#csv-training
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
BuzzFeed published a report claiming that Tumblr was utilized as a distribution channel for Russian agents to influence American voting habits during the 2016 presidential election in Feb 2018.
Text
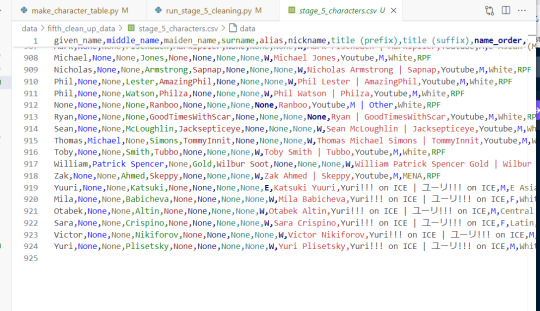
*laughs in still 923 characters in my data set after cleaning up all the duplicate names* 🙃 (down from 975 (unique) old names)
#ship stats#coding#I love csv files they're so satisfying to look at#I'm like THIS 🤏 close to visualising this first version aaaah#I've assigned and completed/corrected (as much as possible) the demographic data#(you need to understand the amount of wikis I had to manually look through for this cleaning process)#now turning everything into csv files again so I can LOOK AT EM BETTER#and then need to look into vis softwares to use o.o#we had bootcamp graduation today also!! 🎉 I am officially a trained data engineer#what will I do with my time now until I have hunted myself a job? hoPEFULLY FINALLY EDIT MY REMAINING MATRIARCHY VIDEOS Q.Q
3 notes
·
View notes
Text
Computer System Validation (CSV) Certification
Are you looking to advance your professional career in pharmaceutical or life sciences technical compliance? Our Computer System Validation Certification is designed for people aiming to apply GxP regulations, 21 CFR Part 11, and validation documentation essentials to real work scenarios. At Pharma Connections, we try to bridge the gap between industry and academia, focusing on hands-on learning, real cases, and expert mentoring.
If you are working on the QA side, IT, or regulatory, the course will equip you to handle audits properly, ensure data integrity, and remain compliant. Practical yet flexible, this course equips you with skills for validation sought after by all top employers. Get started with our course to secure a bright future in pharma.
#computer system validation certification#computer system validation training#computer system validation course#csv certification#computer system validation course online
0 notes
Text
Ensure GMP compliance in your Indore pharmaceutical operations with Zenovel's expert Computer System Validation (CSV) services. We help you validate your critical systems for data integrity and regulatory adherence.
#data integrity#quality assurance#compliance training#Computer System Validation#regulatory requirements#GAP assessment#GMP compliance#software validation#computer validation#csv service work#validation services#GMP Computer System Validation#csv service#computer system validation gmp
0 notes
Text

Learn Computer System Validation (CSV) with IGMPI’s industry-focused program. Gain expertise in regulatory compliance, FDA, GAMP 5 guidelines, and risk assessment for validated systems. Enroll now!
0 notes
Text

Computer System Validation Online Training | Pharma Connections
Enhance your regulatory compliance with Pharma Connections' Computer System Validation Online Training. Specializing in CSV for pharmaceuticals, our expert-led courses, consulting, and auditing services empower your team to meet industry standards. Elevate your compliance strategy today!
0 notes
Text
Computer System Validation Online Training | Pharma Connections
Boost compliance with Pharma Connections' Computer System Validation Online Training. Tailored for CSV in pharmaceuticals, access top-tier instruction, consulting, and auditing services. Elevate your regulatory confidence today!
0 notes
Text
Computer System Validation Training
Unlock precision and compliance in your IT systems with our Computer System Validation Training. Equip your team with the skills needed to ensure seamless operations and regulatory adherence in the pharmaceutical industry. Elevate your validation expertise today.
