#Transcript Annotation Services
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
The total number of visits Tumblr.com received during January 2021 is 327 million.
Text

How Video Transcription Services Improve AI Training Through Annotated Datasets
Video transcription services play a crucial role in AI training by converting raw video data into structured, annotated datasets, enhancing the accuracy and performance of machine learning models.
#video transcription services#aitraining#Annotated Datasets#machine learning#ultimate sex machine#Data Collection for AI#AI Data Solutions#Video Data Annotation#Improving AI Accuracy
0 notes
Text
Audio Transcription and Annotation Services | HAIVO AI
HAIVO AI specializes in Audio Annotation and Transcript Annotation Services. Our expert team delivers precise and reliable solutions for your audio data needs. Explore our services to unlock the potential of your audio content.

0 notes
Text
AI & Tech-Related Jobs Anyone Could Do
Here’s a list of 40 jobs or tasks related to AI and technology that almost anyone could potentially do, especially with basic training or the right resources:
Data Labeling/Annotation
AI Model Training Assistant
Chatbot Content Writer
AI Testing Assistant
Basic Data Entry for AI Models
AI Customer Service Representative
Social Media Content Curation (using AI tools)
Voice Assistant Testing
AI-Generated Content Editor
Image Captioning for AI Models
Transcription Services for AI Audio
Survey Creation for AI Training
Review and Reporting of AI Output
Content Moderator for AI Systems
Training Data Curator
Video and Image Data Tagging
Personal Assistant for AI Research Teams
AI Platform Support (user-facing)
Keyword Research for AI Algorithms
Marketing Campaign Optimization (AI tools)
AI Chatbot Script Tester
Simple Data Cleansing Tasks
Assisting with AI User Experience Research
Uploading Training Data to Cloud Platforms
Data Backup and Organization for AI Projects
Online Survey Administration for AI Data
Virtual Assistant (AI-powered tools)
Basic App Testing for AI Features
Content Creation for AI-based Tools
AI-Generated Design Testing (web design, logos)
Product Review and Feedback for AI Products
Organizing AI Training Sessions for Users
Data Privacy and Compliance Assistant
AI-Powered E-commerce Support (product recommendations)
AI Algorithm Performance Monitoring (basic tasks)
AI Project Documentation Assistant
Simple Customer Feedback Analysis (AI tools)
Video Subtitling for AI Translation Systems
AI-Enhanced SEO Optimization
Basic Tech Support for AI Tools
These roles or tasks could be done with minimal technical expertise, though many would benefit from basic training in AI tools or specific software used in these jobs. Some tasks might also involve working with AI platforms that automate parts of the process, making it easier for non-experts to participate.
4 notes
·
View notes
Note
I just wanna say, DUDE. The majority of what I know about amrev comes from your blog. Your in-depth posts literally have me FOAMING AT THE MOUTHH I don't have much time to read longer books due to school but I wanna feed my obsession so do you have any books on the shorter side or some websites/archives I can research/read a bit quicker? If not it's totally fine.
Also off topic but I'm loving "It Began About Dusk" on AO3 <3
OH MY GOD THE FLATTERY‼️‼️‼️ you’re making me blush here anon. im so glad that you find my posts helpful!!! AND IM SO GLAD YOU LIKE MY FICS i have a chapter of it began about dusk in the drafts rn so you’ll get more content soon
now this is a tricky question because im absolutely insane and ive barely ever read short books. right now im reading His Excellency by Joseph J Ellis and i recommend it!! its only around 2-300 pages which is the shortest history book ive got VSJWBW primary sources can be really good to get in book form, things like Common Sense by Thomas Paine, Rules of Civility and Decent Behavior (Washington’s rule book), and Memoir of Lieut. Col. Tench Tilghman, Secretary and aid to Washington are all primary sources i have on my shelf that are short and sweet.
i also have Hercules Mulligan by Micheal J. Obrien which i haven’t read but is VERY small. there is also James Monroe by Gary Hart which is short but i have not finished (i dont even truly remember reading it but i annotated part of it apparently), The Drillmaster of Valley Forge by Paul Lockhart is a little longer than those others, but still isn’t chernow levels of wrong, but i also haven’t read that one. Thomas Jefferson and the Tripoli Pirates by Brian Kilmeade and Don Yaeger isn’t the most serious history book, but it is pretty good and an easy read.
as for secondary source websites, start with encyclopedias ie Britannica, which post short articles on different historical figures and events that give you the overview. from there im gonna point you to the National Park Service. this is the best thing the US government has ever made for researchers. this is all your battlefields, winter encampments, historical reproductions, and former capitals. also check out private residences turned museums, such as Mount Vernon, Monticello, and Schuyler Mansion. these institutions have an abundance of easily accessible information on more than just the people who lived there.
now the Library of Congress was a good decision on Jefferson’s part, but it can be inaccessible if you don’t know how to use it well because their website is one of my least favorite things about being alive. so instead, i recommend using Founders Online for any primary source regarding the founding fathers or amrev figures. the Washington Papers are filled to the brim with almost everything that went out of headquarters during all 8 years of the war. founders online is the shit
all of these websites i’ve mentioned are free to access, because i do not pay money on any research tools besides books out of spite for late stage capitalism. also any primary source is 100% accessible online. that includes memoirs and court transcripts, which can be very helpful
also i really do recommend watching documentaries and informational videos on the subjects you’re interested in while doing work or other things if you’re someone who does that (ik some people don’t have background noise but im just assuming you’re as neurodivergent as i am) because you can absorb just a little of that information and it being about a subject of interest can make academics seem a little less miserable!
i hope this is helpful and if you have absolutely any further questions, feel free to ask. i know im very privileged to have the time and resources to read long ass books, which is why i very freely share the information i absorb with the public bc i believe education should never be gatekept by anyone. so if you have any questions, im happy to research them for you, or at least point you in the right direction. love ya!!
