#Vector Databases and their Importance
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr has been banned in Indonesia for providing people with access to pornographic content.
Text
Understanding What are Vector Databases and their Importance
Summary: Vector databases manage high-dimensional data efficiently, using advanced indexing for fast similarity searches. They are essential for handling unstructured data and are widely used in applications like recommendation systems and NLP.

Introduction
Vector databases store and manage data as high-dimensional vectors, enabling efficient similarity searches and complex queries. They excel in handling unstructured data, such as images, text, and audio, by transforming them into numerical vectors for rapid retrieval and analysis.
In today's data-driven world, understanding vector databases is crucial because they power advanced technologies like recommendation systems, semantic search, and machine learning applications. This blog aims to clarify how vector databases work, their benefits, and their growing significance in modern data management and analysis.
Read Blog: Exploring Differences: Database vs Data Warehouse.
What are Vector Databases?
Vector databases are specialised databases designed to store and manage high-dimensional data. Unlike traditional databases that handle structured data, vector databases focus on representing data as vectors in a multidimensional space. This representation allows for efficient similarity searches and complex data retrieval operations, making them essential for unstructured or semi-structured data applications.
Key Features
Vector databases excel at managing high-dimensional data, which is crucial for tasks involving large feature sets or complex data representations. These databases can handle various applications, from image and text analysis to recommendation systems, by converting data into vector format.
One of the standout features of vector databases is their ability to perform similarity searches. They allow users to find items most similar to a given query vector, making them ideal for content-based search and personalisation applications.
To handle vast amounts of data, vector databases utilise advanced indexing mechanisms such as KD-trees and locality-sensitive hashing (LSH). These indexing techniques enhance search efficiency by quickly narrowing down the possible matches, thus optimising retrieval times and resource usage.
How Vector Databases Work

Understanding how vector databases function requires a closer look at their data representation, indexing mechanisms, and query processing methods. These components work together to enable efficient and accurate retrieval of high-dimensional data.
Data Representation
In vector databases, data is represented as vectors, which are arrays of numbers. Each vector encodes specific features of an item, such as the attributes of an image or the semantic meaning of a text.
For instance, in image search, each image might be transformed into a vector that captures its visual characteristics. Similarly, text documents are converted into vectors based on their semantic content. This vector representation allows the database to handle complex, high-dimensional data efficiently.
Indexing Mechanisms
Vector databases utilise various indexing techniques to speed up the search and retrieval processes. One common method is the KD-tree, which partitions the data space into regions, making it quicker to locate points of interest.
Another technique is Locality-Sensitive Hashing (LSH), which hashes vectors into buckets based on their proximity, allowing for rapid approximate nearest neighbor searches. These indexing methods help manage large datasets by reducing the number of comparisons needed during a query.
Query Processing
Query processing in vector databases focuses on similarity searches and nearest neighbor retrieval. When a query vector is submitted, the database uses the indexing structure to quickly find vectors that are close to the query vector.
This involves calculating distances or similarities between vectors, such as using Euclidean distance or cosine similarity. The database returns results based on the proximity of the vectors, allowing users to retrieve items that are most similar to the query, whether they are images, texts, or other data types.
By combining these techniques, vector databases offer powerful and efficient tools for managing and querying high-dimensional data.
Use Cases of Vector Databases

Vector databases excel in various practical applications by leveraging their ability to handle high-dimensional data efficiently. Here’s a look at some key use cases:
Recommendation Systems
Vector databases play a crucial role in recommendation systems by enabling personalised suggestions based on user preferences. By representing user profiles and items as vectors, these databases can quickly identify and recommend items similar to those previously interacted with. This method enhances user experience by providing highly relevant recommendations.
Image and Video Search
In visual search engines, vector databases facilitate quick and accurate image and video retrieval. By converting images and videos into vector representations, these databases can perform similarity searches, allowing users to find visually similar content. This is particularly useful in applications like reverse image search and content-based image retrieval.
Natural Language Processing
Vector databases are integral to natural language processing (NLP) tasks, such as semantic search and language models. They store vector embeddings of words, phrases, or documents, enabling systems to understand and process text based on semantic similarity. This capability improves the accuracy of search results and enhances language understanding in various applications.
Anomaly Detection
For anomaly detection, vector databases help in identifying outliers by comparing the vector representations of data points. By analysing deviations from typical patterns, these databases can detect unusual or unexpected data behavior, which is valuable for fraud detection, network security, and system health monitoring.
Benefits of Vector Databases
Vector databases offer several key advantages that make them invaluable for modern data management. They enhance both performance and adaptability, making them a preferred choice for many applications.
Efficiency: Vector databases significantly boost search speed and accuracy by leveraging advanced indexing techniques and optimised algorithms for similarity searches.
Scalability: These databases excel at handling large-scale data efficiently, ensuring that performance remains consistent even as data volumes grow.
Flexibility: They adapt well to various data types and queries, supporting diverse applications from image recognition to natural language processing.
Challenges and Considerations
Vector databases present unique challenges that can impact their effectiveness:
Complexity: Setting up and managing vector databases can be intricate, requiring specialised knowledge of vector indexing and data management techniques.
Data Quality: Ensuring high-quality data involves meticulous preprocessing and accurate vector representation, which can be challenging to achieve.
Performance: Optimising performance necessitates careful consideration of computational resources and tuning to handle large-scale data efficiently.
Addressing these challenges is crucial for leveraging the full potential of vector databases in real-world applications.
Future Trends and Developments
As vector databases continue to evolve, several exciting trends and technological advancements are shaping their future. These developments are expected to enhance their capabilities and broaden their applications.
Advancements in Vector Databases
One of the key trends is the integration of advanced machine learning algorithms with vector databases. This integration enhances the accuracy of similarity searches and improves the efficiency of indexing large datasets.
Additionally, the rise of distributed vector databases allows for more scalable solutions, handling enormous volumes of data with reduced latency. Innovations in hardware, such as GPUs and TPUs, also contribute to faster processing and real-time data analysis.
Potential Impact
These advancements are set to revolutionise various industries. In e-commerce, improved recommendation systems will offer more personalised user experiences, driving higher engagement and sales.
In healthcare, enhanced data retrieval capabilities will support better diagnostics and personalised treatments. Moreover, advancements in vector databases will enable more sophisticated AI and machine learning models, leading to breakthroughs in natural language processing and computer vision.
As these technologies mature, they will unlock new opportunities and applications across diverse sectors, significantly impacting how businesses and organisations leverage data.
Frequently Asked Questions
What are vector databases?
Vector databases store data as high-dimensional vectors, enabling efficient similarity searches and complex queries. They are ideal for handling unstructured data like images, text, and audio by transforming it into numerical vectors.
How do vector databases work?
Vector databases represent data as vectors and use advanced indexing techniques, like KD-trees and Locality-Sensitive Hashing (LSH), for fast similarity searches. They calculate distances between vectors to retrieve the most similar items.
What are the benefits of using vector databases?
Vector databases enhance search speed and accuracy with advanced indexing techniques. They are scalable, flexible, and effective for applications like recommendation systems, image search, and natural language processing.
Conclusion
Vector databases play a crucial role in managing and querying high-dimensional data. They excel in handling unstructured data types, such as images, text, and audio, by converting them into vectors.
Their advanced indexing techniques and efficient similarity searches make them indispensable for modern data applications, including recommendation systems and NLP. As technology evolves, vector databases will continue to enhance data management, driving innovations across various industries.
0 notes
Text
So, you want to make a TTRPG…

Image from Pexels.
I made a post a long while back about what advice you would give to new designers. My opinions have changed somewhat on what I think beginners should start with (I originally talked about probability) but I thought it might be useful to provide some resources for designers, new and established, that I've come across or been told about. Any additions to these in reblogs are much appreciated!
This is going to be a long post, so I'll continue beneath the cut.
SRDs
So, you have an idea for a type of game you want to play, and you've decided you want to make it yourself. Fantastic! The problem is, you're not sure where to start. That's where System Reference Documents (SRDs) can come in handy. There are a lot of games out there, and a lot of mechanical systems designed for those games. Using one of these as a basis can massively accelerate and smooth the process of designing your game. I came across a database of a bunch of SRDs (including the licenses you should adhere to when using them) a while back, I think from someone mentioning it on Tumblr or Discord.
SRDs Database
Probability
So, you have a basic system but want to tweak it to work better with the vision you have for the game. If you're using dice, this is where you might want to consider probability. Not every game needs this step, but it's worth checking that the numbers tell the story you're trying to tell with your game. For this, I'll link the site I did in that first post, AnyDice. It allows you to do a lot of mathematical calculations using dice, and see the probability distribution that results for each. There's documentation that explains how to use it, though it does take practice.
AnyDice
Playtesting
So you've written the rules of your game and want to playtest it but can't convince any of your friends to give it a try. Enter Quest Check. Quest Check is a website created by Trekiros for connecting potential playtesters to designers. I can't speak to how effective it is (I've yet to use it myself) but it's great that a resource like it exists. There's a video he made about the site, and the site can be found here:
Quest Check
Graphic Design and Art
Game is written and tested? You can publish it as-is, or you can make it look cool with graphics and design. This is by no means an essential step, but is useful if you want to get eyes on it. I've got a few links for this. First off, design principles:
Design Cheatsheet
Secondly, art. I would encourage budding designers to avoid AI imagery. You'll be surprised how good you can make your game look with only shapes and lines, even if you aren't confident in your own artistic ability. As another option, public domain art is plentiful, and is fairly easy to find! I've compiled a few links to compilations of public domain art sources here (be sure to check the filters to ensure it's public domain):
Public Domain Sources 1
Public Domain Sources 2
You can also make use of free stock image sites like Pexels or Pixabay (Pixabay can filter by vector graphics, but has recently become much more clogged with AI imagery, though you can filter out most of it, providing it's tagged correctly).
Pexels
Pixabay
Fonts
Turns out I've collected a lot of resources. When publishing, it's important to bear in mind what you use has to be licensed for commercial use if you plan to sell your game. One place this can slip through is fonts. Enter, my saviour (and eternal time sink), Google Fonts. The Open Font License (OFL) has minimal restrictions for what you can do with it, and most fonts here are available under it:
Google Fonts
Publishing
So, game is designed, written, and formatted. Publishing time! There are two places that I go to to publish my work: itch.io and DriveThruRPG. For beginners I would recommend itch - there's less hoops to jump through and you take a much better cut of what you sell your games for, but DriveThruRPG has its own merits (@theresattrpgforthat made great posts here and here for discovering games on each). Itch in particular has regular game jams to take part in to inspire new games. I'll link both sites:
itch.io
DriveThruRPG
Finally, a bunch of other links I wasn't sure where to put, along with a very brief summary of what they are.
Affinity Suite, the programs I use for all my layout and designing. Has an up-front cost to buy but no subscriptions, and has a month-long free trial for each.
Affinity Suite
A database of designers to be inspired by or work with. Bear in mind that people should be paid for their work and their time should be respected.
Designer Directory
An absolute behemoth list of resources for TTRPG creators:
Massive Resources List
A site to make mockups of products, should you decide to go that route:
Mockup Selection
A guide to making published documents accessible to those with visual impairments:
Visual Impairment Guidelines
A post from @theresattrpgforthat about newsletters:
Newsletter Post
Rascal News, a great place to hear about what's going on in the wider TTRPG world:
Rascal News
Lastly, two UK-specific links for those based here, like me:
A list of conventions in the UK & Ireland:
Convention List
A link to the UK Tabletop Industry Network (@uktabletopindustrynetwork) Discord where you can chat with fellow UK-based designers:
TIN Discord
That's all I've got! Feel free to reblog if you have more stuff people might find useful (I almost certainly will be)!
465 notes
·
View notes
Text
You shouldn't trust any site that asks you to turn off an adblocker. Not even "reputable" sites like Youtube.
That's because adblockers are an important safety tool for your browser, maybe the most important thing you can do to secure your web browser.
This is because of "Malvertising", one of the most common ways for malware to spread. This is because it is very easy for criminals to pay to place malware infected ads into the big online advertising networks, such as the one Google operates. This can place their malware on otherwise reputable sites who use these networks. And it's well-established you don't even need to click on the ad to get infected, both the wiki page linked above and this Wired article talks about it.
The ad networks have mechanisms for detecting such malvertising, but like antivirus in general, they are inherently limited. The programs can't flag malware that isn't already in their databases.
All the big advertising networks have problems with malvertising, including Google ads which have been infected many times.
The only good solution for the enduser is to block ads entirely in their browser. Ads are both annoying and a dangerous malware vector, not worth it at all.
Google now trying to block adblockers on Youtube and demanding that users turn them off is even more grotesque in light of this. It's like asking you to turn your firewall.
What to do
Ublock Origin is the most reputable adblocker. It doesn't just block ads, it also blocks non-advertising
Part of this is that unlike Adblock Plus or Brave Browser's built-in adblocker, Ublock actually blocks all ads it can and doesn't fund itself by taking bribes from advertisers to show users "acceptable ads."
