#aws api gateway rest vs http
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
If you dial 1-866-584-6757, you can leave an audio post for your followers.
Text
AWS API Gateway Tutorial for Cloud API Developer | AWS API Gateway Explained with Examples
Full Video Link https://youtube.com/shorts/A-DsF8mbF7U Hi, a new #video on #aws #apigateway #cloud is published on #codeonedigest #youtube channel. @java #java #awscloud @awscloud #aws @AWSCloudIndia #Cloud #CloudComputing @YouTube #you
Amazon AWS API Gateway is an AWS service for creating, publishing, maintaining, monitoring, and securing REST, HTTP, and WebSocket APIs. API developers can create APIs that access AWS or other web services, as well as data stored in the AWS Cloud. As an API Gateway API developer, you can create APIs for use in your own client applications. You can also make your APIs available to third-party…

View On WordPress
#amazon api gateway#amazon web services#api gateway#aws#aws api gateway#aws api gateway http api#aws api gateway http endpoint#aws api gateway http proxy example#aws api gateway http tutorial#aws api gateway http vs rest#aws api gateway lambda#aws api gateway rest api#aws api gateway rest api example#aws api gateway rest api lambda#aws api gateway rest vs http#aws api gateway websocket#aws api gateway websocket tutorial#aws api gatway tutorial
0 notes
Text
Benvenuti! Nel panorama in continua evoluzione dello sviluppo web, l’adozione di architetture moderne come i microservizi e l’architettura serverless è diventata essenziale per costruire applicazioni scalabili, flessibili e resilienti. Questi approcci innovativi permettono alle aziende di gestire grandi volumi di traffico, adattarsi rapidamente alle esigenze del mercato e offrire un’esperienza utente senza interruzioni. In questo articolo approfondiremo questi concetti, esplorando i loro benefici, le sfide associate e come implementarli efficacemente nei vostri progetti. Sommario Cos’è un Microservizio? Cosa Significa Serverless? Microservizi vs Serverless: Quale Scegliere? Casi di Successo Netflix Coca-Cola Airbnb Conclusione Approfondimenti e Risorse Utili Cos’è un Microservizio? Rappresentazione di un'architettura a microservizi con moduli separati che interagiscono tramite API. I microservizi sono un’architettura che suddivide un’applicazione in una serie di servizi piccoli, indipendenti e focalizzati su singole funzionalità. Ogni microservizio comunica con gli altri attraverso API ben definite, spesso utilizzando protocolli leggeri come HTTP/REST o gRPC. Caratteristiche chiave: Indipendenza: ogni servizio può essere sviluppato, distribuito e scalato in modo indipendente. Specializzazione: ogni microservizio è responsabile di un singolo compito o funzionalità. Decentralizzazione: promuovono l’autonomia dei team, consentendo loro di scegliere le tecnologie più adatte. Benefici dei Microservizi Scalabilità Granulare: permette di scalare solo i servizi che ne hanno effettivamente bisogno, ottimizzando le risorse. Flessibilità Tecnologica: consente l’utilizzo di diversi linguaggi di programmazione e stack tecnologici per servizi diversi. Ciclo di Sviluppo Accelerato: team più piccoli e focalizzati possono sviluppare e distribuire nuove funzionalità più rapidamente. Resilienza: un guasto in un microservizio non necessariamente compromette l’intera applicazione. Sfide dei Microservizi Complessità Operativa: la gestione di molti servizi indipendenti aumenta la complessità dell’infrastruttura. Gestione dei Dati: la consistenza dei dati può diventare una sfida quando i microservizi hanno database separati. Monitoraggio e Logging: è fondamentale implementare strumenti avanzati per tracciare le interazioni tra servizi. Sicurezza: l’aumento dei punti di interazione può esporre l’applicazione a nuovi vettori di attacco. Best Practice per l’Implementazione dei Microservizi API Gateway: utilizzo di un gateway per gestire le richieste in entrata e semplificare la comunicazione tra servizi. Containerizzazione: impiego di Docker e Kubernetes per facilitare il deployment e la scalabilità. Automazione CI/CD: implementazione di pipeline di integrazione e distribuzione continua per accelerare il rilascio di nuove funzionalità. Observability: adozione di strumenti per il monitoraggio, il logging e il tracing distribuito. Cosa Significa Serverless? Rappresentazione dell'architettura serverless, con funzioni che emergono dalla nuvola e operano senza gestione server tradizionale. L’architettura serverless consente agli sviluppatori di eseguire codice senza dover gestire l’infrastruttura sottostante. I provider cloud come AWS Lambda, Azure Functions e Google Cloud Functions si occupano dell’esecuzione, scalabilità e gestione dei server. Caratteristiche chiave: Event-Driven: il codice viene eseguito in risposta a eventi specifici. Scalabilità Automatica: il provider gestisce automaticamente la scalabilità in base al carico. Billing Basato sull’Utilizzo: si paga solo per il tempo effettivo di esecuzione del codice. Benefici dell’Architettura Serverless Riduzione dei Costi Operativi: elimina la necessità di investimenti in hardware e manutenzione dei server. Time-to-Market Rapido: permette di concentrarsi sullo sviluppo del codice senza preoccuparsi dell’infrastruttura.
Scalabilità Illimitata: gestisce automaticamente picchi di traffico senza intervento manuale. Manutenzione Ridotta: aggiornamenti e patching dell’infrastruttura sono gestiti dal provider. Sfide dell’Architettura Serverless Cold Start: ritardo iniziale nell’esecuzione delle funzioni inattive che può influenzare le prestazioni. Debugging Limitato: strumenti di debugging meno maturi rispetto alle applicazioni tradizionali. Limitazioni di Runtime: restrizioni su tempo di esecuzione, memoria e dimensione del pacchetto di deployment. Gestione dello Stato: le funzioni sono stateless, il che richiede soluzioni esterne per la gestione dello stato. Best Practice per l’Implementazione Serverless Ottimizzazione delle Funzioni: ridurre al minimo le dipendenze e ottimizzare il codice per migliorare i tempi di cold start. Architettura Event-Driven: progettare l’applicazione intorno a eventi per sfruttare appieno il modello serverless. Utilizzo di Strumenti di Monitoring: implementare strumenti come AWS CloudWatch o Azure Monitor per tracciare le performance. Gestione della Sicurezza: applicare principi di least privilege e utilizzare servizi gestiti per l’autenticazione e l’autorizzazione. Microservizi vs Serverless: Quale Scegliere? Un'illustrazione che mette a confronto la modularità e il controllo dei microservizi con la flessibilità e la scalabilità dell'architettura serverless. Criteri di Valutazione Dimensione e Complessità del Progetto: applicazioni complesse possono beneficiare della modularità dei microservizi, mentre progetti più piccoli possono essere più adatti al serverless. Team e Risorse: la gestione dei microservizi richiede competenze specializzate e team dedicati, mentre il serverless può essere gestito con risorse più limitate. Requisiti di Performance: se la latenza è critica, i microservizi potrebbero offrire maggiore controllo sulle performance. Budget e Costi Operativi: il serverless può ridurre i costi iniziali, ma i microservizi possono essere più economici a lungo termine per carichi costanti. Scenari di Applicazione Microservizi: Applicazioni enterprise con esigenze di integrazione complesse. Sistemi che richiedono elaborazione in tempo reale e bassa latenza. Progetti che necessitano di un elevato grado di personalizzazione e controllo. Serverless: Applicazioni con carichi di lavoro imprevedibili o intermittenti. Prototipazione rapida e MVP (Minimum Viable Product). Funzionalità isolate come elaborazione di immagini, notifiche o task schedulati. Combinare Microservizi e Serverless Molte organizzazioni stanno adottando un approccio ibrido, utilizzando microservizi per le componenti core dell’applicazione e funzioni serverless per task specifici. Questo consente di sfruttare i benefici di entrambi gli approcci, bilanciando controllo e agilità. Esempi di integrazione: Utilizzare funzioni serverless come trigger o processori di eventi per microservizi. Implementare microservizi che orchestrano l’esecuzione di funzioni serverless. Sfruttare servizi gestiti come database serverless all’interno di un’architettura a microservizi. Casi di Successo Tre esempi di successo dell'uso di microservizi e serverless: Netflix per lo streaming, Coca-Cola per le campagne promozionali e Airbnb per la gestione delle operazioni. Netflix Netflix ha rivoluzionato il settore dello streaming adottando un’architettura a microservizi. Gestendo miliardi di richieste al giorno, ha migliorato la scalabilità e la resilienza, permettendo un’esperienza utente fluida anche durante picchi di traffico. Strategie adottate: Decentralizzazione dei servizi per migliorare la resilienza. Utilizzo di strumenti come Hystrix per la tolleranza ai guasti. Implementazione di pipeline CI/CD per un rilascio continuo. Coca-Cola Coca-Cola ha utilizzato l’architettura serverless su AWS per gestire le campagne promozionali. Questo
