#api and web services
Text
Power of Natural Language Processing with AWS
Dive into the world of Natural Language Processing on AWS and learn how to build intelligent applications with services like Amazon Comprehend, Transcribe, and Polly. Explore the future of language-driven AI and cloud computing #AWSNLP #AI #CloudComputing
Natural Language Processing (NLP) has emerged as a transformative force in the realm of artificial intelligence, enabling computers to comprehend and generate human-like text. As businesses increasingly recognize the value of language-driven insights and applications, cloud platforms such as Amazon Web Services (AWS) have played a pivotal role in democratizing access to advanced NLP capabilities.…

View On WordPress
#AI Development#AI Services#Amazon API Gateway#Amazon Comprehend#Amazon Lex#Amazon Polly#Amazon Transcribe#Amazon Translate#amazon web services#aws#AWS Lambda#chatbot development#Cloud Computing#Cloud Services#Conversational Interfaces#Language Processing Applications#Language Understanding#Machine Translation#natural language processing#Neural Machine Translation#NLP#sentiment analysis#speech recognition#Text Analysis#text-to-speech#Voice Interfaces
5 notes
·
View notes
Text

Acemero is a company that strives for excellence and is goal-oriented. We assist both businesses and individuals in developing mobile and web applications for their business.
Our Services include:
Web/UI/UX Design
CMS Development
E-Commerce Website
Mobile Apps
Digital Marketing
Branding
Domain & Hosting
API Integration
Our Products include :
Support Ticket System
Direct Selling Software
Learning Management System
Auditing Software
HYIP Software
E-Commerce Software
#Mobosoftware#software development#software developers#web development#cms web development services#cms website development company#cms#mlm software#hyip#ecommerce software#lms#audit software#API Integration#Branding#Digital Marketing#ui/ux design
2 notes
·
View notes
Text
How to Extract Amazon Product Prices Data with Python 3
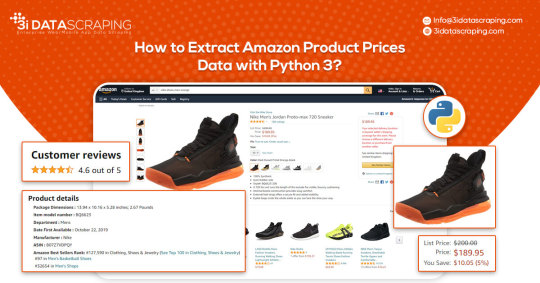
Web data scraping assists in automating web scraping from websites. In this blog, we will create an Amazon product data scraper for scraping product prices and details. We will create this easy web extractor using SelectorLib and Python and run that in the console.
#webscraping#data extraction#web scraping api#Amazon Data Scraping#Amazon Product Pricing#ecommerce data scraping#Data EXtraction Services
3 notes
·
View notes
Text
Tapping into Fresh Insights: Kroger Grocery Data Scraping
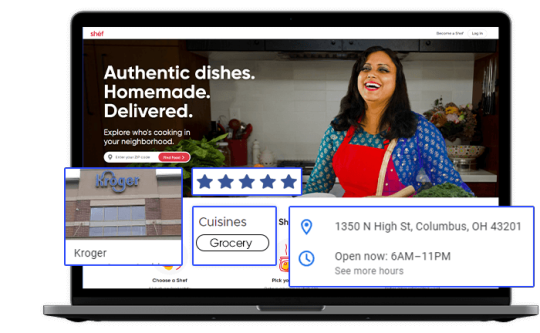
In today's data-driven world, the retail grocery industry is no exception when it comes to leveraging data for strategic decision-making. Kroger, one of the largest supermarket chains in the United States, offers a wealth of valuable data related to grocery products, pricing, customer preferences, and more. Extracting and harnessing this data through Kroger grocery data scraping can provide businesses and individuals with a competitive edge and valuable insights. This article explores the significance of grocery data extraction from Kroger, its benefits, and the methodologies involved.
The Power of Kroger Grocery Data
Kroger's extensive presence in the grocery market, both online and in physical stores, positions it as a significant source of data in the industry. This data is invaluable for a variety of stakeholders:
Kroger: The company can gain insights into customer buying patterns, product popularity, inventory management, and pricing strategies. This information empowers Kroger to optimize its product offerings and enhance the shopping experience.
Grocery Brands: Food manufacturers and brands can use Kroger's data to track product performance, assess market trends, and make informed decisions about product development and marketing strategies.
Consumers: Shoppers can benefit from Kroger's data by accessing information on product availability, pricing, and customer reviews, aiding in making informed purchasing decisions.
