#aws api gateway http tutorial
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr was acquired by Yahoo for $1.1B in 2013.
Text
AWS API Gateway Tutorial for Cloud API Developer | AWS API Gateway Explained with Examples
Full Video Link https://youtube.com/shorts/A-DsF8mbF7U Hi, a new #video on #aws #apigateway #cloud is published on #codeonedigest #youtube channel. @java #java #awscloud @awscloud #aws @AWSCloudIndia #Cloud #CloudComputing @YouTube #you
Amazon AWS API Gateway is an AWS service for creating, publishing, maintaining, monitoring, and securing REST, HTTP, and WebSocket APIs. API developers can create APIs that access AWS or other web services, as well as data stored in the AWS Cloud. As an API Gateway API developer, you can create APIs for use in your own client applications. You can also make your APIs available to third-party…

View On WordPress
#amazon api gateway#amazon web services#api gateway#aws#aws api gateway#aws api gateway http api#aws api gateway http endpoint#aws api gateway http proxy example#aws api gateway http tutorial#aws api gateway http vs rest#aws api gateway lambda#aws api gateway rest api#aws api gateway rest api example#aws api gateway rest api lambda#aws api gateway rest vs http#aws api gateway websocket#aws api gateway websocket tutorial#aws api gatway tutorial
0 notes
Text
The Role of the AWS Software Development Kit (SDK) in Modern Application Development
The Amazon Web Services (AWS) Software Development Kit (SDK) serves as a fundamental tool for developers aiming to create robust, scalable, and secure applications using AWS services. By streamlining the complexities of interacting with AWS's extensive ecosystem, the SDK enables developers to prioritize innovation over infrastructure challenges.
Understanding AWS SDK
The AWS SDK provides a comprehensive suite of software tools, libraries, and documentation designed to facilitate programmatic interaction with AWS services. By abstracting the intricacies of direct HTTP requests, it offers a more intuitive and efficient interface for tasks such as instance creation, storage management, and database querying.
The AWS SDK is compatible with multiple programming languages, including Python (Boto3), Java, JavaScript (Node.js and browser), .NET, Ruby, Go, PHP, and C++. This broad compatibility ensures that developers across diverse technical environments can seamlessly integrate AWS features into their applications.
Key Features of AWS SDK
Seamless Integration: The AWS SDK offers pre-built libraries and APIs designed to integrate effortlessly with AWS services. Whether provisioning EC2 instances, managing S3 storage, or querying DynamoDB, the SDK simplifies these processes with clear, efficient code.
Multi-Language Support: Supporting a range of programming languages, the SDK enables developers to work within their preferred coding environments. This flexibility facilitates AWS adoption across diverse teams and projects.
Robust Security Features: Security is a fundamental aspect of the AWS SDK, with features such as automatic API request signing, IAM integration, and encryption options ensuring secure interactions with AWS services.
High-Level Abstractions: To reduce repetitive coding, the SDK provides high-level abstractions for various AWS services. For instance, using Boto3, developers can interact with S3 objects directly without dealing with low-level request structures.
Support for Asynchronous Operations: The SDK enables asynchronous programming, allowing non-blocking operations that enhance the performance and responsiveness of high-demand applications.
Benefits of Using AWS SDK
Streamlined Development: By offering pre-built libraries and abstractions, the AWS SDK significantly reduces development overhead. Developers can integrate AWS services efficiently without navigating complex API documentation.
Improved Reliability: Built-in features such as error handling, request retries, and API request signing ensure reliable and robust interactions with AWS services.
Cost Optimization: The SDK abstracts infrastructure management tasks, allowing developers to focus on optimizing applications for performance and cost efficiency.
Comprehensive Documentation and Support: AWS provides detailed documentation, tutorials, and code examples, catering to developers of all experience levels. Additionally, an active developer community offers extensive resources and guidance for troubleshooting and best practices.
Common Use Cases
Cloud-Native Development: Streamline the creation of serverless applications with AWS Lambda and API Gateway using the SDK.
Data-Driven Applications: Build data pipelines and analytics platforms by integrating services like Amazon S3, RDS, or Redshift.
DevOps Automation: Automate infrastructure management tasks such as resource provisioning and deployment updates with the SDK.
Machine Learning Integration: Incorporate machine learning capabilities into applications by leveraging AWS services such as SageMaker and Rekognition.
Conclusion
The AWS Software Development Kit is an indispensable tool for developers aiming to fully leverage the capabilities of AWS services. With its versatility, user-friendly interface, and comprehensive features, it serves as a critical resource for building scalable and efficient applications. Whether you are a startup creating your first cloud-native solution or an enterprise seeking to optimize existing infrastructure, the AWS SDK can significantly streamline the development process and enhance application functionality.
Explore the AWS SDK today to unlock new possibilities in cloud-native development.
0 notes
Text
Building Scalable Applications with AWS Lambda: A Complete Tutorial

Are you curious about AWS Lambda but not sure where to begin? Look no further! In this AWS Lambda tutorial, we'll walk you through the basics in simple terms.
AWS Lambda is like having a magic wand for your code. Instead of worrying about servers, you can focus on writing functions to perform specific tasks. It's perfect for building applications that need to scale quickly or handle unpredictable workloads.
To start, you'll need an AWS account. Once you're logged in, navigate to the Lambda console. From there, you can create a new function and choose your preferred programming language. Don't worry if you're not a coding expert – Lambda supports many languages, including Python, Node.js, and Java.
Next, define your function's triggers. Triggers are events that invoke your function, such as changes to a database or incoming HTTP requests. You can set up triggers using services like API Gateway or S3.
After defining your function, it's time to test and deploy. Lambda provides tools for testing your function locally before deploying it to the cloud. Once you're satisfied, simply hit deploy, and Lambda will handle the rest.
Congratulations! You've now dipped your toes into the world of AWS Lambda. Keep experimenting and exploring – the possibilities are endless!
For more detailed tutorials and resources, visit Tutorial and Example.
Now, go forth and build amazing things with AWS Lambda!
0 notes
Text
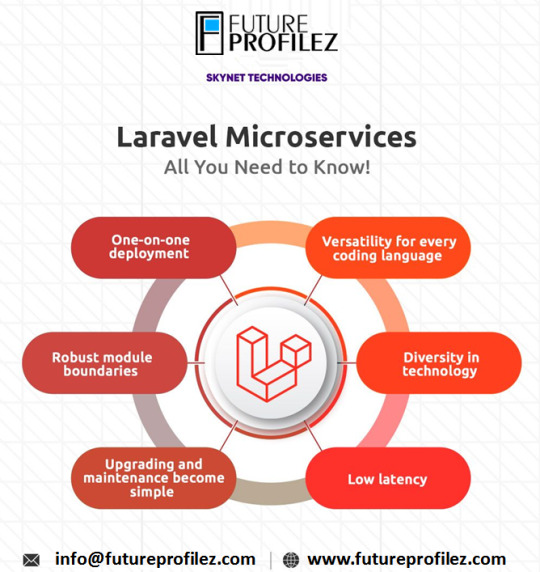
Laravel Development: The Complete Guide for 2023
Introduction :
Laravel Development Company India is a popular PHP framework known for its simplicity, elegance, and robustness. It offers a wide range of features and tools that streamline web application development, making it a preferred choice among developers worldwide. In this comprehensive guide, we will explore the key aspects of Laravel development in 2023.
What is Laravel? :
Laravel is an open-source PHP framework built with the goal of making web development tasks easier and more efficient. It follows the Model-View-Controller (MVC) architectural pattern, providing developers with a structured approach to build web applications. Laravel offers a rich set of features such as routing, caching, session management, authentication, and database abstraction, simplifying common tasks and saving development time. With its expressive syntax and extensive documentation, Laravel has gained significant traction within the PHP community.
Setting up Laravel :
To start with Laravel development, you need to set up your development environment. Ensure you have PHP installed on your system, along with Composer, a dependency management tool for PHP. You can install Laravel using Composer by running a simple command. Once Laravel is installed, you can create a new Laravel project and configure your web server to serve the application. Laravel provides a built-in development server that you can use during the development phase.
Key Features of Laravel :
Laravel offers a plethora of features that simplify the development process. Some notable features include:
a) Routing: Wordpress Development Agency India provides a clean and elegant way to define routes for your application, making it easy to handle different HTTP requests.
b) Eloquent ORM: Laravel's ORM simplifies database interactions by providing an intuitive syntax for querying and manipulating database records.
c) Blade Templating Engine: Laravel's Blade templating engine allows you to create reusable and modular views, enhancing code organization and maintainability.
d) Authentication and Authorization: Laravel comes with built-in authentication and authorization features, making it effortless to implement user authentication and access control.
e) Caching: Wordpress Development Company India provides a unified API for caching data, improving application performance by storing frequently accessed data in memory or other caching systems.
f) Testing: Laravel includes robust testing tools, allowing developers to write unit tests and automate testing processes.
Laravel Packages and Ecosystem :
Laravel's ecosystem is rich with a wide range of packages and libraries contributed by the community. These packages cover various functionalities such as payment gateways, image manipulation, task scheduling, and more. By leveraging these packages, developers can save time and effort by integrating pre-built solutions into their applications. Laravel also has an active community that regularly releases updates, documentation, and tutorials, making it easier to stay up-to-date with the latest advancements.
Deployment and Hosting :
When your Laravel application is ready for deployment, you have multiple options for hosting. You can choose traditional shared hosting, virtual private servers (VPS), cloud hosting providers like AWS or DigitalOcean, or specialized Laravel hosting platforms. Each option has its own advantages and cost considerations. Deployment typically involves configuring the web server, setting up the database, and ensuring the necessary dependencies are installed. Laravel's documentation provides detailed guidelines on the deployment process for different hosting environments.
