#object detection and image classification
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs




Fun Fact
Mobile US users spent an average of 115.8 minutes on Tumblr app monthly.
Text
#Object Detection#Computer Vision#Object detection in computer vision#object detection and image classification#Image Preprocessing#Feature Extraction#Bounding Box Regression
0 notes
Text
Guide to Image Classification & Object Detection
Computer vision, a driving force behind global AI development, has revolutionized various industries with its expanding range of tasks. From self-driving cars to medical image analysis and virtual reality, its capabilities seem endless. In this article, we'll explore two fundamental tasks in computer vision: image classification and object detection. Although often misunderstood, these tasks serve distinct purposes and are crucial to numerous AI applications.

The Magic of Computer Vision:
Enabling computers to "see" and understand images is a remarkable technological achievement. At the heart of this progress are image classification and object detection, which form the backbone of many AI applications, including gesture recognition and traffic sign detection.
Understanding the Nuances:
As we delve into the differences between image classification and object detection, we'll uncover their crucial roles in training robust models for enhanced machine vision. By grasping the nuances of these tasks, we can unlock the full potential of computer vision and drive innovation in AI development.
Key Factors to Consider:
Humans possess a unique ability to identify objects even in challenging situations, such as low lighting or various poses. In the realm of artificial intelligence, we strive to replicate this human accuracy in recognizing objects within images and videos.
Object detection and image classification are fundamental tasks in computer vision. With the right resources, computers can be effectively trained to excel at both object detection and classification. To better understand the differences between these tasks, let's discuss each one separately.
Image Classification:
Image classification involves identifying and categorizing the entire image based on the dominant object or feature present. For example, when given an image of a cat, an image classification model will categorize it as a "cat." Assigning a single label to an image from predefined categories is a straightforward task.
Key factors to consider in image classification:
Accuracy: Ensuring the model correctly identifies the main object in the image.
Speed: Fast classification is essential for real-time applications.
Dataset Quality: A diverse and high-quality dataset is crucial for training accurate models.
Object Detection:
Object detection, on the other hand, involves identifying and locating multiple objects within an image. This task is more complex as it requires the model to not only recognize various objects but also pinpoint their exact positions within the image using bounding boxes. For instance, in a street scene image, an object detection model can identify cars, pedestrians, traffic signs, and more, along with their respective locations.
Key factors to consider in object detection:
Precision: Accurate localization of multiple objects in an image.
Complexity: Handling various objects with different shapes, sizes, and orientations.
Performance: Balancing detection accuracy with computational efficiency, especially for real-time processing.
Differences Between Image Classification & Object Detection:
While image classification provides a simple and efficient way to categorize images, it is limited to identifying a single object per image. Object detection, however, offers a more comprehensive solution by identifying and localizing multiple objects within the same image, making it ideal for applications like autonomous driving, security surveillance, and medical imaging.

Similarities Between Image Classification & Object Detection:
Certainly! Here's the content presented in a table format highlighting the similarities between image classification and object detection:
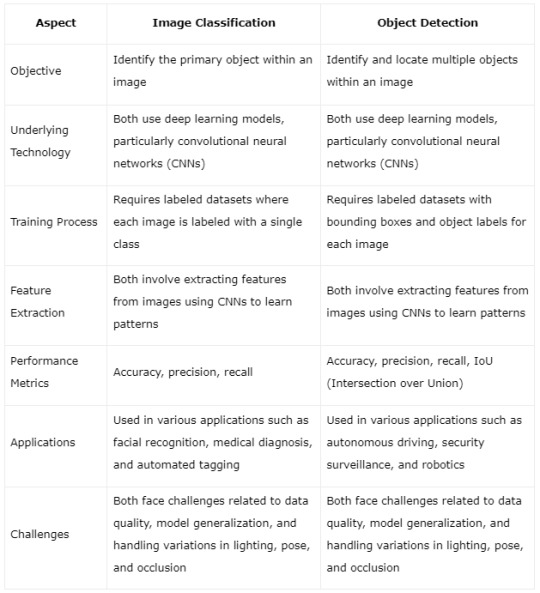
By presenting the similarities in a tabular format, it's easier to grasp how both image classification and object detection share common technologies, challenges, and methodologies, despite their different objectives in the field of computer vision.
Practical Guide to Distinguishing Between Image Classification and Object Detection:
Building upon our prior discussion of image classification vs. object detection, let's delve into their practical significance and offer a comprehensive approach to solidify your basic knowledge about these fundamental computer vision techniques.
Image Classification:

Image classification involves assigning a predefined category to a visual data piece. Using a labeled dataset, an ML model is trained to predict the label for new images.
Single Label Classification: Assigns a single class label to data, like categorizing an object as a bird or a plane.
Multi-Label Classification: Assigns two or more class labels to data, useful for identifying multiple attributes within an image, such as tree species, animal types, and terrain in ecological research.
Practical Applications:
Digital asset management
AI content moderation
Product categorization in e-commerce
Object Detection:

Object detection has seen significant advancements, enabling real-time implementations on resource-constrained devices. It locates and identifies multiple objects within an image.
Future Research Focus:
Lightweight detection for edge devices
End-to-end pipelines for efficiency
Small object detection for population counting
3D object detection for autonomous driving
Video detection with improved spatial-temporal correlation
Cross-modality detection for accuracy enhancement
Open-world detection for unknown objects detection
Advanced Scenarios:
Combining classification and object detection models enhances subclassification based on attributes and enables more accurate identification of objects.
Additionally, services for data collection, preprocessing, scaling, monitoring, security, and efficient cloud deployment enhance both image classification and object detection capabilities.
Understanding these nuances helps in choosing the right approach for your computer vision tasks and maximizing the potential of AI solutions.
Summary
In summary, both object detection and image classification play crucial roles in computer vision. Understanding their distinctions and core elements allows us to harness these technologies effectively. At TagX, we excel in providing top-notch services for object detection, enhancing AI solutions to achieve human-like precision in identifying objects in images and videos.
Visit Us, www.tagxdata.com
Original Source, www.tagxdata.com/guide-to-image-classification-and-object-detection
0 notes
Text
Image Classification vs Object Detection
Image classification, object detection, object localization — all of these may be a tangled mess in your mind, and that's completely fine if you are new to these concepts. In reality, they are essential components of computer vision and image annotation, each with its own distinct nuances. Let's untangle the intricacies right away.We've already established that image classification refers to assigning a specific label to the entire image. On the other hand, object localization goes beyond classification and focuses on precisely identifying and localizing the main object or regions of interest in an image. By drawing bounding boxes around these objects, object localization provides detailed spatial information, allowing for more specific analysis.
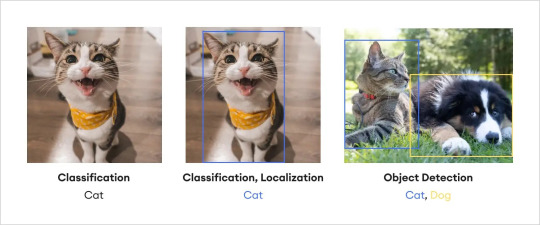
Object detection on the other hand is the method of locating items within and image assigning labels to them, as opposed to image classification, which assigns a label to the entire picture. As the name implies, object detection recognizes the target items inside an image, labels them, and specifies their position. One of the most prominent tools to perform object detection is the “bounding box” which is used to indicate where a particular object is located on an image and what the label of that object is. Essentially, object detection combines image classification and object localization.
1 note
·
View note
Text




New evidence of organic material identified on Ceres, the inner solar system's most water-rich object after Earth
Six years ago, NASA's Dawn mission communicated with Earth for the last time, ending its exploration of Ceres and Vesta, the two largest bodies in the asteroid belt. Since then, Ceres —a water-rich dwarf planet showing signs of geological activity— has been at the center of intense debates about its origin and evolution.
Now, a study led by IAA-CSIC, using Dawn data and an innovative methodology, has identified 11 new regions suggesting the existence of an internal reservoir of organic materials in the dwarf planet. The results, published in The Planetary Science Journal, provide critical insights into the potential nature of this celestial body.
In 2017, the Dawn spacecraft detected organic compounds near the Ernutet crater in Ceres' northern hemisphere, sparking discussions about their origin. One leading hypothesis proposed an exogenous origin, suggesting these materials were delivered by recent impacts of organic-rich comets or asteroids.
