#etl testing process
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Mobile Tumblr US users spend an average of 4.04 minutes per session on the app.
Text
ETL and Data Testing Services: Why Data Quality Is the Backbone of Business Success | GQAT Tech
Data drives decision-making in the digital age. Businesses use data to build strategies, attain insights, and measure performance to plan for growth opportunities. However, data-driven decision-making only exists when the data is clean, complete, accurate, and trustworthy. This is where ETL and Data Testing Services are useful.
GQAT Tech provides ETL (Extract, Transform, Load) and Data Testing Services so your data pipelines can run smoothly. Whether you are migrating legacy data, developing on a data warehouse, or merging with other data, GQAT Tech services help ensure your data is an asset and not a liability.
What is ETL and Why Is It Important?
ETL (extract, transform, load) is a process for data warehousing and data integration, which consists of:
Extracting data from different sources
Transforming the data to the right format or structure
Loading the transformed data into a central system, such as a data warehouse.
Although ETL can simplify data processing, it can also create risks in that data can be lost, misformatted, corrupted, or misapplied transformation rules. This is why ETL testing is very important.
The purpose of ETL testing is to ensure that the data is:
Correctly extracted from the source systems
Accurately transformed according to business logic
Correctly loaded into the destination systems.
Why Choose GQAT Tech for ETL and Data Testing?
At GQAT Tech combine our exceptional technical expertise and premier technology and custom-built frameworks to ensure your data is accurate and certified with correctness.
1. End-to-End Data Validation
We will validate your data across the entire ETL process – extract, transform, and load- to confirm the source and target systems are 100% consistent.
2. Custom-Built Testing Frameworks
Every company has a custom data workflow. We build testing frameworks fit for your proprietary data environments, business rules, and compliance requirements.
3. Automation + Accuracy
We automate to the highest extent using tools like QuerySurge, Talend, Informatica, SQL scripts, etc. This helps a) reduce the amount of testing effort, b) avoid human error.
4. Compliance Testing
Data Privacy and compliance are obligatory today. We help you comply with regulations like GDPR, HIPAA, SOX, etc.
5. Industry Knowledge
GQAT has years of experience with clients in Finance, Healthcare, Telecom, eCommerce, and Retail, which we apply to every data testing assignment.
Types of ETL and Data Testing Services We Offer
Data Transformation Testing
We ensure your business rules are implemented accurately as part of the transformation process. Don't risk incorrect aggregations, mislabels, or logical errors in your final reports.
Data Migration Testing
We ensure that, regardless of moving to the cloud or the legacy to modern migration, all the data is transitioned completely, accurately, and securely.
BI Report Testing
We validate that both dashboards and business reports reflect the correct numbers by comparing visual data to actual backend data.
Metadata Testing
We validate schema, column names, formats, data types, and other metadata to ensure compatibility of source and target systems.
Key Benefits of GQAT Tech’s ETL Testing Services
1. Increase Data Security and Accuracy
We guarantee that valid and necessary data will only be transmitted to your system; we can reduce data leakage and security exposures.
2. Better Business Intelligence
Good data means quality outputs; dashboards and business intelligence you can trust, allowing you to make real-time choices with certainty.
3. Reduction of Time and Cost
We also lessen the impact of manual mistakes, compress timelines, and assist in lower rework costs by automating data testing.
4. Better Customer Satisfaction
Good data to make decisions off of leads to good customer experiences, better insights, and improved services.
5. Regulatory Compliance
By implementing structured testing, you can ensure compliance with data privacy laws and standards in order to avoid fines, penalties, and audits.
Why GQAT Tech?
With more than a decade of experience, we are passionate about delivering world-class ETL & Data Testing Services. Our purpose is to help you operate from clean, reliable data to exercise and action with confidence to allow you to scale, innovate, and compete more effectively.
Visit Us: https://gqattech.com Contact Us: [email protected]
#ETL Testing#Data Testing Services#Data Validation#ETL Automation#Data Quality Assurance#Data Migration Testing#Business Intelligence Testing#ETL Process#SQL Testing#GQAT Tech
0 notes
Text
"Real-Time ETL Testing: Stock Market Data"
ETL testing
ETL testing (Extract, Transform, Load) is a critical component of data management and plays a pivotal role in ensuring data quality in the data pipeline. The ETL process involves extracting data from various sources, transforming it into a suitable format, and loading it into a target destination such as a data warehouse, data lake, or database.

ETL Process:
Data Ingestion: The ETL testing process starts by ingesting live stock market data from various stock exchanges, financial news feeds, and social media platforms. This data includes stock prices, trading volumes, news articles, social media sentiment, and economic indicators.
Real-time Transformation: As data is ingested, it undergoes real-time transformations. For example:
Data cleansing: Removing duplicates, handling missing values, and correcting data anomalies.
Data enrichment: Enhancing raw data with additional information such as company profiles and historical price trends.
Sentiment analysis: Analyzing social media data to gauge market sentiment and news sentiment.
Loading into Data Warehouse: The transformed data is loaded into a data warehouse, which serves as the foundation for real-time analytics, reporting, and visualization.
Key Testing Scenarios:
Data Ingestion Testing:
Verify that data sources are connected and data is ingested as soon as it becomes available.
Test data integrity during the ingestion process to ensure no data loss or corruption occurs.
Real-time Transformation Testing:
Validate that real-time transformations are applied accurately and promptly.
Verify that data cleansing, enrichment, and sentiment analysis are performed correctly and do not introduce delays.
Data Quality and Consistency Testing:
Perform data quality checks in real-time to identify and address data quality issues promptly.
Ensure that transformed data adheres to quality standards and business rules.
Performance Testing:
Stress test the ETL Testing process to ensure it can handle high volumes of real-time data.
Measure the latency between data ingestion and data availability in the data warehouse to meet performance requirements.
Error Handling and Logging Testing:
Validate the error handling mechanisms for any data ingestion failures or transformation errors.
Ensure that appropriate error notifications are generated, and errors are logged for analysis.
Regression Testing:
Continuously run regression tests to ensure that any changes or updates to the ETL process do not introduce new issues.
Real-time Analytics Validation:
Test the accuracy and timeliness of real-time analytics and trading insights generated from the data.
Security and Access Control Testing:
Ensure that data security measures, such as encryption and access controls, are in place to protect sensitive financial data.
Compliance Testing:
Verify that the ETL process complies with financial regulations and reporting requirements.
Documentation and Reporting:
Maintain comprehensive documentation of test cases, test data, and testing results.
Generate reports on the quality and performance of the real-time ETL process for stakeholders.
1 note
·
View note
Text
Legacy Software Modernization Services In India – NRS Infoways
In today’s hyper‑competitive digital landscape, clinging to outdated systems is no longer an option. Legacy applications can slow innovation, inflate maintenance costs, and expose your organization to security vulnerabilities. NRS Infoways bridges the gap between yesterday’s technology and tomorrow’s possibilities with comprehensive Software Modernization Services In India that revitalize your core systems without disrupting day‑to‑day operations.
Why Modernize?
Boost Performance & Scalability
Legacy architectures often struggle under modern workloads. By re‑architecting or migrating to cloud‑native frameworks, NRS Infoways unlocks the flexibility you need to scale on demand and handle unpredictable traffic spikes with ease.
Reduce Technical Debt
Old codebases are costly to maintain. Our experts refactor critical components, streamline dependencies, and implement automated testing pipelines, dramatically lowering long‑term maintenance expenses.
Strengthen Security & Compliance
Obsolete software frequently harbors unpatched vulnerabilities. We embed industry‑standard security protocols and data‑privacy controls to safeguard sensitive information and keep you compliant with evolving regulations.
Enhance User Experience
Customers expect snappy, intuitive interfaces. We upgrade clunky GUIs into sleek, responsive designs—whether for web, mobile, or enterprise portals—boosting user satisfaction and retention.
Our Proven Modernization Methodology
1. Deep‑Dive Assessment
We begin with an exhaustive audit of your existing environment—code quality, infrastructure, DevOps maturity, integration points, and business objectives. This roadmap pinpoints pain points, ranks priorities, and plots the most efficient modernization path.
2. Strategic Planning & Architecture
Armed with data, we design a future‑proof architecture. Whether it’s containerization with Docker/Kubernetes, serverless microservices, or hybrid-cloud setups, each blueprint aligns performance goals with budget realities.
