to reveal the type and severity of the vulnerabilities, the kind of data that might have been exposed and whether there is a compromise in authentication and authorization.
5. Remediation and Further Testing: Before the application is launched, patches and fixes will need to be made to eliminate the detected vulnerabilities. And additional pen tests should be performed to confirm that all loopholes are closed.
Information Gathering

1. Retrieve and Analyze the robot.txt files by using a tool called GNU Wget.
2. Examine the version of the software. DB Details, the error technical component, bugs by the error codes by requesting invalid pages.
3. Implement techniques such as DNS inverse queries, DNS zone Transfers, web-based DNS Searches.
4. Perform Directory style Searching and vulnerability scanning, Probe for URLs, using tools such as NMAP and Nessus.
5. Identify the Entry point of the application using Burp Proxy, OWSAP ZAP, TemperIE, WebscarabTemper Data.
6. By using traditional Fingerprint Tool such as Nmap, Amap, perform TCP/ICMP and service Fingerprinting.
7.By Requesting Common File Extension such as.ASP,EXE, .HTML, .PHP ,Test for recognized file types/Extensions/Directories.
8. Examine the Sources code From the Accessing Pages of the Application front end.
9. Many times social media platform also helps in gathering information. Github links, DomainName search can also give more information on the target. OSINT tool is such a tool which provides lot of information on target.
Authentication Testing

1. Check if it is possible to “reuse” the session after Logout. Verify if the user session idle time.
2. Verify if any sensitive information Remain Stored in browser cache/storage.
3. Check and try to Reset the password, by social engineering crack secretive questions and guessing.
4.Verify if the “Remember my password” Mechanism is implemented by checking the HTML code of the log-in page.
5. Check if the hardware devices directly communicate and independently with authentication infrastructure using an additional communication channel.
6. Test CAPTCHA for authentication vulnerabilities.
7. Verify if any weak security questions/Answer are presented.
8. A successful SQL injection could lead to the loss of customer trust and attackers can steal PID such as phone numbers, addresses, and credit card details. Placing a web application firewall can filter out the malicious SQL queries in the traffic.
Authorization Testing

1. Test the Role and Privilege Manipulation to Access the Resources.
2.Test For Path Traversal by Performing input Vector Enumeration and analyze the input validation functions presented in the web application.
3.Test for cookie and parameter Tempering using web spider tools.
4. Test for HTTP Request Tempering and check whether to gain illegal access to reserved resources.
Configuration Management Testing

1. Check file directory , File Enumeration review server and application Documentation. check the application admin interfaces.
2. Analyze the Web server banner and Performing network scanning.
3. Verify the presence of old Documentation and Backup and referenced files such as source codes, passwords, installation paths.
4.Verify the ports associated with the SSL/TLS services using NMAP and NESSUS.
5.Review OPTIONS HTTP method using Netcat and Telnet.
6. Test for HTTP methods and XST for credentials of legitimate users.
7. Perform application configuration management test to review the information of the source code, log files and default Error Codes.
Session Management Testing
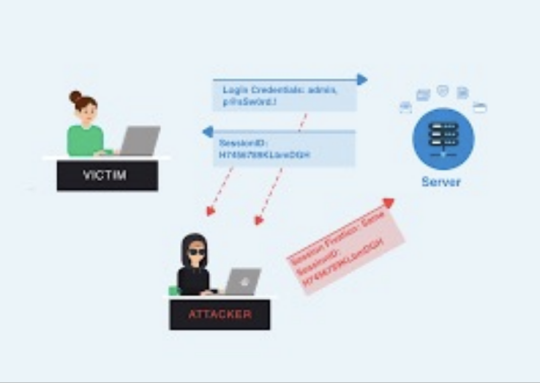
1. Check the URL’s in the Restricted area to Test for CSRF (Cross Site Request Forgery).
2.Test for Exposed Session variables by inspecting Encryption and reuse of session token, Proxies and caching.
3. Collect a sufficient number of cookie samples and analyze the cookie sample algorithm and forge a valid Cookie in order to perform an Attack.
4. Test the cookie attribute using intercept proxies such as Burp Proxy, OWASP ZAP, or traffic intercept proxies such as Temper Data.
5. Test the session Fixation, to avoid seal user session.(session Hijacking )
Data Validation Testing
1. Performing Sources code Analyze for javascript Coding Errors.
2. Perform Union Query SQL injection testing, standard SQL injection Testing, blind SQL query Testing, using tools such as sqlninja, sqldumper, sql power injector .etc.
3. Analyze the HTML Code, Test for stored XSS, leverage stored XSS, using tools such as XSS proxy, Backframe, Burp Proxy, OWASP, ZAP, XSS Assistant.
4. Perform LDAP injection testing for sensitive information about users and hosts.
5. Perform IMAP/SMTP injection Testing for Access the Backend Mail server.
6.Perform XPATH Injection Testing for Accessing the confidential information
7. Perform XML injection testing to know information about XML Structure.
8. Perform Code injection testing to identify input validation Error.
9. Perform Buffer Overflow testing for Stack and heap memory information and application control flow.
10. Test for HTTP Splitting and smuggling for cookies and HTTP redirect information.
Denial of Service Testing

1. Send Large number of Requests that perform database operations and observe any Slowdown and Error Messages. A continuous ping command also will serve the purpose. A script to open browsers in loop for indefinite no will also help in mimicking DDOS attack scenario.
2.Perform manual source code analysis and submit a range of input varying lengths to the applications
3.Test for SQL wildcard attacks for application information testing. Enterprise Networks should choose the best DDoS Attack prevention services to ensure the DDoS attack protection and prevent their network
4. Test for User specifies object allocation whether a maximum number of object that application can handle.
5. Enter Extreme Large number of the input field used by the application as a Loop counter. Protect website from future attacks Also Check your Companies DDOS Attack Downtime Cost.
6. Use a script to automatically submit an extremely long value for the server can be logged the request.
Conclusion:
Web applications present a unique and potentially vulnerable target for cyber criminals. The goal of most web apps is to make services, products accessible for customers and employees. But it's definitely critical that web applications must not make it easier for criminals to break into systems. So, making proper plan on information gathered, execute it on multiple iterations will reduce the vulnerabilities and risk to a greater extent.
1 note
·
View note
Text
Business intelligence Dashboards Saudi Arabia
Business intelligence is the data management solutions provided to various companies using their past or current data to deliver real-time solutions to the companies. BI, is a type of software that uses the power of data within an organization. It offers a different way to sort, compare, and review data in order for companies to make smart and real-time decisions.bi helps in better planning and understanding the data, improves the accuracy of the business strategies, improves sales forecasting, focuses on business operation, and improves decision making. Adding business intelligence software to the company creates a positive action effect that spreads in all parts of the company. It’s not just about improving access to the data in your firm It’s about whether we are using that data to improve profitability. Business intelligence dashboards are the management of data visuals that provide solutions to the data analysis. Dashboards are the most popular platform in Bi analytics which allows us to customize the information we want strategically. Resemble Systems is a top business intelligence provider with a local presence in India, Saudi Arabia, UAE, and Qatar, offering Enterprise Portfolio Management and Project Management database solutions and Digital Transformations that enable customers to digitally transform their data to increase efficiency while optimizing business processes. Resemble Systems follows a closed approach in identifying customer’s business problems and drives those challenges and vital points with unique, cost-effective, and secure solutions that ensure Business Value, Maximum ROI. Power business intelligence is a tool of business analytics that delivers insights throughout the organization. Connecting the data to hundreds of other data sources, to simplify data prep, and drive ad hoc analysis. Produce genuine reports, then publish them for the organization to access on the web and mobile devices. At resemble system, we can create personalized dashboards with a unique, 360-degree view of their business. And measure across the enterprise, with governance and security that is built-in. We help the clients with Reporting and business intelligence Dashboard visually which is presented on the SharePoint Online platform. We use Power BI. PowerPivot and integrate with Excel, SQL Server, also with any 3rd party data sources such as Oracle and SAP.