ha permesso di ridurre i costi operativi e aumentare l’efficienza, eliminando la necessità di gestire l’infrastruttura durante periodi di basso utilizzo. Benefici ottenuti: Scalabilità automatica durante le campagne ad alto traffico. Riduzione del time-to-market per nuove iniziative. Miglioramento della flessibilità operativa. Airbnb Airbnb ha combinato microservizi e serverless per ottimizzare le operazioni interne. Utilizzando funzioni serverless per task come l’elaborazione di immagini e microservizi per la gestione delle prenotazioni, ha migliorato l’efficienza e l’esperienza utente. Approccio integrato: Utilizzo di funzioni serverless per task intensivi ma isolati. Adozione di microservizi per componenti critiche con requisiti di alta disponibilità. Implementazione di strumenti di monitoring avanzati per gestire l’infrastruttura ibrida. Conclusione La scelta tra microservizi e architettura serverless dipende da molteplici fattori, tra cui le esigenze specifiche del progetto, le risorse disponibili e gli obiettivi a lungo termine. Microservizi: offrono controllo e flessibilità per applicazioni complesse ma richiedono una gestione più intensiva. Serverless: permettono rapidità e scalabilità automatica con una minore manutenzione, ideali per carichi variabili e sviluppi rapidi. Raccomandazioni Finali Analisi Preliminare: valutare attentamente i requisiti funzionali e non funzionali prima di scegliere l’architettura. Formazione del Team: investire nella formazione per garantire che il team sia preparato ad affrontare le sfide tecniche. Prototipazione: iniziare con un piccolo progetto pilota per testare l’approccio scelto. Adattabilità: essere pronti ad adattare l’architettura in base al feedback e all’evoluzione delle esigenze. Ricordate, non esiste una soluzione unica che vada bene per tutti. L’importante è scegliere l’approccio che meglio si allinea con gli obiettivi del vostro progetto e che offra il massimo valore ai vostri utenti. Continuate a esplorare, imparare e innovare nel mondo affascinante dello sviluppo web moderno. Approfondimenti e Risorse Utili Per approfondire ulteriormente i concetti di microservizi e architettura serverless, ecco una selezione di risorse autorevoli che possono esservi utili: Martin Fowler - Microservices: un'analisi dettagliata dei principi dei microservizi da parte di uno dei maggiori esperti nel campo dello sviluppo software. Link: martinfowler.com/articles/microservices.html AWS - Microservizi: la guida ufficiale di Amazon Web Services sui microservizi, con best practice e casi d'uso. Link: aws.amazon.com/it/microservices/ Azure - Serverless Computing: documentazione ufficiale di Microsoft Azure sulle architetture serverless e su come implementarle. Link: azure.microsoft.com/it-it/solutions/serverless/ Google Cloud - Serverless Computing: una panoramica dell'offerta serverless di Google Cloud, con dettagli sulle tecnologie e i servizi disponibili. Link: cloud.google.com/serverless/ The Twelve-Factor App: una metodologia per lo sviluppo di applicazioni SaaS che sfruttano al massimo i benefici del cloud, applicabile sia ai microservizi che alle architetture serverless. Link: 12factor.net/it/ InfoQ - Microservices Patterns and Best Practices: una raccolta di articoli e interviste che esplorano i pattern comuni e le migliori pratiche nell'uso dei microservizi. Link: Microservices - InfoQ Serverless Stack: una guida open-source per costruire applicazioni serverless interamente sulla piattaforma AWS. Link: serverless-stack.com Netflix Tech Blog: approfondimenti tecnici dal team di Netflix sull'implementazione dei microservizi e sulle sfide affrontate. Link: netflixtechblog.com
0 notes
Link
AWS is just too hard to use, and it's not your fault. Today I'm joining to help AWS build for App Developers, and to grow the Amplify Community with people who Learn AWS in Public.
Muck
When AWS officially relaunched in 2006, Jeff Bezos famously pitched it with eight words: "We Build Muck, So You Don’t Have To". And a lot of Muck was built. The 2006 launch included 3 services (S3 for distributed storage, SQS for message queues, EC2 for virtual servers). As of Jan 2020, there were 283. Today, one can get decision fatigue just trying to decide which of the 7 ways to do async message processing in AWS to choose.
The sheer number of AWS services is a punchline, but is also testament to principled customer obsession. With rare exceptions, AWS builds things customers ask for, never deprecates them (even the failures), and only lowers prices. Do this for two decades, and multiply by the growth of the Internet, and it's frankly amazing there aren't more. But the upshot of this is that everyone understands that they can trust AWS never to "move their cheese". Brand AWS is therefore more valuable than any service, because it cannot be copied, it has to be earned. Almost to a fault, AWS prioritizes stability of their Infrastructure as a Service, and in exchange, businesses know that they can give it their most critical workloads.
The tradeoff was beginner friendliness. The AWS Console has improved by leaps and bounds over the years, but it is virtually impossible to make it fit the diverse usecases and experience levels of over one million customers. This was especially true for app developers. AWS was a godsend for backend/IT budgets, taking relative cost of infrastructure from 70% to 30% and solving underutilization by providing virtual servers and elastic capacity. But there was no net reduction in complexity for developers working at the application level. We simply swapped one set of hardware based computing primitives for an on-demand, cheaper (in terms of TCO), unfamiliar, proprietary set of software-defined computing primitives.
In the spectrum of IaaS vs PaaS, App developers just want an opinionated platform with good primitives to build on, rather than having to build their own platform from scratch:

That is where Cloud Distros come in.
Cloud Distros Recap
I've written before about the concept of Cloud Distros, but I'll recap the main points here:
From inception, AWS was conceived as an "Operating System for the Internet" (an analogy echoed by Dave Cutler and Amitabh Srivasta in creating Azure).
Linux operating systems often ship with user friendly customizations, called "distributions" or "distros" for short.
In the same way, there proved to be good (but ultimately not huge) demand for "Platforms as a Service" - with 2007's Heroku as a PaaS for Rails developers, and 2011's Parse and Firebase as a PaaS for Mobile developers atop AWS and Google respectively.
The PaaS idea proved early rather than wrong – the arrival of Kubernetes and AWS Lambda in 2014 presaged the modern crop of cloud startups, from JAMstack CDNs like Netlify and Vercel, to Cloud IDEs like Repl.it and Glitch, to managed clusters like Render and KintoHub, even to moonshot experiments like Darklang. The wild diversity of these approaches to improving App Developer experience, all built atop of AWS/GCP, lead me to christen these "Cloud Distros" rather than the dated PaaS terminology.
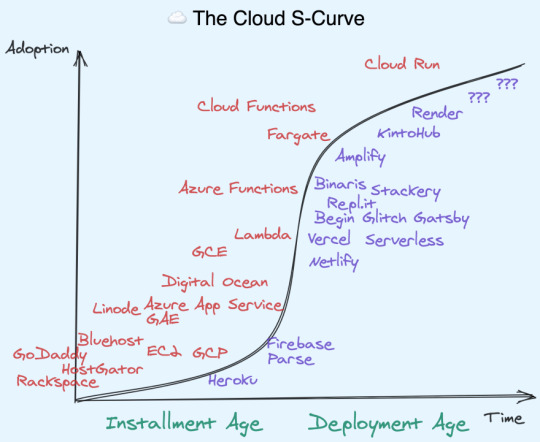
Amplify
Amplify is the first truly first-party "Cloud Distro", if you don't count Google-acquired Firebase. This does not make it automatically superior. Far from it! AWS has a lot of non-negotiable requirements to get started (from requiring a credit card upfront to requiring IAM setup for a basic demo). And let's face it, its UI will never win design awards. That just categorically rules it out for many App Devs. In the battle for developer experience, AWS is not the mighty incumbent, it is the underdog.