Benefits of Grocery Data Extraction from Kroger
Market Understanding: Extracted grocery data provides a deep understanding of the grocery retail market. Businesses can identify trends, competition, and areas for growth or diversification.
Product Optimization: Kroger and other retailers can optimize their product offerings by analyzing customer preferences, demand patterns, and pricing strategies. This data helps enhance inventory management and product selection.
Pricing Strategies: Monitoring pricing data from Kroger allows businesses to adjust their pricing strategies in response to market dynamics and competitor moves.
Inventory Management: Kroger grocery data extraction aids in managing inventory effectively, reducing waste, and improving supply chain operations.
Methodologies for Grocery Data Extraction from Kroger
To extract grocery data from Kroger, individuals and businesses can follow these methodologies:
Authorization: Ensure compliance with Kroger's terms of service and legal regulations. Authorization may be required for data extraction activities, and respecting privacy and copyright laws is essential.
Data Sources: Identify the specific data sources you wish to extract. Kroger's data encompasses product listings, pricing, customer reviews, and more.
Web Scraping Tools: Utilize web scraping tools, libraries, or custom scripts to extract data from Kroger's website. Common tools include Python libraries like BeautifulSoup and Scrapy.
Data Cleansing: Cleanse and structure the scraped data to make it usable for analysis. This may involve removing HTML tags, formatting data, and handling missing or inconsistent information.
Data Storage: Determine where and how to store the scraped data. Options include databases, spreadsheets, or cloud-based storage.
Data Analysis: Leverage data analysis tools and techniques to derive actionable insights from the scraped data. Visualization tools can help present findings effectively.
Ethical and Legal Compliance: Scrutinize ethical and legal considerations, including data privacy and copyright. Engage in responsible data extraction that aligns with ethical standards and regulations.
Scraping Frequency: Exercise caution regarding the frequency of scraping activities to prevent overloading Kroger's servers or causing disruptions.
Conclusion
Kroger grocery data scraping opens the door to fresh insights for businesses, brands, and consumers in the grocery retail industry. By harnessing Kroger's data, retailers can optimize their product offerings and pricing strategies, while consumers can make more informed shopping decisions. However, it is crucial to prioritize ethical and legal considerations, including compliance with Kroger's terms of service and data privacy regulations. In the dynamic landscape of grocery retail, data is the key to unlocking opportunities and staying competitive. Grocery data extraction from Kroger promises to deliver fresh perspectives and strategic advantages in this ever-evolving industry.
#grocerydatascraping#restaurant data scraping#food data scraping services#food data scraping#fooddatascrapingservices#zomato api#web scraping services#grocerydatascrapingapi#restaurantdataextraction
3 notes
·
View notes
Link
A leading ReactJs development company, we provide Reactjs development for your needs. Hire ReactJS developers to get cost-effective services.
#ReactJS development services#reactjs development#react native app development company#react native development company#api development#react native development services#front end development#full stack development#back end developer#react redux#UI Ux development#android#git#web application development#web developer#desktop app#electron app
4 notes
·
View notes
Text
Premier ReactJS Development Services | Expert ReactJS Developers
Discover top-tier ReactJS development with our leading team of experts. At techdev.se, we offer customized ReactJS solutions designed to meet your unique needs. Hire our skilled ReactJS developers for affordable, high-quality services that drive results.
#ReactJS development services#reactjs development#react native app development company#react native development company#api development#react native development services#front end development#full stack development#back end developer#react redux#UI Ux development#android#git#web application development#web developer#desktop app#electron app
1 note
·
View note
Text
Creating efficient, scalable, and maintainable web APIs is crucial in the dynamic world of web development. Design patterns play a significant role in achieving these goals by providing standardized solutions to common problems. One such design pattern that stands out is REPR, which focuses on the representation of resources consistently and predictably. By adhering to the REPR design pattern, developers can create APIs that are not only easy to use but also robust and adaptable to future changes. Read more...
#ASP.NET Core API Development#Web API Development#REPR Design Pattern#microsoft .net#development libraries and frameworks#software development#web app development#.net development company#.net development#custom angular development company#.net 8#.net framework#.net development services
0 notes
Text
Whatsapp Panel
Learn about WhatsApp Panel.” Discover the comprehensive WhatsApp Panel for managing conversations, group chats, and media sharing with ease.
To connect with their audience successfully, businesses and organizations must have effective communication. Within the context of this, a WhatsApp Panel has come out as a vital tool; it provides a centralized platform for managing, automating, and optimizing communications via WhatsApp.
