#Object Detection
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr has a low social media market share in South America.
Text
Applications of Object Detection
Discover the wide-ranging applications of object detection technology, driving innovation and transformation across industries. In retail, object detection enables smart shelves and cashierless checkout systems, enhancing the shopping experience and improving inventory management. In healthcare, it aids in the diagnosis of diseases through medical imaging analysis and assists in surgical procedures with real-time guidance. Meanwhile, in agriculture, object detection helps monitor crop health and optimize yield. With its ability to accurately identify and classify objects in images or video, object detection technology continues to revolutionize countless sectors, paving the way for safer, more efficient, and more intelligent systems.
1 note
·
View note
Text
amateur detective who solves crimes out of curiosity and then just. doesn't bother to tell anyone the identity of the perpetrator
17K notes
·
View notes
Text
Vision in Focus: The Art and Science of Computer Vision & Image Processing.
Sanjay Kumar Mohindroo Sanjay Kumar Mohindroo. skm.stayingalive.in An insightful blog post on computer vision and image processing, highlighting its impact on medical diagnostics, autonomous driving, and security systems.
Computer vision and image processing have reshaped the way we see and interact with the world. These fields power systems that read images, detect objects and analyze video…
#AI#Automated Image Recognition#Autonomous Driving#Collaboration#Community#Computer Vision#data#Discussion#Future Tech#Health Tech#Image Processing#Innovation#Medical Diagnostics#News#Object Detection#Privacy#Sanjay Kumar Mohindroo#Security Systems#Tech Ethics#tech innovation#Video Analysis
0 notes
Text
YOLO V/s Embeddings: A comparison between two object detection models
YOLO-Based Detection Model Type: Object detection Method: YOLO is a single-stage object detection model that divides the image into a grid and predicts bounding boxes, class labels, and confidence scores in a single pass. Output: Bounding boxes with class labels and confidence scores. Use Case: Ideal for real-time applications like autonomous vehicles, surveillance, and robotics. Example Models: YOLOv3, YOLOv4, YOLOv5, YOLOv8 Architecture
YOLO processes an image in a single forward pass of a CNN. The image is divided into a grid of cells (e.g., 13×13 for YOLOv3 at 416×416 resolution). Each cell predicts bounding boxes, class labels, and confidence scores. Uses anchor boxes to handle different object sizes. Outputs a tensor of shape [S, S, B*(5+C)] where: S = grid size (e.g., 13×13) B = number of anchor boxes per grid cell C = number of object classes 5 = (x, y, w, h, confidence) Training Process
Loss Function: Combination of localization loss (bounding box regression), confidence loss, and classification loss.
Labels: Requires annotated datasets with labeled bounding boxes (e.g., COCO, Pascal VOC).
Optimization: Typically uses SGD or Adam with a backbone CNN like CSPDarknet (in YOLOv4/v5). Inference Process
Input image is resized (e.g., 416×416). A single forward pass through the model. Non-Maximum Suppression (NMS) filters overlapping bounding boxes. Outputs detected objects with bounding boxes. Strengths
Fast inference due to a single forward pass. Works well for real-time applications (e.g., autonomous driving, security cameras). Good performance on standard object detection datasets. Weaknesses
Struggles with overlapping objects (compared to two-stage models like Faster R-CNN). Fixed number of anchor boxes may not generalize well to all object sizes. Needs retraining for new classes. Embeddings-Based Detection Model Type: Feature-based detection Method: Instead of directly predicting bounding boxes, embeddings-based models generate a high-dimensional representation (embedding vector) for objects or regions in an image. These embeddings are then compared against stored embeddings to identify objects. Output: A similarity score (e.g., cosine similarity) that determines if an object matches a known category. Use Case: Often used for tasks like face recognition (e.g., FaceNet, ArcFace), anomaly detection, object re-identification, and retrieval-based detection where object categories might not be predefined. Example Models: FaceNet, DeepSORT (for object tracking), CLIP (image-text matching) Architecture
Uses a deep feature extraction model (e.g., ResNet, EfficientNet, Vision Transformers). Instead of directly predicting bounding boxes, it generates a high-dimensional feature vector (embedding) for each object or image. The embeddings are stored in a vector database or compared using similarity metrics. Training Process Uses contrastive learning or metric learning. Common loss functions:
Triplet Loss: Forces similar objects to be closer and different objects to be farther in embedding space.