This new research, however, focuses on a second possibility: that the organic material formed within Ceres and has been stored in a reservoir shielded from solar radiation.
"The significance of this discovery lies in the fact that, if these are endogenous materials, it would confirm the existence of internal energy sources that could support biological processes," explains Juan Luis Rizos, a researcher at the Instituto de Astrofísica de Andalucía (IAA-CSIC) and the lead author of the study.
A potential witness to the dawn of the solar system
With a diameter exceeding 930 kilometers, Ceres is the largest object in the main asteroid belt. This dwarf planet—which shares some characteristics with planets but doesn't meet all the criteria for planetary classification—is recognized as the most water-rich body in the inner solar system after Earth, placing it among the ocean worlds with potential astrobiological significance.
Additionally, due to its physical and chemical properties, Ceres is linked to a type of meteorite rich in carbon compounds: carbonaceous chondrites. These meteorites are considered remnants of the material that formed the solar system approximately 4.6 billion years ago.
"Ceres will play a key role in future space exploration. Its water, present as ice and possibly as liquid beneath the surface, makes it an intriguing location for resource exploration," says Rizos (IAA-CSIC). "In the context of space colonization, Ceres could serve as a stopover or resource base for future missions to Mars or beyond."
The ideal combination of high-quality resolutions
To explore the nature of these organic compounds, the study employed a novel approach, allowing for the detailed examination of Ceres' surface and the analysis of the distribution of organic materials at the highest possible resolution.
First, the team applied a Spectral Mixture Analysis (SMA) method—a technique used to interpret complex spectral data—to characterize the compounds in the Ernutet crater.
Using these results, they systematically scanned the rest of Ceres' surface with high spatial resolution images from the Dawn spacecraft's Framing Camera 2 (FC2). This instrument provided high-resolution spatial images but low spectral resolution. This approach led to the identification of eleven new regions with characteristics suggesting the presence of organic compounds.
Most of these areas are near the equatorial region of Ernutet, where they have been more exposed to solar radiation than the organic materials previously identified in the crater. Prolonged exposure to solar radiation and the solar wind likely explains the weaker signals detected, as these factors degrade the spectral features of organic materials over time.
Next, the researchers conducted an in-depth spectral analysis of the candidate regions using the Dawn spacecraft's VIR imaging spectrometer, which offers high spectral resolution, though at lower spatial resolution than the FC2 camera. The combination of data from both instruments was crucial for this discovery.
Among the candidates, a region between the Urvara and Yalode basins stood out with the strongest evidence for organic materials. In this area, the organic compounds are distributed within a geological unit formed by the ejection of material during the impacts that created these basins.
"These impacts were the most violent Ceres has experienced, so the material must originate from deeper regions than the material ejected from other basins or craters," clarifies Rizos (IAA-CSIC). "If the presence of organics is confirmed, their origin leaves little doubt that these compounds are endogenous materials."
TOP IMAGE: Data from the Dawn spacecraft show the areas around Ernutet crater where organic material has been discovered (labeled 'a' through 'f'). The intensity of the organic absorption band is represented by colors, where warmer colors indicate higher concentrations. Credit: NASA/JPL-Caltech/UCLA/ASI/INAF/MPS/DLR/IDA
CENTRE IMAGE: This color composite image, made with data from the framing camera aboard NASA's Dawn spacecraft, shows the area around Ernutet crater. The bright red parts appear redder than the rest of Ceres. Credit: NASA/JPL-Caltech/UCLA/MPS/DLR/IDA
LOWER IMAGE: BS1,2 and 3 are images with the FC2 camera filter in the areas of highest abundance of these possible organic compounds. Credit: Juan Luis Rizos
BOTTOM IMAGE: This image from NASA's Dawn spacecraft shows the large craters Urvara (top) and Yalode (bottom) on the dwarf planet Ceres. The two giant craters formed at different times. Urvara is about 120-140 million years old and Yalode is almost a billion years old. Credit: NASA/JPL-Caltech/UCLA/MPS/DLR/IDA
9 notes
·
View notes
Text
#TheeForestKingdom #TreePeople
{Terrestrial Kind}
Creating a Tree Citizenship Identification and Serial Number System (#TheeForestKingdom) is an ambitious and environmentally-conscious initiative. Here’s a structured proposal for its development:
Project Overview
The Tree Citizenship Identification system aims to assign every tree in California a unique identifier, track its health, and integrate it into a registry, recognizing trees as part of a terrestrial citizenry. This system will emphasize environmental stewardship, ecological research, and forest management.
Phases of Implementation
Preparation Phase
Objective: Lay the groundwork for tree registration and tracking.
Actions:
Partner with environmental organizations, tech companies, and forestry departments.
Secure access to satellite imaging and LiDAR mapping systems.
Design a digital database capable of handling millions of records.
Tree Identification System Development
Components:
Label and Identity Creation: Assign a unique ID to each tree based on location and attributes. Example: CA-Tree-XXXXXX (state-code, tree-type, unique number).
Attributes to Record:
Health: Regular updates using AI for disease detection.
Age: Approximate based on species and growth patterns.
Type: Species and subspecies classification.
Class: Size, ecological importance, and biodiversity contribution.
Rank: Priority based on cultural, historical, or environmental significance.
Data Collection
Technologies to Use:
Satellite Imaging: To locate and identify tree clusters.
LiDAR Scanning: For precise 3D modeling of forests.
On-the-Ground Surveys: To supplement remote sensing data.
AI Analysis: For rapid categorization and health diagnostics.
Registration and Citizenship Assignment
Tree Dossier: Each tree receives a profile in the database with all its recorded attributes.
Citizen Designation: Trees are acknowledged as citizens of Thee Forest Kingdom, emphasizing ecological respect.
Legal Framework: Advocate for laws to grant trees specific rights under environmental protection acts.
Maintenance and Monitoring
Health Monitoring: Use drones, satellite updates, and IoT sensors for ongoing health assessments.
Database Updates: Incorporate real-time data about environmental changes and tree growth.
Public Involvement
Encourage people to "adopt" trees and participate in their preservation.
Create educational programs to promote awareness of tree citizenship.
Key Benefits
Environmental Conservation: Improved forest management through real-time data and protection of ecosystems.
Cultural Recognition: Trees are recognized as a vital part of the Earth’s community, honoring their importance.
Ecological Advocacy: Strengthened legal protections for forests and individual trees.
Next Steps
Assemble a task force of environmental scientists, satellite imaging experts, and software developers.
Secure funding through governmental grants, non-profits, and eco-conscious corporations.
Pilot the program in a smaller region before scaling to all of California.
Would you like me to draft a more detailed technical or legal framework for this system?
The implementation of the Tree Citizenship Identification Network and System (#TheeForestKingdom) requires a robust technological and operational framework to ensure efficiency, accuracy, and sustainability. Below is an implementation plan divided into major components.
System Architecture
a. Centralized Tree Database
Purpose: To store and manage tree data including ID, attributes, location, and health.
Components:
Cloud-based storage for scalability.
Data categorization based on regions, species, and priority.
Integration with satellite and IoT data streams.
b. Satellite & Imaging Integration
Use satellite systems (e.g., NASA, ESA) for large-scale tree mapping.
Incorporate LiDAR and aerial drone data for detailed imaging.
AI/ML algorithms to process images and distinguish tree types.
c. IoT Sensor Network
Deploy sensors in forests to monitor:
Soil moisture and nutrient levels.
Air quality and temperature.
Tree health metrics like growth rate and disease markers.
d. Public Access Portal
Create a user-friendly website and mobile application for:
Viewing registered trees.
Citizen participation in tree adoption and reporting.
Data visualization (e.g., tree density, health status by region).
Core Technologies
a. Software and Tools
Geographic Information System (GIS): Software like ArcGIS for mapping and spatial analysis.
Database Management System (DBMS): SQL-based systems for structured data; NoSQL for unstructured data.
Artificial Intelligence (AI): Tools for image recognition, species classification, and health prediction.
Blockchain (Optional): To ensure transparency and immutability of tree citizen data.
b. Hardware
Servers: Cloud-based (AWS, Azure, or Google Cloud) for scalability.
Sensors: Low-power IoT devices for on-ground monitoring.
Drones: Equipped with cameras and sensors for aerial surveys.