Hence, this tool is aimed at improving communication strategies, streamlining customer interactions, and enhancing operational efficiency. This article gives an elaborate discussion of what WhatsApp Panel comprises, including its functions, advantages, and how it can revolutionize communication practices.
WhatsApp Panel
An advanced application that seamlessly integrates with WhatsApp to do bulk messaging management, customer interactions, and communication campaigns is WhatsApp Panel. The features provided by it enable users to truncate their messaging tasks, automate their replies as well as evaluate the communication progress.
For businesses and organizations to achieve more effective outreach strategies, the WhatsApp Panel is centralizing communication efforts.
Benefits of Using a WhatsApp Panel
1. Enhanced Efficiency
A WhatsApp Panel significantly enhances communication efficiency through the automation and centralization of messaging processes. Businesses and organizations can easily manage a large number of messages, thus saving time and energy on manual messaging. As a result, teams can dedicate more effort to strategic goals and other crucial areas of their operations.
2. Improved Engagement
Messages that are personalized and sent at the right time are more likely to catch the attention of recipients and create positive interactions with them. Through a WhatsApp Panel, businesses can tailor their communication accordingly hence increasing response rates as well as enhancing customer relations by using the customization and automation features it comes with.
3. Cost-Effective Communication
Using a WhatsApp Panel is cheaper compared to traditional communication approaches such as direct mail and large-scale email campaigns. The capability of reaching many people at a low cost and having high chances of involvement makes it easy for businesses to earn back their money.
4. Scalability
WhatsApp panels can grow along with the business or increase communication demands by adjusting to expanding volumes of messages and contacts. This adaptability guarantees that communications can change in line with evolving needs without needing extensive costs in extra resources again.
5. Data-Driven Insights
Insights derived from analytics and reporting capabilities on communication performance are vital as they enable users to understand what is effective and what requires review. This data-driven impactful understanding allows businesses to improve strategies, increase campaign effectiveness, and enhance results.
6. Streamlined Operations
A WhatsApp Panel ensures that all aspects of operations work together seamlessly by aligning communication efforts with broader business processes. Integration with other systems and tools creates a cohesive communication strategy improving overall workflow and operational efficiency.
Conclusion
The WhatsApp Panel is an essential tool designed to help you administer and improve all your WhatsApp interactions. This tool has everything for sending bulk messages, managing contacts, automating replies, and analyzing conversations; thus giving companies and institutions everything they need to optimize their communication tactics.
Greater effectiveness, enhanced involvement and improved results in their messaging activities can be achieved by users utilizing WhatsApp Panel’s advantages. The WhatsApp Panel has become an important tool for managing complex communication at a time when ways of communicating are changing rapidly.
#malaysia#united arab emirates#bulk whatsapp software#whatsapp web panel price#whatsapp bulk message#whatsapp bulk sender#eyeshadow#whatsapp marketing services#whatsapp business api شرح#whatsapp api#curly hair#whatsappmarketing#lead myntra#singapore
1 note
·
View note
Text
Why Web Security Matters: Why 2FA SMS OTP API Is Vital for Protection

In today’s digital world, web security has become more critical than ever as cyber threats or attacks are increasing day by day. Safeguarding sensitive information is a top priority for businesses and individuals alike. One of the most effective ways to enhance online security is by implementing 2FA (Two-Factor Authentication), particularly through SMS OTP API. Integrating SMS OTP API into your web and mobile applications is essential for your web and mobile app protection.
Why Web Security Important and How It Is Compromise
Robust Web security is the foundation of any online platform, protecting user data, financial transactions, and personal information from unauthorized access. However, there are many reasons for web security breaches. Read the mention below:
1. Weak Passwords: Many users rely on simple, easily guessable passwords, making it easier for hackers to gain unauthorized access to accounts. Don't give a chance to hackers; always use strong passwords and change them on an after-some day.
2. Phishing Attacks: Cyberattackers frequently use phishing emails or websites to trick users into revealing their passwords and other sensitive information. Be aware of fraud Emails and messages.
3. Outdated Software: Using outdated or unpatched software can expose vulnerabilities that hackers can exploit to breach web security.
4. Insufficient Security Measures: Relying solely on passwords without additional layers of security leaves systems vulnerable to attacks.
5. Human Error: Mistakes like sending sensitive information over unsecured networks or clicking on malicious links can also lead to security breaches.
Why 2FA SMS OTP API Is Essential for Online Security
2FA SMS OTP API plays a vital role in strengthening web security by addressing these common vulnerabilities. Here’s how it works:
1. User Authentication: After entering a password, users receive a one-time password (OTP) via SMS, which they must enter to complete the login process. This ensures that even if a password is compromised, unauthorized access is prevented without the OTP.
