#argocd
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Post activity is at the highest at 4:00 pm EDT; notes peak at 10:00 pm EDT.
Text
What is Argo CD? And When Was Argo CD Established?

What Is Argo CD?
Argo CD is declarative Kubernetes GitOps continuous delivery.
In DevOps, ArgoCD is a Continuous Delivery (CD) technology that has become well-liked for delivering applications to Kubernetes. It is based on the GitOps deployment methodology.
When was Argo CD Established?
Argo CD was created at Intuit and made publicly available following Applatix’s 2018 acquisition by Intuit. The founding developers of Applatix, Hong Wang, Jesse Suen, and Alexander Matyushentsev, made the Argo project open-source in 2017.
Why Argo CD?
Declarative and version-controlled application definitions, configurations, and environments are ideal. Automated, auditable, and easily comprehensible application deployment and lifecycle management are essential.
Getting Started
Quick Start
kubectl create namespace argocd kubectl apply -n argocd -f https://raw.githubusercontent.com/argoproj/argo-cd/stable/manifests/install.yaml
For some features, more user-friendly documentation is offered. Refer to the upgrade guide if you want to upgrade your Argo CD. Those interested in creating third-party connectors can access developer-oriented resources.
How it works
Argo CD defines the intended application state by employing Git repositories as the source of truth, in accordance with the GitOps pattern. There are various approaches to specify Kubernetes manifests:
Applications for Customization
Helm charts
JSONNET files
Simple YAML/JSON manifest directory
Any custom configuration management tool that is set up as a plugin
The deployment of the intended application states in the designated target settings is automated by Argo CD. Deployments of applications can monitor changes to branches, tags, or pinned to a particular manifest version at a Git commit.
Architecture
The implementation of Argo CD is a Kubernetes controller that continually observes active apps and contrasts their present, live state with the target state (as defined in the Git repository). Out Of Sync is the term used to describe a deployed application whose live state differs from the target state. In addition to reporting and visualizing the differences, Argo CD offers the ability to manually or automatically sync the current state back to the intended goal state. The designated target environments can automatically apply and reflect any changes made to the intended target state in the Git repository.
Components
API Server
The Web UI, CLI, and CI/CD systems use the API, which is exposed by the gRPC/REST server. Its duties include the following:
Status reporting and application management
Launching application functions (such as rollback, sync, and user-defined actions)
Cluster credential management and repository (k8s secrets)
RBAC enforcement
Authentication, and auth delegation to outside identity providers
Git webhook event listener/forwarder
Repository Server
An internal service called the repository server keeps a local cache of the Git repository containing the application manifests. When given the following inputs, it is in charge of creating and returning the Kubernetes manifests:
URL of the repository
Revision (tag, branch, commit)
Path of the application
Template-specific configurations: helm values.yaml, parameters
A Kubernetes controller known as the application controller keeps an eye on all active apps and contrasts their actual, live state with the intended target state as defined in the repository. When it identifies an Out Of Sync application state, it may take remedial action. It is in charge of calling any user-specified hooks for lifecycle events (Sync, PostSync, and PreSync).
Features
Applications are automatically deployed to designated target environments.
Multiple configuration management/templating tools (Kustomize, Helm, Jsonnet, and plain-YAML) are supported.
Capacity to oversee and implement across several clusters
Integration of SSO (OIDC, OAuth2, LDAP, SAML 2.0, Microsoft, LinkedIn, GitHub, GitLab)
RBAC and multi-tenancy authorization policies
Rollback/Roll-anywhere to any Git repository-committed application configuration
Analysis of the application resources’ health state
Automated visualization and detection of configuration drift
Applications can be synced manually or automatically to their desired state.
Web user interface that shows program activity in real time
CLI for CI integration and automation
Integration of webhooks (GitHub, BitBucket, GitLab)
Tokens of access for automation
Hooks for PreSync, Sync, and PostSync to facilitate intricate application rollouts (such as canary and blue/green upgrades)
Application event and API call audit trails
Prometheus measurements
To override helm parameters in Git, use parameter overrides.
Read more on Govindhtech.com
#ArgoCD#CD#GitOps#API#Kubernetes#Git#Argoproject#News#Technews#Technology#Technologynews#Technologytrends#govindhtech
2 notes
·
View notes
Text

Basil - Multilingual magic. Build and test using Java, C++, Go, Android, iOS and many other languages and platforms.
