#Word Documents Manipulation REST APIs
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs




Fun Fact
1,644 Tumblr posts in 1 second.
Text
Aspose.Cloud Newsletter October 2018: Microsoft Word Documents Manipulation REST APIs & Cloud SDKs
Aspose.Cloud Newsletter for October 2018 has now been published that highlights all the newly supported features offered in the recent releases, such as Microsoft Word Documents Manipulation REST APIs and Cloud SDKs, Perform Complex Word Processing Operation in Any Platform – Any Language, Manipulate Microsoft Word Documents using Cloud SDKs for Ruby and Python, Select HTML Fragments by CSS Selector from HTML Document using Aspose.HTML Cloud APIs, Create Method to Return API Info and Provide Optional Password Parameter for all Methods
Microsoft Word Documents Manipulation REST APIs and Cloud SDKs - Perform Complex Word Processing Operation in Any Platform – Any Language
Aspose.Words Cloud Product Family includes cloud SDKs for .NET, PHP, cURL, Python, Ruby and Node.js to create, edit, covert and render Microsoft Word document (20+ file formats) in any language or platform that is capable to call REST APIs. Developers can easily manipulate document properties, perform document processing operations and execute mail merge feature too. You can also render complete document or even a single page to all popular image file formats. Download FREE 30-Days Trial
Manipulate Microsoft Word Documents using Cloud SDKs for Ruby and Python
Aspose.Words Cloud APIs and SDKs allow developing apps to create, edit, convert or render Word documents without using Microsoft Word. Using the most optimized and scalable cloud SDKs for Ruby and Python – process Word documents even more quickly and easily than before. This version also provides Vector graphics support; and Table detection and recognition improvements while PDF to Word conversion. Read more details.
Select HTML Fragments by CSS Selector from HTML Document using Aspose.HTML Cloud APIs
Aspose.HTML Cloud APIs and SDKs now include new REST API to let you make Selection of the HTML layout fragments from THML document that matches criteria specified by using CSS selectors and returns them as plain text or JSON. Read more details here.
Create Method to Return API Info and Provide Optional Password Parameter for all Methods
Aspose.Slides Cloud APIs and SDKs allow to manipulate Microsoft PowerPoint presentations in any platform. The recent version announces plenty of important features that enable you to: create a method to return API info, remove obsolete xxxNotes export formats and feature of passing color in PUT method body for background resource. Moreover, it also provides support of optional password parameter for all methods. Read more
GET HTML Fragments and HTML Page Images using Aspose.HTML Cloud APIs
Aspose.HTML Cloud APIs and SDKs now add new REST API endpoints such as Get list of HTML fragments matching the specified XPath query by the source page URL and Get all HTML page images packaged as a ZIP archive by the source page URL. Read more
Add New Recurring Tasks and Convert Project Documents to HTML in Cloud
Aspose.Tasks Cloud APIs and SDKs allow cloud developers to manipulate Microsoft Project files in any platform. The latest version supports an optional parameter within the API to convert MS Project document to HTML format that specifies whether project should be returned as a ZIP archive. Read more
Cloud REST APIs to Convert HTML documents to PDF, Images and XPS
Aspose.HTML Cloud APIs and SDKs allow you to manipulate and translate HTML files in any Platform. The latest version adds a group of conversion PUT methods that provide possibility to upload conversion results to specified storage folder. Easily convert HTML files to PDF, XPS and popular image file formats. Read more details
Crop Specific Sections from Images using Aspose.OMR Cloud APIs
Aspose.OMR Cloud APIs and SDKs allow to add OMR (Optical Mark Recognition) capabilities within your cloud apps. The latest version allows clipping the desired area from the image and returns as an image in recognition response. It helps to obtain not only the recognition data but also cropped parts of the original image that may be further processed according to user needs. Read more
Collect a copy of Aspose Newsletter, August 2018 edition
Collect the English version of this newsletter
#Word Documents Manipulation REST APIs#Word Processing in Any Platform#Ruby & Python SDKs#CSS Selector from HTML Document#GET HTML Fragments#Add New Recurring Tasks
0 notes
Text
Intellij idea tutorial for beginners pdf

Intellij idea tutorial for beginners pdf how to#
Intellij idea tutorial for beginners pdf pdf#
Intellij idea tutorial for beginners pdf update#
Intellij idea tutorial for beginners pdf android#
Intellij idea tutorial for beginners pdf software#
Additionally reader should have basic understanding.
Intellij idea tutorial for beginners pdf software#
What are you waiting for? Press the BUY NOW button and start the course. This tutorial assumes preliminary knowledge of software development process and. SO ARE YOU READY TO GET STARTED AS A JAVA DEVELOPER? Students who want to learn java academically People who are looking to transition their way to become a java developer Students who want to start their career working as a java developer
Intellij idea tutorial for beginners pdf how to#
I will also teach you how to build interactive programs by accepting input from the user I will also teach you about object oriented concepts like inheritance, polymorphism, encapsulation and abstraction in java Class Libraries & REST APIs for the developers to manipulate & process Files from Word, Excel, PowerPoint, Visio, PDF, CAD & several other categories in Web. The following is the list of recommended system requirements for running Intellij IDEA 15. Setup In this example we shall use Intellij IDEA 15.0 Community Edition, which can be downloaded from the JetBrains website.
Intellij idea tutorial for beginners pdf pdf#
I will also teach you how to create methods, constructors, classes and objects Besides studying them online you may download the eBook in PDF format Download NOW 1. I will teach you about loops in java and conditional statements I will teach you about variables, data types and different operators in java If your code is scattered around different directories you will have to either print it in. In this course, you will learn what is java and how it works Select the directory that contains all of your source code. Learn concepts of core java and write programs Please request a refund, I only want satisfied students If after taking this course you realize that this is not for you. This course is backed by Udemy's 30 day money back guarantee. Well run through a quick tutorial covering the basics of selecting rows. This is a practical course, where in in every lecture, I will actually write a example program to make you understand the concept IntelliJ IDEA provides methods for installing, uninstalling, and upgrading. So if you are a beginners, don't worry, I am 100% committed to help you succeed. This course is designed keeping beginners in mind, we have made sure that each and every concept is clearly explained in a easy to understand manner.
Intellij idea tutorial for beginners pdf android#
If you are looking to be android developer, you need to learn java programming and that's where this course can help you. This course is java for complete beginners. This course also helps you get started as a java programmer from scratch (Java for beginners). This is not a theoretical course, but instead I will teach you step by step, practically, by writing programming examples. How to import iText 7 in IntelliJ IDEA to create a Hello World PDF In these tutorials, we only define the kernel and the layout projects as dependencies. There are three variants a typed, drawn or uploaded signature. Decide on what kind of signature to create. This course teaches you everything you should know to about Java Programming to become a java developer and get the job. Follow the step-by-step instructions below to design your intellij idea tutorial pdf: Select the document you want to sign and click Upload. New keyword and memory allocation (Section 6) Updated the course with a new section - "Arrays".Īdded 2 new lectures “Learn to write interactive programs in java” and “swap two variables using third variable” We are adding a new section on exception handling. information about the component kit starter, you can check this tutorial. PDF DOWNLOAD EBOOK Kotlin Programming: The Big Nerd Ranch Guide By. The plugin is now installed into your Intellij IDEA, you can start using it. As you may know IntelliJ IDEA provides a tool that converts Java source code into Kotlin. book will also introduce you to JetBrains IntelliJ IDEA development env. Upgraded with 3.5 hours of new content and 17 new lectures which will power up your ability to learn java. Below I want to show you a basic example of how to do this. Updated section 10 : Exception handling by adding resources which contain code samples which students can download and use to execute the programs. New lectures added in section : “Variables, Datatypes and Operators in Java”Īdded supplemental resources to every lecture of this course in the form of PDF handouts.
Intellij idea tutorial for beginners pdf update#
Here is our course update timeline.ģ new sections with 5+ hours of content as below :Ģ new sections with 5+ hours of content - "Collection in java" and "Modifiers in java"Ĭoding challenges and new content added in section : “Conditional statements and loops in Java”Ģ hours of content added in section : “Conditional statements and loops in Java”
Google maven dependencies.This course is updated frequently.
0 notes
Photo

