#bar chart python pandas
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
12.7% of mobile users access Tumblr.
Text
Pandas Plot Bar Chart: A Guide to Visualizing Data in Python
Introduction In the world of data analysis and visualization, Pandas, a popular Python library, plays a pivotal role. In this article, we will delve into the fascinating world of Pandas and explore how to create and customize Pandas Plot bar chart using this powerful library. If you’re looking to present your data in an easily understandable and visually appealing way, you’re in the right…
View On WordPress
#bar chart python pandas#bar plot pandas#bar plot python pandas#pandas bar chart#pandas bar plot#plot bar pandas
0 notes
Text
Python Libraries to Learn Before Tackling Data Analysis
To tackle data analysis effectively in Python, it's crucial to become familiar with several libraries that streamline the process of data manipulation, exploration, and visualization. Here's a breakdown of the essential libraries:
1. NumPy
- Purpose: Numerical computing.
- Why Learn It: NumPy provides support for large multi-dimensional arrays and matrices, along with a collection of mathematical functions to operate on these arrays efficiently.
- Key Features:
- Fast array processing.
- Mathematical operations on arrays (e.g., sum, mean, standard deviation).
- Linear algebra operations.
2. Pandas
- Purpose: Data manipulation and analysis.
- Why Learn It: Pandas offers data structures like DataFrames, making it easier to handle and analyze structured data.
- Key Features:
- Reading/writing data from CSV, Excel, SQL databases, and more.
- Handling missing data.
- Powerful group-by operations.
- Data filtering and transformation.
3. Matplotlib
- Purpose: Data visualization.
- Why Learn It: Matplotlib is one of the most widely used plotting libraries in Python, allowing for a wide range of static, animated, and interactive plots.
- Key Features:
- Line plots, bar charts, histograms, scatter plots.
- Customizable charts (labels, colors, legends).
- Integration with Pandas for quick plotting.
4. Seaborn
- Purpose: Statistical data visualization.
- Why Learn It: Built on top of Matplotlib, Seaborn simplifies the creation of attractive and informative statistical graphics.
- Key Features:
- High-level interface for drawing attractive statistical graphics.
- Easier to use for complex visualizations like heatmaps, pair plots, etc.
- Visualizations based on categorical data.
5. SciPy
- Purpose: Scientific and technical computing.
- Why Learn It: SciPy builds on NumPy and provides additional functionality for complex mathematical operations and scientific computing.
- Key Features:
- Optimized algorithms for numerical integration, optimization, and more.
- Statistics, signal processing, and linear algebra modules.
6. Scikit-learn
- Purpose: Machine learning and statistical modeling.
- Why Learn It: Scikit-learn provides simple and efficient tools for data mining, analysis, and machine learning.
- Key Features:
- Classification, regression, and clustering algorithms.
- Dimensionality reduction, model selection, and preprocessing utilities.
7. Statsmodels
- Purpose: Statistical analysis.
- Why Learn It: Statsmodels allows users to explore data, estimate statistical models, and perform tests.
- Key Features:
- Linear regression, logistic regression, time series analysis.
- Statistical tests and models for descriptive statistics.
8. Plotly
- Purpose: Interactive data visualization.
- Why Learn It: Plotly allows for the creation of interactive and web-based visualizations, making it ideal for dashboards and presentations.
- Key Features:
- Interactive plots like scatter, line, bar, and 3D plots.
- Easy integration with web frameworks.
- Dashboards and web applications with Dash.
9. TensorFlow/PyTorch (Optional)
- Purpose: Machine learning and deep learning.
- Why Learn It: If your data analysis involves machine learning, these libraries will help in building, training, and deploying deep learning models.
- Key Features:
- Tensor processing and automatic differentiation.
- Building neural networks.
10. Dask (Optional)
- Purpose: Parallel computing for data analysis.
- Why Learn It: Dask enables scalable data manipulation by parallelizing Pandas operations, making it ideal for big datasets.
- Key Features:
- Works with NumPy, Pandas, and Scikit-learn.
- Handles large data and parallel computations easily.
Focusing on NumPy, Pandas, Matplotlib, and Seaborn will set a strong foundation for basic data analysis.
6 notes
·
View notes
Text
Data Analysis and Visualization Using Programming Techniques

Data analysis and visualization are crucial skills in today’s data-driven world. With programming, we can extract insights, uncover patterns, and present data in a meaningful way. This post explores how developers and analysts can use programming techniques to analyze and visualize data efficiently.
Why Data Analysis and Visualization Matter
Better Decisions: Informed decisions are backed by data and its interpretation.
Communication: Visualizations make complex data more accessible and engaging.
Pattern Recognition: Analysis helps discover trends, anomalies, and correlations.
Performance Tracking: Measure progress and identify areas for improvement.
Popular Programming Languages for Data Analysis
Python: Rich in libraries like Pandas, NumPy, Matplotlib, Seaborn, and Plotly.
R: Designed specifically for statistics and visualization.
JavaScript: Great for interactive, web-based data visualizations using D3.js and Chart.js.
SQL: Essential for querying and manipulating data from databases.
Basic Workflow for Data Analysis
Collect Data: From CSV files, APIs, databases, or web scraping.
Clean Data: Handle missing values, duplicates, and inconsistent formatting.
Explore Data: Use descriptive statistics and visual tools to understand the dataset.
Analyze Data: Apply transformations, groupings, and statistical techniques.
Visualize Results: Create charts, graphs, and dashboards.
Interpret & Share: Draw conclusions and present findings to stakeholders.
Python Example: Data Analysis and Visualization
import pandas as pd import seaborn as sns import matplotlib.pyplot as plt # Load data data = pd.read_csv('data.csv') # Analyze print(data.describe()) # Visualize sns.histplot(data['sales'], bins=10) plt.title('Sales Distribution') plt.xlabel('Sales') plt.ylabel('Frequency') plt.show()
Common Visualization Types
Bar Chart: Comparing categories
Line Chart: Time series analysis
Pie Chart: Proportional distribution
Scatter Plot: Correlation and clustering
Heatmap: Matrix-like data comparisons
Best Practices for Data Visualization
Keep it simple and avoid clutter.
Use colors to enhance, not distract.
Label axes, legends, and titles clearly.
Choose the right chart type for your data.
Ensure your visualizations are responsive and interactive if web-based.
Useful Libraries and Tools
Pandas & NumPy: Data manipulation
Matplotlib & Seaborn: Static visualizations
Plotly & Dash: Interactive dashboards
D3.js: Custom web-based visualizations
Power BI & Tableau: Business-level dashboarding (non-programming)
Real-World Use Cases
Sales Analysis: Visualize revenue trends and top-selling products.
Marketing Campaigns: Analyze click-through rates and conversions.
Healthcare: Monitor patient data, diagnostics, and treatment outcomes.
Finance: Analyze stock performance and predict market trends.
