#open-source storage for Kubernetes
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
1,644 Tumblr posts in 1 second.
Text
Top 5 Open Source Kubernetes Storage Solutions
Top 5 Open Source Kubernetes Storage Solutions #homelab #ceph #rook #glusterfs #longhorn #openebs #KubernetesStorageSolutions #OpenSourceStorageForKubernetes #CephRBDKubernetes #GlusterFSWithKubernetes #OpenEBSInKubernetes #RookStorage #LonghornKubernetes
Historically, Kubernetes storage has been challenging to configure, and it required specialized knowledge to get up and running. However, the landscape of K8s data storage has greatly evolved with many great options that are relatively easy to implement for data stored in Kubernetes clusters. Those who are running Kubernetes in the home lab as well will benefit from the free and open-source…

View On WordPress
#block storage vs object storage#Ceph RBD and Kubernetes#cloud-native storage solutions#GlusterFS with Kubernetes#Kubernetes storage solutions#Longhorn and Kubernetes integration#managing storage in Kubernetes clusters#open-source storage for Kubernetes#OpenEBS in Kubernetes environment#Rook storage in Kubernetes
0 notes
Text
Big Data Course in Kochi: Transforming Careers in the Age of Information
In today’s hyper-connected world, data is being generated at an unprecedented rate. Every click on a website, every transaction, every social media interaction — all of it contributes to the vast oceans of information known as Big Data. Organizations across industries now recognize the strategic value of this data and are eager to hire professionals who can analyze and extract meaningful insights from it.
This growing demand has turned big data course in Kochi into one of the most sought-after educational programs for tech enthusiasts, IT professionals, and graduates looking to enter the data-driven future of work.
Understanding Big Data and Its Relevance
Big Data refers to datasets that are too large or complex for traditional data processing applications. It’s commonly defined by the 5 V’s:
Volume – Massive amounts of data generated every second
Velocity – The speed at which data is created and processed
Variety – Data comes in various forms, from structured to unstructured
Veracity – Quality and reliability of the data
Value – The insights and business benefits extracted from data
These characteristics make Big Data a crucial resource for industries ranging from healthcare and finance to retail and logistics. Trained professionals are needed to collect, clean, store, and analyze this data using modern tools and platforms.
Why Enroll in a Big Data Course?
Pursuing a big data course in Kochi can open up diverse opportunities in data analytics, data engineering, business intelligence, and beyond. Here's why it's a smart move:
1. High Demand for Big Data Professionals
There’s a huge gap between the demand for big data professionals and the current supply. Companies are actively seeking individuals who can handle tools like Hadoop, Spark, and NoSQL databases, as well as data visualization platforms.
2. Lucrative Career Opportunities
Big data engineers, analysts, and architects earn some of the highest salaries in the tech sector. Even entry-level roles can offer impressive compensation packages, especially with relevant certifications.
3. Cross-Industry Application
Skills learned in a big data course in Kochi are transferable across sectors such as healthcare, e-commerce, telecommunications, banking, and more.
4. Enhanced Decision-Making Skills
With big data, companies make smarter business decisions based on predictive analytics, customer behavior modeling, and real-time reporting. Learning how to influence those decisions makes you a valuable asset.
What You’ll Learn in a Big Data Course
A top-tier big data course in Kochi covers both the foundational concepts and the technical skills required to thrive in this field.
1. Core Concepts of Big Data
Understanding what makes data “big,” how it's collected, and why it matters is crucial before diving into tools and platforms.
2. Data Storage and Processing
You'll gain hands-on experience with distributed systems such as:
Hadoop Ecosystem: HDFS, MapReduce, Hive, Pig, HBase
Apache Spark: Real-time processing and machine learning capabilities
NoSQL Databases: MongoDB, Cassandra for unstructured data handling
3. Data Integration and ETL
Learn how to extract, transform, and load (ETL) data from multiple sources into big data platforms.
4. Data Analysis and Visualization
Training includes tools for querying large datasets and visualizing insights using:
Tableau
Power BI
Python/R libraries for data visualization
5. Programming Skills
Big data professionals often need to be proficient in:
Java
Python
Scala
SQL
6. Cloud and DevOps Integration
Modern data platforms often operate on cloud infrastructure. You’ll gain familiarity with AWS, Azure, and GCP, along with containerization (Docker) and orchestration (Kubernetes).
7. Project Work
A well-rounded course includes capstone projects simulating real business problems—such as customer segmentation, fraud detection, or recommendation systems.
Kochi: A Thriving Destination for Big Data Learning
Kochi has evolved into a leading IT and educational hub in South India, making it an ideal place to pursue a big data course in Kochi.
1. IT Infrastructure
Home to major IT parks like Infopark and SmartCity, Kochi hosts numerous startups and global IT firms that actively recruit big data professionals.
2. Cost-Effective Learning
Compared to metros like Bangalore or Hyderabad, Kochi offers high-quality education and living at a lower cost.
3. Talent Ecosystem
With a strong base of engineering colleges and tech institutes, Kochi provides a rich talent pool and a thriving tech community for networking.
4. Career Opportunities
Kochi’s booming IT industry provides immediate placement potential after course completion, especially for well-trained candidates.
What to Look for in a Big Data Course?
When choosing a big data course in Kochi, consider the following:
Expert Instructors: Trainers with industry experience in data engineering or analytics
Comprehensive Curriculum: Courses should include Hadoop, Spark, data lakes, ETL pipelines, cloud deployment, and visualization tools
Hands-On Projects: Theoretical knowledge is incomplete without practical implementation
Career Support: Resume building, interview preparation, and placement assistance
Flexible Learning Options: Online, weekend, or hybrid courses for working professionals
Zoople Technologies: Leading the Way in Big Data Training
If you’re searching for a reliable and career-oriented big data course in Kochi, look no further than Zoople Technologies—a name synonymous with quality tech education and industry-driven training.
Why Choose Zoople Technologies?
Industry-Relevant Curriculum: Zoople offers a comprehensive, updated big data syllabus designed in collaboration with real-world professionals.
Experienced Trainers: Learn from data scientists and engineers with years of experience in multinational companies.
