#VMware Home Lab Setup
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
1,644 Tumblr posts in 1 second.
Text
Top VMware Home Lab Configurations in 2023
Top VMware Home Lab Configurations in 2023 @vexpert #vmwarecommunities #100daysofhomelab #VMwareHomeLabSetup #VMwareWorkstationHomeLab #ESXiHostConfiguration #NestedVirtualizationVMware #vSANClusterConfiguration #BestVMwareHomeLabConfigurations2023
In 2023, many great options exist for delving into a home lab. Many get into running a home server to learn more skills for their day job, or they like to tinker and play around with technology as a hobby. For many, it is a mix of both. VMware vSphere is the market leader hypervisor in the enterprise. It arguably provides the most features and capabilities of any hypervisor on the market. This…

View On WordPress
#Best VMware Home Lab Configurations 2023.#ESXi Host Configuration#Nested Virtualization VMware#vCenter Server Deployment#VMUG Advantage for Home Labs#VMware Home Lab Setup#VMware vs Open Source Hypervisors#VMware vSAN Explanation#VMware Workstation Home Lab#vSAN Cluster Configuration
0 notes
Text
Junos Gns3

Junos Gns3 Virtualbox
Junos Gns3 Image
June 7, 2018srijit
Are you studying for Juniper Certifications but don’t have access to physical hardware? No worries, you can now get Juniper Junos for GNS3 including vMX & vSRX fully tested and compatible with current version of GNS3.

Looks like you're using an older browser. To get the best experience, please upgrade. UPGRADE MY BROWSER. Junos How to catch inbound traffic according to forwarding-class when using BA classifier 2021.04.27 MX/PTX FPC undetected after routing-engine primary role switchover 2021.04.27 Junos Error: 'Unsigned python script should not be writeable by a user, other than the owner' 2021.04.27 Unable to upload Offline Signature bundles over. JunOS Olive-disk1.vmdk; GNS3 setup. For simulating Cisco routers we relay on Dynamips and for JunOS we’ll use VMware Workstation 12 Player. GNS3 software version I’m using is 1.5.1. Following picture shows current Dynamips settings: VMware setup.
Junos Gns3 Virtualbox

Simply import the appliances and the images and fire up your home lab and start your preparations. Apart from these some important books on Juniper Routing, Switching & Security are also bundled for your reference and self study.
Download Juniper Junos for GNS3 here – https://i.srijit.com/JunOSGNS3
Junos Gns3 Image
Feel free to drop a comment below in case of any further requirements or problems. Hope it helps!
1 note
·
View note
Text
Cisco Nexus 1000 V Ova

Cisco Nexus 1000 V Oval
Cisco Nexus 1000v Ova Download
Posted on 03 Apr 2012 by Ray Heffer
Installing the Cisco Nexus 1000V distributed virtual switch is not that difficult, once you have learned some new concepts. Before I jump straight into installing the Nexus 1000V, lets run through the vSphere networking options and some of the reasons you’d want to implement the Nexus 1000V.
vSS (vSphere Standard Switch)
Often referred to as vSwitch0, the standard vSwitch is the default virtual switch vSphere offers you, and provides essential networking features for the virtualisation of your environment. Some of these features include 802.1Q VLAN tagging, egress traffic shaping, basic security, and NIC teaming. However, the vSS or standard vSwitch, is an individual virtual switch for each ESX/ESXi host and needs to be configured as individual switches. Most large environments rule this out as they need to maintain a consistent configuration across all of their ESX/ESXi hosts. Of course, VMware Host Profiles go some way to achieving this but it’s still lacking in what features in distributed switches.
vDS (vSphere Distributed Switch)
So the vDS, also known as DVS (Distributed Virtual Switch) provides a single virtual switch that spans all of your hosts in the cluster, which makes configuration of multiple hosts in the virtual datacenter far easier to manage. Some of the features available with the vDS includes 802.1q VLAN tagging as before, but also ingress/egress traffic shaping, PVLANs (Private VLANs), and network vMotion. The key with using a distributed virtual switch is that you only have to manage a single switch.
Cisco Nexus 1000V Virtual Security Gateway Version 4.2(1)VSG2(1.1) for VMware vSphere 4.1 +. 1010 OVA - nexus-1000v.VSG2.1.1.1010.ova (md5.
Cisco Nexus 1000V cloud switch is a virtual appliance. It provides integration of physical and virtualized network infrastructure. Cisco Nexus 1000V switch is compatible with VMware ESX and vSphere (ESXi) hypervisors. There is a version for Microsoft Hyper-V and Open KVM as well for additional public cloud and platform support.
1 st – Create the VRF – here mgmt-vrf. 2 nd – Assign the interface to the VRF. As you can see, the interface is by default in shutdown. For my home lab setup I use the 192.168.0.9x range for labbing. I use the X to signify the router – to.91 will be CSR1000V-1,.92 will be CSR1000V-2, and.93 will be CSR1000V-3. Cisco Nexus 1000V Installation and Upgrade Guide, Release 4.2(1)SV1(5.2) Chapter Title. Installing the Cisco Nexus 1000V Software Using ISO or OVA Files. PDF - Complete Book (12.02 MB) PDF - This Chapter (2.79 MB) View with Adobe Reader on a variety of devices. EPub - Complete Book (4.38 MB). Cisco Nexus 1000v Secondary Switch Module Setup Cisco Nexus 1000v Secondary Switch. Open up your vCenter Management Console. Click on File and Deploy OVF Template. Select the same version OVA package that you used for your primary switch. A summary is shown of the Cisco Nexus 1000v virtual appliance.
Cisco Nexus 1000V
In terms of features and manageability, the Nexus 1000V is over and above the vDS as it’s going to be so familiar to those with existing Cisco skills, in addition to a heap of features that the vDS can’t offer. For example, QoS tagging, LACP, and ACLs (Access Control Lists). Recently I have come across two Cisco UCS implementations which require the Nexus 1000V to support PVLANs in their particular configuration (due to the Fabric Interconnects using End-Host Mode). There are many reasons one would choose to implement the Cisco Nexus 1000V, lets call it N1KV for short :)
Without further delay, grab a coffee and we’ll get the N1KV installed!
Components of the Cisco Nexus 1000V on VMware vSphere
There are two main components of the Cisco Nexus 1000V distributed virtual switch; the VSM (Virtual Supervisor Module) and the VEM (Virtual Ethernet Module). If you are familiar with Cisco products and have worked with physical Cisco switches, then you will already know what the supervisor module and ethernet modules are. In essence, a distributed virtual switch, whether we are talking about the vSphere (vDS) or N1KV have a common architecture. That is the control and data plane, which is what makes it ‘distributed’ in the first place. By separating the control plane (VSM), and the data plane (VEM), a distributed switch architecture is possible as illustrated in the diagram here (left).
Another similarity that is the use of port groups. You should be familiar with port groups as they are present on both the VMware vSS and vDS. In Cisco terms, we’re talking about ‘port profiles’, and they are configured with the relevant VLANs, QoS, ACLs, etc. Port profiles are presented to vSphere as a port group.
Installing the Cisco Nexus 1000V
What you need:
A licensed copy of the Cisco Nexus 1000V
vSphere environment with vCenter.
At least one ESX/ESXi host, preferably two or more! - If you are using a lab environment and don’t have the physical hardware available then create a virtual ESXi server (this post by VCritical details how to do this).
You’ll also need to create the following VLANs: Control, Management, and Packet
Note: If you are doing this in a lab environment then you can place all of the VLANs into a single VM network, but in production make sure you have separate VLANs for these.
In the latest release of the Nexus 1000V the Java based installer, which we will come on to in a moment, now deploys the VSM (or two VSMs in HA mode) to vCenter and a GUI install wizard guides you through the steps. This has made deployment of the N1KV even easier than before.
Once you have downloaded the Nexus 1000V from the Cisco website, continue on to the installation steps.
Installation Steps:
1) Extract the .zip file you downloaded from Cisco, and navigate to VSMInstaller_AppNexus1000V-install.jar. Open this (you need Java installed) and it will launch the installation wizard. Enter the vCenter IP address, along with a username and password.
2) Select the vSphere host where the VSM resides and click Next.

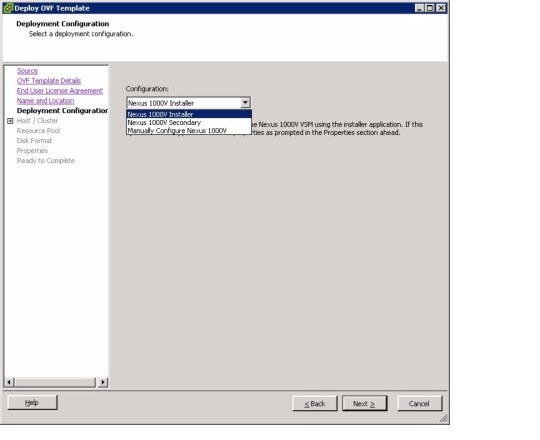
3) Select the OVA (in the VSMInstall directory), system redundancy option, virtual machine name and datastore, then click Next.
Note: This step is new, previously you had to deploy the OVA first, then run this wizard. If you choose HA as the redundancy option, it will append -1 or -2 to the virtual machine name.
4) Now configure the networking by selecting your Control, Management and Packet VLANs. Click Next.
Note: In my home lab, I just created three port groups to illustrate this. Obviously in production you would typically have these VLANs defined, otherwise you can create new ones here on the Nexus 1000V.
5) Configure the VSM by entering the switch name, admin password and IP address settings.
Note: The domain ID is common between the VSMs in HA mode, but you will need a unique domain ID if running multiple N1KV switches. For example, set the domain ID to 10. The native VLAN should be set to 1 unless otherwise specified by your network administrator.
6) You can now review your configuration. If it’s all correct, click Next. Alesis multimix 8 usb drivers.
7) The installer will now start deploying your VSM (or pair if using HA) with the configuration settings you entered during the wizard.
8) Once it has deployed you’ll get an option to migrate this host and networks to the N1KV. Choose No here as we’ll do this later.
Cisco Nexus 1000 V Oval
9) Finally you’ll get the installation summary, and you can close the wizard.
You’ll now see two Nexus 1000V VSM virtual machines in vCenter on your host. In a production environment you would typically have the VSMs on separate hosts for resilience. Within vCenter, if you navigate to Inventory > Networking you should now see the Nexus 1000V switch:
Installing the Cisco Nexus 1000V Virtual Ethernet Module (VEM) to ESXi 5
What we are actually doing here is installing the VEM on each of your ESX/ESXi hosts. In the real world I prefer to use VMware Update Manager (VUM) to do this, as it will automatically add the VEM to a host when it is added to the N1KV virtual switch. However, for this tutorial I will show you how to add the VEM using the command line with ESXi 5.
1) Open a web browser and open the Nexus 1000V web page, http://. You will then be presented with the Cisco Nexus 1000V extension (xml file) and the VEM software. It’s the VEM we are interested in here, so download the VIB that corresponds to your ESX/ESXi build.
2) Copy the VIB file on to your ESX/ESXi host. You must place this into /var/log/vmware as ESXi 5 expects the VIB to be present there.
Note: Use the datastore browser in vCenter to do this.
3) Log into the ESXi console either directly or using SSH (if it is enabled) and enter the following command:
# esxcli software vib install -v /var/log/vmware/cross_cisco-vem-v140-4.2.1.1.5.1.0-3.0.1.vib
You should then see the following result:
4) You can verify that the VEM is installed using the following commands:
Labtec driver keyboard. # esxcli software vib list | grep cisco
# vem status -v
Configuring the Nexus 1000V
Before we add our hosts to the Nexus 1000V we’ll need to create the port profiles, including the uplink port profile. The uplink port profile will be selected when we add our hosts to the switch, and this will typically be a trunk port containing all of the VLANs we wish to trunk to the hosts.
1) Log into the Nexus 1000V using SSH
2) Create a ethernet port profile as follows:
Adding ESX/ESXi Hosts to the Cisco Nexus 1000V
The final step is to add your host(s) to the Cisco Nexus 1000V.
1) Within vCenter, browse to Inventory > Networking and select the Cisco Nexus 1000V switch. Right click, and select ‘Add Host’.
2) Select the vmnic(s) of the host(s) you want to add and choose the VM_Uplink in the dropdown (we created this in the last step) and click Next.
Note: You’ll notice in the above screenshot that I’m adding a spare vmnic as I don’t want to lose connectivity with my standard vSwitch.
3) Migrate your port groups to the Nexus 1000V, such as the Management (vmk). Click Next.
Note: I chose not to do this, this can be done later.
4) You will then have the opportunity to migrate your virtual machines to the N1KV. This is optional and can be done later. Click Next.
5) Review the summary and click Finish.

Summary
We have just downloaded and installed the Cisco Nexus 1000V, installed the VSMs to vCenter, installed the VEM to your host and added the host to the Cisco Nexus 1000V switch. The next steps are to configure the Nexus 1000V, port profiles, etc.Common Questions:
How many Cisco Nexus 1000V virtual switches can be added to vCenter?
vCenter can connect to up to 32 Distributed Virtual Switches, this includes the Nexus 1000V. You’ll need a VSM (or pair for redundancy) for each N1KV switch. A Nexus 1000V can only connect to a single vCenter.
Can the Nexus 1000V stretch across sites?
Since software release 4.2(1)SV1(4a), yes. Table 1 in the release notes contains the configuration limits.
Can the VSM reside on the same ESX/ESXi host as the VEM?
Cisco Nexus 1000v Ova Download
Yes (can also be on a separate host)
Tagged with: vmwarenetworking
0 notes
Link
See this part about NSX-T 3.1 setup for beginners
0 notes
Text
Lenovo ThinkServer RD650 with new Xeon E5-2600 v3 processors
In Septemeber of 2014 we saw the primary press anouncements for Lenovo’s new Grantly platforms with two new rack established servers, the RD550 and RD650. Those have been the first new structures from Lenovo that might use the modern-day Intel Xeon E5-2600 v3 series processors and DDR4 reminiscence. In the lab today we will take a look at the Lenovo ThinkServer RD650.E3-1270 v6
Lenovo ThinkServer RD650 Base Server SpecificationsLenovo makes a number of?Exclusive variations of the ThinkServer RD650 however there are a fixed of common specs:
Processor: Up to two 18-center Intel Xeon E5-2600 v3 SeriesMemory: up to 768 GB DDR4 – 2133 MT/s thru 24 slots (RDIMM/LRDIMM)growth Slots: All chassis up to – 3 x PCIe Gen3: LP x8, 4 x PCIe Gen3: FLFH x8, 1 x PCIe Gen3: HLFH x8Systems control: ThinkServer gadget supervisor. Non-compulsory ThinkServer gadget manager PremiumDimensions: 19.0″ x 3.4″ x 30.1″Weight: starting at 35.Three lbsFrom aspect: 2U Rack MountThe ThinkServer RD650 is available in three simple models that permit for special garage configurations. The first is the 12x 3.5″ power server:
Lenovo ThinkServer RD650 12 x three.Five Inch DrivesLenovo makes a mixed 8x 2.5″ and 9x three.5″ server (are you salivating but vSAN, backup appliance and virtualized ZFS equipment lovers?)
Lenovo ThinkServer RD650 – eight x 2.5 and nine x 3.5 inch DrivesFinally there's a model with 24x 2.5″ drives that's every other commonplace shape thing:
Lenovo ThinkServer RD650 – 24 x 2.5 inch DrivesThe pattern we obtained for review is the ThinkServer RD650 with 12 x three.Five Inch Drives.
Unpacking the Lenovo ThinkServer RD650Let’s take a look at how the RD650 is packed for delivery.
Lenovo ThinkServer RD650 transport boxWe continually like to show how servers are boxed up for transport to look how nicely the server is included from the same old bumps, drops and bins smashed up by using difficult managing. We can see that the RD650 is well included with foam inserts and in this case it's miles further included by being encased in an additional card board field. Down within the bottom underneath the server there's an accent box that is placed in foam inserts and additional knock outs are furnished for extra accessory bins. Along the bottom is the rail package.
This became no longer double boxed like we see in different servers, but there may be empty space around the server itself to protect from punctures.
Lenovo ThinkServer RD650 FrontHere we see the the front of the RD650 with the top lid eliminated. Over all it's miles very much like the earlier Lenovo servers excluding progressed method cooling systems.
Lenovo ThinkServer RD650 BackThe lower back of the RD650 suggests the progressed cooling shroud and the massive variety of growth bays that this server includes.
Lenovo ThinkServer RD650 CPU-RAM AreaThe RD650 CPU region uses passive warmness sinks for cooling. These use everyday socket 2011 R3 rectangular mounting holes and?We found in our trying out they may be?Superb at eliminating heat from the CPU’s. See our rectangular v. Slim ILM manual for the distinction in LGA2011 mounting alternatives. The fan bar includes six redundant warm-swap fanatics with 2 processors load outs. If best one processor is used there will be four enthusiasts mounted that can assist keep electricity.
We have examined a fair number of Lenovo servers in the beyond and located the lovers which can be used offer excessive air float and do no longer make too much noise. The provided air shroud channels air thru the warmth sinks and reminiscence region very successfully and we had no warmth troubles with the server even underneath very heavy hundreds.
Each of those fanatics are warm swappable and the complete cooling bar can be removed with easy locking levers on either side of the bar.
Lenovo ThinkServer RD650 growth BayTwo growth bays just like the one proven above may be geared up into the RD650, each bay can handle up to a few growth cards. These bays can deal with full length expansion playing cards which permit for larger cards to fit right into a 2U chassis.
Lenovo ThinkServer RD650 iKVM and TPM ModuleIn among the two expansion bays are iKVM and TPM modules. These are non-compulsory modules.
Lenovo ThinkServer RD650 Raid ControllerAt the the front of the server the RAID controller card is placed right at the back of the power bays. Right here we've got eliminated the main cooling bar to get a higher observe this. The principle cooling lovers for the server are positioned proper next to the controller card which permits suitable air glide to assist keep this cool.
Putting in place the Lenovo ThinkServer RD650The usual method to install an operating machine onto the RD650 is to use the Lenovo ThinkServer Deployment supervisor. This could stroll you thru installing an OS and drivers for the server.
Lenovo ThinkServer RD650 TDM BIOS SettingTo get admission to the TDM honestly boot the system into the BIOS and head over to the Boot supervisor and select launch TDM.
Lenovo ThinkServer RD650 Deployment ManagerAfter deciding on release TDM you will see the above display. From right here you could regulate just about some thing you can do inside the BIOS and do platform updates. Storage management permits you to setup any Raids which you need for the server earlier than you start installing an working device.
The Deployment alternative will get you began installing your OS of choice.