16 notes
·
View notes
Text
Maximizing Engagement: Powerful Video Marketing Strategies from Leading Digital Marketing Agencies
Introduction: In today's digital landscape, video marketing has emerged as a game-changer, providing businesses with dynamic tools to engage and captivate their target audience. As online platforms continue to evolve, it's imperative for digital marketing agencies to stay ahead of the curve, utilizing innovative strategies to drive engagement and deliver impactful results. In this blog post, we'll explore some proven video marketing strategies employed by top digital marketing agencies that effectively capture attention, foster connections, and boost brand awareness.
Know Your Audience: Before diving into video production, digital marketing agencies conduct thorough research to understand their target audience's preferences, interests, and behaviors. By gaining insights into what resonates with their audience, agencies can tailor their video content to address specific pain points, interests, and desires. Whether it's creating informative tutorials, entertaining product demos, or inspiring brand stories, aligning video content with audience preferences is essential for driving engagement and fostering meaningful connections.
Create Compelling Storytelling: At the heart of successful video marketing lies compelling storytelling. Digital marketing agencies leverage the power of narrative to evoke emotions, spark curiosity, and establish a strong connection with viewers. By crafting stories that are authentic, relatable, and relevant to their brand message, agencies can capture audience attention and leave a lasting impression. Whether it's showcasing customer success stories, behind-the-scenes glimpses, or impactful testimonials, storytelling adds depth and resonance to video content, driving higher engagement and fostering brand loyalty.
Optimize for Search Engines: In today's competitive digital landscape, visibility is key to success. Digital marketing agencies employ SEO strategies to ensure their video content ranks prominently in search engine results, maximizing exposure and driving organic traffic. By conducting keyword research, optimizing video titles, descriptions, and tags, and incorporating relevant metadata, agencies can enhance their video's discoverability and reach a wider audience. Additionally, leveraging transcription services to provide captions and transcripts improves accessibility and further boosts SEO performance, enhancing overall engagement and user experience.
Embrace Interactive Elements: To keep viewers actively engaged and encourage participation, digital marketing agencies integrate interactive elements into their video content. Whether it's interactive polls, quizzes, clickable annotations, or shoppable links, these features enhance viewer engagement, encourage interaction, and drive conversions. By transforming passive viewers into active participants, agencies can create immersive experiences that captivate attention, drive brand interaction, and ultimately, drive business results.
Leverage Social Media Platforms: Social media platforms serve as powerful channels for distributing video content and engaging with target audiences. Digital marketing agencies leverage the reach and targeting capabilities of platforms like Facebook, Instagram, Twitter, LinkedIn, and YouTube to amplify their video marketing efforts. By tailoring content formats and messaging to suit each platform's unique audience and algorithms, agencies can optimize engagement, foster community engagement, and generate buzz around their brand. Additionally, harnessing the power of influencer partnerships, user-generated content, and paid advertising further amplifies reach and drives engagement across social media channels.
Analyze and Iterate: Continuous optimization is key to refining video marketing strategies and maximizing their impact. Digital marketing agencies rely on analytics tools to track key performance metrics, gain insights into audience behavior, and measure the effectiveness of their video campaigns. By analyzing metrics such as view counts, watch time, engagement rates, and conversion metrics, agencies can identify areas for improvement, refine their approach, and iterate on future video content. This data-driven approach ensures that video marketing efforts remain aligned with business objectives, delivering measurable results and driving continuous improvement over time.
Conclusion: In an increasingly competitive digital landscape, video marketing has emerged as a powerful tool for driving engagement, fostering connections, and boosting brand awareness. By leveraging innovative strategies, such as compelling storytelling, SEO optimization, interactive elements, and social media amplification, digital marketing agencies can create impactful video content that resonates with their target audience and drives meaningful results. By staying attuned to audience preferences, embracing creativity, and continuously optimizing their approach, agencies can unlock the full potential of video marketing to achieve their business goals and stay ahead of the competition.
By implementing these strategies, digital marketing agencies can elevate their video marketing efforts, maximize engagement, and drive tangible results for their clients, establishing themselves as leaders in the ever-evolving realm of digital marketing.
2 notes
·
View notes
Text
How Audio Transcription Strengthens Academic Research
Making recorded data clearer, searchable, and more usable in every stage of research.
In academic research, spoken content is everywhere, interviews, lectures, focus groups, field notes. These recordings often capture some of the most insightful and nuanced material, yet they’re also the hardest to work with in their raw form.
Audio transcription offers a practical solution. It transforms hours of spoken data into text you can analyze, reference, and share—making your research process smoother, more accurate, and ultimately more impactful.
Let’s explore how transcription helps at every step of the academic journey.
1. Turning Audio into Searchable, Structured Data
When you're dealing with multiple interviews or hours of recorded material, it becomes nearly impossible to find key moments quickly. Transcripts give structure to your data. You can scan, annotate, and tag themes without constantly replaying audio files.
For qualitative researchers, transcription becomes the foundation for coding and thematic analysis. For students, it makes referencing sources during writing or presentations much easier. In short, it turns scattered recordings into an organized, usable asset.
2. Supporting Deeper and More Accurate Analysis
Listening to audio repeatedly not only eats up time but also increases the risk of overlooking details. A professionally transcribed document gives you the ability to read carefully, cross-reference quotes, and engage more deeply with your content.
