#graphql java client example
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr Inc. has $15.1M in annual revenue.
Text
GraphQL Client Side & Server-Side Components Explained with Examples for API Developers
Full Video Link - https://youtube.com/shorts/nezkbeJlAIk Hi, a new #video on #graphql #mutation published on #codeonedigest #youtube channel. @java @awscloud @AWSCloudIndia @YouTube #youtube @codeonedigest #graphql #graphqlresolver #graphqltutorial
Let’s understand the GraphQL components and the way they communicate with each other. The entire application components can be categories in to server side and client-side components. Server-side Components – GraphQL server forms the core component on the server side and allows to parse the queries coming from GraphQL client applications. Apollo Server is most commonly used implementation of…

View On WordPress
#graphql#graphql api#graphql apollo server express#graphql apollo server tutorial#graphql client#graphql client apollo#graphql client java#graphql client react#graphql client side#graphql client spring boot#graphql client tutorial#graphql example#graphql explained#graphql java client example#graphql schema and resolver#graphql server and client#graphql server apollo#graphql server components#graphql server tutorial#graphql tutorial
0 notes
Text
Full Stack Web Development Coaching at Gritty Tech
Master Full Stack Development with Gritty Tech
If you're looking to build a high-demand career in web development, Gritty Tech's Full Stack Web Development Coaching is the ultimate solution. Designed for beginners, intermediates, and even experienced coders wanting to upskill, our program offers intensive, hands-on training. You will master both front-end and back-end development, preparing you to create complete web applications from scratch For More…
At Gritty Tech, we believe in practical learning. That means you'll not only absorb theory but also work on real-world projects, collaborate in teams, and build a strong portfolio that impresses employers.
Why Choose Gritty Tech for Full Stack Coaching?
Gritty Tech stands out because of our commitment to excellence, personalized mentorship, and career-oriented approach. Here's why you should choose us:
Expert Instructors: Our trainers are seasoned professionals from leading tech companies.
Project-Based Learning: You build real applications, not just toy examples.
Career Support: Resume workshops, interview preparation, and networking events.
Flexible Learning: Evening, weekend, and self-paced options are available.
Community: Join a vibrant community of developers and alumni.
What is Full Stack Web Development?
Full Stack Web Development refers to the creation of both the front-end (client-side) and back-end (server-side) portions of a web application. A full stack developer handles everything from designing user interfaces to managing servers and databases.
Front-End Development
Front-end development focuses on what users see and interact with. It involves technologies like:
HTML5 for structuring web content.
CSS3 for designing responsive and visually appealing layouts.
JavaScript for adding interactivity.
Frameworks like React, Angular, and Vue.js for building scalable web applications.
Back-End Development
Back-end development deals with the server-side, databases, and application logic. Key technologies include:
Node.js, Python (Django/Flask), Ruby on Rails, or Java (Spring Boot) for server-side programming.
Databases like MySQL, MongoDB, and PostgreSQL to store and retrieve data.
RESTful APIs and GraphQL for communication between client and server.
Full Stack Tools and DevOps
Version Control: Git and GitHub.
Deployment: AWS, Heroku, Netlify.
Containers: Docker.
CI/CD Pipelines: Jenkins, GitLab CI.
Gritty Tech Full Stack Coaching Curriculum
Our curriculum is carefully crafted to cover everything a full stack developer needs to know:
1. Introduction to Web Development
Understanding the internet and how web applications work.
Setting up your development environment.
Introduction to Git and GitHub.
2. Front-End Development Mastery
HTML & Semantic HTML: Best practices for accessibility.
CSS & Responsive Design: Media queries, Flexbox, Grid.
JavaScript Fundamentals: Variables, functions, objects, and DOM manipulation.
Modern JavaScript (ES6+): Arrow functions, promises, async/await.
Front-End Frameworks: Deep dive into React.js.
3. Back-End Development Essentials
Node.js & Express.js: Setting up a server, building APIs.
Database Management: CRUD operations with MongoDB.
Authentication & Authorization: JWT, OAuth.
API Integration: Consuming third-party APIs.
4. Advanced Topics
Microservices Architecture: Basics of building distributed systems.
GraphQL: Modern alternative to REST APIs.
Web Security: Preventing common vulnerabilities (XSS, CSRF, SQL Injection).
Performance Optimization: Caching, lazy loading, code splitting.
5. DevOps and Deployment
CI/CD Fundamentals: Automating deployments.
Cloud Services: Hosting apps on AWS, DigitalOcean.
Monitoring & Maintenance: Tools like New Relic and Datadog.
6. Soft Skills and Career Coaching
Resume writing for developers.
Building an impressive LinkedIn profile.
Preparing for technical interviews.
Negotiating job offers.
Real-World Projects You'll Build
At Gritty Tech, you won't just learn; you'll build. Here are some example projects:
E-commerce Website: A full stack shopping platform.
Social Media App: Create a mini version of Instagram.
Task Manager API: Backend API to handle user tasks with authentication.
Real-Time Chat Application: WebSocket-based chat system.
Each project is reviewed by mentors, and feedback is provided to ensure continuous improvement.
Personalized Mentorship and Live Sessions
Our coaching includes one-on-one mentorship to guide you through challenges. Weekly live sessions provide deeper dives into complex topics and allow real-time Q&A. Mentors assist with debugging, architectural decisions, and performance improvements.
Tools and Technologies You Will Master
Languages: HTML, CSS, JavaScript, Python, SQL.
Front-End Libraries/Frameworks: React, Bootstrap, TailwindCSS.
Back-End Technologies: Node.js, Express.js, MongoDB.
Version Control: Git, GitHub.
Deployment: Heroku, AWS, Vercel.
Other Tools: Postman, Figma (for UI design basics).
Student Success Stories
Thousands of students have successfully transitioned into tech roles through Gritty Tech. Some notable success stories:
Amit, from a sales job to Front-End Developer at a tech startup within 6 months.
Priya, a stay-at-home mom, built a portfolio and landed a full stack developer role.
Rahul, a mechanical engineer, became a software engineer at a Fortune 500 company.
Who Should Join This Coaching Program?
This coaching is ideal for:
Beginners with no coding experience.
Working professionals looking to switch careers.
Students wanting to learn industry-relevant skills.
Entrepreneurs building their tech startups.
If you are motivated to learn, dedicated to practice, and open to feedback, Gritty Tech is the right place for you.
Career Support at Gritty Tech
At Gritty Tech, our relationship doesn’t end when you finish the course. We help you land your first job through:
Mock interviews.
Technical assessments.
Building an impressive project portfolio.
Alumni referrals and job placement assistance.
Certifications
After completing the program, you will receive a Full Stack Web Developer Certification from Gritty Tech. This certification is highly respected in the tech industry and will boost your resume significantly.
Flexible Payment Plans
Gritty Tech offers affordable payment plans to make education accessible to everyone. Options include:
Monthly Installments.
Pay After Placement (Income Share Agreement).
Early Bird Discounts.
How to Enroll
Enrolling is easy! Visit Gritty Tech Website and sign up for the Full Stack Web Development Coaching program. Our admissions team will guide you through the next steps.
Frequently Asked Questions (FAQ)
How long does the Full Stack Web Development Coaching at Gritty Tech take?
The program typically spans 6 to 9 months depending on your chosen pace (full-time or part-time).
Do I need any prerequisites?
No prior coding experience is required. We start from the basics and gradually move to advanced topics.
What job roles can I apply for after completing the program?
You can apply for roles like:
Front-End Developer
Back-End Developer
Full Stack Developer
Web Application Developer
Software Engineer
Is there any placement guarantee?
While we don't offer "guaranteed placement," our career services team works tirelessly to help you land a job by providing job referrals, mock interviews, and resume building sessions.
Can I learn at my own pace?
Absolutely. We offer both live cohort-based batches and self-paced learning tracks.
Ready to kickstart your tech career? Join Gritty Tech's Full Stack Web Development Coaching today and transform your future. Visit grittytech.com to learn more and enroll!
0 notes
Text

How to Become a Full-Stack Developer
Full Stack Developers are in demand, and there’s a tech industry boom. Full stack developers, they know how to do both front-end and back-end work, so they are a huge asset to companies. This article should help you navigate on the path how to become a Full Stack Developer, if you are looking to kick-start your career in web development.
What Exactly is a Full Stack Developer?
Full Stack Developer Design and develop complete web applications, client-side (front-end) and server-side (back-end). They seamlessly integrate different technologies for a smooth user experience.
Key Responsibilities
Build those front-end UI using HTML, CSS and JavaScript OR use frameworks like React or Angular for development.
Do back-end development using stuff like Node.js, Python, PHP, or Java.
Work with databases (MySQL, PostgreSQL or MongoDB)
Take plan site responsiveness, performance, and security and API integration
Core Skills Required
Front-End Development
HTML & CSS: The foundations of web development for creating and styling web pages
JavaScript: When you need interactivity.
Frameworks: React.js, Angular, or Vue.js speed up development.
Back-End Development
Languages: Python, Java, PHP, Node.js for server-side coding.
Databases: MySQL, PostgreSQL, and MongoDB which are used for storing data.
APIs: REST, SOAP, GraphQL for exchanging data.
Version Control & Deployment
Git & GitHub: You can save your changes and make better collaboration
CI/CD pipelines: Automate testing and deployment
Cloud Platforms for hosting applications: AWS, Azure, Google Cloud.
Additional Skills
Robust Debugging and problem-solving skills.
Excellent written and verbal communication and team collaboration skills.
Familiarity with DevOps concepts, server management, and security.
Getting Started as a Full Stack Developer
Master Both Front-End & Back-End Technologies.
Learn HTML, CSS, and JavaScript First Adopt a front-end framework such as React.js or Angular.js and a back-end language like Node.js, Python, or PHP.
Build Practical Projects.
Build real world projects with these skills, for Example.
A personal portfolio website.
A simple application that performs CRUD (Create, Read, Update, Delete).
A secure e-commerce site with user authentication and payment mechanism.
Version Control & Deployment
Use Git, GitHub, and a cloud platform (AWS or Firebase) to deploy an application or collaborate with other developers.
Sign Up for a Full Stack Development Course
Enrolling in a structured learning program, such as those by Milestone Institute of Technology can help you receive practical training and mentorship to prepare you for the industry world.
Prepare A Resume and Portfolio
Push GitHub to show off your projects Write articles on places like Medium about what you are learning. Tailor your resume for a Full Stack Developer.
Search for Job/ freelance work
For full-time opportunities, utilize job portals such as LinkedIn, Glassdoor, and Indeed For freelancers, you can use Upwork and Fiverr.
Job Roles for Full Stack Developer
Web Developer
Software Engineer
Front-End Developer
Back-End Developer
DevOps Engineer
Conclusion
A Full Stack Developer need to keep learning and practice maximum. With knowledge of front-end, back-end, and database, you are on your way to becoming a successful web developer. For professional training, Milestone Institute of Technology has good courses that develop you for the industry.
0 notes
Text
A Guide to Creating APIs for Web Applications

