#automating outputs to json
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
12.7% of mobile users access Tumblr.
Text
AvatoAI Review: Unleashing the Power of AI in One Dashboard

Here's what Avato Ai can do for you
Data Analysis:
Analyze CV, Excel, or JSON files using Python and libraries like pandas or matplotlib.
Clean data, calculate statistical information and visualize data through charts or plots.
Document Processing:
Extract and manipulate text from text files or PDFs.
Perform tasks such as searching for specific strings, replacing content, and converting text to different formats.
Image Processing:
Upload image files for manipulation using libraries like OpenCV.
Perform operations like converting images to grayscale, resizing, and detecting shapes or
Machine Learning:
Utilize Python's machine learning libraries for predictions, clustering, natural language processing, and image recognition by uploading
Versatile & Broad Use Cases:
An incredibly diverse range of applications. From creating inspirational art to modeling scientific scenarios, to designing novel game elements, and more.
User-Friendly API Interface:
Access and control the power of this advanced Al technology through a user-friendly API.
Even if you're not a machine learning expert, using the API is easy and quick.
Customizable Outputs:
Lets you create custom visual content by inputting a simple text prompt.
The Al will generate an image based on your provided description, enhancing the creativity and efficiency of your work.
Stable Diffusion API:
Enrich Your Image Generation to Unprecedented Heights.
Stable diffusion API provides a fine balance of quality and speed for the diffusion process, ensuring faster and more reliable results.
Multi-Lingual Support:
Generate captivating visuals based on prompts in multiple languages.
Set the panorama parameter to 'yes' and watch as our API stitches together images to create breathtaking wide-angle views.
Variation for Creative Freedom:
Embrace creative diversity with the Variation parameter. Introduce controlled randomness to your generated images, allowing for a spectrum of unique outputs.
Efficient Image Analysis:
Save time and resources with automated image analysis. The feature allows the Al to sift through bulk volumes of images and sort out vital details or tags that are valuable to your context.
Advance Recognition:
The Vision API integration recognizes prominent elements in images - objects, faces, text, and even emotions or actions.
Interactive "Image within Chat' Feature:
Say goodbye to going back and forth between screens and focus only on productive tasks.
Here's what you can do with it:
Visualize Data:
Create colorful, informative, and accessible graphs and charts from your data right within the chat.
Interpret complex data with visual aids, making data analysis a breeze!
Manipulate Images:
Want to demonstrate the raw power of image manipulation? Upload an image, and watch as our Al performs transformations, like resizing, filtering, rotating, and much more, live in the chat.
Generate Visual Content:
Creating and viewing visual content has never been easier. Generate images, simple or complex, right within your conversation
Preview Data Transformation:
If you're working with image data, you can demonstrate live how certain transformations or operations will change your images.
This can be particularly useful for fields like data augmentation in machine learning or image editing in digital graphics.
Effortless Communication:
Say goodbye to static text as our innovative technology crafts natural-sounding voices. Choose from a variety of male and female voice types to tailor the auditory experience, adding a dynamic layer to your content and making communication more effortless and enjoyable.
Enhanced Accessibility:
Break barriers and reach a wider audience. Our Text-to-Speech feature enhances accessibility by converting written content into audio, ensuring inclusivity and understanding for all users.
Customization Options:
Tailor the audio output to suit your brand or project needs.
From tone and pitch to language preferences, our Text-to-Speech feature offers customizable options for the truest personalized experience.
>>>Get More Info<<<
#digital marketing#Avato AI Review#Avato AI#AvatoAI#ChatGPT#Bing AI#AI Video Creation#Make Money Online#Affiliate Marketing
3 notes
·
View notes
Text
How to Integrate WooCommerce Scraper into Your Business Workflow
In today’s fast-paced eCommerce environment, staying ahead means automating repetitive tasks and making data-driven decisions. If you manage a WooCommerce store, you’ve likely spent hours handling product data, competitor pricing, and inventory updates. That’s where a WooCommerce Scraper becomes a game-changer. Integrated seamlessly into your workflow, it can help you collect, update, and analyze data more efficiently, freeing up your time and boosting operational productivity.

In this blog, we’ll break down what a WooCommerce scraper is, its benefits, and how to effectively integrate it into your business operations.
What is a WooCommerce Scraper?
A WooCommerce scraper is a tool designed to extract data from WooCommerce-powered websites. This data could include:
Product titles, images, descriptions
Prices and discounts
Reviews and ratings
Stock status and availability
Such a tool automates the collection of this information, which is useful for e-commerce entrepreneurs, data analysts, and digital marketers. Whether you're monitoring competitors or syncing product listings across multiple platforms, a WooCommerce scraper can save hours of manual work.
Why Businesses Use WooCommerce Scrapers
Before diving into the integration process, let’s look at the key reasons businesses rely on scraping tools:
Competitor Price Monitoring
Stay competitive by tracking pricing trends across similar WooCommerce stores. Automated scrapers can pull this data daily, helping you optimize your pricing strategy in real time.
Bulk Product Management
Import product data at scale from suppliers or marketplaces. Instead of manually updating hundreds of SKUs, use a scraper to auto-populate your database with relevant information.
Enhanced Market Research
Get a snapshot of what’s trending in your niche. Use scrapers to gather data about top-selling products, customer reviews, and seasonal demand.
Inventory Tracking
Avoid stockouts or overstocking by monitoring inventory availability from your suppliers or competitors.
How to Integrate a WooCommerce Scraper Into Your Workflow
Integrating a WooCommerce scraper into your business processes might sound technical, but with the right approach, it can be seamless and highly beneficial. Whether you're aiming to automate competitor tracking, streamline product imports, or maintain inventory accuracy, aligning your scraper with your existing workflow ensures efficiency and scalability. Below is a step-by-step guide to help you get started.
Step 1: Define Your Use Case
Start by identifying what you want to achieve. Is it competitive analysis? Supplier data syncing? Or updating internal catalogs? Clarifying this helps you choose the right scraping strategy.
Step 2: Choose the Right Scraper Tool
There are multiple tools available, ranging from browser-based scrapers to custom-built Python scripts. Some popular options include:
Octoparse
ParseHub
Python-based scrapers using BeautifulSoup or Scrapy
API integrations for WooCommerce
For enterprise-level needs, consider working with a provider like TagX, which offers custom scraping solutions with scalability and accuracy in mind.
Step 3: Automate with Cron Jobs or APIs
For recurring tasks, automation is key. Set up cron jobs or use APIs to run scrapers at scheduled intervals. This ensures that your database stays up-to-date without manual intervention.
Step 4: Parse and Clean Your Data
Raw scraped data often contains HTML tags, formatting issues, or duplicates. Use tools or scripts to clean and structure the data before importing it into your systems.
Step 5: Integrate with Your CMS or ERP
Once cleaned, import the data into your WooCommerce backend or link it with your ERP or PIM (Product Information Management) system. Many scraping tools offer CSV or JSON outputs that are easy to integrate.
Common Challenges in WooCommerce Scraping (And Solutions)
Changing Site Structures
WooCommerce themes can differ, and any update might break your script. Solution: Use dynamic selectors or AI-powered tools that adapt automatically.
Rate Limiting and Captchas
Some sites use rate limiting or CAPTCHAs to block bots. Solution: Use rotating proxies, headless browsers like Puppeteer, or work with scraping service providers.
Data Duplication or Inaccuracy
Messy data can lead to poor business decisions. Solution: Implement deduplication logic and validation rules before importing data.
Tips for Maintaining an Ethical Scraping Strategy
Respect Robots.txt Files: Always check the site’s scraping policy.
Avoid Overloading Servers: Schedule scrapers during low-traffic hours.
Use the Data Responsibly: Don’t scrape copyrighted or sensitive data.
Why Choose TagX for WooCommerce Scraping?
