#graphql resolver example
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Celebrities use Tumblr as well.
Text
GraphQL Resolver Explained with Examples for API Developers
Full Video Link - https://youtube.com/shorts/PlntZ5ekq0U Hi, a new #video on #graphql #resolver published on #codeonedigest #youtube channel. @java @awscloud @AWSCloudIndia @YouTube #youtube @codeonedigest #graphql #graphqlresolver #codeo
Resolver is a collection of functions that generate response for a GraphQL query. Actually, resolver acts as a GraphQL query handler. Every resolver function in a GraphQL schema accepts four positional arguments. Root – The object that contains the result returned from the resolver on the parent field. args – An object with the arguments passed into the field in the query. context – This is…

View On WordPress
#graphql#graphql api project#graphql example tutorial#graphql resolver arguments#graphql resolver async#graphql resolver best practices#graphql resolver chain#graphql resolver example#graphql resolver example java#graphql resolver field#graphql resolver functions#graphql resolver interface#graphql resolver java#graphql resolver mutation#graphql resolvers#graphql resolvers explained#graphql resolvers tutorial#graphql tutorial#what is graphql
0 notes
Text
Top Full-Stack Developer Interview Questions You Should Know

Frontend Interview Questions
What is the difference between inline, block, and inline-block elements in CSS?
How does the virtual DOM work in frameworks like React?
Can you explain the concept of responsive design? How would you implement it?
Backend Interview Questions
What are RESTful APIs, and how do they differ from GraphQL APIs?
How would you optimize database queries in SQL?
Can you explain middleware in Express.js?
General Full-Stack Questions
What is the role of CORS in web development, and how do you handle it?
How would you implement authentication in a full-stack application?
What’s the difference between monolithic and microservices architecture?
Bonus: Behavioral Questions
Describe a challenging bug you encountered and how you resolved it.
How do you manage your time when working on multiple projects simultaneously?
Looking for More Questions?
For a more comprehensive list of questions, including in-depth examples and answers, check out my Full-Stack Developer Interview Guide. It’s a resource packed with actionable insights to help you ace your next interview.
1 note
·
View note
Text
Top 7 Skills to Become A Full-Stack Developer in 2025
With the ever-increasing pace of technological change, the need for techies with multidisciplinary skills has never been higher. One of the most sought-after jobs in the tech field today is that of a Full-Stack Developer̶ one who could smartly trick both front and back-end development. By 2025, this position promises to be even more dynamic and skill-intensive than before, requiring the developers to be multi-talented, flexible, and always learning. Thus, whether you are just stepping into this profession or you're enhancing your skill set, full stack web development entails mastering as many skills as possible to stay relevant.
Let us check out the top 7 crucial skills that every full-stack developer should develop by 2025. Front-End Expertise The user interface is the first thing people see and interact with--that's why we call this front-end work fundamental. A full-stack developer must have a good working knowledge of HTML, CSS, and JavaScript, the trifecta of front-end development. For 2025, developers who know tools like React.js, Vue.js, and Next.js are in ever-increasing demand, as these frameworks can be used to develop dynamic, highly performant, and mobile-responsive web applications. One should also know a little about aspects such as responsive design and various browser compatibilities. Grasping concepts related to state management on the front end (for example, using Redux, Zustand, or the React Context API) boosts one's professional profile, with companies recognizing these competencies.
Strong Back-End Knowledge While the front-end sees what the user gets, the back-end makes things run in the background. Full-stack developers should command the lease on server-side programming using languages such as JavaScript (Node.js), Python (Django/Flask), Java (Spring Boot), or Ruby on Rails. You would need to know how to build RESTful APIs and work with user sessions, authentication, and authorization with communications to a database. Keeping in mind the social aspect of security and data integrity, it is also important for any practice to involve the rest-audit trail, validation, error handling, etc. Knowledge of cloud platforms like AWS, Google Cloud, or Azure would be an added advantage for deploying a scalable back end.
Database Management Every full-stack developer must have some hardcore database skills. It doesn't matter if it is the relational database world of MySQL or PostgreSQL or the advanced NoSQL world of MongoDB, you need to know how to work with schema design, efficient query writing, and database connection management. In 2025, a developer must know the difference between structured and unstructured data and know when to use what type of database. Indexing, normalization, and transactions will become especially critical to you as you build scalable applications. ORMs (Object Relational Mappers) like Sequelize or Mongoose are also crucial for streamlining code/database interaction.
Understanding of APIs APIs (Application Programming Interfaces) are the glue that binds together the various pieces of a system. A full-stack developer should be able to build and consume APIs. Although REST is still the most-used tool, GraphQL has emerged as an alternative technology due to its speed and flexibility. To properly build and solve any API issues, an understanding of Postman or Insomnia as tools is necessary. Familiarity with authentication methods, such as OAuth2.0, JWT (JSON Web Tokens), and API key management, secures your applications while they communicate with the different services.
Version Control Working on software projects without version control is akin to tight-rope walking without a safety net. Developers can use Git tools to track changes or collaborate more efficiently and roll back to previous versions and full-stack developers should know Git well enough to create branches and merge code to resolve conflicts and manage pull requests. Beyond 2025, GitHub, GitLab, and Bitbucket will be more relevant to the work process of the teams. Apart from collaboration, knowing Git shows the power and the discipline in practice concerning coding.