But Amplify has at least two killer unique attributes that make it compelling to some, and at least worth considering for most:
It scales like AWS scales. All Amplify features are built atop existing AWS services like S3, DynamoDB, and Cognito. If you want to eject to underlying services, you can. The same isn't true of third party Cloud Distros (Begin is a notable exception). This also means you are paying the theoretical low end of costs, since third party Cloud Distros must either charge cost-plus on their users or subsidize with VC money (unsustainable long term). AWS Scale doesn't just mean raw ability to handle throughput, it also means edge cases, security, compliance, monitoring, and advanced functionality have been fully battle tested by others who came before you.
It has a crack team of AWS insiders. I don't know them well yet, but it stands to reason that working on a Cloud Distro from within offers unfair advantages to working on one from without. (It also offers the standard disadvantages of a bigco vs the agility of a startup) If you were to start a company and needed to hire a platform team, you probably couldn't afford this team. If you fit Amplify's target audience, you get this team for free.
Simplification requires opinionation, and on that Amplify makes its biggest bets of all - curating the "best of" other AWS services. Instead of using one of the myriad ways to setup AWS Lambda and configure API Gateway, you can just type amplify add api and the appropriate GraphQL or REST resources are set up for you, with your infrastructure fully described as code. Storage? amplify add storage. Auth? amplify add auth. There's a half dozen more I haven't even got to yet. But all these dedicated services coming together means you don't need to manage servers to do everything you need in an app.
Amplify enables the "fullstack serverless" future. AWS makes the bulk of its money on providing virtual servers today, but from both internal and external metrics, it is clear the future is serverless. A bet on Amplify is a bet on the future of AWS.
Note: there will forever be a place for traditional VPSes and even on-premises data centers - the serverless movement is additive rather than destructive.
For a company famous for having every team operate as separately moving parts, Amplify runs the opposite direction. It normalizes the workflows of its disparate constituents in a single toolchain, from the hosted Amplify Console, to the CLI on your machine, to the Libraries/SDKs that run on your users' devices. And this works the exact same way whether you are working on an iOS, Android, React Native, or JS (React, Vue, Svelte, etc) Web App.
Lastly, it is just abundantly clear that Amplify represents a different kind of AWS than you or I are used to. Unlike most AWS products, Amplify is fully open source. They write integrations for all popular JS frameworks (React, React Native, Angular, Ionic, and Vue) and Swift for iOS and Java/Kotlin for Android. They do support on GitHub and chat on Discord. They even advertise on podcasts you and I listen to, like ShopTalk Show and Ladybug. In short, they're meeting us where we are.
This is, as far as I know, unprecedented in AWS' approach to App Developers. I think it is paying off. Anecdotally, Amplify is growing three times faster than the rest of AWS.
Note: If you'd like to learn more about Amplify, join the free Virtual Amplify Days event from Jun 10-11th to hear customer stories from people who have put every part of Amplify in production. I'll be right there with you taking this all in!
Personal Note
I am joining AWS Mobile today as a Senior Developer Advocate. AWS Mobile houses Amplify, Amplify Console (One stop CI/CD + CDN + DNS), AWS Device Farm (Run tests on real phones), and AppSync (GraphQL Gateway and Realtime/Offline Syncing), and is closely connected to API Gateway (Public API Endpoints) and Amazon Pinpoint (Analytics & Engagement). AppSync is worth a special mention because it is what first put the idea of joining AWS in my head.
A year ago I wrote Optimistic, Offline-first apps using serverless functions and GraphQL sketching out a set of integrated technologies. They would have the net effect of making apps feel a lot faster and more reliable (because optimistic and offline-first), while making it a lot easier to develop this table-stakes experience (because the GraphQL schema lets us establish an eventually consistent client-server contract).
9 months later, the Amplify DataStore was announced at Re:Invent (which addressed most of the things I wanted). I didn't get everything right, but it was clear that I was thinking on the same wavelength as someone at AWS (it turned out to be Richard Threlkeld, but clearly he was supported by others). AWS believed in this wacky idea enough to resource its development over 2 years. I don't think I've ever worked at a place that could do something like that.
I spoke to a variety of companies, large and small, to explore what I wanted to do and figure out my market value. (As an aside: It is TRICKY for developer advocates to put themselves on the market while still employed!) But far and away the smoothest process where I was "on the same page" with everyone was the ~1 month I spent interviewing with AWS. It helped a lot that I'd known my hiring manager, Nader for ~2yrs at this point so there really wasn't a whole lot he didn't already know about me (a huge benefit of Learning in Public btw) nor I him. The final "super day" on-site was challenging and actually had me worried I failed 1-2 of the interviews. But I was pleasantly surprised to hear that I had received unanimous yeses!
Nader is an industry legend and personal inspiration. When I completed my first solo project at my bootcamp, I made a crappy React Native boilerplate that used the best UI Toolkit I could find, React Native Elements. I didn't know it was Nader's. When I applied for my first conference talk, Nader helped review my CFP. When I decided to get better at CSS, Nader encouraged and retweeted me. He is constantly helping out developers, from sharing invaluable advice on being a prosperous consultant, to helping developers find jobs during this crisis, to using his platform to help others get their start. He doesn't just lift others up, he also puts the "heavy lifting" in "undifferentiated heavy lifting"! I am excited he is leading the team, and nervous how our friendship will change now he is my manager.
With this move, I have just gone from bootcamp grad in 2017 to getting hired at a BigCo L6 level in 3 years. My friends say I don't need the validation, but I gotta tell you, it does feel nice.
The coronavirus shutdowns happened almost immediately after I left Netlify, which caused complications in my visa situation (I am not American). I was supposed to start as a US Remote employee in April; instead I'm starting in Singapore today. It's taken a financial toll - I estimate that this coronavirus delay and change in employment situation will cost me about $70k in foregone earnings. This hurts more because I am now the primary earner for my family of 4. I've been writing a book to make up some of that; but all things considered I'm glad to still have a stable job again.
I have never considered myself a "big company" guy. I value autonomy and flexibility, doing the right thing over the done thing. But AWS is not a typical BigCo - it famously runs on "two pizza teams" (not literally true - Amplify is more like 20 pizzas - but still, not huge). I've quoted Bezos since my second ever meetup talk, and have always admired AWS practices from afar, from the 6-pagers right down to the anecdote told in Steve Yegge's Platforms Rant. Time to see this modern colossus from the inside.
0 notes
Photo
How the top 6 million sites are using JavaScript
#464 — November 22, 2019
Read on the Web
JavaScript Weekly
Postwoman: An API Request Builder and Tester — A free alternative to Postman, a popular app for debugging and testing HTTP APIs. Postwoman works in the browser and supports HTTP and WebSocket requests as well as GraphQL. Insomnia is a similar tool if you want to run something as a desktop app.
Liyas Thomas
The State of JavaScript on the Web by the HTTP Archive — The HTTP Archive has released an annual ‘state of the Web’ report focused on data collected from six million sites. There are numerous findings here, including how much JavaScript the Web uses, how long it takes browsers to parse that JavaScript, and what frameworks and libraries are most popularly used.
Houssein Djirdeh
Get Best in Class Error Reporting for Your JavaScript Apps — Time is money. Software bugs waste both. Save time with Bugsnag. Automatically detect and diagnose errors impacting your users. Get comprehensive diagnostic reports, know immediately which errors are worth fixing, and debug in minutes. Try it free.
Bugsnag sponsor
The Differences Between the Same App Created in React and Svelte — Several issues ago we linked to Sunil’s article comparing the same app written in React and Vue and now he’s back with a side by side comparison of some of the differences between an app built in React and Svelte, an increasingly popular build-time framework.
Sunil Sandhu
Node Gains Enabled-By-Default Support for ECMAScript Modules — Node.js 13.2.0 came out this week with both an upgrade to V8 and unflagged support for using ES modules. There are some rules to using them, and you might find this V8 blog entry on JavaScript modules worth revisiting to get a feel for what’s involved. Time to play!
