#importance of python in data science
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
China blocked Tumblr because of pornography and censorship problems in 2013.
Text
Sylus, Xavier, and Caleb: Amazing at coding, advanced mathematics, and data engineering/data science kind of stuff.
Zayne: Understands the importance of such subjects but hardly ever dabbled in it through his schooling. Finds it interestingly like a puzzle though.
Rafayel: Disgusted, unmoisturized, appalled -> "Where did all the numbers go? What is a python? The snake? WHAT DO YOU MEAN THERE ARE IMAGINARY THINGS?!
24 notes
·
View notes
Text
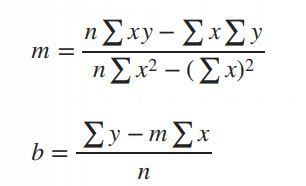
Simple Linear Regression in Data Science and machine learning
Simple linear regression is one of the most important techniques in data science and machine learning. It is the foundation of many statistical and machine learning models. Even though it is simple, its concepts are widely applicable in predicting outcomes and understanding relationships between variables.
This article will help you learn about:
1. What is simple linear regression and why it matters.
2. The step-by-step intuition behind it.
3. The math of finding slope() and intercept().
4. Simple linear regression coding using Python.
5. A practical real-world implementation.
If you are new to data science or machine learning, don��t worry! We will keep things simple so that you can follow along without any problems.
What is simple linear regression?
Simple linear regression is a method to model the relationship between two variables:
1. Independent variable (X): The input, also called the predictor or feature.
2. Dependent Variable (Y): The output or target value we want to predict.
The main purpose of simple linear regression is to find a straight line (called the regression line) that best fits the data. This line minimizes the error between the actual and predicted values.
The mathematical equation for the line is:
Y = mX + b
: The predicted values.
: The slope of the line (how steep it is).
: The intercept (the value of when).
Why use simple linear regression?
click here to read more https://datacienceatoz.blogspot.com/2025/01/simple-linear-regression-in-data.html
#artificial intelligence#bigdata#books#machine learning#machinelearning#programming#python#science#skills#big data#linear algebra#linear b#slope#interception
6 notes
·
View notes
Text
Unlocking the Power of Data: Essential Skills to Become a Data Scientist

In today's data-driven world, the demand for skilled data scientists is skyrocketing. These professionals are the key to transforming raw information into actionable insights, driving innovation and shaping business strategies. But what exactly does it take to become a data scientist? It's a multidisciplinary field, requiring a unique blend of technical prowess and analytical thinking. Let's break down the essential skills you'll need to embark on this exciting career path.
1. Strong Mathematical and Statistical Foundation:
At the heart of data science lies a deep understanding of mathematics and statistics. You'll need to grasp concepts like:
Linear Algebra and Calculus: Essential for understanding machine learning algorithms and optimizing models.
Probability and Statistics: Crucial for data analysis, hypothesis testing, and drawing meaningful conclusions from data.
2. Programming Proficiency (Python and/or R):
Data scientists are fluent in at least one, if not both, of the dominant programming languages in the field:
Python: Known for its readability and extensive libraries like Pandas, NumPy, Scikit-learn, and TensorFlow, making it ideal for data manipulation, analysis, and machine learning.
R: Specifically designed for statistical computing and graphics, R offers a rich ecosystem of packages for statistical modeling and visualization.
3. Data Wrangling and Preprocessing Skills:
Raw data is rarely clean and ready for analysis. A significant portion of a data scientist's time is spent on:
Data Cleaning: Handling missing values, outliers, and inconsistencies.
Data Transformation: Reshaping, merging, and aggregating data.
Feature Engineering: Creating new features from existing data to improve model performance.
4. Expertise in Databases and SQL:
Data often resides in databases. Proficiency in SQL (Structured Query Language) is essential for:
Extracting Data: Querying and retrieving data from various database systems.
Data Manipulation: Filtering, joining, and aggregating data within databases.
5. Machine Learning Mastery:
Machine learning is a core component of data science, enabling you to build models that learn from data and make predictions or classifications. Key areas include:
Supervised Learning: Regression, classification algorithms.
Unsupervised Learning: Clustering, dimensionality reduction.
Model Selection and Evaluation: Choosing the right algorithms and assessing their performance.
6. Data Visualization and Communication Skills:
Being able to effectively communicate your findings is just as important as the analysis itself. You'll need to:
Visualize Data: Create compelling charts and graphs to explore patterns and insights using libraries like Matplotlib, Seaborn (Python), or ggplot2 (R).
Tell Data Stories: Present your findings in a clear and concise manner that resonates with both technical and non-technical audiences.
7. Critical Thinking and Problem-Solving Abilities:
Data scientists are essentially problem solvers. You need to be able to:
Define Business Problems: Translate business challenges into data science questions.
Develop Analytical Frameworks: Structure your approach to solve complex problems.
Interpret Results: Draw meaningful conclusions and translate them into actionable recommendations.
8. Domain Knowledge (Optional but Highly Beneficial):
Having expertise in the specific industry or domain you're working in can give you a significant advantage. It helps you understand the context of the data and formulate more relevant questions.
9. Curiosity and a Growth Mindset:
The field of data science is constantly evolving. A genuine curiosity and a willingness to learn new technologies and techniques are crucial for long-term success.
10. Strong Communication and Collaboration Skills:
Data scientists often work in teams and need to collaborate effectively with engineers, business stakeholders, and other experts.
Kickstart Your Data Science Journey with Xaltius Academy's Data Science and AI Program:
Acquiring these skills can seem like a daunting task, but structured learning programs can provide a clear and effective path. Xaltius Academy's Data Science and AI Program is designed to equip you with the essential knowledge and practical experience to become a successful data scientist.
Key benefits of the program:
Comprehensive Curriculum: Covers all the core skills mentioned above, from foundational mathematics to advanced machine learning techniques.
Hands-on Projects: Provides practical experience working with real-world datasets and building a strong portfolio.
Expert Instructors: Learn from industry professionals with years of experience in data science and AI.
Career Support: Offers guidance and resources to help you launch your data science career.
Becoming a data scientist is a rewarding journey that blends technical expertise with analytical thinking. By focusing on developing these key skills and leveraging resources like Xaltius Academy's program, you can position yourself for a successful and impactful career in this in-demand field. The power of data is waiting to be unlocked – are you ready to take the challenge?
2 notes
·
View notes
Text
What are the skills needed for a data scientist job?
It’s one of those careers that’s been getting a lot of buzz lately, and for good reason. But what exactly do you need to become a data scientist? Let’s break it down.
Technical Skills
First off, let's talk about the technical skills. These are the nuts and bolts of what you'll be doing every day.
Programming Skills: At the top of the list is programming. You’ll need to be proficient in languages like Python and R. These are the go-to tools for data manipulation, analysis, and visualization. If you’re comfortable writing scripts and solving problems with code, you’re on the right track.
