#linkedin data scraper
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr.com is the 103rd most visited website in the world.
Text
Linkedin Data Scraper for Quick Extraction of Professional Profiles and Business Leads Utilize the powerful linkedin data scraper at Scrapin.io to gather comprehensive data from LinkedIn, enhancing your outreach and networking efforts.
0 notes
Text
💼 Unlock LinkedIn Like Never Before with the LinkedIn Profile Explorer!
Need to extract LinkedIn profile data effortlessly? Meet the LinkedIn Profile Explorer by Dainty Screw—your ultimate tool for automated LinkedIn data collection.
✨ What This Tool Can Do:
• 🧑💼 Extract names, job titles, and company details.
• 📍 Gather profile locations and industries.
• 📞 Scrape contact information (if publicly available).
• 🚀 Collect skills, education, and more from profiles!
💡 Perfect For:
• Recruiters sourcing top talent.
• Marketers building lead lists.
• Researchers analyzing career trends.
• Businesses creating personalized outreach campaigns.
🚀 Why Choose the LinkedIn Profile Explorer?
• Accurate Data: Scrapes reliable and up-to-date profile details.
• Customizable Searches: Target specific roles, industries, or locations.
• Time-Saving Automation: Save hours of manual work.
• Scalable for Big Projects: Perfect for bulk data extraction.
🔗 Get Started Today:
Simplify LinkedIn data collection with one click: LinkedIn Profile Explorer
🙌 Whether you’re hiring, marketing, or researching, this tool makes LinkedIn data extraction fast, easy, and reliable. Try it now!
Tags: #LinkedInScraper #ProfileExplorer #WebScraping #AutomationTools #Recruitment #LeadGeneration #DataExtraction #ApifyTools
#LinkedIn scraper#profile explorer#apify tools#automation tools#lead generation#data scraper#data extraction tools#data scraping#100 days of productivity#accounting#recruiting
1 note
·
View note
Text
ShadowDragon sells a tool called SocialNet that streamlines the process of pulling public data from various sites, apps, and services. Marketing material available online says SocialNet can “follow the breadcrumbs of your target’s digital life and find hidden correlations in your research.” In one promotional video, ShadowDragon says users can enter “an email, an alias, a name, a phone number, a variety of different things, and immediately have information on your target. We can see interests, we can see who friends are, pictures, videos.”
The leaked list of targeted sites include ones from major tech companies, communication tools, sites focused around certain hobbies and interests, payment services, social networks, and more. The 30 companies the Mozilla Foundation is asking to block ShadowDragon scrapers are Amazon, Apple, BabyCentre, BlueSky, Discord, Duolingo, Etsy, Meta’s Facebook and Instagram, FlightAware, Github, Glassdoor, GoFundMe, Google, LinkedIn, Nextdoor, OnlyFans, Pinterest, Reddit, Snapchat, Strava, Substack, TikTok, Tinder, TripAdvisor, Twitch, Twitter, WhatsApp, Xbox, Yelp, and YouTube.
437 notes
·
View notes
Quote
In recent months, the signs and portents have been accumulating with increasing speed. Google is trying to kill the 10 blue links. Twitter is being abandoned to bots and blue ticks. There’s the junkification of Amazon and the enshittification of TikTok. Layoffs are gutting online media. A job posting looking for an “AI editor” expects “output of 200 to 250 articles per week.” ChatGPT is being used to generate whole spam sites. Etsy is flooded with “AI-generated junk.” Chatbots cite one another in a misinformation ouroboros. LinkedIn is using AI to stimulate tired users. Snapchat and Instagram hope bots will talk to you when your friends don’t. Redditors are staging blackouts. Stack Overflow mods are on strike. The Internet Archive is fighting off data scrapers, and “AI is tearing Wikipedia apart.” The old web is dying, and the new web struggles to be born.
