#kernel mode heap
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr was created by web developers David Karp and Marco Arment.
Text
>be me
>using laptop
>try and watch a movie on jellyfin
>KERNEL_MODE_HEAP_CORRUPTION
>mfw.jpg

3 notes
·
View notes
Text
Computing nonverbs
Abstract
Active
Ad hoc
Analogue
Argument
Array
Atomic
Attribute
Bay
Bit
Bitmap
Block
Bounds
Branch
Buffer
Bus
Busy
Byte
Cache
Canonical
Capability
Case
Chain
Channel
Character
Checkpoint
Checksum
Child
Chunk
Ciphertext
Class
Client
Clipboard
Clock
Command
Complement
Composite
Concurrent
Condition
Confidentiality
Constant
Context
Continuous
Control
Core dump
Credential
Cursor
Cut
Cycle
Cylinder
Datagram
Dependency
Device
Digital
Direct
Discrete
Document
Domain
Drum
Dynamic
Enclosure
End
Environment
Exception
External
Factor
Fault
Field
File
Flag
Fork
Form
Fragment
Frame
Free
Fresh
Gate
Global
Glyph
Guard
Hash
Head
Heap
Host
Image
Immediate
Implicit
Index
Indirect
Input
Instruction
Instrument
Integer
Integrity
Internal
Kernel
Key
Kind
Language
Layer
Layout
Leaf
Lexical
Line
Local
Lock
Log
Login
Manual
Matrix
Mechanism
Memory
Meta
Method
Mirror
Mode
Module
Monitor
Name
Native
Node
Notation
Null
Object
Octet
Offset
Orthogonal
Output
Overlay
Pack
Package
Packet
Parallel
Parametric
Parent
Parity
Passive
Paste
Path
Pixel
Plaintext
Polymorphism
Precision
Principal
Privilege
Promiscuous
Property
Protocol
Range
Receive
Record
Reflection
Register
Regular
Relation
Relative
Ring
Root
Route
Routine
Sample
Scalar
Scope
Script
Semaphore
Sensitive
Server
Slice
Source
Stack
Stale
State
Statement
Static
Stream
Stride
String
Structure
Switch
Symbol
Syntax
Table
Tag
Tail
Target
Terminal
Thread
Ticket
Timestamp
Token
Tool
Transfer
Transition
Transmit
Transparent
Tree
Type
Union
Unit
Unreliable
User
Valid
Value
Variable
Vector
Violation
Virtual
Volatile
Wait
Watchdog
0 notes
Photo

Sometimes it happens that you are using your Windows system and get a pop-up error message saying kernel mode heap corruption. It is basically shown that your Windows system needs a restart, and the screen turns into blue. Don’t need to worry about this problem, here are many users who face this issue. Read this full article to get the exact causes and solutions or simply call us on (866)558-4555.
0 notes
Link
#Kernel Mode Heap Corruption#Kernel Mode Heap Corruption on Windows 10#kernel-mode heap corruption windows 10 error#free driver updater
0 notes
Text
How to Fix Kernel Mode Heap Corruption
You may get the Kernel Mode Heap Corruption error while using your computer. The BSOD error is quite common and easy to fix. In this article, you will get to know the steps to fix Kernel mode heap corruption error.
Here’s How to Fix Kernel Mode Heap Corruption

• Check for incompatible program
Click on the Windows and R keys together.
Enter “appwiz.cpl” in the prompt box.
Click on the Enter option.
You will get all the installed app on the PC.
You need to right-click on that application, which is creating this issue.
Start the system once you have completed the uninstallation procedure.
You need to check whether the Kernel mode is fixed or not.
• Check your drivers for errors
Click on the Windows and S keys together.
Enter “command prompt” in the prompt box.
You need to right-click on the app.
Choose the Run as administrator option.
After opening the elevated command pop up box, run the below-mentioned command:
verifier
Choose the “Create standard settings” option.
Click on the Next option.
Choose the Automatically select all drivers installed on this computer option.
Press on the Finish option.
Windows start scanning the errors.
You should backup your data first.
If it asks you to restart the system, then you need to do this.
When you open your Windows PC, you will find that all the drivers are already installed on the system.
• Update Drivers
Click on the Windows and R keys together.
It will open the Run prompt box.
Enter “devmgmt.msc” in the prompt box.
Press on the Enter button
It will open the device manager on the PC.
Now, you will get the menu list of all the installed devices against the PC.
Go through all the installed devices.
Search for that application, which is causing this issue.
Press on the Display adapters pulldown to get the installed card.
You need to right-click on the installed card.
Choose the “Update driver” option.
You will get the prompt box.
Choose the Search automatically for updated driver software option.
In case you are not able to update the drivers, then go to the online manufacturer website.
Start downloading the drivers.
You need to choose the second option.
Start updating all the drivers before you start the PC again.
Once you have gone through the restarting process, check whether this issue is fixed or not.
• Perform a System Restore
Click on the Windows and S keys together.
It will open the start menu text field.
Enter “restore” in the prompt box.
Choose the software which is on the top of the screen.
Click on the System Restore option.
It is located in the restore settings tab.
The System Restore option is located at the upper side of the screen below the System Protection option.
In case you wish to choose the custom to restore option, then press on the option.
After that, choose the restore point option by going to the menu list of all the options that are available now.
In case you have multiple systems restore points, then they will be listed in the restore point window.
The Windows will verify the action before starting the restoring process of the computer.
After completing the restore process, sign in to the computer.
Check whether you are getting the blue screen.
Eleanor is a jack of all trades : an experienced IT technicians, writer, researcher, and a self-professed Software expert. As a single software engineer, she has in-depth knowledge of Webroot Antivirus and she likes to write tutorials, reviews, news, and reports about the same under webroot support number
Source: Fix Kernel Mode Heap Corruption
0 notes
Note
Oh, just now noticed your other writing prompts, but how about "the truth behind Laura's scary story"? If you still feel like doing those, of course!
The Truth Behind Laura’s Scary Story
So, this took me... a few hours. Hours in which I probably should have been working on my paper for Monday... but ah well. I’ll just do that after I eat dinner.
It is extremely spoiler filled, so proceed with caution. It is also around fifteen pages long.
Enjoy.
All legends contain a kernel of truth, and this one is no different.
Once upon a time, there was a husband and wife. They were deeply in love, but still very unhappy, for they did not have children. While the goddess they worshipped only had domain over time and space, not fertility, there were other deities out there in the Pantheon, and there was no harm to praying to one that did. So the wife prayed every day for a miracle and was ecstatic when her wish was granted and she gave birth to triplets: A beautiful, eldest boy, and two little girls—identical twin sisters. Their parents were overjoyed, as the children seemed perfect in every way.
…Well, every way but one. Unfortunately, they had inherited their father’s bad genetics when it came to their eyes: they all had coloboma of the iris. They were a bit larger than usual, and the parents feared initially that it may be edging into aniridia territory, but, thankfully, the doctor determined that it just looked like that because the babies’ eyes were still small and developing. So while they would end up with some parts of their irises missing, it wouldn’t be enough that they would suffer too many vision problems—especially if their parents were careful and got them floppy hats and sunglasses to shade and protect their eyes (note—I am not an ophthalmologist or optometrist, I have no idea if this medically correct, though I do know those two conditions exist and cause some interesting and sometimes debilitating eye problems). It was a bit of a shame that it obscured their pretty, baby-blue eyes though. But their mother had the same blue eyes as an adult, so at least a bit of that beautiful color would probably stay with them for the rest of their lives.
They named the boy Eugene, the youngest girl Jessica, and, the eldest girl… well, the eldest girl was to have a very special name. You see, Relatia’s people were in a period of transition. A few months after her 92nd birthday, the Previous Rainbow Child died peacefully in her sleep. No muss or fuss or overt tragedy—she was just old, and it was her time to go. But today, ah, today was the date that she always returned, and while seven months wasn’t quite long enough for a baby to grow to full term, it was still sufficient for a life to survive, and even thrive, under the right conditions, so she was guaranteed to be born somewhere in the world today. Sure, despite many girls being born among Relatia’s people on this day, none had the characteristic Rainbow eyes, but that happened sometimes. The last Rainbow Child, for instance, had been born in a place called “France,” and search parties had to be sent out to find her and bring her back to her true people, so that’s what would happen this time as well. …Hopefully the searchers that were sent this time would be smarter and kinder about it. Relatia had not been pleased when she found out that the searchers she had sent had basically grabbed the child from the middle of the park she was playing in—without informing her parents, or getting their permission. That… had not been pretty, especially since it took a few months for her to be informed of this since obviously the searchers weren’t going to tell her, and the nascent Rainbow Child could not speak English yet. The point was, today was a propitious day, as the period of tense waiting, almost a second mourning, was finally ended, and people could start transitioning into a more welcoming mode and prepare the new generation for the ascension in 13 years. And as it was such a propitious day, and the couple decide to gift their eldest daughter with the popular and propitious name of “Laura.”
I feel it is important to note here that there are many signs that point towards a Rainbow Child. There are the obvious ones such as the Birthday and eye color, and, yes, even the name at times, depending on where she came from/who gave it to her, but those are not always the best ways to tell. As evidenced here, many girls and boys can share a Birthday, and a name… and since eye color is dependent on the iris, even—at least partially, since high amounts of spiritual power/aura can also affect things—in the case of the Rainbow Child… if there is a physical problem with her eyes like, say, coloboma (or turning into a treecko, in one notable case), then one cannot depend on the obvious signs. The eyes may be the window to the soul, but it’s really hard to see things clearly if the window is dirty or broken. In this case, one has to depend on the invisible signs. Among them are the common—love of heights and painting—as well as the uncommon—i.e., the Dimensional Scream ability.
So imagine the parents shock when, at age five, little Jessica came home from a day of play with her siblings, crying about something scary she saw earlier—one of their close neighbors tripping over a rock and getting a bloody gash on his forehead. Of course, the girl’s mother immediately went next door to check on him, and he was perfectly fine. So she scolded her little girl for telling falsehoods… and then had to apologize the next day when the man came home from the healer’s with a bandaged head from where he tripped over a rock and cut a bloody gash in it.
So little Eugene, Laura, and Jessica’s parents immediately took Jessica to the high priest/ess, who called for Relatia, and, lo and behold, it was determined that Jessica was, in fact, the nascent Rainbow Child.