Written transcripts also support collaborative research. Team members can read and interpret the same material without waiting for audio playback—helping everyone stay aligned and efficient.
3. Preserving Accuracy and Context
While automated transcription tools are convenient, they often miss important cues, especially when dealing with heavy accents, domain-specific language, or overlapping speakers.
In academic work, these inaccuracies can compromise your results. A slight misinterpretation of a word or an incorrectly attributed quote can change the meaning entirely. Human transcription offers far greater reliability, especially in research where context matters.
4. Enhancing Accessibility and Inclusivity
Transcripts aren’t just for the researcher—they benefit others who engage with your work. Students with hearing impairments, collaborators from non-native English backgrounds, or peer reviewers can access your material more easily through text.
This level of accessibility supports a more inclusive academic environment and also aligns with many institutions’ requirements for accessible content in publications and presentations.
5. Meeting Ethical and Privacy Standards
Academic research often involves sensitive material—interviews with vulnerable populations, confidential project data, or unpublished findings. It’s critical that this information is handled responsibly.
While some AI tools store uploaded data or use it to train their models, professional academic transcription services typically operate under strict non-disclosure agreements. For researchers working under IRB protocols or institutional guidelines, this level of confidentiality is non-negotiable.
6. Tailoring Output to Academic Needs
Beyond just accuracy, human transcription services can offer custom formatting, speaker labels, timestamps, or APA/MLA style formatting, based on your project’s requirements. This saves time and ensures your transcripts are ready for citation, publishing, or submission.
Quick Comparison: AI vs. Human Transcription
Here’s a side-by-side look at why researchers often opt for human transcription when quality matters:
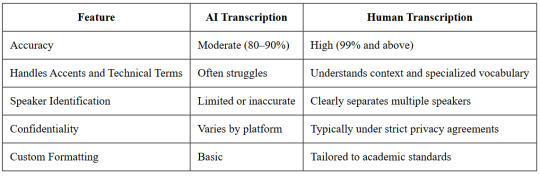
Final Thought
Transcription might not seem like the most glamorous part of research—but it’s one of the most transformative. It bridges the gap between raw, unstructured audio and usable, insightful content.
If your goal is to save time, improve accuracy, and ensure the quality of your findings, transcription isn’t just a helpful tool—it’s a strategic advantage. Partnering with experienced professionals who understand the academic context can make all the difference in how effectively your work moves forward.
0 notes
Text
Data Matters: How to Curate and Process Information for Your Private LLM
In the era of artificial intelligence, data is the lifeblood of any large language model (LLM). Whether you are building a private LLM for business intelligence, customer service, research, or any other application, the quality and structure of the data you provide significantly influence its accuracy and performance. Unlike publicly trained models, a private LLM requires careful curation and processing of data to ensure relevance, security, and efficiency.
This blog explores the best practices for curating and processing information for your private LLM, from data collection and cleaning to structuring and fine-tuning for optimal results.
Understanding Data Curation
Importance of Data Curation
Data curation involves the selection, organization, and maintenance of data to ensure it is accurate, relevant, and useful. Poorly curated data can lead to biased, irrelevant, or even harmful responses from an LLM. Effective curation helps improve model accuracy, reduce biases, enhance relevance and domain specificity, and strengthen security and compliance with regulations.
Identifying Relevant Data Sources
The first step in data curation is sourcing high-quality information. Depending on your use case, your data sources may include:
Internal Documents: Business reports, customer interactions, support tickets, and proprietary research.
Publicly Available Data: Open-access academic papers, government databases, and reputable news sources.
Structured Databases: Financial records, CRM data, and industry-specific repositories.
Unstructured Data: Emails, social media interactions, transcripts, and chat logs.
Before integrating any dataset, assess its credibility, relevance, and potential biases.
Filtering and Cleaning Data
Once you have identified data sources, the next step is cleaning and preprocessing. Raw data can contain errors, duplicates, and irrelevant information that can degrade model performance. Key cleaning steps include removing duplicates to ensure unique entries, correcting errors such as typos and incorrect formatting, handling missing data through interpolation techniques or removal, and eliminating noise such as spam, ads, and irrelevant content.
Data Structuring for LLM Training
Formatting and Tokenization
Data fed into an LLM should be in a structured format. This includes standardizing text formats by converting different document formats (PDFs, Word files, CSVs) into machine-readable text, tokenization to break down text into smaller units (words, subwords, or characters) for easier processing, and normalization by lowercasing text, removing special characters, and converting numbers and dates into standardized formats.
Labeling and Annotating Data
For supervised fine-tuning, labeled data is crucial. This involves categorizing text with metadata, such as entity recognition (identifying names, locations, dates), sentiment analysis (classifying text as positive, negative, or neutral), topic tagging (assigning categories based on content themes), and intent classification (recognizing user intent in chatbot applications). Annotation tools like Prodigy, Labelbox, or Doccano can facilitate this process.
Structuring Large Datasets
To improve retrieval and model efficiency, data should be stored in a structured format such as vector databases (using embeddings and vector search for fast retrieval like Pinecone, FAISS, Weaviate), relational databases (storing structured data in SQL-based systems), or NoSQL databases (storing semi-structured data like MongoDB, Elasticsearch). Using a hybrid approach can help balance flexibility and speed for different query types.
