#audienceintelligence
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr.com is the 103rd most visited website in the world.
Text
La ricezione “social” dei discorsi di fine anno (2019) dei due Presidenti
1. Si offre qui un brevissimo resoconto delle reazioni generate in singole “stanze” delle piattaforme sociali dalla conferenza d fine anno del Presidente del Consiglio e dal discorso di fine anno del Presidente della Repubblica.
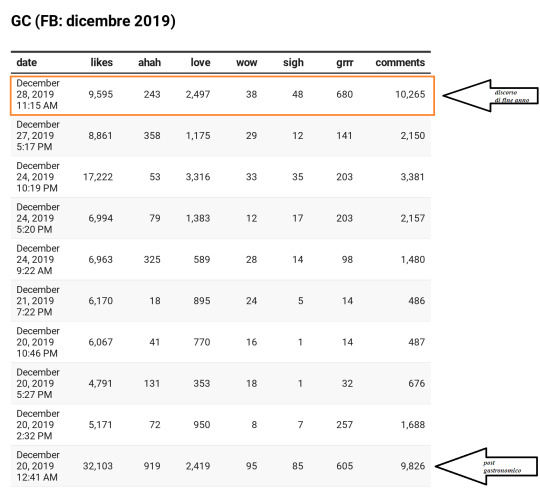
2. La conferenza stampa del presidente Conte è stata trasmessa, se così si può dire, anche sul suo account Facebook ufficiale. Il post corrispondente è risultato il primo post per numero di interazioni generate nel mese di dicembre; ha sopravanzato anche il post (del 20) a tema gastronomico: un tema di successo (se si sta ai “click”) nella prassi social del presidente (è lì, sulle sponde della comunicazione politica, che riposa, per ora al sicuro, la altrove malconcia gastromania).
Una scorsa ora ai commenti. Porre orecchio all’orecchio delle conversazioni (i.e. alle “ricezioni”) [ndr: una delle faccende che in queste righe si prova quotidianamente a sbrigare (all’ingrosso)] è una prassi denigrata da molti commentatori. Hic sunt dragones si direbbe. Inutile ascoltare, e provare, a comprendere i Napalm51, tanto, si dice in italiano neo-standard, non impattano. Eppure, nella nuova semiosfera, dove ci s districa tra le reti sociali onlife, l’attenzione verso qualunque tipo di ricezione (con distinguo operati caso per caso secondo criteri di pertinenza) è indispensabile per indagare la formazione e la trasformazione di forme e frame. Nel nuovo mondo, ogni attività di content e audience intelligence che abbia come oggetto il dato semio-linguistico è di fatto un’attività di media intelligence.
Si diceva dei commenti alla conferenza stampa. Il carotaggio è stato effettuato su 7.000 di questi, prodotto dell’attività di circa 3.500 utenti unici. Quasi 15.000 le reazioni generate.
Se si guarda ai commenti come corpus, gli elementi lessicali più frequenti sono “grande” e “grazie”; entrambi si presentano con maggiore frequenza come collocati di “Presidente”. Tra gli elementi grammaticali, molto frequenti sia “sei” (anche in questo caso come collocato perlopiù di presidente”) che “non”. Se nel primo caso si resta nella dinamica della valutazione (perlopiù positiva) del “Presidente” (con un tono colloquiale), nel secondo, il “non”, ci si addentra in uno scenario discorsivo altro e molto interessante (se vi fosse, e non è questo il caso, l’opportunità di addentrarvisi sul serio). Il “non” compare con maggiore frequenza come collocato di “italiani”. È un piccolo accidente testuale che, come si dice, fa però segno: si tratta di increspature di superficie prodotte dalla profonda e vigorosa tempesta discorsiva e narrativa che da qualche tempo investe con crescente forza il nucleo tematico “italianità”. Un fenomeno certo non nuovo, ma che sta producendo una varietà di esiti testuali di nuovo tipo sia dentro che fuori dai confini della comunicazione politica.

Uno sguardo ora a uno degli indici manifesti della testura “emotiva” del corpus, gli emoji. I più frequenti sono “face with tears of joy” e “clapping hands”, seguiti da “red heart”.