D3 6.0, easy 3D text, Electron 10, and reimplementing promises
#503 — August 28, 2020
Unsubscribe | Read on the Web
JavaScript Weekly
ztext.js: A 3D Typography Effect for the Web — While it initially has a bit of a “WordArt” feel to it, this library actually adds a pretty neat effect to any text you can provide. This is also a good example of a project homepage, complete with demos and example code.
Bennett Feely
D3 6.0: The Data-Driven Document Library — The popular data visualization library (homepage) takes a step forward by switching out a few internal dependencies for better alternatives, adopts ES2015 (a.k.a. ES6) internally, and now passes events directly to listeners. Full list of changes. There’s also a 5.x to 6.0 migration guide for existing users.
Mike Bostock
Scout APM - A Developer’s Best Friend — Scout’s intuitive UI helps you quickly track down issues so you can get back to building your product. Rest easy knowing that Scout is tracking your app’s performance and hunting down small issues before they become large issues. Get started for free.
Scout APM sponsor
Danfo.js: A Pandas-like Library for JavaScript — An introduction to a new library (homepage) that provides high-performance, intuitive, and easy-to-use data structures for manipulating and processing structured data following a similar approach to Python’s Pandas library. GitHub repo.
Rising Odegua (Tensorflow)
Electron 10.0.0 Released — The popular cross-platform desktop app development framework reaches a big milestone, though despite hitting double digits, this isn’t really a feature packed released but more an evolution of an already winning formula. v10 steps up to Chromium 85, Node 12.1.3, and V8 8.5.
Electron Team
Debug Visualizer 2.0: Visualize Data Structures Live in VS Code — We first mentioned this a few months ago but it’s seen a lot of work and a v2.0 release since then. It provides rich visualizations of watched values and can be used to visualize ASTs, results tables, graphs, and more. VS Marketplace link.
Henning Dieterichs
💻 Jobs
Sr. Engineer @ Dutchie, Remote — Dutchie is the world's largest and fastest growing cannabis marketplace. Backed by Howard Schultz, Thrive, Gron & Casa Verde Capital.
DUTCHIE
Find a Job Through Vettery — Create a profile on Vettery to connect with hiring managers at startups and Fortune 500 companies. It's free for job-seekers.
Vettery
📚 Tutorials, Opinions and Stories
Minimal React: Getting Started with the Frontend Library — Dr. Axel explains how to get started with React while using as few libraries as possible, including his state management approach.
Dr. Axel Rauschmayer
A Leap of Faith: Committing to Open Source — Babel maintainer Henry Zhu talks about how he left his role at Adobe to become a full-time open source maintainer, touching upon his faith, the humanity of such a role, and the finances of making it a reality.
The ReadME Project (GitHub)
Faster CI/CD for All Your Software Projects - Try Buildkite ✅ — See how Shopify scaled from 300 to 1800 engineers while keeping their build times under 5 minutes.
Buildkite sponsor
The Headless: Guides to Learning Puppeteer and Playwright — Puppeteer and Playwright are both fantastic high level browser control APIs you can use from Node, whether for testing, automating actions on the Web, scraping, or more. Code examples are always useful when working with such tools and these guides help a lot in this regard.
Checkly
How To Build Your Own Comment System Using Firebase — Runs through how to add a comments section to your blog with Firebase, while learning the basics of Firebase along the way.
Aman Thakur
A Guide to Six Commonly Used React Component Libraries
Max Rozen
Don't Trust Default Timeouts — “Modern applications don’t crash; they hang. One of the main reasons for it is the assumption that the network is reliable. It isn’t.”
Roberto Vitillo
Guide: Get Started with OpenTelemetry in Node.js
Lightstep sponsor
Deno Built-in Tools: An Overview and Usage Guide
Craig Buckler
How I Contributed to Angular Components — A developer shares his experience as an Angular Component contributor.
Milko Venkov
🔧 Code & Tools
fastest-levenshtein: Performance Oriented Levenshtein Distance Implementation — Levenshtein distance is a metric for measuring the differences between two strings (usually). This claims to be the fastest JS implementation, but we’ll let benchmarks be the judge of that :-)
ka-weihe
Yarn 2.2 (The Package Manager and npm Alternative) Released — As well as being smaller and faster, a dedupe command has been added to deduplicate dependencies with overlapping ranges.
Maël Nison
Light Date ⏰: Fast and Lightweight Date Formatting for Node and Browser — Comes in at 157 bytes, is well-tested, compliant with Unicode standards on dates, and written in TypeScript.
Antoni Kepinski
Barebackups: Super-Simple Database Backups — We automatically backup your databases on a schedule. You can use our storage or bring your own S3 account for unlimited backup storage.
Barebackups sponsor
Carbonium: A 1KB Library for Easy DOM Manipulation — Edwin submitted this himself, so I’ll let him explain it in his own words: “It’s for people who don’t want to use a JavaScript framework, but want more than native DOM. It might remind you of jQuery, but this library is only around one kilobyte and only supports native DOM functionality.”
Edwin Martin
DNJS: A JavaScript Subset for Configuration Languages — You might think that JSON can already work as a configuration language but this goes a step further by allowing various other JavaScript features in order to be more dynamic. CUE and Dhall are other compelling options in this space.
Oliver Russell
FullCalendar: A Full Sized JavaScript Calendar Control — An interesting option if you want a Google Calendar style control for your own apps. Has connectors for React, Vue and Angular. The base version is MIT licensed, but there’s a ‘premium’ version too. v5.3.0 just came out.
Adam Shaw
file-type: Detect The File Type of a Buffer, Uint8Array, or ArrayBuffer — For example, give it the raw data from a PNG file, and it’ll tell you it’s a PNG file. Usable from both Node and browser.
Sindre Sorhus
React-PDF: Display PDFs in a React App As Easily As If They Were Images
Wojciech Maj
Meteor 1.11 Released
Filipe Névola
🕰 ICYMI (Some older stuff that's worth checking out...)
Need to get a better understanding of arrow functions? This article from Tania Rascia will help.
Sure, strictly speaking a string in JavaScript is a sequence of UTF-16 code units... but there's more to it.
Zara Cooper explains how to take advantage of schematics in Angular Material and ng2-charts to substantially reduce the time and work that goes into building a dashboard
In this intro to memoizaition Hicham Benjelloun shares how you can optimize a function (by avoiding computing the same things several times).
by via JavaScript Weekly https://ift.tt/3jmo1hQ
0 notes
Text
Consistent Backends and UX: Why Should You Care?
Article Series
Why should you care?
What can go wrong? (Coming soon)
What are the barriers to adoption? (Coming soon)
How do new algorithms help? (Coming soon)
More than ever, new products aim to make an impact on a global scale, and user experience is rapidly becoming the determining factor for whether they are successful or not. These properties of your application can significantly influence the user experience:
Performance & low latency
The application does what you expect
Security
Features and UI
Let's begin our quest toward the perfect user experience!
1) Performance & Low Latency
Others have said it before; performance is user experience (1, 2). When you have caught the attention of potential visitors, a slight increase in latency can make you lose that attention again.
2) The application does what you expect
What does ‘does what you expect’ even mean? It means that if I change my name in my application to ‘Robert’ and reload the application, my name will be Robert and not Brecht. It seems important that an application delivers these guarantees, right?
Whether the application can deliver on these guarantees depends on the database. When pursuing low latency and performance, we end up in the realm of distributed databases where only a few of the more recent databases deliver these guarantees. In the realm of distributed databases, there might be dragons, unless we choose a strongly (vs. eventually) consistent database. In this series, we’ll go into detail on what this means, which databases provide this feature called strong consistency, and how it can help you build awesomely fast apps with minimal effort.
3) Security
Security does not always seem to impact user experience at first. However, as soon as users notice security flaws, relationships can be damaged beyond repair.
4) Features and UI
Impressive features and great UI have a great impact on the conscious and unconscious mind. Often, people only desire a specific product after they have experienced how it looks and feels.
If a database saves time in setup and configuration, then the rest of our efforts can be focused on delivering impressive features and a great UI. There is good news for you; nowadays, there are databases that deliver on all of the above, do not require configuration or server provisioning, and provide easy to use APIs such as GraphQL out-of-the-box.
What is so different about this new breed of databases? Let’s take a step back and show how the constant search for lower latency and better UX, in combination with advances in database research, eventually led to a new breed of databases that are the ideal building blocks for modern applications.
The Quest for distribution
I. Content delivery networks
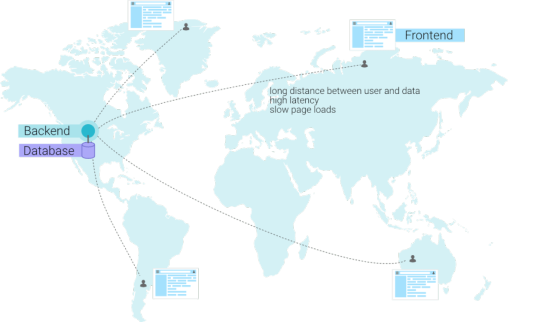
As we mentioned before, performance has a significant impact on UX. There are several ways to improve latency, where the most obvious is to optimize your application code. Once your application code is quite optimal, network latency and write/read performance of the database often remain the bottleneck. To achieve our low latency requirement, we need to make sure that our data is as close to the client as possible by distributing the data globally. We can deliver the second requirement (write/read performance) by making multiple machines work together, or in other words, replicating data.
Distribution leads to better performance and consequently to good user experience. We’ve already seen extensive use of a distribution solution that speeds up the delivery of static data; it’s called a Content Delivery Network (CDN). CDNs are highly valued by the Jamstack community to reduce the latency of their applications. They typically use frameworks and tools such as Next.js/Now, Gatsby, and Netlify to preassemble front end React/Angular/Vue code into static websites so that they can serve them from a CDN.

Unfortunately, CDNs aren't sufficient for every use case, because we can’t rely on statically generated HTML pages for all applications. There are many types of highly dynamic applications where you can’t statically generate everything. For example:
Applications that require real-time updates for instantaneous communication between users (e.g., chat applications, collaborative drawing or writing, games).
Applications that present data in many different forms by filtering, aggregating, sorting, and otherwise manipulating data in so many ways that you can’t generate everything in advance.
II. Distributed databases
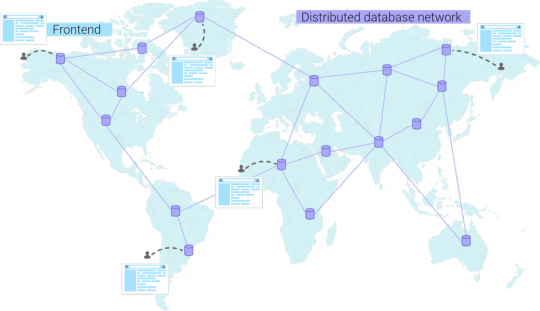
In general, a highly dynamic application will require a distributed database to improve performance. Just like a CDN, a distributed database also aims to become a global network instead of a single node. In essence, we want to go from a scenario with a single database node...
...to a scenario where the database becomes a network. When a user connects from a specific continent, he will automatically be redirected to the closest database. This results in lower latencies and happier end users.
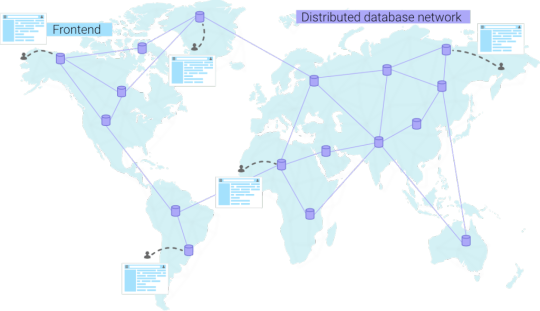
If databases were employees waiting by a phone, the database employee would inform you that there is an employee closer by, and forward the call. Luckily, distributed databases automatically route us to the closest database employee, so we never have to bother the database employee on the other continent.

Distributed databases are multi-region, and you always get redirected to the closest node.
Besides latency, distributed databases also provide a second and a third advantage. The second is redundancy, which means that if one of the database locations in the network were completely obliterated by a Godzilla attack, your data would not be lost since other nodes still have duplicates of your data.
Distributed databases provide redundancy which can save your application when things go wrong.
Distributed databases divide the load by scaling up automatically when the workload increases.
Last but not least, the third advantage of using a distributed database is scaling. A database that runs on one server can quickly become the bottleneck of your application. In contrast, distributed databases replicate data over multiple servers and can scale up and down automatically according to the demands of the applications. In some advanced distributed databases, this aspect is completely taken care of for you. These databases are known as "serverless", meaning you don’t even have to configure when the database should scale up and down, and you only pay for the usage of your application, nothing more.
Distributing dynamic data brings us to the realm of distributed databases. As mentioned before, there might be dragons. In contrast to CDNs, the data is highly dynamic; the data can change rapidly and can be filtered and sorted, which brings additional complexities. The database world examined different approaches to achieve this. Early approaches had to make sacrifices to achieve the desired performance and scalability. Let’s see how the quest for distribution evolved.
Traditional databases' approach to distribution
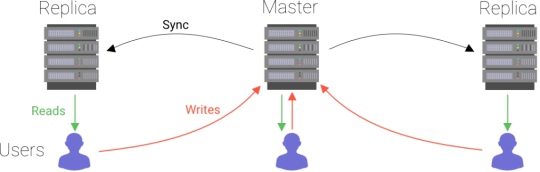
One logical choice was to build upon traditional databases (MySQL, PostgreSQL, SQL Server) since so much effort has already been invested in them. However, traditional databases were not built to be distributed and therefore took a rather simple approach to distribution. The typical approach to scale reads was to use read replicas. A read replica is just a copy of your data from which you can read but not write. Such a copy (or replica) offloads queries from the node that contains the original data. This mechanism is very simple in that the data is incrementally copied over to the replicas as it comes in.
Due to this relatively simple approach, a replica’s data is always older than the original data. If you read the data from a replica node at a specific point in time, you might get an older value than if you read from the primary node. This is called a "stale read". Programmers using traditional databases have to be aware of this possibility and program with this limitation in mind. Remember the example we gave at the beginning where we write a value and reread it? When working with traditional database replicas, you can’t expect to read what you write.
You could improve the user experience slightly by optimistically applying the results of writes on the front end before all replicas are aware of the writes. However, a reload of the webpage might return the UI to a previous state if the update did not reach the replica yet. The user would then think that his changes were never saved.
The first generation of distributed databases
In the replication approach of traditional databases, the obvious bottleneck is that writes all go to the same node. The machine can be scaled up, but will inevitably bump into a ceiling. As your app gains popularity and writes increase, the database will no longer be fast enough to accept new data. To scale horizontally for both reads and writes, distributed databases were invented. A distributed database also holds multiple copies of the data, but you can write to each of these copies. Since you update data via each node, all nodes have to communicate with each other and inform others about new data. In other words, it is no longer a one-way direction such as in the traditional system.
However, these kinds of databases can still suffer from the aforementioned stale reads and introduce many other potential issues related to writes. Whether they suffer from these issues depends on what decision they took in terms of availability and consistency.
This first generation of distributed databases was often called the "NoSQL movement", a name influenced by databases such as MongoDB and Neo4j, which also provided alternative languages to SQL and different modeling strategies (documents or graphs instead of tables). NoSQL databases often did not have typical traditional database features such as constraints and joins. As time passed, this name appeared to be a terrible name since many databases that were considered NoSQL did provide a form of SQL. Multiple interpretations arose that claimed that NoSQL databases:
do not provide SQL as a query language.
do not only provide SQL (NoSQL = Not Only SQL)
do not provide typical traditional features such as joins, constraints, ACID guarantees.
model their data differently (graph, document, or temporal model)
Some of the newer databases that were non-relational yet offered SQL were then called "NewSQL" to avoid confusion.
Wrong interpretations of the CAP theorem
The first generation of databases was strongly inspired by the CAP theorem, which dictates that you can't have both Consistency and Availability during a network Partition. A network partition is essentially when something happens so that two nodes can no longer talk to each other about new data, and can arise for many reasons (e.g., apparently sharks sometimes munch on Google's cables). Consistency means that the data in your database is always correct, but not necessarily available to your application. Availability means that your database is always online and that your application is always able to access that data, but does not guarantee that the data is correct or the same in multiple nodes. We generally speak of high availability since there is no such thing as 100% availability. Availability is mentioned in digits of 9 (e.g. 99.9999% availability) since there is always a possibility that a series of events cause downtime.

