#executequery
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr.com rank in the US is 25.
Text

What is the JDBC Rowset? . . . . For more questions about Java https://bit.ly/465SkSw Check the above link
#blob#clob#function#procedure#resultset#rowset#drivermanager#preparedstatement#execute#executequery#executeupdate#array#arraylist#jdbc#hashMap#computersciencemajor#javatpoint
0 notes
Text
Working on the backend... A LOT
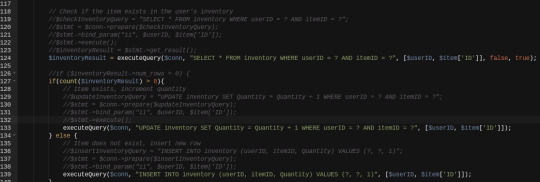
So, I've been working on tidying up the programming code and the file structure. I had pretty much every file just inside of a "BODY" folder before but now i've tidied it up entirely so the game actually has an /assets folder with images, sounds and other stuff like that in there. I've created a /global folder for stuff used all over and even adding an /include folder... The /images folder is totally reorganised, ive deleted a lot of old stuff from when the game was still "soldiers warfare". SO MUCH tidying up has been done. I don't have pictures right now, but I'll try to remember to post some before and after to show the difference. Ive also created a /pages folder with each page in its own folder and then within those an /ajax folder for the Ajax code. I've done a lot of work organising and then re-writing the locations from each file so everything works again after re-organising. it's been a fun day >< I'm very happy with where it's got to. on top of that, I've written some functions in PHP to help tidy the code. I now have a global executeQuery function which will tidy up a lot of the coding, it's a clever function which I can basically use for ANY query I need (SELECT, UPDATE, INSERT, DELETE ) and so it's gonna help a lot. i have a picture to show the difference at the top of the blog. I also have added other functions which i can include globally such as a checkUser and a updateStats functions - these will just help me with page-checks (for if a player is dead/alive or if they're in MASH or not) which will help tidy up the code further. and the Stats function was just because i'd like to start building more functions for the game. Once I implement just these three functions throughout the backend, it's gonna make coding MUCH eaiser and much quicker.
My plan next is to implement the checkUser across the pages, implement executeQuery across the game, implement the updateStats function.... after that I'm gonna go back to work finishing up the squads system and then adding some features to the operations page (some buttons aren't implemented - simple ones like LEave Operation) and tidy up the Garage (like you cant repair vehicles yet) At that point.... I think I'll probably either continue to make functions and do all I can to tidy up the backend. After that, I really want to see what I can do about tidying up Javascript - maybe start building functions (or modules?) in javascript to see if I can tidy that code up. I also want to see about improving the casino ... ive heard of using Websockets or maybe server-sent Events. both of which i've not used before... so yeah, I want to see about what I can do with those. I'm spending my free time reading books on Javascript, Node.JS so that's given me a lot of inspiration to improve the coding side. I would like to discover what it means to write an API - but i dont think i can do that in php? I'm not sure yet. I need a book on PHP too. i should try to find one... But ultimately I think the game itself is pretty much at its "playable" stage on the front end... I am hoping once squads is complete, the game is pretty much ready for alpha testing.. and amybe i can launch it by end of may? Then beyond that, I'd like to try and build a small community around the game, meanwhile I'll work on the backend and coding side so hopefully I can collaborate with other programmers - I'd love to learn from others and improve the game as much as possible. But before collaboration happens, i feel its important to get the code up to some decent standards becuase it currently is not readable >< one of the things that worrys me right now with game is i'm pretty sure the casino is hackable becuase i do logic in the wheel and racetrack in javascript - so yeah, that'll probably need addressing prior to launch. AT least by Beta.
0 notes
Text
ahh i ran into some trouble with the input file containing messed up data rows, so i wrote a method that ruthlessly throws out all lines i cant deal with. blessed regex, my love.
#tütensuppe#it still doesnt write to database for SOME reason but the heavy lifting is done~#i did originally implement a regex checker for the date parser that i just moved over#also at the beginning i have to check if the table i want to write to exists at all and if not create it#there i had some fun issues with the database 'not responding' that turned out to be me using the wrong method#executeQuery expects a data set in return and if you use it with the wrong input it freaks out#use execute(statement) for things like create/alter table/delete!
0 notes
Link
0 notes
Text
Delete Read only column in SharePoint Online
Delete Read only column in SharePoint Online
Hi, I am trying to delete an orphaned column in sharepoint list. Its not getting deleted via browser. I need to create a same column with same internal name. I tried powershell for this. But same error. Sorry, something went wrong You cannot delete a read-only column. Powershell Error:Exception calling “ExecuteQuery” with “0” argument(s): “You cannot delete a read-only column.” At line:1 char:1 +…
View On WordPress
0 notes
Text
[Python] Ejecutar DAX con Power Bi Rest API
Hace un tiempo que se me viene presentando requerimientos de personas no tan afines a Power Bi pero si al análisis de datos más duro que va directo con lenguajes de programación como Python y R.
Los pedidos pasan por poder fácilmente llegar a los datos de modelos tabulares completamente funcionales para respuestas o análisis adhoc que se solicitan en el momento. Naturalmente el pedido solía resultar en comentarles que podía correr Python desde el interior de Power Bi Desktop, exportar sus datos, etc. Todo eso puede ser una solución preventiva pero no creo que se compare a la nueva posibilidad de la API que ahora esta disponible (GA) en Power Bi.
Éste artículo relata las restricciones del request y como formarlo desde el lenguaje de programación Python formando un Pandas DataFrame.
¿De que se trata DAX Query API?
Recientemente Microsoft liberó un nuevo request en su API. Se trata de ejecutar un Post a un Dataset con XMLA Endpoint en el servicio para correr DAX desde la API. Esto nos permitiría obtener rápidas respuestas a preguntas inmediatas como así también acompañar exploraciones o análisis más duros realizados con Python.
Antes de comenzar veamos un poco las restricciones necesarias
Esta operación solo puede ejecutarse en la Nueva Experiencia de Areas de Trabajo (V2)
El usuario que se autentique para realizar el tiro debería tener permisos de construcción en el dataset (build).
La opción Allow XMLA endpoints and Analyze in Excel with on-premises datasets de la configuración de inquilinos del portal de administración debe estar encendida.
Los Datasets almacenados en Azure Analysis Services y conectados directamente no son soportados.
Hay un limite de 100k filas y solo puede ejecutarse una consulta a la vez.
Bastaría con aclarar que necesitamos una app registrada con permisos de lectura/escritura sobre datasets y que una respuesta 400 se refiere a una mala formación de la query o del body. Para más información podemos leer el detalle en la documentación:
https://docs.microsoft.com/es-es/rest/api/power-bi/datasets/execute-queries
Ejecución
Vamos a partir la demo considerando que ya todos saben obtener un Bearer Token para autenticar la App. En caso que no sepas hacerlo simplemente abrí el enlace a mi github más abajo con el código completo.