3. Nella “nuvola” del discorso di fine anno del PdR, “paese”, “vita”, “società”, “cultura”, e “fiducia” sono le cinque parole con maggiore frequenza d’uso.
Il video del discorso del Presidente è stato come al solito pubblicato anche sull’account YouTube ufficiale del Quirinale, ma lì i commenti sono disabilitati. Per testare le reazioni bisogna perciò rivolgersi altrove. Qui si è optato, arbitrariamente, per i video del discorso postati dagli account YouTube dei quotidiani La Stampa e La Repubblica.
Al momento dell’osservazione, il video sull’account de La Repubblica aveva generato quasi 3.500 visualizzazioni, con un numero quasi pari di like e dislike (127 e 110), e 304 commenti. Questi avevano a loro volta generato circa 700 like e 200 risposte, frutto dell’attività di un centinaio di utenti unici. La nuvola delle parole non grammaticali più frequenti vede “presidente”, “Mattarella”, “costituzione”, “governo”, “elezioni” nelle prime posizioni. La modalità di interazione prevalente che è dato osservare è il “confronto” tra gli utenti, più che il giudizio “immediato” verso il Presidente e, o, la sua performance. Il numero maggiore di like va in dote a commenti che criticano il focus del discorso del PdR: la fiducia.
Il video offerto dall’account de La Stampa, al momento dell’osservazione, contava circa 2.500 visualizzazioni, e aveva generato 28 like, 74 dislike, e 199 commenti. Questi, a loro volta, avevano generato 377 like e 150 risposte, frutto dell’attività di poco più di 60 utenti. Anche in questo caso, la modalità di interazione prevalente è il “confronto” tra gli utenti. I commenti che hanno generato più like sono tutti (molto) critici vero il Presidente e il suo discorso.
Per finire, qualche dato frutto del carotaggio effettuato su Twitter, il 31/12/2019, per mezzo della chiave “Mattarella”. L’archivio scandagliato conta 5.000 tweet (prodotti da 3.200 utenti unici), che hanno generato 170.000 like, 32.000 rt’s, e 7.000 risposte. Il picco delle interazioni si è raggiunto durante l’allocuzione del Presidente. La “conversazione” si è poi nuovamente animata, seppur in tono minore, un’ora dopo la conclusione de discorso. Poche, come si vede, le menzioni, rispetto ai tweet “originali”.
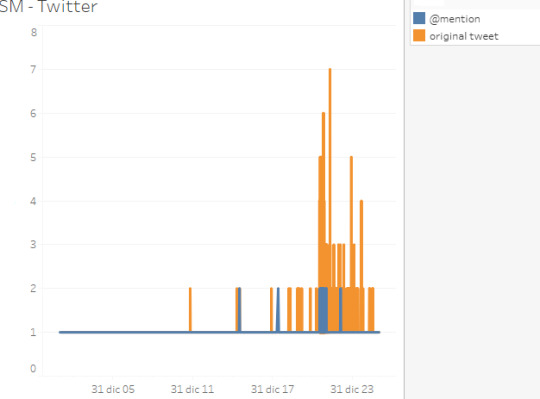
Nella nuvola della “conversazione” (i.e. il corpus costituito dai 5.000 tweet) spiccano i seguenti elementi lessicali: “grazie” (come collocato di #mattarella e “Presidente”); “fiducia” (come collocato di “avere” e “più”); “speranza” (come collocato di “futuro”); “perdiamo” (come collocato di “diritto” e “privilegio”). In quel frangente sono molte, dunque, le citazioni tratte del discorso del Presidente e meno, almeno da quel che è possibile osservare a questo livello, i commenti e le glosse.

#audienceintelligence#contentintelligence#contentstrategy#DIGITALSTRATEGY#semantics#sociallistening#socialmedia#text analysis
0 notes
Photo

A New Hawk in Marketing Technology: Piano Takes AI to the Core of Email - In the #news #kimludcom #ai #audienceIntelligent #machineLearning #marketingTechnology #content http://bit.ly/2TlxAEq
#Pinterest#kimludcom#fashionaccessories#fashioneditorial#fashionbloggers#influencers#fashion#accessor
0 notes
Photo

Our team is working hard to bring you the best media tools. Very soon we will be able to empower you through rich media ad creation, audience intelligence, and engagement insights. The sky's the limit! #marketing #socialmedia #audienceintelligence #data
2 notes
·
View notes
Text
Biscotti e comunicazione politica
Quando si osserva e analizza la struttura formale delle “conversazioni” generate dalle varie occasioni di comunicazione politica, andrebbero comparate le funzioni e non gli usi.