Visualization of the CAP theorem, a balance between consistency and availability in the event of a network partition. We generally speak of high availability since there is no such thing as 100% availability.
But what happens if there is no network partition? Database vendors took the CAP theorem a bit too generally and either chose to accept potential data loss or to be available, whether there is a network partition or not. While the CAP theorem was a good start, it did not emphasize that it is possible to be highly available and consistent when there is no network partition. Most of the time, there are no network partitions, so it made sense to describe this case by expanding the CAP theorem into the PACELC theorem. The key difference is the three last letters (ELC) which stand for Else Latency Consistency. This theorem dictates that if there is no network partition, the database has to balance Latency and Consistency.
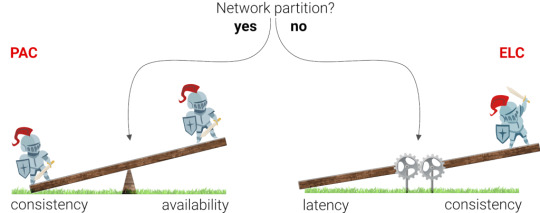
According to the PACELC theorem, increased consistency results in higher latencies (during normal operation).
In simple terms: when there is no network partition, latency goes up when the consistency guarantees go up. However, we’ll see that reality is still even more subtle than this.
How is this related to User Experience?
Let’s look at an example of how giving up consistency can impact user experience. Consider an application that provides you with a friendly interface to compose teams of people; you drag and drop people into different teams.
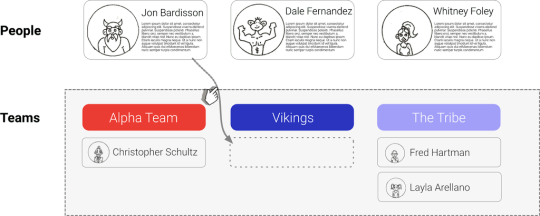
Once you drag a person into a team, an update is triggered to update that team. If the database does not guarantee that your application can read the result of this update immediately, then the UI has to apply those changes optimistically. In that case, bad things can happen:
The user refreshes the page and does not see his update anymore and thinks that his update is gone. When he refreshes again, it is suddenly back.
The database did not store the update successfully due to a conflict with another update. In this case, the update might be canceled, and the user will never know. He might only notice that his changes are gone the next time he reloads.
This trade-off between consistency and latency has sparked many heated discussions between front-end and back-end developers. The first group wanted a great UX where users receive feedback when they perform actions and can be 100% sure that once they receive this feedback and respond to it, the results of their actions are consistently saved. The second group wanted to build a scalable and performant back end and saw no other way than to sacrifice the aforementioned UX requirements to deliver that.
Both groups had valid points, but there was no golden bullet to satisfy both. When the transactions increased and the database became the bottleneck, their only option was to go for either traditional database replication or a distributed database that sacrificed strong consistency for something called "eventual consistency". In eventual consistency, an update to the database will eventually be applied on all machines, but there is no guarantee that the next transaction will be able to read the updated value. In other words, if I update my name to "Robert", there is no guarantee that I will actually receive "Robert" if I query my name immediately after the update.
Consistency Tax
To deal with eventual consistency, developers need to be aware of the limitations of such a database and do a lot of extra work. Programmers often resort to user experience hacks to hide the database limitations, and back ends have to write lots of additional layers of code to accommodate for various failure scenarios. Finding and building creative solutions around these limitations has profoundly impacted the way both front- and back-end developers have done their jobs, significantly increasing technical complexity while still not delivering an ideal user experience.
We can think of this extra work required to ensure data correctness as a “tax” an application developer must pay to deliver good user experiences. That is the tax of using a software system that doesn’t offer consistency guarantees that hold up in todays webscale concurrent environments. We call this the Consistency Tax.
Thankfully, a new generation of databases has evolved that does not require you to pay the Consistency Tax and can scale without sacrificing consistency!
The second generation of distributed databases
A second generation of distributed databases has emerged to provide strong (rather than eventual) consistency. These databases scale well, won't lose data, and won't return stale data. In other words, they do what you expect, and it's no longer required to learn about the limitations or pay the Consistency Tax. If you update a value, the next time you read that value, it always reflects the updated value, and different updates are applied in the same temporal order as they were written. FaunaDB, Spanner, and FoundationDB are the only databases at the time of writing that offer strong consistency without limitations (also called Strict serializability).
The PACELC theorem revisited
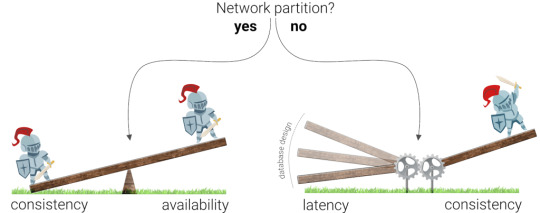
The second generation of distributed databases has achieved something that was previously considered impossible; they favor consistency and still deliver low latencies. This became possible due to intelligent synchronization mechanisms such as Calvin, Spanner, and Percolator, which we will discuss in detail in article 4 of this series. While older databases still struggle to deliver high consistency guarantees at lower latencies, databases built on these new intelligent algorithms suffer no such limitations.
Database designs influence the attainable latency at high consistency greatly.
Since these new algorithms allow databases to provide both strong consistency and low latencies, there is usually no good reason to give up consistency (at least in the absence of a network partition). The only time you would do this is if extremely low write latency is the only thing that truly matters, and you are willing to lose data to achieve it.

intelligent algorithms result in strong consistency and relatively low latencies
Are these databases still NoSQL?
It's no longer trivial to categorize this new generation of distributed databases. Many efforts are still made (1, 2) to explain what NoSQL means, but none of them still make perfect sense since NoSQL and SQL databases are growing towards each other. New distributed databases borrow from different data models (Document, Graph, Relational, Temporal), and some of them provide ACID guarantees or even support SQL. They still have one thing in common with NoSQL: they are built to solve the limitations of traditional databases. One word will never be able to describe how a database behaves. In the future, it would make more sense to describe distributed databases by answering these questions:
Is it strongly consistent?
Does the distribution rely on read-replicas, or is it truly distributed?
What data models does it borrow from?
How expressive is the query language, and what are its limitations?
Conclusion
We explained how applications can now benefit from a new generation of globally distributed databases that can serve dynamic data from the closest location in a CDN-like fashion. We briefly went over the history of distributed databases and saw that it was not a smooth ride. Many first-generation databases were developed, and their consistency choices--which were mainly driven by the CAP theorem--required us to write more code while still diminishing the user experience. Only recently has the database community developed algorithms that allow distributed databases to combine low latency with strong consistency. A new era is upon us, a time when we no longer have to make trade-offs between data access and consistency!
At this point, you probably want to see concrete examples of the potential pitfalls of eventually consistent databases. In the next article of this series, we will cover exactly that. Stay tuned for these upcoming articles:
Article Series
Why should you care?
What can go wrong? (Coming soon)
What are the barriers to adoption? (Coming soon)
How do new algorithms help? (Coming soon)
The post Consistent Backends and UX: Why Should You Care? appeared first on CSS-Tricks.
Consistent Backends and UX: Why Should You Care? published first on https://deskbysnafu.tumblr.com/
0 notes
Text
Enhance the Security of Your Wordpress Website with Latest 5.2.4 Release