Node.js Foundation
jQuery Core Migrating from AMD Modules to ES Modules — Before you say jQuery isn’t relevant, the HTTP Archive has revealed that it’s being used on ~85% of around 6 million sites.
jQuery
Pika Opens Its 'Write Once, Run Natively Everywhere' JavaScript Registry for Early Access — Rather than authors being responsible for formatting and configuring packages, the registry takes care of it. You write the code, they, in theory, do the rest (including creating TypeScript type declarations). Sadly it’s behind an email wall for now, so watch this space.
Pika
⚡️ Quick Releases
video.js 7.7 — Cross-browser video player.
Svelte 3.15.0 — Compile-time app framework.
Leaflet 1.6 — Mobile-friendly interactive maps.
AngularJS 1.7.9 —An update to the original Angular.
CanJS 6.0 — Data-driven app framework.
Ember 3.14
💻 Jobs
Full Stack Engineer — Expensify seeks a self-driven individual passionate about making code effective, with an understanding of algorithms and design patterns.
Expensify
Senior Web Frontend Engineer (CA, IL or NC) — Design what machine learning "looks" like to improve the manufacturing of millions of things. We value great tools like fast builds, simple deploys, & branch environments.
Instrumental
Find a Job Through Vettery — Make a profile, name your salary, and connect with hiring managers from top employers. Vettery is completely free for job seekers.
Vettery
📘 Articles & Tutorials
Getting Started with an Express.js and ES6+ JavaScript Stack — With typical Smashing Magazine quality, this is a thorough beginner-level walkthrough, this time covering how to get started with Node in building a web app backed by a MongoDB database. Definitely for beginners though.
Jamie Corkhill
Techniques for Instantiating Classes — Dr. Axel walks through several approaches for creating instances of classes.
Dr. Axel Rauschmayer
How To Build a Sales Dashboard with React — Improve your data visualization with JavaScript UI controls. Build interactive dashboards quickly and easily.
Wijmo by GrapeCity sponsor
▶ We Should Rebrand JavaScript. Yep? Nope? — A podcast where two pairs of JavaScript developers debate an idea that was recently floated.. should we rebrand JavaScript?
JS Party podcast
Compile-Time Immutability in TypeScript — How to achieve compile-time immutability in TypeScript with const assertions and recursive types.
James Wright
Having Fun with ES6 Proxies — Proxies aren’t going to be useful in day to day programming for most JavaScript developers, but they open up some interesting opportunities if you want more control over how objects behave and are worth understanding.
Maciej Cieślar
▶ How to Build a Budget Calculator App with Angular — A 2 hour video that walks through the entire process of building an Angular app. The gentle pace is well aimed at those new to Angular or the tooling involved.
Devstackr
Composing Angular Components with TypeScript Mixins
Giancarlo Buomprisco
Hey Node Helps You Think, Prototype, and Solve in Node.js — Transforming data, package.json, the module system and more. Bite-size, info-packed tutorials with videos and use cases.
Hey Node by Osio Labs sponsor
Cropping Images to a Specific Aspect Ratio with JavaScript — How to use the HTML canvas API and some basic math to build a tiny crop helper function, making it easy to quickly crop images in various aspect ratios.
Rik Schennink
🔧 Code & Tools
EasyDB: A 'One-Click' Server-Free Database — A quick way to provision a temporary database (that’s basically a key/value store) and use it from JavaScript. Ideal for hackathons or quick once-off scripts, perhaps.
Jake and Tyson
Nodemon: Automatically Restart a Node App When Files Are Changed — A development-time tool to monitor for any changes in your app and automatically restart the server. v2.0 has just been released with CPU and memory use improvements and far fewer dependencies.
Remy Sharp
GraphQuill: Real-Time GraphQL API Exploration in VS Code — A way to test GraphQL API endpoints from within VS Code so you don’t have to keep jumping between multiple tools.
OSLabs Beta
Open Realtime Data - A User’s Guide with Links to a Free Streaming Platform
Ably sponsor
Lambda API: A Lightweight Web Framework for Serverless Apps — A stripped down framework that takes an Express-esque approach to putting together serverless JavaScript apps to run on AWS Lambda behind API Gateway.
Jeremy Daly
ScrollTrigger: Let Your Page React to Scroll Changes — Triggers classes based on the current scroll position. So, for example, when an element enters the viewport you can fade it in.
Erik Terwan
Siriwave: The Apple Siri 'Waveform' Replicated in a JS Library
Flavio Maria De Stefano
by via JavaScript Weekly https://ift.tt/2XI7YS2
0 notes
Text
HDInsight
HDInsight - это корпоративный сервис с открытым кодом от Microsoft для облачной платформы Azure, позволяющий работать с кластером Apache Hadoop в облаке в рамках управления и аналитической работы с большими данными (Big Data).
Экосистема HDInsight
Azure HDInsight – это облачная экосистема компонентов Apache Hadoop на основе платформы данных Hortonworks Data Platform (HDP) [1], которая поддерживает несколько версий кластера Hadoop. Каждая из версий создает конкретную версию платформы HDP и набор компонентов, содержащихся в этой версии. C 4 апреля 2017 г. Azure HDInsight по умолчанию использует версию кластера 3.6 на основе HDP 2.6. Кроме основных 4-х компонентов Hadoop (HDFS, YARN, Hadoop Common и Hadoop MapReduce), в состав HDInsight 3.6 также входят следующие решения Apache Software Foundation [2]: · Pig - высокоуровневый язык обработки данных и фреймворк исполнения этих запросов; · Hive - инфраструктура распределенного хранения информации, поддерживающая запросы к данным; · Spark, Mahout – фреймворки для машинного обучения (Machine Learning); · HCatalog - управление метаданными; · Sqoop - перемещение больших объемов данных между Hadoop и хранилищами структурированных данных; · Flume - распределенный сервис сбора, агрегации и перемещения потоков данных и логов в HDFS; · Zookeeper – централизованная служба координации распределенных приложений; · Oozie – планировщик потоков работ; · Kafka — распределённый программный брокер сообщений; · Ambari – средство мониторинга и автоматизированного управления кластером; · Инструменты бизнес-аналитики (Business intelligence, BI) Hive - ODBC Driver и дополнение для работы с электронными таблицами Excel.

Компоненты экосистемы HDInsight
Как запускается и работает Hadoop-кластер на Microsoft Azure
На портале Microsoft Azure можно создавать кластеры Hadoop размером до 32 узлов, запускать распределенные задачи MapReduce, а также через доступ к интерактивной консоли писать запросы к данным на JavaScript и Hive. Стоимость пользования облачных сервисов Microsoft Azure рассчитывается поминутно на основании потребленных ресурсов для вычислений, хранения информации и обмена данными [3]. Архитектура облачного кластера включает несколько уровней и состоит из следующих компонентов [4]: · Secure Role (Gateway Node) – реверсивный прокси, шлюз кластера, который отвечает за аутентификацию и авторизацию и предоставляет конечные точки для других сервисов (WebHcat, Ambari, HiveServer и Oozie) на 433 порту. · Head Node – виртуальная машина уровня Extra Large (8 ядер, 14 GB RAM), на которой развернуты ключевые элементы кластера Hadoop: сервер имен NameNode, вторичный сервер имен Secondary NameNode и трекер заданий JobTracker. Также Head Node содержит и выполняет операционные сервисы и сервисы данных (HiveServer, Pig, Sqoop, Metastore, Derbyserver, Oozie, Templeton, Ambari). · Worker Nodes (Data Nodes) – это узлы данных на виртуальных машинах уровня Large (4 ядра, 7 GB RAM), которые отвечают за запуск сервисов, поддерживающих планирование задач, исполнение задач и доступ к данным (TaskTracker, DataNode, Pig, Hive Client). · Windows Azure Storage-BLOB (WASB) – файловая система по умолчанию в кластере HDInsight. WASB предоставляет доступ к HDFS через REST API, командную строку или графический интерфейс клиентов (Microsoft Visual Studio Tools for HDInsight, Azure Storage Explorer и т.д.).