Conclusion :
Laravel has evolved into one of the most widely used PHP frameworks, offering a comprehensive set of tools and features for web application development. With its elegant syntax, robust architecture, and a vibrant ecosystem, Laravel Development Agency India continues to empower developers in 2023 and beyond, making it an excellent choice for building modern web applications.
#LaravelDevelopmentCompanyIndia#LaravelDevelopmentAgencyIndia#WordpressDevelopmentCompanyIndia#WordpressDevelopmentAgencyIndia#ShopifyDevelopmentCompanyIndia#MagentoDevelopmentCompanyIndia#DigitalMarketingCompanyIndia#DigitalMarketingAgencyIndia#TopSEOAgencyIndia#SEOCompanyIndia
0 notes
Text
Going Serverless: how to run your first AWS Lambda function in the cloud
A decade ago, cloud servers abstracted away physical servers. And now, “Serverless” is abstracting away cloud servers.
Technically, the servers are still there. You just don’t need to manage them anymore.
Another advantage of going serverless is that you no longer need to keep a server running all the time. The “server” suddenly appears when you need it, then disappears when you’re done with it. Now you can think in terms of functions instead of servers, and all your business logic can now live within these functions.
In the case of AWS Lambda Functions, this is called a trigger. Lambda Functions can be triggered in different ways: an HTTP request, a new document upload to S3, a scheduled Job, an AWS Kinesis data stream, or a notification from AWS Simple Notification Service (SNS).
In this tutorial, I’ll show you how to set up your own Lambda Function and, as a bonus, show you how to set up a REST API all in the AWS Cloud, while writing minimal code.
Note that the Pros and Cons of Serverless depend on your specific use case. So in this article, I’m not going to tell you whether Serverless is right for your particular application — I’m just going to show you how to use it.
First, you’ll need an AWS account. If you don’t have one yet, start by opening a free AWS account here. AWS has a free tier that’s more than enough for what you will need for this tutorial.
We’ll be writing the function isPalindrome, which checks whether a passed string is a palindrome or not.
Above is an example implementation in JavaScript. Here is the link for gist on Github.
A palindrome is a word, phrase, or sequence that reads the same backward as forward, for the sake of simplicity we will limit the function to words only.
As we can see in the snippet above, we take the string, split it, reverse it and then join it. if the string and its reverse are equal the string is a Palindrome otherwise the string is not a Palindrome.
Creating the isPalindrome Lambda Function
In this step we will be heading to the AWS Console to create the Lambda Function:
In the AWS Console go to Lambda.

And then press “Get Started Now.”
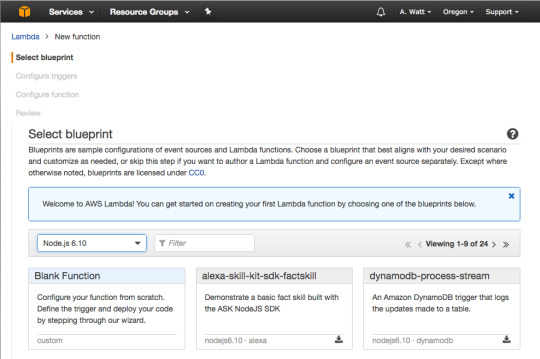
For runtime select Node.js 6.10 and then press “Blank Function.”
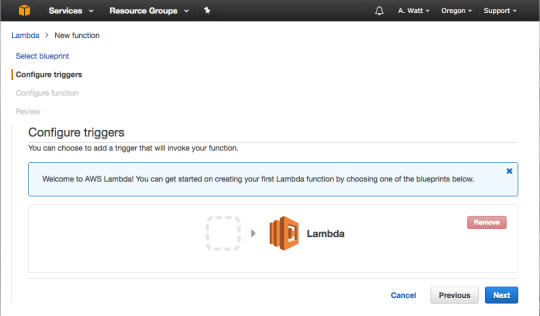
Skip this step and press “Next.”
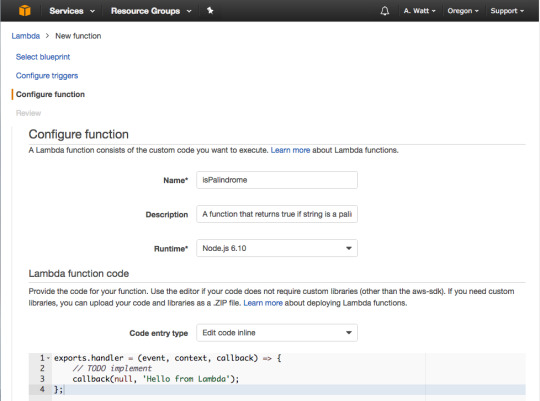
For Name type in isPalindrome, for description type in a description of your new Lambda Function, or leave it blank.
As you can see in the gist above a Lambda function is just a function we are exporting as a module, in this case, named handler. The function takes three parameters: event, context and a callback function.
The callback will run when the Lambda function is done and will return a response or an error message.For the Blank Lambda blueprint response is hard-coded as the string ‘Hello from Lambda’. For this tutorial since there will be no error handling, you will just use Null. We will look closely at the event parameter in the next few slides.
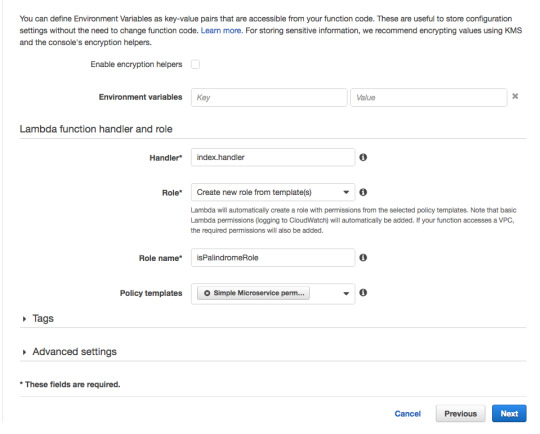
Scroll down. For Role choose “Create new Role from template”, and for Role name use isPalindromeRole or any name, you like.
For Policy templates, choose “Simple Microservice” permissions.
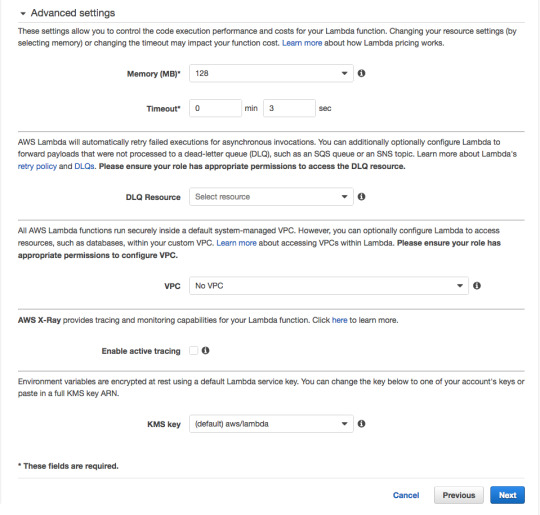
For Memory, 128 megabytes is more than enough for our simple function.
As for the 3 second timeout, this means that — should the function not return within 3 seconds — AWS will shut it down and return an error. Three seconds is also more than enough.
Leave the rest of the advanced settings unchanged.

Press “Create function.”
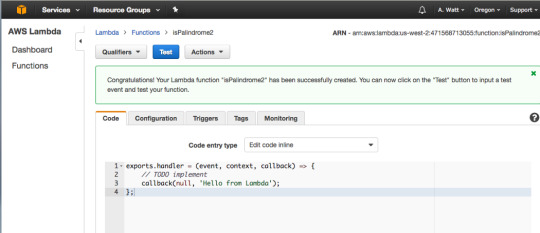
Congratulations — you’ve created your first Lambda Function. To test it press “Test.”
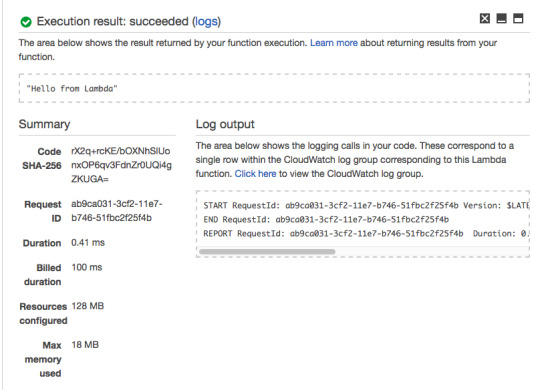
As you can see, your Lambda Function returns the hard-coded response of “Hello from Lambda.”
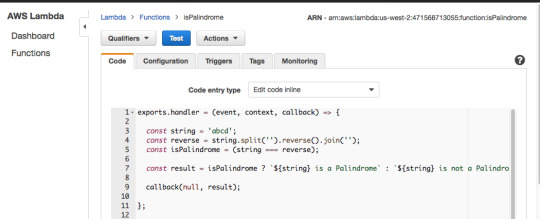
Now add the code from isPalindrome.js to your Lambda Function, but instead of return result use callback(null, result). Then add a hard-coded string value of abcd on line 3 and press “Test.”
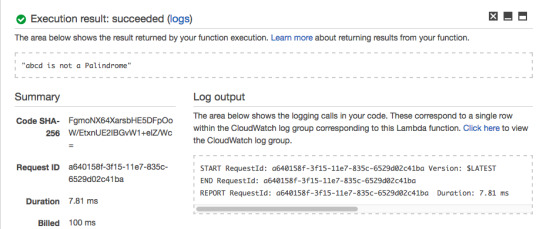
The Lambda Function should return “abcd is not a Palindrome.”