While there are hundreds of sources available to design and develop a website, Wordpress is considered as one of the most essential and feature-rich content management systems in the developer’s community. And, every once in a while, the core Wordpress team never miss the chance to update their download versions.
And, 2019 was the remarkable year in the history of Wordpress as maximum version updates have come in this year. However, most of the website owners, those using 5.2 version must be gluing their eyes on the last few releases of Wordpress that has been specifically announced in October.
So, What’s new in Wordpress 5.2.4 Release?
The core team of Wordpress Developer have pushed out the Wordpress release 5.2.4 on 14th October 2019, addressing six major security issues. All the security vulnerabilities are proposed privately by the Wordpress community people to the Wordpress core team of developers after the release of 5.2.3 version to streamline the website designing procedure further.
Let’s have a quick look at the Security highlights of 5.2.4 Wordpress Core Updates.
The core team of developers have closely analyzed and evaluate the Wordpress release 5.2.3 and identify various security issues that need to be changed urgently. Therefore, 5.2.4 version is completely focused on security issues and fixes these below bugs.
● An issue that allows fictitious posts to be noticed.
● Fix the issue related to Server-side request forgery(SSRF) in the way how URLs are validated.
● Find the method to allow stored XSS to inject JavaScript into <style> tags.
● Fixing bugs with referrer validation in the Wordpress admin.
● Stored cross-site scripting (XSS) can be integrated from the customizer screen.
● A practice that allowed to use the Vary: Origin header to position the cache of JSON GET request (REST API).
I’m sure who have been engaged in Wordpress Development Sevices, can easily understand these technical terms but for non-techies, it might be just fancy words which are difficult to interpret.
Don’t worry, let’s understand each security issue in detail and in simple language:
Wordpress <= 5.2.3 - Viewing Private Post by Unauthenticated Users
Allowing any stranger to view your private files is one of the most dangerous bugs for the website owners. Generally, this issue was located by J.D. Grimes and informed to the Wordpress team. This vulnerability of the 5.2 version fails to restrict the unauthenticated users to view your private or draft posts.
However, this issue has been resolved in the next release, 5.2.4 Wordpress.
Wordpress <= 5.2.3 - SSRF in URL Validation
Let 's make it easy for non-techies!
Server-Side Request Forgery (SSRF) is a critical issue where an attacker can manipulate an HTTP client into making requests on the internet. And with the increasing cyber issues, having this kind of vulnerabilities in your site can be a serious issue for the businesses.
This vulnerability was noticed by Eugene Kolodenker and had 100% fixed in 5.2.4 version. If you still in doubt how would you fix this issue in your website, then look for the Wordpress Development Services to catch the bugs and get the perfect solution in real time.
Wordpress <= 5.2.3 - Stored XSS in Style HTMLTags
Basically, the HTML style tag has been used to add inline CSS to an HTML document, which is nowadays used by attackers to steal the private data. With 5.2.3 version, this was the major vulnerability, reported by Weston Ruter.
With the introduction of Wordpress 5.2.4, some filters have been integrated to protect your data from the stored XSS attacks.
Wordpress <= 5.2.3 - Referer Validation in WP Admin
The 5.2.4 version of Wordpress has affected the bug of Admin Referrer validation. According to the official Wordpress documentation, it now easy to detect from where the user was referred and from which admin page. Apart, WordPress 5.2.4 also includes a couple of other bugs that need to be fixed further.
To indulge in more details, you can get in touch with Wordpress Web Development Company right here.
Now the question is, how can you update your site with 5.2.4 Wordpress Version Safely?
What is the Simplest Way to Upgrade Your Site With 5.2.4 Version?
Wordpress new versions are already rolled out to enhance the security of your site and to enrich the functionality of your Wordpress website. As these major updates were released a couple of months back, therefore, many of the Wordpress websites boasting the 3.7 to 5.2 version have received the new security fixes. And if you are still looking for the ways to upgrade your site, then you are at right place. Let’s learn how you can manage Wordpress customizing adhering new updates?
Basically, there are three ways users can adopt to upgrade their site; enable the “Auto Update” mode on under the “Dashboard” in the Wordpress admin. Second, you can download the latest Wordpress release from the archive and manually run an update to cover the security risks.
Thirdly, hire best Wordpress plugin developers who are well-versed with the latest community updates and able to design the website incorporating the latest security features.
And like any other versions of Wordpress, users can immediately update the dashboard automatically by visiting https://wordpress.org/download/release-archive/ or simply hiring the Wordpress Developers to make it done securely and safely. Rest you can follow the step-by-step instructions for installing and upgrading Wordpress.
Why Should You Use Latest Version of Wordpress?
While it is a bit annoying to update your site time to time with every latest release, but if you are the one who always wanted to keep their site secure and ensuring run smoothly, then it is important to adopt the latest update as soon as possible.
Now the simple thing is, why it is crucial for the website? How can you integrate it efficiently? Let’s learn and dig deep!
1. Enhance Speed
Did you know what the best thing is in your website that attracts a large run of users to your site? Yes, its speed!
There is nothing more annoying than browsing a site with the low loading speed. Ideally, your website page speed should be three to four seconds, and if it is taking more than that, firstly you need to look for the latest version of the Wordpress release.
Wordpress Web Development Companies always adhere to the latest release not only to improve the speed of your site but also for many improvements to make it run fastly. Your efforts to upgrade your site, will lead to quick page loading and maximize your SEO efforts.
2. Bug Fixes
Despite performing multiple testing of your website before its release, there always chance left for bugs. That's where Wordpress Website Development companies always seek out the new releases while developing the site to fix all the minor to major bugs in a real-time.
3. Integrate Latest Features
Undoubtedly, Wordpress never miss the chance to WOW their users with rich features and new releases. And these features will help Wordpress Security Plugin Development companies to manage your site in a better way.
Ending Note
Hopefully, you understand the purpose of introducing Wordpress 5.2.4 release and the major security issues that have been resolved in this update.
However, With the constant releases of Wordpress versions, it becomes complicated to experiment with the site and update its functionalities on your own. However, the best way to approach these bugs is to get in touch with Wordpress Website Development company backed by highly skilled developers that can quickly locate and fix the issues without hampering the other elements of your site.
For more details, you can browse our portfolio and contact us our experts for the project estimation!
0 notes
Text
React: The Basics
React JS is today's most popular JavaScript library for building User Interfaces, which has created by Facebook. We can build modern, fast Single Page Applications or websites with React. React is so popular in the market and beneficial to know for a Web/Frontend Developer.
Is React JS a Library or a Framework?
This is one of the most unclear subjects of React. Let’s make this clear from the beginning. React is a Library, not a Framework.
What is a Library?
A library in programming can be explained as a collection of codes. We use a library to write code in a much simpler way or to import a feature from it into our project. JQuery is a library for example. We can write JavaScript much simpler by using JQuery, or we can import written JQuery features to our project. The project itself is not dependent on a library.
What is a Framework?
A Framework, on the other hand, is a complete package of code with its own functionalities & libraries. A Framework has its own rules, you don’t have much flexibility and the project is dependent on the Framework you use. Angular is an example of a framework. So React is for building User Interfaces, and how you program the rest of the project is up to you. Like JQuery, you can include React in your project partially, or completely. So React JS a library.
React Virtual DOM
To understand the importance of React Virtual DOM, first, you need to know what DOM (Document Object Model) is. DOM is basically a representation of the HTML code on a webpage. The document is the web page itself, the objects are the HTML tags. And finally, the model of DOM is a tree structure:
The Document Object Model (DOM) is a programming interface for HTML and XML documents. It represents the page so that programs can change the document structure, style, and content. The DOM represents the document as nodes and objects. That way, programming languages can connect to the page.
A Web page is a document. This document can be either displayed in the browser window or as the HTML source. But it is the same document in both cases. The Document Object Model (DOM) represents that same document so it can be manipulated. The DOM is an object-oriented representation of the web page, which can be modified with a scripting language such as JavaScript.
What is the benefit of Virtual DOM?
Each time you make a change in the code, DOM will be completely updated and rewritten. This is an expensive operation and consumes lots of time. In this point, React provides a solution: The Virtual DOM.
So when something changes:
React first creates an exact copy of the DOM
Then React figures out which part is new and only updates that specific part in the Virtual DOM
Finally, React copies only the new parts of the Virtual DOM to the actual DOM, rather than completely rewriting it.
This approach makes a webpage much faster than a standard webpage. That’s also one of the reasons why React is so popular.
So what is this JSX?
JSX (JavaScript XML) is a syntax extension to JavaScript used by React. JSX is basically used to write HTML tags inside JavaScript. Later, the JSX code will be translated into normal JavaScript, by Babel.
In summary, React doesn’t have HTML files, HTML tags are rendered directly inside JavaScript. This approach makes React faster.
What is a React Component?
A component is an independent, reusable code block, which divides the UI into smaller pieces. In other words, we can think of components as LEGO blocks. Likewise, we create a LEGO structure from many little LEGO blocks, we create a webpage or UI from many little code blocks (components).
We don’t really want to have thousands of lines of code together in one single file. Maintenance of the code gets more and more complex as the project gets bigger. In this point, dividing the source code into components helps us a lot. Each component has its own JS and CSS code, they are reusable, easier to read, write and test. In web development, as the reasons I explained above, it’s beneficial to use component-based technologies, and React JS is one of them.
React has 2 types of components: Functional (Stateless) and Class (Stateful).
Functional (Stateless) Components
A functional component is basically a JavaScript (or ES6) function which returns a React element. According to React official docs, the function below is a valid React component:
function Welcome(props) {
return <h1>Hello, {props.name}</h1>;
}
IMPORTANT: Functional components are also known as stateless components
So a React Functional Component:
Is a JavaScript / ES6 function
Must return a React element
Take props as a parameter if necessary
Class (Stateful) Components
Class components are ES6 classes. They are more complex than functional components including constructors, life-cycle methods, render( ) function and state (data) management. In the example below, we can see how a simple class component looks like:
import React, { Component } from 'react';
class ParentComponent extends Component {
render() {
return <h1>I'm the parent component.</h1>;
}
}
export default ParentComponent;
So, a React class component:
It is an ES6 class, will be a component once it ‘extends’ React component.
Can accept props (in the constructor) if needed
Can maintain its own data with state
Must have a render( ) method which returns a React element (JSX) or null
Props
Let’s start by defining Component’s props (obviously short for properties) in React. Props are used to customize Component when it’s being created and give it different parameters.
import React, {Component} from 'react'
class Topic extends Component {
render{
return(
<div>
{this.props.name}
</div>
)
}
}
One of the most important features of props is that they can be passed by a parent component to its child components. This allows us to create a component that can be customized with a new set of props every time we use it.
import React, {Component} from 'react'
class Welcome extends Component {
render{
return(
<div>
<p> Welcome to React, today you will learn: </p>
<Topic name="Props"/>
<Topic name="State"/>
</div>
)
}}
Props are passed to the component and are fixed throughout its lifecycle. But there are cases when we want to use data that we know is going to change over time. In this case, we use something called state.
State
Unlike props, the state is a private feature and it strictly belongs to a single Component. The state allows React components to dynamically change output over time in response to certain events.
Component’s state is initialized inside a constructor:
class Counter extends Component{
constructor(props){
super(props);
this.state = {counter: 0}
}
render(){
return(
<p>{this.state.counter}</p>
)
}
And can be changed later using inbuilt setState() function
class Counter extends Component{
constructor(props){
super(props);
this.state = {counter: 0}
this.increment = this.increment.bind(this);
}
increment(){
this.setState({counter: this.state.counter + 1})
}
render(){
return(
<button onClick={this.increment}>Like</button>
<p>{this.state.counter}</p>
)
}
Lifecycle of Components
Each component in React has a lifecycle that you can monitor and manipulate during its three main phases.
The three phases are Mounting, Updating, and Unmounting.
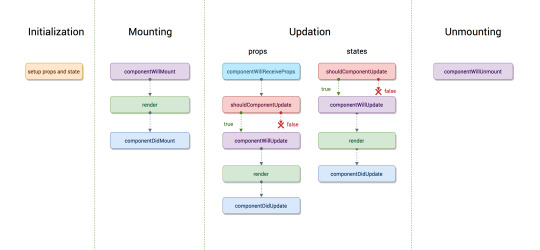
Common React Lifecycle Methods
render()
componentDidMount()
componentDidUpdate()
componentWillUnmount()
render()
The render() method is the most used lifecycle method. You will see it in all React classes. This is because render() is the only required method within a class component in React. As the name suggests it handles the rendering of your component to the UI. It happens during the mounting and updating of your component.
componentDidMount()
Now your component has been mounted and ready, that’s when the next React lifecycle method componentDidMount() comes in play. componentDidMount() is called as soon as the component is mounted and ready. This is a good place to initiate API calls if you need to load data from a remote endpoint.
componentDidUpdate()
This lifecycle method is invoked as soon as the updating happens. The most common use case for the componentDidUpdate() method is updating the DOM in response to prop or state changes. You can call setState() in this lifecycle, but keep in mind that you will need to wrap it in a condition to check for state or prop changes from the previous state. Incorrect usage of setState() can lead to an infinite loop.
componentWillUnmount()
As the name suggests this lifecycle method is called just before the component is unmounted and destroyed. If there are any cleanup actions that you would need to do, this would be the right spot.
Routing
Routing is a key aspect of web applications (and even other platforms) that could not be left out in React. We can make full-fleshed single-page applications with React if we harness the powers of routing. This does not have to be a manual process, we can make use of React-Router.
Switch
Switch component helps us to render the components only when path matches otherwise it fallbacks to the not found component.
<Switch>
<Route exact path="/" component={App} />
<Route path="/users" component={Users} />
<Route path="/contact" component={Contact} />
<Route component={Notfound} />
</Switch>
Browser Router
A <Router> that uses the HTML5 history API (pushState, replaceState, and the popstate event) to keep your UI in sync with the URL.
<BrowserRouter
basename={optionalString}
forceRefresh={optionalBool}
getUserConfirmation={optionalFunc}
keyLength={optionalNumber}>
<App />
</BrowserRouter>
Go through this link for better understanding of Routes: Getting started with React Router
Handling Events
Handling events with React elements is very similar to handling events on DOM elements. There are some syntactic differences:
React events are named using camelCase, rather than lowercase.
With JSX you pass a function as the event handler, rather than a string
<button onClick={activateLasers}></button>
Named Export vs Default Export in ES6
Named Export: (export)
With named exports, one can have multiple named exports per file. Then import the specific exports they want to be surrounded in braces. The name of the imported module has to be the same as the name of the exported module.
// imports
// ex. importing a single named export
import { MyComponent } from "./MyComponent";
// ex. importing multiple named exports
import { MyComponent, MyComponent2 } from "./MyComponent";
// ex. giving a named import a different name by using "as":
import { MyComponent2 as MyNewComponent } from "./MyComponent";
// exports from ./MyComponent.js file
export const MyComponent = () => {}
export const MyComponent2 = () => {}
Default Export: (export default)
One can have only one default export per file. When we import we have to specify a name and import like:
// import
import MyDefaultComponent from "./MyDefaultExport";
// export
const MyComponent = () => {}
export default MyComponent;
Getting Started:
You can just run the create-react-app on the command line, followed by the name of the app you want to create. This creates the react app, with all the necessary functionality you need, already built into the app. Then you can just cd into the react app and start it with npm start.
Command: create-react-app my-app
Basic Structure
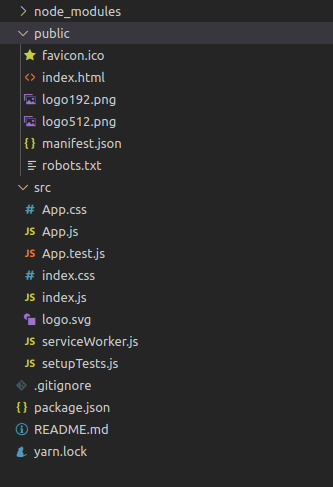
node_modules is where packages installed by NPM or Yarn will reside.
src is where your dynamic files reside. If the file is imported by your JavaScript application or changes contents, put it here.
public is where your static files reside.
0 notes
Text
Amazing JQuery 3.4.1
New Post has been published on https://is.gd/XxMK3S
Amazing JQuery 3.4.1

What is jQuery?
jQuery is a fast, small, and feature-rich JavaScript library. It makes things like HTML document traversal and manipulation, event handling, animation, and Ajax much simpler with an easy-to-use API that works across a multitude of browsers.
JQuery
It is a JavaScript library. Which is the lightweight and main use of jQuery is write less and do more.
The purpose of jQuery is to make easier use of JavaScript on your website.
Add Jquery to your project
Download lib file from jquery.com –https://jquery.com/download/
Include this lib into your Html.
The jQuery library is a single JavaScript file, and you reference it with the HTML <script> tag.
<head> <script src="jquery-3.4.1.min.js"></script> </head>
jQuery CDN
If you don’t want to download and host jQuery yourself, you can include it from a CDN (Content Delivery Network).
Both Google and Microsoft host jQuery.
<head> <script src="https://ajax.googleapis.com/ajax/libs/jquery/3.4.1/jquery.min.js"></script> </head>
jQuery Syntax
It starts with 3S
$ – this is the first S which for jquery
S – this for selector means you need to select the item first before doing any work on that
3S is for shoot the action means you need to call a function or doing some operation like that.
$(selector).shoot_the_action()
$(this).hide() - hides the current element. $("p").hide() - hides all <p> elements. $(".test").hide() - hides all elements with class="test". $("#test").hide() - hides the element with id="test".
How to prevent any jQuery code from running before the document is finished loading?
It is good practice to wait for a fully-loaded document and then you will work on that. For that, you need to use document ready function which runs after the Html document completely loads.
$(document).ready(function() // jQuery methods go here... );
What is the difference between the compressed, uncompressed and slim version of jQuery?
Current version 3.4.1 whose sizes as
Uncompressed:-267 kb
Compresses: 87 kb
Slim: 69 kb
The uncompressed file is best used during development or debugging. the compressed file saves bandwidth and improves performance in production.
Uncompressed Version:- the use of uncompressed version is mainly used in the development environment and main use of this allows you to see what’s causing problems and fix.
Compresses Version: it mainly used in a production environment, the file size much less it’s just 87kb.
In both versions, the core functionality of jQuery shouldn’t be tweaked.
Slim version: in jquery slim following features are removed
Query.fn.extend
jquery.fn.load
jquery.each // Attach a bunch of functions for handling common AJAX events
jQuery.expr.filters.animated
ajax settings like jQuery.ajaxSettings.xhr, jQuery.ajaxPrefilter, jQuery.ajaxSetup, jQuery.ajaxPrefilter, jQuery.ajaxTransport, jQuery.ajaxSetup
xml parsing like jQuery.parseXML,
animation effects like jQuery.easing, jQuery.Animation, jQuery.speed
the slim version saves weight by excluding the ajax and effects modules.
What are CDN and CDN fallback?
CDN– content delivery network refers geographically distributed group of servers which main work is to serve the content faster as per your geolocation. CDN allows you to the quick transfer of assets like Html page, CSS, javascript files, images, and videos.
In simple words, CDN means copy your website content to multiple locations and serves this content to the user as per their location. Means if I have hosted my content on 2 locations like the US and India. And a user whose location Texas if he accesses my site the content is delivered from US server which is nearer to user that’s the whole point of CDN.
Benefits of CDN
Improving website load times
Reducing bandwidth costs
Increasing content availability and redundancy
Improving website security
CDN Fallback
In our project, we use CDN mainly provided by Microsoft or Google. In some situation, if they are not responding or fail we need some alternative solution to include a jQuery in your project.
<html> <head> <title> JQuery Demos </title> <script src="https://ajax.googleapis.com/ajax/libs/d3js/5.12.0/d3.min.j"></script> <script> window.jQuery || document.write(unescape("<script src='/libs/jquery-3.4.1.js' type='text/javascript'%3E%3C/script%3E")); </script> </head> <body> <h1>Hello Sagar</h1> <input type="text" id="txtname" /> <script> $("#txtname").val('Jquery Is Present ') </script> </body> </html>
Above project we misspell the google CDN so it will not work then after that we check whether the jquery is present on-page or not. If It is not present then add local library file of jquery into our Html and rest is working fine.