While it's possible to set up a basic WooCommerce scraper on your own, scaling it, maintaining data accuracy, and handling complex scraping tasks require deep technical expertise. TagX’s professionals offer end-to-end scraping solutions tailored specifically for e-commerce businesses. Whether you're looking to automate product data extraction, monitor competitor pricing, or implement web scraping using AI at scale. Key Reasons to Choose TagX:
AI-Powered Scraping: Go beyond basic extraction with intelligent scraping powered by machine learning and natural language processing.
Scalable Infrastructure: Whether you're scraping hundreds or millions of pages, TagX ensures high performance and minimal downtime.
Custom Integration: TagX enables seamless integration of scrapers directly into your CMS, ERP, or PIM systems, ensuring a streamlined workflow.
Ethical and Compliant Practices: All scraping is conducted responsibly, adhering to industry best practices and compliance standards.
With us, you’re not just adopting a tool—you’re gaining a strategic partner that understands the nuances of modern eCommerce data operations.
Final Thoughts
Integrating a WooCommerce scraper into your business workflow is no longer just a technical choice—it’s a strategic advantage. From automating tedious tasks to extracting market intelligence, scraping tools empower businesses to operate faster and smarter.
As your data requirements evolve, consider exploring web scraping using AI to future-proof your automation strategy. And for seamless implementation, TagX offers the technology and expertise to help you unlock the full value of your data.
0 notes
Text
Identify elements of a search solution
A search index contains your searchable content. In an Azure AI Search solution, you create a search index by moving data through the following indexing pipeline:
Start with a data source: the storage location of your original data artifacts, such as PDFs, video files, and images. For Azure AI Search, your data source could be files in Azure Storage, or text in a database such as Azure SQL Database or Azure Cosmos DB.
Indexer: automates the movement data from the data source through document cracking and enrichment to indexing. An indexer automates a portion of data ingestion and exports the original file type to JSON (in an action called JSON serialization).
Document cracking: the indexer opens files and extracts content.
Enrichment: the indexer moves data through AI enrichment, which implements Azure AI on your original data to extract more information. AI enrichment is achieved by adding and combining skills in a skillset. A skillset defines the operations that extract and enrich data to make it searchable. These AI skills can be either built-in skills, such as text translation or Optical Character Recognition (OCR), or custom skills that you provide. Examples of AI enrichment include adding captions to a photo and evaluating text sentiment. AI enriched content can be sent to a knowledge store, which persists output from an AI enrichment pipeline in tables and blobs in Azure Storage for independent analysis or downstream processing.
Push to index: the serialized JSON data populates the search index.
The result is a populated search index which can be explored through queries. When users make a search query such as "coffee", the search engine looks for that information in the search index. A search index has a structure similar to a table, known as the index schema. A typical search index schema contains fields, the field's data type (such as string), and field attributes. The fields store searchable text, and the field attributes allow for actions such as filtering and sorting.
0 notes
Text
Fuzz Testing: An In-Depth Guide

Introduction
In the world of software development, vulnerabilities and bugs are inevitable. As systems grow more complex and interact with a wider array of data sources and users, ensuring their reliability and security becomes more challenging. One powerful technique that has emerged as a standard for identifying unknown vulnerabilities is Fuzz Testing, also known simply as fuzzing.
Fuzz testing involves bombarding software with massive volumes of random, unexpected, or invalid input data in order to detect crashes, memory leaks, or other abnormal behavior. It’s a unique and often automated method of discovering flaws that traditional testing techniques might miss. By leveraging fuzz testing early and throughout development, developers can harden applications against unexpected input and malicious attacks.
What is Fuzz Testing?
Fuzz Testing is a software testing technique where invalid, random, or unexpected data is input into a program to uncover bugs, security vulnerabilities, and crashes. The idea is simple: feed the software malformed or random data and observe its behavior. If the program crashes, leaks memory, or behaves unpredictably, it likely has a vulnerability.
Fuzz testing is particularly effective in uncovering:
Buffer overflows
Input validation errors
Memory corruption issues
Logic errors
Security vulnerabilities such as injection flaws or crashes exploitable by attackers
Unlike traditional testing methods that rely on predefined inputs and expected outputs, fuzz testing thrives in unpredictability. It doesn’t aim to verify correct behavior — it seeks to break the system by pushing it beyond normal use cases.
History of Fuzz Testing
Fuzz testing originated in the late 1980s. The term “fuzz” was coined by Professor Barton Miller and his colleagues at the University of Wisconsin in 1989. During a thunderstorm, Miller was remotely logged into a Unix system when the connection degraded and began sending random characters to his shell. The experience inspired him to write a program that would send random input to various Unix utilities.
His experiment exposed that many standard Unix programs would crash or hang when fed with random input. This was a startling revelation at the time, showing that widely used software was far less robust than expected. The simplicity and effectiveness of the technique led to increased interest, and fuzz testing has since evolved into a critical component of modern software testing and cybersecurity.
Types of Fuzz Testing
Fuzz testing has matured into several distinct types, each tailored to specific needs and target systems:
1. Mutation-Based Fuzzing
In this approach, existing valid inputs are altered (or “mutated”) to produce invalid or unexpected data. The idea is that small changes to known good data can reveal how the software handles anomalies.
Example: Modifying values in a configuration file or flipping bits in a network packet.
2. Generation-Based Fuzzing
Rather than altering existing inputs, generation-based fuzzers create inputs from scratch based on models or grammars. This method requires knowledge of the input format and is more targeted than mutation-based fuzzing.
Example: Creating structured XML or JSON files from a schema to test how a parser handles different combinations.
3. Protocol-Based Fuzzing
This type is specific to communication protocols. It focuses on sending malformed packets or requests according to network protocols like HTTP, FTP, or TCP to test a system’s robustness against malformed traffic.
4. Coverage-Guided Fuzzing
Coverage-guided fuzzers monitor which parts of the code are executed by the input and use this feedback to generate new inputs that explore previously untested areas of the codebase. This type is very effective for high-security and critical systems.
5. Black Box, Grey Box, and White Box Fuzzing
Black Box: No knowledge of the internal structure of the system; input is fed blindly.
Grey Box: Limited insight into the system’s structure; may use instrumentation for guidance.
White Box: Full knowledge of source code or internal logic; often combined with symbolic execution for deep analysis.
How Does Fuzzing in Testing Work?
The fuzzing process generally follows these steps:
Input Selection or Generation: Fuzzers either mutate existing input data or generate new inputs from defined templates.
Execution: The fuzzed inputs are provided to the software under test.
Monitoring: The system is monitored for anomalies such as crashes, hangs, memory leaks, or exceptions.
Logging: If a failure is detected, the exact input and system state are logged for developers to analyze.
Iteration: The fuzzer continues producing and executing new test cases, often in an automated and repetitive fashion.
This loop continues, often for hours or days, until a comprehensive sample space of unexpected inputs has been tested.
Applications of Fuzz Testing
Fuzz testing is employed across a wide array of software and systems, including:
Operating Systems: To discover kernel vulnerabilities and system call failures.
Web Applications: To test how backends handle malformed HTTP requests or corrupted form data.
APIs: To validate how APIs respond to invalid or unexpected payloads.
Parsers and Compilers: To test how structured inputs like XML, JSON, or source code are handled.
Network Protocols: To identify how software handles unexpected network packets.
Embedded Systems and IoT: To validate robustness in resource-constrained environments.
Fuzz testing is especially vital in security-sensitive domains where any unchecked input could be a potential attack vector.
Fuzz Testing Tools
One of the notable fuzz testing tools in the market is Genqe. It stands out by offering intelligent fuzz testing capabilities that combine mutation, generation, and coverage-based strategies into a cohesive and user-friendly platform.
Genqe enables developers and QA engineers to:
Perform both black box and grey box fuzzing
Generate structured inputs based on schemas or templates
Track code coverage dynamically to optimize test paths
Analyze results with built-in crash diagnostics
Run parallel tests for large-scale fuzzing campaigns
By simplifying the setup and integrating with modern CI/CD pipelines, Genqe supports secure development practices and helps teams identify bugs early in the software development lifecycle.