Hands-On Training: Their learning model emphasizes practical exposure, with real-time projects and live data scenarios.
Placement Assistance: Zoople has a dedicated team to help students with job readiness—mock interviews, resume support, and direct placement opportunities.
Modern Learning Infrastructure: With smart classrooms, cloud labs, and flexible learning modes, students can learn in a professional, tech-enabled environment.
Strong Alumni Network: Zoople’s graduates are placed in top firms across India and abroad, and often return as guest mentors or recruiters.
Zoople Technologies has cemented its position as a go-to institute for aspiring data professionals. By enrolling in their big data course in Kochi, you’re not just learning technology—you’re building a future-proof career.
Final Thoughts
Big data is more than a trend—it's a transformative force shaping the future of business and technology. As organizations continue to invest in data-driven strategies, the demand for skilled professionals will only grow.
By choosing a comprehensive big data course in Kochi, you position yourself at the forefront of this evolution. And with a trusted partner like Zoople Technologies, you can rest assured that your training will be rigorous, relevant, and career-ready.
Whether you're a student, a working professional, or someone looking to switch careers, now is the perfect time to step into the world of big data—and Kochi is the ideal place to begin.
0 notes
Text
Deploy Your First App on OpenShift in Under 10 Minutes
Effective monitoring is crucial for any production-grade Kubernetes or OpenShift deployment. In this article, we’ll explore how to harness the power of Prometheus and Grafana to gain detailed insights into your OpenShift clusters. We’ll cover everything from setting up monitoring to visualizing metrics and creating alerts so that you can proactively maintain the health and performance of your environment.
Introduction
OpenShift, Red Hat’s enterprise Kubernetes platform, comes packed with robust features to manage containerized applications. However, as the complexity of deployments increases, having real-time insights into your cluster performance, resource usage, and potential issues becomes essential. That’s where Prometheus and Grafana come into play, enabling observability and proactive monitoring.
Why Monitor OpenShift?
Cluster Health: Ensure that each component of your OpenShift cluster is running correctly.
Performance Analysis: Track resource consumption such as CPU, memory, and storage.
Troubleshooting: Diagnose issues early through detailed metrics and logs.
Proactive Alerting: Set up alerts to prevent downtime before it impacts production workloads.
Optimization: Refine resource allocation and scaling strategies based on usage patterns.
Understanding the Tools
Prometheus: The Metrics Powerhouse
Prometheus is an open-source systems monitoring and alerting toolkit designed for reliability and scalability. In the OpenShift world, Prometheus scrapes metrics from various endpoints, stores them in a time-series database, and supports complex querying through PromQL (Prometheus Query Language). OpenShift’s native integration with Prometheus gives users out-of-the-box monitoring capabilities.
Key Features of Prometheus:
Efficient Data Collection: Uses a pull-based model, where Prometheus scrapes HTTP endpoints at regular intervals.
Flexible Queries: PromQL allows you to query and aggregate metrics to derive actionable insights.
Alerting: Integrates with Alertmanager for sending notifications via email, Slack, PagerDuty, and more.
Grafana: Visualize Everything
Grafana is a powerful open-source platform for data visualization and analytics. With Grafana, you can create dynamic dashboards that display real-time metrics from Prometheus as well as other data sources. Grafana’s rich set of panel options—including graphs, tables, and heatmaps—lets you drill down into the details and customize your visualizations.
Key Benefits of Grafana:
Intuitive Dashboarding: Build visually appealing and interactive dashboards.
Multi-source Data Integration: Combine data from Prometheus with logs or application metrics from other sources.
Alerting and Annotations: Visualize alert states directly on dashboards to correlate events with performance metrics.
Extensibility: Support for plugins and integrations with third-party services.
Setting Up Monitoring in OpenShift
Step 1: Deploying Prometheus on OpenShift
OpenShift comes with built-in support for Prometheus through its Cluster Monitoring Operator, which simplifies deployment and configuration. Here’s how you can get started:
Cluster Monitoring Operator: Enable the operator from the OpenShift Web Console or using the OpenShift CLI. This operator sets up Prometheus instances, Alertmanager, and the associated configurations.
Configuration Adjustments: Customize the Prometheus configuration according to your environment’s needs. You might need to adjust scrape intervals, retention policies, and alert rules.
Target Discovery: OpenShift automatically discovers important endpoints (e.g., API server, node metrics, and custom application endpoints) for scraping. Ensure that your applications expose metrics in a Prometheus-compatible format.
Step 2: Integrating Grafana
Deploy Grafana: Grafana can be installed as a containerized application in your OpenShift project. Use the official Grafana container image or community Operators available in the OperatorHub.
Connect to Prometheus: Configure a Prometheus data source in Grafana by providing the URL of your Prometheus instance (typically available within your cluster). Test the connection to ensure metrics can be queried.
Import Dashboards: Leverage pre-built dashboards from the Grafana community or build your own custom dashboards tailored to your OpenShift environment. Dashboard templates can help visualize node metrics, pod-level data, and even namespace usage.
Step 3: Configuring Alerts
Both Prometheus and Grafana offer alerting capabilities:
Prometheus Alerts: Write and define alert rules using PromQL. For example, you might create an alert rule that triggers if a node’s CPU usage remains above 80% for a sustained period.
Alertmanager Integration: Configure Alertmanager to handle notifications by setting up routing rules, grouping alerts, and integrating with channels like Slack or email.
Grafana Alerting: Configure alert panels directly within Grafana dashboards, allowing you to visualize metric thresholds and receive alerts if a dashboard graph exceeds defined thresholds.
Best Practices for Effective Monitoring
Baseline Metrics: Establish baselines for normal behavior in your OpenShift cluster. Document thresholds for CPU, memory, and network usage to understand deviations.
Granular Dashboard Design: Create dashboards that provide both high-level overviews and deep dives into specific metrics. Use Grafana’s drill-down features for flexible analysis.
Automated Alerting: Leverage automated alerts to receive real-time notifications about anomalies. Consider alert escalation strategies to reduce noise while ensuring critical issues are addressed promptly.
