#kiddy script
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr has been providing a Korean-language service since 2013.
Text
Oh man, I haven't touched code in a Loooooong time. My first thought was C++ but I don't even know what a compiler looks like nowadays. Maybe Ruby or Python on Rails? Never learned those ones.
Shouting languages probably isn't helpful but I'll tag every one I can think of.
I just had a stupid idea.
Inspired by this post
I can't code worth a chip of flaming chull dung, but I'll do what I can, so here's what we should do: we should create a new incorrect quotes generator using samples from our own WIPs, and then have everyone run their characters through it and turn it into like a tag game where you create three incorrect quotes using the generator and then propose one from your own writing to be added into it or something. Get the vision?
Anyway, here's who I'm recruiting for my crack idea that may never get off the ground (Note: I started working on it right after typing those words. I'm not very far, but progress is being made. If someone else thinks they can get it all coded and stuff before I get it done [which you'd probably be right in thinking], feel free and I'll hand the reins over to you): All my mutuals. All of 'em. Feel free to bring more people into this as well.
So to begin with the tagging: @tildeathiwillwrite, @somethingclevermahogony, @the-ellia-west, @smudged-red-ink (wake up pls I'm still worried), @aesthetic-writer18,
@pastellbg (ik you're not a writing mutual exactly but I said all), @illarian-rambling, @lunaeuphternal, @thewritingautisticat, @aalinaaaaaa,
@elizaellwrites, @cybercelestian, @pluppsauthor, and @corinneglass!
...
I'm not exactly sure what you're supposed to do with this information quite yet, but... I dunno. It's still very possible I'll forget about this within the week, so someone make sure to remind me I started another stupid project, k?
#python#code#script#javascript#C++#Ruby#Rails#PHP#Website development#app development#indie developer#programmer#kiddy script#cyber security
125 notes
·
View notes
Text

This is kind of an on going project, but in a discord server I frequent theres a running gag where whenever somone says something really inappropriate, or for lack of a better term "horny" we respond with the painting of Joseph Smith Jr. rebuking the guards in the jailhouse at Liberty, MI (context at the end of the post) So for the first function of my first ever discord bot, known as "Mormo the Demon King" I have it be able to be invoked in order to rebuke anyone who says something of the sort. I am keeping it private for now, but I may reblog this later with a link to the python script I built it in if it is wanted. Plan on adding more to mormo later down the line. ---CONTEXT--- For those who don't know the story, at one point Joseph Smith Jr. was put into prison in Liberty Missouri for several charges that were later dropped, including banking fraud, conspiracy, and treason against the state. During this stay the guards, either naturally or as a way to attempt to bother the prophet started bragging about their involvement in various campaigns of harassment and terrorism against the displaced Mormons. One even mentioning the infamous Haun's Mill where 17 mormon residents of the community were killed, including several children. We dont know exactly what the jail guards said in their conversation but it was enough to allegedly compel Smith to stand up and confer a heavenly rebuke commanding that they either stop talking or die. Reportedly the guards were so astonished that they remained silent until the change of guard the next morning.
59 notes
·
View notes
Text

old drawing. his name is skydie btw
#roblox#roblox art#roblox oc#robloxian#my art#my boy skydie#pronounced skid-ee#like..... like how script kiddies are called skiddies sometimes...#ok im leaving bye#RAAAGHHSJSOWKNSMDNS@:&'
9 notes
·
View notes
Note
sending you this meme outta love and to set your day off with good vibes (hopefully better today than yesterday <3)



Awwww, tysm!! The bunnies are so cute <33
#And yes I am feeling better#Nothing quite like a 2000 page manual with content like 'script kiddies' to boost ones mood#Asks
2 notes
·
View notes
Text
when i saw that "sudanese hacking group" message I immediately was just like boy you'd have to be a real idiot to buy that lmao and then stopped thinking about it but I guess I forgot what the average person who spends 12 hours a day on ao3 is like
12 notes
·
View notes
Text