Conclusion
Combining data analysis with programming unlocks powerful insights and allows you to communicate results effectively. Whether you’re a beginner or an experienced developer, mastering data visualization techniques will significantly enhance your ability to solve problems and tell compelling data stories.
0 notes
Text
Essential Skills Every Data Scientist Must Learn in 2025

The world of data science is evolving faster than ever, and staying ahead of the curve in 2025 requires a strategic approach to skill development. As businesses rely more on data-driven decision-making, data scientists must continuously refine their expertise to remain competitive in the field. Whether you're an aspiring data scientist or an experienced professional, mastering the right skills is crucial for long-term success.
1. Mastering Programming Languages
At the core of data science lies programming. Proficiency in languages like Python and R is essential for handling data, building models, and deploying solutions. Python continues to dominate due to its versatility and rich ecosystem of libraries such as Pandas, NumPy, Scikit-learn, and TensorFlow.
Key Programming Skills to Focus On:
Data manipulation and analysis using Pandas and NumPy
Implementing machine learning models with Scikit-learn
Deep learning and AI development with TensorFlow and PyTorch
Statistical computing and data visualization with R
2. Strong Foundation in Statistics and Probability
A deep understanding of statistics and probability is non-negotiable for data scientists. These concepts form the backbone of data analysis, helping professionals derive meaningful insights and create predictive models.
Why It’s Important:
Enables accurate hypothesis testing
Supports decision-making with probability distributions
Strengthens machine learning model evaluation
3. Expertise in Machine Learning and Deep Learning
With AI and automation becoming more prevalent, machine learning and deep learning skills are in high demand. Data scientists need to stay updated with advanced techniques to develop intelligent models that can solve complex problems.
Key Areas to Focus On:
Supervised and unsupervised learning techniques
Reinforcement learning and neural networks
Hyperparameter tuning and model optimization
Understanding AI ethics and bias mitigation
For those looking to upskill in machine learning, the Machine Learning Course in Kolkata offers practical, hands-on training. This program is designed to equip learners with the latest industry knowledge and techniques to advance their careers.
4. Data Wrangling and Preprocessing Skills
Data in its raw form is often messy and incomplete. Being able to clean, structure, and preprocess data is a vital skill that every data scientist must master.
Essential Data Wrangling Skills:
Handling missing and inconsistent data
Normalization and standardization techniques
Feature selection and engineering for improved model performance
5. Knowledge of Big Data Technologies
The rise of big data has made it essential for data scientists to work with tools and frameworks designed for handling massive datasets efficiently.
Tools Worth Learning:
Apache Spark for large-scale data processing
Hadoop for distributed storage and computation
Google BigQuery for cloud-based data analytics
6. Data Visualization and Storytelling
Turning raw data into actionable insights requires effective communication. Data scientists should be adept at using visualization tools to present findings in a compelling and understandable way.
Best Practices:
Choose the right visualization type (e.g., bar charts, scatter plots, heatmaps)
Keep charts clean and easy to interpret
Use tools like Matplotlib, Seaborn, Tableau, and Power BI
7. Cloud Computing and MLOps
Cloud platforms are transforming the way data scientists build and deploy models. A strong understanding of cloud-based tools and MLOps practices is crucial in modern data science workflows.
What You Should Learn:
Deploying ML models on cloud platforms like AWS, Google Cloud, and Azure
Implementing MLOps for model lifecycle management
Using Docker and Kubernetes for scalable deployments
8. Domain Knowledge and Business Acumen
While technical skills are critical, understanding the industry you work in can set you apart. A data scientist with domain expertise can develop more impactful and relevant solutions.
Why It Matters:
Helps tailor data-driven strategies to specific industries
Improves collaboration with stakeholders
Enhances problem-solving with business context
9. Soft Skills: Critical Thinking and Effective Communication
Technical know-how is just one part of the equation. Data scientists must also possess strong analytical and problem-solving skills to interpret data effectively and communicate findings to both technical and non-technical audiences.
Key Soft Skills to Develop:
Clear and concise storytelling through data
Adaptability to emerging technologies and trends
Collaboration with cross-functional teams
10. Ethics in AI and Data Governance
As AI systems influence more aspects of daily life, ethical considerations and regulatory compliance have become increasingly important. Data scientists must ensure fairness, transparency, and adherence to privacy regulations like GDPR and CCPA.
Best Practices for Ethical AI:
Identifying and mitigating bias in machine learning models
Implementing robust data privacy and security measures
Promoting transparency in AI decision-making processes
Final Thoughts
In the ever-changing landscape of data science, continuous learning is the key to staying relevant. By mastering these essential skills in 2025, data scientists can future-proof their careers and contribute to the advancement of AI-driven innovations. If you're looking to gain practical expertise, the Data Science Program offers industry-focused training that prepares you for real-world challenges.
Whether you're just starting or looking to refine your skills, investing in these areas will keep you ahead of the curve in the dynamic world of data science.
#best data science institute#data science course#data science training#ai training program#online data science course#data science program#Best Data Science Programs#Machine Learning Course in Kolkata
0 notes
Text
What are Python’s key libraries for data science?
Python is one of the most popular programming languages for data science due to its simplicity, vast ecosystem, and extensive support for statistical and machine learning tasks. Several key libraries make Python the preferred choice for data science professionals.
NumPy – This library provides support for large, multi-dimensional arrays and matrices, along with mathematical functions to operate on them. It forms the foundation for many other scientific computing libraries.
Pandas – Essential for data manipulation and analysis, Pandas offers powerful data structures like DataFrames and Series, making it easy to clean, process, and analyze structured data.
Matplotlib – A popular visualization library that enables the creation of static, animated, and interactive visualizations such as line charts, bar graphs, and scatter plots.
Seaborn – Built on Matplotlib, Seaborn simplifies the process of creating aesthetically pleasing statistical visualizations with just a few lines of code.
Scikit-learn – One of the most widely used libraries for machine learning, Scikit-learn provides tools for classification, regression, clustering, dimensionality reduction, and model evaluation.
TensorFlow & PyTorch – These deep learning libraries support building and training neural networks, making them indispensable for AI-driven data science applications.
Statsmodels – Designed for statistical modeling, Statsmodels includes functionalities for regression analysis, hypothesis testing, and time-series forecasting.
SciPy – Used for scientific computing, SciPy extends NumPy with modules for optimization, integration, interpolation, and signal processing.
NLTK & spaCy – These libraries are essential for natural language processing (NLP) tasks, enabling text analysis, tokenization, and named entity recognition.
For anyone looking to master these tools and build a career in data science, enrolling in a Python certification course can provide structured learning and hands-on experience.
0 notes
Text
Uncovering Alcohol Consumption Patterns with Python Data Visualization
Assignment Overview
For this analysis, I worked with four variables:
S2AQ1: Ever consumed alcohol?
S2AQ2: Consumed at least 12 drinks in the last 12 months?
S2AQ3: Frequency of drinking (occasional to regular).
S2AQ18: Frequency of alcohol consumption over time.