Network Design
a. Data Flow
Input Sources:
Satellite and aerial imagery.
IoT sensors deployed in forests.
Citizen-reported data via mobile app.
Data Processing:
Use AI to analyze images and sensor inputs.
Automate ID assignment and attribute categorization.
Data Output:
Visualized maps and health reports on the public portal.
Alerts for areas with declining tree health.
b. Communication Network
Fiber-optic backbone: For high-speed data transmission between regions.
Cellular Networks: To connect IoT sensors in remote areas.
Satellite Communication: For remote regions without cellular coverage.
Implementation Plan
a. Phase 1: Pilot Program
Choose a smaller, biodiverse region in California (e.g., Redwood National Park).
Test satellite and drone mapping combined with IoT sensors.
Develop the prototype of the centralized database and public portal.
b. Phase 2: Statewide Rollout
Expand mapping and registration to all California regions.
Deploy IoT sensors in vulnerable or high-priority areas.
Scale up database capacity and integrate additional satellite providers.
c. Phase 3: Maintenance & Updates
Establish a monitoring team to oversee system health and data quality.
Update the network with new technologies (e.g., advanced AI models).
Periodically review and revise data collection protocols.
Partnerships
Government Agencies: U.S. Forest Service, California Department of Forestry and Fire Protection.
Tech Companies: Collaborate with Google Earth, Amazon AWS, or Microsoft for cloud and AI capabilities.
Environmental Organizations: Partner with WWF, Sierra Club, or TreePeople for funding and advocacy.
Budget Estimation
Initial Investment:
Satellite data and licenses: $10M
IoT sensors and deployment: $5M
Database and app development: $3M
Operational Costs:
Cloud services and data storage: $2M/year
Maintenance and monitoring: $1M/year
Research and development: $1M/year
Long-term Vision
Expand the system to other states or globally.
Use the database for reforestation efforts and combating deforestation.
Develop educational programs to teach communities about the importance of trees as citizens.
Would you like me to assist in designing the user interface for the public portal or drafting partnership proposals for funding?
To begin building the program for the Tree Citizenship Identification System, we’ll start with a scalable framework that allows us to process, store, and analyze data while preparing for future expansions. Here's an actionable development plan with an initial focus on foundational code and infrastructure:
Step-by-Step Development
Phase 1: Setting Up the Backend Infrastructure
Objective: Create the core database and develop the data pipeline for processing tree data.
Technologies:
Programming Languages: Python, JavaScript (Node.js), SQL.
Frameworks: Flask or FastAPI for APIs, Django for web application backend.
Database: PostgreSQL for structured data, MongoDB for unstructured data.
Code Snippet 1: Database Schema Design (PostgreSQL)
-- Table for Tree Registry CREATE TABLE trees ( tree_id SERIAL PRIMARY KEY, -- Unique Identifier location GEOGRAPHY(POINT, 4326), -- Geolocation of the tree species VARCHAR(100), -- Species name age INTEGER, -- Approximate age in years health_status VARCHAR(50), -- e.g., Healthy, Diseased height FLOAT, -- Tree height in meters canopy_width FLOAT, -- Canopy width in meters citizen_rank VARCHAR(50), -- Class or rank of the tree last_updated TIMESTAMP DEFAULT NOW() -- Timestamp for last update );
-- Table for Sensor Data (IoT Integration) CREATE TABLE tree_sensors ( sensor_id SERIAL PRIMARY KEY, -- Unique Identifier for sensor tree_id INT REFERENCES trees(tree_id), -- Linked to tree soil_moisture FLOAT, -- Soil moisture level air_quality FLOAT, -- Air quality index temperature FLOAT, -- Surrounding temperature last_updated TIMESTAMP DEFAULT NOW() -- Timestamp for last reading );
Code Snippet 2: Backend API for Tree Registration (Python with Flask)
from flask import Flask, request, jsonify from sqlalchemy import create_engine from sqlalchemy.orm import sessionmaker
app = Flask(name)
Database Configuration
DATABASE_URL = "postgresql://username:password@localhost/tree_registry" engine = create_engine(DATABASE_URL) Session = sessionmaker(bind=engine) session = Session()
@app.route('/register_tree', methods=['POST']) def register_tree(): data = request.json new_tree = { "species": data['species'], "location": f"POINT({data['longitude']} {data['latitude']})", "age": data['age'], "health_status": data['health_status'], "height": data['height'], "canopy_width": data['canopy_width'], "citizen_rank": data['citizen_rank'] } session.execute(""" INSERT INTO trees (species, location, age, health_status, height, canopy_width, citizen_rank) VALUES (:species, ST_GeomFromText(:location, 4326), :age, :health_status, :height, :canopy_width, :citizen_rank) """, new_tree) session.commit() return jsonify({"message": "Tree registered successfully!"}), 201
if name == 'main': app.run(debug=True)
Phase 2: Satellite Data Integration
Objective: Use satellite and LiDAR data to identify and register trees automatically.
Tools:
Google Earth Engine for large-scale mapping.
Sentinel-2 or Landsat satellite data for high-resolution imagery.
Example Workflow:
Process satellite data using Google Earth Engine.
Identify tree clusters using image segmentation.
Generate geolocations and pass data into the backend.
Phase 3: IoT Sensor Integration
Deploy IoT devices to monitor health metrics of specific high-priority trees.
Use MQTT protocol for real-time data transmission.
Code Snippet: Sensor Data Processing (Node.js)
const mqtt = require('mqtt'); const client = mqtt.connect('mqtt://broker.hivemq.com');
client.on('connect', () => { console.log('Connected to MQTT Broker'); client.subscribe('tree/sensor_data'); });
client.on('message', (topic, message) => { const sensorData = JSON.parse(message.toString()); console.log(Received data: ${JSON.stringify(sensorData)}); // Save data to database (Example for PostgreSQL) saveToDatabase(sensorData); });
function saveToDatabase(data) { const query = INSERT INTO tree_sensors (tree_id, soil_moisture, air_quality, temperature) VALUES ($1, $2, $3, $4) ; const values = [data.tree_id, data.soil_moisture, data.air_quality, data.temperature]; dbClient.query(query, values, (err) => { if (err) console.error('Error saving to database', err); else console.log('Sensor data saved successfully!'); }); }
Phase 4: Public Portal Development
Frontend Technologies:
React.js or Vue.js for interactive user interfaces.
Mapbox or Leaflet.js for tree visualization on maps.
Features:
Interactive tree maps with search functionality.
User registration for tree adoption programs.
Deployment Plan
Use Docker to containerize the application.
Deploy on AWS, Azure, or Google Cloud for scalability.
Monitor system health using Prometheus and Grafana.
Next Steps
Develop a testing environment for pilot deployment.
Add AI-based disease detection and prediction using TensorFlow or PyTorch.
Create an adoption feature where citizens can adopt trees and track their health.
Would you like me to set up a GitHub repository with this initial framework or assist further with deployment?
I'll prepare the project framework and outline the repository structure for the Tree Citizenship Identification System. Below is the proposed structure for the repository, followed by details of the files and components.
Proposed Repository Structure
tree-citizenship-id-system/ ├── backend/ │ ├── app.py # Flask application for backend API │ ├── database/ │ │ ├── schema.sql # Database schema for PostgreSQL │ │ ├── db_config.py # Database connection configuration │ │ └── seed_data.sql # Initial sample data for testing │ ├── services/ │ │ ├── tree_registration.py # Functions for tree registration │ │ └── sensor_data.py # Functions for processing IoT sensor data │ └── requirements.txt # Python dependencies ├── frontend/ │ ├── public/ │ │ ├── index.html # Main HTML file │ │ └── favicon.ico # Favicon for the app │ ├── src/ │ │ ├── App.js # Main React/Vue app file │ │ ├── components/ │ │ │ ├── TreeMap.js # Map component for visualizing trees │ │ │ └── TreeDetails.js # Component for detailed tree view │ │ └── styles.css # Styling for the frontend │ └── package.json # Frontend dependencies ├── scripts/ │ ├── satellite_data_processor.py # Script for processing satellite data │ └── sensor_data_simulator.py # Mock data generator for IoT sensors ├── deployment/ │ ├── Dockerfile # Docker configuration │ ├── docker-compose.yml # Docker Compose for multi-service setup │ └── cloud_setup_instructions.md # Deployment guide for cloud platforms ├── tests/ │ ├── test_backend.py # Unit tests for backend API │ └── test_frontend.js # Unit tests for frontend ├── README.md # Overview of the project └── LICENSE # Project license
Repository Details
Backend:
app.py: Main Flask app for handling API requests like tree registration and sensor data.
database/schema.sql: SQL script for creating necessary tables.
services/: Directory for modular backend logic.