DANK ACAMEMIA
#chaotic academia#ascii art#script kiddie#dark academia#hackercore#hackademia#web creep#nostalgiacore
2 notes
·
View notes
Text
Wipes "message me" command off post like a smudge
1 note
·
View note
Text
"They don't even have an antivirus." - Penny, probably.
#pokemon#pokemon penny#i love how pokemon's technology situation is so realistic in all of the worst ways#the entire pokemon storage system is held together by a team of 8 hobbyists running the servers out of their basements#and at the very least Paldea's League network has bad enough security that a teenaged script kiddy (Skitty? lol) could get into it
1 note
·
View note
Text
|| whoEvEr just triED to Doxx mE you hAvE thE wronG timElinE lmAoooo ||
#mod glitch#|| sEriously DuDE At lEAst try to vEriFy whAt timElinE A vErsion oF somEonE is From BEForE you Doxx thEm ||#|| i wAs mAkinG BEttEr DoxxEs As A sEvEn swEEp olD sCript kiDDiE mAn | GEt your shit toGEthEr ||#|| this is just sAD ||
1 note
·
View note
Text
"I want to make a visual novel but don't know how"
visual novels are one of the most diverse and varied mediums out there and can be so much fun to make. if you've ever wanted to make one, it's pretty easy to get started!!
Overall Guide
this is a lengthy guide I made going over different parts of visual novels and how people make them! now let's go over some parts~
What Are Visual Novels?
Visual novels are a medium of video games focused on storytelling through the use of static or low-gameplay mechanics. Most can be considered a subsection of interactive fiction. A lot of visual novels have no gameplay or minigames, but some do feature light gameplay. The important aspect is that the gameplay in visual novels is never the focus, and instead the game focuses on a story delivered through dialogue & narration in textboxes on the screen.






Some visual novels are romance, some are fantasy, some are mystery, some are NSFW, some are cutesy, some are kiddie. Visual novels come in all shapes and sizes.
Visual Novel Misconceptions
Visual novels have been around for several decades now, but parts of them are still misunderstood by wider audiences. Here’s some frequent misconceptions about visual novels.
"Every visual novel has sexual content."
Visual novels come in all shapes and sizes, which includes content. Not every visual novel has sexual content, nor is it required to sell well. Visual novels are a medium for storytelling rather than a genre, so they can be anything you want them to be.
"Every visual novel is a dating sim."
Similar to the last one, some people think every visual novel is a romance game or a dating sim. Not every visual novel has romance in it, nor is it required to sell well.
"Every visual novel has choices and multiple endings."
Some of the most popular visual novels out there like Umineko When they Cry don’t have choices. Choices and multiple endings aren’t required to make a visual novel—completely linear experiences are fine.
"Visual novels need to be long."
Some of the top visual novels on itch.io right now are under 25k words, which puts them under 2 hours of playtime. Visual novels don’t have to be a certain length—they can be as long or as short as the story needs them to be. There’s even an annual visual novel jam, O2A2, that focuses on making a visual novel under 1k words with limited assets.
"Visual novels don’t sell well."
This is very much your mileage may vary. Some visual novels sell very, very well, such as how the recent Our Life: Now and Forever Kickstarter gained almost $300k. Marketing is an entire field just like art and writing and isn’t something you can skimp on or push to the end.
"Visual novel players hate reading."
A vast, vast majority of visual novel readers want a visual novel—they want a game that is light on gameplay and heavy on reading. You don’t have to add gameplay to a visual novel to keep people interested. Rather, minigames added at random can deter players. Visual novel players want an engaging story—if you’re worried of losing their attention, then focus on a tighter script or cinematography.
"Visual novels need to be anime style."
Visual novels originated in Japan and most do have an anime style, but visual novels do not need an anime style to sell well. The art style for a game will change the audience for the game—players who want something anime style probably won’t be interested in a semi-realistic style, but other people will be. It’s all about finding the right style for your story and finding the audience who responds well to it.
Visual Novel Terms
Here’s a list of terms you might encounter in visual novel and game dev communities.
EVN / OELVN – stands for English Visual Novel and Original English Language Visual Novel. Two terms used for describing Western VNs that are made in English, although EVN is used more frequently nowadays. An EVN/OELVN is specifically a visual novel made in English first, not a visual novel that has an English translation (and was made in a different language first). There are several variations of this, such as JVN meaning Japanese Visual Novel and RVN meaning Russian Visual Novel.
Kinetic novel – a visual novel that’s linear with few or no choices. Has only one ending. Also called a linear visual novel, linear game, etc.
Game jams – an event where developers have a set amount of time to make a game, ranging from a weekend to several months. Some jams have themes that the games must follow as well as other restrictions while others are more freeform. Nowadays, most jams are hosted on itchio. You can find a list of visual novel game jams here.
Game engine – a piece of software used for developing video games. The most popular ones for making indie VNs in English-speaking areas are Ren’Py and Unity, though Tyranobuilder is very popular in Japan for indies.
Text/code editor – when programming, you’ll need another piece of software to edit and write code that works with the game engine. Some popular text editors are Visual Studio Code, Sublime, Atom, Notepad, and more.
Character sprite – the individual character art that changes expressions and can move around the screen. Can include multiple outfits, pose changes, and more.

