#machinehack
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
There are dozens of funny blogs to kill time on Tumblr.
Text
India's booming AI startup scene, led by companies like Be10x, Yellow.ai, Blend AI, Zoho, and MachineHack, is driving tech innovation. These startups focus on education, customer service automation, e-commerce advertising, software development, and community platforms, positioning India as a global hub for AI technology and growth.
For more information, visit : https://medium.com/@t2801blog/what-are-some-of-the-fastest-growing-ai-startups-in-india-eebd247bf5db
0 notes
Text
ZS Hiring Hackathon : Patient Drug-switch Prediction

Machine Learning and Data Science have stolen the attention of the young generation who are seeking an exciting and well-paid career. With the advent of growth in data volume and technology the gap between Machine Learning Engineers and Data Scientist is narrowing leading companies to look for full-stack data scientists. The demand for such folks with Machine learning and Data Science skills is exponentially increasing and organizations are struggling to find their best fit. Good MLDS profile not only requires a strong analytical and engineering background but also needs a good understanding of the algorithms, advanced statistics, optimization approaches, coding & distributed computing skills. One of the few possible ways to master this new domain is through constant learning, practice and showcasing of skills through hackathons. This is where MachineHack is going to help. With the help of our top hackathons, you can become an expert in handling data and build a path to a successful Machine Learning and Data Science career. MachineHack and ZS Associates bring to you the “Patient Drug-switch Prediction Hackathon” Problem Description Armanik, a multinational pharmaceutical company based in Texas, USA, is one of the largest pharmaceutical companies by both market capitalization and sales. Armanik manufactures drugs across multiple therapy areas – Cardiovascular, Diabetes, HIV and Immunology therapy. Their innovative SGLT 2 is the market leader in diabetes therapy. Recently, the company announced that they have successfully completed a Phase 3 trial for an Anti-TNF drug in Rheumatoid Arthritis therapeutic. The company expects to get approval for its new drug in the next 6 months. Given the competition in the market, Prakash Vishwanathan, CEO of Armanik, has reached out to ZS to help identify the patient population in the U.S who are likely to switch any product in the RA market. ZS has proposed a machine learning-based approach using medical transactional data to first identify the factors that are most closely associated with the switching RA patients that will help predict patients who are likely to switch in the near term. Can you help ZS in achieving the below-mentioned objectives?

Data Sets File Descriptions : Train_data.csv – Data for training (This is a transactional data for feature creation)Train_labels.csv – Outcome flag for train patients (1/0)Test_data.csv – Data for testing (Create final features for modelling)Fitness_values.csv – Fitness values for features created with train data. Must be used to match the fitness values with the Feature created using Train Data Only.Sample Submission.csv – Sample submission Format to submit the Predictions (Don’t Shuffle the Patient_ID, Keep the sequence entact). Train_data.csv
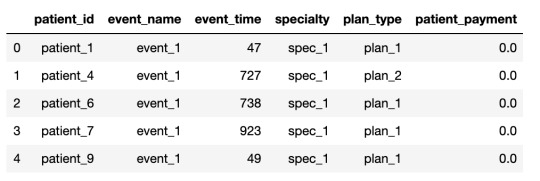
Data Size: Train Data: 627 MBTest Data: 273 MB Packages allowed: PandasNumpyScipyNumbaCython extensionoperator Click here to participate. ABOUT ZS ZS is a professional services firm that works side by side with companies to help develop and deliver products that drive customer value and company results. We leverage our deep industry expertise, leading-edge analytics, technology and strategy to create solutions that work in the real world. With more than 35 years of experience and 6,000-plus ZS-ers in 23 offices worldwide, we are passionately committed to helping companies and their customers thrive. Our most valuable asset is our people—a fact that’s reflected in our values-driven organization in which new perspectives are integral and new ideas are celebrated. We apply our knowledge, capabilities and innovation-oriented approach in industries ranging from healthcare and life sciences to high-tech, financial services, travel and transportation, and beyond. Rules Eligibility: Hackathons are open to all registered users at www.machinehack.com, a participant must be 18 years or older.Only one account is allowed per participant; submissions from multiple accounts will lead to disqualification. This is an individual exercise.We expect that you respect the spirit of the competition and do not cheat. Privately sharing code or data is not permitted—any case of code plagiarism will result in the disqualification of all users involved.It is obligatory to submit a well-commented and reproducible source code that you would generate as part of this contest in .zip or .tar compressed archive or the submission will not be considered.The ideal candidate is expected to hold 2-6 years of experience in working as a Data Scientist or a Machine Learning EngineerThe leaderboard will be updated on the basis of the AUC score of the submitted predictions.Users must have an updated MachineHack profile and must specify their LinkedIn for final shortlisting. Submission limits : You can make a maximum of 3 excel file submissions in a day. Timeline Hackathon will be live from 3rd January 2020 to 13th January 2020. Phase 1: AUC evaluation of submitted predictions - 3rd January 2020 to 10th January 2020. Phase 2: Time complexity evaluation of Submitted code files - 11th January 2020 to 13th January 2020. Submitting Your Files For Evaluation
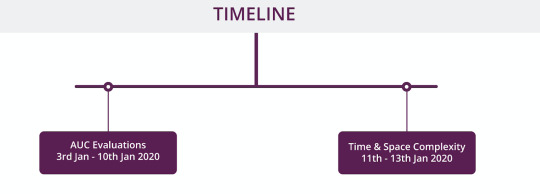
Phase 1 Submission window: January 3rd to January 10th 2020 The hackathon assignment requires participants to submit an excel file (Only .xlsx files are allowed) containing the unique identifier ‘patient_id’ and the corresponding prediction classes ‘outcome_flag’. The submissions are evaluated on AUC score and the leaderboard is updated. Phase 2 Submission window: January 11th to January 13th 2020 The phase 2 submission window (FINAL SUBMISSION) will be enabled to share the following files as a zip post 10th January : The phase 1 submission file with the best AUC score on the leaderboard. (Best Score.xlsx)A csv file containing a list of all the features along with their fitness value. (Fitness_Score.csv)A python script file that can be executed on a machine with RAM of 16 GB to recreate the features and fitness values. (Feature_Pipeline.py)A well commented and reproducible source code(python script) for the best AUC which will be evaluated for time complexity. (Model.py)Fully documented approach in a PPT. Note: Participants must upload the above files in a zip archive to a submission portal which will be enabled on January 11th 2020. Bounty

The best submission will receive a Macbook and a free pass to Machine Learning Developers Summit 2020.The shortlisted participants will get an opportunity to present their approach at MLDS 2020 to a panel of experienced leadership of ZS-ers and participants of the summit. The top 15 participants will get an opportunity to be interviewed for the role of Data Scientist/ Machine Learning Engineer at ZS Associates (The role can be chosen based on your expertise area between the two roles) Click here to participate. Evaluations THE CANDIDATES WILL HAVE TO MAKE SUBMISSIONS AS PER THE GUIDELINES MENTIONED BELOW: Objective 1: Auto Feature Engineering A CSV file containing a list of all the features along with their fitness value.