These options are:
Quantity choice – available garage volumes may be displayedOS choice – pick the OS to be deployed (Linux, home windows, VMware)installation Settings – Time quarter, Language, License Key, laptop call, Admin/root passwordPartition options – two options are to be had:Use present partition – preceding OS set up exists at the driveRepartition the force at some point of installation – sets size of OS partitionAfter you have got selected the essential alternatives the system will start to deploy the working gadget. Our gadget did now not have an DVD drive so we used a USB DVD force to mount the running machine DVD. After the installation turned into completed the gadget completed with us on the login display screen of windows Server 2012 R2 which we used for some of our exams. We may also boot directly from an Ubuntu run DVD and pass the TDM completely the usage of the USB DVD power.
Lenovo ThinkServer RD650 gadget ManagerFor faraway control the RD650 consists of the machine manager. Surely enter the IP address for the server into your browser and login.
The default username/ password login data for the Lenovo ThinkServer RD650 is:
Username: lenovoPassword: len0vOIf you have got an iKVM Module established?You could choose the “release” button to go into far flung control and operate the device that manner.
Lenovo ThinkServer RD650 gadget manager manage ScreenThe next display screen indicates the alternatives that you may monitor and alternate thru the far flung control interface.
Test ConfigurationOur take a look at setup includes the pinnacle end Intel Xeon E5’s which we use in all of our checks. These CPU’s include 18 cores every and gives our system the maximum processor load out. We also crammed all memory slots to present the most load out of memory that we could, the usage of 16GB sticks in each slot, this dropped our memory velocity to 1600MHz.
Processors: 2x Intel Xeon E5-2699 v3Memory: 24x 16GB crucial DDR4 (384GB overall)garage: 1x SanDisk X210 512GB SSDOperating systems: Ubuntu 14.04 LTS and windows Server 2012 R2AIDA64 MemoryWith a complete 24 DIMM’s of DDR4 reminiscence installed the memory pace has dropped right down to 1600MHz. But we are seeing very good outcomes which can be just beneath what a system the use of much less memory at higher speeds.
Memory Latency ranged at ~99ns and our common structures the use of 16x 16GB DIMM’s ranged approximately ~78ns.
RD650 flow ResultsOur circulate test outcomes showed similar outcomes as compared to a gadget strolling 16x 16GB DIMM’s. Using a complete load out and lower reminiscence speeds confirmed ~20 MB/s bandwidth loss.
The memory tests results are as predicted with this big load out of 24x DIMM slots completely populated.
ThinkServer RD650 Linux-Bench ResultsThe complete check outcomes for a pattern?Linux-Bench run may be found right here. RD650 with 2x E5-2699 v3 Linux-Bench
Our pattern server got here with one Intel Xeon E5-2690 v3 and 16GB of DDR4 installed. We also ran our exams with this configuration as it might show a typical setup for an entry stage RD650. RD650 with 1x E5-2690 v3 Linux-Bench
Lenovo ThinkServer RD650 power?ConsumptionOur test configuration did function two very excessive-give up processors which can be at the very pinnacle of Intel’s Xeon E5-2600 V3 product line-up.
RD650 electricity ConsumptionThe common idle strength use of the RD650 turned into ~95watts which is fairly excellent for a server of this type. Whilst we max out the gadget underneath heavy AIDA64 strain test, we noticed ~575watts pulled for the whole system which is a touch excessive for systems like this. Of course adding a complete praise of drives and expansions gadgets will impact those numbers as would using lower energy processors.
ConclusionThe first element that sticks out with the Lenovo ThinkServer RD650 is the sheer number of growth alternatives that this server line up has to offer. 3 distinctive models that provide big abilties in garage options that also include options for two additional company-magnificence M.2 SSD’s for booting in addition to SD card alternatives for hypervisor booting. These servers are designed from the ground up for bendy boot alternatives.?Our pattern server can max out at 96TB’s of spindle storage the use of it’s 12 three.5″ force bays with excessive capability 8TB disks.
With a total of 8 PCIe there may be plenty of expansion space that permits you to scale up I/O if wished.The RD650 additionally offers you the choice of Raid adapters that in shape in the bay between the difficult pressure area and the primary cooling bar. That is a pleasant characteristic as they do no longer absorb and extra PCIe slots within the again and are in a great area for cooling.
In keeping with Lenovo the cooling machine is rated at forty five tiers Celsius / 113 F continuous operation and we discover the cooling gadget is up to the task in our tests. We are always impressed for the cooling setups on Lenovo servers, the fanatics do an awesome job at moving lots of air thru the case and they do not make a variety of noise that is a huge plus for us inside the lab.
We also just like the ThinkServer Deployment manager for its ease in getting a machine up and running. Its rather simple to use and installs all wished drivers throughout the setup and OS installation. We also ran Ubuntu proper off a USB DVD force on our RD650 and had no troubles with drivers on our test setup.
We also noticed Lenovo make a shift from DVI video output which without a doubt is a general to DisplayPort. Within the lab we use a KVM switch with all DVI connections to run our test setups, we can without problems connect up several machines and have all of them walking, however in this situation we could not get a DisplayPort to DVI adapter to work. We ended up simply using far flung management and iKVM to run the server. This worked satisfactory and the majority would use this in a production environment, but for crash carts and other setups used at vicinity a DisplayPort screen might be required.
0 notes
Text
Why did Zoom choose Oracle Cloud?
Zoom going with Oracle Cloud was a puzzling decision to many. This is not a post per se but a collection of interesting notes that emerged from related articles. Anyone accidentally on my blog can skip this.
As per “Cloud Economist” Corey Quinn:
Costs are all networking/egress costs, not compute. Storage is negligible. Data transfer is the lions share.
Oracle is 10X cheaper while not 10X worse and also offers 30% discount for 1-year commitment
Zooms seems fairly cloud agnostic and doesn’t abandon existing existing setups. Just the networking piece.
The below are all quotes from a Hacker News discussion.
On costs
“If you’re building an infrastructure company, or any bandwidth intensive product, it makes sense pretty early. For example, it would be impossible to build a competitive CDN or VPN company based on AWS infrastructure. It would also be hard for Zoom to offer a free tier if they were paying per gigabyte for bandwidth, since it would essentially mean every extra second of a meeting cost them money directly.
The fundamental problem is that AWS (or any major cloud) charges you for the amount of “stuff” you put through the pipe ($/gb),but with colocation you can pay a fixed cost for the size of the pipe ($/gbps).
This allows you to do your own traffic shaping and absorb bandwidth costs without needing to pass them onto your customers.
This is the dirty, open secret of cloud pricing models. It’s also their moat, which makes it infeasible to do something like “build AWS on AWS.”
When you buy your own gear, etc. and co-locate, you pay for the pipe instead of paying-per-GB for what goes through the pipe. This makes sense pretty early on if you’re a bandwidth intensive product, cloud provider markups start becoming insane.
Modern data-centers of non-cloud providers are just servers in a colo.
“Having servers in a colo is pretty much what "having a datacenter" means for the last 10 years or so. I'm surprised at your viewpoint of "having a datacentre" meaning only having direct ownership of the piece of land on which the datacentre resides. That's a pretty rigid and outdated definition.”
“Just to be clear - colocation here is in order of thousands of square feet. The datacenter provider provides redundant utilities. The customer does everything else. ”
On how AWS also does co-lo
“They (AWS) use exclusive sections of an existing colo provider facilities, often called data suites or data halls at least in Australia, where the 3 AZs are split between numerous commercial colo facilities.
They get enough control through their contracts to make sure the hosting provider provides exactly what they need to spec.”
Nuances of data-centers
“Designing and operating datacenter facilities is specialized work, and it's about compliance, auditing, risk management, electrical, plumbing, hvac and other skilled trades. The datacenter industry actually has very little to do with computers, so there is a natural split between the facility and the server / network equipment it houses.
Basically all commercial datacenter providers operate as REITs, which is tax advantageous but extremely limiting in some ways. Amazon can benefit from this (with lower pricing) without dealing with it themselves. Owning can offer some advantages, but it also means you're with that site for the long, long haul. Efficiencies of designs are always increasing, so operating in an old facility costs you money. If you built the site to your own spec, good luck exiting -- the next owner will have to do a total overhaul to get it to industry spec and get customers. Even if you have a 10 year lease, there are always ways to get out if you want to. Especially if you're Amazon.”
“They (Google & Facebook) build sites, but they also lease space from the same providers as everyone else. It's also worth noting that sometimes when a company builds a datacenter in a green field situation, it may be working with a datacenter provider on that project. So the company may own it, but they're paying the provider to use their design elements and potentially to operate it. ”
Oracle cloud is not crap (?!)
“ I migrated the company's services from AWS to OCI at the startup I was at. The trade-off is simple, if Oracle can say $product runs on OCI, they'll put you in front of the biggest industry players who are using their POS, database - and since our sales pipeline pivoted around web integrations this was crucial. They also give a bunch of credits (as do the other providers).
We argued against it in the dev team, but it wasn't the worst cloud migration I've done. The console reminds me of early days AWS as it's essentially just VPC+EC2+S3, but it was refreshing to spin up a server without a pages of config being presented to you. We took the opportunity to containerise our older sites and ran everything in their managed k8s cluster. I very rarely had to use the console for anything, which tbh is a bit of a grab-bag of managed services beyond the core cloud offering. Terraform support is there if you need to do anything serious.”
Possible competitive pressures driving this
“ Why? Is it because of cost? Perhaps nepotism? I don' see a reason why Amazon or Azure would be passed over in favour of Oracle. Why wasn't GCP a contender either? Something seems fishy... someone from Zoom care to chime in?
Maybe they are afraid that Amazon or Microsoft with their tradition of copying competition would pose a threat? Even then, Microsoft is already competing using Microsoft Teams and if Amazon wanted to it wouldn't be hard for them at all to come up with a product.”
“ My guess is simply, they don't want to fund their own competitors. Microsoft is a direct competitor already (so is Google,) and who knows what Amazon will do. That really only leaves IBM and Oracle. I've always been baffled when someone hosts on their competitors' platform. Like Netflix hosting on AWS, and Grocery Stores hosting on AWS. Microsoft & Google rarely have that problem (except on this one.) ”
Walmart (& other retailers) hate AWS
“I’ve been impressed by what I’ve heard about Walmart. They apparently won’t even use a SaaS tool if it’s hosted on Amazon.”
“I worked at walmart labs for 3 years and that is correct. We had one, on premise, service that phoned home for license information to an AWS address and our request to whitelist the ip address had to go up to the CTO.”
“They really don't like AWS. It's all openstack/azure/gcp/vmware depending on the use case”
“I work primarily with grocery retailers, and this is quite accurate. Almost all of them have told us that they will not use any of our services if they are hosted in AWS. They used to be hesitant, but willing, but once Amazon acquired Whole Foods, it became a deal breaker.”
How a panic driven Netflix decided to jump to AWS
“>> I've always been baffled when someone hosts on their competitors' platform. Like Netflix hosting on AWS Netflix had a 5-day outage caused by issues with their private DC back in the day.IT mgmt. decided their expertise wasn't in operating DC's, SV real estate was too expensive, and doing multi-region themselves was too expensive.AWS was picked as it was the only viable cloud offering at the time, and the decision was made to be mono-cloud until later. (Azure was used for storing backups.)Note that AWS was never used for large-scale streaming. Either a partner CDN was used, or now their own CDN.Source: worked at Netflix.”
The hot headline/marketing budget angle of Oracle subsidising Zoom crazily
“If you aren't knowledgeable enough about cloud providers to evaluate them directly on their merits, then you look for signals. Some people might think, hey, Zoom is doing well, they are a well-known, up-and-coming company, and they chose Oracle, from which we infer that Oracle must be good choice.”
0 notes
Text
Kubernetes
Kubernetes 를 공부하면서 했던 메모.
Kubernetes
今こそ始めよう!Kubernetes 入門
History
Google 사내에서 이용하던 Container Cluster Manager “Borg” 에 착안하여 만들어진 Open Source Software (OSS)
2014년 6월 런칭
2015년 7월 version 1.0.
version 1.0 이후 Linux Foundation 의 Could Native Computing Foundation (CNCF) 로 이관되어 중립적 입장에서 개발
version 1.7 Production-Ready
De facto standard
2014년 11월 Google Cloud Platform (GCP) 가 Google Container Engine (GKE, 후에 Google Kuebernetes Engine) 제공 시작
2017년 2월 Microsoft Azure 가 Azure Container Service (AKS) 릴리즈
2017년 11월 Amazon Web Service (AWS) 가 Amazon Elastic Container Service for Kubernetese (Amazon EKS) 릴리즈
Kubernetes 로 가능한 일
Docker 를 Product 레벨에서 이용하기 위해서 고려해야 했던 점들
복수의 Docker Host 관리
Container 의 Scheduling
Rolling-Update
Scaling / Auto Scaling
Monitoring Container Live/Dead
Self Healing
Service Discovery
Load Balancing
Manage Data
Manage Workload
Manage Log
Infrastructure as Code
그 외 Ecosystem과의 연계와 확장
위 문제들을 해결하기 위해 Kubernetes 가 탄생
Kubernetes 에서는 YAML 형식 manifesto 사용
apiVersion: extensions/v1beta1 kind: Deployment metadata: name: sample-deployment spec: replicas: 3 selector: matchLabels: app: sample-app template: metadata: labels: app: sample-app spec: containers: - name: nginx-container image: nginx:latest ports: - containerPort: 80 ` **Kubernets 는,**
복수의 Docker Host 를 관리해서 container cluster 를 구축
같은 container 의 replica 로 실행하여 부하 분산과 장애에 대비 가능
부하에 따라 container 의 replica 수를 조절 (auto scaling) 가능
Disk I/O, Network 통신량 등의 workload 나 ssd, cpu 등의 Docker Host spec에 따라서 Container 배치가 가능
GCP / AWS / OpenStack 등에서 구축할 경우, availability zone 등의 부가 정보로 간단히 multi region 에 container 배치 가능
기본적으로 CPU, Memory 등의 자원 상황에 따라 scaling
자원 부족 등의 경우 Kubernetes cluster auto scaling 이용 가능
container process 감시
container process 가 멈추면 self healing
HTTP/TCP, Shell Script 등을 이용한 Health Check 도 가능
특정 Container 군에 대해 Load Balancing 적용 가능
기능별로 세분화된 micro service architecture 에 필요한 service discovery 가능
Container 와 Service 의 데이터는 Backend 의 etcd 에 보존
Container 에서 공통적으로 설정이나 Application 에서 사용하는 데이터베이스의 암호 등의 정보를 Kubernetes Cluster 에서 중앙 관리 가능
Kubernetes 를 지원
Ansible : Deploy container to Kubernetes
Apache Ignite : Kubernetes 의 Service Discovery 기능을 이용한 자동 cluster 구성과 scaling
Fluentd : Kubernetes 상의 Container Log 를 전송
Jenkins : Deploy container to Kubernetes
OpenStack : Cloud 와 연계된 Kubernetes 구축
Prometheus : Kubernetes 감시
Spark : job 을 Kubernetes 상에서 Native 실행 (YARN 대체)
Spinnaker : Deploy container to Kubernetes
etc…
Kubernetes 에는 기능 확장이 가능하도록 되어 있어 독자적인 기능을 구현하는 것도 가능
Kubernetes 구축 환경 선택
개인 Windows / Mac 상에 로컬 Kubernetes 환경을 구축
구축 툴을 사용한 cluster 구축
public cloud 의 managed Kubernetes 를 이용
환경에 따라서 일부 이용 불가한 기능도 있으나 기본적으로 어떤 환경에서도 동일한 동작이 가능하도록 CNCF 가 Conformance Program 을 제공
Local Kubernetes
Minikube
VirtualBox 필요 (xhyve, VMware Fusion 도 이용 가능)
Homebrew 등을 이용한 설치 가능
Install
`$ brew update $ brew install kubectl $ brew cask install virtualbox $ brew install minikube `
Run
minikube 기동 시, 필요에 따라 kubernetes 버전을 지정 가능 --kubernetes-version
`$ minikube start —kubernetes-version v1.8.0 `
Minikube 용으로 VirtualBox 상에 VM 가 기동될 것이고 kubectl 로 Minikube 의 클러스터를 조작하는 것이 가능
상태 확인
`$ minikube status `
Minikube cluster 삭제
`$ minikube delete `
Docker for Mac
DockerCon EU 17 에 Docker 사에서 Kubernetes support 발표
Kubernetes 의 CLI 등에서 Docker Swarm 을 조작하는 등의 연계 기능 강화
17.12 CE Edge 버전부터 로컬에 Kubernetes 를 기동하는 것이 가능
Kubernetes 버전 지정은 불가
Docker for Mac 설정에서 Enable Kubernetes 지정
이후 kubectl 로 cluster 조작 가능
`$ kubectl config use-context docker-for-desktop `
kubectl 상에선 Docker Host 가 node로 인식
`$ kubectl get nodes `
Kubernetes 관련 component가 container 로서 기동
`$ docker ps --format 'table {{.Image}}\t{{.Command}}' | grep -v pause `
Kubernetes 구축 Tool
kubeadm
Kubernetes 가 공식적으로 제공하는 구축 도구
여기서는 Ubuntu 16.04 기준으로 기록 (환경 및 필요 버전에 따라 일부 변경 필요함)
준비
`apt-get update && apt-get install -y apt-transport-https curl -s https://package.cloud.google.com/apt/doc/apt-key.gpg | apt-key add - cat </etc/aptsources.list.d/kubernetes.list deb http://apt.kubernetes.io/ kubernetes-xenial main EOF apt-get update apt-get install -y kubelet=1.8.5-00 kubeadm=1.8.5-00 kubectl=1.8.5-00 docker.io sysctl net.bridge.bridge-nf-call-iptables=1 `
Master node 를 위한 설정
--pod-network-cidr은 cluster 내 network (pod network) 용으로 Flannel을 이용하기 위한 설정
`$ kubeadm init --pod-network-cidr=10.244.0.0/16 `
위 설정 명령으로 마지막에 Kubernetes node 를 실행하기 위한 명령어가 출력되며 이후 node 추가시에 실행한다.
`$ kubeadm join --token ... 10.240.0.7:6443 --discovery-token-ca-cert-hash sha256:... `
kubectl 에서 사용할 인증 파일 준비
`$ mkdir -p $HOME/.kube $ sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config $ sudo chown $(id -u):$(id -g) $HOME/.kube/config `
Flannel deamon container 기동
`$ kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/v0.9.1/Documentation/kube-flannel.yml `
Flannel 이 외에도 다른 선택이 가능 Installing a pod network add-on
Rancher
Rancher Labs 사
Open Source Container Platform
version 1.0 에서는 Kubernetes 도 서포트 하는 형식
version 2.0 부터는 Kubernetes 를 메인으로
Kubernetes cluster 를 다양한 플랫폼에서 가능 (AWS, OpenStack, VMware etc..)