Processing Data for Model Training
Preprocessing Techniques
Before feeding data into an LLM, preprocessing is essential to ensure consistency and efficiency. This includes data augmentation (expanding datasets using paraphrasing, back-translation, and synthetic data generation), stopword removal (eliminating common but uninformative words like "the," "is"), stemming and lemmatization (reducing words to their base forms like "running" → "run"), and encoding and embedding (transforming text into numerical representations for model ingestion).
Splitting Data for Training
For effective training, data should be split into a training set (80%) used for model learning, a validation set (10%) used for tuning hyperparameters, and a test set (10%) used for final evaluation. Proper splitting ensures that the model generalizes well without overfitting.
Handling Bias and Ethical Considerations
Bias in training data can lead to unfair or inaccurate model predictions. To mitigate bias, ensure diverse data sources that provide a variety of perspectives and demographics, use bias detection tools such as IBM AI Fairness 360, and integrate human-in-the-loop review to manually assess model outputs for biases. Ethical AI principles should guide dataset selection and model training.
Fine-Tuning and Evaluating the Model
Transfer Learning and Fine-Tuning
Rather than training from scratch, private LLMs are often fine-tuned on top of pre-trained models (e.g., GPT, Llama, Mistral). Fine-tuning involves selecting a base model that aligns with your needs, using domain-specific data to specialize the model, and training with hyperparameter optimization by tweaking learning rates, batch sizes, and dropout rates.
Model Evaluation Metrics
Once the model is trained, its performance must be evaluated using metrics such as perplexity (measuring how well the model predicts the next word), BLEU/ROUGE scores (evaluating text generation quality), and human evaluation (assessing outputs for coherence, factual accuracy, and relevance). Continuous iteration and improvement are crucial for maintaining model quality.
Deployment and Maintenance
Deploying the Model
Once the LLM is fine-tuned, deployment considerations include choosing between cloud vs. on-premise hosting depending on data sensitivity, ensuring scalability to handle query loads, and integrating the LLM into applications via REST or GraphQL APIs.
Monitoring and Updating
Ongoing maintenance is necessary to keep the model effective. This includes continuous learning by regularly updating with new data, model drift detection to identify and correct performance degradation, and user feedback integration to use feedback loops to refine responses. A proactive approach to monitoring ensures sustained accuracy and reliability.
Conclusion
Curating and processing information for a private LLM is a meticulous yet rewarding endeavor. By carefully selecting, cleaning, structuring, and fine-tuning data, you can build a robust and efficient AI system tailored to your needs. Whether for business intelligence, customer support, or research, a well-trained private LLM can offer unparalleled insights and automation, transforming the way you interact with data.
Invest in quality data, and your model will yield quality results.
#ai#blockchain#crypto#ai generated#dex#cryptocurrency#blockchain app factory#ico#ido#blockchainappfactory
0 notes
Text
The Importance of Speech Datasets in the Advancement of Voice AI:

Introduction:
Voice AI is Speech Datasets revolutionizing human interaction with technology, encompassing virtual assistants like Siri and Alexa, automated transcription services, and real-time language translation. Central to these innovations is a vital component: high-quality speech datasets. This article examines the significance of speech datasets in the progression of voice AI and their necessity for developing precise, efficient, and intelligent speech recognition systems.
The Significance of Speech Datasets in AI Development
Speech datasets consist of collections of recorded human speech that serve as foundational training resources for AI models. These datasets are crucial for the creation and enhancement of voice-driven applications, including:
Speech Recognition: Facilitating the conversion of spoken language into written text by machines.
Text-to-Speech: Enabling AI to produce speech that sounds natural.
Speaker Identification: Differentiating between various voices for purposes of security and personalization.
Speech Translation: Providing real-time translation of spoken language to enhance global communication.
Essential Characteristics of High-Quality Speech Datasets
To create effective voice AI applications, high-quality speech datasets must encompass:
Diverse Accents and Dialects: Ensuring that AI models can comprehend speakers from various linguistic backgrounds.
Varied Noise Conditions: Training AI to function effectively in real-world settings, such as environments with background noise or multiple speakers.
Multiple Languages: Facilitating multilingual capabilities in speech recognition and translation.
Comprehensive Metadata: Offering contextual details, including speaker demographics, environmental factors, and language specifics.
Prominent Speech Datasets for AI Research
Numerous recognized speech datasets play a crucial role in the development of voice AI, including:
Speech: A comprehensive collection of English speech sourced from audiobooks.
Common Voice: An open-source dataset created by Mozilla, compiled from contributions by speakers worldwide.
VoxCeleb: A dataset focused on speaker identification, containing authentic recordings from various contexts.
Speech Commands: A dataset specifically designed for recognizing keywords and commands.
How Speech Datasets Enhance AI Performance
Speech datasets empower AI models to:
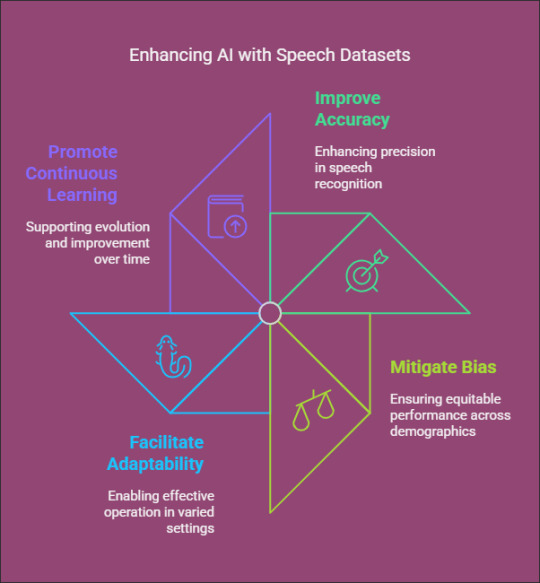
Improve Accuracy: Training on a variety of datasets enhances the precision of speech recognition.