Once the set of mandatory features is created using the training data, evaluate the fitness of these features using the following methodology. (A starter python notebook is available here) Any submission with >1% of error – sum of % errors across fitness values of all features (~40000 features), will be considered as Invalid. Objective 2: Patient Switching Probabilities Test Set Predictions: The test set predictions are evaluated using AUC. An excel file (.xlsx only) containing the prediction probability for all the patients in the test data. The top submissions will be decided based on the leaderboard score and evaluation of other submission documents (code file, .csv file, supporting notebooks, model pipeline- .py file or .ipynb format). All the good submissions will be eligible to receive the bounties Participate Read the full article
0 notes
Quote
The coronavirus outbreak is taking over headlines. Due to the spread of COVID-19, remote work is suddenly an overnight requirement for many. You might be working from home as you are reading this article. With millions working from home for many weeks now, we should seize this opportunity to improve our skills in the domain we are focusing on. Here is my strategy to learn Data Science while working from home with few personal real life projects. "So what should we do?" "Where should we start learning?" Grab your coffee as I explain the process of how you can learn data science sitting at home. This blog is for everyone, from beginners to professionals. Photo by Nick Morrison on Unsplash Prerequisites To start this journey, you will need to cover the prerequisites. No matter which specific field you are in, you will need to learn the following prerequisites for data science. Logic/Algorithms: It’s important to know why we need a particular prerequisite before learning it. Algorithms are basically a set of instructions given to a computer to make it do a specific task. Machine learning is built from various complex algorithms. So you need to understand how algorithms and logic work on a basic level before jumping into complex algorithms needed for machine learning. If you are able to write the logic for any given puzzle with the proper steps, it will be easy for you to understand how these algorithms work and you can write one for yourself. Resources: Some awesome free resources to learn data structures and algorithms in depth. Statistics: Statistics is a collection of tools that you can use to get answers to important questions about data. Machine learning and statistics are two tightly related fields of study. So much so that statisticians refer to machine learning as “applied statistics” or “statistical learning”. Image source : http://me.me/ The following topics should be covered by aspiring data scientists before they start machine learning. Measures of Central Tendency — mean, median, mode, etc Measures of Variability — variance, standard deviation, z-score, etc Probability — probability density function, conditional probability, etc Accuracy — true positive, false positive, sensitivity, etc Hypothesis Testing and Statistical Significance — p-value, null hypothesis, etc Resources: Learn college level statistics in this free 8 hour course. Business: This depends on which domain you want to focus on. It basically involves understanding the particular domain and getting domain expertise before you get into a data science project. This is important as it helps in defining our problem accurately. Resources: Data science for business Brush up your basics This sounds pretty easy but we tend to forget some important basic concepts. It gets difficult to learn more complex concepts and the latest technologies in a specific domain without having a solid foundation in the basics. Here are few concepts you can start revising: Python programming language Python is widely used in data science. Check out this collection of great Python tutorials and these helpful code samples to get started. Image source : memecrunch.com You can also check out this Python3 Cheatsheet that will help you learn new syntax that was released in python3. It'll also help you brush up on basic syntax. And if you want a great free course, check out this Python for Everybody course from Dr. Chuck. General data science skills Want to take a great course on data science concepts? Here's a bunch of data science courses that you can take online, ranked according to thousands of data points. Resources: Data science for beginners - free 6 hour course, What languages should you learn for data science? Data Collection Now it is time for us to explore all the ways you can collect your data. You never know where your data might be hiding. Following are a few ways you can collect your data. Web scraping Web scraping helps you gather structured data from the web, select some of that data, and keep what you selected for whatever use you require. You can start learning BeautifulSoup4 which helps you scrape websites and make your own datasets. Advance Tip: You can automate browsers and get data from interactive web pages such as Firebase using Selenium. It is useful for automating web applications and automating boring web based administration Resources: Web Scraping 101 in Python Cloud servers If your data is stored on cloud servers such as S3, you might need to get familiar with how to get data from there. The following link will help you understand how to implement them using Amazon S3. Resources : Getting started with Amazon S3, How to deploy your site or app to AWS S3 with CloudFront APIs There are millions of websites that provide data through APIs such as Facebook, Twitter, etc. So it is important to learn how they are used and have a good idea on how they are implemented. Resources : What is an API? In English, please, How to build a JSON API with Python, and Getting started with Python API. Data Preprocessing This topic includes everything from data cleaning to feature engineering. It takes a lot of time and effort. So we need to dedicate a lot of time to actually learn it. Image source : https://www.pinterest.com/pin/293648838181843463/ Data cleaning involves different techniques based on the problem and data type. The data needs to be cleaned from irrelevant data, syntax erros, data inconsistencies and missing data. The following guide will get you started with data cleaning. Resources : Ultimate guide to data cleaning Data Preprocessing is an important step in which the data gets transformed, or encoded, so that the machine can easily parse it. It requires time as well as effort to preprocess different types of data which include numerical, textual and image data. Resources : Data Preprocessing: Concepts, All you need to know about text preprocessing for NLP and Machine Learning, Preprocessing for deep learning. Machine Learning Finally we reach our favourite part of data science: Machine Learning. Image source : https://in.pinterest.com/pin/536209899383255279/ My suggestion here would be to first brush up your basic algorithms. Classification — Logistic Regression, RandomForest, SVM, Naive Bayes, Decision Trees Resources : Types of classification algorithms in Machine Learning, Classification Algorithms in Machine Learning Regression — Linear Regression, RandomForest, Polynomial Regression Resources : Introduction to Linear Regression , Use Linear Regression models to predict quadratic, root, and polynomial functions, 7 Regression Techniques you should know, Selecting the best Machine Learning algorithm for your regression problem, Clustering — K-Means Clustering, DBSCAN, Agglomerative Hierarchical Clustering Resources : Clustering algorithms Gradient Boosting — XGBoost, Catboost, AdaBoost Resources : Gradient boosting from scratch, Understanding Gradient Boosting Machines I urge you all to understand the math behind these algorithms so you have a clear idea of how it actually works. You can refer to this blog where I have implemented XGBoost from scratch — Implementing XGBoost from scratch Now you can move on to Neural Networks and start your Deep Learning journey. Resources: Deep Learning for Developers, Introduction to Deep Learning with Tensorflow, How to develop neural networks with Tensorflow, Learn how deep neural networks work You can then further dive deep into how LSTM, Siamese Networks, CapsNet and BERT works. Hackathons: Image Source : https://me.me/ Now we need to implement these algorithms on a competitive level. You can start looking for online Data Science Hackathons. Here is the list of websites where I try to compete with other data scientists. Analytics Vidhya — https://datahack.analyticsvidhya.com/contest/all/ Kaggle — https://www.kaggle.com/competitions Hackerearth — https://www.hackerearth.com/challenges/ MachineHack — https://www.machinehack.com/ TechGig — https://www.techgig.com/challenge Dare2compete — https://dare2compete.com/e/competitions/latest Crowdanalytix — https://www.crowdanalytix.com/community To have a look at a winning solution, here is a link to my winning solution to one online Hackathon on Analytics Vidhya — https://github.com/Sid11/AnalyticsVidhya_DataSupremacy Projects: We see people working on dummy data and still don’t get the taste of how actual data looks like. In my opinion, working on real life data gives you a very clear idea how data in real life looks like. The amount of time and effort required in cleaning real life data takes about 70% of your project’s time. Here are the best free open data sources anyone can use Open Government Data — https://data.gov.in/ Data about real contributed by thousands of users and organizations across the world — https://data.world/datasets/real 19 public datasets for Data Science Project — https://www.springboard.com/blog/free-public-data-sets-data-science-project/ Business Intelligence After you get the results from your project, it is now time to make business decisions from those results. Business Intelligence is a suite of software and services that helps transform data into actionable intelligence and knowledge. This can be done by creating a dashboard from the output of our model. Tableau is a powerful and the fastest growing data visualization tool used in the Business Intelligence Industry. It helps in simplifying raw data into the very easily understandable format. Data analysis is very fast with Tableau and the visualizations created are in the form of dashboards and worksheets.
http://damianfallon.blogspot.com/2020/03/how-to-improve-your-data-science-skills_31.html
1 note
·
View note
Text
Top Data Science Hackathon Platforms with Active Challenges
Hackathons are a terrific method for computer enthusiasts—beginners or experts—to develop new skills and offer solutions. Hackathons have recently started to be used by enterprises and companies as a hiring tool. Big, mid-sized, and small businesses frequently shortlist the winners of these hackathons.