Affiancarsi ai #NutellaBiscuits ha in quest’ottica un effetto di senso diverso sulla personalità semiotica dell’enunciatore di turno. Non si tratta quindi di individuare eventuali somiglianze nello stile comunicativo, ma di capire quali valori etici ed estetici una certa prassi, nel racconto di un certo agente, convoca. Solo in uno dei due casi di recente alla ribalta, per ragioni su cui sarà magari il caso di tornare, l’accostamento tra soggetto e oggetto è funzionale al frame che regge la loro, dei soggetti, personalità semiotica. Per chiudere, per ora, ecco l’elenco di qualche “raw fact”.
Dall’1/11/2019 al 17/11/2019 (mattina), Renzi ha pubblicato 287 tweet.

Quello sui #NutellaBiscuits è del 14/12. In quella data, viene quasi raggiunto il picco delle risposte per il periodo indagato, ma non quello dei like, né quello dei rt’s (sarà lo stesso per i giorni immediatamente successivi). Il picco delle risposte è un segnale che la mossa viene letta dal pubblico (anche il “proprio”, vista l’arena osservata) come anomala, e tale difformità (manifestata nella “conversazione”) influirà poi nella qualità del processo di earned media.
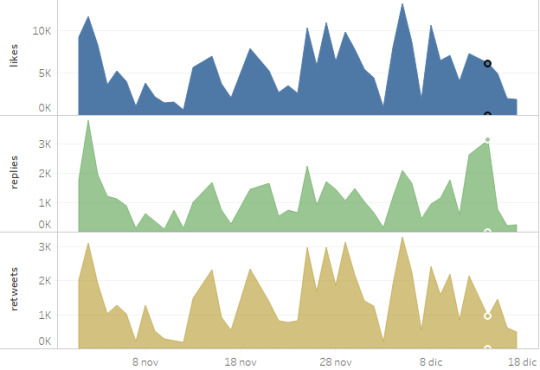
Nello stesso frangente, Salvini ha pubblicato 1.366 tweet (ndr: un “ritmo” che tiene debitamente conto delle affordance delle attuali reti sociali onlife).

La data che in quel periodo (e prendendo come riferimento i soli tweet dell’agente in oggetto) è maggiormente marcata dalla conversazione nutella-centrica è il 6 dicembre (con due tweet che la menzionano, in modo diretto l’uno e obliquo l’altro). In questo caso, il 6 dicembre non si raggiunge il picco per nessuna delle tre “metriche” analizzate; anzi, per like e rt’s si sfiora il record negativo. La mossa appare normale agli occhi del “proprio” pubblico, vellica al contempo, e come al solito, i lettori “alieni”, viene raccontata con il solito tono dai legacy media (i.e. fa il pieno di earned media) e resta perciò conforme alla personalità semiotica dell’agente.

Cosa poi questo possa comportare per il brand si è provato ad accennarlo qui.
#audienceintelligence#contentintelligence#content strategy#digitalstrategy#semantics#branding#marketing research
0 notes
Text
La nuova semiosfera, dove le parole sono sempre azioni
Si è detto che la nuova semiosfera, esito della pervasiva presenza delle reti sociali, è marcata dal fenomeno della disintermediazione, con il potenziale sovraccarico informativo da questo provocato. È invece ormai attestato che le piattaforme hanno innestato un potente meccanismo di reintermediazione tra “autore” e “lettore”, finendo per rimodellare la struttura dei contenuti. Questi sono ormai l’esito di due “costrizioni”: le affordances delle piattaforme e la struttura formale degli enunciati che li esprimono.