Regular Reviews: Regularly review and update your monitoring configurations. As your OpenShift environment evolves, fine-tune metrics, dashboards, and alert rules to reflect new application workloads or infrastructure changes.
Security and Access Control: Ensure that only authorized users have access to monitoring dashboards and alerts. Use OpenShift’s role-based access control (RBAC) to manage permissions for both Prometheus and Grafana.
Common Challenges and Solutions
Data Volume and Retention: As metrics accumulate, database size can become a challenge. Address this by optimizing retention policies and setting up efficient data aggregation.
Performance Overhead: Ensure your monitoring stack does not consume excessive resources. Consider resource limits and autoscaling policies for monitoring pods.
Configuration Complexity: Balancing out-of-the-box metrics with custom application metrics requires regular calibration. Use templated dashboards and version control your monitoring configurations for reproducibility.
Conclusion
Monitoring OpenShift with Prometheus and Grafana provides a robust and scalable solution for maintaining the health of your containerized applications. With powerful features for data collection, visualization, and alerting, this stack enables you to gain operational insights, optimize performance, and react swiftly to potential issues.
As you deploy and refine your monitoring strategy, remember that continuous improvement is key. The combination of Prometheus’s metric collection and Grafana’s visualization capabilities offers a dynamic view into your environment—empowering you to maintain high service quality and reliability for all your applications.
Get started today by setting up your OpenShift monitoring stack, and explore the rich ecosystem of dashboards and integrations available for Prometheus and Grafana! For more information www.hawkstack.com
0 notes
Text
Learn HashiCorp Vault in Kubernetes Using KubeVault

In today's cloud-native world, securing secrets, credentials, and sensitive configurations is more important than ever. That’s where Vault in Kubernetes becomes a game-changer — especially when combined with KubeVault, a powerful operator for managing HashiCorp Vault within Kubernetes clusters.
🔐 What is Vault in Kubernetes?
Vault in Kubernetes refers to the integration of HashiCorp Vault with Kubernetes to manage secrets dynamically, securely, and at scale. Vault provides features like secrets storage, access control, dynamic secrets, and secrets rotation — essential tools for modern DevOps and cloud security.
🚀 Why Use KubeVault?
KubeVault is an open-source Kubernetes operator developed to simplify Vault deployment and management inside Kubernetes environments. Whether you’re new to Vault or running production workloads, KubeVault automates:
Deployment and lifecycle management of Vault
Auto-unsealing using cloud KMS providers
Seamless integration with Kubernetes RBAC and CRDs
Secure injection of secrets into workloads
🛠️ Getting Started with KubeVault
Here's a high-level guide on how to deploy Vault in Kubernetes using KubeVault:
Install the KubeVault Operator Use Helm or YAML manifests to install the operator in your cluster. helm repo add appscode https://charts.appscode.com/stable/
helm install kubevault-operator appscode/kubevault --namespace kubevault --create-namespace
Deploy a Vault Server Define a custom resource (VaultServer) to spin up a Vault instance.
Configure Storage and Unsealer Use backends like GCS, S3, or Azure Blob for Vault storage and unseal via cloud KMS.
Inject Secrets into Workloads Automatically mount secrets into pods using Kubernetes-native integrations.
💡 Benefits of Using Vault in Kubernetes with KubeVault
✅ Automated Vault lifecycle management
✅ Native Kubernetes authentication
✅ Secret rotation without downtime
✅ Easy policy management via CRDs
✅ Enterprise-level security with minimal overhead
🔄 Real Use Case: Dynamic Secrets for Databases
Imagine your app requires database credentials. Instead of hardcoding secrets or storing them in plain YAML files, you can use KubeVault to dynamically generate and inject secrets directly into pods — with rotation and revocation handled automatically.
🌐 Final Thoughts
If you're deploying applications in Kubernetes, integrating Vault in Kubernetes using KubeVault isn't just a best practice — it's a security necessity. KubeVault makes it easy to run Vault at scale, without the hassle of manual configuration and operations.
Want to learn more? Check out KubeVault.com — the ultimate toolkit for managing secrets in Kubernetes using HashiCorp Vault.
1 note
·
View note
Text
Dell Uses IBM Qiskit Runtime for Scalable Quantum Research

Analysis of Classical-Quantum Hybrid Computing
Dell Technologies Platform Models Quantum Applications with IBM Qiskit Runtime Emulator
Dell must exponentially increase compute capacity through a variety of distributed, diverse computing architectures that work together as a system, including quantum computing, to meet the demands of today's digital economy's growing data.
Quantum computation can accelerate simulation, optimisation, and machine learning. IT teams worldwide are investigating how quantum computing will effect operations in the future. There is a prevalent misperception that the quantum computer will replace all conventional computing and can only be accessed locally or remotely via a physical quantum device.
The system can now recreate key quantum environment features using classical resources. IT executives interested in learning more and those who have begun and want to enhance their algorithms may now access the technology. Emulators simulate both quantum and classical features of a quantum system, while simulators just simulate quantum aspects.
Dell Technologies tested a hybrid emulation platform employing the Dell PowerEdge R740xd and IBM's open-source quantum computer containerised service Qiskit Runtime. The platform lets users locally recreate Qiskit Runtime and test quantum applications via an emulator.
IBM's Vice President of Quantum Jay Gambetta said, “This hybrid emulation platform is a significant advancement for the Qiskit Ecosystem and the quantum industry overall.” Because users may utilise Qiskit Runtime on their own classical resources, the platform simplifies algorithm creation and improvement for quantum developers of all levels. Dell wants to work with Dell to expand the quantum sector.
Quantum technology lets the Qiskit Runtime environment calculate in a day what would have taken weeks. Qiskit uses open-source technology, allowing third-party development and integration to progress the field. The hybrid emulation platform will accelerate algorithm development and use case identification and increase developer ecosystem accessibility.
GitHub has all the tested solution information. Testing revealed these important findings:
Quick Setup Cloud-native Kubernetes powers conventional and quantum processing on the platform. Customer deployment to on-premises infrastructure is easy. Customers used to transmit workloads and data to the cloud for processing.