The victors of hackathons receive a variety of prizes in addition to being hired. For tech aficionados, these sites are a terrific way to stay up to date on current and upcoming trends in the AI/ML sector.
Data Science Hackthon
You can participate in data science hackathons on the following platforms to win prizes and get the attention of hiring managers.
MachineHack
MachineHack, the brainchild of Analytics India Magazine, runs multiple hackathons concurrently covering diverse themes within machine learning, deep learning, and other data engineering issues in addition to providing hundreds of courses about machine learning and data science. With the help of this online platform, develop your data science expertise by participating in hackathons organized by the industry.
There are several active hackathons on the website, and several numbers of active hackathons, including Subscriber Prediction Talent Search, Predict the News Category, Predict the Flight Ticket
, and Predict website, there are several numbers of active hackathons, including Subscriber Prediction Talent Search, Predict News Category, Predict the Flight Ticket, and Predict The Price of Books.
Kaggle
The largest online community of data scientists One of the best and most prestigious places to receive honors in data science is Kaggle. On Kaggle, hackathons range in difficulty from beginner to advanced. It is the highest honor in the data science community to earn the badge of Grandmaster, which may be obtained by consistently contributing and winning hackathons.
The NFL Big Data Bowl 2023, OTTO - Multi-Objective Recommender System, Multimodal Single-Cell Integration, and many other competitions are ongoing simultaneously for novices and specialists.
HackerEarth
HackerEarth is a website that focuses on connecting engineers and businesses. It also offers hackathons and challenges related to machine learning. Additionally, businesses can advertise their hackathons on the platform, where coders can participate in streamlining current business procedures and potentially land jobs.
The platform is currently hosting several ongoing hackathons, including the Global Hack for Web3 by CoinBase, IBM's students Contest, and the Smart Odisha Hackathon.
DataHack
DataHack offers a variety of competitions, events, and hackathons where you may compete with top machine learning professionals and data scientists and advance your skill sets to develop a data science profile. You can participate in these hackathons and compete to find solutions to both platform-hosted business challenges and real-world problems.
Predict Number of Upvotes, Food Demand Forecasting, Face Counting Challenges, and Joke Rating Prediction are a few of the ongoing hackathons on DataHack.
DrivenData
Driven Data organizes hackathons that combine data science and social impact, focusing on industries including public services, international development, health, and education. More than 50 organizations as well as thousands of individual developers who work on different projects make up the community.
Some of the society-focused hackathons that are now running on the website include The BiosMassters, Reboot: Box-Plots for Education, and DengAI: Predicting Disease Spread.
Techgig
To create a community of developers who want to contribute and advance their machine-learning skills, Techgig organizes hackathons and challenges for its readers. Experts from a variety of technology fields, including IoT, ML, User Experience, Mobility, etc., created the challenges. Any programming language that the participant prefers may be used to complete the challenges.
0 notes
Photo

How A Business Analyst, A Data Scientist & A Technology Lead Solved “Predict A Doctor’s Consultation Fee” Hackathon #BI #Analytics #BigData #DataScience In this article, we present the winners of Analytics India Magazine’s MachineHack’s recently concluded hackathon “Predict A Doctor’s Consultation Fee Hackathon”.
0 notes
Text
MachineHack, Predict A Doctor’s Consultation Hackathon
http://bit.ly/2Wy34oR
0 notes
Text
ZS Hiring Hackathon : Patient Drug-switch Prediction

Machine Learning and Data Science have stolen the attention of the young generation who are seeking an exciting and well-paid career. With the advent of growth in data volume and technology the gap between Machine Learning Engineers and Data Scientist is narrowing leading companies to look for full-stack data scientists. The demand for such folks with Machine learning and Data Science skills is exponentially increasing and organizations are struggling to find their best fit. Good MLDS profile not only requires a strong analytical and engineering background but also needs a good understanding of the algorithms, advanced statistics, optimization approaches, coding & distributed computing skills. One of the few possible ways to master this new domain is through constant learning, practice and showcasing of skills through hackathons. This is where MachineHack is going to help. With the help of our top hackathons, you can become an expert in handling data and build a path to a successful Machine Learning and Data Science career. MachineHack and ZS Associates bring to you the “Patient Drug-switch Prediction Hackathon” Problem Description Armanik, a multinational pharmaceutical company based in Texas, USA, is one of the largest pharmaceutical companies by both market capitalization and sales. Armanik manufactures drugs across multiple therapy areas – Cardiovascular, Diabetes, HIV and Immunology therapy. Their innovative SGLT 2 is the market leader in diabetes therapy. Recently, the company announced that they have successfully completed a Phase 3 trial for an Anti-TNF drug in Rheumatoid Arthritis therapeutic. The company expects to get approval for its new drug in the next 6 months. Given the competition in the market, Prakash Vishwanathan, CEO of Armanik, has reached out to ZS to help identify the patient population in the U.S who are likely to switch any product in the RA market. ZS has proposed a machine learning-based approach using medical transactional data to first identify the factors that are most closely associated with the switching RA patients that will help predict patients who are likely to switch in the near term. Can you help ZS in achieving the below-mentioned objectives?