Statistical Knowledge: Next up, you’ve got to have a solid grasp of statistics. This isn’t just about knowing the theory; it’s about applying statistical techniques to real-world data. You’ll need to understand concepts like regression, hypothesis testing, and probability.
Machine Learning: Machine learning is another biggie. You should know how to build and deploy machine learning models. This includes everything from simple linear regressions to complex neural networks. Familiarity with libraries like scikit-learn, TensorFlow, and PyTorch will be a huge plus.
Data Wrangling: Data isn’t always clean and tidy when you get it. Often, it’s messy and requires a lot of preprocessing. Skills in data wrangling, which means cleaning and organizing data, are essential. Tools like Pandas in Python can help a lot here.
Data Visualization: Being able to visualize data is key. It’s not enough to just analyze data; you need to present it in a way that makes sense to others. Tools like Matplotlib, Seaborn, and Tableau can help you create clear and compelling visuals.
Analytical Skills
Now, let’s talk about the analytical skills. These are just as important as the technical skills, if not more so.
Problem-Solving: At its core, data science is about solving problems. You need to be curious and have a knack for figuring out why something isn’t working and how to fix it. This means thinking critically and logically.
Domain Knowledge: Understanding the industry you’re working in is crucial. Whether it’s healthcare, finance, marketing, or any other field, knowing the specifics of the industry will help you make better decisions and provide more valuable insights.
Communication Skills: You might be working with complex data, but if you can’t explain your findings to others, it’s all for nothing. Being able to communicate clearly and effectively with both technical and non-technical stakeholders is a must.
Soft Skills
Don’t underestimate the importance of soft skills. These might not be as obvious, but they’re just as critical.
Collaboration: Data scientists often work in teams, so being able to collaborate with others is essential. This means being open to feedback, sharing your ideas, and working well with colleagues from different backgrounds.
Time Management: You’ll likely be juggling multiple projects at once, so good time management skills are crucial. Knowing how to prioritize tasks and manage your time effectively can make a big difference.
Adaptability: The field of data science is always evolving. New tools, techniques, and technologies are constantly emerging. Being adaptable and willing to learn new things is key to staying current and relevant in the field.
Conclusion
So, there you have it. Becoming a data scientist requires a mix of technical prowess, analytical thinking, and soft skills. It’s a challenging but incredibly rewarding career path. If you’re passionate about data and love solving problems, it might just be the perfect fit for you.
Good luck to all of you aspiring data scientists out there!
#artificial intelligence#career#education#coding#jobs#programming#success#python#data science#data scientist#data security
8 notes
·
View notes
Text
Why Tableau is Essential in Data Science: Transforming Raw Data into Insights

Data science is all about turning raw data into valuable insights. But numbers and statistics alone don’t tell the full story—they need to be visualized to make sense. That’s where Tableau comes in.
Tableau is a powerful tool that helps data scientists, analysts, and businesses see and understand data better. It simplifies complex datasets, making them interactive and easy to interpret. But with so many tools available, why is Tableau a must-have for data science? Let’s explore.
1. The Importance of Data Visualization in Data Science
Imagine you’re working with millions of data points from customer purchases, social media interactions, or financial transactions. Analyzing raw numbers manually would be overwhelming.
That’s why visualization is crucial in data science:
Identifies trends and patterns – Instead of sifting through spreadsheets, you can quickly spot trends in a visual format.
Makes complex data understandable – Graphs, heatmaps, and dashboards simplify the interpretation of large datasets.
Enhances decision-making – Stakeholders can easily grasp insights and make data-driven decisions faster.
Saves time and effort – Instead of writing lengthy reports, an interactive dashboard tells the story in seconds.
Without tools like Tableau, data science would be limited to experts who can code and run statistical models. With Tableau, insights become accessible to everyone—from data scientists to business executives.
2. Why Tableau Stands Out in Data Science
A. User-Friendly and Requires No Coding
One of the biggest advantages of Tableau is its drag-and-drop interface. Unlike Python or R, which require programming skills, Tableau allows users to create visualizations without writing a single line of code.
Even if you’re a beginner, you can:
✅ Upload data from multiple sources
✅ Create interactive dashboards in minutes
✅ Share insights with teams easily
This no-code approach makes Tableau ideal for both technical and non-technical professionals in data science.
B. Handles Large Datasets Efficiently
Data scientists often work with massive datasets—whether it’s financial transactions, customer behavior, or healthcare records. Traditional tools like Excel struggle with large volumes of data.
Tableau, on the other hand:
Can process millions of rows without slowing down
Optimizes performance using advanced data engine technology
Supports real-time data streaming for up-to-date analysis
This makes it a go-to tool for businesses that need fast, data-driven insights.
C. Connects with Multiple Data Sources
A major challenge in data science is bringing together data from different platforms. Tableau seamlessly integrates with a variety of sources, including:
Databases: MySQL, PostgreSQL, Microsoft SQL Server
Cloud platforms: AWS, Google BigQuery, Snowflake
Spreadsheets and APIs: Excel, Google Sheets, web-based data sources
This flexibility allows data scientists to combine datasets from multiple sources without needing complex SQL queries or scripts.
D. Real-Time Data Analysis
Industries like finance, healthcare, and e-commerce rely on real-time data to make quick decisions. Tableau’s live data connection allows users to:
Track stock market trends as they happen
Monitor website traffic and customer interactions in real time
Detect fraudulent transactions instantly
Instead of waiting for reports to be generated manually, Tableau delivers insights as events unfold.
E. Advanced Analytics Without Complexity
While Tableau is known for its visualizations, it also supports advanced analytics. You can:
Forecast trends based on historical data
Perform clustering and segmentation to identify patterns
Integrate with Python and R for machine learning and predictive modeling
This means data scientists can combine deep analytics with intuitive visualization, making Tableau a versatile tool.
3. How Tableau Helps Data Scientists in Real Life
Tableau has been adopted by the majority of industries to make data science more impactful and accessible. This is applied in the following real-life scenarios:
A. Analytics for Health Care
Tableau is deployed by hospitals and research institutions for the following purposes:
Monitor patient recovery rates and predict outbreaks of diseases
Analyze hospital occupancy and resource allocation
Identify trends in patient demographics and treatment results
B. Finance and Banking
Banks and investment firms rely on Tableau for the following purposes:
✅ Detect fraud by analyzing transaction patterns
✅ Track stock market fluctuations and make informed investment decisions
✅ Assess credit risk and loan performance
C. Marketing and Customer Insights
Companies use Tableau to:
✅ Track customer buying behavior and personalize recommendations
✅ Analyze social media engagement and campaign effectiveness
✅ Optimize ad spend by identifying high-performing channels
D. Retail and Supply Chain Management
Retailers leverage Tableau to:
✅ Forecast product demand and adjust inventory levels
✅ Identify regional sales trends and adjust marketing strategies
✅ Optimize supply chain logistics and reduce delivery delays
These applications show why Tableau is a must-have for data-driven decision-making.