This code generates individual (univariate) and paired (bivariate) graphs to analyze the center and spread of each variable and explore relationships between them.
Code and Graphs
Python Code
To recreate this analysis, save this code in a Python file and ensure your CSV dataset is in the same directory. Here’s how to do it:
import pandas as pd import numpy as np import matplotlib.pyplot as plt # Load the dataset data = pd.read_csv('nesarc_pds.csv') # Ensure the CSV file is in the same folder # Selecting variables of interest variables = ['S2AQ1', 'S2AQ2', 'S2AQ3', 'S2AQ18'] # Handling missing data by replacing 9 with NaN data = data.replace(9, np.nan) # Plotting each univariate graph separately # Distribution of S2AQ1 plt.figure(figsize=(6, 4)) data['S2AQ1'].value_counts(dropna=False).sort_index().plot(kind='bar', color='skyblue') plt.title('Distribution of S2AQ1') plt.xlabel('S2AQ1 Responses') plt.ylabel('Frequency') plt.tight_layout() plt.show() # Distribution of S2AQ2 plt.figure(figsize=(6, 4)) data['S2AQ2'].value_counts(dropna=False).sort_index().plot(kind='bar', color='lightcoral') plt.title('Distribution of S2AQ2') plt.xlabel('S2AQ2 Responses') plt.ylabel('Frequency') plt.tight_layout() plt.show() # Distribution of S2AQ3 plt.figure(figsize=(6, 4)) data['S2AQ3'].value_counts(dropna=False).sort_index().plot(kind='bar', color='lightgreen') plt.title('Distribution of S2AQ3') plt.xlabel('S2AQ3 Responses') plt.ylabel('Frequency') plt.tight_layout() plt.show() # Distribution of S2AQ18 plt.figure(figsize=(6, 4)) data['S2AQ18'].value_counts(dropna=False).sort_index().plot(kind='bar', color='plum') plt.title('Distribution of S2AQ18') plt.xlabel('S2AQ18 Responses') plt.ylabel('Frequency') plt.tight_layout() plt.show() # Bivariate analysis between S2AQ1 and S2AQ18 plt.figure(figsize=(8, 6)) pd.crosstab(data['S2AQ1'], data['S2AQ18']).plot(kind='bar', stacked=True, colormap='viridis') plt.title('Association between Alcohol Consumption and Frequency (S2AQ1 vs. S2AQ18)') plt.xlabel('Ever Consumed Alcohol (S2AQ1)') plt.ylabel('Count') plt.tight_layout() plt.show()
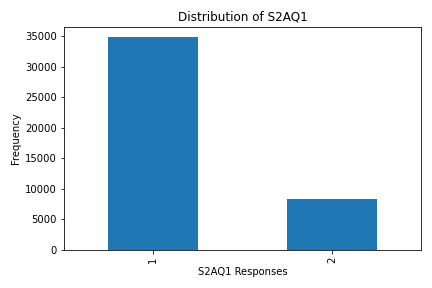
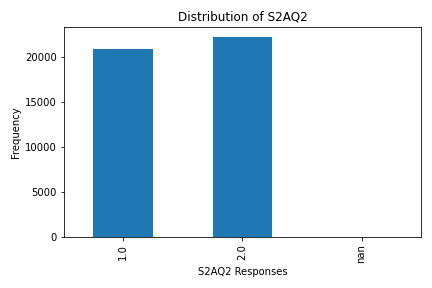
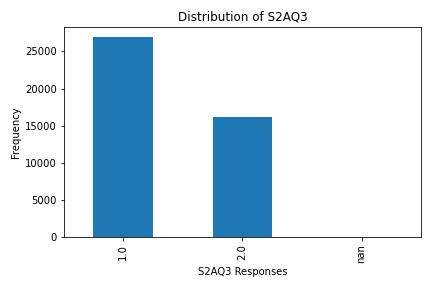
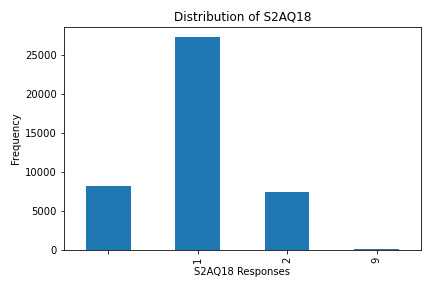
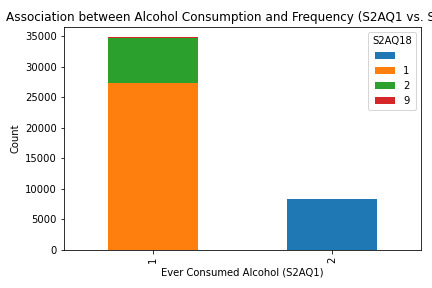
What the Graphs Reveal
S2AQ1 (Ever Consumed Alcohol): Most respondents answered "yes," indicating a significant percentage have tried alcohol.
S2AQ2 (12+ Drinks in Last 12 Months): A smaller group responded affirmatively, showing fewer people have consumed 12+ drinks recently.
S2AQ3 (Frequency of Drinking): Responses varied, with data showing a range of drinking frequencies among participants.
S2AQ18 (Frequency of Alcohol Consumption): This variable had the highest counts for lower-frequency responses, indicating occasional consumption.
Bivariate Analysis (S2AQ1 and S2AQ18)
The stacked bar chart shows an association between ever consuming alcohol (S2AQ1) and consumption frequency (S2AQ18). While many respondents have consumed alcohol, fewer continue to drink regularly, reflecting a potential drop-off in consistent drinking habits.
Summary: In this assignment, I analyzed alcohol consumption data by examining four survey variables using Python. Through univariate graphs, I visualized the distribution and frequency of responses for each variable, revealing that while many respondents have tried alcohol (S2AQ1), fewer reported frequent consumption. Additionally, the bivariate analysis between initial alcohol consumption (S2AQ1) and recent drinking frequency (S2AQ18) highlighted a drop-off in regular drinking among participants. This exercise demonstrated how data visualization can clarify behavioral trends and provided a practical approach to understanding patterns in alcohol use.
0 notes
Text
Getting Started with Python’s Data Visualization Libraries
Data visualization is a vital component of data analysis, enabling us to present data insights in a clear and compelling way. As the world becomes increasingly data-driven, the ability to effectively visualize data is a sought-after skill. Python, with its rich ecosystem of libraries, has emerged as a powerful tool for data visualization. In this blog, we’ll explore some of the most popular Python libraries for data visualization and provide practical examples to get you started.
Why Data Visualization Matters
Data visualization transforms complex data into visual formats like charts and graphs, making it easier to understand and interpret. It allows analysts and decision-makers to spot trends, identify anomalies, and communicate findings effectively. For instance, a well-constructed line graph can reveal sales trends over time more intuitively than raw data in a spreadsheet.
Effective visualization not only enhances comprehension but also engages the audience. In a world inundated with data, the ability to distill and present information visually can differentiate impactful communication from overwhelming information.