Mitigate Bias: Incorporating voices from diverse demographics helps to eliminate AI bias and promotes equitable performance.
Facilitate Adaptability: AI models trained on a wide range of datasets can operate effectively across different settings and applications.
Promote Continuous Learning: Regular updates to datasets enable AI systems to evolve and improve over time.
Challenges in Collecting Speech Data
Despite their significance, the collection of speech datasets presents several challenges, including:
Data Privacy and Ethics: Adhering to regulations and ensuring user anonymity is essential.
High Annotation Costs: The process of labeling and transcribing speech data demands considerable resources.
Noise and Variability: Obtaining high-quality data in various environments can be challenging.
Conclusion
Speech datasets play Globose Technology Solutions a critical role in the advancement of voice AI, providing the foundation for speech recognition, synthesis, and translation technologies. By leveraging diverse and well-annotated datasets, AI researchers and developers can create more accurate, inclusive, and human-like voice AI systems.
0 notes
Text
Annotated Text-to-Speech Datasets for Deep Learning Applications

Introduction:
Text To Speech Dataset technology has undergone significant advancements due to developments in deep learning, allowing machines to produce speech that closely resembles human voice with impressive precision. The success of any TTS system is fundamentally dependent on high-quality, annotated datasets that train models to comprehend and replicate natural-sounding speech. This article delves into the significance of annotated TTS datasets, their various applications, and how organizations can utilize them to create innovative AI solutions.
The Importance of Annotated Datasets in TTS
Annotated TTS datasets are composed of text transcripts aligned with corresponding audio recordings, along with supplementary metadata such as phonetic transcriptions, speaker identities, and prosodic information. These datasets form the essential framework for deep learning models by supplying structured, labeled data that enhances the training process. The quality and variety of these annotations play a crucial role in the model’s capability to produce realistic speech.
Essential Elements of an Annotated TTS Dataset
Text Transcriptions – Precise, time-synchronized text that corresponds to the speech audio.
Phonetic Labels – Annotations at the phoneme level to enhance pronunciation accuracy.
Speaker Information – Identifiers for datasets with multiple speakers to improve voice variety.
Prosody Features – Indicators of pitch, intonation, and stress to enhance expressiveness.
Background Noise Labels – Annotations for both clean and noisy audio samples to ensure robust model training.
Uses of Annotated TTS Datasets
The influence of annotated TTS datasets spans multiple sectors:
Virtual Assistants: AI-powered voice assistants such as Siri, Google Assistant, and Alexa depend on high-quality TTS datasets for seamless interactions.
Audiobooks & Content Narration: Automated voice synthesis is utilized in e-learning platforms and digital storytelling.
Accessibility Solutions: Screen readers designed for visually impaired users benefit from well-annotated datasets.
Customer Support Automation: AI-driven chatbots and IVR systems employ TTS to improve user experience.
Localization and Multilingual Speech Synthesis: Annotated datasets in various languages facilitate the development of global text-to-speech (TTS) applications.
Challenges in TTS Dataset Annotation
Although annotated datasets are essential, the creation of high-quality TTS datasets presents several challenges:
Data Quality and Consistency: Maintaining high standards for recordings and ensuring accurate annotations throughout extensive datasets.
Speaker Diversity: Incorporating a broad spectrum of voices, accents, and speaking styles.
Alignment and Synchronization: Accurately aligning text transcriptions with corresponding speech audio.
Scalability: Effectively annotating large datasets to support deep learning initiatives.
How GTS Can Assist with High-Quality Text Data Collection
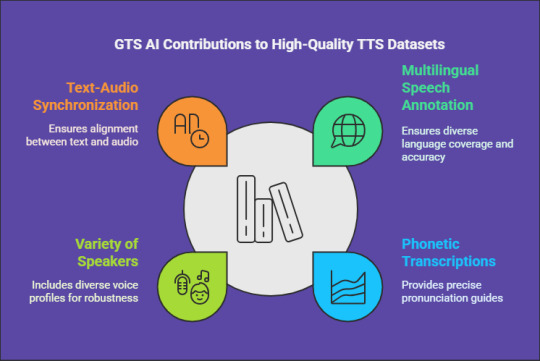
For organizations and researchers in need of dependable TTS datasets, GTS AI provides extensive text data collection services. With a focus on multilingual speech annotation, GTS delivers high-quality, well-organized datasets specifically designed for deep learning applications. Their offerings guarantee precise phonetic transcriptions, a variety of speakers, and flawless synchronization between text and audio.
Conclusion
Annotated text-to-speech datasets are vital for the advancement of high-performance speech synthesis models. As deep learning Globose Technology Solutions progresses, the availability of high-quality, diverse, and meticulously annotated datasets will propel the next wave of AI-driven voice applications. Organizations and developers can utilize professional annotation services, such as those provided by GTS, to expedite their AI initiatives and enhance their TTS solutions.
0 notes
Text
The Ultimate Guide to Data Annotation: How to Scale Your AI Projects Efficiently
In the fast-paced world of artificial intelligence (AI) and machine learning (ML), data is the foundation upon which successful models are built. However, raw data alone is not enough. To train AI models effectively, this data must be accurately labeled—a process known as data annotation. In this guide, we'll explore the essentials of data annotation, its challenges, and how to streamline your data annotation process to boost your AI projects. Plus, we’ll introduce you to a valuable resource: a Free Data Annotation Guide that can help you scale with ease.