I linked to the Firefox Addon page for Ublock origin above, because Ublock Origin works best on Firefox, which is the opinion of the Ublock Origin developers and they explain why in technical detail on the project's github page.
So stay safe online, use Ublock Origin and use it on Firefox so it works the best it can.
For youtube specifically, you need to keep your UBO filters updated and clear your chaches, there are threads on the official UBO subreddit with instructions and explanations.
27 notes
·
View notes
Text
Key Programming Languages Every Ethical Hacker Should Know
In the realm of cybersecurity, ethical hacking stands as a critical line of defense against cyber threats. Ethical hackers use their skills to identify vulnerabilities and prevent malicious attacks. To be effective in this role, a strong foundation in programming is essential. Certain programming languages are particularly valuable for ethical hackers, enabling them to develop tools, scripts, and exploits. This blog post explores the most important programming languages for ethical hackers and how these skills are integrated into various training programs.
Python: The Versatile Tool
Python is often considered the go-to language for ethical hackers due to its versatility and ease of use. It offers a wide range of libraries and frameworks that simplify tasks like scripting, automation, and data analysis. Python’s readability and broad community support make it a popular choice for developing custom security tools and performing various hacking tasks. Many top Ethical Hacking Course institutes incorporate Python into their curriculum because it allows students to quickly grasp the basics and apply their knowledge to real-world scenarios. In an Ethical Hacking Course, learning Python can significantly enhance your ability to automate tasks and write scripts for penetration testing. Its extensive libraries, such as Scapy for network analysis and Beautiful Soup for web scraping, can be crucial for ethical hacking projects.
JavaScript: The Web Scripting Language
JavaScript is indispensable for ethical hackers who focus on web security. It is the primary language used in web development and can be leveraged to understand and exploit vulnerabilities in web applications. By mastering JavaScript, ethical hackers can identify issues like Cross-Site Scripting (XSS) and develop techniques to mitigate such risks. An Ethical Hacking Course often covers JavaScript to help students comprehend how web applications work and how attackers can exploit JavaScript-based vulnerabilities. Understanding this language enables ethical hackers to perform more effective security assessments on websites and web applications.
Biggest Cyber Attacks in the World
youtube
C and C++: Low-Level Mastery
C and C++ are essential for ethical hackers who need to delve into low-level programming and system vulnerabilities. These languages are used to develop software and operating systems, making them crucial for understanding how exploits work at a fundamental level. Mastery of C and C++ can help ethical hackers identify and exploit buffer overflows, memory corruption, and other critical vulnerabilities. Courses at leading Ethical Hacking Course institutes frequently include C and C++ programming to provide a deep understanding of how software vulnerabilities can be exploited. Knowledge of these languages is often a prerequisite for advanced penetration testing and vulnerability analysis.
Bash Scripting: The Command-Line Interface
Bash scripting is a powerful tool for automating tasks on Unix-based systems. It allows ethical hackers to write scripts that perform complex sequences of commands, making it easier to conduct security audits and manage multiple tasks efficiently. Bash scripting is particularly useful for creating custom tools and automating repetitive tasks during penetration testing. An Ethical Hacking Course that offers job assistance often emphasizes the importance of Bash scripting, as it is a fundamental skill for many security roles. Being proficient in Bash can streamline workflows and improve efficiency when working with Linux-based systems and tools.
SQL: Database Security Insights
Structured Query Language (SQL) is essential for ethical hackers who need to assess and secure databases. SQL injection is a common attack vector used to exploit vulnerabilities in web applications that interact with databases. By understanding SQL, ethical hackers can identify and prevent SQL injection attacks and assess the security of database systems. Incorporating SQL into an Ethical Hacking Course can provide students with a comprehensive understanding of database security and vulnerability management. This knowledge is crucial for performing thorough security assessments and ensuring robust protection against database-related attacks.
Understanding Course Content and Fees
When choosing an Ethical Hacking Course, it’s important to consider how well the program covers essential programming languages. Courses offered by top Ethical Hacking Course institutes should provide practical, hands-on training in Python, JavaScript, C/C++, Bash scripting, and SQL. Additionally, the course fee can vary depending on the institute and the comprehensiveness of the program. Investing in a high-quality course that covers these programming languages and offers practical experience can significantly enhance your skills and employability in the cybersecurity field.
Certification and Career Advancement
Obtaining an Ethical Hacking Course certification can validate your expertise and improve your career prospects. Certifications from reputable institutes often include components related to the programming languages discussed above. For instance, certifications may test your ability to write scripts in Python or perform SQL injection attacks. By securing an Ethical Hacking Course certification, you demonstrate your proficiency in essential programming languages and your readiness to tackle complex security challenges. Mastering the right programming languages is crucial for anyone pursuing a career in ethical hacking. Python, JavaScript, C/C++, Bash scripting, and SQL each play a unique role in the ethical hacking landscape, providing the tools and knowledge needed to identify and address security vulnerabilities. By choosing a top Ethical Hacking Course institute that covers these languages and investing in a course that offers practical training and job assistance, you can position yourself for success in this dynamic field. With the right skills and certification, you’ll be well-equipped to tackle the evolving challenges of cybersecurity and contribute to protecting critical digital assets.
3 notes
·
View notes
Text

WIP: Stickers!
I shared these on discord a few times, but I've been working hard on making these stickers! :)
How they're made:



First, I draw them by hand. They don't have to look perfect yet since this is simply the concept phase, but the it does give me a good reference to work from.
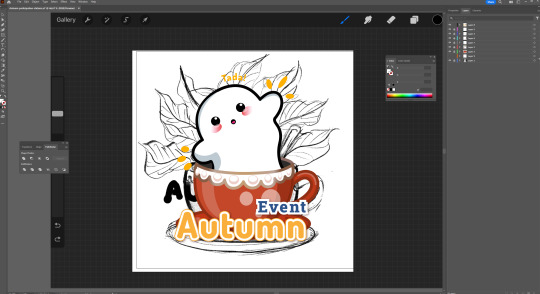
I then trace the important parts of the drawing as a vector, and then from here either change the shape a bit and add/remove what needs doing.
I also then add the text :)
After that, it's just a matter of modifying the code to trigger giving people a sticker when they reached the milestone and adding the sticker to the database!
What stickers am I currently making:
Currently, I got this on my list:
First Upload!
5 Uploads!
10 Uploads!
25 Uploads!
50 Uploads!
75 Uploads!
100 Uploads!
First Story!
First Tutorial!
First Showcase!
First Lookbook!
First Userpost!
Finished a Story! (When set to completed)
If you got some more suggestions, let me know! :)
Are they just going to be stickers on a page?
I'm hoping to later make that a cool "donation" gift. That way, you get a cool sticker and it also helps keeping the site up and running! :)
7 notes
·
View notes
Text
UNLOCKING THE POWER OF AI WITH EASYLIBPAL 2/2

EXPANDED COMPONENTS AND DETAILS OF EASYLIBPAL:
1. Easylibpal Class: The core component of the library, responsible for handling algorithm selection, model fitting, and prediction generation
2. Algorithm Selection and Support:
Supports classic AI algorithms such as Linear Regression, Logistic Regression, Support Vector Machine (SVM), Naive Bayes, and K-Nearest Neighbors (K-NN).
and
- Decision Trees
- Random Forest
- AdaBoost
- Gradient Boosting
3. Integration with Popular Libraries: Seamless integration with essential Python libraries like NumPy, Pandas, Matplotlib, and Scikit-learn for enhanced functionality.
4. Data Handling:
- DataLoader class for importing and preprocessing data from various formats (CSV, JSON, SQL databases).
- DataTransformer class for feature scaling, normalization, and encoding categorical variables.
- Includes functions for loading and preprocessing datasets to prepare them for training and testing.
- `FeatureSelector` class: Provides methods for feature selection and dimensionality reduction.
5. Model Evaluation:
- Evaluator class to assess model performance using metrics like accuracy, precision, recall, F1-score, and ROC-AUC.
- Methods for generating confusion matrices and classification reports.
6. Model Training: Contains methods for fitting the selected algorithm with the training data.
- `fit` method: Trains the selected algorithm on the provided training data.
7. Prediction Generation: Allows users to make predictions using the trained model on new data.
- `predict` method: Makes predictions using the trained model on new data.
- `predict_proba` method: Returns the predicted probabilities for classification tasks.
8. Model Evaluation:
- `Evaluator` class: Assesses model performance using various metrics (e.g., accuracy, precision, recall, F1-score, ROC-AUC).
- `cross_validate` method: Performs cross-validation to evaluate the model's performance.
- `confusion_matrix` method: Generates a confusion matrix for classification tasks.
- `classification_report` method: Provides a detailed classification report.
9. Hyperparameter Tuning:
- Tuner class that uses techniques likes Grid Search and Random Search for hyperparameter optimization.
10. Visualization:
- Integration with Matplotlib and Seaborn for generating plots to analyze model performance and data characteristics.
- Visualization support: Enables users to visualize data, model performance, and predictions using plotting functionalities.
- `Visualizer` class: Integrates with Matplotlib and Seaborn to generate plots for model performance analysis and data visualization.
- `plot_confusion_matrix` method: Visualizes the confusion matrix.
- `plot_roc_curve` method: Plots the Receiver Operating Characteristic (ROC) curve.
- `plot_feature_importance` method: Visualizes feature importance for applicable algorithms.
11. Utility Functions:
- Functions for saving and loading trained models.
- Logging functionalities to track the model training and prediction processes.
- `save_model` method: Saves the trained model to a file.
- `load_model` method: Loads a previously trained model from a file.
- `set_logger` method: Configures logging functionality for tracking model training and prediction processes.
12. User-Friendly Interface: Provides a simplified and intuitive interface for users to interact with and apply classic AI algorithms without extensive knowledge or configuration.
13.. Error Handling: Incorporates mechanisms to handle invalid inputs, errors during training, and other potential issues during algorithm usage.
- Custom exception classes for handling specific errors and providing informative error messages to users.
14. Documentation: Comprehensive documentation to guide users on how to use Easylibpal effectively and efficiently
- Comprehensive documentation explaining the usage and functionality of each component.
- Example scripts demonstrating how to use Easylibpal for various AI tasks and datasets.
15. Testing Suite:
- Unit tests for each component to ensure code reliability and maintainability.
- Integration tests to verify the smooth interaction between different components.
IMPLEMENTATION EXAMPLE WITH ADDITIONAL FEATURES:
Here is an example of how the expanded Easylibpal library could be structured and used:
```python
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from easylibpal import Easylibpal, DataLoader, Evaluator, Tuner
# Example DataLoader
class DataLoader:
def load_data(self, filepath, file_type='csv'):
if file_type == 'csv':
return pd.read_csv(filepath)
else:
raise ValueError("Unsupported file type provided.")
# Example Evaluator
class Evaluator:
def evaluate(self, model, X_test, y_test):
predictions = model.predict(X_test)
accuracy = np.mean(predictions == y_test)
return {'accuracy': accuracy}
# Example usage of Easylibpal with DataLoader and Evaluator
if __name__ == "__main__":
# Load and prepare the data
data_loader = DataLoader()
data = data_loader.load_data('path/to/your/data.csv')
X = data.iloc[:, :-1]
y = data.iloc[:, -1]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Scale features
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# Initialize Easylibpal with the desired algorithm
model = Easylibpal('Random Forest')
model.fit(X_train_scaled, y_train)
# Evaluate the model
evaluator = Evaluator()
results = evaluator.evaluate(model, X_test_scaled, y_test)
print(f"Model Accuracy: {results['accuracy']}")
# Optional: Use Tuner for hyperparameter optimization
tuner = Tuner(model, param_grid={'n_estimators': [100, 200], 'max_depth': [10, 20, 30]})
best_params = tuner.optimize(X_train_scaled, y_train)
print(f"Best Parameters: {best_params}")
```
This example demonstrates the structured approach to using Easylibpal with enhanced data handling, model evaluation, and optional hyperparameter tuning. The library empowers users to handle real-world datasets, apply various machine learning algorithms, and evaluate their performance with ease, making it an invaluable tool for developers and data scientists aiming to implement AI solutions efficiently.
Easylibpal is dedicated to making the latest AI technology accessible to everyone, regardless of their background or expertise. Our platform simplifies the process of selecting and implementing classic AI algorithms, enabling users across various industries to harness the power of artificial intelligence with ease. By democratizing access to AI, we aim to accelerate innovation and empower users to achieve their goals with confidence. Easylibpal's approach involves a democratization framework that reduces entry barriers, lowers the cost of building AI solutions, and speeds up the adoption of AI in both academic and business settings.
Below are examples showcasing how each main component of the Easylibpal library could be implemented and used in practice to provide a user-friendly interface for utilizing classic AI algorithms.