기존의 Kubernetes cluster 를 Rancher 관리로 전환 가능
중앙집중적인 인증, 모니터링, WebUI 등의 기능을 제공
풍부한 Application Catalog
Rancher Server 기동
`docker run -d --restart=unless-stopped -p 8080:8080 rancher/server:v2.0.0-alpha10 `
이 Rancher Server 에서 각 Kubernetes cluster 의 관리와 cloud provider 연계 등을 수행
etc
Techtonic (CoreOS)
Kubespray
kops
OpenStack Magnum
Public Cloud managed Kubernetes
GKE (Google Kubernetes Engine)
많은 편리한 기능을 제공
GCP (Google Cloud Platform) 와 Integration.
HTTP LoadBalancer (Ingress) 사용 가능
NodePool
GUI or gcloud 명령어 사용
cluster version 간단 update
GCE (Google Compute Engine) 를 사용한 cluster 구축 가능
Container 를 사용하여 Kubernetes 노드가 재생성되어도 서비스에 영향을 미치지 않게 설계 가능
Kubernetes cluster 내부의 node 에 label 을 붙여 Group 화 가능
Group 화 하여 Scheduling 에 이용 가능
cloud 명령어로 cluster 구축
`$ gcloud container clusters create example-cluster `
인증 정보 저장
`$ gcloud container clusters get-credentials example-cluster `
etc
Google Kubernetes Engine
AKS (Azure Container Service)
Azure Container Service
EKS (Elastic Container Service for Kubernetes)
Amazon EKS
Kubernetes 기초
Kubernetes 는 실제로 Docker 이외의 container runtime 을 이용한 host 도 관리할 수 있도록 되어 있다. Kubernetes = Kubernetes Master + Kubernetes Node
Kubernetes Master
Kubernetes Node
API endpoint 제공
container scheduling
container scaling
Docker Host 처럼 실제로 container 가 동작하는 host
Kubernetes cluster 를 조작할 땐, CLI tool 인 kubectl 과 YAML 형식 manifest file 을 사용하여 Kubernetes Master 에 resource 등록 kubectl 도 내부적으로는 Kubernetes Master API 를 사용 = Library, curl 등을 이용한 조작도 가능
Kubernetes & Resource
resource 를 등록하면 비동기로 container 실행과 load balancer 작성된다. Resource 종류에 따라 YAML manifest 에 사용되는 parameter 가 상이
Kubernetes API Reference Docs
Kubernetes Resource
Workloads : container 실행에 관련
Discovery & LB : container 외부 공개 같은 endpoint를 제공
Config & Storage : 설정, 기밀정보, Persistent volume 등에 관련
Cluster : security & quota 등에 관련
Metadata : resource 조작
Workloads
cluster 상의 container 를 기동하기 위해 이용 내부적으로 이용하는 것을 제외한 이용자가 직접 이용하는 것으로는 다음과 같은 종류
Pod
ReplicationController
ReplicaSet
Deployment
DaemonSet
StatefulSet
Job
CronJob
Discovery & LB
container 의 service discovery, endpoint 등을 제공 내부적으로 이용하는 것을 제외한 이용자가 직접 이용하는 것으로는 다음과 같은 종류
Service : endpoint 의 제공방식에 따라 복수의 타입이 존재
Ingress
ClusterIP
NodePort
LoadBalancer
ExternalIP
ExternalName
Haedless
Config & Storage
설정이나 기밀 데이터 등을 container 에 넣거나 Persistent volume을 제공
Secret
ConfigMap
PersistentVolumeClaim Secret 과 ConfigMap 은 key-value 형식의 데이터 구조
Cluster
cluster 의 동작을 정의
Namespace
ServiceAccount
Role
ClusterRole
RoleBinding
ClusterRoleBinding
NetworkPolicy
ResourceQuota
PersistentVolume
Node
Metadata
cluster 내부의 다른 resource 동작을 제어
CustomResourceDefinition
LimitRange
HorizontalPodAutoscaler
Namespace 에 따른 가상 cluster 의 분리
Kubernetes 가상 cluster 분리 기능 (완전 분리는 아님) 하나의 Kubernetes cluster 를 복수 팀에서 이용 가능하게 함 Kubernetes cluster 는 RBAC (Role-Based Access Control) 이 기본 설정으로 Namesapce 를 대상으로 권한 설정을 할 수 있어 분리성을 높이는 것이 가능
초기 상태의 3가지 Namespace
default
kube-system : Kubernetes cluster 의 component와 addon 관련
kube-public : 모두가 사용 가능한 ConfigMap 등을 배치
CLI tool kubectl & 인증 정보
kubectl 이 Kubernetes Master 와 통신하기 위해 접속 서버의 정보와 인증 정보 등이 필요. 기본으로는 `~/.kube/config` 에 기록된 정보를 이용 `~/.kube/config` 도 YAML Manifest `~/.kube/config` example <pre>`apiVersion: v1 kind: Config preferences: {} clusters: - name: sample-cluster cluster: server: https://localhost:6443 users: - name: sample-user user: client-certificate-data: agllk5ksdgls2... client-key-data: aglk14l1t1ok15... contexts: - name: sample-context context: cluster: sample-cluster namespace: default user: sample-user current-context: sample-context `</pre>
`~/.kube/config` 에는 기본적으로 cluster, user, context 3가지를 정의 cluster : 접속하기 위한 cluster 정보 user : 인증 정보 context : cluster 와 user 페어에 namespace 지정 kubectl 를 사용한 설정 <pre>`# 클러스터 정의 $ kubectl config set-cluster prd-cluster --server=https://localhost:6443 # 인증정보 정의 $ kubectl config set-credentials admin-user \ --client-certificate \ --client-key=./sample.key \ --embed-certs=true # context(cluster, 인증정보, Namespace 정의) $ kubectl config --set-context prd-admin \ --cluster=prd-cluster \ --user=admin-user \ --namespace=default `</pre>
context 를 전환하는 것으로 복수의 cluster 와 user 를 사용하는 것이 가능
`# context 전환 $ kubectx prd-admin Switched to context "prd-admin". # namespace 전환 $ kubens kube-system Context "prd-admin" is modified. Active Namespace is "kube-system". `
## kubectl & YAML Manifest YAML Manifest 를 사용한 container 기동
pod 작성
`# sample-pod.yml apiVersion: vi kind: Pod metadata: name: sample-pod spec: containers: - name: nginx-container image: nginx:1.12 `
resource 작성
`# create resource $ kubectl create -f sample-pod.yml `
resource 삭제
`# delete resource $ kubectl delete -f sample-pod.yml `
resource update
`# apply 외 set, replace, edit 등도 사용 가능 $ kubectl apply -f sample-pod.yml `
## kubectl 사용법
resource 목록 획득 (get)
`$ kubectl get pods # 획득한 목록 상세 출력 $ kubectl get pods -o wide `
-o, —output 옵션을 사용하여 JSON / YAML / custom-columns / Go Template 등 다양한 형식으로 출력하는 것이 가능. 그리고 상세한 정보까지 확인 가능. pods 를 all 로 바꾸면 모든 리소스 일람 획득
resource 상세 정보 확인 (describe)
`$ kubectl describe pods sample-pod $ kubectl describe node k15l1 `
get 명령어 보다 resource 에 관련한 이벤트나 더 상세한 정보를 확인 가능
로그 확인 (logs)
`# Pod 내 container 의 로그 출력 $ kubectl logs sample-pod # 복수 container 가 포함된 Pod 에서 특정 container 의 로그 출력 $ kubectl logs sample-pod -c nginx-container # log follow option -f $ kubectl logs -f sample-pod # 최근 1시간, 10건, timestamp 표시 $ kubectl logs --since=1h --tail=10 --timestamp=true sample-pod `
Pod 상의 특정 명령 실행 (exec)
`# Pod 내 container 에서 /bin/sh $ kubectl exec -it sample-pod /bin/sh # 복수 container 가 포함된 Pod 의 특정 container 에서 /bin/sh $ kubectl exec -it sample-pod -c nginx-container /bin/sh # 인수가 있는 명령어의 경우, -- 이후에 기재 $ kubectl exec -it sample-pod -- /bin/ls -l / `
port-forward
`# localhost:8888 로 들어오는 데이터를 Pod의 80 포트로 전송 $ kubectl port-forward sample-pod 8888:80 # 이후 localhost:8888 을 통해 Pod의 80 포트로 접근 가능 $ curl localhost:8888 `
shell completion
`# bash $ source <(kubectl completion bash) # zsh completion $ source <(kubectl completion zsh) `
## Kubernetes Workloads Resource ## Workloads Resource
cluster 상에서 container 를 기동하기 위해 이용
8 종류의 resource 존재
Pod
ReplicationController
ReplicaSet
Deployment
DaemonSet
StatefulSet
Job
CronJob
디버그, 확인 용도로 주로 이용
ReplicaSet 사용 추천
Pod 을 scale 관리
scale 관리할 workload 에서 기본적으로 사용 추천
각 노드에 1 Pod 씩 배치
Persistent Data 나 stateful 한 workload 의 경우 사용
work queue & task 등의 container 종료가 필요한 workload 에 사용
정기적으로 Job을 수행
Pod
Kubernetes Workloads Resource 의 최소단위
1개 이상의 container 로 구성
Pod 단위로 IP Address 가 할당
대부분의 경우 하나의 Pod은 하나의 container 를 포함하는 경우가 대부분
proxy, local cache, dynamic configure, ssh 등의 보조 역할을 ��는 container 를 같이 포함 하는 경우도 있다.
같은 Pod 에 속한 container 들은 같은 IP Address
container 들은 localhost 로 서로 통신 가능
Network Namespace 는 Pod 내에서 공유
보조하는 sub container 를 side car 라고 부르기도 한다.
Pod 작성
sample pod 을 작성하는 pod_sample.ymlapiVersion: v1 kind: Pod metadata: name: sample-pod spec: containers: - name: nginx-container image: nginx:1.12 ports: - containerPort: 80
nginx:1.12 image를 사용한 container 가 하나에 80 포트를 개방
설정 파일을 기반으로 Pod 작성
`$ kubectl apply -f ./pod_sample.yml `
기동한 Pod 확인
`$ kubectl get pods # 보다 자세한 정보 출력 $ kubectl get pods --output wide `
**2 개의 container 를 포함한 Pod 작성**
2pod_sample.yml
`apiVersion: v1 kind: Pod metadata: name: sample-2pod spec: containers: - name: nginx-container-112 image: nginx:1.12 ports: - containerPort: 80 - name: nginx-container-113 image: nginx:1.13 ports: - containerPort: 8080 `
**container 내부 진입**
container 의 bash 등을 실행하여 진입
`$ kubectl exec -it sample-pod /bin/bash `
-t : 모의 단말 생성
-i : 표준입력 pass through
ReplicaSet / ReplicationController
Pod 의 replica 를 생성하여 지정한 수의 Pod을 유지하는 resource
초창기 ReplicationController 였으나 ReplicaSet 으로 후에 변경됨
ReplicationController 는 equality-based selector 이용. 폐지 예정.
ReplicaSet 은 set-based selector 이용. 기본적으로 이를 이용할 것.
ReplicaSet 작성
sample ReplicaSet 작성 (rs_sample.yml)
`apiVersion: apps/v1 kind: ReplicaSet metadata: name: sample-rs spec: replicas: 3 selector: matchLabels: app: sample-app template: metadata: labels: app: sample-app spec: containers: - name: nginx-container image: nginx:1.12 ports: - containerPort: 80 `
ReplicaSet 작성
`$ kubectl apply -f ./rs_sample.yml `
ReplicaSet 확인
`$ kubectl get rs -o wide `
Label 지정하여 Pod 확인
`$ kubectl get pod -l app=sample-app -o wide `
**Pod 정지 & auto healing**
auto healing = ReplicaSet 은 node 나 pod 에 장애가 발생해도 pod 수를 지정한 수만큼 유지되도록 별도의 node 에 container 를 기동해주기에 장애에 대비하여 영향을 최소화할 수 있도록 가능하다.
Pod 삭제
`$ kubectl delete pod sample-rs-7r6sr `
Pod 삭제 후 다시 Pod 확인 하면 ReplicaSet 이 새로 Pod 이 생성된 것을 확인 가능
ReplicaSet 의 Pod 증감은 kubectl describe rs 명령어로 이력을 확인 가능
Label & ReplicaSet
ReplicaSet 은 Kubernetes 가 Pod 을 감시하여 수를 조정
감시하기 위한 Pod Label 은 spec.selector 에서 지정
특정 라벨이 붙은 Pod 의 수를 세는 것으로 감시
부족하면 생성, 초과하면 삭제
`selector: matchLabels: app: sample-app `
생성되는 Pod Label 은 labels 에 정의.
spec.template.metadata.labels 의 부분에도 app:sample-app 식으로 설정이 들어가서 Label 가 부여된 상태로 Pod 이 생성됨.
`labels: app: sample-app `
spec.selector 와 spec.template.metadata.labels 가 일치하지 않으면 Pod 이 끝없이 생성되다가 에러가 발생하게 될 것…
ReplicaSet 을 이용하지 않고 외부에서 별도로 동일한 label 을 사용하는 Pod 을 띄우면 초과한 수만큼의 Pod 을 삭제하게 된다. 이 때, 어느 Pod 이 지워지게 될지는 알 수 없으므로 주의가 필요
하나의 container 에 복수 label 을 부여하는 것도 가능
`labels: env: dev codename: system_a role: web-front `
**Pod scaling**
yaml config 을 수정하여 kubectl apply -f FILENAME 을 실행하여 변경된 설정 적용
kubectl scale 명령어로 scale 처리
scale 명령어로 처리 가능한 대상은
Deployment
Job
ReplicaSet
ReplicationController
`$ kubectl scale rs sample-rs --replicas 5 `
## Deployment
복수의 ReplicaSet 을 관리하여 rolling update 와 roll-back 등을 실행 가능
방식
전환 방식
Kubernetes 에서 가장 추천하는 container 의 기동 방법
새로운 ReplicaSet 을 작성
새로운 ReplicaSet 상의 Replica count 를 증가시킴
오래된 ReplicaSet 상의 Replica count 를 감소시킴
2, 3 을 반복
새로운 ReplicaSet 상에서 container 가 기동하는지, health check를 통과하는지 확인하면서
ReplicaSet 을 이행할 때의 Pod 수의 상세 지정이 가능
Deployment 작성
deployment_sample.yml
`apiVersion: apps/v1 kind: Deployment metadata: name: sample-deployment spec: replicas: 3 selector: matchLabels: app: sample-app template: metadata: labels: app: sample-app spec: containers: - name: nginx-container image: nginx:1.12 ports: - containerPort: 80 `
deployment 작성
`# record 옵션을 사용하여 update 시 이력을 보존 가능 $ kubectl apply -f ./deployment_sample.yml --record `
이력은 metadata.annotations.kubernetes.io/change-cause에 보존
현재 ReplicaSet 의 Revision 번호는 metadata.annotations.deployment.kubernetes.io/revision에서 확인 가능
`$ kubectl get rs -o yaml | head `
kubectl run 으로 거의 같은 deployment 를 생성하는 것도 가능
다만 default label run:sample-deployment 가 부여되는 차이 정도
`$ kubectl run sample-deployment --image nginx:1.12 --replicas 3 --port 80 `
deployment 확인
`$ kubectl get deployment $ kubectl get rs $ kubectl get pods `
container update
`# nginx container iamge 버전을 변경 $ kubectl set image deployment sample-deployment nginx-container=nginx:1.13 `
**Deployment update condition**
Deployment 에서 변경이 있으면 ReplicaSet 이 생성된다.
replica 수는 변경 사항 대상에 포함되지 않는다
생성되는 Pod 의 내용 변경이 대상
spec.template 의 변경이 있으면 ReplicaSet 을 신규 생성하여 rolling update 수행
spec.template이하의 구조체 해쉬값을 계산하여 그것을 이용해 label 을 붙이고 관리를 한다.
`# Deployment using hash value $ kubectl get rs sample-deployment-xxx -o yaml `
**Roll-back**
ReplicaSet 은 기본적으로 이력으로서 형태가 남고 replica 수를 0으로 하고 있다.
변경 이력 확인 kubectl rollout history
`$ kubectl rollout history deployment sample-deployment `
deployment 작성 시 —record 를 사용하면 CHANGE_CAUSE 부분의 값도 존재
roll-back 시 revision 값 지정 가능. 미지정시 하나 전 revision 사용.
`# 한 단계 전 revision (default --to-revision = 0) $ kubectl rollout undo deployment sample-deployment # revision 지정 $ kubectl rollout undo deployment sample-deployment --to-revision 1 `
roll-back 기능보다 이전 YAML 파일을 kubectl apply로 적용하는게 더 편할 수 있음.
spec.template을 같은 걸로 돌리면 Template Hash 도 동일하여 kubectl rollout 과 동일한 동작을 수행하게 된다.
Deployment Scaling
ReplicaSets 와 동일한 방법으로 kubectl scale or kubectl apply -f을 사용하여 scaling 가능
보다 고급진 update 방법
recreate 라는 방식이 존재
DaemonSet
ReplicaSet 의 특수한 형식
모든 Node 에 1 pod 씩 배치
모든 Node 에서 반드시 실행되어야 하는 process 를 위해 이용
replica 수 지정 불가
2 pod 씩 배치 불가
ReplicaSet 은 각 Kubernetes Node 상에 상황에 따라 Pod 을 배치하는 것이기에 균등하게 배포된다는 보장이 없다.