Data Sets File Descriptions : Train_data.csv – Data for training (This is a transactional data for feature creation)Train_labels.csv – Outcome flag for train patients (1/0)Test_data.csv – Data for testing (Create final features for modelling)Fitness_values.csv – Fitness values for features created with train data. Must be used to match the fitness values with the Feature created using Train Data Only.Sample Submission.csv – Sample submission Format to submit the Predictions (Don’t Shuffle the Patient_ID, Keep the sequence entact). Train_data.csv
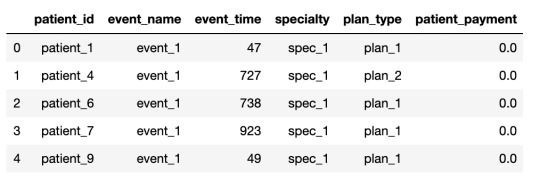
Data Size: Train Data: 627 MBTest Data: 273 MB Packages allowed: PandasNumpyScipyNumbaCython extensionoperator Click here to participate. ABOUT ZS ZS is a professional services firm that works side by side with companies to help develop and deliver products that drive customer value and company results. We leverage our deep industry expertise, leading-edge analytics, technology and strategy to create solutions that work in the real world. With more than 35 years of experience and 6,000-plus ZS-ers in 23 offices worldwide, we are passionately committed to helping companies and their customers thrive. Our most valuable asset is our people—a fact that’s reflected in our values-driven organization in which new perspectives are integral and new ideas are celebrated. We apply our knowledge, capabilities and innovation-oriented approach in industries ranging from healthcare and life sciences to high-tech, financial services, travel and transportation, and beyond. Rules Eligibility: Hackathons are open to all registered users at www.machinehack.com, a participant must be 18 years or older.Only one account is allowed per participant; submissions from multiple accounts will lead to disqualification. This is an individual exercise.We expect that you respect the spirit of the competition and do not cheat. Privately sharing code or data is not permitted—any case of code plagiarism will result in the disqualification of all users involved.It is obligatory to submit a well-commented and reproducible source code that you would generate as part of this contest in .zip or .tar compressed archive or the submission will not be considered.The ideal candidate is expected to hold 2-6 years of experience in working as a Data Scientist or a Machine Learning EngineerThe leaderboard will be updated on the basis of the AUC score of the submitted predictions.Users must have an updated MachineHack profile and must specify their LinkedIn for final shortlisting. Submission limits : You can make a maximum of 3 excel file submissions in a day. Timeline Hackathon will be live from 3rd January 2020 to 13th January 2020. Phase 1: AUC evaluation of submitted predictions - 3rd January 2020 to 10th January 2020. Phase 2: Time complexity evaluation of Submitted code files - 11th January 2020 to 13th January 2020. Submitting Your Files For Evaluation
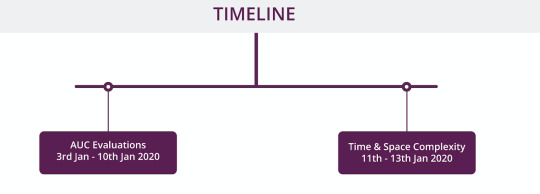
Phase 1 Submission window: January 3rd to January 10th 2020 The hackathon assignment requires participants to submit an excel file (Only .xlsx files are allowed) containing the unique identifier ‘patient_id’ and the corresponding prediction classes ‘outcome_flag’. The submissions are evaluated on AUC score and the leaderboard is updated. Phase 2 Submission window: January 11th to January 13th 2020 The phase 2 submission window (FINAL SUBMISSION) will be enabled to share the following files as a zip post 10th January : The phase 1 submission file with the best AUC score on the leaderboard. (Best Score.xlsx)A csv file containing a list of all the features along with their fitness value. (Fitness_Score.csv)A python script file that can be executed on a machine with RAM of 16 GB to recreate the features and fitness values. (Feature_Pipeline.py)A well commented and reproducible source code(python script) for the best AUC which will be evaluated for time complexity. (Model.py)Fully documented approach in a PPT. Note: Participants must upload the above files in a zip archive to a submission portal which will be enabled on January 11th 2020. Bounty

The best submission will receive a Macbook and a free pass to Machine Learning Developers Summit 2020.The shortlisted participants will get an opportunity to present their approach at MLDS 2020 to a panel of experienced leadership of ZS-ers and participants of the summit. The top 15 participants will get an opportunity to be interviewed for the role of Data Scientist/ Machine Learning Engineer at ZS Associates (The role can be chosen based on your expertise area between the two roles) Click here to participate. Evaluations THE CANDIDATES WILL HAVE TO MAKE SUBMISSIONS AS PER THE GUIDELINES MENTIONED BELOW: Objective 1: Auto Feature Engineering A CSV file containing a list of all the features along with their fitness value.

Once the set of mandatory features is created using the training data, evaluate the fitness of these features using the following methodology. (A starter python notebook is available here) Any submission with >1% of error – sum of % errors across fitness values of all features (~40000 features), will be considered as Invalid. Objective 2: Patient Switching Probabilities Test Set Predictions: The test set predictions are evaluated using AUC. An excel file (.xlsx only) containing the prediction probability for all the patients in the test data. The top submissions will be decided based on the leaderboard score and evaluation of other submission documents (code file, .csv file, supporting notebooks, model pipeline- .py file or .ipynb format). All the good submissions will be eligible to receive the bounties Participate Read the full article
0 notes
Text
Data Science Hackathon: Win Prizes By Using Machine Learning to Predict Food Delivery Time

The entire world is transforming digitally and our relationship with technology has grown exponentially over the last few years. We have grown closer to technology, and it has made our life a lot easier by saving time and effort. Today everything is accessible with smartphones — from groceries to cooked food and from medicines to doctors. In this hackathon, we provide you with data that is a by-product as well as a thriving proof of this growing relationship. Click here to head to the hackathon. About The Dataset When was the last time you ordered food online? And how long did it take to reach you? In this hackathon, we are providing you with data from thousands of restaurants in India regarding the time they take to deliver food for online order. As data scientists, your goal is to predict the online order delivery time based on the given factors. Analytics India Magazine and IMS Proschool bring to you ‘Predicting Food Delivery Time Hackathon’. Size of training set: 11,094 records Size of test set: 2,774 records FEATURES: Restaurant: A unique ID that represents a restaurant.Location: The location of the restaurant.Cuisines: The cuisines offered by the restaurant.Average_Cost: The average cost for one person/order.Minimum_Order: The minimum order amount.Rating: Customer rating for the restaurant.Votes: The total number of customer votes for the restaurant.Reviews: The number of customer reviews for the restaurant.Delivery_Time: The order delivery time of the restaurant.(Target Classes) MachineHack as a platform is dedicated to bringing out the best in our growing data science community. The data is gathered from credible sources and we welcome all the young data scientists out there to play with the data till you become good at it. Challenge yourself with this hackathon, learn a lot and win exciting prizes. To participate in the hackathon click here. About IMS Proschool IMS, since 1977, has worked towards building a long term successful career for its students. It emerged as the fourth most trusted education brands in an AC Nielsen and Brand Equity Survey. IMS Proschool is the extension of the same mission. Proschool helps individuals realize their potential by mentoring and imparting skills. Prizes The top contestant will receive an Amazon cash voucher worth ₹25,000. The top 3 contestants will also receive a free pass to Machine Learning Developers Summit 2020 (MLDS-20) India’s first conference exclusively for Machine Learning practitioners’ ecosystem. Machine Learning Developers Summit 2020 (MLDS-20) brings together India’s leading Machine Learning innovators and practitioners to share their ideas and experiences about machine learning tools, advanced development in this sphere and gives the attendees a first look at new trends & developer products. To participate in the hackathon click here. How To Register Head to MachineHack and sign up. Select Hackathons and click on ‘Predicting Food Delivery Time - Hackathon By IMS Proschool’. For detailed instructions on how to use MachineHack read the below article: HOW TO GET STARTED WITH MACHINEHACK, A DATA SCIENTIST’S DESTINATION FOR COMPETITIONS & PRACTISE To participate in the hackathon click here. Read the full article
0 notes
Text
Docker Solution For TensorFlow 2.0: How To Get Started