AI is killing the old web, and the new web struggles to be born
67 notes
·
View notes
Link
[ad_1] In this tutorial, we walk you through building an enhanced web scraping tool that leverages BrightData’s powerful proxy network alongside Google’s Gemini API for intelligent data extraction. You’ll see how to structure your Python project, install and import the necessary libraries, and encapsulate scraping logic within a clean, reusable BrightDataScraper class. Whether you’re targeting Amazon product pages, bestseller listings, or LinkedIn profiles, the scraper’s modular methods demonstrate how to configure scraping parameters, handle errors gracefully, and return structured JSON results. An optional React-style AI agent integration also shows you how to combine LLM-driven reasoning with real-time scraping, empowering you to pose natural language queries for on-the-fly data analysis. !pip install langchain-brightdata langchain-google-genai langgraph langchain-core google-generativeai We install all of the key libraries needed for the tutorial in one step: langchain-brightdata for BrightData web scraping, langchain-google-genai and google-generativeai for Google Gemini integration, langgraph for agent orchestration, and langchain-core for the core LangChain framework. import os import json from typing import Dict, Any, Optional from langchain_brightdata import BrightDataWebScraperAPI from langchain_google_genai import ChatGoogleGenerativeAI from langgraph.prebuilt import create_react_agent These imports prepare your environment and core functionality: os and json handle system operations and data serialization, while typing provides structured type hints. You then bring in BrightDataWebScraperAPI for BrightData scraping, ChatGoogleGenerativeAI to interface with Google’s Gemini LLM, and create_react_agent to orchestrate these components in a React-style agent. class BrightDataScraper: """Enhanced web scraper using BrightData API""" def __init__(self, api_key: str, google_api_key: Optional[str] = None): """Initialize scraper with API keys""" self.api_key = api_key self.scraper = BrightDataWebScraperAPI(bright_data_api_key=api_key) if google_api_key: self.llm = ChatGoogleGenerativeAI( model="gemini-2.0-flash", google_api_key=google_api_key ) self.agent = create_react_agent(self.llm, [self.scraper]) def scrape_amazon_product(self, url: str, zipcode: str = "10001") -> Dict[str, Any]: """Scrape Amazon product data""" try: results = self.scraper.invoke( "url": url, "dataset_type": "amazon_product", "zipcode": zipcode ) return "success": True, "data": results except Exception as e: return "success": False, "error": str(e) def scrape_amazon_bestsellers(self, region: str = "in") -> Dict[str, Any]: """Scrape Amazon bestsellers""" try: url = f" results = self.scraper.invoke( "url": url, "dataset_type": "amazon_product" ) return "success": True, "data": results except Exception as e: return "success": False, "error": str(e) def scrape_linkedin_profile(self, url: str) -> Dict[str, Any]: """Scrape LinkedIn profile data""" try: results = self.scraper.invoke( "url": url, "dataset_type": "linkedin_person_profile" ) return "success": True, "data": results except Exception as e: return "success": False, "error": str(e) def run_agent_query(self, query: str) -> None: """Run AI agent with natural language query""" if not hasattr(self, 'agent'): print("Error: Google API key required for agent functionality") return try: for step in self.agent.stream( "messages": query, stream_mode="values" ): step["messages"][-1].pretty_print() except Exception as e: print(f"Agent error: e") def print_results(self, results: Dict[str, Any], title: str = "Results") -> None: """Pretty print results""" print(f"\n'='*50") print(f"title") print(f"'='*50") if results["success"]: print(json.dumps(results["data"], indent=2, ensure_ascii=False)) else: print(f"Error: results['error']") print() The BrightDataScraper class encapsulates all BrightData web-scraping logic and optional Gemini-powered intelligence under a single, reusable interface. Its methods enable you to easily fetch Amazon product details, bestseller lists, and LinkedIn profiles, handling API calls, error handling, and JSON formatting, and even stream natural-language “agent” queries when a Google API key is provided. A convenient print_results helper ensures your output is always cleanly formatted for inspection. def main(): """Main execution function""" BRIGHT_DATA_API_KEY = "Use Your Own API Key" GOOGLE_API_KEY = "Use Your Own API Key" scraper = BrightDataScraper(BRIGHT_DATA_API_KEY, GOOGLE_API_KEY) print("🛍️ Scraping Amazon India Bestsellers...") bestsellers = scraper.scrape_amazon_bestsellers("in") scraper.print_results(bestsellers, "Amazon India Bestsellers") print("📦 Scraping Amazon Product...") product_url = " product_data = scraper.scrape_amazon_product(product_url, "10001") scraper.print_results(product_data, "Amazon Product Data") print("👤 Scraping LinkedIn Profile...") linkedin_url = " linkedin_data = scraper.scrape_linkedin_profile(linkedin_url) scraper.print_results(linkedin_data, "LinkedIn Profile Data") print("🤖 Running AI Agent Query...") agent_query = """ Scrape Amazon product data for in New York (zipcode 10001) and summarize the key product details. """ scraper.run_agent_query(agent_query) The main() function ties everything together by setting your BrightData and Google API keys, instantiating the BrightDataScraper, and then demonstrating each feature: it scrapes Amazon India’s bestsellers, fetches details for a specific product, retrieves a LinkedIn profile, and finally runs a natural-language agent query, printing neatly formatted results after each step. if __name__ == "__main__": print("Installing required packages...") os.system("pip install -q langchain-brightdata langchain-google-genai langgraph") os.environ["BRIGHT_DATA_API_KEY"] = "Use Your Own API Key" main() Finally, this entry-point block ensures that, when run as a standalone script, the required scraping libraries are quietly installed, and the BrightData API key is set in the environment. Then the main function is executed to initiate all scraping and agent workflows. In conclusion, by the end of this tutorial, you’ll have a ready-to-use Python script that automates tedious data collection tasks, abstracts away low-level API details, and optionally taps into generative AI for advanced query handling. You can extend this foundation by adding support for other dataset types, integrating additional LLMs, or deploying the scraper as part of a larger data pipeline or web service. With these building blocks in place, you’re now equipped to gather, analyze, and present web data more efficiently, whether for market research, competitive intelligence, or custom AI-driven applications. Check out the Notebook. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter. Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences. [ad_2] Source link
0 notes
Text
10 Common Causes of Data Loss and How DataReclaimer Can Help
In the digital age, data is a critical asset for businesses and individuals alike. However, data loss remains a prevalent issue, often resulting in significant setbacks. Understanding the common causes of data loss and how to mitigate them is essential. DataReclaimer offers solutions to help recover and protect your valuable information.
1. Hardware Failures
Hard drives and other storage devices can fail due to mechanical issues, manufacturing defects, or wear and tear. Regular backups and monitoring can help detect early signs of failure.