In un simile contesto, ormai innervato anche dal potere di “scrittura”, “lettura” e “giudizio” (sic) dell’AI , gli agenti economici (e politici) rischiano di trovarsi in una situazione di costante asimmetria informativa e, di conseguenza, narrativa e “pratica”. La dimensione pratica, nel mondo della vita, coincide con la dimensione “linguistica” (in senso lato). Data questa architettura relazionale, desta sempre sorpresa ascoltare, anche da pulpiti insospettabili, degli inviti a comunicare meno (ma, inutile dirlo, meglio), in un mondo dove le parole sono sempre azioni, e dove delle associazioni tra unità lessicali e sintagmatiche non soltanto producono degli effetti perlocutori sul pubblico, ma addirittura conducono in automatico delle entità oracolari a prendere decisioni “pratiche” immediate (si veda quello che succede sui mercati azionari, ormai descritto anche in opere divulgative [tipo Orioli, Gli oracoli della moneta]).
Non presidiare (ascoltare, analizzare, produrre contenuti) in modo permanente le conversazioni (in tutte le arene rilevanti) non mette solo in pericolo il capitale reputazionale dell’agente (l’unico tema che per ora gode di un certo consenso, seppur non ancora così diffuso), ma il suo capitale semantico, narrativo e, di conseguenza, la sua stessa esistenza come agente.
Come hanno notato Boccia Artieri e Martinelli nell’introduzione a un recente numero (2018/3) di Problemi dell’informazione: ““La scommessa per tutti è quella di mettere a valore il potenziale engagement delle audience, rinunciando all’idea che il «messaggio» possa essere semplicemente distribuito e arrivare in modo incontaminato ai destinatari e accettando, allo stesso tempo, che il potere di definizione si giochi in uno spazio discorsivo conteso, a volte contraddittorio e pesantemente conflittuale.”
Ma ancora, per esempio, soprattutto quanto si discute della dimensione linguistica che presiede alle azioni dell’AI, o finanche di alcuni effetti del parlare degli agenti sulle intenzioni di ricerca degli utenti, mediate dai “motori”, la faccenda si trova ormai catalogata tra i fait divers, e invece degli effetti (e delle pratiche da dispiegare per stare nel nuovo mondo) ci si mette a discutere di intenzioni e motivazioni (con le solite derive che si generano quando si battono quelle strade, come la discussione sul caso Johnson già dimostra); oppure ci si mette a utilizzare il nuovo fait divers come diversivo (come insegnava Bourdieu, e come l’opera di per diligenti nell’affare DB testimonia).
Nella nuova semiosfera, le asimmetrie informative generano asimmetrie narrative e interpretative (nella guerra dei frame), e le asimmetrie narrative generano asimmetrie “reali”, “[…] perché gli algoritmi diventano sempre più bravi a percepire il contesto nel quale devono agire, fino a modellare l’ambiente e influenzare il comportamento dei singoli umani nelle loro reciproche interazioni.” (Chiriatti; #Humanless. L’algoritmo egoista).
Ciò comporta delle conseguenze pratiche capitali, e delle responsabilità precise, per gli agenti economici e politici che devono osservare in modo permanente le conversazioni, conoscerne la struttura formale, comprenderne gli effetti di senso, ed esprimersi di conseguenza.
#ai#audienceintelligence#contentintelligence#content strategy#socialmedia#social listening#Web listening#semantics#semiotics#language#text analysis
0 notes
Text
Il marketing dell’italiano
Il tema della funzione identitaria della lingua italiana è piombato sul tappeto mobile della catena onlife del passaparola, trascinato da una (non recente) polemica politica; se ne dirà in coda a questo episodio della newsletter. L’italiano, nelle sue tante declinazioni lessicali, concettuali, e tematiche, è un potente strumento di marketing, come effetto della gloriosa (e paradossalmente secolare) tradizione culturale del made in Italy. Uno strumento semiotico potente che, di conseguenza, ha un’estensione semantica molto ampia e che andrebbe perciò maneggiato con una cura che non sempre si osserva in chi, con grande frequenza, lo utilizza. Nel suo piccolo, ne è testimone anche tropic, che nella sua attività quotidiana di verifica dell’efficacia dell’advertising, incorre spesso nella constatazione degli effetti controfattuali di un uso del tema dell’italianità purtroppo non sempre attento alle possibili ricezioni. Nell’èra della saturazione dei mercati, della saturazione delle arene, della saturazione dell’attenzione, e della personalizzazione (di massa), la ricerca della distinzione rispetto ai competitor e il processo di identificazione tra brand/prodotto, pubblico e contesto (integration) fondato sul “country of origin effect” deve poggiare su una conoscenza dettagliata della struttura semiotica dei tre fattori, ancor più nel caso del potente dispositivo del “made in Italy”.
