#architectural engineering software
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
1,644 Tumblr posts in 1 second.
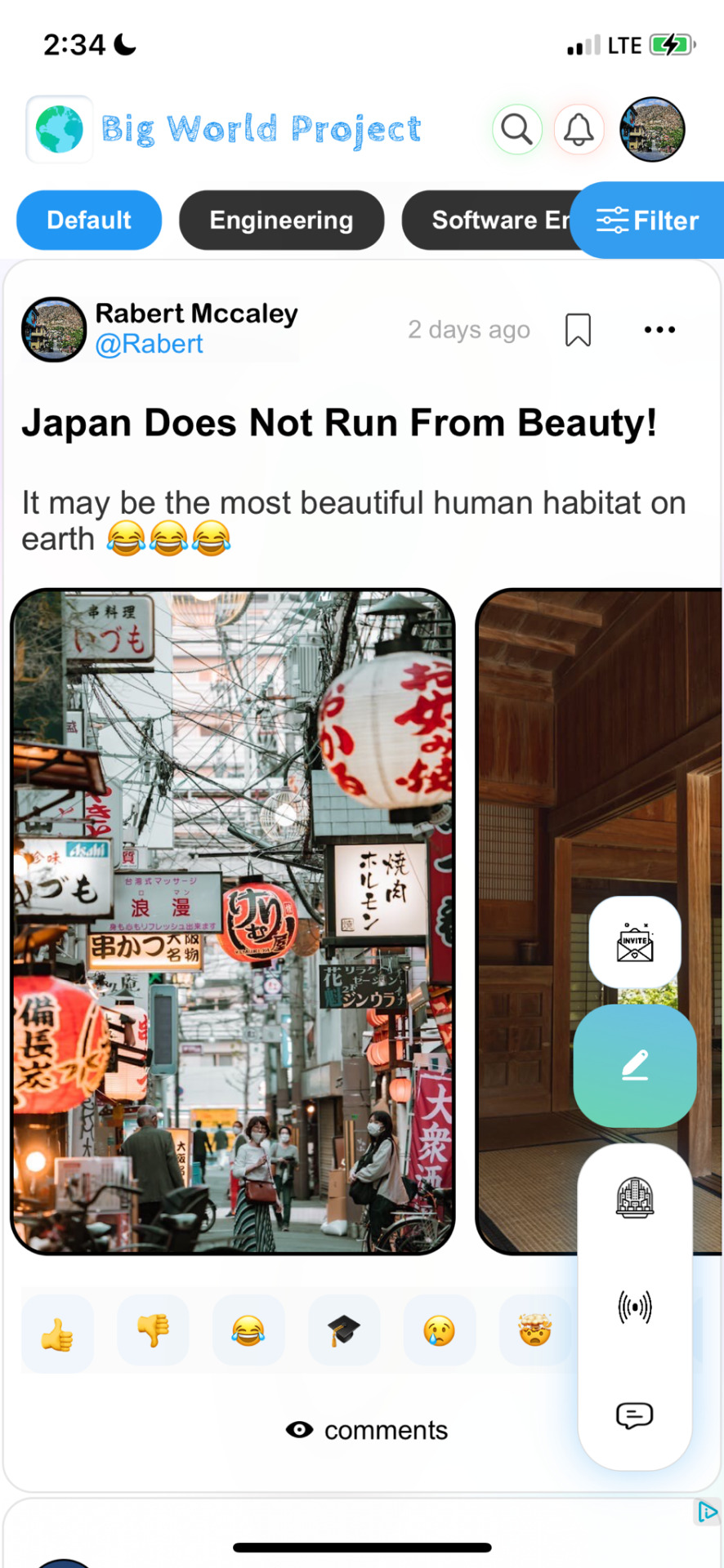
Text

The most awaited article of the year is here ... Evolution of automation is all yours now !!!
#aerospace#automation#machine learning#artificial intelligence#success#inspiring quotes#architecture#article#trending#viral#viral trends#market trends#viralpost#automotive#automatically generated text#software#engineering#search engine optimization
9 notes
·
View notes
Photo





(via "Let me take a look at this I'm an engineer" Essential T-Shirt for Sale by Abdosh1999)
#findyourthing#redbubble#engineering#engineer#biomedical engineering#civil engineering#architecture#mechanical engineering#electrical engineering#commercial heating engineers#engineersoldier#software engineers#engineers#gas engineers#tshirt
2 notes
·
View notes
Text

credit @lusi-1
#nerding#memes#studying#nerd#architecture#engineering#software#development#game dev#funny haha#we do a little trolling#me fr
2 notes
·
View notes
Text
We are a social app built for people to share and celebrate everything bright & nerdy. We specialize in content related to engineering, medicine, comics, art, architecture, science, anime, gaming, and more. We plan to be the biggest content delivery system for everything nerdy.