Faster Results Running and queuing each quantum circuit is no longer essential. Performance and development time are improved by combining conventional and quantum algorithms.
Enhanced Security Classical computing—data processing, optimisation, and algorithm execution—can be done on-premises, improving privacy and security.
Selectivity and Cost Using an on-premise infrastructure solution might save money and provide you an edge over cloud service providers. This model may be run using the Qiskit Aer simulator or other systems, giving quantum solution selection freedom.
The rising workload levels for quantum computing need expansion of classical infrastructure, including servers, desktops, storage, networking, GPUs, and FPGAs. The hybrid emulation platform is what IT directors need to simulate quantum and traditional calculations on their infrastructure.
Running Dell Qiskit
Qiskit Dell Runtime runs classical-quantum programs locally and on-premises. This platform develops and executes hybrid classical-quantum code bundles. The Qiskit Runtime API-powered execution paradigm integrates quantum and conventional execution.
Simulation, emulation, and quantum hardware can be integrated on this platform. Qiskit lets developers abstract source code for simple execution across execution environments.
Windows and Linux are used to test Qiskit-Dell-Runtime.
Introduction to Qiskit
Qiskit Dell Runtime does hybrid classical-quantum calculations locally and remotely. Qiskit experience is recommended before using the platform.
Architecture
The platform offers server-side and client-side provider components.
Client-side provider
DellRuntimeProvider must be installed on client devices. The provider defaults to local execution and may be used immediately. This provider can also connect to server-side platforms, letting users operate servers and accomplish operations from one API.
Server-side components
Simple design gives server-side components a lightweight execution environment. Orchestrator, a long-running microservice, handles DellRuntimeProvider requests.
Starting a job will create a pod to perform classical and vQPU workloads at runtime.
Configuring Database
Code and execution parameters supplied by users will be stored in a database. This platform deploys MySQL by default. Users who want to switch databases should check these installations' database settings.
SSO
SSO integration is disabled by default to simplify sandbox creation. Integration hooks provide easy integration with several SSO systems on the platform.
Multi-Backend Support
The Qiskit Aer simulation engine handles quantum execution by default. Change the quantum backend by providing backend-name in the task input area. Qiskit may support several emulation, simulation, and QPU backends simply altering the code.
Emulation vs. Simulation
Emulation engines utilise deterministic calculations to calculate algorithm outputs, whereas simulation engines use quantum circuits to quantify probabilities.
The Hybrid Emulation Platform simulates and emulates depending on the backend.
The VQE example in the manual or a Qiskit lesson might help you decide when to use simulation or emulation.
#technology#technews#govindhtech#news#technologynews#IBM Qiskit Runtime#Qiskit Runtime#Dell Qiskit Runtime#Qiskit IBM Runtime#Qiskit#IBM Qiskit#Qiskit Dell Runtime
0 notes
Text
Cloud Computing vs. DevOps: What Should You Learn?
If you’re starting out in tech or planning to upgrade your skills, you’ve probably come across two terms everywhere: Cloud Computing and DevOps. Both are in demand, both offer strong career growth, and both often show up together in job descriptions.
So how do you decide which one to focus on?
Let’s break it down in simple terms so you can choose the one that best fits your interests and goals.
What Is Cloud Computing?
Cloud computing is about delivering computing services—like storage, servers, databases, and software—over the internet. Instead of buying expensive hardware, companies can rent resources on platforms like Amazon Web Services (AWS), Microsoft Azure, or Google Cloud.
These services help businesses store data, run applications, and manage systems from anywhere, anytime.
Key Roles in Cloud Computing:
Cloud Engineer
Cloud Architect
Solutions Architect
Cloud Administrator
Skills You’ll Need:
Understanding of networking and storage
Basics of operating systems (Linux, Windows)
Knowledge of cloud platforms like AWS, Azure, or GCP
Some scripting (Python, Bash)
What Is DevOps?
DevOps is a practice that focuses on collaboration between development (Dev) and operations (Ops) teams. It’s all about building, testing, and releasing software faster and more reliably.
DevOps isn’t a tool—it’s a culture supported by tools. It brings automation, continuous integration, and continuous delivery into one process.
Key Roles in DevOps:
DevOps Engineer
Release Manager
Site Reliability Engineer
Automation Engineer
Skills You’ll Need:
Strong scripting and coding knowledge
Familiarity with tools like Jenkins, Docker, Git, Kubernetes
Understanding of CI/CD pipelines
Basic cloud knowledge helps
Cloud vs. DevOps: Key Differences
Aspect
Cloud Computing
DevOps
Focus
Infrastructure and service delivery
Process improvement and automation
Tools
AWS, Azure, GCP
Docker, Jenkins, Git, Kubernetes
Goal
Scalable, cost-efficient computing
Faster and reliable software releases
Learning Curve
Starts simple, grows with experience
Needs a good mix of coding and tools
Job Demand
Very high, especially in large enterprises
High in tech-focused and agile teams
What Should You Learn First?
If you enjoy working with infrastructure, managing systems, or want to work for companies that are moving to the cloud, cloud computing is a strong starting point. You can always build on this foundation by learning DevOps later.
If you love automation, scripting, and speeding up software delivery, then DevOps might be a better fit. It often requires some cloud knowledge too, so you’ll likely learn a bit of both anyway.
Many students from a college of engineering in Bhubaneswar often begin with cloud fundamentals in their curriculum and then expand into DevOps through workshops, online courses, or internships.
Can You Learn Both?
Absolutely. In fact, many companies look for professionals who understand both areas. You don’t have to master both at the same time—but building skills in one will make it easier to transition into the other.
For example, a cloud engineer who understands DevOps practices is more valuable. Similarly, a DevOps engineer with solid cloud knowledge is better equipped for real-world challenges.
Learning paths are flexible. The key is to get hands-on practice—build small projects, join open-source contributions, and use free or student credits from cloud providers.
Career Scope in India
In India, both cloud and DevOps are growing quickly. As more startups and large companies move to the cloud and adopt automation, the demand for skilled professionals continues to rise.
Recruiters often visit top institutions, and a college of engineering in Bhubaneswar that focuses on tech training and industry tie-ups can give students a solid head start in either of these fields.