2. Human Error
Accidental deletion or overwriting of files is a common cause of data loss. Implementing user training and permission controls can reduce such incidents.
3. Software Corruption
Software bugs or crashes can corrupt files or entire systems. Keeping software updated and using reliable applications minimizes this risk.
4. Malware and Viruses
Malicious software can delete, encrypt, or corrupt data. Utilizing robust antivirus programs and practicing safe browsing habits are key preventive measures.
5. Power Outages and Surges
Sudden power loss or surges can interrupt data writing processes, leading to corruption. Using uninterruptible power supplies (UPS) can safeguard against this.
6. Natural Disasters
Events like floods, fires, or earthquakes can physically damage storage devices. Off-site backups and cloud storage solutions offer protection against such scenarios.
7. Theft or Loss of Devices
Losing laptops, USB drives, or other portable devices can result in data loss. Encrypting data and using tracking software can mitigate the impact.
8. Operating System Failures
System crashes or failures can render data inaccessible. Regular system maintenance and backups are essential preventive strategies.
9. Firmware Corruption
Firmware issues in storage devices can lead to data inaccessibility. Regular updates and monitoring can help prevent such problems.
10. Improper Shutdowns
Not shutting down systems properly can cause data corruption. Ensuring proper shutdown procedures are followed is a simple yet effective preventive measure.
How DataReclaimer Can Assist
DataReclaimer specializes in data recovery and protection solutions. Their services include:
Data Recovery Services: Recovering lost or corrupted data from various storage devices.
LinkedIn & Sales Navigator Profile Scraper: Safely extract and back up LinkedIn and Sales Navigator data, ensuring valuable contact information is preserved.
Bulk Email Finder Tool: Retrieve and manage email contacts efficiently, reducing the risk of losing important communication channels.
Data Extraction Solutions: Securely extract and store data from various platforms, minimizing the risk of loss.
By leveraging DataReclaimer's expertise, businesses and individuals can safeguard their data against common loss scenarios.
Conclusion
Data loss can have severe consequences, but understanding its causes and implementing preventive measures can significantly reduce risks. Partnering with experts like DataReclaimer ensures that, even in the face of data loss, recovery is possible, and future incidents are mitigated.
0 notes
Text
BIGDATASCRAPING
Powerful web scraping platform for regular and professional use, offering high-performance data extraction from any website. Supports collection and analysis of data from diverse sources with flexible export formats, seamless integrations, and custom solutions. Features specialized scrapers for Google Maps, Instagram, Twitter (X), YouTube, Facebook, LinkedIn, TikTok, Yelp, TripAdvisor, and Google News, designed for enterprise-level needs with prioritized support.
1 note
·
View note
Text
Unlock SEO & Automation with Python
In today’s fast-paced digital world, marketers are under constant pressure to deliver faster results, better insights, and smarter strategies. With automation becoming a cornerstone of digital marketing, Python has emerged as one of the most powerful tools for marketers who want to stay ahead of the curve.
Whether you’re tracking SEO performance, automating repetitive tasks, or analyzing large datasets, Python offers unmatched flexibility and speed. If you're still relying solely on traditional marketing platforms, it's time to step up — because Python isn't just for developers anymore.
Why Python Is a Game-Changer for Digital Marketers
Python’s growing popularity lies in its simplicity and versatility. It's easy to learn, open-source, and supports countless libraries that cater directly to marketing needs. From scraping websites for keyword data to automating Google Analytics reports, Python allows marketers to save time and make data-driven decisions faster than ever.
One key benefit is how Python handles SEO tasks. Imagine being able to monitor thousands of keywords, track competitors, and audit websites in minutes — all without manually clicking through endless tools. Libraries like BeautifulSoup, Scrapy, and Pandas allow marketers to extract, clean, and analyze SEO data at scale. This makes it easier to identify opportunities, fix issues, and outrank competitors efficiently.
Automating the Routine, Empowering the Creative
Repetitive tasks eat into a marketer's most valuable resource: time. Python helps eliminate the grunt work. Need to schedule social media posts, generate performance reports, or pull ad data across platforms? With just a few lines of code, Python can automate these tasks while you focus on creativity and strategy.
In Dehradun, a growing hub for tech and education, professionals are recognizing this trend. Enrolling in a Python Course in Dehradun not only boosts your marketing skill set but also opens up new career opportunities in analytics, SEO, and marketing automation. Local training programs often offer real-world marketing projects to ensure you gain hands-on experience with tools like Jupyter, APIs, and web scrapers — critical assets in the digital marketing toolkit.
Real-World Marketing Use Cases
Python's role in marketing isn’t just theoretical — it’s practical. Here are a few real-world scenarios where marketers are already using
Python to their advantage:
Content Optimization: Automate keyword research and content gap analysis to improve your blog and web copy.
Email Campaign Analysis: Analyze open rates, click-throughs, and conversions to fine-tune your email strategies.
Ad Spend Optimization: Pull and compare performance data from Facebook Ads, Google Ads, and LinkedIn to make smarter budget decisions.
Social Listening: Monitor brand mentions or trends across Twitter and Reddit to stay responsive and relevant.