1. Core Components
Easylibpal Class Example:
```python
class Easylibpal:
def __init__(self, algorithm):
self.algorithm = algorithm
self.model = None
def fit(self, X, y):
# Simplified example: Instantiate and train a model based on the selected algorithm
if self.algorithm == 'Linear Regression':
from sklearn.linear_model import LinearRegression
self.model = LinearRegression()
elif self.algorithm == 'Random Forest':
from sklearn.ensemble import RandomForestClassifier
self.model = RandomForestClassifier()
self.model.fit(X, y)
def predict(self, X):
return self.model.predict(X)
```
2. Data Handling
DataLoader Class Example:
```python
class DataLoader:
def load_data(self, filepath, file_type='csv'):
if file_type == 'csv':
import pandas as pd
return pd.read_csv(filepath)
else:
raise ValueError("Unsupported file type provided.")
```
3. Model Evaluation
Evaluator Class Example:
```python
from sklearn.metrics import accuracy_score, classification_report
class Evaluator:
def evaluate(self, model, X_test, y_test):
predictions = model.predict(X_test)
accuracy = accuracy_score(y_test, predictions)
report = classification_report(y_test, predictions)
return {'accuracy': accuracy, 'report': report}
```
4. Hyperparameter Tuning
Tuner Class Example:
```python
from sklearn.model_selection import GridSearchCV
class Tuner:
def __init__(self, model, param_grid):
self.model = model
self.param_grid = param_grid
def optimize(self, X, y):
grid_search = GridSearchCV(self.model, self.param_grid, cv=5)
grid_search.fit(X, y)
return grid_search.best_params_
```
5. Visualization
Visualizer Class Example:
```python
import matplotlib.pyplot as plt
class Visualizer:
def plot_confusion_matrix(self, cm, classes, normalize=False, title='Confusion matrix'):
plt.imshow(cm, interpolation='nearest', cmap=plt.cm.Blues)
plt.title(title)
plt.colorbar()
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes, rotation=45)
plt.yticks(tick_marks, classes)
plt.ylabel('True label')
plt.xlabel('Predicted label')
plt.show()
```
6. Utility Functions
Save and Load Model Example:
```python
import joblib
def save_model(model, filename):
joblib.dump(model, filename)
def load_model(filename):
return joblib.load(filename)
```
7. Example Usage Script
Using Easylibpal in a Script:
```python
# Assuming Easylibpal and other classes have been imported
data_loader = DataLoader()
data = data_loader.load_data('data.csv')
X = data.drop('Target', axis=1)
y = data['Target']
model = Easylibpal('Random Forest')
model.fit(X, y)
evaluator = Evaluator()
results = evaluator.evaluate(model, X, y)
print("Accuracy:", results['accuracy'])
print("Report:", results['report'])
visualizer = Visualizer()
visualizer.plot_confusion_matrix(results['cm'], classes=['Class1', 'Class2'])
save_model(model, 'trained_model.pkl')
loaded_model = load_model('trained_model.pkl')
```
These examples illustrate the practical implementation and use of the Easylibpal library components, aiming to simplify the application of AI algorithms for users with varying levels of expertise in machine learning.
EASYLIBPAL IMPLEMENTATION:
Step 1: Define the Problem
First, we need to define the problem we want to solve. For this POC, let's assume we want to predict house prices based on various features like the number of bedrooms, square footage, and location.
Step 2: Choose an Appropriate Algorithm
Given our problem, a supervised learning algorithm like linear regression would be suitable. We'll use Scikit-learn, a popular library for machine learning in Python, to implement this algorithm.
Step 3: Prepare Your Data
We'll use Pandas to load and prepare our dataset. This involves cleaning the data, handling missing values, and splitting the dataset into training and testing sets.
Step 4: Implement the Algorithm
Now, we'll use Scikit-learn to implement the linear regression algorithm. We'll train the model on our training data and then test its performance on the testing data.
Step 5: Evaluate the Model
Finally, we'll evaluate the performance of our model using metrics like Mean Squared Error (MSE) and R-squared.
Python Code POC
```python
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error, r2_score
# Load the dataset
data = pd.read_csv('house_prices.csv')
# Prepare the data
X = data'bedrooms', 'square_footage', 'location'
y = data['price']
# Split the data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Create and train the model
model = LinearRegression()
model.fit(X_train, y_train)
# Make predictions
predictions = model.predict(X_test)
# Evaluate the model
mse = mean_squared_error(y_test, predictions)
r2 = r2_score(y_test, predictions)
print(f'Mean Squared Error: {mse}')
print(f'R-squared: {r2}')
```
Below is an implementation, Easylibpal provides a simple interface to instantiate and utilize classic AI algorithms such as Linear Regression, Logistic Regression, SVM, Naive Bayes, and K-NN. Users can easily create an instance of Easylibpal with their desired algorithm, fit the model with training data, and make predictions, all with minimal code and hassle. This demonstrates the power of Easylibpal in simplifying the integration of AI algorithms for various tasks.
```python
# Import necessary libraries
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.naive_bayes import GaussianNB
from sklearn.neighbors import KNeighborsClassifier
class Easylibpal:
def __init__(self, algorithm):
self.algorithm = algorithm
def fit(self, X, y):
if self.algorithm == 'Linear Regression':
self.model = LinearRegression()
elif self.algorithm == 'Logistic Regression':
self.model = LogisticRegression()
elif self.algorithm == 'SVM':
self.model = SVC()
elif self.algorithm == 'Naive Bayes':
self.model = GaussianNB()
elif self.algorithm == 'K-NN':
self.model = KNeighborsClassifier()
else:
raise ValueError("Invalid algorithm specified.")
self.model.fit(X, y)
def predict(self, X):
return self.model.predict(X)
# Example usage:
# Initialize Easylibpal with the desired algorithm
easy_algo = Easylibpal('Linear Regression')
# Generate some sample data
X = np.array([[1], [2], [3], [4]])
y = np.array([2, 4, 6, 8])
# Fit the model
easy_algo.fit(X, y)
# Make predictions
predictions = easy_algo.predict(X)
# Plot the results
plt.scatter(X, y)
plt.plot(X, predictions, color='red')
plt.title('Linear Regression with Easylibpal')
plt.xlabel('X')
plt.ylabel('y')
plt.show()
```
Easylibpal is an innovative Python library designed to simplify the integration and use of classic AI algorithms in a user-friendly manner. It aims to bridge the gap between the complexity of AI libraries and the ease of use, making it accessible for developers and data scientists alike. Easylibpal abstracts the underlying complexity of each algorithm, providing a unified interface that allows users to apply these algorithms with minimal configuration and understanding of the underlying mechanisms.
ENHANCED DATASET HANDLING
Easylibpal should be able to handle datasets more efficiently. This includes loading datasets from various sources (e.g., CSV files, databases), preprocessing data (e.g., normalization, handling missing values), and splitting data into training and testing sets.
```python
import os
from sklearn.model_selection import train_test_split
class Easylibpal:
# Existing code...
def load_dataset(self, filepath):
"""Loads a dataset from a CSV file."""
if not os.path.exists(filepath):
raise FileNotFoundError("Dataset file not found.")
return pd.read_csv(filepath)
def preprocess_data(self, dataset):
"""Preprocesses the dataset."""
# Implement data preprocessing steps here
return dataset
def split_data(self, X, y, test_size=0.2):
"""Splits the dataset into training and testing sets."""
return train_test_split(X, y, test_size=test_size)
```
Additional Algorithms
Easylibpal should support a wider range of algorithms. This includes decision trees, random forests, and gradient boosting machines.
```python
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import GradientBoostingClassifier
class Easylibpal:
# Existing code...
def fit(self, X, y):
# Existing code...
elif self.algorithm == 'Decision Tree':
self.model = DecisionTreeClassifier()
elif self.algorithm == 'Random Forest':
self.model = RandomForestClassifier()
elif self.algorithm == 'Gradient Boosting':
self.model = GradientBoostingClassifier()
# Add more algorithms as needed
```
User-Friendly Features
To make Easylibpal even more user-friendly, consider adding features like:
- Automatic hyperparameter tuning: Implementing a simple interface for hyperparameter tuning using GridSearchCV or RandomizedSearchCV.
- Model evaluation metrics: Providing easy access to common evaluation metrics like accuracy, precision, recall, and F1 score.
- Visualization tools: Adding methods for plotting model performance, confusion matrices, and feature importance.
```python
from sklearn.metrics import accuracy_score, classification_report
from sklearn.model_selection import GridSearchCV
class Easylibpal:
# Existing code...
def evaluate_model(self, X_test, y_test):
"""Evaluates the model using accuracy and classification report."""
y_pred = self.predict(X_test)
print("Accuracy:", accuracy_score(y_test, y_pred))
print(classification_report(y_test, y_pred))
def tune_hyperparameters(self, X, y, param_grid):
"""Tunes the model's hyperparameters using GridSearchCV."""
grid_search = GridSearchCV(self.model, param_grid, cv=5)
grid_search.fit(X, y)
self.model = grid_search.best_estimator_
```
Easylibpal leverages the power of Python and its rich ecosystem of AI and machine learning libraries, such as scikit-learn, to implement the classic algorithms. It provides a high-level API that abstracts the specifics of each algorithm, allowing users to focus on the problem at hand rather than the intricacies of the algorithm.
Python Code Snippets for Easylibpal
Below are Python code snippets demonstrating the use of Easylibpal with classic AI algorithms. Each snippet demonstrates how to use Easylibpal to apply a specific algorithm to a dataset.
# Linear Regression
```python
from Easylibpal import Easylibpal
# Initialize Easylibpal with a dataset
Easylibpal = Easylibpal(dataset='your_dataset.csv')
# Apply Linear Regression
result = Easylibpal.apply_algorithm('linear_regression', target_column='target')
# Print the result
print(result)
```
# Logistic Regression
```python
from Easylibpal import Easylibpal
# Initialize Easylibpal with a dataset
Easylibpal = Easylibpal(dataset='your_dataset.csv')
# Apply Logistic Regression
result = Easylibpal.apply_algorithm('logistic_regression', target_column='target')
# Print the result
print(result)
```
# Support Vector Machines (SVM)
```python
from Easylibpal import Easylibpal
# Initialize Easylibpal with a dataset
Easylibpal = Easylibpal(dataset='your_dataset.csv')
# Apply SVM
result = Easylibpal.apply_algorithm('svm', target_column='target')
# Print the result
print(result)
```
# Naive Bayes
```python
from Easylibpal import Easylibpal
# Initialize Easylibpal with a dataset
Easylibpal = Easylibpal(dataset='your_dataset.csv')
# Apply Naive Bayes
result = Easylibpal.apply_algorithm('naive_bayes', target_column='target')
# Print the result
print(result)
```
# K-Nearest Neighbors (K-NN)
```python
from Easylibpal import Easylibpal
# Initialize Easylibpal with a dataset
Easylibpal = Easylibpal(dataset='your_dataset.csv')
# Apply K-NN
result = Easylibpal.apply_algorithm('knn', target_column='target')
# Print the result
print(result)
```
ABSTRACTION AND ESSENTIAL COMPLEXITY
- Essential Complexity: This refers to the inherent complexity of the problem domain, which cannot be reduced regardless of the programming language or framework used. It includes the logic and algorithm needed to solve the problem. For example, the essential complexity of sorting a list remains the same across different programming languages.
- Accidental Complexity: This is the complexity introduced by the choice of programming language, framework, or libraries. It can be reduced or eliminated through abstraction. For instance, using a high-level API in Python can hide the complexity of lower-level operations, making the code more readable and maintainable.
HOW EASYLIBPAL ABSTRACTS COMPLEXITY
Easylibpal aims to reduce accidental complexity by providing a high-level API that encapsulates the details of each classic AI algorithm. This abstraction allows users to apply these algorithms without needing to understand the underlying mechanisms or the specifics of the algorithm's implementation.
- Simplified Interface: Easylibpal offers a unified interface for applying various algorithms, such as Linear Regression, Logistic Regression, SVM, Naive Bayes, and K-NN. This interface abstracts the complexity of each algorithm, making it easier for users to apply them to their datasets.
- Runtime Fusion: By evaluating sub-expressions and sharing them across multiple terms, Easylibpal can optimize the execution of algorithms. This approach, similar to runtime fusion in abstract algorithms, allows for efficient computation without duplicating work, thereby reducing the computational complexity.
- Focus on Essential Complexity: While Easylibpal abstracts away the accidental complexity; it ensures that the essential complexity of the problem domain remains at the forefront. This means that while the implementation details are hidden, the core logic and algorithmic approach are still accessible and understandable to the user.
To implement Easylibpal, one would need to create a Python class that encapsulates the functionality of each classic AI algorithm. This class would provide methods for loading datasets, preprocessing data, and applying the algorithm with minimal configuration required from the user. The implementation would leverage existing libraries like scikit-learn for the actual algorithmic computations, abstracting away the complexity of these libraries.
Here's a conceptual example of how the Easylibpal class might be structured for applying a Linear Regression algorithm:
```python
class Easylibpal:
def __init__(self, dataset):
self.dataset = dataset
# Load and preprocess the dataset
def apply_linear_regression(self, target_column):
# Abstracted implementation of Linear Regression
# This method would internally use scikit-learn or another library
# to perform the actual computation, abstracting the complexity
pass
# Usage
Easylibpal = Easylibpal(dataset='your_dataset.csv')
result = Easylibpal.apply_linear_regression(target_column='target')
```
This example demonstrates the concept of Easylibpal by abstracting the complexity of applying a Linear Regression algorithm. The actual implementation would need to include the specifics of loading the dataset, preprocessing it, and applying the algorithm using an underlying library like scikit-learn.