4. Tableau vs. Other Data Visualization Tools
There are many visualization tools available, but Tableau consistently ranks as one of the best. Here’s why:
Tableau vs. Excel – Excel struggles with big data and lacks interactivity; Tableau handles large datasets effortlessly.
Tableau vs. Power BI – Power BI is great for Microsoft users, but Tableau offers more flexibility across different data sources.
Tableau vs. Python (Matplotlib, Seaborn) – Python libraries require coding skills, while Tableau simplifies visualization for all users.
This makes Tableau the go-to tool for both beginners and experienced professionals in data science.
5. Conclusion
Tableau has become an essential tool in data science because it simplifies data visualization, handles large datasets, and integrates seamlessly with various data sources. It enables professionals to analyze, interpret, and present data interactively, making insights accessible to everyone—from data scientists to business leaders.
If you’re looking to build a strong foundation in data science, learning Tableau is a smart career move. Many data science courses now include Tableau as a key skill, as companies increasingly demand professionals who can transform raw data into meaningful insights.
In a world where data is the driving force behind decision-making, Tableau ensures that the insights you uncover are not just accurate—but also clear, impactful, and easy to act upon.
#data science course#top data science course online#top data science institute online#artificial intelligence course#deepseek#tableau
3 notes
·
View notes
Text
The Growing Importance of Data Science in the Digital Age Data science has emerged as a transformative field, fueling industries across the globe with actionable insights. In today’s data-driven world, organizations are leveraging data to make informed decisions, predict trends, and uncover hidden patterns.
2 notes
·
View notes
Text
Mastering Data Structures: A Comprehensive Course for Beginners
Data structures are one of the foundational concepts in computer science and software development. Mastering data structures is essential for anyone looking to pursue a career in programming, software engineering, or computer science. This article will explore the importance of a Data Structure Course, what it covers, and how it can help you excel in coding challenges and interviews.
1. What Is a Data Structure Course?
A Data Structure Course teaches students about the various ways data can be organized, stored, and manipulated efficiently. These structures are crucial for solving complex problems and optimizing the performance of applications. The course generally covers theoretical concepts along with practical applications using programming languages like C++, Java, or Python.
By the end of the course, students will gain proficiency in selecting the right data structure for different problem types, improving their problem-solving abilities.
2. Why Take a Data Structure Course?
Learning data structures is vital for both beginners and experienced developers. Here are some key reasons to enroll in a Data Structure Course:
a) Essential for Coding Interviews
Companies like Google, Amazon, and Facebook focus heavily on data structures in their coding interviews. A solid understanding of data structures is essential to pass these interviews successfully. Employers assess your problem-solving skills, and your knowledge of data structures can set you apart from other candidates.
b) Improves Problem-Solving Skills
With the right data structure knowledge, you can solve real-world problems more efficiently. A well-designed data structure leads to faster algorithms, which is critical when handling large datasets or working on performance-sensitive applications.
c) Boosts Programming Competency
A good grasp of data structures makes coding more intuitive. Whether you are developing an app, building a website, or working on software tools, understanding how to work with different data structures will help you write clean and efficient code.
3. Key Topics Covered in a Data Structure Course
A Data Structure Course typically spans a range of topics designed to teach students how to use and implement different structures. Below are some key topics you will encounter:
a) Arrays and Linked Lists
Arrays are one of the most basic data structures. A Data Structure Course will teach you how to use arrays for storing and accessing data in contiguous memory locations. Linked lists, on the other hand, involve nodes that hold data and pointers to the next node. Students will learn the differences, advantages, and disadvantages of both structures.
b) Stacks and Queues
Stacks and queues are fundamental data structures used to store and retrieve data in a specific order. A Data Structure Course will cover the LIFO (Last In, First Out) principle for stacks and FIFO (First In, First Out) for queues, explaining their use in various algorithms and applications like web browsers and task scheduling.
c) Trees and Graphs
Trees and graphs are hierarchical structures used in organizing data. A Data Structure Course teaches how trees, such as binary trees, binary search trees (BST), and AVL trees, are used in organizing hierarchical data. Graphs are important for representing relationships between entities, such as in social networks, and are used in algorithms like Dijkstra's and BFS/DFS.
d) Hashing
Hashing is a technique used to convert a given key into an index in an array. A Data Structure Course will cover hash tables, hash maps, and collision resolution techniques, which are crucial for fast data retrieval and manipulation.
e) Sorting and Searching Algorithms
Sorting and searching are essential operations for working with data. A Data Structure Course provides a detailed study of algorithms like quicksort, merge sort, and binary search. Understanding these algorithms and how they interact with data structures can help you optimize solutions to various problems.
4. Practical Benefits of Enrolling in a Data Structure Course
a) Hands-on Experience
A Data Structure Course typically includes plenty of coding exercises, allowing students to implement data structures and algorithms from scratch. This hands-on experience is invaluable when applying concepts to real-world problems.
b) Critical Thinking and Efficiency
Data structures are all about optimizing efficiency. By learning the most effective ways to store and manipulate data, students improve their critical thinking skills, which are essential in programming. Selecting the right data structure for a problem can drastically reduce time and space complexity.
c) Better Understanding of Memory Management
Understanding how data is stored and accessed in memory is crucial for writing efficient code. A Data Structure Course will help you gain insights into memory management, pointers, and references, which are important concepts, especially in languages like C and C++.
5. Best Programming Languages for Data Structure Courses
While many programming languages can be used to teach data structures, some are particularly well-suited due to their memory management capabilities and ease of implementation. Some popular programming languages used in Data Structure Courses include:
C++: Offers low-level memory management and is perfect for teaching data structures.
Java: Widely used for teaching object-oriented principles and offers a rich set of libraries for implementing data structures.
Python: Known for its simplicity and ease of use, Python is great for beginners, though it may not offer the same level of control over memory as C++.
6. How to Choose the Right Data Structure Course?
Selecting the right Data Structure Course depends on several factors such as your learning goals, background, and preferred learning style. Consider the following when choosing:
a) Course Content and Curriculum
Make sure the course covers the topics you are interested in and aligns with your learning objectives. A comprehensive Data Structure Course should provide a balance between theory and practical coding exercises.
b) Instructor Expertise
Look for courses taught by experienced instructors who have a solid background in computer science and software development.
c) Course Reviews and Ratings
Reviews and ratings from other students can provide valuable insights into the course’s quality and how well it prepares you for real-world applications.
7. Conclusion: Unlock Your Coding Potential with a Data Structure Course
In conclusion, a Data Structure Course is an essential investment for anyone serious about pursuing a career in software development or computer science. It equips you with the tools and skills to optimize your code, solve problems more efficiently, and excel in technical interviews. Whether you're a beginner or looking to strengthen your existing knowledge, a well-structured course can help you unlock your full coding potential.
By mastering data structures, you are not only preparing for interviews but also becoming a better programmer who can tackle complex challenges with ease.