El Post a ejecutar consiste de tres argumentos necesarios para construirlo. La consulta (código DAX que devuelva una tabla), el token (autenticador de la API) y dataset (el id que podemos tomar de la URL de Power Bi Service cuando abrimos el mismo). Con estos tres vamos a construir el request para la API.
Considerando un argumento query, auth_token y dataset veamos como queda en python las tres partes necesarias
url= "https://api.powerbi.com/v1.0/myorg/datasets/"+dataset+"/executeQueries" body = {"queries": [{"query": query}], "serializerSettings": {"incudeNulls": "true"}} headers={'Content-Type': 'application/json', "Authorization": "Bearer {}".format(auth_token)}
En un principio todo se ve sencillo y ajustado. Ahora bien, hay un detalle que debemos tener presentes. Los diccionarios de python, como el formado en el body, no son un json aceptable por la API de microsoft. Es por eso que antes de ejecutarlo vamos a usar la librería Json para convertirlo de la siguiente manera:
res = requests.post(url, data = json.dumps(body), headers = headers)
Fíjense que el body estará rodeado de json.dumps que nos ayudará a no recibir un 400 por mal armado del tiro.
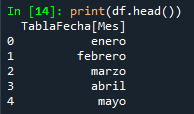
Ahora logramos obtener nuestra respuestas que sería un código bastante complicado de interpretar. Veamos un ejemplo sencillo de como regresan los datos. Ejecutando una DAX que solo pide los nombres de meses distintivos de una TablaFecha
EVALUATE VALUES(TablaFecha[Mes])
Tendríamos una respuestas así:

Como podemos ver la respuestas es un diccionario con varios hijos anidados. Comenzando con results, siguiente por tables hasta llegar a rows. Las rows son un diccionario nieto con key nombre de columna (TablaFecha[Mes]) y value como dato (abril).
Para poder interpretar esto vamos a ir extrayendo distintos datos que formen nuestro DataFrame. Cabe aclarar que vamos a importar pandas as pd. Un frame se forma por datos y columnas. Ahora bien para obtener los datos de semejante diccionario sería necesario recorrer y usar un for. Veamos entonces el siguiente código que nos regresaría las columnas, las filas (cantidad para recorrer) y una list comprehension que forme los datos.

columnas = list(res.json()['results'][0]['tables'][0]['rows'][0].keys()) filas = len(res.json()['results'][0]['tables'][0]['rows']) datos = [list(res.json()['results'][0]['tables'][0]['rows'][n].values()) for n in range(filas-1)]
Extrapolamos las columnas obteniendo las keys del diccionario nieto de rows. Luego vemos la cantidad de filas involucradas con un len del diccionario de rows. Finalmente hacemos un for que recorra los values del diccionario de rows la cantidad de veces que obtuvimos hace un momento -1 por tema de índices.
De este modo podemos construir nuestro dataframe:
df = pd.DataFrame(data=datos, columns=columnas)
Llegamos a algo tipo:
Ahora si estamos listos para explotar nuestros datos en Python jugando con pandas.
Espero que esto les sea de ayuda para diversas situaciones. Aquí les dejo un enlace a mi github con el código completo.
#powerbi#power bi#dax#python#power bi python#dax tips#power bi tips#power bi argentina#power bi cordoba#power bi jujuy#python power bi
0 notes
Text
Exploring the .NET open source hybrid ORM library RepoDB
It's nice to explore alternatives, especially in open source software. Just because there's a way, or an "official" way doesn't mean it's the best way.
Today I'm looking at RepoDb. It says it's "a hybrid ORM library for .NET. It is your best alternative ORM to both Dapper and Entity Framework." Cool, let's take a look.
Michael Pendon, the author puts his micro-ORM in the same category as Dapper and EF. He says "RepoDb is a new hybrid micro-ORM for .NET designed to cater the missing pieces of both micro-ORMs and macro-ORMs (aka full-ORMs). Both are fast, efficient and easy-to-use. They are also addressing different use-cases."
Dapper is a great and venerable library that is great if you love SQL. Repo is a hybrid ORM and offers more than one way to query, and support a bunch of popular databases:
SqlServer
SqLite
MySql
PostgreSql
Here's some example code:
/* Dapper */ using (var connection = new SqlConnection(ConnectionString)) { var customers = connection.Query<Customer>("SELECT Id, Name, DateOfBirth, CreatedDateUtc FROM [dbo].[Customer];"); } /* RepoDb - Raw */ using (var connection = new SqlConnection(ConnectionString)) { var customers = connection.ExecuteQuery<Customer>("SELECT Id, Name, DateOfBirth, CreatedDateUtc FROM [dbo].[Customer];"); } /* RepoDb - Fluent */ using (var connection = new SqlConnection(ConnectionString)) { var customers = connection.QueryAll<Customer>(); }
I like RepoDB's strongly typed Fluent insertion syntax:
/* RepoDb - Fluent */ using (var connection = new SqlConnection(connectionString)) { var id = connection.Insert<Customer, int>(new Customer { Name = "John Doe", DateOfBirth = DateTime.Parse("1970/01/01"), CreatedDateUtc = DateTime.UtcNow }); }
Speaking of inserts, it's BulkInsert (my least favorite thing to do) is super clean:
using (var connection = new SqlConnection(ConnectionString)) { var customers = GenerateCustomers(1000); var insertedRows = connection.BulkInsert(customers); }
The most interesting part of RepoDB is that it formally acknowledges 2nd layer caches and has a whole section on caching in the excellent RepoDB official documentation. I have a whole LazyCache subsystem behind my podcast site that is super fast but added some complexity to the code with more Func<T> that I would have preferred.
This is super clean, just passing in an ICache when you start the connection and then mention the key when querying.
var cache = CacheFactory.GetMemoryCache(); using (var connection = new SqlConnection(connectionString).EnsureOpen()) { var products = connection.QueryAll<Product>(cacheKey: "products", cache: cache); } using (var repository = new DbRepository<Product, SqlConnection>(connectionString)) { var products = repository.QueryAll(cacheKey: "products"); }
It also shows how to do generated cache keys...also clean:
// An example of the second cache key convention: var cache = CacheFactory.GetMemoryCache(); using (var connection = new SqlConnection(connectionString).EnsureOpen()) { var productId = 5; Query<Product>(product => product.Id == productId, cacheKey: $"product-id-{productId}", cache: cache); }
And of course, if you like to drop into SQL directly for whatever reason, you can .ExecuteQuery() and call sprocs or use inline SQL as you like. So far I'm enjoying RepoDB very much. It's thoughtfully designed and well documented and fast. Give it a try and see if you like it to?
Why don't you head over to https://github.com/mikependon/RepoDb now and GIVE THEM A STAR. Encourage open source. Try it on your own project and go tweet the author and share your thoughts!