Read More: https://www.skillbee.co.in/courses/certificate-in-computer-system-validation/
0 notes
Text
i feel like this trying to train a fucking NLP model

#like Microsoft has one where i dont need to convert word docs to csv files via python. cool#now there's the issue of. I've never trained an AI model and have no fucking clue what i am doing#but boy. We Are Trying#miscellaneous#also maybe doesnt help i did not sleep well last night but we are pushing through ^^;
1 note
·
View note
Text
AO3 Data Scraped for AI Training Dataset
What is happening, and what you can do. Check for potential edits with additions at the end of the post!
What is happening? What do we know?
A user going by "nyuuzyou" on the HuggingFace platform uploaded a dataset a few days ago - containing scraped content from AO3. HuggingFace is a very popular platform and widely used for sharing machine learning and AI models/datasets. The scraped dataset includes fics, fanart, and other fanworks - all taken without permission and intended for use in training gen AI models. You can find more information in this Reddit post.
This dataset is one of several compiled from various websites—at least seven in total. While two datasets have been removed, the AO3 one was only disabled on HuggingFace. This means that it’s not downloadable at the moment but still visible. It may also return if takedown efforts end up being challenged/reversed by that user.
Key Details
Scope: On AO3, all content with work IDs between 1 and 63,200,000 has been targeted. The work ID is the number at the end of a work's URL — for example, in https://archiveofourown.org/works/12345678, 12345678 is the work ID. You can find it by simply opening the work and checking the URL in your browser’s address bar. So, if your work falls in that range and is publicly accessible (i.e., not locked and open to everyone, including guests), it’s mostly likely included in the dataset. This dataset is currently disabled on HuggingFace, but that doesn't mean it's gone. It's only a temporary takedown as of now.
Takedown notices have been issued, but this user has also uploaded the dataset to other sites after backlash and partial removal.
There are talks in the discussion forums of potentially moving this dataset to Telegram, torrents, and/or other private channels.
HuggingFace AO3 dataset page
Other distributed sites listed here (as per a Reddit comment)
Currently deleted from ModelScope
What can you do?
Should the dataset return again and you see that your work was affected: file your own DMCA or copyright takedown notice. The uploader, in their own words, "has not agreed to take down the entire repo. At this time, the scraper has agreed with taking down art from the person who owns the copyright. That means each of you will need to request a takedown."
Instructions and a sample CSV template to list your work IDs for removal are provided in this guide. You can find more details in this announcement by PaperDemon.
Lock your works! It would limit visibility to registered users only, and is a very good step to prevent scraping or unauthorized use. To lock all your works on AO3, go to “My Works,” click “Edit Works,” and select all. Then click “Edit” and check the box labeled “Only show to registered users.” Scroll down and click “Update All Works” to apply the change.
⚠️ | Final Notes:
This user has so far shown no signs of stopping and is continuing to redistribute the data across multiple sites, even after numerous takedown requests (read more here). So, we can only recommend to be cautious and beware, lock your works, feel free to make use of takedown notices if you're unfortunately affected, and spread the word to fellow creators.
Follow up on this and get the latest updated in the Fanfic Communities Network (FCN) Discord Server!
If you have more information regarding this - e.g. if works from other sites are affected too - please reach out to us in the FCN!!
Edit (2025-04-26):
The user who has scraped the works has, upon request by another person, posted a way to convert ao3 json to markdown:
https://huggingface.co/datasets/nyuuzyou/archiveofourown/discussions/170
https://gist.github.com/nyuuzyou/b2f83669ad80a22e435728245ebcdf9f
This shows us that nyuuzyou continues to show no signs of taking down the scraped works.
Edit (2025-04-28):
A user warned that even archive-locked AO3 fics were included in a scraped dataset (most likely taken while the scraper was logged in, before they were banned or switched to public-only access). Some public works were missed as well:
https://huggingface.co/datasets/nyuuzyou/archiveofourown/discussions/213#680fcdb76d9e022324a70cf1
Edit (2025-05-03):
Hey everybody, this is a bit late, but the AO3 dataset has been permanently removed from HuggingFace: https://huggingface.co/datasets/nyuuzyou/archiveofourown. While this unfortunately doesn’t prevent it from being shared elsewhere (like torrents) nor does it guarantee any deletion of past downloads and whatnot, having it taken down from a major platform like HF is still a significant step forward. (There is more info about other sites on PaperDemon.)
