#data bias for ml
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr was attacked by a cross-site scripting worm deployed by the Internet troll group GNAA on Dec 3, 2012.
Text
The surprising truth about data-driven dictatorships

Here’s the “dictator’s dilemma”: they want to block their country’s frustrated elites from mobilizing against them, so they censor public communications; but they also want to know what their people truly believe, so they can head off simmering resentments before they boil over into regime-toppling revolutions.
These two strategies are in tension: the more you censor, the less you know about the true feelings of your citizens and the easier it will be to miss serious problems until they spill over into the streets (think: the fall of the Berlin Wall or Tunisia before the Arab Spring). Dictators try to square this circle with things like private opinion polling or petition systems, but these capture a small slice of the potentially destabiziling moods circulating in the body politic.
Enter AI: back in 2018, Yuval Harari proposed that AI would supercharge dictatorships by mining and summarizing the public mood — as captured on social media — allowing dictators to tack into serious discontent and diffuse it before it erupted into unequenchable wildfire:
https://www.theatlantic.com/magazine/archive/2018/10/yuval-noah-harari-technology-tyranny/568330/
Harari wrote that “the desire to concentrate all information and power in one place may become [dictators] decisive advantage in the 21st century.” But other political scientists sharply disagreed. Last year, Henry Farrell, Jeremy Wallace and Abraham Newman published a thoroughgoing rebuttal to Harari in Foreign Affairs:
https://www.foreignaffairs.com/world/spirals-delusion-artificial-intelligence-decision-making
They argued that — like everyone who gets excited about AI, only to have their hopes dashed — dictators seeking to use AI to understand the public mood would run into serious training data bias problems. After all, people living under dictatorships know that spouting off about their discontent and desire for change is a risky business, so they will self-censor on social media. That’s true even if a person isn’t afraid of retaliation: if you know that using certain words or phrases in a post will get it autoblocked by a censorbot, what’s the point of trying to use those words?
The phrase “Garbage In, Garbage Out” dates back to 1957. That’s how long we’ve known that a computer that operates on bad data will barf up bad conclusions. But this is a very inconvenient truth for AI weirdos: having given up on manually assembling training data based on careful human judgment with multiple review steps, the AI industry “pivoted” to mass ingestion of scraped data from the whole internet.
But adding more unreliable data to an unreliable dataset doesn’t improve its reliability. GIGO is the iron law of computing, and you can’t repeal it by shoveling more garbage into the top of the training funnel:
https://memex.craphound.com/2018/05/29/garbage-in-garbage-out-machine-learning-has-not-repealed-the-iron-law-of-computer-science/
When it comes to “AI” that’s used for decision support — that is, when an algorithm tells humans what to do and they do it — then you get something worse than Garbage In, Garbage Out — you get Garbage In, Garbage Out, Garbage Back In Again. That’s when the AI spits out something wrong, and then another AI sucks up that wrong conclusion and uses it to generate more conclusions.
To see this in action, consider the deeply flawed predictive policing systems that cities around the world rely on. These systems suck up crime data from the cops, then predict where crime is going to be, and send cops to those “hotspots” to do things like throw Black kids up against a wall and make them turn out their pockets, or pull over drivers and search their cars after pretending to have smelled cannabis.
The problem here is that “crime the police detected” isn’t the same as “crime.” You only find crime where you look for it. For example, there are far more incidents of domestic abuse reported in apartment buildings than in fully detached homes. That’s not because apartment dwellers are more likely to be wife-beaters: it’s because domestic abuse is most often reported by a neighbor who hears it through the walls.
So if your cops practice racially biased policing (I know, this is hard to imagine, but stay with me /s), then the crime they detect will already be a function of bias. If you only ever throw Black kids up against a wall and turn out their pockets, then every knife and dime-bag you find in someone’s pockets will come from some Black kid the cops decided to harass.
That’s life without AI. But now let’s throw in predictive policing: feed your “knives found in pockets” data to an algorithm and ask it to predict where there are more knives in pockets, and it will send you back to that Black neighborhood and tell you do throw even more Black kids up against a wall and search their pockets. The more you do this, the more knives you’ll find, and the more you’ll go back and do it again.
This is what Patrick Ball from the Human Rights Data Analysis Group calls “empiricism washing”: take a biased procedure and feed it to an algorithm, and then you get to go and do more biased procedures, and whenever anyone accuses you of bias, you can insist that you’re just following an empirical conclusion of a neutral algorithm, because “math can’t be racist.”
HRDAG has done excellent work on this, finding a natural experiment that makes the problem of GIGOGBI crystal clear. The National Survey On Drug Use and Health produces the gold standard snapshot of drug use in America. Kristian Lum and William Isaac took Oakland’s drug arrest data from 2010 and asked Predpol, a leading predictive policing product, to predict where Oakland’s 2011 drug use would take place.
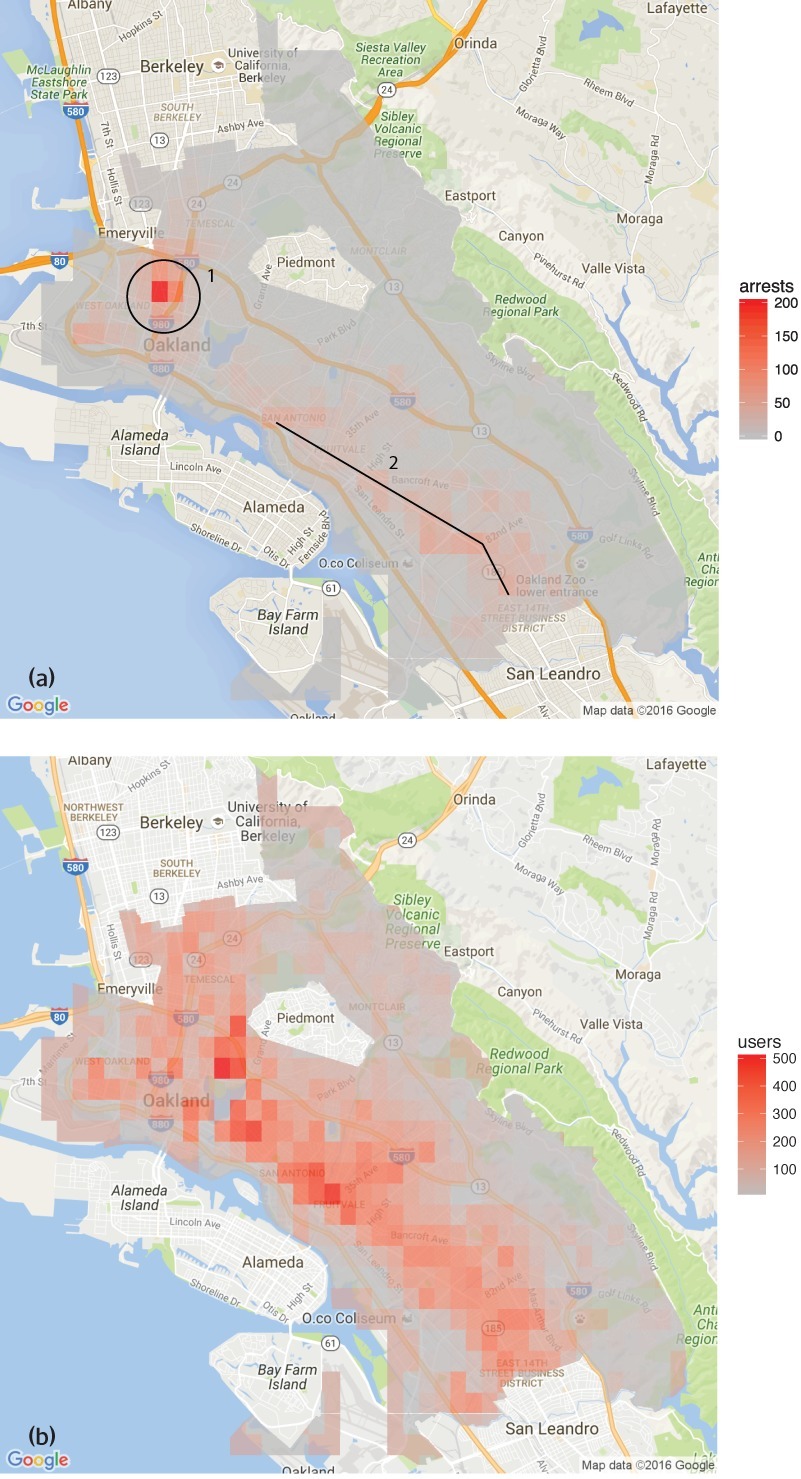
[Image ID: (a) Number of drug arrests made by Oakland police department, 2010. (1) West Oakland, (2) International Boulevard. (b) Estimated number of drug users, based on 2011 National Survey on Drug Use and Health]
Then, they compared those predictions to the outcomes of the 2011 survey, which shows where actual drug use took place. The two maps couldn’t be more different:
https://rss.onlinelibrary.wiley.com/doi/full/10.1111/j.1740-9713.2016.00960.x
Predpol told cops to go and look for drug use in a predominantly Black, working class neighborhood. Meanwhile the NSDUH survey showed the actual drug use took place all over Oakland, with a higher concentration in the Berkeley-neighboring student neighborhood.