0 notes
Text

In this blog post, we’ll explore the journey of transitioning from Flux to Argo CD and the reasons why you might consider making the switch.
0 notes
Text
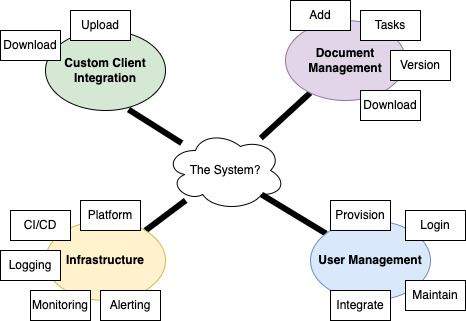
In interviewing for higher level architecture positions, you will be sometimes be asked to do design a new system to demonstrate your capabilities. The following is from such an interview around PHP, Laravel, Nuxt, MySQL, Redis, AWS, and K8s.
0 notes
Text

Azure DevOps Training Online New Batch
Join Now Team ID: 479 864 819 691
Password: pxxffv
Attend New Online Batch On Azure DevSecOps by Mr. Sudheer.
Batch on: 12th October @ 7:00 AM (IST).
Contact us: 099899 71070
Visit:https://www.visualpath.in/Microsoft-Azure-DevOps-online-Training.html
#Grafana#AzureDevOps#Azure#DevOps#MicrosoftAzure#Visualpath#newbatch#security#DevSecOps#azureadmin#Terraform#terragrunt#ansible#azuredevopstraining#Dockers#elk#ArgoCD#HelmCharts#SHELLSCRIPTING#azuremonitor#prometheus#OWASP#continersecurity#sonarqube#gileaks#softwaretraining#traininginstitute#newtechnology#trendingcourse
0 notes
Text
How to Monitor ArgoCD using Prometheus
Any given environment, it is important to monitoring. It helps to track the application/tool performance and also it helps to optimize the application. Similar, in a complex environment where we have numerous teams deploying both monoliths and microservices to Kubernetes, it’s almost a given that operations won’t always run perfectly. Argo CD provides us with a plenty of metrics that enable us to…

View On WordPress
0 notes
Text
Top 10 DevOps Containers in 2023
Top 10 DevOps Containers in your Stack #homelab #selfhosted #DevOpsContainerTools #JenkinsContinuousIntegration #GitLabCodeRepository #SecureHarborContainerRegistry #HashicorpVaultSecretsManagement #ArgoCD #SonarQubeCodeQuality #Prometheus #nginxproxy
If you want to learn more about DevOps and building an effective DevOps stack, several containerized solutions are commonly found in production DevOps stacks. I have been working on a deployment in my home lab of DevOps containers that allows me to use infrastructure as code for really cool projects. Let’s consider the top 10 DevOps containers that serve as individual container building blocks…

View On WordPress
#ArgoCD Kubernetes deployment#DevOps container tools#GitLab code repository#Grafana data visualization#Hashicorp Vault secrets management#Jenkins for continuous integration#Prometheus container monitoring#Secure Harbor container registry#SonarQube code quality#Traefik load balancing
0 notes
Quote
これは、オープンソース化するときに家を手放すべきではない理由をよくまとめたものです。 問題はまさにこれでした。Earthly がオープンソースであるため、Earthy Satellite ユーザーはすでに Earthly CI の 95% からメリットを享受していました 。 私はオープンソースの大ファンですが、ビジネス モデルにオープンソース モデルが含まれている場合は、差別化要因が必要です。 驚異的な速さ(tm)を超えて。 人々がクレジット カードを差し出す理由、あるいはもっと言えば、会計上の発注プロセスを差し出す理由が必要です。 魅力的なものにするために、オープンソース製品から提供しない機能やサービスが必要です。 GitLab は、CI/CD を有料の顧客に制限しています。 オープンソースでない限り、Travis/CircleCI によるビルド時間/クレジットの制限。 Azure DevOps は悪魔です。 ArgoCD は複雑です。 ランナーを実行するハードウェアがある場合、GitHub アクションは便利です。 Jenkins の Swarm は、企業内でほとんどの人が慣れ親しんでいるものです。 元 DevOps ディレクターとして、私の当面の疑問は、自分でホストするのではなく、どの機能を購入したくなるかということです。 技術的には有能なんです。 ビジネスにとって最も合理的な方法で従業員のためにクラウドと DevOps パイプラインを実行できるのに、なぜ貴社を購入する必要があるのでしょうか? 最も意味のあることを理解するのを手伝ってください。 *編集* 私は、ソフトウェアの動作に不可欠な機能を保留することを提案しているのではなく、サポートやエンタープライズレベルの統合を提供するビジネス機能を保留することを提案しています。 パワーユーザーがより自分自身をサポートするため、支払いが少なくなるように階層化することさえあるのでしょうか?