#social media#anime#comics#artwork#business#economics#makeup#science#biology#engineering#physics#maths#computer#film#architecture#diy#biochemistry#chemistry#astronomy#geology#oceanography#botany#neuroscience#zoology#Social Science#psychology#technology#software#civil engineering#chemical engineering
3 notes
·
View notes
Text

BIM Software Learning | BIM Certificate Programs- Aeczone Academy
#architecture#certificate in building information modelling#online bim certificate programs#learn bim online#bim classes#bim architecture course#bim certification courses#bim course with placement#bim modeling course#building information modeling course#bim engineer course#bim learning online#bim software learning
3 notes
·
View notes
Text
Figuring out how tumbler works

#software engineering#programming#photography#science#illustration#design#art#architecture#nostalgia#japan
2 notes
·
View notes
Text
Loving Travis
For most of my open-source software projects, I use the Actions platform built into GitHub for CI (continuous integration). GitHub Actions provides virtual machines to run workflows, so I don't have to administer build environments for Linux, MacOS, Windows, and so on. It's modern, convenient (if you use GitHub instead of, say, GitLab), fairly reliable, and (best of all) free (for public repos).
For me, the main limitation of Actions is that all their hosted runners use the x64 architecture. Sometimes I want to build and/or test on Arm CPUs---for instance my Libbulletjme project, which has a bunch of platform-sensitive C++ code.
For Libbulletjme, I still depend on the older TravisCI platform, run by a private firm in Berlin. In addition to a huge selection of build environments based on AMD CPUs, Travis also provides Arm-based Linux environments. (Officially, they're a "beta-stage" feature, but they've been in beta for years.) Like Actions, Travis is also free to open-source projects, though their notion of "open-source" seems a bit stricter than GitHub's.
I mention Travis because my experiments with the Vulkan API exposed a limitation in Libbulletjme, which led me to begin work on a new release of Libbulletjme, which led me to discover an issue with Travis's Arm-based build environments. A recent change to these environments caused all my Arm-based builds to fail. I could only go a bit further with Vulkan before I would have to make hard choices about how to work around the limitations of Libbulletjme v18.5.0 .
At 20:09 hours UTC yesterday (a Sunday), I e-mailed TravisCI customer support and explained my issue. At 12:25 hours UTC today, Travis announced a hotfix to solve my issue. That's pretty good turnaround, for a non-paying customer having issues with a "beta-stage" feature on a summer weekend.
Bottom line: I still love Travis. <3
#continuous integration#vulkan#computer architecture#software engineering#open source#github#hosting#upcoming releases#customer support#making progress#software testing#war stories#love#berlin
3 notes
·
View notes
Photo

The Zonohedral Cathedral Built by a Software Engineer
Rob Bell is a San Francisco-based artist, designer, and professional software engineer who started a company called Zomadic. It is a design/build company focussing on CNC technology’s creative use. In other words, it is a long time goal for Bell to combine his skills as a programmer with his desire to create concrete objects. So in 2001, he started to take lessons and create his first geometric works, followed by other non-rectilinear geometric designs. Built in 2013 in Nevada, the Zonohedral Cathedral is one of Bell’s Zomadic structures.





#rob bell#artist#san francisco-based artist#designer#professional software engineer#zonohedral cathedral#architecture#zomadic#cnc technology#nevada
3 notes
·
View notes
Text
Daily Affirmations to Fix Backend Bottlenecks and Boost Performance