2 notes
·
View notes
Text
Exploring Data Science Tools: My Adventures with Python, R, and More
Welcome to my data science journey! In this blog post, I'm excited to take you on a captivating adventure through the world of data science tools. We'll explore the significance of choosing the right tools and how they've shaped my path in this thrilling field.
Choosing the right tools in data science is akin to a chef selecting the finest ingredients for a culinary masterpiece. Each tool has its unique flavor and purpose, and understanding their nuances is key to becoming a proficient data scientist.
I. The Quest for the Right Tool
My journey began with confusion and curiosity. The world of data science tools was vast and intimidating. I questioned which programming language would be my trusted companion on this expedition. The importance of selecting the right tool soon became evident.
I embarked on a research quest, delving deep into the features and capabilities of various tools. Python and R emerged as the frontrunners, each with its strengths and applications. These two contenders became the focus of my data science adventures.
II. Python: The Swiss Army Knife of Data Science
Python, often hailed as the Swiss Army Knife of data science, stood out for its versatility and widespread popularity. Its extensive library ecosystem, including NumPy for numerical computing, pandas for data manipulation, and Matplotlib for data visualization, made it a compelling choice.
My first experiences with Python were both thrilling and challenging. I dove into coding, faced syntax errors, and wrestled with data structures. But with each obstacle, I discovered new capabilities and expanded my skill set.

III. R: The Statistical Powerhouse
In the world of statistics, R shines as a powerhouse. Its statistical packages like dplyr for data manipulation and ggplot2 for data visualization are renowned for their efficacy. As I ventured into R, I found myself immersed in a world of statistical analysis and data exploration.
My journey with R included memorable encounters with data sets, where I unearthed hidden insights and crafted beautiful visualizations. The statistical prowess of R truly left an indelible mark on my data science adventure.
IV. Beyond Python and R: Exploring Specialized Tools
While Python and R were my primary companions, I couldn't resist exploring specialized tools and programming languages that catered to specific niches in data science. These tools offered unique features and advantages that added depth to my skill set.

For instance, tools like SQL allowed me to delve into database management and querying, while Scala opened doors to big data analytics. Each tool found its place in my toolkit, serving as a valuable asset in different scenarios.
V. The Learning Curve: Challenges and Rewards
The path I took wasn't without its share of difficulties. Learning Python, R, and specialized tools presented a steep learning curve. Debugging code, grasping complex algorithms, and troubleshooting errors were all part of the process.
However, these challenges brought about incredible rewards. With persistence and dedication, I overcame obstacles, gained a profound understanding of data science, and felt a growing sense of achievement and empowerment.
VI. Leveraging Python and R Together
One of the most exciting revelations in my journey was discovering the synergy between Python and R. These two languages, once considered competitors, complemented each other beautifully.

I began integrating Python and R seamlessly into my data science workflow. Python's data manipulation capabilities combined with R's statistical prowess proved to be a winning combination. Together, they enabled me to tackle diverse data science tasks effectively.
VII. Tips for Beginners
For fellow data science enthusiasts beginning their own journeys, I offer some valuable tips:
Embrace curiosity and stay open to learning.
Work on practical projects while engaging in frequent coding practice.
Explore data science courses and resources to enhance your skills.
Seek guidance from mentors and engage with the data science community.
Remember that the journey is continuous—there's always more to learn and discover.
My adventures with Python, R, and various data science tools have been transformative. I've learned that choosing the right tool for the job is crucial, but versatility and adaptability are equally important traits for a data scientist.
As I summarize my expedition, I emphasize the significance of selecting tools that align with your project requirements and objectives. Each tool has a unique role to play, and mastering them unlocks endless possibilities in the world of data science.
I encourage you to embark on your own tool exploration journey in data science. Embrace the challenges, relish the rewards, and remember that the adventure is ongoing. May your path in data science be as exhilarating and fulfilling as mine has been.
Happy data exploring!
22 notes
·
View notes
Text
The Role of Machine Learning Engineer: Combining Technology and Artificial Intelligence

Artificial intelligence has transformed our daily lives in a greater way than we can’t imagine over the past year, Impacting how we work, communicate, and solve problems. Today, Artificial intelligence furiously drives the world in all sectors from daily life to the healthcare industry. In this blog we will learn how machine learning engineer build systems that learn from data and get better over time, playing a huge part in the development of artificial intelligence (AI). Artificial intelligence is an important field, making it more innovative in every industry. In the blog, we will look career in Machine learning in the field of engineering.
What is Machine Learning Engineering?
Machine Learning engineer is a specialist who designs and builds AI models to make complex challenges easy. The role in this field merges data science and software engineering making both fields important in this field. The main role of a Machine learning engineer is to build and design software that can automate AI models. The demand for this field has grown in recent years. As Artificial intelligence is a driving force in our daily needs, it become important to run the AI in a clear and automated way.
A machine learning engineer creates systems that help computers to learn and make decisions, similar to human tasks like recognizing voices, identifying images, or predicting results. Not similar to regular programming, which follows strict rules, machine learning focuses on teaching computers to find patterns in data and improve their predictions over time.
Responsibility of a Machine Learning Engineer:
Collecting and Preparing Data
Machine learning needs a lot of data to work well. These engineers spend a lot of time finding and organizing data. That means looking for useful data sources and fixing any missing information. Good data preparation is essential because it sets the foundation for building successful models.
Building and Training Models
The main task of Machine learning engineer is creating models that learn from data. Using tools like TensorFlow, PyTorch, and many more, they build proper algorithms for specific tasks. Training a model is challenging and requires careful adjustments and monitoring to ensure it’s accurate and useful.
Checking Model Performance
When a model is trained, then it is important to check how well it works. Machine learning engineers use scores like accuracy to see model performance. They usually test the model with separate data to see how it performs in real-world situations and make improvements as needed.
Arranging and Maintaining the Model
After testing, ML engineers put the model into action so it can work with real-time data. They monitor the model to make sure it stays accurate over time, as data can change and affect results. Regular updates help keep the model effective.
Working with Other Teams
ML engineers often work closely with data scientists, software engineers, and experts in the field. This teamwork ensures that the machine learning solution fits the business goals and integrates smoothly with other systems.
Important skill that should have to become Machine Learning Engineer:
Programming Languages
Python and R are popular options in machine learning, also other languages like Java or C++ can also help, especially for projects needing high performance.
Data Handling and Processing
Working with large datasets is necessary in Machine Learning. ML engineers should know how to use SQL and other database tools and be skilled in preparing and cleaning data before using it in models.
Machine Learning Structure
ML engineers need to know structure like TensorFlow, Keras, PyTorch, and sci-kit-learn. Each of these tools has unique strengths for building and training models, so choosing the right one depends on the project.
Mathematics and Statistics
A strong background in math, including calculus, linear algebra, probability, and statistics, helps ML engineers understand how algorithms work and make accurate predictions.