Performance Optimization Your web app must not just work, but also work fast. Performance optimization is nowadays inevitable in an era where user experience rules. On the front ends, such performance optimization encompasses reduced render time, reduced bundle size, lazy loading of components, or using CDNs. Back-end-side optimizations include the use of caching systems such as Redis, optimization in database query usage, and using effective server-side rendering methodologies. A full-stack developer should know how to use performance monitoring tools, such as Lighthouse and Google Web Vitals, and also backend profiling tools to identify and resolve bottlenecks.
Problem-Solving & Soft Skills: While technical skills are backbone assets in development, soft skills with problem-solving capabilities do much more to separate the wheat from the chaff in talented developers. This also includes proficiency in debugging codes and high-level thinking with systematic approaches toward solving problems in everyday development. Just as essential are communication, working as a team, and working in an agile environment. More and more, employers are looking for people who work as teammates but can also adjust easily to keep pace with ever-changing requirements, while contributing positively to the dynamics of a team.
Take up a Course: If in 2025, you really want to be a Full-Stack Developer, going for a regular course is going to be an accelerator in your skills. Make sure you find one that comes with hands-on projects, industry tools, and mentorship from seasoned pros. The course should be extensive — everything from HTML and JavaScript to back-end programming and deployment. Practical experience is the name of the game; the course should emphasize building an entire web application from scratch.
Conclusion Being a full-stack developer in 2025 will entail much more than just coding: it means knowing how every part of a web application fits together-from the user interface to the database. Mastering the above-mentioned seven basic skills will ensure your position as a really well-capable and competitive developer in today's technology-enriched world.
#fullstackdevelopercourseincoimbatorewithplacement#bestfullstackdevelopercourseincoimbatore#fullstackdevelopmenttrainingincoimbatore#javafullstackdevelopercourseincoimbatore#pythonfullstackdevelopercourseincoimbatore#fullstackwebdevelopmentcoursedetails#webdevelopmentcoursecoimbatore#advancedwebdevelopmenttrainingcoimbatore#learnfullstackwebdevelopmentintamil
0 notes
Text
Career Path and Growth Opportunities for Integration Specialists
The Growing Demand for Integration Specialists.
Introduction
In today’s interconnected digital landscape, businesses rely on seamless data exchange and system connectivity to optimize operations and improve efficiency. Integration specialists play a crucial role in designing, implementing, and maintaining integrations between various software applications, ensuring smooth communication and workflow automation. With the rise of cloud computing, APIs, and enterprise applications, integration specialists are essential for driving digital transformation.
What is an Integration Specialist?
An Integration Specialist is a professional responsible for developing and managing software integrations between different systems, applications, and platforms. They design workflows, troubleshoot issues, and ensure data flows securely and efficiently across various environments. Integration specialists work with APIs, middleware, and cloud-based tools to connect disparate systems and improve business processes.
Types of Integration Solutions
Integration specialists work with different types of solutions to meet business needs:
API Integrations
Connects different applications via Application Programming Interfaces (APIs).
Enables real-time data sharing and automation.
Examples: RESTful APIs, SOAP APIs, GraphQL.
Cloud-Based Integrations
Connects cloud applications like SaaS platforms.
Uses integration platforms as a service (iPaaS).
Examples: Zapier, Workato, MuleSoft, Dell Boomi.
Enterprise System Integrations
Integrates large-scale enterprise applications.
Connects ERP (Enterprise Resource Planning), CRM (Customer Relationship Management), and HR systems.
Examples: Salesforce, SAP, Oracle, Microsoft Dynamics.
Database Integrations
Ensures seamless data flow between databases.
Uses ETL (Extract, Transform, Load) processes for data synchronization.
Examples: SQL Server Integration Services (SSIS), Talend, Informatica.
Key Stages of System Integration
Requirement Analysis & Planning
Identify business needs and integration goals.
Analyze existing systems and data flow requirements.
Choose the right integration approach and tools.
Design & Architecture
Develop a blueprint for the integration solution.
Select API frameworks, middleware, or cloud services.
Ensure scalability, security, and compliance.
Development & Implementation
Build APIs, data connectors, and automation workflows.
Implement security measures (encryption, authentication).
Conduct performance optimization and data validation.
Testing & Quality Assurance
Perform functional, security, and performance testing.
Identify and resolve integration errors and data inconsistencies.
Conduct user acceptance testing (UAT).
Deployment & Monitoring
Deploy integration solutions in production environments.
Monitor system performance and error handling.
Ensure smooth data synchronization and process automation.
Maintenance & Continuous Improvement
Provide ongoing support and troubleshooting.
Optimize integration workflows based on feedback.
Stay updated with new technologies and best practices.
Best Practices for Integration Success
✔ Define clear integration objectives and business needs. ✔ Use secure and scalable API frameworks. ✔ Optimize data transformation processes for efficiency. ✔ Implement robust authentication and encryption. ✔ Conduct thorough testing before deployment. ✔ Monitor and update integrations regularly. ✔ Stay updated with emerging iPaaS and API technologies.
Conclusion
Integration specialists are at the forefront of modern digital ecosystems, ensuring seamless connectivity between applications and data sources. Whether working with cloud platforms, APIs, or enterprise systems, a well-executed integration strategy enhances efficiency, security, and scalability. Businesses that invest in robust integration solutions gain a competitive edge, improved automation, and streamlined operations.