Frontend:
App.js: Main entry point for the frontend application.
TreeMap.js: Integrates Mapbox/Leaflet.js for displaying tree locations.
TreeDetails.js: Displays detailed information about a selected tree.
Scripts:
satellite_data_processor.py: Automates the extraction and classification of tree data from satellite imagery.
sensor_data_simulator.py: Generates fake sensor readings for development and testing.
Deployment:
Docker configuration ensures that the app runs consistently across environments.
Cloud setup instructions provide guidelines for deploying on platforms like AWS, Azure, or GCP.
Tests:
Unit tests ensure the reliability of both the backend and frontend.
Next Steps
I will initialize the repository structure locally.
Package the files and components needed for the first version.
Provide a link to the repository for access.
I’ll get started. Please hold on for a moment.
4 notes
·
View notes
Text




Through the Years → Felipe VI of Spain (2,879/∞) 27 September 2022 | Felipe VI during his visit to the Central Command and Control Group (GRUCEMAC), at the Torrejon de Ardoz air base, in Torrejon de Ardoz, Madrid, Spain. The Central Command and Control Group controls the airspace of national sovereignty (surveillance, detection, identification and classification of air objects entering it), and that of the air police missions and, where appropriate, air defense, assigned to it, on a continuous basis 24 hours a day, 7 days a week and the Space Surveillance Operations Center has as its mission the surveillance and knowledge of the space situation of interest and the provision of services in support of the operations of the Armed Forces. (Photo By Alejandro Martinez Velez/Europa Press via Getty Images)
#King Felipe VI#Spain#2022#Alejandro Martinez Velez#Europa Press via Getty Images#through the years: Felipe
1 note
·
View note
Text
How Can Beginners Master Python For AI Projects?
Mastering Python for AI as a beginner involves a step-by-step learning approach. Start with understanding Python basics data types, loops, conditionals, and functions. Once comfortable, move to intermediate topics like object-oriented programming, file handling, and error management. After this foundation, explore libraries essential for AI such as NumPy (for numerical operations), pandas (for data manipulation), and Matplotlib (for data visualization).
The next phase includes diving into machine learning libraries like Scikit-learn and deep learning frameworks such as TensorFlow or PyTorch. Practice is key work on mini-projects like spam detection, movie recommendation, or simple image classification. These projects help apply theory to real-world problems. You can also explore platforms like Kaggle to find datasets and challenges.
Understanding AI concepts like supervised/unsupervised learning, neural networks, and model evaluation is crucial. Combine your coding knowledge with a basic understanding of statistics and linear algebra to grasp AI fundamentals better. Lastly, consistency is essential code daily and read documentation regularly.
If you're just starting out, a structured Python course for beginners can be a good foundation.
0 notes
Text
Behind the Scenes with Artificial Intelligence Developer
The wizardry of artificial intelligence prefers to conceal the attention to detail that occurs backstage. As the commoner sees sophisticated AI at work,near-human conversationalists, guess-my-intent recommendation software, or image classification software that recognizes objects at a glance,the real alchemy occurs in the day-in, day-out task of an artificial intelligence creator.
The Morning Routine: Data Sleuthing
The last day typically begins with data exploration. An artificial intelligence developers arrives at raw data in the same way that a detective does when he is at a crime scene. Numbers, patterns, and outliers all have secrets behind them that aren't obvious yet. Data cleaning and preprocessing consume most of the time,typically 70-80% of any AI project.
This phase includes the identification of missing values, duplication, and outliers that could skew the results. The concrete data point in this case is a decision the AI developer must make as to whether it is indeed out of the norm or not an outlier. These kinds of decisions will cascade throughout the entire project and impact model performance and accuracy.
Model Architecture: The Digital Engineering Art
Constructing an AI model is more of architectural design than typical programming. The builder of artificial intelligence needs to choose from several diverse architectures of neural networks that suit the solution of distinct problems. Convolutional networks are suited for image recognition, while recurrent networks are suited for sequential data like text or time series.
It is an exercise of endless experimentation. Hyperparameter tuning,tweaking the learning rate, batch size, layer count, and activation functions,requires technical skills and intuition. Minor adjustments can lead to colossus-like leaps in performance, and thus this stage is tough but fulfilling.
Training: The Patience Game
Training an AI model tests patience like very few technical ventures. A coder waits for hours, days, or even weeks for models to converge. GPUs now have accelerated the process dramatically, but computation-hungry models consume lots of computation time and resources.
During training, the programmer attempts to monitor such measures as loss curves and indices of accuracy for overfitting or underfitting signs. These are tuned and fine-tuned by the programmer based on these measures, at times starting anew entirely when initial methods don't work. This tradeoff process requires technical skill as well as emotional resilience.
The Debugging Maze
Debugging is a unique challenge when AI models misbehave. Whereas bugs in traditional software take the form of clear-cut error messages, AI bugs show up as esoteric performance deviations or curious patterns of behavior. An artificial intelligence designer must become an electronic psychiatrist, trying to understand why a given model is choosing something.
Methods such as gradient visualization, attention mapping, and feature importance analysis shed light on the model's decision-making. Occasionally the problem is with the data itself,skewed training instances or lacking diversity in the dataset. Other times it is architecture decisions or training practices.
Deployment: From Lab to Real World
Shifting into production also has issues. An AI developer must worry about inference time, memory consumption, and scalability. A model that is looking fabulous on a high-end development machine might disappoint in a low-budget production environment.
Optimization is of the highest priority. Techniques like model quantization, pruning, and knowledge distillation minimize model sizes with no performance sacrifice. The AI engineer is forced to make difficult trade-offs between accuracy and real-world limitations, usually getting in their way badly.
Monitoring and Maintenance
Deploying an AI model into production is merely the beginning, and not the final, effort for the developer of artificial intelligence. Data in the real world naturally drifts away from training data, resulting in concept drift,gradual deterioration in the performance of a model over time.
Continual monitoring involves the tracking of main performance metrics, checking prediction confidence scores, and flagging deviant patterns. When performance falls to below satisfactory levels, the developer must diagnose reasons and perform repairs, in the mode of retraining, model updates, or structural changes.
The Collaborative Ecosystem
New AI technology doesn't often happen in isolation. An artificial intelligence developer collaborates with data scientists, subject matter experts, product managers, and DevOps engineers. They all have various ideas and requirements that shape the solution.
Communication is as crucial as technical know-how. Simplifying advanced AI jargon to stakeholders who are not technologists requires infinite patience and imagination. The technical development team must bridge business needs to technical specifications and address the gap in expectations of what can and cannot be done using AI.
Keeping Up with an Evolving Discipline
The area of AI continues developing at a faster rate with fresh paradigms, approaches, and research articles emerging daily. The AI programmer should have time to continue learning, test new approaches, and learn from the achievements in the area.
It is this commitment to continuous learning that distinguishes great AI programmers from the stragglers. The work is a lot more concerned with curiosity, experimentation, and iteration than with following best practices.
Part of the AI creator's job is to marry technical astuteness with creative problem-solving ability, balancing analytical thinking with intuitive understanding of complex mechanisms. Successful AI implementation "conceals" within it thousands of hours of painstaking work, taking raw data and turning them into intelligent solutions that forge our digital destiny.
0 notes
Text
What to Expect from an Artificial Intelligence Classroom Course in Bengaluru: Curriculum, Tools & Career Scope
In the heart of India’s Silicon Valley, Bengaluru stands as a thriving hub for technology, innovation, and future-ready education. Among the many tech programs gaining traction, one stands out as a gateway to tomorrow’s digital careers—the Artificial Intelligence Classroom Course in Bengaluru.
With the global demand for AI professionals skyrocketing, classroom-based programs offer a structured, interactive, and hands-on way to acquire skills in artificial intelligence, machine learning, and data science. This blog will walk you through what to expect from such a course, including the typical curriculum, industry-standard tools, and the exciting career opportunities that wait after completion.
Why Choose a Classroom Course for AI in Bengaluru?