Wrapping Up
Both cloud computing and DevOps offer promising careers. They’re not competing paths, but rather parts of a larger system. Whether you choose to start with one or explore both, what matters most is your willingness to learn and apply your skills.
Pick a starting point, stay consistent, and take small steps. The opportunities are out there—you just need to start.
#top 5 engineering colleges in bhubaneswar#top engineering colleges in odisha#bhubaneswar b tech colleges#college of engineering and technology bhubaneswar#best colleges in bhubaneswar#college of engineering bhubaneswar
0 notes
Text
Google Cloud Platform Coaching at Gritty Tech
Introduction to Google Cloud Platform (GCP)
Google Cloud Platform (GCP) is a suite of cloud computing services offered by Google. It provides a range of hosted services for compute, storage, and application development that run on Google hardware. With the rising demand for cloud expertise, mastering GCP has become essential for IT professionals, developers, and businesses alike For More…
At Gritty Tech, we offer specialized coaching programs designed to make you proficient in GCP, preparing you for real-world challenges and certifications.
Why Learn Google Cloud Platform?
The technology landscape is shifting rapidly towards cloud-native applications. Organizations worldwide are migrating to cloud environments to boost efficiency, scalability, and security. GCP stands out among major cloud providers for its advanced machine learning capabilities, seamless integration with open-source technologies, and powerful data analytics tools.
By learning GCP, you can:
Access a global infrastructure.
Enhance your career opportunities.
Build scalable, secure applications.
Master in-demand tools like BigQuery, Kubernetes, and TensorFlow.
Gritty Tech's GCP Coaching Approach
At Gritty Tech, our GCP coaching is crafted with a learner-centric methodology. We believe that practical exposure combined with strong theoretical foundations is the key to mastering GCP.
Our coaching includes:
Live instructor-led sessions.
Hands-on labs and real-world projects.
Doubt-clearing and mentoring sessions.
Exam-focused training for GCP certifications.
Comprehensive Curriculum
Our GCP coaching at Gritty Tech covers a broad range of topics, ensuring a holistic understanding of the platform.
1. Introduction to Cloud Computing and GCP
Overview of Cloud Computing.
Benefits of Cloud Solutions.
Introduction to GCP Services and Solutions.
2. Google Cloud Identity and Access Management (IAM)
Understanding IAM roles and policies.
Setting up identity and access management.
Best practices for security and compliance.
3. Compute Services
Google Compute Engine (GCE).
Managing virtual machines.
Autoscaling and load balancing.
4. Storage and Databases
Google Cloud Storage.
Cloud SQL and Cloud Spanner.
Firestore and Bigtable basics.
5. Networking in GCP
VPCs and subnets.
Firewalls and routes.
Cloud CDN and Cloud DNS.
6. Kubernetes and Google Kubernetes Engine (GKE)
Introduction to Containers and Kubernetes.
Deploying applications on GKE.
Managing containerized workloads.
7. Data Analytics and Big Data
Introduction to BigQuery.
Dataflow and Dataproc.
Real-time analytics and data visualization.
8. Machine Learning and AI
Google AI Platform.
Building and deploying ML models.
AutoML and pre-trained APIs.
9. DevOps and Site Reliability Engineering (SRE)
CI/CD pipelines on GCP.
Monitoring, logging, and incident response.
Infrastructure as Code (Terraform, Deployment Manager).
10. Preparing for GCP Certifications
Associate Cloud Engineer.
Professional Cloud Architect.
Professional Data Engineer.
Hands-On Projects
At Gritty Tech, we emphasize "learning by doing." Our GCP coaching involves several hands-on projects, including:
Setting up a multi-tier web application.
Building a real-time analytics dashboard with BigQuery.
Automating deployments with Terraform.
Implementing a secure data lake on GCP.
Deploying scalable ML models using Google AI Platform.
Certification Support
Certifications validate your skills and open up better career prospects. Gritty Tech provides full support for certification preparation, including:
Practice exams.
Mock interviews.
Personalized study plans.
Exam registration assistance.
Our Expert Coaches
At Gritty Tech, our coaches are industry veterans with years of hands-on experience in cloud engineering and architecture. They hold multiple GCP certifications and bring real-world insights to every session. Their expertise ensures that you not only learn concepts but also understand how to apply them effectively.
Who Should Enroll?
Our GCP coaching is ideal for:
IT professionals looking to transition to cloud roles.
Developers aiming to build scalable cloud-native applications.
Data engineers and scientists.
System administrators.
DevOps engineers.
Entrepreneurs and business owners wanting to leverage cloud solutions.
Flexible Learning Options
Gritty Tech understands that every learner has unique needs. That's why we offer flexible learning modes:
Weekday batches.
Weekend batches.
Self-paced learning with recorded sessions.
Customized corporate training.
Success Stories
Hundreds of students have transformed their careers through Gritty Tech's GCP coaching. From landing jobs at Fortune 500 companies to successfully migrating businesses to GCP, our alumni have achieved remarkable milestones.
What Makes Gritty Tech Stand Out?
Choosing Gritty Tech means choosing quality, commitment, and success. Here’s why:
100% practical-oriented coaching.
Experienced and certified trainers.
Up-to-date curriculum aligned with latest industry trends.
Personal mentorship and career guidance.
Lifetime access to course materials and updates.
Vibrant learner community for networking and support.
Real-World Use Cases in GCP
Understanding real-world applications enhances learning outcomes. Our coaching covers case studies like:
Implementing disaster recovery solutions using GCP.
Optimizing cloud costs with resource management.
Building scalable e-commerce applications.
Data-driven decision-making with Google BigQuery.
Career Opportunities After GCP Coaching
GCP expertise opens doors to several high-paying roles such as:
Cloud Solutions Architect.
Cloud Engineer.
DevOps Engineer.
Data Engineer.
Site Reliability Engineer (SRE).
Machine Learning Engineer.
Salary Expectations
With GCP certifications and skills, professionals can expect:
Entry-level roles: $90,000 - $110,000 per annum.
Mid-level roles: $110,000 - $140,000 per annum.