私たちは最速の CI を構築しましたが、失敗しました。 ハッカーニュース
3 notes
·
View notes
Text
Unlocking SRE Success: Roles and Responsibilities That Matter
In today’s digitally driven world, ensuring the reliability and performance of applications and systems is more critical than ever. This is where Site Reliability Engineering (SRE) plays a pivotal role. Originally developed by Google, SRE is a modern approach to IT operations that focuses strongly on automation, scalability, and reliability.

But what exactly do SREs do? Let’s explore the key roles and responsibilities of a Site Reliability Engineer and how they drive reliability, performance, and efficiency in modern IT environments.
🔹 What is a Site Reliability Engineer (SRE)?
A Site Reliability Engineer is a professional who applies software engineering principles to system administration and operations tasks. The main goal is to build scalable and highly reliable systems that function smoothly even during high demand or failure scenarios.
🔹 Core SRE Roles
SREs act as a bridge between development and operations teams. Their core responsibilities are usually grouped under these key roles:
1. Reliability Advocate
Ensures high availability and performance of services
Implements Service Level Objectives (SLOs), Service Level Indicators (SLIs), and Service Level Agreements (SLAs)
Identifies and removes reliability bottlenecks
2. Automation Engineer
Automates repetitive manual tasks using tools and scripts
Builds CI/CD pipelines for smoother deployments
Reduces human error and increases deployment speed
3. Monitoring & Observability Expert
Sets up real-time monitoring tools like Prometheus, Grafana, and Datadog
Implements logging, tracing, and alerting systems
Proactively detects issues before they impact users
4. Incident Responder
Handles outages and critical incidents
Leads root cause analysis (RCA) and postmortems
Builds incident playbooks for faster recovery
5. Performance Optimizer
Analyzes system performance metrics
Conducts load and stress testing
Optimizes infrastructure for cost and performance
6. Security and Compliance Enforcer
Implements security best practices in infrastructure
Ensures compliance with industry standards (e.g., ISO, GDPR)
Coordinates with security teams for audits and risk management
7. Capacity Planner
Forecasts traffic and resource needs
Plans for scaling infrastructure ahead of demand
Uses tools for autoscaling and load balancing
🔹 Day-to-Day Responsibilities of an SRE
Here are some common tasks SREs handle daily:
Deploying code with zero downtime
Troubleshooting production issues
Writing automation scripts to streamline operations
Reviewing infrastructure changes
Managing Kubernetes clusters or cloud services (AWS, GCP, Azure)
Performing system upgrades and patches
Running game days or chaos engineering practices to test resilience
🔹 Tools & Technologies Commonly Used by SREs
Monitoring: Prometheus, Grafana, ELK Stack, Datadog
Automation: Terraform, Ansible, Chef, Puppet
CI/CD: Jenkins, GitLab CI, ArgoCD
Containers & Orchestration: Docker, Kubernetes
Cloud Platforms: AWS, Google Cloud, Microsoft Azure
Incident Management: PagerDuty, Opsgenie, VictorOps
🔹 Why SRE Matters for Modern Businesses
Reduces system downtime and increases user satisfaction
Improves deployment speed without compromising reliability
Enables proactive problem solving through observability
Bridges the gap between developers and operations
Drives cost-effective scaling and infrastructure optimization
🔹 Final Thoughts
Site Reliability Engineering roles and responsibilities are more than just monitoring systems—it’s about building a resilient, scalable, and efficient infrastructure that keeps digital services running smoothly. With a blend of coding, systems knowledge, and problem-solving skills, SREs play a crucial role in modern DevOps and cloud-native environments.