What is Data Annotation?
Data annotation is the process of labeling data—such as images, videos, text, or audio—to make it recognizable to AI models. This labeled data acts as a training set, enabling machine learning algorithms to learn patterns and make predictions. Whether it’s identifying objects in an image, transcribing audio, or categorizing text, data annotation is crucial for teaching AI models how to interpret and respond to data accurately.
Why is Data Annotation Important for AI Success?
Improves Model Accuracy: Labeled data ensures that AI models learn correctly, reducing errors in predictions.
Speeds Up Development: High-quality annotations reduce the need for repetitive training cycles.
Enhances Data Quality: Accurate labeling minimizes biases and improves the reliability of AI outputs.
Supports Diverse Use Cases: From computer vision to natural language processing (NLP), data annotation is vital across all AI domains.
Challenges in Data Annotation
While data annotation is critical, it is not without challenges:
Time-Consuming: Manual labeling can be labor-intensive, especially with large datasets.
Costly: High-quality annotations often require skilled annotators or advanced tools.
Scalability Issues: As projects grow, managing data annotation efficiently can become difficult.
Maintaining Consistency: Ensuring all data is labeled uniformly is crucial for model performance.
To overcome these challenges, many AI teams turn to automated data annotation tools and platforms. Our Free Data Annotation Guide provides insights into choosing the right tools and techniques to streamline your process.
Types of Data Annotation
Image Annotation: Used in computer vision applications, such as object detection and image segmentation.
Text Annotation: Essential for NLP tasks like sentiment analysis and entity recognition.
Audio Annotation: Needed for voice recognition and transcription services.
Video Annotation: Useful for motion tracking, autonomous vehicles, and video analysis.
Best Practices for Effective Data Annotation
To achieve high-quality annotations, follow these best practices:
1. Define Clear Guidelines
Before starting the annotation process, create clear guidelines for annotators. These guidelines should include:
Annotation rules and requirements
Labeling instructions
Examples of correctly and incorrectly labeled data
2. Automate Where Possible
Leverage automated tools to speed up the annotation process. Tools with features like pre-labeling, AI-assisted labeling, and workflow automation can significantly reduce manual effort.
3. Regularly Review and Validate Annotations
Quality control is crucial. Regularly review annotated data to identify and correct errors. Validation techniques, such as using a secondary reviewer or implementing a consensus approach, can enhance accuracy.
4. Ensure Annotator Training
If you use a team of annotators, provide them with proper training to maintain labeling consistency. This training should cover your project’s specific needs and the annotation guidelines.
5. Use Scalable Tools and Platforms
To handle large-scale projects, use a data annotation platform that offers scalability, supports multiple data types, and integrates seamlessly with your AI development workflow.
For a more detailed look at these strategies, our Free Data Annotation Guide offers actionable insights and expert advice.
How to Scale Your Data Annotation Efforts
Scaling your data annotation process is essential as your AI projects grow. Here are some tips:
Batch Processing: Divide large datasets into manageable batches.
Outsource Annotations: When needed, collaborate with third-party annotation services to handle high volumes.
Implement Automation: Automated tools can accelerate repetitive tasks.
Monitor Performance: Use analytics and reporting to track progress and maintain quality.
Benefits of Downloading Our Free Data Annotation Guide
If you're looking to improve your data annotation process, our Free Data Annotation Guide is a must-have resource. It offers:
Proven strategies to boost data quality and annotation speed
Tips on choosing the right annotation tools
Best practices for managing annotation projects at scale
Insights into reducing costs while maintaining quality
Conclusion
Data annotation is a critical step in building effective AI models. While it can be challenging, following best practices and leveraging the right tools can help you scale efficiently. By downloading our Free Data Annotation Guide, you’ll gain access to expert insights that will help you optimize your data annotation process and accelerate your AI model development.
Start your journey toward efficient and scalable data annotation today!
#DataAnnotation#MachineLearning#AIProjects#ArtificialIntelligence#DataLabeling#AIDevelopment#ComputerVision#ScalableAI#Automation#AITools
0 notes
Text
Service; POST 27 – January
Continuing my work with historical document transcription, I have encountered an unexpected challenge that is deciphering marginalia. Many of the pages I work on contain notes scribbled in the margins, sometimes added long after the original document was written. These annotations often provide additional context or commentary, but they can also be incredibly difficult to interpret, which has forced me to approach the task with an even greater level of attention to detail. On another note, I also have started researching common abbreviations used in historical documents to aid my understanding of them, which helps speed things up. While these aspects of the work made it more demanding, I also see something rather rewarding in them: there is an appeal to the aesthetic of these outdated, borderline archaic dialects of English.


0 notes
Text

Unlock the potential of your AI models with accurate video transcription services. From precise annotations to seamless data preparation, transcription is essential for scalable AI training.
#video transcription services#video transcription#video data transcription#AI Training#Data Annotation#Accurate Transcription#Dataset Quality#AI Data Preparation#Machine Learning Training#Scalable AI Solutions
0 notes
Text
Transforming Audio into Insights: Accurate Transcription & Annotation Services
Unlock valuable insights from audio data with Haivo AI's professional audio transcription and annotation services. From detailed agriculture image labeling to comprehensive dataset creation, we provide AI training data solutions in Lebanon that fuel innovation and accuracy. Click here to know more.