CGs – although it typically stands for Computer Generated, CGs in visual novels typically means the cut scene art where no sprites are shown (unless there's a side sprite on the textbox). CGs are usually reserved for special scenes and are the type of artwork you’d see in a CG Gallery or as promotional artwork.


UI / GUI – the User Interface / Graphical User Interface. This is what the player interacts with such as the textbox, main menu, save / load screen, settings, and more.
ADV mode – the standard reading mode for visual novels, short for Adventure mode. The textbox is located at the bottom of the screen. Popular examples of this are Steins;Gate, AI: The Somnium Files, and Amnesia.


NVL mode – a different reading mode for visual novels, short for Novel mode. The textbox covers most of the screen. Popular examples of this are Fate/stay night, Tsukihime, and Umineko When they Cry.


Dating simulator – dating sims are some of the oldest forms of visual novels and are essentially stat raisers where you spend time with various characters with the goal being to romance them by getting your stats high enough. In Western spheres dating sim has become synonymous with a romance game, where stat raising is not involved, but it’s important to note that dating sims refer to stat raisers a lot of the time. Unlike otome, a dating sim doesn’t refer to a specific sexual orientation.
Otome / Otoge – roughly translates to “maiden’s love” and is used to describe games with a female demographic, usually dating sims & romance games which feature male love interests and a female protagonist. Some otome games feature female and other gendered LIs, but male LIs are still the primary focus.
Eroge – an erotic game. If a game has sexual content in it, it’s an eroge. The original Fate/stay night (not the remastered version on Steam) is a popular example of an eroge.
Resources
And now, let's look at some tools and links for actually making visual novels.
Engines & Programming
Ren’Py – free visual novel engine
Twine – free text-based game engine (usually used for interactive fiction)
Naninovel – Unity-based tool for making Unity VNs
tiny tools – collection of various game dev tools
Ren’Edit Add-On – Ren’Py script editing & feedback tool
Ren’Py Accessibility Add-On
Feniks Ren’Py resources – various add-ons and tutorials by Feniks
Game Jam & Short Dev Advice
Game Jam Survival Guide - Essential Tips and Tricks
Releasing 8+ games (ft. game jams) and when to take a break
making game development backup plans
Advice for Leading VN Game Jam Teams
How to Make a Visual Novel Solo
How to Finish Your Visual Novel
Design
How to Make Visual Novels
Visual Novel Conference Talks
Visual Novel Cinematography & Design
Art Direction & Execution in Visual Novels
Making Impactful, Impressive Character Sprites
Post-production Techniques for VNs
Vimi’s Visual Novel Design
Writing
Writing Interactive – guides for narrative games writers
Visual Novel Conference Talks
Writing Mystery Visual Novels
How to Design Interesting Choices in VNs
The Intrigue of Ambiguity
Artwork
Clip Studio Paint
Krita
FireAlpaca
Medibang
GIMP
FastStone Photo Resizer – batch photo resizer and editor
FotoSketcher – various settings to apply artistic filters to photos
Marketing
How to Market Visual Novels
Marketing Visual Novels FAQ
Marketing Fundamentals for Indie Game Developers
Marketing your first indie game – What we learned from releasing the same game twice
The stairstep approach to indie game marketing
Marketing your Visual Novel for Kickstarter
Visual Novel Press-Kits
Audio
Eric Matyas music & SFX
Vita-chi SFX & graphics
Free Music Archive
Free Sound
dova-syndrome
Misc.
Lemmasoft Creative Commons Forum
itch.io visual novel resources
Google Fonts – free fonts
Uncle Mugen backgrounds
Canva – browser & desktop graphic design tool
Unsplash – free photos
Wrapping Up
all in all, visual novels are a fun medium to explore and play around with. if you want to make something short as a test run, try joining a game jam! if you want to see how varied visual novels can be, try playing some indies from itchio! at the end of the day there's no bad way to start making your own visual novel. hit the ground running and go for it!!
I've been developing visual novels for over 10 years now, blogging about them on my own blog and releasing visual novels through my studio Crystal Game Works. I hope this guide helped shed light on how to get into the medium!