With so many uses, Python is quickly becoming the Swiss army knife for marketers. You don’t need to become a software engineer — even a basic understanding can dramatically improve your workflow.
Getting Started with Python
Whether you're a fresh graduate or a seasoned marketer, investing in the right training can fast-track your career. A quality Python training in Dehradun will teach you how to automate marketing workflows, handle SEO analytics, and visualize campaign performance — all with practical, industry-relevant projects.
Look for courses that include modules on digital marketing integration, data handling, and tool-based assignments. These elements ensure you're not just learning syntax but applying it to real marketing scenarios. With Dehradun's increasing focus on tech education, it's a great place to gain this in-demand skill.
Python is no longer optional for forward-thinking marketers. As SEO becomes more data-driven and automation more essential, mastering Python gives you a clear edge. It simplifies complexity, drives efficiency, and helps you make smarter, faster decisions.
Now is the perfect time to upskill. Whether you're optimizing search rankings or building powerful marketing dashboards, Python is your key to unlocking smarter marketing in 2025 and beyond.
Python vs Ruby, What is the Difference? - Pros & Cons
youtube
#python course#python training#education#python#pythoncourseinindia#pythoninstitute#pythoninstituteinindia#pythondeveloper#Youtube
0 notes
Text
The Future of Professional Networking: Exploring LinkedIn Scraping
In the digital age, the importance of professional networking cannot be overstated. LinkedIn, the premier platform for business and career networking, hosts millions of profiles and a plethora of company information. For businesses and individuals alike, accessing this wealth of data can offer significant advantages. This is where the concept of LinkedIn scraping comes into play, revolutionizing how we gather and utilize information.
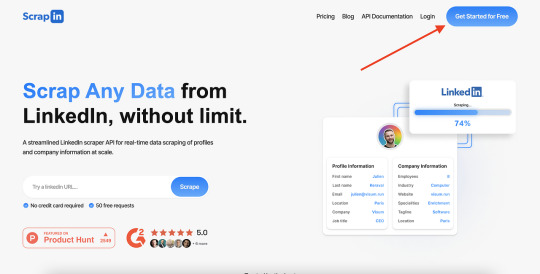
Understanding LinkedIn Scraping
They refers to the process of extracting data from LinkedIn profiles and company pages using automated tools. This technique allows users to collect a wide range of data points such as job titles, skills, endorsements, company details, and much more. By automating the data collection process, scraping LinkedIn provides a more efficient and scalable way to gather crucial information compared to manual methods.
The Benefits of LinkedIn Scraping
The advantages ofLinkedIn data scrape are multifaceted, catering to various needs across different sectors:
1. Recruitment: For recruitment agencies and HR professionals, scraping LinkedIn can streamline the talent acquisition process. By extracting detailed profiles, recruiters can quickly identify and contact potential candidates that match specific job criteria.
2. Sales and Marketing: Sales teams can leverage scraping LinkedIn to build comprehensive lead lists. By targeting profiles that fit their ideal customer persona, businesses can enhance their outreach efforts and improve conversion rates.
3. Market Research: Companies conducting market research can use LinkedIn scraping to gather data on competitors, industry trends, and demographic information. This insight can inform strategic decisions and help businesses stay ahead of the curve.
Ethical and Legal Considerations
While LinkedIn scraping offers numerous benefits, it is crucial to navigate the ethical and legal landscape carefully. LinkedIn's terms of service explicitly prohibit unauthorized scraping of their data. Violating these terms can lead to legal repercussions and the banning of accounts. Therefore, it is essential to use compliant and ethical methods when performing LinkedIn scraping.
Introducing a Streamlined LinkedIn Scraper API
For those looking to implement LinkedIn scraping on a large scale, a streamlined LinkedIn scraper API is an invaluable tool. This API enables real-time data scraping of profiles and company information, providing up-to-date insights and information. By using such an API, businesses can efficiently gather and process data at scale without compromising on accuracy or speed.
Best Practices for LinkedIn Scraping
To ensure successful and compliant LinkedIn scraping, consider the following best practices:
1. Respect LinkedIn’s Terms of Service: Always adhere to LinkedIn’s guidelines to avoid potential legal issues. Use scraping tools that are designed to operate within these constraints.
2. Data Accuracy: Ensure that the scraping tool you use can accurately capture the necessary data points without errors. This reliability is crucial for maintaining the quality of your data.
3. Privacy Considerations:��Be mindful of user privacy and data protection laws. Avoid scraping personal information that is not publicly available or necessary for your use case.

Conclusion:
LinkedIn scraping is transforming the way we access and utilize professional data. Whether for recruitment, sales, marketing, or research, the ability to extract and analyze LinkedIn data efficiently can provide a competitive edge. By using a streamlined LinkedIn scraper API, businesses can achieve real-time data scraping of profiles and company information at scale, ensuring they have the most current and relevant information at their fingertips. For those seeking a reliable solution,Scrapin.io offers a robust platform designed to meet these needs, enabling users to harness the full potential of LinkedIn data scraping while maintaining compliance and ethical standards.