1 note
·
View note
Text
Future-Proofing Speech Datasets: Trends and Predictions

Introduction
Speech Datasets serve as the foundation for contemporary voice-enabled artificial intelligence systems, facilitating a wide range of applications from virtual assistants to transcription services. Nevertheless, the swift advancement of artificial intelligence, machine learning, and speech recognition technologies presents an increasing challenge in keeping these datasets both relevant and of high quality. To future-proof speech datasets, it is essential to anticipate shifts in technology, language, and user expectations, all while ensuring high levels of accuracy and inclusivity.
Emerging Trends in Speech Data Collection and Utilization
Expansion of Multilingual and Dialectal Representation As AI-driven speech technologies continue to gain traction worldwide, there is an increasing demand for speech datasets that encompass a broader spectrum of languages and dialects. Future datasets must reflect various linguistic nuances to enhance accessibility and performance across different cultural and regional contexts.
Mitigation of Bias and Ethical Considerations Historically, speech datasets have been plagued by biases in representation, often prioritizing dominant languages, accents, and demographic groups. The evolution of speech datasets will necessitate more equitable data collection methodologies, ensuring that marginalized communities are sufficiently represented. Additionally, ethical sourcing and adherence to privacy regulations will be essential components in the development of these datasets.
Adaptation to Noisy and Real-World Environments For speech recognition systems to operate effectively in a variety of settings, ranging from tranquil offices to bustling streets, future speech datasets must include a wider array of real-world conditions. This will involve the integration of background noise, overlapping speech, and diverse microphone qualities to bolster the systems’ resilience.
Synthetic Data and AI-Augmented Datasets Recent developments in AI-driven speech synthesis and data augmentation methods facilitate the generation of synthetic datasets that complement actual recordings. This strategy effectively mitigates data scarcity challenges for underrepresented languages and niche areas, while simultaneously enhancing the flexibility of speech recognition systems.
Enhanced Annotation and Labeling Techniques The process of manually annotating speech datasets is both labor-intensive and costly. The future is likely to witness a greater implementation of AI-supported labeling, utilizing machine learning to streamline and improve transcription precision. Furthermore, the incorporation of more comprehensive metadata tagging, including aspects such as speaker emotion and intent, will significantly enhance the functionality of speech datasets.
Predictions for the Future of Speech Datasets

Integration of Multimodal Data: There will be a growing trend to merge speech datasets with text, video, and contextual metadata, enhancing AI’s comprehension of human communication.
Real-Time Adaptation: Speech datasets are set to develop in a manner that enables AI systems to learn and adjust in real-time, thereby enhancing their effectiveness in ever-changing environments.
Blockchain for Enhanced Data Security: The application of blockchain technology for decentralized data management may provide improved transparency and security in the utilization and distribution of speech datasets.
Open-Source Collaboration: The movement towards open-source speech datasets is expected to persist, promoting innovation and inclusivity within the realm of AI development.
Conclusion
Ensuring the longevity and relevance of speech datasets necessitates a forward-thinking strategy encompassing data collection, diversity, ethical considerations, and advancements in technology. Organizations that prioritize the development of high-quality speech datasets must remain vigilant regarding industry trends to guarantee the sustained accuracy and efficacy of their AI models. For those seeking premier speech data collection services, Globose Technology Solutions Speech Data Collection Services offers innovative solutions tailored for your AI applications.
0 notes
Text
Challenges and Opportunities in Using Healthcare Datasets for Machine Learning
Introduction

The incorporation of machine learning (ML) within the healthcare sector has opened up new avenues for advancements in diagnostics, treatment strategies, and patient management. Nevertheless, the success of these AI-based solutions is significantly influenced by the quality and accessibility of healthcare datasets. While ML offers a multitude of opportunities for the medical domain, it also presents considerable challenges. This article examines the obstacles and potential associated with the use of Healthcare Datasets for Machine Learning.
Challenges in Utilizing Healthcare Datasets for Machine Learning
Data Privacy and Security: Healthcare information is extremely sensitive, and rigorous regulations such as the Health Insurance Portability and Accountability Act (HIPAA) and the General Data Protection Regulation (GDPR) enforce strict guidelines on data collection and utilization. Maintaining patient confidentiality while ensuring data is available for ML applications poses a significant challenge.
Data Accessibility and Sharing Limitations: Healthcare organizations frequently maintain patient records in proprietary systems that are not readily available for research purposes. Agreements for data sharing among healthcare providers, research entities, and AI developers must navigate the delicate balance between fostering innovation and adhering to ethical standards.
Data Quality and Standardization: Healthcare data is typically gathered from various sources, including electronic health records (EHRs), medical imaging, and wearable technology. Disparities in data formats, incomplete records, and inconsistencies in annotations can impede the training and efficacy of ML models.
Bias and Fairness in Data: The presence of bias within healthcare datasets can result in misleading and inequitable predictions generated by artificial intelligence. A lack of diversity in training data may cause machine learning models to perform inadequately for specific demographic groups, thereby contributing to unequal healthcare outcomes.
Computational Challenges: The analysis of extensive healthcare datasets necessitates considerable computational resources and storage capacity. The deployment of machine learning solutions in real-time clinical environments can be resource-demanding, requiring a scalable and efficient technological framework.
Opportunities in Utilizing Healthcare Datasets for Machine Learning

Improved Disease Diagnosis and Prediction: Machine learning models that are trained on diverse and high-quality healthcare datasets can enhance the early detection of diseases. AI-driven diagnostic tools assist radiologists and pathologists in identifying conditions such as cancer, diabetic retinopathy, and cardiovascular diseases with increased precision.