While online courses offer convenience, a classroom-based learning experience brings structure, discipline, and direct mentorship that many learners find invaluable. Bengaluru, being the IT capital of India, offers an ideal ecosystem for AI education. With top AI companies, research labs, and startups located nearby, classroom learning often comes with better networking opportunities, on-ground internships, and real-time collaboration.
Moreover, the interactive environment of a classroom promotes peer-to-peer learning, immediate doubt resolution, and better preparation for real-world challenges.
Who Should Enroll in an Artificial Intelligence Classroom Course in Bengaluru?
The Artificial Intelligence Classroom Course in Bengaluru is designed for:
Fresh graduates from engineering, mathematics, statistics, or computer science backgrounds.
Working professionals looking to switch careers or upskill in AI.
Entrepreneurs aiming to leverage AI for their tech startups.
Research enthusiasts interested in neural networks, deep learning, and intelligent automation.
Whether you're a beginner or a mid-career tech professional, these courses are often structured to accommodate different experience levels.
What Does the Curriculum Typically Include?
The curriculum of an Artificial Intelligence Classroom Course in Bengaluru is carefully crafted to balance theoretical concepts with real-world applications. While every institute may offer a slightly different structure, most comprehensive programs include the following core modules:
1. Introduction to Artificial Intelligence
History and evolution of AI
Types of AI (Narrow, General, Super AI)
Applications across industries (Healthcare, Finance, Retail, etc.)
2. Python for AI
Python basics
Libraries: NumPy, Pandas, Matplotlib
Data preprocessing and visualization
3. Mathematics and Statistics for AI
Linear Algebra, Probability, and Calculus
Statistical inference
Hypothesis testing
4. Machine Learning (ML)
Supervised vs. Unsupervised Learning
Algorithms: Linear Regression, Decision Trees, Random Forest, SVM
Model evaluation and tuning
5. Deep Learning
Neural networks basics
Convolutional Neural Networks (CNNs)
Recurrent Neural Networks (RNNs)
Transformers and Attention Mechanisms
6. Natural Language Processing (NLP)
Text preprocessing
Word embeddings
Sentiment analysis
Chatbot development
7. Computer Vision
Image classification
Object detection
Real-time video analysis
8. AI Ethics and Responsible AI
Bias in AI
Data privacy
Ethical deployment of AI systems
9. Capstone Projects and Case Studies
Real-world projects in healthcare, e-commerce, finance, or autonomous systems.
Team collaborations to simulate industry-like environments.
This curriculum ensures that learners not only understand the foundational theory but also gain the technical know-how to build deployable AI models.
Classroom Environment: What Makes It Unique?
In Bengaluru, the classroom experience is enriched by:
Experienced faculty: Often working professionals or researchers from top tech companies.
Hands-on labs: In-person project work, hackathons, and weekend workshops.
Peer collaboration: Group assignments and presentations simulate workplace dynamics.
Industry exposure: Guest lectures from AI professionals, startup founders, and data scientists.
Placement support: Resume building, mock interviews, and connections with hiring partners.
Moreover, institutes like the Boston Institute of Analytics (BIA) in Bengaluru offer a balanced mix of theory and practice, ensuring learners are ready for the workforce immediately after completion.
Career Scope After Completion
One of the biggest draws of enrolling in an Artificial Intelligence Classroom Course in Bengaluru is the booming career potential. With Bengaluru being home to top companies like Infosys, Wipro, IBM, and Amazon, along with a growing startup culture, job opportunities are vast.
Here are some in-demand roles you can pursue post-course:
1. AI Engineer
Develop intelligent systems and deploy machine learning models at scale.
2. Machine Learning Engineer
Design and optimize ML algorithms for real-time applications.
3. Data Scientist
Use statistical techniques to interpret complex datasets and drive insights.
4. Deep Learning Engineer
Specialize in neural networks for image, voice, or text applications.
5. NLP Engineer
Build voice assistants, chatbots, and text classification tools.
6. Computer Vision Engineer
Work on facial recognition, object detection, and image analytics.
7. AI Product Manager
Oversee the development and strategy behind AI-powered products.
8. AI Research Associate
Contribute to academic or industrial AI research projects.
Top recruiters in Bengaluru include:
Google AI India
Microsoft Research
Amazon India
Flipkart
TCS
Fractal Analytics
Mu Sigma
Boston Institute of Analytics alumni partners
Entry-level salaries in Bengaluru range from ₹6 LPA to ₹10 LPA for certified AI professionals, with mid-senior roles offering packages upwards of ₹25 LPA depending on experience and specialization.
Final Thoughts
The world is embracing artificial intelligence at an unprecedented pace, and Bengaluru is at the epicenter of this digital transformation in India. If you're looking to break into this high-demand field, enrolling in an Artificial Intelligence Classroom Course in Bengaluru is a powerful first step.
From a robust curriculum and access to modern AI tools to hands-on training and strong job placement support, classroom courses in Bengaluru offer an unmatched learning experience. Whether you're aiming to become a data scientist, AI engineer, or research specialist, the city provides the environment, opportunities, and mentorship to turn your aspirations into reality.
Ready to start your AI journey? Choose a classroom course in Bengaluru and empower yourself with skills that are shaping the future.
#Best Data Science Courses in Bengaluru#Artificial Intelligence Course in Bengaluru#Data Scientist Course in Bengaluru#Machine Learning Course in Bengaluru
0 notes
Text
Data Labeling Services | AI Data Labeling Company
AI models are only as effective as the data they are trained on. This service page explores how Damco’s data labeling services empower organizations to accelerate AI innovation through structured, accurate, and scalable data labeling.

Accelerate AI Innovation with Scalable, High-Quality Data Labeling Services
Accurate annotations are critical for training robust AI models. Whether it’s image recognition, natural language processing, or speech-to-text conversion, quality-labeled data reduces model errors and boosts performance.
Leverage Damco’s Data Labeling Services
Damco provides end-to-end annotation services tailored to your data type and use case.
Computer Vision: Bounding boxes, semantic segmentation, object detection, and more
NLP Labeling: Text classification, named entity recognition, sentiment tagging
Audio Labeling: Speaker identification, timestamping, transcription services
Who Should Opt for Data Labeling Services?
Damco caters to diverse industries that rely on clean, labeled datasets to build AI solutions:
Autonomous Vehicles
Agriculture
Retail & Ecommerce
Healthcare
Finance & Banking
Insurance
Manufacturing & Logistics
Security, Surveillance & Robotics
Wildlife Monitoring
Benefits of Data Labeling Services
Precise Predictions with high-accuracy training datasets
Improved Data Usability across models and workflows
Scalability to handle projects of any size
Cost Optimization through flexible service models
Why Choose Damco for Data Labeling Services?
Reliable & High-Quality Outputs
Quick Turnaround Time
Competitive Pricing
Strict Data Security Standards
Global Delivery Capabilities
Discover how Damco’s data labeling can improve your AI outcomes — Schedule a Consultation.
#data labeling#data labeling services#data labeling company#ai data labeling#data labeling companies
0 notes
Text
When AI Meets Medicine: Periodontal Diagnosis Through Deep Learning by Para Projects
In the ever-evolving landscape of modern healthcare, artificial intelligence (AI) is no longer a futuristic concept—it is a transformative force revolutionizing diagnostics, treatment, and patient care. One of the latest breakthroughs in this domain is the application of deep learning to periodontal disease diagnosis, a condition that affects millions globally and often goes undetected until it progresses to severe stages.
In a pioneering step toward bridging technology with dental healthcare, Para Projects, a leading engineering project development center in India, has developed a deep learning-based periodontal diagnosis system. This initiative is not only changing the way students approach AI in biomedical domains but also contributing significantly to the future of intelligent, accessible oral healthcare.
Understanding Periodontal Disease: A Silent Threat Periodontal disease—commonly known as gum disease—refers to infections and inflammation of the gums and bone that surround and support the teeth. It typically begins as gingivitis (gum inflammation) and, if left untreated, can lead to periodontitis, which causes tooth loss and affects overall systemic health.

The problem? Periodontal disease is often asymptomatic in its early stages. Diagnosis usually requires a combination of clinical examinations, radiographic analysis, and manual probing—procedures that are time-consuming and prone to human error. Additionally, access to professional diagnosis is limited in rural and under-resourced regions.