So please don’t be disheartened—every action counts, and this shows that pushing back and filing DMCAs and copyright notices as appropriate does make a difference. We’ll certainly keep an eye out for more info and post updates here, but thank you again to everyone who helped report, spread the word, or supported the effort. Keep reading, keep writing. ♥️
#fanfiction#community#discordserver#fanfiction community#theft#ao3 works being stolen#fanfic theft#fanfiction stealing#ao3
155 notes
·
View notes
Text
The Future
It's always grating to read or listen to random members of the public talk about AI in the media, and it is much more grating to listen to "futurists" or politicians or so-called experts who have absolutely no domain expertise nor background in machine learning talk about things "AI" will be able to do in the future. A lot of the time, they will predict that AI (which means conversational agents based on large language models trained with transformers and attention) will do things in the future that can already be done by humans, and by computers without any AI, machine learning, or large text corpora, back in the 90s. Politicians on the other hand sometimes use "AI" to deflect criticisms of infeasible ideas. How will this work, exactly? AI!
Sometimes using AI as a buzzword is the point. Nobody wants to hear "we will develop another app".
It usually doesn't take extreme forms like "In the future, AI will allow us to transplant human hearts", but I have seen weaker forms like "In the future, technologies like ChatGPT will make genome-wide association studies and automatic drug discovery possible". You don't need large language models for GWAS or drug discovery. The data sets for this are very different, and I doubt a system like ChatGPT could just absorb a large CSV file of medial data if you pasted it into the conversation.
If you look at claims about "the future" from the recent past, you see the same thing said about blockchain, web 2.0 mash-ups and tagging, the semantic web/ontologies, smart homes, and so on. "In the future, we will all have smart fridges" – "In the future you will begin your day by asking Siri what your appointments are and what you should eat for breakfast" – "In the future your PC will print your newspaper at home." – "In the future you will pay for groceries out of your Bitcoin Wallet."
If you push back, and you point out that a this new claim sounds like a bullshit claim about blockchain, smart fridges, and the semantic web, you usually hear "That's what they said about cars. That's what they said about television." Never mind who "they" are. Never mind that they didn't say that about cars, they said that about Bitcoin. Cars are just a massive outlier. Cars were immensely successful, and they were largely unchanged for 120 years, with for wheels and an internal combustion engine that runs on petrol. Cars are noisy, smelly, and dangerous to pedestrians and occupants. For decades, leaded petrol used in cars distributed lead into the air and int the food supply. Cars depend on an infrastructure of asphalt roads and petrol stations. This is different from what they said about CDs or monorail or QR codes or pneumatic tubes. As for TV, it is usually invoked to say "People thought TV would rot our brains, yet here we are". There is no denying that TV had profoundly changed how people spend their time, changed politics, changed how fast the news cycle is, and so on, often for the worse.
It's so easy to refute "that's what they said about cars" that I could probably fill 50 A4 pages with the history of technologies that failed in some way, purely from memory, and then find old newspaper quotes from optimists and futurists that compared the naysayers (correct in hindsight) with car skeptics, and I could fill another 50 pages with ways inventions like cars and TV and the Internet profoundly changed society, and then find quotes from futurists that explain that the Internet is really just a better fax machine, and the car is like a faster horse, so we have nothing to worry about.
There's another way to dismiss skeptics of new technology, and it's harder to refute, even though it operates on the same kind of hindsight bias:
Imagine the year is 1995. What couldn't you achieve if only you knew that computers and the Internet would be big? Imagine you can send a letter to yourself in 1995. Wouldn't you want to tell your former self that the Internet will be the Next Big Thing? Wouldn't you want to tell your former self that by 2015, everybody will have an Internet-connected computer in their pockets?
It's easy to refute the hindsight bias of "that's what they said about cars" with example after example of technologies that didn't catch on for 100 years like cars did.
Where's the error here? If you say something like "Language-model AI is the future! Wouldn't you rather get on the bandwagon sooner than later?" you risk investing your money into a scam just to get in on the ground floor.