Easylibpal abstracts the complexity of classic AI algorithms by providing a simplified interface that hides the intricacies of each algorithm's implementation. This abstraction allows users to apply these algorithms with minimal configuration and understanding of the underlying mechanisms. Here are examples of specific algorithms that Easylibpal abstracts:
To implement Easylibpal, one would need to create a Python class that encapsulates the functionality of each classic AI algorithm. This class would provide methods for loading datasets, preprocessing data, and applying the algorithm with minimal configuration required from the user. The implementation would leverage existing libraries like scikit-learn for the actual algorithmic computations, abstracting away the complexity of these libraries.
Here's a conceptual example of how the Easylibpal class might be structured for applying a Linear Regression algorithm:
```python
class Easylibpal:
def __init__(self, dataset):
self.dataset = dataset
# Load and preprocess the dataset
def apply_linear_regression(self, target_column):
# Abstracted implementation of Linear Regression
# This method would internally use scikit-learn or another library
# to perform the actual computation, abstracting the complexity
pass
# Usage
Easylibpal = Easylibpal(dataset='your_dataset.csv')
result = Easylibpal.apply_linear_regression(target_column='target')
```
This example demonstrates the concept of Easylibpal by abstracting the complexity of applying a Linear Regression algorithm. The actual implementation would need to include the specifics of loading the dataset, preprocessing it, and applying the algorithm using an underlying library like scikit-learn.
Easylibpal abstracts the complexity of feature selection for classic AI algorithms by providing a simplified interface that automates the process of selecting the most relevant features for each algorithm. This abstraction is crucial because feature selection is a critical step in machine learning that can significantly impact the performance of a model. Here's how Easylibpal handles feature selection for the mentioned algorithms:
To implement feature selection in Easylibpal, one could use scikit-learn's `SelectKBest` or `RFE` classes for feature selection based on statistical tests or model coefficients. Here's a conceptual example of how feature selection might be integrated into the Easylibpal class for Linear Regression:
```python
from sklearn.feature_selection import SelectKBest, f_regression
from sklearn.linear_model import LinearRegression
class Easylibpal:
def __init__(self, dataset):
self.dataset = dataset
# Load and preprocess the dataset
def apply_linear_regression(self, target_column):
# Feature selection using SelectKBest
selector = SelectKBest(score_func=f_regression, k=10)
X_new = selector.fit_transform(self.dataset.drop(target_column, axis=1), self.dataset[target_column])
# Train Linear Regression model
model = LinearRegression()
model.fit(X_new, self.dataset[target_column])
# Return the trained model
return model
# Usage
Easylibpal = Easylibpal(dataset='your_dataset.csv')
model = Easylibpal.apply_linear_regression(target_column='target')
```
This example demonstrates how Easylibpal abstracts the complexity of feature selection for Linear Regression by using scikit-learn's `SelectKBest` to select the top 10 features based on their statistical significance in predicting the target variable. The actual implementation would need to adapt this approach for each algorithm, considering the specific characteristics and requirements of each algorithm.
To implement feature selection in Easylibpal, one could use scikit-learn's `SelectKBest`, `RFE`, or other feature selection classes based on the algorithm's requirements. Here's a conceptual example of how feature selection might be integrated into the Easylibpal class for Logistic Regression using RFE:
```python
from sklearn.feature_selection import RFE
from sklearn.linear_model import LogisticRegression
class Easylibpal:
def __init__(self, dataset):
self.dataset = dataset
# Load and preprocess the dataset
def apply_logistic_regression(self, target_column):
# Feature selection using RFE
model = LogisticRegression()
rfe = RFE(model, n_features_to_select=10)
rfe.fit(self.dataset.drop(target_column, axis=1), self.dataset[target_column])
# Train Logistic Regression model
model.fit(self.dataset.drop(target_column, axis=1), self.dataset[target_column])
# Return the trained model
return model
# Usage
Easylibpal = Easylibpal(dataset='your_dataset.csv')
model = Easylibpal.apply_logistic_regression(target_column='target')
```
This example demonstrates how Easylibpal abstracts the complexity of feature selection for Logistic Regression by using scikit-learn's `RFE` to select the top 10 features based on their importance in the model. The actual implementation would need to adapt this approach for each algorithm, considering the specific characteristics and requirements of each algorithm.
EASYLIBPAL HANDLES DIFFERENT TYPES OF DATASETS
Easylibpal handles different types of datasets with varying structures by adopting a flexible and adaptable approach to data preprocessing and transformation. This approach is inspired by the principles of tidy data and the need to ensure data is in a consistent, usable format before applying AI algorithms. Here's how Easylibpal addresses the challenges posed by varying dataset structures:
One Type in Multiple Tables
When datasets contain different variables, the same variables with different names, different file formats, or different conventions for missing values, Easylibpal employs a process similar to tidying data. This involves identifying and standardizing the structure of each dataset, ensuring that each variable is consistently named and formatted across datasets. This process might include renaming columns, converting data types, and handling missing values in a uniform manner. For datasets stored in different file formats, Easylibpal would use appropriate libraries (e.g., pandas for CSV, Excel files, and SQL databases) to load and preprocess the data before applying the algorithms.
Multiple Types in One Table
For datasets that involve values collected at multiple levels or on different types of observational units, Easylibpal applies a normalization process. This involves breaking down the dataset into multiple tables, each representing a distinct type of observational unit. For example, if a dataset contains information about songs and their rankings over time, Easylibpal would separate this into two tables: one for song details and another for rankings. This normalization ensures that each fact is expressed in only one place, reducing inconsistencies and making the data more manageable for analysis.
Data Semantics
Easylibpal ensures that the data is organized in a way that aligns with the principles of data semantics, where every value belongs to a variable and an observation. This organization is crucial for the algorithms to interpret the data correctly. Easylibpal might use functions like `pivot_longer` and `pivot_wider` from the tidyverse or equivalent functions in pandas to reshape the data into a long format, where each row represents a single observation and each column represents a single variable. This format is particularly useful for algorithms that require a consistent structure for input data.
Messy Data
Dealing with messy data, which can include inconsistent data types, missing values, and outliers, is a common challenge in data science. Easylibpal addresses this by implementing robust data cleaning and preprocessing steps. This includes handling missing values (e.g., imputation or deletion), converting data types to ensure consistency, and identifying and removing outliers. These steps are crucial for preparing the data in a format that is suitable for the algorithms, ensuring that the algorithms can effectively learn from the data without being hindered by its inconsistencies.
To implement these principles in Python, Easylibpal would leverage libraries like pandas for data manipulation and preprocessing. Here's a conceptual example of how Easylibpal might handle a dataset with multiple types in one table:
```python
import pandas as pd
# Load the dataset
dataset = pd.read_csv('your_dataset.csv')
# Normalize the dataset by separating it into two tables
song_table = dataset'artist', 'track'.drop_duplicates().reset_index(drop=True)
song_table['song_id'] = range(1, len(song_table) + 1)
ranking_table = dataset'artist', 'track', 'week', 'rank'.drop_duplicates().reset_index(drop=True)
# Now, song_table and ranking_table can be used separately for analysis
```
This example demonstrates how Easylibpal might normalize a dataset with multiple types of observational units into separate tables, ensuring that each type of observational unit is stored in its own table. The actual implementation would need to adapt this approach based on the specific structure and requirements of the dataset being processed.
CLEAN DATA
Easylibpal employs a comprehensive set of data cleaning and preprocessing steps to handle messy data, ensuring that the data is in a suitable format for machine learning algorithms. These steps are crucial for improving the accuracy and reliability of the models, as well as preventing misleading results and conclusions. Here's a detailed look at the specific steps Easylibpal might employ:
1. Remove Irrelevant Data
The first step involves identifying and removing data that is not relevant to the analysis or modeling task at hand. This could include columns or rows that do not contribute to the predictive power of the model or are not necessary for the analysis .
2. Deduplicate Data
Deduplication is the process of removing duplicate entries from the dataset. Duplicates can skew the analysis and lead to incorrect conclusions. Easylibpal would use appropriate methods to identify and remove duplicates, ensuring that each entry in the dataset is unique.
3. Fix Structural Errors
Structural errors in the dataset, such as inconsistent data types, incorrect values, or formatting issues, can significantly impact the performance of machine learning algorithms. Easylibpal would employ data cleaning techniques to correct these errors, ensuring that the data is consistent and correctly formatted.
4. Deal with Missing Data
Handling missing data is a common challenge in data preprocessing. Easylibpal might use techniques such as imputation (filling missing values with statistical estimates like mean, median, or mode) or deletion (removing rows or columns with missing values) to address this issue. The choice of method depends on the nature of the data and the specific requirements of the analysis.
5. Filter Out Data Outliers
Outliers can significantly affect the performance of machine learning models. Easylibpal would use statistical methods to identify and filter out outliers, ensuring that the data is more representative of the population being analyzed.
6. Validate Data
The final step involves validating the cleaned and preprocessed data to ensure its quality and accuracy. This could include checking for consistency, verifying the correctness of the data, and ensuring that the data meets the requirements of the machine learning algorithms. Easylibpal would employ validation techniques to confirm that the data is ready for analysis.
To implement these data cleaning and preprocessing steps in Python, Easylibpal would leverage libraries like pandas and scikit-learn. Here's a conceptual example of how these steps might be integrated into the Easylibpal class:
```python
import pandas as pd
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import StandardScaler
class Easylibpal:
def __init__(self, dataset):
self.dataset = dataset
# Load and preprocess the dataset
def clean_and_preprocess(self):
# Remove irrelevant data
self.dataset = self.dataset.drop(['irrelevant_column'], axis=1)
# Deduplicate data
self.dataset = self.dataset.drop_duplicates()
# Fix structural errors (example: correct data type)
self.dataset['correct_data_type_column'] = self.dataset['correct_data_type_column'].astype(float)
# Deal with missing data (example: imputation)
imputer = SimpleImputer(strategy='mean')
self.dataset['missing_data_column'] = imputer.fit_transform(self.dataset'missing_data_column')
# Filter out data outliers (example: using Z-score)
# This step requires a more detailed implementation based on the specific dataset
# Validate data (example: checking for NaN values)
assert not self.dataset.isnull().values.any(), "Data still contains NaN values"
# Return the cleaned and preprocessed dataset
return self.dataset
# Usage
Easylibpal = Easylibpal(dataset=pd.read_csv('your_dataset.csv'))
cleaned_dataset = Easylibpal.clean_and_preprocess()
```
This example demonstrates a simplified approach to data cleaning and preprocessing within Easylibpal. The actual implementation would need to adapt these steps based on the specific characteristics and requirements of the dataset being processed.
VALUE DATA
Easylibpal determines which data is irrelevant and can be removed through a combination of domain knowledge, data analysis, and automated techniques. The process involves identifying data that does not contribute to the analysis, research, or goals of the project, and removing it to improve the quality, efficiency, and clarity of the data. Here's how Easylibpal might approach this:
Domain Knowledge
Easylibpal leverages domain knowledge to identify data that is not relevant to the specific goals of the analysis or modeling task. This could include data that is out of scope, outdated, duplicated, or erroneous. By understanding the context and objectives of the project, Easylibpal can systematically exclude data that does not add value to the analysis.
Data Analysis
Easylibpal employs data analysis techniques to identify irrelevant data. This involves examining the dataset to understand the relationships between variables, the distribution of data, and the presence of outliers or anomalies. Data that does not have a significant impact on the predictive power of the model or the insights derived from the analysis is considered irrelevant.
Automated Techniques
Easylibpal uses automated tools and methods to remove irrelevant data. This includes filtering techniques to select or exclude certain rows or columns based on criteria or conditions, aggregating data to reduce its complexity, and deduplicating to remove duplicate entries. Tools like Excel, Google Sheets, Tableau, Power BI, OpenRefine, Python, R, Data Linter, Data Cleaner, and Data Wrangler can be employed for these purposes .
Examples of Irrelevant Data
- Personal Identifiable Information (PII): Data such as names, addresses, and phone numbers are irrelevant for most analytical purposes and should be removed to protect privacy and comply with data protection regulations .
- URLs and HTML Tags: These are typically not relevant to the analysis and can be removed to clean up the dataset.
- Boilerplate Text: Excessive blank space or boilerplate text (e.g., in emails) adds noise to the data and can be removed.
- Tracking Codes: These are used for tracking user interactions and do not contribute to the analysis.