3. Incremental Refactoring & Re‑engineering
To mitigate risk, we adopt a phased approach. Modules are refactored or rewritten in modern languages—often leveraging Java Spring Boot, .NET Core, or Node.js—while maintaining functional parity. Continuous integration pipelines ensure rapid, reliable deployments.
4. Data Migration & Integration
Smooth, loss‑less data transfer is critical. Our team employs advanced ETL processes and secure APIs to migrate databases, synchronize records, and maintain interoperability with existing third‑party solutions.
5. Rigorous Quality Assurance
Automated unit, integration, and performance tests catch issues early. Penetration testing and vulnerability scans validate that the revamped system meets stringent security and compliance benchmarks.
6. Go‑Live & Continuous Support
Once production‑ready, we orchestrate a seamless rollout with minimal downtime. Post‑deployment, NRS Infoways provides 24 × 7 monitoring, performance tuning, and incremental enhancements so your modernized platform evolves alongside your business.
Key Differentiators
Domain Expertise: Two decades of transforming systems across finance, healthcare, retail, and logistics.
Certified Talent: AWS, Azure, and Google Cloud‑certified architects ensure best‑in‑class cloud adoption.
DevSecOps Culture: Security baked into every phase, backed by automated vulnerability management.
Agile Engagement Models: Fixed‑scope, time‑and‑material, or dedicated team options adapt to your budget and timeline.
Result‑Driven KPIs: We measure success via reduced TCO, improved response times, and tangible ROI, not just code delivery.
Success Story Snapshot
A leading Indian logistics firm grappled with a decade‑old monolith that hindered real‑time shipment tracking. NRS Infoways migrated the application to a microservices architecture on Azure, consolidating disparate data silos and introducing RESTful APIs for third‑party integrations. The results? A 40 % reduction in server costs, 60 % faster release cycles, and a 25 % uptick in customer satisfaction scores within six months.
Future‑Proof Your Business Today
Legacy doesn’t have to mean liability. With NRS Infoways’ Legacy Software Modernization Services In India, you gain a robust, scalable, and secure foundation ready to tackle tomorrow’s challenges—whether that’s AI integration, advanced analytics, or global expansion.
Ready to transform?
Contact us for a free modernization assessment and discover how our Software Modernization Services In India can accelerate your digital journey, boost operational efficiency, and drive sustainable growth.
0 notes
Text
Top 5 Alternative Data Career Paths and How to Learn Them

The world of data is no longer confined to neat rows and columns in traditional databases. We're living in an era where insights are being unearthed from unconventional, often real-time, sources – everything from satellite imagery tracking retail traffic to social media sentiment predicting stock movements. This is the realm of alternative data, and it's rapidly creating some of the most exciting and in-demand career paths in the data landscape.
Alternative data refers to non-traditional information sources that provide unique, often forward-looking, perspectives that conventional financial reports, market research, or internal operational data simply cannot. Think of it as peering through a new lens to understand market dynamics, consumer behavior, or global trends with unprecedented clarity.
Why is Alternative Data So Critical Now?
Real-time Insights: Track trends as they happen, not just after quarterly reports or surveys.
Predictive Power: Uncover leading indicators that can forecast market shifts, consumer preferences, or supply chain disruptions.
Competitive Edge: Gain unique perspectives that your competitors might miss, leading to smarter strategic decisions.
Deeper Context: Analyze factors previously invisible, from manufacturing output detected by sensors to customer foot traffic derived from geolocation data.
This rich, often unstructured, data demands specialized skills and a keen understanding of its nuances. If you're looking to carve out a niche in the dynamic world of data, here are five compelling alternative data career paths and how you can equip yourself for them.
1. Alternative Data Scientist / Quant Researcher
This is often the dream role for data enthusiasts, sitting at the cutting edge of identifying, acquiring, cleaning, and analyzing alternative datasets to generate actionable insights, particularly prevalent in finance (for investment strategies) or detailed market intelligence.
What they do: They actively explore new, unconventional data sources, rigorously validate their reliability and predictive power, develop sophisticated statistical models and machine learning algorithms (especially for unstructured data like text or images) to extract hidden signals, and present their compelling findings to stakeholders. In quantitative finance, this involves building systematic trading strategies based on these unique data signals.
Why it's growing: The competitive advantage gleaned from unique insights derived from alternative data is immense, particularly in high-stakes sectors like finance where even marginal improvements in prediction can yield substantial returns.
Key Skills:
Strong Statistical & Econometric Modeling: Expertise in time series analysis, causality inference, regression, hypothesis testing, and advanced statistical methods.
Machine Learning: Profound understanding and application of supervised, unsupervised, and deep learning techniques, especially for handling unstructured data (e.g., Natural Language Processing for text, Computer Vision for images).
Programming Prowess: Master Python (with libraries like Pandas, NumPy, Scikit-learn, PyTorch/TensorFlow) and potentially R.
Data Engineering Fundamentals: A solid grasp of data pipelines, ETL (Extract, Transform, Load) processes, and managing large, often messy, datasets.
Domain Knowledge: Critical for contextualizing and interpreting the data, understanding potential biases, and identifying genuinely valuable signals (e.g., financial markets, retail operations, logistics).
Critical Thinking & Creativity: The ability to spot unconventional data opportunities and formulate innovative hypotheses.
How to Learn:
Online Specializations: Look for courses on "Alternative Data for Investing," "Quantitative Finance with Python," or advanced Machine Learning/NLP. Platforms like Coursera, edX, and DataCamp offer relevant programs, often from top universities or financial institutions.
Hands-on Projects: Actively work with publicly available alternative datasets (e.g., from Kaggle, satellite imagery providers like NASA, open-source web scraped data) to build and validate predictive models.
Academic Immersion: Follow leading research papers and attend relevant conferences in quantitative finance and data science.
Networking: Connect actively with professionals in quantitative finance or specialized data science roles that focus on alternative data.
2. Alternative Data Engineer
While the Alternative Data Scientist unearths the insights, the Alternative Data Engineer is the architect and builder of the robust infrastructure essential for managing these unique and often challenging datasets.
What they do: They meticulously design and implement scalable data pipelines to ingest both streaming and batch alternative data, orchestrate complex data cleaning and transformation processes at scale, manage cloud infrastructure, and ensure high data quality, accessibility, and reliability for analysts and scientists.
Why it's growing: Alternative data is inherently diverse, high-volume, and often unstructured or semi-structured. Without specialized engineering expertise and infrastructure, its potential value remains locked away.
Key Skills:
Cloud Platform Expertise: Deep knowledge of major cloud providers like AWS, Azure, or GCP, specifically for scalable data storage (e.g., S3, ADLS, GCS), compute (e.g., EC2, Azure VMs, GCE), and modern data warehousing (e.g., Snowflake, BigQuery, Redshift).
Big Data Technologies: Proficiency in distributed processing frameworks like Apache Spark, streaming platforms like Apache Kafka, and data lake solutions.
Programming: Strong skills in Python (for scripting, API integration, and pipeline orchestration), and potentially Java or Scala for large-scale data processing.
Database Management: Experience with both relational (e.g., PostgreSQL, MySQL) and NoSQL databases (e.g., MongoDB, Cassandra) for flexible data storage needs.
ETL Tools & Orchestration: Mastery of tools like dbt, Airflow, Prefect, or Azure Data Factory for building, managing, and monitoring complex data workflows.
API Integration & Web Scraping: Practical experience in fetching data from various web sources, public APIs, and sophisticated web scraping techniques.
How to Learn:
Cloud Certifications: Pursue certifications like AWS Certified Data Analytics, Google Cloud Professional Data Engineer, or Azure Data Engineer Associate.
Online Courses: Focus on "Big Data Engineering," "Data Pipeline Development," and specific cloud services tailored for data workloads.
Practical Experience: Build ambitious personal projects involving data ingestion from diverse APIs (e.g., social media APIs, financial market APIs), advanced web scraping, and processing with big data frameworks.
Open-Source Engagement: Contribute to or actively engage with open-source projects related to data engineering tools and technologies.
3. Data Product Manager (Alternative Data Focus)
This strategic role acts as the crucial bridge between intricate business challenges, the unique capabilities of alternative data, and the technical execution required to deliver impactful data products.
What they do: They meticulously identify market opportunities for new alternative data products or enhancements, define a clear product strategy, meticulously gather and prioritize requirements from various stakeholders, manage the end-to-end product roadmap, and collaborate closely with data scientists, data engineers, and sales teams to ensure the successful development, launch, and adoption of innovative data-driven solutions. They possess a keen understanding of both the data's raw potential and the specific business problem it is designed to solve.