Sponsor: Have you tried developing in Rider yet? This fast and feature-rich cross-platform IDE improves your code for .NET, ASP.NET, .NET Core, Xamarin, and Unity applications on Windows, Mac, and Linux.
© 2020 Scott Hanselman. All rights reserved.





Exploring the .NET open source hybrid ORM library RepoDB published first on https://deskbysnafu.tumblr.com/
0 notes
Text
Exploring the .NET open source hybrid ORM library RepoDB
It's nice to explore alternatives, especially in open source software. Just because there's a way, or an "official" way doesn't mean it's the best way.
Today I'm looking at RepoDb. It says it's "a hybrid ORM library for .NET. It is your best alternative ORM to both Dapper and Entity Framework." Cool, let's take a look.
Michael Pendon, the author puts his micro-ORM in the same category as Dapper and EF. He says "RepoDb is a new hybrid micro-ORM for .NET designed to cater the missing pieces of both micro-ORMs and macro-ORMs (aka full-ORMs). Both are fast, efficient and easy-to-use. They are also addressing different use-cases."
Dapper is a great and venerable library that is great if you love SQL. Repo is a hybrid ORM and offers more than one way to query, and support a bunch of popular databases:
SqlServer
SqLite
MySql
PostgreSql
Here's some example code:
/* Dapper */ using (var connection = new SqlConnection(ConnectionString)) { var customers = connection.Query<Customer>("SELECT Id, Name, DateOfBirth, CreatedDateUtc FROM [dbo].[Customer];"); } /* RepoDb - Raw */ using (var connection = new SqlConnection(ConnectionString)) { var customers = connection.ExecuteQuery<Customer>("SELECT Id, Name, DateOfBirth, CreatedDateUtc FROM [dbo].[Customer];"); } /* RepoDb - Fluent */ using (var connection = new SqlConnection(ConnectionString)) { var customers = connection.QueryAll<Customer>(); }
I like RepoDB's strongly typed Fluent insertion syntax:
/* RepoDb - Fluent */ using (var connection = new SqlConnection(connectionString)) { var id = connection.Insert<Customer, int>(new Customer { Name = "John Doe", DateOfBirth = DateTime.Parse("1970/01/01"), CreatedDateUtc = DateTime.UtcNow }); }
Speaking of inserts, it's BulkInsert (my least favorite thing to do) is super clean:
using (var connection = new SqlConnection(ConnectionString)) { var customers = GenerateCustomers(1000); var insertedRows = connection.BulkInsert(customers); }
The most interesting part of RepoDB is that it formally acknowledges 2nd layer caches and has a whole section on caching in the excellent RepoDB official documentation. I have a whole LazyCache subsystem behind my podcast site that is super fast but added some complexity to the code with more Func<T> that I would have preferred.
This is super clean, just passing in an ICache when you start the connection and then mention the key when querying.
var cache = CacheFactory.GetMemoryCache(); using (var connection = new SqlConnection(connectionString).EnsureOpen()) { var products = connection.QueryAll<Product>(cacheKey: "products", cache: cache); } using (var repository = new DbRepository<Product, SqlConnection>(connectionString)) { var products = repository.QueryAll(cacheKey: "products"); }
It also shows how to do generated cache keys...also clean:
// An example of the second cache key convention: var cache = CacheFactory.GetMemoryCache(); using (var connection = new SqlConnection(connectionString).EnsureOpen()) { var productId = 5; Query<Product>(product => product.Id == productId, cacheKey: $"product-id-{productId}", cache: cache); }
And of course, if you like to drop into SQL directly for whatever reason, you can .ExecuteQuery() and call sprocs or use inline SQL as you like. So far I'm enjoying RepoDB very much. It's thoughtfully designed and well documented and fast. Give it a try and see if you like it to?
Why don't you head over to https://github.com/mikependon/RepoDb now and GIVE THEM A STAR. Encourage open source. Try it on your own project and go tweet the author and share your thoughts!
Sponsor: Have you tried developing in Rider yet? This fast and feature-rich cross-platform IDE improves your code for .NET, ASP.NET, .NET Core, Xamarin, and Unity applications on Windows, Mac, and Linux.
© 2020 Scott Hanselman. All rights reserved.





Exploring the .NET open source hybrid ORM library RepoDB published first on http://7elementswd.tumblr.com/
0 notes
Text
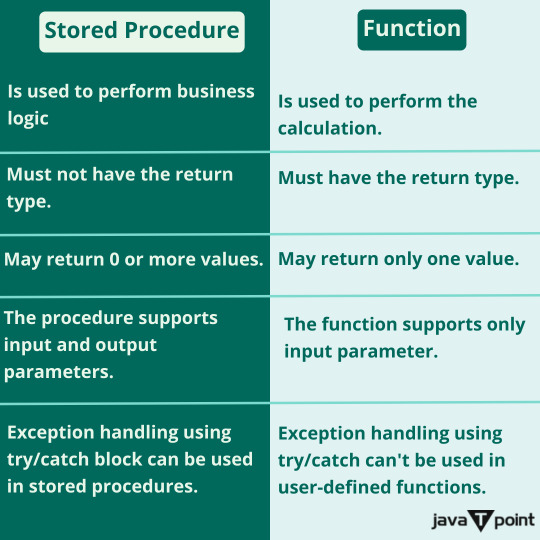
What are the differences between stored procedure and functions? . . . . For more questions about Java https://bit.ly/465SkSw Check the above link
#blob#clob#function#procedure#resultset#rowset#drivermanager#preparedstatement#execute#executequery#executeupdate#array#arraylist#jdbc#hashMap#computersciencemajor#javatpoint
0 notes
Link
Topmost Important JDBC Interview FAQs ##FreeCourse ##udemycoupon #FAQs #Important #Interview #JDBC #Topmost Topmost Important JDBC Interview FAQs JDBC is one of the very important foundation course for any persistence technologies like Hibernate,JPA etc.Hence this topic play very important role in the interview room. In this course we discussed the following most common interview faqs on jdbc. Q1. Explain JDBC Architecture? Q2. Explain about how JAVA is Platform Independent & Database Independent ? Q3. What is Driver and How many Drivers are available in JDBC? Q4. Which JDBC Driver should be used? Q5. What are various standard steps to develop JDBC Application? Q6. Explain about various types of Statements available in JDBC(Statement,PreparedStatement and CallableStatement)? Q7. Explain Differences between Statement & PreparedStatement in JDBC? Q8. Explain advantages and disadvantages of Batch updates? Q9. How Many Execute Methods Are Avaialble in JDBC(executeQuery(),executeUpdate(),execute() and executeBatch()) ? Q10. Explain about BLOB and CLOB in JDBC? Who is the target audience? Academic Students who are having Java Course in their Curriculum Java Programmers who are fancy about Database programming 👉 Activate Udemy Coupon 👈 Free Tutorials Udemy Review Real Discount Udemy Free Courses Udemy Coupon Udemy Francais Coupon Udemy gratuit Coursera and Edx ELearningFree Course Free Online Training Udemy Udemy Free Coupons Udemy Free Discount Coupons Udemy Online Course Udemy Online Training 100% FREE Udemy Discount Coupons https://www.couponudemy.com/blog/topmost-important-jdbc-interview-faqs/
0 notes
Text
Building a GraphQL interface to Amazon QLDB with AWS AppSync: Part 2