Архитектура кластера Hadoop от Microsoft Windows Azure
Преимущества HDInsight
Можно выделить 3 ключевых достоинства этого облачного решения: 1. Интеграция с другими сервисами Microsoft [1]: · с Active Directory с целью управления и гибкой настройки политики безопасности и контроля доступа; · с облачными сервисами хранения Azure Blob Storage и Amazon S3 с целью получения данных из внешних источников; · с System Center для управления кластером и всей корпоративной IT-средой$ · c журналами Azure Monitor для мониторинга всех кластеров в едином интерфейсе. 2. Поддержка многих сред разработки (Visual Studio, VS Code, Eclipse, IntelliJ) и языков программирования (Scala, Python, R, Java, .NET, C#, Java, JavaScript) [1]; 3. Особенности хранения данных [4]: · все данные, хранимые в WASB, в т.ч. из облачных приложений и сервисов, запущенных вне HDInsight, доступны для использования в кластере; · все данные, хранимые в WASB, останутся нетронутыми после удаления кластера HDInsight и могут использоваться в новом кластере. 4. Удобство пользования [5]: · возможность прямого доступа к кластеру HDInsight через браузер; · наличие REST API для постановки и снятий заданий (Job), а также запросов статуса их выполнения.
История появления и развития
HDInsight как облачный Hadoop-сервис впервые анонсирован Microsoft Azure в 2011 году, а публично стал доступен с февраля 2013 года. Изначально HDInsight был представлен следующими 2-мя вариантами [5]: · облачный сервис на Windows Azure – Windows Azure HDInsight; · локальный кластер на Windows Server 2008/2012 – Microsoft HDInsight to Windows Server (CTP). HDInsight 3.3 был последней версией под управлением Windows, срок поддержки которой истек 27 июня 2016 г. С версии 3.4 корпорация Майкрософт выпускает HDInsight только для операционной системы Linux. На июнь 2019 года доступна последняя версия HDInsight 4.0, однако по умолчанию при создании облачного кластера Hadoop используется версия 3.6 на основе дистрибутива Hortonworks HDP 2.6 [2].

Варианты Hadoop-решений от Microsoft
Примеры использования HDInsight
Microsoft Azure вообще и HDInsight в частности, держатся в топе корпоративных PaaS- и IaaS-решений, уступая лидеру облачного рынка Amazon [6]. HDInsight как облачная платформа для Big Data проектов широко применяется по всему миру, в том числе в нашей стране. Например, популярный онлайн-сервис для изучения английского языка LinguaLeo и мониторинг социальных медиа YouScan используют Microsoft Azure [7].

Сравнение популярности PaaS-решений Отметим еще некоторые интересные кейсы использования HDInsight в Big Data проектах [4]: · обработка генома человека (политехнический институт Вирджинии, США); · научные исследования при разработке натуральных ингредиентов для продуктовых, фармакологических и сельскохозяйственных производств (компания Chr. Hansen, Дания); · аналитические исследования данных, полученных от более 50 миллионов продаж онлайн-игр серии Halo (компания разработчик компьютерных игр 343 Industries, США); · хранение и анализ данных по клиническим исследованиям из большого числа источников (медицинская компания Ascribe Ltd, Великобритания). Источники 1. https://docs.microsoft.com/ru-ru/azure/hdinsight/hadoop/apache-hadoop-introduction 2. https://docs.microsoft.com/ru-ru/azure/hdinsight/hdinsight-component-versioning 3. https://ru.wikipedia.org/wiki/Microsoft_Azure 4. https://habr.com/ru/post/200750/ 5. https://www.codeinstinct.pro/2012/12/hdinsight.html 6. http://la.by/blog/sravnenie-uslug-oblachnyh-provayderov-microsoft-azure-aws-ili-google-cloud 7. https://msdn.microsoft.com/ru-ru/dn305109 Read the full article
0 notes
Text
gRPC to AWS Lambda: Is it Possible?
At Coinbase, we have been evaluating gRPC for new services and have had a positive experience so far. We’ve also been closely watching the trends of the industry towards “Serverless” architectures. We’ve been experimenting with the AWS Lambda platform as a location to run various types of workloads, including API endpoints. However, we are curious if there’s a way to unify these.
There are two main ways to invoke a Lambda function synchronously: API Gateway or a direct “invoke” API call to AWS. API Gateway allows for incoming requests to be made over HTTP/2 with HTTP/1 requests bundled and forwarded to Lambda. Direct invocation of Lambdas requires tight coupling with AWS SDKs.
I was curious about whether it was even possible to make a gRPC call through API gateway to a Lambda and have a response return all the way to the client. Turns out, it’s very close to possible for unary request / response gRPC calls.
Prior to diving in here, it can be helpful to read gRPC On HTTP/2: Engineering A Robust, High Performance Protocol to gain a deeper understanding of gRPC itself.
Bootstrapping
To get started, I followed the AWS SAM quick start guide to get Hello World Lambda deployed.
Then I started bootstrapping a very simple gRPC service with a single RPC that accepted and sent a very simple message.
https://medium.com/media/e6b0e1419a70787f876a406c855e7f30/href
To build the proto into compiled Golang, I installed the protoc compiler for Golang and compiled the hello protobuf file into a Golang package.
https://medium.com/media/7dbc9c5dfe3f4eba879e2194e014470b/href
I created a very simple gRPC Golang client for the RPC API.
https://medium.com/media/7e17cf2a17f1f5560ecebdf63629e16d/href
First Attempt: Send out a gRPC Request
The first error that comes up is related to the content-type of the response.
err making request: rpc error: code = Internal desc = transport: received the unexpected content-type “application/json”
This makes sense as the default lambda is sending back JSON to the gRPC client, which won’t work because of a mismatch. gRPC clients expect “application/grpc+proto” back. The first fix involves setting the correct content-type in the API response from Lambda. This can be done in the Headers field of the APIGatewayProxyResponse struct as below.
https://medium.com/media/cc7d377b8d55c552ef734d64615c018a/href
Second Attempt: Protobuf Response
After returning the correct content type, the next error is absolutely bizarre.
err making request: rpc error: code = ResourceExhausted desc = grpc: received message larger than max (1701604463 vs. 4194304)
gRPC has a max-size of 16 MB returned in a response, and our function was clearly not returning that much data. However, we are simply returning a string, so it seems now is the time to return a protobuf.
The next handler looks like this:
https://medium.com/media/454434f27c2399da826c866ec1ae70cb/href
First, we construct a protobuf struct, then serialize to a byte array, then base64 encode into the final response body. Base64 encoding is required in order for API Gateway to return a binary response.
There’s also two incantations required to actually get API gateway to convert the response to binary. First, we need to set the integration response type to “CONVERT_TO_BINARY”.
This can be done in the CLI below:
aws apigateway update-integration-response \ -rest-api-id XXX \ -resource-id YYY \ -http-method GET \ -status-code 200 \ -patch-operations ‘[{“op” : “replace”, “path” : “/contentHandling”, “value” : “CONVERT_TO_BINARY”}]’
In addition, the “Binary Media Types” setting needs to be set to “*/*”

Note: AWS Console Screenshot
Third Attempt: Length-prefixed Response
However, we still get the same ResourceExhausted error. Let’s double check that API Gateway is properly sending back a binary protobuf response.
To debug more, we can set:
export GODEBUG=http2debug=2
This will give us output about what is going back and forth over the wire for the HTTP/2 requests.
https://medium.com/media/540ad4fdd82b5132f2c8348f2f548994/href
We see that as our request goes up, it writes a DATA frame with the content “\x00\x00\x00\x00\a\n\x05Hello”. However, what we get back is “\n\rHello, world.”. What are all those \x00 values in the request? This turns out to be a special serialization format that gRPC uses called “Length Prefixed Messages”. On the wire, this looks like:

See the gRPC HTTP/2 protocol mapping for more detail.
Here’s a quick and dirty implementation of the prefix construction with an updated handler.
https://medium.com/media/6abc871c40b73d657f39e6ebec4c62f8/href
Final Attempt: Missing trailing headers
After returning the correct prefix, we run into the final error.
err making request: rpc error: code = Internal desc = server closed the stream without sending trailers
This error is saying that API gateway closed the stream without returning trailing headers. Turns out that gRPC clients make a fundamental assumption that the response contains trailing headers with the stream closed. For example, here is what a proper response looks like:
HEADERS (flags = END_HEADERS) :status = 200 grpc-encoding = gzip content-type = application/grpc+proto
DATA <Length-Prefixed Message>
HEADERS (flags = END_STREAM, END_HEADERS) grpc-status = 0 # OK
This is helpful for streaming, but may not be needed for unary request / response RPC invocations. In fact, there is an entire effort within the gRPC community to build compatibility with HTTP/1.1 or browsers with gRPC-Web.