Why it's growing: As alternative data moves from niche to mainstream, companies desperately need strategists who can translate its complex technical potential into tangible, commercially viable products and actionable business insights.
Key Skills:
Product Management Fundamentals: Strong grasp of agile methodologies, product roadmap planning, user story creation, and sophisticated stakeholder management.
Business Acumen: A deep, nuanced understanding of the specific industry where the alternative data is being applied (e.g., quantitative finance, retail strategy, real estate analytics).
Data Literacy: The ability to understand the technical capabilities, inherent limitations, potential biases, and ethical considerations associated with diverse alternative datasets.
Exceptional Communication: Outstanding skills in articulating product vision, requirements, and value propositions to both highly technical teams and non-technical business leaders.
Market Research: Proficiency in identifying unmet market needs, analyzing competitive landscapes, and defining unique value propositions for data products.
Basic SQL/Data Analysis: Sufficient technical understanding to engage meaningfully with data teams and comprehend data capabilities and constraints.
How to Learn:
Product Management Courses: General PM courses provide an excellent foundation (e.g., from Product School, or online specializations on platforms like Coursera/edX).
Develop Deep Domain Expertise: Immerse yourself in industry news, read analyst reports, attend conferences, and thoroughly understand the core problems of your target industry.
Foundational Data Analytics/Science: Take introductory courses in Python/R, SQL, and data visualization to understand the technical underpinnings.
Networking: Actively engage with existing data product managers and leading alternative data providers.
4. Data Ethicist / AI Policy Analyst (Alternative Data Specialization)
The innovative application of alternative data, particularly when combined with AI, frequently raises significant ethical, privacy, and regulatory concerns. This crucial role ensures that data acquisition and usage are not only compliant but also responsible and fair.
What they do: They meticulously develop and implement robust ethical guidelines for the collection, processing, and use of alternative data. They assess potential biases inherent in alternative datasets and their potential for unfair outcomes, ensure strict compliance with evolving data privacy regulations (like GDPR, CCPA, and similar data protection acts), conduct comprehensive data protection and impact assessments, and advise senior leadership on broader AI policy implications related to data governance.
Why it's growing: With escalating public scrutiny, rapidly evolving global regulations, and high-profile incidents of data misuse, ethical and compliant data practices are no longer merely optional; they are absolutely critical for maintaining an organization's reputation, avoiding severe legal penalties, and fostering public trust.
Key Skills:
Legal & Regulatory Knowledge: A strong understanding of global and regional data privacy laws (e.g., GDPR, CCPA, etc.), emerging AI ethics frameworks, and industry-specific regulations that govern data use.
Risk Assessment & Mitigation: Expertise in identifying, analyzing, and developing strategies to mitigate ethical, privacy, and algorithmic bias risks associated with complex data sources.
Critical Thinking & Bias Detection: The ability to critically analyze datasets and algorithmic outcomes for inherent biases, fairness issues, and potential for discriminatory impacts.
Communication & Policy Writing: Exceptional skills in translating complex ethical and legal concepts into clear, actionable policies, guidelines, and advisory reports for diverse audiences.
Stakeholder Engagement: Proficiency in collaborating effectively with legal teams, compliance officers, data scientists, engineers, and business leaders.
Basic Data Literacy: Sufficient understanding of how data is collected, stored, processed, and used by AI systems to engage meaningfully with technical teams.
How to Learn:
Specialized Courses & Programs: Look for postgraduate programs or dedicated courses in Data Ethics, AI Governance, Technology Law, or Digital Policy, often offered by law schools, public policy institutes, or specialized AI ethics organizations.
Industry & Academic Research: Stay current by reading reports and white papers from leading organizations (e.g., World Economic Forum), academic research institutions, and major tech companies' internal ethics guidelines.
Legal Background (Optional but Highly Recommended): A formal background in law or public policy can provide a significant advantage.
Engage in Professional Forums: Actively participate in discussions and communities focused on data ethics, AI policy, and responsible AI.
5. Data Journalist / Research Analyst (Alternative Data Focused)
This captivating role harnesses the power of alternative data to uncover compelling narratives, verify claims, and provide unique, data-driven insights for public consumption or critical internal strategic decision-making in sectors like media, consulting, or advocacy.
What they do: They meticulously scour publicly available alternative datasets (e.g., analyzing satellite imagery for environmental impact assessments, tracking social media trends for shifts in public opinion, dissecting open government data for policy analysis, or using web-scraped data for market intelligence). They then expertly clean, analyze, and, most importantly, effectively visualize and communicate their findings through engaging stories, in-depth reports, and interactive dashboards.
Why it's growing: The ability to tell powerful, evidence-based stories from unconventional data sources is invaluable for modern journalism, influential think tanks, specialized consulting firms, and even for robust internal corporate communications.
Key Skills:
Data Cleaning & Wrangling: Expertise in preparing messy, real-world data for analysis, typically using tools like Python (with Pandas), R (with Tidyverse), or advanced Excel functions.
Data Visualization: Proficiency with powerful visualization tools such as Tableau Public, Datawrapper, Flourish, or programming libraries like Matplotlib, Seaborn, and Plotly for creating clear, impactful, and engaging visual narratives.
Storytelling & Communication: Exceptional ability to translate complex data insights into clear, concise, and compelling narratives that resonate with both expert and general audiences.
Research & Investigative Skills: A deep sense of curiosity, persistence in finding and validating diverse data sources, and the analytical acumen to uncover hidden patterns and connections.
Domain Knowledge: A strong understanding of the subject matter being investigated (e.g., politics, environmental science, consumer trends, public health).
Basic Statistics: Sufficient statistical knowledge to understand trends, interpret correlations, and draw sound, defensible conclusions from data.
How to Learn:
Data Journalism Programs: Some universities offer specialized master's or certificate programs in data journalism.
Online Courses: Focus on courses in data visualization, storytelling with data, and introductory data analysis on platforms like Coursera, Udemy, or specific tool tutorials.
Practical Experience: Actively engage with open data portals (e.g., data.gov, WHO, World Bank), and practice analyzing, visualizing, and writing about these datasets.
Build a Portfolio: Create a strong portfolio of compelling data stories and visualizations based on alternative data projects, demonstrating your ability to communicate insights effectively.
The landscape of data is evolving at an unprecedented pace, and alternative data is at the heart of this transformation. These career paths offer incredibly exciting opportunities for those willing to learn the specialized skills required to navigate and extract profound value from this rich, unconventional frontier. Whether your passion lies in deep technical analysis, strategic product development, ethical governance, or impactful storytelling, alternative data provides a fertile ground for a rewarding and future-proof career.
0 notes
Text
Data Engineering vs Data Science: Which Course Should You Take Abroad?
In today’s data-driven world, careers in tech and analytics are booming. Two of the most sought-after fields that international students often explore are Data Engineering and Data Science. Both these disciplines play critical roles in helping businesses make informed decisions. However, they are not the same, and if you're planning to pursue a course abroad, understanding the difference between the two is crucial to making the right career move.
In this comprehensive guide, we’ll explore:
What is Data Engineering?
What is Data Science?
Key differences between the two fields
Skills and tools required
Job opportunities and career paths
Best countries to study each course
Top universities offering these programs
Which course is better for you?
What is Data Engineering?
Data Engineering is the backbone of the data science ecosystem. It focuses on the design, development, and maintenance of systems that collect, store, and transform data into usable formats. Data engineers build and optimize the architecture (pipelines, databases, and large-scale processing systems) that data scientists use to perform analysis.
Key Responsibilities:
Developing, constructing, testing, and maintaining data architectures
Building data pipelines to streamline data flow
Managing and organizing raw data
Ensuring data quality and integrity
Collaborating with data analysts and scientists
Popular Tools:
Apache Hadoop
Apache Spark
SQL/NoSQL databases (PostgreSQL, MongoDB)
Python, Scala, Java
AWS, Azure, Google Cloud
What is Data Science?
Data Science, on the other hand, is more analytical. It involves extracting insights from data using algorithms, statistical models, and machine learning. Data scientists interpret complex datasets to identify patterns, forecast trends, and support decision-making.