Blog Source URL :
#linkedin scraper#linkedin scraping#linkedin data scraping#linkedin data scraper#scraping linkedin#scrape linkedin#scrape linkedin data#linkedin profile scraper#scrape linkedin profiles#linkedin scraping tool#scraping linkedin data#linkedin scraper tool#linkedin data extractor#linkedin data scrape#extract data from linkedin#scrape data from linkedin#linkedin scraper api#linkedin data scraping tool#linkedin data extraction tool#extract information from linkedin
0 notes
Text
Learn how to scrape LinkedIn profile data at scale using Scrapingdog’s LinkedIn API and Make.com. Perfect for recruiters, marketers, and data professionals.
0 notes
Text

Struggling to find verified leads for your marketing or sales campaigns? We get it — high-quality data is the lifeblood of successful outreach, but it’s often expensive, outdated, or just plain wrong.
At ProspectList.Store, we’re changing that.
That’s right. We want to prove the quality of our data with zero risk on your end. Whether you’re targeting CEOs in tech or marketing managers in eCommerce, we’ve got the contacts you need.
Full Name
Job Title
Company Name
Email Address (verified)
LinkedIn Profile
Phone (verified)
Industry & Location filters
Customized to your niche!
We combine the power of LinkedIn Sales Navigator, Apollo.io, custom scrapers, and manual verification to deliver accurate, ready-to-use contact lists.
our data gives you the edge.
Don’t waste time scraping or guessing. Let us deliver the right leads so you can focus on closing deals.
#LeadGeneration#B2BLeads#ColdEmail#SalesLeads#Prospecting#apolloio#Salesnavigator#MarketingTools#StartupGrowth#LinkedInMarketing#SalesStrategy#OutreachTools#EmailMarketing#ProspectListStore
1 note
·
View note
Link
[ad_1] In this tutorial, we walk you through building an enhanced web scraping tool that leverages BrightData’s powerful proxy network alongside Google’s Gemini API for intelligent data extraction. You’ll see how to structure your Python project, install and import the necessary libraries, and encapsulate scraping logic within a clean, reusable BrightDataScraper class. Whether you’re targeting Amazon product pages, bestseller listings, or LinkedIn profiles, the scraper’s modular methods demonstrate how to configure scraping parameters, handle errors gracefully, and return structured JSON results. An optional React-style AI agent integration also shows you how to combine LLM-driven reasoning with real-time scraping, empowering you to pose natural language queries for on-the-fly data analysis. !pip install langchain-brightdata langchain-google-genai langgraph langchain-core google-generativeai We install all of the key libraries needed for the tutorial in one step: langchain-brightdata for BrightData web scraping, langchain-google-genai and google-generativeai for Google Gemini integration, langgraph for agent orchestration, and langchain-core for the core LangChain framework. import os import json from typing import Dict, Any, Optional from langchain_brightdata import BrightDataWebScraperAPI from langchain_google_genai import ChatGoogleGenerativeAI from langgraph.prebuilt import create_react_agent These imports prepare your environment and core functionality: os and json handle system operations and data serialization, while typing provides structured type hints. You then bring in BrightDataWebScraperAPI for BrightData scraping, ChatGoogleGenerativeAI to interface with Google’s Gemini LLM, and create_react_agent to orchestrate these components in a React-style agent. class BrightDataScraper: """Enhanced web scraper using BrightData API""" def __init__(self, api_key: str, google_api_key: Optional[str] = None): """Initialize scraper with API keys""" self.api_key = api_key self.scraper = BrightDataWebScraperAPI(bright_data_api_key=api_key) if google_api_key: self.llm = ChatGoogleGenerativeAI( model="gemini-2.0-flash", google_api_key=google_api_key ) self.agent = create_react_agent(self.llm, [self.scraper]) def scrape_amazon_product(self, url: str, zipcode: str = "10001") -> Dict[str, Any]: """Scrape Amazon product data""" try: results = self.scraper.invoke( "url": url, "dataset_type": "amazon_product", "zipcode": zipcode ) return "success": True, "data": results except Exception as e: return "success": False, "error": str(e) def scrape_amazon_bestsellers(self, region: str = "in") -> Dict[str, Any]: """Scrape Amazon bestsellers""" try: url = f" results = self.scraper.invoke( "url": url, "dataset_type": "amazon_product" ) return "success": True, "data": results except Exception as e: return "success": False, "error": str(e) def scrape_linkedin_profile(self, url: str) -> Dict[str, Any]: """Scrape LinkedIn profile data""" try: results = self.scraper.invoke( "url": url, "dataset_type": "linkedin_person_profile" ) return "success": True, "data": results except Exception as e: return "success": False, "error": str(e) def run_agent_query(self, query: str) -> None: """Run AI agent with natural language query""" if not hasattr(self, 'agent'): print("Error: Google API key required for agent functionality") return try: for step in self.agent.stream( "messages": query, stream_mode="values" ): step["messages"][-1].pretty_print() except Exception as e: print(f"Agent error: e") def print_results(self, results: Dict[str, Any], title: str = "Results") -> None: """Pretty print results""" print(f"\n'='*50") print(f"title") print(f"'='*50") if results["success"]: print(json.dumps(results["data"], indent=2, ensure_ascii=False)) else: print(f"Error: results['error']") print() The BrightDataScraper class encapsulates all BrightData web-scraping logic and optional Gemini-powered intelligence under a single, reusable interface. Its methods enable you to easily fetch Amazon product details, bestseller lists, and LinkedIn profiles, handling API calls, error handling, and JSON formatting, and even stream natural-language “agent” queries