— Arimia
2K notes
·
View notes
Text
autism agere things :3
♾️ stimming to kids songs
♾️ echolalia / scripting responses with disney shows or other babie media
♾️ stuffies of ur fav characters
♾️ safe foods on kiddie plates
♾️ floor time!
♾️ baby talk vocal stims
♾️ ear defenders w fun patterns!
♾️ kids books on ur special interests
♾️ swinging, hanging upside down, etc
♾️ fidgeting w baby toys
768 notes
·
View notes
Text
every day I regret going to disneyland as a wee one and not being able to buy every one of the phineas and ferb shirts that they had that were specially themed to the rides
I do own this one and I wear it every time I go there. rip tower of terror you are missed

I love all the little details in this one like the boat being called lindana and candace specifically being hit by the back side of water lol. I would love to hear whatever rendition phineas does of the corny skipper script

this one is a bit kiddy for my taste but I love space mountain so it’s cute

then there’s pirates. super cute 10/10 design

358 notes
·
View notes
Note
i’m curious what your opinion is on the finer points of the case mentioned in the JSTOR post you reblogged earlier. the two sources in the post say that JSTOR didn’t press charges against him and had already settled with him by the time he killed himself. from what i read on wikipedia, the concern seems to be that JSTOR complied with a subpoena, which i don’t believe they have a choice to ignore? if anything it seems like the us government had reason to want him dead for wikileaks and public court records reasons, so they took a terms of use violation and blew it up into a dozen federal crimes.
is there more context i should be aware of? i have no particular affection or malice for JSTOR but the sources i found don’t exactly implicate the database or its employees in murder.
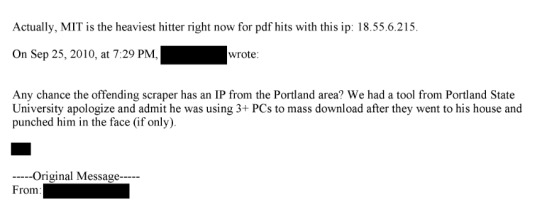





That's from page 175 of this document. This line: "The activity noted is outright theft and may merit a call with university counsel, and even the local police, to ensure not only that the activity has stopped but that - e.g. the visiting scholar who left - isn't leaving with a hard drive containing our database" is where I think the culpability starts.

If someone is downloading 1000s of articles (what seems like reasonable threshold for us to take action), what's wrong with us - or the university in collaboration with us - alerting the cyber-crimes division of law enforcement and initiating an investigation, having cop search dorm room and try to retrieve any hard drive that contains our content, etc. Our content is extraordinarily valuable and hard to replicate by the sweat of one's brow, but can be duplicated by savvy hackers and who knows what they want to do with the content?



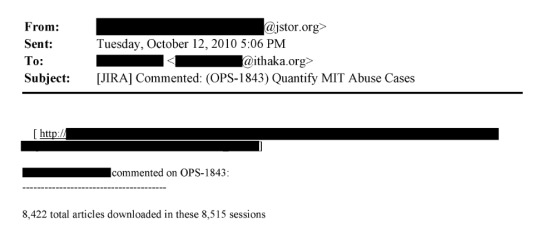






Page 379: "Does the university contact law enforcement? Would they be willing to do so in this instance?





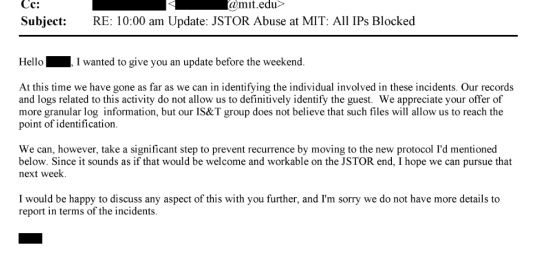



From page 1296:

I think the important thing to note here is that JSTOR had worked with MIT and had plans in place to prevent future similar downloads, but remained focused on identifying the person responsible for the downloads and ensuring that their data was deleted.

"I might just be irked because I am up dealing with this person on a Sunday night, but I am starting to feel like they need to get a hold of this situation right away or we need to offer to send them some help (read FBI).