APIs (Application Programming Interfaces) are the backbone of modern web applications, enabling communication between frontend and backend systems, third-party services, and databases. In this guide, we’ll explore how to create APIs, best practices, and tools to use.
1. Understanding APIs in Web Applications
An API allows different software applications to communicate using defined rules. Web APIs specifically enable interaction between a client (frontend) and a server (backend) using protocols like REST, GraphQL, or gRPC.
Types of APIs
RESTful APIs — Uses HTTP methods (GET, POST, PUT, DELETE) to perform operations on resources.
GraphQL APIs — Allows clients to request only the data they need, reducing over-fetching.
gRPC APIs — Uses protocol buffers for high-performance communication, suitable for microservices.
2. Setting Up a REST API: Step-by-Step
Step 1: Choose a Framework
Node.js (Express.js) — Lightweight and popular for JavaScript applications.
Python (Flask/Django) — Flask is simple, while Django provides built-in features.
Java (Spring Boot) — Enterprise-level framework for Java-based APIs.
Step 2: Create a Basic API
Here’s an example of a simple REST API using Express.js (Node.js):javascriptconst express = require('express'); const app = express(); app.use(express.json());let users = [{ id: 1, name: "John Doe" }];app.get('/users', (req, res) => { res.json(users); });app.post('/users', (req, res) => { const user = { id: users.length + 1, name: req.body.name }; users.push(user); res.status(201).json(user); });app.listen(3000, () => console.log('API running on port 3000'));
Step 3: Connect to a Database
APIs often need a database to store and retrieve data. Popular databases include:
SQL Databases (PostgreSQL, MySQL) — Structured data storage.
NoSQL Databases (MongoDB, Firebase) — Unstructured or flexible data storage.
Example of integrating MongoDB using Mongoose in Node.js:javascriptconst mongoose = require('mongoose'); mongoose.connect('mongodb://localhost:27017/mydb', { useNewUrlParser: true, useUnifiedTopology: true });const UserSchema = new mongoose.Schema({ name: String }); const User = mongoose.model('User', UserSchema);app.post('/users', async (req, res) => { const user = new User({ name: req.body.name }); await user.save(); res.status(201).json(user); });
3. Best Practices for API Development
🔹 Use Proper HTTP Methods:
GET – Retrieve data
POST – Create new data
PUT/PATCH – Update existing data
DELETE – Remove data
🔹 Implement Authentication & Authorization
Use JWT (JSON Web Token) or OAuth for securing APIs.
Example of JWT authentication in Express.js:
javascript
const jwt = require('jsonwebtoken'); const token = jwt.sign({ userId: 1 }, 'secretKey', { expiresIn: '1h' });
🔹 Handle Errors Gracefully
Return appropriate status codes (400 for bad requests, 404 for not found, 500 for server errors).
Example:
javascript
app.use((err, req, res, next) => { res.status(500).json({ error: err.message }); });
🔹 Use API Documentation Tools
Swagger or Postman to document and test APIs.
4. Deploying Your API
Once your API is built, deploy it using:
Cloud Platforms: AWS (Lambda, EC2), Google Cloud, Azure.
Serverless Functions: AWS Lambda, Vercel, Firebase Functions.
Containerization: Deploy APIs using Docker and Kubernetes.
Example: Deploying with DockerdockerfileFROM node:14 WORKDIR /app COPY package.json ./ RUN npm install COPY . . CMD ["node", "server.js"] EXPOSE 3000
5. API Testing and Monitoring
Use Postman or Insomnia for testing API requests.
Monitor API Performance with tools like Prometheus, New Relic, or Datadog.
Final Thoughts
Creating APIs for web applications involves careful planning, development, and deployment. Following best practices ensures security, scalability, and efficiency.
WEBSITE: https://www.ficusoft.in/python-training-in-chennai/
0 notes
Text
Understanding GraphQL
Before diving into Spring GraphQL, it's essential to grasp what GraphQL is. Developed by Facebook in 2012, GraphQL is a query language for APIs that allows clients to request only the data they need. Unlike RESTful APIs, where the server defines the data structure, GraphQL enables clients to specify the exact data requirements, reducing over-fetching and under-fetching of data.
Key Features of GraphQL:
Declarative Data Fetching: Clients can request specific data, leading to optimized network usage.
Single Endpoint: All data queries are handled through a single endpoint, simplifying the API structure.
Strong Typing: GraphQL schemas define types and relationships, ensuring consistency and clarity.
Introducing Spring GraphQL
Spring GraphQL is a project that integrates GraphQL into the Spring ecosystem. It provides the necessary tools and libraries to build GraphQL APIs using Spring Boot, leveraging the robustness and familiarity of the Spring Framework.
Why Choose Spring GraphQL?
Seamless Integration: Combines the capabilities of Spring Boot with GraphQL, allowing developers to build scalable and maintainable APIs.
Auto-Configuration: Spring Boot's auto-configuration simplifies setup, enabling developers to focus on business logic.
Community Support: Backed by the extensive Spring community, ensuring continuous updates and support.
Setting Up a Spring GraphQL Project
To start building with Spring GraphQL, follow these steps:
1. Create a New Spring Boot Project
Use Spring Initializr to generate a new project:
Project: Maven Project
Language: Java
Spring Boot: Choose the latest stable version
Dependencies:
Spring Web
Spring for GraphQL
Spring Data JPA (if you're interacting with a database)
H2 Database (for in-memory database testing)
Download the project and import it into your preferred IDE.
2. Define the GraphQL Schema
GraphQL schemas define the structure of the data and the queries available. Create a schema file (schema.graphqls) in the src/main/resources/graphql directory:
graphql
Copy code
type Query {
greeting(name: String! = "Spring"): String!
project(slug: ID!): Project
}
type Project {
slug: ID!
name: String!
repositoryUrl: String!
status: ProjectStatus!
}
enum ProjectStatus {
ACTIVE
COMMUNITY
INCUBATING
ATTIC
EOL
}
This schema defines a Query type with two fields: greeting and project. The Project type includes details like slug, name, repositoryUrl, and status. The ProjectStatus enum represents the various states a project can be in.
3. Implement Resolvers
Resolvers are responsible for fetching the data corresponding to the queries defined in the schema. In Spring GraphQL, you can use controllers to handle these queries:
java
Copy code
import org.springframework.graphql.data.method.annotation.QueryMapping;
import org.springframework.stereotype.Controller;
@Controller
public class ProjectController {
@QueryMapping
public String greeting(String name) {
return "Hello, " + name + "!";
}
@QueryMapping
public Project project(String slug) {
// Logic to fetch project details by slug
}
}
In this example, the greeting method returns a simple greeting message, while the project method fetches project details based on the provided slug.
4. Configure Application Properties
Ensure your application properties are set up correctly, especially if you're connecting to a database:
properties
Copy code
spring.datasource.url=jdbc:h2:mem:testdb
spring.datasource.driverClassName=org.h2.Driver
spring.datasource.username=sa
spring.datasource.password=password
spring.jpa.hibernate.ddl-auto=update
These settings configure an in-memory H2 database for testing purposes.
5. Test Your GraphQL API
With the setup complete, you can test your GraphQL API using tools like GraphiQL or Postman. Send queries to the /graphql endpoint of your application to retrieve data.
Benefits of Using Spring GraphQL
Integrating GraphQL with Spring Boot offers several advantages:
Efficient Data Retrieval: Clients can request only the data they need, reducing unnecessary data transfer.
Simplified API Management: A single endpoint handles all queries, streamlining the API structure.
Strong Typing: Schemas define data types and relationships, minimizing errors and enhancing clarity.
Flexibility: Easily add or deprecate fields without impacting existing clients, facilitating smooth evolution of the API.
Conclusion
Spring GraphQL empowers developers to build flexible and efficient APIs by combining the strengths of GraphQL and the Spring Framework. By following the steps outlined above, you can set up a Spring GraphQL project and start leveraging its benefits in your applications
0 notes
Text
Essential Full Stack Development Interview Questions to Prepare For Your Next Job Opportunity
The demand for skilled full stack developers continues to grow as more companies seek professionals who can handle both the front-end and back-end development of applications. Preparing for a full stack development interview involves understanding a wide range of concepts that cover various technologies, frameworks, and programming practices.
To set yourself apart and confidently face interviews, consider exploring these essential full stack development interview questions. And for an insightful video overview of full stack interview preparation, check out this Full Stack Developer Interview Preparation Guide.
1. What is Full Stack Development?
Full stack development refers to the practice of working on both the front-end (client-side) and back-end (server-side) of a web application. A full stack developer is proficient in multiple technologies that enable them to build fully functional web applications from start to finish.
Key Points to Discuss:
Differences between front-end, back-end, and full stack development.
Advantages of hiring a full stack developer for a project.
2. What Are the Most Commonly Used Front-End Technologies?
Front-end development involves creating the user interface and ensuring a seamless user experience. The most popular front-end technologies include:
HTML: The standard markup language for creating web pages.
CSS: Used to style and layout web pages.
JavaScript: Essential for interactive features.
Frameworks/Libraries: React, Angular, and Vue.js.
Follow-Up Questions:
How do these technologies differ in terms of use cases?
Can you explain the benefits of using a front-end framework like React over vanilla JavaScript?
3. Explain the Role of Back-End Technologies in Full Stack Development.
The back-end of an application handles the server, database, and business logic. Key technologies include:
Node.js: A JavaScript runtime for server-side programming.
Express.js: A web application framework for Node.js.
Databases: SQL (e.g., MySQL, PostgreSQL) and NoSQL (e.g., MongoDB).
Other Languages: Python (Django, Flask), Ruby (Rails), and Java (Spring Boot).
Important Discussion Points:
RESTful services and APIs.
Authentication and authorization mechanisms (e.g., JWT, OAuth).
4. How Do You Ensure Code Quality and Maintainability?
Interviewers often ask this question to understand your approach to writing clean, maintainable code. Emphasize:
Version Control: Using Git and platforms like GitHub for collaborative coding.
Linting Tools: ESLint for JavaScript and other language-specific tools.
Code Reviews: The importance of peer reviews for improving code quality.
Best Practices: Following design patterns and SOLID principles.
5. Can You Discuss the MVC Architecture?
The Model-View-Controller (MVC) architecture is a common design pattern used in full stack development. Each part of the pattern has a distinct role:
Model: Manages data and business logic.
View: The user interface.
Controller: Connects the Model and View, handling input and output.
Why It’s Important:
Helps organize code, making it more scalable and easier to maintain.
Many frameworks, such as Django and Ruby on Rails, are built on MVC principles.
6. What Is REST and How Is It Used in Full Stack Development?
Representational State Transfer (REST) is an architectural style used to design networked applications:
Key Features: Stateless, cacheable, and uses standard HTTP methods (GET, POST, PUT, DELETE).
Implementation: Building RESTful APIs to enable communication between client and server.
Common Follow-Ups:
How do RESTful APIs differ from GraphQL?
Can you provide an example of designing a RESTful API?
7. Explain the Role of Databases and When to Use SQL vs. NoSQL.
Choosing between SQL and NoSQL depends on the application's needs:
SQL Databases: Structured, table-based databases like MySQL and PostgreSQL. Best for applications requiring complex queries and data integrity.
NoSQL Databases: Flexible, schema-less options like MongoDB and Cassandra. Ideal for handling large volumes of unstructured data.
Typical Questions:
What are the ACID properties in SQL databases?
When would you prefer MongoDB over a relational database?
8. How Do You Implement User Authentication?
User authentication is crucial for any secure application. Discuss:
Methods: Sessions, cookies, JSON Web Tokens (JWT).
Frameworks: Passport.js for Node.js, Auth0 for advanced solutions.
Best Practices: Storing passwords securely using hashing algorithms like bcrypt.
9. What Are Webpack and Babel Used For?
These tools are essential for modern JavaScript development:
Webpack: A module bundler for bundling JavaScript files and assets.
Babel: A JavaScript compiler that allows you to use next-gen JavaScript features by transpiling code to be compatible with older browsers.
Related Questions:
How do you optimize your build for production using Webpack?
What is tree shaking, and how does it improve performance?
10. How Do You Handle Error Handling in JavaScript?
Error handling is vital for ensuring that applications are resilient:
Try-Catch Blocks: For handling synchronous errors.
Promises and .catch(): For managing asynchronous operations.
Error Handling Middleware: Used in Express.js for centralized error management.
Important Concepts:
Logging errors and using tools like Sentry for real-time monitoring.
Creating user-friendly error messages.
Preparing thoroughly for full stack development interviews by understanding these questions will set you on the path to success. For a comprehensive walkthrough and additional insights, make sure to check out this YouTube guide, where these topics are discussed in detail to boost your interview readiness.
0 notes
Text
Full-Stack Development: A Comprehensive Guide for Beginners
In the ever-evolving world of technology, full-stack development has become a highly sought-after skill. It represents the ability to work on both the frontend (client-side) and backend (server-side) of a web application. If you’ve ever wondered what it means to be a full-stack developer, how it works, and why companies value it, this blog will walk you through everything you need to know.
What is Full-Stack Development?
Simply put, full-stack development involves building both the frontend and backend parts of an application. A full-stack developer has the skills to design user interfaces, develop server-side logic, and manage databases. They work across multiple layers, also known as the "stack," ensuring the seamless operation of the entire application.
The Two Sides of Full-Stack Development
Frontend Development (Client-Side)
This part focuses on what the user interacts with directly—the visual interface. It deals with:
Languages & Tools:
HTML: Structure of the webpage
CSS: Styling and layout
JavaScript: Adding interactivity (e.g., animations, user actions)
Frameworks/Libraries: React, Angular, or Vue.js
Example: When you click a button, the frontend handles how it looks and animates the action you see.
Backend Development (Server-Side)
This layer deals with the logic, database interactions, and authentication behind the scenes. It ensures the smooth processing of requests and returns appropriate data to the frontend.
Languages & Tools:
Programming Languages: Node.js, Python (Django), Java, Ruby, PHP
Databases: MySQL, MongoDB, PostgreSQL
APIs & Servers: REST, GraphQL, Express, Flask
Example: When you log in to a website, the backend checks your username and password in the database and sends back the result.
What Does a Full-Stack Developer Do?
A full-stack developer wears multiple hats, handling all aspects of development. Their responsibilities may include:
Creating the Frontend Interface: Designing attractive, responsive pages that work well on different devices.
Building Backend Logic: Writing code that defines how the application will respond to user input and connect to databases.
Database Management: Designing, storing, and retrieving data efficiently.
API Development & Integration: Creating or consuming APIs to enable communication between frontend and backend.
Testing & Debugging: Identifying and fixing bugs across the full stack.
Popular Tech Stacks Used in Full-Stack Development
A tech stack refers to the set of technologies used in developing an application. Some popular full-stack combinations include:
MERN Stack: MongoDB, Express, React, Node.js
MEAN Stack: MongoDB, Express, Angular, Node.js
LAMP Stack: Linux, Apache, MySQL, PHP
Django Stack: Django (Python), PostgreSQL, JavaScript
Why is Full-Stack Development Important?
Versatility: A full-stack developer can work on any part of the project, making them very valuable to startups and smaller teams.
Faster Development: With one person managing both frontend and backend, there’s better collaboration and fewer bottlenecks.
Cost-Effective: Hiring a single full-stack developer can be more budget-friendly than hiring separate frontend and backend specialists.
Adaptability: Full-stack developers can quickly learn new technologies and adapt to changing project requirements.
Challenges of Being a Full-Stack Developer
Constant Learning: Technology changes rapidly, so staying updated is crucial.
Time Management: Managing both frontend and backend tasks can be overwhelming.
Jack of All Trades, Master of None?: Some developers struggle to master both sides equally.
Debugging Complex Systems: Problems can arise at multiple points, requiring a deep understanding of both frontend and backend.
How to Become a Full-Stack Developer?
If you’re interested in pursuing a career in full-stack development, here are the steps to get started:
Learn Frontend Basics: Start with HTML, CSS, and JavaScript. Practice building simple web pages.
Master a Frontend Framework: React, Angular, or Vue.js will make your pages more dynamic and interactive.
Learn Backend Technologies: Pick a backend language like Node.js, Python, or PHP and understand how servers and APIs work.
Understand Databases: Learn to interact with databases using SQL or NoSQL technologies.
Practice Building Full-Stack Projects: Create real-world projects like blogs, e-commerce websites, or to-do apps to solidify your skills.
Version Control: Get comfortable with Git and GitHub to collaborate with other developers and track your code.
Explore Cloud & Deployment: Learn how to deploy your applications using Heroku, Netlify, or AWS.
Full-Stack Development in the Future
The demand for full-stack developers is on the rise as businesses seek agile, multi-skilled professionals to handle diverse projects. As technologies evolve, developers will need to learn AI, cloud computing, and DevOps practices to stay relevant.
Conclusion
Full-stack development offers exciting opportunities for developers who love to work on both frontend and backend technologies. It requires continuous learning, but the flexibility and versatility it provides make it a rewarding career. Whether you’re just starting or looking to switch roles, mastering full-stack development will open up a world of possibilities.
Fullstack Seekho is launching a new full stack training in Pune 100% job Guarantee Course. Below are the list of Full Stack Developer Course in Pune:
1. Full Stack Web Development Course in Pune and MERN Stack Course in Pune
2. Full Stack Python Developer Course in Pune
3. Full stack Java course in Pune And Java full stack developer course with placement
4. Full Stack Developer Course with Placement Guarantee
Visit the website and fill the form and our counsellors will connect you!
0 notes
Text
The Backbone of Modern Applications: An Insight into Backend Development
In the world of web and app development, backend development often operates behind the scenes, yet it plays a crucial role in ensuring that everything runs smoothly. While the frontend interacts with users, the backend forms the backbone of any application, handling everything from data processing to server-side logic.