DaemonSet 작성
ds_sample.yml
`apiVersion: apps/v1 kind: DaemonSet metadata: name: sample-ds spec: selector: matchLabels: app: sample-app template: metadata: labels: app: sample-app spec: containers: - name: nginx-container image: nginx:1.12 ports: - containerPort: 80 `
DaemonSet 작성
`$ kubectl apply -f ./ds_sample.yml `
확인
`$ kubectl get pods -o wide `
## StatefulSet
ReplicaSet 의 특수한 형태
database 처럼 stateful 한 workloads 에 대응하기 위함
생성되는 Pod 명이 숫자로 indexing
persistent 성
sample-statefulset-1, sample-statefulset-2, …
PersistentVolume을 사용하는 경우 같은 disk 를 이용하여 재작성
Pod 명이 바뀌지 않음
StatefulSet 작성
spec.volumeClaimTemplates 지정 가능
statefulset-sample.yml
persistent data 영역을 재사용하여 pod 이 복귀했을 때 동일 데이터를 사용하여 container 가 작성되도록 가능
`apiVersion: apps/v1 kind: StatefulSet metadata: name: sample-statefulset spec: replicas: 3 selector: matchLabels: app: sample-app template: metadata: labels: app: sample-app spec: containers: - name: nginx-container image: nginx:1.12 ports: - containerPort: 80 volumeMounts: - name: www mountPath: /usr/share/nginx/html volumeClaimTemplates: - metadata: name: www spec: accessModes: - ReadWriteOnce resources: requests: storage: 1Gi `
StatefulSet 작성
`$ kubectl apply -f ./statefulset_sample.yml `
확인 (ReplicaSet 과 거의 동일한 정보)
`$ kubectl get statefulset # Pod 이름에 연속된 수로 index 가 suffix 된 것을 확인 $ kubectl get pods -o wide `
scale out 시 0, 1, 2 의 순으로 만들어짐
scale in 시 2, 1, 0 의 순으로 삭제
StatefulSet Scaling
ReplicaSets 와 동일 kubectl scale or kubectl apply -f
Persistent 영역 data 보존 확인
`$ kubectl exec -it sample-statefulset-0 ls /usr/share/nginx/html/sample.html ls: cannot access /usr/share/nginx/html/sample.html: No such file or directory $ kubectl exec -it sample-statefulset-0 touch /usr/share/nginx/html/sample.html $ kubectl exec -it sample-statefulset-0 ls /usr/share/nginx/html/sample.html /usr/share/nginx/html/sample.html `
kubectl 로 Pod 삭제를 하던지 container 내부에서 Exception 등이 발생하는 등으로 container 가 정지해도 file 이 사라지지 않는다.
Pod 명이 바뀌지 않아도 IP Address 는 바뀔 수 있다.
Life Cycle
ReplicaSet 과 다르게 복수의 Pod 을 병렬로 생성하지 않고 1개씩 생성하여 Ready 상태가 되면 다음 Pod 을 작성한다.
삭제 시, index 가 가능 큰 (최신) container 부터 삭제
index:0 이 Master 가 되도록 구성을 짤 수 있다.
Job
container 를 이용하여 일회성 처리를 수행
병렬 실행이 가능하면서 지정한 횟수만큼 container 를 실행 (정상종료) 하는 것을 보장
Job 을 이용 가능한 경우와 Pod 과의 차이
Pod 이 정지하는 것을 전제로 만들어져 있는가?
Pod, ReplicaSets 에서 정지=예상치 못한 에러
Job 은 정지=정상종료
patch 등의 처리에 적합
Job 작성
job_sample.yml : 60초 sleep
ReplicaSets 와 동일하게 label 과 selector 를 지정가능하지만 kubernetes 에서 자동으로 충돌하지 않도록 uuid 를 자동 생성함으로 굳이 지정할 필요 없다.
`apiVersion: batch/v1 kind: Job metadata: name: sample-job spec: completions: 1 parallelism: 1 backoffLimit: 10 template: spec: containers: - name: sleep-container image: centos:latest command: ["sleep"] args: ["60"] restartPolicy: Never `
Job 작성
`$ kubectl apply -f job_sample.yml `
Job 확인
`$ kubectl get jobs $ kubectl get pods `
**restartPolicy**
spec.template.spec.restartPolicy 에는 OnFailure or Never 지정 가능
Never : 장애 시 신규 Pod 작성
OnFailure : 장애 시 동일 Pod 이용하여 Job 재개 (restart count 가 올라간다)
Parallel Job & work queue
completions : 실행 횟수
parallelism : 병렬수
backoffLimit : 실패 허용 횟수. 미지정 시 6
1개씩 work queue 형태로 실행할 경우 completions 를 미지정
parallelism만 지정하면 Persistent 하게 Job을 계속 실행
deployment 등과 동일하게 kubectl scale job… 명령으로 나중에 제어 하는 것도 가능
CronJob
ScheduledJob -> CronJob 으로 명칭 변경됨
Cron 처럼 scheduling 된 시간에 Job 을 생성
create CronJob
cronjob_sample.yml : 60초 마다 30초 sleep
`apiVersion: batch/v1beta1 kind: CronJob metadata: name: sample-cronjob spec: schedule: "*/1 * * * *" concurrencyPolicy: Forbid startingDeadlineSeconds: 30 successfulJobHistoryLimit: 5 failedJobsHistoryLimit: 5 jobTemplate: spec: template: spec: containers: - name: sleep-container image: centos:latest command: ["sleep"] args: ["30"] restartPolicy: Never `
create
`$ kubectl apply -f cronjob_sample.yml `
별도 설정없이 kubectl run —schedule 로 create 가능
`$ kubectl run sample-cronjob --schedule = "*/1 * * *" --restart Never --image centos:latest -- sleep 30 `
확인
`$ kubectl get cronjob $ kubectl get job `
**일시 정지**
spec.suspend 가 true 로 설정되어 있으면 schedule 대상에서 제외됨
YAML 을 변경한 후 kubectl apply
kubectl patch 명령어로도 가능
`$ kubectl patch cronjob sample-cronjob -p '{"spec":{"suspend":true}}' `
kubectl patch에서는 내부적으로 HTTP PATCH method 를 사용하여 Kubernetes 독자적인 Strategic Merge Patch 가 수행된다.
실제로 수행되는 request 를 확인하고 싶으면 -v (Verbose) 옵션 사용
`$ kubectl -v=10 patch cronjob sample-cronjob -p '{"spec":{"suspend":true}}' `
kubectl get cronjob 에서 SUSPEND 항목이 True 로 된 것을 확인
다시 scheduling 대상에 넣고 싶으면 spec.suspend 를 false 로 설정
동시 실행 제어
spec.concurrencyPolicy
spec.startingDeadlineSeconds : Kubernetes Master 가 일시적으로 동작 불가한 경우 등 Job 개시 시간이 늦어졌을 때 Job 을 개시 허용할 수 있는 시간(초)를 지정
spec.successfulJobsHistoryLimit : 보존하는 성공 Job 수.
spec.failedJobsHistoryLimit : 보존하는 실패 Job 수.
Allow (default) : 동시 실행과 관련 제어 하지 않음
Forbid : 이전 Job 이 종료되지 않았으면 새로운 Job 을 실행하지 않음.
Replace : 이전 Job 을 취소하고 새로운 Job 을 실행
300 의 경우, 지정된 시간 보다 5분 늦어도 실행 가능
기본으론 늦어진 시간과 관계없이 Job 생성 가능
default 3.
0 은 바로 삭제.
default 3.
0 은 바로 삭제
Discovery & LB resource
cluster 상의 container 에 접근할 수 있는 endpoint 제공과 label 이 일치하는 container 를 찾을 수 있게 해줌
2 종류가 존재
Service : Endpoint 의 제공방법이 다른 type 이 몇가지 존재
Ingress
ClusterIP
NodePort
LoadBalancer
ExternalIP
ExternalName
Headless (None)
Cluster 내 Network 와 Service
Kubernetes 에서 cluster 를 구축하면 Pod 을 위한 Internal 네트워크가 구성된다.
Internal Network 의 구성은 CNI (Common Network Interface) 라는 pluggable 한 module 에 따라 다르지만, 기본적으로는 Node 별로 상이한 network segment 를 가지게 되고, Node 간의 traffic 은 VXLAN 이나 L2 Routing 을 이용하여 전송된다.
Kubernetes cluster 에 할당된 Internal network segment 는 자동적으로 분할되어 node 별로 network segment 를 할당하기 때문에 의식할 필요 없이 공통의 internal network 를 이용 가능하다.
이러한 특징으로 기본적으로 container 간 통신이 가능하지만 Service 기능을 이용함으로써 얻을 수 있는 이점이 있다.
Pod 에 발생하는 traffic 의 load balancing
Service discovery & internal dns
위 2가지 이점은 모든 Service Type 에서 이용 가능
Pod Traffic 의 load balancing
Service 는 수신한 traffic을 복수의 Pod 에 load balancing 하는 기능을 제공
Endpoint 의 종류에는 cluster 내부에서 이용 가능한 VIP (Virtual IP Address) 와 외부의 load balancer 의 VIP 등 다양한 종류가 제공된다
example) deployment_sample.yml
Deployment 로 복수 Pod 이 생성되면 제각각 다른 IP Address 를 가지게 되는데 이대로는 부하분산을 이용할 수 없지만 Service 가 복수의 Pod 을 대상으로 load balancing 가능한 endpoint 를 제공한다.
`apiVersion: apps/v1 kind: Deployment metadata: name: sample-deployment spec: replicas: 3 selector: matchLabels: app: sample-app template: metadata: labels: app: sample-app spec: containers: - name: nginx-container image: nginx:1.12 ports: - containerPort: 80 `
`$ kubectl apply -f deployment_sample.yml `
Deployment 로 생성된 Pod 의 label 과 pod-template-hash 라벨을 사용한다.
`$ kubectl get pods sample-deployment-5d.. -o jsonpath='{.metadata.labels}' map[app:sample-app pod-template-hash:...]% `
전송할 Pod 은 spec.selector 를 사용하여 설정 (clusterip_sample.yml)
`apiVersion: v1 kind: Service metadata: name: sample-clusterip spec: type: ClusterIP ports: - name: "http-port" protocol: "TCP" port: 8080 targetPort: 80 selector: app: sample-app `
`$ kubectl apply -f clusterip_sample.yml `
Service 를 만들면 상세정보의 Endpoint 부분에 복수의 IP Address 와 Port 가 표시된다. 이는 selector 에 지정된 조건에 매칭된 Pod 의 IP Address 와 Port.
`$ kubectl describe svc sample-clusterip `
Pod 의 IP 를 비교하기 위해 특정 JSON path 를 column 으로 출력
`$ kubectl get pods -l app=sample-app -o custom-columns="NAME:{metadata.name},IP:{status.podIP}" `
load balancing 확인을 쉽게 위해 테스트로 각 pod 상의 index.html 을 변경.
Pod 의 이름을 획득하고 각각의 pod 의 hostname 을 획득한 것을 index.html 에 기록
`for PODNAME in `kubectl get pods -l app=sample-app -o jsonpath='{.items[*].metadata.name}'`; do kubectl exec -it ${PODNAME} -- sh -c "hostname > /usr/share/nginx/html/index.html"; done `
일시적으로 Pod 을 기동하여 Service 의 endpoint 로 request
`$ kubectl run --image=centos:7 --restart=Never --rm -i testpod -- curl -s http://[load balancer ip]:[port] `
**Service Discovery 와 Internal DNS**
Service Discovery
Service Discovery 방법
Service 가 제공
특정 조건의 대상이 되는 member 를 열거하거나, 이름으로 endpoint 를 판별
Service 에 속하는 Pod 을 열거하거나 Service 이름으로 endpoint 정보를 반환
A record 를 이용
SRV record 를 이용
환경변수를 이용
A record 를 이용한 Service Discovery
Service 를 만들면 DNS record 가 자동적으로 등록된다
내부적으로는 kube-dns 라는 system component가 endpoint 를 대상으로 DNS record를 생성
Service 를 이용하여 DNS 명을 사용할 수 있으면 IP Address 관련한 관리나 설정을 신경쓰지 않아도 되기 때문에 이를 사용하는 것이 편리
`# IP 대신에 sample-clusterip 라는 Service 명을 이용 가능 $ kubectl run --image=centos:7 --restart=Never --rm -i testpod -- curl -s http://sample-clusterip:8080 `
실제로 kube-dns 에 등록되는 정식 FQDN 은 [Service name].[Namespace name].svc.[ClusterDomain name]
`# container 내부에서 sample-clusterip.default.svc.cluster.local 를 조회 $ kubectl run --image=centos:6 --restart=Never --rm -i testpod -- dig sample-clusterip.default.svc.cluster.local `
FQDN 에서는 Service 충돌을 방지하기 위해 Namespace 등이 포함되어 있으나 container 내부의 /etc/resolv.conf 에 간략한 domain 이 지정되어 있어 실제로는 sample-clusterip.default 나 sample-clusterip 만으로도 조회가 가능하다.
IP 로도 FQDN 을 반대로 조회하는 것도 가능
`$ kubectl run --image=centos:6 --restart=Never --rm -i testpod -- dig -x 10.11.245.11 `
**SRV record 를 이용한 Service Discovery**
[_Service Port name].[_Protocol].[Service name].[Namespace name].svc.[ClusterDomain name]의 형식으로도 확인 가능
`$ kubectl run --image=centos:6 --restart=Never --rm -i testpod -- dig _http-port._tcp.sample-clusterip.default.svc.cluster.local SRV `
**환경변수를 이용한 Service Discovery**
Pod 내부에서는 환경변수로도 같은 Namespace 의 서비스가 확인 가능하도록 되어 있다.
‘-‘ 가 포함된 서비스 이름은 ‘_’ 로, 그리고 대문자로 변환된다.
docker --links ...와 같은 형식으로 환경변수가 보존
container 기동 후에 Service 추가나 삭제에 따라 환경변수가 갱신되는 것은 아니라서 예상 못한 사고가 발생할 가능성도 있다.
Service 보다 Pod 이 먼저 생성된 경우에는 환경변수가 등록되어 있지 않기에 Pod 을 재생성해야 한다.
Docker 만으로 이용하던 환경에서 이식할 때에도 편리
`$ kubectl exec -it sample-deployment-... env | grep -i sample_clusterip `
**복수 port 를 사용하는 Service 와 Service Discovery**
clusterip_multi_sample.yml
`apiVersion: v1 kind: Service metadata: name: sample-clusterip spec: type: ClusterIP ports: - name: "http-port" protocol: "TCP" port: 8080 targetPort: 80 - name: "https-port" protocol: "TCP" port: 8443 targetPort: 443 selector: app: sample-app `
## ClusterIP
가장 기본
Kubernetes cluster 내부에서만 접근 가능한 Internal Network 의 VIP 가 할당된다
ClusterIP 로의 통신은 node 상에서 동작하는 system component 인 kube-proxy가 Pod을 대상으로 전송한다. (Proxy-mode 에 따라 상이)
Kubernetes cluster 외부에서의 접근이 필요없는 곳에 이용한다
기본으로는 Kubernetes API 에 접속하기 위한 Service 가 만들어져 있고 ClusterIP 가 를 사용한다.
`# TYPE 의 ClusterIP 확인 $ kubectl get svc `
**create ClusterIP Service**
clusterip_sample.yml
`apiVersion: v1 kind: Service metadata: name: sample-clusterip spec: type: ClusterIP ports: - name: "http-port" protocol: "TCP" port: 8080 targetPort: 80 selector: app: sample-app `
type: ClusterIP 지정
spec.ports[x].port 에는 ClusterIP로 수신하는 Port 번호
spec.ports[x].targetPort 는 전달할 container 의 Port 번호
Static ClusterIP VIP 지정
database 를 이용하는 등 기본적으로는 Kubernetes Service에 등록된 내부 DNS record를 이용하여 host 지정하는 것을 추천
수동으로 지정할 경우 spec.clusterIP를 지정 (clusterip_vip_sample.yml)
`apiVersion: v1 kind: Service metadata: name: sample-clusterip spec: type: ClusterIP clusterIP: 10.11.111.11 ports: - name: "http-port" protocol: "TCP" port: 8080 targetPort: 80 selector: app: sample-app `
이미 ClusterIP Service가 생성되어 있는 상태에서는 ClusterIP 를 변경할 수 없다.
kubectl apply 로도 불가능
먼저 생성된 Service 를 삭제해야 한다.
ExternalIP
특정 Kubernetes Node 의 IP:Port 로 수신한 traffic 을 container 로 전달하는 방식으로 외부와 연결
create ExternalIP Service
externalip_sample.yml
`apiVersion: v1 kind: Service metadata: name: sample-externalip spec: type: ClusterIP externalIPs: - 10.1.0.7 - 10.1.0.8 ports: - name: "http-port" protocol: "TCP" port: 8080 targetPort: 80 selector: app: sample-app `
type: ExternalIP 가 아닌 type: ClusterIP 인 것에 주의
spec.ports[x].port 는 ClusterIP 로 수신하는 Port
spec.ports[x].targetPort 는 전달할 container 의 Port
모든 Kubernetes Node 를 지정할 필요는 없음
ExternalIP 에 이용 가능한 IP Address 는 node 정보에서 확인
GKE 는 OS 상에서는 global IP Address가 인식되어 있지 않아서 이용 불가
`# IP address 확인 $ kubectl get node -o custom-columns="NAME:{metadata.name},IP:{status.addresses[].address}" `
ExternalIP Service 를 생성해도 container 내부에서 사용할 ClusterIP 도 자동적으로 할당된다.
container 안에서 DNS로 ExternalIP Service 확인
`$ kubectl run --image=centos:6 --restart=Never --rm -i testpod -- dig sample-externalip.default.svc.cluster.local `
ExternalIP 를 이용하는 node 의 port 상태
`$ ss -napt | grep 8080 `
ExternalIP 를 사용하면 Kubernetes cluster 밖에서도 접근이 가능하고 또한 Pod 에 분산된다.
NodePort
모든 Kubernetes Node 의 IP:Port 에서 수신한 traffic 을 container 에 전송
ExternalIP Service 의 모든 Node 버전 비슷한 느낌
Docker Swarm 의 Service 를 Expose 한 경우와 비슷
create NodePort Service
nodeport_sample.yml
`apiVersion: v1 kind: Service metadata: name: sample-nodeport spec: type: NodePort ports: - name: "http-port" protocol: "TCP" port: 8080 targetPort: 80 nodePort: 30080 selector: app: sample-app `
spec.ports[x].port 는 ClusterIP 로 수신하는 Port
spec.ports[x].targetPort 는 전달할 container Port
spec.ports[x].nodePort 는 모든 Kubernetes Node 에서 수신할 Port
container 안에서 통신에 사용할 ClusterIP 도 자동적으로 할당된다
지정하지 않으면 자동으로 비어있는 번호를 사용
Kubernetes 기본으로는 이용할 수 있는 번호가 30000~32767
복수의 NodePort 가 동일 Port 사용 불가
Kubernetes Master 설정에서 변경 가능
`$ kubectl get svc `
container 안에서 확인하면 내부 DNS 가 반환하는 IP Address 는 External IP 가 아닌 Cluster IP
`$ kubectl run --image=centos:6 --restart=Never --rm -i testpod -- dig sample-nodeport.default.svc.cluster.local `
Kubernetes Node 상에서 Port 상태를 확인하면 nodePort 에 지정한 값으로 Listen
`$ ss -napt | grep 30080 `
ExternalIP 와 다르게 모든 Node 의 IP Address 로 Kubernetes Cluster 외부에서 접근 가능하며 Pod 으로의 request 도 분산된다.