Behind every reliable software product engineering service, there’s an engineering mind quietly solving invisible problems before they become visible failures. Whether you're a backend developer tuning queries or a CTO overseeing large-scale deployments, the need to consistently fix performance bottlenecks is a part of your daily reality.
Technical decisions in complex systems are often made under pressure. Without clarity, that pressure can lead to reactive patches instead of long-term solutions.
Daily affirmations offer a simple but effective mental framework to help engineering leaders stay aligned with their priorities. You can utilize them as daily reminders to think intentionally, act early, and design systems that handle high traffic loads and stay reliable.
Why Mindset Matters to Fix Performance Bottlenecks?
Performance bottlenecks are the result of accumulated delays, overlooked warning signs, or rushed decisions made under pressure. In such situations, how engineers and CTOs think is just as important as what they do.
When managing high-demand systems, mindset influences how performance issues in scaling applications are approached. A reactive mindset is needed to strategize to eliminate performance bottlenecks. It may rely on quick patches that fail under future load.
Engineering leaders with a performance-first mindset regularly evaluate their infrastructure. They identify slow APIs, review system logs, and test their scaling strategies, not only when something goes wrong but as a habit. It reduces system downtime and aligns everyone around one shared goal, to fix performance bottlenecks before they impact the user experience.
The Reality Behind System Performance Pressure
In today’s high-demand digital environments, the responsibility to fix performance bottlenecks consistently falls on backend engineers and CTOs. Whether scaling a cloud-native application or debugging a slow deployment, the pressure to maintain smooth performance is constant, and often underestimated.
📊 Relevant Statistics:
48% of critical system outages were due to unresolved performance bottlenecks during traffic spikes, many of which could have been prevented with better monitoring and testing.
According to GitLab’s Developer Survey, 64% of engineers say that performance issues in scaling applications cause the most stress during production releases.
Gartner estimates the average cost of server crashes caused by backend failure at $5,600 per minute, highlighting the financial impact of poor backend planning.
Common Stereotypes in Performance Management
In the digital business, common stereotypes often delay efforts to fix performance bottlenecks and misguide system optimization priorities. Often, you’ve come across such pre-defined business hurdle mindsets, like,
🔹 It’ll scale automatically, Assuming auto-scaling during traffic surges solves everything, ignoring the need to optimize system backend response times.
🔹 Monitoring is an Ops job, Overlooking the role of developers by using real-time traffic monitoring solutions to detect issues before they escalate.
🔹 Only frontend matters to users, Ignoring how slow APIs and unoptimized backend services directly affect user experience and retention.
🔹 We’ll fix it after launch, Short-term business thinking instead of building systems with proactive software scaling and performance reviews in mind.
This context shows why performance isn’t just about tools, it’s about thinking ahead and designing systems that are stable under pressure!
How Daily Self-Talk Influences Technical Decisions?
Engineering isn’t just technical, it’s intensely mental. The decisions that fix or cause performance bottlenecks often happen in high-pressure moments. During deployment windows, incident triaging, or architecture reviews, the internal dialogue engineers and CTOs carry with them can shape everything from system design to response strategies.
Daily self-talk, especially when it’s structured and intentional like affirmations, gives engineers a moment of clarity before making decisions. Instead of rushing through logs or hastily patching backend services, they pause, reflect, and choose a solution that aligns with long-term scalability.
For example, a developer who starts the day thinking “I design with scale in mind” is more likely to review queue behavior or optimize backend response time rather than simply increasing timeouts.
A CTO who reinforces, “My job is to ask the right performance questions,” may invest in performance audits or challenge assumptions around slow APIs and data-heavy routes.
Affirmations don’t eliminate stress, but they reframe how technical challenges are approached. When mindset becomes method, engineers respond to bottlenecks with structure, not stress.
Daily Affirmations to Fix Performance Bottlenecks
1. Focus on Clarity Before Code
Before writing a single line, engineers should map system workflows, define expected loads, and isolate high-traffic APIs. This reduces system architectural flaws that often cause performance bottlenecks under pressure.
2. Performance is a Product, Not a Patch
Instead of fixing response delays reactively, engineers should embed system performance optimization into development cycles. Regularly reviewing queries, queuing logic, and Redis usage can make performance part of CI/CD quality checks. For CTOs, setting this expectation early builds a culture where system bottlenecks are treated with the same priority as bugs.
3. Slow APIs Need Your Attention First
APIs handling the most business-critical functions must be profiled consistently. Use tools like Laravel Telescope, Blackfire, or Postman monitors to measure call frequency, payload size, and latency. Resolving these issues early not only improves user experience but also fixes performance bottlenecks that often go unnoticed in the background.
4. Use Data to Drive Scaling Decisions
Scaling decisions should come from real metrics, not assumptions!
Analyze real-time traffic monitoring solutions to understand peak patterns, failed requests, and queue lengths. This enables smarter use of autoscaling groups, queue thresholds, and database read replicas, preventing resource waste and avoiding costly performance degradation.
5. Simulate Load Before It Finds You
Before peak events or deployment, run stress-testing tools like JMeter or Artillery to simulate traffic spikes. Monitor how APIs, job queues, and DBs respond under pressure. This often reveals performance issues that otherwise go undetected in normal QA routines.
6. Test Failure, Not Just Success