Popular Python Data Visualization Libraries
Python boasts a variety of libraries tailored for data visualization. Here are some of the most widely used:
MatplotlibMatplotlib is the foundational library for creating static, animated, and interactive visualizations in Python. It is highly customizable, making it suitable for a wide range of applications.Installation:bashCopy codepip install matplotlib Basic Example:pythonCopy codeimport matplotlib.pyplot as plt x = [1, 2, 3, 4, 5] y = [2, 3, 5, 7, 11] plt.plot(x, y) plt.title('Simple Line Plot') plt.xlabel('X-axis') plt.ylabel('Y-axis') plt.show() This code snippet generates a simple line plot. You can easily customize the appearance by adding labels, titles, and styles.
SeabornBuilt on top of Matplotlib, Seaborn simplifies the creation of visually appealing statistical graphics. It offers built-in themes and color palettes for more attractive presentations.Installation:bashCopy codepip install seaborn Basic Example:pythonCopy codeimport seaborn as sns import matplotlib.pyplot as plt tips = sns.load_dataset('tips') sns.barplot(x='day', y='total_bill', data=tips) plt.title('Total Bill by Day') plt.show() In this example, we visualize the average total bill across different days using a bar plot. Seaborn also provides advanced features like categorical plots and pair plots for exploring relationships in data.
PlotlyFor interactive visualizations, Plotly is a fantastic choice. It allows users to create complex visualizations that can be embedded in web applications.Installation:bashCopy codepip install plotly Basic Example:pythonCopy codeimport plotly.express as px df = px.data.iris() fig = px.scatter(df, x='sepal_width', y='sepal_length', color='species') fig.show() This code creates an interactive scatter plot that displays different species of iris flowers based on their sepal dimensions. Users can hover over points for additional information, making it great for exploratory data analysis.
Pandas VisualizationWhile primarily a data manipulation library, Pandas has built-in capabilities for quick visualizations, allowing you to plot directly from DataFrames.Basic Example:pythonCopy codeimport pandas as pd import matplotlib.pyplot as plt data = {'Year': [2018, 2019, 2020, 2021], 'Sales': [150, 200, 250, 300]} df = pd.DataFrame(data) df.plot(x='Year', y='Sales', kind='line', title='Sales Over Years') plt.show() This approach offers a quick way to visualize data directly from your DataFrame, facilitating a seamless workflow from data analysis to visualization.
Getting Started with Basic Examples
To begin, it’s essential to install the necessary libraries. Use the following command to install all the libraries discussed:
bash
Copy code
pip install matplotlib seaborn plotly pandas
Now, let’s dive deeper into how to use these libraries effectively. For example, combining Matplotlib and Seaborn can enhance your visualizations:
python
Copy code
import seaborn as sns import matplotlib.pyplot as plt # Load the Titanic dataset titanic = sns.load_dataset('titanic') # Create a count plot of survivors sns.countplot(x='class', hue='survived', data=titanic) plt.title('Survivors by Class') plt.show()
This code creates a count plot showing the number of survivors by class on the Titanic, demonstrating how you can combine datasets and visualizations to glean insights.
"Take the First Step Towards Your Coding Career: join python training institute.
Advanced Visualization Techniques
Once you're comfortable with the basics, you can explore more advanced visualizations. Libraries like Bokeh and Altair provide functionalities for creating complex and interactive plots, such as time series analyses or geographical data representations.
Bokeh: Best for creating interactive plots that can be easily integrated into web applications.
Altair: Focused on declarative statistical visualizations, which make it easier to create complex plots with less code.
Best Practices in Data Visualization
To create effective visualizations, consider the following best practices:
Keep it Simple: Avoid clutter. Focus on the most important data points and minimize distractions.
Use Color Wisely: Choose a color palette that enhances readability and accessibility.
Label Clearly: Ensure all axes and legends are clearly labeled, providing context for your audience.
Tell a Story: Structure your visualizations to convey a narrative, guiding the audience through the data.
Conclusion
Mastering data visualization in Python is an invaluable skill that can significantly enhance your data analysis capabilities. By leveraging libraries like Matplotlib, Seaborn, Plotly, and Pandas, you can create compelling visual representations of data, making it easier to communicate insights and drive decision-making.
As you embark on your journey into data visualization, practice is key. Experiment with different libraries and visual styles, and always keep the principles of effective visualization in mind. With time and experience, you'll be able to craft stunning visual narratives that bring your data to life.
Call to Action
Ready to dive deeper into Python and data visualization? Join our upcoming courses at [Your Training Institute Name] to sharpen your skills and connect with like-minded learners. Let’s explore the fascinating world of data together!
DO YOU WANT TO LEARN PYTHON TRAINING COURSE WITH US?IF YES THEN MEET US IN PYTHON TRAINING INSTITUTE...
1 note
·
View note
Text
Can somebody provide step by step to learn Python for data science?
Absolutely the right decision—to learn Python for data science. Segmenting it into something doable may be a good way to go about it honestly. Let the following guide you through a structured way.
1. Learning Basic Python
Syntax and semantics: Get introduced to the basics in syntax, variables, data types, operators, and some basic control flow.
Functions and modules: You will be learning how to define functions, call functions, utilize built-in functions, and import modules.
Data Structures: Comfortable with lists, tuples, dictionaries, and sets.
File I/O: Practice reading from and writing to files.
Resources: Automate the Boring Stuff with Python book.
2. Mastering Python for Data Science Libraries
NumPy: Learn to use NumPy for numerical operations and array manipulations.
Pandas: The course would revolve around data manipulation through the Pandas library, series, and data frames. Try out the cleaning, transformation, and analysis of data.
Familiarize yourself with data visualization libraries: Matplotlib/Seaborn. Learn to make plots, charts, and graphs.
Resources:
NumPy: official NumPy documentation, DataCamp's NumPy Course
Pandas: pandas documentation, DataCamp's Pandas Course
Matplotlib/Seaborn: matplotlib documentation, seaborn documentation, Python Data Science Handbook" by Jake VanderPlas
3. Understand Data Analysis and Manipulation
Exploratory Data Analysis: Techniques to summarize and understand data distributions
Data Cleaning: missing values, outliers, data inconsistencies.
Feature Engineering: Discover how to create and select the features used in your machine learning models.
Resources: Kaggle's micro-courses, "Data Science Handbook" by Jake VanderPlas
4. Be able to apply Data Visualization Techniques
Basic Visualizations: Learn to create line plots, bar charts, histograms and scatter plots
Advanced Visualizations: Learn heatmaps, pair plots, and interactive visualizations using libraries like Plotly.
Communicate Your Findings Effectively: Discover how to communicate your findings in the clearest and most effective way.
Resource: " Storytelling with Data" – Cole Nussbaumer Knaflic.
5. Dive into Machine Learning
Scikitlearn: Using this package, the learning of concepts in supervised and unsupervised learning algorithms will be covered, such as regression and classification, clustering, and model evaluation.