2. 2FA Authentication: Implementing 2FA Authentication through SMS OTP for web and mobile applications significantly reduces the risk of unauthorized access. It adds an extra layer of security, requiring both something the user knows (password) and something they have (OTP).
3. Ease of Use: SMS OTP services are user-friendly and do not require additional hardware or software. Users receive the OTP directly on their mobile devices, making it a convenient and efficient way to secure online transactions and logins.
4. Versatility: Whether securing a web or mobile app, MyOTP.APP offers a flexible solution that integrates seamlessly into existing systems. This makes it a versatile choice for businesses of all sizes. Check out the SMS OTP Service plan today!
Protecting Your Users and Business
Adopting 2FA SMS OTP API for your businesses can protect your users from potential threats and enhance the overall security of their platforms. This not only builds trust with customers but also helps comply with regulatory requirements for data protection.
Protecting Your Users and Business
Adopting 2FA SMS OTP API for your businesses can protect your users from potential threats and enhance the overall security of their platforms. This not only builds trust with customers but also helps comply with regulatory requirements for data protection.
In conclusion, as web security becomes increasingly vital, integrating 2FA with SMS OTP API is crucial in protecting your digital assets. Whether for web or mobile applications, SMS OTP services provide an effective, easy-to-use solution that significantly enhances security, ensuring your users’ data remains safe from unauthorized access. Visit us today and explore our services with ready-to-use code in any language. MyOtp.App is a trustworthy SMS OTP Service provider visit us today.
#2FA Online Security#2FA Web Security#Web Security Matters#2FA SMS OTP API#SMS OTP Services 2FA#multi-factor authentication
0 notes
Text
#shopify web design services#shopify web design company#shopify website development services#shopify web development services#shopify store development services#shopify theme development#shopify custom theme development#API integration shopify#shopify payment integration#shopify API integration services#shopify store help#help with shopify store#shopify developer support#shopify assistance#help with shopify setup#shopify expert help#shopify developer help
1 note
·
View note
Text
#web development#android app development#webdesign#software development#web application development#web applications#app#digital marketing#erp software development services#app developers#bulk whatsapp marketing services#bulk whatsapp marketing services noida#bulk whatsapp marketing services delhi#whatsapp business api service provider in delhi#whatsapp business api service provider in india
1 note
·
View note
Text
Flight Price Monitoring Services | Scrape Airline Data
We Provide Flight Price Monitoring Services in USA, UK, Singapore, Italy, Canada, Spain and Australia and Extract or Scrape Airline Data from Online Airline / flight website and Mobile App like Booking, kayak, agoda.com, makemytrip, tripadvisor and Others.

#flight Price Monitoring#Scrape Airline Data#Airfare Data Extraction Service#flight prices scraping services#Flight Price Monitoring API#web scraping services
2 notes
·
View notes
Text
Building APIs in Laravel - Pixxelu Digital Technology
Looking for the best way to build APIs in Laravel? Pixxelu Digital Technology offers expert solutions for seamless and efficient API development tailored to your needs.
#Custom Laravel Web Solutions#Enterprise Development Solutions#Laravel API Development#Laravel CRM Development#Laravel Migration Services#Laravel Cloud Integration
0 notes
Text
Top MLOps Tools Guide: Weights & Biases, Comet and More
New Post has been published on https://thedigitalinsider.com/top-mlops-tools-guide-weights-biases-comet-and-more/
Top MLOps Tools Guide: Weights & Biases, Comet and More
Machine Learning Operations (MLOps) is a set of practices and principles that aim to unify the processes of developing, deploying, and maintaining machine learning models in production environments. It combines principles from DevOps, such as continuous integration, continuous delivery, and continuous monitoring, with the unique challenges of managing machine learning models and datasets.
As the adoption of machine learning in various industries continues to grow, the demand for robust MLOps tools has also increased. These tools help streamline the entire lifecycle of machine learning projects, from data preparation and model training to deployment and monitoring. In this comprehensive guide, we will explore some of the top MLOps tools available, including Weights & Biases, Comet, and others, along with their features, use cases, and code examples.
What is MLOps?
MLOps, or Machine Learning Operations, is a multidisciplinary field that combines the principles of ML, software engineering, and DevOps practices to streamline the deployment, monitoring, and maintenance of ML models in production environments. By establishing standardized workflows, automating repetitive tasks, and implementing robust monitoring and governance mechanisms, MLOps enables organizations to accelerate model development, improve deployment reliability, and maximize the value derived from ML initiatives.