Key Responsibilities:
Analyzing large datasets to extract actionable insights
Using machine learning and predictive modeling
Communicating findings to stakeholders through visualization
A/B testing and hypothesis validation
Data storytelling
Popular Tools:
Python, R
TensorFlow, Keras, PyTorch
Tableau, Power BI
SQL
Jupyter Notebook
Career Paths and Opportunities
Data Engineering Careers:
Data Engineer
Big Data Engineer
Data Architect
ETL Developer
Cloud Data Engineer
Average Salary (US): $100,000–$140,000/year Job Growth: High demand due to an increase in big data applications and cloud platforms.
Data Science Careers:
Data Scientist
Machine Learning Engineer
Data Analyst
AI Specialist
Business Intelligence Analyst
Average Salary (US): $95,000–$135,000/year Job Growth: Strong demand across sectors like healthcare, finance, and e-commerce.
Best Countries to Study These Courses Abroad
1. United States
The US is a leader in tech innovation and offers top-ranked universities for both fields.
Top Universities:
Massachusetts Institute of Technology (MIT)
Stanford University
Carnegie Mellon University
UC Berkeley
Highlights:
Access to Silicon Valley
Industry collaborations
Internship and job opportunities
2. United Kingdom
UK institutions provide flexible and industry-relevant postgraduate programs.
Top Universities:
University of Oxford
Imperial College London
University of Edinburgh
University of Manchester
Highlights:
1-year master’s programs
Strong research culture
Scholarships for international students
3. Germany
Known for engineering excellence and affordability.
Top Universities:
Technical University of Munich (TUM)
RWTH Aachen University
University of Freiburg
Highlights:
Low or no tuition fees
High-quality public education
Opportunities in tech startups and industries
4. Canada
Popular for its friendly immigration policies and growing tech sector.
Top Universities:
University of Toronto
University of British Columbia
McGill University
Highlights:
Co-op programs
Pathway to Permanent Residency
Tech innovation hubs in Toronto and Vancouver
5. Australia
Ideal for students looking for industry-aligned and practical courses.
Top Universities:
University of Melbourne
Australian National University
University of Sydney
Highlights:
Focus on employability
Vibrant student community
Post-study work visa options
6. France
Emerging as a strong tech education destination.
Top Universities:
HEC Paris (Data Science for Business)
École Polytechnique
Grenoble Ecole de Management
Highlights:
English-taught master’s programs
Government-funded scholarships
Growth of AI and data-focused startups
Course Curriculum: What Will You Study?
Data Engineering Courses Abroad Typically Include:
Data Structures and Algorithms
Database Systems
Big Data Analytics
Cloud Computing
Data Warehousing
ETL Pipeline Development
Programming in Python, Java, and Scala
Data Science Courses Abroad Typically Include:
Statistical Analysis
Machine Learning and AI
Data Visualization
Natural Language Processing (NLP)
Predictive Analytics
Deep Learning
Business Intelligence Tools
Which Course Should You Choose?
Choosing between Data Engineering and Data Science depends on your interests, career goals, and skillset.
Go for Data Engineering if:
You enjoy backend systems and architecture
You like coding and building tools
You are comfortable working with databases and cloud systems
You want to work behind the scenes, ensuring data flow and integrity
Go for Data Science if:
You love analyzing data to uncover patterns
You have a strong foundation in statistics and math
You want to work with machine learning and AI
You prefer creating visual stories and communicating insights
Scholarships and Financial Support
Many universities abroad offer scholarships for international students in tech disciplines. Here are a few to consider:
DAAD Scholarships (Germany): Fully-funded programs for STEM students
Commonwealth Scholarships (UK): Tuition and living costs covered
Fulbright Program (USA): Graduate-level funding for international students
Vanier Canada Graduate Scholarships: For master’s and PhD students in Canada
Eiffel Scholarships (France): Offered by the French Ministry for Europe and Foreign Affairs
Final Thoughts: Make a Smart Decision
Both Data Engineering and Data Science are rewarding and in-demand careers. Neither is better or worse—they simply cater to different strengths and interests.
If you're analytical, creative, and enjoy experimenting with models, Data Science is likely your path.
If you're system-oriented, logical, and love building infrastructure, Data Engineering is the way to go.
When considering studying abroad, research the university's curriculum, available electives, internship opportunities, and career support services. Choose a program that aligns with your long-term career aspirations.
By understanding the core differences and assessing your strengths, you can confidently decide which course is the right fit for you.
Need Help Choosing the Right Program Abroad?
At Cliftons Study Abroad, we help students like you choose the best universities and courses based on your interests and future goals. From counselling to application assistance and visa support, we’ve got your journey covered.
Contact us today to start your journey in Data Science or Data Engineering abroad!
#study abroad#study in uk#study abroad consultants#study in australia#study in germany#study in ireland#study blog
0 notes
Text
How can I choose a good swimming pool robot manufacturer?
Many suppliers promise high quality, but not all deliver. The wrong choice could cost time and money. Look for proven experience,
quality control, and customization options to find the right pool robot manufacturer.
Our American customers told us,,I learned this lesson the hard way during one of my early sourcing trips. I trusted an unverified supplier.
It delayed my shipments, and I missed an entire selling season.
In the following text, I will analyze from several aspects to help you understand how to choose a suitable swimming pool robot manufacturer.
What makes a pool robot manufacturer reliable?
Experience and transparency are key. A reliable manufacturer shows their process and proves their capability.
**Choose a supplier with production experience, clear communication, and real customer success stories.
Some factories say they have 10 years of experience. But when you ask for past customer feedback or shipment records, they hesitate.
That’s a red flag.
I only trust manufacturers that are:
- Open about their production capacity
- Willing to provide references
- Transparent with certifications and test reports
Here’s a quick table I use when evaluating manufacturers:
Criteria
What to Check
Red Flags
Years in Business
Factory license, export history
No verified documents
Client Testimonials
References,Google/Alibaba reviews
Only internal reviews
Factory Visit Allowed
Video calls or on-site visit options
Avoids face-to-face meetings
Main Markets
Match your target regions
Claims “global” with no proof
This is especially important for robot products, where long-term reliability affects brand reputation.

How important is certification and compliance?
Certifications protect your brand and prevent shipping issues.
A reliable pool robot supplier must offer CE, FCC, and RoHS certifications for global shipping.
Not all certificates are created equal
Once, a supplier gave me a “certificate” with fake agency stamps. That experience taught me to verify every document directly with the testing lab.
Key certificates for pool robots:
Region
Certificate Needed
What It Proves
Europe
CE, RoHS
Electrical safety, environmental safety
North America
FCC, ETL
Radio frequency and safety compliance
Asia
PSE (Japan), KC
National electrical safety standards
Also ask:
- Who issued the certificate?
- Is the certificate under the supplier’s name or their customer’s?
- Can you contact the lab for verification?
Good factories won’t hesitate to give you test reports and links to public databases.
Can they support flexible customization needs?
Custom branding is critical for private label success. Your supplier must support it fast and efficiently.
Pick a partner that supports private labeling, design tweaks, and packaging customization with low MOQs.
Customization isn’t just logo printing
When I work with mid-to-high-end client from the U.S., design is not just an aesthetic concern—it’s a marketing tool. They often ask:
- Can you change the brush type?
- Is it possible to add app control or remote features?
- Can the robot be color-matched to our brand?
These are reasonable requests. But not all suppliers have in-house engineering or design teams to handle them quickly.
What I look for:
Custom Option
Why It Matters
Supplier Should Provide
Hardware adjustment
Adaptability to pool types
Engineering support
Software integration
Market trend and smart features
App or Bluetooth integration
Packaging design
In-store branding or eCommerce appeal
Graphic team or dieline template
Good factories usually have a project manager who coordinates these changes from start to finish.
A good-looking sample doesn’t mean mass production will meet your standards.
Make sure the supplier has standard QC checks and third-party inspection reports for every order
The real meaning of "quality control"
I’ve seen it too often. A buyer gets a great sample, places a bulk order, and receives inconsistent products. That’s not bad luck—it’s bad quality control.
Ask your supplier:
- Do they allow third-party inspections?
- What internal QC methods do they use?
- How many inspectors per production line?
For example, in our factory, we apply a 5-step inspection:
1. Incoming Material Check
2. In-Process QC
3. Finished Product Inspection
4. Random Sampling
5. Pre-shipment Inspection
Each step is logged in an internal system. If your supplier cannot describe something similar, it’s a warning.
Also, make sure they understand:
- IPX rating for waterproof robots
- Battery safety for lithium parts
- Cable durability tests for tangle-free operation
These are critical for pool robot safety and longevity.
http://a2.ldycdn.com/cloud/lmBprKqkliSRiliompjkio/weixintupian_20250519175438.png
How can I verify product quality before shipment?