At this point, any sane parent would tell their little girl what was going on, right? If not that she was the actual Rainbow Child—since that is, admittedly, a lot of responsibility to heap on a five year old who doesn’t even know how to read yet—then at least that they found out something special about her, and that in the future she would need some extra lessons in order to help her understand some things and make sure that things were easier for her when she was older, and that of course they loved and cared for her brother and sister just as much as they always had, and, y’know, it might not be a half bad idea to offer them some more lessons and training as well, since the bond between siblings is often very strong and this is going to have a big impact on them in future? Well, you would be right.
Unfortunately, these were not any sane parents, and while there was no doubt that they loved their children, all their children, just as much has they did before, the prospect of having a famous child and more direct attention from their goddess went way, way to their heads. So they decided that their first course of action was to force their daughters to switch names. And then not tell them why. And then force the new Laura into some intensive training and classes… and not tell any of their kids why, or what they were for.
This, of course, led to extreme jealousy and hurt in the new Jessica, who had liked her old name and didn’t understand why her sister got to take both it and a lot more of Mommy and Daddy’s attention, and confusion, jealousy, and hurt from the new Laura, who didn’t want a new name, and who wanted to be able to go and play outside all day like she used to, like her siblings still could, like they were all supposed to since Mommy and Daddy had said they wouldn’t start school until they were six. And poor, poor Eugene was pretty much shuffled off to the side—a bit jealous at the lack of attention, but mostly upset that it meant he was the only available target for the new Jessica’s anger and unhappiness since, again, his parents and other sister were now sequestered away a lot of the time.
The siblings’ relationship only deteriorated from there—though there were some moments of unity and closeness, where they decided to just forgo their parents’ names altogether and call each other by special nicknames. Iris, for the new Jessica, because of the coloboma messing with her irises. Pupil for the new Laura, both because it was a play on the eye condition she shared with her sister and the alternate definition of the word—a student—because of how much of her time was now spent studying. Genie for Eugene, since they couldn’t think of any more eye puns and Pupil shared the same sorts of nicknaming conventions that her eventual successor would have—which, really, should have been another early indicator of who she was, as she had practically forced everyone to call her “Jessie” when her legal name had still been Jessica.
But, again, though these small moments of unity existed, they were not enough to save the close relationship the siblings once had—one close enough that they used to count as her partners when it came to the Dimensional Scream. But gradually those slowed down as trust was lost. Jealously can lead people to act very badly, and, in a desperate bid for attention, Iris would often act out causing problems and then blaming them on her sister. One would think that it would be obvious who exactly was acting out… but biases can do strange things to people as well. It isn’t uncommon to assume that children in positions of power will act like spoiled brats sometimes, so everyone assumed that the position of Rainbow Child had just gone to Pupil’s head, and made her act bratty—so, really, punishing her was a good thing, as it would teach her the humility she would need when she actually grew into her power. Of course, because the adults all knew who she was, as did the children when they turned 13, they forgot that Pupil would not assume she was anything other than an average child—albeit one with the Dimensional Scream ability—and so would have no idea the scrutiny her actions were put under. Complaints about the unfair treatment would, of course, only further the idea that she was a good-for-nothing brat who needed to learn some responsibility, and that her sister—who was, in reality, the true perpetrator of the misdeeds—was a real trooper, a little angel, and it must be so hard for her to try and resist her sister’s temptations, so of course a little misbehavior here and there is acceptable. She probably just wants some attention.
Genie, of course, was stuck between a rock and a hard place, because on the one hand, he actually bothered to check and differentiate between his sisters and knew who was really misbehaving—in part because Iris was quickly becoming a bully and would coerce him into helping her—so he knew that a lot of the treatment towards Pupil was unfair. On the other hand… going along with Iris’ plans still netted him some positive attention. And stopped her from punching him. So as much as he tried to play mediator or throw Pupil the occasional bone… he started to become a little bit of a bully as well. And yet… those occasional bones did let him continue to act as a Dimensional Scream partner, even if the resulting visions were far weaker than they should have been… but that only furthered the problems of the sibling dynamics.
Of course, pretty much all of this went over Relatia’s head, because everyone was nothing but doting towards Pupil whenever the goddess was around—which definitely caused some emotional whiplash—and the siblings actually genuinely got along more-or-less when she was around, because she loved to spend time with all of them—even if she still favored Pupil. She thought it was great that this Rainbow Child had a built-in set of friends and allies, and that she didn’t have to be lonely when Relatia was away. And no one—not even the children—would ever dare tell her otherwise because… well, she was a goddess. And even though she was typically benevolent, there were tons of stories about how volatile her temper could get, and exactly what happened when she was unhappy, and even if the kids didn’t really understand her interest, they knew enough to read the room and mood and determine for themselves that it probably wouldn’t end well for the majority of the townsfolk if they found out exactly what was going on when she wasn’t around.
But Relatia at least noticed enough to see that pupil was getting more stressed as she got older, even if she didn’t really know the cause, so when she and her siblings were about 12, she decided that she would take this nascent Rainbow Child on the traditional, at least once a lifetime Rainbow Child trip to the Pokémon World—maybe even extending the trip long enough for her to ascend there, if she seemed to be having a good time. So she packed everyone up and they headed to the pokemon world, arriving at the home of one of her liasons—a ninetales with an extremely powerful and potent grasp on the Dimensional Scream.
She had the group stay there for a little bit since the trip was short notice and those worshippers who lived in the pokemon world—human and pokemon alike—weren’t prepared for such a big group. This… was probably a mistake. Well, it was definitely a mistake, especially given what would happen later, but what was more of a mistake is the fact that Relatia didn’t stick around for introductions or instructions beyond “Don’t let these people die or wander away into the freezing cold mountains,” so Ninetales had no idea that the nascent Rainbow Child was part of the group. Or that she had two siblings—one of whom was an identical twin. Or that said twin had a wildly different personality to her given their upbringing, and that the reason she no longer really went out of her way to try and talk to people or start conversations was because she didn’t really expect kindness or belief any more from anyone who wasn’t Relatia or—occasionally—her siblings (meaning her brother, typically). Least of all from a strange adult pokemon who looked intimidating (as both an adult and as a pokemon in general, since this was Pupil’s first time seeing one in real life) and was already annoyed at having to play host to a bunch of strangers. The kids’ bratty behavior did not endear them to her at all—in Iris’ case because she was the one actually acting bratty and rude and in Genie’s case because he wasn’t stopping her, and Ninetales was too proud to deign to look beneath the surface and realize that it was out of fear of his sister’s behavior. And Pupil was so quiet as to be beneath her notice—Ninetales literally had no idea she was there, as any glimpses she saw she attributed to actually being glimpses of Iris—in part because Pupil was too nervous to really venture far from her parents while Iris had no such compunctions and basically went wherever she pleased in the cave—and assumed that these moments of silent staring and not acknowledging her complaints, lectures, and warnings, were more bouts of rudeness rather than a completely separate person who had no idea what she was talking about. Ninetales was glad when Relatia finally came back for them and she was left alone. She never wanted them to come back, ever, and swore that she wouldn’t help them of her own volition if they ever did come back.
Luckily, the group of people that Relatia took them to next had actually been prepped about the visitors’ identities and were very happy and willing to meet with everyone. They were also more open to people in general, and actually took the time to look beneath the surface and differentiate between the siblings. They didn’t put up with any of Iris’ nonsense, as they knew very well who was really causing all the trouble. But they still weren’t quite able to get to the bottom of the spoiled relationship or realize just how rotten it had become, nor did they bother to inform the parents about what was up—other than some raised eyebrows whenever the adults tried to claim that Pupil was in any way a brat.
There were also some pokemon in the group who became especially close to the triplets. A shuppet at first became close friends with Pupil, a gardevoir would become close with Genie, and a haunter would initially be interested in Iris. She was not very happy with this, especially when the haunter realized what a jerk she was and started to keep more of a distance and the shuppet realized that Iris had way more jealously that Pupil did and became fixated on her due to out of fascination/mild hunger. The gardevoir friendship was extremely unexpected… at least as first. But it became clearer as Genie could afford to let his walls down more in this new world, and could actually escape from Iris for a bit and act like a real brother to Pupil without fear of retribution. And Gardevoir could sense that from the beginning. Pupil, of course, was enthralled to find people who actually liked her and were nice to her… but she was still shy and wary. The siblings had a lot more free time in general in this world, in part because the whole thing was basically being treated as a learning experience for Pupil anyways and she was so close to ascension that formal lessons could be held off for now… as well as the fact the pokemon were subtly keeping her parents and the others from the human world away from her as much as possible since they could tell that something was wrong. Relatia was also too busy to keep that many tabs on her, since she had taken the group to some of her worshippers who lived in a different region than the Golden Child did—meaning she hadn’t had as much contact with them as she probably should, and the smaller amount of Time Gears in the area made things a bit more volatile in general. It was something of a work in progress, and the Golden Child was too busy with other things to join them right away.
This meant that it was fairly easy for Pupil to slip away to just hang out with her brother and gardevoir—and to start having Dimensional Screams again now that she could trust him better. She particularly liked hanging out on top of a cliff/bluff overlooking the sea—because the Rainbow Child is always fixated on tall things, the ocean, and combinations therof. This would eventually come back to bite her, hard, when Iris finally found out where she was going, about a week before their thirteenth birthday.
She was not happy. At all. Not with the fact that she wasn’t invited, not with the way things were going in general, not with how unfair and terrible all three of her siblings’ lives had been up to that point. So she took it out on Pupil, Pupil finally gained enough confidence to fight back, Genie tried to intervene because, despite everything, he really did love both his sisters, and, well…
The fact that they didn’t know whose fault it ultimately was would haunt them for the rest of their lives. Did Iris push her? Did Genie? Did she simply lose her footing? …Did she finally decide she couldn’t handle it any more and jump off herself?
Whatever the cause, the effect was Pupil, lying at the bottom of the cliff, blood everywhere… unconscious, but not quite dead. Not yet. And the very world itself seemed frantic to keep it that way. A Rainbow Child had never yet died before ascension, after all, and no one knew quite what would happen if Pupil was the first.