But really think it through: Imagine the year is 1985. A time traveller tells you that computers are going to be big. Everybody is going to have one. What do you do? Do you quit your job and work in the computer industry? If not, do you buy a computer? Which one? A C64? An IBM PC XT? Atari ST?
I don't know how much you could really do with this information. Should you invest your savings into Atari? Should you learn to program?
Imagine the year is 1985. A timer traveller tells you that the CD is going to replace vinyl and cassette tapes, then there will be mp3 players, but nothing will really replace mp3 players, and then streaming music from centralised servers will replace mp3 players. Nothing will really replace the CD, but the music industry will be completely different. Nobody will sell music on SD cards, mini discs are better than CDs in terms of technology, but they solve the wrong problem. All the cool indie bands that released free promo mp3s in the 2000s will split up or sell out. "What's an mp3?", you ask.
Imagine the year is 2005. Every pseudo-intellectual Internet commenter seems to think VHS won against BetaMax because of pornography. They are going to produce pornography for HD-DVD. You think Blu-Ray is dead in the water. A time traveller appears, and he tells you that actually, VHS won against BetaMax because the tapes are longer, and it allows you to VCR a long television program. Yes, they are going to produce pornography for the HD-DVD first, but it doesn't matter. Ever since Internet pornography, nobody goes to the sex shop anyway, just to risk coming out of the door with a shopping bag full of HD-DVDs, just as his neighbour's wife is coming out of the liquor store across the street. Still the Blu-ray won't replace DVDs like DVDs replaced VHS, because you can still play a DVD in a Blu-ray player, and it will all be streaming in a couple of years anyway.
What will you do with this information, other than buy a Blu-ray player?
Imagine the year is 1923. A time traveller tells you that cars are going to be big. Really big. Everybody will own one, and a garage. Petrol stations are everywhere already, but soon there will be traffic jams. Cities will be planned for cars, not people.
Should you buy a car now? Should you wait for the technology to mature?
The year is 2025. Somebody tells you that LLMs are going to be big. Bigger than they are. Bigger than ever. Bigger than Jesus. He tells you you're a sucker if you don't use ChatGPT. You think he's right, but you don't work in a job that can be done by ChatGPT. You work at a bakery. Maybe just not yet?
What should you do?
I think the idea that you should get in now, and you will "miss the boat" if you don't learn to use GenAI and conversational agents, that idea is just stupid. It's half special pleading, half Pascal's Wager, and a lot of hindsight bias. You couldn't really "get into" other technologies before they matured. Futurists confidently predicted in 2022 that "prompt engineer" was going to be a job, when obviously companies like Google, Anthropic, and OpenAI had every reason and every incentive to work on making their systems better understand users, to make prompt engineering obsolete. At some point owning a car meant learning to be a car mechanic or having a chauffeur who was your personal car mechanic, and then the technology matured. Cars are more complex now, and harder to repair when something breaks, but they are also more reliable and have diagnostic lights.
So should you use ChatGPT or Claude now, just to get ready for "The Future"? I don't know. All I know is that AI won't be a faster horse.
13 notes
·
View notes
Text
Latest AO3 scrape into AI database
Please read this if you're an AO3 user with public, not archive-locked works. This is information on the latest known instance of someone taking AO3 works to build datasets on which to train AI and the ongoing process to get them removed. I don't really make posts adressing people, but I am furious about my work being used and I know some of my mutuals don't have their fics archive-locked so I hope I can at least get the information to some people.
Earlier this month (April) a, to my understanding, rp fanworks website named PaperDemon.com got word that a user of an AI dataset website, HuggingFace, had scraped its contents, as well as those of a bunch of other websites among which AO3 is included, where they can be freely downloaded to train generative AI models. For AO3 specifically, the user themselves reports that all public works with IDs ranging from 1 to 63,200,000 have been scraped.