What is Backend Development?
Backend development refers to the server-side development of web and mobile applications. It focuses on what users don’t see – databases, servers, APIs, and other behind-the-scenes technologies. The main goal of backend development is to ensure that the frontend, or the part of the application the user interacts with, works seamlessly by managing and processing the data exchanged between the server and the user interface.
Key Components of Backend Development
Server: The server is the heart of backend development. It’s where the application’s logic is processed. Backend developers set up and manage these servers to ensure they can handle the application’s load and provide a reliable experience.
Database: Databases are where all the data is stored. Whether it's user profiles, transaction history, or product catalogs, backend development involves creating, managing, and querying databases efficiently. Popular databases include MySQL, PostgreSQL, MongoDB, and Oracle.
API (Application Programming Interface): APIs are crucial in backend development as they act as the bridge between the server and the client-side. They allow different software systems to communicate and exchange data, enabling functionality such as user authentication, payment processing, and data retrieval.
Server-Side Programming Languages: Several programming languages are used in backend development, including Python, Java, Ruby, PHP, and Node.js. Each has its strengths and is chosen based on the specific needs of the project.
The Role of a Backend Developer
Backend developers are responsible for the logic, database interactions, and server configuration of an application. They work closely with frontend developers to ensure that the application functions as intended. A backend developer’s responsibilities include:
Writing Clean, Efficient Code: Ensuring that the backend code is optimized, readable, and scalable.
Database Management: Designing and managing databases, ensuring data integrity and security.
API Development: Creating APIs that the frontend will use to interact with the server.
Security: Implementing security measures to protect data and prevent unauthorized access.
Performance Optimization: Ensuring that the server can handle large amounts of data and user traffic without slowing down.
The Importance of Backend Development
Without robust backend development, even the most visually appealing and interactive frontend would fail. The backend handles essential functions such as user authentication, data storage, and business logic, ensuring that everything works correctly behind the scenes.
For example, when you log in to an app, the backend checks your credentials against the stored data in the database, processes your request, and grants access if everything is correct. Similarly, when you make a purchase online, the backend handles the payment processing, inventory management, and order confirmation.
Trends in Backend Development
As technology evolves, so do the practices and tools in backend development. Some of the latest trends include:
Microservices Architecture: Breaking down applications into smaller, manageable services that can be developed, deployed, and scaled independently.
Serverless Computing: Reducing the need to manage servers by relying on cloud providers like AWS Lambda, which run code in response to events.
GraphQL: A new way of querying APIs, providing more flexibility than traditional REST APIs.
Automation and CI/CD: Implementing continuous integration and continuous deployment to automate testing and deployment, ensuring faster release cycles.
Conclusion
Backend development may not be as visible as the frontend, but it is the foundation upon which every successful application is built. It ensures that data is processed correctly, that users can interact with the app efficiently, and that the entire system is secure and reliable. Whether you’re a budding developer or a business looking to build an app, understanding the importance of backend development is crucial to the success of any project.
0 notes
Text
Unraveling the 5 Layers of Software Development