Tailored Medicine and Treatment Strategies: Healthcare datasets facilitate machine learning models in examining genetic data, patient histories, and responses to treatments. This capability allows for the development of personalized treatment strategies that are customized for individual patients, thereby enhancing therapeutic outcomes.
Streamlining Administrative Processes: Machine learning can facilitate the automation of administrative functions, including medical billing, appointment management, and transcription services. This alleviates the workload on healthcare professionals and improves operational efficiency.
Drug Discovery and Development: Pharmaceutical companies leverage machine learning to scrutinize extensive biomedical datasets, thereby expediting the drug discovery process. Predictive modeling aids researchers in identifying potential drug candidates and assessing their effects prior to clinical trials.
Remote Monitoring and Telemedicine: The advent of wearable health technology and the Internet of Things (IoT) in the healthcare sector enables machine learning to evaluate real-time patient information for remote monitoring purposes. Telemedicine solutions powered by artificial intelligence significantly improve patient care by delivering immediate medical insights.
Enhanced Healthcare Accessibility: AI-driven healthcare innovations, supported by a variety of datasets, can help eliminate barriers to medical access. Solutions such as remote diagnostics, AI-enabled chatbots, and automated health evaluations can offer essential medical assistance in areas with limited healthcare resources.
Conclusion
Despite the considerable challenges associated with utilizing healthcare datasets for machine learning, the potential benefits greatly surpass the difficulties. It is essential to tackle issues related to data privacy, enhance standardization, and ensure equity in AI models to facilitate the effective integration of machine learning in healthcare. As technological advancements continue, the ethical application of healthcare data has the potential to transform patient care, rendering it more efficient, personalized, and accessible. For further information on how AI is reshaping the healthcare landscape, please visit GTS AI.
0 notes
Text
Speech Recognition Dataset for Machine Learning Applications

Introduction
Speech recognition technology has evolved from enabling humans to interact with machines in ways they never thought possible, such as having voice assistants to transcribing speech. High-quality datasets form the crux of all these advancements as they enable the machine learning models to understand, process, and generate human speech accurately. In this blog, we will explore why speech recognition datasets are important and point out one of the best examples, which is Libri Speech.
Why Are Speech Recognition Datasets Crucial?
Speech recognition datasets are essentially the backbone of ASR systems. These datasets consist of labeled audio recordings, which is the raw material that can be used for training, validation, and testing ML models. Superior datasets ensure:
Model Accuracy: The more the variation in accents, speaking styles, and background noises, the more it helps the model generalize over realistic scenarios.
Language Coverage: Multilingual datasets help build speech recognition systems catering to a global audience.
Noise Robustness: Data with noisy samples enhances the model's robustness, making the ASR system give better and reliable responses for even bad conditions.
Innovation: Open-source datasets inspire new research and innovation in ASR technology.
Key Features of a Good Speech Recognition Dataset
A good speech recognition dataset should have the following characteristics:
Diversity: It should contain a wide variety of speakers, accents, and dialects.
High-Quality Audio: Clear, high-fidelity recordings with minimal distortions.
Annotations: Time-aligned transcriptions, speaker labels, and other metadata.
Noise Variations: Samples with varying levels of background noise to train noise-resilient models.
Scalability: Sufficient data volume for training complex deep learning models.
Case Study: Libri Speech Dataset
One such well-known speech recognition dataset is LibriSpeech, an open-source corpus used extensively within the ASR community. Below is an overview of its features and impact:
Overview of Libri Speech
Libri Speech is a large corpus extracted from public domain audiobooks. The dataset includes around 1,000 hours of audio recordings along with transcriptions, thus being one of the most widely used datasets for ASR research and applications.
Key Characteristics
Diverse Speakers: Covers a wide number of speakers of diverse gender, age, and accents.
Annotated Data: With every audio sample is included good-quality time aligned transcript.
Noise-free recordings: Noise-free recordings Many of the speech samples are of excellent quality noise free with an audio quality very conducive for input into the trainer. It has opened source accessibility allowing free researchers access worldwide.
Applications of Libri Speech
Training ASR Models: Libri Speech has been used for training many of the state-of-the-art ASR systems, including Google's Speech-to-Text API and open-source projects like Mozilla Deep Speech.
Benchmarking: Libri Speech is a standard benchmark dataset that allows for fair comparisons across different algorithms based on model performance.
Transfer Learning: Pretrained models on Libri Speech generally perform well when fine-tuned for domain-specific tasks.
Applications of Speech Recognition Datasets in ML
Speech recognition datasets are used to power a wide range of machine learning applications, including:
Voice Assistants: Datasets train systems like Alexa, Siri, and Google Assistant to understand and respond to user commands.
Transcription Services: High-quality datasets enable accurate conversion of speech to text for applications like Otter.ai and Rev.
Language Learning Tools: Speech recognition models enhance pronunciation feedback and language learning experiences.
Accessibility Tools: Assistive technologies such as real-time captioning and screen readers rely on strong speech models.
Customer Support Automation: ASR-based systems greatly enhance the flow of call center operations as it transcribes and analyzes the customer interactions.
Conclusion
The development of effective speech recognition systems depends on the availability and quality of datasets. Datasets such as Libri Speech have set benchmarks for the industry, allowing researchers and developers to push the boundaries of what ASR technology can achieve. As machine learning applications continue to evolve, so will the demand for diverse, high-quality speech recognition datasets.
Harnessing the power of these datasets is the key to building more inclusive, accurate, and efficient speech recognition systems that transform the way we interact with technology. GTS AI is committed to driving innovation by providing state-of-the-art solutions and insights into the world of AI-driven speech recognition.
1 note
·
View note