Model Evaluation: It defines accuracy, precision, recall, F1 score, ROC-AUC, etc.
Hyperparameter Tuning: GridSearch, RandomSearch
For basic learning, Coursera's Machine Learning by Andrew Ng.
6. Real Projects
Kaggle Competitions: Practice what's learned by involving in Kaggle competitions and learn from others.
Personal Projects: Make projects on things that interest you—that is scraping, analyzing, and model building.
Collaboration: Work on a project with other students so as to get the feeling of working at a company.
Tools: Datasets, competitions, and the community provided in Kaggle, GitHub for project collaboration
7. Continue Learning
Advanced topics: Learn deep learning using TensorFlow or PyTorch, Natural Language Processing, and Big Data Technologies such as Spark.
Continual Learning: Next comes following blogs, research papers, and online courses that can help you track the most current trends and technologies in data science.
Resources: "Deep Learning" by Ian Goodfellow, Yoshua Bengio, and Aaron Courville, Fast.ai for practical deep learning courses.
Additional Tips
Practice regularly: The more you code and solve real problems, the better you will be at it.
Join Communities: Join as many online forums as possible, attend meetups, and join data science communities to learn from peers.
In summary, take those steps and employ the outlined resources to grow in building a solid base in Python for data science and be well on your way to be proficient in the subject.
0 notes
Text
What libraries do data scientists use to plot data in Python?
Hi,
When it comes to visualizing data in Python, data scientists have a suite of powerful libraries at their disposal. Each library has unique features that cater to different types of data visualization needs:
Matplotlib: Often considered the foundational plotting library in Python, Matplotlib offers a wide range of plotting capabilities. Its pyplot module is particularly popular for creating basic plots such as line charts, scatter plots, bar graphs, and histograms. It provides extensive customization options to adjust every aspect of a plot.
Seaborn: Built on top of Matplotlib, Seaborn enhances the aesthetics of plots and simplifies the creation of complex visualizations. It excels in generating attractive statistical graphics such as heatmaps, violin plots, and pair plots, making it a favorite for exploring data distributions and relationships.
Pandas: While primarily known for its data manipulation capabilities, Pandas integrates seamlessly with Matplotlib to offer quick and easy plotting options. DataFrames in Pandas come with built-in methods to generate basic plots, such as line plots, histograms, and bar plots, directly from the data.
Plotly: This library is geared towards interactive plots. Plotly allows users to create complex interactive charts that can be embedded in web applications. It supports a wide range of chart types and interactive features like zooming and hovering, making it ideal for presentations and dashboards.
Altair: Known for its concise syntax and declarative approach, Altair is used to create interactive visualizations with minimal code. It’s especially good for handling large datasets and generating charts like bar charts, scatter plots, and line plots in a clear and straightforward manner.
Bokeh: Bokeh specializes in creating interactive and real-time streaming plots. It’s particularly useful for building interactive dashboards and integrating plots into web applications. Bokeh supports various types of plots and offers flexibility in customizing interactions.

Each of these libraries has its strengths, and data scientists often use them in combination to leverage their unique features and capabilities, ensuring effective and insightful data visualization.
Drop the message to learn more!!
0 notes
Text
Data Science With Python
Data Science with Python course in Nepal offers a comprehensive approach to mastering the intricacies of data analytics. Designed to empower participants with essential skills for success in the data science field, this program delves into Python basics, data manipulation with Pandas, visualization using Matplotlib and Seaborn, and machine learning algorithms with Scikit-learn. Through hands-on projects, participants solidify their understanding and gain practical experience.
If you are interested in this course, it is available at Upskills Nepal.

Course Module For Data Science With Python
1. Understanding Python Basics
This course starts with initializing your Python environment and choosing between local installations or cloud-based platforms. You will dive into Python by learning about its syntax and exploring variables, data types, and operators. This also includes understanding other Python basics.
2. Mastering Data Manipulation with Pandas
This part includes installing the Pandas library, exploring its features, and learning to read and write data from various formats, including CSV and Excel files. You can get hands-on with data cleaning and manipulation techniques such as filtering, sorting, and grouping.
Data Visualization with Matplotlib and Seaborn
This module helps you install and explore the Matplotlib library, and create essential plots like line graphs, bar charts, and scatter plots. Enhance your plots with custom labels, colours, and styles for clarity and aesthetics.
Introduction to Machine Learning with Scikit-learn
Data science with Python includes installing and getting familiar with the Scikit-learn library and understanding the basics of supervised learning, including classification and regression, training a basic model using Scikit-learn to grasp the process and learning to evaluate model performance using various metrics.
For more IT and non-IT courses, you can visit this website.
0 notes
Text
Introduction to Python and Data Science
Python has become the go-to programming language for data science due to its simplicity and powerful libraries. If you're just starting your journey into the world of data science, Python is an excellent choice. This guide will take you through the essential Python programming concepts you need to know to embark on your data science adventure.
Setting Up Your Python Environment
Before diving into Python, you'll need to set up your environment. The good news is, Python is free and easy to install. You can download it from the official Python website and choose from various Integrated Development Environments (IDEs) such as PyCharm, Jupyter Notebook, or VS Code. These tools provide a user-friendly interface for writing and executing Python code.
Python Basics: Variables, Data Types, and Operators
Let's start with the basics. In Python, you use variables to store data. Variables can hold different types of data, such as numbers, strings (text), lists, and more. Python also provides various operators for mathematical operations, comparisons, and logical operations. Understanding these basics sets the foundation for more complex data manipulation.
Control Flow: Making Decisions with Python
Control flow statements allow you to dictate the flow of your program. With if statements, for loops, and while loops, you can control how your code executes based on conditions. This is crucial for data analysis, where you often need to filter and process data based on specific criteria.
Python Functions: Building Blocks for Data Analysis
Functions in Python are reusable blocks of code that perform specific tasks. They help in organizing your code and making it more modular. You'll learn how to create functions, pass arguments, and return values. This knowledge becomes invaluable as you start working with larger datasets and complex operations.
Working with Data: Libraries and Data Structures
Python's strength in data science comes from its powerful libraries. Two essential libraries for data manipulation are NumPy and Pandas. NumPy provides support for large, multi-dimensional arrays and matrices, while Pandas offers data structures like DataFrames, which are ideal for data manipulation and analysis.
Data Analysis with Pandas: Your Data Science Swiss Army Knife
Pandas is a game-changer for data scientists. It allows you to read data from various sources, clean and preprocess data, perform statistical analysis, and much more. With Pandas DataFrames, you can slice and dice your data, filter rows and columns, and aggregate information with ease.
Visualization with Matplotlib: Bringing Data to Life
A picture is worth a thousand words, especially in data science. Matplotlib is a plotting library that enables you to create various types of visualizations, including line plots, bar charts, histograms, and scatter plots. Visualizations help in understanding trends, patterns, and relationships within your data, making complex information more accessible.