Cosine Similarity Loss: Maximizes similarity between identical objects.
Center Loss: Ensures class centers are well-separated. Training datasets can be either:
Labeled (e.g., with identity labels for face recognition).
Self-supervised (e.g., CLIP uses image-text pairs). Inference Process
Extract embeddings from a new image using a CNN or transformer. Compare embeddings with stored vectors using cosine similarity or Euclidean distance. If similarity is above a threshold, the object is recognized. Strengths
Scalable: New objects can be added without retraining.
Better for recognition tasks: Works well for face recognition, product matching, anomaly detection.
Works without predefined classes (zero-shot learning). Weaknesses
Requires a reference database of embeddings. Not good for real-time object detection (doesn’t predict bounding boxes directly). Can struggle with hard negatives (objects that look similar but are different).
Weaknesses
Struggles with overlapping objects (compared to two-stage models like Faster R-CNN). Fixed number of anchor boxes may not generalize well to all object sizes. Needs retraining for new classes. Embeddings-Based Detection Model Type: Feature-based detection Method: Instead of directly predicting bounding boxes, embeddings-based models generate a high- dimensional representation (embedding vector) for objects or regions in an image. These embeddings are then compared against stored embeddings to identify objects. Output: A similarity score (e.g., cosine similarity) that determines if an object matches a known category. Use Case: Often used for tasks like face recognition (e.g., FaceNet, ArcFace), anomaly detection, object re-identification, and retrieval-based detection where object categories might not be predefined. Example Models: FaceNet, DeepSORT (for object tracking), CLIP (image-text matching) Architecture
Uses a deep feature extraction model (e.g., ResNet, EfficientNet, Vision Transformers). Instead of directly predicting bounding boxes, it generates a high-dimensional feature vector (embedding) for each object or image. The embeddings are stored in a vector database or compared using similarity metrics. Training Process Uses contrastive learning or metric learning. Common loss functions:
Triplet Loss: Forces similar objects to be closer and different objects to be farther in embedding space.
Cosine Similarity Loss: Maximizes similarity between identical objects.
Center Loss: Ensures class centers are well-separated. Training datasets can be either:
Labeled (e.g., with identity labels for face recognition).
Self-supervised (e.g., CLIP uses image-text pairs). Inference Process
Extract embeddings from a new image using a CNN or transformer. Compare embeddings with stored vectors using cosine similarity or Euclidean distance. If similarity is above a threshold, the object is recognized. Strengths
Scalable: New objects can be added without retraining.
Better for recognition tasks: Works well for face recognition, product matching, anomaly detection.
Works without predefined classes (zero-shot learning). Weaknesses
Requires a reference database of embeddings. Not good for real-time object detection (doesn’t predict bounding boxes directly). Can struggle with hard negatives (objects that look similar but are different).
1 note
·
View note

Text
https://www.futureelectronics.com/p/semiconductors--analog--sensors--time-off-flight-sensors/vl6180xv0nr-1-stmicroelectronics-4173292
Time of Flight 3D camera developed, Light Sensing, robot navigation
VL6180X Series 3 V Proximity and Ambient Light Sensing (ALS) Module - LGA-12
#STMicroelectronics#VL6180XV0NR/1#Sensors#Time of Flight (ToF) Sensors#3D camera developed#Light Sensing#robot navigation#Lock-in#camera#Object detection#RF-module light sources#Real-time simulation#phone#vehicle monitoring#people counting
1 note
·
View note
Text
Real-time Object Detection: Color USB Camera Solutions for Modern Warehouses

Success in the fast-paced logistics world of today depends on effective operations. The color USB camera is one of the most revolutionary technologies supporting this endeavor. These cameras are essential for real-time object detection, which guarantees precise and efficient inventory management in warehouses. Knowing the advantages of color USB cameras becomes more important as companies work to streamline their supply chains. They promote accuracy and safety in the handling of commodities in addition to operational efficiency.