GKE 도 GCE에 할당된 global IP Address 로 접근 가능
Node 간 통신의 배제 (Node 를 건넌 load balancing 배제)
NodePort 에서는 Node 상의 NodePort 에 도달한 packet 은 Node 를 건너서도 load balancing 이 이루어진다
DaemonSet 등을 사용하면 각 Node에 1 Pod 이 존재하기에 같은 Node 상의 Pod 에만 전달하고 싶을 때 사용
spec.externalTrafficPolicy 를 사용하여 실현 가능
externalTrafficPolicy 를 Cluster 에서 Local 로 변경하기 위해선 YAML 이용 (nodeport_local_sample.yml)
Cluster (Default)
Local
Node 에 도달한 후 각 Node 에 load balancing
실제로는 kube-proxy 설정으로 iptables 의 proxy mode를 사용할 경우, 자신의 Node 에 좀 더 많이 전달되도록 되는 것으로 보여짐 (iptables-save 등으로 statistics 부분을 확인)
도달한 Node 에 속한 Pod 에 전달 (no load balancing)
만약 Pod 이 존재하지 않으면 Response 불가
만일 Pod 이 복수 존재한다면 균등하게 분배
`apiVersion: v1 kind: Service metadata: name: sample-nodeport-local spec: type: NodePort externalTrafficPolicy: Local ports: - name: "http-port" protocol: "TCP" port: 8080 targetPort: 80 nodePort: 30081 selector: app: sample-app `
## LoadBalancer
가장 사용성이 좋고 실용적
Kubernetes Cluster 외부의 LoadBalancer 에 VIP 를 할당 가능
NodePort 등에선 결국 Node 에 할당된 IP Address 에 endpoint 역할까지 담당시키는 것이라 SPoF (Single Point of Failure) 로 Node 장애에 약하다
외부의 load balancer 를 이용하는 것으로 Kubernetes Node 장애에 강하다
단 외부 LoadBalancer 와 연계 가능한 환경으로 GCP, AWS, Azure, OpenStack 등의 CloudProvider 에 한정된다 (이는 추후에 점차 확대될 수 있다)
NodePort Service 를 만들어서 Cluster 외부의 Load Balancer 에서 Kubernetes Node 에 balancing 한다는 느낌
create LoadBalancer Service
lb_sample.yml
`apiVersion: v1 kind: Service metadata: name: sample-lb spec: type: LoadBalancer ports: - name: "http-port" protocol: "TCP" port: 8080 targetPort: 80 nodePort: 30082 selector: app: sample-app `
spec.ports[x].port 는 LoadBalancer VIP 와 ClusterIP 로 수신하는 Port
spec.ports[x].targetPort 는 전달할 container Port
NodePort 도 자동적으로 할당됨으로 spec.ports[x].nodePort 의 지정도 가능
확인
`$ kubectl get svc sample-lb `
EXTERNAL-IP 가 pending 상태인 경우 LoadBalancer 가 준비되는데 시간이 필요한 경우
Container 내부 통신에는 Cluster IP 를 사용하기에 ClusterIP 도 자동할당
NodePort 도 생성
VIP 는 Kubernetes Node 에 분산되기 때문에 Kubernetes Node 의 scaling 시 변경할 것이 없다
Node 간 통신 배제 (Node 를 건넌 load balancing 배제)
NodePort 와 동일하게 externalTrafficPolicy 를 이용 가능
LoadBalancer VIP 지정
spec.LoadBalancerIP 로 외부의 LoadBalancer IP Address 지정 가능
`# lb_fixip_sample.yml apiVersion: v1 kind: Service metadata: name: sample-lb-fixip spec: type: LoadBalancer loadBalancerIP: xxx.xxx.xxx.xxx ports: - name: "http-port" protocol: "TCP" port: 8080 targetPort: 80 nodePort: 30083 selector: app: sample-app `
미지정 시 자동 할당
GKE 등의 cloud provider 의 경우 주의
GKE 에서는 LoadBalancer service 를 생성하면 GCLB 가 생성된다.
GCP LoadBalancer 등으로 비용이 증가 되지 않도록 주의
IP Address 중복이 허용되거나 deploy flow 상 문제가 없으면 가급적 Service 를 정리할 것
Service 를 만든 상태에서 GKE cluster 를 삭제하면 GCLB 가 과금 되는 상태로 남아버리므로 주의
Headless Service
Pod 의 IP Address 가 반환되는 Service
보통 Pod 의 IP Address 는 자주 변동될 수 있기 때문에 Persistent 한 StatefulSet 한정하여 사용 가능
IP endpoint 를 제공하는 것이 아닌 DNS Round Robin (DNS RR) 을 사용한 endpoint 제공
DNS RR 은 전달할 Pod 의 IP Address 가 cluster 안의 DNS 에서 반환되는 형태로 부하분산이 이루어지기에 client 쪽 cache 에 주의할 필요가 있다.
기본적으로 Kubernetes 는 Pod 의 IP Address 를 의식할 필요가 없도록 되어 있어서 Pod 의 IP Address 를 discovery 하기 위해서는 API 를 사용해야만 한다
Headless Service 를 이용하여 StatefulSet 한정으로 Service 경유로 IP Address 를 discovery 하는 것이 가능하다
create Headless Service
3가지 조건이 충족되어야 한다
Service 의 spec.type 이 ClusterIP
Service 의 metadata.name 이 StatefulSet 의 spec.serviceName 과 같을 것
Service 의 spec.clusterIP 가 None 일것
위 조건들이 충족되지 않으면 그냥 Service 로만 동작하고 Pod 이름을 얻는 등이 불가능하다.
`# headless_sample.yml apiVersion: v1 kind: Service metadata: name: sample-svc spec: type: ClusterIP clusterIP: None ports: - name: "http-port" protocol: "TCP" port: 80 targetPort: 80 selector: app: sample-app `
**Headless Service 를 이용한 Pod 이름 조회**
보통 Service 를 만들면 복수 Pod 에 대응하는 endpoint 가 만들어져 해당 endpoint. 에 대응하여 이름을 조회하는 것이 가능하지만 각각의 Pod 의 이름 조회는 불가능하다
보통 Service 의 이름 조회는 [Service name].[Namespace name].svc.[domain name] 로 조회가 가능하도록 되어 있지만 Headless Service 로 그대로 조회하면 DNS Round Robin 으로 Pod 중의 IP 가 반환되기에 부하 분산에는 적합하지 않다
StatefulSet 의 경우에만, [Pod name].[Service name].[Namespace name].svc.[domain name] 형식으로 Pod 이름 조회가 가능하다
container 의 resolv.conf 등에 search 로 entry 가 들어가 있다면 [Pod name].[Service name] 혹은 [Pod name].[Service name].[Namespace] 등으로 조회 가능
ReplicaSet 등의 Resource 에서도 가능
ExternalName
다른 Service 들과 다르게 Service 이름 조회에 대응하여 CNAME 을 반환하는 Service
주로 다른 이름을 설정하고 싶거나 cluster 안에서 endpoint 를 전환하기 쉽게 하고 싶을 때 사용
create ExternalName service
`# externalname_sample.yml apiVersion: v1 kind: Service metadata: name: sample-externalname namespace: default spec: type: ExternalName externalName: external.example.com `
`$ kubectl get svc `
EXTERNAL-IP 부분에 CNAME 용의 DNS 가 표시된다
container 내부에서 [Service name] 이나 [Service name].[Namespace name].svc.[domain name] 으로 조회하면 CNAME 가 돌아오는 것을 확인 가능
`$ dig sample-externalname.default.svc.cluster.local CNAME `
**Loosely Coupled with External Service**
Cluster 내부에서는 Pod 로의 통신에 Service 이름 조회를 사용하는 것으로 서비스 간의 Loosely Coupled 를 가지는 것이 가능했지만, SaaS 나 IaaS 등의 외부 서비스를 이용하는 경우에도 필요가 있다.
Application 등에서 외부 endpoint를 설정하면 전환할 때 Application 쪽 설정 변경이 필요해지는데 ExternalName을 이용하여 DNS 의 전환은 ExternalName Service 의 변경만으로 가능하여 Kubernetes 상에서 가능해지고 외부와 Kubernetes Cluster 사이의 Loosely Coupled 상태도 유지 가능하다.
외부 서비스와 내부 서비스 간의 전환
ExternalName 이용으로 외부 서비스와의 Loosely Coupled 확보하고 외부 서비스와 Kubernetes 상의 Cluster 내부 서비스의 전환도 유연하게 가능하다
Ingress
L7 LoadBalancer 를 제공하는 Resource
Kubernetes 의 Network Policy resource 에 Ingress/Egress 설정항목과 관련 없음
Ingress 종류
아직 Beta Service 일 가능성
크게 구분하여 2가지
Cluster 외부의 Load Balancer를 이용한 Ingress
Cluster 내부에 Ingress 용의 Pod 을 생성하여 이용하는 Ingress
GKE
Nginx Ingress
Nghttpx Ingress
Cluster 외부의 Load Balancer 를 이용한 Ingress
GKE 같은 Cluster 외부의 Load Balancer를 이용한 Ingress 의 경우, Ingress rosource 를 만드는 것만으로 LoadBalancer 의 VIP 가 만들어져 이용하는 것이 가능
GCP의 GCLB (Google Cloud Load Balancer) 에서 수신한 traffic을 GCLB 에서 HTTPS 종단이나 path base routing 등을 수행하여 NodePort에 traffic을 전송하는 것으로 대상 Pod 에 도달
Cluster 내부에 Ingress 용의 Pod 을 생성하여 이용하는 Ingress
L7 역할을 할 Pod을 Cluster 내부에 생성하는 형태로 실현
Cluster 외부에서 접근 가능하도록 별도 Ingress 용 Pod에 LoadBalancer Service를 작성하는 등의 준비가 필요하다
Ingress 용의 Pod 이 HTTPS 종단이나 path base routing 등의 L7 역할을 하기 위해 Pod 의 replica 수의 auto scale 등도 고려할 필요가 있다.
LB와 일단 Nginx Pod 에 전송하여 Nginx 가 L7 역할을 하여 처리한 후 대상 Pod 에 전송한다.
NodePort 경유하지 않고 직접 Pod IP 로 전송
create Ingress resource
사전 준비가 필요
사전에 만들어진 Service를 Back-end로서 활용하여 전송을 하는 형태
Back-end 로 이용할 Service 는 NodePort 를 지정
`# sample-ingress-apps apiVersion: apps/v1 kind: Deployment metadata: name: sample-ingress-apps spec: replicas: 1 selector: matchLabels: ingress-app: sample template: metadata: labels: ingress-app: sample spec: containers: - name: nginx-container image: zembutsu/docker-sample-nginx:1.0 ports: - containerPort: 80 `
`# ingress service sample apiVersion: v1 kind: Service metadata: name: svc1 spec: type: NodePort ports: - name: "http-port" protocol: "TCP" port: 8888 targetPort: 80 selector: ingress-app: sample `
Ingress 로 HTTPS 를 이용하는 경우에는 인증서는 사전에 Secret 으로 등록해둘 필요가 있다.
Secret 은 인증서의 정보를 바탕으로 YAML 파일을 직접 만들거나 인증서 파일을 지정하여 만든다.
`# 인증서 작성 $ openssl req -x509 -nodes -days 365 -newkey rsa:2048 -keyout /tmp/tls.key -out /tmp/tls.crt -subj "/CN=sample.example.com" # Secret 작성 (인증서 파일을 지정하는 경우) $ kubectl create secret tls tls-sample --key /tmp/tls.key --cert /tmp/tls.crt `
Ingress resource 는 L7 Load Balancer 이기에 특정 host 명에 대해 request path > Service back-end 의 pair 로 전송 rule 을 설정한다.
하나의 IP Address 로 복수의 Host 명을 가지는 것이 가능하다.
spec.rules[].http.paths[].backend.servicePort 에 설정하는 Port 는 Service 의 spec.ports[].port 를 지정
`# ingress_sample.yml apiVersion: extensions/v1beta1 kind: Ingress metadata: name: sample-ingress annotations: ingress.kubernetes.io/rewrite-target: / spec: rules: - host: sample.example.com http: paths: - path: /path1 backend: serviceName: svc1 servicePort: 8888 backend: serviceName: svc1 servicePort: 8888 tls: - hosts: - sample.example.com secretName: tls-sample `
**Ingress resource & Ingress Controller**
Ingress resource = YAML file 에 등록된 API resource
Ingress Controller = Ingress resource 가 Kubernetes 에 등록되었을 때, 어떠한 처리를 수행하는 것
GCP 의 GCLB 를 조작하여 L7 LoadBalancer 설정을 하는 것이나,
Nginx 의 Config 를 변경하여 reload 하는 등
GKE 의 경우
GKE 의 경우, 기본으로 GKE 용 Ingress Controller 가 deploy 되어 있어 딱히 의식할 필요 없이 Ingress resource 마다 자동으로 IP endpoint 가 만들어진다.
Nginx Ingress 의 경우
Nginx Ingress 를 이용하는 경우에는 Nginx Ingress Controller 를 작성해야 한다.
Ingress Controller 자체가 L7 역할을 하는 Pod 이 되기도 하기에 Controller 라는 이름이지만 실제 처리도 수행한다.
GKE 와 같이 cluster 외부에서도 접근을 허용하기 위해서는 Nginx Ingress Controller 으로의 LoadBalancer Service (NodePort 등도 가능) 를 작성할 필요가 있다.
개별적으로 Service 를 만드는 것이기에 kubectl get ingress 등으로 endpoint IP Address 를 확인 불가 하기에 주의가 필요하다.
rule 에 매칭되지 않을 경우의 default 로 전송할 곳을 작성할 필요가 있으니 주의
실제로는 RBAC, resource 제한, health check 간격 등 세세한 설정해 둬야 할 수 있다.
nginx ingress 추천 설정
`# Nginx ingress를 이용하는 YAML sample apiVersion: apps/v1 kind: Deployment metadata: name: default-http-backend labels: app: default-http-backend spec: replicas: 1 selector: matchLabels: app: default-http-backend template: metadata: labels: app: default-http-backend spec: containers: - name: default-http-backend image: gcr.io/google_containers/defaultbackend:1.4 livenessProbe: httpGet: path: /healthz port: 8080 scheme: HTTP ports: - containerPort: 8080 --- apiVersion: v1 kind: Service metadata: name: default-http-backend labels: app: default-http-backend spec: ports: - port: 80 targetPort: 8080 selector: app: default-http-backend --- apiVersion: apps/v1 kind: Deployment metadata: name: nginx-ingress-controller spec: replicas: 1 selector: matchLabels: app: ingress-nginx template: metadata: labels: app: ingress-nginx spec: containers: - name: nginx-ingress-controller image: quay.io/kubernetes-ingress-controller/nginx-ingress-controller:0.14.0 args: - /nginx-ingress-controller - --default-backend-service=$(POD_NAMESPACE)/default-http-backend env: - name: POD_NAME valueFrom: fieldRef: fieldPath: metadata.name - name: POD_NAMESPACE valueFrom: fieldRef: fieldPath: metadata.namespace ports: - name: http containerPort: 80 - name: https containerPort: 443 livenessProbe: httpGet: path: /healthz port: 10254 scheme: HTTP readinessProbe: httpGet: path: /healthz port: 10254 scheme: HTTP --- apiVersion: v1 kind: Service metadata: name: ingress-endpoint labels: app: ingress-nginx spec: type: LoadBalancer ports: - port: 80 targetPort: 8080 selector: app: ingress-nginx `
default back-end pod 이나 L7 처리할 Nginx Ingress Controller Pod 의 replica 수가 고정이면 traffic 이 늘었을 때 감당하지 못할 가능성도 있으니 Pod auto scaling 을 수행하는 Horizontal Pod Autoscaler (HPA) 의 이용도 검토해야 할 수 있음
deploy 한 Ingress Controller 는 cluster 상의 모든 Ingress resource 를 봐 버리기에 충돌할 가능성이 있다.
상세 사양
Ingress Class 를 이용하여 처리하는 대상 Ingress resource 를 분리하는 것이 가능
Ingress resource 에 Ingress Class Annotation 을 부여하여 Nginx Ingress Controller 에 대상으로 하는 Ingress Class를 설정하는 것으로 대상 분리 가능
Nginx Ingress Controller 의 기동 시 --ingress-class 옵션 부여
Ingress resource Annotation
/nginx-ingress-controller --ingress-class=system_a ...
kubernetes.io/ingress.class: "system_a"
정리
Kubernetes Service & Ingress
Service
Ingress
L4 Load Balancing
Cluster 내부 DNS 로 lookup
label 을 이용한 Pod Service Discovery
L7 Load Balancing
HTTPS 종단
path base routing
Kubernetes Service
ClusterIP : Kubernetes Cluster 내부 한정으로 통신 가능한 VIP
ExternalIP : 특정 Kubernetes Node 의 IP
NodePort : 모든 Kubernetes Node 의 모든 IP (0.0.0.0)
LoadBalancer : Cluster 외부에 제공되는 Load Balancer의 VIP
ExternalName : CNAME 을 사용한 Loosely Coupled
Headless : Pod 의 IP 를 사용한 DNS Round Robin
Kubernetes Ingress
Cluster 외부의 Load Balancer 를 이용한 Ingress : GKE
Cluster 내부의 Ingress 용 Pod 을 이용한 Ingress : Nginx Ingress, Nghttpx Ingress
Kubernetes Config & Storage resource
container 에 대한 설정 파일, 암호 등의 기밀 정보나 Persistent Volume 등에 관한 resource
3 종류
Secret
ConfigMap
PersistentVolumeClaim
환경변수 이용
Kubernetes 에서는 개별 container에 대한 설정의 내용은 환경변수나 파일이 포함된 영역을 mount 해서 넘기는 것이 일반적이다
환경변수를 넘기려면 pod template 에 env 혹은 envFrom 을 지정
5개의 정보 source로부터 환경변수를 심는 것이 가능
정적설정
Pod 정보
Container 정보
Secret resource 의 기밀 정보
ConfigMap resource 의 Key-Value 값
정적설정
spec.containers[].env 에 정적 값을 정의
`apiVersion: v1 kind: Pod metadata: name: sample-env labels: app: sample-app spec: containers: - name: nginx-container image: nginx:1.12 env: - name: MAX_CONNECTION value: "100" `
Pod 정보
Pod 이 속한 Node 나, Pod 의 IP Address, 기동시간 등의 Pod 에 관련된 정보는 fieldRef를 사용하여 참조할 수 있다.