This post is the second installment of a two-post series discussing how to integrate Amazon Quantum Ledger Database (QLDB) and AWS AppSync. This combination provides a versatile, GraphQL-powered API on top of the Amazon QLDB-managed ledger database. For information about connecting Amazon QLDB and AWS AppSync by building an AWS Lambda function and running a query, see Building a GraphQL interface to Amazon QLDB with AWS AppSync: Part 1. This post continues developing the integration to support more complex queries and mutation of data in QLDB from AWS AppSync. The walkthrough also adds support for querying historical data that Amazon QLDB and AWS AppSync capture. Both posts in this series use a DMV dataset of driver vehicle information for its queries. You can also review the complete application in the GitHub repo. The following diagram shows the high-level architecture for this project. You can craft PartiQL queries to fulfill various operations that you run on Amazon QLDB integration function in Lambda by using AWS AppSync resolvers. Most of this post focuses on creating new resolvers to interact with Amazon QLDB in new ways, but you also extend the integration function to support multiple queries in a single transaction. Adding support for multi-step transactions When working with Amazon QLDB, you often need to look up a value, for example, a document ID, before executing a subsequent query. The version of the integration function discussed in the first post in this series supported a single query per transaction. In this post, you modify the function to support running multiple queries in a single transaction. Many of the queries you need to support the DMV use case require inspection of results in one query before passing to the next, so you add support for JMESPath to retrieve values from the proceeding query. JMESPath is a query language for JSON that allows the extraction of data from elements in a JSON document. Consider the use case in which you need to look up a specific owner’s vehicles. You first need to query the Person table to retrieve the document ID for the owner (a government identifier, such as a driver’s license number). For instructions, see Using the BY Clause to Query Document ID. You also want to find the driver’s vehicles in the VehicleRegistration table before you retrieve vehicle details in the Vehicle table. You perform these steps with a single JOIN query. For more information, see Joins. The first query retrieves the document ID for a given person using the BY clause. See the following code: SELECT id FROM Person AS t BY id WHERE t.GovId = ? The result of that query includes the ID needed for the subsequent query of the Vehicle table. This query also allows you to review how PartiQL queries can interact with nested data. In this case, the query matches against a nested field in the Owners field. See the following code: SELECT Vehicle FROM Vehicle INNER JOIN VehicleRegistration AS r ON Vehicle.VIN = r.VIN WHERE r.Owners.PrimaryOwner.PersonId = ? The preceding query also makes use of a JOIN across the VehicleRegistration and Vehicle tables. If you are familiar with SQL, this is an inner join query so you can traverse from the vehicle ownership information (stored in VehicleRegistration) to the vehicle data (in the Vehicle table). To support this type of transaction in the API, adjust the integration function code with the following code: private String executeTransaction(List queries) { try (QldbSession qldbSession = createQldbSession()) { List result = new ArrayList(); qldbSession.execute((ExecutorNoReturn) txn -> { for (Query q : queries) { LOGGER.info("Executing query: {}", q.query); String lastResult = result.size() > 0 ? result.get(result.size() - 1) : ""; result.add(executeQuery(txn, q, lastResult)); } }, (retryAttempt) -> LOGGER.info("Retrying due to OCC conflict...")); return result.get(result.size() - 1); } catch (QldbClientException e) { LOGGER.error("Unable to create QLDB session: {}", e.getMessage()); } return "{}"; } private String executeQuery(TransactionExecutor txn, Query query, String lastResult) { final List params = new ArrayList(); query.getArgs().forEach((a) -> { LOGGER.debug("Adding arg {} to query", a); try { String arg = a.startsWith("$.") && !lastResult.isEmpty() ? queryWithJmesPath(lastResult, a.substring(2)) : a; params.add(MAPPER.writeValueAsIonValue(arg)); } catch (IOException e) { LOGGER.error("Could not write value as Ion: {}", a); } }); // Execute the query and transform response to JSON string... List json = new ArrayList(); txn.execute(query.getQuery(), params).iterator().forEachRemaining(r -> { String j = convertToJson(r.toPrettyString()); json.add(j); }); return json.toString(); } You extend these two functions so a single call can support multiple queries to the function. This allows for more complex, multi-step queries and mutations. In the following section, you explore how to use this new functionality in the DMV use case. But you first need to add support for searching the result using JMESPath. Arguments that require a JMESPath expression to retrieve data from the proceeding result are prepended by “$” (a convenient indicator, nothing more; it’s stripped from the expression). To run the search, introduce a new function with the following code: private String queryWithJmesPath(String json, String jmesExpression) throws IOException { LOGGER.debug("Query with JMESPath: {} on {}", jmesExpression, json); JmesPath jmespath = new JacksonRuntime(); Expression expression = jmespath.compile(jmesExpression); ObjectMapper om = new ObjectMapper(); JsonNode input = om.readTree(json); return om.writeValueAsString(expression.search(input)).replaceAll("^"|"$", ""); } The preceding code allows the passing of more complex queries, such as finding vehicles by owner. You can also implement multi-step queries with AWS AppSync pipeline resolvers; adding to the integration function was a design decision. Next, you add support for this query and a few mutations to the GraphQL API and implement appropriate resolvers. Extending the DMV GraphQL API In AWS AppSync, the GraphQL schema defines the shape of the data and operations available for a given API. You started constructing the schema for the DMV API in the previous post and continue to extend it here by adding a second query to find vehicles by owner. You also add a new type, mutations, which provides operations that change data in Amazon QLDB. See the following code: type Query { ... vehiclesByOwner(govId:ID!):[Vehicle] } type Mutation { updateVehicleOwner(vin:ID!, govId:ID!):Boolean addSecondaryOwner(vin:ID!, govId:ID!):Boolean } schema { query: Query mutation: Mutation } To implement the `vehiclesByOwner` query, attach a new resolver that uses the integration function data source with the following request mapping template: { "version": "2017-02-28", "operation": "Invoke", "payload": { "action": "Query", "payload": [ { "query": "SELECT id FROM Person AS t BY id WHERE t.GovId = ?", "args": [ "$ctx.args.govId" ] }, { "query": "SELECT Vehicle FROM Vehicle INNER JOIN VehicleRegistration AS r ON Vehicle.VIN = r.VIN WHERE r.Owners.PrimaryOwner.PersonId = ?", "args": [ "$.