when a Google API key is provided. A convenient print_results helper ensures your output is always cleanly formatted for inspection. def main(): """Main execution function""" BRIGHT_DATA_API_KEY = "Use Your Own API Key" GOOGLE_API_KEY = "Use Your Own API Key" scraper = BrightDataScraper(BRIGHT_DATA_API_KEY, GOOGLE_API_KEY) print("🛍️ Scraping Amazon India Bestsellers...") bestsellers = scraper.scrape_amazon_bestsellers("in") scraper.print_results(bestsellers, "Amazon India Bestsellers") print("📦 Scraping Amazon Product...") product_url = " product_data = scraper.scrape_amazon_product(product_url, "10001") scraper.print_results(product_data, "Amazon Product Data") print("👤 Scraping LinkedIn Profile...") linkedin_url = " linkedin_data = scraper.scrape_linkedin_profile(linkedin_url) scraper.print_results(linkedin_data, "LinkedIn Profile Data") print("🤖 Running AI Agent Query...") agent_query = """ Scrape Amazon product data for in New York (zipcode 10001) and summarize the key product details. """ scraper.run_agent_query(agent_query) The main() function ties everything together by setting your BrightData and Google API keys, instantiating the BrightDataScraper, and then demonstrating each feature: it scrapes Amazon India’s bestsellers, fetches details for a specific product, retrieves a LinkedIn profile, and finally runs a natural-language agent query, printing neatly formatted results after each step. if __name__ == "__main__": print("Installing required packages...") os.system("pip install -q langchain-brightdata langchain-google-genai langgraph") os.environ["BRIGHT_DATA_API_KEY"] = "Use Your Own API Key" main() Finally, this entry-point block ensures that, when run as a standalone script, the required scraping libraries are quietly installed, and the BrightData API key is set in the environment. Then the main function is executed to initiate all scraping and agent workflows. In conclusion, by the end of this tutorial, you’ll have a ready-to-use Python script that automates tedious data collection tasks, abstracts away low-level API details, and optionally taps into generative AI for advanced query handling. You can extend this foundation by adding support for other dataset types, integrating additional LLMs, or deploying the scraper as part of a larger data pipeline or web service. With these building blocks in place, you’re now equipped to gather, analyze, and present web data more efficiently, whether for market research, competitive intelligence, or custom AI-driven applications. Check out the Notebook. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter. Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences. [ad_2] Source link
0 notes
Text
Unlocking Sales Leads: How LinkedIn Data Extraction Tool Works with Sales Navigator Scraper – Powered by Data Reclaimer
In the digital era, sales success is no longer about cold calls and guesswork — it’s about smart data, targeted outreach, and precision prospecting. That’s where LinkedIn Sales Navigator and modern scraping tools like Sales Navigator Scraper come into play. Designed to enhance B2B lead generation, these tools extract actionable business intelligence directly from the world’s largest professional network. But how does a LinkedIn data extraction tool work? And what makes tools like those offered by Data Reclaimer a game-changer for sales professionals?
Let’s explore.
What Is LinkedIn Sales Navigator?
LinkedIn Sales Navigator is a premium tool provided by LinkedIn, tailored for sales teams and B2B marketers. It offers advanced search filters, lead recommendations, CRM integrations, and insights into buyer intent — all aimed at helping users connect with the right decision-makers.
However, manually collecting and organizing data from Sales Navigator can be time-consuming and inefficient. This is where data extraction tools or Sales Navigator scrapers come in, automating the process of pulling valuable data from LinkedIn profiles, company pages, and lead lists.
How LinkedIn Data Extraction Tools Work
When we ask "How LinkedIn Data Extraction Tool Works?", the answer lies in a combination of intelligent web scraping, automation frameworks, and ethical data handling practices.
1. User Authentication & Input
First, the user logs into their LinkedIn account — typically through Sales Navigator — and defines search parameters such as industry, location, job title, company size, or keywords.
2. Automated Crawling
Once parameters are set, the tool initiates an automated crawl through the search results. Using browser automation (often through headless browsers like Puppeteer or Selenium), it navigates LinkedIn just like a human would — scrolling, clicking, and viewing profiles.
3. Data Extraction
The scraper extracts public or semi-public information such as:
Full Name
Job Title
Company Name
Location
LinkedIn Profile URL
Contact info (if available)
Industry and seniority level
Connection level (1st, 2nd, 3rd)
4. Data Structuring
After extraction, the data is parsed and organized into a clean format — usually a CSV or JSON file — for easy import into CRMs like HubSpot, Salesforce, or marketing automation platforms.
5. Export and Integration
Finally, users can download the dataset or directly sync it to their sales stack, ready for outreach, segmentation, or analysis.
Why Use Sales Navigator Scraper by Data Reclaimer?
Data Reclaimer offers a cutting-edge Sales Navigator Scraper designed to be user-friendly, accurate, and compliant with best practices. Here’s why it stands out:
✅ High Accuracy & Speed
Unlike basic scrapers that miss key data points or get blocked, Data Reclaimer’s tool uses advanced logic to mimic human interaction, ensuring minimal detection and high-quality results.
✅ Custom Filters & Targeting
Pull data based on highly specific LinkedIn Sales Navigator filters such as seniority, department, activity, and more — allowing for razor-sharp targeting.