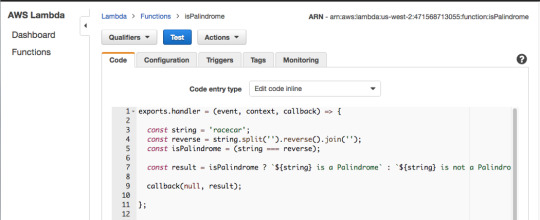
For the hard-coded string value of “racecar”, The Lambda Function returns “racecar is a Palindrome.”
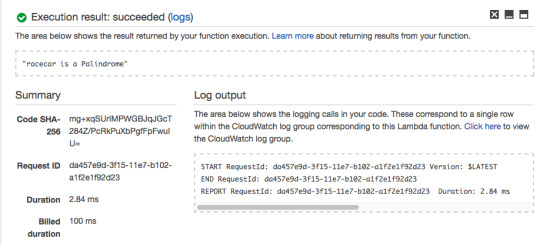
So far, the Lambda Function we created is behaving as expected.
In the next steps, I’ll show you how to trigger it and pass it a string argument using an HTTP request.
If you’ve built REST APIs from scratch before using a tool like Express.js, the snippet above should make sense to you. You first create a server, and then define all your routes one-by-one.
In this section, I’ll show you how to do the same thing using the AWS API Gateway.
Creating the API Gateway
Go to your AWS Console and press “API Gateway.”

And then press “Get Started.”
In Create new API dashboard select “New API.”
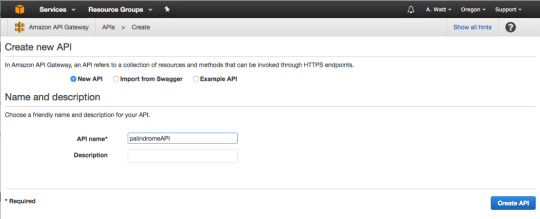
For API name, use “palindromeAPI.” For description, type in a description of your new API or just leave it blank.
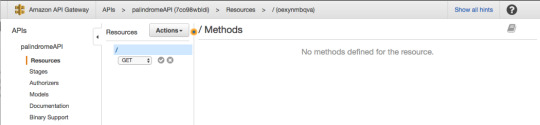
Our API will be a simple one, and will only have one GET method that will be used to communicate with the Lambda Function.
In the Actions menu, select “Create Method.” A small sub-menu will appear. Go ahead and select GET, and click on the checkmark to the right.
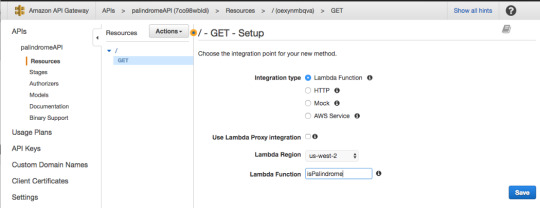
For Integration type, select Lambda Function.
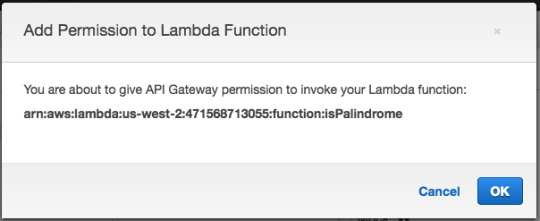
Then press “OK.”
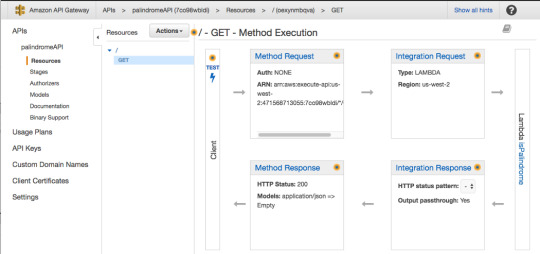
In the GET — Method Execution screen press “Integration Request.”
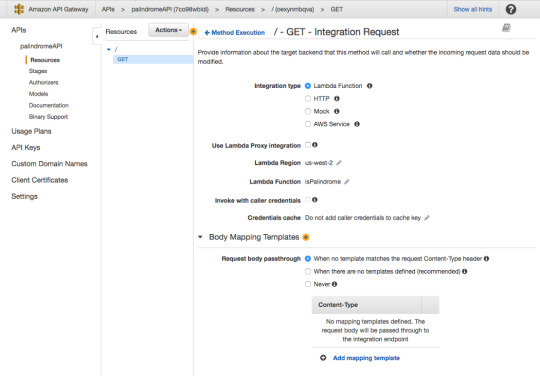
For Integration type, make sure Lambda Function is selected.
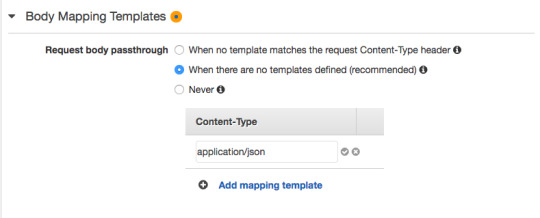
For request body passthrough, select “When there are no templates defined” and then for Content-Type enter “application/json”.
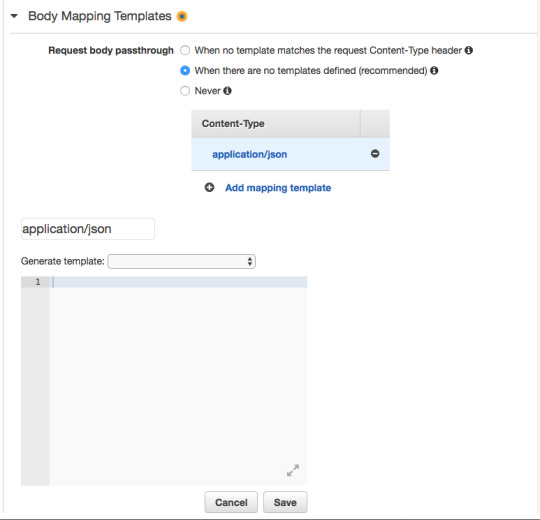
In the blank space add the JSON object shown below. This JSON object defines the parameter “string” that will allow us to pass through string values to the Lambda Function using an HTTP GET request. This is similar to using req.params in Express.js.
In the next steps, we’ll look at how to pass the string value to the Lambda Function, and how to access the passed value from within the function.

The API is now ready to be deployed. In the Actions menu click “Deploy API.”
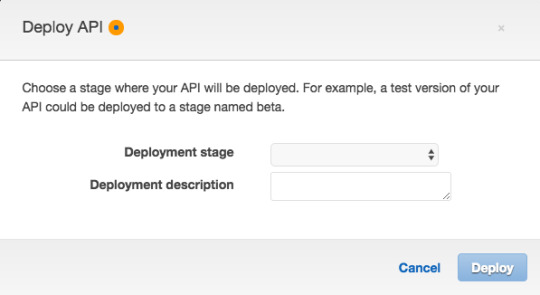
For Deployment Stage select “[New Stage]”.
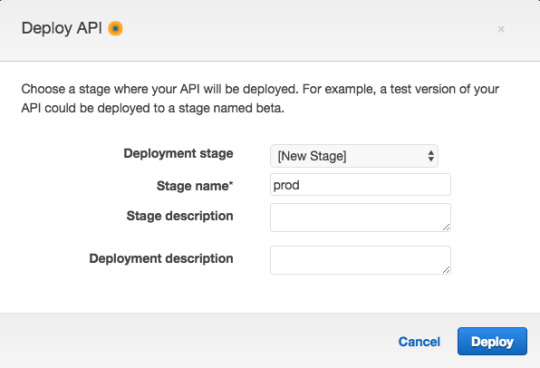
And for Stage name use “prod” (which is short for “production”).
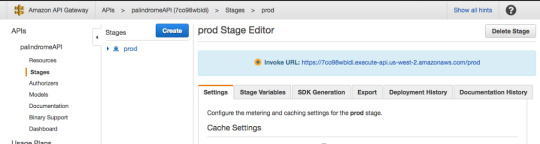
The API is now deployed, and the invoke URL will be used to communicate via HTTP request with Lambda. If you recall, in addition to a callback, Lambda takes two parameters: event and context.
To send a string value to Lambda you take your function’s invoke URL and add to it ?string=someValue and then the passed value can be accessed from within the function using event.string.
Modify code by removing the hard-coded string value and replacing it with event.string as shown below.
Now in the browser take your function’s invoke URL and add ?string=abcd to test your function via the browser.
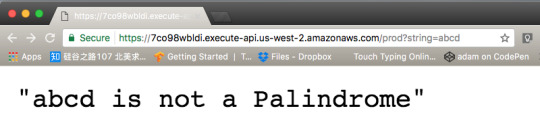
As you can see Lambda replies that abcd is not a Palindrome. Now do the same for racecar.
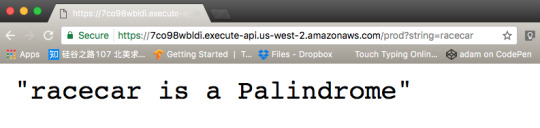
If you prefer you can use Postman as well to test your new isPalindrome Lambda Function. Postman is a great tool for testing your API endpoints, you can learn more about it here.