This is where AI steps in, offering the potential for automated, consistent, and accurate detection of periodontal disease through the analysis of dental radiographs and clinical data.
The Role of Deep Learning in Medical Diagnostics Deep learning, a subset of machine learning, mimics the human brain’s neural network to analyze complex data patterns. In the context of medical diagnostics, it has proven particularly effective in image recognition, classification, and anomaly detection.
When applied to dental radiographs, deep learning models can be trained to:
Identify alveolar bone loss
Detect tooth mobility or pocket depth
Differentiate between healthy and diseased tissue
Classify disease severity levels
This not only accelerates the diagnostic process but also ensures objective and reproducible results, enabling better clinical decision-making.
Para Projects: Where Innovation Meets Education Recognizing the untapped potential of AI in dental diagnostics, Para Projects has designed and developed a final-year engineering project titled “Deep Periodontal Diagnosis: A Hybrid Learning Approach for Accurate Periodontitis Detection.” This project serves as a perfect confluence of healthcare relevance and cutting-edge technology.
With a student-friendly yet professionally guided approach, Para Projects transforms a complex AI application into a doable and meaningful academic endeavor. The project has been carefully designed to offer:
Real-world application potential
Exposure to biomedical datasets and preprocessing
Use of deep learning frameworks like TensorFlow and Keras
Comprehensive support from coding to documentation
Inside the Project: How It Works The periodontal diagnosis project by Para Projects is structured to simulate a real diagnostic system. Here’s how it typically functions:
Data Acquisition and Preprocessing Students are provided with a dataset of dental radiographs (e.g., panoramic X-rays or periapical films). Using tools like OpenCV, they learn to clean and enhance the images by:
Normalizing pixel intensity

Removing noise and irrelevant areas
Annotating images using bounding boxes or segmentation maps
Feature Extraction Using convolutional neural networks (CNNs), the system is trained to detect and extract features such as
Bone-level irregularities
Shape and texture of periodontal ligaments
Visual signs of inflammation or damage
Classification and Diagnosis The extracted features are passed through layers of a deep learning model, which classifies the images into categories like
Healthy
Mild periodontitis
Moderate periodontitis
Severe periodontitis
Visualization and Reporting The system outputs visual heatmaps and probability scores, offering a user-friendly interpretation of the diagnosis. These outputs can be further converted into PDF reports, making it suitable for both academic submission and potential real-world usage.
Academic Value Meets Practical Impact For final-year engineering students, working on such a project presents a dual benefit:
Technical Mastery: Students gain hands-on experience with real AI tools, including neural network modeling, dataset handling, and performance evaluation using metrics like accuracy, precision, and recall.
Social Relevance: The project addresses a critical healthcare gap, equipping students with the tools to contribute meaningfully to society.
With expert mentoring from Para Projects, students don’t just build a project—they develop a solution that has real diagnostic value.
Why Choose Para Projects for AI-Medical Applications? Para Projects has earned its reputation as a top-tier academic project center by focusing on three pillars: innovation, accessibility, and support. Here’s why students across India trust Para Projects:
🔬 Expert-Led Guidance: Each project is developed under the supervision of experienced AI and domain experts.
📚 Complete Project Kits: From code to presentation slides, students receive everything needed for successful academic evaluation.
💻 Hands-On Learning: Real datasets, practical implementation, and coding tutorials make learning immersive.
💬 Post-Delivery Support: Para Projects ensures students are prepared for viva questions and reviews.
💡 Customization: Projects can be tailored based on student skill levels, interest, or institutional requirements.
Whether it’s a B.E., B.Tech, M.Tech, or interdisciplinary program, Para Projects offers robust solutions that connect education with industry relevance.
From Classroom to Clinic: A Future-Oriented Vision Healthcare is increasingly leaning on predictive technologies for better outcomes. In this context, AI-driven dental diagnostics can transform public health—especially in regions with limited access to dental professionals. What began as a classroom project at Para Projects can, with further development, evolve into a clinical tool, contributing to preventive healthcare systems across the world.
Students who engage with such projects don’t just gain knowledge—they step into the future of AI-powered medicine, potentially inspiring careers in biomedical engineering, health tech entrepreneurship, or AI research.
Conclusion: Diagnosing with Intelligence, Healing with Innovation The fusion of AI and medicine is not just a technological shift—it’s a philosophical transformation in how we understand and address disease. By enabling early, accurate, and automated diagnosis of periodontal disease, deep learning is playing a vital role in improving oral healthcare outcomes.
With its visionary project on periodontal diagnosis through deep learning, Para Projects is not only helping students fulfill academic goals—it’s nurturing the next generation of tech-enabled healthcare changemakers.

Are you ready to engineer solutions that impact lives? Explore this and many more cutting-edge medical and AI-based projects at https://paraprojects.in. Let Para Projects be your partner in building technology that heals.
0 notes
Text
CNN Python Projects in chennai
Enhance your AI skills with CNN Python Projects in Chennai! Learn to build Convolutional Neural Networks for tasks like image classification, face detection, and object recognition using Python, TensorFlow, and Keras. Leading project centers offer hands-on training, expert guidance, and real-time datasets. Ideal for final year students aiming to work in computer vision. Start your journey into deep learning with practical CNN projects in Chennai!
0 notes
Text
What AI Skills Will Make You the Most Money in 2025? Here's the Inside Scoop
If you’ve been even slightly tuned into the tech world, you’ve heard it: AI is taking over. But here’s the good news—it’s not here to replace everyone; it’s here to reward those who get ahead of the curve. The smartest move you can make right now? Learn AI skills that are actually in demand and highly paid.

We're stepping into a world where AI is not just automating jobs, it’s creating new, high-paying careers—and they’re not all for coders. Whether you’re a techie, creative, strategist, or entrepreneur, there’s something in AI that can fuel your next big leap.
So, let’s break down the 9 most income-generating AI skills for 2025, what makes them hot, and how you can start developing them today.
1. Machine Learning (ML) Engineering
Machine learning is the brain behind modern AI. From YouTube recommendations to fraud detection, it powers everything.
Why it pays: Businesses are using ML to cut costs, boost sales, and predict customer behavior. ML engineers can expect salaries from $130,000 to $180,000+ depending on experience and location.
What to learn: Python, TensorFlow, PyTorch, data modeling, algorithms
Pro tip: Get hands-on with Kaggle competitions to build your portfolio.
2. Natural Language Processing (NLP)
NLP is how machines understand human language—think ChatGPT, Alexa, Grammarly, or AI content moderation.
Why it pays: NLP is exploding thanks to chatbots, AI customer support, and automated content. Salaries range between $110,000 to $160,000.
What to learn: SpaCy, NLTK, BERT, GPT models, tokenization, sentiment analysis
Real-life bonus: If you love languages and psychology, NLP blends both.
3. AI Product Management
Not all high-paying AI jobs require coding. AI Product Managers lead AI projects from concept to launch.
Why it pays: Every tech company building AI features needs a PM who gets it. These roles can bring in $120,000 to $170,000, and more in startups with equity.
What to learn: Basics of AI, UX, Agile methodologies, data analysis, prompt engineering
Starter tip: Learn how to translate business problems into AI product features.
4. Computer Vision
This is the tech that lets machines "see" — powering facial recognition, self-driving cars, and even AI-based medical imaging.
Why it pays: Industries like healthcare, retail, and automotive are investing heavily in vision-based AI. Salaries are typically $130,000 and up.
What to learn: OpenCV, YOLO, object detection, image classification, CNNs (Convolutional Neural Networks)
Why it’s hot: The AR/VR boom is only just beginning—and vision tech is at the center.
5. AI-Driven Data Analysis
Data is gold, but AI turns it into actionable insights. Data analysts who can use AI to automate reports and extract deep trends are in high demand.
Why it pays: AI-powered analysts often pull $90,000 to $130,000, and can climb higher in enterprise roles.
What to learn: SQL, Python (Pandas, NumPy), Power BI, Tableau, AutoML tools
Great for: Anyone who loves solving puzzles with numbers.
6. Prompt Engineering
Yes, it’s a real job now. Prompt engineers design inputs for AI tools like ChatGPT or Claude to get optimal results.
Why it pays: Businesses pay up to $250,000 a year for prompt experts because poorly written prompts can cost time and money.
What to learn: How LLMs work, instruction tuning, zero-shot vs. few-shot prompting, language logic
Insider fact: Even content creators are using prompt engineering to boost productivity and generate viral ideas.