In CDN fallback means in case our google or Microsoft CDN is not working then we switch over local server or a local file to serve the content.
0 notes
Text
Top 10 Image Formats That Are Best for Custom Web Development
custom web development is one of the biggest trends in this era because now a day’s software has tons of functionality that cannot work properly on our hand held devices and our home computers.
So the software industry moved software applications on cloud platforms to utilize the resources effectively. No user needs an application all the time neither does an application have large number of users.
The biggest chunk of data that creates bottlenecks is images so it necessary to resize images to correct resolution with latest image formats that offers high quality images with minimal size. Before discussing the best image formats let’s get to know the basics about images.
There are mainly two types of image files Raster and Vector with respect to which we have created dozens of image formats that we are using today.
Bitmap or Raster Vs. Vector and their image formats
Raster images are created by gathering pixels together which are painted in different colours, on zooming raster images one can easily observe the pixels. Raster images have the capability to create colour gradients with a subtle blend of multiple colours.
Raster images are used for cameras and tile shaped images in which colour detailing and visual effects can be embedded easily. Raster images have JPEG, PNG, GIF, TIFF Make an Inquiry about this newsand many other image formats.
Raster images are usually edited with paint, Photoshop etcetera.
Vector images are created by mathematical calculation in programming from one point to the other, on zooming vector images one easily observe that rendered image show same visual graphics without distortion. Vector images doesn’t have the capability of creating colour gradient nor they have support for wide range of colours.
Therefore, they are being used to create logos and charts in data analytics applications which do not distort on enlarging images. Vector images have SVG, WEBP, BMP, EPS and many other image formats.

Vector images are usually edited with adobe Photoshop, illustrator, Inkspace, BoxySVG and office suites.
JPEG
JPEG image format supports lossy compression for digital images. JPEG image format is normally used for tile shaped images as it achieves 10:1 compression with little loss in image quality.
JPEG2000
JPEG 2000 image format was developed by Joint Photographic Experts group in the year 2000. JPEG 2000 offers superior compression ratio, error resilience, HDR support and progressive transmission by pixel with which smaller parts of images are loaded first to show a blurred image and rest of the pixels are loaded later on to display high quality image.
This image format reduces the first time of interaction for websites which projects the custom web development to be highly responsive on user’s end.
JPEG XR
JPEG XR image format was developed by Microsoft. This image format supports lossless and lossy compression with a better compression rate which provides little bit more clarity than JPEG 2000 at almost same size.
PNG
PNG is a raster graphics file format that supports lossless data compression. This image format was designed for transferring images over internet but images are bulky in PNG.
Web designers Make an Inquiry about this news are still using PNG image format because it is possible to create images like logos which do not have any background layers in images.

GIF
GIF is a raster image format developed by a team from CompuServe led by an American computer scientist Steve Wilhite in 1987. Images in this format have a slightly better compression ratio than PNG but the main reason for popularity of this image format is that one can create motion graphics with this image format.
Video clips of about 5 seconds can be converted into GIF of smaller size and can be added as image in the content.
TIFF
TIFF is a raster image format for storing raster graphics images, popular among graphic artists, the publishing industry and photographers. TIFF is widely supported by scanning, faxing, word processing, optical character recognition, image manipulation, desktop publishing, page-layout and 3D applications.
WEBP
WEBP is a raster image format developed by google and was first launched in 2010. as a new open standard for lossy compressed true-color graphics for web.
This image format provides superior lossless and lossy compression that generates images which are 26 to 34% smaller than JPG images making it by far the best format for custom web development. Google provides image converting utilities to WEBP image format for all operating systems and APIs that developers can integrate in to their code to dynamically converting uploaded images in to WEBP.
SVG
SVG is an XML based vector image format developed as open standard by world wide web consortium in 1999. SVG images and their behaviours are defined in XML text files which means they can be edited by any text editor as well as drawing software.
These files in SVG image format can be searched, indexed, scripted, and compressed but they have limited support for colours but it is not possible to swiftly blend multiple colours together to create colour gradients. SVG images will not distort on enlarging them because they are composed of fixed set of shapes so web designers use SVG image format to create logos.
EPS
EPS is a Postscript based vector image format that was developed by Adobe. EPS images are postscript documents which contains text as well as images.
EPS images can be converted in to bitmap image formats PNG, JPG, TIFF and PDF with adobe illustrator.

AI
AI image format file is a drawing created with Adobe Illustrator which is a vector graphics editing program. It is composed of paths connected by points, rather than raster image data.
AI files are commonly used in creating logos. Since Illustrator image format files are saved in a vector format, they can be enlarged without losing image quality.
Some third-party programs can open AI files but they might raster the image where the vector data will be converted to a bitmap format.
Those who read it till the end of my list, here are two bonus formats for custom web development.
PDF
PDF image format is a multi-platform document created by Adobe Acrobat or another PDF application. The PDF image format is commonly used for saving documents and publications in a standard format that can be viewed on multiple platforms.
In many cases, PDF files are created from existing documents. Pdf image format files are based on the PostScript language which encapsulates a complete description of a fixed-layout flat document, including the text, fonts, vector graphics, raster images and other information required to display it.
SWF
SWF is an Adobe Flash file format Make an Inquiry about this news used for multimedia, vector graphics and Action Script. SWF image format files can contain animations or applets of varying degrees of interactivity and functions.
They may also occur in programs, commonly browser games, using Action-script for displaying motion graphics.
article source
#app developers toronto#custom web development toronto#custom web development#mobile app developers#ecommerce development#ecommerce web design toronto
0 notes
Link