Building and Maintaining ML Pipelines
While building any machine learning-based product or service, training and evaluating the model on a few real-world samples does not necessarily mean the end of your responsibilities. You need to make that model available to the end users, monitor it, and retrain it for better performance if needed. A traditional machine learning (ML) pipeline is a collection of various stages that include data collection, data preparation, model training and evaluation, hyperparameter tuning (if needed), model deployment and scaling, monitoring, security and compliance, and CI/CD.
A machine learning engineering team is responsible for working on the first four stages of the ML pipeline, while the last two stages fall under the responsibilities of the operations team. Since there is a clear delineation between the machine learning and operations teams for most organizations, effective collaboration and communication between the two teams are essential for the successful development, deployment, and maintenance of ML systems. This collaboration of ML and operations teams is what you call MLOps and focuses on streamlining the process of deploying the ML models to production, along with maintaining and monitoring them. Although MLOps is an abbreviation for ML and operations, don’t let it confuse you as it can allow collaborations among data scientists, DevOps engineers, and IT teams.
The core responsibility of MLOps is to facilitate effective collaboration among ML and operation teams to enhance the pace of model development and deployment with the help of continuous integration and development (CI/CD) practices complemented by monitoring, validation, and governance of ML models. Tools and software that facilitate automated CI/CD, easy development, deployment at scale, streamlining workflows, and enhancing collaboration are often referred to as MLOps tools. After a lot of research, I have curated a list of various MLOps tools that are used across some big tech giants like Netflix, Uber, DoorDash, LUSH, etc. We are going to discuss all of them later in this article.
Types of MLOps Tools
MLOps tools play a pivotal role in every stage of the machine learning lifecycle. In this section, you will see a clear breakdown of the roles of a list of MLOps tools in each stage of the ML lifecycle.
Pipeline Orchestration Tools
Pipeline orchestration in terms of machine learning refers to the process of managing and coordinating various tasks and components involved in the end-to-end ML workflow, from data preprocessing and model training to model deployment and monitoring.
MLOps software is really popular in this space as it provides features like workflow management, dependency management, parallelization, version control, and deployment automation, enabling organizations to streamline their ML workflows, improve collaboration among data scientists and engineers, and accelerate the delivery of ML solutions.
Model Training Frameworks
This stage involves the process of creating and optimizing predictive models with labeled and unlabeled data. During training, the models learn the underlying patterns and relationships in the data, adjusting its parameters to minimize the difference between predicted and actual outcomes. You can consider this stage as the most code-intensive stage of the entire ML pipeline. This is the reason why data scientists need to be actively involved in this stage as they need to try out different algorithms and parameter combinations.
Machine learning frameworks like scikit-learn are quite popular for training machine learning models while TensorFlow and PyTorch are popular for training deep learning models that comprise different neural networks.
Model Deployment and Serving Platforms
Once the development team is done training the model, they need to make this model available for inference in the production environment where these models can generate predictions. This typically involves deploying the model to a serving infrastructure, setting up APIs for communication, model versioning and management, automated scaling and load balancing, and ensuring scalability, reliability, and performance.
MLOps tools offer features such as containerization, orchestration, model versioning, A/B testing, and logging, enabling organizations to deploy and serve ML models efficiently and effectively.
Monitoring and Observability Tools
Developing and deploying the models is not a one-time process. When you develop a model on a certain data distribution, you expect the model to make predictions for the same data distribution in production as well. This is not ideal because data distribution is prone to change in the real world which results in degradation in the model’s predictive power, this is what you call data drift. There is only one way to identify the data drift, by continuously monitoring your models in production.
Model monitoring and observability in machine learning include monitoring key metrics such as prediction accuracy, latency, throughput, and resource utilization, as well as detecting anomalies, drift, and concept shifts in the data distribution. MLOps monitoring tools can automate the collection of telemetry data, enable real-time analysis and visualization of metrics, and trigger alerts and actions based on predefined thresholds or conditions.
Collaboration and Experiment Tracking Platforms
Suppose you are working on developing an ML system along with a team of fellow data scientists. If you are not using a mechanism that tracks what all models have been tried, who is working on what part of the pipeline, etc., it will be hard for you to determine what all models have already been tried by you or others. There could also be the case that two developers are working on developing the same features which is really a waste of time and resources. And since you are not tracking anything related to your project, you can most certainly not use this knowledge for other projects thereby limiting reproducibility.