What’s even more vivid is what happens when you simulate running Predpol on the new arrest data that would be generated by cops following its recommendations. If the cops went to that Black neighborhood and found more drugs there and told Predpol about it, the recommendation gets stronger and more confident.
In other words, GIGOGBI is a system for concentrating bias. Even trace amounts of bias in the original training data get refined and magnified when they are output though a decision support system that directs humans to go an act on that output. Algorithms are to bias what centrifuges are to radioactive ore: a way to turn minute amounts of bias into pluripotent, indestructible toxic waste.
There’s a great name for an AI that’s trained on an AI’s output, courtesy of Jathan Sadowski: “Habsburg AI.”
And that brings me back to the Dictator’s Dilemma. If your citizens are self-censoring in order to avoid retaliation or algorithmic shadowbanning, then the AI you train on their posts in order to find out what they’re really thinking will steer you in the opposite direction, so you make bad policies that make people angrier and destabilize things more.
Or at least, that was Farrell(et al)’s theory. And for many years, that’s where the debate over AI and dictatorship has stalled: theory vs theory. But now, there’s some empirical data on this, thanks to the “The Digital Dictator’s Dilemma,” a new paper from UCSD PhD candidate Eddie Yang:
https://www.eddieyang.net/research/DDD.pdf
Yang figured out a way to test these dueling hypotheses. He got 10 million Chinese social media posts from the start of the pandemic, before companies like Weibo were required to censor certain pandemic-related posts as politically sensitive. Yang treats these posts as a robust snapshot of public opinion: because there was no censorship of pandemic-related chatter, Chinese users were free to post anything they wanted without having to self-censor for fear of retaliation or deletion.
Next, Yang acquired the censorship model used by a real Chinese social media company to decide which posts should be blocked. Using this, he was able to determine which of the posts in the original set would be censored today in China.
That means that Yang knows that the “real” sentiment in the Chinese social media snapshot is, and what Chinese authorities would believe it to be if Chinese users were self-censoring all the posts that would be flagged by censorware today.
From here, Yang was able to play with the knobs, and determine how “preference-falsification” (when users lie about their feelings) and self-censorship would give a dictatorship a misleading view of public sentiment. What he finds is that the more repressive a regime is — the more people are incentivized to falsify or censor their views — the worse the system gets at uncovering the true public mood.
What’s more, adding additional (bad) data to the system doesn’t fix this “missing data” problem. GIGO remains an iron law of computing in this context, too.
But it gets better (or worse, I guess): Yang models a “crisis” scenario in which users stop self-censoring and start articulating their true views (because they’ve run out of fucks to give). This is the most dangerous moment for a dictator, and depending on the dictatorship handles it, they either get another decade or rule, or they wake up with guillotines on their lawns.
But “crisis” is where AI performs the worst. Trained on the “status quo” data where users are continuously self-censoring and preference-falsifying, AI has no clue how to handle the unvarnished truth. Both its recommendations about what to censor and its summaries of public sentiment are the least accurate when crisis erupts.
But here’s an interesting wrinkle: Yang scraped a bunch of Chinese users’ posts from Twitter — which the Chinese government doesn’t get to censor (yet) or spy on (yet) — and fed them to the model. He hypothesized that when Chinese users post to American social media, they don’t self-censor or preference-falsify, so this data should help the model improve its accuracy.
He was right — the model got significantly better once it ingested data from Twitter than when it was working solely from Weibo posts. And Yang notes that dictatorships all over the world are widely understood to be scraping western/northern social media.
But even though Twitter data improved the model’s accuracy, it was still wildly inaccurate, compared to the same model trained on a full set of un-self-censored, un-falsified data. GIGO is not an option, it’s the law (of computing).
Writing about the study on Crooked Timber, Farrell notes that as the world fills up with “garbage and noise” (he invokes Philip K Dick’s delighted coinage “gubbish”), “approximately correct knowledge becomes the scarce and valuable resource.”
https://crookedtimber.org/2023/07/25/51610/
This “probably approximately correct knowledge” comes from humans, not LLMs or AI, and so “the social applications of machine learning in non-authoritarian societies are just as parasitic on these forms of human knowledge production as authoritarian governments.”

The Clarion Science Fiction and Fantasy Writers’ Workshop summer fundraiser is almost over! I am an alum, instructor and volunteer board member for this nonprofit workshop whose alums include Octavia Butler, Kim Stanley Robinson, Bruce Sterling, Nalo Hopkinson, Kameron Hurley, Nnedi Okorafor, Lucius Shepard, and Ted Chiang! Your donations will help us subsidize tuition for students, making Clarion — and sf/f — more accessible for all kinds of writers.
Libro.fm is the indie-bookstore-friendly, DRM-free audiobook alternative to Audible, the Amazon-owned monopolist that locks every book you buy to Amazon forever. When you buy a book on Libro, they share some of the purchase price with a local indie bookstore of your choosing (Libro is the best partner I have in selling my own DRM-free audiobooks!). As of today, Libro is even better, because it’s available in five new territories and currencies: Canada, the UK, the EU, Australia and New Zealand!
[Image ID: An altered image of the Nuremberg rally, with ranked lines of soldiers facing a towering figure in a many-ribboned soldier's coat. He wears a high-peaked cap with a microchip in place of insignia. His head has been replaced with the menacing red eye of HAL9000 from Stanley Kubrick's '2001: A Space Odyssey.' The sky behind him is filled with a 'code waterfall' from 'The Matrix.']
Image: Cryteria (modified) https://commons.wikimedia.org/wiki/File:HAL9000.svg
CC BY 3.0 https://creativecommons.org/licenses/by/3.0/deed.en
—
Raimond Spekking (modified) https://commons.wikimedia.org/wiki/File:Acer_Extensa_5220_-_Columbia_MB_06236-1N_-_Intel_Celeron_M_530_-_SLA2G_-_in_Socket_479-5029.jpg
CC BY-SA 4.0 https://creativecommons.org/licenses/by-sa/4.0/deed.en
—
Russian Airborne Troops (modified) https://commons.wikimedia.org/wiki/File:Vladislav_Achalov_at_the_Airborne_Troops_Day_in_Moscow_%E2%80%93_August_2,_2008.jpg
“Soldiers of Russia” Cultural Center (modified) https://commons.wikimedia.org/wiki/File:Col._Leonid_Khabarov_in_an_everyday_service_uniform.JPG
CC BY-SA 3.0 https://creativecommons.org/licenses/by-sa/3.0/deed.en
#pluralistic#habsburg ai#self censorship#henry farrell#digital dictatorships#machine learning#dictator's dilemma#eddie yang#preference falsification#political science#training bias#scholarship#spirals of delusion#algorithmic bias#ml#Fully automated data driven authoritarianism#authoritarianism#gigo#garbage in garbage out garbage back in#gigogbi#yuval noah harari#gubbish#pkd#philip k dick#phildickian
833 notes
·
View notes
Text
Alright, I have to rant about something. I'm taking a course of data science this trimester. As part of that, I have to write an essay of ethics in data sci. One of the paragraphs is supposed to be on "fairness in algorithmic systems".