2 notes
·
View notes
Text
Understanding Important Differences Between Laravel Vs CodeIgniter
PHP is a modern framework in software development with a lot more flexibility in terms of a structured coding pattern with scope for applications that we deliver to perform better is required. The security feature of Laravel is quick in taking action when in security violation and for CodeIgniter too. The syntax guides of Laravel are expressive and elegant. The differences between Laravel vs CodeIgniter are as under:
Essential differences between Laravel vs CodeIgniter
Assistance for PHP 7
As a major announcement of the server-side programming language, PHP 7 comes with several unique features and improvements. The new features let programmers magnify the performance of web applications and lessen memory consumption. Both Laravel and CodeIgniter support version 7 of PHP. But several programmers have highlighted the issues faced by them while developing and testing CodeIgniter applications on PHP 7.
Produced in Modules
Most developers part big and complex web applications into a number of small modules to simplify and advance the development process. Laravel is designed with built-in modularity features. It allows developers to divide a project into small modules through a bundle. They can further reuse the modules over multiple projects. But CodeIgniter is not planned with built-in modularity specialties. It requires CodeIgniter developers to create and control modules by using Modular Extension additionally.
Support for Databases
Both PHP frameworks support an array of databases including MySQL, PostgreSQL, Microsoft Bi, and MongoDB. However in the fight of Laravel vs CodeIgniter, additionally supports a plethora of databases including Oracle, Microsoft SQL Server, IBM DB2, orientdb, and JDBC compatible. Hence, CodeIgniter supports a prominent number of databases that Laravel.
Database Scheme Development
Despite encouraging several popular databases, CodeIgniter does not provide any particular features to clarify database schema migration. Though the DB agnostic migrations emphasize provided by Laravel makes it simpler for programmers to alter and share the database schema of the application without rewriting complicated code. The developer can further develop a database schema of the application easily by combining the database agnostic migration with the schema builder provided by Laravel.
Fluent ORM
Unlike CodeIgniter, Laravel empowers developers to take advantage of Graceful ORM. They can practice the object-relational mapper (ORM) system to operate with a diversity of databases more efficiently by Active Record implementation. Fluent ORM further allows users to interact with databases directly through the specific model of individual database tables. They can even use the model to accomplish common tasks like including new records and running database queries.
Built-in Template Engine
Laravel comes with a simple but robust template engine like Blade. Blade template engine enables PHP programmers to optimize the representation of the web application by improving and managing views. But CodeIgniter seems not appear with a built-in template engine. The developers need to unite the framework with robust template engines like Smarty to accomplish common tasks and boost the performance of the website.
REST API Development
The RESTful Controllers provided by Laravel allows laravel development company to build a diversity of REST APIs without embedding extra time and effort. They can simply set the restful property as true in the RESTful Controller to build custom REST APIs without writing extra code. But CodeIgniter does not provide any specific features to simplify development of REST APIs. The users have to write extra code to create custom REST APIs while developing web applications with CodeIgniter.
Routing

The routing choices given by both PHP frameworks work identically. But the features presented by Laravel facilitate developers to route requests in an easy yet efficient way. The programmers can take advantage of the routing feature of Laravel to define most routes for a web application in a single file. Each basic Laravel route further accepts a single URI and closure. However, the users still have the option to register a route with the capability to respond to multiple HTTP verbs concurrently.
HTTPS Guide
Maximum web developers opt for HTTPS protocol to obtain the application send and acquire sensitive information securely. Laravel empowers programmers to set custom HTTPs routes. The developers also have the choice to create a distinct URL for each HTTPS route. Laravel further keeps the data transmission secure by adding https:// protocol before the URL automatically. But CodeIgniter appears not support HTTPS fully. The programmers should practice URL helpers to keep the data transmission secure by generating pats.
Authentication
The Authentication Class presented by Laravel makes it simpler for developers to execute authentication and authorization. The extensible and customizable class further permits users to manage the web application secure by executing comprehensive user login and managing the routes secure with filters. However, CodeIgniter does not appear with such built-in authentication features. The users are asked to authenticate and authorize users by drafting custom CodeIgniter extensions.
Unit Testing
Laravel accounts for additional PHP frameworks in the division of unit testing. It enables programmers to check the application code thoroughly and continuously with PHPUnit. In extension to being a broadly accepted unit testing tool, PHPUnit arises with a variety of out-of-box extensions. Hence, programmers have to use added unit testing tools to evaluate the quality of application code throughout the development process.
Learning Curve
youtube
Unlike Laravel, CodeIgniter has a petite footprint. But Laravel presents extra features and tools than CodeIgniter. The additional features make Laravel complex. Hence, the beginners have to put additional time and effort to learn all the features of Laravel and use it efficiently. The trainees find it simpler to learn and use CodeIgniter within a short period of time.
Community Support
Both are open source PHP framework. Each framework is also backed by a great community. But numerous web developers have said that members of the Laravel community are major active than members of the CodeIgniter community. The developers regularly find it simpler to avail online help and quick solutions while developing web applications with Laravel.
The developers yet require to evaluate the features of Laravel vs CodeIgniter according to the precise needs of each project to choose the best PHP framework.
If analyzed statistically, Laravel seems to be more accepted than CodeIgniter by a wide margin. This is validated by Sitepoint’s 2015 survey results, where Laravel was honored as the most popular PHP framework according to a massive 7800 entries. CodeIgniter, according to the study, pursues at number 4. Users also report that Laravel is more marketable since clients have often heard about the framework previously, giving a Laravel an enormous market value than CodeIgniter.
Some would claim that the predominance or the market shares are not enough reasons to pick one framework across another, and it is a strong point. A good developer should examine the overall features, performance, and functionalities that are particular to their web application before executing ANY framework.
Among Laravel vs CodeIgniter, well-seasoned master developers can find that they can avail several great features if they opt for Laravel since it requires an absolute command on the MVC architecture as well as a strong grip on OOP (Object Oriented Programming) concepts.
Conclusion
If you are looking to create a resilient and maintainable application, Laravel is a nice choice. The documentation is accurate, the community is large and you can develop fully emphasized complex web applications. There are still many developers in PHP community preferring CodeIgniter for developing medium to small applications in simple developing environment. Conserving in mind the pros and cons of each, in reverence to the precise project, you can reach the perfect verdict. Read Full Article on: https://www.cyblance.com/laravel/understanding-important-differences-between-laravel-vs-codeigniter/
#laravel development company#laravel development#laravel developer#laravel development services#laravel development company india#laravel application development#laravel web development#php laravel developer#laravel web development company#laravel application development company#laravel web development services#best laravel development company#laravel web developer#laravel web application development company#remote laravel developer#laravel framework development#laravel app development#dedicated laravel developer#laravel website development#remote laravel#certified laravel developer#laravel development india
1 note
·
View note
Text
Business Analyst Finance Domain Sample Resume

This is just a sample Business Analyst resume for freshers as well as for experienced job seekers in Finance domain of business analyst or system analyst. While this is only a sample resume, please use this only for reference purpose, do not copy the same client names or job duties for your own purpose. Always make your own resume with genuine experience.
Name: Justin Megha
Ph no: XXXXXXX
your email here.