To verify it works, here’s a Palindrome:
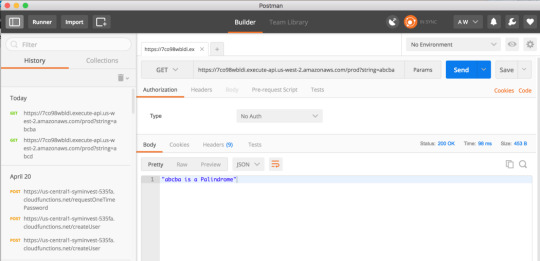
And here’s a non-palindrome:
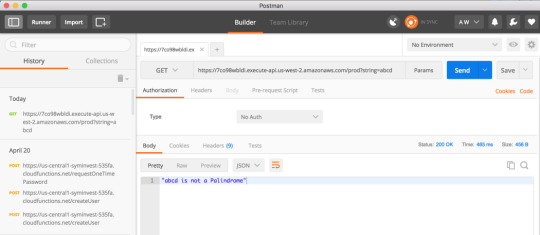
Congratulations — you have just set up and deployed your own Lambda Function!
Thanks for reading!
5 notes
·
View notes
Text
Nodejs rest api

#Nodejs rest api full
At last you will learn to build serverless application using Node.js.
#Nodejs rest api full
Based on Apollo, our GraphQL plugin offers a full compatibility with the whole GraphQL. Later you will learn to test and verify API using Postman and set up API Gateway for the Rest API. You can use a standard RESTful API or GraphQL to query your content. It revolves around resource where every component is a resource and a resource is accessed by a common interface using HTTP standard methods. REST is web standards based architecture and uses HTTP Protocol. In this course, you will learn to set up Node.js, learn about important modules in Node.js, Events with Event loop and Event Emitter, Streams and stream pipes, after node you will learn about Express and Creating Rest API using express with both MySQL and MongoDB. Node.js - RESTful API Advertisements Previous Page Next Page What is REST architecture REST stands for REpresentational State Transfer. At last creating and deploying serverless project on AWS Lambda. Integrating Gateway to route the request and keep track of everything. STEP-1: Create a separate folder and with the help of a terminal or command prompt navigate to this folder: STEP-2: Create package.json by typing the following command in the terminal: npm init -y. Postman is an API testing tool and gives wide support for all possible HTTP methods. It will show the installed version of NodeJs to our system as shown in the below screenshot. Create and configure middleware to add things like logging, authentication and authorization, and other web. Express is a node.js web application framework and MySQL, MongoDB are databases used to manage data. A RESTful API is an Application Programming Interface (API) that uses HTTP verbs like GET, PUT, POST, and DELETE to operate data. Use Express for Node.js to build RESTful APIs. In this course, you will set up Node.js and create Rest API using express with both MySQL and MongoDB and test it using Postman. For now, let’s start creating our secure REST API using Node.js In this tutorial, we are going to create a pretty common (and very practical) REST API for a resource called users. Node.js uses an event-driven, non-blocking I/O model that makes it lightweight and efficient, perfect for data-intensive real-time applications that run across distributed devices. It is used for building fast and scalable network applications. Node.js is a server-side platform built on Google Chrome's JavaScript Engine. If you are going to create the routes in a simple and easy manner with out much understanding much about node js framework, you can go with Express JS.
0 notes
Link
6 notes
·
View notes
Link
To provide you with the best posts from the past month to go back and read, here are the five most popular blog posts in May 2020: 1: Meet Anshi, the four-year-old MuleSoft developerWorking from home has forced us all to be get more creative, especially for those balancing calls with finding fun diversions to occupy the kids. Unexpectedly for the Perla family, one of these entertaining activities for their daughter, Anshi, who just turned four, turned into a huge hit on social media. See how this four-year-old set a record by making an API using MuleSoft. Read her story. 2: Threading model changes in Mule 4.3Performance is a major topic of the Mule 4.3 release. With it, we enhanced the threading model by unifying the thread pools to improve the Mule runtime’s auto-tuning feature and make better use of available resources. Learn more. 3: What is DataWeave Tutorial SeriesReady to get started using DataWeave? Check out MuleSoft’s new three-part tutorial to teach you everything you need to know. See this three-part series. 4: Mule 4 migration made easy with Mule Migration AssistantMule 4.3 is now better-equipped than ever before to welcome Mule 3 applications into Mule 4. With this release, we also unveil the Mule Migration Assistant, a command-line assistant that helps in the migration process by converting select components of a Mule 3 app to a Mule 4 app. See how to use it. 5: Installing Runtime Fabric on a local PCAnypoint Runtime Fabric is a container service that automates the deployment and orchestration of Mule applications and API gateways. Learn how to install Runtime Fabric on a local PC, to test its functionality without the need to run expensive AWS or Azure instances. Read more. Enjoy what you’re reading? Sign up for our newsletter above! And if you have any suggested blog topics, leave a comment below. Filed under: Business | #blog round up
0 notes
Text
AWS Lambda Compute Service Tutorial for Amazon Cloud Developers
Full Video Link - https://youtube.com/shorts/QmQOWR_aiNI Hi, a new #video #tutorial on #aws #lambda #awslambda is published on #codeonedigest #youtube channel. @java @awscloud @AWSCloudIndia @YouTube #youtube @codeonedigest #codeonedigest #aws #amaz
AWS Lambda is a serverless compute service that runs your code in response to events and automatically manages the underlying compute resources for you. These events may include changes in state such as a user placing an item in a shopping cart on an ecommerce website. AWS Lambda automatically runs code in response to multiple events, such as HTTP requests via Amazon API Gateway, modifications…

View On WordPress
#amazon lambda java example#aws#aws cloud#aws lambda#aws lambda api gateway#aws lambda api gateway trigger#aws lambda basic#aws lambda code#aws lambda configuration#aws lambda developer#aws lambda event trigger#aws lambda eventbridge#aws lambda example#aws lambda function#aws lambda function example#aws lambda function s3 trigger#aws lambda java#aws lambda server#aws lambda service#aws lambda tutorial#aws training#aws tutorial#lambda service
0 notes
Text
31 marca 2020

◢ #unknownews ◣
Wracam po krótkiej przerwie. Dziś w ramach powrotu do normalności, w zestawieniu nie ma ani jednego linka związanego z panującą na świecie i w kraju sytuacją. Uwierzcie mi na słowo, że trudno było odfiltrować te newsy. Zapraszam do czytania.
1) Skynet Simulator - wciągająca gra będąca symulatorem hackingu (coś w stylu Uplink, ale w trybie tekstowym) - uwaga: ekstremalnie wciąga http://skynetsimulator.com INFO: kilka minut zajmie Ci rozgryzienie co i jak działa. Dwie podpowiedzi: nie musisz czytać postów na forach w grze + możesz trzymać dane na dysku A i rozpakowywać je na dysk B gdy kończy Ci się miejsce. Grę ukończyłem w nieco ponad 1h
2) Postawmy bazę danych w kontenerze! - a jak to wpłynie na jej wydajność? https://www.percona.com/blog/2020/03/18/how-container-networking-affects-database-performance/ INFO: ciekawa analiza przeprowadzona przez Percona. Tutaj przykład z bazą MySQL.
3) Lista 10 konferencji odbywających się w kwietniu, w których możesz uczestniczyć zdalnie https://dev.to/tbublik/10-conferences-in-april-you-can-attend-from-home-5d14 INFO: co ciekawe, większość jest darmowa lub posiada bilet w modelu 'pay what you want'
4) Darmowe narzędzie online do tworzenia diagramów (tzw. flow charts) https://app.diagrams.net INFO: gotowy diagram można zapisać w chmurze (Dropbox/gdrive) lub pobrać na dysk
5) API List - serwis agregujący liczne, publicznie dostępne API zdatne do użycia (najczęściej za darmo) w Twoim projekcie https://apilist.fun INFO: wszystkie API podzielone są na kategorie. Zwróć uwagę, że lista kategorii jest scrollowalna! (można tego nie zauważyć)
6) Lista 50 playlist z muzyką do programowania i nauki - wszystkie ze Spotify https://dev.to/softwaredotcom/music-for-coding-50-spotify-playlists-for-developers-41n8 INFO: playlisty podzielone są na kilka kategorii. Może coś akurat trafi w Twój gust muzyczny
7) Przestań używać console.log() i zacznij poprawnie używać DevToolsów https://dev.to/yashints/stop-using-console-log-start-using-your-devtools-2aod INFO: świetny poradnik odnośnie tego, jak używać wspomnianego narzędzia
8) Jak zabezpieczyć swoje serverlessowe, otwarte API postawione na AWS? https://dev.to/rolfstreefkerk/how-to-protect-serverless-open-api-s-5eem INFO: poradnik wykorzystuje API Gateway, AWS WAF, AWS Cognito, AWS Lambda i kilka innych rozwiązań
9) Jak zdokeryzować aplikację NodeJS i uruchomić ją na infrastrukturze Heroku? https://dev.to/pacheco/how-to-dockerize-a-node-app-and-deploy-to-heroku-3cch INFO: tutorial przedstawia także przygotowanie podziału środowisk na DEV i PROD.
10) Lista 10 'wpływowych', a zarazem zazwyczaj martwych języków programowania https://www.hillelwayne.com/post/influential-dead-languages/ INFO: COBOL, Smalltalk, ALGOL... coś Ci mówią te nazwy? jakie były powody zaprzestania ich użycia i rozwoju?
11) Stock Jump - coś jak Sky Jump Delux, ale online, a zamiast skoczni mamy prawdziwe notowania spółek giełdowych http://stockjump.sos.gd INFO: kliknij sobie na flagę Polski i poskacz na naszych spółkach. Tylko nie graj na tak emocjonujących spółkach jak np. Tauron :D
12) Pseudo-klasy i pseudo-elementy w CSS o których prawdopodobnie nie słyszałeś https://dev.to/lampewebdev/css-pseudo-elements-classes-you-have-never-heard-of-30hl INFO: ::backdrop, ::grammar-error, :lang, :placeholder-shown, :any-link - coś Ci mówią?