And there it is. Page 3093 of the document.
JSTOR can hem and haw about it all they want, but you can't un-call the cops.
MIT was working with JSTOR on preventing future incidents of pirating, but JSTOR repeatedly said that they weren't going to let it go, that it was unacceptable to drop the issue, that they were going to continue to pursue the pirate.
You can scroll through the document and see the JSTOR tech department and abuse team talking about Swartz as a script kiddie, and a hacker. You can see someone talking about how this was real theft - making the comparison to stealing books even while admitting that piracy doesn't close others out of access.
You can see the thread starts with a joke about punching someone in the face for hacking their system, and includes the tech team ominously considering whether they should threaten the MIT librarians with the FBI.
There's something really important to note here which I don't think that people who aren't PRETTY DEEP into hackery shit aren't aware of: US law enforcement is absolutely rabidly feral about prosecuting hackers. People may be more aware of this now because of Chelsea Manning and Edward Snowden (and perhaps a bit on tumblr because of maia arson crimew), but people who work in tech and who are in infosec - like the people joking about calling the FBI in these emails - would be aware of the bonkers disproportionate punishments faced by hackers. And knowing that, they kept pushing and pushing and pushing for identification of the hacker. They kept digging with MIT, they kept saying that simply preventing future incidents wasn't enough.
Early in the exchange someone from JSTOR asked "what's wrong with us - or the university in collaboration with us - alerting the cyber-crimes division of law enforcement and initiating an investigation, having cop search dorm room and try to retrieve any hard drive that contains our content, etc." and the answer is what happened to Aaron Swartz.
It is absolute bullshit for JSTOR to say "we arrived at a solution privately and didn't want to press charges" after law enforcement has gotten involved with a hacking case, especially one where they're talking about "real theft" and are attempting to quantify and emphasize the amount that was "stolen" from them.
The *public* may believe that private individuals or institutions are the ones who "press charges" but that's simply not the case. It's prosecutors who decide whether or not to go ahead with charges; they do it based on what cases they think they can win and what their office's perspective is on the crime. When you hear about people choosing to press charges it simply means that they decided to tell the prosecutor they wanted the case to go forward. It's up to the prosecutor whether or not that happens.
And the tech team at JSTOR had to know that law enforcement wasn't just going to wag a finger at an academic hacker.
There's a parallel here that happens sometimes when people have their identities stolen by their parents. If you mom takes out a credit card in your name, that's identity theft. That's fraud. That's illegal. If you reach the age of 25 and realize that your credit is ruined because your mom has been defaulting on cards in your name, you've got two choices to fix that: one is to accept the debt and pay it off and build up credit, and the other is to report the identity theft - which will end up with your mom in prison for a decade or so. Ruin your own personal finances, or your mom goes to jail for ruining your finances. So if you find out that your mom stole your identity you can't just call the cops to pressure her into transferring the debt to her name or something. That's not an option. The cops are not a threat to wave over people, they are not a way to get people to fall in line or act right. They aren't someone you can send to a college student's dorm room to retrieve a hard drive and have the matter drop.
When you call the cops on someone you are sending the full force of the law after them, and the full force of the law falls really heavily on hackers, and how heavy that blow can be is something that the JSTOR team must have been aware of when they were making snide comments about calling the FBI because they were frustrated with the noncommittal responses they were getting from librarians.
Ultimately it was the carceral state that killed Aaron Swartz, but they would not have been involved if JSTOR didn't think that what he did constituted theft.
Taking an *EVEN LARGER* step back from that, the idea that information can be owned and locked behind a paywall is what killed Aaron Swartz, someone who fought for information to be free.
Like. JSTOR is a licensing company. At the end of the day, cute social media posts and all, they're the same as the RIAA and ASCAB. They exist to extract a fee from people attempting to access information.
Aaron Swartz and all that he stood for are an existential threat to their core function.
Are JSTOR's hands as dirty as the federal prosecutors? Absolutely not. But they operate on a model that puts them in opposition to open information activists and it ended up with a hammer falling on Aaron Swartz that they dropped.
2K notes
·
View notes
Text
Seeing a lot of python hate on the dash today... fight me guys. I love python. I am a smoothbrained python enjoyer and I will not apologize for it
Python has multiple noteworthy virtues, but the most important one is that you can accomplish stuff extremely fast in it if you know what you are doing.
This property is invaluable when you're doing anything that resembles science, because
Most of the things you do are just not gonna work out, and you don't want to waste any time "designing" them "correctly." You can always go back later and give that kind of treatment to the rare idea that actually deserves it.
Many of your problems will be downstream from the limitations in how well you can "see" things (high-dimensional datasets, etc.) that humans aren't naturally equipped to engage with. You will be asking lots and lots of weirdly shaped, one-off questions, all the time, and the faster they get answered the better. Ideally you should be able to get into a flow state where you barely remember that you're technically "coding" on a "computer" -- you feel like you're just looking at something, from an angle of your choice, and then another.
You will not completely understand the domain/problem you're working on, at the outset. Any model you express of it, in code, will be a snapshot of a bad, incomplete mental model you'll eventually grow to hate, unless you're able to (cheaply) discard it and move on. These things should be fast to write, fast to modify, and not overburdened by doctrinaire formal baggage or a scale-insensitive need to chase down tiny performance gains. You can afford to wait 5 seconds occasionally if it'll save you hours or days every time your mental map of reality shifts.
The flipside of this is that it is also extremely (and infamously) easy to be a bad python programmer.
In python doing the obvious thing usually just works, which means you can get away with not knowing why it works and usually make it through OK. Yes, this is cringe or whatever, fine. But by the same token, if you do know what the right thing to do is, that thing is probably very concise and pretty-looking and transparent, because someone explicitly thought to design things that way. What helps (or enables) script kiddies can also be valuable to power users; it's not like there's some fundamental reason the interests of these two groups cannot ever align.
559 notes
·
View notes
Text
Google reneged on the monopolistic bargain