Business Analyst, Business Systems Analyst
SUMMARY
Accomplished in Business Analysis, System Analysis, Quality Analysis and Project Management with extensive experience in business products, operations and Information Technology on the capital markets space specializing in Finance such as Trading, Fixed Income, Equities, Bonds, Derivatives(Swaps, Options, etc) and Mortgage with sound knowledge of broad range of financial instruments. Over 11+ Years of proven track record as value-adding, delivery-loaded project hardened professional with hands-on expertise spanning in System Analysis, Architecting Financial applications, Data warehousing, Data Migrations, Data Processing, ERP applications, SOX Implementation and Process Compliance Projects. Accomplishments in analysis of large-scale business systems, Project Charters, Business Requirement Documents, Business Overview Documents, Authoring Narrative Use Cases, Functional Specifications, and Technical Specifications, data warehousing, reporting and testing plans. Expertise in creating UML based Modelling views like Activity/ Use Case/Data Flow/Business Flow /Navigational Flow/Wire Frame diagrams using Rational Products & MS Visio. Proficient as long time liaison between business and technology with competence in Full Life Cycle of System (SLC) development with Waterfall, Agile, RUP methodology, IT Auditing and SOX Concepts as well as broad cross-functional experiences leveraging multiple frameworks. Extensively worked with the On-site and Off-shore Quality Assurance Groups by assisting the QA team to perform Black Box /GUI testing/ Functionality /Regression /System /Unit/Stress /Performance/ UAT's. Facilitated change management across entire process from project conceptualization to testing through project delivery, Software Development & Implementation Management in diverse business & technical environments, with demonstrated leadership abilities. EDUCATION
Post Graduate Diploma (in Business Administration), USA Master's Degree (in Computer Applications), Bachelor's Degree (in Commerce), TECHNICAL SKILLS
Documentation Tools UML, MS Office (Word, Excel, Power Point, Project), MS Visio, Erwin
SDLC Methodologies Waterfall, Iterative, Rational Unified Process (RUP), Spiral, Agile
Modeling Tools UML, MS Visio, Erwin, Power Designer, Metastrom Provision
Reporting Tools Business Objects X IR2, Crystal Reports, MS Office Suite
QA Tools Quality Center, Test Director, Win Runner, Load Runner, QTP, Rational Requisite Pro, Bugzilla, Clear Quest
Languages Java, VB, SQL, HTML, XML, UML, ASP, JSP
Databases & OS MS SQL Server, Oracle 10g, DB2, MS Access on Windows XP / 2000, Unix
Version Control Rational Clear Case, Visual Source Safe
PROFESSIONAL EXPERIENCE
SERVICE MASTER, Memphis, TN June 08 - Till Date
Senior Business Analyst
Terminix has approximately 800 customer service agents that reside in our branches in addition to approximately 150 agents in a centralized call center in Memphis, TN. Terminix customer service agents receive approximately 25 million calls from customers each year. Many of these customer's questions are not answered or their problems are not resolved on the first call. Currently these agents use an AS/400 based custom developed system called Mission to answer customer inquiries into branches and the Customer Communication Center. Mission - Terminix's operation system - provides functionality for sales, field service (routing & scheduling, work order management), accounts receivable, and payroll. This system is designed modularly and is difficult to navigate for customer service agents needing to assist the customer quickly and knowledgeably. The amount of effort and time needed to train a customer service representative using the Mission system is high. This combined with low agent and customer retention is costly.
Customer Service Console enables Customer Service Associates to provide consistent, enhanced service experience, support to the Customers across the Organization. CSC is aimed at providing easy navigation, easy learning process, reduced call time and first call resolution.
Responsibilities
Assisted in creating Project Plan, Road Map. Designed Requirements Planning and Management document. Performed Enterprise Analysis and actively participated in buying Tool Licenses. Identified subject-matter experts and drove the requirements gathering process through approval of the documents that convey their needs to management, developers, and quality assurance team. Performed technical project consultation, initiation, collection and documentation of client business and functional requirements, solution alternatives, functional design, testing and implementation support. Requirements Elicitation, Analysis, Communication, and Validation according to Six Sigma Standards. Captured Business Process Flows and Reengineered Process to achieve maximum outputs. Captured As-Is Process, designed TO-BE Process and performed Gap Analysis Developed and updated functional use cases and conducted business process modeling (PROVISION) to explain business requirements to development and QA teams. Created Business Requirements Documents, Functional and Software Requirements Specification Documents. Performed Requirements Elicitation through Use Cases, one to one meetings, Affinity Exercises, SIPOC's. Gathered and documented Use Cases, Business Rules, created and maintained Requirements/Test Traceability Matrices. Client: The Dun & Bradstreet Corporation, Parsippany, NJ May' 2007 - Oct' 2007
Profile: Sr. Financial Business Analyst/ Systems Analyst.
Project Profile (1): D&B is the world's leading source of commercial information and insight on businesses. The Point of Arrival Project and the Data Maintenance (DM) Project are the future applications of the company that the company would transit into, providing an effective method & efficient report generation system for D&B's clients to be able purchase reports about companies they are trying to do business.
Project Profile (2): The overall purpose of this project was building a Self Awareness System(SAS) for the business community for buying SAS products and a Payment system was built for SAS. The system would provide certain combination of products (reports) for Self Monitoring report as a foundation for managing a company's credit.
Responsibilities:
Conducted GAP Analysis and documented the current state and future state, after understanding the Vision from the Business Group and the Technology Group. Conducted interviews with Process Owners, Administrators and Functional Heads to gather audit-related information and facilitated meetings to explain the impacts and effects of SOX compliance. Played an active and lead role in gathering, analyzing and documenting the Business Requirements, the business rules and Technical Requirements from the Business Group and the Technological Group. Co - Authored and prepared Graphical depictions of Narrative Use Cases, created UML Models such as Use Case Diagrams, Activity Diagrams and Flow Diagrams using MS Visio throughout the Agile methodology Documented the Business Requirement Document to get a better understanding of client's business processes of both the projects using the Agile methodology. Facilitating JRP and JAD sessions, brain storming sessions with the Business Group and the Technology Group. Documented the Requirement traceability matrix (RTM) and conducted UML Modelling such as creating Activity Diagrams, Flow Diagrams using MS Visio. Analysed test data to detect significant findings and recommended corrective measures Co-Managed the Change Control process for the entire project as a whole by facilitating group meetings, one-on-one interview sessions and email correspondence with work stream owners to discuss the impact of Change Request on the project. Worked with the Project Lead in setting realistic project expectations and in evaluating the impact of changes on the organization and plans accordingly and conducted project related presentations. Co-oordinated with the off shore QA Team members to explain and develop the Test Plans, Test cases, Test and Evaluation strategy and methods for unit testing, functional testing and usability testing Environment: Windows XP/2000, SOX, Sharepoint, SQL, MS Visio, Oracle, MS Office Suite, Mercury ITG, Mercury Quality Center, XML, XHTML, Java, J2EE.
GATEWAY COMPUTERS, Irvine, CA, Jan 06 - Mar 07
Business Analyst
At Gateway, a Leading Computer, Laptop and Accessory Manufacturer, was involved in two projects,
Order Capture Application: Objective of this Project is to Develop Various Mediums of Sales with a Centralized Catalog. This project involves wide exposure towards Requirement Analysis, Creating, Executing and Maintaining of Test plans and Test Cases. Mentored and trained staff about Tech Guide & Company Standards; Gateway reporting system: was developed with Business Objects running against Oracle data warehouse with Sales, Inventory, and HR Data Marts. This DW serves the different needs of Sales Personnel and Management. Involved in the development of it utilized Full Client reports and Web Intelligence to deliver analytics to the Contract Administration group and Pricing groups. Reporting data mart included Wholesaler Sales, Contract Sales and Rebates data.