Would you like me to add recommendations for integration tools or comparisons of middleware solutions? 🚀
Integration Specialist:
#SystemIntegration
#APIIntegration
#CloudIntegration
#DataAutomation
#EnterpriseSolutions
0 notes
Text
How to Integrate Multiple APIs with GraphQL | Real-World Example
1. Introduction 1.1 Brief Explanation GraphQL offers a powerful solution to integrate multiple APIs into a single query, reducing the complexity of managing API calls. This approach consolidates data from various services, improves performance, and provides a unified interface for frontend applications. 1.2 What You Will Learn How to design a GraphQL schema. Resolving data from multiple APIs…
0 notes
Text
hi--
"I’m a seasoned Full Stack Java Developer with over 12 years of experience designing and delivering scalable, high-performance enterprise applications. I specialize in modernizing legacy systems, building Microservices architectures, and optimizing cloud infrastructure on platforms like AWS. Throughout my career, I’ve consistently delivered measurable results, such as reducing API response times by 40%, achieving 30% cost savings through cloud migrations, and automating CI/CD pipelines to cut release cycles from 2 weeks to just 1 day. I’m passionate about leveraging technology to solve complex business problems and drive innovation."
2. Tailor Your Achievements to the Role
Focus on the most relevant accomplishments and skills for the job. For example:
If the role emphasizes backend development: "At Bank of America, I architected Java-based APIs for investment products, improving performance by 35% and reducing latency by 40% using Redis for distributed caching. I also optimized database performance, reducing query execution time by 20%, and scaled applications to handle 1,000+ users with 99.9% uptime."
If the role emphasizes cloud and DevOps: "I led the migration of legacy systems to AWS, achieving 30% cost savings and enabling auto-scaling capabilities. I also automated CI/CD pipelines using Jenkins and Terraform, reducing deployment times from 2 weeks to just 1 day, which saved over 200 engineering hours annually."
If the role emphasizes leadership or mentorship: "I’ve mentored junior developers, improving team productivity by 20% and code quality through pair programming and code reviews. I also led a $2M Microservices transformation project, reducing maintenance costs by 50% and ensuring seamless scalability."
3. Use the STAR Method for Behavioral Questions
When asked about specific situations, use the STAR method (Situation, Task, Action, Result) to structure your answers:
Example: "Tell me about a time you solved a complex technical problem." "At Chase Bank, we faced challenges with slow database queries impacting user experience (Situation). My task was to optimize database performance and reduce query execution time (Task). I analyzed the queries using Dynatrace, implemented indexing strategies, and leveraged Hibernate caching (Action). As a result, query execution time improved by 20%, and user engagement increased by 30% (Result)."
4. Highlight Leadership and Strategic Impact
Showcase your ability to lead projects and drive business outcomes:
"I led a $2M project to transform monolithic systems into Microservices, reducing maintenance costs by 50% and improving scalability."
"I automated serverless workflows using AWS Lambda, cutting manual intervention by 50% and saving $200K in project costs."
"I mentored junior developers, improving team productivity by 20% and fostering a culture of continuous learning."
5. Demonstrate Problem-Solving Skills
Employers value candidates who can solve complex problems:
"I identified performance bottlenecks using Dynatrace and Splunk, resolving issues that improved API response times by 40%."
"I implemented distributed tracing with OpenTelemetry, which helped identify bottlenecks and improve debugging efficiency."
"I designed GraphQL APIs to optimize data fetching, reducing network overhead and improving frontend performance."
6. Showcase Adaptability and Continuous Learning
Highlight your ability to learn and adapt to new technologies:
"I’m always exploring new tools and frameworks to stay ahead of industry trends. For example, I recently integrated Prometheus and Grafana for real-time monitoring, which enhanced application observability and reliability."
"I’m AWS Certified and Oracle Certified, and I continuously upskill to deliver cutting-edge solutions."
7. Ask Insightful Questions
End the interview by asking thoughtful questions that demonstrate your experience and interest:
"Can you share more about the team’s current challenges with scalability or performance? I’d love to discuss how my experience with Microservices and cloud optimization could help."
"What does success look like in this role, and how can I contribute to achieving those goals?"
"Are there opportunities to mentor junior developers or lead initiatives to improve CI/CD processes?"
8. Close with Confidence
End the interview on a strong note: "I’m excited about the opportunity to bring my expertise in Java, Microservices, and cloud technologies to your team. I’m confident that my track record of delivering measurable results and driving innovation aligns well with your goals. Thank you for the opportunity to discuss how I can contribute to your organization’s success."
0 notes
Text
Introduction to GraphQL for Full Stack Applications
What is GraphQL?
GraphQL is a query language for APIs and a runtime for executing those queries by leveraging a type system defined for the data. Developed by Facebook in 2012 and open-sourced in 2015, GraphQL provides a flexible and efficient alternative to REST APIs by allowing clients to request exactly the data they need — nothing more, nothing less.
Why Use GraphQL for Full Stack Applications?
Traditional REST APIs often come with challenges such as over-fetching, under-fetching, and versioning complexities. GraphQL solves these issues by offering:
Flexible Queries: Clients can specify exactly what data they need.