Senior roles: $140,000 - $180,000+ per annum.
Continuous Learning and Community Support
Technology evolves rapidly, and staying updated is crucial. At Gritty Tech, we offer continuous learning opportunities post-completion:
Free webinars and workshops.
Access to updated course modules.
Community forums and discussion groups.
Invitations to exclusive tech meetups and conferences.
Conclusion: Your Path to GCP Mastery Starts Here
The future belongs to the cloud, and Gritty Tech is here to guide you every step of the way. Our Google Cloud Platform Coaching empowers you with the knowledge, skills, and confidence to thrive in the digital world.
Join Gritty Tech today and transform your career with cutting-edge GCP expertise!
0 notes
Text
Using Docker in Software Development

Docker has become a vital tool in modern software development. It allows developers to package applications with all their dependencies into lightweight, portable containers. Whether you're building web applications, APIs, or microservices, Docker can simplify development, testing, and deployment.
What is Docker?
Docker is an open-source platform that enables you to build, ship, and run applications inside containers. Containers are isolated environments that contain everything your app needs—code, libraries, configuration files, and more—ensuring consistent behavior across development and production.
Why Use Docker?
Consistency: Run your app the same way in every environment.
Isolation: Avoid dependency conflicts between projects.
Portability: Docker containers work on any system that supports Docker.
Scalability: Easily scale containerized apps using orchestration tools like Kubernetes.
Faster Development: Spin up and tear down environments quickly.
Basic Docker Concepts
Image: A snapshot of a container. Think of it like a blueprint.
Container: A running instance of an image.
Dockerfile: A text file with instructions to build an image.
Volume: A persistent data storage system for containers.
Docker Hub: A cloud-based registry for storing and sharing Docker images.
Example: Dockerizing a Simple Python App
Let’s say you have a Python app called app.py: # app.py print("Hello from Docker!")
Create a Dockerfile: # Dockerfile FROM python:3.10-slim COPY app.py . CMD ["python", "app.py"]
Then build and run your Docker container: docker build -t hello-docker . docker run hello-docker
This will print Hello from Docker! in your terminal.
Popular Use Cases
Running databases (MySQL, PostgreSQL, MongoDB)
Hosting development environments
CI/CD pipelines
Deploying microservices
Local testing for APIs and apps
Essential Docker Commands
docker build -t <name> . — Build an image from a Dockerfile
docker run <image> — Run a container from an image
docker ps — List running containers
docker stop <container_id> — Stop a running container
docker exec -it <container_id> bash — Access the container shell
Docker Compose
Docker Compose allows you to run multi-container apps easily. Define all your services in a single docker-compose.yml file and launch them with one command: version: '3' services: web: build: . ports: - "5000:5000" db: image: postgres
Start everything with:docker-compose up
Best Practices
Use lightweight base images (e.g., Alpine)
Keep your Dockerfiles clean and minimal
Ignore unnecessary files with .dockerignore
Use multi-stage builds for smaller images
Regularly clean up unused images and containers
Conclusion
Docker empowers developers to work smarter, not harder. It eliminates "it works on my machine" problems and simplifies the development lifecycle. Once you start using Docker, you'll wonder how you ever lived without it!
0 notes
Text
How to Become an AI Agent Developer: A Step-by-Step Guide

We see that the arrival of artificial intelligence (AI) and how it is revolutionizing many sectors at high speed, with AI agents being the leaders in this revolution. From chatbots and virtual assistants to autonomous decision-making systems, AI agents are the future of technology. To become an AI agent developer, this manual will guide you through the essential steps, skills, and tools needed to enter this holding field.
Understanding AI Agents
AI agent is a program performing the functions of making the environment discoverable and the subsequent process of data analysis and final action execution to meet the object. These agent machines using machine learning, natural language processing (NLP), and deep learning deliver their main functionality. Organizations are majorly using AI agents to do jobs that are repetitive, like for instance redirecting fault tickets to the right person, help customers engage, and retouch whatever workflows may be already in place which just makes AI agent development a skill that you should possess and is in great demand.
Step 1: Gain a Strong Foundation in AI and Machine Learning
An excellent approach to begin your journey in AI agent development is to become familiar with artificial intelligence and machine learning theories. This is how it begins:
Learn the Basics of AI and ML
Explore core AI concepts like the supervised and unsupervised learning, reinforcement learning, and neural networks. Attend online courses via Coursera, Udacity, and edX.
Study books like Artificial Intelligence: A Guide for Thinking Humans by Melanie Mitchell and Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow by Aurélien Géron. Learn Essential Programming Languages Python:--
This is the most popular AI and ML programming language that has multiple libraries (like TensorFlow, PyTorch, Scikit-learn, etc.), and it is. Documenting the the even more extensive. Java and C++: are useful for the application of AI in computer games and robotics. R: This is good for the computation of statistical analysis and data.
Step 2: Understand Natural Language Processing (NLP)
NLP is the skill of understanding and generating human language by computers. Since AI agents are the main way humans interact with AI, NLP is essential expertise. Here’s what you can retrofit to accord matters:
Tokenization, stemming, and lemmatization
Named Entity Recognition (NER)
Sentiment analysis
Speech recognition
Libraries like NLTK, spaCy, and Hugging Face’s Transformers
Step 3: Develop Proficiency in AI Agent Development Frameworks
A careful study of AI development frameworks will familiarize you with different technologies:
Open-Source AI Frameworks
TensorFlow and PyTorch – are the most two popular frameworks for deep learning model training and deployment.
OpenAI Gym – this one performs reinforcement learning tasks only.
Rasa – For conversational AI and chatbot development AI Agent Development Tools Dialogflow – Google’s NLP-based chatbot framework Microsoft Bot Framework – Use the AI-driven chatbot creation tool IBM Watson – Gives very high-tech AI agent development solutions
Step 4: Gain Experience with Cloud Computing and Deployment
AI agents quite often need cloud-based infrastructure for training, storage, and deployment. It is your mission to configure the following:
AWS AI & ML Services
Google Cloud AI Platform
Microsoft Azure AI
Learning about DevOps tools such as Docker and Kubernetes is also a must in order to scale AI agent development solutions.