Responsibilities:
Product Manager for Enterprise Level Order Entry Systems - Phone, B2B, Gateway.com and Cataloging System. Modeled the Sales Order Entry process to eliminate bottleneck process steps using ERWIN. Adhered and practiced RUP for implementing software development life cycle. Gathered Requirements from different sources like Stakeholders, Documentation, Corporate Goals, Existing Systems, and Subject Matter Experts by conducting Workshops, Interviews, Use Cases, Prototypes, Reading Documents, Market Analysis, Observations Created Functional Requirement Specification documents - which include UMLUse case diagrams, Scenarios, activity, work Flow diagrams and data mapping. Process and Data modeling with MS VISIO. Worked with Technical Team to create Business Services (Web Services) that Application could leverage using SOA, to create System Architecture and CDM for common order platform. Designed Payment Authorization (Credit Card, Net Terms, and Pay Pal) for the transaction/order entry systems. Implemented A/B Testing, Customer Feedback Functionality to Gateway.com Worked with the DW, ETL teams to create Order entry systems Business Objects reports. (Full Client, Web I) Worked in a cross functional team of Business, Architects and Developers to implement new features. Program Managed Enterprise Order Entry Systems - Development and Deployment Schedule. Developed and maintained User Manuals, Application Documentation Manual, on Share Point tool. Created Test Plansand Test Strategies to define the Objective and Approach of testing. Used Quality Center to track and report system defects and bug fixes. Written modification requests for the bugs in the application and helped developers to track and resolve the problems. Developed and Executed Manual, Automated Functional, GUI, Regression, UAT Test cases using QTP. Gathered, documented and executed Requirements-based, Business process (workflow/user scenario), Data driven test cases for User Acceptance Testing. Created Test Matrix, Used Quality Center for Test Management, track & report system defects and bug fixes. Performed Load, stress Testing's & Analyzed Performance, Response Times. Designed approach, developed visual scripts in order to test client & server side performance under various conditions to identify bottlenecks. Created / developed SQL Queries (TOAD) with several parameters for Backend/DB testing Conducted meetings for project status, issue identification, and parent task review, Progress Reporting. AMC MORTGAGE SERVICES, CA, USA Oct 04 - Dec 05
Business Analyst
The primary objective of this project is to replace the existing Internal Facing Client / Server Applications with a Web enabled Application System, which can be used across all the Business Channels. This project involves wide exposure towards Requirement Analysis, Creating, Executing and Maintaining of Test plans and Test Cases. Demands understanding and testing of Data Warehouse and Data Marts, thorough knowledge of ETL and Reporting, Enhancement of the Legacy System covered all of the business requirements related to Valuations from maintaining the panel of appraisers to ordering, receiving, and reviewing the valuations.
Responsibilities:
Gathered Analyzed, Validated, and Managed and documented the stated Requirements. Interacted with users for verifying requirements, managing change control process, updating existing documentation. Created Functional Requirement Specification documents - that include UML Use case diagrams, scenarios, activity diagrams and data mapping. Provided End User Consulting on Functionality and Business Process. Acted as a client liaison to review priorities and manage the overall client queue. Provided consultation services to clients, technicians and internal departments on basic to intricate functions of the applications. Identified business directions & objectives that may influence the required data and application architectures. Defined, prioritized business requirements, Determine which business subject areas provide the most needed information; prioritize and sequence implementation projects accordingly. Provide relevant test scenarios for the testing team. Work with test team to develop system integration test scripts and ensure the testing results correspond to the business expectations. Used Test Director, QTP, Load Runner for Test management, Functional, GUI, Performance, Stress Testing Perform Data Validation, Data Integration and Backend/DB testing using SQL Queries manually. Created Test input requirements and prepared the test data for data driven testing. Mentored, trained staff about Tech Guide & Company Standards. Set-up and Coordinate Onsite offshore teams, Conduct Knowledge Transfer sessions to the offshore team. Lloyds Bank, UK Aug 03 - Sept 04 Business Analyst Lloyds TSB is leader in Business, Personal and Corporate Banking. Noted financial provider for millions of customers with the financial resources to meet and manage their credit needs and to achieve their financial goals. The Project involves an applicant Information System, Loan Appraisal and Loan Sanction, Legal, Disbursements, Accounts, MIS and Report Modules of a Housing Finance System and Enhancements for their Internet Banking.
Responsibilities:
Translated stakeholder requirements into various documentation deliverables such as functional specifications, use cases, workflow / process diagrams, data flow / data model diagrams. Produced functional specifications and led weekly meetings with developers and business units to discuss outstanding technical issues and deadlines that had to be met. Coordinated project activities between clients and internal groups and information technology, including project portfolio management and project pipeline planning. Provided functional expertise to developers during the technical design and construction phases of the project. Documented and analyzed business workflows and processes. Present the studies to the client for approval Participated in Universe development - planning, designing, Building, distribution, and maintenance phases. Designed and developed Universes by defining Joins, Cardinalities between the tables. Created UML use case, activity diagrams for the interaction between report analyst and the reporting systems. Successfully implemented BPR and achieved improved Performance, Reduced Time and Cost. Developed test plans and scripts; performed client testing for routine to complex processes to ensure proper system functioning. Worked closely with UAT Testers and End Users during system validation, User Acceptance Testing to expose functionality/business logic problems that unit testing and system testing have missed out. Participated in Integration, System, Regression, Performance, and UAT - Using TD, WR, Load Runner Participated in defect review meetings with the team members. Worked closely with the project manager to record, track, prioritize and close bugs. Used CVS to maintain versions between various stages of SDLC. Client: A.G. Edwards, St. Louis, MO May' 2005 - Feb' 2006
Profile: Sr. Business Analyst/System Analyst
Project Profile: A.G. Edwards is a full service Trading based brokerage firm in Internet-based futures, options and forex brokerage. This site allows Users (Financial Representative) to trade online. The main features of this site were: Users can open new account online to trade equitiies, bonds, derivatives and forex with the Trading system using DTCC's applications as a Clearing House agent. The user will get real-time streaming quotes for the currency pairs they selected, their current position in the forex market, summary of work orders, payments and current money balances, P & L Accounts and available trading power, all continuously updating in real time via live quotes. The site also facilitates users to Place, Change and Cancel an Entry Order, Placing a Market Order, Place/Modify/Delete/Close a Stop Loss Limit on an Open Position.
Responsibilities:
Gathered Business requirements pertaining to Trading, equities and Fixed Incomes like bonds, converted the same into functional requirements by implementing the RUP methodology and authored the same in Business Requirement Document (BRD). Designed and developed all Narrative Use Cases and conducted UML modeling like created Use Case Diagrams, Process Flow Diagrams and Activity Diagrams using MS Visio. Implemented the entire Rational Unified Process (RUP) methodology of application development with its various workflows, artifacts and activities. Developed business process models in RUP to document existing and future business processes. Established a business Analysis methodology around the Rational Unified Process. Analyzed user requirements, attended Change Request meetings to document changes and implemented procedures to test changes. Assisted in developing project timelines/deliverables/strategies for effective project management. Evaluated existing practices of storing and handling important financial data for compliance. Involved in developing the test strategy and assisted in developed Test scenarios, test conditions and test cases Partnered with the technical Business Analyst Interview questions areas in the research, resolution of system and User Acceptance Testing (UAT).