I used to think a few product photos were enough. I learned the hard way.
Use third-party inspections, full-function tests, and video confirmations before shipment.
Ask for Real-Time Video Checks
I now request a live video demo before every shipment. I ask them to:
- Unbox random units
- Run cleaning cycles in real-time
- Show remote controls and app pairing
These steps expose any hidden defects or shortcuts.
Sample Testing
For new suppliers, I always request 1-2 full-function units to test locally. If they hesitate, that’s a red flag. Quality products can speak for themselves.
What mistakes should I avoid when sourcing swimming pool robots?
It’s easy to get trapped by low prices or over-promises.
Avoid vague communication, skipping factory visits, and over-relying on supplier claims.
Don't Trust Every Brochure
Glossy PDFs don’t mean they can deliver. Ask for:
- Live factory tours
- Tooling molds or assembly footage
- Real customer reviews
I once trusted a “French-designed” robot, only to receive a weak motor model from an unknown brand.
Avoid One-Time Suppliers
Some factories disappear after the first order. I ask:
- Do you have a company domain email?
- Can you provide customs export records?
- Do you offer long-term contracts or exclusivity?
Reliable suppliers think long-term, not short-term profit.
Pay Attention to Shipping Readiness
Even a good product fails if delayed. Ask:
- Do you pre-stock components?
- What’s your typical port of shipment?
- Can you handle DDP (Delivered Duty Paid)?
I once lost two months of peak sales waiting for customs clearance. Now, I work only with suppliers who offer end-to-end logistics help.
Conclusion
Find the right manufacturer by mixing research, smart questions, and clear verification. We believe that through the above key points,
you will choose a suitable swimming pool robot manufacturer. Additionally, Lincinco is a reliable Chinese swimming pool robot manufacturer.
Welcome to consult us for more detailed information. We are willing to help you obtain customizable high-quality swimming pool robots.
0 notes
Text
Data Testing Fundamentals
Data is everywhere, but how often do we check if it’s actually reliable? The Data Testing Fundamentals course teaches exactly that—how to test data for accuracy, consistency, and usability. Tailored for students, working professionals, and QA testers, this course is your entry point into the growing field of data validation. It’s structured in a way that even someone with no prior testing background can follow. Topics range from understanding different types of data issues to using test strategies that ensure data meets quality standards. You'll also learn about real-time applications like testing during ETL processes, validating after data migration, and ensuring clean data input/output in analytics systems. With data playing such a central role in decision-making today, this course helps bridge the gap between raw information and meaningful, trustworthy insights.
👉 Discover the fundamentals of data testing—join the course and get started today.
0 notes
Text
#IoT Testing#Internet of Things#Device Testing#Functional Testing#Performance Testing#Security Testing#Interoperability Testing#Usability Testing#Regression Testing#IoT Security#Smart Devices#Connected Systems#IoT Protocols#GQATTech#IoT Solutions#Data Privacy#System Integration#User Experience#IoT Performance#Compliance Testing#POS Testing#Point of Sale#Retail Technology#Transaction Processing#System Reliability#Customer Experience#Compatibility Testing#Retail Operations#Payment Systems#PCI DSS Compliance
0 notes
Text
Overview
Our client runs a cloud-based platform that turns complex data from sources like firewalls and SIEMs into clear insights for better decision-making. It uses advanced ETL processes to gather and process large volumes of data, making it easy for users to access accurate and real-time information.
Why They Chose Us
As they launched a new app, they needed a testing partner to ensure high performance and reliability. They chose Appzlogic for our expertise in functional and automation testing. We built a custom automation framework tailored to their needs.
Our Testing Strategy
We started with manual testing (sanity, smoke, functional, regression) and later automated key UI and API workflows. Poor data quality and manual ETL testing are major reasons why BI projects fail. We addressed this by ensuring data accuracy and reducing manual work.
Manual Testing Process:
Requirement Analysis: Understood the product and its goals
Scope Definition: Identified what to test
Test Case Design: Created test cases for all scenarios
Execution & Defect Logging: Ran tests and reported issues in JIRA
Automation Testing Results:
We reduced manual effort by 60%. Automated tests were created for data validation across AWS and Azure services. Modular and end-to-end tests boosted efficiency and coverage.
Source Data Flow Overview

These events flowed through the volume controller and were distributed across multiple processing nodes, with one rule node actively handling 1 event. The transformation stage processed 1 event, which was then successfully delivered to the Raw-S3-1 destination. This streamlined flow highlights a well-structured and reliable data processing pipeline.
Centralized Data Operations Briefly

The Data Command Center showcases a well-orchestrated flow of data with 2,724 sources feeding into 3,520 pipelines, resulting in 98.4k events ingested and 21.3 MB of log data processed, all at an average rate of 1 EPS (event per second). Every connected destination received 100% of the expected data with zero loss. Additionally, 51 devices were newly discovered and connected, with no pending actions. This dashboard reflects a highly efficient and reliable data pipeline system in action.
Smooth and Reliable Data Flow

The source TC-DATAGENERATOR-SOURCE-STATUS-1745290102 is working well and is active. It collected 9.36k events and processed 933 KB of data. All events were successfully delivered to the Sandbox with no data loss. The graph shows a steady flow of data over time, proving the system is running smoothly and efficiently.
Tools & Frameworks Used:
Python + Pytest: For unit and functional tests
RequestLibrary: For API testing
Selenium: For UI automation
GitHub + GitHub Actions: For CI/CD
Boto3: To work with AWS
Paramiko: For remote server access
Conclusion
Our testing helped the client build a reliable and scalable platform. With a mix of manual and automated testing, we boosted test accuracy, saved time, and supported their continued growth.
We are The Best IT Service Provider across the globe.
Contact Us today.
0 notes
Text
ETL Testing: How to Validate Your Python ETL Pipelines
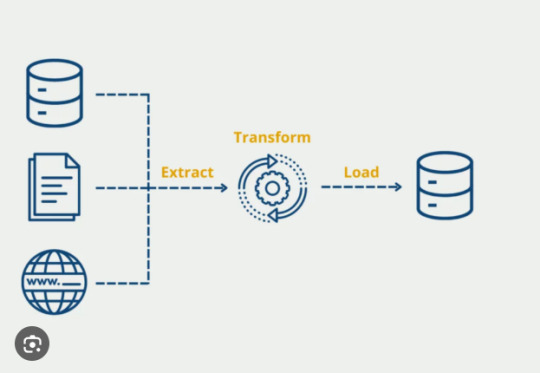
In the world of data engineering, building a strong Extract Transform Load (ETL) process is only half the battle. Ensuring that your ETL pipelines are reliable, accurate, and efficient is just as crucial. When working with Extract Transform Load Python workflows, proper ETL testing is essential to maintain data quality, catch errors early, and guarantee trustworthy outputs for downstream applications. In this article, we'll explore why ETL testing matters and how to effectively validate your Python ETL pipelines.
Why ETL Testing Is Critical
ETL processes move and transform data between systems — often at massive scales. A small mistake during extraction, transformation, or loading can result in significant business consequences, from incorrect analytics to failed reporting. Especially when using Extract Transform Load Python pipelines, where flexibility is high and custom scripts are common, thorough testing helps to:
Detect data loss or corruption
Ensure transformations are applied correctly
Validate that data is loaded into the target system accurately
Confirm that performance meets expectations
Maintain data consistency across different stages
Without systematic ETL testing, you risk pushing flawed data into production, which could impact decision-making and operations.
Key Types of ETL Testing
When validating Extract Transform Load Python pipelines, several types of testing should be performed:
1. Data Completeness Testing
This ensures that all the expected data from the source system is extracted and made available for transformation and loading. You might use row counts, checksum comparisons, or aggregate validations to detect missing or incomplete data.
2. Data Transformation Testing
In this step, you verify that transformation rules (like calculations, data type changes, or standardizations) have been correctly applied. Writing unit tests for transformation functions is a best practice when coding ETL logic in Python.
3. Data Accuracy Testing
Data must be correctly inserted into the target system without errors. Validation includes checking field mappings, constraints (like foreign keys), and ensuring values match expectations after loading.
4. Performance Testing
An efficient Extract Transform Load Python pipeline should process data within acceptable timeframes. Performance testing identifies slow stages and bottlenecks in your ETL workflow.