Iris freaked out and ran away, back to camp, both to try and hide the evidence and because she was horrified by what happened since, deep down, she still loved her sister dearly. But the others stayed. Haunter forced himself to evolve into Gengar so that he would be able to grab Pupil’s spirit and force it back if it tried to leave her body. Shuppet did his best to help. And Gardevoir somehow, someway used her powers to call for help—grabbing the greatest rescuer ever—a Lucario—from a distant time in order to help their group make it back to camp—not realizing at the time that she was actually creating a bit of a paradox, as it would be this rescue which would cement him in history as the greatest long before he was even born. As well as… one other effect, which would not become apparent until later, and which neither of them would probably realize the significance of in the aftermath. At least, not right away.
But in any case, they made it back to camp after an arduous journey. The Lucario was sent to his proper time once more. Pupil remained clinging to life by the barest threads, but it was hard. And Gengar and Shuppet were exhausted from their efforts. But they couldn’t exactly hand the task off to anyone else at this point, because the thread was so delicate that an attempt would likely snap it. Instead, some sort of power-up or psychic boost would be more helpful. Which is when Shuppet remembered that he’d heard something about ninetales’ tails being full of psychic energy—even down to the smallest bit of fur, and Genie remembered where a ninetales lived, and Garevoir remembered where she could acquire the TM for the move Teleport.
But none of them remembered that Ninetales all but hated Genie and his sister, nor did they realize that she had no idea that he had more than two.
Genie made it back, holding some fur which was full of psychic energy—and also, though unknown to him, slightly cursed. Gardevoir did not. And Genie refused to tell anyone what happened. Just as he, Iris, and the
But the fur worked, despite the curse. Though it did leave somewhat of an imprint of the events seared into Pupil’s unconscious psyche… a distorted version always staiying just in the back of mind, transcending all her lives in the form of a scary story. And she even woke up one last time, the morning of her thirteenth birthday, when energy coursed through her as she ascended. She didn’t have much time left, but what little time she did she used to bless her siblings.
For, you see, all legends have kernels of truth within in them, even as they become distorted over time. According to legend, Relatia is the one who charged the Time Gears. According to legend, Relatia is the one who blessed the Rainbow Child with the gift of reincarnation. But the truth is that Relatia had nothing to do with it—the Rainbow Child did both things all on her own. And she could tell that there was curse nearby, even if she was too out of it to determine which sibling it had been laid on. And she wanted another chance to know them, when their relationship wasn’t so tainted by what had happened in this life. So… she gave them a blessing. A small twist on the curse. One chance at reincarnation. One hope that they would meet again. No knowledge if she had done enough to let them remember, or if she—or the curse—would leave their memories in a state similar to hers whenever she reincarnated. And then she died.
And then her siblings found out that she was the Rainbow Child. And realized how much their lives had been ruined, despite knowing how much love persisted in their family, despite the rot. And Relatia took everyone home, and decided that it was too dangerous for the Rainbow Child to visit other worlds, and that she was too upset by this experience and wouldn’t come of her own volition anymore either—only if someone called her for help, like if Temporal Tower started to decay.
So people in the pokemon world gradually forgot the legends, and no one thought to call her when Temporal Tower started crumbling. And the Spirit Trio forgot the true purpose of the Time Gears. And when a Rainbow Child did finally return, it was nearly a thousand years later—possibly longer, since it’s kind of hard to tell how many years have actually passed when the world is paralyzed and the pokemon in charge of time has gone insane.
Meanwhile, upon return to the human world, Iris bolted pretty much immediately. She ran away from home and from her people as soon as she could, and no one really tried to stop her—beyond ensuring the typical protections so that Relatia’s people could remain secret and safe—and no one ever found out what happened to her. So her parents essentially lost both their daughters.
Genie stayed. He actually became an acolyte and guard… and fourteen or so years later, he met a blonde girl with eyes like rainbows, on the day of her ascension as the Rainbow Child. She was looking for her little brother, who had run away during preparations for her and her family’s parade through the crowd as part of the ceremony, since he was embarrassed and ashamed to show his facial scars to everyone in the crowd—facial scars which he shared with his sister, from the fire that killed their parents and was started when their alcoholic cousin, who was visiting at the time, fell asleep on the couch while smoking a cigarette. She and her brother had been living with their grandparents when she was found, and her grandparents had actually been very happy to bring the remains of their little family over to join Relatia’s people, as they thought a bit of change would be good for their darling grandchildren after all the trauma they’d endured. But she was still trying to get used to things—especially the new language, and the fact that everyone’s first instinct was to call her by a different name, “Laura,” than the one she’d used all her life, and she knew that her brother would still be in the same boat, and now hopelessly lost on top of everything else, so if Genie could please help her, that would be really great.
Genie asked if she recognized him. She said his outfit looked kind of familiar? Maybe she’d seen him around the temple? But that was it.
He asked for a posting in a temple far away, maybe by the portals which the Rainbow Child was now forbidden to visit?
His request was granted, and he lived a long, if quiet, life, and died peacefully in his sleep.
And nearly a thousand years later, he was reincarnated as a ghastly, with no memories of his former life until he turned thirteen and began remembering more, little by little. Starting with the fact that he used to be human.
And it wasn’t until the curse of Gardevoir—and the remnants on him which his former incarnation’s sister’s blessing couldn’t fully remove—that he started to remember he had siblings.
And it wasn’t until much, much later, that he began to remember everything that happened that fateful day on the cliff.
But he still never found out what caused his sister to fall.
But by that point… it didn’t really matter any more.
#pokemon mystery dungeon#explorers of sky#rescue team#the world's treasure#spoilers#fanfiction#writing
3 notes
·
View notes
Text
How To Fix Kernel Mode Heap Corruption Error In Windows 10
#windows
Kernel Mode Heap Corruption – BSODs should be a common thing to you by now as a Windows user. Kernel Mode Heap Corruption Error could be caused by outdated or malfunctioning drivers, memory leaks, and hardware faults. This article will explain how to fix the Kernel Mode Heap Corruption error. Here are some fixes to help resolve the Kernel Mode Heap Corruption blue screen error on Windows…

View On WordPress
0 notes
Text
Neo4j Python
要通过python来操作Neo4j,首先需要安装py2neo,可以直接使用pip安装。 pip install py2neo 在完成安装之后,在python中调用py2neo即可,常用的有Graph,Node,Relationship。 from py2neo import Graph,Node,Relationship 连接Neo4j的方法很简单:. The Python Driver 1.7 supports older versions of python, Neo4j 4.1 will work in fallback mode with that driver. Neo4j Cypher Tutorial With Python. In this course student will learn what is graph database, how it is different from traditional relational database, why graph database is important today, what is neo4j, why neo4j is the best graph database available in the market, students will also get the idea about cypher query and uses of cypher query(all CRUD operations and complete sets of uses cases.
Neo4j Python Book
Neo4jDeveloper(s)Neo4jInitial release2007; 14 years ago(1)Stable releaseRepositoryWritten inJavaTypeGraph databaseLicense
Source code:GPLv3 and AGPLv3
Binaries:Freemiumregisterware
Websiteneo4j.com
Neo4j (Network Exploration and Optimization 4 Java) is a graph database management system developed by Neo4j, Inc. Described by its developers as an ACID-compliant transactional database with native graph storage and processing,(3) Neo4j is available in a GPL3-licensed open-source 'community edition', with online backup and high availability extensions licensed under a closed-source commercial license.(4) Neo also licenses Neo4j with these extensions under closed-source commercial terms.(5)
Neo4j is implemented in Java and accessible from software written in other languages using the Cypher query language through a transactional HTTP endpoint, or through the binary 'bolt' protocol.(6)(7)(8)(9)
History(edit)
Version 1.0 was released in February 2010.(10)
Neo4j version 2.0 was released in December 2013.(11)
Neo4j version 3.0 was released in April 2016.(12)
In November 2016 Neo4j successfully secured $36M in Series D Funding led by Greenbridge Partners Ltd.(13)
In November 2018 Neo4j successfully secured $80M in Series E Funding led by One Peak Partners and Morgan Stanley Expansion Capital, with participation from other investors including Creandum, Eight Roads and Greenbridge Partners.(14)
Release history(edit)
Release historyReleaseFirst release(15)Latest
minor version(16)
Latest release(16)End of Support Date(15)Milestones1.02010-02-23Old version, no longer maintained: 1.0N/A2011-08-23Kernel, Index, Remote-graphdb, Shell(17)1.12010-07-30Old version, no longer maintained: 1.1N/A2012-01-30Graph-algo, Online-backup(17)1.22010-12-29Old version, no longer maintained: 1.2N/A2012-06-29Server including Web Admin, High Availability, Usage Data Collection(17)1.32011-04-12Old version, no longer maintained: 1.3N/A2012-09-12Neo4j Community now licensed under GPL, 256 Billion database primitives, Gremlin 0.8(17)1.42011-07-08Old version, no longer maintained: 1.4N/A2013-01-08The first iteration of the Cypher Query Language, Experimental support for batch operations in REST1.52011-11-09Old version, no longer maintained: 1.5N/A2013-03-09Store Format Change, Added DISTINCT to all aggregate functions in Cypher,