1 note
·
View note
Text
RMAN QUICK LEARN– FOR THE BEGINNERS
Oracle Recovery Manager (RMAN) is Oracle’s preferred method or tools by which we are able to take backups and restore and recover our database. You must develop a proper backup strategy which provides maximum flexibility to Restore & Recover the DB from any kind of failure. To develop a proper backup strategy you must decide the type of requirement then after think the possible backup option. The recommended backup strategy must include the backup of all datafiles, Archivelog and spfile & controlfile autobackup. To take online or hot backups database must be in archivelog mode. You can however use RMAN to take an offline or cold backup.Note: Selecting the backup storage media is also important consideration. If you are storing your backup on disk then it is recommended to keep an extra copy of backup at any other server. CREATING RECOVERY CATALOG: Oracle recommended to use separate database for RMAN catalog. Consider in below steps the database is already created: 1. Create tablespace for RMAN: SQL> create tablespace RTBS datafile 'D:ORACLEORADATARTBS01.DBF' size 200M extent management local uniform size 5M; 2. Create RMAN catalog user: SQL> create user CATALOG identified by CATALOG default tablespace RTBS quota unlimited on RTBS; 3. Grant some privileges to RMAN user: SQL> Grant connect, resource to CATALOG; SQL> grant recovery_catalog_owner to CATALOG; 4. Connect into catalog database and create the catalog: % rman catalog RMAN_USER/RMAN_PASSWORD@cat_db log=create_catalog.log RMAN> create catalog tablespace RTBS; RMAN> exit; 5. Connect into the target database and into the catalog database: % rman target sys/oracle@target_db RMAN> connect catalog RMAN_USER/RMAN_PASSWORD@cat_db 6. Connected into the both databases, register target database: RMAN> register database; The following list gives an overview of the commands and their uses in RMAN. For details description search the related topics of separate post on my blog: http://shahiddba.blogspot.com/INITIALIZATION PARAMETER: Some RMAN related database initialization parameters: control_file_record_keep_time: Time in days to retention records in the Control File. (default: 7 days) large_pool_size: Memory pool used for RMAN in backup/restore operations. shared_pool_size: Memory pool used for RMAN in backup/restore operations (only if large pool is not configured). CONNECTING RMANexport ORACLE_SID= --Linux platformset ORACLE_SID== --Windows platformTo connect on a target database execute RMAN.EXE then RMAN>connect target / RMAN>connect target username/password RMAN>connect target username/password@target_db To connect on a catalog database:RMAN>connect catalog username/password RMAN>connect catalog username/password@catalog_db To connect directly from the command prompt:C:>rman target / --target with nocatalog Recovery Manager: Release 9.2.0.1.0 - ProductionCopyright (c) 1995, 2002, Oracle Corporation. All rights reserved.connected to target database: RMAN (DBID=63198018)using target database controlfile instead of recovery catalogC:>rman target sys/oracle@orcl3 catalog catalog/catalog@rman --with catalogRecovery Manager: Release 9.2.0.1.0 - ProductionCopyright (c) 1995, 2002, Oracle Corporation. All rights reserved.connected to target database: SADHAN (DBID=63198018)connected to recovery catalog databaseRMAN PARAMETERSRMAN parameters can be set to a specified value and remain persistent. This information is stored in the target database’s controlfile (By default). Alternatively you can store this backup information into recovery catalog. If you connect without catalog or only to the target database, your repository should be in the controlfile.SHOW/CONFIGURE – SHOW command will show current values for set parameters and CONFIGURE – Command to set new value for parameterRMAN> show all;using target database control file instead of recovery catalogRMAN configuration parameters are:CONFIGURE RETENTION POLICY TO REDUNDANCY 1; # defaultCONFIGURE BACKUP OPTIMIZATION OFF; # defaultCONFIGURE DEFAULT DEVICE TYPE TO ; # defaultCONFIGURE CONTROLFILE AUTOBACKUP ON;RMAN>show datafile backup copies; RMAN>show default device type; RMAN>show device type; RMAN>show channel; RMAN>show retention policy;RMAN> CONFIGURE CONTROLFILE AUTOBACKUP ON;old RMAN configuration parameters:CONFIGURE CONTROLFILE AUTOBACKUP OFF;new RMAN configuration parameters:CONFIGURE CONTROLFILE AUTOBACKUP ON; new RMAN configuration parameters are successfully stored CONFIGURE channel device type disk format 'D:oraback%U'; You can set many parameters by configuring them first and making them persistent or you can override them (discard any persistent configuration) by specifying them explicitly in your RMAN backup command. Setting Default Recommended Controlfile autobackup off on Retention policy to redundancy 1 to recovery window of 30 days Device type disk parallelism 1 ... disk|sbt prallelism 2 ... Default device type to disk to disk Backup optimization off off Channel device type none disk parms=‘...’ Maxsetsize unlimited depends on your database size Appending CLEAR or NONE at the last of configuration parameter command will reset the configuration to default and none setting.CONFIGURE RETENTION POLICY CLEAR;CONFIGURE RETENTION POLICY NONE; Overriding the configured retention policy: change backupset 421 keep forever nologs; change datafilecopy 'D:oracleoradatausers01.dbf' keep until 'SYSDATE+30';RMAN BACKUP SCRIPTS:Backing up the database can be done with just a few commands or can be made with numerous options. RMAN> backup database;RMAN> backup as compressed backupset database;RMAN> Backup INCREMENTAL level=0 database;RMAN> Backup database TAG=Weekly_Sadhan;RMAN> Backup database MAXSETSIZE=2g;RMAN> backup TABLESPACE orafin;You may also combine options together in a single backup and for multi channel backup.RMAN> Backup INCREMENTAL level=1 as COMPRESSED backupset databaseFORMAT 'H:ORABACK%U' maxsetsize 2G; backup full datafile x,y,z incremental level x include current controlfile archivelog all delete input copies x filesperset x maxsetsize xM diskratio x format = 'D:oraback%U';run {allocate channel d1 type disk FORMAT "H:orabackWeekly_%T_L0_%d-%s_%p.db";allocate channel d2 type disk FORMAT "H:orabackWeekly_%T_L0_%d-%s_%p.db";allocate channel d3 type disk FORMAT "H:orabackWeekly_%T_L0_%d-%s_%p.db"; backup incremental level 0 tag Sadhan_Full_DBbackup filesperset 8 FORMAT "H:orabackWeekly_%T_FULL_%d-%s_%p.db" DATABASE; SQL 'ALTER SYSTEM ARCHIVE LOG CURRENT'; backup archivelog all tag Sadhan_Full_Archiveback filesperset 8 format "H:orabackWeekly_%T_FULL_%d-%s_%p.arch"; release channel d1; release channel d2; release channel d3; } The COPY command and some copy scripts: copy datafile 'D:oracleoradatausers01.dbf' TO 'H:orabackusers01.dbf' tag=DF3, datafile 4 to TO 'H:orabackusers04.dbf' tag=DF4, archivelog 'arch_1060.arch' TO 'arch_1060.bak' tag=CP2ARCH16; run { allocate channel c1 type disk; copy datafile 'd:oracleoradatausers01.dbf' TO 'h:orabackusers01.dbf' tag=DF3, archivelog 'arch_1060.arch' TO 'arch_1060.bak' tag=CP2ARCH16; }COMPRESSED – Compresses the backup as it is taken.INCREMENTAL – Selecting incremental allows to backup only changes since last full backup.FORMAT – Allows you to specify an alternate location.TAG – You can name your backup.MAXSETSIZE – Limits backup piece size.TABLESPACE – Allows you to backup only a tablespace.RMAN MAINTAINANCE :You can review your RMAN backups using the LIST command. You can use LIST with options to customize what you want RMAN to return to you.RMAN> list backup SUMMARY;RMAN> list ARCHIVELOG ALL;RMAN> list backup COMPLETED before ‘02-FEB-09’;RMAN> list backup of database TAG Weekly_sadhan; RMAN> list backup of datafile "D:oracleoradatasadhanusers01.dbf" SUMMARY;You can test your backups using the validate command.RMAN> list copy of tablespace "SYSTEM"; You can ask RMAN to report backup information. RMAN> restore database validate; RMAN> report schema; RMAN> report need backup; RMAN> report need backup incremental 3 database; RMAN> report need backup days 3; RMAN> report need backup days 3 tablespace system; RMAN>report need backup redundancy 2; RMAN>report need backup recovery window of 3 days; RMAN> report