So I look for case studies, and what do I find?

Motherfucker, you told the AI to discriminate against poor people, and then you were surprised when it discriminated against poor people! (and black people, in-particular, which is why it was caught)
These people are "industry leaders" too. Goodness only knows what the industry followers are fucking up!
11 notes
·
View notes
Text
𝐅𝐮𝐭𝐮𝐫𝐞 𝐨𝐟 𝐀𝐈-:

𝐖𝐡𝐚𝐭 ����𝐬 𝐀𝐫𝐭𝐢𝐟𝐢𝐜𝐢𝐚𝐥 𝐈𝐧𝐭𝐞𝐥𝐥𝐢𝐠𝐞𝐧𝐜𝐞 ?
Artificial intelligence (AI) refers to computer systems capable of performing complex tasks that historically only a human could do, such as reasoning, making decisions, or solving problems.
𝐂𝐮𝐫𝐫𝐞𝐧𝐭 𝐀𝐈 𝐂𝐚𝐩𝐚𝐛𝐢𝐥𝐢𝐭𝐢𝐞𝐬-:
AI today exhibits a wide range of capabilities, including natural language processing (NLP), machine learning (ML), computer vision, and generative AI. These capabilities are used in various applications like virtual assistants, recommendation systems, fraud detection, autonomous vehicles, and image generation. AI is also transforming industries like healthcare, finance, transportation, and creative domains.
𝐀𝐈 𝐀𝐩𝐩𝐬/𝐓𝐨𝐨𝐥𝐬-:
ChatGpt, Gemini, Duolingo etc are the major tools/apps of using AI.

𝐑𝐢𝐬𝐤𝐬 𝐨𝐟 𝐀𝐈-:
1. Bias and Discrimination: AI algorithms can be trained on biased data, leading to discriminatory outcomes in areas like hiring, lending, and even criminal justice.
2. Security Vulnerabilities: AI systems can be exploited through cybersecurity attacks, potentially leading to data breaches, system disruptions, or even the misuse of AI in malicious ways.
3. Privacy Violations: AI systems often rely on vast amounts of personal data, raising concerns about privacy and the potential for misuse of that data.
4. Job Displacement: Automation driven by AI can lead to job losses in various sectors, potentially causing economic and social disruption.

5. Misuse and Weaponization: AI can be used for malicious purposes, such as developing autonomous weapons systems, spreading disinformation, or manipulating public opinion.
6. Loss of Human Control: Advanced AI systems could potentially surpass human intelligence and become uncontrollable, raising concerns about the safety and well-being of humanity.
𝐅𝐮𝐭𝐮𝐫𝐞 𝐨𝐟 𝐀𝐈:-
Healthcare:AI will revolutionize medical diagnostics, personalize treatment plans, and assist in complex surgical procedures.
Workplace:AI will automate routine tasks, freeing up human workers for more strategic and creative roles.

Transportation:Autonomous vehicles and intelligent traffic management systems will enhance mobility and safety.
Finance:AI will reshape algorithmic trading, fraud detection, and economic forecasting.
Education:AI will personalize learning experiences and offer intelligent tutoring systems.
Manufacturing:AI will enable predictive maintenance, process optimization, and quality control.
Agriculture:AI will support precision farming, crop monitoring, and yield prediction.
#AI#Futuristic#technology#development#accurate#realistic#predictions#techworld#machinelearning#robotic
4 notes
·
View notes
Text

What Is a Desktop Appraisal and How Does It Work?
As technology continues to transform the real estate and mortgage industry, many traditional processes are being reimagined for efficiency and convenience. One such innovation is the desktop appraisal - a modern alternative to the conventional home appraisal method. For homeowners, buyers and lenders, understanding what a desktop appraisal is and how it works can offer clarity and potentially faster, cost-effective options for property valuation.
Understanding the Basics: What Is a Desktop Appraisal?
A desktop appraisal is a type of real estate valuation where the appraiser evaluates a property's value remotely - without ever setting foot on the premises. Instead of visiting the property in person, the appraiser relies on available digital data sources, such as:
Tax assessments
Multiple Listing Service (MLS) data
Public property records
Floor plans
Aerial or satellite imagery
Renovation permits and building records
By analyzing these records from their office, appraisers can generate a professional opinion of value. Desktop appraisals have become more prominent in recent years, especially during periods when in-person inspections are impractical or unnecessary, such as during the COVID-19 pandemic.
How Does a Desktop Appraisal Differ from Other Appraisal Types?
There are a few different types of appraisals in real estate and each serves a unique purpose:
Traditional Appraisals: The appraiser visits the property in person, inspects the interior and exterior and creates a comprehensive report based on direct observation and comparable sales.
Hybrid Appraisals: A third party (not the appraiser) collects on-site property data, including photos and measurements. The appraiser then reviews the collected data remotely and completes the appraisal.
Desktop Appraisals: The appraiser performs the entire valuation remotely, using only publicly available or third-party data. There is no physical inspection at all.
While a traditional appraisal is the gold standard for accuracy, desktop appraisals are gaining traction for being faster and more scalable, especially in low-risk or high-volume scenarios.
When Are Desktop Appraisals Used?
Desktop appraisals aren’t suitable for every transaction. However, they are an excellent option under the right circumstances. Common uses include:
Mortgage pre-approvals or purchase transactions
Home equity loans or home equity lines of credit (HELOCs)
Portfolio evaluations for banks and investors
Tax appeal support
Insurance valuation purposes
Market analysis for sellers determining listing prices
According to Fannie Mae guidelines, desktop appraisals are typically only allowed for purchase transactions and may come with property-type and loan-to-value (LTV) restrictions.
Advantages of Desktop Appraisals
Faster Turnaround Time: Without the need for scheduling on-site visits, a desktop appraisal can often be completed in a matter of days - sometimes even hours - compared to the one to three weeks it may take for a full appraisal.
Cost-Effective: Desktop appraisals are typically less expensive than traditional ones, with costs often ranging between $75 to $200, compared to $300 to $500 or more for full appraisals.
Less Intrusive: Since no one needs to visit the home, desktop appraisals are more convenient for homeowners who may not want the hassle of coordinating an in-person inspection.
Reduced Bias: With no physical interaction, the likelihood of subjective bias due to a home's appearance, location or occupant decreases.
Scalability for Lenders: Lenders with large loan portfolios can quickly obtain valuations across multiple properties, making this an efficient solution for bulk transactions.
Limitations and Risks of Desktop Appraisals
Limited Data Accuracy: If the data sources are outdated, inaccurate or incomplete, the final appraisal may not reflect the property's true market value.
Not Universally Accepted: Many lenders and loan products still require traditional appraisals. Desktop appraisals may not meet FHA, VA or USDA lending guidelines.
Not Suitable for Complex Properties: Homes with unusual features, major upgrades or located in volatile markets may require more detailed, in-person evaluation.
Regulatory Compliance: Appraisers must ensure that their desktop appraisal complies with USPAP (Uniform Standards of Professional Appraisal Practice), including proper disclosures, data verification and scope of work documentation.
Desktop Appraisal Forms and Tools
To conduct a desktop appraisal, professionals typically use specific appraisal forms. The most common is Form 1004 Desktop, a variant of the Uniform Residential Appraisal Report. In some cases, a Form 70D may be used when fewer reporting requirements apply.
Appraisers may also rely on automated systems such as:
Fannie Mae's Desktop Underwriter® (DU)
Freddie Mac's Loan Product Advisor®
These systems assist underwriters in evaluating credit risk and qualifying borrowers efficiently, using data such as credit scores, income, assets and appraisal results.
Who Can Perform Desktop Appraisals?
Licensed or certified appraisers are the only professionals authorized to perform a desktop appraisal. However, appraiser trainees can complete them under direct supervision, making it a good training tool.
Importantly, the appraiser should have prior experience in the subject’s market area to ensure accurate interpretations of local market conditions.