To implement these steps in Python, Easylibpal might use pandas for data manipulation and filtering. Here's a conceptual example of how to remove irrelevant data:
```python
import pandas as pd
# Load the dataset
dataset = pd.read_csv('your_dataset.csv')
# Remove irrelevant columns (example: email addresses)
dataset = dataset.drop(['email_address'], axis=1)
# Remove rows with missing values (example: if a column is required for analysis)
dataset = dataset.dropna(subset=['required_column'])
# Deduplicate data
dataset = dataset.drop_duplicates()
# Return the cleaned dataset
cleaned_dataset = dataset
```
This example demonstrates how Easylibpal might remove irrelevant data from a dataset using Python and pandas. The actual implementation would need to adapt these steps based on the specific characteristics and requirements of the dataset being processed.
Detecting Inconsistencies
Easylibpal starts by detecting inconsistencies in the data. This involves identifying discrepancies in data types, missing values, duplicates, and formatting errors. By detecting these inconsistencies, Easylibpal can take targeted actions to address them.
Handling Formatting Errors
Formatting errors, such as inconsistent data types for the same feature, can significantly impact the analysis. Easylibpal uses functions like `astype()` in pandas to convert data types, ensuring uniformity and consistency across the dataset. This step is crucial for preparing the data for analysis, as it ensures that each feature is in the correct format expected by the algorithms.
Handling Missing Values
Missing values are a common issue in datasets. Easylibpal addresses this by consulting with subject matter experts to understand why data might be missing. If the missing data is missing completely at random, Easylibpal might choose to drop it. However, for other cases, Easylibpal might employ imputation techniques to fill in missing values, ensuring that the dataset is complete and ready for analysis.
Handling Duplicates
Duplicate entries can skew the analysis and lead to incorrect conclusions. Easylibpal uses pandas to identify and remove duplicates, ensuring that each entry in the dataset is unique. This step is crucial for maintaining the integrity of the data and ensuring that the analysis is based on distinct observations.
Handling Inconsistent Values
Inconsistent values, such as different representations of the same concept (e.g., "yes" vs. "y" for a binary variable), can also pose challenges. Easylibpal employs data cleaning techniques to standardize these values, ensuring that the data is consistent and can be accurately analyzed.
To implement these steps in Python, Easylibpal would leverage pandas for data manipulation and preprocessing. Here's a conceptual example of how these steps might be integrated into the Easylibpal class:
```python
import pandas as pd
class Easylibpal:
def __init__(self, dataset):
self.dataset = dataset
# Load and preprocess the dataset
def clean_and_preprocess(self):
# Detect inconsistencies (example: check data types)
print(self.dataset.dtypes)
# Handle formatting errors (example: convert data types)
self.dataset['date_column'] = pd.to_datetime(self.dataset['date_column'])
# Handle missing values (example: drop rows with missing values)
self.dataset = self.dataset.dropna(subset=['required_column'])
# Handle duplicates (example: drop duplicates)
self.dataset = self.dataset.drop_duplicates()
# Handle inconsistent values (example: standardize values)
self.dataset['binary_column'] = self.dataset['binary_column'].map({'yes': 1, 'no': 0})
# Return the cleaned and preprocessed dataset
return self.dataset
# Usage
Easylibpal = Easylibpal(dataset=pd.read_csv('your_dataset.csv'))
cleaned_dataset = Easylibpal.clean_and_preprocess()
```
This example demonstrates a simplified approach to handling inconsistent or messy data within Easylibpal. The actual implementation would need to adapt these steps based on the specific characteristics and requirements of the dataset being processed.
Statistical Imputation
Statistical imputation involves replacing missing values with statistical estimates such as the mean, median, or mode of the available data. This method is straightforward and can be effective for numerical data. For categorical data, mode imputation is commonly used. The choice of imputation method depends on the distribution of the data and the nature of the missing values.
Model-Based Imputation
Model-based imputation uses machine learning models to predict missing values. This approach can be more sophisticated and potentially more accurate than statistical imputation, especially for complex datasets. Techniques like K-Nearest Neighbors (KNN) imputation can be used, where the missing values are replaced with the values of the K nearest neighbors in the feature space.
Using SimpleImputer in scikit-learn
The scikit-learn library provides the `SimpleImputer` class, which supports both statistical and model-based imputation. `SimpleImputer` can be used to replace missing values with the mean, median, or most frequent value (mode) of the column. It also supports more advanced imputation methods like KNN imputation.
To implement these imputation techniques in Python, Easylibpal might use the `SimpleImputer` class from scikit-learn. Here's an example of how to use `SimpleImputer` for statistical imputation:
```python
from sklearn.impute import SimpleImputer
import pandas as pd
# Load the dataset
dataset = pd.read_csv('your_dataset.csv')
# Initialize SimpleImputer for numerical columns
num_imputer = SimpleImputer(strategy='mean')
# Fit and transform the numerical columns
dataset'numerical_column1', 'numerical_column2' = num_imputer.fit_transform(dataset'numerical_column1', 'numerical_column2')
# Initialize SimpleImputer for categorical columns
cat_imputer = SimpleImputer(strategy='most_frequent')
# Fit and transform the categorical columns
dataset'categorical_column1', 'categorical_column2' = cat_imputer.fit_transform(dataset'categorical_column1', 'categorical_column2')
# The dataset now has missing values imputed
```
This example demonstrates how to use `SimpleImputer` to fill in missing values in both numerical and categorical columns of a dataset. The actual implementation would need to adapt these steps based on the specific characteristics and requirements of the dataset being processed.
Model-based imputation techniques, such as Multiple Imputation by Chained Equations (MICE), offer powerful ways to handle missing data by using statistical models to predict missing values. However, these techniques come with their own set of limitations and potential drawbacks:
1. Complexity and Computational Cost
Model-based imputation methods can be computationally intensive, especially for large datasets or complex models. This can lead to longer processing times and increased computational resources required for imputation.
2. Overfitting and Convergence Issues
These methods are prone to overfitting, where the imputation model captures noise in the data rather than the underlying pattern. Overfitting can lead to imputed values that are too closely aligned with the observed data, potentially introducing bias into the analysis. Additionally, convergence issues may arise, where the imputation process does not settle on a stable solution.
3. Assumptions About Missing Data
Model-based imputation techniques often assume that the data is missing at random (MAR), which means that the probability of a value being missing is not related to the values of other variables. However, this assumption may not hold true in all cases, leading to biased imputations if the data is missing not at random (MNAR).
4. Need for Suitable Regression Models
For each variable with missing values, a suitable regression model must be chosen. Selecting the wrong model can lead to inaccurate imputations. The choice of model depends on the nature of the data and the relationship between the variable with missing values and other variables.
5. Combining Imputed Datasets
After imputing missing values, there is a challenge in combining the multiple imputed datasets to produce a single, final dataset. This requires careful consideration of how to aggregate the imputed values and can introduce additional complexity and uncertainty into the analysis.
6. Lack of Transparency
The process of model-based imputation can be less transparent than simpler imputation methods, such as mean or median imputation. This can make it harder to justify the imputation process, especially in contexts where the reasons for missing data are important, such as in healthcare research.
Despite these limitations, model-based imputation techniques can be highly effective for handling missing data in datasets where a amusingness is MAR and where the relationships between variables are complex. Careful consideration of the assumptions, the choice of models, and the methods for combining imputed datasets are crucial to mitigate these drawbacks and ensure the validity of the imputation process.
USING EASYLIBPAL FOR AI ALGORITHM INTEGRATION OFFERS SEVERAL SIGNIFICANT BENEFITS, PARTICULARLY IN ENHANCING EVERYDAY LIFE AND REVOLUTIONIZING VARIOUS SECTORS. HERE'S A DETAILED LOOK AT THE ADVANTAGES:
1. Enhanced Communication: AI, through Easylibpal, can significantly improve communication by categorizing messages, prioritizing inboxes, and providing instant customer support through chatbots. This ensures that critical information is not missed and that customer queries are resolved promptly.
2. Creative Endeavors: Beyond mundane tasks, AI can also contribute to creative endeavors. For instance, photo editing applications can use AI algorithms to enhance images, suggesting edits that align with aesthetic preferences. Music composition tools can generate melodies based on user input, inspiring musicians and amateurs alike to explore new artistic horizons. These innovations empower individuals to express themselves creatively with AI as a collaborative partner.
3. Daily Life Enhancement: AI, integrated through Easylibpal, has the potential to enhance daily life exponentially. Smart homes equipped with AI-driven systems can adjust lighting, temperature, and security settings according to user preferences. Autonomous vehicles promise safer and more efficient commuting experiences. Predictive analytics can optimize supply chains, reducing waste and ensuring goods reach users when needed.
4. Paradigm Shift in Technology Interaction: The integration of AI into our daily lives is not just a trend; it's a paradigm shift that's redefining how we interact with technology. By streamlining routine tasks, personalizing experiences, revolutionizing healthcare, enhancing communication, and fueling creativity, AI is opening doors to a more convenient, efficient, and tailored existence.
5. Responsible Benefit Harnessing: As we embrace AI's transformational power, it's essential to approach its integration with a sense of responsibility, ensuring that its benefits are harnessed for the betterment of society as a whole. This approach aligns with the ethical considerations of using AI, emphasizing the importance of using AI in a way that benefits all stakeholders.
In summary, Easylibpal facilitates the integration and use of AI algorithms in a manner that is accessible and beneficial across various domains, from enhancing communication and creative endeavors to revolutionizing daily life and promoting a paradigm shift in technology interaction. This integration not only streamlines the application of AI but also ensures that its benefits are harnessed responsibly for the betterment of society.
USING EASYLIBPAL OVER TRADITIONAL AI LIBRARIES OFFERS SEVERAL BENEFITS, PARTICULARLY IN TERMS OF EASE OF USE, EFFICIENCY, AND THE ABILITY TO APPLY AI ALGORITHMS WITH MINIMAL CONFIGURATION. HERE ARE THE KEY ADVANTAGES:
- Simplified Integration: Easylibpal abstracts the complexity of traditional AI libraries, making it easier for users to integrate classic AI algorithms into their projects. This simplification reduces the learning curve and allows developers and data scientists to focus on their core tasks without getting bogged down by the intricacies of AI implementation.
- User-Friendly Interface: By providing a unified platform for various AI algorithms, Easylibpal offers a user-friendly interface that streamlines the process of selecting and applying algorithms. This interface is designed to be intuitive and accessible, enabling users to experiment with different algorithms with minimal effort.
- Enhanced Productivity: The ability to effortlessly instantiate algorithms, fit models with training data, and make predictions with minimal configuration significantly enhances productivity. This efficiency allows for rapid prototyping and deployment of AI solutions, enabling users to bring their ideas to life more quickly.
- Democratization of AI: Easylibpal democratizes access to classic AI algorithms, making them accessible to a wider range of users, including those with limited programming experience. This democratization empowers users to leverage AI in various domains, fostering innovation and creativity.
- Automation of Repetitive Tasks: By automating the process of applying AI algorithms, Easylibpal helps users save time on repetitive tasks, allowing them to focus on more complex and creative aspects of their projects. This automation is particularly beneficial for users who may not have extensive experience with AI but still wish to incorporate AI capabilities into their work.
- Personalized Learning and Discovery: Easylibpal can be used to enhance personalized learning experiences and discovery mechanisms, similar to the benefits seen in academic libraries. By analyzing user behaviors and preferences, Easylibpal can tailor recommendations and resource suggestions to individual needs, fostering a more engaging and relevant learning journey.
- Data Management and Analysis: Easylibpal aids in managing large datasets efficiently and deriving meaningful insights from data. This capability is crucial in today's data-driven world, where the ability to analyze and interpret large volumes of data can significantly impact research outcomes and decision-making processes.
In summary, Easylibpal offers a simplified, user-friendly approach to applying classic AI algorithms, enhancing productivity, democratizing access to AI, and automating repetitive tasks. These benefits make Easylibpal a valuable tool for developers, data scientists, and users looking to leverage AI in their projects without the complexities associated with traditional AI libraries.
2 notes
·
View notes
Text
Intel Xeon Platinum 8480+: Modern Workload Scalability

Introduction
Sapphire Rapids and Xeon Platinum 8480+ were released by Intel. This generation prioritises memory bandwidth, I/O extension, AI acceleration, and compute density. It used Intel 7 (10nm Enhanced SuperFin) fabrication.
The 8480+, a flagship model in this generation, has 56 cores and 112 threads, a significant boost over prior Xeon variants.
Architectural Innovation
MCM Multichip Module
The Xeon Platinum 8480+ has four processing tiles coupled by an Intel EMIB in an MCM design. This architecture balances performance and manufacturing efficiency to improve yields and thermal characteristics.
Memory bandwidth and DDR5
The Xeon Platinum 8480+ supports DDR5-4800, which boosts bandwidth over DDR4. It supports large-scale simulations, AI inference, and in-memory databases with 8 memory channels.
Supports PCIe 5.0
This processor's 80 PCIe Gen 5.0 lanes can swiftly link GPUs, FPGAs, SSDs, and networking devices. This benefits accelerator card-based AI systems and hybrid cloud infrastructure.
Built-In Accelerators
The high-core Intel Xeon Platinum 8480+ contains hardware accelerators to relieve CPU cores of certain tasks.
Amx from Intel
AMX increases AI and deep learning performance by enabling matrix multiplication. It enhances inference tasks like image recognition and NLP.