Conclusion
Fuzz testing has proven itself to be a valuable and essential method in the realm of software testing and security. By introducing unpredictability into the input space, it helps expose flaws that might never be uncovered by traditional test cases. From operating systems to web applications and APIs, fuzz testing reveals how software behaves under unexpected conditions — and often uncovers vulnerabilities that attackers could exploit.
While fuzz testing isn’t a silver bullet, its strength lies in its ability to complement other testing techniques. With modern advancements in automation and intelligent fuzzing engines like Genqe, it’s easier than ever to integrate fuzz testing into the development lifecycle. As software systems continue to grow in complexity, the role of fuzz testing will only become more central to creating robust, secure, and trustworthy applications.
0 notes
Text
The Sequence Radar #554 : The New DeepSeek R1-0528 is Very Impressive
New Post has been published on https://thedigitalinsider.com/the-sequence-radar-554-the-new-deepseek-r1-0528-is-very-impressive/
The Sequence Radar #554 : The New DeepSeek R1-0528 is Very Impressive
The new model excels at math and reasoning.
Created Using GPT-4o
Next Week in The Sequence:
In our series about evals, we discuss multiturn benchmarks. The engineering section dives into the amazing Anthropic Circuits for ML interpretability. In research, we discuss some of UC Berkeley’s recent work in LLM reasoning. Our opinion section dives into the state of AI interpretablity.
You can subscribe to The Sequence below:
TheSequence is a reader-supported publication. To receive new posts and support my work, consider becoming a free or paid subscriber.
📝 Editorial: The New DeepSeek R1-0528 is Very Impressive
This week, DeepSeek AI pushed the boundaries of open-source language modeling with the release of DeepSeek R1-0528. Building on the foundation of the original R1 release, this update delivers notable gains in mathematical reasoning, code generation, and long-context understanding. With improvements derived from enhanced optimization and post-training fine-tuning, R1-0528 marks a critical step toward closing the performance gap between open models and their proprietary counterparts like GPT-4 and Gemini 1.5.
At its core, DeepSeek R1-0528 preserves the powerful 672B Mixture-of-Experts (MoE) architecture, activating 37B parameters per forward pass. This architecture delivers high-capacity performance while optimizing for efficiency, especially in inference settings. One standout feature is its support for 64K-token context windows, enabling the model to engage with substantially larger inputs—ideal for technical documents, structured reasoning chains, and multi-step planning.
In terms of capability uplift, the model shows remarkable progress in competitive benchmarks. On AIME 2025, DeepSeek R1-0528 jumped from 70% to an impressive 87.5%, showcasing an increasingly sophisticated ability to tackle complex mathematical problems. This leap highlights not just better fine-tuning, but a fundamental improvement in reasoning depth—an essential metric for models serving scientific, technical, and educational use cases.
For software engineering and development workflows, R1-0528 brings meaningful updates. Accuracy on LiveCodeBench rose from 63.5% to 73.3%, confirming improvements in structured code synthesis. The inclusion of JSON-formatted outputs and native function calling support positions the model as a strong candidate for integration into automated pipelines, copilots, and tool-augmented environments where structured outputs are non-negotiable.
To ensure broad accessibility, DeepSeek also launched a distilled variant: R1-0528-Qwen3-8B. Despite its smaller footprint, this model surpasses Qwen3-8B on AIME 2024 by over 10%, while rivaling much larger competitors like Qwen3-235B-thinking. This reflects DeepSeek’s commitment to democratizing frontier performance, enabling developers and researchers with constrained compute resources to access state-of-the-art capabilities.
DeepSeek R1-0528 is more than just a model upgrade—it’s a statement. In an ecosystem increasingly dominated by closed systems, DeepSeek continues to advance the case for open, high-performance AI. By combining transparent research practices, scalable deployment options, and world-class performance, R1-0528 signals a future where cutting-edge AI remains accessible to the entire community—not just a privileged few.
Join Me for a Chat About AI Evals and Benchmarks:
🔎 AI Research
FLEX-Judge: THINK ONCE, JUDGE ANYWHERE
Lab: KAIST AI Summary: FLEX-Judge is a reasoning-first multimodal evaluator trained on just 1K text-only explanations, achieving zero-shot generalization across images, audio, video, and molecular tasks while outperforming larger commercial models. Leverages textual reasoning alone to train a judge model that generalizes across modalities without modality-specific supervision.
Learning to Reason without External Rewards
Lab: UC Berkeley & Yale University Summary: INTUITOR introduces a novel self-supervised reinforcement learning framework using self-certainty as intrinsic reward, matching supervised methods on math and outperforming them on code generation without any external feedback. The technique proposes self-certainty as an effective intrinsic reward signal for reinforcement learning, replacing gold labels.
Beyond Markovian: Reflective Exploration via Bayes-Adaptive RL for LLM Reasoning
AI Lab: Google DeepMind & Northwestern University Summary: This paper introduces BARL, a novel Bayes-Adaptive RL algorithm that enables large language models to perform test-time reflective reasoning by switching strategies based on posterior beliefs over MDPs. The authors show that BARL significantly outperforms Markovian RL approaches in math reasoning tasks by improving token efficiency and adaptive exploration.
rStar-Coder: Scaling Competitive Code Reasoning with a Large-Scale Verified Dataset
AI Lab: Microsoft Research Asia Summary: The authors present rStar-Coder, a dataset of 418K competitive programming problems and 580K verified long-reasoning code solutions, which drastically boosts the performance of Qwen models on code reasoning benchmarks. Their pipeline introduces a robust input-output test case synthesis method and mutual-verification mechanism, achieving state-of-the-art performance even with smaller models.
MME-Reasoning: A Comprehensive Benchmark for Logical Reasoning in MLLMs
AI Lab: Fudan University, CUHK MMLab, Shanghai AI Lab Summary: MME-Reasoning offers a benchmark of 1,188 multimodal reasoning tasks spanning inductive, deductive, and abductive logic, revealing significant limitations in current MLLMs’ logical reasoning. The benchmark includes multiple question types and rigorous metadata annotations, exposing reasoning gaps especially in abductive tasks.
DeepResearchGym: A Free, Transparent, and Reproducible Evaluation Sandbox for Deep Research
AI Lab: Carnegie Mellon University, NOVA LINCS, INESC-ID Summary: DeepResearchGym is an open-source sandbox providing reproducible search APIs and evaluation protocols over ClueWeb22 and FineWeb for benchmarking deep research agents. It supports scalable dense retrieval and long-form response evaluation using LLM-as-a-judge assessments across dimensions like relevance and factual grounding.
Fine-Tuning Large Language Models with User-Level Differential Privacy
AI Lab: Google Research Summary: This study compares two scalable user-level differential privacy methods (ELS and ULS) for LLM fine-tuning, with a novel privacy accountant that tightens DP guarantees for ELS. Experiments show that ULS generally offers better utility under large compute budgets or strong privacy settings, while maintaining scalability to hundreds of millions of parameters and users.
🤖 AI Tech Releases
DeepSeek-R1-0528
DeeSeek released a new version of its marquee R1 model.
Anthropic Circuits
Anthropic open sourced its circuit interpretability technology.
Perplexity Labs
Perplexity released a new tool that can generate charts, spreadsheets and dashboards.
Codestral Embed
Mistral released Codestral Embed, an embedding model specialized in coding.
🛠 AI in Production
Multi-Task Learning at Netflix
Netflix shared some details about its multi-task prediction strategy for user intent.
📡AI Radar
Salesforce agreed to buy Informatica for $8 billion.
xAI and Telegram partnered to enable Grok for its users.
Netflix’s Reed Hastings joined Anthropic’s board of directors.
Grammarly raised $1 billion to accelerate sales and acquisitions.
Spott raises $3.2 million for an AI-native recruiting firm.
Buildots $45 million for its AI for construction platform.
Context raised $11 million to power an AI-native office suite.
Rillet raised $25 million to enable AI for mid market accounting.
HuggingFace unveiled two new open source robots.