[0].id" ] } ] } } This resolver is similar to the `getVehicle` resolver in the previous post, but adds a second query to the payload. These are the same queries as discussed earlier that allow lookup of vehicles owned by a person. The first query takes as an argument a value (govId) passed via the GraphQL operation; the second uses JMESPath to retrieve a value from the proceeding query. For more information about the response mapping template, see the GitHub repo. Run the vehiclesByOwner query using a GraphQL payload such as the following code: query VehiclesByOwner { vehiclesByOwner(govId:"LOGANB486CG") { VIN Make Model } } You receive the following response: { "data": { "vehiclesByOwner": [ { "VIN": "KM8SRDHF6EU074761", "Make": "Tesla", "Model": "Model S" } ] } } The values selected in each PartiQL query are hardcoded in the request mapping. Although you don’t implement it here, you can extend the integration function to select only the values included in the GraphQL selection set (VIN, Make, and Model in the preceding query). Returning only the desired values could improve performance because only the needed data is returned. AWS AppSync provides a list of the selected values in the $context.info section of the GraphQL request available to the mapping template. For more information, see AWS AppSync and the GraphQL Info Object. Mutations Implementing a mutation (an operation that changes data) is very similar to the preceding query. Instead of using a SELECT statement, use a CREATE or UPDATE statement. The following code implements the resolver for the updateVehicleOwner mutation: "version": "2017-02-28", "operation": "Invoke", "payload": { "action": "Query", "payload": [ { "query": "SELECT id FROM Person AS t BY id WHERE t.GovId = ?", "args": [ "$ctx.args.govId" ] }, { "query": "UPDATE VehicleRegistration AS v SET v.Owners.PrimaryOwner.PersonId = ? WHERE v.VIN = ?", "args": [ "$.[0].id", "$ctx.args.vin" ] } ] } } This mutation is very similar to the earlier query. Again, you find the document ID for the person associated with the passed govId value. In the second operation, you use an UPDATE statement to change a nested value in the VehicleRegistration table. The API returns the result of the mutation (true if successful; otherwise false); however, you could also add a third operation to retrieve updated data and return that to the caller. Querying historical data Amazon QLDB uses an immutable transaction log, called a journal, to maintain a history of changes to data. This history is complete and verifiable, meaning you can traverse back over changes in the journal to confirm that the data hasn’t been tampered with. Doing so involves verifying the cryptographically-chained signature of each transaction. In the DMV use case, it’s useful to track vehicle ownership over time. You can easily query for this type of change without needing an audit table by using the Amazon QLDB journal. To add a vehicle ownership query, start by adding it to the AWS AppSync schema (getOwnershipHistory). See the following code: type Query { ... getOwnershipByHistory(vin:ID!, monthsAgo:Int):[History] } The getOwnershipHistory query takes two arguments: the VIN for the vehicle and the number of months to search back. The query also returns a new data type that you need to add to the schema: History. See the following code: type History { id: ID! version: Int! txTime: AWSDateTime! # transaction timestamp txId: ID! # transaction ID data: HistoryData hash: String! } union HistoryData = Person | Owner | Vehicle | VehicleRegistration The History type includes a field called data that uses the union type HistoryData. Union types in GraphQL allow for different types that don’t share any common fields to be returned in a single type. For the DMV API, you specify that HistoryData could include any of the other types in the API. The getOwnershipHistory query is similar to the other resolvers described earlier and uses the same integration function as a data source. For this use case, calculate the timestamp for the start of the search as well (defaulting to 3 months). See the following code: #set( $months = $util.defaultIfNull($ctx.args.monthsAgo, 3) ) #set( $currEpochTime = $util.time.nowEpochMilliSeconds() ) #set( $fromEpochTime = $currEpochTime - ($months * 30 * 24 * 60 * 60 * 1000) ) #set( $fromTime = $util.time.epochMilliSecondsToISO8601($fromEpochTime) ) { "version": "2017-02-28", "operation": "Invoke", "payload": { "action": "Query", "payload": [ { "query": "SELECT id FROM VehicleRegistration AS t BY id WHERE t.VIN = ?", "args": [ "$ctx.args.vin" ] }, { "query": "SELECT * FROM history(VehicleRegistration, `$fromTime`) AS h WHERE h.metadata.id = ?", "args": [ "$.[0].id" ] } ] } } This query uses the history function, a PartiQL extension, to retrieve revisions from the system view of the table. The history function can accept an optional start and end time in ISO 8601 format, denoted as Ion timestamps (be sure to surround each with backticks). For more information, see Querying Revision History. The response mapping template is somewhat more complex because the history response from Amazon QLDB includes data that the API doesn’t return. The template iterates through each item in the response and builds an object that matches the shape of History. You also need to set the __typename field for HistoryData to support the use of the union type (the value is always “VehicleRegistration” for this query). See the following code: #set( $result = $util.parseJson($ctx.result.result) ) #set( $history = [] ) #foreach($item in $result) #set( $data = $item.data ) $util.qr($data.put("__typename", "VehicleRegistration")) #set( $h = { "id": "$item.metadata.id", "version": $item.metadata.version, "txTime": "$item.metadata.txTime", "txId": "$item.metadata.txId", "hash": "$item.hash", "data": $data } ) $util.qr($history.add($h)) #end $util.toJson($history) To query for the ownership history of a particular vehicle, enter the following the GraphQL query: query GetVehicleHistory { getOwnershipHistory(vin:"3HGGK5G53FM761765") { version txTime data { ... on VehicleRegistration { Owners { PrimaryOwner { FirstName LastName } } } } } } Before running this query, use the updateVehicleOwner mutation to change the primary owner of this vehicle. This operation is equivalent to one person selling the vehicle to another. The following code is the query result: { "data": { "getOwnershipHistory": [ { "version": 0, "txTime": "2020-01-30T16:11:00.549Z", "data": { "Owners": { "PrimaryOwner": { "FirstName": "Alexis", "LastName": "Pena" } } } }, { "version": 1, "txTime": "2020-02-05T22:17:36.262Z", "data": { "Owners": { "PrimaryOwner": { "FirstName": "Brent", "LastName": "Logan" } } } } ] } } In the result, you can quickly find not just who owned the vehicle, but also when the owner Alexis sold the vehicle to Brent. Amazon QLDB captures this data transparently in the journal and makes it easy to query. Amazon QLDB also supports data verification to make sure that it hasn’t been tampered with, though that process is outside of the scope of this post. Conclusion Integrating Amazon QLDB with AWS AppSync enables powerful features as part of GraphQL APIs. A flexible integration function allows a single Lambda data source to support a multitude of PartiQL queries, including the history of data in Amazon QLDB. For more information and the complete source code, see the GitHub repo. AWS welcomes feedback. Please share how you’re using Amazon QLDB and integrating with other AWS services by reaching out on the Amazon QLDB forum. About the Author Josh Kahn is a Principal Solutions Architect at Amazon Web Services. He works with the AWS customers to provide guidance and technical assistance on database projects, helping them improve the value of their solutions when using AWS. https://probdm.com/site/MjEzNzY
0 notes
Link
In this article, we will talk about closures, curried functions, and play around with these concepts to build cool abstractions. I want to show the idea behind each concept, but also make it very practical with examples and refactor code to make it more fun.