Step 5: Work on AI Agent Development Projects
Nothing is as great as the ability to practically apply what you have studied in class thus real-world projects stand as the key to becoming an expert AI agent developer. Possible project ideas can be:
Developing a virtual assistant using Dialogflow
Building a chatbot with Rasa for customer service
Creating an AI-powered recommendation system
Designing the autonomous trading bot using reinforcement learning
Contribute to open-source AI agent development projects on GitHub to empower your portfolio and get together with the professionals.
Step 6: Join an AI Agent Development Company or Freelance
Once you have a strong portfolio, consider:
Applying to an AI agent development company specializing in building AI-powered solutions.
Offering AI agent development services as a freelancer on platforms like Upwork and Toptal.
Collaborating with startups to integrate AI-driven automation in business processes.
Step 7: Stay Updated and Network in the AI Community
AI is a fast-growing arena which expects you to be up to speed with the latest advancements.
Gain insight by:
Reading AI research papers such as those published on arXiv, IEEE AI Journal, and Google AI Blog.
Attending AI conferences such as NeurIPS, CVPR, and ICML. Engaging with AI communities on platforms like Kaggle, GitHub, and LinkedIn.
Conclusion
The development of AI Agents requires a balanced expertise in technology, hands-on experience, and continuous learning. Through knowledge of AI applications, creating innovative projects, and following the latest research, you are a good candidate for having a successful career in the field of AI agent development. The field of AI is limitless. You can join the industry and work on AI agent project at a company or realize your own projects. Get to it now and be a part of the AI revolution!
0 notes
Text
🚀 Why You Should Choose "Enterprise Kubernetes Storage with Red Hat OpenShift Data Foundation (DO370)" for Your Next Career Move
In today’s cloud-native world, Kubernetes is the gold standard for container orchestration. But when it comes to managing persistent storage for stateful applications, things get complex — fast. This is where Red Hat OpenShift Data Foundation (ODF) comes in, providing a unified and enterprise-ready solution to handle storage seamlessly in Kubernetes environments.
If you’re looking to sharpen your Kubernetes expertise and step into the future of cloud-native storage, the DO370 course – Enterprise Kubernetes Storage with Red Hat OpenShift Data Foundation is your gateway.
🎯 Why Take the DO370 Course?
Here’s what makes DO370 not just another certification, but a career-defining move:
1. Master Stateful Workloads in OpenShift
Stateless applications are easy to deploy, but real-world applications often need persistent storage — think databases, logging systems, and message queues. DO370 teaches you how to:
Deploy and manage OpenShift Data Foundation.
Use block, file, and object storage in a cloud-native way.
Handle backup, disaster recovery, and replication with confidence.
2. Hands-On Experience with Real-World Use Cases
This is a lab-heavy course. You won’t just learn theory — you'll work with scenarios like deploying storage for Jenkins, MongoDB, PostgreSQL, and more. You'll also learn how to scale and monitor ODF clusters for production-ready deployments.
3. Leverage the Power of Ceph and NooBaa
Red Hat OpenShift Data Foundation is built on Ceph and NooBaa. Understanding these technologies means you’re not only skilled in OpenShift storage but also in some of the most sought-after open-source storage technologies in the market.
💡 Career Growth and Opportunities
🔧 DevOps & SRE Engineers
This course bridges the gap between developers and infrastructure teams. As storage becomes software-defined and container-native, DevOps professionals need this skill set to stay ahead.
🧱 Kubernetes & Platform Engineers
Managing platform-level storage at scale is a high-value skill. DO370 gives you the confidence to run stateful applications in production-grade Kubernetes.
☁️ Cloud Architects
If you're designing hybrid or multi-cloud strategies, you’ll learn how ODF integrates across platforms — from bare metal to AWS, Azure, and beyond.
💼 Career Advancement
Red Hat certifications are globally recognized. Completing DO370:
Enhances your Red Hat Certified Architect (RHCA) portfolio.
Adds a high-impact specialization to your résumé.
Boosts your value in organizations adopting OpenShift at scale.
🚀 Future-Proof Your Skills
Organizations are moving fast to adopt cloud-native infrastructure. And with OpenShift being the enterprise Kubernetes leader, having deep knowledge in managing enterprise storage in OpenShift is a game-changer.
As applications evolve, storage will always be a critical component — and skilled professionals will always be in demand.
📘 Final Thoughts
If you're serious about growing your Kubernetes career — especially in enterprise environments — DO370 is a must-have course. It's not just about passing an exam. It's about:
✅ Becoming a cloud-native storage expert ✅ Understanding production-grade OpenShift environments ✅ Standing out in a competitive DevOps/Kubernetes job market
👉 Ready to dive in? Explore DO370 and take your skills — and your career — to the next level.
For more details www.hawkstack.com
0 notes
Text
Monitoring Kubernetes Clusters with Prometheus and Grafana
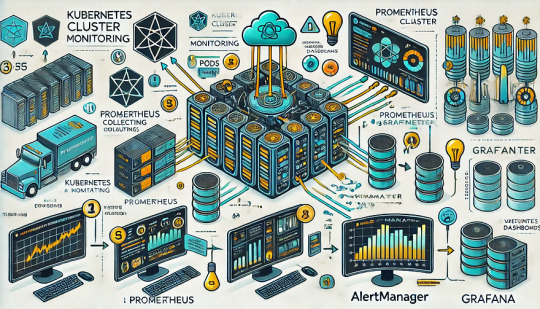
Introduction
Kubernetes is a powerful container orchestration platform, but monitoring it is crucial for ensuring reliability, performance, and scalability.
Prometheus and Grafana are two of the most popular open-source tools for monitoring and visualizing Kubernetes clusters.
In this guide, we’ll walk you through setting up Prometheus and Grafana on Kubernetes and configuring dashboards for real-time insights.
Why Use Prometheus and Grafana for Kubernetes Monitoring?
Prometheus: The Monitoring Backbone
Collects metrics from Kubernetes nodes, pods, and applications.
Uses a powerful query language (PromQL) for analyzing data.