5. Regression Testing
Whenever changes are made to the ETL code, regression testing ensures that new updates don't break existing functionality.
How to Perform ETL Testing in Python
Python provides a wide range of tools and libraries that make ETL testing approachable and powerful. Here’s a practical roadmap:
1. Write Unit Tests for Each Stage
Use Python’s built-in unittest framework or popular libraries like pytest to create test cases for extraction, transformation, and loading functions individually. This modular approach ensures early detection of bugs.
2. Validate Data with Pandas
Pandas is excellent for comparing datasets. For example, after extracting data, you can create Pandas DataFrames and use assertions like:
python
CopyEdit
import pandas as pd
3. Create Test Data Sets
Set up controlled test databases or files containing predictable datasets. Using mock data ensures that your Extract Transform Load Python process can be tested repeatedly under consistent conditions.
4. Automate ETL Test Workflows
Incorporate your ETL testing into automated CI/CD pipelines. Tools like GitHub Actions, Jenkins, or GitLab CI can trigger tests automatically whenever new code is pushed.
5. Use Data Validation Libraries
Libraries like great_expectations can make ETL testing even more robust. They allow you to define "expectations" for your data — such as field types, allowed ranges, and value uniqueness — and automatically validate your data against them.
Common ETL Testing Best Practices
Always test with real-world data samples when possible.
Track and log all test results to maintain visibility into pipeline health.
Isolate failures to specific ETL stages to debug faster.
Version-control both your ETL code and your test cases.
Keep test cases updated as your data models evolve.
Final Thoughts
Validating your Extract Transform Load Python pipelines with thorough ETL testing is vital for delivering trustworthy data solutions. From unit tests to full-scale validation workflows, investing time in testing ensures your ETL processes are accurate, reliable, and scalable. In the fast-paced world of data-driven decision-making, solid ETL testing isn't optional — it’s essential.
0 notes
Text
h
Technical Skills (Java, Spring, Python)
Q1: Can you walk us through a recent project where you built a scalable application using Java and Spring Boot? A: Absolutely. In my previous role, I led the development of a microservices-based system using Java with Spring Boot and Spring Cloud. The app handled real-time financial transactions and was deployed on AWS ECS. I focused on building stateless services, applied best practices like API versioning, and used Eureka for service discovery. The result was a 40% improvement in performance and easier scalability under load.
Q2: What has been your experience with Python in data processing? A: I’ve used Python for ETL pipelines, specifically for ingesting large volumes of compliance data into cloud storage. I utilized Pandas and NumPy for processing, and scheduled tasks with Apache Airflow. The flexibility of Python was key in automating data validation and transformation before feeding it into analytics dashboards.
Cloud & DevOps
Q3: Describe your experience deploying applications on AWS or Azure. A: Most of my cloud experience has been with AWS. I’ve deployed containerized Java applications to AWS ECS and used RDS for relational storage. I also integrated S3 for static content and Lambda for lightweight compute tasks. In one project, I implemented CI/CD pipelines with Jenkins and CodePipeline to automate deployments and rollbacks.
Q4: How have you used Docker or Kubernetes in past projects? A: I've containerized all backend services using Docker and deployed them on Kubernetes clusters (EKS). I wrote Helm charts for managing deployments and set up autoscaling rules. This improved uptime and made releases smoother, especially during traffic spikes.
Collaboration & Agile Practices
Q5: How do you typically work with product owners and cross-functional teams? A: I follow Agile practices, attending sprint planning and daily stand-ups. I work closely with product owners to break down features into stories, clarify acceptance criteria, and provide early feedback. My goal is to ensure technical feasibility while keeping business impact in focus.
Q6: Have you had to define technical design or architecture? A: Yes, I’ve been responsible for defining the technical design for multiple features. For instance, I designed an event-driven architecture for a compliance alerting system using Kafka, Java, and Spring Cloud Streams. I created UML diagrams and API contracts to guide other developers.
Testing & Quality
Q7: What’s your approach to testing (unit, integration, automation)? A: I use JUnit and Mockito for unit testing, and Spring’s Test framework for integration tests. For end-to-end automation, I’ve worked with Selenium and REST Assured. I integrate these tests into Jenkins pipelines to ensure code quality with every push.
Behavioral / Cultural Fit
Q8: How do you stay updated with emerging technologies? A: I subscribe to newsletters like InfoQ and follow GitHub trending repositories. I also take part in hackathons and complete Udemy/Coursera courses. Recently, I explored Quarkus and Micronaut to compare their performance with Spring Boot in cloud-native environments.
Q9: Tell us about a time you challenged the status quo or proposed a modern tech solution. A: At my last job, I noticed performance issues due to a legacy monolith. I advocated for a microservices transition. I led a proof-of-concept using Spring Boot and Docker, which gained leadership buy-in. We eventually reduced deployment time by 70% and improved maintainability.
Bonus: Domain Experience
Q10: Do you have experience supporting back-office teams like Compliance or Finance? A: Yes, I’ve built reporting tools for Compliance and data reconciliation systems for Finance. I understand the importance of data accuracy and audit trails, and have used role-based access and logging mechanisms to meet regulatory requirements.
0 notes
Text
Your Data Science Career Roadmap: Navigating the Jobs and Levels

The field of data science is booming, offering a myriad of exciting career opportunities. However, for many, the landscape of job titles and progression paths can seem like a dense forest. Are you a Data Analyst, a Data Scientist, or an ML Engineer? What's the difference, and how do you climb the ladder?
Fear not! This guide will provide a clear roadmap of common data science jobs and their typical progression levels, helping you chart your course in this dynamic domain.
The Core Pillars of a Data Science Career
Before diving into specific roles, it's helpful to understand the three main pillars that define much of the data science ecosystem:
Analytics: Focusing on understanding past and present data to extract insights and inform business decisions.
Science: Focusing on building predictive models, often using machine learning, to forecast future outcomes or automate decisions.
Engineering: Focusing on building and maintaining the infrastructure and pipelines that enable data collection, storage, and processing for analytics and science.
While there's often overlap, many roles lean heavily into one of these areas.
Common Data Science Job Roles and Their Progression
Let's explore the typical roles and their advancement levels:
I. Data Analyst
What they do: The entry point for many into the data world. Data Analysts collect, clean, analyze, and visualize data to answer specific business questions. They often create dashboards and reports to present insights to stakeholders.
Key Skills: SQL, Excel, data visualization tools (Tableau, Power BI), basic statistics, Python/R for data manipulation (Pandas, dplyr).
Levels:
Junior Data Analyst: Focus on data cleaning, basic reporting, and assisting senior analysts.
Data Analyst: Independent analysis, creating comprehensive reports and dashboards, communicating findings.
Senior Data Analyst: Leading analytical projects, mentoring junior analysts, working on more complex business problems.
Progression: Can move into Data Scientist roles (by gaining more ML/statistical modeling skills), Business Intelligence Developer, or Analytics Manager.
II. Data Engineer
What they do: The architects and builders of the data infrastructure. Data Engineers design, construct, and maintain scalable data pipelines, data warehouses, and data lakes. They ensure data is accessible, reliable, and efficient for analysts and scientists.
Key Skills: Strong programming (Python, Java, Scala), SQL, NoSQL databases, ETL tools, cloud platforms (AWS, Azure, GCP), big data technologies (Hadoop, Spark, Kafka).
Levels:
Junior Data Engineer: Assisting in pipeline development, debugging, data ingestion tasks.
Data Engineer: Designing and implementing data pipelines, optimizing data flows, managing data warehousing.
Senior Data Engineer: Leading complex data infrastructure projects, setting best practices, mentoring, architectural design.
Principal Data Engineer / Data Architect: High-level strategic design of data systems, ensuring scalability, security, and performance across the organization.
Progression: Can specialize in Big Data Engineering, Cloud Data Engineering, or move into Data Architect roles.
III. Data Scientist
What they do: The problem-solvers who use advanced statistical methods, machine learning, and programming to build predictive models and derive actionable insights from complex, often unstructured data. They design experiments, evaluate models, and communicate technical findings to non-technical audiences.
Key Skills: Python/R (with advanced libraries like Scikit-learn, TensorFlow, PyTorch), advanced statistics, machine learning algorithms, deep learning (for specialized roles), A/B testing, data modeling, strong communication.
Levels:
Junior Data Scientist: Works on specific model components, assists with data preparation, learns from senior scientists.
Data Scientist: Owns end-to-end model development for defined problems, performs complex analysis, interprets results.