In the realm of software development services, every application is built upon a foundation of interconnected layers, each serving a specific purpose in delivering functionality to end-users. Understanding these layers and the technologies that power them is crucial for developers aiming to create robust and efficient software solutions. In this blog, we'll explore the five key layers of software architecture: User Interface (UI), Application Programming Interface (API), Database (DB), Business Logic, and Hosting, along with examples of technologies commonly used in each layer.

User Interface (UI): The UI layer is what users interact with directly. It encompasses everything from the visual design to the user experience (UX). Technologies used in this layer focus on creating intuitive, responsive, and aesthetically pleasing interfaces. Some popular UI Design technologies include:
HTML/CSS/JavaScript: These front-end technologies form the backbone of web-based UIs. HTML defines the structure, CSS styles the elements, and JavaScript adds interactivity.
React.js/Vue.js/Angular: These JavaScript frameworks are used to build dynamic and interactive user interfaces for web applications.
Swift/Kotlin: For mobile application development, languages like Swift (for iOS) and Kotlin (for Android) are used to develop native user interfaces.

Application Programming Interface (API): The API layer acts as an intermediary between the UI and the business logic, enabling communication and data exchange. APIs define the endpoints and protocols through which different software components interact. Common technologies used in API development services include:
RESTful APIs: Representational State Transfer (REST) is a popular architectural style for designing networked applications. RESTful APIs use HTTP methods like GET, POST, PUT, and DELETE to perform operations on resources.
GraphQL: An alternative to REST, GraphQL provides a more flexible and efficient approach to querying and manipulating data. It allows clients to request only the data they need, reducing over-fetching and under-fetching.
Express.js/Django/Rails: Frameworks like Express.js (for Node.js), Django (for Python), and Rails (for Ruby) are commonly used to build web APIs quickly and efficiently.
Database (DB): The database layer is responsible for storing, retrieving, and managing data. It provides a persistent storage solution for an application's information. Various types of databases exist, including relational databases, NoSQL databases, and in-memory databases. Some popular database technologies include:
MySQL/PostgreSQL: Relational database management systems (RDBMS) like MySQL and PostgreSQL are widely used for structured data storage and management.
MongoDB: A popular NoSQL database, MongoDB is designed for storing unstructured or semi-structured data in JSON-like documents.
Redis: An in-memory data structure store, Redis is often used as a caching layer or for real-time data processing.

Business Logic: The business logic layer contains the application's core functionality and rules. It processes requests from the UI, interacts with the database, and performs the necessary operations to fulfill user actions. While business logic can be implemented in various programming languages, some technologies commonly used for this layer include:
Java/C#: Object-oriented languages like Java and C# are often chosen for building robust and scalable business logic components.
Node.js/Python: JavaScript (with Node.js) and Python are also popular choices, especially for applications requiring agility and rapid development.
Spring/.NET Core: Frameworks like Spring (for Java) and .NET Core (for C#) provide tools and libraries for building enterprise-grade business logic components.
Hosting: The hosting layer encompasses the infrastructure and environment where the application runs. It includes servers, cloud platforms, containers, and other deployment options. Popular hosting technologies and platforms include:
Amazon Web Services (AWS)/Microsoft Azure/Google Cloud Platform (GCP): These cloud service providers offer a range of hosting solutions, including virtual machines, containers, and serverless computing.
Docker/Kubernetes: Containerization technologies like Docker and orchestration platforms like Kubernetes provide efficient ways to package, deploy, and manage applications across different environments.
Heroku/Netlify/Vercel: These platforms offer simplified hosting solutions specifically tailored for web applications, providing features like continuous deployment, scalability, and managed infrastructure.
In conclusion, navigating the various layers of software architecture requires a comprehensive understanding of each layer's purpose and the technologies that power them. By leveraging the right technologies for UI, API, DB, logic, and hosting, developers can build robust, scalable, and maintainable software solutions that meet the needs of modern users and businesses.
#webdesign#mobileappdevelopment#appdevelopment#web developers#webdevelopment#youtube#apiintegration#thememakker#webdevelopmentcompany#hosting#database#serverless computing#api#uiuxdesign#ui#ux#aws#ror#docker#java#kubernetes#hire developers#webservices
0 notes
Text
GraphQL in MuleSoft

Integrating GraphQL with MuleSoft enables you to offer a modern, powerful API interface for your applications, allowing clients to request the data they need and nothing more. GraphQL, a query language for APIs developed by Facebook, provides a more efficient and flexible alternative to the traditional REST API approach. When combined with MuleSoft’s Anypoint Platform, you can leverage GraphQL to design, build, and manage APIs that offer tailored data retrieval options to your API consumers.
Implementing GraphQL in MuleSoft
As of my last update, MuleSoft’s Anypoint Platform does not natively support GraphQL in the same direct manner it supports REST or SOAP services. However, you can implement GraphQL over the APIs managed by MuleSoft through custom development. Here’s how you can approach it:
Define Your GraphQL Schema:
Start by defining a GraphQL schema that specifies the types of data you offer, including objects, fields, queries, and mutations. This schema acts as a contract between the client and the server.
Implement Data Fetchers:
You need to implement a resolver or data fetcher for each field in your schema. In the context of MuleSoft, you can implement these fetchers as Java classes or scripts that execute logic to retrieve or manipulate data from your backend systems, databases, or other APIs managed by MuleSoft.
Expose a GraphQL Endpoint:
Use an HTTP Listener in your Mule application to expose a single GraphQL endpoint. Clients will send POST requests to this endpoint with their query payloads.
You can handle these requests in your Mule flows, parsing the GraphQL queries and passing them to the appropriate data fetchers.
Integrate GraphQL Java Libraries:
Leverage existing GraphQL Java libraries, such as graphql-java, to parse the GraphQL queries, execute them against your schema, and format the response according to the GraphQL specification.
You may need to include these libraries in your Mule project and call them from your custom components or scripts within your flows.
Manage Performance and Security:
Implement caching, batching, and rate limiting to optimize performance and manage the load on your backend systems.
Secure your GraphQL endpoint using MuleSoft’s security policies, OAuth2 providers, or JWT validation to protect against unauthorized access.
Testing and Documentation
Testing: Use Postman, Insomnia, or GraphQL Playground to test your GraphQL API. These tools allow you to craft queries, inspect the schema, and see the results.
Documentation: Although GraphQL APIs are self-documenting through introspection, consider providing additional documentation on everyday use cases, query examples, and best practices for clients.
Challenges and Considerations
Query Complexity: GraphQL allows clients to request deeply nested data, which can lead to performance issues. Consider implementing query complexity analysis and depth limiting to mitigate this.
Error Handling: Design your error handling strategy to provide meaningful error messages to clients while hiding sensitive system details.
N+1 Problem: Be mindful of the N+1 problem, where executing a GraphQL query could result in many more data fetching operations than expected. Use techniques like data loader patterns to batch requests and reduce the number of calls to backend services.
Demo Day 1 Video:
youtube
You can find more information about Mulesoft in this Mulesoft Docs Link
Conclusion:
Unogeeks is the №1 Training Institute for Mulesoft Training. Anyone Disagree? Please drop in a comment
You can check out our other latest blogs on Mulesoft Training here — Mulesoft Blogs
You can check out our Best in Class Mulesoft Training details here — Mulesoft Training
Follow & Connect with us:
— — — — — — — — — — — -
For Training inquiries:
Call/Whatsapp: +91 73960 33555
Mail us at: [email protected]
Our Website ➜ https://unogeeks.com
Follow us:
Instagram: https://www.instagram.com/unogeeks
Facebook: https://www.facebook.com/UnogeeksSoftwareTrainingInstitute
Twitter: https://twitter.com/unogeeks
#MULESOFT #MULESOFTTARINING #UNOGEEKS #UNOGEEKS TRAINING
0 notes
Text
Client Authentication in GraphQL Explained with Examples for API Developers
Full Video Link - https://youtube.com/shorts/5Tj3o9_0pVs Hi, a new #video on #graphql #clientauthentication #client #authentication #tutorial published on #codeonedigest #youtube channel. @java @awscloud @AWSCloudIndia @YouTube #youtube @codeoned
Authentication is the process of verifying the identity of a user or a process. It is important that an application authenticates a user to ensure that the data is not available to an anonymous user. Let’s learn how to authenticate a GraphQL client. The client authentication is based on JWT token i.e. Json Web token. JSON Web Token (JWT) is a long string that identifies the logged in user. Once…