I'm on tour with my new novel The Bezzle! Catch me TONIGHT in SALT LAKE CITY (Feb 21, Weller Book Works) and TOMORROW in SAN DIEGO (Feb 22, Mysterious Galaxy). After that, it's LA, Seattle, Portland, Phoenix and more!

A funny thing happened on the way to the enshittocene: Google – which astonished the world when it reinvented search, blowing Altavista and Yahoo out of the water with a search tool that seemed magic – suddenly turned into a pile of shit.
Google's search results are terrible. The top of the page is dominated by spam, scams, and ads. A surprising number of those ads are scams. Sometimes, these are high-stakes scams played out by well-resourced adversaries who stand to make a fortune by tricking Google:
https://www.nbcnews.com/tech/tech-news/phone-numbers-airlines-listed-google-directed-scammers-rcna94766
But often these scams are perpetrated by petty grifters who are making a couple bucks at this. These aren't hyper-resourced, sophisticated attackers. They're the SEO equivalent of script kiddies, and they're running circles around Google:
https://pluralistic.net/2023/02/24/passive-income/#swiss-cheese-security
Google search is empirically worsening. The SEO industry spends every hour that god sends trying to figure out how to sleaze their way to the top of the search results, and even if Google defeats 99% of these attempts, the 1% that squeak through end up dominating the results page for any consequential query:
https://downloads.webis.de/publications/papers/bevendorff_2024a.pdf
Google insists that this isn't true, and if it is true, it's not their fault because the bad guys out there are so numerous, dedicated and inventive that Google can't help but be overwhelmed by them:
https://searchengineland.com/is-google-search-getting-worse-389658
It wasn't supposed to be this way. Google has long maintained that its scale is the only thing that keeps us safe from the scammers and spammers who would otherwise overwhelm any lesser-resourced defender. That's why it was so imperative that they pursue such aggressive growth, buying up hundreds of companies and integrating their products with search so that every mobile device, every ad, every video, every website, had one of Google's tendrils in it.
This is the argument that Google's defenders have put forward in their messaging on the long-overdue antitrust case against Google, where we learned that Google is spending $26b/year to make sure you never try another search engine:
https://www.bloomberg.com/news/articles/2023-10-27/google-paid-26-3-billion-to-be-default-search-engine-in-2021
Google, we were told, had achieved such intense scale that the normal laws of commercial and technological physics no longer applied. Take security: it's an iron law that "there is no security in obscurity." A system that is only secure when its adversaries don't understand how it works is not a secure system. As Bruce Schneier says, "anyone can design a security system that they themselves can't break. That doesn't mean it works – just that it works for people stupider than them."
And yet, Google operates one of the world's most consequential security system – The Algorithm (TM) – in total secrecy. We're not allowed to know how Google's ranking system works, what its criteria are, or even when it changes: "If we told you that, the spammers would win."
Well, they kept it a secret, and the spammers won anyway.
A viral post by Housefresh – who review air purifiers – describes how Google's algorithmic failures, which send the worst sites to the top of the heap, have made it impossible for high-quality review sites to compete:
https://housefresh.com/david-vs-digital-goliaths/
You've doubtless encountered these bad review sites. Search for "Best ______ 2024" and the results are a series of near-identical lists, strewn with Amazon affiliate links. Google has endlessly tinkered with its guidelines and algorithmic weights for review sites, and none of it has made a difference. For example, when Google instituted a policy that reviewers should "discuss the benefits and drawbacks of something, based on your own original research," sites that had previously regurgitated the same lists of the same top ten Amazon bestsellers "peppered their pages with references to a ‘rigorous testing process,’ their ‘lab team,’ subject matter experts ‘they collaborated with,’ and complicated methodologies that seem impressive at a cursory look."
But these grandiose claims – like the 67 air purifiers supposedly tested in Better Homes and Gardens's Des Moines lab – result in zero in-depth reviews and no published data. Moreover, these claims to rigorous testing materialized within a few days of Google changing its search ranking and said that high rankings would be reserved for sites that did testing.
Most damning of all is how the Better Homes and Gardens top air purifiers perform in comparison to the – extensively documented – tests performed by Housefresh: "plagued by high-priced and underperforming units, Amazon bestsellers with dubious origins (that also underperform), and even subpar devices from companies that market their products with phrases like ‘the Tesla of air purifiers.’"
One of the top ranked items on BH&G comes from Molekule, a company that filed for bankruptcy after being sued for false advertising. The model BH&G chose was ranked "the worst air purifier tested" by Wirecutter and "not living up to the hype" by Consumer Reports. Either BH&G's rigorous testing process is a fiction that they infused their site with in response to a Google policy change, or BH&G absolutely sucks at rigorous testing.