The Importance of Color USB Cameras in Warehouse
Color USB cameras are invaluable in modern warehouses for various reasons. First and foremost, their ability to provide real-time data allows warehouse managers to monitor stock levels and inventory movements seamlessly. This capability is essential for making informed decisions quickly, helping to minimize downtime and improve overall productivity.
Additionally, the high-resolution color output of these cameras enhances object recognition capabilities. Unlike traditional monochrome cameras, color USB cameras can differentiate between items more effectively, reducing the risk of errors during sorting and stocking processes. This feature is crucial for warehouses that deal with multiple products, ensuring that items are stored and retrieved accurately.
Enhanced Inventory Management with Color USB Camera Technology
Implementing color USB camera technology in warehouses significantly enhances inventory management systems. With real-time object detection, these cameras can track products as they move through various stages of the supply chain, from receiving to shipping. The cameras’ ability to analyze and report data instantly allows for better inventory forecasting, reducing instances of overstocking or stockouts.
Moreover, integrating color USB cameras with inventory management software creates a powerful solution for warehouse operations. This synergy enables automated tracking and management of goods, streamlining processes that once required manual intervention. As a result, businesses can reduce labor costs while increasing accuracy and efficiency.
Improving Safety and Security in Warehouses
In addition to inventory management, color USB cameras contribute significantly to enhancing safety and security within warehouse environments. These cameras can monitor areas for unauthorized access and detect potential hazards in real-time. By capturing high-definition color footage, they provide clear visuals that can help identify safety compliance issues or security breaches promptly.
Furthermore, having a visual record of warehouse activities aids in investigating incidents or accidents. Color USB cameras allow management to review footage for training purposes, ensuring that employees understand safety protocols and best practices. This proactive approach to safety not only protects workers but also mitigates potential liabilities for the business.
The Future of Color USB Cameras in Warehouse Automation
As technology evolves, the role of color USB cameras in warehouse automation is expected to expand further. Innovations such as artificial intelligence and machine learning will enhance their capabilities, allowing for even more sophisticated object detection and analysis. These advancements will enable warehouses to automate various processes, from sorting items to managing inventory levels autonomously.
Additionally, the integration of color USB cameras with Internet of Things (IoT) devices will create a more connected and efficient warehouse environment. This interconnectedness will facilitate real-time data sharing across various platforms, empowering businesses to make strategic decisions based on accurate, up-to-the-minute information.
Ready to employ cutting-edge technologies to streamline your warehouse operations? Discover how our selection of color USB cameras with real-time object identification capabilities may improve your safety procedures and inventory control. Get in touch with us right now to find out more about our creative solutions and to start down the path to a warehouse that operates more efficiently.
This account's blog entries are all based on in-depth study and personal experience. To ensure that there are no skewed viewpoints, each product is only featured after undergoing extensive testing and assessment. If you encounter any issues, don't be afraid to get in touch with us.
0 notes
Text
#Object Detection#Computer Vision#Object detection in computer vision#object detection and image classification#Image Preprocessing#Feature Extraction#Bounding Box Regression
0 notes
Text
Why Should IITs Implement Face Recognition Technology?
Our latest blog post explores the transformative power of face recognition technology! Discover why IITs should embrace Face Recognition Technology innovation and how it can significantly enhance their educational institutions.
From improving attendance and video surveillance to object detection, activity monitoring, and identification, face recognition technology offers comprehensive benefits for campus safety and efficiency.
#face recognition technology#iit#campus#biometrics#video surveillance#object detection#face biometrics#cctv based solutions#cctv face recognition
1 note
·
View note
Text
Guide to Image Classification & Object Detection
Computer vision, a driving force behind global AI development, has revolutionized various industries with its expanding range of tasks. From self-driving cars to medical image analysis and virtual reality, its capabilities seem endless. In this article, we'll explore two fundamental tasks in computer vision: image classification and object detection. Although often misunderstood, these tasks serve distinct purposes and are crucial to numerous AI applications.