As of April 25 and per the updating Paper Demon publication, 2 of 8 affected sites have gotten their content removed and the rest have achieved temporary disabling (supposedly data is visible but not downloadable) pending a counter-notice from the scraper, who appears to be set on the aim of dismissing the request as unfounded. Furthermore, the AO3 dataset has already been downloaded 2,244 times in the last month. On earlier updates of the PD post they mentioned that the scraper agreed to remove, on an individual basis, the content of those who file a Copyright infringement report. So far there are about 150 reports against the AO3 dataset. The scraper also uploaded them to another website, but appears to have removed at least the PD ones, as well as to his personal website which the PD post doesn't even link for safety reasons. The platform HuggingFace has also been made aware of the situation (that's what got us the temporary disabling)
I have personally filed a Copyright infringement report using the helpful guide put together by the PD team and have emailed the scraper on the address listed there providing the title and URL of my work and requesting for it to be removed from the dataset.
I have one concern regarding the PD guide, though (disclaimer: this is coming from someone with a very limited knowledge on computers & digital information and my understanding of the majority of concepts is from 3h of internet searches + ms help page + messing around in my laptop) They rightly recommend to not publish the work URLs in the report and instead instruct to collect them in a spreadsheet in .cvs filetype. This, however, has a problem of personally-identifying metadata being stored "alongside" the file itself and it can be accessed. The MS Excel Inspector tool allows the removal of this type of data, but apparently only when it's shared through the MS account? For Google sheets there is a different problem, which is that you can't just make your spreadsheet in .csv filetype, you need to download it and the reupload it (if there is a way, it's not easily accessible; i looked at like 4 step-by-step guides and they all said to download) which again adds properties to the file that may contain personal information.
I was very sleep deprived and very close to giving up, because I do not wish to provide a person that's massively stealing content any information linked to my identity, but then I thought I could just send the info on the email body itself. It's not the best solution but I think it's better than the alternative.
I am beyond mad that this happened and will archive-lock my affected work as soon as I receive a response (or after enough days of silence, I guess, but I hope my report won't be ignored). Unfortunately I can't file a DMCA take-down notice, because it requires personal information which might be shared with the infringer if they file a counter-notice, but I have hope that, if everyone whose works were scraped files Copyright infringement reports, AO3's DMCA won't be dismissed.
I encourage anyone who has read this to also file a report to get their work(s) removed asap and, if anyone is more informed or knowledgeable on the topic, to please share any useful info you have. I might also email AO3 to inquire about the DMCA status later because the PD publication is understandably only really tracking theirs.
#i don't feel comfortable tagging anyone in this but i might come into my mutuals' inboxes to tell you if i know your fics aren't locked#i don't want to be annoying about this but i can't imagine anyone will be happy their work got stolen and fed to genAI#mine is just one piece of fanart but i am still disgusted by this#tagging my two main fandoms so it can hopefully be seen#aftg#all for the game#txf#the x files#ao3#archive of our own
12 notes
·
View notes
Text
Computer System Validation Course
Want to build your skills in Computer System Validation (CSV)? Pharma Connections offers an industry-focused computer system validation course for pharma and life sciences professionals.
This course will teach you GxP compliance, 21 CFR Part 11, data integrity, and validation activities—all necessary in regulated environments. You will gain insight from the industry's greatest experts by working on practical projects, attending actual case studies, and taking flexible online lessons.
If you are in QA, IT, or compliance, this course will prepare you for key positions in regulated systems. Update your skills, prepare for audits, and advance your career with training that addresses current industry requirements and future challenges. Join Our CSV Certification Program: https://pharmaconnections.in/computer-system-validation/
#computer system validation training#online computer certification courses#computer system validation course#csv certification
0 notes
Text
yesterday I had a meeting with my future boss to go over an issue I asked the whole sales dept to work on cause it was causing customer-facing data problems.
explaining the multiple root causes of everything that led to this one issue felt like describing a negative skill tree. as in, here're all the branching points of failures these guys have been earning over the years to continuously do their jobs dumber and worse.
convo went:
salespeople either do not adequately manage their customers' inventories or don't attempt managing them.
salespeople either do not create processes, do not document processes, or do not train others to follow processes.
salespeople do not understand how to format csv file downloads to begin managing inventory unassisted. their overall knowledge of excel is frighteningly limited.