Senior Data Scientist: Leads significant data science initiatives, mentors juniors, contributes to strategic direction, handles ambiguous problems.
Principal Data Scientist / Lead Data Scientist: Drives innovation, sets technical standards, leads cross-functional projects, influences product/business strategy with data insights.
Progression: Can move into Machine Learning Engineer, Research Scientist, Data Science Manager, or even Product Manager (for data products).
IV. Machine Learning Engineer (MLE)
What they do: Bridge the gap between data science models and production systems. MLEs focus on deploying, optimizing, and maintaining machine learning models in real-world applications. They ensure models are scalable, reliable, and perform efficiently in production environments (MLOps).
Key Skills: Strong software engineering principles, MLOps tools (Kubeflow, MLflow), cloud computing, deployment frameworks, understanding of ML algorithms, continuous integration/delivery (CI/CD).
Levels:
Junior ML Engineer: Assists in model deployment, monitoring, and basic optimization.
ML Engineer: Responsible for deploying and maintaining ML models, building robust ML pipelines.
Senior ML Engineer: Leads the productionization of complex ML systems, optimizes for performance and scalability, designs ML infrastructure.
Principal ML Engineer / ML Architect: Defines the ML architecture across the organization, researches cutting-edge deployment strategies, sets MLOps best practices.
Progression: Can specialize in areas like Deep Learning Engineering, NLP Engineering, or move into AI/ML leadership roles.
V. Other Specialized & Leadership Roles
As you gain experience and specialize, other roles emerge:
Research Scientist (AI/ML): Often found in R&D departments or academia, these roles focus on developing novel algorithms and pushing the boundaries of AI/ML. Requires strong theoretical understanding and research skills.
Business Intelligence Developer/Analyst: More focused on reporting, dashboards, and operational insights, often using specific BI tools.
Quantitative Analyst (Quant): Primarily in finance, applying complex mathematical and statistical models for trading, risk management, and financial forecasting.
Data Product Manager: Defines, develops, and launches data-driven products, working at the intersection of business, technology, and data science.
Data Science Manager / Director / VP of Data Science / Chief Data Officer (CDO): Leadership roles that involve managing teams, setting strategy, overseeing data initiatives, and driving the overall data culture of an organization. These roles require strong technical acumen combined with excellent leadership and business communication skills.
Charting Your Own Path
Your data science career roadmap isn't linear, and transitions between roles are common. To advance, consistently focus on:
Continuous Learning: The field evolves rapidly. Stay updated with new tools, techniques, and research.
Building a Portfolio: Showcase your skills through personal projects, Kaggle competitions, and open-source contributions.
Domain Expertise: Understanding the business context where you apply data science makes your work more impactful.
Communication Skills: Being able to clearly explain complex technical concepts to non-technical stakeholders is paramount for leadership.
Networking: Connect with other professionals in the field, learn from their experiences, and explore new opportunities.
Whether you aspire to be a deep-dive researcher, a production-focused engineer, or a strategic leader, the data science landscape offers a fulfilling journey for those willing to learn and adapt. Where do you see yourself on this exciting map?
#data scientist#online course#ai#artificial intelligence#technology#data science#data science course#data science career
0 notes
Text
Commercial Refrigeration Cooling Fans: How High-Efficiency Solutions Boost Performance & Equipment Lifespan?

In industries like cold chain logistics, food processing, and medical refrigeration, reliable freezer operation is non-negotiable. Cooling fans - the unsung heroes of refrigeration systems - directly impact energy efficiency and equipment durability. As an industrial fan manufacturer with 26+ years of expertise, Cooltron breaks down the engineering behind premium freezer cooling fans and reveals how optimized thermal management cuts costs while maximizing uptime.
Why Commercial Freezer Fans Are Your System's Silent Guardians
Continuous freezer operation generates intense heat buildup. Without proper dissipation, this leads to: • Compressor overload (+27% energy waste*) • Premature component failure (85% of refrigeration repairs stem from overheating**) • Safety risks in temperature-sensitive storage
Industry data shows: Low-quality fans account for 62% of unplanned cold storage shutdowns due to motor burnout and corrosion issues.
5 Must-Check Specifications When Selecting Industrial Freezer Fans
CFM & Static Pressure Match airflow (cubic feet/minute) to your unit's BTU output. Pro Tip: Cooltron's engineers provide free CFD simulations to prevent oversizing/undersizing.
Motor Efficiency BLDC motors outperform AC models with:
30-40% lower power consumption
<45 dBA noise levels (meets OSHA workplace standards)
Built-in surge protection
Durability Features Seek IP55-rated aluminum housings and salt spray resistance - critical for seafood processing plants and coastal facilities.
Bearing System Dual ball bearings (60,000+ hour lifespan) vs. sleeve bearings (15,000 hours) = 4X less maintenance.
Certifications UL/CE/ETL listings ensure compliance with US NEC and international electrical codes.
Cooltron's Edge: Engineered for American Industrial Demands
As a 26-year veteran in OEM/ODM manufacturing, we deliver purpose-built solutions:
Precision Fit: 20mm-400mm sizes | 5V-240V voltage compatibility
Smart Integration: PWM speed control syncs with PT100/PTC sensors
Rapid Scaling: 7-day prototype turnaround | 1M+ unit annual capacity
Global Reach: Trusted by 1,000+ clients across North America, Europe, MENA & APAC regions
Case Study: 22% Energy Savings for Midwest Frozen Food Distributor
After upgrading to Cooltron's EC Fan Series: ✓ $18,700 annual power cost reduction ✓ 76% fewer service calls ✓ Full ROI in 11 months "Cooltron's plug-and-play design eliminated retrofitting costs. Their 24/7 Chicago support team sealed the deal." - Maintenance Manager
3 Pro Maintenance Tips from Our Engineers
Monthly: Clean fan blades with compressed air (never water!)
Quarterly: Check amp draw - >10% increase signals bearing wear
Biannually: Test automatic shutoff triggers at 185°F (85°C)
Download our FREE "Fan Product Catalog" or schedule a FaceTime facility audit with our US-based engineers!
0 notes
Text
Data Engineering vs Data Science: Which Course Should You Take Abroad?
The rapid growth of data-driven industries has brought about two prominent and in-demand career paths: Data Engineering and Data Science. For international students dreaming of a global tech career, these two fields offer promising opportunities, high salaries, and exciting work environments. But which course should you take abroad? What are the key differences, career paths, skills needed, and best study destinations?
In this blog, we’ll break down the key distinctions between Data Engineering and Data Science, explore which path suits you best, and highlight the best countries and universities abroad to pursue these courses.
What is Data Engineering?
Data Engineering focuses on designing, building, and maintaining data pipelines, systems, and architecture. Data Engineers prepare data so that Data Scientists can analyze it. They work with large-scale data processing systems and ensure that data flows smoothly between servers, applications, and databases.
Key Responsibilities of a Data Engineer:
Developing, testing, and maintaining data pipelines
Building data architectures (e.g., databases, warehouses)
Managing ETL (Extract, Transform, Load) processes
Working with tools like Apache Spark, Hadoop, SQL, Python, and AWS
Ensuring data quality and integrity
What is Data Science?
analysis, machine learning, and data visualization. Data Scientists use data to drive business decisions, create predictive models, and uncover trends.
Key Responsibilities of a Data Scientist:
Cleaning and analyzing large datasets
Building machine learning and AI models
Creating visualizations to communicate findings
Using tools like Python, R, SQL, TensorFlow, and Tableau
Applying statistical and mathematical techniques to solve problems
Which Course Should You Take Abroad?
Choosing between Data Engineering and Data Science depends on your interests, academic background, and long-term career goals. Here’s a quick guide to help you decide:
Take Data Engineering if:
You love building systems and solving technical challenges.
You have a background in software engineering, computer science, or IT.
You prefer backend development, architecture design, and working with infrastructure.
You enjoy automating data workflows and handling massive datasets.
Take Data Science if:
You’re passionate about data analysis, problem-solving, and storytelling with data.
You have a background in statistics, mathematics, computer science, or economics.
You’re interested in machine learning, predictive modeling, and data visualization.
You want to work on solving real-world problems using data.
Top Countries to Study Data Engineering and Data Science
Studying abroad can enhance your exposure, improve career prospects, and provide access to global job markets. Here are some of the best countries to study both courses:
1. Germany
Why? Affordable education, strong focus on engineering and analytics.