Containers have a long history that dates back to the ‘60s. Over time, this technology has advanced to a great deal and has become one of the most useful tools in the software industry. Today, Docker has become synonymous for containers. In one of our previous articles, we discussed how Docker is helping in the Machine Learning space. Today, we will implement one of the many use cases of Docker in the development of ML applications. What you will learn Introduction To Docker Installing & Setting Up Docker Getting Started With Docker TensorFlow 2.0 Container Downloading Tensorflow 2.0-Docker Firing Up Container Accessing The Jupyter Notebook Sharing Files Installing Missing Dependencies Committing Changes & Saving The container Instance Running Container From The New Image Introduction To Docker Docker is a very popular and widely-used container technology. Docker has an entire ecosystem for managing containers which includes a repository of images, container registries and command-line interfaces, among others. Docker also comes with cluster management for containers which allows multiple containers to be managed collectively in a distributed environment. Installing & Setting Up Docker Head to https://hub.docker.com/ and sign up with a Docker ID. Once you are in, you will see the following page.
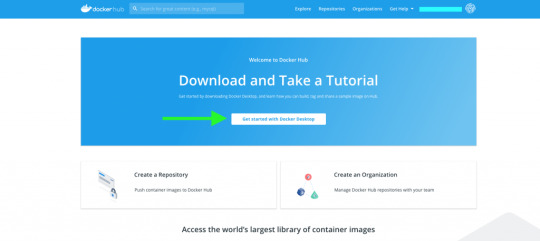
Click on the Get started with Docker Desktop button.
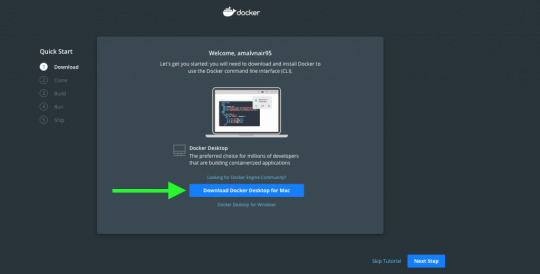
Click to download the right version for your operating system. Once the file is downloaded, open it to install Docker Desktop. Follow the standard procedure for installation based on your operating system and preferences. On successful installation, you will be able to see Docker on your taskbar.

You can click on the icon to set your Docker preferences and to update it.
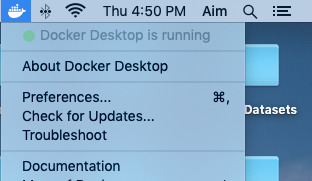
If you see a green dot which says Docker Desktop is running we are all set to fire up containers. Also, execute the following command in the terminal or command prompt to ensure that everything is perfect: docker --version If everything is fine, it should return the installed version of the docker. Output: Docker version 19.03.4, build 9013bf5 Getting Started With Docker Before we begin, there are a few basic things that you need to know. Images: An image or Docker Image is a snapshot of a Linux operating system or environment which is very lightweight. Docker Hub which is Docker’s official repository contains thousands of images which can be used to create containers. Check out the official Docker images here. Containers: Containers are the running instances of a docker image. We use an image to fire up multiple containers. Some basic docker commands: Get familiar with the following commands. docker pull The above command downloads the specified version of a docker image from the specified repository. docker images The above command will return a table of images in your local (local machine) repository. docker run The above command fires up a container from a specified image. docker ps The above command will return a table of all the running docker containers. docker ps -a -q The above command will display all the containers both running and inactive. docker rmi The above command can be used to delete a docker image from the local repository. docker stop The above command stops a running container. docker rm -f The above command can be used to delete or remove a running Docker container. The -f flag force removes the container if it’s running. Like images, containers also have IDs and names. We will be using the above commands a lot when dealing with Docker containers. We will also learn some additional commands in the following sections. TensorFlow 2.0 Container We will use TensorFlow’s official Docker image with Jupyter named tensorflow:nightly-py3-jupyter. The image comes with preinstalled Jupyter Notebook and the latest TensorFlow 2.0 version. Downloading TensorFlow 2.0 Docker Image To download the image run the following command. docker pull tensorflow/tensorflow:nightly-py3-jupyter Once all the downloading and extracting is complete, type docker images command to list the Docker images in your machine.