Next Steps
To recap, our goal through this exercise was to see how closely we could get to a Lambda successfully responding to a gRPC client’s request, without modifying the client. We were able to make it almost all the way, but ran into a fundamental assumption that gRPC clients make about trailing headers.
There’s two possible paths forward. Either API Gateway needs to respond with the proper trailing HEADERS frame or gRPC clients need to relax their constraints around expecting trailing headers for unary request / response calls.
However, is it actually worth communicating with Lambdas over gRPC? Maybe. For us, there would be value to standardizing API interactions with Lambdas and containerized environments. The typed interface of Protobuf behind gRPC ensures a strong contract between the client and server that would be difficult to enforce otherwise
Unfortunately, gRPC behind lambda would not support any of the server, client, or bidi streaming solutions that benefit gRPC in a highly stateful environment.
There are other interesting solutions in the community to this problem, such as Twirp (by Twitch) and gRPC-Web.
If you’re interested in helping us build a modern, scalable platform for the future of crypto markets, we’re hiring in San Francisco and Chicago!
This website may contain links to third-party websites or other content for information purposes only (“Third-Party Sites”). The Third-Party Sites are not under the control of Coinbase, Inc., and its affiliates (“Coinbase”), and Coinbase is not responsible for the content of any Third-Party Site, including without limitation any link contained in a Third-Party Site, or any changes or updates to a Third-Party Site. Coinbase is not responsible for webcasting or any other form of transmission received from any Third-Party Site. Coinbase is providing these links to you only as a convenience, and the inclusion of any link does not imply endorsement, approval or recommendation by Coinbase of the site or any association with its operators.
Unless otherwise noted, all images provided herein are by Coinbase.
gRPC to AWS Lambda: Is it Possible? was originally published in The Coinbase Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Money 101 https://blog.coinbase.com/grpc-to-aws-lambda-is-it-possible-4b29a9171d7f?source=rss----c114225aeaf7---4 via http://www.rssmix.com/
0 notes
Text
Notes from Root Conf Day 2 - 2017
On day 2, I spent a considerable amount of time networking and attend only four sessions.
Spotswap: running production APIs on Spot instance
Amazon EC2 spot instances are cheaper than on-demand server costs. Spot instances run when the bid price is greater than market/spot instance price.
Mapbox API server uses spot instances which are part of auto-scaling server
Auto scaling group is configured with min, desired, max parameters.
Latency should be low and cost effective
EC2 has three types of instances: On demand, reserved and spot. The spot instance comes from unused space and unstable pricing.
Spot market starts with bid price and market price.
In winter 2015 traffic increased and price also increased increased
To spin up a new machine with code takes almost two minutes
Our machine fleet encompasses of spot and on-demand instances
When one spot machine from the fleet goes down, and auto scaling group spins up an on-demand machine.
Race condition: several instances go down at same time.
Aggressive spin up in on-demand machines when market is volatile.
Tag EC2 machines going down and then spin up AWS lambda. When spot instance returns shit down a lambda or on-demand instance. Auto Scaling group can take care of this.
Savings 50% to 80%
Source code: https://github.com/mapbox/spotswap
No latency because over-provisioned
Set bid price as on-demand price.
Didn't try to increase spot instance before going on-demand
Cfconfig to deploy and Cloud formation template from AWS
Adventures with Postgres
Speaker: I’m an Accidental DBA
The talk is a story of a Postgres debugging.
Our services include Real-time monitoring, on demand business reporting to e-commerce players. 4000 stores and 10 million events per day. Thousands of customers in a single database.
Postgres 9.4, M4.xlarge,16GB, 750 GB disk space with Extensive monitoring
Reads don't block writes, Multi-Version Concurrency Model.
Two Clients A, B read X value as 3. When B updates the value X to 4, A reads the X value and gets back as 3. A reads the X value as 4 when B’s transaction succeeds.
Every transaction has a unique ID - XID.
XID - 32 bit, max transaction id is 4 billion.
After 2 billion no transaction happens.
All writes stop and server shutdown. Restarts in single user mode,
Read replicas work without any issue.
Our server reached 1 billion ids. 600k transaction per hour, so in 40 days transaction id will hit the maximum limit.
How to prevent?
Promote standby to master? But XID is also replicated.
Estimate the damage - txid_current - Current Transaction ID
Every insert and update is wrapped inside a transaction
Now add begin and commit for a group of statements, this bought some time.
With current rate, 60 days is left to hit max transaction limit.
TOAST - The Oversized Attribute Storage Technique
Aggressive maintenance. Config tweaks: autovacuum_workers, maintenance_work_mem, autovaccum_nap_time - knife to gun fight. Didn’t help
rds_superuser prevented from modifying pg system tables
Never thought about rds_superuser can be an issue.
VACUUM -- garbage-collect and optionally analyze a database
vacuum freeze (*) worked. Yay!
What may have caused issues - DB had a large number of tables. Thousands of tables
Better shard per customer
Understand the schema better
Configuration tweaks - max_workers, nap_time, cost_limit, maintenance_work_mem
Keep an eye out XID; Long-lived transactions are problem
Parallel vacuum introduced in 9.5
pg_visibility improvements in 9.6
Similar problem faced other companies like GetSentry
MySQL troubleshooting
Step 1 - Define the problem, know what is normal, read the manual
Step 2: collect diagnostics data (OS, MySQL). pt_stalk tool to collect diagnostics error
Lookup MySQL error log when DB misbehaves.
Check OOM killer
General performance issues - show global variables, show global status, show indexes, profile the query
Table corruption InnoDB, system can't startup. Worst strategy force recovery and start from backup.
Log message for table corruption is marked as crashed
Replication issues - show master status, my.cnf/my.ini, show global variables, show slave status
OTR Session - Micro Service
OTR - Off The Record session is a group discussion. Few folks come together and moderate the session. Ramya, Venkat, Ankit and Anand C where key in answering and moderating the session.
What is service and micro service? Micro is independent, self-contained and owned by the single team. Growing code base is unmanageable, and the number of deploys increases. So break them at small scale. Ease of coupling with other teams. No clear boundary
Advantages of Microservices - team size, easy to understand, scale it. Security aspects. Two pizza team, eight-member team. Able to pick up right tools for the job, and change the data store to experiment, fix perf issues.
How to verify your app needs micro service?
Functional boundary, behavior which is clear. Check out and Delivery
PDF/Document parsing is a good candidate for Micro Service, and parsing is CPU intensive. Don't create nano-service :-)
Failure is inevitable. Have logic for handling failures on another service. Say when MS 1 fails MS2 code base should handle gracefully.
Message queue Vs Simple REST service architecture. Sync Vs Async.The choice depends on the needs and functionality.
Service discovery? Service registry and discover from them.
Use swagger for API
Overwhelming tooling - you can start simple and add as per requirements
Good have to think from beginnings - how you deploy, build pipelines.
Auth for internal services - internal auth say Service level auth and user token for certain services. Convert monolithic to modular and then micro level.
API gateway to maintain different versions and rate limiting When to use role-based access and where does scope originate? Hard and no correct way. Experiment with one and move on.
Debugging in monolithic and micro service is different.
When you use vendor-specific software use mock service to test them. Also, use someone else micro service. Integration test for microservices are hard.
Use continuous delivery and don't make large number of service deployment in one release.
The discussion went on far for 2 hours! I moved out after an hour. Very exhaustive discussion on the topic.
1 note
·
View note
Text
Ionic 4 + AppSync: Build a mobile app with a GraphQL backend - Part 1
A year ago I wrote a tutorial for building a GraphQL backend for an Ionic app with Graphcool.
Around the same time, Amazon Web Services (AWS) released their own GraphQL service called AWS AppSync. Amazon Web Services are widely used by many (big) companies and they offer more than 100 different types of services which you can use to create a complete backend for any type of app.
AWS offers free tiers for almost all their services so it's free to get started with AppSync.
In this tutorial series I'll give you an introduction to GrahpQL and show you how to easily build an AppSync GraphQL API. Following that, we'll build a mobile app with Ionic 4 that uses this GraphQL API.