How to Prepare for a Desktop Appraisal
If you’re involved in a transaction where a desktop appraisal might be used, here are a few steps to ensure a smooth process:
Provide Updated Property Information: Share recent renovation details, photos or available floor plans.
Ensure Public Records Are Correct: Verify that tax records and MLS listings accurately reflect the property’s square footage, lot size, and features.
Be Aware of Eligibility Requirements: Understand that not all properties qualify for desktop appraisals.
Understand the Timeline: While faster than traditional appraisals, the timeline still depends on data availability and the appraiser's schedule.
The Future of Desktop Appraisals
As digital solutions continue to reshape real estate, desktop appraisals are expected to play a larger role, particularly in:
Pandemic or disaster response situations
High-volume markets
Remote property evaluations
Green-lighting fast closings in competitive markets
Government-sponsored enterprises (GSEs) like Fannie Mae and Freddie Mac have already tested the risk performance of desktop appraisals and found them comparable to traditional ones in certain scenarios. As tools and datasets become more robust, expect desktop appraisals to become even more common in mortgage lending.
Final Thoughts
Desktop appraisals are a sign of the digital transformation sweeping across the real estate industry. They offer speed, cost savings and convenience- but they aren’t a one-size-fits-all solution. By understanding how they work, when they’re used, and what their strengths and limitations are, both lenders and borrowers can make informed decisions about property valuation.
At Suntel Global, we specialize in staying ahead of industry trends. Whether you're processing a mortgage, managing real estate portfolios or just exploring modern valuation tools, our expert team is here to support your goals with data-backed insights and scalable solutions.
#SuntelGlobal#suntelglobal#appraisalqcreviewservices#appraisalqcreview#appraisalreview#MortgageLending#AppraisalQC#mortgageprocessing#Outsourcing#residentialappraisalexperts#QualityControl#UnderwritingSupport#trustedappraisalsolutions#appraisalcompliance#valuationreview#appraisalaudit#ResidentialAppraisal#RealEstateSupport#RiskManagement#appraisalreport#homebuyingtips#MortgageSupport#MedicalBilling#TechSolutions#propertyvaluation#USA#UnitedStates#America
2 notes
·
View notes
Text
What is artificial intelligence (AI)?

Imagine asking Siri about the weather, receiving a personalized Netflix recommendation, or unlocking your phone with facial recognition. These everyday conveniences are powered by Artificial Intelligence (AI), a transformative technology reshaping our world. This post delves into AI, exploring its definition, history, mechanisms, applications, ethical dilemmas, and future potential.
What is Artificial Intelligence? Definition: AI refers to machines or software designed to mimic human intelligence, performing tasks like learning, problem-solving, and decision-making. Unlike basic automation, AI adapts and improves through experience.
Brief History:
1950: Alan Turing proposes the Turing Test, questioning if machines can think.
1956: The Dartmouth Conference coins the term "Artificial Intelligence," sparking early optimism.
1970s–80s: "AI winters" due to unmet expectations, followed by resurgence in the 2000s with advances in computing and data availability.
21st Century: Breakthroughs in machine learning and neural networks drive AI into mainstream use.
How Does AI Work? AI systems process vast data to identify patterns and make decisions. Key components include:
Machine Learning (ML): A subset where algorithms learn from data.
Supervised Learning: Uses labeled data (e.g., spam detection).
Unsupervised Learning: Finds patterns in unlabeled data (e.g., customer segmentation).
Reinforcement Learning: Learns via trial and error (e.g., AlphaGo).
Neural Networks & Deep Learning: Inspired by the human brain, these layered algorithms excel in tasks like image recognition.
Big Data & GPUs: Massive datasets and powerful processors enable training complex models.
Types of AI
Narrow AI: Specialized in one task (e.g., Alexa, chess engines).
General AI: Hypothetical, human-like adaptability (not yet realized).
Superintelligence: A speculative future AI surpassing human intellect.
Other Classifications:
Reactive Machines: Respond to inputs without memory (e.g., IBM’s Deep Blue).
Limited Memory: Uses past data (e.g., self-driving cars).
Theory of Mind: Understands emotions (in research).
Self-Aware: Conscious AI (purely theoretical).
Applications of AI
Healthcare: Diagnosing diseases via imaging, accelerating drug discovery.
Finance: Detecting fraud, algorithmic trading, and robo-advisors.
Retail: Personalized recommendations, inventory management.
Manufacturing: Predictive maintenance using IoT sensors.
Entertainment: AI-generated music, art, and deepfake technology.
Autonomous Systems: Self-driving cars (Tesla, Waymo), delivery drones.
Ethical Considerations
Bias & Fairness: Biased training data can lead to discriminatory outcomes (e.g., facial recognition errors in darker skin tones).
Privacy: Concerns over data collection by smart devices and surveillance systems.
Job Displacement: Automation risks certain roles but may create new industries.
Accountability: Determining liability for AI errors (e.g., autonomous vehicle accidents).
The Future of AI
Integration: Smarter personal assistants, seamless human-AI collaboration.
Advancements: Improved natural language processing (e.g., ChatGPT), climate change solutions (optimizing energy grids).
Regulation: Growing need for ethical guidelines and governance frameworks.
Conclusion AI holds immense potential to revolutionize industries, enhance efficiency, and solve global challenges. However, balancing innovation with ethical stewardship is crucial. By fostering responsible development, society can harness AI’s benefits while mitigating risks.
2 notes
·
View notes
Text
The Dos and Don’ts of AI & ML in Digital Marketing

Artificial intelligence (AI) and machine learning (ML) are revolutionizing the digital marketing landscape, offering unprecedented opportunities for personalization, automation, and optimization. However, like any powerful tool, AI and ML must be wielded wisely. This blog outlines the dos and don'ts of leveraging these technologies effectively in your digital marketing strategies.
The Dos:
Do Define Clear Objectives: Before implementing any AI/ML solution, clearly define your marketing goals. What are you trying to achieve? Increased conversions? Improved customer engagement? Specific objectives will guide your AI/ML strategy and ensure you're measuring the right metrics.
Do Focus on Data Quality: AI/ML algorithms are only as good as the data they are trained on. Prioritize collecting clean, accurate, and relevant data. Invest in data cleansing and validation processes to ensure the reliability of your AI-driven insights.
Do Start Small and Iterate: Don't try to implement everything at once. Begin with a specific use case, such as automating social media posting or personalizing email campaigns. Test, refine, and iterate on your approach before scaling up.
Do Prioritize Personalization: AI/ML excels at personalization. Leverage these technologies to create tailored content, product recommendations, and offers for individual customers based on their behavior, preferences, and demographics.
Do Embrace Automation: AI can automate repetitive tasks, freeing up marketers to focus on strategic initiatives. Identify areas where AI can streamline workflows, such as ad campaign optimization, content curation, or customer service interactions.
Do Focus on Transparency and Explainability: Understand how your AI/ML models work and ensure they are transparent and explainable. This is crucial for building trust and addressing ethical concerns.
Do Measure and Analyze Results: Track the performance of your AI/ML-driven marketing campaigns and analyze the data to identify areas for improvement. Use data to inform your decisions and optimize your strategies.
Do Stay Updated: The field of AI/ML is constantly evolving. Keep up with the latest advancements, new tools, and best practices to ensure you're maximizing the potential of these technologies.
The Don'ts:
Don't Treat AI as a Magic Bullet: AI/ML is a powerful tool, but it's not a magic solution. It requires careful planning, implementation, and ongoing management. Don't expect overnight results without putting in the effort.
Don't Neglect Human Oversight: While AI can automate tasks, it's essential to maintain human oversight. Human judgment is still crucial for strategic decision-making, creative development, and ethical considerations.
Don't Over-Rely on Automation: While automation is beneficial, don't over-automate to the point where you lose the human touch. Maintain a balance between automation and human interaction to ensure a personalized and engaging customer experience.
Don't Ignore Ethical Implications: AI/ML raises ethical concerns about data privacy, bias, and transparency. Be mindful of these issues and ensure that your AI-driven marketing practices are ethical and responsible.
Don't Forget About Data Security: Protecting customer data is paramount. Implement robust security measures to safeguard your data from unauthorized access and breaches.