✅ Real-Time Data Updates
Stay ahead of outdated contact lists. The tool extracts real-time profile data, ensuring your leads are current and relevant.
✅ GDPR-Aware Extraction
Data Reclaimer ensures its scraping tools align with ethical and legal standards, including GDPR compliance by focusing only on publicly accessible data.
✅ Scalable for Agencies and Teams
Whether you're a solo marketer or part of a large agency, the Sales Navigator Scraper supports bulk extraction for large-scale lead generation.
Use Cases for LinkedIn Data Extraction Tools
From recruiters and B2B marketers to SDRs and startup founders, many professionals benefit from LinkedIn data scraping:
Lead Generation: Build targeted B2B lead lists quickly without manual searching.
Competitor Research: Analyze hiring trends, employee roles, or client networks.
Market Segmentation: Understand demographics within an industry or region.
Recruitment: Identify potential candidates based on roles and skills.
Corporate Intelligence: Map organizational charts and influencer hierarchies.
Ethical Considerations & Best Practices
Using a LinkedIn data extraction tool should always follow responsible use practices. Data Reclaimer advises:
Avoid scraping excessive data that may violate LinkedIn's terms of use.
Only extract information that is publicly available.
Use scraped data for B2B networking and not for spam or harassment.
Clearly disclose how data will be used when reaching out to prospects.
Respect for data privacy not only ensures compliance but also builds trust with your leads.
Tips for Maximizing Sales Navigator Scraper Efficiency
Refine Your Filters: The more specific your Sales Navigator search, the cleaner and more targeted your data output.
Use Proxy Rotation: To avoid IP blocks, consider rotating proxies or using a tool that automates this for you.
Limit Daily Requests: Over-scraping can trigger LinkedIn’s anti-bot systems. Stick to daily limits suggested by your scraper provider.
Enrich and Verify Data: Use email verification tools or enrichment platforms to validate and enhance extracted data.
Integrate with Your CRM: Automate lead nurturing by syncing extracted leads into your CRM system for immediate follow-up.
Conclusion: Sales Prospecting at Scale, the Smart Way
In today’s hyper-competitive B2B landscape, the ability to access high-quality, targeted leads can set you apart from the competition. Understanding how LinkedIn data extraction tools work, especially through powerful solutions like the Sales Navigator Scraper by Data Reclaimer, empowers sales teams to focus on closing deals instead of chasing contact information.
From startups to enterprise sales departments and B2B agencies, tools like these are not just about automation — they’re about intelligence, efficiency, and scalability.
1 note
·
View note
Text
Data/Web Scraping
What is Data Scraping ?
Data scraping is the process of extracting information from websites or other digital sources. It also Knows as web scraping.
Benefits of Data Scraping
1. Competitive Intelligence
Stay ahead of competitors by tracking their prices, product launches, reviews, and marketing strategies.
2. Dynamic Pricing
Automatically update your prices based on market demand, competitor moves, or stock levels.
3. Market Research & Trend Discovery
Understand what’s trending across industries, platforms, and regions.
4. Lead Generation
Collect emails, names, and company data from directories, LinkedIn, and job boards.
5. Automation & Time Savings
Why hire a team to collect data manually when a scraper can do it 24/7.
Who used Data Scraper ?

Businesses, marketers,E-commerce, travel,Startups, analysts,Sales, recruiters, researchers, Investors, agents Etc
Top Data Scraping Browser Extensions
Web Scraper.io
Scraper
Instant Data Scraper
Data Miner
Table Capture
Top Data Scraping Tools
BeautifulSoup
Scrapy
Selenium
Playwright
Octoparse
Apify
ParseHub
Diffbot
Custom Scripts
Legal and Ethical Notes

Not all websites allow scraping. Some have terms of service that forbid it, and scraping too aggressively can get IPs blocked or lead to legal trouble
Apply For Data/Web Scraping : https://www.fiverr.com/s/99AR68a
1 note
·
View note
Text
Social Media Scrape: Unlocking Business Insights Through Data Intelligence
Social media platforms are a goldmine of information, offering valuable insights into consumer behavior, industry trends, and brand sentiment. By leveraging social media scrape, businesses can extract real-time data to optimize strategies, track competitors, and enhance engagement. But what exactly is social media scraping, and how can it benefit your business?

Understanding Social Media Scraping
Social media scraping refers to the process of extracting public data from platforms like Facebook, Twitter, LinkedIn, and Instagram. This data can include user comments, trending hashtags, engagement metrics, and even competitor activity. With the right social media data intelligence services, businesses can collect, analyze, and utilize this data effectively.
Why Businesses Need Social Media Scraping
1. Competitor Analysis
By scraping competitor profiles, businesses can gain insights into their marketing strategies, audience engagement levels, and content performance. This helps in refining one’s own approach and staying ahead in the market.
2. Trend Monitoring
Social media trends change rapidly. Scraping social media ensures that businesses stay updated with viral topics, trending hashtags, and emerging industry developments.
3. Customer Sentiment Analysis
Understanding what customers think about your brand or industry helps in shaping marketing and customer service strategies. By analyzing social media mentions and reviews, businesses can gauge public sentiment effectively.