Closures
So closure is a common topic in JavaScript and we will start with it. As MDN web docs defines: "A closure is the combination of a function bundled together (enclosed) with references to its surrounding state (the lexical environment)." Basically, every time a function is created, a closure is also created and it gives access to all state (variables, constants, functions, etc). The surrounding state is known as the lexical environment. Let's show a simple example:
function makeFunction() { const name = 'TK'; function displayName() { console.log(name); } return displayName; };
What do we have here?
Our main function called makeFunction
A constant named name assigned with a string 'TK'
The definition of the displayName function (that just log the name constant)
And finally the makeFunction returns the displayName function
This is just a definition of a function. When we call the makeFunction, it will create everything within it: constant and function in this case. As we know, when the displayName function is created, the closure is also created and it makes the function aware of the environment, in this case, the name constant. This is why we can console.log the name without breaking anything. The function knows about the lexical environment.
const myFunction = makeFunction(); myFunction(); // TK
Great! It works as expected! The return of the makeFunction is a function that we store it in the myFunction constant, call it later, and displays TK. We can also make it work as an arrow function:
const makeFunction = () => { const name = 'TK'; return () => console.log(name); };
But what if we want to pass the name and display it? A parameter!
const makeFunction = (name = 'TK') => { return () => console.log(name); }; // Or a one-liner const makeFunction = (name = 'TK') => () => console.log(name);
Now we can play with the name:
const myFunction = makeFunction(); myFunction(); // TK const myFunction = makeFunction('Dan'); myFunction(); // Dan
Our myFunction is aware of the arguments passed: default or dynamic value. The closure does make the created function not only aware of constants/variables, but also other functions within the function. So this also works:
const makeFunction = (name = 'TK') => { const display = () => console.log(name); return () => display(); }; const myFunction = makeFunction(); myFunction(); // TK
The returned function knows about the display function and it is able to call it. One powerful technique is to use closures to build "private" functions and variables. Months ago I was learning data structures (again!) and wanted to implement each one. But I was always using the object oriented approach. As a functional programming enthusiast, I wanted to build all the data structures following FP principles (pure functions, immutability, referential transparency, etc). The first data structure I was learning was the Stack. It is pretty simple. The main API is:
push: add an item to the first place of the stack
pop: remove the first item from the stack
peek: get the first item from the stack
isEmpty: verify if the stack is empty
size: get the number of items the stack has
We could clearly create a simple function to each "method" and pass the stack data to it. It use/transform the data and return it. But we can also create a private stack data and exposes only the API methods. Let's do this!
const buildStack = () => { let items = []; const push = (item) => items = [item, ...items]; const pop = () => items = items.slice(1); const peek = () => items[0]; const isEmpty = () => !items.length; const size = () => items.length; return { push, pop, peek, isEmpty, size, }; };
As we created the items stack data inside our buildStack function, it is "private". It can be accessed only within the function. In this case, only the push, pop, etc could touch the data. And this is what we're looking for. And how do we use it? Like this:
const stack = buildStack(); stack.isEmpty(); // true stack.push(1); // [1] stack.push(2); // [2, 1] stack.push(3); // [3, 2, 1] stack.push(4); // [4, 3, 2, 1] stack.push(5); // [5, 4, 3, 2, 1] stack.peek(); // 5 stack.size(); // 5 stack.isEmpty(); // false stack.pop(); // [4, 3, 2, 1] stack.pop(); // [3, 2, 1] stack.pop(); // [2, 1] stack.pop(); // [1] stack.isEmpty(); // false stack.peek(); // 1 stack.pop(); // [] stack.isEmpty(); // true stack.size(); // 0
So, when the stack is created, all the functions are aware of the items data. But outside the function, we can't access this data. It's private. We just modify the data by using the stack builtin API.
Curry
"Currying is the process of taking a function with multiple arguments and turning it into a sequence of functions each with only a single argument." - Wikipedia So imagine you have a function with multiple arguments: f(a, b, c). Using currying, we achieve a function f(a) that returns a function g(b) the returns a function h(c). Basically: f(a, b, c) —> f(a) => g(b) => h(c) Let's build a simple example: add two numbers. But first, without currying!
const add = (x, y) => x + y; add(1, 2); // 3
Great! Super simple! Here we have a function with two arguments. To transform it into a curried function we need a function that receives x and returns a function that receives y and returns the sum of both values.
const add = (x) => { function addY(y) { return x + y; } return addY; };
We can refactor this addY into a anonymous arrow function:
const add = (x) => { return (y) => { return x + y; } };
Or simplify it by building one liner arrow functions:
const add = (x) => (y) => x + y;
These three different curried functions have the same behavior: build a sequence of functions with only one argument. How we use it?
add(10)(20); // 30
At first, it can look a bit strange, but it has a logic behind it. add(10) returns a function. And we call this function with the 20 value. This is the same as:
const addTen = add(10); addTen(20); // 30
And this is interesting. We can generate specialized functions by calling the first function. Imagine we want an increment function. We can generate it from our add function by passing the 1 as the value.
const increment = add(1); increment(9); // 10
When I was implementing the Lazy Cypress, a npm library to record the user behavior in a form page and generate Cypress testing code, I want to build a function to generate this string input[data-testid="123"]. So here we have the element (input), the attribute (data-testid), and the value (123). Interpolating this string in JavaScript would look like this: ${element}[${attribute}="${value}"]. the first implementation in mind is to receive these three values as parameters and return the interpolated string above.
const buildSelector = (element, attribute, value) => `${element}[${attribute}="${value}"]`; buildSelector('input', 'data-testid', 123); // input[data-testid="123"]
And it is great. I achieved what I was looking for. But at the same time, I wanted to build a more idiomatic function. Something I could write "get an element X with attribute Y and value Z". So what if we break this phrase into three steps:
"get an element X": get(x)
"with attribute Y": withAttribute(y)
"and value Z": andValue(z)
We can transform the buildSelector(x, y, z) into get(x) ⇒ withAttribute(y) ⇒ andValue(z) by using the currying concept.
const get = (element) => { return { withAttribute: (attribute) => { return { andValue: (value) => `${element}[${attribute}="${value}"]`, } } }; };
Here we use a different idea: returning an object with function as key-value. This way we can achieve this syntax: get(x).withAttribute(y).andValue(z). And for each returned object, we have the next function and argument. Refactoring time! Remove the return statements:
const get = (element) => ({ withAttribute: (attribute) => ({ andValue: (value) => `${element}[${attribute}="${value}"]`, }), });
I think it looks prettier. And we use it like:
const selector = get('input') .withAttribute('data-testid') .andValue(123); selector; // input[data-testid="123"]
The andValue function knows about the element and attribute values because it is aware of the lexical environment as we talked about closures before.