New layout of the property store(s), Upgraded to Lucene version 3.5(17)
1.62012-01-22Old version, no longer maintained: 1.6N/A2013-07-22Cypher allShortestPaths, management bean for the diagnostics logging SPI, gremlin 1.4(17)1.72012-04-18Old version, no longer maintained: 1.7N/A2013-10-18Moved BatchInserter to a different package, lock free atomic array cache, GC monitor(17)1.82012-09-28Old version, no longer maintained: 1.8N/A2014-03-28Bidirectional traversals, Multiple start nodes(17)1.92013-05-21Old version, no longer maintained: 1.9.92014-10-132014-11-21Performance improvement on initial loading of relationship types during startup,
Pulled out Gremlin as separate plugin to support different versions(17)
2.02013-12-11Old version, no longer maintained: 2.0.42014-07-082015-06-11Extending model to “labeled” property graph and introduced visual IDE(17)(18)2.12014-05-29Old version, no longer maintained: 2.1.82015-04-012015-11-29Cypher new cost based planner, Fixes issue in ReferenceCache, potential omission, potential lock leak(17)2.22015-03-25Old version, no longer maintained: 2.2.102016-06-162016-09-25Massive Write Scalability, Massive Read Scalability, Cost-based query optimizer,
Query plan visualization(19)
2.32015-10-21Old version, no longer maintained: 2.3.122017-12-122017-04-21Break free of JVM-imposed limitations by moving the database cache off-heap,
Spring Data Neo4j 4.0, Neo4j-Docker Image, Windows Powershell Support, Mac Installer, and Launcher(20)
3.02016-04-16Old version, no longer maintained: 3.0.122017-10-032017-10-31user-defined/stored procedures called APOC (Awesome Procedures on Cypher),
Bolt binary protocol, in-house language drivers for Java, .NET, JavaScript and Python(21)(18)
3.12016-12-13Old version, no longer maintained: 3.1.92018-06-052018-06-13Causal Clustering, Enterprise-Class Security and Control, User-Defined Functions,
Neo4j IBM POWER8 CAPI Flash, User and role-based security and directory integrations(22)(18)
3.22017-05-11Old version, no longer maintained: 3.2.142019-02-262018-11-31Multi-Data Center Support, Causal Clustering API, Compiled Cypher Runtime, Node Keys,
Query Monitoring, Kerberos Encryption, Clustering on CAPI Flash, Schema constraints,
new indexes and new Cypher editor with syntax highlights and autocompletion(23)(18)
3.32017-10-24Old version, no longer maintained: 3.3.92018-11-022019-04-28Write performance is 55% faster than Neo4j 3.2, Neo4j Data Lake Integrator toolkit, Neo4j ETL(24)3.42018-05-17Old version, no longer maintained: 3.4.172019-11-192020-03-31Multi-Clustering, New Data Types for Space and Time, Performance Improvements(25)3.52018-11-29Older version, yet still maintained: 3.5.282021-04-202021-11-28Native indexing, Full-text search, The recommended index provider to use is native-btree-1.0(26)4.02020-01-15Older version, yet still maintained: 4.0.112021-01-112021-07-14Java 11 is required, Multiple databases, Internal metadata repository “system” database,
Schema-based security and Role-Based Access Control, Role and user management capabilities,
Sharding and federated access, A new neo4j:// scheme(27)(28)
4.12020-06-23Older version, yet still maintained: 4.1.82021-03-192021-12-23Graph privileges in Role-Based Access Control (RBAC) security, Database privileges for transaction management, Database management privileges, PUBLIC built-in role, Cluster Leadership Control, Cluster Leadership Balancing, Cypher Query Replanning Option, Cypher PIPELINED Runtime operators, Automatic routing of administration commands(29)4.22020-11-17Current stable version:4.2.5 2021-04-092022-05-16(Administration) ALIGNED store format, Procedures to observe the internal scheduler, Dynamic settings at startup, WAIT/NOWAIT in Database Management, Index and constraint administration commands, Filtering in SHOW commands, Backup/Restore improvements, Compress metrics on rotation, Database namespace for metrics, neo4j-admin improvements, HTTP port selective settings (Causal Cluster) Run/Pause Read Replicas, Database quarantine (Cypher) Planner improvements, Octal literals (Functions and Procedures) round() function, dbms.functions() procedure (Security) Procedures and user defined function privileges, Role-Based Access Control Default graph, PLAINTEXT and ENCRYPTED password in user creation, SHOW CURRENT USER, SHOW PRIVILEGES as commands, OCSP stapling support for Java driver(30)
Old version
Latest version
Future release
Licensing and editions(edit)
Neo4j comes in 2 editions: Community and Enterprise. It is dual-licensed: GPL v3 and a commercial license. The Community Edition is free but is limited to running on one node only due to the lack of clustering and is without hot backups.(31)
The Enterprise Edition unlocks these limitations, allowing for clustering, hot backups, and monitoring. The Enterprise Edition is available under a closed-source Commercial license.
Data structure(edit)
In Neo4j, everything is stored in the form of an edge, node, or attribute. Each node and edge can have any number of attributes. Both nodes and edges can be labelled. Labels can be used to narrow searches. As of version 2.0, indexing was added to Cypher with the introduction of schemas.(32) Previously, indexes were supported separately from Cypher.(33)
Neo4j, Inc.(edit)
Neo4j is developed by Neo4j, Inc., based in the San Francisco Bay Area, United States, and also in Malmö, Sweden. The Neo4j, Inc. board of directors consists of Michael Treskow (Eight Roads), Emmanuel Lang (Greenbridge), Christian Jepsen, Denise Persson (CMO of Snowflake), David Klein (One Peak), and Emil Eifrem (CEO of Neo4j).(34)
See also(edit)
References(edit)
^Neubauer, Peter (@peterneubauer) (17 Feb 2010). '@sarkkine #Neo4j was developed as part of a CMS SaaS 2000-2007, became released OSS 2007 when Neo Technology spun out' (Tweet) – via Twitter.
^https://neo4j.com/release-notes/neo4j-4-2-5/.
^Neo Technology. 'Neo4j Graph Database'. Retrieved 2015-11-04.
^Philip Rathle (November 15, 2018). 'Simplicity Wins: We're Shifting to an Open Core Licensing Model for Neo4j Enterprise Edition'. Retrieved 2019-01-16.
^Emil Eifrem (April 13, 2011). 'Graph Databases, Licensing and MySQL'. Archived from the original on 2011-04-26. Retrieved 2011-04-29.
^'Bolt Protocol'.
^Todd Hoff (June 13, 2009). 'Neo4j - a Graph Database that Kicks Buttox'. High Scalability. Possibility Outpost. Retrieved 2010-02-17.
^Gavin Terrill (June 5, 2008). 'Neo4j - an Embedded, Network Database'. InfoQ. C4Media Inc. Retrieved 2010-02-17.
^'5.1. Transactional Cypher HTTP endpoint'. Retrieved 2015-11-04.
^'The top 10 ways to get to know Neo4j'. Neo4j Blog. February 16, 2010. Retrieved 2010-02-17.
^'Neo4j 2.0 GA - Graphs for Everyone'. Neo4j Blog. December 11, 2013. Retrieved 2014-01-10.
^'Neo4j 3.0.0 - Neo4j Graph Database Platform'. Release Date. April 26, 2016. Retrieved 2020-04-23.
^'Neo Technology closes $36 million in funding as graph database adoption soars'. SiliconANGLE. Retrieved 2016-11-21.
^'Graph database platform Neo4j locks in $80 mln Series E'. PE Hub Wire. Archived from the original on 2019-04-26. Retrieved 2018-11-01.
^ ab'Neo4j Supported Versions'. Neo4j Graph Database Platform. Retrieved 2020-11-26.
^ ab'Release Notes Archive'. Neo4j Graph Database Platform. Retrieved 2021-04-20.
^ abcdefghijk'neo4j/neo4j'. GitHub. Retrieved 2020-01-28.
^ abcd'Neo4j Open Source Project'. Neo4j Graph Database Platform. Retrieved 2020-01-28.
^'Neo4j 2.2.0'. Neo4j Graph Database Platform. Retrieved 2020-01-28.
^'Neo4j 2.3.0'. Neo4j Graph Database Platform. Retrieved 2020-01-28.
^'Neo4j 3.0.0'. Neo4j Graph Database Platform. Retrieved 2020-01-28.
^'Neo4j 3.1.0'. Neo4j Graph Database Platform. Retrieved 2020-01-28.
^'Neo4j 3.2.0'. Neo4j Graph Database Platform. Retrieved 2020-01-28.
^'Neo4j 3.3.0'. Neo4j Graph Database Platform. Retrieved 2020-01-28.
^'Neo4j 3.4.0'. Neo4j Graph Database Platform. Retrieved 2020-01-28.
^'Neo4j 3.5.0'. Neo4j Graph Database Platform. Retrieved 2020-01-28.
^'Neo4j 4.0.0'. Neo4j Graph Database Platform. Retrieved 2020-01-28.
^'2.1. System requirements - Chapter 2. Installation'. neo4j.com. Retrieved 2020-01-28.
^'Neo4j 4.1.0'. Neo4j Graph Database Platform. Retrieved 2020-06-23.
^'Neo4j 4.2.0'. Neo4j Graph Database Platform. Retrieved 2020-11-26.
^'The Neo4j Editions'.
^'The Neo4j Manual v2.1.5'.
^'The Neo4j Manual v1.8.3'.
^Neo4j. 'Staff - Neo4j Graph Database'. Retrieved 2020-06-19.
External links(edit)
Official website
Neo4j Python Book
Retrieved from 'https://en.wikipedia.org/w/index.php?title=Neo4j&oldid=1020554218'
0 notes
Photo

Go and check our new article 8 assured and effective methods to fix "kernel mode heap corruption error" [2021] #troubleshooting #troubleshoot #troubleshooter #troubleshootinglife #troubleshooters #pc #pcproblems #pcmc #pcsetup #pcissues #laptop #laptopproblems #laptops #laptopproblem #laptopissues #pctroubleshooting #laptoptroubleshooting #windows10 #windows10home #windows10problems #microsoft #microsoftexcel @hp @hp_india @asus @asusindia @ibm @ibmdata @microsoft @windows @pctroubleshooter_ https://www.instagram.com/p/CPNMO8VMqzH/?utm_medium=tumblr
#troubleshooting#troubleshoot#troubleshooter#troubleshootinglife#troubleshooters#pc#pcproblems#pcmc#pcsetup#pcissues#laptop#laptopproblems#laptops#laptopproblem#laptopissues#pctroubleshooting#laptoptroubleshooting#windows10#windows10home#windows10problems#microsoft#microsoftexcel
0 notes
Text
Docker Machine Xhyve

Elasticsearch will then only be accessible from the host machine itself. The Docker named volumes data01, data02, and data03 store the node data directories so the data persists across restarts. If they don’t already exist, docker-compose creates them when you bring up the cluster. Make sure Docker Engine is allotted at least 4GiB of memory. Docker Engine 1.12 introduced a new swarm mode for natively managing a cluster of Docker Engines called a swarm. Docker swarm mode implements Raft Consensus Algorithm and does not require using external key value store anymore, such as Consul or etcd. If you want to run a swarm cluster on a developer’s machine, there are several options.
« Install Elasticsearch with Windows MSI InstallerInstall Elasticsearch on macOS with Homebrew »
Elasticsearch is also available as Docker images.The images use centos:8 as the base image.