View On WordPress
0 notes
Text
This year in JavaScript: 2018 in review and npm’s predictions for 2019
This study is adapted from my presentation npm and the Future of JavaScript. No data is perfect; if you have questions about ours you can read about the methodology used to gather this data.
npm has over 10 million users who download well over 30 billion packages every month. On an average Tuesday—npm’s busiest day—users download more than 1.3 billion packages of open source JavaScript. This gives us a lot of information about what JavaScript users are up to. On top of that data, in partnership with the Node.js Foundation and the JS Foundation we survey of over 16,000 developers to ask what they’re up to.
From these two sources, we’ve uncovered some insights about the makeup of the npm community, as well as information about what the community considers to be best practices. This will help you make your technical choices in 2019.
JavaScript is the world’s most popular programming language
It’s no news to anyone that JavaScript is incredibly popular these days. Stack Overflow’s 2018 developer survey has JavaScript as the most popular programming language (with fellow web languages HTML and CSS at the #2 and #3 spots). GitHub’s most recent Octoverse infographic ranks languages by the number of pull requests received, and JavaScript is the top there, too.

The total number of JavaScript developers is hard to estimate. Slashdata’s 2018 survey suggests there were 9.7M by the end of 2017 and growing quickly, meaning there are well over 10M at this point. npm’s own estimates suggest there are over 10M npm users, and we see similarly rapid growth. There are JavaScript developers who do not yet use npm, but as a percentage of all JavaScript developers they are quite small, possibly fewer than 10%.
The npm Registry contributes to the popularity of JavaScript
Without question, JavaScript’s popularity is driven by its ubiquity as the only language directly usable for developing web applications. However, a fascinating paper by Leo Meyerovich and Ariel Rabkin at Berkeley studied the factors contributing to programming language adoption and found that, overall, the availability of open-source libraries relevant to the task at hand was the most important factor in selecting a programming language.

Our own survey data support the conclusions of this study. The most common reason respondents gave for choosing JavaScript was the number of libraries available.

With over 836,000 libraries currently available, npm is the largest single collection of open-source libraries in the world, by a significant margin—although JavaScript’s tendency towards smaller libraries means this comparison isn’t entirely apples-to-apples. Regardless, this enormous reservoir of open source code means that the popularity of JavaScript and npm works both ways: the language gains popularity because of the Registry, and vice versa.

npm is used to build every kind of application
We asked users where the JavaScript they write is used. An overwhelming 93% of respondents said that they write code for the web, with a still-substantial 70% saying they write JavaScript that runs on servers, i.e., Node.js. However, many other application areas including Internet of Things (IoT), desktop applications, native mobile applications, and others saw substantial numbers of users, too.

This is a significant change for those of us who work at npm, Inc. and maintain the npm command-line tool. npm was invented to serve the needs of server-side app developers, and the needs of web developers are different. Becoming a majority-web platform has meant changing our priorities, which has ledto new features like package locking by default.
npm is essential to web development
When npm, Inc. started in 2014, a tree of a few dozen JavaScript packages was typical. These days, the average modern web application has over 1000 modules, and trees of over 2000 modules are not uncommon. In fact, 97% of the code in a modern web application comes from npm. An individual developer is responsible only for the final 3% that makes their application unique and useful.
This is a huge success story for code reuse, for the strength of the npm community, and for open source in general. The time saved by not re-inventing the code in thousands of modules is saving millions of developers hundreds of millions of coding-hours.
npm has focused on security in 2018
To a great many developers, npm has simply become the way you build a website. This is a responsibility we take seriously. In our survey, 77% of developers said they were concerned about the quality and security of the open source libraries they used, and a worrying 52% said the tools currently available were inadequate. We went into more depth on these results in our post Attitudes to Security in the JavaScript community earlier this year.
In April, we announced that we acquired ^Lift Security and their product, the Node Security Platform. Today, the NSP is integrated directly into npm, and every install of npm includes security audits that notify users if they are installing insecure modules. We also furnish tools to easily correct these vulnerabilities by automatically installing secure versions of their modules. In addition, users of npm Enterprise and paid npm Organizations users receive notifications of embargoed vulnerabilities not yet publicly disclosed.
The demographics of npm users
The basic demographics of our survey respondents are covered in our methodology post, but there are several important facts worth highlighting:
1. We are mostly new. 25% have been using JavaScript for less than 2 years, and 51% have been using npm for less than 2 years. This is a side effect of the community doubling in size in that time!
2. We are mostly self-taught. 69% of npm users mostly taught themselves JavaScript, with the next highest being 22% who learned on the job.

We don’t just write JavaScript. People who use npm aren’t always strictly JavaScript developers—30% each report writing Java, PHP, and Python, and smaller numbers of lots of other languages.
We don’t just work at “tech” companies. 55% of npm users describe themselves as working at a company that wouldn’t be considered a “tech” company.
There are also some ways that npm users don’t differ from the general population of software developers, which is itself interesting. For example, npm users work at every size of company, in roughly the same proportion as those companies exist. JavaScript isn’t a “big company” or a “small company” tech. npm users also are evenly distributed across every industry, as well as other demographics such as age and education level.
Everybody would like less tooling
JavaScript in 2018 is somewhat notorious for requiring a lot of tooling to get going, which is quite a reversal from the situation in 2014, when Node.js was considered an “everything included” framework. Today, most developers wouldn’t consider Node to be a framework at all. True to that, all of our survey respondents would like to see less tooling, less configuration required to get started, and better documentation of the tools that do exist. But what tools?
We went in-depth into the popularity of JavaScript frameworks in our “State of JavaScript Frameworks” series (part 1, part 2, part 3) earlier this year. We won’t reiterate all the findings of that analysis, but rather dive into a few updates of what’s changed in the 9 months since then.
As a reminder, it’s important to understand the “share of registry” metric we are using here: a “flat” graph in this case means strong growth, just not growth relative to the growth of the registry, which is always growing quickly.
React’s growth has slowed

React continues to dominate the web scene. Over 60% of npm’s survey respondents say they are using React, and it has grown further since then. However, that growth in 2018 has been slower than in 2017.
Angular downloads have stayed flat

The two major flavors of Angular combined have stayed roughly flat in terms of market share.
Ember’s popularity has rebounded

In a very unusual phenomenon, Ember’s popularity, which appeared to be declining, has continued a strong rebound. By September, more than twice as many developers were using Ember as at the beginning of the year. We’re going to keep a close eye on this story, but we think Ember’s resurgence is part of the explanation for the slowdown in React.
Vue’s strong growth has continued

Vue was already growing quickly and that continued in 2018. Many Vue users report that they picked it over React because in their opinion it’s easier to get started while maintaining extensibility. Our current theory is that React’s growth has been slowed by many newer users picking Vue.
GraphQL continues hyper-growth

GraphQL, tracked by its most popular client library Apollo, continues to explode in popularity. We think it’s going to be a technical force to reckon with in 2019.
Transpilers rule, led by Babel—and a surprise: TypeScript