Putting It All Together: A Simple Data Analysis Project
To wrap up your beginner's journey, we'll walk through a simple data analysis project. You'll apply everything you've learned by loading a dataset, cleaning and preparing the data with Pandas, performing some basic analysis, and creating visualizations with Matplotlib. This hands-on project will solidify your understanding and prepare you for more advanced data science tasks.
0 notes
Text
Getting Started with Python for Data Analysis: A Comprehensive Guide
In today's data-driven landscape, mastering data analysis with Python is a valuable skill. Python, with its robust ecosystem of libraries like Pandas, NumPy, and Matplotlib, offers powerful tools for handling, manipulating, and visualizing data. This blog post presents a step-by-step approach to help beginners learn data analysis with Python effectively, enabling them to unlock insights from datasets and make data-driven decisions.
Unlock the power of data with our cutting-edge Python training in Pune level up your skills and become a python programmer.

To Learn Data Analysis With Python, You Can Follow These Steps:
Step 1: Grasping Python Fundamentals Before delving into data analysis, it's crucial to establish a strong foundation in Python programming. Familiarize yourself with the language's syntax, data types, control structures, and functions. Numerous online tutorials, interactive courses, and books provide excellent resources for learning Python.
Step 2: Installing Python and Essential Libraries Install the latest version of Python from the official Python website. Additionally, ensure that you have the necessary libraries installed, such as Pandas, NumPy, and Matplotlib. These libraries can be easily installed using the pip package manager.
Step 3: Exploring Data Analysis Libraries Pandas, NumPy, and Matplotlib are the cornerstones of data analysis in Python. Dive into the documentation, explore sample code, and understand the core functionalities of these libraries. Pandas empowers you with powerful data manipulation and analysis capabilities, NumPy enables numerical computing, and Matplotlib provides versatile data visualization tools.
Step 4: Hands-on Practice with Datasets To gain practical experience, work with real datasets. You can find publicly available datasets or use your own data. Platforms like Kaggle offer a diverse array of datasets suitable for different projects and skill levels. Start with smaller datasets and gradually progress to larger and more complex ones.
Step 5: Mastering Pandas for Data Manipulation Pandas is a vital library for efficient data manipulation and analysis. Learn how to read data from various sources, clean and preprocess data, filter and select data based on specific criteria, perform grouping and aggregation operations, handle missing values, and reshape data. Apply these techniques to real-world datasets to become proficient in using Pandas effectively.
Continuous learning, facilitated by resources such as a Best Python Online Training is not just a choice but a necessity to remain competitive.

Step 6: Proficiency in NumPy for Numerical Computing NumPy is a fundamental library for numerical computing in Python. Develop a solid understanding of multidimensional arrays, array operations, mathematical functions, and indexing techniques provided by NumPy. These skills will prove invaluable when working with large datasets and performing complex computations.
Step 7: Visualizing Data with Matplotlib Data visualization is essential for effective data analysis. Matplotlib offers a wealth of plotting functions and customization options. Learn how to create various types of plots, such as line plots, scatter plots, bar charts, and histograms. Experiment with adding labels, titles, legends, and annotations to enhance the clarity and visual appeal of your visualizations.
Step 8: Expanding Your Toolkit Once you have a strong grasp of the core libraries, consider exploring additional libraries that complement your data analysis skills. For instance, Seaborn builds upon Matplotlib and provides a high-level interface for statistical data visualization. Scikit-learn is a powerful library for machine learning tasks, which can be useful for predictive analysis.
Step 9: Real-World Projects and Portfolio Building Solidify your skills and demonstrate your expertise by working on real-world data analysis projects. Find datasets aligned with your interests or industry and apply your knowledge to clean, explore, and derive insights from the data. Document your projects and build a portfolio to showcase your proficiency in Python data analysis.
Embarking on the journey of learning data analysis with Python opens doors to endless possibilities in the realm of data-driven decision-making. By following the step-by-step approach outlined in this comprehensive guide, beginners can acquire the necessary skills to handle, manipulate, and visualize data using Python's powerful libraries. Regular practice, hands-on projects, and a curious mindset will ensure continued growth and expertise in data analysis.
0 notes
Text
Data Visualization in Python From Matplotlib to Seaborn
Data visualization is an Important aspect of data analysis and machine learning.You can give key insights into your data through different graphical representations. It helps in understanding the data, uncovering patterns, and communicating insights effectively. Python provides several powerful libraries for data visualization, graphing libraries, namely Matplotlib, Seaborn, Plotly, and Bokeh.
Data visualization is an easier way of presenting the data.It may sometimes seem easier to go through of data points and build insights but usually this process many not yield good result. Additionally, most of the data sets used in real life are too big to do any analysis manually.There could be a lot of things left undiscovered as a result of this process.. This is essentially where data visualization steps in.
However complex it is, to analyze trends and relationships amongst variables with the help of pictorial representation.
The Data Visualization advantages are as follows
Identifies data patterns even for larger data points
Highlights good and bad performing areas
Explores relationship between data points
Easier representation of compels data
Python Libraries
There are lot of Python librariers which could be used to build visualization like vispy,bokeh , matplotlib plotly seaborn cufflinks folium,pygal and networkx. On this many Matplotlib and seaborn very widely used for basic to intermediate level of visualization
Matplotlib is a library in Python being two of the most widely used Data visualization is a crucial part of data analysis and machine learning . That enables users to generate visualizations like scatter plots, histograms, pie charts, bar charts, and much more. It helps in understanding the data, uncovering patterns,and communicating insights effectively. Seaborn is a visualization that built on top of Matplotlib. It provides data visualizations that are more typically statistically and aesthetic sophisticated.
Matplotlib;- Matplotlib is a comprehensive library for creating animated, static, , and interactive visualizations in Python. It provides a lot of flexibility and control over the appearance of plots but can sometimes require a lot of code for simple tasks. Matplotlib makes easy things easy and hard things possible.
Basic Example with Matplotlib
Use a rich array of third-party packages build on Matplotli
Export to many file formats
Make interactive figures that can pan,zoom, update.
Embed in Graphical and jupyterLab User Interfaces
Crete public quality plots.
Seaborn;-Seaborn is a python data visualization built on top of Matplotlib . It provides a high-level interface for drawing attractive and informative statistical graphics. It is particularly well-suited for visualizing data from Pandas data frames
Basic Example with Seaborn
Advanced Visualizations
Plots for categorical data
Pairplot for Multivariate Analysis
Combining Matplotlib and Seaborn
Distributional representations
Both Matplotlib and Seaborn are powerful tools for data visualization in Python. Matplotlib provides fine-grained control over plot appearance, while Seaborn offers high-level functions for statistical plots and works seamlessly with Pandas data frames. Understanding how to use both libraries effectively can greatly enhance your ability to analyze and present data.
Can I use Matplotlib and seaborn together?
You can definitely use Matplotlib and Seaborn together in your data visualizations. Since Seaborn Provides an API on top of Matplotlib, you can combine the functionality of both libraries to create more complex and customized plots. Here’s how you can integrate Matplotlib with Seaborn to take advantage of both libraries' strengths.