Don't Be Afraid to Experiment: AI/ML is a field of experimentation. Don't be afraid to try new approaches, test different algorithms, and learn from your mistakes.
Don't Underestimate the Importance of Training: Proper training is essential for effectively using AI/ML tools and understanding their capabilities and limitations. Invest in training for your marketing team to ensure they have the skills they need to succeed.
Digital Marketing & AI Certification Program: Your Path to AI-Powered Marketing Mastery
Want to become a sought-after digital marketing professional with expertise in AI and ML? Consider enrolling in a Digital Marketing & AI Certification Program. These programs provide comprehensive training on the latest AI/ML tools and techniques, preparing you to leverage the power of these technologies in your marketing strategies. You'll learn how to:
Develop and implement AI/ML-driven marketing campaigns.
Analyze data and generate actionable insights.
Choose and use the right AI/ML marketing tools.
Address ethical considerations related to AI/ML in marketing.
Conclusion:
AI and ML are transforming the landscape of digital marketing, offering unprecedented opportunities for growth and innovation. By following these dos and don'ts, marketers can harness the power of these technologies effectively and responsibly, driving better results and achieving their marketing goals. The future of digital marketing is intelligent, and it's powered by AI and ML.
#technology#artificial intelligence#online course#ai#marketing#digital marketing#ai in digital marketing
4 notes
·
View notes
Text
Exploring Explainable AI: Making Sense of Black-Box Models

Artificial intelligence (AI) and machine learning (ML) have become essential components of contemporary data science, driving innovations from personalized recommendations to self-driving cars.
However, this increasing dependence on these technologies presents a significant challenge: comprehending the decisions made by AI models. This challenge is especially evident in complex, black-box models, where the internal decision-making processes remain unclear. This is where Explainable AI (XAI) comes into play — a vital area of research and application within AI that aims to address this issue.
What Is a Black-Box Model?
Black-box models refer to machine learning algorithms whose internal mechanisms are not easily understood by humans. These models, like deep neural networks, are highly effective and often surpass simpler, more interpretable models in performance. However, their complexity makes it challenging to grasp how they reach specific predictions or decisions. This lack of clarity can be particularly concerning in critical fields such as healthcare, finance, and criminal justice, where trust and accountability are crucial.
The Importance of Explainable AI in Data Science
Explainable AI aims to enhance the transparency and comprehensibility of AI systems, ensuring they can be trusted and scrutinized. Here’s why XAI is vital in the fields of data science and artificial intelligence:
Accountability: Organizations utilizing AI models must ensure their systems function fairly and without bias. Explainability enables stakeholders to review models and pinpoint potential problems.
Regulatory Compliance: Numerous industries face regulations that mandate transparency in decision-making, such as GDPR’s “right to explanation.” XAI assists organizations in adhering to these legal requirements.
Trust and Adoption: Users are more inclined to embrace AI solutions when they understand their functioning. Transparent models build trust among users and stakeholders.
Debugging and Optimization: Explainability helps data scientists diagnose and enhance model performance by identifying areas for improvement.
Approaches to Explainable AI
Various methods and tools have been created to enhance the interpretability of black-box models. Here are some key approaches commonly taught in data science and artificial intelligence courses focused on XAI:
Feature Importance: Techniques such as SHAP (SHapley Additive exPlanations) and LIME (Local Interpretable Model-Agnostic Explanations) evaluate how individual features contribute to model predictions.
Visualization Tools: Tools like TensorBoard and the What-If Tool offer visual insights into model behavior, aiding data scientists in understanding the relationships within the data.
Surrogate Models: These are simpler models designed to mimic the behavior of a complex black-box model, providing a clearer view of its decision-making process.
Rule-Based Explanations: Some techniques extract human-readable rules from complex models, giving insights into how they operate.
The Future of Explainable AI
With the increasing demand for transparency in AI, explainable AI (XAI) is set to advance further, fueled by progress in data science and artificial intelligence courses that highlight its significance. Future innovations may encompass:
Improved tools and frameworks for real-time explanations.
Deeper integration of XAI within AI development processes.
Establishment of industry-specific standards for explainability and fairness.
Conclusion
Explainable AI is essential for responsible AI development, ensuring that complex models can be comprehended, trusted, and utilized ethically. For data scientists and AI professionals, mastering XAI techniques has become crucial. Whether you are a student in a data science course or a seasoned expert, grasping and implementing XAI principles will empower you to navigate the intricacies of contemporary AI systems while promoting transparency and trust.
2 notes
·
View notes
Text
What is Artificial Intelligence?? A Beginner's Guide to Understand Artificial Intelligence
1) What is Artificial Intelligence (AI)??
Artificial Intelligence (AI) is a set of technologies that enables computer to perform tasks normally performed by humans. This includes the ability to learn (machine learning) reasoning, decision making and even natural language processing from virtual assistants like Siri and Alexa to prediction algorithms on Netflix and Google Maps.
The foundation of the AI lies in its ability to simulate cognitive tasks. Unlike traditional programming where machines follow clear instructions, AI systems use vast algorithms and datasets to recognize patterns, identify trends and automatically improve over time.
2) Many Artificial Intelligence (AI) faces
Artificial Intelligence (AI) isn't one thing but it is a term that combines many different technologies together. Understanding its ramifications can help you understand its versatility:
Machine Learning (ML): At its core, AI focuses on enabling ML machines to learn from data and make improvements without explicit programming. Applications range from spam detection to personalized shopping recommendations.
Computer Vision: This field enables machines to interpret and analyze image data from facial recognition to medical image diagnosis. Computer Vision is revolutionizing many industries.
Robotics: By combining AI with Engineering Robotics focuses on creating intelligent machines that can perform tasks automatically or with minimal human intervention.
Creative AI: Tools like ChatGPT and DALL-E fail into this category. Create human like text or images and opens the door to creative and innovative possibilities.
3) Why is AI so popular now??
The Artificial Intelligence (AI) explosion may be due to a confluence of technological advances:
Big Data: The digital age creates unprecedented amounts of data. Artificial Intelligence (AI) leverages data and uses it to gain insights and improve decision making.
Improved Algorithms: Innovations in algorithms make Artificial Intelligence (AI) models more efficient and accurate.
Computing Power: The rise of cloud computing and GPUs has provided the necessary infrastructure for processing complex AI models.
Access: The proliferation of publicly available datasets (eg: ImageNet, Common Crawl) has provided the basis for training complex AI Systems. Various Industries also collect a huge amount of proprietary data. This makes it possible to deploy domain specific AI applications.
4) Interesting Topics about Artificial Intelligence (AI)
Real World applications of AI shows that AI is revolutionizing industries such as Healthcare (primary diagnosis and personalized machine), finance (fraud detection and robo advisors), education (adaptive learning platforms) and entertainment (adaptive platforms) how??
The role of AI in "Creativity Explore" on how AI tools like DALL-E and ChatGPT are helping artists, writers and designers create incredible work. Debate whether AI can truly be creative or just enhance human creativity.
AI ethics and Bias are an important part of AI decision making, it is important to address issues such as bias, transparency and accountability. Search deeper into the importance of ethical AI and its impact on society.
AI in everyday life about how little known AI is affecting daily life, from increasing energy efficiency in your smart home to reading the forecast on your smartphone.
The future of AI anticipate upcoming advance services like Quantum AI and their potential to solve humanity's biggest challenges like climate change and pandemics.
5) Conclusion
Artificial Intelligence (AI) isn't just a technological milestone but it is a paradigm shift that continues to redefine our future. As you explore the vast world of AI, think outside the box to find nuances, applications and challenges with well researched and engaging content
Whether unpacking how AI works or discussing its transformative potential, this blog can serve as a beacon for those eager to understand this underground branch.
"As we stand on the brink of an AI-powered future, the real question isn't what AI can do for us, but what we dare to imagine next"
"Get Latest News on www.bloggergaurang.com along with Breaking News and Top Headlines from all around the World !!"
2 notes
·
View notes
Text
@girderednerve replied to your post coming out on tumblr as someone whose taught "AI bootcamp" courses to middle school students AMA:
did they like it? what kinds of durable skills did you want them to walk away with? do you feel bullish on "AI"?