unrecoverable; RMAN> report obsolete; RMAN> delete obsolete; RMAN> delete noprompt obsolete; RMAN> crosscheck; RMAN> crosscheck backup; RMAN> crosscheck backupset of database; RMAN> crosscheck copy; RMAN> delete expired; --use this after crosscheck command RMAN> delete noprompt expired backup of tablespace users; To delete backup and copies: RMAN> delete backupset 104; RMAN> delete datafilecopy 'D:oracleoradatausers01.dbf'; To change the status of some backups or copies to unavailable come back to available: RMAN>change backup of controlfile unavaliable; RMAN>change backup of controlfile available; RMAN>change datafilecopy 'H:orabackusers01.dbf' unavailable; RMAN>change copy of archivelog sequence between 230 and 240 unavailable; To catalog or uncatalog in RMAN repository some copies of datafiles, archivelogs and controlfies made by users using OS commands: RMAN>catalog datafilecopy 'F:orabacksample01.dbf'; RMAN>catalog archivelog 'E:oraclearch_404.arc', 'F:oraclearch_410.arc'; RMAN>catalog controlfilecopy 'H:oracleoradatacontrolfile.ctl'; RMAN> change datafilecopy 'F:orabacksample01.dbf' uncatalog; RMAN> change archivelog 'E:oraclearch_404.arc', 'E:oraclearch_410.arc' uncatalog; RMAN> change controlfilecopy 'H:oracleoradatacontrolfile.ctl' uncatalog; RESTORING & RECOVERING WITH RMAN BACKUPYou can perform easily restore & recover operation with RMAN. Depending on the situation you can select either complete or incomplete recovery process. The complete recovery process applies all the redo or archivelog where as incomplete recovery does not apply all of the redo or archive logs. In this case of recovery, as you are not going to complete recovery of the database to the most current time, you must tell Oracle when to terminate recovery. Note: You must open your database with resetlogs option after each incomplete recovery. The resetlogs operation starts the database with a new stream of log sequence number starting with sequence 1. DATAFILE – Restore specified datafile.CONTROLFILE – To restore controlfile from backup database must be in nomount.ARCHIVELOG or ARCHIVELOG from until – Restore archivelog to location there were backed up.TABLESPACE – Restores all the datafiles associated with specified tablespace. It can be done with database open.RECOVER TABLESPACE/DATAFILE:If a non-system tablespace or datafile is missing or corrupted, recovery can be performed while the database remains open.STARTUP; (you will get ora-1157 ora-1110 and the name of the missing datafile, the database will remain mounted)Use OS commands to restore the missing or corrupted datafile to its original location, ie: cp -p /user/backup/uman/user01.dbf /user/oradata/u01/dbtst/user01.dbfSQL>ALTER DATABASE DATAFILE3 OFFLINE; (tablespace cannot be used because the database is not open)SQL>ALTER DATABASE OPEN;SQL>RECOVER DATAFILE 3;SQL>ALTER TABLESPACE ONLINE; (Alternatively you can use ‘alter database’ command to take datafile online)If the problem is only the single file then restore only that particualr file otherwise restore & recover whole tablespace. The database can be in use while recovering the whole tablespace.run { sql ‘alter tablespace users offline’; allocate channel c1 device type disk|sbt; restore tablespace users; recover tablespace users; sql ‘alter tablespace users online’;}If the problem is in SYSTEM datafile or tableapce then you cannnot open the database. You need sifficient downtime to recover it. If problem is in more than one file then it is better to recover whole tablepace or database.startup mountrun { allocate channel c1 device type disk|sbt; allocate channel c2 device type disk|sbt; restore database check readonly; recover database; alter database open;}DATABASE DISASTER RECOVERY:Disaster recovery plans start with risk assessment. We need to identify all the risks that our data center can face such as: All datafiles are lost, All copies of current controlfile are lost, All online redolog group member are lost, Loss of OS, loss of a disk drive, complete loss of our server etc: Our disaster plan should give brief description about recovery from above disaster. Planning Disaster Recovery in advance is essential for DBA to avoid any worrying or panic situation.The below method is used for complete disaster recovery on the same as well as different server. set dbid=xxxxxxxstartup nomount;run {allocate channel c1 device type disk|sbt;restore spfile to ‘some_location’ from autobackup;recover database; alter database open resetlogs;}shutdown immediate;startup nomount;run { allocate channel c1 device type disk|sbt; restore controlfile from autobackup;alter database mount; } RMAN> restore database;RMAN> recover database; --no need incase of cold backupRMAN> alter database open resetlogs;}DATABASE POINT INTIME RECOVERY:DBPITR enables you to recover a database to some time in the past. For example, if logical error occurred today at 10.00 AM, DBPITR enables you to restore the entire database to the state it was in at 09:59 AM there by removing the effect of error but also remove all other valid update that occur since 09:59 AM. DBPTIR requires the database is in archivelog mode, and existing backup of database created before the point in time to which you wish to recover must exists, and all the archivelog and online logs created from the time of backup until the point in time to which you wish to recover must exist as well. RMAN> shutdown Abort; RMAN> startup mount; RMAN> run { Set until time to_date('12-May-2012 00:00:00′, ‘DD-MON-YYYY HH24:MI:SS'); restore database; recover database; }RMAN> alter database open resetlogs;Caution: It is highly recommended that you must backup your controlfile and online redo log file before invoking DBPITR. So you can recover back to the current point in time in case of any issue.Oracle will automatically stop recovery when the time specified in the RECOVER command has been reached. Oracle will respond with a recovery successful message.SCN/CHANGE BASED RECOVERY:Change-based recovery allows the DBA to recover to a desired point of System change number (SCN). This situation is most likely to occur if archive logfiles or redo logfiles needed for recovery are lost or damaged and cannot be restored.Steps:– If the database is still open, shut down the database using the SHUTDOWN command with the ABORT option.– Make a full backup of the database including all datafiles, a control file, and the parameter files in case an error is made during the recovery.– Restore backups of all datafiles. Make sure the backups were taken before the point in time you are going to recover to. Any datafiles added after the point in time you are recovering to should not be restored. They will not be used in the recovery and will have to be recreated after recovery is complete. Any data in the datafiles created after the point of recovery will be lost.– Make sure read-only tablespace are offline before you start recovery so recovery does not try to update the datafile headers.RMAN> shutdown Abort; RMAN> startup mount; RMAN>run { set until SCN 1048438; restore database; recover database; alter database open resetlogs; }RMAN> restore database until sequence 9923; --Archived log sequence number RMAN> recover database until sequence 9923; --Archived log sequence number RMAN> alter database open resetlogs;Note: Query with V$LOG_HISTORY and check the alert.log to find the SCN of an event and recover to a prior SCN.IMPORTANT VIEW: Views to consult into the target database: v$backup_device: Device types accepted for backups by RMAN. v$archived_log: Redo logs archived. v$backup_corruption: Corrupted blocks in backups. v$copy_corruption: Corrupted blocks in copies. v$database_block_corruption: Corrupted blocks in the database after last backup. v$backup_datafile: Backups of datafiles. v$backup_redolog: Backups of redo logs. v$backup_set: Backup sets made. v$backup_piece: Pieces of previous backup sets made. v$session_long_ops: Long operations running at this time. Views to consult into the RMAN catalog database: rc_database: Information about the target database. rc_datafile: Information about the datafiles of target database. rc_tablespace: Information about the tablespaces of target database. rc_stored_script: Stored scripts. rc_stored_script_line: Source of stored scripts. For More Information on RMAN click on the below link: Different RMAN Recovery Scenarios 24-Feb-13 Synchronizes the Test database with RMAN Cold Backup 16-Feb-13 Plan B: Renovate old Apps Server Hardware 27-Jan-13 Plan A: Renovate old Apps Server Hardware 25-Jan-13 Planning to Renovate old Apps Server Hardware 24-Jan-13 Duplicate Database with RMAN without Connecting to Target Database 23-Jan-13 Different RMAN Errors and their Solution 24-Nov-12 Block Media Recovery using RMAN 4-Nov-12 New features in RMAN since Oracle9i/10g 14-Oct-12 A Shell Script To Take RMAN Cold/Hot and Export Backup 7-Oct-12 Automate Rman Backup on Windows Environment 3-Sep-12 How to take cold backup of oracle database? 