Why to become a Machine Learning engineer?
A career as a machine learning engineer is both challenging and creative, allowing you to work with the latest technology. This field is always changing, with new tools and ideas coming up every year. If you like to enjoy solving complex problems and want to make a real impact, ML engineering offers an exciting path.
Conclusion
Machine learning engineer plays an important role in AI and data science, turning data into useful insights and creating systems that learn on their own. This career is great for people who love technology, enjoy learning, and want to make a difference in their lives. With many opportunities and uses, Artificial intelligence is a growing field that promises exciting innovations that will shape our future. Artificial Intelligence is changing the world and we should also keep updated our knowledge in this field, Read AI related latest blogs here.
2 notes
·
View notes
Text
Top Free Python Courses & Tutorials Online Training | NareshIT
Top Free Python Courses & Tutorials Online Training | NareshIT
In today’s tech-driven world, Python has emerged as one of the most versatile and popular programming languages. Whether you're a beginner or an experienced developer, learning Python opens doors to exciting opportunities in web development, data science, machine learning, and much more.
At NareshIT, we understand the importance of providing quality education. That’s why we offer free Python courses and tutorials to help you kick-start or advance your programming career. With expert instructors, hands-on training, and project-based learning, our Python online training ensures that you not only grasp the fundamentals but also gain real-world coding experience.
Why Choose NareshIT for Python Training?
Comprehensive Curriculum: We cover everything from Python basics to advanced concepts such as object-oriented programming, data structures, and frameworks like Django and Flask.
Expert Instructors: Our team of experienced instructors ensures that you receive the best guidance, whether you're learning Python from scratch or brushing up on advanced topics.
Project-Based Learning: Our free tutorials are not just theoretical; they are packed with real-life projects and assignments that make learning engaging and practical.
Flexible Learning: With our online format, you can access Python tutorials and training anytime, anywhere, and learn at your own pace.
Key Features of NareshIT Python Courses
Free Python Basics Tutorials: Get started with our easy-to-follow Python tutorials designed for beginners.
Advanced Python Concepts: Dive deeper into topics like file handling, exception handling, and working with APIs.
Hands-on Practice: Learn through live coding sessions, exercises, and project work.
Certification: Upon completion of the course, earn a certificate that adds value to your resume.
Who Can Benefit from Our Python Courses?
Students looking to gain a solid foundation in programming.
Professionals aiming to switch to a career in tech or data science.
Developers wanting to enhance their Python skills and explore new opportunities.
Enthusiasts who are passionate about learning a new skill.
Start Learning Python for Free
At NareshIT, we are committed to providing accessible education for everyone. That’s why our free Python courses are available online for anyone eager to learn. Whether you want to build your first Python program or become a pro at developing Python applications, we’ve got you covered.
Ready to Dive into Python?
Sign up for our free Python tutorials today and embark on your programming journey with NareshIT. With our structured courses and expert-led training, mastering Python has never been easier. Get started now, and unlock the door to a world of opportunities!

#python#pythontraining#freepythoncourse#onlinetraining#coding#pythontutorials#pythonforbeginners#programming#pythononline#learnpython#softwaretraining#freelearning#pythonprogramming#onlinetutorial#techtraining#pythoncourses#onlineeducation#pythoncode#codingforbeginners
2 notes
·
View notes
Text
My Recommended Pathway to Learning Code
Why Learn to Code?
Unleash Creativity: Coding is like painting with words. You get to create digital masterpieces, bring ideas to life, and build things you've always imagined.
Problem-Solving Superpower: Ever felt the satisfaction of solving a puzzle? Coding is a series of problem-solving adventures where you're the hero armed with logic and creativity.
Endless Possibilities: From websites to apps, games, and beyond, coding opens doors to endless possibilities. Imagine the impact you can make in the digital realm!
Where to Begin?
Starting your coding journey can be overwhelming, and I don't blame you for thinking so. Begin with these beginner-friendly languages:
HTML/CSS: The dynamic duo for web development. HTML structures content, while CSS styles it. Perfect for creating your first website. Think of HTML as the structure for a building. The frame, if you will. CSS will be the decor of it all.
JavaScript: The language of the web. It adds interactivity to your sites, making them dynamic and engaging.
Python: A versatile language, loved for its readability. Great for beginners and used in various fields, from web development to data science.
The Importance of Learning Foundations:
Think of coding as building a house. You wouldn't start with the roof, right? Learning foundational languages like HTML, CSS, and JavaScript is like laying a strong foundation. Here's why it matters:
Understanding the Basics: Foundations teach you the core concepts of programming, helping you understand how code works.
Transferable Skills: The skills you gain are transferable to other languages. Once you grasp the logic, moving on becomes a smoother journey. You can't read a book if you don't know the alphabet.
Confidence Booster: Starting with the basics builds confidence. It's like leveling up in a game – you become more adept and ready for the next challenge.
Problem-Solving Mindset: Foundations instill a problem-solving mindset. As you conquer challenges, you develop a resilient approach to coding conundrums.
Starting up:
I highly recommend using what you have on hand. Notepad on Windows works great but if you'd like something more code based try out:
Notepad++
Sublime
Visual Code Studio
Coffee Cup
Atom (This has been sunset though, so use at your own risk)
Any questions? Please feel free to message me! I might take 24 hours to respond, but I will get back to you!
#CodingJourney#HTML#CSS#JavaScript#Python#WebDevelopment#learn#pathway#recommendation#cs#computer#science#compsci#programming#edu#educational#codeblr#studyblr
10 notes
·
View notes
Text
Understanding Outliers in Machine Learning and Data Science

In machine learning and data science, an outlier is like a misfit in a dataset. It's a data point that stands out significantly from the rest of the data. Sometimes, these outliers are errors, while other times, they reveal something truly interesting about the data. Either way, handling outliers is a crucial step in the data preprocessing stage. If left unchecked, they can skew your analysis and even mess up your machine learning models.
In this article, we will dive into:
1. What outliers are and why they matter.
2. How to detect and remove outliers using the Interquartile Range (IQR) method.
3. Using the Z-score method for outlier detection and removal.
4. How the Percentile Method and Winsorization techniques can help handle outliers.
This guide will explain each method in simple terms with Python code examples so that even beginners can follow along.
1. What Are Outliers?
An outlier is a data point that lies far outside the range of most other values in your dataset. For example, in a list of incomes, most people might earn between $30,000 and $70,000, but someone earning $5,000,000 would be an outlier.
Why Are Outliers Important?
Outliers can be problematic or insightful:
Problematic Outliers: Errors in data entry, sensor faults, or sampling issues.
Insightful Outliers: They might indicate fraud, unusual trends, or new patterns.
Types of Outliers
1. Univariate Outliers: These are extreme values in a single variable.
Example: A temperature of 300°F in a dataset about room temperatures.
2. Multivariate Outliers: These involve unusual combinations of values in multiple variables.
Example: A person with an unusually high income but a very low age.