7. AI Ethics and Policy
As AI becomes mainstream, the need for regulation, fairness, and transparency is growing fast. Enter AI ethicists and policy strategists.
Why it pays: Roles range from $100,000 to $160,000, especially in government, think tanks, and large corporations.
What to learn: AI bias, explainability, data privacy laws, algorithmic fairness
Good fit for: People with legal, social science, or philosophical backgrounds.
8. Generative AI Design
If you’re a designer, there’s gold in gen AI tools. Whether it’s building AI-powered logos, animations, voiceovers, or 3D assets—creativity now meets code.
Why it pays: Freelancers can earn $5,000+ per project, and full-time creatives can make $100,000+ if they master the tools.
What to learn: Midjourney, Adobe Firefly, RunwayML, DALL·E, AI video editors
Hot tip: Combine creativity with some basic scripting (Python or JavaScript) and you become unstoppable.
9. AI Integration & Automation (No-Code Tools)
Not a tech whiz? No problem. If you can use tools like Zapier, Make.com, or Notion AI, you can build automation flows that solve business problems.
Why it pays: Businesses pay consultants $80 to $200+ per hour to set up custom AI workflows.
What to learn: Zapier, Make, Airtable, ChatGPT APIs, Notion, AI chatbots
Perfect for: Entrepreneurs and freelancers looking to scale fast without hiring.
How to Get Started Without Burning Out
Pick one lane. Don’t try to learn everything. Choose one skill based on your background and interest.
Use free platforms. Coursera, YouTube, and Google’s AI courses offer incredible resources.
Practice, don’t just watch. Build projects, join AI communities, and ask for feedback.
Show your work. Post projects on GitHub, Medium, or LinkedIn. Even small ones count.
Stay updated. AI changes fast. Follow influencers, subscribe to newsletters, and keep tweaking your skills.
Real Talk: Do You Need a Degree?
Nope. Many high-earning AI professionals are self-taught. What really counts is your ability to solve real-world problems using AI tools. If you can do that and show results, you’re golden.
Even companies like Google, Meta, and OpenAI look at what you can do, not just your college transcript.
Final Thoughts
AI isn’t some far-off future—it’s happening right now. The people who are getting rich off this tech are not just coding geniuses or math wizards. They’re creators, problem-solvers, and forward thinkers who dared to learn something new.
The playing field is wide open—and if you start today, 2025 could be your most profitable year yet.
So which skill will you start with?
0 notes
Text
Accelerate AI Development

Artificial Intelligence (AI) is no longer a futuristic concept — it’s a present-day driver of innovation, efficiency, and automation. From self-driving cars to intelligent customer service chatbots, AI is reshaping the way industries operate. But behind every smart algorithm lies an essential component that often doesn’t get the spotlight it deserves: data.
No matter how advanced an AI model may be, its potential is directly tied to the quality, volume, and relevance of the data it’s trained on. That’s why companies looking to move fast in AI development are turning their attention to something beyond algorithms: high-quality, ready-to-use datasets.
The Speed Factor in��AI
Time-to-market is critical. Whether you’re a startup prototyping a new feature or a large enterprise deploying AI at scale, delays in sourcing, cleaning, and labeling data can slow down innovation. Traditional data collection methods — manual scraping, internal sourcing, or custom annotation — can take weeks or even months. This timeline doesn’t align with the rapid iteration cycles that AI teams are expected to maintain.
The solution? Pre-collected, curated datasets that are immediately usable for training machine learning models.
Why Pre-Collected Datasets Matter
Pre-collected datasets offer a shortcut without compromising on quality. These datasets are:
Professionally Curated: Built with consistency, structure, and clear labeling standards.
Domain-Specific: Tailored to key AI areas like computer vision, natural language processing (NLP), and audio recognition.
Scalable: Ready to support models at different stages of development — from testing hypotheses to deploying production systems.
Instead of spending months building your own data pipeline, you can start training and refining your models from day one.
Use Cases That Benefit
The applications of AI are vast, but certain use cases especially benefit from rapid access to quality data:
Computer Vision: For tasks like facial recognition, object detection, autonomous driving, and medical imaging, visual datasets are vital. High-resolution, diverse, and well-annotated images can shave weeks off development time.
Natural Language Processing (NLP): Chatbots, sentiment analysis tools, and machine translation systems need text datasets that reflect linguistic diversity and nuance.
Audio AI: Whether it’s voice assistants, transcription tools, or sound classification systems, audio datasets provide the foundation for robust auditory understanding.
With pre-curated datasets available, teams can start experimenting, fine-tuning, and validating their models immediately — accelerating everything from R&D to deployment.
Data Quality = Model Performance
It’s a simple equation: garbage in, garbage out. The best algorithms can’t overcome poor data. And while it’s tempting to rely on publicly available datasets, they’re often outdated, inconsistent, or not representative of real-world complexity.
Using high-quality, professionally sourced datasets ensures that your model is trained on the type of data it will encounter in the real world. This improves performance metrics, reduces bias, and increases trust in your AI outputs — especially critical in sensitive fields like healthcare, finance, and security.
Save Time, Save Budget
Data acquisition can be one of the most expensive parts of an AI project. It requires technical infrastructure, human resources for annotation, and ongoing quality control. By purchasing pre-collected data, companies reduce:
Operational Overhead: No need to build an internal data pipeline from scratch.
Hiring Costs: Avoid the expense of large annotation or data engineering teams.
Project Delays: Eliminate waiting periods for data readiness.
It’s not just about moving fast — it’s about being cost-effective and agile.
Build Better, Faster
When you eliminate the friction of data collection, you unlock your team’s potential to focus on what truly matters: experimentation, innovation, and performance tuning. You free up data scientists to iterate more often. You allow product teams to move from ideation to MVP more quickly. And you increase your competitive edge in a fast-moving market.
Where to Start
If you’re looking to power up your AI development with reliable data, explore BuyData.Pro. We provide a wide range of high-quality, pre-labeled datasets in computer vision, NLP, and audio. Whether you’re building your first model or optimizing one for production, our datasets are built to accelerate your journey.
Website: https://buydata.pro Contact: [email protected]
0 notes
Text
How a PGD in Machine Learning and AI Equips You for High-Demand Tech Roles
In today's rapidly evolving technological landscape, the demand for professionals skilled in Artificial Intelligence (AI) and Machine Learning (ML) is surging. A Postgraduate Diploma (PGD) in Machine Learning and AI offers a strategic pathway for individuals aiming to enter or advance in this dynamic field. This article explores how such a program equips learners with the necessary skills and knowledge to thrive in high-demand tech roles.
Understanding the Significance of AI and ML in the Modern World
AI and ML are at the forefront of technological innovation, driving advancements across various sectors including healthcare, finance, education, and transportation. These technologies enable systems to learn from data, make decisions, and improve over time without explicit programming. As organizations increasingly adopt AI and ML solutions, the need for proficient professionals in these areas has become paramount.
Core Competencies Developed Through a PGD in AI and ML
A comprehensive PG Diploma in Artificial Intelligence and Machine Learning is designed to provide both theoretical foundations and practical skills. Key competencies developed include:
Programming Proficiency: Mastery of programming languages such as Python, along with libraries like NumPy, Pandas, and Matplotlib, essential for data manipulation and analysis.
Statistical and Mathematical Foundations: A solid understanding of linear algebra, probability, and statistics to comprehend and develop ML algorithms.
Machine Learning Techniques: Knowledge of supervised and unsupervised learning methods, including regression, classification, clustering, and dimensionality reduction.
Deep Learning and Neural Networks: Insights into neural network architectures, backpropagation, and frameworks like TensorFlow and PyTorch for building deep learning models.
Natural Language Processing (NLP): Skills to process and analyze textual data, enabling applications such as sentiment analysis, language translation, and chatbots.
Computer Vision: Techniques to interpret and process visual data, facilitating developments in image recognition, object detection, and autonomous systems.
Model Deployment and MLOps: Understanding of deploying models into production environments, including concepts like containerization, continuous integration, and monitoring.
Career Opportunities Post-PGD in AI and ML
Graduates of a PGD in AI and ML are well-positioned to pursue various roles, such as:
Data Scientist: Analyzing complex datasets to derive actionable insights and inform strategic decisions.