We can also implement functions using "partial currying". Separate only the first argument from the rest for example. Doing web development for a long time, I commonly used the event listener Web API. It is used this way:
const log = () => console.log('clicked'); button.addEventListener('click', log);
I wanted to create an abstraction to build specialized event listeners and use them by passing the element and callback handler.
const buildEventListener = (event) => (element, handler) => element.addEventListener(event, handler);
This way I can create different specialized event listeners and use it as functions.
const onClick = buildEventListener('click'); onClick(button, log); const onHover = buildEventListener('hover'); onHover(link, log);
With all these concepts, I could create a SQL query using JavaScript syntax. I wanted to SQL query a JSON data like:
const json = { "users": [ { "id": 1, "name": "TK", "age": 25, "email": "[email protected]" }, { "id": 2, "name": "Kaio", "age": 11, "email": "[email protected]" }, { "id": 3, "name": "Daniel", "age": 28, "email": "[email protected]" } ] }
So I built a simple engine to handle this implementation:
const startEngine = (json) => (attributes) => ({ from: from(json, attributes) }); const buildAttributes = (node) => (acc, attribute) => ({ ...acc, [attribute]: node[attribute] }); const executeQuery = (attributes, attribute, value) => (resultList, node) => node[attribute] === value ? [...resultList, attributes.reduce(buildAttributes(node), {})] : resultList; const where = (json, attributes) => (attribute, value) => json .reduce(executeQuery(attributes, attribute, value), []); const from = (json, attributes) => (node) => ({ where: where(json[node], attributes) });
With this implementation, we can start the engine with the JSON data:
const select = startEngine(json);
And use it like a SQL query:
select(['id', 'name']) .from('users') .where('id', 1); result; // [{ id: 1, name: 'TK' }]
That's it for today. We could go on and on showing a lot of different examples of abstractions, but now I let you play with those concepts.
0 notes
Text
JQXGRID not showing any data from mySQL connection
I am creating my first database stack with a mySQL database, eclipse, java hibernate, apache, and jqxgrid. When I load the page from the apache sever, I only see an empty jqxgrid without data. I’m not sure why the data isn’t populating the grid. Is there an obvious error with my JSP file below?
<%@ page import="java.sql.*"%> <%@ page import="com.google.gson.*"%> <%@ page language="java" contentType="text/html; charset=ISO-8859-1" pageEncoding="ISO-8859-1"%> <% // (A) database connection // "jdbc:mysql://localhost:8080/titnd" - the database url of the form jdbc:subprotocol:subname // "dbusername" - the database user on whose behalf the connection is being made // "dbpassword" - the user's password Connection dbConnection = DriverManager.getConnection( "jdbc:mysql://localhost:3306/titanicDB", "root", "EZOPS"); // (B) retrieve necessary records from database Statement getFromDb = dbConnection.createStatement(); ResultSet employees = getFromDb .executeQuery("SELECT PassengerID, Survived, Sex, Age, Fare FROM titanicD"); // (C) format returned ResultSet as a JSON array JsonArray recordsArray = new JsonArray(); while (employees.next()) { JsonObject currentRecord = new JsonObject(); currentRecord.add("PassengerID", new JsonPrimitive(employees.getString("PassengerID"))); currentRecord.add("Survived", new JsonPrimitive(employees.getString("Survived"))); currentRecord.add("Sex", new JsonPrimitive(employees.getString("Sex"))); currentRecord.add("Age", new JsonPrimitive(employees.getString("Age"))); currentRecord.add("Fare", new JsonPrimitive(employees.getString("Fare"))); recordsArray.add(currentRecord); } // (D) out.print(recordsArray); out.flush(); %> <!DOCTYPE html> <html> <head> <meta charset="ISO-8859-1"> <title>Insert title here</title> </head> <body> </body> </html>
Archive from: https://stackoverflow.com/questions/59021521/jqxgrid-not-showing-any-data-from-mysql-connection
from https://knowledgewiki.org/jqxgrid-not-showing-any-data-from-mysql-connection/
0 notes
Text
Java- What is the difference between execute, executeQuery, executeUpdate?
What is the difference between execute, executeQuery, executeUpdate?
Statement execute(String query) is used to execute any SQL query and it returns TRUE if the result is an ResultSet such as running Select queries. The output is FALSE when there is no ResultSet object such as running Insert or Update queries. We can use getResultSet() to get the ResultSet and getUpdateCount() method to retrieve the update count.
Statement executeQuery(String query) is used to execute Select queries and returns the ResultSet. ResultSet returned is never null even if there are no records matching the query. When executing select queries we should use executeQuery method so that if someone tries to execute insert/update statement it will throw java.sql.SQLException with message “executeQuery method can not be used for update”.
Statement executeUpdate(String query) is used to execute Insert/Update/Delete (DML) statements or DDL statements that returns nothing. The output is int and equals to the row count for SQL Data Manipulation Language (DML) statements. For DDL statements, the output is 0.
You should use execute() method only when you are not sure about the type of statement else use executeQuery or executeUpdate method.
In case you are facing any challenges with these java interview questions, please comment your problems in the section below. Apart from this Java Interview Questions Blog, if you want to get trained from professionals on this technology, you can opt for a structured training from edureka!