26-Aug-12 Deleting RMAN Backups 22-Aug-12 Script: RMAN Hot Backup on Linux Environment 1-Aug-12 How RMAN behave with the allocated channel during backup 31-Jul-12 RMAN Important Commands Description. 7-Jul-12 Script: Crontab Use for RMAN Backup 2-Jun-12 RMAN Report and Show Commands 16-May-12 RMAN backup on a Windows server thruogh DBMS_SCHEDULING 15-May-12 Format Parameter of Rman Backup 12-May-12 Rman Backup with Stored Script 12-May-12 Rman: Disaster Recovery from the Scratch 6-May-12 RMAN- Change-Based (SCN) Recovery 30-Apr-12 RMAN-Time-Based Recovery 30-Apr-12 RMAN – Cold backup Restore 23-Apr-12 RMAN Backup on Network Storage 22-Apr-12 Rman Catalog Backup Script 18-Apr-12 Point to be considered with RMAN Backup Scripts 11-Apr-12 Monitoring RMAN Through V$ Views 7-Apr-12 RMAN Weekly and Daily Backup Scripts 25-Mar-12 Unregister Database from RMAN: 6-Mar-12
1 note
·
View note
Link
https://www.enteros.com/ Enteros Professional Services Organization (PSO) helps our clients to realize the maximum value possible from Enteros’ database management solutions. A wide range of client services are available. Database Oracle SQL Server database tuning database optimization database performance machine learning
1 note
·
View note
Text
GCP Database Migration Service Boosts PostgreSQL migrations

GCP database migration service
GCP Database Migration Service (DMS) simplifies data migration to Google Cloud databases for new workloads. DMS offers continuous migrations from MySQL, PostgreSQL, and SQL Server to Cloud SQL and AlloyDB for PostgreSQL. DMS migrates Oracle workloads to Cloud SQL for PostgreSQL and AlloyDB to modernise them. DMS simplifies data migration to Google Cloud databases.
This blog post will discuss ways to speed up Cloud SQL migrations for PostgreSQL / AlloyDB workloads.
Large-scale database migration challenges
The main purpose of Database Migration Service is to move databases smoothly with little downtime. With huge production workloads, migration speed is crucial to the experience. Slower migration times can affect PostgreSQL databases like:
Long time for destination to catch up with source after replication.
Long-running copy operations pause vacuum, causing source transaction wraparound.
Increased WAL Logs size leads to increased source disc use.
Boost migrations
To speed migrations, Google can fine-tune some settings to avoid aforementioned concerns. The following options apply to Cloud SQL and AlloyDB destinations. Improve migration speeds. Adjust the following settings in various categories:
DMS parallels initial load and change data capture (CDC).
Configure source and target PostgreSQL parameters.
Improve machine and network settings
Examine these in detail.
Parallel initial load and CDC with DMS
Google’s new DMS functionality uses PostgreSQL multiple subscriptions to migrate data in parallel by setting up pglogical subscriptions between the source and destination databases. This feature migrates data in parallel streams during data load and CDC.
Database Migration Service’s UI and Cloud SQL APIs default to OPTIMAL, which balances performance and source database load. You can increase migration speed by selecting MAXIMUM, which delivers the maximum dump speeds.
Based on your setting,
DMS calculates the optimal number of subscriptions (the receiving side of pglogical replication) per database based on database and instance-size information.
To balance replication set sizes among subscriptions, tables are assigned to distinct replication sets based on size.
Individual subscription connections copy data in simultaneously, resulting in CDC.
In Google’s experience, MAXIMUM mode speeds migration multifold compared to MINIMAL / OPTIMAL mode.
The MAXIMUM setting delivers the fastest speeds, but if the source is already under load, it may slow application performance. So check source resource use before choosing this option.
Configure source and target PostgreSQL parameters.
CDC and initial load can be optimised with these database options. The suggestions have a range of values, which you must test and set based on your workload.
Target instance fine-tuning
These destination database configurations can be fine-tuned.
max_wal_size: Set this in range of 20GB-50GB
The system setting max_wal_size limits WAL growth during automatic checkpoints. Higher wal size reduces checkpoint frequency, improving migration resource allocation. The default max_wal_size can create DMS load checkpoints every few seconds. Google can set max_wal_size between 20GB and 50GB depending on machine tier to avoid this. Higher values improve migration speeds, especially beginning load. AlloyDB manages checkpoints automatically, therefore this argument is not needed. After migration, modify the value to fit production workload requirements.
pglogical.synchronous_commit : Set this to off
As the name implies, pglogical.synchronous_commit can acknowledge commits before flushing WAL records to disc. WAL flush depends on wal_writer_delay parameters. This is an asynchronous commit, which speeds up CDC DML modifications but reduces durability. Last few asynchronous commits may be lost if PostgreSQL crashes.
wal_buffers : Set 32–64 MB in 4 vCPU machines, 64–128 MB in 8–16 vCPU machines
Wal buffers show the amount of shared memory utilised for unwritten WAL data. Initial load commit frequency should be reduced. Set it to 256MB for greater vCPU objectives. Smaller wal_buffers increase commit frequency, hence increasing them helps initial load.
maintenance_work_mem: Suggested value of 1GB / size of biggest index if possible
PostgreSQL maintenance operations like VACUUM, CREATE INDEX, and ALTER TABLE ADD FOREIGN KEY employ maintenance_work_mem. Databases execute these actions sequentially. Before CDC, DMS migrates initial load data and rebuilds destination indexes and constraints. Maintenance_work_mem optimises memory for constraint construction. Increase this value beyond 64 MB. Past studies with 1 GB yielded good results. If possible, this setting should be close to the destination’s greatest index to replicate. After migration, reset this parameter to the default value to avoid affecting application query processing.
max_parallel_maintenance_workers: Proportional to CPU count
Following data migration, DMS uses pg_restore to recreate secondary indexes on the destination. DMS chooses the best parallel configuration for –jobs depending on target machine configuration. Set max_parallel_maintenance_workers on the destination for parallel index creation to speed up CREATE INDEX calls. The default option is 2, although the destination instance’s CPU count and memory can increase it. After migration, reset this parameter to the default value to avoid affecting application query processing.
max_parallel_workers: Set proportional max_worker_processes
The max_parallel_workers flag increases the system’s parallel worker limit. The default value is 8. Setting this above max_worker_processes has no effect because parallel workers are taken from that pool. Maximum parallel workers should be equal to or more than maximum parallel maintenance workers.
autovacuum: Off
Turn off autovacuum in the destination until replication lag is low if there is a lot of data to catch up on during the CDC phase. To speed up a one-time manual hoover before promoting an instance, specify max_parallel_maintenance_workers=4 (set it to the Cloud SQL instance’s vCPUs) and maintenance_work_mem=10GB or greater. Note that manual hoover uses maintenance_work_mem. Turn on autovacuum after migration.