#2024#2025#Accessibility#accounting#acquisitions#agents#ai#algorithm#amazing#amp#anthropic#APIs#architecture#Art#audio#benchmark#benchmarking#benchmarks#billion#board#budgets#Building#Buildots#Carnegie Mellon University#charts#code#code generation#coding#Community#Competitive Programming
0 notes
Text
Steps to Use the OCR API
Using the OCR API is simple and quick:
Upload the document image.
The API processes and extracts the text.
Receive a clean, structured JSON output. No complex setup is needed, and you can test and integrate it within minutes. Ideal for automating identity verification, this API reduces manual effort and speeds up data collection. SprintVerify helps businesses digitize processes with ready-to-deploy APIs.
0 notes
Text
VeryPDF Website Screenshot API for Developers
How to Use VeryPDF Website Screenshot API for Developers to Capture Full-Page Screenshots in Seconds
Meta Description: Capture pixel-perfect full-page screenshots in seconds using VeryPDF Website Screenshot API—built for developers who need reliability, scale, and speed.

Every developer has hit this wall.
You’re building a dashboard or automating reports, and someone on your team says, “Can we just drop in a live screenshot of the page?” You think: Sure, I’ll just use an open-source tool.
A few hours later, you’re buried in headless browser configs, broken rendering, and timing issues where content loads after the shot’s already taken.
I’ve been there. More times than I want to admit.
This is why when I stumbled on VeryPDF Website Screenshot API for Developers, it felt like skipping the queue straight to the solution. No more fiddling with Puppeteer or spinning up Chrome instances. Just one call to the API, and boom—full-page, retina-quality screenshots in any format I needed.
Let me walk you through how this tool saved my time, my sanity, and probably my server bill.
The Problem With Most Screenshot Tools Let’s be honest.
Most “free” or “open-source” screenshot solutions are a headache. They break on:
Lazy-loaded content
Single-page apps
Sticky headers or parallax
Mobile views
Cookie pop-ups and ads
And don’t get me started on maintenance. Keeping a headless browser updated and rendering properly across different environments? That’s a full-time job.
Even the paid tools I tried didn’t scale well. I once had to generate 500,000 screenshots for a client’s SEO archive project. The tool I was using crumbled after 20,000.
That’s when I found VeryPDF’s Website Screenshot API.
Why VeryPDF Screenshot API is Built Differently This isn’t just a Chrome wrapper.
This thing is built on Chrome + AWS Lambda, designed to scale from 1 to over a million screenshots per month. I put it to the test on a real project involving weekly newsletter screenshots for over 600 clients—worked flawlessly.
Here’s how it works:
You call the API with a URL and desired output (JPG, PNG, PDF, or WebP)
It renders a pixel-perfect, full-page screenshot
You get it delivered as a direct file or as JSON response
No need to babysit it. No need to patch updates. And the docs? Actually usable.
Features That Actually Make a Difference Here are a few things that stood out while using it:
Full-Page + Mobile + Custom Viewport You’re not limited to what’s visible above the fold.
You can set it to scroll the full page, emulate mobile devices, or control the viewport width and height precisely.
Use case: I had to generate side-by-side desktop and mobile previews for a web agency’s landing pages. Set two API calls with different widths. Done. No extra code.
Block Annoyances (Ads, Cookie Banners) Ever taken a screenshot only to find a cookie banner covering the CTA?
VeryPDF lets you block those automatically.
This saved me hours when I was creating snapshots for compliance reports. No need to manually filter or edit the images after.
Just add --no-cookie-banner or --no-ads in the query and it’s clean.
HD Retina Output (2x, 3x Resolution) This was a big win.
You can request screenshots with @2x or @3x resolution, which is clutch if you're producing assets for high-DPI displays.
I used this for an app promo page targeting MacBook Pro users. Result? Razor-sharp screenshots that looked fantastic on retina displays.
How I Used It in a Real Project I had a client who ran a stock trading platform.
They wanted weekly archive PDFs of their homepage, including news tickers, embedded charts, and live data—captured exactly as it appeared to users.
I used VeryPDF’s API like this:
http://online.verypdf.com/api/?apikey=MYAPIKEY&app=html2image&infile=https://clientsite.com&outfile=homepage.pdf
One line. That’s it.
I set a cron job, and every Monday morning the API would capture a full-page, retina-quality PDF of their homepage with zero delay or manual work.
Compared to using headless Chrome with my own server—which took me two days to stabilise and still failed randomly—this was plug-and-play.
Who Should Be Using This API This isn’t just for devs building dashboards.
Here’s who will benefit from it:
SaaS teams needing snapshots for analytics or audit logs
Marketing teams creating before/after visuals
Legal and compliance who archive live content regularly
QA testers capturing layout bugs in different viewports
Developers automating PDF reports from web content
Whether you're doing 1 screenshot a week or 1,000,000 a month, this tool just works. No surprises.
Other Tools vs VeryPDF Let’s break it down.
Headless Chrome? You’ll be maintaining a mini browser farm. Not worth the time.
Open-source tools? Half of them don’t support full-page rendering or break on JavaScript-heavy sites.
Other APIs? Some work, but fall apart at scale or charge insane overage fees.
VeryPDF’s Screenshot API?
Fast
Reliable
Handles complexity
Actually scales
And most importantly, it doesn’t make you feel like you're constantly fixing it.
Want to Try It Out? I highly recommend giving this a shot if you're drowning in manual screenshot tasks or just want a fire-and-forget API that works like it should.
Start here: 👉 https://www.verypdf.com/online/webpage-to-pdf-converter-cloud-api/
You get 100 free screenshots just to try it—no credit card needed.
Need Something Custom-Built? VeryPDF also offers custom development if you’ve got unique needs.
Whether you want this API integrated into your Windows server, a mobile app, or embedded into an existing reporting platform—they’ve got you covered.
They support:
Windows API, Linux, macOS, Android, iOS
C#, Python, PHP, .NET, JavaScript, and more
Custom virtual printers that capture print jobs as PDFs or images
OCR, barcode reading, document parsing, font conversion—you name it
If your team needs tailored PDF or image handling, you can contact their support team here: 👉 http://support.verypdf.com/
FAQs
How do I get started with the API? Visit the product page and grab your free API key. No credit card required.
What file formats are supported? You can export to JPG, PNG, PDF, and WebP.
Can I customise the viewport or resolution? Yes. Set custom width, height, and even device pixel ratio (@2x, @3x).
Is this secure for sensitive data? Yes. All API calls use HTTPS, and you control access with your API key.
Can I schedule automatic screenshots? Absolutely. Use cron jobs or backend triggers with the API for automated capture.
Keywords/Tags: website screenshot API, capture full-page screenshots, html to image api, verypdf screenshot tool, automated webpage snapshots, pdf website screenshot api, developer tools screenshot, chrome rendering screenshot api, scalable image capture API, high-res webpage screenshot tool
From day one, this tool felt like a hidden gem. If you need to capture full-page screenshots fast, reliably, and at scale—VeryPDF Website Screenshot API is the tool I wish I’d found sooner.
0 notes
Text
Best LinkedIn Lead Generation Tools in 2025
In today’s competitive digital landscape, finding the right tools can make all the difference when it comes to scaling your outreach. Whether you’re a small business owner or part of an in-house marketing team, leveraging advanced platforms will help you target prospects more effectively. If you’re looking to boost your B2B pipeline, integrating the latest solutions—alongside smart linkedin advertising singapore strategies—can supercharge your lead flow.
1. LinkedIn Sales Navigator LinkedIn’s own premium platform remains a top choice for many professionals. It offers: • Advanced lead and company search filters for pinpoint accuracy. • Lead recommendations powered by LinkedIn’s AI to discover new prospects. • InMail messaging and CRM integrations to streamline follow-ups. • Real-time insights and alerts on saved leads and accounts.
2. Dux-Soup Dux-Soup automates connection and outreach workflows, helping you: • Auto-view profiles based on your search criteria. • Send personalized connection requests and follow-up messages. • Export prospect data to your CRM or spreadsheet. • Track interaction history and engagement metrics—all without leaving your browser.