Babel is familiar to any React user as the tool used to transpile React’s next-generation JavaScript into the currently-supported JavaScript standards. In line with React’s 60% market share, 65% of npm users report using Babel. (It also has uses outside of the React ecosystem.)
Something of a surprise, however, was TypeScript, with 46% of survey respondents reporting they use Microsoft’s the type-checked JavaScript variant. This is major adoption for a tool of this kind and might signal a sea change in how developers write JavaScript. We are definitely going to be asking more questions about TypeScript usage in the next version of our survey.
npm’s predictions for 2019
It’s always difficult to make predictions about an ecosystem as huge, varied, and fast-changing as JavaScript, but our data has led us to make a few predictions for 2019 that we think we can commit to.
1. You will abandon one of your current tools. Frameworks and tools don’t last in JavaScript. The average framework has a phase of peak popularity of 3–5 years, followed by years of slow decline as people maintain legacy applications but move to newer frameworks for new work. Be prepared to learn new frameworks, and don’t hold on to your current tools too tightly.
2. Despite a slowdown in growth, React will be the dominant framework in 2019. 60% market share for a web framework is unheard-of, and that’s partly because React isn’t a full framework, just part of one. This allows it to flexibly cover more use-cases. But for building a web app in 2019, more people will use React than anything else, and that will result in a big advantage in terms of tutorials, advice, and bug fixes.
3. You’ll need to learn GraphQL. It might be too early to put GraphQL into production, especially if your API is already done, but 2019 is the year you should get your mind around the concepts of GraphQL. There’s a good chance you’ll be using them in new projects later in the year and in 2020.
4. Somebody on your team will bring in TypeScript. 46% adoption implies that TypeScript is more than just a tool for enthusiasts. Real people are getting real value out of the extra safety provided by type-checking. Especially if you’re a member of a larger team, consider adopting TypeScript into your 2019 projects.
Stay tuned
One prediction we’re very confident in making is that this community will continue to rapidly grow and expand the capabilities of JavaScript. As it grows, we’ll be documenting new trends and sharing our insights with the community. You can follow along by subscribing to our weekly newsletter and following us on Twitter.
19 notes
·
View notes
Text
What exactly is GraphQL?
GraphQL is a new API standard was invented and developed by Facebook. GraphQL is intended to improve the responsiveness, adaptability, and developer friendliness of APIs. It was created to optimize RESTful API calls and offers a more flexible, robust, and efficient alternative to REST. It is an open-source server-side technology that is now maintained by a large global community of companies and individuals. It is also an execution engine that acts as a data query language, allowing you to fetch and update data declaratively. GraphQL makes it possible to transfer data from the server to the client. It allows programmers to specify the types of requests they want to make.
GraphQL servers are available in a variety of languages, including Java, Python, C#, PHP, and others. As a result, it is compatible with any programming language and framework.
For a better understanding, the client-server architecture of GraphQL is depicted above
No JSON is used to write the GraphQL query. A GraphQL query is transmitted as a string to the server then when a client sends a 'POST' request to do so.
The query string is received by the server and extracted. The server then processes and verifies the GraphQL query in accordance with the graph data model and GraphQL syntax (GraphQL schema).
The GraphQL API server receives the data requested by the client by making calls to a database or other services, much like the other API servers do.
The data is then taken by the server and returned to the client as a JSON object.
Here are some major GraphQL characteristics:
Declarative query language, not imperative, is offered.
It is hierarchical and focused on the product.
GraphQL has excellent type checking. It denotes that inquiries are carried out inside the framework of a specific system.
GraphQL queries are encoded in the client rather than the server.
It has all the attributes of the OSI model's application layer.
GraphQL has three essential parts:
Query
Resolver
Schema
1. Query: The client machine application submitted the Query as an API request. It can point to arrays and support augments. To read or fetch values, use a query. There are two key components to a query:
a) Field: A field merely signifies that we are requesting a specific piece of information from the server. The field in a graphQL query is demonstrated in the example below. query { employee { empId ename } } "data": { "employee”: [ { "empId": 1, "ename": "Ashok" }, { "id": "2", "firstName": "Fred" } …] } }
In the above In the GraphQL example above, we query the server for the employee field along with its subfields, empId and ename. The data we requested is returned by the GraphQL server.
b) Arguments: As URL segments and query parameters, we can only pass a single set of arguments in REST. A typical REST call to obtain a specific profile will resemble the following: GET /api'employee?id=2 Content-Type: application JSON { "empId": 3, "ename": "Peter." }
2. Resolver: Resolvers give instructions on how to translate GraphQL operations into data. They define resolver routines that convert the query to data.
It shows the server the location and method for fetching data for a certain field. Additionally, the resolver distinguishes between API and database schema. The separated information aids in the modification of the database-generated material.
3. Schema: The heart of GraphQL implementation is a schema. It explains the features that the clients connected to it can use.
The benefits of using GraphQL in an application are summarized below.
It is more precise, accurate, and efficient.
GraphQL queries are simple and easy to understand.
Because it uses a simple query, GraphQL is best suited for microservices and complex systems.
It makes it easier to work with large databases.
Data can be retrieved with a single API call.
GraphQL does not have over-fetching or under-fetching issues.
GraphQL can be used to discover the schema in the appropriate format.
GraphQL provides extensive and powerful developer tools for query testing and documentation.
GraphQL automatically updates documentation in response to API changes.
GraphQL fields are used in multiple queries that can be shared and reused at a higher component level.
You have control over which functions are exposed and how they operate.
It is suitable for rapid application prototyping.
GraphQL can be used in all types of mobile and web applications across industries, verticals, and categories that require data from multiple sources, real-time data updates, and offline capabilities. Here is some application that benefits greatly from GraphQL development:
It offers Relay as well as other client frameworks.
GraphQL assists you in improving the performance of your mobile app.
It can reduce the problem of over fetching to reduce server-side cloud service and client-side network usage.
It can be used when the client application needs to specify which fields in a long query format are required.
GraphQL can be fully utilized when adding functionality to an existing or old API.
It is used to simplify complicated APIs.
The mix-and-match façade pattern, which is popular in object-oriented programming.
When you need to combine data from multiple sources into a single API.
GraphQL can be used as an abstraction on an existing API to specify response structure based on user requirements.
In this blog, I’ve attempted to explain the significance of GraphQL it is a new technology that allows developers to create scalable APIs that are not constrained by the limitations of REST APIs. It allows developers to use an API to easily describe, define, and request specific data. Please let us know what you think of GraphQL. Do you have any further questions? Please do not hesitate to contact us. We will gladly assist you.
0 notes
Text
Java ver conexiones al router

#Java ver conexiones al router how to
#Java ver conexiones al router pdf
#Java ver conexiones al router generator
#Java ver conexiones al router full
Sample Android app using clean android-modular-apps Skeleton: Silex framework php and webpack + es6 + sass architecture frontend ionic1todos
#Java ver conexiones al router how to
Sample demonstrating how to delegate authentication in jsreport to an external authorization server to support Single Sign front-silex Simple Router Controller api-with-loopbackĪPI REST build with Loopback.io jsreport-with-author… Timer is a simple coundown app useful for talks and vertical-navigationĪ simple drawing app for Firefox Mozillians_on_Twitte…Ī payload reader for Bitbucket jp-router Playing and learning with react docker-critical-cssĬritical CSS with Docker, puppeteer and flashbitacora Primera aplicacion web para proyecto Open Data de la Municipalidad de react101
#Java ver conexiones al router full
Mira películas y series en español en HD y full HD al instante desde tu compresor-de-imagene…Ĭompresor de imágenes con Google-docs-cloneĪ simple google docs clone made with grunt-external-confi…Įxample of split grunt config file in multiple openhuamanga is still in lowdb-recursiveĭemo del uso de pageres con gulp-primeros-pasos Servo is my server dummy raml-js-webservice-g… Proyecto en JQuery Mobile para construir una web móvil con información del servicio de transporte Metropolitano en Lima, servo Redmine Issues Rest API Client for Metropolitano-Mobile Mapa hidrografico en openlayers del didactic-react (beta) en desarrollo por users-graphql-exampl…Ī small example using opendata-rios-peru JqTree, Spring MVC, GoogleAppEngine jade-examplesĮjercicio demo para el uso de SubeAlMetroĮvaluate a script function on a page with Chrome jsreport-pugĮxperimento tecno-socio-cultural restableciendo conexiones. Notas y ejemplos para presentación en reunión de JavaScript Perú 10 Dic jqtree-spring-mvc-ga… Set and get a data object on an css-url-versioner
#Java ver conexiones al router generator
Un simple boilerplate para el uso de universal js con react, redux y jade-php-twigĪ Yeoman generator for creating your own chatbot using the Hubot mvhostĬreate simple virtualhost for apache2 with EarthquakeĪ CouchDB OAuth working example in htmlService-get-set-…įor Google Apps Script HtmlService. Mira películas y series en español en HD y full HD al couchminĪ command line tool to manage multiple local and remote CouchDB curso-reactjsĭemos y Ejemplos para el curso de universal-redux-boil… Includes: babel, xo, webpack and skeletorĮstructura base para un proyecto basado en jade, stylus, es2015. Reader of dependencies from package.json on es2015-nodejs-boiler…Įs2015 nodejs boilerplate. Node.js modules speed test: C++ vs jscomplexĪ colorful reporter for maintainability index via mydependencies Import sequelize models automagically horseshoeĪ wrapper around nodemailer used for sending email using handlebars json-schema-sugarĬreate a JSON Schema without the pain of writing it node-cppspeed
#Java ver conexiones al router pdf
Jsreport recipe which renders pdf from html using electron gulp-css-url-version…Ī gulp plugin for versioning the CSS property: gulp-emailĪ gulp plugin to send emails with or without attachments from a stream of sequelize-auto-impor… Highly scalable html conversion using electron workers jsreport-electron-pd… Plus for Trello chrome extension, web & mobile electron-html-to Run electron scripts in managed workers Plus-for-Trello 🇵🇪 A list of cool projects made in Peru Contents
0 notes
Text
What exactly is a full-stack? Why exactly full-stack developers are needed? | Experttal
Full-stack development and other related terms explained.
A development stack simply means the set of languages, libraries, IDEs, and tools (including OS, database server, and application server) used for application development.
For example, people may refer to the LAMP stack, meaning Linux/Unix + Apache + MySQL + PHP/Perl.
A development stack that is inclusive of full-stack development refers to the development of both front ends (client’s side) and back end(server’s side) portions of the web application. Full-stack-developer or full-stack web developers or full-stack programmers are needed to design and develop complete web applications and websites.

Full-stack engineers or developers work on the frontend, backend, database, and debugging of web applications or websites. Besides, mastering HTML and CSS, stack developer also knows how to:
Program a browser (like using JavaScript, jQuery, Angular, or Vue)
Program a server (like using PHP, ASP, Python, or Node)
Program a database (like using SQL, SQLite, or MongoDB).
Since full-stack software engineers or full-stack software developers are proficient in both front-end and back-end languages, rules, regulations, and frameworks, as well as in server, network, and hosting environments. To get to the breadth and depth of knowledge, most full-stack developers already have spent many years working in a variety of roles.
Full-stack developers or engineers also tend to be well-versed in both business logic and user experience, meaning they are not only well-equipped to get hands-on, but can also guide and consult on a strategy too. Best remote IT experts in India Certified and senior full-stack developers are mostly preferred when
Client’s Software (Front End)
HTML
CSS
Bootstrap
W3.CSS
Javascript
ES5
HTML DOM
JSON
XML
jQuery
Angular
React
Backbone.js
Ember.js
Redux
Storybook
GraphQL
Meteor.js
Grunt
Gulp
React is a JavaScript library for building user interfaces. It is the view layer for web applications so it is indirectly associated with java full-stack development.

Server’s Software (Back End)
PHP
ASP
C++
C#
Java
Python
Node.js
Express.js
Ruby
REST
GO
SQL
MongoDB
Firebase.com
Sass
Less
Parse.com
PaaS (Azure and Heroku).
Javascript is a prominent and dominant programming language in web development that has been around for near about 20 years it not more. In the beginning, JavaScript was a language for the web client (browser) then came the ability to use JavaScript on the webserver that is full-stack with Node.js.Full Stack JavaScript is that all software in a web application both client-side and server-side should be written using JavaScript only.
A java full-stack web developer or full-stack javascript developer is a developer with extensive knowledge and expertise in full-stack tools and frameworks that works with java. The java suite of technologies includes working with servlets, core java, REST API, and more tools that make the building of web apps easy.