Firing Up The Container To start the container we will use the Docker run command. docker run -it -p 1234:8888 -v /Users/aim/Documents/Docker:/tf/ image_id Let's break it down: docker run: used to fire up containers from a docker image -it: This flag enables interactive mode. It lets us see what's going on after the container is created. -p: This parameter is used for port mapping. The above command maps the port 1234 of the local machine with the internal port 8888 of the docker container. -v: This parameter is used to mount a volume or directory to the running container. This enables data sharing between the container and the local machine. The above command mounts the directory /Users/aim/Documents/Docker inside the docker containers /tf directory. Image_id or name: The name or ID of the docker image from which the container is to be created.
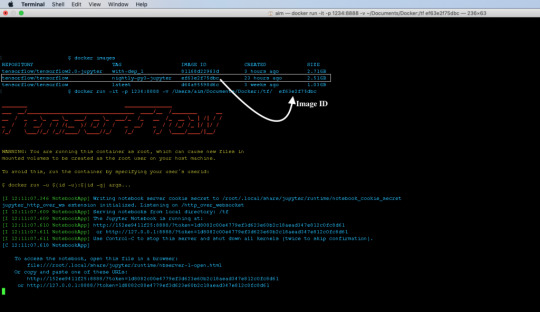
We can now list the running containers in the system using docker ps command. To stop the container use docker stop. The container id will be returned by the docker ps command. Accessing The Jupyter Notebook On successful execution of the run command, the Jupyter Notebook will be served on port 1234 of the localhost. Open up your browser and enter the following url. http://localhost:1234/
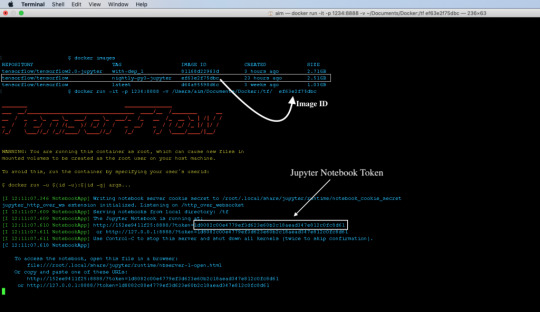
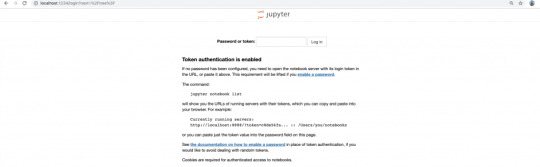
Copy the token from the logs and use it to log in to Jupyter Notebook.
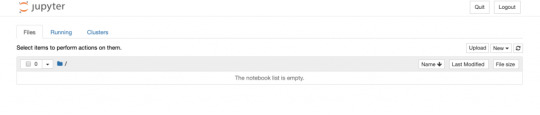
Once logged in you will see an empty directory which is pointing to the /tf/ directory in the container. This directory is mapped to the Documents/Docker directory of the local machine.
Sharing Files While running the container, we mounted a local volume to the container that maps to the /tf/ directory within the container. To share any files with the container, simply copy the required files into the local folder that was mounted to the container. In this case copy the file to /Users/aim/Documents/Docker to access it in the Jupyter Notebook. Once you copy and refresh the notebook, you will find your files there.

Installing Missing Dependencies Find an example notebook below. In the following notebook we will try to predict the cost of used cars from MachineHack’s Predicting The Costs Of Used Cars - Hackathon. Sign up to download the datasets for free. Download the above notebook along with the datasets and copy them into your mounted directory. (/Users/aim/Document/Docker - in my case). Now let's start from where we left off with our Jupyter Notebook running on docker. Open the notebook and try to import some of the necessary modules. import tensorflow as tf print(tf.__version__) import numpy as np import pandas as pd Output:
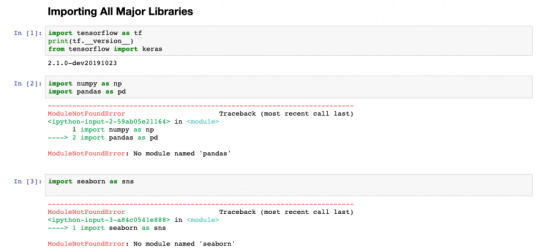
You will find that most of the modules are missing. Now let's fix this. There are two ways to fix this. We can either use pip install from the Jupyter Notebook and commit changes in the container or we can go inside the container install all the missing dependencies and commit changes. Let's take the second approach. Entering The Docker Container Note: Since we have used -it flag we will not be able to use the existing terminal /command prompt window. Open a new terminal for the following process. Get the container id using docker ps and use the following command to enter inside the running container. docker exec -it /bin/bash
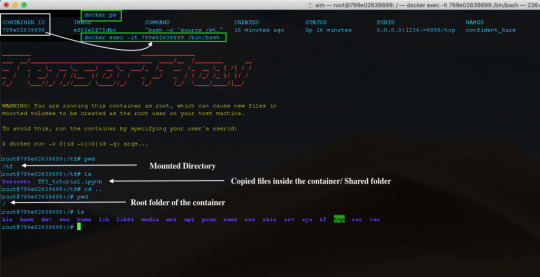
Since containers are lightweight Linux kernels, all you need to know are some basic Linux commands. So let's install all those necessary modules that we need. For this example, I will install 4 modules that I found missing. Inside the container do pip install for all the missing libraries: pip install pandas pip install xlrd pip install sklearn pip install seaborn

Exit from the container instance by typing exit. Note: The easiest way to do it is by listing all the missing modules inside a requirements.txt file from your local machine and copying it into the shared directory of the container and run pip install -r requirements.txt. You can also use pip freeze > requirements.txt command to export the installed modules from your local environment into requirements.txt file. Now go back to your Jupyter Notebook and try importing all those modules again.

Hooray! No more missing modules error! Committing Changes & Saving The container Instance Now that we have our development environment ready with all dependencies let's save it so that we don't have to install all of them again. Use the following command to commit the changes made to the container and save it as a new image/version. docker commit new_name_for_image Eg: docker commit ae6071309f1f tensorflow/tensorflow2.0:all_deps_installed