4. Lead Generation & Marketing Insights
Scraping user profiles and interactions helps businesses identify potential leads and personalize their marketing efforts, increasing conversion rates.
How Social Media Scraping Works
Data Collection: Automated scrapers collect publicly available data from social media platforms.
Data Processing: The extracted data is cleaned and structured for analysis.
Analysis & Insights: AI and data analytics tools process the information to uncover trends and patterns.
Implementation: Businesses use these insights to optimize their social media strategies and decision-making.
Additional Data Scraping Solutions
Apart from social media scraping, businesses can leverage various data extraction services to enhance decision-making:
Zillow Scraper: Extract property listings, pricing trends, and real estate insights.
Extract Job Listings: Gather job postings from multiple platforms to stay updated with hiring trends.
News Extract: Collect real-time news data for media monitoring and competitive analysis.
Scrape Zillow: Access crucial real estate market data for investment and market research.
Conclusion
Social media scraping is a game-changer for businesses looking to leverage data-driven decision-making. With the right social media data intelligence services, companies can unlock valuable insights, enhance customer engagement, and maintain a competitive edge. Explore the power of data extraction today and take your business strategy to the next level!
For more details on social media data scraping, check out our social media data intelligence services today!
#social media data intelligence services#Zillow Scraper#Extract Job Listings#News Extract#Scrape Zillow
0 notes
Text
Unveiling the Power of LinkedIn Scraping: Enhancing Your Networking Game
In the fast-paced world of professional networking, having a strong online presence is essential. LinkedIn, being the go-to platform for professionals across various industries, offers a plethora of opportunities for networking, job hunting, and business development. However, manually extracting data from LinkedIn profiles can be time-consuming and tedious. This is where LinkedIn profile scraper come into play, revolutionizing the way we gather valuable information for our networking endeavors.
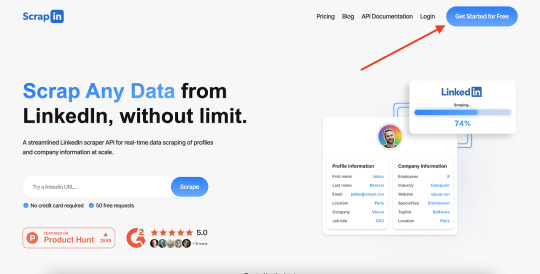
The Rise of LinkedIn Scraping Tools
LinkedIn scraping tools have gained popularity among professionals and businesses alike for their ability to automate the process of extracting data from LinkedIn profiles swiftly and efficiently. These tools leverage web scraping techniques to gather information such as names, job titles, companies, education backgrounds, and even contact details from LinkedIn profiles.
With the click of a button, LinkedIn scraper tool can comb through hundreds or even thousands of profiles, saving users valuable time and effort. Whether you're a recruiter looking to build a talent pipeline, a salesperson seeking leads, or a marketer conducting market research, LinkedIn scraping tools can provide you with the data you need to fuel your endeavors.
Enhancing Your Networking Strategy
By harnessing the power of LinkedIn scrapers, professionals can enhance their networking strategy significantly. Instead of manually browsing through profiles one by one, users can now extract relevant information in bulk, allowing them to identify potential connections more efficiently.
For job seekers, LinkedIn scrapers can be invaluable in gathering insights about hiring managers and recruiters, helping them tailor their applications and outreach efforts effectively. Similarly, sales professionals can use LinkedIn scraping tools to identify decision-makers within target companies, enabling them to craft personalized pitches and drive more meaningful conversations.
The Benefits of Real-Time Data Scraping
One of the key advantages of LinkedIn scraping tools is their ability to provide real-time data scraping of profiles and company information at scale. This means that users can access the most up-to-date information available on LinkedIn, ensuring that their networking efforts are based on accurate and timely data.
Whether you're tracking industry trends, monitoring competitor activity, or keeping tabs on potential leads, real-time data scraping can give you a competitive edge in today's dynamic business landscape. With LinkedIn scrapers, you can stay ahead of the curve and make informed decisions based on the latest insights available.
Your Go-To LinkedIn Scraping Solution
When it comes to LinkedIn scraping tools, Scrapin stands out as a reliable and user-friendly solution for professionals and businesses seeking to streamline their networking efforts. With its intuitive interface and powerful features, Scrapin makes it easy to extract valuable data from LinkedIn profiles with precision and speed.
Whether you're a seasoned recruiter, a sales ninja, or a budding entrepreneur, Scrapin has got you covered. With its streamlined LinkedIn scraper API, you can access real-time data scraping capabilities and unlock a world of opportunities for networking and business growth.

Conclusion:
LinkedIn scraping tools such as Scrapin offer a game-changing solution for professionals looking to elevate their networking game. By automating the process of extracting data from LinkedIn profiles, these tools empower users to gather valuable insights quickly and efficiently, giving them a competitive edge in today's digital landscape. So why waste time manually browsing through profiles when you can harness the power of LinkedIn scraping? Try Scrapin.io today and supercharge your networking efforts like never before!
Blog Source URL :
#linkedin data scraper#scraping linkedin#scrape linkedin#scrape linkedin data#linkedin profile scraper#scrape linkedin profiles#linkedin scraping tool#scraping linkedin data#linkedin scraper tool
0 notes