📥 Click Here: Site Reliability Engineering certification training program
0 notes
Text
Mastering OpenShift at Scale: Red Hat OpenShift Administration III (DO380)
In today’s cloud-native world, organizations are increasingly adopting Kubernetes and Red Hat OpenShift to power their modern applications. As these environments scale, so do the challenges of managing complex workloads, automating operations, and ensuring reliability. That’s where Red Hat OpenShift Administration III: Scaling Kubernetes Workloads (DO380) steps in.
What is DO380?
DO380 is an advanced-level training course offered by Red Hat that focuses on scaling, performance tuning, and managing containerized applications in production using Red Hat OpenShift Container Platform. It is designed for experienced OpenShift administrators and DevOps professionals who want to deepen their knowledge of Kubernetes-based platform operations.
Who Should Take DO380?
This course is ideal for:
✅ System Administrators managing large-scale containerized environments
✅ DevOps Engineers working with CI/CD pipelines and automation
✅ Platform Engineers responsible for OpenShift clusters
✅ RHCEs or OpenShift Certified Administrators (EX280 holders) aiming to level up
Key Skills You Will Learn
Here’s what you’ll master in DO380:
🔧 Advanced Cluster Management
Configure and manage OpenShift clusters for performance and scalability.
📈 Monitoring & Tuning
Use tools like Prometheus, Grafana, and the OpenShift Console to monitor system health, tune workloads, and troubleshoot performance issues.
📦 Autoscaling & Load Management
Configure Horizontal Pod Autoscaling (HPA), Cluster Autoscaler, and manage workloads efficiently with resource quotas and limits.
🔐 Security & Compliance
Implement security policies, use node taints/tolerations, and manage namespaces for better isolation and governance.
🧪 CI/CD Pipeline Integration
Automate application delivery using Tekton pipelines and manage GitOps workflows with ArgoCD.
Course Prerequisites
Before enrolling in DO380, you should be familiar with:
Red Hat OpenShift Administration I (DO180)
Red Hat OpenShift Administration II (DO280)
Kubernetes fundamentals (kubectl, deployments, pods, services)
Certification Path
DO380 also helps you prepare for the Red Hat Certified Specialist in OpenShift Scaling and Performance (EX380) exam, which counts towards the Red Hat Certified Architect (RHCA) credential.
Why DO380 Matters
With enterprise workloads becoming more dynamic and resource-intensive, scaling OpenShift effectively is not just a bonus — it’s a necessity. DO380 equips you with the skills to:
✅ Maximize infrastructure efficiency
✅ Ensure high availability
✅ Automate operations
✅ Improve DevOps productivity
Conclusion
Whether you're looking to enhance your career, improve your organization's cloud-native capabilities, or take the next step in your Red Hat certification journey — Red Hat OpenShift Administration III (DO380) is your gateway to mastering OpenShift at scale.
Ready to elevate your OpenShift expertise?
Explore DO380 training options with HawkStack Technologies and get hands-on with real-world OpenShift scaling scenarios.
For more details www.hawkstack.com
0 notes
Text
Kubernetes Cluster Management at Scale: Challenges and Solutions
As Kubernetes has become the cornerstone of modern cloud-native infrastructure, managing it at scale is a growing challenge for enterprises. While Kubernetes excels in orchestrating containers efficiently, managing multiple clusters across teams, environments, and regions presents a new level of operational complexity.
In this blog, we’ll explore the key challenges of Kubernetes cluster management at scale and offer actionable solutions, tools, and best practices to help engineering teams build scalable, secure, and maintainable Kubernetes environments.
Why Scaling Kubernetes Is Challenging
Kubernetes is designed for scalability—but only when implemented with foresight. As organizations expand from a single cluster to dozens or even hundreds, they encounter several operational hurdles.
Key Challenges:
1. Operational Overhead
Maintaining multiple clusters means managing upgrades, backups, security patches, and resource optimization—multiplied by every environment (dev, staging, prod). Without centralized tooling, this overhead can spiral quickly.
2. Configuration Drift
Cluster configurations often diverge over time, causing inconsistent behavior, deployment errors, or compliance risks. Manual updates make it difficult to maintain consistency.
3. Observability and Monitoring
Standard logging and monitoring solutions often fail to scale with the ephemeral and dynamic nature of containers. Observability becomes noisy and fragmented without standardization.
4. Resource Isolation and Multi-Tenancy
Balancing shared infrastructure with security and performance for different teams or business units is tricky. Kubernetes namespaces alone may not provide sufficient isolation.