Running Container From The New Image Now we have a new image with all the dependencies installed, we can remove the downloaded image and use the new one instead. To delete or remove an image, use the following command: docker rmi Eg: docker rmi tensorflow/tensorflow:nightly-py3-jupyter Note: To remove an image you must first kill all the running containers of that image. Use docker stop command to stop and docker rm command to remove containers. To fire up containers from the new image, use the following command: docker run -p localmachine_port:container_port -v localmachine_directory:container_directory image_name:version Eg. docker run -it -p 8081:8888 -v /Users/aim/Documents/Docker:/tf/ tensorflow/tensorflow2.0 all_deps_installed Note: You can create as many containers as your machine would permit. In the above example, you can run multiple Jupyter notebooks by mapping different local machine ports to different containers. Great! You can now set up different development environments for each of your projects! Read the full article
0 notes
Quote
The coronavirus outbreak is taking over headlines. Due to the spread of COVID-19, remote work is suddenly an overnight requirement for many. You might be working from home as you are reading this article. With millions working from home for many weeks now, we should seize this opportunity to improve our skills in the domain we are focusing on. Here is my strategy to learn Data Science while working from home with few personal real life projects. "So what should we do?" "Where should we start learning?" Grab your coffee as I explain the process of how you can learn data science sitting at home. This blog is for everyone, from beginners to professionals. Photo by Nick Morrison on Unsplash Prerequisites To start this journey, you will need to cover the prerequisites. No matter which specific field you are in, you will need to learn the following prerequisites for data science. Logic/Algorithms: It’s important to know why we need a particular prerequisite before learning it. Algorithms are basically a set of instructions given to a computer to make it do a specific task. Machine learning is built from various complex algorithms. So you need to understand how algorithms and logic work on a basic level before jumping into complex algorithms needed for machine learning. If you are able to write the logic for any given puzzle with the proper steps, it will be easy for you to understand how these algorithms work and you can write one for yourself. Resources: Some awesome free resources to learn data structures and algorithms in depth. Statistics: Statistics is a collection of tools that you can use to get answers to important questions about data. Machine learning and statistics are two tightly related fields of study. So much so that statisticians refer to machine learning as “applied statistics” or “statistical learning”. Image source : http://me.me/ The following topics should be covered by aspiring data scientists before they start machine learning. Measures of Central Tendency — mean, median, mode, etc Measures of Variability — variance, standard deviation, z-score, etc Probability — probability density function, conditional probability, etc Accuracy — true positive, false positive, sensitivity, etc Hypothesis Testing and Statistical Significance — p-value, null hypothesis, etc Resources: Learn college level statistics in this free 8 hour course. Business: This depends on which domain you want to focus on. It basically involves understanding the particular domain and getting domain expertise before you get into a data science project. This is important as it helps in defining our problem accurately. Resources: Data science for business Brush up your basics This sounds pretty easy but we tend to forget some important basic concepts. It gets difficult to learn more complex concepts and the latest technologies in a specific domain without having a solid foundation in the basics. Here are few concepts you can start revising: Python programming language Python is widely used in data science. Check out this collection of great Python tutorials and these helpful code samples to get started. Image source : memecrunch.com You can also check out this Python3 Cheatsheet that will help you learn new syntax that was released in python3. It'll also help you brush up on basic syntax. And if you want a great free course, check out this Python for Everybody course from Dr. Chuck. General data science skills Want to take a great course on data science concepts? Here's a bunch of data science courses that you can take online, ranked according to thousands of data points. Resources: Data science for beginners - free 6 hour course, What languages should you learn for data science? Data Collection Now it is time for us to explore all the ways you can collect your data. You never know where your data might be hiding. Following are a few ways you can collect your data. Web scraping Web scraping helps you gather structured data from the web, select some of that data, and keep what you selected for whatever use you require. You can start learning BeautifulSoup4 which helps you scrape websites and make your own datasets. Advance Tip: You can automate browsers and get data from interactive web pages such as Firebase using Selenium. It is useful for automating web applications and automating boring web based administration Resources: Web Scraping 101 in Python Cloud servers If your data is stored on cloud servers such as S3, you might need to get familiar with how to get data from there. The following link will help you understand how to implement them using Amazon S3. Resources : Getting started with Amazon S3, How to deploy your site or app to AWS S3 with CloudFront APIs There are millions of websites that provide data through APIs such as Facebook, Twitter, etc. So it is important to learn how they are used and have a good idea on how they are implemented. Resources : What is an API? In English, please, How to build a JSON API with Python, and Getting started with Python API. Data Preprocessing This topic includes everything from data cleaning to feature engineering. It takes a lot of time and effort. So we need to dedicate a lot of time to actually learn it. Image source : https://www.pinterest.com/pin/293648838181843463/ Data cleaning involves different techniques based on the problem and data type. The data needs to be cleaned from irrelevant data, syntax erros, data inconsistencies and missing data. The following guide will get you started with data cleaning. Resources : Ultimate guide to data cleaning Data Preprocessing is an important step in which the data gets transformed, or encoded, so that the machine can easily parse it. It requires time as well as effort to preprocess different types of data which include numerical, textual and image data. Resources : Data Preprocessing: Concepts, All you need to know about text preprocessing for NLP and Machine Learning, Preprocessing for deep learning. Machine Learning Finally we reach our favourite part of data science: Machine Learning. Image source : https://in.pinterest.com/pin/536209899383255279/ My suggestion here would be to first brush up your basic algorithms. Classification — Logistic Regression, RandomForest, SVM, Naive Bayes, Decision Trees Resources : Types of classification algorithms in Machine Learning, Classification Algorithms in Machine Learning Regression — Linear Regression, RandomForest, Polynomial Regression Resources : Introduction to Linear Regression , Use Linear Regression models to predict quadratic, root, and polynomial functions, 7 Regression Techniques you should know, Selecting the best Machine Learning algorithm for your regression problem, Clustering — K-Means Clustering, DBSCAN, Agglomerative Hierarchical Clustering Resources : Clustering algorithms Gradient Boosting — XGBoost, Catboost, AdaBoost Resources : Gradient boosting from scratch, Understanding Gradient Boosting Machines I urge you all to understand the math behind these algorithms so you have a clear idea of how it actually works. You can refer to this blog where I have implemented XGBoost from scratch — Implementing XGBoost from scratch Now you can move on to Neural Networks and start your Deep Learning journey. Resources: Deep Learning for Developers, Introduction to Deep Learning with Tensorflow, How to develop neural networks with Tensorflow, Learn how deep neural networks work You can then further dive deep into how LSTM, Siamese Networks, CapsNet and BERT works. Hackathons: Image Source : https://me.me/ Now we need to implement these algorithms on a competitive level. You can start looking for online Data Science Hackathons. Here is the list of websites where I try to compete with other data scientists. Analytics Vidhya — https://datahack.analyticsvidhya.com/contest/all/ Kaggle — https://www.kaggle.com/competitions Hackerearth — https://www.hackerearth.com/challenges/ MachineHack — https://www.machinehack.com/ TechGig — https://www.techgig.com/challenge Dare2compete — https://dare2compete.com/e/competitions/latest Crowdanalytix — https://www.crowdanalytix.com/community To have a look at a winning solution, here is a link to my winning solution to one online Hackathon on Analytics Vidhya — https://github.com/Sid11/AnalyticsVidhya_DataSupremacy Projects: We see people working on dummy data and still don’t get the taste of how actual data looks like. In my opinion, working on real life data gives you a very clear idea how data in real life looks like. The amount of time and effort required in cleaning real life data takes about 70% of your project’s time. Here are the best free open data sources anyone can use Open Government Data — https://data.gov.in/ Data about real contributed by thousands of users and organizations across the world — https://data.world/datasets/real 19 public datasets for Data Science Project — https://www.springboard.com/blog/free-public-data-sets-data-science-project/ Business Intelligence After you get the results from your project, it is now time to make business decisions from those results. Business Intelligence is a suite of software and services that helps transform data into actionable intelligence and knowledge. This can be done by creating a dashboard from the output of our model. Tableau is a powerful and the fastest growing data visualization tool used in the Business Intelligence Industry. It helps in simplifying raw data into the very easily understandable format. Data analysis is very fast with Tableau and the visualizations created are in the form of dashboards and worksheets.