GroupDocs Cloud Newsletter February 2019 edition brings together updates, news and information from recent API releases and other happenings during the last month. Major highlight of the month is GroupDocs.Signature Cloud SDK for Ruby platform, which helps you in incorporating different e-signatures into Microsoft Word, Excel, PowerPoint, PDF, OpenDocument and image file formats in your Ruby based Cloud apps.
In other news, rendering your Microsoft Outlook data files of PST, OST and CGM formats within your cloud apps becomes that much more convenient with the help of GroupDocs.Viewer Cloud SDKs. Looking to annotate your business documents and images? Try GroupDocs.Annotation Cloud REST APIs, which include advanced document annotation features for a host of file formats.
Continue reading at the newsletter blog – http://bit.ly/groupdocs-cloud-newsletter-february-2019
Subscribe to GroupDocs Cloud on YouTube – http://bit.ly/2QIMt2U
#groupdocs cloud#newsletter#esignature#eSigning#SDK#rendering#document viewer#Cloud APIs#Cloud REST API#image
0 notes
Link
1. Authentication feature and Authorization :
The execution of verification systems is extremely basic with Laravel. Nearly everything is arranged remarkably. It has a straightforward strategy to make approval and furthermore controls the entrance to its assets by confirming clients directly toward the start, this to avoid unapproved client get to, which is a noteworthy concern. This progression enables the engineers to be without strain! Laravel Development Company were uses this features for fast development strategy.
2. Inbuilt Object-Orientation Libraries functions :
One reason why the interest for Laravel is higher than different systems is on the grounds that it accompanies the truly necessary pre-introduced object-arranged libraries. It has more than 20 pre-introduced libraries with the verification library being the most celebrated. It additionally accompanies the most recent security highlights, for example, database and login protections, CSRF assurance and encryption among others.
3. Integration of Mail Services :
The SwiftMailer library alongside the perfect and basic APIs are the center quality of Laravel. Drivers like SparPost, Amazon SES, SMTP, Ailgun, Mandrill and so forth… give mail administrations joining to Laravel Framework. Perhaps the greatest bit of leeway to Laravel is that it accompanies email-availability. When reconciliation with email administrations is done, any Laravel-based web application can use any cloud-based or neighborhood administration to begin to send Mail.
Mails can likewise be sent over an assortment of conveyance channels including Slack and SMS through Nexmo. Click To Tweet
4. Database Migration :
Keeping the database b/w development machines in sync is a pain for most developers! Since they will in general make a great deal of changes to the database that is difficult to monitor, alternatives like MySQL Workbench for information. In any case, the information movement is simple in Laravel, with the assistance relocations and seeding. For whatever length of time that all the database work is put in relocations and seeds, you can move the progressions into any advancement machine effectively.
5. Supports MVC Architecture :
Laravel Development Services completely supports MVC (Model-View-Controller) Architecture which helps in easier code security and maintenances by placing them in layers/tiers. Here it will easier to edit a particular template or the underlying code without affecting the rest as data-manipulating logic is different from that which handles the display/ presentation. It helps in better documentation and improves performance. It also contains many other much needed built-in functionalities making it yet another reason to choose Laravel.
6. Security :
Laravel deals with the security inside its structure and uses salted and hashed secret phrase (Decrypted hashing calculation can be for creating a scrambled portrayal of a secret word). It has basic strategies to keep away from client infusion of the <script> tag. It utilizes arranged SQL explanations to maintain a strategic distance from infusion assaults to the database.
It also comes with Email-Readiness features which save the time of Developers
The post Imbedded Features in Laravel Development for Web Developers appeared first on Digital Ideas.
via Digital Ideas
0 notes
Text
Original Post from FireEye Author: Chong Rong Hwa
In the past, hackers have attempted to compromise targeted organizations by sending phishing email directly to their users. However, there seems to be a shift away from this trend in the recent years. Hackers were observed to conduct multi-prong approaches to targeting the organization of interest and their affiliated companies. For example, in July 2011, ESTsoft’s ALZip update server was compromised in an attack on CyWorld and Nate users.1
In one of our investigations, a malicious email was found to be targeting a Taiwanese technology company that deals heavily with the finance services industry (FSI) and the government in Taiwan (see Figure 1 below). To trick the user into opening the malicious document, the attacker made use of an announcement by the Taiwanese Ministry of Finance (see Figure 2).
Figure 1. Email targeting Taiwanese technology firm
Figure 2. Related Taiwanese news — Radio Taiwan International (2012)2
The malicious document was password-protected using an auspicious number “888888.” In Chinese, the number eight (pinyin “BA”) is auspicious because it sounds like “FA” (发) which means gaining wealth. By encrypting the malicious payload using the default Word protection mechanism, it would effectively evade pattern-matching detection without using a zero-day exploit. In this case, the attacker has exploited the vulnerability (CVE-2012-0158) in “MSCOMCTL.ocx.” The technical analysis will be detailed in the following sections: Protected Document Analysis, Shellcode Analysis, Payload Analysis, and Indicators of Compromise.
Protected Document Analysis
As shown in Figure 3, the ExifTool indicates that the hacker was using a simplified Chinese environment. This is interesting because it contradicts the email content that was written in traditional Chinese, which is the language mainly used in Taiwan.
It was also observed that the malicious Word document loaded “MSCOMCTL.ocx” prior exploiting the application as depicted in Figure 4.
Figure 3. ExifTool information
Figure 4. Loading of MSCOMCTL.OCX
The attacker leveraged CVE-2012-0158 to exploit unpatched Microsoft Word. The vulnerable code inside the MSCOMCTL copied the malicious data into the stack with the return pointer overwritten with 0x27583C30 (see Figure 5). The purpose of overwriting the return pointer is to control the EIP in order to execute the malicious shellcode that is loaded into the stack. The instruction that is disassembled from 0x27583C30 is JMP ESP, which effectively executes the shellcode in the stack (see Figure 6).
Figure 5. Corrupting the stack
Figure 6. JMP ESP
Shellcode Analysis
The shellcode was analyzed to perform the following tasks:
Decrypt and copy the malicious executable (payload) to the temp folder as “A.tmp“
Launch “A.tmp” with WinExec
Delete Word Resiliency registry key (using Shlwapi.SHDeleteKeyA) to prevent Word application from performing recovery
Decrypt and copy the decoy Word document into the temp folder
Launch decoy document using the WinExec command. Command line is as follows: cmd.exe /c tasklist&”C:Program FilesMicrosoft OfficeOffice12WINWORD.EXE” “%temp% ” /q
Terminate compromised Word application
The hook-hopping technique was used heavily by the shellcode to bypass inline-hooking codes patched by API monitoring software such as host-based IPS and AV (see Figure 7). By doing so, the shellcode would be able to invoke the API without the knowledge of the monitoring software. This same technique was also used in the Operation Aurora attack against Google.
Figure 7. Hook-hopping technique
The body of the shellcode was encrypted using a simple XOR key 0x70 to deter analysis (see Figure 8).
Figure 8. Before/After decrypting shellcode
The encrypted executable and decoy files were embedded within the malicious document at offset 0x10000 and 0x48000 respectively. It was observed that both payloads were encrypted using the same algorithm “counter based XOR with ROR” (see below).
Figure 9. Embedded file decryption
Payload Analysis
This APT malware was stealthy and complex due a number of anti-analysis techniques deployed. It made use of multi-staging, hook-hopping, encryption, anti-sandboxing, and anti-disassembly techniques to deter both behavioral and (dynamic/static) code analysis. It is obvious that the attacker took deliberate effort to evade both automated (using signature and sandbox) and manual analysis of the malware to delay or evade detection.
After the shellcode extracted the malicious payload “A.tmp” and the decoy document, “A.tmp” was executed. When “A.tmp” was first executed, it duplicated itself with the filename generated using “GetTempFileName” API with “Del” as prefix. An example of the generated filename is “DelA.tmp.” Before “A.tmp” terminates, it executed its duplicate with the following command line parameters: “ .” The spawned duplicate used the process handle to wait for the termination of “A.tmp” and deleted it using the module path before continuing to execute the rest of the malicious codes.
While debugging “DelA.tmp,” it is interesting to note that the anti-sandbox technique is used. The anti-sandbox technique depicted in Figure 10 checks whether the “Sleep” API is manipulated by a sandbox. For example, the Sleep API call could be skipped by a sandbox without accounting for the “accelerated” time. Hence, when the malware tries to get “System Time” interleaved with a Sleep API call, the time difference could be less than a second. In this case, if the time difference before and after sleeping for two seconds is not more than a second, it would then assume to be running inside a sandbox and terminate itself.
Figure 10. Anti-sandbox trick
Before continuing to the next stage of infection, “DelA.tmp” decrypted a resource and injected it into the memory space of the suspended “C:/Windows/Notepad.exe” process that was launched by “DelA.tmp.” Before the process was resumed, EAX of the thread context was updated with the starting address of the injected malicious code (see Figure 11). This is because when a process starts, EAX is referenced for the starting address. By doing so, it disrupts debugging. As a counter-measure for analysis, we could make use of memory-modifying software to modify the memory content of Notepad.exe at the address indicated by EAX (0x0100 1130) to become “EB FE” (opcode for JMP -2). By this way, the process would be resumed in a spin-lock manner which allows the analyst to attach a debugger to the process and continue debugging injected malicious code.
Figure 11. EAX of thread context to point to start of malicious code
To further complicate the situation, the injected code dropped a DLL named “irron.dll” and registered it as a windows service. While debugging this DLL inside “ServiceMain,” it was observed that the section named “test” was decrypted. This decrypted content was run as code in a separate thread to deter static code analysis. Inside this newly spawned thread, all the secrets were encrypted and anti-disassembling tricks were used to counter-reverse engineering. For example, strings are deliberately placed in between codes to confuse disassembler due to the code-data duality property (see Figure 12).
Figure 12. Anti-disassembly codes
This Windows service was analyzed to be an information stealer, which has the capability to allow remote control by the attacker with the CnC Server domain as ftp.skydnastwm.com over port 15836 using TCP communication. The figure below reveals how this multi-staged infection was conducted.
Figure 13. Flow of APT malware infection
Taking a deeper look into the registered domain, it is interesting to see that this domain was registered on September 2012, which was not too long before the attack against the Taiwanese company (see figure below). Additionally, this domain was registered with Shanghai Yovole Networks, Inc. based in China; this could imply that this attack could have originated from China. Additionally, it is observed that the registrar did not validate the name that was used by the attacker. “William” should be read as a name rather as separated first and last name.
Figure 14. Registered malicious domain
Indicators of Compromise
The presence of the following file, system, and network artifacts (generated by the shellcode and dropped executable payload) could indicate that a computer is compromised.
%temp%/
%temp%/Del%c.tmp (It may in the form of “DelA.tmp” and etc.)
%windir%/System32/irron.dll
Event name “DragonOK“
Registered service “irmon” with description, “The irmon service monitors for infrared devices such as mobile phones, and initiates the file transfer wizard.”
Resolving to “ftp.skydnastwm.com” and connects to “15836″
Conclusion
Targeted attacks are continuing to be real threats where one incident is considered too many. In this example, we can see that the attack plan was deliberated. Hackers attempt to hit their target by phishing companies that are affiliated with them. This could be even more effective than spear phishing their well-defended targets. Hence, it is recommended that organizations ensure that all their closely affiliated companies are at least equally protected.