Single Endpoint: Unlike REST, which may require multiple endpoints, GraphQL exposes a single endpoint for all queries.
Strongly Typed Schema: Ensures clear data structure and validation.
Efficient Data Fetching: Reduces network overhead by retrieving only necessary fields.
Easier API Evolution: No need for versioning — new fields can be added without breaking existing queries.
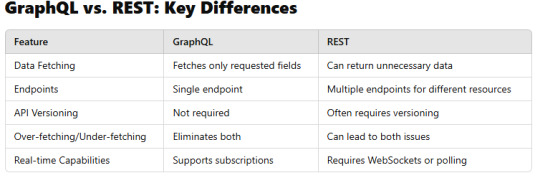
GraphQL vs. REST: Key Differences
Core Concepts of GraphQL
1. Schema & Types
GraphQL APIs are built on schemas that define the data structure.
Example schema:graphqltype User { id: ID! name: String! email: String! }type Query { getUser(id: ID!): User }
2. Queries
Clients use queries to request specific data.graphqlquery { getUser(id: "123") { name email } }
3. Mutations
Used to modify data (Create, Update, Delete).graphqlmutation { createUser(name: "John Doe", email: "[email protected]") { id name } }
4. Subscriptions
Enable real-time updates using Web Sockets.graphqlsubscription { newUser { id name } }
Setting Up GraphQL in a Full Stack Application
Backend: Implementing GraphQL with Node.js and Express
GraphQL servers can be built using Apollo Server, Express-GraphQL, or other libraries.
Example setup with Apollo Server:javascriptimport { ApolloServer, gql } from "apollo-server"; const typeDefs = gql` type Query { hello: String } `;const resolvers = { Query: { hello: () => "Hello, GraphQL!", }, };const server = new ApolloServer({ typeDefs, resolvers });server.listen().then(({ url }) => { console.log(`Server running at ${url}`); });
Frontend: Querying GraphQL with React and Apollo Client
Example React component using Apollo Client:javascriptimport { useQuery, gql } from "@apollo/client";const GET_USER = gql` query { getUser(id: "123") { name email } } `;function User() { const { loading, error, data } = useQuery(GET_USER); if (loading) return <p>Loading...</p>; if (error) return <p>Error: {error.message}</p>; return <div>{data.getUser.name} - {data.getUser.email}</div>; }
GraphQL Best Practices for Full Stack Development
Use Batching and Caching: Tools like Apollo Client optimize performance.
Secure the API: Implement authentication and authorization.
Optimize Resolvers: Use DataLoader to prevent N+1 query problems.
Enable Rate Limiting: Prevent abuse and excessive API calls.
Conclusion
GraphQL provides a powerful and efficient way to manage data fetching in full-stack applications. By using GraphQL, developers can optimize API performance, reduce unnecessary data transfer, and create a more flexible architecture.
Whether you’re working with React, Angular, Vue, or any backend framework, GraphQL offers a modern alternative to traditional REST APIs.
WEBSITE: https://www.ficusoft.in/full-stack-developer-course-in-chennai/
0 notes
Text
Understanding GraphQL
Before diving into Spring GraphQL, it's essential to grasp what GraphQL is. Developed by Facebook in 2012, GraphQL is a query language for APIs that allows clients to request only the data they need. Unlike RESTful APIs, where the server defines the data structure, GraphQL enables clients to specify the exact data requirements, reducing over-fetching and under-fetching of data.
Key Features of GraphQL:
Declarative Data Fetching: Clients can request specific data, leading to optimized network usage.
Single Endpoint: All data queries are handled through a single endpoint, simplifying the API structure.
Strong Typing: GraphQL schemas define types and relationships, ensuring consistency and clarity.
Introducing Spring GraphQL
Spring GraphQL is a project that integrates GraphQL into the Spring ecosystem. It provides the necessary tools and libraries to build GraphQL APIs using Spring Boot, leveraging the robustness and familiarity of the Spring Framework.
Why Choose Spring GraphQL?
Seamless Integration: Combines the capabilities of Spring Boot with GraphQL, allowing developers to build scalable and maintainable APIs.
Auto-Configuration: Spring Boot's auto-configuration simplifies setup, enabling developers to focus on business logic.
Community Support: Backed by the extensive Spring community, ensuring continuous updates and support.
Setting Up a Spring GraphQL Project
To start building with Spring GraphQL, follow these steps:
1. Create a New Spring Boot Project
Use Spring Initializr to generate a new project:
Project: Maven Project
Language: Java
Spring Boot: Choose the latest stable version
Dependencies:
Spring Web
Spring for GraphQL
Spring Data JPA (if you're interacting with a database)
H2 Database (for in-memory database testing)
Download the project and import it into your preferred IDE.
2. Define the GraphQL Schema
GraphQL schemas define the structure of the data and the queries available. Create a schema file (schema.graphqls) in the src/main/resources/graphql directory:
graphql
Copy code
type Query {
greeting(name: String! = "Spring"): String!
project(slug: ID!): Project
}
type Project {
slug: ID!
name: String!
repositoryUrl: String!
status: ProjectStatus!
}
enum ProjectStatus {
ACTIVE
COMMUNITY
INCUBATING
ATTIC
EOL
}
This schema defines a Query type with two fields: greeting and project. The Project type includes details like slug, name, repositoryUrl, and status. The ProjectStatus enum represents the various states a project can be in.