The Magic of Computer Vision:
Enabling computers to "see" and understand images is a remarkable technological achievement. At the heart of this progress are image classification and object detection, which form the backbone of many AI applications, including gesture recognition and traffic sign detection.
Understanding the Nuances:
As we delve into the differences between image classification and object detection, we'll uncover their crucial roles in training robust models for enhanced machine vision. By grasping the nuances of these tasks, we can unlock the full potential of computer vision and drive innovation in AI development.
Key Factors to Consider:
Humans possess a unique ability to identify objects even in challenging situations, such as low lighting or various poses. In the realm of artificial intelligence, we strive to replicate this human accuracy in recognizing objects within images and videos.
Object detection and image classification are fundamental tasks in computer vision. With the right resources, computers can be effectively trained to excel at both object detection and classification. To better understand the differences between these tasks, let's discuss each one separately.
Image Classification:
Image classification involves identifying and categorizing the entire image based on the dominant object or feature present. For example, when given an image of a cat, an image classification model will categorize it as a "cat." Assigning a single label to an image from predefined categories is a straightforward task.
Key factors to consider in image classification:
Accuracy: Ensuring the model correctly identifies the main object in the image.
Speed: Fast classification is essential for real-time applications.
Dataset Quality: A diverse and high-quality dataset is crucial for training accurate models.
Object Detection:
Object detection, on the other hand, involves identifying and locating multiple objects within an image. This task is more complex as it requires the model to not only recognize various objects but also pinpoint their exact positions within the image using bounding boxes. For instance, in a street scene image, an object detection model can identify cars, pedestrians, traffic signs, and more, along with their respective locations.
Key factors to consider in object detection:
Precision: Accurate localization of multiple objects in an image.
Complexity: Handling various objects with different shapes, sizes, and orientations.
Performance: Balancing detection accuracy with computational efficiency, especially for real-time processing.
Differences Between Image Classification & Object Detection:
While image classification provides a simple and efficient way to categorize images, it is limited to identifying a single object per image. Object detection, however, offers a more comprehensive solution by identifying and localizing multiple objects within the same image, making it ideal for applications like autonomous driving, security surveillance, and medical imaging.

Similarities Between Image Classification & Object Detection:
Certainly! Here's the content presented in a table format highlighting the similarities between image classification and object detection:
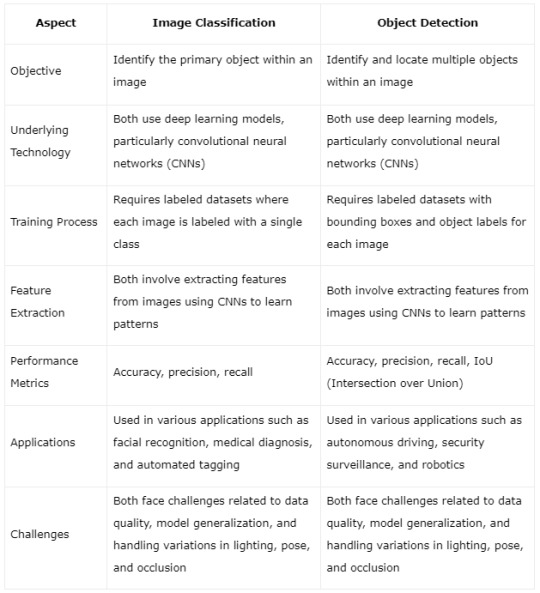
By presenting the similarities in a tabular format, it's easier to grasp how both image classification and object detection share common technologies, challenges, and methodologies, despite their different objectives in the field of computer vision.
Practical Guide to Distinguishing Between Image Classification and Object Detection:
Building upon our prior discussion of image classification vs. object detection, let's delve into their practical significance and offer a comprehensive approach to solidify your basic knowledge about these fundamental computer vision techniques.
Image Classification:

Image classification involves assigning a predefined category to a visual data piece. Using a labeled dataset, an ML model is trained to predict the label for new images.
Single Label Classification: Assigns a single class label to data, like categorizing an object as a bird or a plane.