La persistenza degli attributi correlati al “made in Italy” si può facilmente apprezzare, per esempio, guardando oggi un documento storico (citato da Dellapiana in apertura del suo “Il design e l’invenzione del Made in Italy”): si tratta di un cinegiornale del 1953 dell’Istituto Luce, in cui si elencano i portenti del “fabbricato in Italia”, con citazioni dal mondo dell’industria pesante, dei trasporti, dell’abbigliamento, della nautica, delle automobili, della ceramica, dei tessuti, dell’alimentazione, della musica, del cinema, e via elencando.
Molti di questi si ritrovano tra le parole, e i temi, maggiormente menzionati in una selezione di 10.000 messaggi rilevanti, che hanno assieme generato più di 7 milioni di interazioni, selezionati da tropic in un vastissimo corpus di 681 mila messaggi (prodotti da circa 400 mila fonti), in cui compare la parola italiano (con alcune sue varianti morfologiche). Una messe con una reach stimata in 27 milioni di potenziali lettori. Sono messaggi pubblicati in una porzione molto ampia del web di lingua italiana dal 7 dicembre al 5 gennaio scorsi.
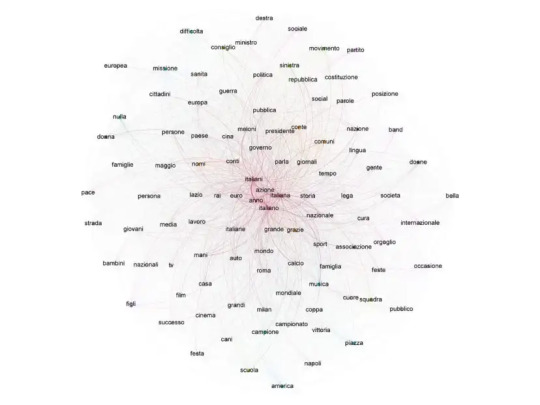
Nella struttura del campo semantico si notano gli effetti della convocazione, nel dibattito politico, del tema del ruolo della lingua italiana, ma si rintracciano già alcuni argomenti correlati, come l’orgoglio nazionale, il confronto con l’estero, la musica, lo sport, le auto, il cinema (tutti temi non a caso declinati nel formato della politica pop nella ormai permanente campagna elettorale, con maggiore o minore perizia certo).
Il trend mostra un andamento delle menzioni piuttosto omogeneo, eccezion fatta per la pausa natalizia.
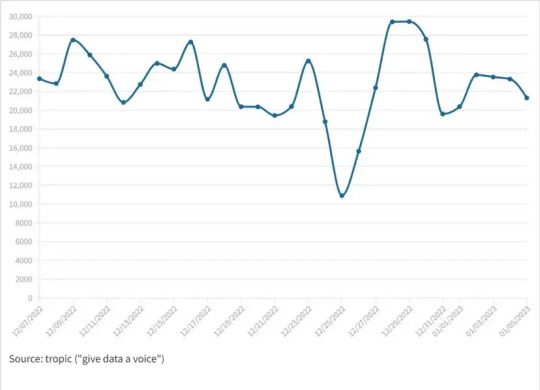
Il sentiment generale è francamente positivo (nonostante la coincidenza potenzialmente “polarizzante” della polemica politica).

La lingua italiana compare tra i topic maggiormente rilevanti nel corpus “maggiore”.

Mentre tra gli hashtag #madeinitaly occupa un posto preminente.

Lo scorso anno, la chiave “italiano” ha registrato il volume di ricerca maggiore sui motori di ricerca tra gennaio e aprile.
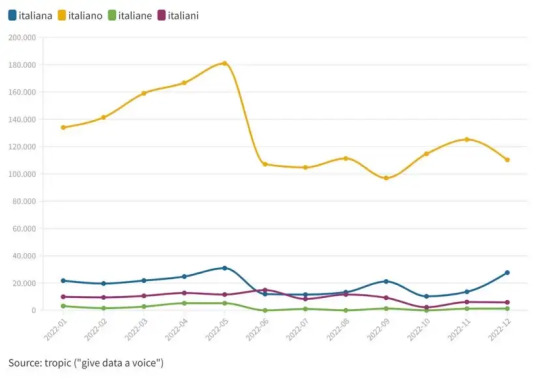
E, come conseguenza del dato appena mostrato, domina il kpi del traffic share rispetto ad alcune varianti.