3. Contextual Outliers: These depend on the context.
Example: A high temperature in winter might be an outlier, but not in summer.
2. Outlier Detection and Removal Using the IQR Method
The Interquartile Range (IQR) method is one of the simplest ways to detect outliers. It works by identifying the middle 50% of your data and marking anything that falls far outside this range as an outlier.
Steps:
1. Calculate the 25th percentile (Q1) and 75th percentile (Q3) of your data.
2. Compute the IQR:
{IQR} = Q3 - Q1
Q1 - 1.5 \times \text{IQR}
Q3 + 1.5 \times \text{IQR} ] 4. Anything below the lower bound or above the upper bound is an outlier.
Python Example:
import pandas as pd
# Sample dataset
data = {'Values': [12, 14, 18, 22, 25, 28, 32, 95, 100]}
df = pd.DataFrame(data)
# Calculate Q1, Q3, and IQR
Q1 = df['Values'].quantile(0.25)
Q3 = df['Values'].quantile(0.75)
IQR = Q3 - Q1
# Define the bounds
lower_bound = Q1 - 1.5 * IQR
upper_bound = Q3 + 1.5 * IQR
# Identify and remove outliers
outliers = df[(df['Values'] < lower_bound) | (df['Values'] > upper_bound)]
print("Outliers:\n", outliers)
filtered_data = df[(df['Values'] >= lower_bound) & (df['Values'] <= upper_bound)]
print("Filtered Data:\n", filtered_data)
Key Points:
The IQR method is great for univariate datasets.
It works well when the data isn’t skewed or heavily distributed.
3. Outlier Detection and Removal Using the Z-Score Method
The Z-score method measures how far a data point is from the mean, in terms of standard deviations. If a Z-score is greater than a certain threshold (commonly 3 or -3), it is considered an outlier.
Formula:
Z = \frac{(X - \mu)}{\sigma}
is the data point,
is the mean of the dataset,
is the standard deviation.
Python Example:
import numpy as np
# Sample dataset
data = {'Values': [12, 14, 18, 22, 25, 28, 32, 95, 100]}
df = pd.DataFrame(data)
# Calculate mean and standard deviation
mean = df['Values'].mean()
std_dev = df['Values'].std()
# Compute Z-scores
df['Z-Score'] = (df['Values'] - mean) / std_dev
# Identify and remove outliers
threshold = 3
outliers = df[(df['Z-Score'] > threshold) | (df['Z-Score'] < -threshold)]
print("Outliers:\n", outliers)
filtered_data = df[(df['Z-Score'] <= threshold) & (df['Z-Score'] >= -threshold)]
print("Filtered Data:\n", filtered_data)
Key Points:
The Z-score method assumes the data follows a normal distribution.
It may not work well with skewed datasets.
4. Outlier Detection Using the Percentile Method and Winsorization
Percentile Method:
In the percentile method, we define a lower percentile (e.g., 1st percentile) and an upper percentile (e.g., 99th percentile). Any value outside this range is treated as an outlier.
Winsorization:
Winsorization is a technique where outliers are not removed but replaced with the nearest acceptable value.
Python Example:
from scipy.stats.mstats import winsorize
import numpy as np
Sample data
data = [12, 14, 18, 22, 25, 28, 32, 95, 100]
Calculate percentiles
lower_percentile = np.percentile(data, 1)
upper_percentile = np.percentile(data, 99)
Identify outliers
outliers = [x for x in data if x < lower_percentile or x > upper_percentile]
print("Outliers:", outliers)
# Apply Winsorization
winsorized_data = winsorize(data, limits=[0.01, 0.01])
print("Winsorized Data:", list(winsorized_data))
Key Points:
Percentile and Winsorization methods are useful for skewed data.
Winsorization is preferred when data integrity must be preserved.
Final Thoughts
Outliers can be tricky, but understanding how to detect and handle them is a key skill in machine learning and data science. Whether you use the IQR method, Z-score, or Wins
orization, always tailor your approach to the specific dataset you’re working with.
By mastering these techniques, you’ll be able to clean your data effectively and improve the accuracy of your models.
#science#skills#programming#bigdata#books#machinelearning#artificial intelligence#python#machine learning#data centers#outliers#big data#data analysis#data analytics#data scientist#database#datascience#data
3 notes
·
View notes
Text
What are the latest trends in the IT job market?

Introduction
The IT job market is changing quickly. This change is because of new technology, different employer needs, and more remote work.
For jobseekers, understanding these trends is crucial to positioning themselves as strong candidates in a highly competitive landscape.
This blog looks at the current IT job market. It offers insights into job trends and opportunities. You will also find practical strategies to improve your chances of getting your desired role.
Whether you’re in the midst of a job search or considering a career change, this guide will help you navigate the complexities of the job hunting process and secure employment in today’s market.
Section 1: Understanding the Current IT Job Market
Recent Trends in the IT Job Market
The IT sector is booming, with consistent demand for skilled professionals in various domains such as cybersecurity, cloud computing, and data science.
The COVID-19 pandemic accelerated the shift to remote work, further expanding the demand for IT roles that support this transformation.
Employers are increasingly looking for candidates with expertise in AI, machine learning, and DevOps as these technologies drive business innovation.
According to industry reports, job opportunities in IT will continue to grow, with the most substantial demand focused on software development, data analysis, and cloud architecture.
It’s essential for jobseekers to stay updated on these trends to remain competitive and tailor their skills to current market needs.
Recruitment efforts have also become more digitized, with many companies adopting virtual hiring processes and online job fairs.
This creates both challenges and opportunities for job seekers to showcase their talents and secure interviews through online platforms.
NOTE: Visit Now
Remote Work and IT
The surge in remote work opportunities has transformed the job market. Many IT companies now offer fully remote or hybrid roles, which appeal to professionals seeking greater flexibility.
While remote work has increased access to job opportunities, it has also intensified competition, as companies can now hire from a global talent pool.
Section 2: Choosing the Right Keywords for Your IT Resume
Keyword Optimization: Why It Matters
With more employers using Applicant Tracking Systems (ATS) to screen resumes, it’s essential for jobseekers to optimize their resumes with relevant keywords.
These systems scan resumes for specific words related to the job description and only advance the most relevant applications.
To increase the chances of your resume making it through the initial screening, jobseekers must identify and incorporate the right keywords into their resumes.
When searching for jobs in IT, it’s important to tailor your resume for specific job titles and responsibilities. Keywords like “software engineer,” “cloud computing,” “data security,” and “DevOps” can make a huge difference.
By strategically using keywords that reflect your skills, experience, and the job requirements, you enhance your resume’s visibility to hiring managers and recruitment software.
Step-by-Step Keyword Selection Process
Analyze Job Descriptions: Look at several job postings for roles you’re interested in and identify recurring terms.
Incorporate Specific Terms: Include technical terms related to your field (e.g., Python, Kubernetes, cloud infrastructure).