Multi-Label Classification: Assigns two or more class labels to data, useful for identifying multiple attributes within an image, such as tree species, animal types, and terrain in ecological research.
Practical Applications:
Digital asset management
AI content moderation
Product categorization in e-commerce
Object Detection:

Object detection has seen significant advancements, enabling real-time implementations on resource-constrained devices. It locates and identifies multiple objects within an image.
Future Research Focus:
Lightweight detection for edge devices
End-to-end pipelines for efficiency
Small object detection for population counting
3D object detection for autonomous driving
Video detection with improved spatial-temporal correlation
Cross-modality detection for accuracy enhancement
Open-world detection for unknown objects detection
Advanced Scenarios:
Combining classification and object detection models enhances subclassification based on attributes and enables more accurate identification of objects.
Additionally, services for data collection, preprocessing, scaling, monitoring, security, and efficient cloud deployment enhance both image classification and object detection capabilities.
Understanding these nuances helps in choosing the right approach for your computer vision tasks and maximizing the potential of AI solutions.
Summary
In summary, both object detection and image classification play crucial roles in computer vision. Understanding their distinctions and core elements allows us to harness these technologies effectively. At TagX, we excel in providing top-notch services for object detection, enhancing AI solutions to achieve human-like precision in identifying objects in images and videos.
Visit Us, www.tagxdata.com
Original Source, www.tagxdata.com/guide-to-image-classification-and-object-detection
0 notes
Text
Autonomous Vehicles: LiDAR Modeling and Sharps Object Detection by Daniel Reitberg
Driving cars that drive themselves just got easier. Advanced self-driving car companies are using LiDAR (Light Detection and Ranging) technology more and more to improve how they see and find objects. While LiDAR systems make high-resolution, point-by-point models of their surroundings, they work like very fast 3D laser scanners, sending out millions of pulses per second. However, LiDAR works well in low light, rain, and fog, while cameras have trouble with changing lighting conditions.
Self-driving cars can "see" the world in new and amazing detail thanks to this accurate 3D mapping. LiDAR is a very accurate way to tell the difference between things like people walking, bicycles, and even abandoned cars. This means better navigation, especially in cities with lots of traffic and surprising obstacles. With LiDAR, self-driving cars can see their surroundings clearly and completely, which lets them respond quickly and correctly to changing conditions on the road.
LiDAR is a big step forward in the development of self-driving cars. Self-driving cars can travel more safely and more efficiently in the future thanks to LiDAR's better ability to find objects.
#artificial intelligence#machine learning#deep learning#technology#robotics#autonomous vehicles#robots#collaborative robots#business#lidar#lidar technology#object detection
0 notes
Text
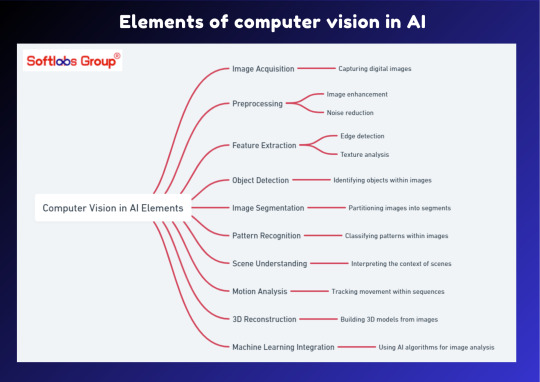
Explore the fundamental elements of computer vision in AI with our insightful guide. This simplified overview outlines the key components that enable machines to interpret and understand visual information, powering applications like image recognition and object detection. Perfect for those interested in unlocking the capabilities of artificial intelligence. Stay informed with Softlabs Group for more insightful content on cutting-edge technologies.
0 notes
Text

my piece for the @fragmentsoffatezine :)
#YOU'D BEST START BELIEVING IN GHOST STORIES DETECTIVE. YOURE IN ONE#is the caption I wouldve put but I must pay my respects to the zine that let me into their lovely book haha#just imagine how cool that wouldve been#with the tiny text and everything#thank you so much for having me fragments of fate zine!!#It's sold out now but they have digital copies and a few leftover merch items for sale still#My piece is Lynne surrounded by various inanimate objects from the game#:)#ghost trick#ghost trick phantom detective#lynne ghost trick#my art
2K notes
·
View notes
Text
Ultrasonic Sensors: A Comprehensive Guide
Ultrasonic sensors are devices that use ultrasonic waves, which are sound waves with frequencies higher than the audible range for humans (typically above 20,000 hertz), for various applications.