참조 가능한 값은 kubectl get pods -o yaml 등으로 확인할 수 있다.
등록한 YAML file 의 정보와 별도로 IP, host 정도 등도 추가되었다.
`# 동작 중인 Pod 의 정보 확인 $ kubectl get pod nginx-pod -o yaml ... spec: nodeName: gke-k8s-... ... `
`# env-pod-sample.yml # set Kubernetes Node's name to env K8S_NODE apiVersion: v1 kind: Pod metadata: name: sample-env-pod labels: app: sample-app spec: containers: - name: nginx-container image: nginx:1.12 env: - name: K8S_NODE valueFrom: fieldRef: fieldPath: spec.nodeName `
**Container 정보**
Container 에 관련한 정보는 resourceFieldRef를 사용하여 참조할 수 있다.
Pod 에는 복수 container 의 정보가 포함되어 있어서 각 container에 설정 가능한 값에 대해서는 fieldRef로는 참조할 수 없는 것에 주의.
참조 가능한 값에 관해선 kubectl get pods -o yaml 등오로 확인 가능
`# env-container-sample.yml #set CPU Requests/Limits to ENV apiVersion: v1 kind: Pod metadata: name: sample-env-container labels: app: sample-app spec: containers: - name: nginx-container image: nginx:1.12 env: - name: CPU_REQUEST valueFrom: resourceFieldRef: containerName: nginx-container resource: requests.cpu - name: CPU_LIMIT valueFrom: resourceFieldRef: containerName: nginx-container resource: limits.cpu `
**Secret resource 기밀 정보**
기밀 정보는 별도 Secret resource 를 만들어 환경변수로 참조 시키는 것을 추천
ConfigMap resource 에서 Key-Value 값
단순한 Key-Value 값이나 설정 파일 등은 ConfigMap 으로 관리하는 것이 가능
일괄 변경이나 중복이 많이 많은 경우 ConfigMap 을 사용하는 것이 유용할 수 있음
환경변수 이용 시 주의점
`# env fail sample apiVersion: v1 kind: Pod metadata: name: sample-fail-env labels: app: sample-app spec: containers: - name: nginx-container image: nginx:1.12 command: ["echo"] args: ["${TESTENV}", "${HOSTNAME}"] env: - name: TESTENV value: "100" `
command 나 args 에 환경변수를 이용하기 위해선 ${} 가 아닌 $()를 사용해야 한다
command 나 args 에서 참조가능한 환경 변수는 해당 Pod template 내부에서 정의된 환경 변수에 제한된다. (위 예제에서는 TESTENV 값만 참조 가능)
OS 등에서만 참조할 수 있는 환경 변수를 이용하기 위해서는 script 등을 이용하여 실행하도록 해야 한다.
Secret
DataBase 등을 사용할 때 필요한 유저, 암호 등의 인증에 필요한 경우 이용할 수 있는 방식
유저명과 암호를 별도 resource 로 정의해두고 Pod 에서 이를 불러들여 사용하기 위한 resource
Secret이 정의된 YAML Manifest를 암호화하는 ::kubesec:: 이란 OSS 존재
gpg, Google Cloud KMS, AWS KMS 등을 이용하여 간단하게 data.* 부분만 암호화할 수 있어 외부로 공개되어도 문제 소지가 적다.
Docker build 시 Container Image 에 첨부
환경변수나 실행 인수 등에 포함시켜 Container Image 를 build.
기밀 정보를 포함하고 있는 만큼 해당 Image 를 외부에 공개하거나 배포하기 곤란하며 인증 정보가 변경된다면 Image 를 다시 build 해야 하는 등 불편
Pod 이나 Deployment YAML Manifest 에 첨부
이 역시 YAML 이 외부에 알려져서는 안되고 복수 Application 에서 동일한 정보를 사용하게 된다면 여기저기 퍼지게 되는 것이라 이 역시 문제
Secret 분류
Generic (type: Opaque)
TLS (type: kubernetes.io/tls)
Docker Registry (type: kubernetes.io/dockerconfigjson)
Service Account (type: kubernetes.io/service-account-token)
Generic (type: Opaque)
보통 사용하는 암호 등에 이용
작성 방법
file 을 이용 (--from-file)
yaml
kubectl 이용하어 직접 생성 (--from-literal)
envfile
Secret 에서는 복수의 Key-Value 값이 보존된다.
db-auth 라는 이름의 Secret 에는 username, password 라는 Key가 있고 그에 해당하는 Value 값이 존재할 수 있다.
복수의 DB를 사용하는 경우, Secret 이름이 겹치지 않게 정의하거나 시스템별로 Namespace를 분할하는 등의 작업이 필요
from File
--from-file 옵션을 사용하여 파일을 지정하여 사용한다
파일명이 곧 Key 가 되기에 파일명에 포함된 확장자 등은 제거하는게 좋을 수 있다.
확장자를 제거하기 싫다면, --from-file=username=username.txt 처럼 사용할 수도 있다.
파일에 개행문자(\n)가 들어가지 않도록 echo -n 을 사용하는 등으로 주의해야 한다.
`# source 파일 생성 $ echo -n "user" > ./username $ echo -n "password" > ./password # Secret 생성 $ kubectl create secret generic sample-db-auth --from-file=./username --from-file=./password # json 형식으로 base64 형식으로 encode 된 Secret data 부분을 확인 $ kubectl get secret sample-db-auth -o json | jq .data # base64 형식으로 encode 된 내용을 평문으로 확인 $ kubectl get secret sample-db-auth -o json | jq -r .data.username | base64 -d `
from yaml
`apiVersion: v1 kind: Secret metadata: name: sample-db-auth type: Opaque data: username: dXNlcgo= password: cGFzc3dvcmQK `
using kubectl (--from-literal)
—from-literal 옵션 사용
`$ kubectl create secret generic sample-db-auth --from-literal=username=user --from-literal=password=password `
from envfile
일괄적으로 처리할 때 이용가능하며 Docker 에서 —env-file 옵션을 사용하여 container를 사용하고 있었다면 그대로 Secret 에 이식하는 것도 가능하다.
`username=user password=password $ kubectl create secret generic sample-db-auth --from-env-file ./env_secret `
TLS (type: kubernetes.io/tls)
Ingress 등에서 참조 가능한 TLS 용 Secret
주로 인증서 등을 이용하기 위해 사용하며 일반적으로 파일을 이용하여 이용한다.
--key 와 —cert 로 비밀키와 인증서를 지정한다.
`# create certificate $ openssl req -x509 -nodes -days 365 -newkey rsa:2048 -keyout /tmp/tls.key -out /tmp/tls.crt - subj "/CN=sample1.example.com" # create TLS Secret $ kubectl create secret tls tls-sample --key /tmp/tls.key --cert /tmp/tls.crt `
Docker Registry (type: kubernetes.io/dockerconfigjson)
Docker Registry 인증 정보용
using kubectl
kubectl 을 이용할 경우 Registry 서버와 인증정보를 인수로 지정한다.
`$ kubectl create secret docker-registry sample-registry-auth \ --docker-server=REGISTRY_SERVER \ --docker-username=REGISTRY_USER \ --docker-password=REGISTRY_USER_PASSWORD \ --docker-email=REGISTRY_USER_EMAIL # get $ kubectl get secret -o json sample-registry-auth | jq .data `
Secret 을 이용한 image 획득
인증이 필요한 Docker Registry 나 Docker Hub 의 Private repository 의 Image 를 가져오기 위해서 Secret 을 사전에 만들어놓고 Pod 의 spec.imagePullSecrets 에 docker-registry 타입의 Secret 을 지정한다.
`# secret-pull_sample.yml apiVersion: v1 kind: Pod metadata: name: sample-pod spec: containers: - name: secret-image-container image: REGISTRY_NAME/secret-image:latest imagePullSecrets: - name: sample-registry-auth `
Service Account
수동으로 만드는 것은 아니지만 Pod 에 Service Account 의 Token 을 mount 하기 위함
Secret 이용
Secret 을 container에서 이용할 경우, 크게 나눠서 2가지 패턴
환경변수
Volume으로 mount
Secret 의 특정 Key 한정
Secret 의 모든 Key
Secret의 특정 Key 한정
Secret 의 모든 키
환경변수
환경변수로 넘길 경우, 특정 Key만을 넘기 던가, Secret 전체를 넘기던가.
특정 key 만을 넘길 경우, spec.containers[].env 의 valueFrom.secretKeyRef 를 사용하여 넘길 키를 지정
`# secret_single_env_sample.yml apiVersion: v1 kind: Pod metadata: name: sample-secret-single-env spec: containers: - name: secret-container image: nginx:1.12 env: - name: DB_USERNAME valueFrom: secretKeyRef: name: sample-db-auth key: username `
env 로 1개씩 정의가 가능하여 환경변수 명을 지정 가능하다.
Secret 전체를 넘길 경우
`# secret_multi_env_sample.yml apiVersion: v1 kind: Pod metadata: name: sample-secret-multi-env spec: containers: - name: secret-container image: nginx:1.12 envFrom: - secretRef: name: sample-db-auth `
Key 를 일일이 지정하지 않아도 되어 간결하지만 Secret 에 저장되어 있는 값을 Pod Template 로는 파악하기 힘들다. **Volume Mount**
특정 Key 만을 넘길 경우, spec.volumes[] 의 secret.item[] 을 사용하여 지정한다.
`# secret_single_volume_sample.yml apiVersion: v1 kind: Pod metadata: name: sample-secret-single-volume spec: containers: - name: secret-container image: nginx:1.12 volumeMounts: - name: config-volume mountPath: /config volumes: - name: config-volume secret: secretName: sample-db-auth items: - key: username path: username.txt `
mount 할 파일을 1개씩 정의할 수 있어 파일명을 지정 가능하다. <pre>`$ kubectl exec -it sample-secret-single-volume cat /config/username.txt `</pre>
Secret 전체를 변수로 넘길 경우
`# secret_multi_volume_sample.yml apiVersion: v1 kind: Pod metadata: name: sample-secret-multi-volume spec: containers: - name: secret-container image: nginx:1.12 volumeMounts: - name: config-volume mountPath: /config volumes: - name: config-volume secret: secretName: sample-db-auth `
`$ kubectl exec -it sample-secret-multi-volume ls /config `
**동적 Secret 갱신** Volume Mount 으로 Secret 을 이용할 경우 일정 기간 주기 (kubelet 의 Sync Loop 의 타이밍) 로 kube-apiserver 에 변경을 확인해서 변경이 있을 경우 갱신한다. 기본적으로 SyncLoop의 간격은 60초로 설정되어 있으나 kuebelet 의 옵션 `—sync-frequency` 로 변경 가능하다. (이는 환경변수를 이요하는 경우에는 이용 불가 하다.) 이 경우 Volume 에 마운트 된 파일의 값이 바뀌어도 Pod 이 재생성 되는 것이 아니어서 끊기는 것을 걱정할 필요도 없다. Secret 에서 삭제된 것 역시 같이 삭제된다. ## ConfigMap ConfigMap 은 설정 정보 등을 Key-Value 로 보존할 수 있는 데이터를 저장하기 위한 resource. Key-Value 라고 해도 nginx.conf 나 httpd.conf 와 같은 설정 파일 그 자체도 보존가능하다. **create ConfigMap** Generic type Secret 과 거의 동일한 방법.
3가지 방법
파일을 사용 (—from-file)
yaml 파일을 사용
kubectl로 직접 생성 (—from-literal)
ConfigMap 에는 복수의 Key-Value 값이 들어간다. nginx.conf 전체를 ConfigMap 안에 넣거나 nginx.conf 의 설정 parameter만 넣어도 된다.
파일을 사용
파일을 사용할 경우. —from-file 을 지정한다. 보통 파일명이 그대로 Key 로 사용되며 Key명을 변경하고 싶을 경우, —from-file=nginx.conf=sample-nginx.conf 와 같은 형식으로 지정한다.
`# create ConfigMap $ kubectl create configmap sample-configmap --from-file=./nginx.conf # 확인 $ kubectl get configmap sample-configmap -o json | jq .data # describe $ kubectl describe configmap sample-configmap `
YAML 파일을 사용
Value 값이 길 경우, Key: | 처럼 정의
`apiVersion: v1 kind: ConfigMap metadata: name: sample-configmap data: thread: "16" connection.max: "100" connection.min: "10" sample.properties: | property.1=value-1 property.2=value-2 property.3=value-3 nginx.conf: | user nginx; worker_processes auto; error_log /var/log/nginx/error.log; pid /run/nginx.pid; ... `
kubectl 을 사용 (—from-literal)
`$ kubectl create configmap web-config \ --from-literal=connection.max=100 \ --from-literal=connection.min=10 `
ConfigMap 이용
환경변수
Volume mount
특정 Key
모든 Key
특정 Key
모든 Key
환경변수
특정 Key만 넘길 경우, spec.containers[].env 의 valueFrom.configMapKeyRef 를 사용
`# configmap_single_env_sample.yml apiVersion: v1 kind: Pod metadata: name: sample-configmap-single-env spec: containers: - name: configmap-container image: nginx:1.12 env: - name: CONNECTION_MAX valueFrom: configMapKeyRef: name: sample-configmap key: connection.max `
env 한개씩 정의가 가능해서 환경변수명을 지정 가능
모든 Key를 넘길 경우, 한개씩 정의할 필요가 없어 YAML 이 간략해지지만 YAML 만으로는 어떤 값이 있는지 판단하긴 힘들다
`# configmap_multi_env_sample.yml apiVersion: v1 kind: Pod metadata: name: sample-configmap-multi-env spec: containers: - name: configmap-container imgae: nginx:1.12 envFrom: - configMapRef: name: sample-configmap `
환경변수를 이용하는 경우, 다음과 같은 패턴은 표현할 수 없어 전달되지 않는다.
. 이 포함되는 경우
개행이 포함되는 경우. (Key. | 로 정의된 경우)
Volume Mount
특정 Key 만 넘길 경우, spec.volumes[] 의 configMap.items[] 를 사용한다.
`# configmap_single_volume_sample.yml apiVersion: v1 kind: Pod metadata: name: sample-configmap-single-volume spec: containers: - name: configmap-container image: nginx:1.12 volumeMounts: - name: config-volume mountPath: /config volumes: - name: config-volume configMap: name: sample-configmap items: - key: nginx.conf path: nginx-sample.conf `
mount 할 파일을 하나씩 정의하므로 파일명을 지정 가능하다. <pre>`$ kubectl exec -it sample-configmap-single-volume cat /config/nginx-sample.conf `</pre>
모든 Key 를 넘길 경우, YAML 이 간결해지지만 YAML 만으로는 어떤 값이 있는지 판단하기 힘들다.
`# configmap_multi_volume_sample.yml apiVersion: v1 kind: Pod metadata: name: sample-configmap-multi-volume spec: containers: - name: configmap-container image: nginx:1.12 volumeMounts: - name: config-volume mountPath: /config volumes: - name: config-volume configMap: name: sample-configmap `
`$ kubectl exec -it sample-configmap-multi-volume ls /config `
**동적 ConfigMap 갱신** volume mount 를 이용하는 경우, 일정시간 주기 (kubelet 의 Sync Loop 타이밍)로 kube-apiserver 에 변경을 확인해서, 변경이 있으면 갱신한다. SyncLoop 의 기본값은 60초로 설정되어 있으나 이를 변경하고 싶을 경우, kubelet 의 `—sync-frequency` 를 사용하여 설정한다. (환경 변수의 경우 동적 갱신이 불가) ## Volume 과 PersistentVolume, PersistentVolumeClaim 의 차이 Volume 은 기존의 Volume (host 영역, NFS, Ceph, GCP Volume) 등을 YAML Manifest 에 직접 지정하여 이용 가능하게 하는 것이다. 그래서 이용자가 신규로 Volume 을 작성하거나, 기존의 Volume 을 삭제하는 등의 조작이 불가능하다. 그리고 YAML Manifest 로 Volume resource 를 만드는 등의 처리도 불가능하다. PersistentVolume은 외부의 Persistent 한 Volume을 제공하는 시스템과 연계하여 신규 Volume 을 만들거나 기존의 Volume 을 삭제하는 것이 가능하다. 구체적으로는 YAML Manifest 등을 통해 Persistent Volume resource 를 별도 만드는 형식이다. PersistentVolume 의 plug-in 에서는 Volume 의 생성과 삭제와 같은 life cycle 을 처리하는 것이 가능하지만 Volume 의 plug-in 의 경우, 이미 있는 Volume 을 사용하는 것만 가능하다. PersistentVolumeClaim 은 PersistentVolume resource 에서 assign 하기 위한 resource. PersistentVolume은 cluster에 volume 을 등록하기만 하는거라, 실제로 Pod 에서 이용하기 위해서는 PersistentVolumeClaim 을 정의해야 한다. Dynamic Provisioning 기능을 이용할 경우, PersistentVolumeClaim을 이용하는 시점에 Persistent Volume 을 동적으로 생성하는 것이 가능해서 순서가 반대가 될 수 있다. ## Volume [Volume Plug-in](https://kubernetes.io/docs/concepts/storage/volumes/) PersistentVolume과 달리 Pod 에 대해 정적으로 영역을 지정하기 위한 형태가 되기 때문에 충돌(경쟁)에 주의 **EmptyDir**
Pod 의 일시적인 디스크 영역으로 이용 가능
Pod 이 Terminate 되면 삭제됨
`# emptydir-sample.yml apiVersion: v1 kind: Pod metadata: name: sample-emptydir spec: containers: - image: nginx:1.12 name: nginx-container volumeMounts: - mountPath: /cache name: cache-volume volumes: - name: cache-volume emptyDir: {} `
**HostPath**
Kubernetes Node 상의 영역을 container 에 mapping 하기 위한 plug-in.
type
Directory
DirectoryOrCreate
File
Socket
BlockDevice
`# hostpath-sample.yml apiVersion: v1 kind: Pod metadata: name: sample-hostpath spec: containers: - image: nginx:1.12 name: nginx-container volumeMounts: - mountPath: /srv name: hostpath-sample volumes: - name: hostpath-sample hostPath: path: /data type: DirectoryOrCreate `
## PersistentVolume (PV)
Volume 이 Pod 정의에 포함되었다면 PersistentVolume은 resource 로 별도로 작성
엄밀히 말하면 Config&Storage resource 보다 Cluster resource.
PersistentVolume 종류
기본적으로 network 를 이용해 disk attach 한다.