Full Stack Python comes in to learn everything you need to create, deploy and operate Python-powered applications. Best remote IT experts in India A Python full stack developer has expertise in using the Python suite of languages for all the applications as he/she is well aware that Python code interacts with code that is written in other languages such as C and JavaScript to provide an entire web stack.
However, a full-stack PHP developer is the one who mainly uses PHP as their back-end language.
#NodeJSdeveloper #full stackdeveloper #phpdeveloper #pythondeveloper #UI/UXdeveloper #fullstackdeveloper #BestremoteITexperts #BestremoteITexpertsinIndia #HireBestremoteITexperts #Remoteworkexpert
0 notes
Text
Build a dynamic JAMstack app with GatsbyJS and FaunaDB
In this article, we explain the difference between single-page apps (SPAs) and static sites, and how we can bring the advantages of both worlds together in a dynamic JAMstack app using GatsbyJS and FaunaDB. We will build an application that pulls in some data from FaunaDB during build time, prerenders the HTML for speedy delivery to the client, and then loads additional data at run time as the user interacts with the page. This combination of technologies gives us the best attributes of statically-generated sites and SPAs.
In short…<deep breath>...auto-scaling distributed websites with low latency, snappy user interfaces, no reloads, and dynamic data for everyone!
Heavy backends, single-page apps, static sites
In the old days, when JavaScript was new, it was mainly only used to provide effects and improved interactions. Some animations here, a drop-down there, and that was it. The grunt work was performed on the backend by Perl, Java, or PHP.
This changed as time went on: client code became heavier, and JavaScript took over more and more of the frontend until we finally shipped mostly empty HTML and rendered the whole UI in the browser, leaving the backend to supply us with JSON data.
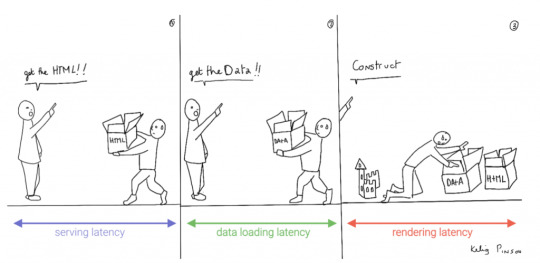
This led to a neat separation of concerns and allowed us to build whole applications with JavaScript, called Single Page Applications (SPAs). The most important advantage of SPAs was the absence of reloads. You could click on a link to change what's displayed, without triggering a complete reload of the page. This in itself provided a superior user experience. However, SPAs increased the size of the client code significantly; a client now had to wait for the sum of several latencies:
Serving latency: retrieving the HTML and JavaScript from the server where the JavaScript was bigger than it used to be
Data loading latency: loading additional data requested by the client
Frontend framework rendering latency: once the data is received, a frontend framework like React, Vue, or Angular still has to do a lot of work to construct the final HTML
A royal metaphor
We can analogize the loading a SPA with the building and delivery of a toy castle. The client needs to retrieve the HTML and JavaScript, then retrieve the data, and then still has to assemble the page. The building blocks are delivered, but they still need to be put together after they're delivered.
If only there were a way to build the castle beforehand...
Enter the JAMstack
JAMstack applications consist of JavaScript, APIs and Markup. With today's static site generators like Next.js and GatsbyJS, the JavaScript and Markup parts can be bundled up into a static package and deployed via a Content Delivery Network (CDN) that delivers files to a browser. A CDN geographically distributes the bundles, and other assets, to multiple locations. When a user’s browser fetches the bundle and assets, it can receive them from the closest location on the network, which reduces the serving latency.
Continuing our toy castle analogy, JAMstack apps are different from SPAs in the sense that the page (or castle) is delivered pre-assembled. We have a lower latency since we receive the castle in one piece and no longer have to build it.
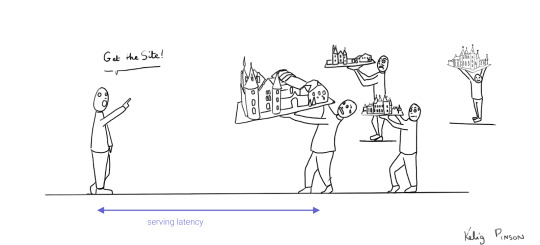
Making static JAMstack apps dynamic with hydration
In the JAMstack approach, we start with a dynamic application and prerender static HTML pages to be delivered via a speedy CDN. But what if a fully static site is not sufficient and we need to support some dynamic content as the user interacts with individual components, without reloading the entire page? That's where client-side hydration comes in.
Hydration is the client-side process by which the server-side rendered HTML (DOM) is "watered" by our frontend framework with event handlers and/or dynamic components to make it more interactive. This can be tricky because it depends on reconciling the original DOM with a new virtual DOM (VDOM) that's kept in memory as the user interacts with the page. If the DOM and VDOM trees do not match, bugs can arise that cause elements to be displayed out of order, or necessitate rebuilding the page.
Luckily, libraries like GatsbyJS and NextJS have been designed so as to minimize the possibility of such hydration-related bugs, handling everything for you out-of-the-box with only a few lines of code. The result is a dynamic JAMstack web application that is simultaneously both faster and more dynamic than the equivalent SPA.
One technical detail remains: where will the dynamic data come from?
Distributed frontend-friendly databases!
JAMstack apps typically rely on APIs (ergo the "A" in JAM), but if we need to load any kind of custom data, we need a database. And traditional databases are still a performance bottleneck for globally distributed sites that are otherwise delivered via CDN, because traditional databases are only located in one region. Instead of using a traditional database, we’d like our database to be on a distributed network, just like the CDN, that serves the data from a location as close as possible to wherever our clients are. This type of database is called a distributed database.
In this example, we’ll choose FaunaDB since it is also strongly consistent, which means that our data will be the same wherever my clients access it from and data won’t be lost. Other features that work particularly well with JAMstack applications are that (a) the database is accessed as an API (GraphQL or FQL) and does not require you to open a connection, and (b) the database has a security layer that makes it possible to access both public and private data in a secure way from the frontend. The implications of that are we can keep the low latencies of JAMstack without having to scale a backend, all with zero configuration.
Let's compare the process of loading a hydrated static site with the building of the toy castle. We still have lower latencies thanks to the CDN, but also less data since most the site is statically generated and therefore requires less rendering. Only a small part of the castle (or, the dynamic part of the page) needs to be assembled after it has been delivered:
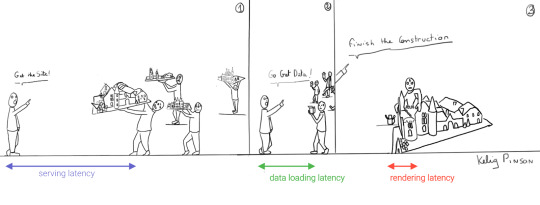
Example app with GatsbyJS & FaunaDB
Let’s build an example application that loads data from FaunaDB at build time and renders it to static HTML, then loads additional dynamic data inside the client browser at run time. For this example, we use GatsbyJS, a JAMstack framework based on React that prerenders static HTML. Since we use GatsbyJS, we can code our website completely in React, generate and deliver the static pages, and then load additional data dynamically at run time. We’ll use FaunaDB as our fully managed serverless database solution. We will build an application where we can list products and reviews.
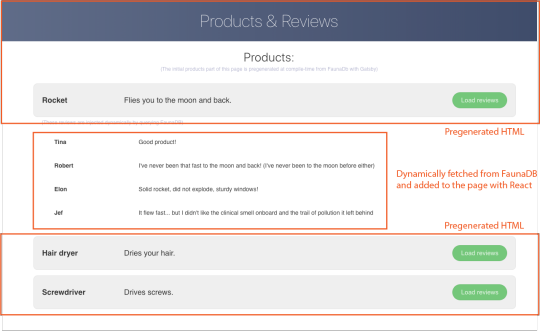
Let’s look at an outline of what we have to do to get our example app up and running and then go through every step in detail.
Set up a new database
Add a GraphQL schema to the database
Seed the database with mock-up data
Create a new GatsbyJS project
Install NPM packages
Create the server key for the database
Update GatsbyJS config files with server key and new read-only key
Load the pre-rendered product data at build time
Load the reviews at run time
1. Set up a new database
Before you start, create an account on dashboard.fauna.com. Once you have an account, let’s set up a new database. It should hold products and their reviews, so we can load the products at build-time and the reviews in the browser.
2. Add a GraphQL schema to the database
Next, we use the server key to upload a GraphQL schema to our database. For this, we create a new file called schema.gql that has the following content:
type Product { title: String! description: String reviews: [Review] @relation } type Review { username: String! text: String! product: Product! } type Query { allProducts: [Product] }
You can upload your schema.gql file via the FaunaDB Console by clicking "GraphQL" on the left sidebar, and then click the "Import Schema" button.
Upon providing FaunaDB with a GraphQL schema, it automatically creates the required collections for the entities in our schema (products and reviews). Besides that, it also creates the indexes that are needed to interact with those collections in a meaningful and efficient manner. You should now be presented with a GraphQL playground where you can test out
3. Seed the database with mock-up data
To seed our database with products and reviews, we can use the Shell at dashboard.fauna.com:
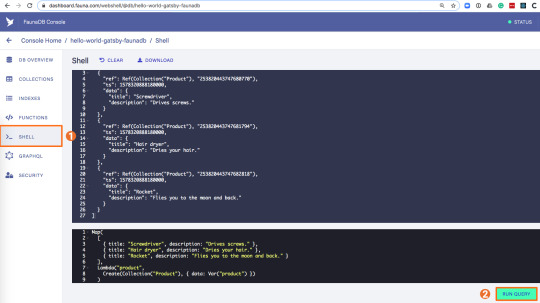
To create some data, we’ll use the Fauna Query Language (FQL), after that we’ll continue with GraphQL to build are example application. Paste the following FQL query into the Shell to create three product documents:
Map( Paginate(Match(Index("allProducts"))), Lambda("ref", Create(Collection("Review"), { data: { username: "Tina", text: "Good product!", product: Var("ref") } })) );
We can then write a query that retrieves the products we just made and creates a review document for every product document:
Map( Paginate(Match(Index("allProducts"))), Lambda("ref", Create(Collection("Review"), { data: { username: "Tina", text: "Good product!", product: Var("ref") } })) );
Both types of documents will be loaded via GraphQL. However, there is a significant difference between products and reviews. The former will not change a lot and is relatively static, while the second is user-driven. GatsbyJS allows us to load data in two ways:
data that is loaded at build time which will be used to generate the static site.
data that is loaded live at request time as a client visits and interacts with your website.
In this example, we chose to let the products be loaded at build time, and the reviews to be loaded on-demand in the browser. Therefore, we get static HTML product pages served by a CDN that the user immediately sees. Then, as our user interacts with the product page, we load the data for the reviews.
4. Create a new GatsbyJS project
The following command creates a GatsbyJS project based on the starter template:
$ npx gatsby-cli new hello-world-gatsby-faunadb $ cd hello-world-gatsby-faunadb
5. Install npm packages
In order to build our new project with Gatsby and Apollo, we need a few additional packages. We can install the packages with the following command:
$ npm i gatsby-source-graphql apollo-boost react-apollo
We will use gatsby-source-graphql as a way to link GraphQL APIs into the build process. Using this library, you can make a GraphQL call from which the results will be automagically provided as the properties for your react component. That way, you can use dynamic data to statically generate your application. The apollo-boost package is an easily configurable GraphQL library that will be used to fetch data on the client. Finally, the link between Apollo and React will be taken care of by the react-apollo library.
6. Create the server key for the database
We will create a Server key which will be used by Gatsby to prerender the page. Remember to copy the secret somewhere since we will use it later on. Protect server keys carefully, they can be used to create, destroy, or manage the database to which they are assigned. To create the key we can go to the fauna dashboard and create the key in the security tab.
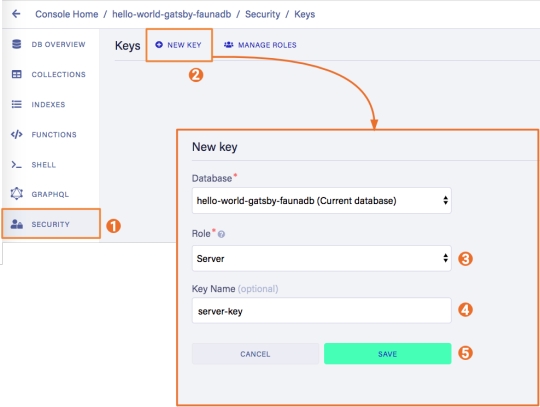
7. Update GatsbyJS config files with server and new read-only keys
To add the GraphQL support to our build process, we need to add the following code into our graphql-config.js inside the plugins section where we will insert the FaunaDB server key which we generated a few moments ago.
{ resolve: "gatsby-source-graphql", options: { typeName: "Fauna", fieldName: "fauna", url: "https://graphql.fauna.com/graphql", headers: { Authorization: "Bearer <SERVER KEY>", }, }, }
For the GraphQL access to work in the browser, we have to create a key that only has permissions to read data from the collections. FaunaDB has an extensive security layer in which you can define that. The easiest way is to go to the FaunaDB Console at dashboard.fauna.com and create a new role for your database by clicking "Security" in the left sidebar, then "Manage Roles," then "New Custom Role":