3. Octopus CRM Octopus CRM is a user-friendly LinkedIn extension designed for: • Crafting multi-step outreach campaigns with conditional logic. • Auto-sending connection requests, messages, and profile visits. • Building custom drip sequences to nurture leads over time. • Exporting campaign reports to Excel or Google Sheets for analytics.
4. Zopto Ideal for agencies and teams, Zopto provides cloud-based automation with: • Region and industry-specific targeting to refine your list. • Easy A/B testing of outreach messages. • Dashboard with engagement analytics and performance benchmarks. • Team collaboration features to share campaigns and track results.
5. LeadFuze LeadFuze goes beyond LinkedIn to curate multi-channel lead lists: • Combines LinkedIn scraping with email and phone data. • Dynamic list building based on job titles, keywords, and company size. • Automated email outreach sequences with performance tracking. • API access for seamless integration with CRMs and sales tools.
6. PhantomBuster PhantomBuster’s flexible automation platform unlocks custom workflows: • Pre-built “Phantoms” for LinkedIn searches, views, and message blasts. • Scheduling and chaining of multiple actions for sophisticated campaigns. • Data extraction capabilities to gather profile details at scale. • Webhooks and JSON output for developers to integrate with other apps.
7. Leadfeeder Leadfeeder uncovers which companies visit your website and marries that data with LinkedIn: • Identifies anonymous web traffic and matches it to LinkedIn profiles. • Delivers daily email alerts on high-value company visits. • Integrates with your CRM to enrich contact records automatically. • Provides engagement scoring to prioritise outreach efforts.
8. Crystal Knows Personality insights can transform your messaging. Crystal Knows offers: • Personality reports for individual LinkedIn users. • Email templates tailored to each prospect’s communication style. • Chrome extension that overlays insight cards on LinkedIn profiles. • Improved response rates through hyper-personalised outreach.
Key Considerations for 2025 When choosing a LinkedIn lead generation tool, keep these factors in mind: • Compliance & Safety: Ensure the platform follows LinkedIn’s terms and respects user privacy. • Ease of Integration: Look for native CRM connectors or robust APIs. • Scalability: Your tool should grow with your outreach volume and team size. • Analytics & Reporting: Data-driven insights help you refine messaging and targeting.
Integrating with Your Singapore Strategy For businesses tapping into Asia’s growth markets, combining these tools with linkedin advertising singapore campaigns unlocks both organic and paid lead channels. By syncing automated outreach with sponsored content, you’ll cover every stage of the buyer journey—from initial awareness to final conversion.
Conclusion
As 2025 unfolds, LinkedIn lead generation continues to evolve with smarter AI, more seamless integrations, and deeper analytics. By selecting the right mix of tools—from Sales Navigator’s native power to specialized platforms like Crystal Knows—you can craft a robust, efficient pipeline. Pair these solutions with targeted linkedin advertising singapore tactics, and you’ll be well-positioned to capture high-quality leads, nurture them effectively, and drive sustained growth in the competitive B2B arena.
0 notes
Text
Python Programming with Red Hat (AD141): Empowering IT Automation and Development
In today’s fast-paced IT landscape, Python has emerged as one of the most powerful and versatile programming languages. From infrastructure automation to application development, Python plays a crucial role in modern enterprise environments. Recognizing this, Red Hat Training offers a purpose-built course — Python Programming with Red Hat (AD141) — designed to help system administrators, developers, and IT professionals harness Python for real-world tasks.
🔍 What is AD141?
Python Programming with Red Hat (AD141) is a hands-on, lab-intensive course that introduces learners to the core Python programming language and its practical applications in a Red Hat Enterprise Linux (RHEL) environment. Unlike generic Python courses, AD141 is tailored specifically for IT professionals who want to automate systems, manage tasks, or build lightweight applications on Red Hat platforms.
🧰 Key Learning Objectives
Participants in AD141 will:
Understand and apply basic Python syntax and constructs (loops, functions, data types, conditionals).
Learn to write and troubleshoot Python scripts in Linux environments.
Automate common sysadmin tasks using Python.
Parse and manipulate files, text, and system output.
Use Python libraries relevant to Red Hat automation (e.g., os, subprocess, json).
Explore real-world use cases such as log parsing, report generation, and file management.
🏗️ Who Should Enroll?
AD141 is ideal for:
System administrators looking to automate repetitive tasks.
DevOps professionals aiming to integrate Python into automation pipelines.
Red Hat Certified System Administrators (RHCSA) preparing for more advanced automation roles.
Developers who want to work efficiently in Red Hat Linux environments.
A basic understanding of command-line Linux and shell scripting is recommended before taking this course.
🎯 Why Choose Red Hat’s Python Training?
While there are countless Python tutorials available online, AD141 sets itself apart by aligning Python skills with Red Hat best practices and enterprise automation strategies. Learners don’t just write Python — they solve real sysadmin challenges, interact with Linux tools, and gain confidence in deploying Python in production-grade environments.
Additionally, participants gain access to Red Hat’s hands-on lab environment, which mimics real-world systems, giving learners the confidence to apply their skills immediately after training.
🧑🎓 Certification Path and Career Growth
Though AD141 does not lead to a certification directly, it acts as a foundational course for Red Hat’s automation and DevOps certification paths. Learners can progress toward advanced credentials like:
Red Hat Certified Engineer (RHCE) – focusing on automation with Ansible.
Red Hat Certified Architect (RHCA) – with a specialization in DevOps or infrastructure.
Adding Python to your toolkit is a smart career move for IT professionals who aim to stay ahead in automation, scripting, and cloud-native technologies.
🚀 Start Your Python Journey with Red Hat
Whether you're a sysadmin tired of repeating tasks or a developer aiming to optimize workflows, Python Programming with Red Hat (AD141) equips you with the practical skills to thrive in modern Linux environments.
Ready to future-proof your skillset?
👉 Enroll in AD141 through HawkStack Technologies – Your Trusted Red Hat Training Partner. Contact us today for corporate training, private sessions, or subscription-based learning options. For more details visit - www.hawkstack.com
0 notes
Text
Scraping Product Details from Shopee.com

Scraping Product Details from Shopee.com
Unlock Growth with Shopee.com Product Details Scraping Services. In today's highly competitive eCommerce landscape, staying ahead requires more than just quality products — it demands timely, accurate market insights. Shopee.com, one of Southeast Asia’s largest online marketplaces, hosts millions of product listings across a wide variety of categories.Extracting valuable product data from Shopee.com can help you optimize pricing strategies, expand your product range, and gain a significant competitive advantage. Unlock valuable market insights and boost your eCommerce strategy with our Shopee.com Product Details Scraping Services.
At Datascrapingservices.com, we offer specialized Shopee.com product details scraping services that deliver clean, structured, and actionable data — customized to your business needs.
List of Data Fields
Product Name
Product Price
Brand Name
Product Description
Product Specifications
Available Sizes/Colors
Product Category/Subcategory
Discounts & Promotions
Stock Availability
Seller Information
Ratings and Customer Reviews
Shipping Details
Product Images
SKU Numbers
Whether you're looking to track pricing trends, monitor competitors, or build a stronger inventory strategy, having access to these data points can be a game-changer.
Benefits of Shopee.com Product Data Scraping
✅ Market Analysis Identify trending products, customer preferences, and pricing strategies within your niche. Stay updated with real-time market dynamics to make data-driven decisions.
✅ Competitive Pricing Strategies Monitor your competitors' pricing and promotional tactics to stay ahead. Adjust your pricing models based on real-time insights to maintain a competitive edge.
✅ Inventory Management Avoid stockouts and overstock situations by understanding demand patterns.
✅ Product Research & Expansion Discover untapped opportunities by analyzing which products are gaining popularity. Plan new product launches more strategically.
✅ Boost Marketing Campaigns Tailor your messaging based on actual product features, reviews, and customer expectations.