It was an extracurricular thing so the students were quite self-selecting and all were already interested in the topic or in doing well in the class. Probably what most interested me about the demographic of students taking the courses (they were online) was the number who were international students outside of the imperial core probably eventually looking to go abroad for college, like watching/participating in the cogs of brain drain.
I'm sure my perspective is influenced because my background is in statistics and not computer science. But I hope that they walked away with a greater understanding and familiarity with data and basic statistical concepts. Things like sample bias, types of data (categorical/quantitative/qualitative), correlation (and correlation not being causation), ways to plot and examine data. Lots of students weren't familiar before we started the course with like, what a csv file is/tabular data in general. I also tried to really emphasize that data doesn't appear in a vacuum and might not represent an "absolute truth" about the world and there are many many ways that data can become biased especially when its on topics where people's existing demographic biases are already influencing reality.
Maybe a bit tangential but there was a part of the course material that was teaching logistic regression using the example of lead pipes in flint, like, can you believe the water in this town was undrinkable until it got Fixed using the power of AI to Predict Where The Lead Pipes Would Be? it was definitely a trip to ask my students if they'd heard of the flint water crisis and none of them had. also obviously it was a trip for the course material to present the flint water crisis as something that got "fixed by AI". added in extra information for my students like, by the way this is actually still happening and was a major protest event especially due to the socioeconomic and racial demographics of flint.
Aside from that, python is a really useful general programming language so if any of the students go on to do any more CS stuff which is probably a decent chunk of them I'd hope that their coding problemsolving skills and familiarity with it would be improved.
do i feel bullish on "AI"? broad question. . . once again remember my disclaimer bias statement on how i have a stats degree but i definitely came away from after teaching classes on it feeling that a lot of machine learning is like if you repackaged statistics and replaced the theoretical/scientific aspects where you confirm that a certain model is appropriate for the data and test to see if it meets your assumptions with computational power via mass guessing and seeing if your mass guessing was accurate or not lol. as i mentioned in my tags i also really don't think things like linear regression which were getting taught as "AI" should be considered "ML" or "AI" anyways, but the larger issue there is that "AI" is a buzzy catchword that can really mean anything. i definitely think relatedly that there will be a bit of an AI bubble in that people are randomly applying AI to tasks that have no business getting done that way and they will eventually reap the pointlessness of these projects.
besides that though, i'm pretty frustrated with a lot of AI hysteria which assumes that anything that is labeled as "AI" must be evil/useless/bad and also which lacks any actual labor-based understanding of the evils of capitalism. . . like AI (as badly formed as I feel the term is) isn't just people writing chatGPT essays or whatever, it's also used for i.e. lots of cutting edge medical research. if insanely we are going to include "linear regression" as an AI thing that's probably half of social science research too. i occasionally use copilot or an LLM for my work which is in public health data affiliated with a university. last week i got driven batty by a post that was like conspiratorially speculating "spotify must have used AI for wrapped this year and thats why its so bad and also why it took a second longer to load, that was the ai generating everything behind the scenes." im saying this as someone who doesnt use spotify, 1) the ship on spotify using algorithms sailed like a decade ago, how do you think your weekly mixes are made? 2) like truly what is the alternative did you think that previously a guy from minnesota was doing your spotify wrapped for you ahead of time by hand like a fucking christmas elf and loading it personally into your account the night before so it would be ready for you? of course it did turned out that spotify had major layoffs so i think the culprit here is really understaffing.
like not to say that AI like can't have a deleterious effect on workers, like i literally know people who were fired through the logic that AI could be used to obviate their jobs. which usually turned out not to be true, but hasn't the goal of stretching more productivity from a single worker whether its effective or not been a central axiom of the capitalist project this whole time? i just don't think that this is spiritually different from retail ceos discovering that they could chronically understaff all of their stores.
2 notes
·
View notes
Text
Every algorithm is “bias at scale”.
Every. One.
From GPTs to ML to a flow chart taped to a wall, it’s all bias at scale.
The difference is with experience you can see where the flow chart is wrong and fix it. You can get data about why your ML model is making a particular recommendation and decide if your training data needs to be changed or you need a different algorithm. GPTs? Fuckin black box. Do not recommend for anything you wouldn’t trust to a magic 8-ball.
I'm just saying, "We created a computer to make decisions for us, but it assimilated all of the bias that was implicit in the dataset and now makes incredibly racist decisions that we don't question because computers are logical and don't make mistakes" literally sounds like a planet-of-the-week morality play on the original Star Trek.
47K notes
·
View notes
Text
How Bias Will Kill Your AI/ML Strategy and What to Do About It
New Post has been published on https://thedigitalinsider.com/how-bias-will-kill-your-ai-ml-strategy-and-what-to-do-about-it/
How Bias Will Kill Your AI/ML Strategy and What to Do About It
‘Bias’ in models of any type describes a situation in which the model responds inaccurately to prompts or input data because it hasn’t been trained with enough high-quality, diverse data to provide an accurate response. One example would be Apple’s facial recognition phone unlock feature, which failed at a significantly higher rate for people with darker skin complexions as opposed to lighter tones. The model hadn’t been trained on enough images of darker-skinned people. This was a relatively low-risk example of bias but is exactly why the EU AI Act has put forth requirements to prove model efficacy (and controls) before going to market. Models with outputs that impact business, financial, health, or personal situations must be trusted, or they won’t be used.
Tackling Bias with Data
Large Volumes of High-Quality Data
Among many important data management practices, a key component to overcoming and minimizing bias in AI/ML models is to acquire large volumes of high-quality, diverse data. This requires collaboration with multiple organizations that have such data. Traditionally, data acquisition and collaborations are challenged by privacy and/or IP protection concerns–sensitive data can’t be sent to the model owner, and the model owner can’t risk leaking their IP to a data owner. A common workaround is to work with mock or synthetic data, which can be useful but also have limitations compared to using real, full-context data. This is where privacy-enhancing technologies (PETs) provide much-needed answers.
Synthetic Data: Close, but not Quite
Synthetic data is artificially generated to mimic real data. This is hard to do but becoming slightly easier with AI tools. Good quality synthetic data should have the same feature distances as real data, or it won’t be useful. Quality synthetic data can be used to effectively boost the diversity of training data by filling in gaps for smaller, marginalized populations, or for populations that the AI provider simply doesn’t have enough data. Synthetic data can also be used to address edge cases that might be difficult to find in adequate volumes in the real world. Additionally, organizations can generate a synthetic data set to satisfy data residency and privacy requirements that block access to the real data. This sounds great; however, synthetic data is just a piece of the puzzle, not the solution.
One of the obvious limitations of synthetic data is the disconnect from the real world. For example, autonomous vehicles trained solely on synthetic data will struggle with real, unforeseen road conditions. Additionally, synthetic data inherits bias from the real-world data used to generate it–pretty much defeating the purpose of our discussion. In conclusion, synthetic data is a useful option for fine tuning and addressing edge cases, but significant improvements in model efficacy and minimization of bias still rely upon accessing real world data.
A Better Way: Real Data via PETs-enabled Workflows
PETs protect data while in use. When it comes to AI/ML models, they can also protect the IP of the model being run–”two birds, one stone.” Solutions utilizing PETs provide the option to train models on real, sensitive datasets that weren’t previously accessible due to data privacy and security concerns. This unlocking of dataflows to real data is the best option to reduce bias. But how would it actually work?
For now, the leading options start with a confidential computing environment. Then, an integration with a PETs-based software solution that makes it ready to use out of the box while addressing the data governance and security requirements that aren’t included in a standard trusted execution environment (TEE). With this solution, the models and data are all encrypted before being sent to a secured computing environment. The environment can be hosted anywhere, which is important when addressing certain data localization requirements. This means that both the model IP and the security of input data are maintained during computation–not even the provider of the trusted execution environment has access to the models or data inside of it. The encrypted results are then sent back for review and logs are available for review.
This flow unlocks the best quality data no matter where it is or who has it, creating a path to bias minimization and high-efficacy models we can trust. This flow is also what the EU AI Act was describing in their requirements for an AI regulatory sandbox.