13) "Product Tours Libs" - przegląd bibliotek do prezentacji produktu. Masz nowego usera w swoim projekcie? chcesz zrobić mu onboarding? https://blog.bitsrc.io/7-awesome-javascript-web-app-tour-libraries-6b5d220fb862 INFO: łącznie 7 bibliotek zaprezentowanych także od strony kodu źródłowego (jak to wdrożyć?)
14) Pełne archiwum zestawień unknowNews od 2015 roku do dziś (4100+ linków) w formacie pliku Excela (XLSX) https://pliki.mrugalski.pl/unknownews_do_202003.xlsx INFO: za duże aby to po prostu czytać, ale do przeszukiwania przez CTRL+F nadaje się świetnie.
15) Jak usunąć swoje konto z danego serwisu? Nie wszędzie jest to tak proste jak mogłoby się wydawać - poradniki https://justdelete.me INFO: ciekawe jest to, że z niektórych platform nie da się usunąć swojego konta, a na niektórych jest to bardzo skomplikowane
16) Krisp.ai - narzędzie do usuwania dźwięków tła z konferencji i wideokonferencji https://krisp.ai INFO: już raz to wrzucałem, ale z racji tego, że wiele osób pracuje teraz z domu, to warto przypomnieć
17) Jak przerobić swój prosty program w usługę działającą na Linuksie z użyciem systemd? https://bulldogjob.pl/news/989-usluga-linuxa-z-systemd INFO: tutaj pokazano to na przykładzie przerabiania skryptu PHP, ale metoda zadziała równie dobrze na każdej innej technologii
18) Jak opisać komuś kolor który chodzi Ci po głowie? można np tak... https://colors.lol INFO: należy to traktować w formie żartu, ale i tak trzeba przyznać, że opisy niektórych kolorów zasługują na medal za kreatywność ;)
19) Maza - coś jak Pi-hole na Raspberry pi... tylko, że bez potrzeby użycia Raspberry i działające lokalnie ;) https://github.com/tanrax/maza-ad-blocking INFO: działa na Linuksie i Macu (na tym drugim wymagany jest 'brew')
20) Jenkinsfile - co to jest i jak go stworzyć? Użyteczne jeśli korzystasz z Jenkinsa (film, 35 minut) https://www.youtube.com/watch?v=7KCS70sCoK0 INFO: posiadając taki plik w repozytorium swojego projektu, jesteś w stanie szybko skonfigurować builda na dowolnej instancji Jenkinsa
21) YouTube obniża domyślną jakość odtwarzanych filmów na świecie - zbyt wielu userów jednocześnie ogląda filmy w domach https://www.bloomberg.com/news/articles/2020-03-24/youtube-to-limit-video-quality-around-the-world-for-a-month INFO: oczywiście zawsze możesz ręcznie tę jakość zwiększyć. Chodzi tylko o ustawienie domyślne. Zmiana została wprowadzona tymczasowo na miesiąc.
22) Darling - narzędzie do uruchamiania aplikacji z macOS na Linuksie https://darlinghq.org INFO: zupełnie darmowe rozwiązanie. To nie jest emulator - to coś jak Wine, czyli alternatywna implementacja API danego systemu operacyjnego
23) Tworzymy prostą, tekstową grę przygodową w czystym C - krok po kroku http://home.hccnet.nl/r.helderman/adventures/htpataic01.html INFO: pełen poradnik wyjaśniający jak zaprogramować wczytywanie poleceń, prezentację świata, poruszanie się po mapie itp.
== LINKI TYLKO DLA PATRONÓW ==
24) Kolekcja filmów/wywiadów/artykułów na temat rozwoju startupu i własnego biznesu w branży IT - 700+ materiałów rekomendowanych przez 'Y Combinator' https://uw7.org/un_5e83164141da5 INFO: wszystko podzielone na 33 tematy i ponad 400 podkategorii. Jest z czego wybierać. Przykładowe tematy: Wzrost firmy, zdobywanie userów, skalowanie, szukanie inwestorów itp.
25) Kolekcja niemal 200 narzędzi online dla webdeveloperów https://uw7.org/un_5e831646b0511 INFO: generatory, snippety, porady i inne. Prawdziwa skarbnica wiedzy i tooli
26) Darmowe kursy online, ebooki i narzędzia (większość po polsku!) dla przedsiębiorców, blogerów itp https://uw7.org/un_5e83164d855cf INFO: link do wpisu na blogu agregujący to wszystko. Pobierając niektóre z materiałów trzeba się zarejestrować lub podać maila
== Chcesz aby Twój link pojawił się tutaj? Po prostu mi go zgłoś. To zupełnie NIC nie kosztuje - dodaję jednak tylko to, co mi przypadnie do gustu. https://bit.ly/unDodaj
Zostań patronem 👇 https://patronite.pl/unknow
0 notes
Photo
How the top 6 million sites are using JavaScript
#464 — November 22, 2019
Read on the Web
JavaScript Weekly
Postwoman: An API Request Builder and Tester — A free alternative to Postman, a popular app for debugging and testing HTTP APIs. Postwoman works in the browser and supports HTTP and WebSocket requests as well as GraphQL. Insomnia is a similar tool if you want to run something as a desktop app.
Liyas Thomas
The State of JavaScript on the Web by the HTTP Archive — The HTTP Archive has released an annual ‘state of the Web’ report focused on data collected from six million sites. There are numerous findings here, including how much JavaScript the Web uses, how long it takes browsers to parse that JavaScript, and what frameworks and libraries are most popularly used.
Houssein Djirdeh
Get Best in Class Error Reporting for Your JavaScript Apps — Time is money. Software bugs waste both. Save time with Bugsnag. Automatically detect and diagnose errors impacting your users. Get comprehensive diagnostic reports, know immediately which errors are worth fixing, and debug in minutes. Try it free.
Bugsnag sponsor
The Differences Between the Same App Created in React and Svelte — Several issues ago we linked to Sunil’s article comparing the same app written in React and Vue and now he’s back with a side by side comparison of some of the differences between an app built in React and Svelte, an increasingly popular build-time framework.
Sunil Sandhu
Node Gains Enabled-By-Default Support for ECMAScript Modules — Node.js 13.2.0 came out this week with both an upgrade to V8 and unflagged support for using ES modules. There are some rules to using them, and you might find this V8 blog entry on JavaScript modules worth revisiting to get a feel for what’s involved. Time to play!
Node.js Foundation
jQuery Core Migrating from AMD Modules to ES Modules — Before you say jQuery isn’t relevant, the HTTP Archive has revealed that it’s being used on ~85% of around 6 million sites.
jQuery
Pika Opens Its 'Write Once, Run Natively Everywhere' JavaScript Registry for Early Access — Rather than authors being responsible for formatting and configuring packages, the registry takes care of it. You write the code, they, in theory, do the rest (including creating TypeScript type declarations). Sadly it’s behind an email wall for now, so watch this space.
Pika
⚡️ Quick Releases
video.js 7.7 — Cross-browser video player.
Svelte 3.15.0 — Compile-time app framework.
Leaflet 1.6 — Mobile-friendly interactive maps.
AngularJS 1.7.9 —An update to the original Angular.
CanJS 6.0 — Data-driven app framework.
Ember 3.14
💻 Jobs
Full Stack Engineer — Expensify seeks a self-driven individual passionate about making code effective, with an understanding of algorithms and design patterns.
Expensify
Senior Web Frontend Engineer (CA, IL or NC) — Design what machine learning "looks" like to improve the manufacturing of millions of things. We value great tools like fast builds, simple deploys, & branch environments.
Instrumental
Find a Job Through Vettery — Make a profile, name your salary, and connect with hiring managers from top employers. Vettery is completely free for job seekers.
Vettery
📘 Articles & Tutorials
Getting Started with an Express.js and ES6+ JavaScript Stack — With typical Smashing Magazine quality, this is a thorough beginner-level walkthrough, this time covering how to get started with Node in building a web app backed by a MongoDB database. Definitely for beginners though.
Jamie Corkhill
Techniques for Instantiating Classes — Dr. Axel walks through several approaches for creating instances of classes.
Dr. Axel Rauschmayer
How To Build a Sales Dashboard with React — Improve your data visualization with JavaScript UI controls. Build interactive dashboards quickly and easily.
Wijmo by GrapeCity sponsor
▶ We Should Rebrand JavaScript. Yep? Nope? — A podcast where two pairs of JavaScript developers debate an idea that was recently floated.. should we rebrand JavaScript?
JS Party podcast
Compile-Time Immutability in TypeScript — How to achieve compile-time immutability in TypeScript with const assertions and recursive types.
James Wright
Having Fun with ES6 Proxies — Proxies aren’t going to be useful in day to day programming for most JavaScript developers, but they open up some interesting opportunities if you want more control over how objects behave and are worth understanding.
Maciej Cieślar
▶ How to Build a Budget Calculator App with Angular — A 2 hour video that walks through the entire process of building an Angular app. The gentle pace is well aimed at those new to Angular or the tooling involved.
Devstackr
Composing Angular Components with TypeScript Mixins
Giancarlo Buomprisco
Hey Node Helps You Think, Prototype, and Solve in Node.js — Transforming data, package.json, the module system and more. Bite-size, info-packed tutorials with videos and use cases.