5. Security and Policy Enforcement
Enforcing consistent RBAC policies, network segmentation, and compliance rules across multiple clusters can lead to blind spots and misconfigurations.
Best Practices and Scalable Solutions
To manage Kubernetes at scale effectively, enterprises need a layered, automation-driven strategy. Here are the key components:
1. GitOps for Declarative Infrastructure Management
GitOps leverages Git as the source of truth for infrastructure and application deployment. With tools like ArgoCD or Flux, you can:
Apply consistent configurations across clusters.
Automatically detect and rollback configuration drifts.
Audit all changes through Git commit history.
Benefits:
· Immutable infrastructure
· Easier rollbacks
· Team collaboration and visibility
2. Centralized Cluster Management Platforms
Use centralized control planes to manage the lifecycle of multiple clusters. Popular tools include:
Rancher – Simplified Kubernetes management with RBAC and policy controls.
Red Hat OpenShift – Enterprise-grade PaaS built on Kubernetes.
VMware Tanzu Mission Control – Unified policy and lifecycle management.
Google Anthos / Azure Arc / Amazon EKS Anywhere – Cloud-native solutions with hybrid/multi-cloud support.
Benefits:
· Unified view of all clusters
· Role-based access control (RBAC)
· Policy enforcement at scale
3. Standardization with Helm, Kustomize, and CRDs
Avoid bespoke configurations per cluster. Use templating and overlays:
Helm: Define and deploy repeatable Kubernetes manifests.
Kustomize: Customize raw YAMLs without forking.
Custom Resource Definitions (CRDs): Extend Kubernetes API to include enterprise-specific configurations.
Pro Tip: Store and manage these configurations in Git repositories following GitOps practices.
4. Scalable Observability Stack
Deploy a centralized observability solution to maintain visibility across environments.
Prometheus + Thanos: For multi-cluster metrics aggregation.
Grafana: For dashboards and alerting.
Loki or ELK Stack: For log aggregation.
Jaeger or OpenTelemetry: For tracing and performance monitoring.
Benefits:
· Cluster health transparency
· Proactive issue detection
· Developer fliendly insights
5. Policy-as-Code and Security Automation
Enforce security and compliance policies consistently:
OPA + Gatekeeper: Define and enforce security policies (e.g., restrict container images, enforce labels).
Kyverno: Kubernetes-native policy engine for validation and mutation.
Falco: Real-time runtime security monitoring.
Kube-bench: Run CIS Kubernetes benchmark checks automatically.
Security Tip: Regularly scan cluster and workloads using tools like Trivy, Kube-hunter, or Aqua Security.
6. Autoscaling and Cost Optimization
To avoid resource wastage or service degradation:
Horizontal Pod Autoscaler (HPA) – Auto-scales pods based on metrics.
Vertical Pod Autoscaler (VPA) – Adjusts container resources.
Cluster Autoscaler – Scales nodes up/down based on workload.
Karpenter (AWS) – Next-gen open-source autoscaler with rapid provisioning.
Conclusion
As Kubernetes adoption matures, organizations must rethink their management strategy to accommodate growth, reliability, and governance. The transition from a handful of clusters to enterprise-wide Kubernetes infrastructure requires automation, observability, and strong policy enforcement.
By adopting GitOps, centralized control planes, standardized templates, and automated policy tools, enterprises can achieve Kubernetes cluster management at scale—without compromising on security, reliability, or developer velocity.
0 notes
Text
Faster, Safer Deployments: How CI/CD Transforms Cloud Operations
In today’s high-velocity digital landscape, speed alone isn't enough—speed with safety is what defines successful cloud operations. As businesses shift from legacy systems to cloud-native environments, Continuous Integration and Continuous Deployment (CI/CD) has become the engine powering faster and more reliable software delivery.
CI/CD automates the software lifecycle—from code commit to production—ensuring rapid, repeatable, and error-free deployments. In this blog, we’ll explore how CI/CD transforms cloud operations, enabling teams to deliver updates with confidence, reduce risk, and accelerate innovation.
🔧 What Is CI/CD?
CI/CD stands for:
Continuous Integration (CI): The practice of frequently integrating code changes into a shared repository, automatically triggering builds and tests to detect issues early.
Continuous Deployment (CD): The process of automatically releasing validated changes to production or staging environments without manual intervention.
Together, they create a streamlined pipeline that supports rapid, reliable delivery.