Additionally, a number of tell-tale signs indicate that this malware could have originated from China. Firstly, the Word document was created in a simplified Chinese environment despite the use of traditional Chinese inside the email body. Secondly, the domain was registered with a company located in Shanghai. Thirdly, the malware used the event name “DragonOK,” where Dragon is an auspicious creature in Chinese mythology and folklore.
Lastly, we observed that APT malware is becoming increasingly complex with the use of anti-analysis techniques. Hence, it is important to defend the organization against traditional and modern threats through policy, awareness programs, and technologies.
Reference
1 Command Five Pty Ltd. (September, 2011). SK Hack by an Advanced Persistent Threat. Retrieved from http://www.commandfive.com/papers/C5_APT_SKHack.pdf
2Radio Taiwan International. (28 11, 2012). Retrieved from http://news.rti.org.tw
3 Liston, T., & Skoudis, E. (2006). On the Cutting Edge: Thwarting Virtual Machine Detection.
#gallery-0-5 { margin: auto; } #gallery-0-5 .gallery-item { float: left; margin-top: 10px; text-align: center; width: 33%; } #gallery-0-5 img { border: 2px solid #cfcfcf; } #gallery-0-5 .gallery-caption { margin-left: 0; } /* see gallery_shortcode() in wp-includes/media.php */
Go to Source Author: Chong Rong Hwa Hackers Targeting Taiwanese Technology Firm Original Post from FireEye Author: Chong Rong Hwa In the past, hackers have attempted to compromise targeted…
0 notes
Text
Fwd: Urgent requirements of below positions
New Post has been published on https://www.hireindian.in/fwd-urgent-requirements-of-below-positions-45/
Fwd: Urgent requirements of below positions
Please find the Job description below, if you are available and interested, please send us your word copy of your resume with following detail to [email protected] or please call me on 703-594-5490 to discuss more about this position.
We are planning for a weekend drive on 2nd Feb and 3rd Feb and hence need your extended support for that. Will be expecting an active participation from each of you.
Position
Location
Salesforce Developer
Columbus / Indianapolis, IN
SFDC Business Analyst
Peoria, IL
CPQ/Apttus Consultant
Minneapolis, MN
SFDC Developer
Austin, TX
Salesforce Sales Cloud + APTTUS CLM (Senior Developer) OR Cloud Craze
Houston, TX
SFDC Community Cloud developer
San Francisco, CA
Sr. Developer Lightning Community
Trevose, PA
Job Description
Job Title: Salesforce Developer
Location: Columbus or Indianapolis, IN
Duration: Contract
Work Authorization: USC/GC ONLY
Mandatory Skills: SFDC Lightning, Apex, Visual Force Looking for Field Service Experience Field Service implementation (Siebel, ServiceMax etc..)
Desired Skills: HTML, CSS, Ajax, JavaScript, J Query
Experience: 10+ Years is mandatory
Job Description:
5+ years of SFDC (Salesforce) experience.
Must have Hands on Customization APEX, Lightning, Visual Force, Triggers, Batch, Schedule Apex, VF Components, Test Class etc. and Good experience in SFDC configuration and mapping features to the business requirements.
Good Experience in Data Migration using SFDC import and export utilities.
Experience in implementing integration solutions between CRM, ERP and Financial systems
Strong RDBMS knowledge and building SQL queries. Experience in working with HTML, CSS, Ajax, JavaScript, JQuery will be a plus.
Look for candidates with Salesforce Developer Certification.- Experience developing customer-facing user interface
Able to read, modify and debug complex code.
Job itle: SFDC Business Analyst
Location: Peoria, IL
Duration: Contract
Mandatory Skills: Business Analyst, Salesforce.com, Sales Cloud, Apex
Job Description:
Over 10 years of IT experience with about 5 years of experience in the Salesforce platform as a Business Analyst
Experienced working with Salesforce.com Sales cloud, Service Cloud, Communities
Experience in interacting with business stake holders and capturing business requirements
Good knowledge on Apex development in creating Objects, Triggers, Apex Classes, Standard Controllers, Custom Controllers and Controller Extensions
Experienced in building Custom Applications that includes administration configuration implementing and support experience with Salesforce.com platform
Proficiency in administrative tasks like Creating Roles Profiles Users Email Services Page Layouts Workflow Alerts Actions Reports and Approval Processes
Implemented security and sharing rules at object field and record level for different users at different levels of organization. Also created various profiles and configured the permissions based on the organizational hierarchy
Experienced working with salesforce.com sandbox and production environments also with Eclipse IDE Force.com Plug-in environments
Technology savvy with aptitude and experience in adopting modern methodologies and innovative techniques to boost work efficiency
Detail-oriented energetic team player motivated with multi-tasking capabilities problem solver and hands-on leader with exceptional presentation and client/customer relation skills
Strong communication and inter-personal skills with ability to work well in a dynamic team environment.
Certified Salesforce Developer or Administrator would be preferred.
Position: CPQ/Apttus Consultant
Location: Minneapolis, MN
Contract: Longterm
Required Qualification
At least 1 year or 2 projects experience in Angular JS.
At least 1 year or 2 projects experience in CPQ development such as Apttus callbacks.
At least 1 year or 2 projects experience in Apttus CPQ (Configure/price and quote) with good understanding on how Apttus CPQ works. Don’t need experience in Apttus CLM or other module.
4-5 years of solid SFDC development experience. No compromise here since there should be enough people with this level experience.
SFDC Integration using SOAP/REST API’s must
Knowledge of Continuous Integration (Deployment) using SVN tools (JENKINS/GIT) must.
Responsibilities
Manage day to day development activities on the salesforce.com platform and Apttus tool using Apex and Visual Force
Support the creation of customizations and integrations required to solution delivery
Configure the Salesforce.com application based on the business requirements
Develop custom applications using Apex, Visualforce, JavaScript, AJAX, HTML, CSS
Apply best practices and experience to build Salesforce.com applications.
Develop estimates for projects
Work closely with other developers in the team, business analyst, QA analyst and project managers.
Research Salesforce.com and Apttus CPQ capabilities as needed to suit business requirements, and provide gap analysis
Position: SFDC Developer
Location: Austin, TX
Duration: Contract
Job Description:
Responsibilities:
• Work with stakeholders and existing engineering teams to gather requirements and translate them into efficient salesforce solutions.
• Develop, maintain and test new Salesforce processes using Salesforce techniques such as custom objects, APEX triggers, workflow rules, validation rules and Lightning.
• Design and implement for API endpoints for internal integrations.
• Carry out system maintenance, configuration, development and testing.
• Documenting designs and implementation
• Creating training materials for users.
• Ensuring that migration to new platform is successful.
Minimum qualifications:
• 3+ Salesforce Development Experience including hands-on experience in Apex Code, SOQL queries, Triggers, Validation Rules, workflows, flows/process builder and migration of code, Visualforce, backup of sandbox/ repository.
• Experience implementing Web Service SOAP, REST API and bulk APIs
• Flexible engineer, with strong communication and team working skills
• Experience with complete lifecycle of software development, from design to product ionization.
• Experience with working with distributed teams and a great team player
• Good writtenand verbal communication skills.
• Degree in Computer Science, Engineering or related areas.
Preferred qualifications:
• Salesforce Certified Administrator
• Experience with Salesforce Security Models
• Experience with C++ development
Position: Salesforce Sales Cloud + APTTUS CLM (Senior Developer) OR Cloud Craze
Location: Houston, TX
Duration: Contract
Mandatory Skills: Salesforce Sales Cloud and Apttus CLM, HTML, CSS, JavaScript
Experience: 8+ Years
Job Description:
The Salesforce Developer will perform hands-on technical implementation, with a focus on delivering functional solutions on the Salesforce.com platform.
Salesforce Developer will take a lead role in the design, implementation, deployment, and documentation of projects that leverage the Salesforce.com tool set. This is an Apttus CLM environment on Force.com (Salesforce) platform.
Required Technical and Professional Expertise
5+ years Salesforce development experience
Hands-on experience in Apttus CLM
2+ years’ experience HTML, CSS, JavaScript, Ajax, JQuery
Design, develop implement and support custom business solutions for a variety of industries
Effectively translate business requirements into systems solutions using Visual force and Apex
Drive projects from concept and design to testing, and implementation
Strong SOQL experience
SFDC architecture experience
Excellent, highly professional written and oral communication skills required
Strong analytical and problem-solving skills
Ability to work effectively both independently and as part of a team
Experience with project automation technology: Jenkins, automated unit testing, Ant etc. is preferable
Preferred Tech and Prof Experience
Bachelor's degree or Master’s Degree in Computer Science or related field is preferred
Job Title: SFDC Community Cloud developer
Location: San Francisco, CA
Duration: 6-8 months
Mandatory skills: Experience with Community Cloud development.(MUST)
Job description:
Proficiency in SFDC Administrative tasks like creating profiles, roles & users, manipulating page layouts and record types, setting up email services, configuring approvals, designing workflows, creating reports & dashboards, working in both the Classic UI and Lightning
Hands-on design and architect of custom solutions on the force.com platform including significant work in Apex, Visual Force, SOQL, and application integration patterns.
Solid understanding of Salesforce Connect to call external API.
Experience in developing client-specific solutions on the force.com platform using Apex, Visual force, Lightning.
Experience in SFDC development using Apex classes, batch scripts and triggers, Visual force pages and components (in both Classic UI and lightning), Force.com IDE, SOQL, SOSL, REST & Web Services APIs, Flow Designer.
Experience with Community Cloud development.(MUST)
Configure and maintain Salesforce Community portals. Understanding of community user permissions, design of components for use in Community Builder, editing community styles and templates.
Create Web Services APIs, Flow Designer.
Configure APIs and Web Services between Salesforce and other systems.
Proficiency in object oriented software design methodologies, data modeling, data extraction & transformation, data loading, scheduling, monitoring, and reporting in a multi-tenant, cloud computing environment
Job Title: Sr. Developer Lightning Community
Location: Trevose, PA
Duration: Contract
Experience: 8+ years
Work Authorization: USC/GC/H1b
Mandatory skills: Salesforce- Sales Cloud, Lightning community, Apex, Visual Force
Job Description:
Deep understanding of Salesforce – Sales Cloud, Service Cloud, Communities / Portals and Force.com.
Salesforce Configuration and Design of Partner & Customer Communities. This would leverage the Lightning Community Builder, Lightning Components – standard and custom, and also Visualforce and other tools where needed.
Previous experience working with Salesforce Communities is a must. Experience leveraging both the Visualforce / tabs and Lightning Template approaches is must.
Operational experience in how a community is used – for Customers, is required. Candidate must have an understanding of how users leverage Communities in multiple use cases: Self Service, Public Discussion / Collaboration, and Partner.
Communities Consultant, Sales Consultant or Service Consultant certification is preferred.
Strong ability to problem solve and understand how a business process can be enhanced and improved using Salesforce, coupled with the knowledge of choosing the most effective option for a customer.
Ability to document requirements for developers a must. Must be hands on with an understanding of what can be done with Lightning/Apex/Visualforce/Web Services is a must.
Ability to work in a self-sufficient manner, but also with a team.
Translating the Customer’s requirements and using best practices, crafting a solution with Salesforce that will support their processes, with standard and custom development.
Develop technical requirements for internal developers to build solutions where needed.
Provide End User Training and Documentation during roll-out
Thanks, Steve Hunt Talent Acquisition Team – North America Vinsys Information Technology Inc SBA 8(a) Certified, MBE/DBE/EDGE Certified Virginia Department of Minority Business Enterprise(SWAM) 703-594-5490 www.vinsysinfo.com
To unsubscribe from future emails or to update your email preferences click here .
0 notes
Link