A list of all published Docker images and tags is available atwww.docker.elastic.co. The source filesare inGithub.
This package contains both free and subscription features.Start a 30-day trial to try out all of the features.
Obtaining Elasticsearch for Docker is as simple as issuing a docker pull commandagainst the Elastic Docker registry.
To start a single-node Elasticsearch cluster for development or testing, specifysingle-node discovery to bypass the bootstrap checks:
Starting a multi-node cluster with Docker Composeedit
To get a three-node Elasticsearch cluster up and running in Docker,you can use Docker Compose:
This sample docker-compose.yml file uses the ES_JAVA_OPTSenvironment variable to manually set the heap size to 512MB. We do not recommendusing ES_JAVA_OPTS in production. See Manually set the heap size.
This sample Docker Compose file brings up a three-node Elasticsearch cluster.Node es01 listens on localhost:9200 and es02 and es03 talk to es01 over a Docker network.
Please note that this configuration exposes port 9200 on all network interfaces, and given howDocker manipulates iptables on Linux, this means that your Elasticsearch cluster is publically accessible,potentially ignoring any firewall settings. If you don’t want to expose port 9200 and instead usea reverse proxy, replace 9200:9200 with 127.0.0.1:9200:9200 in the docker-compose.yml file.Elasticsearch will then only be accessible from the host machine itself.
The Docker named volumesdata01, data02, and data03 store the node data directories so the data persists across restarts.If they don’t already exist, docker-compose creates them when you bring up the cluster.
Make sure Docker Engine is allotted at least 4GiB of memory.In Docker Desktop, you configure resource usage on the Advanced tab in Preference (macOS)or Settings (Windows).
Docker Compose is not pre-installed with Docker on Linux.See docs.docker.com for installation instructions:Install Compose on Linux
Run docker-compose to bring up the cluster:
Submit a _cat/nodes request to see that the nodes are up and running:
Log messages go to the console and are handled by the configured Docker logging driver.By default you can access logs with docker logs. If you would prefer the Elasticsearchcontainer to write logs to disk, set the ES_LOG_STYLE environment variable to file.This causes Elasticsearch to use the same logging configuration as other Elasticsearch distribution formats.

To stop the cluster, run docker-compose down.The data in the Docker volumes is preserved and loadedwhen you restart the cluster with docker-compose up.To delete the data volumes when you bring down the cluster,specify the -v option: docker-compose down -v.
See Encrypting communications in an Elasticsearch Docker Container andRun the Elastic Stack in Docker with TLS enabled.
The following requirements and recommendations apply when running Elasticsearch in Docker in production.
The vm.max_map_count kernel setting must be set to at least 262144 for production use.
How you set vm.max_map_count depends on your platform:
Linux
The vm.max_map_count setting should be set permanently in /etc/sysctl.conf:
To apply the setting on a live system, run:
macOS with Docker for Mac
The vm.max_map_count setting must be set within the xhyve virtual machine:
From the command line, run:
Press enter and use`sysctl` to configure vm.max_map_count:
To exit the screen session, type Ctrl a d.
Windows and macOS with Docker Desktop
The vm.max_map_count setting must be set via docker-machine:
Windows with Docker Desktop WSL 2 backend
The vm.max_map_count setting must be set in the docker-desktop container:
Configuration files must be readable by the elasticsearch useredit
By default, Elasticsearch runs inside the container as user elasticsearch usinguid:gid 1000:0.
One exception is Openshift,which runs containers using an arbitrarily assigned user ID.Openshift presents persistent volumes with the gid set to 0, which works without any adjustments.
If you are bind-mounting a local directory or file, it must be readable by the elasticsearch user.In addition, this user must have write access to the config, data and log dirs(Elasticsearch needs write access to the config directory so that it can generate a keystore).A good strategy is to grant group access to gid 0 for the local directory.
For example, to prepare a local directory for storing data through a bind-mount:
You can also run an Elasticsearch container using both a custom UID and GID. Unless youbind-mount each of the config, data` and logs directories, you must passthe command line option --group-add 0 to docker run. This ensures that the userunder which Elasticsearch is running is also a member of the root (GID 0) group inside thecontainer.
As a last resort, you can force the container to mutate the ownership ofany bind-mounts used for the data and log dirs through theenvironment variable TAKE_FILE_OWNERSHIP. When you do this, they will be owned byuid:gid 1000:0, which provides the required read/write access to the Elasticsearch process.
Increased ulimits for nofile and nprocmust be available for the Elasticsearch containers.Verify the init systemfor the Docker daemon sets them to acceptable values.
To check the Docker daemon defaults for ulimits, run:
If needed, adjust them in the Daemon or override them per container.For example, when using docker run, set:
Swapping needs to be disabled for performance and node stability.For information about ways to do this, see Disable swapping.
If you opt for the bootstrap.memory_lock: true approach,you also need to define the memlock: true ulimit in theDocker Daemon,or explicitly set for the container as shown in the sample compose file.When using docker run, you can specify:
The image exposesTCP ports 9200 and 9300. For production clusters, randomizing thepublished ports with --publish-all is recommended,unless you are pinning one container per host.
By default, Elasticsearch automatically sizes JVM heap based on a nodes’sroles and the total memory available to the node’s container. Werecommend this default sizing for most production environments. If needed, youcan override default sizing by manually setting JVM heap size.
To manually set the heap size in production, bind mount a JVMoptions file under /usr/share/elasticsearch/config/jvm.options.d thatincludes your desired heap size settings.

For testing, you can also manually set the heap size using the ES_JAVA_OPTSenvironment variable. For example, to use 16GB, specify -eES_JAVA_OPTS='-Xms16g -Xmx16g' with docker run. The ES_JAVA_OPTS variableoverrides all other JVM options. The ES_JAVA_OPTS variable overrides all otherJVM options. We do not recommend using ES_JAVA_OPTS in production. Thedocker-compose.yml file above sets the heap size to 512MB.
Pin your deployments to a specific version of the Elasticsearch Docker image. Forexample docker.elastic.co/elasticsearch/elasticsearch:7.12.0.
You should use a volume bound on /usr/share/elasticsearch/data for the following reasons:
The data of your Elasticsearch node won’t be lost if the container is killed
Elasticsearch is I/O sensitive and the Docker storage driver is not ideal for fast I/O
It allows the use of advancedDocker volume plugins
If you are using the devicemapper storage driver, do not use the default loop-lvm mode.Configure docker-engine to usedirect-lvm.
Consider centralizing your logs by using a differentlogging driver. Alsonote that the default json-file logging driver is not ideally suited forproduction use.
When you run in Docker, the Elasticsearch configuration files are loaded from/usr/share/elasticsearch/config/.
To use custom configuration files, you bind-mount the filesover the configuration files in the image.
You can set individual Elasticsearch configuration parameters using Docker environment variables.The sample compose file and thesingle-node example use this method.
To use the contents of a file to set an environment variable, suffix the environmentvariable name with _FILE. This is useful for passing secrets such as passwords to Elasticsearchwithout specifying them directly.
For example, to set the Elasticsearch bootstrap password from a file, you can bind mount thefile and set the ELASTIC_PASSWORD_FILE environment variable to the mount location.If you mount the password file to /run/secrets/bootstrapPassword.txt, specify:
You can also override the default command for the image to pass Elasticsearch configurationparameters as command line options. For example:
While bind-mounting your configuration files is usually the preferred method in production,you can also create a custom Docker imagethat contains your configuration.
Create custom config files and bind-mount them over the corresponding files in the Docker image.For example, to bind-mount custom_elasticsearch.yml with docker run, specify:
The container runs Elasticsearch as user elasticsearch usinguid:gid 1000:0. Bind mounted host directories and files must be accessible by this user,and the data and log directories must be writable by this user.
By default, Elasticsearch will auto-generate a keystore file for secure settings. Thisfile is obfuscated but not encrypted. If you want to encrypt yoursecure settings with a password, you must use theelasticsearch-keystore utility to create a password-protected keystore andbind-mount it to the container as/usr/share/elasticsearch/config/elasticsearch.keystore. In order to providethe Docker container with the password at startup, set the Docker environmentvalue KEYSTORE_PASSWORD to the value of your password. For example, a dockerrun command might have the following options:
In some environments, it might make more sense to prepare a custom image that containsyour configuration. A Dockerfile to achieve this might be as simple as:
You could then build and run the image with:
Some plugins require additional security permissions.You must explicitly accept them either by:
Attaching a tty when you run the Docker image and allowing the permissions when prompted.
Inspecting the security permissions and accepting them (if appropriate) by adding the --batch flag to the plugin install command.
See Plugin managementfor more information.
You now have a test Elasticsearch environment set up. Before you startserious development or go into production with Elasticsearch, you must do some additionalsetup:
Learn how to configure Elasticsearch.
Configure important Elasticsearch settings.
Configure important system settings.
« Install Elasticsearch with Windows MSI InstallerInstall Elasticsearch on macOS with Homebrew »
Most Popular
-->
This section lists terms and definitions you should be familiar with before getting deeper into Docker. For further definitions, see the extensive glossary provided by Docker.
Container image: A package with all the dependencies and information needed to create a container. An image includes all the dependencies (such as frameworks) plus deployment and execution configuration to be used by a container runtime. Usually, an image derives from multiple base images that are layers stacked on top of each other to form the container's filesystem. An image is immutable once it has been created.
Dockerfile: A text file that contains instructions for building a Docker image. It's like a batch script, the first line states the base image to begin with and then follow the instructions to install required programs, copy files, and so on, until you get the working environment you need.
Brew Docker-machine-driver-xhyve
Build: The action of building a container image based on the information and context provided by its Dockerfile, plus additional files in the folder where the image is built. You can build images with the following Docker command:
Container: An instance of a Docker image. A container represents the execution of a single application, process, or service. It consists of the contents of a Docker image, an execution environment, and a standard set of instructions. When scaling a service, you create multiple instances of a container from the same image. Or a batch job can create multiple containers from the same image, passing different parameters to each instance.
Volumes: Offer a writable filesystem that the container can use. Since images are read-only but most programs need to write to the filesystem, volumes add a writable layer, on top of the container image, so the programs have access to a writable filesystem. The program doesn't know it's accessing a layered filesystem, it's just the filesystem as usual. Volumes live in the host system and are managed by Docker.