Persistent Volumes - Kubernetes
GCE Persistent Disk
AWS Elastic Block Store
NFS
iSCSI
Ceph
OpenStack Cinder
GlusterFS
create PersistentVolume
label
용량
access mode
reclaim policy
mount option
storage class
setting for each PersistentVolume
`# pv_sample.yml apiVersion: v1 kind: PersistentVolume metadata: name: sample-pv labels: type: nfs envrionment: stg spec: capacity: storage: 10G accessModes: - ReadWriteMany persistentVolumeReclaimPolicy: Retain storageClassName: slow mountOptions: - hard nfs: server: xxx.xxx.xxx.xxx path: /nfs/sample `
`$ kubectl get pv `
**Label** Dynamic Provisioining 을 사용하지 않고 PersistentVolume을 사용하는 경우, 종류가 알 수 없게 되기 쉬우니 type, environment, speed 등의 label 을 붙이는걸 추천한다. Label 을 붙이면 PersistentVolumeClaim 에서 Volume 의 Label 을 지정가능하여 scheduling 을 유난하게 수행할 수 있다. **용량** Dynamic Provisioning 을 이용할 수 없을 경우, 무작정 용량을 크게 잡아선 안 된다. 요구한 용량과 가장 가까운 용량을 가진 storage 가 사용되기 때문. **access mode**
ReadWriteOnce (RWO) : 단일 node 에서 Read / Write
ReadOnlyMany (ROX) : 단일 node 에서 Write, 복수 노드에서 Read
ReadWriteMany (RWX) : 복수 node 에서 Read / Write
Persistent Volumes - Kubernetes
Reclaim Policy
Persistent Volume 사용이 끝난 후 처리방법
Retain
Recycle
Delete
data 를 삭제하지 않고 보존
다른 PersistentVolumeClaim 으로 재 mount 되는 일은 없다
data 삭제 (rm -rf ./*), 재이용가능한 상태로
다른 PersistentVolumeClaim 에서 재 mount 가능
PersistentVolume 삭제
주로 외부 volume 을 사용할 때 사용
Mount Options
PersistentVolume 의 종류에 따라 상이. 확인.
Storage Class
Dynamic Provisioning 의 경우 사용자가 PersistentVolumeClaim 을 사용하여 PersistentVolume 을 요구할 때 원하는 디스크를 지정하기 위해 사용.
Storage Class 선택 = 외부 Volume 종류 선택
`#storageclass_sample.yml apiVersion: storage.k8s.io/v1 kind: StorageClass metadata: name: sample-storageclass parameters: availability: test-zone-la type: scaleio provisioner: kubernetes.io/cinder `
PersistentVolume plug-in 별 설정
실제로는 종류에 따라 제각가이라 확인 필요
PersistentVolumeClaim (PVC)
PersistemtVolumeClaim 에 지정된 조건을 가지고 요구하여 Scheduler 는 현재 보유하고 있는 PersistentVolume 에서 적합한 Volume 을 할당
PersistentVolumeClaim 설정
label selector
capacity
access mode
Storage Class
PVC 에서 요구하는 용량이 PV 용량보다 작으면 할당된다. 8기가를 요구 했는데 딱 맞는게 없고 그 보다 큰 20 기가가 있으면 20기가 를 할당.
NFS 의 경우 Quota 가 걸려 있지 않아 PV 의 용량이 사실상 무시된다.
create PersistentVolumeClaim
`# pvc_sample.yml apiVersion: v1 kind: PersistentVolumeClaim metadata: name: sample-pvc spec: selector: matchLabels: type: "nfs" matchExpressions: - {key: environment, operator: In, values: [stg]} accessModes: - ReadWriteOnce resources: requests: storage: 4Gi `
`$ kubectl get pvc $ kubectl get pv `
PVC 가 PV 확보에 실패하면 pending 상태가 유지된다.
Retain Policy 를 사용하고 있을 경우, Pod 이 종료되면 Bound 상태에서 Released 상태로 바뀐다. 이 Released 상태가 된 PV 는 PVC 가 재할당하지 않는다.
use in Pod
spec.volumes 의 persistentVolumeClaim.claimName 을 사용
`# pvc_pod_sample.yml apiVersion: v1 kind: Pod metadata: name: sample-pvc-pod spec: containers: - name: nginx-container image: nginx ports: - containerPort: 80 name: "http" volumeMounts: - mountPath: "/usr/share/nginx/html" name: nginx-pvc volumes: - name: nginx-pvc persistentVolumeClaim: className: sample-pvc `
Dynamic Provisioning
동적으로 PV 를 만들기 때문에 용량을 효율적으로 사용하는 것이 가능하고 사전에 PV 를 만들어 둘 필요가 없다.
많은 Provisioner 가 ReadWriteOnce 밖에 지원하지 않는 경우가 많다.
`# Storage Class # storageclass_sample.yml apiVersion: storage.k8s.io/v1 kind: StorageClass metadata: name: sample-storageclass parameters: type: pd-standard provisioner: kubernetes.io/gce-pd reclaimPolicy: Delete `
`# PVC # pvc_provisioner_sample.yml apiVersion: v1 kind: PersistentVolumeClaim metadata: name: sample-pvc-provisioner annotations: volume.beta.kubernetes.io/storage-class: sample-storageclass spec: accessModes: - ReadWriteOnce resources: requests: storage: 3Gi `
`# Pod # pvc_provisioner_pod_sample.yml apiVersion: v1 kind: Pod metadata: name: sample-pvc-provisioner-pod spec: containers: - name: nginx-container image: nginx prots: - containerPort: 80 name: "http" volumeMounts: - mountPath: "/usr/share/nginx/html" name: nginx-pvc volumes: - name: nginx-pvc persistentVolumeClaim: claimName: sample-pvc-provisioner `
`$ kubectl get pv `
PersistentVolumeClaim in StatefulSet
StatefulSet 에서는 PersistentVolumeClaim 을 이용할 경우가 많고spec.volumeClaimTemplate 을 이용하면 별도로 PVC 를 정의할 필요 없다.
`apiVersion: apps/v1beta1 kind: StatefulSet metadata: ... spec: template: spec: containers: - name: sample-pvct image: nginx:1.12 volumeMounts: - name: pvc-template-volume mountPath: /tmp volumeClaimTemplates: - matadata: name: pvc-template-volume spec: accessModes: - ReadWriteOnce resources: requests: storage: 10Gi storageClassName: "sample-storageclass"
0 notes
Text
By Isaac Kohen
Due to COVID-19, companies have found themselves in the middle of the world’s largest work-from-home experiment. Many hail remote work as a blessing, allowing employees to continue working while practicing social distancing during this uncertain time
Of course, even before coronavirus grabbed our attention, many companies were already adapting various telecommuting and remote work policies. A 2019 study by Owl Labs found that 16% of global companies were fully remote, and 40% were hybrid (companies who offer both remote and in-office options). There are good reasons why companies have been embracing the remote work culture. From boosting productivity, reducing the cost of operations, and enabling access to a larger talent pool, remote work has many benefits.
However, for all its advantages, remote work also presents many unique challenges. Companies must establish communication norms, address diminished productivity due to lack of supervision, and create systems for managing accountability, tracking projects, executing payroll, and prioritizing cybersecurity. Taken together, these hurdles pose a significant hindrance to fruitful remote work. Fortunately, with the right strategy and tools, you can effectively identify and address these issues to fully reap the benefits of a remote team.
For those enacting a rapid transition to digital work or even for veteran leaders of decentralized teams, here are five best practices to ensure that your operation runs smoothly.
#1 Adopt Remote Security Measures
Ensuring security, privacy, and data protection in a fully remote setup will be difficult. Traditional intrusion prevention systems, firewalls, and sandboxes are not enough now that employees are no longer under your corporate security perimeter. While VPNs are being advertised as a solution, they are not the quick fix that many companies expect them to be.
One workaround is an endpoint-based data loss prevention (eDLP) solution. It can monitor and protect your employees’ workstations instead of just the servers and nodes on your network. This has the benefit of preventing data leaks by mitigating risk at the user level, where the majority of cybersecurity threats occur.
Another approach that companies can take is to utilize virtual machines on Windows, VMware Horizon, AWS/Azure/GCP, or set up a Terminal Server for their remote team. With this arrangement, employees can then login to the server using RDP while continuing to protect the company’s sensitive network and repositories. This is particularly useful if you have third-party contractors or other external users you need to support.
#2 Implement a Communication Policy
Frequent and fluid communications are keys to a successful remote team. Zoom, Slack, Microsoft Teams, Google Hangout, Telegram, 8×8, WebEx, and Jabber all are useful tools. Many of them are offering free services for a limited time. In many cases, cell phone providers are also extending or removing the data cap.
However, due to increased demand, you may experience some limitations and disruptions. For example, Zoom recently removed the dial-in by phone audio conferencing capabilities from its Basic plan. Most recently, Microsoft Teams went down for over two hours because it was overloaded with activity. It’s a good idea to have a backup plan in case your default service fails.
Regardless of your brand preference, select one that has end-to-end encryption. If you want better protection, you can adapt a Data Loss Prevention (DLP), Content Monitoring and Filtering (CMF), or Extrusion Prevention System (EPS) solution. Many of these have real-time monitoring for email and IM/chat conversations to prevent sensitive data exfiltration over your communication channels.
#3 Utilize Team Collaboration Tools
Office 365, Google Apps, and other collaboration suites have built-in tools that allow employees to work together seamlessly. You can also use cloud drives to enable document sharing. When doing so, don’t forget to implement access control policies so that sensitive documents don’t get into the wrong hands.
Use project management tools for assigning team responsibilities, defining project priorities and tasks, and providing clear directions. This is critical for remote team collaborations. The right tools provide employee clock-ins, create and track projects and tasks in real-time, integrate with your support systems/PM systems, and many other useful features to improve team collaboration and engagement.
#4 Monitor Employee Engagement and Productivity
Remote workers can be highly productive. However, flexible and “always-on” hours can lead to a burnout culture that neither supports employee well being nor promotes company priorities. Therefore, establishing a consistent workflow that measures team performance is critical to ensuring that your team stays productive and doesn’t suffer alienation, burnout, or app-overload.
Specifically, a user and entity behavior analytics (UEBA) software can be utilized to track employee behavior for signs of stress or other abnormalities. Of course, companies should implement this software carefully because many employee monitoring and time tracking software solutions allow you to record screens. This can be demotivating and hamper productivity. Instead, focus on activity and outcomes to support both employees and employers.
#5 Manage Your Remote Team with (Special) Care
The truth is, many managers are not trained to manage remote employees. After all, traditional management practices focus on personalized interactions, body language, and other soft skills that do not translate well in a virtual world.
Remote employees also have unique needs that require special attention. For example, a survey conducted by Buffer found that remote workers struggle with unplugging from work, loneliness, and collaboration/communications. Make sure your managers are mindful of these social elements. It seems counterintuitive, but technology can help address many of these “human” challenges. Conducting daily one-to-ones, using video conferencing, organizing “shenanigans,” “watercooler,” or casual team time, ideas generation sessions (for example, using Mural for remote brainstorming and engagement), flexible scheduling – all are useful tips. The key is to invest in the extra effort and pay attention to your employees.
While painful, this could be the watershed moment for the work-from-home movement. By the time we reach the end of the COVID-19 pandemic, remote work will likely be even more normative than before. Companies should prepare now with a full understanding of the remote workflow, security, productivity, and monitoring tools so that they can manage decentralized teams at scale – for the future of remote work is already here.
Go to our website: www.ncmalliance.com
5 Remote Working Best Practices and Tips in the Era of the Coronavirus Pandemic By Isaac Kohen By Isaac Kohen Due to COVID-19, companies have found themselves in the middle of the world’s largest work-from-home experiment…
0 notes
Text
Top 5 Home Lab Storage Solutions in 2023
Top 5 Home Lab Storage Solutions in 2023 @vexpert #vmwarecommunities #homelab #100daysofhomelab #HomeLabStorage #HomeLab2023 #LocalStorageSolutions #TrueNASStorage #ProxmoxCeph #XCPngXOSAN #VMwarevSAN #NASServer #HomeServerSetup #VirtualMachinesStorage
When building a home lab solution, looking at the primary components of your home lab build includes considering your storage requirements. There are many options for building a home lab solution and storage considerations to be made. The great thing about building a home lab is you can build it according to your needs and the workloads you will be running. For many, starting with locally…

View On WordPress
#Home Lab 2023#Home Lab Storage#Home Server Setup#Local Storage Solutions#NAS Server#Proxmox Ceph#TrueNAS Storage#Virtual Machines Storage#VMware vSphere vSAN#XCP-ng XOSAN
0 notes
Text
In this video guide, we will be covering how you can deploy...
youtube
In this video guide, we will be covering how you can deploy Windows operating systems in Microsoft SCCM. Link to Step By Step Playlist: http://bit.ly/SCCMHomeLab This will cover all the fundamentals that are required for basic imaging in SCCM. Topics covered will include Boot Images (WinPE), Operating System Images (WIMs), Drivers, Driver Packages, PXE, and More! #Bibi #SCCM #WSUS #TOPTECH #SCCMCLIENT – More Videos – Vmware vSphere - How to build awesome vmware home lab with VMware vSphere 6.7 (ESXi & vCSA) 2019 https://youtu.be/TWUfvrsGl-U Windows Server 2016: Installing Active Directory Domain Controller, DHCP, DNS https://www.youtube.com/watch?v=8w_2vsYJRcQ Can You Still Upgrade To Windows 10 For Free 2019 https://youtu.be/b75N-gghEG0 How to fix Audio Sound problem not working on windows 10 https://youtu.be/pAa0SLIIB4E How to clean your computer - clear cache windows 10 (2019) https://youtu.be/GH27lV3_xlk How to download windows 10 Free | How to Create bootable usb 2019 https://youtu.be/ZDnRWgP3VsA Deploy SCCM Package: How to Create and Deploy SCCM Package https://youtu.be/sWEjpKQhTc0 How To Configure WSUS with SCCM https://youtu.be/ngkinxJzqyM How to Deploy and Manage Microsoft Patches For Windows via SCCM Step by step https://youtu.be/OIFcn8fC69o Deploy Software Updates SCCM setup Configure Automatic Deployment Rules ADR https://youtu.be/4Zza_kCah7U Configure SCCM Custom Client Settings - SCCM Training for Beginners Part 11 https://youtu.be/ueOj-ymJ640 Operating System Deployment via SCCM OSD Windows 10 https://www.youtube.com/watch?v=eA1Y26ACvwA&feature=youtu.be ** Bibi * I hope you find this “Operating System Deployment” video helpful and if you have any questions, please post them in the comment section and I will answer them. If you find this episode helpful, please click the LIKE button below the video; it would mean a lot to me. Operating System Deployment Please subscribe to my YouTube channel by visiting on the link below: https://www.youtube.com/c/TopTechHowTo?sub_confirmation=1 by Bibi Tech Videos
0 notes
Text
In this video guide, we will be covering how you can deploy...
youtube
In this video guide, we will be covering how you can deploy Windows operating systems in Microsoft SCCM. Link to Step By Step Playlist: http://bit.ly/SCCMHomeLab This will cover all the fundamentals that are required for basic imaging in SCCM. Topics covered will include Boot Images (WinPE), Operating System Images (WIMs), Drivers, Driver Packages, PXE, and More! #Bibi #SCCM #WSUS #TOPTECH #SCCMCLIENT – More Videos – Vmware vSphere - How to build awesome vmware home lab with VMware vSphere 6.7 (ESXi & vCSA) 2019 https://youtu.be/TWUfvrsGl-U Windows Server 2016: Installing Active Directory Domain Controller, DHCP, DNS https://www.youtube.com/watch?v=8w_2vsYJRcQ Can You Still Upgrade To Windows 10 For Free 2019 https://youtu.be/b75N-gghEG0 How to fix Audio Sound problem not working on windows 10 https://youtu.be/pAa0SLIIB4E How to clean your computer - clear cache windows 10 (2019) https://youtu.be/GH27lV3_xlk How to download windows 10 Free | How to Create bootable usb 2019 https://youtu.be/ZDnRWgP3VsA Deploy SCCM Package: How to Create and Deploy SCCM Package https://youtu.be/sWEjpKQhTc0 How To Configure WSUS with SCCM https://youtu.be/ngkinxJzqyM How to Deploy and Manage Microsoft Patches For Windows via SCCM Step by step https://youtu.be/OIFcn8fC69o Deploy Software Updates SCCM setup Configure Automatic Deployment Rules ADR https://youtu.be/4Zza_kCah7U Configure SCCM Custom Client Settings - SCCM Training for Beginners Part 11 https://youtu.be/ueOj-ymJ640 Operating System Deployment via SCCM OSD Windows 10 https://www.youtube.com/watch?v=eA1Y26ACvwA&feature=youtu.be ** Bibi * I hope you find this “Operating System Deployment” video helpful and if you have any questions, please post them in the comment section and I will answer them. If you find this episode helpful, please click the LIKE button below the video; it would mean a lot to me. Operating System Deployment Please subscribe to my YouTube channel by visiting on the link below: https://www.youtube.com/c/TopTechHowTo?sub_confirmation=1 by Bibi Tech Videos
0 notes
Video
youtube
In this video guide, we will be covering how you can deploy Windows operating systems in Microsoft SCCM. Link to Step By Step Playlist: http://bit.ly/SCCMHomeLab This will cover all the fundamentals that are required for basic imaging in SCCM. Topics covered will include Boot Images (WinPE), Operating System Images (WIMs), Drivers, Driver Packages, PXE, and More! #Bibi #SCCM #WSUS #TOPTECH #SCCMCLIENT -- More Videos -- Vmware vSphere - How to build awesome vmware home lab with VMware vSphere 6.7 (ESXi & vCSA) 2019 https://youtu.be/TWUfvrsGl-U Windows Server 2016: Installing Active Directory Domain Controller, DHCP, DNS https://www.youtube.com/watch?v=8w_2vsYJRcQ Can You Still Upgrade To Windows 10 For Free 2019 https://youtu.be/b75N-gghEG0 How to fix Audio Sound problem not working on windows 10 https://youtu.be/pAa0SLIIB4E How to clean your computer - clear cache windows 10 (2019) https://youtu.be/GH27lV3_xlk How to download windows 10 Free | How to Create bootable usb 2019 https://youtu.be/ZDnRWgP3VsA Deploy SCCM Package: How to Create and Deploy SCCM Package https://youtu.be/sWEjpKQhTc0 How To Configure WSUS with SCCM https://youtu.be/ngkinxJzqyM How to Deploy and Manage Microsoft Patches For Windows via SCCM Step by step https://youtu.be/OIFcn8fC69o Deploy Software Updates SCCM setup Configure Automatic Deployment Rules ADR https://youtu.be/4Zza_kCah7U Configure SCCM Custom Client Settings - SCCM Training for Beginners Part 11 https://youtu.be/ueOj-ymJ640 Operating System Deployment via SCCM OSD Windows 10 https://www.youtube.com/watch?v=eA1Y26ACvwA&feature=youtu.be ** Bibi * I hope you find this "Operating System Deployment" video helpful and if you have any questions, please post them in the comment section and I will answer them. If you find this episode helpful, please click the LIKE button below the video; it would mean a lot to me. Operating System Deployment Please subscribe to my YouTube channel by visiting on the link below: https://www.youtube.com/c/TopTechHowTo?sub_confirmation=1 by Bibi Tech Videos
0 notes
Video
youtube
Home Lab Setup - pfSense, VMware ESXi Cluster, DIY SAN and more! (2017) - https://youtu.be/pXfrfbw4LXQ
0 notes
Text
Powerful Desktop And Mobile Machines
Workstation
Engineered and built in Germany and Japan, CELSIUS workstations from Fujitsu help creativity, simulation, calculation and visualization at the highest specialist level. YOU WILL Require IVF Equipment AND IVF Consumables like,MAKLER COUNTING CHAMBER,AUTOMATIC SPERM ANALYSERS,Sperm Class Analyser,Coda Inline and Xtra Inline Filters,IVF Workstation,IVF Chamber,CO2 Mini Incubator,Portable CO2 Incubator,Craft Suction Pump,CO2 Incubator,IVF Controlled Price Freezer,micromanipulator firm,micromanipulator,Laser for PGD and Embryo Biopsy,Oocyte and Embryo Analysis Application,Oosight Imaging Program,glass Heating device for Microscopes,Heating Systems for microscopes,Anti-vibration Platform and Table,Modular Incubator Chamber,IUI Catheters,Embryo Transfer Catheters,Oocyte Collection Sets,Micropipettes for ICSI,ivf Pipettes,IVF Media for Assisted Reproduction,Seminal Collection Device,IVF Plasticware,Centrifuge and Spermfuge,Warming Plate and tray,Water Bath,Block Heater,Dry Bath,Transportable Test Tube Warmer,Mixer or Shaker,Adjustable Volume Pipettor and Tips,Pipette Pump,Cryogenic Equipment,Cord Blood,Stem Cell,Lab High quality Management etc.