Embed Text, Image, Digital, Barcode or QRCode esignatures into your secure Microsoft Word DOCX, Excel XLSX, PowerPoint PPTX, PDF documents and JPEG, WEBP, TIFF images electronically using the .NET esignature API. It is a UI less REST API solution, helping app developers to build document esigning applications for mobile, desktop or web platforms. Perform signature verifications, passwords-protect your files or apply image manipulation effects and filters to digital signatures. Manage different measure units together with an array of other signature properties effortlessly in .NET based electronic file formats. Get a free trial of GroupDocs.Signature for .NET today – https://bit.ly/2NNGmIl
Watch YouTube video tutorials of the GroupDocs API – https://bit.ly/2F6yONN
#groupdocs#.net api#.net esignature api#eSigning#digital signatures#electronic signatures#PDF#Microsoft Office#JPEG#TIFF
0 notes
Photo

Code Your First API With Node.js and Express: Understanding REST APIs
Understanding REST and RESTful APIs
If you've spent any amount of time with modern web development, you will have come across terms like REST and API. If you've heard of these terms or work with APIs but don't have a complete understanding of how they work or how to build your own API, this series is for you.
In this tutorial series, we will start with an overview of REST principles and concepts. Then we will go on to create our own full-fledged API that runs on a Node.js Express server and connects to a MySQL database. After finishing this series, you should feel confident building your own API or delving into the documentation of an existing API.
Prerequisites
In order to get the most out of this tutorial, you should already have some basic command line knowledge, know the fundamentals of JavaScript, and have Node.js installed globally.
What Are REST and RESTful APIs?
Representational State Transfer, or REST, describes an architectural style for web services. REST consists of a set of standards or constraints for sharing data between different systems, and systems that implement REST are known as RESTful. REST is an abstract concept, not a language, framework, or type of software.
A loose analogy for REST would be keeping a collection of vinyl vs. using a streaming music service. With the physical vinyl collection, each record must be duplicated in its entirety to share and distribute copies. With a streaming service, however, the same music can be shared in perpetuity via a reference to some data such as a song title. In this case, the streaming music is a RESTful service, and the vinyl collection is a non-RESTful service.
An API is an Application Programming Interface, which is an interface that allows software programs to communicate with each other. A RESTful API is simply an API that adheres to the principles and constraints of REST. In a Web API, a server receives a request through a URL endpoint and sends a response in return, which is often data in a format such as JSON.
REST Principles
Six guiding constraints define the REST architecture, outlined below.
Uniform Interface: The interface of components must be the same. This means using the URI standard to identify resources—in other words, paths that could be entered into the browser's location bar.
Client-Server: There is a separation of concerns between the server, which stores and manipulates data, and the client, which requests and displays the response.
Stateless Interactions: All information about each request is contained in each individual request and does not depend on session state.
Cacheable: The client and server can cache resources.
Layered System: The client can be connected to the end server, or an intermediate layer such as a load-balancer.
Code on Demand (Optional): A client can download code, which reduces visibility from the outside.
Request and Response
You will already be familiar with the fact that all websites have URLs that begin with http (or https for the secure version). HyperText Transfer Protocol, or HTTP, is the method of communication between clients and servers on the internet.
We see it most obviously in the URL bar of our browsers, but HTTP can be used for more than just requesting websites from servers. When you go to a URL on the web, you are actually doing a GET request on that specific resource, and the website you see is the body of the response. We will go over GET and other types of requests shortly.
HTTP works by opening a TCP (Transmission Control Protocol) connection to a server port (80 for http, 443 for https) to make a request, and the listening server responds with a status and a body.
A request must consist of a URL, a method, header information, and a body.
Request Methods
There are four major HTTP methods, also referred to as HTTP verbs, that are commonly used to interact with web APIs. These methods define the action that will be performed with any given resource.
HTTP request methods loosely correspond to the paradigm of CRUD, which stands for Create, Update, Read, Delete. Although CRUD refers to functions used in database operations, we can apply those design principles to HTTP verbs in a RESTful API.
Read—GET: Retrieves a resource
Create—POST: Creates a new resource
Update—PUT: Updates an existing resource
Delete—DELETE: Deletes a resource
GET is a safe, read-only operation that will not alter the state of a server. Every time you hit a URL in your browser, such as https://www.google.com, you are sending a GET request to Google's servers.
POST is used to create a new resource. A familiar example of POST is signing up as a user on a website or app. After submitting the form, a POST request with the user data might be sent to the server, which will then write that information into a database.
PUT updates an existing resource, which might be used to edit the settings of an existing user. Unlike POST, PUT is idempotent, meaning the same call can be made multiple times without producing a different result. For example, if you sent the same POST request to create a new user in a database multiple times, it would create a new user with the same data for each request you made. However, using the same PUT request on the same user would continuously produce the same result.
DELETE, as the name suggests, will simply delete an existing resource.
Response Codes
Once a request goes through from the client to the server, the server will send back an HTTP response, which will include metadata about the response known as headers, as well as the body. The first and most important part of the response is the status code, which indicates if a request was successful, if there was an error, or if another action must be taken.
The most well-known response code you will be familiar with is 404, which means Not Found. 404 is part of the 4xx class of status codes, which indicate client errors. There are five classes of status codes that each contain a range of responses.
1xx: Information
2xx: Success
3xx: Redirection
4xx: Client Error
5xx: Server Error
Other common responses you may be familiar with are 301 Moved Permanently, which is used to redirect websites to new URLs, and 500 Internal Server Error, which is an error that comes up frequently when something unexpected has happened on a server that makes it impossible to fulfil the intended request.
With regards to RESTful APIs and their corresponding HTTP verbs, all the responses should be in the 2xx range.
GET: 200 (OK) POST: 201 (Created) PUT: 200 (OK) DELETE: 200 (OK), 202 (Accepted), or 204 (No Content)
200 OK is the response that indicates that a request is successful. It is used as a response when sending a GET or PUT request. POST will return a 201 Created to indicate that a new resource has been created, and DELETE has a few acceptable responses, which convey that either the request has been accepted (202), or there is no content to return because the resource no longer exists (204).
We can test the status code of a resource request using cURL, which is a command-line tool used for transferring data via URLs. Using curl, followed by the -i or --include flag, will send a GET request to a URL and display the headers and body. We can test this by opening the command-line program and testing cURL with Google.
curl -i https://www.google.com
Google's server will respond with the following.
HTTP/2 200 date: Tue, 14 Aug 2018 05:15:40 GMT expires: -1 cache-control: private, max-age=0 content-type: text/html; charset=ISO-8859-1 ...
As we can see, the curl request returns multiple headers and the entire HTML body of the response. Since the request went through successfully, the first part of the response is the 200 status code, along with the version of HTTP (this will either be HTTP/1.1 or HTTP/2).
Since this particular request is returning a website, the content-type (MIME type) being returned is text/html. In a RESTful API, you will likely see application/json to indicate the response is JSON.
Interestingly, we can see another type of response by inputting a slightly different URL. Do a curl on Google without the www.
curl -i https://google.com
HTTP/2 301 location: https://www.google.com/ content-type: text/html; charset=UTF-8
Google redirects google.com to www.google.com, and uses a 301 response to indicate that the resource should be redirected.
REST API Endpoints
When an API is created on a server, the data it contains is accessible via endpoints. An endpoint is the URL of the request that can accept and process the GET, POST, PUT, or DELETE request.
An API URL will consist of the root, path, and optional query string.
Root e.g. https://api.example.com or https://api.example.com/v2: The root of the API, which may consist of the protocol, domain, and version.
Path e.g. /users/or /users/5: Unique location of the specific resource.
Query Parameters (optional) e.g. ?location=chicago&age=29: Optional key value pairs used for sorting, filtering, and pagination. We can put them all together to implement something such as the example below, which would return a list of all users and use a query parameter of limit to filter the responses to only include ten results.
https://api.example.com/users?limit=10
Generally, when people refer to an API as a RESTful API, they are referring to the naming conventions that go into building API URL endpoints. A few important conventions for a standard RESTful API are as follows:
Paths should be plural: For example, to get the user with an id of 5, we would use /users/5, not /user/5.
Endpoints should not display the file extension: Although an API will most likely be returning JSON, the URL should not end in .json.
Endpoints should use nouns, not verbs: Words like add and delete should not appear in a REST URL. In order to add a new user, you would simply send a POST request to /users, not something like /users/add. The API should be developed to handle multiple types of requests to the same URL.
Paths are case sensitive, and should be written in lowercase with hyphens as opposed to underscores.
All of these conventions are guidelines, as there are no strict REST standards to follow. However, using these guidelines will make your API consistent, familiar, and easy to read and understand.
Conclusion
In this article, we learned what REST and RESTful APIs are, how HTTP request methods and response codes work, the structure of an API URL, and common RESTful API conventions. In the next tutorial, we will learn how to put all this theory to use by setting up an Express server with Node.js and building our own API.
by Tania Rascia via Envato Tuts+ Code https://ift.tt/2MJ3JT8
0 notes
Text
Aspose.Cloud Newsletter August 2018: REST APIs for Office, PDF & Email Formats in Cloud
Aspose.Cloud Newsletter for August 2018 has now been published that highlights all the newly supported features offered in the recent releases. It includes information about Aspose REST APIs for working with MSOffice, PDF and Email Formats. It also includes information about preserving Bookmarks while PDF to Word conversion, support of Format validation for Image Resource, Recognize Marks Data from PDF, Barcodes and QR-Codes, Detect Keywords in the HTML Document Text Content, code example for exporting Shape in Slide to SVG Format in Cloud.
Aspose REST APIs for Office, PDF and Email Formats Manipulate Documents using Any Language, Any Platform
Aspose.Total Cloud Product Family is a collection of REST based APIs for document generation, conversion, rendering and automation in cloud. Web and mobile apps developers take full control to manipulate Microsoft Word, Excel, PowerPoint, Project, PDF, Email, Barcode, OCR, OMR, HTML, Video and commonly used image file formats. The REST API can be called from any platform: .NET, Java, Ruby, Python, PHP, Rails, Salesforce, Amazon and many more. Start a free trial
Preserve Bookmarks while PDF to Word Conversion in Cloud
Aspose.Words Cloud API provides new SaveOptions and support for preserving bookmarks in PDF to Word conversion. The Word Cloud API also supports document conversion to DOC, DOCX, XPS, TIFF, PDF, HTML, SWF, PCL and many other file formats. Read more details
Support of Format Validation for Image Resource in Aspose.Slides Cloud API
Aspose.Slides Cloud is a REST API for processing Microsoft PowerPoint file formats. You can easily create, edit and convert presentation files in cloud. The latest version now supports format validation for image resource as well as using PDF, SWF and TIFF formats instead with NotesPosition export option for adding PdfNotes. Read more Recognize Marks Data from PDF, Barcodes and QR-Codes in Cloud
Aspose.OMR Cloud has the capability to capture human-marked data from PDF documents and recognize images in PDF Format with high accuracy. You can add Barcodes, QR-codes and Aruco codes onto your template and recognize Barcodes and QR-codes in documents like surveys, questionnaires, examination paper. Read more
Detect Keywords in the HTML Document Text Content using REST APIs
Aspose.HTML Cloud is a REST API to create, manipulate, convert and render HTML files in cloud. The latest version adds support for getting HTML document keywords using the keyword detection service or reference the URL of the document on web as an argument.
Code Example: Detecting Headers and Footers while PDF to Word Conversion using REST APIs
Aspose.Words Cloud offers advanced REST APIs to create, edit, convert or render Microsoft Word document formats. The latest version allows to perform text and document classification using machine learning and natural language processing techniques. Moreover, sections of PDF pages containing page numbers and document names will be converted as headers and footers in Word document that do not affect rest of the page layout and are not moved while the document is being edited.
Code Example: Export Shape in a Slide to SVG Format in Cloud
Aspose.Slides Cloud now adds SVG to shape export formats. Just specify export options in request body for POST method of SaveAs resource for a shape. Moreover, position parameter added to shapes, paragraphs and portions APIs that allow users to insert an item to a list at the specified position instead of just at the end of the list.
Collect a copy of Aspose Newsletter, August 2018 edition
Collect the English version of this newsletter
Contact Information
Aspose Pty Ltd Suite 163,
79 Longueville Road Lane Cove,
NSW, 2066 Australia
Aspose - The File Format Experts
Phone: 888.277.6734
Fax: 866.810.9465
#REST APIs for MS Office#PDF to Word Conversion in Cloud#Preserve PDF Bookmarks#Format Validation for Image Resource#Recognize Marks Data from Barcodes#Detect Keywords in the HTML Document
0 notes
Text
Week 11 Reading
Workflow app: So, basically yet another automation app, but iOS specific. I think I’ll probably end up sticking with IFTTT, mostly because I am unable to use Workflow (no iOS device!). Still, the integration seems as if it could be quite useful.
What is it, how does it work?: I can see the convenience of automation if one is actually doing a lot of repetitive tasks. Of course, if one isn’t, then it loses a lot of its value proposition. Due to its success, I can only imagine that many of us are doing trivial things - though I wonder if that’s because we have to or because we’re intentionally using up time?
How to use the workflow app: Ah, the joys of reading in Incognito mode, because of the sandbox environment it provides (read: a malicious ad finds it harder to get at the rest of your computer). I will admit that its ability to save workflows to the home screen and allow one to activate many actions with a single touch is nice - I suppose it says something that it took this long for batch processing to become a think on mobile phones. Or perhaps that its is finally becoming a thing - have we crossed a complexity threshold, I wonder?
What is Temboo: A code generator/library of processes that virtualizes the process of interfacing with APIs, so you don’t have to know each and every one of them yourself. Useful for prototyping, though maybe not for a final product. Basically your IoT skeleton Key.
Your own internet of things: Temboo facilitates fast development with new connected devices, allowing savings in time and memory (important for microcontrollers, which have a limited amount of the latter) by shifting the burden of complexity to the cloud. Of course, this presupposes a working internet connection and introduces another point of vulnerability / failure, which I’m not entirely comfortable with. Still, I suppose the support of multiple programming languages and ability to test is good, but abstracting everything isn’t an answer in the long run.
Building an app with flexibility and power: Temboo wants to make building apps more accessible to regular people, which is well and good, except that this is mostly a technical shortcut, and as responsive as they are to their users, how many people will ever really hear about it, except those already moving in design/development circles? If we want to make building apps more accessible to regular people, we have to foster a level of technical and design literacy among the population at large, so people can, if not be expert programmers and designers, have a basic understanding of what they do, and what some of the tools are if they are interested in building something. Right now, there’s a huge hurdle when it comes to taking that first step, and its mostly mental.
Programming hardware without coding: Page is missing.
Connecting Arduino to 100s of API's: Technically, Temboo is not necessary to make these hacks, though it is nice to see them partnering with a variety of device manufacturers. Given the other material on them, that they have an interest in helping people build their IoT clusters and apps seems about right - though that’s still dependent on hardware compatibility and interfacing. Oh, and making sure your organization actually supports IoT devices connecting to the internet, which they very well might not (Penn’s internet is not IoT friendly, as I discovered while tinkering, and connecting to the net proper again, opens one up to extra vulnerabilities).
Connecting API's without wrappers: The word ‘silo’ is one that’s been brought across to quite a few other fields, I note with some amusement. That said, while Temboo is being pushed as a killer app that removes the need to learn how APIs work and makes updating easier...the platform itself is not intuitive to use, the documentation isn’t especially great, and what happens if Temboo’s choreo library stops working or has a problem?
How to build a cloud saving electricity monitor: The fact that open source tutorials exist for the maker community is rather convenient for anyone seeking to get into it. However...the hardware requirement (and extra cost/effort) is still a significant barrier to adoption and experimentation. Yes, it may not be that expensive, but if I have to go out of my way to get an Arduino or other device, wait for it to arrive in the mail, build it, and then hope and pray that my internet will support it. Well...essentially, it is great that this exists, but that alone isn’t going to make me interested in building something.
Ultra-Contextual design: So many assumptions in this article, like “Wi-Fi is so ingrained in modern life that it disappears into the background.“ While reading all of articles, Erika Hall’s statement that “Assumptions are Insults” lingers in the back of my mind - and is brought up time and time again. Nevertheless... this defines context aware systems as those that "provide information and utilities to people based on the tasks they are trying to accomplish”. Transitioning from a dumb system to a context aware one, however, is not easy, and requires not only understanding the context of use, but what kind of contextual design would fit best. There are many ways to tackle any one problem, after all, and which one is right...depends.
A UX perspective of design for context-aware adaption pdf white paper: Automated methods to assess quality of life may not be best, as this paper notes, given that one only has limited inputs to work from. How much can one realistically interface with and be aware of at any given time? With many studies in context-aware adaption failing to include the user in the process of developing or adapting HCI policy and implementations...we’re going to keep running into issues, as not all users are the same, and every use case is slightly different. Automation is good, but it isn’t everything.
Wharton - on why UX is about Data: Individual UX has become table stakes - if you can’t do that much, you shouldn’t be playing the app game. And well, you can’t really get a good personalized UX without data to understand each user’s context - though it is important to note that having a non-offending default set of parameters might be useful as well, and that pinging for data to improve an experience can quickly become aggravating, if that is not what a consumer is interested in. A user may not want a smart solution - a user may simply want something ‘dumb’ - or to be completely in control, without having data fed to him or her. Still, I’ll agree with the statement that “it’s common for apps to have a long-winded sign-up process that asks you every question under the sun. This is not a recipe for success.”
Even IFTTT was guilty of that. I just wanted to browse what their library of interactions was capable of without having to first connect to every bloody service I intended to use. It might seem dumb, because why not integrate sign-in with browsing, right, but maybe I don’t want to sign in if the interaction I want isn’t there. Maybe I don’t want to have another point of failure/slowdown/frustration when I’m trying to build an applet. Today’s UX may be all about the individual user experience, but still having good design to fall back on couldn’t hurt, especially if the process of gathering the data is a pain in and of itself.
Context aware computing? Contextual philosophy, how droll. It is important to remember that, per ACM, context is in and of itself an abstraction, and that abstractions are not easy to talk about. Sure, we can say that “context, in the general sense, is something we create in the process of being and doing, a thing we make with our mind in our body so we can interact with another mind in another body,” but what does that really mean? With such a definition, pretty much anything can be context (and whether it can be calculated or not, whether it is embodied or emergent from interactions is a whole other can of worms). What makes this article interesting is that it tries to see what lies at the intersection of these, the common ground, the interfaces between ideas and cultures, and argues that design should be about foregrounding culture and backgrounding technology, which is something that most of the other readings missed.
Don Norman: TED talk 3 ways design make you happy: The talk of neurotransmitters and how the brain functions at different of processing is rather fascinating, especially when we think about how it interacts with the design choices we make, and how various levels and emotions can be played against one another. By synthesizing beauty, functionality, and reflectiveness - the ability to tell stories about an experience, or create a coherent one, we can make more effect, coherent designs. Designs resilient in the face of user stress or frustration, designs which are salutogenic.
Drone TED talk: Important points to note from this talk are towards the end, when he mentions how “Interaction doesn't have to be virtual. It can be physical.” And there almost always is a physical component to interaction, since we can’t automate all of our lives. In the end though, as with so much technology, how it affects us and how pervasive it is may not be a technical choice, but a social one.
Grocery store video: Supermarket experiences are inherently manipulative through appealing to people’s senses, and the experiences they choose to present. Color and smell (why fresh fruit and veggie displays, and flower displays) are some of the first things you encounter. Also, the small verbal cues and hints - the mere suggestion of something in another context - can be enough to get someone thinking about something subconsciously, which, when it later boils up to the surface, seems as if it was their idea to begin with. I mean, this really isn’t too different in principle from Jobs (or any other boss) hearing an employee’s idea, automatically dismissing it or brushing it off, and a week later presenting it as their own, believing that they came up with it completely in and of themselves. More than just the direct message of manipulation, what I take away from this is how tightly everything is connected, and how everything influences everything else.
0 notes