✅ Save Time and Resources
Our automated scraping solutions ensure fast, accurate, and reliable data extraction, freeing up your team to focus on core business activities.
Why Choose Datascrapingservices.com?
Customizable Solutions tailored to your specific needs
GDPR-Compliant and Ethical data extraction practices
Real-Time or Scheduled Updates (daily, weekly, or monthly)
Multiple Output Formats like CSV, Excel, JSON, or API feeds
Best eCommerce Data Scraping Services Provider
Wayfair Product Details Extraction
Gap Product Pricing Extraction
Homedepot Product Pricing Data Scraping
Product Reviews Data Extraction
Macys.com Product Listings Scraping
Scraping Woolworths.com.au Product Prices Daily
Zalando.it Product Details Scraping
Amazon.co.uk Product Prices Extraction
Kmart.com.au Product Listing Scraping
Best Buy Product Price Extraction
Best Product Details Scraping Services in USA:
Long Beach, Denver, Fresno, Bakersfield, Atlanta, Austin, Fort Worth, Washington, Orlando, Mesa, Indianapolis, Houston, San Jose, Tulsa, Omaha, Colorado, Wichita, San Antonio, Fresno, Long Beach, New Orleans, Philadelphia, Louisville, Chicago, San Francisco, Oklahoma City, Raleigh, Seattle, Memphis, Jacksonville, Las Vegas, El Paso, Charlotte, Milwaukee, Sacramento, Sacramento, Virginia Beach, Columbus, Dallas, Nashville, Boston, Tucson and New York.
Ready to Gain a Competitive Edge? Let Datascrapingservices.com empower your business with real-time product insights from Shopee.com.
📩 Email: [email protected]🌐 Visit: Datascrapingservices.com
Let's transform raw data into powerful business strategies!
#scrapingproductdetailsfromshopee#extractingproductinformationfromshopee#ecommercedatascraping#productdetailsextraction#leadgeneration#datadrivenmarketing#webscrapingservices#businessinsights#digitalgrowth#datascrapingexperts
0 notes
Text
Automating Pipeline Failure Notifications Using Logic Apps and Azure Monitor

Automating Pipeline Failure Notifications Using Logic Apps and Azure Monitor
When data pipelines fail silently, the cost is more than just delayed reports — it’s lost trust, poor decisions, and operational hiccups. Fortunately, with Azure Monitor and Logic Apps, you can build a smart alerting system that automatically notifies the right team when an Azure Data Factory pipeline fails.
In this blog, we’ll walk through how to automate failure notifications using native Azure services — no code-heavy solutions or third-party tools required.
🔍 Why Automate Failure Notifications?
Manual monitoring of pipelines just doesn’t scale. Automating your alerts provides:
⏱ Faster response times
📉 Reduced downtime
📬 Instant notifications via Email, Teams, Slack, etc.
🚀 Better SLA adherence
🧰 Tools You’ll Need
Azure Data Factory (ADF) — where your pipelines live
Azure Monitor — for diagnostics and alert rules
Azure Logic Apps — to define workflows triggered by alerts
(Optional) Microsoft Teams, Email, Webhooks, etc. — for notification endpoints
⚙️ Step-by-Step: Setting Up Automatic Notifications
Step 1: Enable Diagnostic Logging in Azure Data Factory
Go to your ADF instance.
Navigate to Monitoring > Diagnostic Settings.
Create a new diagnostic setting and select:
PipelineRuns
ActivityRuns
Output to Log Analytics (you’ll need this for Azure Monitor to track failures)
Step 2: Create a Log Analytics Query to Detect Failures
Head to your Log Analytics workspace and run a query like this:kustoADFActivityRun | where Status == "Failed" | project PipelineName, ActivityName, Status, Error, RunStart, RunEnd
This pulls failure logs that you’ll use to trigger notifications.
Step 3: Set Up an Azure Monitor Alert
Navigate to Azure Monitor > Alerts > New Alert Rule.
Scope: Choose your Log Analytics workspace.
Condition: Use a custom Kusto query like the one above.
Threshold: Set to fire when the count > 0.
Action Group: Create one and select Logic App as the action type.
Step 4: Build the Logic App Workflow
In Logic Apps:
Use the trigger: When an HTTP request is received (this is called by Azure Monitor).
Add actions such as:
Send an email using Outlook
Post to Microsoft Teams channel
Send a webhook to an incident management tool like PagerDuty or OpsGenie
You can enrich the payload with pipeline name, time, and error message.
📦 Example: Email Notification Payload
json{ "subject": "🔴 Data Factory Pipeline Failed", "body": "Pipeline 'CustomerETL' failed at 3:42 PM with error: 'Timeout on Copy Activity'." }
This can be dynamically populated using Logic App variables.
✅ Bonus Tips
Add logic to suppress duplicate alerts within a short time span.
Include retry logic in Logic App to handle flaky endpoints.
Use adaptive cards in Teams for interactive alerts (e.g., ‘Acknowledge’, ‘Escalate’).
🧠 Wrapping Up
By combining Azure Monitor + Logic Apps, you can create a low-maintenance, scalable notification system that catches issues in real-time. This not only improves reliability but empowers your team to fix issues faster.
Whether you’re running dozens of pipelines or scaling up to hundreds, this setup keeps you informed — automatically.
WEBSITE: https://www.ficusoft.in/azure-data-factory-training-in-chennai/
0 notes
Text
Shopee Scraper: How to Collect Reviews, Product Details, and Market Data

Shopee is one of the fastest-growing e-commerce platforms in Southeast Asia, attracting millions of users daily. With a current valuation of $38 billion and projections to reach $150 billion by 2025, Shopee is a key player in the online marketplace. For businesses, this presents a valuable opportunity to extract actionable insights from the platform.
A Shopee scraper allows you to collect Shopee reviews, product details, and competitor data at scale. According to a recent study 92.4% of buyers check reviews before purchasing, user-generated content on Shopee holds immense value for understanding customer preferences and improving product strategies.
Whether you're tracking best-selling products, analyzing customer sentiment, or conducting market research, scraping Shopee data can give you a competitive edge. In this guide, we’ll explain how to use a Shopee scraper to gather product information, mine reviews, and extract market insights—while ensuring your data collection process is both scalable and ethical.
What is a Shopee Scraper?
A Shopee scraper is a digital tool, script, or software designed to automatically collect data from Shopee’s website. This includes retrieving real-time product listings, prices, seller details, stock status, and most importantly, customer reviews. With automation, a scraper significantly reduces the manual effort required to gather and organize this information.
Instead of spending hours scrolling through pages and copying data, a scraper can work in the background to extract clean, structured, and actionable insights that can help inform business strategies and improve competitive positioning.
Key Features of a Shopee Data Scraper
1. Ability to scrape Shopee reviews and analyze customer satisfaction.
2. Extract detailed product information like pricing, seller name, discounts, and availability.
3. Monitor product ratings and top-selling items.
4. Automate market research and pricing analysis across competitors.
5. Provide structured data output in formats like CSV, JSON, or XML for analytics and reporting.
Why Use a Shopee Scraper?
Shopee’s native API has limited public access and restrictive usage terms. For companies relying on comprehensive and timely market insights, using a Shopee data scraper is the best way to gather essential information.
Utilizing a scraper can help businesses stay ahead of the competition, optimize their pricing, monitor inventory fluctuations, and enhance their customer service based on review sentiment.
Core Benefits
Using a scraper to extract Shopee product and review data has multiple business advantages:
Detailed Market Insights:��Understand what features and pricing are resonating with customers.
Competitor Monitoring: Analyze other sellers' strategies in real-time.
Review Mining: Identify common pain points or praise through Shopee review scraper tools.
Time Efficiency: Automate a previously manual and repetitive task.
Product Optimization: Fine-tune product offerings by analyzing trends and customer feedback.
How to Scrape Shopee Reviews
Reviews play a critical role in e-commerce success. As highlighted earlier, 92.4% of online shoppers rely on reviews before making purchase decisions. With that much influence, reviews offer far more than user feedback—they offer business intelligence.