salespeople do not communicate problems or needs when they do not have the skills or tools to resolve problems effectively on their own. instead, they choose to act on impulse without fundamental understanding of how their actions might impact anything.
salespeople intentionally misuse editable attribute fields in our system to suit their random one-off needs, creating bad data.
salespeople have created such an incredible amount of bad data (and continue to do so) that many basic filters are completely unusable.
salespeople do not understand (or care) how bad data affects other parts of our system.
salespeople have far too many permissions to edit critical data in our system.
the combination of salespeople's wide range of permissions and lack of processes (or just plain inconsiderate behavior) allows them to circumvent critical checks and balances (and I've caught them doing this shit before).
salespeople have been allowed to show blatant hostility for so long that it is impossible to bring issues to their attention and have those issues resolved. they refuse to work toward solutions if they feel slighted.
I could go on.
22 notes
·
View notes
Text
Python Libraries to Learn Before Tackling Data Analysis
To tackle data analysis effectively in Python, it's crucial to become familiar with several libraries that streamline the process of data manipulation, exploration, and visualization. Here's a breakdown of the essential libraries:
1. NumPy
- Purpose: Numerical computing.
- Why Learn It: NumPy provides support for large multi-dimensional arrays and matrices, along with a collection of mathematical functions to operate on these arrays efficiently.
- Key Features:
- Fast array processing.
- Mathematical operations on arrays (e.g., sum, mean, standard deviation).
- Linear algebra operations.
2. Pandas
- Purpose: Data manipulation and analysis.
- Why Learn It: Pandas offers data structures like DataFrames, making it easier to handle and analyze structured data.
- Key Features:
- Reading/writing data from CSV, Excel, SQL databases, and more.
- Handling missing data.
- Powerful group-by operations.
- Data filtering and transformation.
3. Matplotlib
- Purpose: Data visualization.
- Why Learn It: Matplotlib is one of the most widely used plotting libraries in Python, allowing for a wide range of static, animated, and interactive plots.
- Key Features:
- Line plots, bar charts, histograms, scatter plots.
- Customizable charts (labels, colors, legends).
- Integration with Pandas for quick plotting.
4. Seaborn
- Purpose: Statistical data visualization.
- Why Learn It: Built on top of Matplotlib, Seaborn simplifies the creation of attractive and informative statistical graphics.
- Key Features:
- High-level interface for drawing attractive statistical graphics.
- Easier to use for complex visualizations like heatmaps, pair plots, etc.
- Visualizations based on categorical data.
5. SciPy
- Purpose: Scientific and technical computing.
- Why Learn It: SciPy builds on NumPy and provides additional functionality for complex mathematical operations and scientific computing.
- Key Features:
- Optimized algorithms for numerical integration, optimization, and more.
- Statistics, signal processing, and linear algebra modules.
6. Scikit-learn
- Purpose: Machine learning and statistical modeling.
- Why Learn It: Scikit-learn provides simple and efficient tools for data mining, analysis, and machine learning.
- Key Features:
- Classification, regression, and clustering algorithms.
- Dimensionality reduction, model selection, and preprocessing utilities.
7. Statsmodels
- Purpose: Statistical analysis.
- Why Learn It: Statsmodels allows users to explore data, estimate statistical models, and perform tests.
- Key Features:
- Linear regression, logistic regression, time series analysis.
- Statistical tests and models for descriptive statistics.
8. Plotly
- Purpose: Interactive data visualization.
- Why Learn It: Plotly allows for the creation of interactive and web-based visualizations, making it ideal for dashboards and presentations.
- Key Features:
- Interactive plots like scatter, line, bar, and 3D plots.
- Easy integration with web frameworks.
- Dashboards and web applications with Dash.
9. TensorFlow/PyTorch (Optional)
- Purpose: Machine learning and deep learning.
- Why Learn It: If your data analysis involves machine learning, these libraries will help in building, training, and deploying deep learning models.
- Key Features:
- Tensor processing and automatic differentiation.
- Building neural networks.