Intel AVX512
Scientific computing, cryptography, and large-scale simulations use the AVX-512. It speeds up vector operations, which are crucial to HPC workloads.
Intel QuickAssist Technology
QAT increases security by outsourcing cryptography and compression and reducing CPU demand. Important for data centres that handle massive compression workloads or encrypted communications.
In-Memory Analytics Accelerator
IAA accelerates database workloads and data analytics by scanning, filtering, and transforming data in memory.
Applications in Real Life
The Xeon Platinum 8480+ is designed for industry-specific deployments and raw computation.
The Cloud and Virtualisation
The 8480+'s 56 cores and support for Intel VT-x, VT-d, and EPT boost hyperconverged infrastructure (HCI) and multi-tenant cloud systems. Consolidating workloads reduces overhead.
High-performance computing
Vector-heavy calculations in genomics, seismic studies, and aeronautical simulations benefit from the processor's AVX-512 and AMX.
Machine Learning, AI
This CPU can handle deep learning inference workloads without GPUs with built-in AI accelerators, saving money and energy.
Data Analysis
With its massive L3 cache and IAA, it can process large datasets directly in memory, speeding up ETL and OLAP.
Edge and network computing
DLB and Intel QAT give the Xeon Platinum 8480+ low-latency processing for 5G and telecom operators, making it ideal for high-throughput packets.
Security Upgrades
Modern infrastructure prioritises security, therefore Intel has multiple defences:
The Intel SGX software guard extensions for safe havens
Intel TME encrypts all memory.
Intel Boot Guard and PFR
Crypto Acceleration & Key Locker for fast, secure cryptography
Pricing, availability
The Xeon Platinum 8480+ MSRP is $10,710 USD, although vendor and volume buy agreements affect pricing. Dell, HPE, Lenovo, and Supermicro sell pre-configured and customised server platforms.
In conclusion
A strong server CPU for prospective data-driven activities is the Intel Xeon Platinum 8480+. DDR5 compatibility, PCIe 5.0, 56 cores, and integrated accelerators give it power and intelligent computing for AI, data analytics, and cloud infrastructure. Intel's ecosystem and customised accelerators make the 8480+ appealing to many organisations despite AMD EPYC series competition.
#XeonPlatinum8480#IntelXeonPlatinum#XeonPlatinum#Platinum8480#Intel8480#IntelXeon8480#technology#technews#technologynews#news#govindhtech
0 notes
Text
Top 8 Security Practices Every Blockchain Developer Must Follow in 2025

Blockchain development has become one of the most exciting and lucrative fields in technology, but with great opportunity comes great responsibility. As a blockchain developer, you're not just writing code you're handling potentially millions of dollars in digital assets and building systems that users trust with their financial futures. One small security oversight can lead to devastating consequences, as we've seen in numerous high-profile hacks and exploits.
The good news? Most blockchain security vulnerabilities can be prevented by following established best practices. Whether you're building your first smart contract or developing complex DeFi protocols, implementing robust security measures should be your top priority. This comprehensive guide outlines the eight most critical security practices that every blockchain developer needs to master.
Why Blockchain Security Matters More Than Ever
Before diving into specific practices, it's crucial to understand why security in blockchain development is non-negotiable. Unlike traditional applications where bugs might cause inconvenience or data loss, blockchain vulnerabilities can result in permanent, irreversible financial losses. The immutable nature of blockchain means that once a malicious transaction is confirmed, there's often no way to reverse it.
Recent statistics show that over $3 billion was lost to blockchain security breaches in 2024 alone. These aren't just numbers—they represent real people's savings, retirement funds, and business investments. As a blockchain developer, your code literally protects people's livelihoods.
1. Implement Comprehensive Smart Contract Auditing
Smart contract auditing should be your first line of defense in blockchain development. Never deploy a smart contract to mainnet without thorough testing and preferably a third-party audit. Even experienced blockchain developers can miss subtle vulnerabilities that could be exploited later.
Start with automated tools like Slither, Mythril, or Securify to catch common vulnerabilities. These tools can identify issues like reentrancy attacks, integer overflows, and gas limit problems. However, don't rely solely on automated tools—they can't catch logic errors or complex attack vectors that require human insight.
Consider hiring professional auditing firms for critical projects. Yes, it's expensive, but the cost of an audit pales in comparison to the potential losses from a security breach. Many successful blockchain projects allocate 10-15% of their development budget to security auditing.
2. Follow the Principle of Least Privilege
In blockchain development, the principle of least privilege means giving contracts and users only the minimum permissions necessary to function. This approach significantly reduces your attack surface and limits the damage if a component is compromised.
Design your smart contracts with role-based access control. Not every function needs to be public, and not every user needs administrative privileges. Use modifiers to restrict access to sensitive functions, and implement time locks for critical operations like fund withdrawals or parameter changes.
Consider implementing multi-signature requirements for high-value operations. This ensures that no single private key can compromise your entire system, adding an extra layer of security that's especially important for DeFi protocols and treasury management.
3. Secure Private Key Management
Private key security is fundamental to blockchain development, yet it's where many developers make critical mistakes. Your private keys are literally the keys to the kingdom—lose them, and you lose everything. Compromise them, and so does everyone who trusts your system.
Never store private keys in plain text, whether in code, configuration files, or databases. Use hardware security modules (HSMs) or secure key management services for production systems. For development and testing, use environment variables and secrets management tools to keep keys separate from your codebase.
Implement proper key rotation policies and have secure backup procedures. Consider using threshold cryptography for critical operations, where multiple key shares are required to perform sensitive actions. This approach distributes risk and prevents single points of failure.
4. Validate and Sanitize All Inputs
Input validation in blockchain development goes beyond preventing SQL injection—you're dealing with financial transactions where malformed data can cause permanent losses. Every piece of data entering your smart contracts should be thoroughly validated and sanitized.
Check for integer overflows and underflows, especially when dealing with token amounts or mathematical operations. Use SafeMath libraries or built-in overflow protection in newer Solidity versions. Validate address formats, ensure amounts are within expected ranges, and check for zero values where they shouldn't be allowed.
Don't trust external data sources without verification. If your blockchain development project relies on oracles or external APIs, implement multiple data sources and anomaly detection to prevent manipulation attacks. Bad data can be just as dangerous as malicious code.
5. Implement Proper Error Handling and Logging
Effective error handling in blockchain development serves two purposes: it prevents your contracts from failing unexpectedly and provides valuable information for debugging and security monitoring. However, be careful not to leak sensitive information through error messages.
Use require statements to validate conditions and provide meaningful error messages that help with debugging without revealing internal system details. Implement proper exception handling to ensure your contracts fail safely when unexpected conditions occur.
Create comprehensive logging systems that track all significant operations, especially those involving value transfers or permission changes. These logs are invaluable for post-incident analysis and can help you identify attack patterns before they cause major damage.
6. Test Extensively Across Different Scenarios
Testing in blockchain development isn't just about ensuring your code works—it's about ensuring it works securely under all possible conditions, including adversarial ones. Your test suite should include normal operations, edge cases, and potential attack scenarios.
Implement unit tests for every function, integration tests for contract interactions, and end-to-end tests for complete user journeys. Use fuzzing tools to test your contracts with random inputs and extreme values. This can uncover edge cases that manual testing might miss.
Create specific tests for security scenarios: What happens if someone tries to call functions in an unexpected order? How does your contract handle reentrancy attacks? Can someone manipulate gas costs to their advantage? These aren't hypothetical questions—they're real attack vectors that need to be tested.
7. Keep Dependencies Updated and Secure
Modern blockchain development relies heavily on libraries and frameworks, but each dependency introduces potential vulnerabilities. Staying on top of dependency security is crucial for maintaining a secure codebase.
Regularly audit your dependencies for known vulnerabilities. Use tools like npm audit for JavaScript projects or check security advisories for your specific blockchain platform. Subscribe to security mailing lists and follow security researchers who focus on blockchain technology.
When updating dependencies, don't just blindly update to the latest version. Test thoroughly in a staging environment first, and be aware of breaking changes that might introduce new vulnerabilities. Sometimes the cure can be worse than the disease if not properly implemented.
8. Design for Upgradability and Emergency Response
Even with all security measures in place, vulnerabilities can still be discovered after deployment. Smart blockchain development includes planning for the unexpected with upgradeable contracts and emergency response procedures.
Implement upgrade patterns like proxy contracts that allow you to fix vulnerabilities without losing state data. However, balance upgradability with decentralization—too much upgrade power in the wrong hands can be just as dangerous as a security vulnerability.
Create emergency response procedures that can be activated quickly when threats are detected. This might include pause functions, emergency withdrawals, or circuit breakers that can halt operations until issues are resolved. Document these procedures clearly and ensure your team knows how to execute them under pressure.
Building Security into Your Blockchain Development Process
Security isn't something you add at the end of blockchain development—it needs to be baked into every stage of your process. From initial design to ongoing maintenance, security considerations should guide your decisions.
Start each project with a threat model that identifies potential attack vectors and mitigation strategies. Make security reviews a standard part of your code review process. Create security checklists that developers must complete before deploying code.
Remember that blockchain development security is an ongoing responsibility, not a one-time task. Stay informed about new attack vectors, participate in the security community, and continuously improve your security practices. The blockchain space evolves rapidly, and so do the threats.
The investment you make in security today will pay dividends in the trust and confidence users place in your blockchain applications. In a space where reputation is everything and mistakes can be costly, following these security practices isn't just good development—it's good business.
#gaming#mobile game development#multiplayer games#metaverse#nft#blockchain#unity game development#game#vr games
0 notes
Text
Key Highlights from AWS re:Invent 2023: A Leap Forward in AI and Cloud Computing

As another impactful AWS re:Invent concludes, it’s clear that AWS is pushing the boundaries in AI and cloud innovation. Here are the standout developments:
Amazon Bedrock expansion: Introducing new AI models and a feature for selecting the best foundational model, Amazon Bedrock is now more robust and adaptable for diverse business needs.
Next-generation AI infrastructure: AWS unveiled the Graviton4 processor and Trainium2 chips, marking a significant leap in AI compute performance. Their extended partnership with Nvidia paves the way for groundbreaking AI applications.
Amazon SageMaker evolution: With the launch of SageMaker HyperPod and SageMaker Inference, AWS streamlines the training and deployment of large language models, optimizing both time and cost efficiency.
Revolutionizing data warehousing with Zero-ETL: AWS is redefining data integration and analysis, streamlining the traditionally complex ETL processes and integrating support for vector databases in Amazon Bedrock.
The Introduction of Amazon Q: A new generative AI assistant, Amazon Q, is set to transform application development and business intelligence, showcasing AWS’s commitment to advancing AI utility in business.
Quantum computing access with Amazon Braket Direct: This program offers unprecedented access to quantum computers, accelerating quantum research and applications.
AWS Cost Optimization Hub:This new feature centralizes cost optimization across AWS services, enabling more effective financial management for enterprises.
These advancements from AWS re:Invent 2023 underscore the growing importance of expert guidance in navigating the complex landscape of cloud computing and AI. For businesses looking to leverage these new technologies, Centizen Cloud Consulting Services offers specialized expertise to help you harness the full potential of AWS innovations for your unique business needs.
0 notes
Text
Top Benefits of Using Microsoft Visio for Business & IT Projects
Microsoft Visio is one of the most widely used diagramming and vector graphics tools in the business and IT world. It is designed to help professionals visualize complex processes, workflows, systems, and data with ease. Whether you’re working on a business process flow, network diagram, or organizational chart, Visio offers powerful features that can streamline collaboration and boost productivity. This article explores the top benefits of using Microsoft Visio for business and IT projects, showing why it’s a valuable tool for professionals across different industries.
Easy-to-Create Visual Diagrams for windows 11 home One of the key benefits of using Microsoft Visio is its ability to simplify complex information through easy-to-understand visual diagrams. Visio enables users to create a wide range of diagrams, from flowcharts and organizational charts to network diagrams and data visualizations. These diagrams can break down intricate processes, systems, and ideas into clear, visually engaging representations that are much easier to understand than text-based documents. Whether you’re mapping out a workflow, designing a network architecture, or illustrating a business process, Visio helps to communicate complex concepts in a straightforward way, making it an invaluable tool for decision-making and analysis.

Improved Collaboration and Communication Microsoft Visio is equipped with collaborative features that make it ideal for teamwork in business and IT projects. One of the most important benefits of using Visio is the ability to work on diagrams with team members in real-time, especially when using the cloud-based version, Visio for the Web. Multiple users can edit and update a diagram simultaneously, streamlining the review process and ensuring that everyone is on the same page. Additionally, Visio allows users to embed comments and annotations directly on the diagrams, which further enhances communication and feedback. This collaborative functionality ensures that all stakeholders, whether they’re in the same office or spread across multiple locations, can contribute to the creation and refinement of visual projects.