To begin scraping reviews from Shopee:
Start by collecting the URLs of the product pages you're interested in. Then, use a scraper or tool capable of handling dynamic content and review data. A good Shopee review scraper will extract details like review text, star ratings, reviewer name, and timestamps. Once collected, this data can be stored in a database or spreadsheet for analysis.
Analyzing reviews can uncover:
Common complaints or praises.
Changes in sentiment over time.
Features or aspects that matter most to customers.
Buyer language and keywords for SEO strategy.
Shopee Product Scraper: Extracting Valuable Product Details
A Shopee product scraper lets businesses and developers access a treasure trove of data points from individual product listings. This data is key to understanding market dynamics, competitive positioning, and consumer behavior.
With a product scraper, you can extract:
Product titles, unique IDs, and full descriptions.
Category tags and attributes.
Images and videos.
Pricing, promotions, currency, and availability.
Seller ratings, shipping methods, and SKUs.
These insights can then be used to:
Optimize your product catalog by benchmarking top competitors.
Identify trends in pricing and discounts.
Discover gaps in the market based on product availability.
Enhance your SEO by using similar keywords and formatting.
Best Practices to Extract Shopee Product Details Efficiently
Scraping requires more than just tools—it demands careful planning and execution. Here are a few best practices to consider:
1. Respect Platform Rules
Ensure your scraping activity is compliant with Shopee’s terms of service. Avoid scraping personal data, and respect the platform’s privacy standards.
2. Handle Dynamic Pages
Shopee’s interface includes dynamic JavaScript elements. Use browser automation frameworks like Puppeteer or Selenium to render and extract this content.
3. Structured Data Output
Store the scraped information in structured formats like JSON or CSV for smooth integration with analytics tools.
4. Automate the Workflow
If you need regular updates, implement a scheduling system to trigger scraping at fixed intervals. This way, your datasets always stay current.
Common Use Cases for a Shopee Scraper
Businesses from a variety of sectors can benefit from Shopee data scraping. Here are a few high-value applications:
For E-commerce Retailers
Monitor best-selling products in your category.
Track your competitors’ pricing and promotional strategies.
Discover products gaining traction based on reviews and ratings.
For Market Analysts
Conduct customer sentiment studies using Shopee review data.
Analyze emerging product trends before they go mainstream.
Forecast demand based on listing frequency and sales volume.
For Developers and SaaS Platforms
Build review aggregation or price comparison tools.
Integrate real-time Shopee data into dashboards or mobile apps.
Create business intelligence tools powered by Shopee product feeds.
How to Scrape Shopee Data: Tools and Tips
Different tools serve different needs. Here’s how to choose and use them effectively:
Tools of the Trade
Scrapy/BeautifulSoup (Python): Great for basic data extraction
Selenium/Puppeteer: Ideal for dynamic, JavaScript-rendered content
Rotating Proxies and User Agents: Prevent IP bans during large-scale scraping
Practical Tips
Use browser headers that mimic normal users to reduce bot detection
Implement caching so unchanged pages aren’t repeatedly scraped
Build retry logic in case of failed page loads or changed URLs
Hire a Shopee Scraper Data Provider
Shopee scraper setup takes time and resources.
A provider like TagX handles the complexity for you.
Get clean, ready-to-use data, delivered on time.
Challenges in Shopee Scraping and How to Overcome Them
Scraping comes with its share of obstacles. Here’s how to handle them:
1. IP Blocks and Rate Limits
Use proxy servers and delay functions to mimic human browsing patterns.
CAPTCHA Verification
Incorporate CAPTCHA-solving APIs or browser-based scraping to work around verification barriers.
2. Changing Site Structure
Shopee frequently updates its website. Regularly update your scraper code to reflect these changes.
3. Legal and Ethical Considerations
Always review Shopee’s robots.txt and terms of service before starting your scraping project. Avoid collecting personal or sensitive information. Use the data for legitimate business insights only, and ensure compliance with local and international data laws.
Why Choose TagX for Shopee Data Scraping?
TagX offers tailor-made Shopee data scraping solutions built to serve diverse business needs—from startups to large-scale enterprises. Here's why businesses choose TagX:
Customized Data Feeds: Get exactly the data you need, from product info to detailed customer reviews.
High Accuracy: Our scrapers are constantly updated to adapt to changes in Shopee's website structure.
Scalability: Whether you need data from hundreds or millions of listings, we can scale as you grow.
Dedicated Support: Get assistance from a team that understands your goals and industry.
Data in Your Format: Receive data in CSV, JSON, Excel, or through API access With TagX, you gain access to reliable, actionable data without dealing with the complexity of web scraping.
Conclusion
Shopee is quickly becoming a dominant force in e-commerce, with its valuation projected to grow from $38 billion to $150 billion by 2025. To stay competitive in such a fast-paced market, businesses must leverage every available advantage—including data.
A Shopee scraper allows you to access insights that were previously locked behind web pages. Whether you're tracking reviews, product listings, or seller performance, scraping Shopee data helps you make smarter, faster business decisions.
However, building your own scraper can be complex and time-consuming. That’s why partnering with a professional data provider like TagX can make all the difference. TagX handles everything—from scraper maintenance to data delivery—so you can focus on using insights, not chasing them. With a commitment to accuracy, speed, and customization, TagX empowers businesses to grow faster, make better decisions, and stay ahead of the competition.
Ready to supercharge your e-commerce strategy? TagX is here to help. Our advanced data extraction services are tailored to deliver high-quality, structured Shopee data that fuels growth and innovation.
Original Source, https://www.tagxdata.com/shopee-scraper-how-to-collect-reviews-product-details-and-market-data
0 notes
Text
Industrial AI solution Data CAMP Easy to use No-code Recipe UI | AHHA Labs

AHHA Labs' DataCAMP is an industrial AI solution designed to enhance manufacturing efficiency through advanced data analysis, real-time monitoring, and AI-driven predictive maintenance. It provides a comprehensive data management and AI automation system that enables industrial sites to optimize processes, reduce downtime, and improve product quality.
Data CAMP Easy to use No-code Recipe UI
Easily implement data pipelines optimized for manufacturing processes with a recipe-based, no-code, block-coding UI.
Easily organize your data pipelines with a no-code block-coding UI
Data CAMP supports a recipe-based, no-code block-coding UI. Users can combine individual recipe items with a drag-and-drop interface to visually configure and modify the entire pipeline, including data pre-processing and transformation.
For example, users can batch collect data such as sensor readings, inspection results, images, and acoustic data from various facilities and inspection equipment by specifying communication protocols like FTP and MELSEC. The collected data can be automatically converted to required formats, such as CSV or JSON, and set to automatically perform basic operations for analysis, including referencing, inserting, removing, merging data, pre-processing for statistics, and triggering events. The output file format for transmission and storage can be specified, and the communication protocol used by the parent system, such as DB or MES, can be specified to automatically transmit and store the processed data.
In short, users can efficiently collect, pre-process, transmit, store, and analyze massive amounts of manufacturing data without the need for complex coding.
High reliability with no-code solution
With a simple UI/UX based on no-code recipes, the application is also more reliable. Human coding can introduce errors, and poorly developed software can sometimes have cascading effects on manufacturing equipment. In the worst-case scenario, the entire system can go down.
This is unlikely to happen with Data CAMP, which uses pre-made recipe files to change settings, minimizing human error. Additionally, because it is organized as micro services, even if a recipe file is written incorrectly, it will only cause a specific pipeline to stop working and not have a cascading effect on other systems.
If you are looking for an industrial AI platform, you can find it at AHHA Labs.
Click here if you are interested in AHHA Labs products.
View more: Industrial AI solution Data CAMP Easy to use No-code Recipe UI
0 notes
Text
To guide you through the entire data transcription and processing workflow, here’s a detailed explanation with specific steps and tips for each part:
Choose a Transcription Tool
OpenRefine:
Ideal for cleaning messy data with errors or inconsistencies.