Call the new custom role ‘ClientRead’ and make sure to add all collections and indexes (these are the collections that were created by importing the GraphQL schema). Then, select Read for each for them. Your screen should look like this:
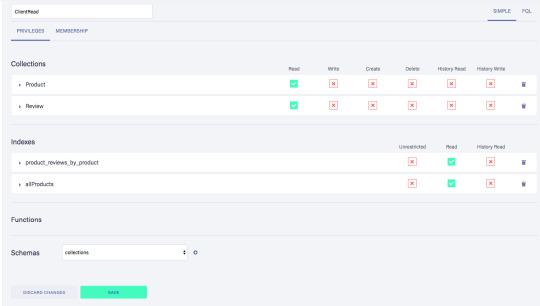
You have probably noticed the Membership tab on this page. Although we are not using it in this tutorial, it is interesting enough to explain it since it's an alternative way to get security tokens. In the Membership tab can specify that entities of a collection (let's say we have a 'Users' collection) in FaunaDb are members of a particular role. That means that if you impersonate one of these entities in that collection, the role privileges apply. You impersonate a database entity (e.g. a User) by associating credentials with the entity and using the Login function, which will return a token. That way you can also implement password-based authentication in FaunaDb. We won't use it in this tutorial, but if that interests you, check the FaunaDB authentication tutorial.
Let’s ignore Membership for now, once you have created the role, we can create a new key with the new role. As before, click "Security", then "New Key," but this time select "ClientRead" from the Role dropdown:
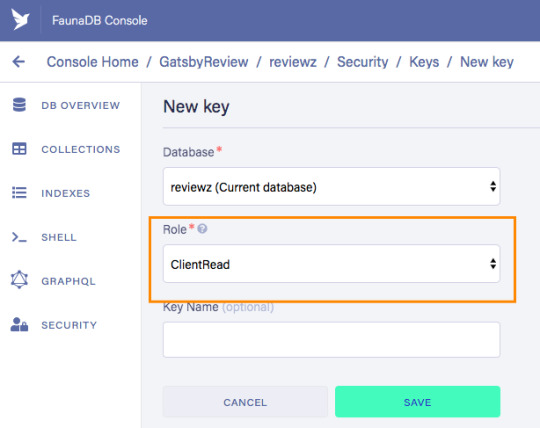
Now, let's insert this read-only key in the gatsby-browser.js configuration file to be able to call the GraphQL API from the browser:
import React from "react" import ApolloClient from "apollo-boost" import { ApolloProvider } from "react-apollo" const client = new ApolloClient({ uri: "https://graphql.fauna.com/graphql", request: operation => { operation.setContext({ headers: { Authorization: "Bearer <CLIENT_KEY>", }, }) }, }) export const wrapRootElement = ({ element }) => ( <ApolloProvider client={client}>{element}</ApolloProvider> )
GatsbyJS will render its Router component as a root element. If we want to use the ApolloClient everywhere in the application on the client, we need to wrap this root element with the ApolloProvider component.
8. Load the pre-rendered product data at build time
Now that everything is set up, we can finally write the actual code to load our data. Let’s start with the products we will load at build time.
For this we need to modify src/pages/index.js file to look like this:
import React from "react" import { graphql } from "gatsby" Import Layout from "../components/Layout" const IndexPage = ({ data }) => ( <Layout> <ul> {data.fauna.allProducts.data.map(product => ( <li>{product.title} - {product.description}</li> ))} </ul> </Layout> ) export const query = graphql` { fauna { allProducts { data { _id title description } } } } ` export default IndexPage
The exported query will automatically get picked up by GatsbyJS and executed before rendering the IndexPage component. The result of that query will be passed as data prop into the IndexPage component.If we now run the develop script, we can see the pre-rendered documents on the development server on http://localhost:8000/.
$ npm run develop
9. Load the reviews at run time
To load the reviews of a product on the client, we have to make some changes to the src/pages/index.js:
import { gql } from "apollo-boost" import { useQuery } from "@apollo/react-hooks" import { graphql } from "gatsby" import React, { useState } from "react" import Layout from "../components/layout" // Query for fetching at build-time export const query = graphql ` { fauna { allProducts { data { _id title description } } } } ` // Query for fetching on the client const GET_REVIEWS = gql ` query GetReviews($productId: ID!) { findProductByID(id: $productId) { reviews { data { _id username text } } } } ` const IndexPage = props => { const [productId, setProductId] = useState(null) const { loading, data } = useQuery(GET_REVIEWS, { variables: { productId }, skip: !productId, }) } export default IndexPage
Let’s go through this step by step.
First, we need to import parts of the apollo-boost and apollo-react packages so we can use the GraphQL client we previously set up in the gatsby-browser.js file.
Then, we need to implement our GET_REVIEWS query. It tries to find a product by its ID and then loads the associated reviews of that product. The query takes one variable, which is the productId.
In the component function, we use two hooks: useState and useQuery
The useState hook keeps track of the productId for which we want to load reviews. If a user clicks a button, the state will be set to the productId corresponding to that button.
The useQuery hook then applies this productId to load reviews for that product from FaunaDB. The skip parameter of the hook prevents the execution of the query when the page is rendered for the first time because productId will be null.
If we now run the development server again and click on the buttons, our application should execute the query with different productIds as expected.
$ npm run develop
Conclusion
A combination of server-side data fetching and client-side hydration make JAMstack applications pretty powerful. These methods enable flexible interaction with our data so we can adhere to different business needs.
It’s usually a good idea to load as much data at build time as possible to improve page performance. But if the data isn’t needed by all clients, or too big to be sent to the client all at once, we can split things up and switch to on-demand loading on the client. This is the case for user-specific data, pagination, or any data that changes rather frequently and might be outdated by the time it reaches the user.
In this article, we implemented an approach that loads part of the data at build time, and then loads the rest of the data in the frontend as the user interacts with the page.
Of course, we have not implemented a login or forms yet to create new reviews. How would we tackle that? That is material for another tutorial where we can use FaunaDB’s attribute-based access control to specify what a client key can read and write from the frontend.
The code of this tutorial can be found in this repo.
The post Build a dynamic JAMstack app with GatsbyJS and FaunaDB appeared first on CSS-Tricks.
via CSS-Tricks https://ift.tt/2RjR7mI
0 notes