Collaboration and experiment-tracking MLOps tools allow data scientists and engineers to collaborate effectively, share knowledge, and reproduce experiments for model development and optimization. These tools offer features such as experiment tracking, versioning, lineage tracking, and model registry, enabling teams to log experiments, track changes, and compare results across different iterations of ML models.
Data Storage and Versioning
While working on the ML pipelines, you make significant changes to the raw data in the preprocessing phase. For some reason, if you are not able to train your model right away, you want to store this preprocessed data to avoid repeated work. The same goes for the code, you will always want to continue working on the code that you have left in your previous session.
MLOps data storage and versioning tools offer features such as data versioning, artifact management, metadata tracking, and data lineage, allowing teams to track changes, reproduce experiments, and ensure consistency and reproducibility across different iterations of ML models.
Compute and Infrastructure
When you talk about training, deploying, and scaling the models, everything comes down to computing and infrastructure. Especially in the current time when large language models (LLMs) are making their way for several industry-based generative AI projects. You can surely train a simple classifier on a system with 8 GB RAM and no GPU device, but it would not be prudent to train an LLM model on the same infrastructure.
Compute and infrastructure tools offer features such as containerization, orchestration, auto-scaling, and resource management, enabling organizations to efficiently utilize cloud resources, on-premises infrastructure, or hybrid environments for ML workloads.
Best MLOps Tools & Platforms for 2024
While Weights & Biases and Comet are prominent MLOps startups, several other tools are available to support various aspects of the machine learning lifecycle. Here are a few notable examples:
MLflow: MLflow is an open-source platform that helps manage the entire machine learning lifecycle, including experiment tracking, reproducibility, deployment, and a central model registry.
Kubeflow: Kubeflow is an open-source platform designed to simplify the deployment of machine learning models on Kubernetes. It provides a comprehensive set of tools for data preparation, model training, model optimization, prediction serving, and model monitoring in production environments.
BentoML: BentoML is a Python-first tool for deploying and maintaining machine learning models in production. It supports parallel inference, adaptive batching, and hardware acceleration, enabling efficient and scalable model serving.
TensorBoard: Developed by the TensorFlow team, TensorBoard is an open-source visualization tool for machine learning experiments. It allows users to track metrics, visualize model graphs, project embeddings, and share experiment results.
Evidently: Evidently AI is an open-source Python library for monitoring machine learning models during development, validation, and in production. It checks data and model quality, data drift, target drift, and regression and classification performance.
Amazon SageMaker: Amazon Web Services SageMaker is a comprehensive MLOps solution that covers model training, experiment tracking, model deployment, monitoring, and more. It provides a collaborative environment for data science teams, enabling automation of ML workflows and continuous monitoring of models in production.
What is Weights & Biases?
Weights & Biases (W&B) is a popular machine learning experiment tracking and visualization platform that assists data scientists and ML practitioners in managing and analyzing their models with ease. It offers a suite of tools that support every step of the ML workflow, from project setup to model deployment.
Key Features of Weights & Biases
Experiment Tracking and Logging: W&B allows users to log and track experiments, capturing essential information such as hyperparameters, model architecture, and dataset details. By logging these parameters, users can easily reproduce experiments and compare results, facilitating collaboration among team members.
import wandb # Initialize W&B wandb.init(project="my-project", entity="my-team") # Log hyperparameters config = wandb.config config.learning_rate = 0.001 config.batch_size = 32 # Log metrics during training wandb.log("loss": 0.5, "accuracy": 0.92)
Visualizations and Dashboards: W&B provides an interactive dashboard to visualize experiment results, making it easy to analyze trends, compare models, and identify areas for improvement. These visualizations include customizable charts, confusion matrices, and histograms. The dashboard can be shared with collaborators, enabling effective communication and knowledge sharing.
# Log confusion matrix wandb.log("confusion_matrix": wandb.plot.confusion_matrix(predictions, labels)) # Log a custom chart wandb.log("chart": wandb.plot.line_series(x=[1, 2, 3], y=[[1, 2, 3], [4, 5, 6]]))
Model Versioning and Comparison: With W&B, users can easily track and compare different versions of their models. This feature is particularly valuable when experimenting with different architectures, hyperparameters, or preprocessing techniques. By maintaining a history of models, users can identify the best-performing configurations and make data-driven decisions.