3. Implement Resolvers
Resolvers are responsible for fetching the data corresponding to the queries defined in the schema. In Spring GraphQL, you can use controllers to handle these queries:
java
Copy code
import org.springframework.graphql.data.method.annotation.QueryMapping;
import org.springframework.stereotype.Controller;
@Controller
public class ProjectController {
@QueryMapping
public String greeting(String name) {
return "Hello, " + name + "!";
}
@QueryMapping
public Project project(String slug) {
// Logic to fetch project details by slug
}
}
In this example, the greeting method returns a simple greeting message, while the project method fetches project details based on the provided slug.
4. Configure Application Properties
Ensure your application properties are set up correctly, especially if you're connecting to a database:
properties
Copy code
spring.datasource.url=jdbc:h2:mem:testdb
spring.datasource.driverClassName=org.h2.Driver
spring.datasource.username=sa
spring.datasource.password=password
spring.jpa.hibernate.ddl-auto=update
These settings configure an in-memory H2 database for testing purposes.
5. Test Your GraphQL API
With the setup complete, you can test your GraphQL API using tools like GraphiQL or Postman. Send queries to the /graphql endpoint of your application to retrieve data.
Benefits of Using Spring GraphQL
Integrating GraphQL with Spring Boot offers several advantages:
Efficient Data Retrieval: Clients can request only the data they need, reducing unnecessary data transfer.
Simplified API Management: A single endpoint handles all queries, streamlining the API structure.
Strong Typing: Schemas define data types and relationships, minimizing errors and enhancing clarity.
Flexibility: Easily add or deprecate fields without impacting existing clients, facilitating smooth evolution of the API.
Conclusion
Spring GraphQL empowers developers to build flexible and efficient APIs by combining the strengths of GraphQL and the Spring Framework. By following the steps outlined above, you can set up a Spring GraphQL project and start leveraging its benefits in your applications
0 notes
Text
How to Hire the Best ReactJS Developers: Tips for Evaluating Skills and Experience
ReactJS has become one of the most popular JavaScript libraries for building dynamic user interfaces. With its growing popularity, the demand for skilled reactjs developers has surged, making the hiring process more competitive. Whether you're a startup or a well-established company, finding the right talent can significantly impact the success of your projects. This blog will guide you through the key factors to consider and the best practices for evaluating the skills and experience of ReactJS developers.
1. Understanding the Role of a ReactJS Developer
Before diving into the hiring process, it’s crucial to have a clear understanding of what a ReactJS developer does. ReactJS developers are responsible for building and maintaining user interfaces, ensuring that the applications are fast, responsive, and scalable. They work closely with designers, back-end developers, and project managers to bring the front-end of web applications to life.
2. Key Skills to Look For
When evaluating potential candidates, there are several core skills you should focus on:
Proficiency in JavaScript and ES6+: ReactJS is built on JavaScript, so a strong foundation in JavaScript, particularly ES6+ features, is essential. Look for developers who are comfortable with modern JavaScript syntax, including arrow functions, destructuring, and promises.
Deep Understanding of ReactJS: The candidate should have a solid grasp of ReactJS fundamentals, such as components, props, state, and lifecycle methods. They should also be familiar with hooks, context API, and how to manage component state efficiently.
Experience with State Management: State management is a crucial aspect of ReactJS development. Candidates should have experience with state management libraries like Redux, MobX, or Context API. They should also understand the principles of immutability and how to structure state to optimize performance.
Familiarity with RESTful APIs and GraphQL: Most ReactJS applications rely on APIs to fetch and update data. Ensure the developer is experienced with RESTful APIs and has a working knowledge of GraphQL, which is increasingly popular for managing data in ReactJS applications.
Version Control with Git: Proficiency in version control systems like Git is non-negotiable. A good ReactJS developer should know how to manage branches, merge code, and resolve conflicts using Git.
Testing and Debugging: Quality assurance is vital, and a strong ReactJS developer should have experience with testing frameworks like Jest, Enzyme, or React Testing Library. They should also be skilled in debugging tools and techniques to troubleshoot issues effectively.
Understanding of Webpack and Build Tools: A good developer should be comfortable with build tools like Webpack, Babel, and npm scripts, which are essential for optimizing the performance of ReactJS applications.
3. Evaluating Experience and Portfolio
Experience is a significant factor when hiring a ReactJS developer. Look for candidates with a proven track record of working on ReactJS projects. Review their portfolio to see examples of their work. Pay attention to the complexity of the projects they’ve worked on and their role in those projects.
Ask for specific examples of challenges they faced and how they overcame them. This will give you insight into their problem-solving abilities and their depth of knowledge in ReactJS.
4. Conducting Technical Interviews
A technical interview is an excellent way to assess a candidate’s skills. Here are some tips for conducting an effective interview:
Coding Challenges: Present candidates with a coding challenge that involves building a small ReactJS component or a simple application. This will allow you to evaluate their coding style, problem-solving abilities, and familiarity with ReactJS.
Whiteboard Sessions: Whiteboard sessions can help you assess a candidate’s understanding of algorithms, data structures, and their ability to explain their thought process. This is especially useful for senior developers who are expected to contribute to architectural decisions.