0 notes
Text
Java composite interface
The Composite interface, along with CompositeContext, defines the methods to compose a draw primitive with the underlying graphics area. After the Composite is set in the Graphics2D context, it combines a shape, text, or an image being rendered with the colors that have already been rendered according to pre-defined rules. The classes implementing this interface provide the rules and a method to create the context for a particular operation. CompositeContext is an environment used by the compositing operation, which is created by the Graphics2D prior to the start of the operation. CompositeContext contains private information and resources needed for a compositing operation. When the CompositeContext is no longer needed, the Graphics2D object disposes of it in order to reclaim resources allocated for the operation. What is starvation in java? What is the difference between arraylist and vector in java? What is the difference between arraylist and linkedlist? What is the difference between Iterator and ListIterator? What is the difference between Iterator and Enumeration? what is the difference between list and set in java? what is the difference between set and map in java? what is the difference between hashset and treeset in java? what is the difference between hashset and hashmap in java? what is the difference between hashmap and treemap in java? what is the difference between hashmap and hashtable in java? what is the difference between collection and collections in java? what is the difference between comparable and comparator interfaces? what is the hashcode method in java? What is garbage collection in java? What is garbage collector in java? What is gc() in java? What is finalize() method in java? Can an unreferenced objects be referenced again in java? What kind of thread is the garbage collector thread in java? what is serialization in java? what is Deserialization in java? What is transient keyword? Interview questions on java Interview questions on main Interview questions on final Interview questions on constructor Interview questions on access modifiers Interview questions on method overloading Interview questions on method overriding Interview questions on inheritance Interview questions on interface Interview questions on abstract class Interview questions on string handling Interview questions on exception handling Interview questions on multithreading Interview questions on collections Interview questions on Servlet Interview questions on JSP Interview questions on Struts Interview questions on JSF Interview questions on Hibernate Interview questions on Javamail Interview questions on Quartz Interview questions on JDBC Interview questions on SQL Interview questions on generics Interview questions on JUnit Interview questions on Log4j Interview questions on JavaScript Interview questions on PLSQL What is a Web application? What is a Web browser? What is different between web server and application server? What is a servlet container? What is MIME Type? Why do we need a constructor in a servlet if we use the init method? When servlet object is created? Who is responsible for creating the servlet object? What is the difference between HttpServlet and GenericServlet? What is HTTPServletRequest class? What is HTTPServletResponse class? How can we create deadlock condition on our servlet? For initializing a servlet can we use a constructor in place of init()? How to read form data in servlet? How to write html contents using servlets? How to send an authentication error from a servlet? What is servlet collaboration? What is lazy loading? How do we call one servlet from another servlet? What is the difference between sendRedirect and RequestDispatcher? Can we call a jsp from the servlet? How to configure a central error handling page in servlets? How to get session object? How to set attribute in session object? How to get attribute from session object? What are JSP lifecycle methods? Which JSP lifecycle methods can be overridden? How to disable session in JSP? Which directive is used in jsp custom tag? How can a thread safe JSP page be implemented? Can we use JSP implicit objects in a method defined in JSP Declaration? Which implicit object is not available in normal JSP pages? What is difference between include directive and jsp:include action? How to disable caching on back button of the browser? What are the types of JSTL tags? How is scripting disabled? How to extend java class in jsp? What is MVC? What is the difference between struts1 and struts2? Explain struts 2 request life cycle. What are the core components of a Struct2 based application? What are the types of validators in struts 2? How tag libraries are defined in Struts? Is Struts thread safe? What is the significance of @ManagedProperty annotation? How to terminate the session in JSF? Is it possible to have more than one Faces Configuration file? What are the core components are of hibernate architecture? What is SessionFactory? Is SessionFactory a thread-safe object? What is Session? Is Session a thread-safe object? What will happen if we don’t have no-args constructor in Entity bean? Can we make an hibernate entity class final? How to log hibernate generated sql queries in log files? What is POP? Explain SMTP? Explain IMAP? What is the use of MIME within message makeup? What is the difference between execute, executequery, executeupdate? What is the difference between Statement and PreparedStatement in jdbc? How can we execute stored procedures and functions? How to rollback a JDBC transaction? Explain JDBC Savepoint. What is the use of blob and clob datatypes in JDBC? What is Connection Pooling? How do you implement connection pooling? What is 2 phase commit? What are the different types of locking in JDBC? What is a “dirty read”? What is DBMS? What is RDBMS? Difference between DBMS and RDBMS What are various DDL commands in SQL? What are various DML commands in SQL?
0 notes
Text
Exploring the .NET open source hybrid ORM library RepoDB
It's nice to explore alternatives, especially in open source software. Just because there's a way, or an "official" way doesn't mean it's the best way.
Today I'm looking at RepoDb. It says it's "a hybrid ORM library for .NET. It is your best alternative ORM to both Dapper and Entity Framework." Cool, let's take a look.
Michael Pendon, the author puts his micro-ORM in the same category as Dapper and EF. He says "RepoDb is a new hybrid micro-ORM for .NET designed to cater the missing pieces of both micro-ORMs and macro-ORMs (aka full-ORMs). Both are fast, efficient and easy-to-use. They are also addressing different use-cases."
Dapper is a great and venerable library that is great if you love SQL. Repo is a hybrid ORM and offers more than one way to query, and support a bunch of popular databases:
SqlServer
SqLite
MySql
PostgreSql
Here's some example code:
/* Dapper */ using (var connection = new SqlConnection(ConnectionString)) { var customers = connection.Query<Customer>("SELECT Id, Name, DateOfBirth, CreatedDateUtc FROM [dbo].[Customer];"); } /* RepoDb - Raw */ using (var connection = new SqlConnection(ConnectionString)) { var customers = connection.ExecuteQuery<Customer>("SELECT Id, Name, DateOfBirth, CreatedDateUtc FROM [dbo].[Customer];"); } /* RepoDb - Fluent */ using (var connection = new SqlConnection(ConnectionString)) { var customers = connection.QueryAll<Customer>(); }
I like RepoDB's strongly typed Fluent insertion syntax:
/* RepoDb - Fluent */ using (var connection = new SqlConnection(connectionString)) { var id = connection.Insert<Customer, int>(new Customer { Name = "John Doe", DateOfBirth = DateTime.Parse("1970/01/01"), CreatedDateUtc = DateTime.UtcNow }); }
Speaking of inserts, it's BulkInsert (my least favorite thing to do) is super clean:
using (var connection = new SqlConnection(ConnectionString)) { var customers = GenerateCustomers(1000); var insertedRows = connection.BulkInsert(customers); }
The most interesting part of RepoDB is that it formally acknowledges 2nd layer caches and has a whole section on caching in the excellent RepoDB official documentation. I have a whole LazyCache subsystem behind my podcast site that is super fast but added some complexity to the code with more Func<T> that I would have preferred.
This is super clean, just passing in an ICache when you start the connection and then mention the key when querying.
var cache = CacheFactory.GetMemoryCache(); using (var connection = new SqlConnection(connectionString).EnsureOpen()) { var products = connection.QueryAll<Product>(cacheKey: "products", cache: cache); } using (var repository = new DbRepository<Product, SqlConnection>(connectionString)) { var products = repository.QueryAll(cacheKey: "products"); }
It also shows how to do generated cache keys...also clean:
// An example of the second cache key convention: var cache = CacheFactory.GetMemoryCache(); using (var connection = new SqlConnection(connectionString).EnsureOpen()) { var productId = 5; Query<Product>(product => product.Id == productId, cacheKey: $"product-id-{productId}", cache: cache); }
And of course, if you like to drop into SQL directly for whatever reason, you can .ExecuteQuery() and call sprocs or use inline SQL as you like. So far I'm enjoying RepoDB very much. It's thoughtfully designed and well documented and fast. Give it a try and see if you like it to?
Why don't you head over to https://github.com/mikependon/RepoDb now and GIVE THEM A STAR. Encourage open source. Try it on your own project and go tweet the author and share your thoughts!
Sponsor: Have you tried developing in Rider yet? This fast and feature-rich cross-platform IDE improves your code for .NET, ASP.NET, .NET Core, Xamarin, and Unity applications on Windows, Mac, and Linux.
© 2020 Scott Hanselman. All rights reserved.





Exploring the .NET open source hybrid ORM library RepoDB published first on https://deskbysnafu.tumblr.com/
0 notes