BH&G's competitors commit the same sins – literally, the exact same sins. Real Simple's reviews list the same photographer and the photos seem to have been taken in the same place. They also list the same person as their "expert." Real Simple has the same corporate parent as BH&G: Dotdash Meredith. As Housefresh shows, there's a lot of Dotdash Meredith review photos that seem to have been taken in the same place, by the same person.
But the competitors of these magazines are no better. Buzzfeed lists 22 air purifiers, including that crapgadget from Molekule. Their "methodology" is to include screenshots of Amazon reviews.
A lot of the top ranked sites for air purifiers are once-great magazines that have been bought and enshittified by private equity giants, like Popular Science, which began as a magazine in 1872 and became a shambling zombie in 2023, after its PE owners North Equity LLC decided its googlejuice was worth more than its integrity and turned it into a metastatic chumbox of shitty affiliate-link SEO-bait. As Housefresh points out, the marketing team that runs PopSci makes a lot of hay out of the 150 years of trust that went into the magazine, but the actual reviews are thin anaecdotes, unbacked by even the pretense of empiricism (oh, and they loooove Molekule).
Some of the biggest, most powerful, most trusted publications in the world have a side-hustle in quietly producing SEO-friendly "10 Best ___________ of 2024" lists: Rolling Stone, Forbes, US News and Report, CNN, New York Magazine, CNN, CNET, Tom's Guide, and more.
Google literally has one job: to detect this kind of thing and crush it. The deal we made with Google was, "You monopolize search and use your monopoly rents to ensure that we never, ever try another search engine. In return, you will somehow distinguish between low-effort, useless nonsense and good information. You promised us that if you got to be the unelected, permanent overlord of all information access, you would 'organize the world's information and make it universally accessible and useful.'"
They broke the deal.
Companies like CNET used to do real, rigorous product reviews. As Housefresh points out, CNET once bought an entire smart home and used it to test products. Then Red Ventures bought CNET and bet that they could sell the house, switch to vibes-based reviewing, and that Google wouldn't even notice. They were right.
https://www.cnet.com/home/smart-home/welcome-to-the-cnet-smart-home/
Google downranks sites that spend money and time on reviews like Housefresh and GearLab, and crams botshittened content mills like BH&G into our eyeballs instead.
In 1558, Thomas Gresham coined (ahem) Gresham's Law: "Bad money drives out good." When counterfeit money circulates in the economy, anyone who gets a dodgy coin spends it as quickly as they can, because the longer you hold it, the greater the likelihood that someone will detect the fraud and the coin will become worthless. Run this system long enough and all the money in circulation is funny money.
An internet run by Google has its own Gresham's Law: bad sites drive out good. It's not just that BH&G can "test" products at a fraction of the cost of Housefresh – through the simple expedient of doing inadequate tests or no tests at all – so they can put a lot more content up that Housefresh. But that alone wouldn't let them drive Housefresh off the front page of Google's search results. For that, BH&G has to mobilize some of their savings from the no test/bad test lab to do real rigorous science: science in defeating Google's security-through-obscurity system, which lets them command the front page despite publishing worse-than-useless nonsense.
Google has lost the spam wars. In response to the plague of botshit clogging Google search results, the company has invested in…making more botshit:
https://pluralistic.net/2023/02/16/tweedledumber/#easily-spooked
Last year, Google did a $70b stock buyback. They also laid off 12,000 staffers (whose salaries could have been funded for 27 years by that stock buyback). They just laid off thousands more employees.
That wasn't the deal. The deal was that Google would get a monopoly, and they would spend their monopoly rents to be so good that you could just click "I'm feeling lucky" and be teleported to the very best response to your query. A company that can't figure out the difference between a scam like Better Homes and Gardens and a rigorous review site like Housefresh should be pouring every spare dime it brings in into fixing this problem. Not buying default search status on every platform so that we never try another search engine: they should be fixing their shit.
When Google admits that it's losing the war to these kack-handed spam-farmers, that's frustrating. When they light $26b/year on fire making sure you don't ever get to try anything else, that's very frustrating. When they vaporize seventy billion dollars on financial engineering and shoot one in ten engineers, that's outrageous.
Google's scale has transcended the laws of business physics: they can sell an ever-degrading product and command an ever-greater share of our economy, even as their incompetence dooms any decent, honest venture to obscurity while providing fertile ground – and endless temptation – for scammers.