Hey Node by Osio Labs sponsor
Cropping Images to a Specific Aspect Ratio with JavaScript — How to use the HTML canvas API and some basic math to build a tiny crop helper function, making it easy to quickly crop images in various aspect ratios.
Rik Schennink
🔧 Code & Tools
EasyDB: A 'One-Click' Server-Free Database — A quick way to provision a temporary database (that’s basically a key/value store) and use it from JavaScript. Ideal for hackathons or quick once-off scripts, perhaps.
Jake and Tyson
Nodemon: Automatically Restart a Node App When Files Are Changed — A development-time tool to monitor for any changes in your app and automatically restart the server. v2.0 has just been released with CPU and memory use improvements and far fewer dependencies.
Remy Sharp
GraphQuill: Real-Time GraphQL API Exploration in VS Code — A way to test GraphQL API endpoints from within VS Code so you don’t have to keep jumping between multiple tools.
OSLabs Beta
Open Realtime Data - A User’s Guide with Links to a Free Streaming Platform
Ably sponsor
Lambda API: A Lightweight Web Framework for Serverless Apps — A stripped down framework that takes an Express-esque approach to putting together serverless JavaScript apps to run on AWS Lambda behind API Gateway.
Jeremy Daly
ScrollTrigger: Let Your Page React to Scroll Changes — Triggers classes based on the current scroll position. So, for example, when an element enters the viewport you can fade it in.
Erik Terwan
Siriwave: The Apple Siri 'Waveform' Replicated in a JS Library
Flavio Maria De Stefano
by via JavaScript Weekly https://ift.tt/2XI7YS2
0 notes
Link
Practical Serverless development for Beginners ##udemy ##UdemyOnlineCourse #Beginners #Development #Practical #Serverless Practical Serverless development for Beginners Serverless computing allows you to build and run applications and services without thinking about servers. With serverless computing, your application still runs on servers, but all the server management is done by cloud providers (in this case AWS). Serverless lets you focus on your application code instead of worrying about provisioning, configuring, and managing servers. You will being with a 10,000 feet overview of cloud computing and serverless and then get your hands dirty with real serverless development. You are going to build an imaginary inventory management services "Inventoria". Once you have understood cloud computing and serverless, you are going to build and assemble all the pieces together to create real endpoints. You are going to understand serverless database DynamoDB and how it works. You are then going to design and create the table. Once you have designed your database, it's time to create microservices and you are learn AWS Lambda to create inventory servcies using Node.JS 8.10. It's time to create endpoints, so inventory services are consumed by any front-end or consumer applications. You are going to explore AWS API gateway to create endpoints for your inventory services. Once all the endpoints have been created, it's time to test them, so whatever you have created works. Action time with my bonus lecture to integrate all your endpoints with an Angular 7 app (it can be any front-end application, you might choose to integrate with). You will also examine serverless frameworks for example serverless and AWS SAM (Serverless Application Model), so you are ready for serverless development locally. At the end of this course, you are fully aware about serverless and serverless development using AWS. You can expand this further with Azure and Google Cloud. 👉 Activate Udemy Coupon 👈 Free Tutorials Udemy Review Real Discount Udemy Free Courses Udemy Coupon Udemy Francais Coupon Udemy gratuit Coursera and Edx ELearningFree Course Free Online Training Udemy Udemy Free Coupons Udemy Free Discount Coupons Udemy Online Course Udemy Online Training 100% FREE Udemy Discount Coupons https://www.couponudemy.com/blog/practical-serverless-development-for-beginners/
0 notes
Text
sslnotify.me - yet another OpenSource Serverless MVP
After ~10 years of experience in managing servers at small and medium scales, and despite the fact that I still love doing sysadmin stuff and I constantly try to learn new and better ways to approach and solve problems, there's one thing that I think I've learned very well: it's hard to get the operation part right, very hard.
Instead of dealing with not-so-interesting problems like patching critical security bugs or adding/removing users or troubleshooting obscure network connectivity issues, what if we could just cut to the chase and invest most of our time in what we as engineers are usually hired for, i.e. solving non-trivial problems?
TL;DL - try the service and/or check out the code
sslnotify.me is an experimental web service developed following the Serverless principles. You can inspect all the code needed to create the infrastructure, deploy the application, and of course the application itself on this GitHub repository.
Enter Serverless
The Serverless trend has been the last to join the list of paradigms which are supposedly going to bring ops bliss into our technical lives. If Infrastructure as a Service didn't spare us from the need of operational work (sometimes arguably making it even harder), nor Platfrom as a Service was able to address important concerns like technical lock-in and price optimization, Function as a Service is brand new and feels like a fresh new way of approaching software development.
These are some of the points I find particually beneficial in FaaS:
very fast prototyping speed
sensible reduction in management complexity
low (mostly zero while developing) cost for certain usage patterns
natual tendency to design highly efficient and scalable architectures
This in a nutshell seems to be the FaaS promise so far, and I'd like to find out how much of this is true and how much is just marketing.
Bootstrapping
The Net is full of excellent documentation material for who wants to get started with some new technology, but what I find most beneficial to myself is to get my hands dirty with some real project, as I recently did with Go and OpenWhisk.
Scratching an itch also generally works well for me as source of inspiration, so after issuing a Let's Encrypt certificate for this OpenWhisk web service I was toying with, I thought would be nice to be alerted when the certificate is going to expire. To my surprise, a Google search for such a service resulted in a list of very crappy or overly complicated web sites which are in the best case hiding the only functionality I needed between a bloat of other services.
That's basically how sslnotify.me was born.
Choosing the stack
The purpose of the project was yes to learn new tools and get some hands on experience with FaaS, but doing so in the simpliest possible way (i.e. following KISS principle as much as possible), so keep in mind that many of the choices might not necessary be the "best" nor most efficient nor elegant ones, they are representative of what looked like the simpliest and most straightforward option to me while facing problems while they were rising.
That said, this is the software stack taken from the project README:
Chalice framework - to expose a simple REST API via AWS API Gateway
Amazon Web Services:
Lambda (Python 2.7.10) - for almost everything else
DynamoDB (data persistency)
S3 (data backup)
SES (email notifications)
Route53 (DNS records)
CloudFront (delivery of frontend static files via https, redirect of http to https)
ACM (SSL certificate for both frontend and APIs)
CloudWatch Logs and Events (logging and reporting, trigger for batch jobs)
Bootstrap + jQuery (JS frontend)
Moto and Py.test (unit tests, work in progress)
I know, at first sight this list is quite a slap in the face of the beloved KISS principle, isn't it? I have to agree, but what might seem an over complication in terms of technologies, is in my opinion mitigated by the almost-zero maintenance and management required to keep the service up and running. Let's dig a little more into the implementation details to find out.
Architecture
sslnotify.me is basically a daily monitoring notification system, where the user can subscribe and unsubscribe via a simple web page to get email notifications if and when a chosen SSL certificate is expiring before a certain amount of days which the user can also specify.
Under the hoods the JS frontend interacts with the backend available at the api.sslnotify.me HTTPS endpoint to register/unregister the user and to deliver the feeedback form content, otherwise polls the sslexpired.info service when the user clicks the Check now button.
The actual SSL expiration check is done by this other service which I previously developed with OpenWhisk and deployed on IBM Bluemix platform, in order to be used indipendently as a validation backend and to learn a bit more of Golang along the way, but that's for another story...
The service core functionality can be seen as a simple daily cronjob (the cron lambda triggered by CloudWatch Events) which sets the things in motion to run the checks and deliver notifications when an alert state is detected.
To give you a better idea of how it works, this is the sequence of events behind it: - a CloudWatch Event invokes the cron lambda async execution (at 6:00 UTC every day) - cron lambda invokes data lambda (blocking) to retrieve the list of users and domains to be checked - data lambda connects to DynamoDB and get the content of the user table, sends the content back to the invoker lambda (cron) - for each entry in the user table, cron lambda asyncrounosly invokes one checker lambda, writes an OK log to the related CloudWatch Logs stream, and exits - each checker lambda executes indipendently and concurrently, sending a GET request to the sslexpired.info endpoint to validate the domain; if no alert condition is present, logs OK and exits, otherwise asyncrounosly invokes a mailer lambda execution and exits - any triggered mailer lambda runs concurrently, connects to the SES service to deliver the alert to the user via email, logs OK and exits
Beside the main cron logic, there are a couple of other simpler cron-like processes:
a daily reporter lambda, collecting logged errors or exceptions and bounce/feedback emails delivered (if any) since the day before, and sending me an email with the content (if any)
an hourly backup of the DynamoDB tables to a dedicated S3 bucket, implemented by the data lambda
Challenges
Everyone interested in Serverless seems to agree on one thing: being living its infancy it is still not very mature, especially in regards of tooling around it. Between other novelties, you'll have to understand how to do logging right, how to test properly, and so on. It's all true, but thankfully there's a lot going on on this front, frameworks and tutorials and hands-on and whitepapers are popping up at a mindblowing rate and I'm quite sure it's just a matter of time before the ecosystem makes it ready for prime time.
Here though I'd like to focus on something else which I found interesting and suprisingly to me not that much in evidence yet. Before starting to getting the actual pieces together, I honestly underestimated the complexity that even a very very simple service like this could hide, not much in the actual coding required (that was the easy part) but from the infrastructure setup perspective, so I actually think that what's in the Terraform file here is the interesting part of this project that might be helpful to whoever is starting from scratch.
For example, take setting SES properly, it is non trivial at all, you have to take care of DNS records to make DKIM work, setup proper bounces handling and so on, and I couldn't find that much of help just googling around, so I had to go the hard way, i.e. reading in details the AWS official documentation, which sometimes unfortunately is not that exhaustive, especially if you plan to do things right, meaning hitting the APIs in a programmatic way instead of clicking around the web console (what an heresy!) as shown in almost every single page of the official docs.