Offers advanced transformation functions.
Download it from OpenRefine.org.
Google Sheets:
Best for basic transcription and organization.
Requires a Google account; accessible through Google Drive.
Other Alternatives:
Excel for traditional spreadsheet handling.
Online OCR tools (e.g., ABBYY FineReader, Google Docs OCR) if the data is in scanned images.
Extract Data from the Image
If your data is locked in the image you uploaded:
Use OCR (Optical Character Recognition) tools to convert it into text:
Upload the image to a tool like OnlineOCR or [Google Docs OCR].
Extract the text and review it for accuracy.
Alternatively, I can process the image to extract text for you. Let me know if you need that.
Copy or Input the Data
Manual Input:
Open your chosen tool (Google Sheets, OpenRefine, or Excel).
Create headers for your dataset to categorize your data effectively.
Manually type in or paste extracted text into the cells.
Bulk Import:
If the data is large, export OCR output or text as a .CSV or .TXT file and directly upload it to the tool.
Clean and Format the Data
In Google Sheets or Excel:
Use "Find and Replace" to correct repetitive errors.
Sort or filter data for better organization.
Use built-in functions (e.g., =TRIM() to remove extra spaces, =PROPER() for proper case).
In OpenRefine:
Use the "Clustering" feature to identify and merge similar entries.
Perform transformations using GREL (General Refine Expression Language).
Export or Use the Data
Save Your Work:
Google Sheets: File > Download > Choose format (e.g., CSV, Excel, PDF).
OpenRefine: Export cleaned data as CSV, TSV, or JSON.
Further Analysis:
Import the cleaned dataset into advanced analytics tools like Python (Pandas), R, or Tableau for in-depth processing.
Tools Setup Assistance:
If you'd like, I can guide you through setting up these tools or provide code templates (e.g., in Python) to process the data programmatically. Let me know how you'd prefer to proceed!
import csv
Function to collect data from the user
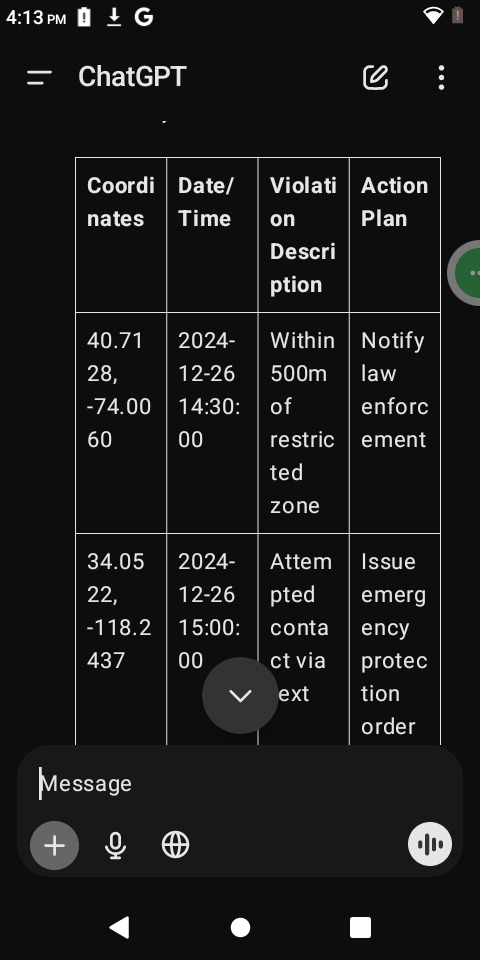
def collect_data(): print("Enter the data for each violation (type 'done' to finish):") data = [] while True: coordinates = input("Enter GPS Coordinates (latitude, longitude): ") if coordinates.lower() == 'done': break timestamp = input("Enter Date/Time (YYYY-MM-DD HH:MM:SS): ") violation = input("Enter Violation Description: ") action = input("Enter Action Plan: ") data.append({ "Coordinates": coordinates, "Date/Time": timestamp, "Violation Description": violation, "Action Plan": action }) return data
Function to save the data to a CSV file
def save_to_csv(data, filename="violations_report.csv"): with open(filename, mode='w', newline='') as file: writer = csv.DictWriter(file, fieldnames=["Coordinates", "Date/Time", "Violation Description", "Action Plan"]) writer.writeheader() writer.writerows(data) print(f"Data saved successfully to {filename}")
Main function
def main(): print("Restraining Order Violation Tracker") print("-----------------------------------") data = collect_data() save_to_csv(data)
Run the program
if name == "main": main()
Here’s a Python program to automate the transcription and organization of the data. The program will take input of GPS coordinates, violations, and actions, then output a structured CSV file for easy use.
Python Script: Data Transcription Program
import csv
Function to collect data from the user
def collect_data(): print("Enter the data for each violation (type 'done' to finish):") data = [] while True: coordinates = input("Enter GPS Coordinates (latitude, longitude): ") if coordinates.lower() == 'done': break timestamp = input("Enter Date/Time (YYYY-MM-DD HH:MM:SS): ") violation = input("Enter Violation Description: ") action = input("Enter Action Plan: ") data.append({ "Coordinates": coordinates, "Date/Time": timestamp, "Violation Description": violation, "Action Plan": action }) return data
Function to save the data to a CSV file
def save_to_csv(data, filename="violations_report.csv"): with open(filename, mode='w', newline='') as file: writer = csv.DictWriter(file, fieldnames=["Coordinates", "Date/Time", "Violation Description", "Action Plan"]) writer.writeheader() writer.writerows(data) print(f"Data saved successfully to {filename}")
Main function
def main(): print("Restraining Order Violation Tracker") print("-----------------------------------") data = collect_data() save_to_csv(data)
Run the program
if name == "main": main()
How It Works:
Input:
The program prompts you to enter GPS coordinates, date/time, violation descriptions, and proposed actions for each incident.
Type "done" when all entries are complete.
Processing:
The data is structured into a Python dictionary.
Output:
The program saves the collected data into a CSV file named violations_report.csv.
Sample Output (CSV Format):
Requirements:
Install Python (if not already installed).
Save the script as a .py file and run it.
The resulting CSV can be opened in Excel, Google Sheets, or similar tools.
Would you like help running or modifying the script?
0 notes
Text
Meta AI Releases Llama 3.3 70B Instruct
Explore Llama 3.3 70B Instruct As It Sets New Standards In AI With Enhanced Reasoning, Multilingual, And Cost-Efficient Features

Meta has introduced the Llama 3.3 70B Instruct, an advanced AI model that sets a new benchmark in reasoning, coding, and following instructions. As one of the most adaptable open models available, Llama 3.3 70B brings forth impressive capabilities with a wide array of applications.

Enhanced Functionality and Multilingual Support This model shines in producing structured outputs, especially in step-by-step reasoning and JSON formatting, ensuring reliability and accuracy for developers. With support for eight major languages, including English, French, and Hindi, it aims to facilitate global communication.
Revolutionizing Software Development The improvements in coding encompass extensive language support, better error handling, and comprehensive feedback, enabling developers to enhance their productivity. Llama 3.3’s task-aware tool usage optimizes resource utilization by intelligently activating tools only when needed.
Cost-Effective and Responsible AI Offering performance comparable to larger models like the 405B but at a significantly lower cost, Llama 3.3 makes high-quality AI accessible to more users. It incorporates safety measures such as Llama Guard 3 and Prompt Guard, ensuring secure operations that adhere to ethical AI standards, making it a trustworthy option for sensitive applications.
Real-World Applications From improving education with multilingual assistants to revolutionizing software development processes, the influence of Llama 3.3 is extensive. In business settings, it enhances customer support, refines data analysis, and automates content creation, reinforcing its importance across various industries.
Accessible on platforms like Hugging Face, Llama 3.3 embodies Meta’s commitment to open, responsible, and accessible AI. As generative AI continues to evolve, Meta’s latest development serves as a foundational element for progress and integrity in the field.
For more news like this: thenextaitool.com/news
0 notes