youtube
HP and SOLIDWORKS announce the Ultimate SOLIDWORKS Bundle: SOLIDWORKS Premium + Z2 Mini, Big Efficiency at a modest value. Created for the most demanding workstation and server-class applications. The much more basic of the new HP Z Workstations is the only one to not support dual CPUs and its RAM caps at 256GB, though it nonetheless offers dual M.two slots for HP Z Turbo Drive PCIe SSDs and a decent performance increase from the earlier Z440. Researching laptop and desktop computers and software is essential to obtaining just the appropriate one for you and your family members. Nonetheless, the critical thing is that it is a fairly modern day Computer. Digital Audio Workstations usually don’t call for too a lot processing power, but do contemplate receiving a faster computer if achievable.
In short it can be mentioned that computer workstations are practically an essentiality for every office. Scan 3XS Pro Graphics workstations are created to provide the ultimate in overall performance, responsiveness and reliability. Nice post Scott, i may possibly just add the fact that you can use the gaming graphics card with the workstation video driver to get the best of both worlds. To update this series, HP now gives the ZBook 14 G2 These two new mobile workstations consist of newer dual core two.4 GHz Intel Core i7 Broadwell CPUs, 16GB of non-ECC 1600 RAM, and AMD FirePro M4150 GPUs with 1GB of committed RAM. Then along came the 32-bit NT Workstation editions – such as Windows NT Workstation 4. launched in 1996 The term Workstation fell away as Microsoft labelled its operating systems Server, Home, Pro, Enterprise, and so on.
But, if you need to have to check lots of disks on a regular basis and your time is useful then an option is a Difficult Drive Docking Station These comparatively new items are generally permanently connected to your Pc or Mac through USB and you then basically slot” or dock” the challenging drive into the docking station”. In an era of limitless world wide web access and smartphones, the mobile application is the easiest way to search for a holiday location. The security processor reported that the entry key is too big to fit in the trusted information shop. Keys for student offices can be picked up from John Baker , at the front desk in CERAS. If you can afford it, VMware Workstation is a single of the greatest virtualization applications out there.
Brooke M. Perry is an ardent technician related with Qresolve on the web tech assistance , with wide knowledge of fixing problems with PCs, laptops, tablets and smartphones. The new revised HP Z Series has a 2nd Generation Xeon Processor that permits for up to 16 cores in a single method. I am certainly honored to have had a part in the conservation of such a potent and magnificent species…but equally effective and magnificent has been the influence this project has had on so numerous folks more than the years, all more than the globe. Lenovo hails this model as the world’s initial multi-mode workstation, a single that manages to combine energy and creativity thanks to a 360-degree hinge that has, to some extent, set the common when it comes to convertible or 2-in-1 styles.
This model also has some configurations accessible with an larger efficiency GeForce GTX 965M which can be valuable if you are hunting into operating programs that demand a greater GPU such as Photoshop and Autocad. Moreover, a company overview, income share, and SWOT analysis of the top players in the Docking Station market place is obtainable in the report. We suggest employing a specialist graphics card from the NVIDIA Quadro variety. Mr. Coupal’s in depth knowledge and expertise enables him to fully analyze client systems to advocate the most efficient technologies and options that will both optimize their organization processes and fulfill instant and future ambitions. Evetech’s variety of Intel Core i9 Workstation PCs possesses the extraordinary energy of Intel’s most dominant enthusiast CPUs ever released.
With the HP Z238 Workstation, you will achieve peace of mind from our intense test and validation processes created for mission-vital environments. A lot of of these workplace cubicle setups consist of modular computer desks, modular desk walls, and desktop hutches. The B132L (introduced 1996 19 ), B160L, B132L+, B180L, C132L, C160L and C180L workstations are based on the PA-7300LC processor, a improvement of the PA-7100LC with integrated cache and GSC bus controller. As such, even though most processors come complete with a graphics unit, a separate graphics card is nevertheless the way to go. This allows for a fantastic FPS price, enabling for smooth transitions when rotating, panning, or zooming. I use a custom made workstation boasting dual six core Intel Xeon X5660, Sata 3 primary difficult drive 24 GB RAM and Nvidia Quadro 4000 graphic card plus 8TB hard drive mixture in Raid array.
On this page, we will only discuss the troubles with regards to some postures and ergonomically made computer components. Several professions that use engineering, animation, rendering of graphics, and mathematical plotting benefit drastically from a potent workstation. Configure with NVIDIA® Quadro® cards and accelerate your creativity with the world’s most potent workstation graphics. The 1st laptop mouse plan was conceived decades prior to folks began making use of their computers every single day at work and on the web when operate. After we have already reviewed 3 modern day ZBooks from HP ( 15u G3 , 15 G3 and Studio G3 ), we now have a closer look at the most significant model of the series, the ZBook 17 G3. You do not have to worry about the overall performance of this workstation, simply because the manufacturer has a clear focus on the functionality and not the thinnest building.
By picking Workstation Specialists you can be assured of a personal experience with ongoing right after sales support to assist you attain your organization prospective. With a Dual Core Xeon processor and up to 48GB RAM you can see why this machine became popular inside the inventive industry……However, the new HP Z Series offered in April is set to leading this. It’s equipped with dual Intel Xeon Bronze, Silver, Gold. The new point is the reality that these radio stations are stepping up their efforts and listeners look to be, nicely, listening. The zoom hardware allows the displayed video and graphics to be independently magnified in x and y by an integer value in between 1 and 16. Hardware zoom replicates pixels to acquire the preferred magnification and, as opposed to interpolated zoom, it can be supported in genuine time.
1. HP Remote Graphics Software program requires Windows and an net connection. The Workstation Refresh System is an Information Technology Baseline service for all state-funded and self-support units. Pc desks are often taken up by a lot of pieces of gear that you use and this can get in your way particularly at school. Keyboard workstations offer you with a higher palette for making original sounds and effects than other sorts of skilled keyboards. Workplace workstations are critical simply because they allow businesses to be a lot more effective in their usage of the workplace and have helped to reduce fees when leasing or buying the space necessary for their employees to perform. These days with much more and a lot more men and women are discovering the benefits of ergonomics.
Share CAD associated news, ask queries about CAD software, ask how to get into the business or show of your latest 3D model. This add-on is very useful, if you want to run a number of operating systems at the identical time on your laptop such as Windows 7, Chrome OS or the most current Linux. When it really is time to upgrade your method, be confident you happen to be up to speed on CPU, GPU, and RAM technologies. There are standard ones that just have a prime and an open storage space beneath while much more versatile ones have a surface area on leading, plus open or closed storage beneath, like some that have doors, drawers or both for keeping your items out of view. As opposed to the installation of industrial panel PCs, which can lead to key upheaval and disruption to supply chains, computer workstations for use in industrial settings do not require drastic alterations to computer software, processes and infrastructure.
The flagship Dell Precision 17 comes with a 4K UHD show, can tote 4TB of storage, and is offered with either i5, i7, or Xeon 7th generation processors and up to 64GB of memory. Access Intelligent gives distinctive, high-good quality, integrated hardware and software program packages that securely manage crucial data over wired and wireless networks, computer systems, Point-of-Sale devices, kiosks, and any other device that can accept and communicate through that guy smartcard technologies. Bottom Line: The Dell OptiPlex 7440 AIO is an excellent enterprise all-in-a single desktop with great overall performance, a lot of ports, and a 4K screen that gives you far more space to work. Still, if this device had been to have hit the market, it would have likely had the greatest camera of any tablet at the time.
from KelsusIT.com – Refurbished laptops, desktop computers , servers http://bit.ly/2vyDzrl via IFTTT
0 notes
Text
HowTo Install RHEVH VMware Workstation Home Lab Setup - Part-4
HowTo Install RHEVH VMware Workstation Home Lab Setup – Part-4
Most of the interested Administrators/Learners would like to practice at home using there own high configuration Workstations/Computers. Already virtualized environment do you want again enable for virtualization.? is it possible to do so, i say yes we can still do an virtualized virtual machine can be virtualized for installing RHEVH/Hyper-V/VMware ESX/ESXi. Using same method we are going to…
View On WordPress
0 notes
Text
Life after death for Apple's Xserve Some of our perusers still get use out of equipment Apple left behind.
Apple put the last nail in the Xserve's casket in January 2011 when it authoritatively quit offering rack-mounted servers. Rather, the organization began pushing server clients toward Mac Pros and Minis. On Sept. 20 of this current year, Apple brought down that pine box into the ground when macOS Sierra dropped programming support for the frameworks. And keeping in mind that Xserves running El Capitan will continue getting security refreshes for two or three years and the present form of the macOS Server programming still keeps running on El Capitan, the equipment will soon be totally covered.
For a couple of years after the Xserve's passing, the organization offered Mac Pro and Mac Mini Server designs (PDF) that could do a portion of similar things, however even those choices in the long run vanished. Despite the fact that Apple never offered genuine server-class equipment again, that doesn't mean the equipment isn't in any case out there doing its employment. In our Sierra audit we solicited those from you who are as yet utilizing Xserves to connect, and a lot of you did.
Why Xserve?
macOS Server began getting more straightforward not long after Apple stopped the Xserve. For huge numbers of those basic undertakings, a quad-center Mac Mini with two hard drives took care of business while protecting put away information ish. However, the Xserve's equipment had a couple of special things that Apple's repurposed buyer desktops couldn't replicate.The most conspicuous of those components is likely Lights Out Management (LOM), an equipment highlight that permitted heads to remotely screen temperature, fan speeds, and other sensor information. Servers are regularly kept in remote areas and not associated with screens, so having the capacity to keep an eye those numbers was profitable. But since LOM requires a different coprocessor, it was never added to the Mac Mini or Mac Pro servers.
Since virtualization rations control and rearranges server substitutions, redesigns, and organization, it turned into a well known approach to combine equipment around the turn of the decade. The Xserve's number of processor centers and vast banks of RAM made it a solid match for virtualization.
"We have five 2009 Xserves still being used, all running [VMWare] ESXi 6 as a bunch," composes Elizabeth Harvey-Forsythe, a senior frameworks design at the MIT Media Lab. "Need a Mac VM? It's generally uncommon contrasted with Linux around here, however some of our understudies do, and for that you require Apple equipment, and we have no place for anything we can't rackmount or that we can't put fiber channel and 10Gbps Ethernet cards inside."
Alex Clay, a product advancement chief at Suran Systems, utilizes a Xserve to virtualize Mavericks with the goal that he can virtualize Mac OS 9. It's an imaginative and convoluted arrangement that is by and by "a hell of significantly more solid and stable than swapping out 10 or more year-old equipment each time a HDD goes midsection up."
"In spite of the fact that it won't run Windows, shockingly, Xserves can really run VMWare ESXi impeccably," composed Nick Neely, another fulfilled Xserve client. "From that point I can run whatever working framework I need. At present, numerous occurrences of Windows Server 2012. Obscenity, I know."Firsthand unwavering quality, used costs
The Xserve's unwavering quality was specified by more than one individual. Which bodes well, since server equipment must be worked to be more strong and face more use than your standard customer PC. Mud specified that his shop at Suran Systems had effectively moved its generation servers to Mac Minis, yet adulated Xserves for being "monsters [that] kept running with almost no support required."
Neil Miller, a director at an advertisement organization with around two dozen Mac-driven clients, revealed to us that the "end is in sight" for his Xserve, however that "it's not here yet."
"Our Xserve still works, despite the fact that not each and every piece of it—no doubt restrictive drives/sleds, we're discussing you!" he kept in touch with Ars. "The Xserve is a ridiculously well-assembled bit of unit, and I'll be sorry to learn it go."
More than one individual who purchased Xserve equipment used for shoddy revealed to us that finding used parts to make fixes isn't excessively troublesome. Turns out that absolutely ending an item and radically improving the product that keeps running on it is a decent approach to make something drop in esteem.
"It's really simple to discover prior Xserve models on eBay for alongside nothing (under $100), in light of the fact that individuals assume that they're stuck running Lion on the things," composed Neely. "I'm running a Xserve 2.1 [the mid 2008 model] with double quad-center Xeons, and I got a better than average arrangement on it a year ago at $75." Though some of those more established Xserves were dropped much sooner than El Capitan and Sierra, Neely says "install[ing] an essential illustrations card and trick[ing] the installer into running as far as possible up to El Capitan" is moderately simple.
Furthermore, a couple of the Xserves still in operation are out there in light of the fact that the IT world is a moderate moving spot, where relocating starting with one stage then onto the next can be troublesome, expensive, and tedious.
"Despite everything I have four Xserve's underway," composed system director Dave Walsh. "Two are on the grounds that they haven't bombed yet, so I haven't moved DNS onto a more current Linux box. However, two are as yet online in light of the fact that regardless we utilize Network Homes, and that requires an OpenDirectory server to keep up."
"Organize Homes" were Apple's rendition of Windows' "Meandering User Profiles," and they're utilized for the most part to make bouncing starting with one PC then onto the next simpler. Sign into any of your concern's Macs with your system account and the Mac knows to look on the server for your client profile and documents rather than the neighborhood drive. Walsh says that his school has been pushing understudies and staff far from Network Homes in the course of the most recent couple of years, however the procedure isn't done yet.
"When I can place the last nail in the box of Network Homes," Walsh let us know, "then I can move full steam into Linux and a VM situation. Be that as it may, until then I'm stuck keeping up legacy gear."For fundamental system administrations like document sharing, DNS, or RADIUS verification, a lot of Linux-based choices can keep running off-the-rack server equipment. In those cases, chairmen have various choices with regards to supplanting both their Xserve equipment and the product they run, regardless of the possibility that that implies changing in accordance with another interface.
"We will probably run with a Dell, HP, or (my inclination) Lenovo rack mount server with 8-10 centers, 128GB RAM, and a couple TB of plate space," composed Ars peruser tmoldovan. "That is ordinarily in the area of $3-6000." He hopes to get approximately six years of utilization out of such a machine and would stack it with Windows Server before exchanging his virtualized servers over from the Xserve.
"We toyed with getting Mac Pros as VM hosts," he proceeded, "however they don't fit too perfectly in server racks, and with Apple surrendering/changing equipment without notice, it would be excessively of a hazard."
A few, similar to Harvey-Forsythe, will change their work processes enough so they can supplant their Macs with Linux or Windows servers.
"At the point when either the equipment kicks the bucket or ESXi essentially can't keep running on it we'll need to consider both the interest for virtual Macs and Apple's authorizing necessities in actuality at the time," she composes. "Interest for Mac VMs is genuinely low and, truly, I can't consider anything to date that somebody has asked for that, with some exertion, couldn't have been done similarly well with Linux or Windows. While some business programming is surely Mac-driven, very little is Mac-just anymore."For others, similar to James Roodhouse, the arrangement is to make a bounce to buyer review Mac equipment and manage without the Xserve's propelled equipment highlights. Roodhouse is an innovation organizer who right now utilizes a Xserve to convey modified OS pictures to around 1,100 Macs over numerous schools in various areas. He wants to supplant the crate with a few Mac Minis, notwithstanding worries about adaptation to internal failure and information repetition.
"The way ahead for my situation is most likely to convey the undertaking to Mac Minis with strong state stockpiling," he told Ars. "The Xserve was pleasant since it could deal with a RAID setup, had double power supplies, and could deal with all picture obligations from a solitary machine."
Mill operator additionally revealed to us that "an excess match of Mac Minis is likely the substitution" for his office's Xserve since macOS Server is as yet a solid match on the product side. Be that as it may, there's as yet a cost despite the fact that the Mac Mini is less expensive than the Xserve at any point was.
"Take note of that refreshing the peripherals from FireWire 800 to Thunderbolt/USB 3 will cost us more than the new Mac server equipment," he said.
Tragically, now that Apple has pretty much quit offering server arrangement of any of its machines, some server heads who need to run with new Macs are experiencing difficulty deciding.
"I would love to purchase another Mac, yet I can't legitimize it," composes Evan Walker, a bolster designer who at present uses a Xserve as a remote workstation, to virtualize past OS X renditions, to store iOS reinforcements, and to reserve programming refreshes. "The Mac Pros aren't exceptionally speaking to me, and the MacBook Pro line is quite recently so far obsolete processor-wise it doesn't bode well. The following Mac I'm probably going to purchase is a Mac Mini to make sure I can toss it in my rack and not stress over it. Be that as it may, and, after its all said and done I'm not very enthused about them."
"Apple truly needs to consider the endeavor condition more," Walker included.
0 notes