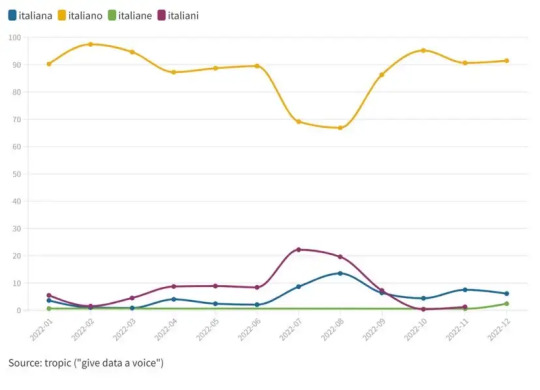
2. La funzione identitaria della lingua italiana
Queste poche righe sono un piccolo addendum, sempre e solo nella prospettiva adottata da tropic: le ricerche di marketing. L’italiano è infatti uno strumento potente pure del marketing politico, e tropic ne osserva con interesse pure lì i vari esemplari.
L’eco di un certo dirigismo in materia di fatti linguistici è risuonato nella polemica politica correlata alla proposta di riconoscimento della lingua italiana come lingua ufficiale della Repubblica, e alle doglianze sull’eccesso di parole straniere in uso nella lingua dei media, del commercio, e dell’amministrazione pubblica. Proposta e doglianze che, rispetto alle sue più immediate potenzialità di marketing per chi la avanza, è correlata alla funzione identitaria della lingua.
È un tema (la “difesa dell’identità italiana delle nostre città e paesi”) esplicitato in un utile approfondimento, coevo alla polemica politica, pubblicato dal quotidiano Domani. L’articolo, a firma di un’esperta reputata, ricorda pure che “ l a legge ordinaria, in linea con l’impostazione costituzionale, riconosce espressamente l’italiano come “lingua ufficiale della Repubblica” (l. n. 482/1999)”.
Il tema del “riconoscimento giuridico” dell’italiano quale lingua ufficiale della Repubblica, e della sua “costituzionalizzazione”, non è infatti nuovo. Un illustre testimone ha di recente ricordato che nel 2006 anche l’Accademia della Crusca era stata mobilitata e che, come esito, era stata addirittura già approntata una bozza di articolo.
Se si osserva il tema della “difesa” della lingua italiana dalle influenze esterne da una prospettiva semio-linguistica, un utile supporto viene dalla lettura di un saggio che nel 1987 un illustre linguista dedicò alla faccenda, dal titolo Morbus anglicus. Oltre a varie proposte di adattamento di parole straniere in uso (tra cui vendissimo per bestseller, contributo sanitario per ticket, numerico, o cifrale, per digitale), vi si ritrovano, tra le fonti, delle lamentele sul “parlare esotico” che risalgono già all’inizio degli anni ’60 del secolo scorso.
Addedum n. 2
Il lettore interessato invece agli studi non sull’italiano in Costituzione, ma sull’italiano della Costituzione, troverà invece un valido supporto nell’introduzione che De Mauro ha dedicato alla questione nell’introduzione de “La Costituzione della Repubblica del 1947” (per UTET).
Addendum n. 3
Grazie agli archivi cifrali digitali della Camera è possibile consultare la revisione del testo della Costituzione svolta tra il 1946 e il 1947 da Pietro Pancrazi. Il testo, con una nota autografa conclusiva, conserva memoria di alcune della proposte stilistiche di revisione poi accolte, come il passo “L’Italia è Repubblica democratica […]” che, grazie a Pancrazi, diviene “L’Italia è una Repubblica democratica […]”.
1 note
·
View note
Text
La conversazione generata dall’#ITVDebate del 19/11/2019 tra Corbyn e Johnson
Si offrono qui alcuni dati relativi alla conversazione “social” generata dal dibattito promosso dalla rete televisiva ITV News, tra Johnson e Corbyn, leader rispettivamente del partito conservatore e del partito laburista, a Salford (Greater Manchester), il 19/11/2019, in vista delle prossime elezioni generali.