Pair Programming: Pair programming sessions can give you a glimpse of how the candidate works in a team setting. It allows you to see how they approach problems, communicate, and collaborate with others.
5. Soft Skills Matter Too
While technical skills are crucial, soft skills shouldn’t be overlooked. A great ReactJS developer should be a good communicator, able to explain complex technical concepts to non-technical stakeholders. They should also be adaptable, willing to learn new tools and technologies as the React ecosystem evolves.
Problem-solving, creativity, and a strong sense of ownership are other important traits. Look for candidates who show initiative and have a track record of going above and beyond to deliver high-quality work.
6. Cultural Fit and Long-Term Potential
Hiring a developer who fits well with your company culture is essential for long-term success. During the interview process, assess whether the candidate’s values align with your company’s mission and work environment. Consider their long-term potential—will they grow with the company and take on more responsibilities over time?
7. References and Background Checks
Finally, don’t forget to check references and conduct background checks. Speaking with previous employers or colleagues can provide valuable insights into the candidate’s work ethic, reliability, and performance in real-world scenarios.
Conclusion
Hiring the best reactjs developers requires a combination of evaluating technical skills, assessing experience, and considering cultural fit. By focusing on these key areas, you can build a strong team of developers who will contribute to the success of your projects. Remember that the right hire can make a significant difference, not just in the quality of the code but in the overall progress and success of your development efforts.
0 notes
Text
GraphQL WhereInputs
When you resolve properties in GraphQL types, especially resolving relational types, you usually take a single ID & expand it into an object.
Frustratingly, GraphQL doesn’t support the same resolver behaviour for input types. Typically you’d have to send up the ID as a standalone property - which you need to know/lookup beforehand. And what about bulk queries, where you (atomically) can’t fetch all IDs at once to perform updates?

To address this issue I tend to build a series of "WhereInput" types into the GraphQL project, which are small reusable inputs throughout the schema, to create a uniform way to filter entries or select a relational entry when creating/updating entries:

An example usage of these might include:

Implementing WhereInputs into your GraphQL project has plenty of benefits & side effects, the top three include:
Unify how you specify relational entities in your GraphQL schema. Rather than using a quick entryID input property (e.g. author: $userID) you can use a uniform object (e.g. author: { id: $userID } or author: { email: $email }). And, depending on how you structure your Input functions, you could perform additional validation on the relational entry you want to use) e.g. { id: $userID, status: ACTIVE }).
When you want to filter entries by a new property, e.g. a user’s favourite colour, you add a few lines of code in one function & now anywhere you already filter users can now filter by email!
A good WhereInput implementation can also give your application logic a unified way of searching for entries by your WhereInput query, simplifying your application logic further.
Remarks
By habit, I tend to append "Input"/"Enum" to the end of these types so when used throughout the codebase, it's always clear that what type I'm using.
It would be nice to have a type/input class that works for both reading & writing though!
If you’re building a GraphQL API in Node.JS without dataloader or graphql-resolve-batch be sure to check them out - both libraries make bulk-loading data ruthlessly efficient!
You can combine your Inputs with a Dataloader instance to create a uniform way of fetching entry IDs from a schema-defined object internally. This is incredibly useful within your resolvers but throughout the rest of your application too!

0 notes
Link
0 notes
Text
GraphQL Client Side & Server-Side Components Explained with Examples for API Developers
Full Video Link - https://youtube.com/shorts/nezkbeJlAIk Hi, a new #video on #graphql #mutation published on #codeonedigest #youtube channel. @java @awscloud @AWSCloudIndia @YouTube #youtube @codeonedigest #graphql #graphqlresolver #graphqltutorial
Let’s understand the GraphQL components and the way they communicate with each other. The entire application components can be categories in to server side and client-side components. Server-side Components – GraphQL server forms the core component on the server side and allows to parse the queries coming from GraphQL client applications. Apollo Server is most commonly used implementation of…

View On WordPress
#graphql#graphql api#graphql apollo server express#graphql apollo server tutorial#graphql client#graphql client apollo#graphql client java#graphql client react#graphql client side#graphql client spring boot#graphql client tutorial#graphql example#graphql explained#graphql java client example#graphql schema and resolver#graphql server and client#graphql server apollo#graphql server components#graphql server tutorial#graphql tutorial
0 notes
Text
GraphQL in MuleSoft

Integrating GraphQL with MuleSoft enables you to offer a modern, powerful API interface for your applications, allowing clients to request the data they need and nothing more. GraphQL, a query language for APIs developed by Facebook, provides a more efficient and flexible alternative to the traditional REST API approach. When combined with MuleSoft’s Anypoint Platform, you can leverage GraphQL to design, build, and manage APIs that offer tailored data retrieval options to your API consumers.
Implementing GraphQL in MuleSoft
As of my last update, MuleSoft’s Anypoint Platform does not natively support GraphQL in the same direct manner it supports REST or SOAP services. However, you can implement GraphQL over the APIs managed by MuleSoft through custom development. Here’s how you can approach it:
Define Your GraphQL Schema:
Start by defining a GraphQL schema that specifies the types of data you offer, including objects, fields, queries, and mutations. This schema acts as a contract between the client and the server.