Facilitating Ethical and Legal Compliance
Acquiring good quality, real data is tough. Data privacy and localization requirements immediately limit the datasets that organizations can access. For innovation and growth to occur, data must flow to those who can extract the value from it.
Art 54 of the EU AI Act provides requirements for “high-risk” model types in terms of what must be proven before they can be taken to market. In short, teams will need to use real world data inside of an AI Regulatory Sandbox to show sufficient model efficacy and compliance with all the controls detailed in Title III Chapter 2. The controls include monitoring, transparency, explainability, data security, data protection, data minimization, and model protection–think DevSecOps + Data Ops.
The first challenge will be to find a real-world data set to use–as this is inherently sensitive data for such model types. Without technical guarantees, many organizations may hesitate to trust the model provider with their data or won’t be allowed to do so. In addition, the way the act defines an “AI Regulatory Sandbox” is a challenge in and of itself. Some of the requirements include a guarantee that the data is removed from the system after the model has been run as well as the governance controls, enforcement, and reporting to prove it.
Many organizations have tried using out-of-the-box data clean rooms (DCRs) and trusted execution environments (TEEs). But, on their own, these technologies require significant expertise and work to operationalize and meet data and AI regulatory requirements. DCRs are simpler to use, but not yet useful for more robust AI/ML needs. TEEs are secured servers and still need an integrated collaboration platform to be useful, quickly. This, however, identifies an opportunity for privacy enhancing technology platforms to integrate with TEEs to remove that work, trivializing the setup and use of an AI regulatory sandbox, and therefore, acquisition and use of sensitive data.
By enabling the use of more diverse and comprehensive datasets in a privacy-preserving manner, these technologies help ensure that AI and ML practices comply with ethical standards and legal requirements related to data privacy (e.g., GDPR and EU AI Act in Europe). In summary, while requirements are often met with audible grunts and sighs, these requirements are simply guiding us to building better models that we can trust and rely upon for important data-driven decision making while protecting the privacy of the data subjects used for model development and customization.
#ai#ai act#AI bias#ai tools#AI/ML#apple#Art#autonomous vehicles#Bias#birds#box#Building#Business#challenge#Collaboration#collaboration platform#compliance#comprehensive#computation#computing#confidential computing#data#Data Governance#Data Management#data owner#data privacy#data privacy and security#data protection#data security#data-driven
0 notes
Text
Artificial Intelligence Course Online India: For Working Professionals and Students
In the age of digital transformation, Artificial Intelligence (AI) is no longer a futuristic concept — it’s a present-day necessity. From self-driving cars and chatbots to predictive analytics and recommendation systems, AI is transforming industries at lightning speed. As a result, the demand for professionals skilled in AI has skyrocketed across India.
Whether you're a working professional looking to upskill or a student aiming to future-proof your career, enrolling in an Artificial Intelligence course online in India is a strategic move. But with hundreds of programs out there, how do you choose the right one that fits your schedule, goals, and learning needs?
In this guide, we break down why AI is a must-learn skill, how online courses can fit different lifestyles, and which programs stand out for both professionals and students in India.
Why Learn Artificial Intelligence in 2025?
AI is no longer limited to research labs or Silicon Valley companies. In India, businesses across sectors — healthcare, finance, e-commerce, manufacturing, and education — are adopting AI solutions at a rapid pace.
Key Reasons to Learn AI:
High Demand: Over 1 million AI-related job openings are projected in India by 2026 (NASSCOM report).
Lucrative Salaries: AI professionals earn between ₹8 LPA to ₹25+ LPA depending on experience.
Wide Applications: From data analysis and robotics to natural language processing and deep learning.
Global Recognition: AI skills are valued not just in India but worldwide.
Who Should Consider an AI Course Online in India?
1. Working Professionals
Software developers
Data analysts or engineers
IT professionals looking to transition
Project managers seeking AI understanding
Marketing, sales, and HR professionals using AI tools
2. Students and Recent Graduates
B.Tech / BCA / B.Sc (CS/Maths/Stats) students
Fresh graduates aiming to specialize in AI
Postgraduate students in engineering, data science, or business
Features to Look for in the Best Online AI Courses in India
Before enrolling, make sure the program offers:
Live or Mentor-Supported Sessions
Hands-On Projects in Python, ML, and Deep Learning
Access to Cloud Platforms (AWS, Azure, GCP)
Capstone Project and Portfolio Building
Industry-Aligned Curriculum
Placement Assistance or Internship Support
Global Certifications (if possible)
Boston Institute of Analytics (BIA) – Online AI Course
Duration: 6 months (part-time) or 3 months (intensive)
Mode: Live Online + Recorded Sessions
Highlights:
Curriculum covering Python, ML, Deep Learning, NLP, and AI ethics
Real-world case studies & capstone projects
Globally recognized certification
Strong placement support
Best For: Working professionals & students looking for international certification + job assistance
Key Skills You'll Learn in a Quality AI Course
Regardless of format, a good AI course should teach:
Programming: Python, R
Mathematics: Linear algebra, calculus, statistics
Machine Learning: Supervised, unsupervised algorithms
Deep Learning: Neural networks, CNNs, RNNs
Natural Language Processing
Model Deployment: APIs, Flask, Streamlit
Cloud Tools: AWS, Azure
Ethics in AI: Bias, fairness, privacy
Tips to Succeed in an Online AI Course
Be consistent: Set weekly study goals.
Engage with peers: Join discussion forums or WhatsApp/Slack groups.
Complete projects: They matter more than just watching videos.
Ask questions: Leverage mentor sessions for clarity.
Build a portfolio: Showcase your GitHub, Kaggle, or personal blog.
Final Thoughts
Whether you're a student preparing for a tech-driven future or a professional eyeing career growth, now is the perfect time to invest in anArtificial Intelligence course online in India.
These programs offer the flexibility to learn at your own pace, without compromising on the quality of content or outcomes. Platforms like Boston Institute of Analytics are leading the way by offering globally respected certifications, real-world projects, and career support tailored for Indian learners.
The AI revolution is happening — are you ready to be part of it?
#Best Data Science Courses Online India#Artificial Intelligence Course Online India#Data Scientist Course Online India#Machine Learning Course Online India
0 notes
Text
I have a lifelong grudge against machine learning as a practice for this exact highly specific reason: you cannot debug an ML model. It's just a pile of magic numbers (load-bearing unlabelled numerical constants) and if you find out it's doing something wrong (which it usually will because training data tends to have inherent bias) you're kind of fucked. I don't trust programs I can't prove theorems about.
There was a paper in 2016 exploring how an ML model was differentiating between wolves and dogs with a really high accuracy, they found that for whatever reason the model seemed to *really* like looking at snow in images, as in thats what it pays attention to most.
Then it hit them. *oh.*
*all the images of wolves in our dataset has snow in the background*
*this little shit figured it was easier to just learn how to detect snow than to actually learn the difference between huskies and wolves. because snow = wolf*
Shit like this happens *so often*. People think trainning models is like this exact coding programmer hackerman thing when its more like, coralling a bunch of sentient crabs that can do calculus but like at the end of the day theyre still fucking crabs.
37K notes
·
View notes
Text
Become a Certified Generative AI Expert: Lead Innovation with CGAIE Certification
Generative AI is reshaping every industry from content creation and software development to finance and marketing. For professionals looking to specialize in this cutting-edge domain, GSDC’s Certified Generative AI Expert (CGAIE) program offers a globally respected credential. If you're aiming to become a generative AI expert, this is the certification that sets you apart.
📘 Why Choose the CGAIE Program? The CGAIE course is one of the most comprehensive generative AI expert certifications available today. It offers hands-on training in prompt engineering, model development, data curation, bias mitigation, and deployment of generative models like GPT and DALL·E. With this certification, you'll earn your generative AI expert certificate while mastering AI’s most advanced capabilities.
🎯 Who Should Enroll?
Data Scientists & AI Researchers
ML Engineers & Developers
Tech Strategists & Innovation Leads
Anyone seeking AI expert certification
This certification also serves professionals aiming for broader AI expert certifications to enhance their portfolios in an AI-first job market.