🚀 Why CI/CD Is Essential in Cloud Environments
Cloud infrastructure is dynamic, scalable, and ever-evolving. Manual deployments introduce bottlenecks, inconsistencies, and human error. CI/CD addresses these challenges by automating key aspects of software and infrastructure delivery.
Here’s how CI/CD transforms cloud operations:
1. Accelerates Deployment Speed
CI/CD pipelines reduce the time from code commit to deployment from days to minutes. Automation removes delays caused by manual approvals, environment setups, or integration conflicts—empowering developers to release updates faster than ever before.
For cloud-native companies that rely on agility, this speed is a game-changer.
2. Improves Deployment Safety
CI/CD introduces automated testing, validation, and rollback mechanisms at every stage. This ensures only tested and secure code reaches production. It also supports blue/green and canary deployments to minimize risk during updates.
The result? Fewer bugs, smoother releases, and higher system uptime.
3. Enables Continuous Feedback and Monitoring
CI/CD tools integrate with monitoring solutions like Prometheus, Datadog, or CloudWatch, providing real-time insights into application health and deployment success. This feedback loop helps teams quickly identify and resolve issues before users are affected.
4. Enhances Collaboration Across Teams
DevOps thrives on collaboration. With CI/CD, developers, testers, and operations teams work together on shared pipelines, using pull requests, automated checks, and deployment logs to stay aligned. This cross-functional synergy eliminates silos and speeds up troubleshooting.
5. Supports Infrastructure as Code (IaC)
CI/CD pipelines can also manage infrastructure using IaC tools like Terraform or Ansible. This enables automated provisioning and testing of cloud resources, ensuring consistent environments across dev, test, and production.
Incorporating IaC into CI/CD helps teams deploy full-stack applications—code and infrastructure—reliably and repeatedly.
🔄 Key Components of a CI/CD Pipeline
Source Control (e.g., GitHub, GitLab)
Build Automation (e.g., Jenkins, GitHub Actions, CircleCI)
Automated Testing (e.g., JUnit, Selenium, Postman)
Artifact Management (e.g., Docker Registry, Nexus)
Deployment Automation (e.g., Spinnaker, ArgoCD)
Monitoring and Alerts (e.g., Prometheus, New Relic)
Each step is designed to catch errors early, maintain code quality, and reduce deployment time.
🏢 How Salzen Cloud Helps You Build CI/CD Excellence
At Salzen Cloud, we specialize in building robust, secure, and scalable CI/CD pipelines tailored for cloud-native operations. Our team helps you:
Automate build, test, and deployment workflows
Integrate security and compliance checks (DevSecOps)
Streamline rollback and disaster recovery mechanisms
Optimize cost and performance across multi-cloud environments
With Salzen Cloud, your teams can release more frequently—with less stress and more control.
📌 Final Thoughts
CI/CD isn’t just a developer convenience—it’s the backbone of modern cloud operations. From faster time-to-market to safer releases, CI/CD enables organizations to innovate at scale while minimizing risk.
If you’re looking to implement or optimize your CI/CD pipeline for the cloud, let Salzen Cloud be your trusted partner in transformation. Together, we’ll build a deployment engine that fuels your growth—one commit at a time.
0 notes
Text

DeliveryOctopus - A declarative, GitOps Continuous Delivery tool for Kubernetes
0 notes
Text
Senior DevOps Engineer (IAC Infra Coding - GO, Python, Java, GitOps, ArgoCD) / Signavio
We help the world run betterAt SAP, we enable you to bring out your best. Our company culture is focused on collaboration and a shared passion to help the world run better. How? We focus every day on building the foundation for tomorrow and creating a workplace that embraces differences, values flexibility, and is aligned to our purpose-driven and future-focused work. We offer a highly…
0 notes
Text
Navigating the AI-Powered Era: Why Modern Deployment Platforms Must Evolve Beyond Jenkins & ArgoCD
http://securitytc.com/TJTD6V
0 notes
Text
How to Configure Alerts and Event Handling with Argo CD
As of today, GitOps is game changing technique which streamline application deployments and automation workflows. In this, Argo CD is a powerful continuous delivery tool and contributes major role. It leverages Git repositories as the single source of truth for application deployments. Argo CD not only provides deployment feature, it also supports for real-time event handling, notifications with…

View On WordPress
0 notes