Integration with Microsoft Office and Other Applications Visio’s seamless integration with other Microsoft Office applications, such as Word, Excel, and PowerPoint, makes it an even more powerful tool for business and IT professionals. For instance, users can easily import data from Excel into Visio to create data-driven diagrams, ensuring that the visuals are automatically updated when the data changes. Similarly, Visio diagrams can be embedded in Word documents or PowerPoint presentations to provide context or enhance the visual appeal of reports and presentations. This integration simplifies the workflow, enabling users to efficiently incorporate diagrams into other types of work without having to switch between different applications.
Customizable Templates for Various Business and IT Needs Microsoft Visio provides an extensive library of customizable templates and shapes that are tailored to different business and IT needs. Whether you’re designing a network topology, creating an organizational structure, or documenting a process flow, Visio has specialized templates that cater to specific industries and project types. For IT professionals, Visio offers templates for designing network diagrams, server configurations, and database models, among others. Similarly, business users can create flowcharts, Gantt charts, and timelines with ease. These pre-designed templates save time by providing a starting point for the creation of diagrams, ensuring consistency and accuracy in the final product.
Enhanced Data Visualization and Reporting Another significant advantage of using Microsoft Visio for business and IT projects is its ability to create dynamic, data-driven diagrams. Visio can link diagrams to external data sources, such as Excel spreadsheets, databases, or SharePoint lists, allowing users to create diagrams that automatically update when the data changes. This functionality is particularly useful for IT projects that require real-time data visualization, such as network monitoring or system performance tracking. By using Visio’s data linking features, users can gain deeper insights into their data, visualize trends, and present information in a more digestible and actionable format. This feature enhances reporting and helps organizations make data-driven decisions more effectively.
Streamlined Workflow with Automation Features Microsoft Visio also includes automation features that can help streamline repetitive tasks and improve productivity. For example, Visio’s Shape Data feature allows users to associate specific information or metadata with shapes in a diagram. This can be particularly useful in business process modeling or when tracking the status of tasks and activities. Additionally, Visio supports the use of custom macros and scripts to automate diagram creation and updates, further reducing manual work and errors. The ability to automate routine tasks in Visio enables teams to focus on higher-level tasks, such as analysis and decision-making, rather than spending time on repetitive diagram modifications.
Scalability for Large and Complex Projects For businesses and IT projects that require scaling, Microsoft Visio offers a level of flexibility and scalability that few other diagramming tools can match. Visio can handle complex, multi-page diagrams with ease, allowing users to design large systems, processes, and projects that span multiple pages or require detailed, intricate designs. For example, IT professionals can use Visio to map out entire IT infrastructures, including data centers, networks, and communication systems, and then drill down into specific areas with additional pages or zoomed-in diagrams. This scalability is essential for large projects that require detailed documentation and clear visual communication at multiple levels of abstraction.

Support for Standardization and Best Practices For businesses looking to maintain consistency across projects or departments, Visio offers tools that help standardize diagram creation. With Visio, users can create custom stencils and templates that ensure diagrams adhere to company-specific guidelines and industry best practices. This feature is particularly valuable in larger organizations where multiple teams are working on related projects. By standardizing the look and feel of diagrams, businesses can ensure that all stakeholders are using the same symbols, color schemes, and layouts, which helps maintain consistency and professionalism in visual communications.
Conclusion Microsoft Visio is an invaluable tool for both business and IT projects due to its ability to simplify complex information, foster collaboration, integrate with other Microsoft applications, and provide powerful data visualization capabilities. With customizable templates, enhanced automation, and scalability for large projects, Visio is designed to meet the needs of professionals who require clarity and precision in their diagrams. Whether you’re visualizing business processes, designing network architectures, or creating data-driven reports, Visio offers the tools necessary to communicate your ideas effectively and enhance project outcomes.
0 notes
Text
Mastering Data Science: A Roadmap for Beginners and Aspiring Professionals
Understanding the Foundation of Data Science
Data science has emerged as one of the most sought-after career paths in today’s digital economy. It combines statistics, computer science, and domain knowledge to extract meaningful insights from data. Before diving deep into complex topics, it’s crucial to understand the foundational concepts that shape this field. From data cleaning to basic data visualization techniques, beginners must grasp these essential skills. Additionally, programming languages like Python and R are the primary tools used by data scientists worldwide. Building a strong base in these languages can set the stage for more advanced learning. It’s also important to familiarize yourself with databases, as querying and manipulating data efficiently is a key skill in any data-driven role. Solidifying these basics ensures a smoother transition to more complex areas such as artificial intelligence and machine learning.
Machine Learning for Beginners: The Essential Guide
Once you have a solid foundation, the next logical step is to explore machine learning. Machine Learning for Beginners is an exciting journey filled with numerous algorithms and techniques designed to help computers learn from data. Beginners should start with supervised learning models like linear regression and decision trees before progressing to unsupervised learning and reinforcement learning. Understanding the mathematical intuition behind algorithms such as k-nearest neighbors (KNN) and support vector machines (SVM) can enhance your analytical skills significantly. Online resources, workshops, and hands-on projects are excellent ways to strengthen your knowledge. It’s also vital to practice with real-world datasets, as this will expose you to the challenges and nuances faced in actual data science projects. Remember, mastering machine learning is not just about memorizing algorithms but about understanding when and why to use them.
Interview Preparation for Data Scientists: Key Strategies
Entering the job market as a data scientist can be both thrilling and intimidating. Effective interview preparation for data scientists requires more than just technical knowledge; it demands strategic planning and soft skill development. Candidates should be prepared to tackle technical interviews that test their understanding of statistics, machine learning, and programming. Additionally, behavioral interviews are equally important, as companies seek individuals who can collaborate and communicate complex ideas clearly. Mock interviews, coding challenges, and portfolio projects can significantly boost your confidence. It is beneficial to review common interview questions, such as explaining the bias-variance tradeoff or detailing a machine learning project you have worked on. Networking with professionals and seeking mentorship opportunities can also open doors to valuable insights and career advice. A strong preparation strategy combines technical mastery with effective storytelling about your experiences.
Advancing Your Data Science Career Through Specialization
After entering the field, data scientists often find themselves gravitating towards specialized roles like machine learning engineer, data analyst, or AI researcher. Specializing allows professionals to deepen their expertise and stand out in a competitive job market. Those passionate about prediction models might specialize in machine learning, while others who enjoy working with big data might lean towards data engineering. Continuous learning is essential in this rapidly evolving field. Enrolling in advanced courses, attending industry conferences, and contributing to open-source projects can all accelerate your career growth. Furthermore, staying updated with the latest tools and technologies, such as cloud-based machine learning platforms and advanced data visualization libraries, can give you an edge. A proactive approach to career development ensures you remain adaptable and competitive, regardless of how the industry changes.
Conclusion: Your Gateway to Success in Data Science
The journey to becoming a successful data scientist is both challenging and rewarding. It requires a balance of technical knowledge, practical experience, and continuous learning. Building a strong foundation, mastering machine learning basics, strategically preparing for interviews, and eventually specializing in a niche area are all key steps toward achieving your career goals. For those seeking comprehensive resources to guide them through every phase of their journey, visiting finzebra.com offers access to valuable tools and insights tailored for aspiring data science professionals. By following a structured learning path and leveraging the right resources, anyone can transform their passion for data into a fulfilling career.
0 notes
Text
Enhancing Security in Backend Development: Best Practices for Developers
In today’s rapidly evolving digital environment, security in backend systems is paramount. As the backbone of web applications, the backend handles sensitive data processing, storage, and communication. Any vulnerabilities in this layer can lead to catastrophic breaches, affecting user trust and business integrity. This article highlights essential best practices to ensure your backend development meets the highest security standards.
1. Implement Strong Authentication and Authorization
One of the primary steps in securing backend development services is implementing robust authentication and authorization protocols. Password-based systems alone are no longer sufficient. Modern solutions like OAuth 2.0 and JSON Web Tokens (JWT) offer secure ways to manage user sessions. Multi-factor authentication (MFA) adds another layer of protection, requiring users to verify their identity using multiple methods, such as a password and a one-time code.
Authorization should be handled carefully to ensure users only access resources relevant to their role. By limiting privileges, you reduce the risk of sensitive data falling into the wrong hands. This practice is particularly crucial for applications that involve multiple user roles, such as administrators, managers, and end-users.
2. Encrypt Data in Transit and at Rest
Data encryption is a non-negotiable aspect of backend security. When data travels between servers and clients, it is vulnerable to interception. Implement HTTPS to secure this communication channel using SSL/TLS protocols. For data stored in databases, use encryption techniques that prevent unauthorized access. Even if an attacker gains access to the storage, encrypted data remains unreadable without the decryption keys.
Managing encryption keys securely is equally important. Store keys in hardware security modules (HSMs) or use services like AWS Key Management Service (KMS) to ensure they are well-protected. Regularly rotate keys to further reduce the risk of exposure.
3. Prevent SQL Injection and Other Injection Attacks
Injection attacks, particularly SQL injections, remain one of the most common threats to backend technologies for web development. Attackers exploit poorly sanitized input fields to execute malicious SQL queries. This can lead to unauthorized data access or even complete control of the database.
To mitigate this risk, always validate and sanitize user inputs. Use parameterized queries or prepared statements, which ensure that user-provided data cannot alter the intended database commands. Additionally, educate developers on the risks of injection attacks and implement static code analysis tools to identify vulnerabilities during the development process.
4. Employ Secure API Design
APIs are integral to backend development but can also serve as entry points for attackers if not secured properly. Authentication tokens, input validation, and rate limiting are essential to preventing unauthorized access and abuse. Moreover, all API endpoints should be designed with security-first principles.
For example, avoid exposing sensitive information in API responses. Error messages should be generic and not reveal the backend structure. Consider using tools like API gateways to enforce security policies, including data masking, IP whitelisting, and token validation.
5. Keep Dependencies Updated and Patched
Third-party libraries and frameworks streamline development but can introduce vulnerabilities if not updated regularly. Outdated software components are a common attack vector. Perform routine dependency checks and integrate automated vulnerability scanners like Snyk or Dependabot into your CI/CD pipeline.
Beyond updates, consider using tools to analyze your application for known vulnerabilities. For instance, dependency management tools can identify and notify you of outdated libraries, helping you stay ahead of potential risks.
6. Adopt Role-Based Access Control (RBAC)
Access management is a critical component of secure backend systems. Role-Based Access Control (RBAC) ensures users and applications have access only to what they need. Define roles clearly and assign permissions at a granular level. For example, a customer service representative may only access user profile data, while an admin might have permissions to modify backend configurations.
Implementing RBAC reduces the potential damage of a compromised user account. For added security, monitor access logs for unusual patterns, such as repeated failed login attempts or unauthorized access to restricted resources.
7. Harden Your Database Configurations
Databases are at the heart of backend systems, making them a prime target for attackers. Properly configuring your database is essential. Start by disabling unnecessary services and default accounts that could be exploited. Enforce strong password policies and ensure that sensitive data, such as passwords, is hashed using secure algorithms like bcrypt or Argon2.
Database permissions should also be restricted. Grant the least privilege necessary to applications interacting with the database. Regularly audit these permissions to identify and eliminate unnecessary access.
8. Monitor and Log Backend Activities
Real-time monitoring and logging are critical for detecting and responding to security threats. Implement tools like Logstash, Prometheus, and Kibana to track server activity and identify anomalies. Logs should include information about authentication attempts, database queries, and API usage.
However, ensure that logs themselves are secure. Store them in centralized, access-controlled environments and avoid exposing them to unauthorized users. Use log analysis tools to proactively identify patterns that may indicate an ongoing attack.
9. Mitigate Cross-Site Scripting (XSS) Risks
Cross-site scripting attacks can compromise your backend security through malicious scripts. To prevent XSS attacks, validate and sanitize all inputs received from the client side. Implement Content Security Policies (CSP) that restrict the types of scripts that can run within the application.
Another effective measure is to encode output data before rendering it in the user’s browser. For example, HTML encoding ensures that malicious scripts cannot execute, even if injected.
10. Secure Cloud Infrastructure
As businesses increasingly migrate to the cloud, backend developers must adapt to the unique challenges of cloud security. Use Identity and Access Management (IAM) features provided by cloud platforms like AWS, Google Cloud, and Azure to define precise permissions.
Enable encryption for all data stored in the cloud and use virtual private clouds (VPCs) to isolate your infrastructure from external threats. Regularly audit your cloud configuration to ensure compliance with security best practices.
11. Foster a Culture of Security
Security isn’t a one-time implementation — it’s an ongoing process. Regularly train your development team on emerging threats, secure coding practices, and compliance standards. Encourage developers to follow a security-first approach at every stage of development.
Conduct routine penetration tests and code audits to identify weaknesses. Establish a response plan to quickly address breaches or vulnerabilities. By fostering a security-conscious culture, your organization can stay ahead of evolving threats.
Thus, Backend security is an ongoing effort requiring vigilance, strategic planning, and adherence to best practices. Whether you’re managing APIs, databases, or cloud integrations, securing backend development services ensures the reliability and safety of your application.