Implement Data Fetchers:
You need to implement a resolver or data fetcher for each field in your schema. In the context of MuleSoft, you can implement these fetchers as Java classes or scripts that execute logic to retrieve or manipulate data from your backend systems, databases, or other APIs managed by MuleSoft.
Expose a GraphQL Endpoint:
Use an HTTP Listener in your Mule application to expose a single GraphQL endpoint. Clients will send POST requests to this endpoint with their query payloads.
You can handle these requests in your Mule flows, parsing the GraphQL queries and passing them to the appropriate data fetchers.
Integrate GraphQL Java Libraries:
Leverage existing GraphQL Java libraries, such as graphql-java, to parse the GraphQL queries, execute them against your schema, and format the response according to the GraphQL specification.
You may need to include these libraries in your Mule project and call them from your custom components or scripts within your flows.
Manage Performance and Security:
Implement caching, batching, and rate limiting to optimize performance and manage the load on your backend systems.
Secure your GraphQL endpoint using MuleSoft’s security policies, OAuth2 providers, or JWT validation to protect against unauthorized access.
Testing and Documentation
Testing: Use Postman, Insomnia, or GraphQL Playground to test your GraphQL API. These tools allow you to craft queries, inspect the schema, and see the results.
Documentation: Although GraphQL APIs are self-documenting through introspection, consider providing additional documentation on everyday use cases, query examples, and best practices for clients.
Challenges and Considerations
Query Complexity: GraphQL allows clients to request deeply nested data, which can lead to performance issues. Consider implementing query complexity analysis and depth limiting to mitigate this.
Error Handling: Design your error handling strategy to provide meaningful error messages to clients while hiding sensitive system details.
N+1 Problem: Be mindful of the N+1 problem, where executing a GraphQL query could result in many more data fetching operations than expected. Use techniques like data loader patterns to batch requests and reduce the number of calls to backend services.
Demo Day 1 Video:
youtube
You can find more information about Mulesoft in this Mulesoft Docs Link
Conclusion:
Unogeeks is the №1 Training Institute for Mulesoft Training. Anyone Disagree? Please drop in a comment
You can check out our other latest blogs on Mulesoft Training here — Mulesoft Blogs
You can check out our Best in Class Mulesoft Training details here — Mulesoft Training
Follow & Connect with us:
— — — — — — — — — — — -
For Training inquiries:
Call/Whatsapp: +91 73960 33555
Mail us at: [email protected]
Our Website ➜ https://unogeeks.com
Follow us:
Instagram: https://www.instagram.com/unogeeks
Facebook: https://www.facebook.com/UnogeeksSoftwareTrainingInstitute
Twitter: https://twitter.com/unogeeks
#MULESOFT #MULESOFTTARINING #UNOGEEKS #UNOGEEKS TRAINING
0 notes
Text
Google Cloud SQL’s Linear Optimization Vector Search Magic

On Google Cloud SQL, linear optimizes data and scalability with vector search capability
The goal of Linear is to enable product teams to deliver excellent software. In order to assist customers in streamlining processes throughout the product development process, They have dedicated the previous several years to developing an extensive project and problem tracking system. Although began as an issue tracker, have developed software into a potent project management tool for users worldwide and cross-functional teams.
For example, Linear Asks streamlines cooperation for users of her platform who don’t have Linear accounts by enabling businesses to handle request processes like bug and feature requests over Slack. Furthermore,Have included a feature called Similar Issues, which keeps duplicate or overlapping tickets at bay and guarantees more accurate and clearer data representation for expanding businesses.
Workflow and product management tools are becoming more and more necessary as clients’ companies expand and they have more users on the platform and problems to monitor. Her goal is to facilitate this expansion while maintaining her high standards for performance, stability, quality, and features that enable intricate technical setups and excellent user experiences.
Looking for a vector search database that is scalable
Google had a PostgreSQL database with the pgvector extension hosted on a PaaS during early development period, however it wasn’t indexed or used for production workloads.They had to update databases to handle production workloads and find a solution that supported vector search, since this is the most effective approach to categorize and detect related problems based on common traits or patterns. They can easily detect related or duplicate concerns by identifying commonalities across the vector representations of the issues. By streamlining bug tracking and assisting customers in resolving problems more successfully, this feature improves processes overall and saves time and resources.
Google Cloud SQL’s Vector Search
Google looked into and ultimately tried a number of the recently launched database products that are specifically designed to store vectors. However, in addition to the comparatively expensive cost for a function that wasn’t essential to the offering, google also encountered issues with indexing speed and excessive downtime while growing. They decided on Google Cloud SQL for PostgreSQL once pgvector support was enabled, considering Linear’s current data volume and objectives for finding an affordable solution. Its dependability and scalability pleased us. The learning curve for team was nonexistent since this decision was also in line with how to now use databases, models, ORMs, etc.
The magnitude and number of vectors had to deal with for the production dataset initially made migration procedure from development to production difficult. But were able to correctly index each division after divided the problems table into 300 chunks. The migration went well and used the typical procedure of building a follower from the current PostgreSQL database.
Linear uses Google Cloud to enable its real-time sync
Today, Google Cloud SQL for PostgreSQL powers main working database.Similarity-search features’ vectors might be stored in a separate database as Google Cloud SQL for PostgreSQL comes with the pgvector extension. This is accomplished by employing OpenAI ada embeddings to encode the semantic meaning of problems into a vector, which is then combined with additional filters to assist in the identification of related and pertinent things.