One thing that really surprises me all the time is how broken are the security defaults suggested there. For example, when setting up a new lambda, docs usually show something like this as policy for the lambda role:
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "logs:CreateLogGroup", "logs:CreateLogStream", "logs:PutLogEvents", "logs:DescribeLogStreams" ], "Resource": [ "arn:aws:logs:*:*:*" ] } ] }
I didn't check but I think it's what you actually get when creating a new lambda from the web console. Mmmm... read-write permission to ANY log group and stream... seriously? Thankfully with Terraform is not that hard to set lambdas permission right, i.e. to create and write only to their dedicated stream, and in practice it looks something like this:
data "aws_iam_policy_document" "lambda-reporter-policy" { statement { actions = [ "logs:CreateLogStream", "logs:PutLogEvents", ] resources = ["${aws_cloudwatch_log_group.lambda-reporter.arn}"] } [...]
Nice and clean, and definitely safer. For more details on how Terraform was used, you can find the whole setup here. It's also taking care of crating the needed S3 buckets, especially the one for the frontend which is actually delivered via CloudFront using our SSL certificate, and to link the SSL certificate to the API backend too.
Unfortunately I couldn't reduce to zero the 'point and click' work, some was needed to validate ownership of the sslnotify.me domain (obviously a no-go for Terraform), some to deal with the fact that CloudFront distributions take a very long time to be in place.
Nevertheless, I'm quite happy with the result and I hope this could help who's going down this path to get up to speed quicker then me. For example, I was also suprised not to find any tutorial on how to setup an HTTPS static website using cloud services: lots for HTTP only examples, but with ACM and Let's encrypt out in the wild and totally free of charge, there's really no more excuse for not serving HTTP traffic via SSL in 2017.
What's missing
The more I write the more I feel there's much more to say, for example I didn't touch at all the frontend part yet, mostly because I had almost zero experience with CSS, JS, CORS, sitemaps, and holy moly how much you need to know just to get started with something so simple... the web party is really hard for me and thankfully I got great support from some very special friends while dealing with it.
Anyway, this was thought as an MVP (minimum viable product) from the very beginning, so obviously there's a huge room from improvement almost everywhere, especially on the frontend side of the fence. If you feel like giving some advise or better patch the code, please don't hold that feeling and go ahead! I highly value any feedback I receive and I'll be more then happy to hear about what you think about it.
Conclusion
I personally believe Serverless is here to stay and, it's fun to work with, and the event driven paradigm pushes you to think on how to develop highly efficient applications made up of short lived processes, which are easy to be scaled (by the platform, without you moving a finger) and naturally adapt to usage pattern, with the obvious benefits of cost reduction (you pay for the milliseconds your code is executed) and almost zero work needed to keep the infrastructure up and running. The platform under the hood is now taking care of provisioning resources on demand and scaling out as many parallel lambda executions as needed to serve the actual user load; on top of this (or, better, on the bottom of it) built-in functionalities like DynamoDB TTL fileds, S3 objects lifecycles or CloudWatch logs expirations spare us from the need of writing the same kind of scripts, again and again, to deal with basic tech needs like purging old resources.
That said, keeping it simple is in practice very hard to follow, and this case was no different. It's important not to get fooled into thinking FaaS is the panacea to every complexity pain, because it's not the case (and this is valid as a general advise, you can replace FaaS with any cool tech out there and still stands true). There are still many open questions and challenges waiting down the road, for example setting up an environment in a safe and predictible way is not as easy as it may look at a first sight, even if you're an experienced engineer; there are lots of small details you'll have to learn and figure out in order to make all the setup rock solid, but it's definitely doable and worth the initial pain of going through pages and pages of documentation. The good part is that it's very easy to start experimenting with it, and the generous free tiers offered by all the cloud providers make it even easier to step in.
What's next
Speaking of free tiers, the amazing 300USD Google Compute Cloud credit, together with the enthusiasm of some friend already using it, convinced me to play with this amazing toy they call Kubernetes; let's see if I'll be able to come up with something interesting to share, given the amount of docs and tutorials out there I highly doubt that, but never say never. Till the next time... try Serverless and have fun with it!
2 notes
·
View notes
Link

I've known for a while that API Gateway can integrate directly with other AWS services without needing Lambda to play traffic cop. But how does that work and can we leverage this to build small stack applications? Let's find out!
tl;dr
Just want to see how I did it? Okay, here's my repo.
Table of Contents
AWS CDK
DynamoDB
Table of Kittens
API Gateway
IAM
AWS Service Integration
Methods
Security
Next Steps
AWS CDK
I wrote a fair amount about how to set this up and have a nice linting and testing experience in this post. No need to repeat myself. I'm loosely basing this project on this sample project. This one is a good primer on using API Gateway and Lambda together with CDK. My goal was to more or less build the same application, but without Lambda.
DynamoDB
I couldn't possibly do DynamoDB justice in this post and in fact am a bit of a novice. There are lots of great resources out there. I'm just going to create a simple table that will allow CRUD operations. Readers who haven't experienced DynamoDB yet but know either RDBMS or something like MongoDB will not too lost, however the really special thing about DynamoDB is that it is a fully managed service in every sense. With a more traditional cloud-hosted database, I might be able to provision the database using a tool or some variety of infrastructure-as-code, but then I would need to manage credentials, users, connection strings, schemas, etc. With DynamoDB, I don't need to do any of that. I will use IAM Roles to connect to my table and only need to provide a few basic parameters about it to get started.
Table of Kittens
The first thing we'll do is create a table. The example code we're working from named the table Items, which is not just generic and boring, but is also a little confusing since a "row" in a DynamoDB table is called an item. If you prefer Puppies or AardvarkCubs, feel free to make the substitution.
import { AwsIntegration, Cors, RestApi } from '@aws-cdk/aws-apigateway'; import { AttributeType, Table, BillingMode } from '@aws-cdk/aws-dynamodb'; import { Effect, Policy, PolicyStatement, Role, ServicePrincipal } from '@aws-cdk/aws-iam'; import { Construct, RemovalPolicy, Stack, StackProps } from '@aws-cdk/core'; export class ApigCrudStack extends Stack { constructor(scope: Construct, id: string, props?: StackProps) { super(scope, id, props); const modelName = 'Kitten'; const dynamoTable = new Table(this, modelName, { billingMode: BillingMode.PAY_PER_REQUEST, partitionKey: { name: `${modelName}Id`, type: AttributeType.STRING, }, removalPolicy: RemovalPolicy.DESTROY, tableName: modelName, }); } }
Here we've imported the constructs we'll need (spoiler - not using them all yet). We're creating a new DynamoDB table. When we describe our table, we only need to give a partition key. A real use case would probably include a sort key and possibly additional indices (again, this article is not your one-stop tutorial for DynamoDB). If we run this, we'll get a table we can immediately start using via AWS CLI.
$ aws dynamodb put-item --table-name Kitten --item \ "{\"KittenId\":{\"S\":\"abc-123\"},\"Name\":{\"S\":\"Fluffy\"},\"Color\":{\"S\":\"white\"}}"
When we run that, it creates a new Kitten item. We can read our table by executing
$ aws dynamodb scan --table-name Kitten { "Items": [ { "KittenId": { "S": "abc-123" }, "Name": { "S": "Fluffy" }, "Color": { "S": "white" } } ], "Count": 1, "ScannedCount": 1, "ConsumedCapacity": null }
We can do all of our normal table operations this way. Want Fluffy to turn blue? Want her to express musical taste? No problem.
$ aws dynamodb put-item --table-name Kitten --item \ "{\"KittenId\":{\"S\":\"abc-123\"},\"Name\":{\"S\":\"Fluffy\"},\"Color\":{\"S\":\"blue\"},\"FavoriteBand\":{\"S\":\"Bad Brains\"}}" $ aws dynamodb scan --table-name Kitten { "Items": [ { "Color": { "S": "blue" }, "FavoriteBand": { "S": "Bad Brains" }, "KittenId": { "S": "abc-123" }, "Name": { "S": "Fluffy" } } ], "Count": 1, "ScannedCount": 1, "ConsumedCapacity": null }
We'll also want to give delete-item, get-item and query a look when exploring the aws cli for dynamodb. If you don't mind escaping your JSON and doing everything at the command line, you are now done and your app has shipped. Congrats, knock off early today!
API Gateway
API Gateway will let us create our own public endpoint that will allow http traffic to our service. A lot of the time we think about using API Gateway to invoke Lambda functions, but as we shall see, there are plenty of other things we can do. We've already installed the required component libraries, @aws-cdk/aws-apigateway and @aws-cdk/aws-iam. We'll start by creating a basic RestApi. API Gateway supports HTTP protocols in two main flavors: RestApi and HttpApi. HttpApi is a stripped down, leaner specification that offers substantial cost savings for many use cases, but unfortunately not ours. HttpApi doesn't support AWS Service Integrations, so we won't be using it.
const api = new RestApi(this, `${modelName}Api`, { defaultCorsPreflightOptions: { allowOrigins: Cors.ALL_ORIGINS, }, restApiName: `${modelName} Service`, });
I'm naming my API "Kitten Service". Yours might be "AardvarkPup Service" or even "Pizza Service" if you like to keep those as pets. The CORS bit there is very cool and shows some real CDK value. This will automatically set up OPTIONS responses (using the MOCK type - meaning nothing else gets called) for all your endpoints. Of course you can specify your own domain or anything else that is legal for CORS. This is a fairly recent feature of CDK and in fact in the example I'm working from, they had to do it the long way. The next thing we'll do is add a couple of resources. This is super easy to do!
const allResources = api.root.addResource(modelName.toLocaleLowerCase()); const oneResource = allResources.addResource('{id}');
Unfortunately this doesn't actually do very much by itself. In order for these resources to have any meaning, we will need to attach methods (HTTP verbs), integrations and responses to the resources. However, we can understand the resource creation mechanism here. We will add a route named kitten which will refer to the entire collection and optionally allow an id to specify a specific kitten that we want to take some action on.