0 notes
Text
QGIS Course: Get Job-Ready with Practical GIS Training
In today's data-driven world, Geographic Information Systems (GIS) have become a crucial part of urban planning, environmental monitoring, disaster management, and much more. QGIS (Quantum GIS), a free and open-source platform, empowers professionals and learners with tools to visualize, manage, and analyze spatial data. Whether you're a student, engineer, environmentalist, or a researcher, a QGIS course can open doors to exciting opportunities across various industries.
Why Learn QGIS?
QGIS has become a go-to tool for both beginners and professionals due to its ease of use, robust community support, and constant updates. Here's why enrolling in a QGIS course makes sense:
Open-source and free: No licensing fees, which makes it ideal for individuals and startups.
Highly versatile: Supports vector, raster, and database formats.
Advanced features: Includes georeferencing, spatial analysis, plugin support, and 3D mapping.
Cross-industry applications: Useful in fields like agriculture, geology, city planning, and more.
What You Will Learn in a QGIS Course:
A comprehensive QGIS training program typically includes:
Introduction to GIS and spatial data types
Navigating the QGIS interface
Creating and managing shapefiles and layers
Georeferencing scanned maps
Performing spatial queries and analysis
Using plugins for advanced mapping
Creating interactive web maps
Real-world project-based learning
Courses may be structured for absolute beginners, intermediate users, or even advanced professionals, depending on your goals.
Case Studies:
Case Study 1: Mapping Urban Green Spaces in Bengaluru, India
Objective: To identify, measure, and map green cover in different wards of Bengaluru city.
Tools Used: QGIS, OpenStreetMap, and Sentinel satellite imagery
Process:
Satellite images were imported into QGIS and overlaid with city ward boundaries.
NDVI (Normalized Difference Vegetation Index) analysis was conducted using raster tools.
Green cover was calculated per ward and visualized on a thematic map.
Outcome:
The project revealed that only 14% of the city had consistent green cover.
Results were used by the city council to propose urban tree plantation drives in low-green areas.
Case Study 2: Disaster Risk Mapping in Nepal
Objective: To create a hazard map for earthquake-prone zones in Nepal.
Tools Used: QGIS, GPS survey data, DEM (Digital Elevation Models)
Process:
Field data was collected from various rural regions and imported into QGIS.
Slope and elevation maps were generated using DEM.
Layers were overlaid to identify regions at highest seismic risk.
Outcome:
Local authorities used the map to guide future construction projects and implement early-warning systems in critical zones.
Case Study 3: Agricultural Monitoring in Punjab
Objective: To monitor cropping patterns and improve irrigation efficiency in Punjab’s agricultural belt.
Tools Used: QGIS, Landsat imagery, Field survey data
Process:
Crop classification was done using supervised classification in QGIS.
Raster and vector data were combined to assess changes in crop types over time.
A report was generated to identify areas with over-irrigation.
Outcome:
Farmers received recommendations for crop rotation and water conservation.
The project helped reduce water usage by 18% over two years.
Career Opportunities After a QGIS Course:
Completing a QGIS certification course can lead to a variety of career paths, such as:
GIS Analyst
Remote Sensing Specialist
Urban Planner
Environmental Consultant
Agricultural GIS Expert
GIS Developer
With QGIS being recognized globally, your skills are applicable not just in India, but around the world.
Conclusion:
A QGIS course equips you with essential skills to analyze spatial data, contribute to real-world projects, and build a rewarding career. From urban development to environmental sustainability, GIS professionals are in high demand — and QGIS is your gateway to entering this dynamic field.
0 notes
Text
Python is a popular programming language used in a variety of industries such as data science, machine learning, web development, and more. If you're a Python engineer looking to create or update your resume, it's important to highlight the skills and experiences that make you stand out as a candidate. In this article, we'll discuss the top skills that you should consider including in your resume to demonstrate your proficiency as a Python engineer. These skills include programming languages, web frameworks, databases, software development life cycle, soft skills, data analysis and visualization, and cloud computing. By including these skills in your resume, you can showcase your expertise and increase your chances of landing your next job as a Python engineer. Python Programming Knowledge Python is a popular high-level programming language that is widely used in data analysis, web development, scientific computing, and artificial intelligence/machine learning. As a Python engineer, you should have a deep understanding of the language and be proficient in writing clean, efficient, and scalable code. Some of the key areas to focus on include: Syntax: You should be familiar with the syntax and basic programming concepts in Python, such as variables, loops, conditionals, functions, and error handling. Libraries and frameworks: Python has a vast ecosystem of libraries and frameworks that can be used for various purposes. As a Python engineer, you should be comfortable working with popular libraries such as NumPy, Pandas, Matplotlib, and SciPy, as well as web frameworks such as Flask and Django. Object-oriented programming: Python supports object-oriented programming, which is a powerful paradigm for building modular and reusable code. You should be familiar with OOP principles such as classes, objects, inheritance, and polymorphism. Code optimization: Writing efficient code is important for achieving good performance and scalability. You should be aware of techniques such as vectorization, caching, and profiling to optimize your code. Object-oriented Programming (OOP) Object-oriented programming (OOP) is a programming paradigm that focuses on creating objects that have properties (attributes) and methods (functions) to interact with other objects. In Python, OOP is widely used for building complex software systems that are modular, extensible, and maintainable. Here are some key concepts in OOP that you should be familiar with: Classes and objects: A class is a blueprint for creating objects, while an object is an instance of a class. You can define classes to encapsulate data and behavior, and create objects that can interact with each other. Inheritance: Inheritance is a mechanism for creating new classes based on existing ones. You can create a subclass that inherits attributes and methods from a parent class and adds or modifies its own. Polymorphism: Polymorphism is the ability of objects to take on different forms or behaviors depending on the context. You can achieve polymorphism in Python through methods overriding and duck typing. Encapsulation: Encapsulation is a way of hiding the complexity of an object from the outside world. You can use access modifiers to restrict the visibility of attributes and methods, and provide public interfaces for interacting with the object. Data Structures and Algorithms Data structures and algorithms are fundamental concepts in computer science and programming. As a Python engineer, you should be proficient in using data structures and algorithms to solve problems efficiently and effectively. Some key areas to focus on include: Data structures: Data structures are containers for storing and organizing data. You should be familiar with built-in data structures in Python, such as lists, tuples, dictionaries, and sets, as well as more advanced data structures such as trees, graphs, and hash tables. Algorithms: Algorithms are step-by-step procedures for solving problems.
You should be familiar with common algorithms such as sorting, searching, and graph traversal, as well as algorithm design techniques such as recursion, divide and conquer, and dynamic programming. Complexity analysis: Analyzing the time and space complexity of algorithms is important for understanding their performance characteristics. You should be able to analyze the worst-case, average-case, and best-case complexity of algorithms, and choose the most appropriate algorithm for a given problem. SQL SQL (Structured Query Language) is a standard language for managing relational databases. As a Python engineer, you may need to work with databases to store and retrieve data, perform data analysis, or build web applications. Here are some key areas to focus on: Basic SQL syntax: You should be familiar with basic SQL syntax, including commands for creating tables, inserting data, querying data, and modifying data. Joins and subqueries: Joining tables and using subqueries are common techniques for combining and filtering data from multiple tables. You should be able to write complex queries that involve joins and subqueries. Database design: Designing a database involves deciding on the structure of the data and the relationships between tables. You should be able to design a database schema that is normalized, efficient, and scalable. ORMs: Object-Relational Mapping (ORM) frameworks such as SQLAlchemy provide a way to interact with databases using Python objects instead of raw SQL. You should be familiar with using ORMs to perform CRUD operations and handle database migrations. Web Development Web development involves building websites and web applications using a combination of front-end technologies (HTML, CSS, JavaScript) and back-end technologies (server-side programming, databases). As a Python engineer, you may need to work with web development frameworks and tools to build web applications. Here are some key areas to focus on: Web frameworks: Web frameworks provide a structure and set of tools for building web applications. Python has several popular web frameworks such as Flask and Django. You should be familiar with the basics of web frameworks such as routing, templates, and request/response handling. Front-end technologies: Although Python is mostly used for back-end development, it's useful to have some knowledge of front-end technologies such as HTML, CSS, and JavaScript. You should be able to create and style web pages, and use JavaScript to add interactivity. RESTful APIs: REST (Representational State Transfer) is a design pattern for building web services that provide access to data and functionality. You should be able to design and implement RESTful APIs using web frameworks and tools. Testing and Debugging Testing and debugging are important skills for ensuring the quality and reliability of software systems. As a Python engineer, you should be able to write tests and debug code effectively. Here are some key areas to focus on: Testing frameworks: Python has several testing frameworks such as unittest and pytest that provide a way to write and run tests. You should be familiar with the basics of testing frameworks and how to write unit tests, integration tests, and functional tests. Debugging tools: Debugging tools such as print statements, logging, and debuggers are essential for finding and fixing bugs in code. You should be able to use these tools effectively to diagnose and resolve issues. Code quality: Writing high-quality code is important for maintainability and readability. You should be familiar with best practices such as code formatting, documentation, and version control, and use tools such as pylint and black to ensure code quality. Software Development Life Cycle Software development life cycle (SDLC) is a process for building software that involves several stages such as requirements gathering, design, development, testing, deployment, and maintenance.
As a Python engineer, you should be familiar with the SDLC and be able to follow best practices for each stage. Here are some key areas to focus on: Requirements gathering: Requirements gathering involves understanding the needs and goals of the software system. You should be able to work with stakeholders to gather and document requirements. Design: Design involves creating a high-level architecture and detailed design for the software system. You should be able to create design documents and use tools such as UML diagrams to communicate the design. Development: Development involves writing code to implement the design. You should be able to follow best practices such as modularization, encapsulation, and abstraction. Testing: Testing involves ensuring that the software system meets the requirements and works as expected. You should be able to write and execute tests, and use tools such as test coverage and code analysis to measure the effectiveness of testing. Deployment: Deployment involves releasing the software system to production. You should be familiar with deployment tools and techniques such as version control, continuous integration, and deployment pipelines. Maintenance: Maintenance involves fixing bugs and making enhancements to the software system after it has been deployed. You should be able to work with stakeholders to prioritize and address maintenance issues. Soft Skills Soft skills are non-technical skills that are important for success as a Python engineer. These skills include communication, collaboration, problem-solving, and time management. Here are some key areas to focus on: Communication: Communication skills are important for working effectively with stakeholders and team members. You should be able to communicate clearly and concisely, both verbally and in writing. Collaboration: Collaboration skills are important for working effectively in a team environment. You should be able to work with team members from diverse backgrounds and with different skill sets. Problem-solving: Problem-solving skills are important for identifying and resolving issues in software systems. You should be able to use critical thinking and analytical skills to diagnose and solve problems. Time management: Time management skills are important for managing deadlines and priorities. You should be able to prioritize tasks and manage your time effectively to meet project deadlines. Continuous learning: Continuous learning skills are important for staying up-to-date with new technologies and trends. You should be able to learn new skills and technologies on your own and stay abreast of industry developments. Data Analysis and Visualization Python is a popular language for data analysis and visualization due to its robust libraries such as Pandas, NumPy, and Matplotlib. As a Python engineer, you may be required to work with data to build data-driven applications or to analyze and visualize data for insights. Here are some key areas to focus on: Data manipulation: Data manipulation involves cleaning and transforming data to make it usable for analysis. You should be able to use Pandas and other libraries to manipulate data. Data analysis: Data analysis involves applying statistical and machine learning techniques to data to extract insights. You should be familiar with common data analysis techniques such as regression, clustering, and classification. Data visualization: Data visualization involves creating visual representations of data to communicate insights. You should be able to use Matplotlib and other visualization libraries to create charts, graphs, and other visualizations. Cloud Computing Cloud computing involves using remote servers to store, manage, and process data instead of using local servers or personal devices. As a Python engineer, you should be familiar with cloud computing technologies and platforms such as AWS, Azure, and Google Cloud Platform. Here are some key areas to focus on:
Cloud platforms: Cloud platforms provide infrastructure and services for building, deploying, and scaling applications in the cloud. You should be familiar with cloud platforms such as AWS, Azure, and Google Cloud Platform and understand how to use them to deploy and manage applications. Containerization: Containerization involves packaging an application with its dependencies into a container that can be run consistently across different environments. You should be able to use containerization tools such as Docker and Kubernetes to deploy and manage containers in the cloud. Serverless computing: Serverless computing is a cloud computing model where the cloud provider manages the infrastructure and automatically scales resources as needed. You should be able to use serverless computing platforms such as AWS Lambda and Azure Functions to build serverless applications in Python. In conclusion, as a Python engineer, your resume is your chance to showcase your skills and expertise to potential employers. Including the right skills can make a significant difference in whether or not you land an interview. In this article, we've discussed the top skills that you should consider including in your resume as a Python engineer. These skills include programming languages, web frameworks, databases, software development life cycle, soft skills, data analysis and visualization, and cloud computing. Remember to tailor your resume to the specific job you're applying for and highlight the skills that are most relevant to the position. By doing so, you'll increase your chances of impressing hiring managers and landing your next job as a Python engineer.
0 notes