If you'd like an essay-formatted version of this post to read or share, here's a link to it on pluralistic.net, my surveillance-free, ad-free, tracker-free blog:
https://pluralistic.net/2024/02/21/im-feeling-unlucky/#not-up-to-the-task
#pluralistic#monopoly#seo#dark seo#google#search#enshittification#platform decay#product reviews#spam#antitrust#trustbusting
729 notes
·
View notes
Text
"Bots on the internet are nothing new, but a sea change has occurred over the past year. For the past 25 years, anyone running a web server knew that the bulk of traffic was one sort of bot or another. There was googlebot, which was quite polite, and everyone learned to feed it - otherwise no one would ever find the delicious treats we were trying to give away. There were lots of search engine crawlers working to develop this or that service. You'd get 'script kiddies' trying thousands of prepackaged exploits. A server secured and patched by a reasonably competent technologist would have no difficulty ignoring these.
"...The surge of AI bots has hit Open Access sites particularly hard, as their mission conflicts with the need to block bots. Consider that Internet Archive can no longer save snapshots of one of the best open-access publishers, MIT Press, because of cloudflare blocking. Who know how many books will be lost this way? Or consider that the bots took down OAPEN, the worlds most important repository of Scholarly OA books, for a day or two. That's 34,000 books that AI 'checked out' for two days. Or recent outages at Project Gutenberg, which serves 2 million dynamic pages and a half million downloads per day. That's hundreds of thousands of downloads blocked! The link checker at doab-check.ebookfoundation.org (a project I worked on for OAPEN) is now showing 1,534 books that are unreachable due to 'too many requests.' That's 1,534 books that AI has stolen from us! And it's getting worse.
"...The thing that gets me REALLY mad is how unnecessary this carnage is. Project Gutenberg makes all its content available with one click on a file in its feeds directory. OAPEN makes all its books available via an API. There's no need to make a million requests to get this stuff!! Who (or what) is programming these idiot scraping bots? Have they never heard of a sitemap??? Are they summer interns using ChatGPT to write all their code? Who gave them infinite memory, CPUs and bandwidth to run these monstrosities? (Don't answer.)
"We are headed for a world in which all good information is locked up behind secure registration barriers and paywalls, and it won't be to make money, it will be for survival. Captchas will only be solvable by advanced AIs and only the wealthy will be able to use internet libraries."
#ugh#AI#generative AI#literally a plagiarism machine#and before you're like “oH bUt Ai Is DoInG sO mUcH gOoD...” that's machine learning AI doing stuff like finding cancer#generative AI is just stealing and then selling plagiarism#open access#OA#MIT Press#OAPEN#Project Gutenberg#various AI enthusiasts just wrecking the damn internet by Ctrl+Cing all over the damn place and not actually reading a damn thing
46 notes
·
View notes