10. Dask (Optional)
- Purpose: Parallel computing for data analysis.
- Why Learn It: Dask enables scalable data manipulation by parallelizing Pandas operations, making it ideal for big datasets.
- Key Features:
- Works with NumPy, Pandas, and Scikit-learn.
- Handles large data and parallel computations easily.
Focusing on NumPy, Pandas, Matplotlib, and Seaborn will set a strong foundation for basic data analysis.
8 notes
·
View notes
Text
Breakthrough SAAS Delivers High-Quality Buyer Traffic From YouTube for Just Pennies
Unlock Unlimited Leads with Targeted Buyer Traffic from YouTube Ads – A Level of Targeting You Won’t Find on Facebook!
What is TubeTarget? Video marketing was one of the biggest trends in 2019! YouTube continues to grow in viewership and engagement, even as interest in other social platforms declines. Marketers are keen to discover the next big thing beyond Facebook, and YouTube ads are proving to be just that.
This powerful SAAS provides Facebook-level targeting for your video advertisements. You can explore specific niches and precisely pinpoint the videos and channels your target audience is watching.
The Result: You reach the most targeted audience possible, ensuring they see your ad while actively seeking the product or service you offer.
Users can easily export the targeting options into a Google Ads-compatible CSV file, allowing them to have their ads running in just minutes.
The included training provides your customers with a clear roadmap to achieve the best returns from their ad campaigns.
SAAS + Training: The Perfect Combination for Your Eager Customers
Discover the exact videos your niche audience is watching.
Identify the specific channels that your target market follows.
Create your personalized targeting catalog and export it in a Google Ads-compatible CSV file.
Benefit from detailed training on how to become a winner with video ads.
A Solution the Market Is Searching For
Facebook advertising costs are soaring due to increased competition for bids, and the active audience is dwindling. Many users have grown weary of the political content and opinionated posts, resulting in a significant drop in time spent on the platform. Facebook has shifted from a space for personal sharing to one dominated by political discourse.
In contrast, YouTube is experiencing impressive growth, with more people watching than ever before, and audiences are spending increased amounts of time on the platform.
YouTube ads are now a legitimate and powerful alternative to Facebook ads. This product simplifies the process for users to start using YouTube ads and profit from them.
Full features without compromise – powerful capabilities included.
Maintained and supported by a professional company.
Offers precise targeting to help you dominate your niche effectively.
The included training makes it accessible for even beginners to get started with YouTube ads.
The Most Powerful YouTube Ads Targeting System Ever Created
Better targeting than Facebook: Connect with your audience when they’re actively searching for your products.
Still underutilized, offering ample opportunities for growth and sales.
Locate thousands of targeted videos in any niche and easily export them for immediate targeting.
Identify hundreds of popular, high-authority channels in your niche for instant targeting.
Enjoy cheaper clicks and a larger audience than any other social media platform.
Comprehensive YouTube ads training makes starting easy, even for those with zero skills.
Continuously develop campaigns centered around specific niches or keywords, and quickly create export files ready for Google Ads.
High-Quality Product + Training Available in One Package [Click to Watch the Demo]
Why Partner with TubeTarget?
Trustworthy since 2013
Over $3.5 million in sales
60 successful product launches
More than 120,000 satisfied customers
A perfect record of sales and services
A Proven Track Record of Prosperous, Well-Received, and Well-Maintained Products
#youtube marketing#youtube ads#youtube#marketingstrategy#googleads#search engine marketing#digitalmarketing#facebookads#make money online#make money from home#google#graphic design#marketing#youtubemusic#youtube video#automation#marketing tools#small business marketing#small business ideas#small business support#small business owner#small business tips#etsy#etsyseller#etsyshop
2 notes
·
View notes
Text
Computer System Validation Course Online
The Computer System Validation Course Online is a comprehensive program designed to equip individuals with the knowledge and skills needed to ensure the integrity, reliability, and compliance of computer systems in regulated industries. Participants will learn industry best practices, regulatory requirements, and validation strategies to effectively validate and maintain computerized systems.
0 notes