Machine Learning Engineer: Designing and implementing ML models and algorithms to solve real-world problems.
AI Research Scientist: Conducting research to advance the field of AI and develop innovative solutions.
Business Intelligence Developer: Creating data-driven strategies to enhance business performance.
AI Product Manager: Overseeing the development and deployment of AI-powered products and services.
These roles are prevalent across industries, reflecting the versatile applicability of AI and ML skills.
The Growing Demand for AI and ML Professionals
The global AI market is experiencing exponential growth, with projections indicating a significant increase in the coming years. This expansion translates to a robust job market for AI and ML professionals. Organizations are actively seeking individuals who can harness these technologies to drive innovation and maintain competitive advantages.
Advantages of Pursuing a PGD in AI and ML
Opting for a PG Diploma in Artificial Intelligence and Machine Learning offers several benefits:
Industry-Relevant Curriculum: Programs are often designed in collaboration with industry experts, ensuring alignment with current technological trends and employer expectations.
Practical Experience: Emphasis on hands-on projects and real-world applications facilitates the transition from academic learning to professional practice.
Flexible Learning Options: Many institutions offer part-time or online courses, accommodating working professionals and diverse learning preferences.
Networking Opportunities: Engaging with peers, instructors, and industry professionals can lead to valuable connections and career prospects.
Conclusion
Embarking on a PGD in Machine Learning and AI is a smart move for those aiming to make a mark in the ever-evolving tech industry. The program offers a perfect blend of theoretical foundations and real-world applications, enabling learners to step confidently into high-demand roles like data scientists, ML engineers, and AI researchers. As the world becomes more data-driven, this qualification positions you at the forefront of innovation.
For students seeking quality education in this field, AURO University offers a comprehensive curriculum designed to meet industry expectations and prepare students for impactful careers in Artificial Intelligence and Machine Learning.
0 notes
Text
Unlocking Intelligence: A Deep Dive into AI Analysis Tools
Artificial Intelligence (AI) has rapidly evolved from a futuristic concept into a transformative force reshaping nearly every industry. At the heart of this revolution lie AI analysis tools—powerful software platforms and frameworks designed to process vast amounts of data, uncover hidden patterns, and provide actionable insights. These tools are pivotal in driving innovation, boosting efficiency, and enabling data-driven decision-making.
In this blog, we explore what AI analysis tools are, the different types available, how they are applied across industries, and the trends shaping their future.
What Are AI Analysis Tools?
AI analysis tools are software systems that use machine learning (ML), deep learning, natural language processing (NLP), and other AI techniques to interpret complex datasets. These tools go beyond traditional analytics by not just describing data but predicting outcomes, automating decision-making, and sometimes even making recommendations autonomously.

Key capabilities of AI analysis tools include:
Data mining and preparation
Pattern recognition and anomaly detection
Predictive modeling
Natural language understanding
Computer vision and image analysis
They are essential in scenarios where data is vast, unstructured, or too complex for conventional analytics.
Categories of AI Analysis Tools
There are various types of AI analysis tools, depending on their purpose and technology stack. Here's a breakdown of the major categories:
1. Machine Learning Platforms
These platforms allow data scientists and analysts to build, train, and deploy ML models. They often come with pre-built algorithms and visual interfaces.
Examples:
Google Cloud AI Platform
Amazon SageMaker
Azure Machine Learning
DataRobot
These platforms support both supervised and unsupervised learning techniques and offer tools for model management, performance tracking, and deployment at scale.
2. Natural Language Processing (NLP) Tools
NLP tools focus on analyzing and understanding human language. They are crucial for tasks like sentiment analysis, chatbot development, and document summarization.
Examples:
SpaCy
IBM Watson NLP
OpenAI GPT models (like ChatGPT)
Hugging Face Transformers
These tools power applications in customer service, healthcare, legal tech, and more.
3. Business Intelligence (BI) Enhanced with AI
Traditional BI tools are evolving by integrating AI to enhance insights through automation and predictive analytics.
Examples:
Tableau with Einstein Analytics (Salesforce)
Power BI with Azure AI
Qlik Sense with AutoML
These platforms allow non-technical users to interact with AI-driven dashboards and generate insights without writing code.
4. Computer Vision Tools
These tools analyze visual data such as images and videos to detect objects, recognize faces, or interpret scenes.
Examples:
OpenCV
TensorFlow for image classification
AWS Rekognition
Google Vision AI
They are widely used in surveillance, autonomous driving, retail analytics, and medical diagnostics.
5. Automated Machine Learning (AutoML) Tools
AutoML platforms democratize ML by enabling users without deep technical skills to create powerful models through automation.
Examples:
H2O.ai
Google AutoML
DataRobot AutoML
RapidMiner
AutoML handles preprocessing, model selection, tuning, and even deployment, making AI accessible to broader teams.
Applications Across Industries
AI analysis tools are not limited to tech giants or data scientists. Their applications span across various sectors, delivering real-world impact.
Healthcare
AI tools help in diagnostic imaging, drug discovery, patient monitoring, and personalized medicine. For example, deep learning models analyze radiology images with near-human accuracy.
Finance
Banks and fintech firms use AI tools for fraud detection, credit scoring, algorithmic trading, and risk assessment. Real-time anomaly detection models are crucial for identifying suspicious transactions.
Retail and E-commerce
AI-driven recommendation engines, dynamic pricing algorithms, and customer sentiment analysis have revolutionized the retail experience, leading to increased sales and customer loyalty.
Manufacturing
Predictive maintenance powered by AI tools minimizes downtime and optimizes supply chains. Vision systems detect defects on assembly lines faster than human inspectors.
Marketing and Sales
AI analysis tools help marketers segment customers, predict churn, personalize campaigns, and automate content creation using NLP and generative AI.
Benefits of AI Analysis Tools
Implementing AI analysis tools brings several advantages:
Speed and Scalability: AI can analyze millions of data points in seconds, far surpassing human capabilities.
Cost Efficiency: Automating complex tasks reduces the need for large analytical teams and cuts operational costs.
Accuracy and Objectivity: AI eliminates biases and errors often present in manual analysis.
Real-Time Insights: Many tools provide continuous monitoring and instant alerts, essential in sectors like finance and cybersecurity.
Decision Support: By identifying trends and forecasting outcomes, AI tools support better strategic decisions.
Challenges and Considerations
Despite their potential, AI analysis tools come with challenges:
Data Quality and Availability: AI is only as good as the data it’s trained on. Incomplete or biased data leads to poor models.
Interpretability: Many AI models are black boxes, making it hard to explain their decisions—especially critical in healthcare and finance.
Security and Privacy: Handling sensitive data requires robust governance, especially with regulations like GDPR and HIPAA.
Skill Gap: There’s a shortage of skilled professionals who can effectively implement and manage AI tools.
Cost of Implementation: High-quality AI tools can be expensive and resource-intensive to deploy.
Organizations must address these issues to fully realize the benefits of AI analysis.
Future Trends in AI Analysis
The field of AI analysis is constantly evolving. Here are key trends to watch:
1. Explainable AI (XAI)
There’s growing demand for tools that can explain how they reach decisions. XAI frameworks are being integrated into more platforms to ensure transparency.
2. Edge AI
Instead of processing data in the cloud, AI is increasingly running on edge devices—allowing for faster decisions in environments like manufacturing floors and autonomous vehicles.
3. AI-as-a-Service (AIaaS)
Major cloud providers are offering AI tools as subscription services, lowering the entry barrier for smaller businesses.
4. Integration with IoT and Big Data
AI analysis is becoming a critical layer on top of IoT systems, enabling smarter automation and anomaly detection at scale.
5. Generative AI for Analytics
Tools like ChatGPT are being used to generate analytical reports, summarize insights, and assist with data interpretation—making analytics more conversational and intuitive.
Conclusion
AI analysis tools are reshaping how organizations understand data and make decisions. Whether it's diagnosing diseases, predicting customer behavior, or optimizing supply chains, these tools empower businesses to unlock new levels of efficiency and innovation.
As the technology matures, and becomes more accessible and interpretable, it will likely become a standard part of every organization’s analytics toolkit. The key lies in choosing the right tools, ensuring data quality, and building a culture that embraces data-driven thinking.
Investing in AI analysis tools is not just a tech upgrade—it’s a strategic move toward a smarter, faster, and more competitive future.
0 notes