http://damianfallon.blogspot.com/2020/03/how-to-improve-your-data-science-skills_85.html
0 notes
Quote
The coronavirus outbreak is taking over headlines. Due to the spread of COVID-19, remote work is suddenly an overnight requirement for many. You might be working from home as you are reading this article. With millions working from home for many weeks now, we should seize this opportunity to improve our skills in the domain we are focusing on. Here is my strategy to learn Data Science while working from home with few personal real life projects. "So what should we do?" "Where should we start learning?" Grab your coffee as I explain the process of how you can learn data science sitting at home. This blog is for everyone, from beginners to professionals. Photo by Nick Morrison on Unsplash Prerequisites To start this journey, you will need to cover the prerequisites. No matter which specific field you are in, you will need to learn the following prerequisites for data science. Logic/Algorithms: It’s important to know why we need a particular prerequisite before learning it. Algorithms are basically a set of instructions given to a computer to make it do a specific task. Machine learning is built from various complex algorithms. So you need to understand how algorithms and logic work on a basic level before jumping into complex algorithms needed for machine learning. If you are able to write the logic for any given puzzle with the proper steps, it will be easy for you to understand how these algorithms work and you can write one for yourself. Resources: Some awesome free resources to learn data structures and algorithms in depth. Statistics: Statistics is a collection of tools that you can use to get answers to important questions about data. Machine learning and statistics are two tightly related fields of study. So much so that statisticians refer to machine learning as “applied statistics” or “statistical learning”. Image source : http://me.me/ The following topics should be covered by aspiring data scientists before they start machine learning. Measures of Central Tendency — mean, median, mode, etc Measures of Variability — variance, standard deviation, z-score, etc Probability — probability density function, conditional probability, etc Accuracy — true positive, false positive, sensitivity, etc Hypothesis Testing and Statistical Significance — p-value, null hypothesis, etc Resources: Learn college level statistics in this free 8 hour course. Business: This depends on which domain you want to focus on. It basically involves understanding the particular domain and getting domain expertise before you get into a data science project. This is important as it helps in defining our problem accurately. Resources: Data science for business Brush up your basics This sounds pretty easy but we tend to forget some important basic concepts. It gets difficult to learn more complex concepts and the latest technologies in a specific domain without having a solid foundation in the basics. Here are few concepts you can start revising: Python programming language Python is widely used in data science. Check out this collection of great Python tutorials and these helpful code samples to get started. Image source : memecrunch.com You can also check out this Python3 Cheatsheet that will help you learn new syntax that was released in python3. It'll also help you brush up on basic syntax. And if you want a great free course, check out this Python for Everybody course from Dr. Chuck. General data science skills Want to take a great course on data science concepts? Here's a bunch of data science courses that you can take online, ranked according to thousands of data points. Resources: Data science for beginners - free 6 hour course, What languages should you learn for data science? Data Collection Now it is time for us to explore all the ways you can collect your data. You never know where your data might be hiding. Following are a few ways you can collect your data. Web scraping Web scraping helps you gather structured data from the web, select some of that data, and keep what you selected for whatever use you require. You can start learning BeautifulSoup4 which helps you scrape websites and make your own datasets. Advance Tip: You can automate browsers and get data from interactive web pages such as Firebase using Selenium. It is useful for automating web applications and automating boring web based administration Resources: Web Scraping 101 in Python Cloud servers If your data is stored on cloud servers such as S3, you might need to get familiar with how to get data from there. The following link will help you understand how to implement them using Amazon S3. Resources : Getting started with Amazon S3, How to deploy your site or app to AWS S3 with CloudFront APIs There are millions of websites that provide data through APIs such as Facebook, Twitter, etc. So it is important to learn how they are used and have a good idea on how they are implemented. Resources : What is an API? In English, please, How to build a JSON API with Python, and Getting started with Python API. Data Preprocessing This topic includes everything from data cleaning to feature engineering. It takes a lot of time and effort. So we need to dedicate a lot of time to actually learn it. Image source : https://www.pinterest.com/pin/293648838181843463/ Data cleaning involves different techniques based on the problem and data type. The data needs to be cleaned from irrelevant data, syntax erros, data inconsistencies and missing data. The following guide will get you started with data cleaning. Resources : Ultimate guide to data cleaning Data Preprocessing is an important step in which the data gets transformed, or encoded, so that the machine can easily parse it. It requires time as well as effort to preprocess different types of data which include numerical, textual and image data. Resources : Data Preprocessing: Concepts, All you need to know about text preprocessing for NLP and Machine Learning, Preprocessing for deep learning. Machine Learning Finally we reach our favourite part of data science: Machine Learning. Image source : https://in.pinterest.com/pin/536209899383255279/ My suggestion here would be to first brush up your basic algorithms. Classification — Logistic Regression, RandomForest, SVM, Naive Bayes, Decision Trees Resources : Types of classification algorithms in Machine Learning, Classification Algorithms in Machine Learning Regression — Linear Regression, RandomForest, Polynomial Regression Resources : Introduction to Linear Regression , Use Linear Regression models to predict quadratic, root, and polynomial functions, 7 Regression Techniques you should know, Selecting the best Machine Learning algorithm for your regression problem, Clustering — K-Means Clustering, DBSCAN, Agglomerative Hierarchical Clustering Resources : Clustering algorithms Gradient Boosting — XGBoost, Catboost, AdaBoost Resources : Gradient boosting from scratch, Understanding Gradient Boosting Machines I urge you all to understand the math behind these algorithms so you have a clear idea of how it actually works. You can refer to this blog where I have implemented XGBoost from scratch — Implementing XGBoost from scratch Now you can move on to Neural Networks and start your Deep Learning journey. Resources: Deep Learning for Developers, Introduction to Deep Learning with Tensorflow, How to develop neural networks with Tensorflow, Learn how deep neural networks work You can then further dive deep into how LSTM, Siamese Networks, CapsNet and BERT works. Hackathons: Image Source : https://me.me/ Now we need to implement these algorithms on a competitive level. You can start looking for online Data Science Hackathons. Here is the list of websites where I try to compete with other data scientists. Analytics Vidhya — https://datahack.analyticsvidhya.com/contest/all/ Kaggle — https://www.kaggle.com/competitions Hackerearth — https://www.hackerearth.com/challenges/ MachineHack — https://www.machinehack.com/ TechGig — https://www.techgig.com/challenge Dare2compete — https://dare2compete.com/e/competitions/latest Crowdanalytix — https://www.crowdanalytix.com/community To have a look at a winning solution, here is a link to my winning solution to one online Hackathon on Analytics Vidhya — https://github.com/Sid11/AnalyticsVidhya_DataSupremacy Projects: We see people working on dummy data and still don’t get the taste of how actual data looks like. In my opinion, working on real life data gives you a very clear idea how data in real life looks like. The amount of time and effort required in cleaning real life data takes about 70% of your project’s time. Here are the best free open data sources anyone can use Open Government Data — https://data.gov.in/ Data about real contributed by thousands of users and organizations across the world — https://data.world/datasets/real 19 public datasets for Data Science Project — https://www.springboard.com/blog/free-public-data-sets-data-science-project/ Business Intelligence After you get the results from your project, it is now time to make business decisions from those results. Business Intelligence is a suite of software and services that helps transform data into actionable intelligence and knowledge. This can be done by creating a dashboard from the output of our model. Tableau is a powerful and the fastest growing data visualization tool used in the Business Intelligence Industry. It helps in simplifying raw data into the very easily understandable format. Data analysis is very fast with Tableau and the visualizations created are in the form of dashboards and worksheets.
http://damianfallon.blogspot.com/2020/03/how-to-improve-your-data-science-skills.html
0 notes