Engineers must validate how their systems behave under failure. By simulating database disconnects, queue overloads, or delayed third-party APIs, one can measure how resilient the system truly is. These tests reduce the risk of server crashes in production and strengthen backend logic by exposing weak failover paths early.
7. Build Redundancy Into Everything
A single point of failure can take down an entire product, especially in the monoliths.
Engineering leaders must plan well for handling traffic spikes, using techniques like multi-zone deployments, caching layers, mirrored databases, and distributed load balancers. This redundancy ensures consistent uptime when traffic increases or systems degrade under pressure.
8. Lead with Observability, Not Assumptions
Businesses must ensure every critical component of their stack is observable through logs, metrics, and alerts. Using real-time traffic monitoring solutions, you can catch slowdowns, memory leaks, or surging error rates before users experience them. Observability allows leaders to fix performance bottlenecks before they cascade into outages.
9. Design Systems That Reflect Scalability, Not Complexity
Engineers should focus on building scalable system architecture using principles like decoupled services, message queues, and load-agnostic routing. It becomes easier to scale specific functions independently without overhauling the entire stack. It leads to faster and cleaner performance tuning.
10. Stay Calm When Load Peaks
Rely on tested autoscaling during traffic surges, CDN caching, and database load balancing to absorb the system pressure. A stable mindset during traffic spikes ensures that performance bottlenecks are handled proactively, not after users report them.
Performance Culture Tips for Engineering Leaders
Creating a strong performance culture doesn’t rely on tools alone, it depends on how engineering leaders define priorities. By setting the right expectations and building habits around system health, CTOs and architects make it easier to fix performance bottlenecks before they affect real users.
1. Embed Performance Metrics into Daily Workflows
Integrate real-time traffic monitoring solutions directly into your development and deployment pipelines. Tools like Prometheus or New Relic can provide continuous insights, enabling teams to proactively fix performance bottlenecks before they escalate.
2. Promote a Culture of Continuous Feedback
Establish regular, informal check-ins focused on system performance optimization. Encourage team members to share observations about slow APIs or other issues, fostering an environment where performance concerns are addressed promptly.
3. Invest in Targeted Training Programs
Offer workshops and training sessions on topics like stress testing and backend response time optimization. Empowering engineers with the latest knowledge ensures they are equipped to handle performance issues in scaling applications effectively.
4. Encourage Cross-Functional Collaboration
Facilitate collaboration between development, operations, and QA teams to identify and resolve performance challenges. This holistic approach ensures that backend services are optimized in conjunction with frontend and infrastructure components.
5. Recognize and Reward Performance Improvements
Acknowledge team members who contribute to enhancing system performance. Celebrating successes in proactive software scaling and fixing performance bottlenecks reinforces the importance of performance culture within the organization.
Bottomline
Whether writing backend logic, reviewing deployments, or managing releases, each task should align to detect and eliminate inefficiencies before they affect production!
It just requires a consistent focus on monitoring API latency, validating scaling behavior, testing job queues under pressure, and reviewing resource consumption metrics. These actions not only improve system reliability but reduce firefighting and accelerate system delivery cycles.
Technical teams must review real-time traffic patterns and maintain test coverage for load-sensitive endpoints. Furthermore, audit critical flows for processing delays or concurrency issues are also crucial. When the technical leadership of any business treats performance not as a checkpoint but as a discipline, the process to fix performance bottlenecks becomes structured, measurable, and eventually predictable.
FAQs
1. What causes performance bottlenecks in backend systems?
Performance bottlenecks are often caused by unoptimized database queries, inefficient API logic, high memory usage, or poor concurrency management. It also includes a lack of stress testing, missing caching layers, and heavily synchronous operations.
System performance bottlenecks usually emerge when system load increases. Continuous profiling and real-time monitoring help detect them early. Addressing them requires a combination of architecture review and runtime metrics.
2. How often should I review system performance?
System performance demands regular review, ideally during every deployment cycle and also as part of weekly or bi-weekly operational reviews.
Monitoring key metrics like API response time, error rate, and queue lengths helps prevent issues before they affect users. For high-traffic systems, continuous performance evaluation is essential, it can be achieved wth the adoption of best tools for infrastructure scaling and monitoring.
3. What’s the difference between stress testing and load testing?
Load testing measures system behavior under expected levels of traffic to evaluate stability and response time. Stress testing goes a step further, it pushes the system beyond normal limits to identify failure points and recovery behavior. While load tests validate capacity, stress tests prepare the system for worst-case scenarios.
4. Can any software product engineering service help improve backend performance in enterprise systems?
Yes, Acquaint Softtech specializes in backend performance engineering, especially for Laravel, Node.js, and custom architectures. Our software experts help identify performance bottlenecks, restructure unscalable components, and implement real-time observability across systems.
#Performance Bottlenecks#Scalable Architecture#Backend Optimization#Engineering Mindset#Software Reliability
0 notes
Text
10 Things You Should Know About Structural Engineering and Design
Discover 10 essential facts about structural engineering and design – Pinnacle Infotech. Learn what structural engineers do and understand the difference from architecture. Explore top tools and gain career insights. Find out how Pinnacle Infotech leads in innovative structural engineering services. Civil engineer and construction worker manager holding digital tablet and blueprints , talking and…