This tutorial is split up into these parts: Part 1 - Introduction to GraphQL & AWS AppSync (this post) Part 2 - Create an AWS AppSync API with Amplify (more parts will be added later)
By the end of this series, I hope you'll have a good understanding of GraphQL and the capabilities of AppSync. I'll assume you have some experience with either Ionic or Angular, but don't worry if you don't, we'll build the whole thing from scratch!
If you have absolutely no idea what Ionic is, you can learn more about it here.
What is GraphQL and why should I care about it?
GraphQL is a query language specification which was developed by Facebook in 2012 to build an API for their mobile apps that could handle the complexity of their data and still be easy to use.
Facebook then open sourced GraphQL in 2015 and it was adopted by other companies to replace their REST API's. Here is a list of companies that have already implemented GraphQL API's:
Github
PayPal
Twitter
AirBnB
Shopify
and more
GraphQL vs REST
GraphQL gives you the ability to communicate in a more flexible way with a backend than a traditional REST API.
With REST you have multiple endpoints for querying resources whereas with GraphQL you have just one endpoint. You define in your GrahpQL request exactly which data you want to receive back from the endpoint.
It's called GraphQL because it allows you to query graphs of data, you can get all the data you need with one request instead of having to send multiple requests. This data could be coming from a relational or non-relational database, a file store, other API's, or any other source of data.
Let's have a quick look at an example: let's say you want to retrieve a blog post with all its comments and author details.
With a REST API, you'd have to send multiple requests to query the post, comments, and author details.
With a GraphQL API, you can get all this data in just one response from the backend because you are defining what you want the backend to return with your request query. This means that you can get your data faster because it's only one roundtrip and you're only getting the data you actually need, so less bytes to transfer over the wire.
GraphQL Schemas
In order for a client to know which data it can query from the GraphQL backend, the backend provides a schema which is written using the GraphQL Schema Definition Language.
The schema is a data model, it describes the types of data in your application and the relationships between these types. In the next part of this tutorial I'll show you how to create a simple schema.
GraphQL is only a specification, so in order to use it, you'll need a service to implement this specification. You can either create your own GrahpQL service with something like Apollo Server and manage your own servers or you can go serverless by using a GraphQL service like AppSync.
OK, tell me more about AppSync
AppSync is a fully managed GraphQL service which uses other AWS services under the hood to store and get data, combine data from multiple sources, and run serverless functions. AppSync also supports real-time updates for your app with GraphQL subscriptions.
In this tutorial we will be using Amazon DynamoDB (NoSQL database) as the data store because that's supported by AppSync out-of-the-box.
However, can use other types of databases with Amazon Relational Database Service (RDS), it just means a bit more work because you will have to use AWS Lambda (serverless functions) to do the mapping from the GraphQL schema to the database.
You might think at this point that it's going to be a lot of work to create your GraphQL schema and set up all the backend resources, but I'm happy to tell you that there is a tool that will help you set up your entire GraphQL backend in minutes!
Supercharge your development workflow with AWS Amplify
AWS Amplify is an open source CLI tool which helps developers get started quickly with building AppSync API's and integrating them into their apps.
All you have to do is define the types and relationships in your schema and Amplify will generate the full schema with CRUDL queries and mutations and push that to your AWS account where the AppSync API will be created for you along with the DynamoDB tables.
The CLI doesn't only help you with setting up AppSync, here is a list of all the AWS services that are currently supported by Amplify:
Authentication (Amazon Cognito)
Storage (Amazon S3 & Amazon DynamoDB)
Serverless Functions (AWS Lambda)
GraphQL API (AWS AppSync)
REST API (Amazon API Gateway)
Analytics (Amazon Pinpoint)
Hosting (Amazon S3 and Amazon CloudFront distribution)
Notifications (Amazon Pinpoint)
Chatbots (Amazon Lex)
Besides managing the AWS backend for your app, Amplify also helps you on the client side in your mobile and web apps.
Amplify automatically sets up the configuration for your AppSync endpoint and it can generate TypeScript classes for your GraphQL types and generate views for sign up/in which work with your backend out-of-the-box.
GraphQL client libraries
You can communicate with a GraphQL backend from your client application through HTTP requests. There is a bit of boilerplate involved in setting up these requests for your queries and mutations but to take make development easier, it's recommended to use a GraphQL client library in your app.
These libraries also take care of common client requirements like caching, optimistic UI, handling real-time updates with subscriptions, and more.
Amplify comes with its own GraphQL client which we can use in our Ionic app, but it doesn't support offline usage and client-side caching.
We can also use the the official AWS AppSync JavaScript SDK which has a GraphQL client implementation that supports offline usage and caching.
The AppSync SDK uses Appolo Client under the hood which is a very popular GraphQL client built by the folks from Meteor. It's framework agnostic and there is an integration package for Angular, so it's easy to use in Ionic apps.
To keep things simple for now I'll only use the Amplify GraphQL client in this tutorial, but if you need caching/offline support have a look at the AppSync SDK.
If you want to learn more about Apollo Client, you can see how I used it in my tutorial series with Graphcool.
What's next?
In the next part I'll show you how to set up an AppSync API with the Amplify CLI and following that we'll create an Ionic app that uses this backend.
I hope this introduction got you excited about GraphQL and AppSync, if it didn't please let me know in the comments what you think. I can imagine GraphQL might not be the best solution for your use case, but I'd love to get your opinion and I want to make sure I'm explaining GraphQL in a way that's easy to understand.
If you've already used AppSync or other GraphQL services before and stumbled upon this post somehow, I would love to know what your experiences with it are.
Here are a couple of links to learn more about GraphQL:
How To GraphQL - I really liked this one, it helped me get started with GraphQL
Official GraphQL Docs
via Gone Hybrid https://ift.tt/2J8NGcQ
0 notes
Link
Get hands-on training in AWS, Python, Java, blockchain, management, and many other topics.
Develop and refine your skills with 100+ new live online trainings we opened up for April and May on our learning platform.
Space is limited and these trainings often fill up.