Top Universities:
Technical University of Munich
RWTH Aachen University
University of Mannheim
2. United Kingdom
Why? Globally recognized degrees, data-focused programs.
Top Universities:
University of Oxford
Imperial College London
4. Sweden
Why? Innovation-driven, excellent data education programs.
Top Universities:
KTH Royal Institute of Technology
Lund University
Chalmers University of Technology
Course Structure Abroad
Whether you choose Data Engineering or Data Science, most universities abroad offer:
Bachelor’s Degrees (3-4 years):
Focus on foundational subjects like programming, databases, statistics, algorithms, and software engineering.
Recommended for students starting out or looking to build from scratch.
Master’s Degrees (1-2 years):
Ideal for those with a bachelor’s in CS, IT, math, or engineering.
Specializations in Data Engineering or Data Science.
Often include hands-on projects, capstone assignments, and internship opportunities.
Certifications & Short-Term Diplomas:
Offered by top institutions and platforms (e.g., MITx, Coursera, edX).
Helpful for career-switchers or those seeking to upgrade their skills.
Career Prospects and Salaries
Both fields are highly rewarding and offer excellent career growth.
Career Paths in Data Engineering:
Data Engineer
Data Architect
Big Data Engineer
ETL Developer
Cloud Data Engineer
Average Salary (Globally):
Entry-Level: $70,000 - $90,000
Mid-Level: $90,000 - $120,000
Senior-Level: $120,000 - $150,000+
Career Paths in Data Science:
Data Scientist
Machine Learning Engineer
Business Intelligence Analyst
Research Scientist
AI Engineer
Average Salary (Globally):
Entry-Level: $75,000 - $100,000
Mid-Level: $100,000 - $130,000
Senior-Level: $130,000 - $160,000+
Industry Demand
The demand for both data engineers and data scientists is growing rapidly across sectors like:
E-commerce
Healthcare
Finance and Banking
Transportation and Logistics
Media and Entertainment
Government and Public Policy
Artificial Intelligence and Machine Learning Startups
According to LinkedIn and Glassdoor reports, Data Engineer roles have surged by over 50% in recent years, while Data Scientist roles remain in the top 10 most in-demand jobs globally.
Skills You’ll Learn Abroad
Whether you choose Data Engineering or Data Science, here are some skills typically covered in top university programs:
For Data Engineering:
Advanced SQL
Data Warehouse Design
Apache Spark, Kafka
Data Lake Architecture
Python/Scala Programming
Cloud Platforms: AWS, Azure, GCP
For Data Science:
Machine Learning Algorithms
Data Mining and Visualization
Statistics and Probability
Python, R, MATLAB
Tools: Jupyter, Tableau, Power BI
Deep Learning, AI Basics
Internship & Job Opportunities Abroad
Studying abroad often opens doors to internships, which can convert into full-time job roles.
Countries like Germany, Canada, Australia, and the UK allow international students to work part-time during studies and offer post-study work visas. This means you can gain industry experience after graduation.
Additionally, global tech giants like Google, Amazon, IBM, Microsoft, and Facebook frequently hire data professionals across both disciplines.
Final Thoughts: Data Engineering vs Data Science – Which One Should You Choose?
There’s no one-size-fits-all answer, but here’s a quick recap:
Choose Data Engineering if you’re technically inclined, love working on infrastructure, and enjoy building systems from scratch.
Choose Data Science if you enjoy exploring data, making predictions, and translating data into business insights.
Both fields are highly lucrative, future-proof, and in high demand globally. What matters most is your interest, learning style, and career aspirations.
If you're still unsure, consider starting with a general data science or computer science program abroad that allows you to specialize in your second year. This way, you get the best of both worlds before narrowing down your focus.
Need Help Deciding Your Path?
At Cliftons Study Abroad, we guide students in selecting the right course and country tailored to their goals. Whether it’s Data Engineering in Germany or Data Science in Canada, we help you navigate admissions, visa applications, scholarships, and more.
Contact us today to take your first step towards a successful international data career!
0 notes
Text
How to Ace a Data Engineering Interview: Tips & Common Questions
The demand for data engineers is growing rapidly, and landing a job in this field requires thorough preparation. If you're aspiring to become a data engineer, knowing what to expect in an interview can help you stand out. Whether you're preparing for your first data engineering role or aiming for a more advanced position, this guide will provide essential tips and common interview questions to help you succeed. If you're in Bangalore, enrolling in a Data Engineering Course in Hebbal, Data Engineering Course in Indira Nagar, or Data Engineering Course in Jayanagar can significantly boost your chances of success by providing structured learning and hands-on experience.
Understanding the Data Engineering Interview Process
Data engineering interviews typically consist of multiple rounds, including:
Screening Round – A recruiter assesses your background and experience.
Technical Round – Tests your knowledge of SQL, databases, data pipelines, and cloud computing.
Coding Challenge – A take-home or live coding test to evaluate your problem-solving abilities.
System Design Interview – Focuses on designing scalable data architectures.
Behavioral Round – Assesses your teamwork, problem-solving approach, and communication skills.
Essential Tips to Ace Your Data Engineering Interview
1. Master SQL and Database Concepts
SQL is the backbone of data engineering. Be prepared to write complex queries and optimize database performance. Some important topics include:
Joins, CTEs, and Window Functions
Indexing and Query Optimization
Data Partitioning and Sharding
Normalization and Denormalization
Practice using platforms like LeetCode, HackerRank, and Mode Analytics to refine your SQL skills. If you need structured training, consider a Data Engineering Course in Indira Nagar for in-depth SQL and database learning.
2. Strengthen Your Python and Coding Skills
Most data engineering roles require Python expertise. Be comfortable with:
Pandas and NumPy for data manipulation
Writing efficient ETL scripts
Automating workflows with Python
Additionally, learning Scala and Java can be beneficial, especially for working with Apache Spark.
3. Gain Proficiency in Big Data Technologies
Many companies deal with large-scale data processing. Be prepared to discuss and work with:
Hadoop and Spark for distributed computing
Apache Airflow for workflow orchestration
Kafka for real-time data streaming
Enrolling in a Data Engineering Course in Jayanagar can provide hands-on experience with these technologies.
4. Understand Data Pipeline Architecture and ETL Processes
Expect questions on designing scalable and efficient ETL pipelines. Key topics include:
Extracting data from multiple sources
Transforming and cleaning data efficiently
Loading data into warehouses like Redshift, Snowflake, or BigQuery
5. Familiarize Yourself with Cloud Platforms
Most data engineering roles require cloud computing expertise. Gain hands-on experience with:
AWS (S3, Glue, Redshift, Lambda)
Google Cloud Platform (BigQuery, Dataflow)
Azure (Data Factory, Synapse Analytics)
A Data Engineering Course in Hebbal can help you get hands-on experience with cloud-based tools.
6. Practice System Design and Scalability
Data engineering interviews often include system design questions. Be prepared to:
Design a scalable data warehouse architecture
Optimize data processing pipelines
Choose between batch and real-time data processing
7. Prepare for Behavioral Questions
Companies assess your ability to work in a team, handle challenges, and solve problems. Practice answering:
Describe a challenging data engineering project you worked on.
How do you handle conflicts in a team?
How do you ensure data quality in a large dataset?
Common Data Engineering Interview Questions
Here are some frequently asked questions:
SQL Questions:
Write a SQL query to find duplicate records in a table.
How would you optimize a slow-running query?
Explain the difference between partitioning and indexing.
Coding Questions: 4. Write a Python script to process a large CSV file efficiently. 5. How would you implement a data deduplication algorithm? 6. Explain how you would design an ETL pipeline for a streaming dataset.
Big Data & Cloud Questions: 7. How does Apache Kafka handle message durability? 8. Compare Hadoop and Spark for large-scale data processing. 9. How would you choose between AWS Redshift and Google BigQuery?
System Design Questions: 10. Design a data pipeline for an e-commerce company that processes user activity logs. 11. How would you architect a real-time recommendation system? 12. What are the best practices for data governance in a data lake?
Final Thoughts
Acing a data engineering interview requires a mix of technical expertise, problem-solving skills, and practical experience. By focusing on SQL, coding, big data tools, and cloud computing, you can confidently approach your interview. If you’re looking for structured learning and practical exposure, enrolling in a Data Engineering Course in Hebbal, Data Engineering Course in Indira Nagar, or Data Engineering Course in Jayanagar can provide the necessary training to excel in your interviews and secure a high-paying data engineering job.
0 notes