Linear’s online and desktop clients synchronize with backend in real-time, according to architectural design. they run synchronized WebSocket servers, public and private GraphQL APIs, and background job task runners on Google Cloud.
All of them operate as independently scalable Kubernetes workloads. They are confident in choice of Google Cloud SQL for PostgreSQL as major database option, and whole technological stack is built using NodeJS and Typescript. Google’s managed Memorystore for Redis as a cache and event bus.
Cloud SQL for PostgreSQL allows for future innovation and seamless scalability
For Linear,Google Cloud SQL for PostgreSQL has been quite helpful.they must depend on managed services since lack a dedicated operations staff. It’s great for operations and frees up engineering time to focus on creating user-facing features since it lets us extend database seamlessly into tens of terabytes of data without needing significant technical work.
In addition, They have received positive comments from clients, particularly with respect to Linear’s capability to recognize duplicate problems when they file a bug report. The program now makes suggestions for possible duplication when a user opens a new problem. Furthermore, Linear shows potential relevant defects that have previously been noted while managing client tickets using customer support application connections like Zendesk.
In the future, want to include machine learning (ML) into Linear to improve the user experience, automate processes, and provide smart recommendations within the product. Additionally, dedicated to improving similarity search features and going beyond vector similarity to include other signals in computations. have no doubt that Google Cloud will play a crucial role in assisting us in realizing this goal.
Read more on Govindhtech.com
0 notes
Text
Integration Specialist: Bridging the Gap Between Systems and Efficiency
The Key to Scalable, Secure, and Future-Ready IT Solutions.
Introduction
In today’s interconnected digital landscape, businesses rely on seamless data exchange and system connectivity to optimize operations and improve efficiency. Integration specialists play a crucial role in designing, implementing, and maintaining integrations between various software applications, ensuring smooth communication and workflow automation. With the rise of cloud computing, APIs, and enterprise applications, integration specialists are essential for driving digital transformation.
What is an Integration Specialist?
An Integration Specialist is a professional responsible for developing and managing software integrations between different systems, applications, and platforms. They design workflows, troubleshoot issues, and ensure data flows securely and efficiently across various environments. Integration specialists work with APIs, middleware, and cloud-based tools to connect disparate systems and improve business processes.
Types of Integration Solutions
Integration specialists work with different types of solutions to meet business needs:
API Integrations
Connects different applications via Application Programming Interfaces (APIs).
Enables real-time data sharing and automation.
Examples: RESTful APIs, SOAP APIs, GraphQL.
Cloud-Based Integrations
Connects cloud applications like SaaS platforms.
Uses integration platforms as a service (iPaaS).
Examples: Zapier, Workato, MuleSoft, Dell Boomi.
Enterprise System Integrations
Integrates large-scale enterprise applications.
Connects ERP (Enterprise Resource Planning), CRM (Customer Relationship Management), and HR systems.
Examples: Salesforce, SAP, Oracle, Microsoft Dynamics.
Database Integrations
Ensures seamless data flow between databases.
Uses ETL (Extract, Transform, Load) processes for data synchronization.
Examples: SQL Server Integration Services (SSIS), Talend, Informatica.
Key Stages of System Integration
Requirement Analysis & Planning
Identify business needs and integration goals.
Analyze existing systems and data flow requirements.
Choose the right integration approach and tools.
Design & Architecture
Develop a blueprint for the integration solution.
Select API frameworks, middleware, or cloud services.
Ensure scalability, security, and compliance.
Development & Implementation
Build APIs, data connectors, and automation workflows.
Implement security measures (encryption, authentication).
Conduct performance optimization and data validation.
Testing & Quality Assurance
Perform functional, security, and performance testing.
Identify and resolve integration errors and data inconsistencies.
Conduct user acceptance testing (UAT).
Deployment & Monitoring
Deploy integration solutions in production environments.
Monitor system performance and error handling.
Ensure smooth data synchronization and process automation.
Maintenance & Continuous Improvement
Provide ongoing support and troubleshooting.
Optimize integration workflows based on feedback.
Stay updated with new technologies and best practices.
Best Practices for Integration Success
✔ Define clear integration objectives and business needs. ✔ Use secure and scalable API frameworks. ✔ Optimize data transformation processes for efficiency. ✔ Implement robust authentication and encryption. ✔ Conduct thorough testing before deployment. ✔ Monitor and update integrations regularly. ✔ Stay updated with emerging iPaaS and API technologies.
Conclusion
Integration specialists are at the forefront of modern digital ecosystems, ensuring seamless connectivity between applications and data sources. Whether working with cloud platforms, APIs, or enterprise systems, a well-executed integration strategy enhances efficiency, security, and scalability. Businesses that invest in robust integration solutions gain a competitive edge, improved automation, and streamlined operations.
Would you like me to add recommendations for integration tools or comparisons of middleware solutions? 🚀
0 notes
Text
GraphQL Resolver Authentication: Real-World Example
1. Introduction Authentication is a cornerstone of modern web applications, ensuring only authorized users can access specific functionalities and data. In GraphQL, unlike REST APIs, we often handle authentication within our resolvers – the functions responsible for fetching data and executing mutations. This approach allows for granular control and elegant integration with the data retrieval…
0 notes