# Save model artifact wandb.save("model.h5") # Log multiple versions of a model with wandb.init(project="my-project", entity="my-team"): # Train and log model version 1 wandb.log("accuracy": 0.85) with wandb.init(project="my-project", entity="my-team"): # Train and log model version 2 wandb.log("accuracy": 0.92)
Integration with Popular ML Frameworks: W&B seamlessly integrates with popular ML frameworks such as TensorFlow, PyTorch, and scikit-learn. It provides lightweight integrations that require minimal code modifications, allowing users to leverage W&B’s features without disrupting their existing workflows.
import wandb import tensorflow as tf # Initialize W&B and log metrics during training wandb.init(project="my-project", entity="my-team") wandb.tensorflow.log(tf.summary.scalar('loss', loss))
What is Comet?
Comet is a cloud-based machine learning platform where developers can track, compare, analyze, and optimize experiments. It is designed to be quick to install and easy to use, allowing users to start tracking their ML experiments with just a few lines of code, without relying on any specific library.
Key Features of Comet
Custom Visualizations: Comet allows users to create custom visualizations for their experiments and data. Additionally, users can leverage community-provided visualizations on panels, enhancing their ability to analyze and interpret results.
Real-time Monitoring: Comet provides real-time statistics and graphs about ongoing experiments, enabling users to monitor the progress and performance of their models as they train.
Experiment Comparison: With Comet, users can easily compare their experiments, including code, metrics, predictions, insights, and more. This feature facilitates the identification of the best-performing models and configurations.
Debugging and Error Tracking: Comet allows users to debug model errors, environment-specific errors, and other issues that may arise during the training and evaluation process.
Model Monitoring: Comet enables users to monitor their models and receive notifications when issues or bugs occur, ensuring timely intervention and mitigation.
Collaboration: Comet supports collaboration within teams and with business stakeholders, enabling seamless knowledge sharing and effective communication.
Framework Integration: Comet can easily integrate with popular ML frameworks such as TensorFlow, PyTorch, and others, making it a versatile tool for different projects and use cases.
Choosing the Right MLOps Tool
When selecting an MLOps tool for your project, it’s essential to consider factors such as your team’s familiarity with specific frameworks, the project’s requirements, the complexity of the model(s), and the deployment environment. Some tools may be better suited for specific use cases or integrate more seamlessly with your existing infrastructure.
Additionally, it’s important to evaluate the tool’s documentation, community support, and the ease of setup and integration. A well-documented tool with an active community can significantly accelerate the learning curve and facilitate troubleshooting.
Best Practices for Effective MLOps
To maximize the benefits of MLOps tools and ensure successful model deployment and maintenance, it’s crucial to follow best practices. Here are some key considerations:
Consistent Logging: Ensure that all relevant hyperparameters, metrics, and artifacts are consistently logged across experiments. This promotes reproducibility and facilitates effective comparison between different runs.
Collaboration and Sharing: Leverage the collaboration features of MLOps tools to share experiments, visualizations, and insights with team members. This fosters knowledge exchange and improves overall project outcomes.
Documentation and Notes: Maintain comprehensive documentation and notes within the MLOps tool to capture experiment details, observations, and insights. This helps in understanding past experiments and facilitates future iterations.
Continuous Integration and Deployment (CI/CD): Implement CI/CD pipelines for your machine learning models to ensure automated testing, deployment, and monitoring. This streamlines the deployment process and reduces the risk of errors.
_*]:min-w-0″ readability=”23″>
Code Examples and Use Cases
To better understand the practical usage of MLOps tools, let’s explore some code examples and use cases.
Experiment Tracking with Weights & Biases
Weights & Biases provides seamless integration with popular machine learning frameworks like PyTorch and TensorFlow. Here’s an example of how you can log metrics and visualize them during model training with PyTorch:
import wandb import torch import torchvision # Initialize W&B wandb.init(project="image-classification", entity="my-team") # Load data and model train_loader = torch.utils.data.DataLoader(...) model = torchvision.models.resnet18(pretrained=True) # Set up training loop optimizer = torch.optim.SGD(model.parameters(), lr=0.01) criterion = torch.nn.CrossEntropyLoss() for epoch in range(10): for inputs, labels in train_loader: optimizer.zero_grad() outputs = model(inputs) loss = criterion(outputs, labels) loss.backward() optimizer.step() # Log metrics wandb.log("loss": loss.item()) # Save model torch.save(model.state_dict(), "model.pth") wandb.save("model.pth")
In this example, we initialize a W&B run, train a ResNet-18 model on an image classification task, and log the training loss at each step. We also save the trained model as an artifact using wandb.save(). W&B automatically tracks system metrics like GPU usage, and we can visualize the training progress, loss curves, and system metrics in the W&B dashboard.