Tag: A mark or label you can apply to images so that different images or versions of the same image (depending on the version number or the target environment) can be identified.
Multi-stage Build: Is a feature, since Docker 17.05 or higher, that helps to reduce the size of the final images. In a few sentences, with multi-stage build you can use, for example, a large base image, containing the SDK, for compiling and publishing the application and then using the publishing folder with a small runtime-only base image, to produce a much smaller final image.
Docker Machine Xhyve Game
Repository (repo): A collection of related Docker images, labeled with a tag that indicates the image version. Some repos contain multiple variants of a specific image, such as an image containing SDKs (heavier), an image containing only runtimes (lighter), etc. Those variants can be marked with tags. A single repo can contain platform variants, such as a Linux image and a Windows image.
Registry: A service that provides access to repositories. The default registry for most public images is Docker Hub (owned by Docker as an organization). A registry usually contains repositories from multiple teams. Companies often have private registries to store and manage images they've created. Azure Container Registry is another example.
Multi-arch image: For multi-architecture, it's a feature that simplifies the selection of the appropriate image, according to the platform where Docker is running. For example, when a Dockerfile requests a base image mcr.microsoft.com/dotnet/sdk:5.0 from the registry, it actually gets 5.0-nanoserver-1909, 5.0-nanoserver-1809 or 5.0-buster-slim, depending on the operating system and version where Docker is running.
Docker Hub: A public registry to upload images and work with them. Docker Hub provides Docker image hosting, public or private registries, build triggers and web hooks, and integration with GitHub and Bitbucket.
Azure Container Registry: A public resource for working with Docker images and its components in Azure. This provides a registry that's close to your deployments in Azure and that gives you control over access, making it possible to use your Azure Active Directory groups and permissions.
Docker Trusted Registry (DTR): A Docker registry service (from Docker) that can be installed on-premises so it lives within the organization's datacenter and network. It's convenient for private images that should be managed within the enterprise. Docker Trusted Registry is included as part of the Docker Datacenter product. For more information, see Docker Trusted Registry (DTR).
Docker Community Edition (CE): Development tools for Windows and macOS for building, running, and testing containers locally. Docker CE for Windows provides development environments for both Linux and Windows Containers. The Linux Docker host on Windows is based on a Hyper-V virtual machine. The host for Windows Containers is directly based on Windows. Docker CE for Mac is based on the Apple Hypervisor framework and the xhyve hypervisor, which provides a Linux Docker host virtual machine on macOS X. Docker CE for Windows and for Mac replaces Docker Toolbox, which was based on Oracle VirtualBox.
Docker Enterprise Edition (EE): An enterprise-scale version of Docker tools for Linux and Windows development.
Compose: A command-line tool and YAML file format with metadata for defining and running multi-container applications. You define a single application based on multiple images with one or more .yml files that can override values depending on the environment. After you've created the definitions, you can deploy the whole multi-container application with a single command (docker-compose up) that creates a container per image on the Docker host.
Cluster: A collection of Docker hosts exposed as if it were a single virtual Docker host, so that the application can scale to multiple instances of the services spread across multiple hosts within the cluster. Docker clusters can be created with Kubernetes, Azure Service Fabric, Docker Swarm and Mesosphere DC/OS.
Docker Machine Xhyve Tool
Orchestrator: A tool that simplifies management of clusters and Docker hosts. Orchestrators enable you to manage their images, containers, and hosts through a command-line interface (CLI) or a graphical UI. You can manage container networking, configurations, load balancing, service discovery, high availability, Docker host configuration, and more. An orchestrator is responsible for running, distributing, scaling, and healing workloads across a collection of nodes. Typically, orchestrator products are the same products that provide cluster infrastructure, like Kubernetes and Azure Service Fabric, among other offerings in the market.
0 notes
Link
Dalam posting ini, admin akan menunjukkan kepada kalian cara mengatasi kernel mode heap corruption yang menyebabkan BSOD.
0 notes
Text
Investigating Intel’s Compiler
I don’t think there’s been a more controversial programming tool to ever be released than Intel’s own C++ compiler. The biggest controversy, for those who don’t know, basically involved Intel using their compiler to slow down their competitor’s chips. Whether that’s true or not, is what I’ll be going into in this post.
Why?
A lot of tech enthusiasts are, for good reason, very skeptical of Intel. Even a surface-level dive into the semiconductor industry reveals some troubling skeletons in Intel’s closet, including several anti-trust violations in both America and Europe.
But, times do change, and so, I’ve decided to investigate whether Intel’s compiler is still used as a weapon against their rivals, AMD in particular.
How?
Testing will actually be really simple: I just need to compile my test programs twice: Once with Intel’s compiler, and once with Visual Studio. I would use QTCreator given how lightweight it is, but my installation seems to be corrupted. That and Intel’s compiler has Visual Studio integration, so that will help keep things consistent. No need for me to write a batch file just to compile the tests.
By switching between two different compilers, one from Intel and the other vendor-agnostic, the various data points can be used to come to a conclusion. If Intel’s compiler is deliberately slowing down code that runs on my AMD hardware, then the difference will be very clear.
Once the tests have been compiled, I’ll run them, record the time, and then come to a conclusion. But note that I will not average the scores from different tests. This is because it’s simply unnecessary, and will make the data more murky. Especially given some programs will rely on certain algorithms more than others.
The Tests
In order to test this, I thought it too imprecise to find a program online, compile it, and run it. While that would provide a very realistic workload, I don’t think it would reveal too much about Intel’s slowdown methods, if they utilize any. In particular, 7-Zip, while free and open source, would be terrible for this because it’s mainly I/O bound. Any slowdown wouldn’t be noticed too well, and partially masked by either of my drives.
So instead, I decided to write my own suite of tests. Unfortunately these are all single-threaded tests, as multithreaded testing would be too difficult to do right. That’s not really the point anyway: If the compiler does indeed use tactics to slow down AMD chips, then even a single-threaded test will be able to reveal them.
These are the tests I wrote and why:
QuickSort. Reason being, it's a fairly simple algorithm with fairly predictable performance.
Counting Sort. Another sorting algorithm, but this one relies very little on branching. In fact, a proper implementation has no if statements at all. May not be a great indicator of real-world performance loss, but it’s a simple test, so I decided to throw it in.
Binary Tree. This one isn’t very indicative, but basically: It takes random data, builds a binary search tree with it, then locates a random element.
Note: In order to ensure that the testing is fair, the test will have to be rather large. This won’t be a 5-second thousand-element sort, no. Think 1 million elements. The exact testing parameters will be detailed below.
Test Machine
Of course, it’s important to contextualize the hardware on which these tests are done. This entire post would be a big waste of time if I was still rocking an i5-7600K. So below are all the relevant parts (and some irrelevant ones):
CPU: AMD Ryzen 5 1600 @ Stock
Cooler: AMD Wraith Spire (cu*)
RAM: 16 GB DDR4-3000 Team Vulkan-Z @ DDR4-2933**
Mobo: ASUS TUF GAMING B450M
* Has a copper slug. Just in case you were curious
** Otherwise stock. Also, F for my underutilized RAM :(
Testing Methodology
For each compiler, each test will be run 10 times, and the time taken averaged out. No major programs running in the background, not that it’ll impact anything. I/O, such as loading/generating data to be sorted, will not be counted towards any timed portions.
Every time the compiler is swapped, settings are checked to ensure fairness, and
There will be three tests: One with Visual Studio set to Debug mode, one with Release mode with standard O2 optimization, and one with Release mode and optimizations disabled.
The Results
Well, I wasn’t expecting what I found, in all honesty. First, Debug mode, as that’s what people will most likely test with at first.

Just as a reminder, this is running on AMD hardware. And I have triple-checked these numbers, and they’re accurate. No funny business. I even tested the Visual Studio compiler before installing the Intel compiler.
Maybe there’s shenanigans going on in Release mode + Od?
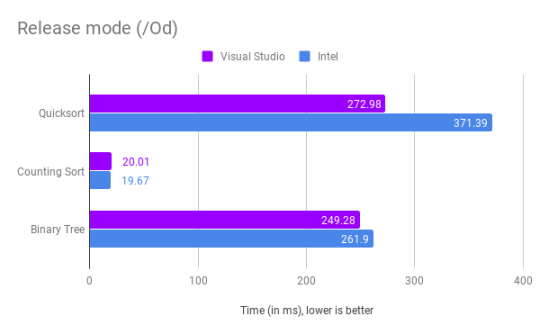
Well, quicksort is slower on Intel now. So it would seem that the Visual Studio compiler does more optimizations even when you tell it to not do anything special.
I do find it curious that Counting Sort takes longer with Release mode, but that could just be per-run variance. Overall, I’m not too concerned.
And finally, the most disappointing, Release mode + O2 optimization:
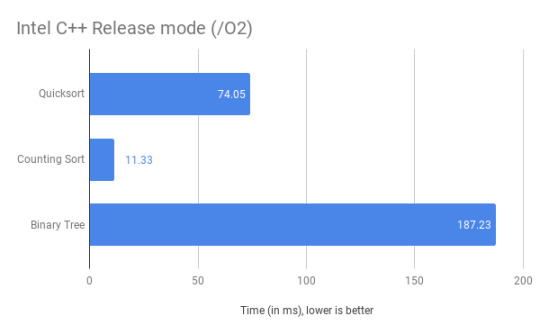
Unfortunately, I couldn’t get the Visual Studio compiler to produce anything useful despite being given more than enough time. It just sits around, twiddling its thumbs on a single thread. Eventually it complains about a lack of heap space, despite my system having 16 GBs of RAM. So the Intel compiler is the only one I was able to test.
But wait, there’s more!
So, being the super-paranoid programmer I am, I was thinking there had to be a catch. So I went ahead and threw the Intel-compiled code into HxD, a hex editor. It’ll let me see the individual instructions that make up the program, and tell me what an instruction means in x86.
Initially, I just looked for the instruction 0x0FA2, as that is the CPUID instruction in x86. CPUID lets programs see what hardware they’re running on, as it will return a string depending on which vendor made it. The string is vendor-dependent, so AMD could make a CPU that has an Intel vendor ID (though I doubt software would like that).