Source instance configurations for fine tuning
Finally, for source instance fine tuning, consider these configurations:
Shared_buffers: Set to 60% of RAM
The database server allocates shared memory buffers using the shared_buffers argument. Increase shared_buffers to 60% of the source PostgreSQL database‘s RAM to improve initial load performance and buffer SELECTs.
Adjust machine and network settings
Another factor in faster migrations is machine or network configuration. Larger destination and source configurations (RAM, CPU, Disc IO) speed migrations.
Here are some methods:
Consider a large machine tier for the destination instance when migrating with DMS. Before promoting the instance, degrade the machine to a lower tier after migration. This requires a machine restart. Since this is done before promoting the instance, source downtime is usually unaffected.
Network bandwidth is limited by vCPUs. The network egress cap on write throughput for each VM depends on its type. VM network egress throughput limits disc throughput to 0.48MBps per GB. Disc IOPS is 30/GB. Choose Cloud SQL instances with more vCPUs. Increase disc space for throughput and IOPS.
Google’s experiments show that private IP migrations are 20% faster than public IP migrations.
Size initial storage based on the migration workload’s throughput and IOPS, not just the source database size.
The number of vCPUs in the target Cloud SQL instance determines Index Rebuild parallel threads. (DMS creates secondary indexes and constraints after initial load but before CDC.)
Last ideas and limitations
DMS may not improve speed if the source has a huge table that holds most of the data in the database being migrated. The current parallelism is table-level due to pglogical constraints. Future updates will solve the inability to parallelise table data.
Do not activate automated backups during migration. DDLs on the source are not supported for replication, therefore avoid them.
Fine-tuning source and destination instance configurations, using optimal machine and network configurations, and monitoring workflow steps optimise DMS migrations. Faster DMS migrations are possible by following best practices and addressing potential issues.
Read more on govindhtech.com
#GCP#GCPDatabase#MigrationService#PostgreSQL#CloudSQL#AlloyDB#vCPU#CPU#VMnetwork#APIs#news#technews#technology#technologynews#technologytrends#govindhtech
0 notes
Text
How Dedicated Gaming Server Can Help You?
If you really feel that your business/ internet site witness heavy flow of web traffic, data storage space needs improved and maximum safety and security procedures and shared hosting atmosphere is no more offering the performance and also solutions that your site requires then, definitely devoted internet server or committed holding is the requirement of the hour.
A specialized web server is an equipment with all its sources specifically at its owner's service. You do not share your web server or its sources with anybody so your websites stay safe and untouched by various other web sites. You obtain full control over the web server, consisting of the choice of selecting operating system and equipment etc. They additionally have massive quantity of data source to save your substantial amount of information. Therefore, Dedicated Gaming Server Set Up supplies the advantages of high efficiency, safety, as well as control.
Keeping this in mind, I have actually assembled a listing of important factors which if thought about while selecting a devoted organizing company will certainly aid you in making right decision.
Quality server Equipment utilized by the service provider-.
Devoted Servers which you intend to select, need to include latest generation hardware and technologies as type of equipment used by devoted provider can influence the efficiency of your website and also application substantially. Other factors which need consideration are.

Processor- It helps in the faster speed and also performance of servers. For e.g. internet site with CPU-intensive manuscripts, servers made use of for particular functions such as Game server setup online, require rapid and strong servers with several cpus, such as quad cpu, solitary or double Xeon servers.
Running systems- Linux and also Windows are two major as well as widely utilized os for committed organizing web servers. Your hosting provider should run both of them so that you can choose any kind of one out of them relying on the technology called for by your site. Like Microsoft Windows is best matched for hosting ASP.NET code, MS SQL Server as well as Linux OS is suited for open source pile such as Apache/PHP/ MySQL (LIGHT).
Devoted web servers valuing structure- committed organizing is bit pricey in contrast to various other web hosting strategies. Yet you need to check different kinds of prices which you will certainly run into while purchasing a devoted internet server. Examine the monthly website traffic which is consisted of in the month-to-month cost, configuration fees, software program licensing fees, scalability costs, down time prices, cost of upgrades and also components, migration and also decommissioning costs etc.
Free Worth included solutions- As dedicated servers are bit expensive in comparison to other web hosting plans, if you can obtain some totally free as well as worth included services packed with the selected strategy, they can verify to be a benefit for your internet site.
For More Info:- Best ARK Server Hosting
1 note
·
View note
Text
Unlock Real-Time Insights with SQL Server Change Data Capture
Introduction:
In today's fast-paced digital landscape, businesses need real-time insights to stay competitive. SQL Server Change Data Capture (CDC) is a powerful feature that enables organizations to capture and track changes made to their SQL Server databases. In this article, we will explore the benefits of SQL Server Change Data Capture and how it empowers businesses to make informed decisions based on real-time data.

Efficient Tracking of Data Changes:
SQL Server Change Data Capture provides a reliable and efficient way to track changes made to the database. With CDC, you can capture changes at the row level, including inserts, updates, and deletes. This granular level of tracking allows you to understand the evolution of your data over time and enables you to analyze trends, identify anomalies, and make data-driven decisions. By capturing changes efficiently, CDC reduces the overhead on your SQL Server and ensures minimal impact on the database performance.
Real-Time Data Integration:
One of the significant advantages of SQL Server Change Data Capture is its ability to facilitate real-time data integration. CDC captures and stores changed data in a separate change table, allowing you to easily access and integrate it with other systems or applications. This enables real-time data synchronization between different databases, data warehouses, or analytical platforms. By having access to up-to-date data, you can gain valuable insights, streamline business processes, and improve decision-making efficiency.
Auditing and Compliance:
Maintaining data integrity and meeting regulatory compliance requirements are essential for businesses across various industries. SQL Server Change Data Capture helps organizations fulfill auditing and compliance needs by providing a reliable and transparent trail of all changes made to the database. The captured change data includes the old and new values, timestamps, and user information, allowing you to track and monitor data modifications. This level of auditing capability ensures data accountability and helps organizations comply with industry regulations and internal policies.
Simplified Data Warehousing and Reporting:
SQL Server Change Data Capture simplifies the process of data warehousing and reporting. By capturing changes at the source database, CDC eliminates the need for complex and time-consuming extraction, transformation, and loading (ETL) processes. You can directly access the captured change data and populate your data warehouse in near real-time, enabling faster and more accurate reporting. This streamlined approach to data warehousing enhances the overall efficiency of your analytics and reporting workflows.
Efficient Data Recovery and Rollbacks:
In the event of data corruption or unintended changes, SQL Server Change Data Capture proves invaluable for efficient data recovery and rollbacks. By utilizing the captured change data, you can identify and isolate specific changes made to the database. This allows you to restore the affected data to its previous state, minimizing the impact of errors and reducing downtime. The ability to quickly recover and roll back changes enhances data reliability and safeguards the integrity of your SQL Server databases.
Integration with Third-Party Tools:
SQL Server Change Data Capture seamlessly integrates with various third-party tools and technologies. Whether you need to feed change data into a data integration platform, perform advanced analytics using business intelligence tools, or trigger event-driven workflows, CDC provides the necessary flexibility and compatibility. This integration capability expands the possibilities of utilizing change data across your entire data ecosystem, enabling you to derive maximum value from your SQL Server databases.
Conclusion:
SQL Server Change Data Capture empowers organizations to unlock real-time insights and make informed decisions based on up-to-date data. With efficient tracking of data changes, real-time data integration, auditing and compliance features, simplified data warehousing, efficient data recovery, and seamless integration with third-party tools, CDC offers a comprehensive solution for capturing and utilizing change data. By implementing SQL Server Change Data Capture, businesses can stay ahead of the competition, improve decision-making processes, and drive success in today's data-driven world.
0 notes