Model Monitoring with Evidently
Evidently is a powerful tool for monitoring machine learning models in production. Here’s an example of how you can use it to monitor data drift and model performance:
import evidently import pandas as pd from evidently.model_monitoring import ModelMonitor from evidently.model_monitoring.monitors import DataDriftMonitor, PerformanceMonitor # Load reference data ref_data = pd.read_csv("reference_data.csv") # Load production data prod_data = pd.read_csv("production_data.csv") # Load model model = load_model("model.pkl") # Create data and performance monitors data_monitor = DataDriftMonitor(ref_data) perf_monitor = PerformanceMonitor(ref_data, model) # Monitor data and performance model_monitor = ModelMonitor(data_monitor, perf_monitor) model_monitor.run(prod_data) # Generate HTML report model_monitor.report.save_html("model_monitoring_report.html")
In this example, we load reference and production data, as well as a trained model. We create instances of DataDriftMonitor and PerformanceMonitor to monitor data drift and model performance, respectively. We then run these monitors on the production data using ModelMonitor and generate an HTML report with the results.
Deployment with BentoML
BentoML simplifies the process of deploying and serving machine learning models. Here’s an example of how you can package and deploy a scikit-learn model using BentoML:
import bentoml from bentoml.io import NumpyNdarray from sklearn.linear_model import LogisticRegression # Train model clf = LogisticRegression() clf.fit(X_train, y_train) # Define BentoML service class LogisticRegressionService(bentoml.BentoService): @bentoml.api(input=NumpyNdarray(), batch=True) def predict(self, input_data): return self.artifacts.clf.predict(input_data) @bentoml.artifacts([LogisticRegression.artifacts]) def pack(self, artifacts): artifacts.clf = clf # Package and save model svc = bentoml.Service("logistic_regression", runners=[LogisticRegressionService()]) svc.pack().save() # Deploy model svc = LogisticRegressionService.load() svc.start()
In this example, we train a scikit-learn LogisticRegression model and define a BentoML service to serve predictions. We then package the model and its artifacts using bentoml.Service and save it to disk. Finally, we load the saved model and start the BentoML service, making it available for serving predictions.
Conclusion
In the rapidly evolving field of machine learning, MLOps tools play a crucial role in streamlining the entire lifecycle of machine learning projects, from experimentation and development to deployment and monitoring. Tools like Weights & Biases, Comet, MLflow, Kubeflow, BentoML, and Evidently offer a range of features and capabilities to support various aspects of the MLOps workflow.
By leveraging these tools, data science teams can enhance collaboration, reproducibility, and efficiency, while ensuring the deployment of reliable and performant machine learning models in production environments. As the adoption of machine learning continues to grow across industries, the importance of MLOps tools and practices will only increase, driving innovation and enabling organizations to harness the full potential of artificial intelligence and machine learning technologies.
#ai#alerts#Algorithms#Amazon#Amazon Web Services#amp#Analysis#anomalies#API#APIs#architecture#Article#artificial#Artificial Intelligence#automation#bugs#Building#Business#Capture#change#chart#charts#CI/CD#Cloud#code#collaborate#Collaboration#collaborative#comet#communication
0 notes
Text
Latest Trends In Web Development For 2024

With 2024 in the picture, a lot of shifts and advancements are expected as far as web development is concerned. Considering the rapid evolution of the trends, developers must keep themselves updated with the latest trends and technologies in order to stay competitive. In this post, we have compiled a list of Web Development Trends for 2024.
Are you excited to embrace the Latest Web Development Technologies that are going to dominate the trend?
Read More
#intelliatech#itsbenefits#it services#software engineering#itandsoftware#API-first Design#UI Dark Mode UI#Front-end Development#Trends Front-end Development#Headless CMS#JavaScript Frameworks 2024#Latest Web Development Technologies#Low-Code/No-Code Development#Progressive Web Apps (PWA)#Responsive Design#Static Site Generators#UX Design Trends 2024#Voice Search Optimization#web development trends#web development trends and technology
0 notes
Text
In the world of software, APIs (Application Programming Interfaces) act as bridges between different services. They help applications talk to each other by sending requests and receiving responses. Think of them as messengers, delivering messages between clients (like apps or websites) and servers (where data or actions are stored). Read more...
#Designing REST APIs#RESTful APIs#Web APIs#Web API development#Web API development services#REST APIs Design
1 note
·
View note
Last Seen Blogs

popinch
Popinch

setonallison
№1 blood lover

ankamedikal-blog
Anka Medikal

pixsaladpit
ditzy

screechingsoulking
Nisher Developer