Creating Serverless APIs with AWS Lambda and API Gateway, April 6
Getting Started with Amazon Web Services (AWS), April 19-20
Python Data Handling: A Deeper Dive, April 20
How Product Management Leads Change in the Enterprise, April 23
Beyond Python Scripts: Logging, Modules, and Dependency Management, April 23
Beyond Python Scripts: Exceptions, Error Handling, and Command-Line Interfaces, April 24
Getting Started with Go, April 24-25
End-to-End Data Science Workflows in Jupyter Notebooks, April 27
Getting Started with Vue.js, April 30
Java Full Throttle with Paul Deitel: A One-Day, Code-Intensive Java Standard Edition Presentation, April 30
Building a Cloud Roadmap, May 1
Git Fundamentals, May 1-2
AWS Certified SysOps Administrator (Associate) Crash Course , May 1-2
OCA Java SE 8 Programmer Certification Crash Course, May 1-3
Getting Started with DevOps in 90 Minutes, May 2
Learn the Basics of Scala in 3 hours, May 2
IPv4 Subnetting, May 2-3
SQL Fundamentals for Data, May 2-3
SAFe 4.5 (Scaled Agile Framework) Foundations, May 3
Managing Team Conflict, May 3
Hands-On Machine Learning with Python: Clustering, Dimension Reduction, and Time Series Analysis, May 3
Google Cloud Platform Professional Cloud Architect Certification Crash Course, May 3-4
Cyber Security Fundamentals, May 3-4
Advanced Agile: Scaling in the Enterprise, May 4
Network Troubleshooting Using the Half Split and OODA, May 4
Software Architecture for Developers, May 4
Hands-On Machine Learning with Python: Classification and Regression, May 4
Building and Managing Kubernetes Applications, May 7
Introducing Blockchain, May 7
Get Started with NLP, May 7
Introduction to Digital Forensics and Incident Response (DFIR), May 7
Essential Machine Learning and Exploratory Data Analysis with Python and Jupyter Notebooks, May 7-8
Building Deployment Pipelines with Jenkins 2, May 7 and 9
Introduction to Apache Spark 2.x, May 7-9
Deep Learning Fundamentals, May 8
Acing the CCNA Exam, May 8
Emotional Intelligence for Managers, May 8
Scala Core Programming: Methods, Classes, and Traits, May 8
Design Patterns Boot Camp, May 8-9
Introduction to Lean, May 9
Beginner’s Guide to Creating Prototypes in Sketch, May 9
AWS Certified Solutions Architect Associate Crash Course, May 9-10
Cloud Native Architecture Patterns, May 9-10
Amazon Web Services: Architect Associate Certification - AWS Core Architecture Concepts, May 9-11
Blockchain Applications and Smart Contracts, May 10
Deep Reinforcement Learning, May 10
Getting Started with Machine Learning, May 10
Introduction to Ethical Hacking and Penetration Testing, May 10-11
Explore, Visualize, and Predict using pandas and Jupyter, May 10-11
Scalable Web Development with Angular, May 10-11
Apache Hadoop, Spark, and Big Data Foundations, May 11
Visualizing Software Architecture with the C4 Model, May 11
Write Your First Hadoop MapReduce Program, May 14
Write Your First Spark Program in Java, May 14
Interactive Java with Java 9’s JShell, May 14
Bash Shell Scripting in 3 Hours, May 14
Learn Linux in 3 Hours, May 14
Cybersecurity Blue Teams vs. Red Teams, May 14
Next-Generation Java testing with JUnit 5, May 14
Product Management in Practice, May 14-15
IoT Fundamentals, May 14-15
Porting from Python 2 to Python 3, May 15
Red Hat Certified System Administrator (RHCSA) Crash Course, May 15-18
Introduction to Analytics for Product Managers, May 16
Architecture Without an End State, May 16-17
Deploying Container-Based Microservices on AWS, May 16-17
Agile for Everybody, May 17
Introduction to Google Cloud Platform, May 17
Practical Data Cleaning with Python, May 17-18
Hands-on Introduction to Apache Hadoop and Spark Programming, May 17-18
Troubleshooting Agile, May 18
Managing your Manager, May 18
Building Chatbots with AWS, May 18
Your First 30 Days as a Manager, May 21
Introduction to Unreal Engine 4 with Blueprints, May 21
Introduction to Critical Thinking, May 21
Testing and Validating Product Ideas with Lean, May 21
From Developer to Software Architect, May 22-23
CISSP Crash Course, May 22-23
Introduction to Kubernetes, May 22
CCNP R/S ROUTE (300-101) Crash Course, May 22-24
Advanced SQL for Data Analysis (with Python, R, and Java), May 23
Docker: Beyond the Basics (CI & CD), May 23-24
Introduction to TensorFlow, May 23-24
Leadership Communication Skills for Managers, May 24
Cyber Security Defense, May 24
End-to-End Data Science Workflows in Jupyter Notebooks, May 24
The DevOps Toolkit, May 24-25
Introduction to Cisco Next-Generation Firewalls, May 24-25
Amazon Web Services: Architect Associate Certification - AWS Core Architecture Concepts, May 24-25
Kubernetes in 3 Hours, May 25
Ansible in 3 Hours, May 25
Design Fundamentals for Non-Designers, May 25
Python Data Handling - A Deeper Dive, May 29
Introduction to Modularity with the Java 9 Platform Module System (JPMS), May 29
CCNA Security Crash Course, May 29-30
Scala: Beyond the Basics, May 29-30
Microservices Architecture and Design, May 29-30
Docker: Up and Running, May 29-30
High Performance TensorFlow in Production: Hands on with GPUs and Kubernetes, May 29-30
Rethinking REST: A Hands-On Guide to GraphQL and Queryable APIs, May 30
PMP Crash Course, May 31-June 1
Test Driven Development in Java, May 31-June 1
Architecture Without an End State, May 31-June 1
Building Microservices with Spring Boot, Spring Cloud, and Cloud Foundry, July 2-3
Visit our learning platform for more information on these and other live online trainings.
Continue reading 100+ new live online trainings just launched on O'Reilly's learning platform.
from All - O'Reilly Media https://ift.tt/2q5z0lQ
0 notes
Link
Serverless Architecture
Serverless is an application framework for building a serverless application without having to worry about managing infrastructures. It is based on the principle of third party service (BaaS) and on custom codes which run on a container(FaaS). Serverless architecture doesn’t mean we don’t have a server. With the serverless architecture, we still have a server to run our application, it’s just that we don’t need to manage it on our end. We can just focus on developing our application rest will be handled automatically.
AWS SAM
The AWS Serverless Application Model (AWS SAM) is a model to define serverless applications. AWS SAM is natively supported by AWS CloudFormation and defines a simplified syntax for expressing serverless resources. The specification currently covers APIs, Lambda functions, and Amazon DynamoDB tables. AWS SAM uses Cloudformation template to deploy the lambda in a cloud formation stack. These templates are written in JSON or YAML file which states the step to execute in the cloud stack. So our main motive of this blog is to focus on lambda so the rest of the content will be on lambda functions.
AWS Lambda
AWS Lambda is a serverless framework so we can just create an application, make an artifact out of it and just upload it. AWS Lambda will handle the rest. It runs the application based on the language, scale it whenever required and the best part of it is that we are charged for only when we run a lambda function i.e NO CHARGE for not running it.
Building blocks of AWS lambda-based application:
Lambda function: It consists of our application code and related dependencies which we upload as an artifact.
Events: An AWS service, such as Amazon SNS, or a custom service, that triggers your function and executes its logic. For more information
Downstream resources: Like DynamoDB or S3 which can be used to trigger a lambda function.
Log streams: Logs are automatically maintained in cloud watch which we can use to analyze the execution flow and performance of the lambda function.
AWS SAM: It defines a serverless model which provide support to AWS cloudformation for creating the deployment cycle for our application.
AWS Lambda supports the following runtime versions:
Node.js – v4.3.2 and 6.10.3
Java – Java 8
Python – Python 3.6 and 2.7
.NET Core – .NET Core 1.0.1 and .NET Core 2.0
Go – Go 1.x
Let us see a simple lambda function written in Java.
package com.knoldus import com.amazonaws.services.lambda.runtime.Context; public class Lambda { // Lambda function public String requestHandler(String name, Context context) { return String.format("Hello %s.", name); } }
In this example, we have a requestHandler function which we have taken as our lambda function. It contains 2 parameters. The first argument is the input parameter to the function and the second is the context object. The context object allows you to access useful information available within the Lambda execution environment like the memory limit, request id etc.
After creating the function we will create an artifact with all the dependencies and upload that to the AWS Lambda console and specify the handler as com.knoldus.Lambda::requestHandler (package.class::method-reference). Then we will specify a trigger for it i.e when this lambda function needs to be triggered like specifying an API gateway or triggering the function when something is pushed to S3 etc.
There may be questions in your mind like,
“Why Lambda? Why not ECS?”
“When to use what?”
“Lambda vs ECS?”
“Which AWS service should I use?”
I have answers for these.
Why Lambda? Why not ECS?
Both AWS Lambda and AWS ECS are similar in some regard as both of them do the same job but there are some differences that we need to keep in mind and use one of them according to our needs.
Lambda vs ECS
AWS Lambda does not provide any visibility into the server infrastructure environment used to run the application code, while Amazon ECS actively exposes the servers used in the cluster as standard Amazon EC2 instances and allows the user to size and scale themselves.
AWS Lambda supports only a few languages but ECS will run any code written in any language.
AWS Lambda is best when we have a small function instead of complex function as it will affect its execution on the other hand AWS ECS can run any type of code.
In Lambda we don’t have to worry about scaling our application as it is automatically handled but on the other hand in ECS either we need to scale up manually or we have to use tools for auto-scaling.
When to use what?
Lambda should be used when we have few functions which don’t have complex dependencies on other functions in the code. It is mainly used when we are handling event-based requests. It has only a few supported languages so we need to have a check on those.
Amazon ECS allows running Docker containers in a standardized, AWS-optimized environment. The containers can contain any code or application module written in any language.
Which AWS service should I use?
Again the answer is simple it is based on the needs i.e it depends on the code written.
In my next blog, I will give a complete step by step procedure for creating a Lambda function and setting up the function in the AWS Lambda console.
Hope this content helps you in some ways. Let’s meet in my next blog. Till then
Happy reading…!!
References:
AWS Lambda Documentation
diginomica.com
0 notes