Intel has “GenuineIntel”, and AMD has “AuthenticAMD”, though at one point they had “AMDisbetter!”. There’s other x86 vendors that have their own respective vendor strings.
Anyway, I dug through an executable or two, didn’t find anything significant. Even dug through the Visual Studio compiled code. Weirdly, it does seem to call CPUID later on in the program, towards the end actually. I have no idea why it would do this.
That is, until I was editing this blog post. I noticed that the gains going from Debug to Release Od were rather small, so I went ahead and threw that code in particular into HxD. Look at what I found:

There’s two things that stick out:
1. The mangled GenuineIntel vendor ID string.
2. The CPUID call that’s in the general area.
So at this point, I’m getting a little paranoid, so I go back and look at the other results. Turns out I did find more damning evidence and I was just being a tunnel-visioned idiot. This code is from the Debug compilation:
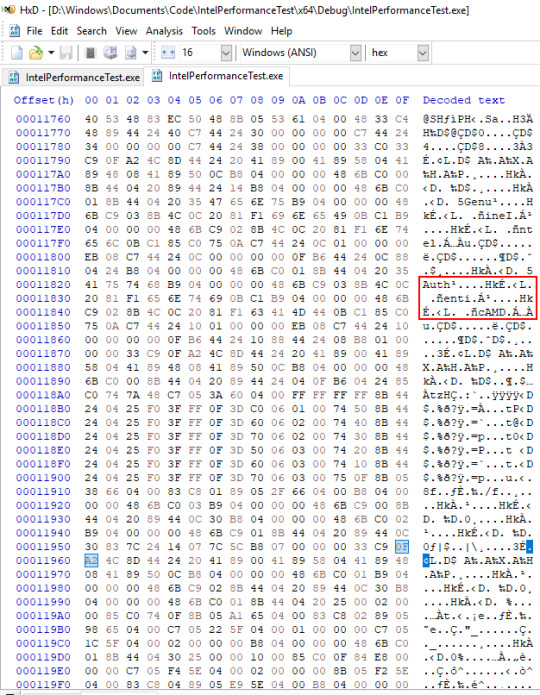
What the hell is that AuthenticAMD vendor string doing in Intel-compiled code? HMMM... Honestly I’m not sure. The code runs significantly faster than the Visual Studio code, so it doesn’t seem to be sabotage at first glance.
So I looked at the compiled executable sizes. And as compiling Visual Studio for Release is difficult, I just went ahead and only compiled for Debug.
Turns out the Visual Studio compiler is the bigger one, at 727 KBs versus Intel’s ~323 KBs (note: don’t have the exact number, forgot to jot it down).
So at this point I’m just... confused. What is going on? So I crack open the VS-compiled executable in HxD and... well...
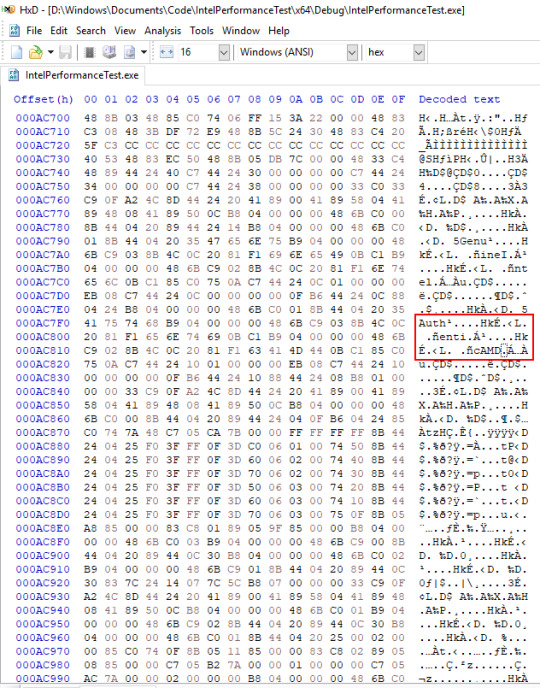
I found the exact same string. Different place, but the same string nonetheless. Not only that, the same code surrounds it. So it’s not Intel-exclusive. None of what’s here is exclusive to Intel’s compiler, unless there’s some crazy conspiracy that both Intel and Microsoft are into. Which I highly doubt, given that would be a massive conflict of interest for Microsoft. Imagine, if Visual Studio’s C++ compiler was sabotaging AMD hardware. That would be a massive blow to their own consoles, given a lot of them may just be compiled with Visual Studio.
And for the record, there are no other instances of AMD’s vendor ID string anywhere in either compiled executables. I would mention it if there was.
Final Word
No, Intel’s compiler is not running deliberately slow code on AMD hardware. Or at least, as far as it seems. In fact, it seems to run faster code overall than Visual Studio’s own compiler.
Although I wouldn’t recommend using Intel’s software suite, given it has been found that their Math Kernel Library does indeed run intentionally worse on AMD hardware. I may do my own experimenting on it and see if I can replicate the results, but for now I’m just done with experimenting with Intel’s software. I’m going back to tinkering with Vulkan.
If you want to see the code I used to test this, here it is: https://github.com/Elusivehawk/IntelPerformanceTest
0 notes
Text
How to root Android with Odin download?
Although there are many methods through a heap of rooting applications, finding the best way is always important. Those who heard about Odin can follow our simple instructions to get to know how to root Android throughout? Though it is a well-known flashing tool, there is a special way that the same Samsung users can go through to archive root-only features. If you have been gone through its flash operation, then this will not that complicated. To get all super powers on your odd and bothersome handset, there is only one way call rooting. So let’s see how can we easily come across?

How to root Android with Odin download?
Odin download cannot introduce as a rooting tool. In simply, it is the official Samsung Android flashing tool. But of course, it gives you a chance to bring root permission to a Smartphone or a tablet comes as a Samsung. For that you should compile a recommended kernel that we often arrange as CF auto root. Since it available as tar type files and that even compatible with Odin, you can set the file to the respective tool section and let it flash. As usual like devices with root permission that gone through some other rooting tools, you can play whatever feature with Superuser permission.
Important facts for Android root with Odin
It is important make certain that the rooting tool you have been selected can bring root permission there for you. If it is Odin, make sure that you are with a Samsung handset. And download the respective kernel in accordance with your smartphone from CF auto root page. Create a backup is important before rooting. And for it is with Odin, you have to put the device into Odin mode. And also arrange a Windows computer with a connectable USB cable.

How to root with Odin?
Arrange a full backup of data
Put the device into Odin/download mode
Install USB drivers to the compiled Windows computer
Download Odin and CF auto root
Extract files respectively
Run Odin file and open the user interface
Click respective buttons to browse files
If files have been uploaded, use the Start button at the lower section of the interface
Keep the handset on the table and wait until the handset arrange a reboot
So then you can unplug it and install root checker app available for free in the Google Play store
0 notes
Text
System hardening in Android 11
Posted by Platform Hardening Team
In Android 11 we continue to increase the security of the Android platform. We have moved to safer default settings, migrated to a hardened memory allocator, and expanded the use of compiler mitigations that defend against classes of vulnerabilities and frustrate exploitation techniques.
Initializing memory
We’ve enabled forms of automatic memory initialization in both Android 11’s userspace and the Linux kernel. Uninitialized memory bugs occur in C/C++ when memory is used without having first been initialized to a known safe value. These types of bugs can be confusing, and even the term “uninitialized” is misleading. Uninitialized may seem to imply that a variable has a random value. In reality it isn’t random. It has whatever value was previously placed there. This value may be predictable or even attacker controlled. Unfortunately this behavior can result in a serious vulnerability such as information disclosure bugs like ASLR bypasses, or control flow hijacking via a stack or heap spray. Another possible side effect of using uninitialized values is advanced compiler optimizations may transform the code unpredictably, as this is considered undefined behavior by the relevant C standards.
In practice, uses of uninitialized memory are difficult to detect. Such errors may sit in the codebase unnoticed for years if the memory happens to be initialized with some “safe” value most of the time. When uninitialized memory results in a bug, it is often challenging to identify the source of the error, particularly if it is rarely triggered. Eliminating an entire class of such bugs is a lot more effective than hunting them down individually. Automatic stack variable initialization relies on a feature in the Clang compiler which allows choosing initializing local variables with either zeros or a pattern. Initializing to zero provides safer defaults for strings, pointers, indexes, and sizes. The downsides of zero init are less-safe defaults for return values, and exposing fewer bugs where the underlying code relies on zero initialization. Pattern initialization tends to expose more bugs and is generally safer for return values and less safe for strings, pointers, indexes, and sizes.
Initializing Userspace:
Automatic stack variable initialization is enabled throughout the entire Android userspace. During the development of Android 11, we initially selected pattern in order to uncover bugs relying on zero init and then moved to zero-init after a few months for increased safety. Platform OS developers can build with `AUTO_PATTERN_INITIALIZE=true m` if they want help uncovering bugs relying on zero init.
Initializing the Kernel:
Automatic stack and heap initialization were recently merged in the upstream Linux kernel. We have made these features available on earlier versions of Android’s kernel including 4.14, 4.19, and 5.4. These features enforce initialization of local variables and heap allocations with known values that cannot be controlled by attackers and are useless when leaked. Both features result in a performance overhead, but also prevent undefined behavior improving both stability and security.
For kernel stack initialization we adopted the CONFIG_INIT_STACK_ALL from upstream Linux. It currently relies on Clang pattern initialization for stack variables, although this is subject to change in the future.
Heap initialization is controlled by two boot-time flags, init_on_alloc and init_on_free, with the former wiping freshly allocated heap objects with zeroes (think s/kmalloc/kzalloc in the whole kernel) and the latter doing the same before the objects are freed (this helps to reduce the lifetime of security-sensitive data). init_on_alloc is a lot more cache-friendly and has smaller performance impact (within 2%), therefore it has been chosen to protect Android kernels.
Scudo is now Android’s default native allocator
In Android 11, Scudo replaces jemalloc as the default native allocator for Android. Scudo is a hardened memory allocator designed to help detect and mitigate memory corruption bugs in the heap, such as:
Double free,
Arbitrary free,
Heap-based buffer overflow,
Use-after-free
Scudo does not fully prevent exploitation but it does add a number of sanity checks which are effective at strengthening the heap against some memory corruption bugs.