Use Action Verbs: Keywords like “developed,” “designed,” or “implemented” help demonstrate your experience in a tangible way.
Test Your Resume: Use online tools to see how well your resume aligns with specific job postings and make adjustments as necessary.
Section 3: Customizing Your Resume for Each Job Application
Why Customization is Key
One size does not fit all when it comes to resumes, especially in the IT industry. Jobseekers who customize their resumes for each job application are more likely to catch the attention of recruiters. Tailoring your resume allows you to emphasize the specific skills and experiences that align with the job description, making you a stronger candidate. Employers want to see that you’ve taken the time to understand their needs and that your expertise matches what they are looking for.
Key Areas to Customize:
Summary Section: Write a targeted summary that highlights your qualifications and goals in relation to the specific job you’re applying for.
Skills Section: Highlight the most relevant skills for the position, paying close attention to the technical requirements listed in the job posting.
Experience Section: Adjust your work experience descriptions to emphasize the accomplishments and projects that are most relevant to the job.
Education & Certifications: If certain qualifications or certifications are required, make sure they are easy to spot on your resume.
NOTE: Read More
Section 4: Reviewing and Testing Your Optimized Resume
Proofreading for Perfection
Before submitting your resume, it’s critical to review it for accuracy, clarity, and relevance. Spelling mistakes, grammatical errors, or outdated information can reflect poorly on your professionalism.
Additionally, make sure your resume is easy to read and visually organized, with clear headings and bullet points. If possible, ask a peer or mentor in the IT field to review your resume for content accuracy and feedback.
Testing Your Resume with ATS Tools
After making your resume keyword-optimized, test it using online tools that simulate ATS systems. This allows you to see how well your resume aligns with specific job descriptions and identify areas for improvement.
Many tools will give you a match score, showing you how likely your resume is to pass an ATS scan. From here, you can fine-tune your resume to increase its chances of making it to the recruiter’s desk.
Section 5: Trends Shaping the Future of IT Recruitment
Embracing Digital Recruitment
Recruiting has undergone a significant shift towards digital platforms, with job fairs, interviews, and onboarding now frequently taking place online.
This transition means that jobseekers must be comfortable navigating virtual job fairs, remote interviews, and online assessments.
As IT jobs increasingly allow remote work, companies are also using technology-driven recruitment tools like AI for screening candidates.
Jobseekers should also leverage platforms like LinkedIn to increase visibility in the recruitment space. Keeping your LinkedIn profile updated, networking with industry professionals, and engaging in online discussions can all boost your chances of being noticed by recruiters.
Furthermore, participating in virtual job fairs or IT recruitment events provides direct access to recruiters and HR professionals, enhancing your job hunt.
FAQs
1. How important are keywords in IT resumes?
Keywords are essential in IT resumes because they ensure your resume passes through Applicant Tracking Systems (ATS), which scans resumes for specific terms related to the job. Without the right keywords, your resume may not reach a human recruiter.
2. How often should I update my resume?
It’s a good idea to update your resume regularly, especially when you gain new skills or experience. Also, customize it for every job application to ensure it aligns with the job’s specific requirements.
3. What are the most in-demand IT jobs?
Some of the most in-demand IT jobs include software developers, cloud engineers, cybersecurity analysts, data scientists, and DevOps engineers.
4. How can I stand out in the current IT job market?
To stand out, jobseekers should focus on tailoring their resumes, building strong online profiles, networking, and keeping up-to-date with industry trends. Participation in online forums, attending webinars, and earning industry-relevant certifications can also enhance visibility.
Conclusion
The IT job market continues to offer exciting opportunities for jobseekers, driven by technological innovations and changing work patterns.
By staying informed about current trends, customizing your resume, using keywords effectively, and testing your optimized resume, you can improve your job search success.
Whether you are new to the IT field or an experienced professional, leveraging these strategies will help you navigate the competitive landscape and secure a job that aligns with your career goals.
NOTE: Contact Us
2 notes
·
View notes
Text
Is it possible to transition to a data scientist from a non-tech background at the age of 28?
Hi,
You can certainly shift to become a data scientist from a nontechnical background at 28. As a matter of fact, very many do. Most data scientists have actually shifted to this field from different academic and professional backgrounds, with some of them having changed careers even in their midlife years.

Build a Strong Foundation:
Devour some of the core knowledge about statistics, programming, and data analysis. Online classes, bootcamps—those are good and many, many convenient resources. Give it a whirl with Coursera and Lejhro for specific courses related to data science, machine learning and programming languages like Python and R.
A data scientist needs to be proficient in at least one or two programming languages. Python is the most used language for data science, for it is simple, and it has many libraries. R is another language that might come in handy for a data scientist, mostly in cases connected with statistical analysis. The study of manipulation libraries for study data and visualization tools includes Pandas for Python and Matplotlib and Seaborn for data, respectively.
Develop Analytical Skills:
The field of data science includes much analytics and statistics. Probability, hypothesis testing, regression analysis would be essential. These skills will help you derive meaningful information out of the data and also allow you to use statistical methods for real-world problems.
Practical experience is very important in the field of data science. In order to gain experience, one might work on personal projects or contribute to open-source projects in the same field. For instance, data analysis on publicly available datasets, machine learning, and creating models to solve particular problems, all these steps help to make the field more aware of skills with one's profile.
Though formal education in data science is by no means a requirement, earning a degree or certification in the discipline you are considering gives you great credibility. Many reputed universities and institutions offer courses on data science, machine learning, and analytics.
Connect with professionals in the same field: try to be part of communities around data science and attend events as well. You would be able to find these opportunities through networking and mentoring on platforms like LinkedIn, Kaggle, and local meetups. This will keep you abreast of the latest developments in this exciting area of research and help you land job opportunities while getting support.
Look out for entry-level job opportunities or internships in the field of data science; this, in effect, would be a great way to exercise your acquired experience so far. Such positions will easily expose one to a real-world problem related to data and allow seizing the occasion to develop practical skills. These might be entry-level positions, such as data analysts or junior data scientists, to begin with.
Stay Current with Industry Trends: Data science keeps on evolving with new techniques, tools, and technologies. Keep up to date with the latest trends and developments in the industry by reading blogs and research papers online and through courses.
Conclusion:
It is definitely possible to move into a data scientist role if one belongs to a non-tech profile and is eyeing this target at the age of 28. Proper approach in building the base of strong, relevant skills, gaining practical experience, and networking with industry professionals helps a lot in being successful in the transition. This is because data science as a field is more about skills and the ability to solve problems, which opens its doors to people from different backgrounds.
#bootcamp#data science course#datascience#python#big data#machinelearning#data analytics#ai#data privacy
3 notes
·
View notes
Text
From Zero to Hero: Grow Your Data Science Skills
Understanding the Foundations of Data Science
We produce around 2.5 quintillion bytes of data worldwide, which is enough to fill 10 million DVDs! That huge amount of data is more like a goldmine for data scientists, they use different tools and complex algorithms to find valuable insights.