View On WordPress
#BIM service#engineering design services#free structural engineering software#pinnacle infotech#Structural BIM Service#structural design#structural designer vs structural engineer#structural engineer#structural engineering job#structural engineering vs architecture#what are structural engineers#what does a structural design engineer do#what is structural design#what structural engineers do
0 notes
Text
KPIT Technologies Collaborates with Mercedes-Benz Research and Development India to Accelerate Software-Defined Vehicle Development
KPIT Technologies has announced a collaboration with Mercedes-Benz Research and Development India (MBRDI) to accelerate the development and realization of Software-Defined Vehicles (SDVs). This partnership aims to drive faster innovation, reduce time-to-market, and enhance operational efficiencies by leveraging KPIT’s cross-domain expertise in mobility technologies. Mercedes-Benz is advancing…

View On WordPress
#automotive industry#automotive innovation India#automotive R&D#automotive R&D India#automotive software#automotive software engineering#automotive software solutions#automotive technology#connected car technology#connected vehicles#electric vehicle software#future of mobility#KPIT collaboration#KPIT Mercedes-Benz collaboration#KPIT Technologies#KPIT Technologies partnership#Mercedes-Benz#Mercedes-Benz innovation#Mercedes-Benz Research and Development India#mobility solutions#next-gen mobility solutions#next-gen vehicles#R&D India#SDV transformation#smart vehicle software#software engineering#software-defined vehicle development#software-defined vehicles#vehicle architecture development#vehicle development
0 notes
Text
Understanding the Liskov Substitution Principle (LSP) in Swift
In this article, we'll explore how Liskov Subtitution Principle (LSP) works in Swift with practical examples, including a mock implementation for testing and a real implementation that loads data remotely. We will also discuss common pitfalls and best practices for ensuring LSP compliance in your Swift applications.
The Liskov Substitution Principle (LSP) is one of the five SOLID principles of object-oriented design. It states that: “Objects of a superclass should be replaceable with objects of a subclass without affecting the correctness of the program.” (Paraphrased from Barbara Liskov’s) Barbara Liskov, a pioneering computer scientist, introduced this principle in 1987 as part of her research on data…
#Clean Architecture#Good Programming Practice#Ios Development#Liskov Subtitution Principle#Software Development#Software Engineering#SOLID
0 notes
Text
Understanding the Problem Before Solving It: A Principal Systems Architect’s Perspective
🚀 New Blog Post! 🚀 Solving problems without fully understanding them leads to wasted effort and technical debt. As a Principal Systems Architect, I’ve learned that deep problem analysis is the key to designing scalable, effective systems. #ArtificialIntelligence #Innovation #Technology #SoftwareEngineering ##Productivity #Automation #digitaltransformation #SystemsArchitecture #ProblemSolving #CriticalThinking #AI #Engineering #SoftwareDevelopment
The Engineer’s Dilemma: Jumping to Solutions Too Soon In the world of systems architecture, there’s a temptation to jump straight into solution mode—especially when deadlines loom and stakeholders demand progress. Engineers, especially those skilled in AI and software development, often pride themselves on rapid problem-solving. But here’s the catch: Solving the wrong problem efficiently is still…
#AI Strategy#Critical Thinking#Decision Making#Engineering#Problem-Solving#Software Development#Systems Architecture
0 notes
Text
"How SketchUp Pro Enhances Engineering & Architecture Workflow | PI Software"
"Learn how SketchUp Pro improves engineering and architectural workflows with precise modeling, seamless integrations, and efficient design processes. Discover its benefits for professionals."
#SketchUp Pro#Architecture Software#Engineering Design#3D Modeling#CAD Software#Design Workflow#Building Information Modeling (BIM)#Construction Technology#Architectural Visualization#Digital Design Tools#Engineering Workflow#Structural Design
0 notes
Text
Benefits of Isometric Drawing Applications in Cryogenic Piping Systems