🧠 What You’ll Gain:
Deep understanding of transformer-based models
Advanced prompt tuning techniques
Ethical deployment and governance frameworks
Real-world applications in business, design, and automation
💼 Whether you're a tech veteran or an aspiring innovator, becoming a generative AI expert opens doors in every digital sector. With the CGAIE credential, you join an elite community of generative AI experts prepared to shape the future of intelligent automation.
Get your generative AI expert certification from GSDC and prove you're ready to lead in the next wave of AI transformation.
🌍 Learn more and enroll here: https://www.gsdcouncil.org/generative-ai-expert-certification
#GenerativeAIExpert #GenerativeAIExpertCertification #GenerativeAIExpertCertificate #CGAIE #AIExpertCertification #AIExpertCertifications #GenerativeAIExperts #GSDCCertification #AILeadership
#certified generative ai expert#generative ai expert certification#generative ai expert#Cgaie#ai expert certification#generative ai experts#generative ai expert certificate#ai expert certifications#generative ai expert certifications
0 notes
Text
What is PEA, How Does PEA Work in Quantum Noise Mitigation

PEA: Probabilistic Error Amplification
This page explains PEA and how it works.
Probabilistic Error Amplification Improves Scalable Quantum Error Mitigation.
quantum computing has the potential to revolutionise complex problem-solving, but noisy hardware is still a major obstacle. Even while error-correcting codes solve the problem in the long run, near-term devices need error mitigation to limit noise and produce reliable output. A promising utility-scale quantum error mitigation solution is Probabilistic Error Amplification (PEA), a hybrid approach that promises accurate noise modelling without the complexity of conventional methods.
Error cancellation to amplification
Two main error mitigation methods have been used:
After learning noise behaviour, Probabilistic Error Cancellation (PEC) actively removes it in post-processing. Despite its theoretical ideality and impartiality, PEC's exponential sampling resource requirements make it unfeasible for moderate-sized circuits.
ZNE assesses outputs from purposely amplified noise and extrapolates back to find zero-noise. It is simpler to construct and more scalable than PEC, but inappropriate application compromises bias guarantees.
PEA combines ZNE's efficiency and scalability with PEC's accuracy and bias management.
PEA Works How?
PEA comprises three phases.
Noise-learning calibration
The system uses control circuits, commonly Pauli twirling, to characterise each layer of two-qubit gate noise. These calibration findings create a layered noise profile needed for further phases.
Probability-Based Amplification
At varied noise amplification levels, the algorithm re-executes the target quantum circuit. Instead of prolonging pulses or reproducing gates, PEA randomly injects noise based on the learning profile to reduce circuit depth and control error escalation.
Noiseless Extrapolation
Expectation values from various noise levels are fitted to a linear or exponential model and extrapolated to estimate the result in a noise-free condition.
This preserves ZNE's simpler, depth-friendly structure while retaining PEC's accuracy and avoiding its resource-intensive constraints.
The “Utility-Scale” of PEA
In real-world quantum circuits with tens to hundreds of qubits and deep circuit layers, gate-folding ZNE often fails due to gate-count overhead or incorrect noise scaling. PEC is impractical due of exponential sampling.
PEA is best-of-both-worlds because:
Preventing gate duplication: No circuit depth increase.
Statistical models and calibrated noise reduce sampling overhead.
Maintains bias control and produces unbiased estimators like PEC.
Scalability: Supports realistic circuit complexity.
IBM’s Qiskit Runtime includes PEA demonstrations for “utility-scale” circuits on 127-qubit machines, proving its suitability for real computing workloads.
Also read Nu Quantum's London Quantum Datacenter Alliance Forum.
Quantum Computing Implications
Scaling Near-Term Devices
PEA allows noise-limited circuits to function deeper and over more qubits, offering near-term quantum advantage.
Bridge to Fault Tolerance
Even while it cannot replace error correction, PEA reduces logical errors competitively, especially in cases of limited physical qubit resources.
Widening Algorithms
PEA improves VQE, QAOA, and quantum chemistry simulation accuracy without increasing hardware requirements.
Enhancing New Methods
Hybrid methods like tensor-network-based mitigation (TEM) combine PEA with post-processing for efficiency.
Looking Ahead
Continuous development and benchmarking shape PEA's trajectory:
PEA is being tested in dynamic circuits that integrate mid-circuit data and classical feedforward, formerly a PEC restriction.
Asymptotic sampling and PEA's ability to reduce bias at larger scales are validated by theoretical models.
PEA-ML-driven error reduction hybrid mediation strategies are being studied to dynamically react to hardware drift and noise fluctuations.
In conclusion
Probabilistic mistake Amplification improves error mitigation with precision, scalability, and efficiency. PEA uses smart extrapolation and anchoring error management in well-characterized noise behaviour to perform deeper, more accurate quantum computations without fault-tolerant hardware. As quantum processors increase, PEA's utility-scale promise may unlock real-world quantum advantage.
#coherence#AlpineQuantumTechnologies#PIASTQ#quantummechanics#ions#quantumgates#qubits#artificialintelligence#machinelearning#News#Technews#Technology#Technologynews#Technologytrends#Govindhtech
0 notes
Text
AI in Healthcare: Transforming Patient Care and Medical Innovation
Artificial intelligence is rapidly reshaping the healthcare landscape. As hospitals and clinics face growing patient volumes, rising costs, and clinician shortages, AI emerges as a powerful ally—not just enhancing efficiency, but reimagining how care is delivered, diseases are diagnosed, and treatments are developed.
Core Technologies Powering AI in Healthcare
Machine Learning (ML): ML models analyze clinical data—from electronic health records to genetic profiles—to uncover patterns, predict outcomes, and detect anomalies. These models improve over time as they learn from new data, making them invaluable in diagnostics, risk assessment, and treatment planning.
Natural Language Processing (NLP): NLP interprets unstructured clinical notes, discharge summaries, and reports, automating documentation and extracting actionable insights. This streamlines workflows and supports better decision-making.
Computer Vision: AI-driven image analysis detects subtle abnormalities in X-rays, MRIs, and CT scans, supporting earlier and more accurate diagnosis of conditions like cancer and fractures.
AI-Powered Robotics: Robots assist in minimally invasive surgeries and rehabilitation, providing precision and adaptability. AI enables real-time tracking and adaptive assistance, reducing complications and speeding recovery.
Generative AI: These models generate synthetic data, simulate patient outcomes, and aid in drug discovery. They shorten research timelines and reduce costs in pharmaceutical development.
Major Use Cases of AI in Healthcare
Enhanced Diagnostics: AI rapidly analyzes medical images and patient histories, spotting disease patterns with high accuracy and supporting earlier intervention.
Personalized Medicine: AI integrates genetic, behavioral, and environmental data to tailor therapies, predict treatment response, and minimize side effects.
Drug Discovery and Development: AI accelerates research by predicting how compounds interact with biological targets, reducing R&D timelines and costs.
Remote Monitoring: AI-powered wearables and home devices continuously track patient vitals, enabling early intervention and reducing hospital visits.
Workflow Optimization: AI automates billing, scheduling, and data extraction, reducing administrative burdens and improving clinician and patient experience.
Key Benefits and Challenges
Improved Accuracy and Efficiency: AI analyzes vast datasets quickly, reducing errors and enabling faster, more precise care.
Cost Reduction: AI minimizes unnecessary testing and manual labor, optimizing resource allocation and lowering operational costs.
Expanded Access: AI-driven tools bring high-quality care to remote and underserved areas.
Data Privacy and Security: Protecting sensitive patient information remains a critical challenge.
Algorithmic Bias: Ensuring diverse, representative training data is essential to prevent disparities in care.
The Future of AI in Healthcare
AI is poised to become a cornerstone of modern medicine, with innovations like explainable AI, edge computing, and federated learning driving smarter, faster, and more accessible care for all.
For more in-depth details on AI in healthcare—including key benefits, challenges, future trends, and real-world use cases—follow the blog and stay informed on the latest breakthroughs shaping the future of medicine.
0 notes