Il video, con commenti disabilitati, è stato postato sul canale YouTube del canale.
Qui si dà conto di qualche risultato di una rapidissima hashtag research, fatta per osservare il tono della conversazione generata dal programma tv.
La chiave di ricerca è, appunto, #ITVdebate. L’osservazione si è svolta tra il 19/11 e il 20/11, in un lasso di circa 36 ore.
A ridosso del confronto, il canale ha pubblicato i Twitter moments, mentre YouGov ha reso pubblico un sondaggio dettagliato, con un campione di 1.646 spettatori del dibattito chiamati a valutare le performance dei due oratori.
Il campione consta di circa 85.000 tweet, prodotti da poco più di 29.000 utenti unici. Circa 1.622.000 i like generati, 538.000 i rt’s e 123.000 le risposte.
Corbyn, adiuvato da altri account ufficiali del suo “campo”, è stato il più efficace nel posizionarsi sull’hashtag che ha canalizzato la conversazione. Johnson, e gli account ufficiali a lui correlati, paiono aver invece preferito posizionarsi sull’hashtag #LeadersDebate.
Il modo con cui i due hanno scelto di “lanciare” mediaticamente il confronto, su Twitter, presenta interessanti differenze sia figurative che formali (fatto rilevante, su cui qui non ci si può soffermare, e che dice delle due diverse personalità semiotiche in gioco). Il teaser di Corbyn è stato questo:

Quello di Johnson è stato questo:

Di seguito il volume delle citazioni nel tempo (i.e. durante le ore del dibattito e quelle precedenti) dei due, Johnson e Cobyn:
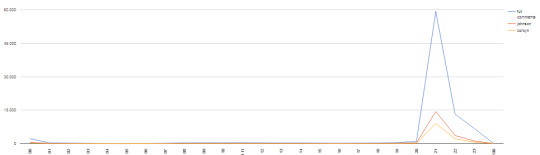
Il volume di citazioni per Johnson e Corbyn, nel complesso, è quasi identico: circa 12.500, con un lieve vantaggio per Corbyn. La situazione cambia se invece si osserva la frequenza dei nomi, Boris e Jeremy, con il primo che ottiene un volume di citazioni quasi quattro volte superiore rispetto al secondo (12.000 circa vs 4.000).
Corbyn risulta però più efficace, seppur in modo obliquo e in termini quantitativi, nel tentativo di “occupare” il livello tecnico meta della conversazione, tramite gli hashtag, come già in parte accennato. Tra quelli più usati, accanto ai “neutri” #LeadersDebate e #GE2019, vi sono infatti #winforcorbyn, #voteeducation, #schoolcuts e #buildingsocialhousing.
La parità, quantitativa, si riscontra anche nel numero di menzioni che i due account hanno collezionato, prossime alle 3.500 in entrambi i casi (un po’ più per Corbyn, e un po’ meno per Johnson).
Rispetto ai segnali lessicali (l’unico elemento sui cui qui, per non annoiare ulteriormente il gentile lettore, l’agente mobile, ci si sofferma), vi è da segnalare che “people” e “audience” fanno registrare una frequenza più alta di “party” (i tre elementi sono comunque tutti molto frequenti, nella lista delle prime 50 parole non grammaticali).
Nel dominio degli argomenti, “brexit” fa registrare la frequenza più alta (circa 7.000 occorrenze). Seguono “NHS” (circa 3.000 occorrenze) e “climate” (quasi 1.500 occorrenze).
I partiti. “Labour” conta circa 3.000 occorrenze, l’account ufficiale raccoglie meno di 1.000 menzioni. Lo stesso accade ai Conservatives, che però nel complesso raggiungono un numero di citazioni leggermente superiore, il plesso “conservatives” più “tories” raggiunge le 3.500 citazioni circa.
Escluso il rumore, “brexit” e “won” sono i primi collocati di “Corbyn”, mentre “brexit” e “trust” sono i primi collocati di “Corbyn”.
#politics#communication#social listening#socialmedia#ge2019#itv debate#audienceintelligence#contentintelligence#contentstrategy
0 notes