Cryogenic piping systems, designed to transport extremely low-temperature fluids like liquid nitrogen or liquefied natural gas (LNG), are a cornerstone of industries such as aerospace, healthcare, and energy. The design and maintenance of these systems require precision, as any error can result in inefficiencies or, worse, safety hazards. One essential tool in managing these challenges is the use of isometric drawing applications. These advanced tools transform the way cryogenic piping systems are visualized, constructed, and maintained.
Isometric Drawing is a type of technical drawing that represents a three-dimensional object in two dimensions. It is commonly used in engineering, architecture, and design to provide a clear visual representation of an object or structure. In an isometric drawing, the three principal axes of the object (height, width, and depth) are represented equally foreshortened and inclined at equal angles, typically 120° apart from each other. By using isometric drawing, designers can communicate complex ideas visually and ensure precision in construction or manufacturing processes.
Learn more: https://blog.prototechsolutions.com/top-5-benefits-of-isometric-drawing-applications-in-cryogenic-piping-systems/
0 notes
Text
Services Offered by NEC UAE
NEC UAE is a leading engineering solutions provider specializing in cutting-edge infrastructure development and innovative design services. With a commitment to excellence and sustainability, NEC leverages advanced technology to deliver high-quality engineering solutions for large-scale projects across various industries.
1. Infrastructure Engineering
NEC delivers comprehensive infrastructure engineering solutions, focusing on sustainable and efficient systems to support modern communities. Key Engineering Services include:
Designing and constructing roads and bridges.
Developing water supply and wastewater management systems.
Implementing advanced electrical and telecommunications networks.
2. Road and Highway Engineering:
NEC specializes in designing and constructing roads and highways to optimize traffic flow and enhance safety. Their expertise includes:
Efficient and sustainable road designs.
Solutions to address traffic congestion and improve transportation networks.
Integrating features such as bike lanes and pedestrian pathways.
3. Architectural Design
Nec-uae offers innovative architectural design services that blend functionality with aesthetic appeal. Their services include:
Designing residential, commercial, and mixed-use buildings.
Developing sustainable, eco-friendly design solutions.
Using advanced tools for spatial analysis and design optimization.
4. Structural Design
NEC provides robust and innovative structural design services to ensure safety and durability. Their expertise includes:
Designing foundations and substructures tailored to diverse soil conditions.
Engineering solutions to withstand seismic and wind forces.
Renovating and retrofitting existing buildings for improved performance.
5. Engineering Tools & Software
NEC uses state-of-the-art engineering tools and software to enhance the accuracy and efficiency of projects. These tools aid in:
Precise design modeling and analysis.
Streamlining project workflows.
Ensuring seamless collaboration among teams.
BIM Services
NEC is at the forefront of Building Information Modeling (BIM) technology, offering a range of services to streamline project management and execution:
1. BIM-Project Life Cycle:
Managing the entire project lifecycle from conceptualization to operation using BIM tools.
Ensuring smooth transitions between project phases.
2. BIM Process Flow:
Coordinating workflows among project teams to minimize conflicts.
Utilizing BIM for clash detection and improving project efficiency.
3. BIM Tools & Software:
Employing advanced BIM software for detailed modeling and simulation.
Enhancing visualization with tools like Revit and Navisworks.
With a strong focus on innovation, quality, and sustainability, NEC UAE is a trusted partner for engineering and Construction Management. Whether it's infrastructure development, road engineering, or advanced BIM services, NEC delivers excellence at every step.
#Infrastructure Engineering#Road and Highway Engineering#Architectural Design#Structural Design#Engineering Tools & Software#BIM Services#BIM-Project Life Cycle#BIM Process Flow#BIM Tools & Software
1 note
·
View note