0 notes
Text
Leveraging Python for Data Science: Tools and Libraries You Should Know

In the realm of data science, Python has emerged as a lingua franca, largely due to its simplicity and robust ecosystem of data-centric libraries and tools. For entities like Softs Solution Service, an esteemed IT Training Institute in Ahmedabad, the emphasis on Python development training is more than a curriculum choice; it's a strategic necessity to arm the workforce with tools essential for the digital economy.
Python: The Cornerstone for Data Scientists
Python’s ascent as the programming language of choice for data scientists is not accidental. Its syntax is clear and concise, which makes Python an ideal language for professionals who may not come from a programming background but are venturing into data science. Python's versatility allows it to be used for everything from simple data analysis to complex machine learning algorithms, and this is the very reason why Python Development Courses are increasingly in demand.
Libraries and Tools That Empower Python in Data Science
NumPy: At the heart of Python's data science stack is NumPy, a library that provides support for large, multi-dimensional arrays and matrices, along with a collection of mathematical functions to operate on these arrays. It's the foundational library that other libraries are built upon.
Pandas: Data manipulation becomes seamless with Pandas. It provides high-level data structures and functions designed to make data analysis fast and easy in Python. Pandas is particularly skilled at handling tabular data, like you would find in SQL tables or Excel spreadsheets.
Matplotlib: Visualization is key in data science, and Matplotlib is the go-to library for creating static, interactive, and animated visualizations in Python. Its flexibility allows for the creation of histograms, power spectra, bar charts, error charts, scatter plots, and more with just a few lines of code.
Scikit-learn: For those enrolled in a Python Development Training program at an IT Training Center in Ahmedabad, mastering Scikit-learn is a must. It is one of the most widely used libraries for machine learning and provides simple and efficient tools for data mining and data analysis.
TensorFlow and Kera's: When it comes to deep learning, TensorFlow and its high-level API Kera's are the libraries of choice. TensorFlow allows for easy deployment of computation across various platforms, and Kera's provides a more intuitive interface for creating deep learning models.
Seaborn: Built on top of Matplotlib, Seaborn is a statistical plotting library that simplifies the process of creating informative and attractive statistical graphics.
Stats Models: For those looking to dive deeper into statistical modeling, Stats Models offers classes and functions for the estimation of many different statistical models, as well as for conducting statistical tests, and statistical data exploration.
Why Python Development Training is Essential?
The rise of data science as a key competence area in the tech industry has made Python Development Course vital. Institutions like Softs Solution Service not only recognize this trend but also offer tailored Python Development Training to meet the surging demands. For a city like Ahmedabad, which is fast becoming an IT hub, having an IT Training Center that provides such future-ready courses is a boon for aspirants.
The comprehensive training programs at these centers not only cover the aforementioned libraries but also focus on real-world application, problem-solving, and project-based learning, which are crucial for grasping the practical aspects of Python in data science.
Choosing the Right IT Training Institute
The choice of an IT Training Institute is pivotal. Prospective students should look for a center that:
Provides a comprehensive curriculum covering the latest tools and libraries in Python for data science.
Offers hands-on experience with real-world data sets.
Has experienced instructors who are industry veterans.
Facilitates a collaborative learning environment.
Assists with placement and career advancement post-training.
Conclusion
Python is not just a programming language; it is a gateway to the vast universe of data science. The tools and libraries it offers are powerful aids in data analysis, visualization, and machine learning. For ambitious individuals seeking to forge a career in this domain, enrolling in a Python Development Course at a reputed IT Training Center like Softs Solution Service in Ahmedabad could be the first step towards a successful future in data science.
As organizations continue to generate and rely on data, the demand for skilled data scientists will only grow. Whether you're a student, professional, or an organization looking to upskill your team, leveraging Python for data science through targeted training can unlock a world of opportunities. With the right foundation, one can not only interpret the digital language of data but also mold it to create technology that betters the world.
#softs solution service#it training center in ahmedabad#python development course#it training institute in ahmedabad#php development training
0 notes
Text
Best online Python data science course
In the dynamic realm of data science, Python stands as an undisputed champion, wielding its versatility and simplicity to unlock the mysteries hidden within vast datasets. As a programming language, Python seamlessly integrates into the data science workflow, offering an extensive range of libraries and tools that streamline the entire analytical process.
Python's Prowess in Data Manipulation and Analysis
At the heart of Python's prowess lies its ability to handle data with finesse. The Pandas library, a cornerstone of data manipulation, empowers data scientists to effortlessly clean, transform, And data sets. Its intuitive Data science course online with placement structure facilitates efficient handling of tabular data, making tasks such as filtering, grouping, and aggregating a breeze.
Whether dealing with CSV files or SQL databases, Pandas simplifies the complexities of data wrangling, laying a solid foundation for subsequent analysis. Complementing Pandas is NumPy, a fundamental library for numerical operations in Python. NumPy's array-based computations accelerate mathematical operations, providing the computational muscle necessary for scientific computing. From basic arithmetic to Advance linear algebra, NumPy enhances the efficiency of data manipulation, laying the groundwork for statistical analyses and machine learning algorithms.
Visualizing Insights with Matplotlib and Seaborn
Data, when transformed into visual narratives, becomes more accessible and interpretable. Matplotlib, a comprehensive 2D plotting library, enables the creation of a myriad of static, animated, and interactive visualizations. Customizable and feature-rich, Matplotlib caters to diverse needs, from line plots and scatter plots to bar charts and heatmaps.
seaborn, built on top of Matplotlib, adds an aesthetic layer to data visualization. With its high-level interface, Seaborn simplifies the creation of attractive statistical graphics. Heatmaps, violin plots, and pair plots come to life with just a few lines of code, enhancing the communication of complex patterns and relationships within the data.
Machine Learning Mastery with Scikit-Learn
Python's prowess extends seamlessly into the realm of machine learning, and the Scikit-Learn library serves as the vanguard. Offering a cohesive and user-friendly interface, Scikit-Learn transforms complex machine learning algorithms into accessible tools for data scientists. Classification, regression, clustering, and dimensionality reduction are within reach, thanks to a comprehensive suite of algorithms. scikit-Learn also provides utilities for model selection, hyperparameter tuning, and performance evaluation.
With an extensive array of metrics and tools, it empowers data scientists to fine-tune models and assess their predictive capabilities. Harnessing the power of Scikit-Learn, Python becomes a playground for experimenting with machine learning models and translating data into actionable insights.

The Notebooks Revolution
Notebooks, an interactive computing environment, have revolutionized the way data scientists work with Python. Combining code, visualizations, and narrative text in a single document, Notebooks facilitate collaborative and reproducible data science. From exploratory data analysis to building machine learning models, Notebooks provide an interactive canvas where ideas come to life.