It also proactively organizes the heap in a way that makes exploitation of memory corruption more difficult, by reducing the predictability of the allocation patterns, and separating allocations by sizes.
In our internal testing, Scudo has already proven its worth by surfacing security and stability bugs that were previously undetected.
Finding Heap Memory Safety Bugs in the Wild (GWP-ASan)
Android 11 introduces GWP-ASan, an in-production heap memory safety bug detection tool that’s integrated directly into the native allocator Scudo. GWP-ASan probabilistically detects and provides actionable reports for heap memory safety bugs when they occur, works on 32-bit and 64-bit processes, and is enabled by default for system processes and system apps.
GWP-ASan is also available for developer applications via a one line opt-in in an app’s AndroidManifest.xml, with no complicated build support or recompilation of prebuilt libraries necessary.
Software Tag-Based KASAN
Continuing work on adopting the Arm Memory Tagging Extension (MTE) in Android, Android 11 includes support for kernel HWASAN, also known as Software Tag-Based KASAN. Userspace HWASAN is supported since Android 10.
KernelAddressSANitizer (KASAN) is a dynamic memory error detector designed to find out-of-bound and use-after-free bugs in the Linux kernel. Its Software Tag-Based mode is a software implementation of the memory tagging concept for the kernel. Software Tag-Based KASAN is available in 4.14, 4.19 and 5.4 Android kernels, and can be enabled with the CONFIG_KASAN_SW_TAGS kernel configuration option. Currently Tag-Based KASAN only supports tagging of slab memory; support for other types of memory (such as stack and globals) will be added in the future.
Compared to Generic KASAN, Tag-Based KASAN has significantly lower memory requirements (see this kernel commit for details), which makes it usable on dog food testing devices. Another use case for Software Tag-Based KASAN is checking the existing kernel code for compatibility with memory tagging. As Tag-Based KASAN is based on similar concepts as the future in-kernel MTE support, making sure that kernel code works with Tag-Based KASAN will ease in-kernel MTE integration in the future.
Expanding existing compiler mitigations
We’ve continued to expand the compiler mitigations that have been rolled out in prior releases as well. This includes adding both integer and bounds sanitizers to some core libraries that were lacking them. For example, the libminikin fonts library and the libui rendering library are now bounds sanitized. We’ve hardened the NFC stack by implementing both integer overflow sanitizer and bounds sanitizer in those components.
In addition to the hard mitigations like sanitizers, we also continue to expand our use of CFI as an exploit mitigation. CFI has been enabled in Android’s networking daemon, DNS resolver, and more of our core javascript libraries like libv8 and the PacProcessor.
The effectiveness of our software codec sandbox
Prior to the Release of Android 10 we announced a new constrained sandbox for software codecs. We’re really pleased with the results. Thus far, Android 10 is the first Android release since the infamous stagefright vulnerabilities in Android 5.0 with zero critical-severity vulnerabilities in the media frameworks.
Thank you to Jeff Vander Stoep, Alexander Potapenko, Stephen Hines, Andrey Konovalov, Mitch Phillips, Ivan Lozano, Kostya Kortchinsky, Christopher Ferris, Cindy Zhou, Evgenii Stepanov, Kevin Deus, Peter Collingbourne, Elliott Hughes, Kees Cook and Ken Chen for their contributions to this post.
System hardening in Android 11 published first on https://phonetracking.tumblr.com/ System hardening in Android 11 published first on https://leolarsonblog.tumblr.com/
0 notes
Text
System hardening in Android 11
Posted by Platform Hardening Team
In Android 11 we continue to increase the security of the Android platform. We have moved to safer default settings, migrated to a hardened memory allocator, and expanded the use of compiler mitigations that defend against classes of vulnerabilities and frustrate exploitation techniques.
Initializing memory
We’ve enabled forms of automatic memory initialization in both Android 11’s userspace and the Linux kernel. Uninitialized memory bugs occur in C/C++ when memory is used without having first been initialized to a known safe value. These types of bugs can be confusing, and even the term “uninitialized” is misleading. Uninitialized may seem to imply that a variable has a random value. In reality it isn’t random. It has whatever value was previously placed there. This value may be predictable or even attacker controlled. Unfortunately this behavior can result in a serious vulnerability such as information disclosure bugs like ASLR bypasses, or control flow hijacking via a stack or heap spray. Another possible side effect of using uninitialized values is advanced compiler optimizations may transform the code unpredictably, as this is considered undefined behavior by the relevant C standards.
In practice, uses of uninitialized memory are difficult to detect. Such errors may sit in the codebase unnoticed for years if the memory happens to be initialized with some "safe" value most of the time. When uninitialized memory results in a bug, it is often challenging to identify the source of the error, particularly if it is rarely triggered. Eliminating an entire class of such bugs is a lot more effective than hunting them down individually. Automatic stack variable initialization relies on a feature in the Clang compiler which allows choosing initializing local variables with either zeros or a pattern. Initializing to zero provides safer defaults for strings, pointers, indexes, and sizes. The downsides of zero init are less-safe defaults for return values, and exposing fewer bugs where the underlying code relies on zero initialization. Pattern initialization tends to expose more bugs and is generally safer for return values and less safe for strings, pointers, indexes, and sizes.
Initializing Userspace:
Automatic stack variable initialization is enabled throughout the entire Android userspace. During the development of Android 11, we initially selected pattern in order to uncover bugs relying on zero init and then moved to zero-init after a few months for increased safety. Platform OS developers can build with `AUTO_PATTERN_INITIALIZE=true m` if they want help uncovering bugs relying on zero init.
Initializing the Kernel:
Automatic stack and heap initialization were recently merged in the upstream Linux kernel. We have made these features available on earlier versions of Android’s kernel including 4.14, 4.19, and 5.4. These features enforce initialization of local variables and heap allocations with known values that cannot be controlled by attackers and are useless when leaked. Both features result in a performance overhead, but also prevent undefined behavior improving both stability and security.
For kernel stack initialization we adopted the CONFIG_INIT_STACK_ALL from upstream Linux. It currently relies on Clang pattern initialization for stack variables, although this is subject to change in the future.
Heap initialization is controlled by two boot-time flags, init_on_alloc and init_on_free, with the former wiping freshly allocated heap objects with zeroes (think s/kmalloc/kzalloc in the whole kernel) and the latter doing the same before the objects are freed (this helps to reduce the lifetime of security-sensitive data). init_on_alloc is a lot more cache-friendly and has smaller performance impact (within 2%), therefore it has been chosen to protect Android kernels.
Scudo is now Android's default native allocator
In Android 11, Scudo replaces jemalloc as the default native allocator for Android. Scudo is a hardened memory allocator designed to help detect and mitigate memory corruption bugs in the heap, such as:
Double free,
Arbitrary free,
Heap-based buffer overflow,
Use-after-free
Scudo does not fully prevent exploitation but it does add a number of sanity checks which are effective at strengthening the heap against some memory corruption bugs.
It also proactively organizes the heap in a way that makes exploitation of memory corruption more difficult, by reducing the predictability of the allocation patterns, and separating allocations by sizes.
In our internal testing, Scudo has already proven its worth by surfacing security and stability bugs that were previously undetected.
Finding Heap Memory Safety Bugs in the Wild (GWP-ASan)
Android 11 introduces GWP-ASan, an in-production heap memory safety bug detection tool that's integrated directly into the native allocator Scudo. GWP-ASan probabilistically detects and provides actionable reports for heap memory safety bugs when they occur, works on 32-bit and 64-bit processes, and is enabled by default for system processes and system apps.
GWP-ASan is also available for developer applications via a one line opt-in in an app's AndroidManifest.xml, with no complicated build support or recompilation of prebuilt libraries necessary.
Software Tag-Based KASAN
Continuing work on adopting the Arm Memory Tagging Extension (MTE) in Android, Android 11 includes support for kernel HWASAN, also known as Software Tag-Based KASAN. Userspace HWASAN is supported since Android 10.
KernelAddressSANitizer (KASAN) is a dynamic memory error detector designed to find out-of-bound and use-after-free bugs in the Linux kernel. Its Software Tag-Based mode is a software implementation of the memory tagging concept for the kernel. Software Tag-Based KASAN is available in 4.14, 4.19 and 5.4 Android kernels, and can be enabled with the CONFIG_KASAN_SW_TAGS kernel configuration option. Currently Tag-Based KASAN only supports tagging of slab memory; support for other types of memory (such as stack and globals) will be added in the future.
Compared to Generic KASAN, Tag-Based KASAN has significantly lower memory requirements (see this kernel commit for details), which makes it usable on dog food testing devices. Another use case for Software Tag-Based KASAN is checking the existing kernel code for compatibility with memory tagging. As Tag-Based KASAN is based on similar concepts as the future in-kernel MTE support, making sure that kernel code works with Tag-Based KASAN will ease in-kernel MTE integration in the future.
Expanding existing compiler mitigations
We’ve continued to expand the compiler mitigations that have been rolled out in prior releases as well. This includes adding both integer and bounds sanitizers to some core libraries that were lacking them. For example, the libminikin fonts library and the libui rendering library are now bounds sanitized. We’ve hardened the NFC stack by implementing both integer overflow sanitizer and bounds sanitizer in those components.
In addition to the hard mitigations like sanitizers, we also continue to expand our use of CFI as an exploit mitigation. CFI has been enabled in Android’s networking daemon, DNS resolver, and more of our core javascript libraries like libv8 and the PacProcessor.
The effectiveness of our software codec sandbox
Prior to the Release of Android 10 we announced a new constrained sandbox for software codecs. We’re really pleased with the results. Thus far, Android 10 is the first Android release since the infamous stagefright vulnerabilities in Android 5.0 with zero critical-severity vulnerabilities in the media frameworks.
Thank you to Jeff Vander Stoep, Alexander Potapenko, Stephen Hines, Andrey Konovalov, Mitch Phillips, Ivan Lozano, Kostya Kortchinsky, Christopher Ferris, Cindy Zhou, Evgenii Stepanov, Kevin Deus, Peter Collingbourne, Elliott Hughes, Kees Cook and Ken Chen for their contributions to this post.
System hardening in Android 11 published first on https://phonetracking.tumblr.com/
0 notes