Here's the deal: data science is all about finding valuable insights from the raw data. It's more like playing a jigsaw puzzle with a thousand parts and figuring out how they all go together. Begin with the basics, Learn how to gather, clean, analyze, and present data in a straightforward and easy-to-understand way.
Here Are The Skill Needed For A Data Scientists
Okay, let’s talk about the skills you’ll need to be a pro in data science. First up: programming. Python is your new best friend, it is powerful and surprisingly easy to learn. By using the libraries like Pandas and NumPy, you can manage the data like a pro.
Statistics is another tool you must have a good knowledge of, as a toolkit that will help you make sense of all the numbers and patterns you deal with. Next is machine learning, and here you train the data model by using a huge amount of data and make predictions out of it.
Once you analyze and have insights from the data, and next is to share this valuable information with others by creating simple and interactive data visualizations by using charts and graphs.
The Programming Language Every Data Scientist Must Know
Python is the language every data scientist must know, but there are some other languages also that are worth your time. R is another language known for its statistical solid power if you are going to deal with more numbers and data, then R might be the best tool for you.
SQL is one of the essential tools, it is the language that is used for managing the database, and if you know how to query the database effectively, then it will make your data capturing and processing very easy.
Exploring Data Science Tools and Technologies
Alright, so you’ve got your programming languages down. Now, let’s talk about tools. Jupyter Notebooks are fantastic for writing and sharing your code. They let you combine code, visualizations, and explanations in one place, making it easier to document your work and collaborate with others.
To create a meaningful dashboard Tableau is the tool most commonly used by data scientists. It is a tool that can create interactive dashboards and visualizations that will help you share valuable insights with people who do not have an excellent technical background.
Building a Strong Mathematical Foundation
Math might not be everyone’s favorite subject, but it’s a crucial part of data science. You’ll need a good grasp of statistics for analyzing data and drawing conclusions. Linear algebra is important for understanding how the algorithms work, specifically in machine learning. Calculus helps optimize algorithms, while probability theory lets you handle uncertainty in your data. You need to create a mathematical model that helps you represent and analyze real-world problems. So it is essential to sharpen your mathematical skills which will give you a solid upper hand in dealing with complex data science challenges.
Do Not Forget the Data Cleaning and Processing Skills
Before you can dive into analysis, you need to clean the data and preprocess the data. This step can feel like a bit of a grind, but it’s essential. You’ll deal with missing data and decide whether to fill in the gaps or remove them. Data transformation normalizing and standardizing the data to maintain consistency in the data sets. Feature engineering is all about creating a new feature from the existing data to improve the models. Knowing this data processing technique will help you perform a successful analysis and gain better insights.
Diving into Machine Learning and AI
Machine learning and AI are where the magic happens. Supervised learning involves training models using labeled data to predict the outcomes. On the other hand, unsupervised learning assists in identifying patterns in data without using predetermined labels. Deep learning comes into play when dealing with complicated patterns and producing correct predictions, which employs neural networks. Learn how to use AI in data science to do tasks more efficiently.
How Data Science Helps To Solve The Real-world Problems
Knowing the theory is great, but applying what you’ve learned to real-world problems is where you see the impact. Participate in data science projects to gain practical exposure and create a good portfolio. Look into case studies to see how others have tackled similar issues. Explore how data science is used in various industries from healthcare to finance—and apply your skills to solve real-world challenges.
Always Follow Data Science Ethics and Privacy
Handling data responsibly is a big part of being a data scientist. Understanding the ethical practices and privacy concerns associated with your work is crucial. Data privacy regulations, such as GDPR, set guidelines for collecting and using data. Responsible AI practices ensure that your models are fair and unbiased. Being transparent about your methods and accountable for your results helps build trust and credibility. These ethical standards will help you maintain integrity in your data science practice.
Building Your Data Science Portfolio and Career
Let’s talk about careers. Building a solid portfolio is important for showcasing your skills and projects. Include a variety of projects that showcase your skills to tackle real-world problems. The data science job market is competitive, so make sure your portfolio is unique. Earning certifications can also boost your profile and show your dedication in this field. Networking with other data professionals through events, forums, and social media can be incredibly valuable. When you are facing job interviews, preparation is critical. Practice commonly asked questions to showcase your expertise effectively.
To Sum-up
Now you have a helpful guideline to begin your journey in data science. Always keep yourself updated in this field to stand out if you are just starting or want to improve. Check this blog to find the best data science course in Kolkata. You are good to go on this excellent career if you build a solid foundation to improve your skills and apply what you have learned in real life.
2 notes
·
View notes
Text
Essential Skills for Aspiring Data Scientists in 2024

Welcome to another edition of Tech Insights! Today, we're diving into the essential skills that aspiring data scientists need to master in 2024. As the field of data science continues to evolve, staying updated with the latest skills and tools is crucial for success. Here are the key areas to focus on:
1. Programming Proficiency
Proficiency in programming languages like Python and R is foundational. Python, in particular, is widely used for data manipulation, analysis, and building machine learning models thanks to its rich ecosystem of libraries such as Pandas, NumPy, and Scikit-learn.
2. Statistical Analysis
A strong understanding of statistics is essential for data analysis and interpretation. Key concepts include probability distributions, hypothesis testing, and regression analysis, which help in making informed decisions based on data.
3. Machine Learning Mastery
Knowledge of machine learning algorithms and frameworks like TensorFlow, Keras, and PyTorch is critical. Understanding supervised and unsupervised learning, neural networks, and deep learning will set you apart in the field.
4. Data Wrangling Skills
The ability to clean, process, and transform data is crucial. Skills in using libraries like Pandas and tools like SQL for database management are highly valuable for preparing data for analysis.
5. Data Visualization
Effective communication of your findings through data visualization is important. Tools like Tableau, Power BI, and libraries like Matplotlib and Seaborn in Python can help you create impactful visualizations.
6. Big Data Technologies
Familiarity with big data tools like Hadoop, Spark, and NoSQL databases is beneficial, especially for handling large datasets. These tools help in processing and analyzing big data efficiently.
7. Domain Knowledge
Understanding the specific domain you are working in (e.g., finance, healthcare, e-commerce) can significantly enhance your analytical insights and make your solutions more relevant and impactful.
8. Soft Skills
Strong communication skills, problem-solving abilities, and teamwork are essential for collaborating with stakeholders and effectively conveying your findings.
Final Thoughts
The field of data science is ever-changing, and staying ahead requires continuous learning and adaptation. By focusing on these key skills, you'll be well-equipped to navigate the challenges and opportunities that 2024 brings.
If you're looking for more in-depth resources, tips, and articles on data science and machine learning, be sure to follow Tech Insights for regular updates. Let's continue to explore the fascinating world of technology together!
#artificial intelligence#programming#coding#python#success#economy#career#education#employment#opportunity#working#jobs
2 notes
·
View notes