These sensors operate on the principle of sending out ultrasonic waves and measuring the time it takes for the waves to bounce back after hitting an object. This information can then be used to determine the distance or presence of the object.
Ultrasonic Sensors Working Principle
The working principle of ultrasonic sensors is based on the transmission and reception of ultrasonic waves. Here’s a step-by-step explanation of how these sensors operate:
Generation of Ultrasonic Waves:
Ultrasonic sensors consist of a transducer, typically a piezoelectric crystal, that can convert electrical energy into ultrasonic waves. When an electrical voltage is applied to the crystal, it vibrates and generates ultrasonic waves in the frequency range beyond human hearing (typically above 20,000 hertz).
Wave Emission:
The ultrasonic sensor emits a short burst of ultrasonic waves into the surrounding environment. This burst of waves travels outward from the sensor.
Wave Propagation:
The ultrasonic waves move through the air until they encounter an object in their path. The waves continue to propagate until they hit a surface.
Reflection of Ultrasonic Waves:
When the ultrasonic waves strike an object, they are reflected back towards the sensor. The reflection occurs because the ultrasonic waves encounter a change in the medium (from air to the object’s surface), causing the waves to bounce back.
Reception of Reflected Waves:
The same transducer that emitted the ultrasonic waves now acts as a receiver. It detects the reflected waves returning from the object.
Time Measurement:
The sensor measures the time it takes for the ultrasonic waves to travel from the sensor to the object and back. This time measurement is crucial for determining the distance to the object.
Distance Calculation:
Using the known speed of sound in the air, which is approximately 343 meters per second (at room temperature), the sensor calculates the distance to the object. The formula for distance (D) is given by D = (Speed of Sound × Time) / 2.
Output Signal:
The calculated distance information is then processed by the sensor’s electronics, and the output is provided in a suitable format, often as an analog voltage, digital signal, or distance reading.
These sensors work by emitting ultrasonic waves, detecting their reflections from objects, measuring the time taken for the round trip, and using this time information to calculate the distance to the objects in their detection range. This working principle is fundamental to various applications, including distance measurement, object detection, and obstacle avoidance.
Ultrasonic Sensors Pins Configurations
The pin configurations of ultrasonic sensors may vary depending on the specific model and manufacturer. However, We will discuss general overview of the typical pin configuration for a commonly used ultrasonic sensor module, like the HC-SR04. This module is widely used in hobbyist and educational projects.
The HC-SR04 ultrasonic sensor typically has four pins:
VCC (Voltage Supply):
This pin is used to provide power to the sensor. It typically requires a voltage in the range of 5V.
Trig (Trigger):
The Trig pin is used to trigger the start of the ultrasonic pulse. When a pulse of at least 10 microseconds is applied to this pin, the sensor emits an ultrasonic wave.
Echo:
The Echo pin is used to receive the ultrasonic waves that are reflected back from an object. The duration of the pulse received on this pin is proportional to the time it takes for the ultrasonic waves to travel to the object and back.
GND (Ground):
This pin is connected to the ground (0V) of the power supply.
Read More: Ultrasonic Sensors
#ultra sonic#ultrasonic sensors#ultrasonic technology#sensor technology#sensor applications#non-contact measurement#distance measurement#level measurement#flow measurement#object detection#obstacle avoidance#industrial automation#automotive industry#robotics#healthcare#home automation#smart homes#IoT#internet of things#technology#innovation#engineering#science#research#development#education#learning#acoustics#sound waves#frequency
0 notes
Text
Object detection and its Real-World Applications
The real-world applications of object detection can be seen in many crucial areas of our lives such as medical imaging, video tracking, movement detection, facial recognition, object recognition and even in autonomous vehicles.
0 notes