IAM
IAM is the AWS service that establishes a roles and permissions framework for all the other AWS offerings. Services communicate via publicly-available APIs but by default most actions are not allowed - we cannot query our DynamoDB table without credentials and a role that allows us to take that action. In order for our API Gateway to call into DynamoDB, we will need to give it roles that allow it to do that. In fact, each individual integration can have its own role. That would mean our POST HTTP verb might only be able to invoke put-item while our GET HTTP verb can scan, query or get-item. This is known as the principle of least privilege. To me, it's debatable whether it's really necessary for each endpoint to have its own role vs. one shared (and slightly more permissive) role for all the endpoints pointing to my table, but this is an experiment in the possible so we will exercise the tightest possible permissions by creating several roles. Roles by themselves do nothing. They must have policies attached that specify actions the role allows and the resources they may be exercised by.
const getPolicy = new Policy(this, 'getPolicy', { statements: [ new PolicyStatement({ actions: ['dynamodb:GetItem'], effect: Effect.ALLOW, resources: [dynamoTable.tableArn], }), ], });
This policy allows the GetItem action to be taken against the table we just created. We could get lazy and write actions: ['dynamodb:*'] and resources: ['*'], but we might get dinged in a security review or worse, provide a hacker an onramp to our resources. Notice that our policy can be made up of multiple policy statements and each statement can comprise multiple actions and resources. Like I said, the rules can get pretty fine-grained here. Let's create the role that will use this policy.
const getRole = new Role(this, 'getRole', { assumedBy: new ServicePrincipal('apigateway.amazonaws.com'), }); getRole.attachInlinePolicy(getPolicy);
The role specifies a ServicePrincipal, which means that the role will be used by an AWS service, not a human user or a specific application. A "principal" is a human or machine that wants to take some action. We attach the policy as an inline policy, meaning a policy we just defined as opposed to a policy that already exists in our AWS account. This makes sense as the policy only applies to resources we're defining here and has no reason to exist outside of this stack. We can go ahead and define additional roles to provide the other CRUD operations for our API.
AWS Service Integration
To create integrations to AWS services we will use the AwsIntegration construct. This construct requires that we define request templates (what will we send to our service) and integration responses (how we handle various HTTP responses). I defined a couple of error responses and a standard response like this:
const errorResponses = [ { selectionPattern: '400', statusCode: '400', responseTemplates: { 'application/json': `{ "error": "Bad input!" }`, }, }, { selectionPattern: '5\\d{2}', statusCode: '500', responseTemplates: { 'application/json': `{ "error": "Internal Service Error!" }`, }, }, ]; const integrationResponses = [ { statusCode: '200', }, ...errorResponses, ];
We'd probably want to add some additional responses and maybe some more information for a production application. The selectionPattern property is a regular expression on the HTTP status code the service returns. In order to understand how the AwsIntegration works, let's go back to our CLI commands. To fetch the record for Fluffy we created earlier, we can use aws dynamodb query --table-name Kitten --key-condition-expression "KittenId = :1" --expression-attribute-values "{\":1\":{\"S\":\"abc-123\"}}". We know that we're going to provide the service name (dynamodb), an action (query) and then give a payload (the name of the table and the key for our item). From that, AwsIntegration will be able to perform the get-item operation on the named table.
const getIntegration = new AwsIntegration({ action: 'GetItem', options: { credentialsRole: getRole, integrationResponses, requestTemplates: { 'application/json': `{ "Key": { "${modelName}Id": { "S": "$method.request.path.id" } }, "TableName": "${modelName}" }`, }, }, service: 'dynamodb', });
We're referencing the standard integration responses object we previously defined. Then we're defining a requestTemplate inline. This template uses The Apache Velocity Engine and Velocity Template Language (VTL), a java-based open source project that will let us introduce some logical and templating capabilities to API Gateway. There's obviously a fair amount of complexity we could get into with VTL and at a certain point it's probably just a lot better to write a Lambda function than try to handle extremely complex transformations or decision trees in VTL. Here it's not too bad. In case it's not obvious, our request templates are written using template literals. The ${modelName} substitutions happen when my CloudFormation template is created by CDK (when I build), while $method.request.path.id is provided during the request at runtime. Many of the common property mappings can be found in the API Gateway documentation. My template will grab the id from the request path and pass it to DynamoDB. We can also pull properties from the request body. Let's look at the integration for creating a new Kitten.
const createIntegration = new AwsIntegration({ action: 'PutItem', options: { credentialsRole: putRole, integrationResponses: [ { statusCode: '200', responseTemplates: { 'application/json': `{ "requestId": "$context.requestId" }`, }, }, ...errorResponses, ], requestTemplates: { 'application/json': `{ "Item": { "${modelName}Id": { "S": "$context.requestId" }, "Name": { "S": "$input.path('$.name')" }, "Color": { "S": "$input.path('$.color')" } }, "TableName": "${modelName}" }`, }, }, service: 'dynamodb', });
The request body is mapped to $ and can be accessed via $input.path and dot-property access. We're also taking the requestId and using that as a unique identifier in my table. Depending on our use case, that might be a worthwhile thing to do or maybe it would be better to just key off the kitten's name. We have mapped a custom response template into this integration so that we return the requestId - which is now the partition key for the item we just created. We don't want to have to scan our table to get that, so it's convenient to return it in the same request. The rest of our integrations follow the same pattern and use the same techniques. Rather than repeat myself here, you can just go and check it out in my repo. I wrote some tests as well.
Methods
Ready to go? Not quite. We still have to tie an integration to a resource with an HTTP verb. This is quite easy and our code could look like this:
const methodOptions = { methodResponses: [{ statusCode: '200' }, { statusCode: '400' }, { statusCode: '500' }] }; allResources.addMethod('GET', getAllIntegration, methodOptions); allResources.addMethod('POST', createIntegration, methodOptions); oneResource.addMethod('DELETE', deleteIntegration, methodOptions); oneResource.addMethod('GET', getIntegration, methodOptions); oneResource.addMethod('PUT', updateIntegration, methodOptions);
I think that is pretty intuitive if you know much about REST or HTTP. We've mapped several HTTP verbs to our resources If we wanted to return a 404 response on the other ones, we'd need to do a little bit of extra work. By default any request that can't be handled by RestApi returns a 403 with the message "Missing Authentication Token". This is probably to keep malicious users from snooping endpoints and while it may seem confusing to us the first time we see that error, it's probably fine, especially for a demo project. We've got all the pieces in place at last! How does it work? Just fine.
$ curl -i -X POST \ -H "Content-Type:application/json" \ -d \ '{"name": "Claws", "color": "black"}' \ 'https://my-url.execute-api.us-east-1.amazonaws.com/prod/kitten' { "requestId": "e10c6c16-7c84-4035-9d6b-8663c37f62a7" }
$ curl -i -X GET \ 'https://my-url.execute-api.us-east-1.amazonaws.com/prod/kitten/0a9b49c8-b8d2-4c42-9500-571a5b4a79ae' {"Item":{"KittenId":{"S":"0a9b49c8-b8d2-4c42-9500-571a5b4a79ae"},"Name":{"S":"Claws"},"Color":{"S":"black"}}}
Security
Most of the APIs we build will require some kind of security, so how do protect this one? Out of the box we can support Cognito User Pools or IAM roles. We can also provide a custom Lambda authorizer.
Next Steps
So now that we know we can do this, the question is is it a good idea? My CDK code doesn't look too different from the Lambda code in the AWS example. I think as long as the code is simple enough, this is a viable option. If things get more complicated, we'll probably want a Lambda function to handle our request. This approach gives us the option of switching any of our AWS Integrations to Lambda Integrations if we hit that complexity threshold. Another consideration will often be cost. To understand the price difference, we need to do some math. If we built our API using HttpApi and Lambda and got 100 million requests per month, the cost for API Gateway would be $100 and the cost for Lambda (assuming 100ms requests and 256MB memory) would be $429.80. The AWS Integration + RestApi approach would do 100 million requests for $350, a savings of $179.80 monthly. If our Lambda functions could operate at 128MB, then that method would only cost $321.47 and now the AWS Integration is slightly more expensive. If the Lambda functions were significantly slower or required more memory, then we might start seeing real savings. I probably wouldn't do this just for cost, but we also have to consider the effort of writing, maintaining and updating our Lambda functions. Yes, they are small, but every code footprint costs something and it's nice to have the option to just skip simple boilerplate. Lastly, now that we can do this with DynamoDB, what about other services? Does your Lambda function do nothing but pass a message to SNS? Does it just drop a file on S3? It might be better to consider a Service Integration. Keep this pattern in mind for Step Functions as well. You can basically do the same thing.
0 notes
Link
1 note
·
View note
Text
Building a real-time Serverless App in Blazor using AWS
Building a real-time Serverless App in Blazor using AWS
In this Blazor tutorial, we will build an interactive dashboard using Blazor that reacts in real-time to events that happen in the real world. We will connect the Blazor application through to a serverless backend built in .Net. We will use a managed service called Amazon API Gateway and take advantage of it’s WebSockets support.
source https://morioh.com/p/9455450a7e13
View On WordPress
0 notes