The notebooks support a plethora of programming languages, but their seamless integration with Python has made them a staple in the data science toolkit. With the ability to share notebooks via platforms like GitHub and Hub collaboration among data scientists transcends geographical boundaries. This interactive and collaborative nature accelerates the pace of discovery and innovation within the data science community.
Deep Learning: Python's Gateway to Artificial Intelligence
In the era of artificial intelligence, Python emerges as a key player, with libraries like TensorFlow and Python leading the charge in deep learning. These frameworks enable the creation and training of neural networks for tasks ranging from image recognition to natural language processing. Python's simplicity and community support make it an ideal environment for delving into the complexities of deep learning.
TensorFlow, developed by Google, provides a comprehensive platform for building and deploying machine learning models, especially those involving neural networks. Its flexibility and scalability make it suitable for projects of varying sizes and complexities. Python, with its dynamic computation graph, appeals to researchers and practitioners alike, offering an intuitive and flexible approach to building deep learning models.
youtube
The Python Community: A Driving Force in Innovation
Beyond its technical capabilities, Python's strength lies in its vibrant and expansive community. From forums like Stack Overflow to dedicated data science communities, Python enthusiasts actively engage in knowledge-sharing and problem-solving. This collaborative spirit ensures that challenges encountered in data science projects are met with a wealth of collective wisdom and experience.
Moreover, the open-source nature of Python and its libraries fosters continuous development and innovation. The community-driven evolution of tools and packages ensures that data scientists always have access to cutting-edge technologies and methodologies. This dynamic ecosystem reinforces Python's position as the language of choice for those venturing into the ever-evolving landscape of data science.
Conclusion: Python's Enduring Legacy in Data Science
In the realm of data science, Python stands as a reliable and innovative companion, seamlessly guiding Best data science course with placement through the intricate maze of data manipulation, visualization, and machine learning. From the simplicity of Pandas to the sophistication of deep learning with TensorFlow and Python offers a comprehensive toolkit that adapts to the diverse needs of data science Projects As technology advances and data science continues to evolve, Python's enduring legacy lies not just in its technical capabilities but also in the collaborative spirit of its community. With Python as the driving force, data scientists navigate the complexities of their work with confidence, transforming raw data into meaningful insights and driving innovation in the ever-expanding field of data science.
0 notes
Text
Data Analysis Software Tools
In the era of big data, data analysis software tools have become indispensable for businesses seeking to make informed decisions and gain valuable insights from their data. These powerful tools streamline the data analysis process, allowing data analysts and professionals to explore, visualize, and interpret data with efficiency and accuracy. This article delves into the world of data analysis software tools, showcasing their versatility, features, and impact on driving data-driven success for organizations.
1. Understanding Data Analysis Software Tools:
Data analysis software tools are applications specifically designed to facilitate the process of data analysis. They cater to a wide range of users, from data analysts and scientists to business professionals and executives. These tools empower users to import, clean, manipulate, and visualize data, making the data analysis process accessible and user-friendly. To maximize your proficiency with these tools, consider enrolling in a data analytics course.
2. Popular Data Analysis Software Tools:
A variety of data analysis software tools are available in the market, catering to different user preferences and requirements. Some of the most popular and widely used tools include:
- Microsoft Excel: A familiar and widely accessible spreadsheet tool that offers basic data analysis capabilities through built-in functions and charting tools.
- Tableau: A powerful data visualization tool that allows users to create interactive and visually compelling dashboards and reports. Enhance your skills with data analytics training to fully leverage its capabilities.
- Python: A versatile programming language with robust libraries, such as Pandas and NumPy, which enable data manipulation, analysis, and modeling. Consider pursuing a data analytics certification to harness the full potential of these tools for your analytical endeavors.
- R: A programming language dedicated to statistical computing and data visualization, with a rich collection of packages for advanced data analysis.
- SQL: A language for managing and querying relational databases, essential for data extraction and manipulation.
- Power BI: A business analytics tool by Microsoft that enables interactive data visualization and real-time reporting. Explore its capabilities further through a data analytics institute to master its potential.
3. Features and Capabilities:
Data analysis software tools offer a plethora of features and capabilities to cater to diverse analytical needs. These tools often provide functionalities like data import from various sources, data cleaning and transformation, data aggregation, statistical analysis, and data visualization. Some advanced tools also include machine learning algorithms, allowing for predictive modeling and prescriptive analysis. To fully leverage these tools, consider enrolling in a data analytics training course.
Moreover, data analysis software tools offer the advantage of automation, significantly reducing the manual effort required for data processing and analysis. This automation accelerates the decision-making process, enabling businesses to respond swiftly to changing market dynamics.
4. Data Visualization and Communication:
Data visualization is a critical aspect of data analysis, as it facilitates effective communication of insights to stakeholders. Data analysis software tools offer a wide array of visualization options, including bar charts, line graphs, scatter plots, heat maps, and more. Interactive visualization features enable users to explore data from different angles and uncover hidden patterns.
Clear and impactful data visualizations enhance understanding and decision-making, enabling professionals to convey complex information in a visually compelling manner.
Refer this article: How much is the Data Analytics course fee in India?
5. Empowering Non-Technical Stakeholders:
Data analysis software tools have democratized data analysis, making it accessible to non-technical stakeholders. With user-friendly interfaces and intuitive drag-and-drop features, these tools empower executives, managers, and marketers to derive insights directly from data without extensive technical expertise.
By enabling data-driven decision-making across all levels of an organization, data analysis software tools foster a data-centric culture and drive innovation.
6. Integration with Big Data and Cloud Computing:
As the volume of data continues to grow exponentially, data analysis software tools have evolved to accommodate big data analytics. Many tools offer integration with big data platforms and cloud computing services, enabling efficient processing and analysis of large datasets.
Cloud-based data analysis solutions also provide scalability and flexibility, allowing businesses to adapt their analytical capabilities to changing data requirements.
7. Future Trends and Innovations:
The field of data analysis software tools is continually evolving, with ongoing advancements and innovations. Machine learning capabilities within these tools are expanding, enabling users to leverage sophisticated algorithms for predictive and prescriptive analytics.
Additionally, data analysis software tools are embracing automation and natural language processing, simplifying the data analysis process even further.
Conclusion:
Data analysis software tools are a driving force behind the data-driven revolution, empowering businesses and professionals to extract valuable insights from data with ease and precision. From Microsoft Excel's accessibility to Tableau's powerful visualization capabilities and Python's versatility, these tools cater to a diverse range of analytical needs.
By democratizing data analysis and enhancing data visualization and communication, data analysis software tools bridge the gap between technical and non-technical stakeholders, enabling informed decision-making at all levels of an organization.
As these tools continue to evolve and incorporate cutting-edge technologies, the future of data analysis looks promising. With automation, machine learning, and cloud integration, data analysis software tools are poised to play an even more significant role in driving data-driven success and innovation for businesses worldwide. Embrace the power of data analysis software tools, and unlock the full potential of your data to thrive in the data-centric world of tomorrow.
0 notes