Supports alerting based on predefined conditions.
Grafana: The Visualization Tool
Provides rich dashboards with graphs and metrics.
Allows integration with multiple data sources (e.g., Prometheus, Loki, Elasticsearch).
Enables alerting and notification management.
Step 1: Installing Prometheus and Grafana on Kubernetes
Prerequisites
Before starting, ensure you have:
A running Kubernetes cluster
kubectl and Helm installed
1. Add the Prometheus Helm Chart Repository
Helm makes it easy to deploy Prometheus and Grafana using predefined configurations.shhelm repo add prometheus-community https://prometheus-community.github.io/helm-charts helm repo update
2. Install Prometheus and Grafana Using Helm
shhelm install prometheus prometheus-community/kube-prometheus-stack --namespace monitoring --create-namespace
This command installs: ✅ Prometheus — For collecting metrics ✅ Grafana — For visualization ✅ Alertmanager — For notifications ✅ Node-exporter — To collect system-level metrics
Step 2: Accessing Prometheus and Grafana
Once deployed, we need to access the Prometheus and Grafana web interfaces.
1. Accessing Prometheus
Check the Prometheus service:shkubectl get svc -n monitoring
Forward the Prometheus server port:shkubectl port-forward svc/prometheus-kube-prometheus-prometheus 9090 -n monitoring
Now, open http://localhost:9090 in your browser.
2. Accessing Grafana
Retrieve the Grafana admin password:shkubectl get secret --namespace monitoring prometheus-grafana -o jsonpath="{.data.admin-password}" | base64 --decodeForward the Grafana service port:shkubectl port-forward svc/prometheus-grafana 3000:80 -n monitoring
Open http://localhost:3000, and log in with:
Username: admin
Password: (obtained from the previous command)
Step 3: Configuring Prometheus as a Data Source in Grafana
Open Grafana and navigate to Configuration > Data Sources.
Click Add data source and select Prometheus.
Set the URL to:
sh
http://prometheus-kube-prometheus-prometheus.monitoring.svc.cluster.local:9090
Click Save & Test to verify the connection.
Step 4: Importing Kubernetes Dashboards into Grafana
Grafana provides ready-made dashboards for Kubernetes monitoring.
Go to Dashboards > Import.
Enter a dashboard ID from Grafana’s dashboard repository.
Example: Use 3119 for Kubernetes cluster monitoring.
Select Prometheus as the data source and click Import.
You’ll now have a real-time Kubernetes monitoring dashboard! 🎯
Step 5: Setting Up Alerts in Prometheus and Grafana
Creating Prometheus Alerting Rules
Create a ConfigMap for alerts:yamlapiVersion: v1 kind: ConfigMap metadata: name: alert-rules namespace: monitoring data: alert.rules: | groups: - name: InstanceDown rules: - alert: InstanceDown expr: up == 0 for: 5m labels: severity: critical annotations: summary: "Instance {{ $labels.instance }} is down"
Apply it to the cluster:shkubectl apply -f alert-rules.yaml
Configuring Grafana Alerts
Navigate to Alerting > Notification Channels.
Set up a channel (Email, Slack, or PagerDuty).
Define alert rules based on metrics from Prometheus.
Step 6: Enabling Persistent Storage for Prometheus
By default, Prometheus stores data in memory. To make the data persistent, configure storage:
Modify the Helm values:yamlprometheus: server: persistentVolume: enabled: true size: 10Gi
Apply the changes:shhelm upgrade prometheus prometheus-community/kube-prometheus-stack -f values.yaml
Conclusion
In this guide, we’ve set up Prometheus and Grafana to monitor a Kubernetes cluster. You now have: ✅ Real-time dashboards in Grafana ✅ Prometheus alerts to detect failures ✅ Persistent storage for historical metrics
WEBSITE: https://www.ficusoft.in/devops-training-in-chennai/
0 notes
Text
Apache Spark: Transforming Big Data Processing
A Game-Changer in Big Data Analytics
In the era of big data, organizations generate massive volumes of structured and unstructured data daily. Processing this data efficiently is a challenge that traditional frameworks struggle to handle. Apache Spark, an open-source distributed computing system, has emerged as a revolutionary tool, offering unparalleled speed, scalability, and versatility. By leveraging in-memory computation and optimized execution models, Spark has redefined the way businesses analyze and process data.

Why Apache Spark is Faster and More Efficient
Unlike Hadoop MapReduce, which uses disk-based storage for intermediate computations, Apache Spark processes data in memory, significantly boosting speed.It utilizes a Directed Acyclic Graph (DAG) execution model that optimizes task scheduling and execution, reducing unnecessary computations. This speed advantage makes Spark ideal for real-time analytics, fraud detection, and machine learning applications.
A Powerful and Flexible Ecosystem
One of the biggest strengths of Apache Spark is its rich ecosystem of components. Spark SQL enables seamless querying of structured data, while MLlib provides built-in machine learning algorithms for predictive analytics.
For handling real-time data, Spark Streaming processes continuous streams from sources like Kafka and Flume. Additionally, GraphX brings graph processing capabilities, making Spark a comprehensive solution for diverse big data challenges.
Real-World Applications Across Industries
Apache Spark is widely adopted by tech giants and enterprises across industries. Netflix and Uber use Spark for real-time customer analytics and operational insights. Financial institutions rely on MLlib for fraud detection and risk assessment, while healthcare researchers leverage Spark to process genomic data at unprecedented speeds. E-commerce companies like Amazon utilize Spark’s recommendation engine to enhance user experiences, proving its versatility in handling complex data-driven tasks.
Alibaba: Enhancing E-Commerce with Big Data
Alibaba, one of the world’s largest e-commerce platforms, relies on Apache Spark for processing massive datasets related to customer transactions, inventory management, and personalized recommendations. Spark Streaming enables Alibaba to track real-time purchase behaviors, helping merchants optimize pricing and promotions. Additionally, GraphX is used to detect fraudulent transactions and improve security.
PayPal: Fraud Detection at Scale
With millions of global transactions daily, fraud detection is a critical challenge for PayPal. By using Apache Spark’s MLlib,PayPalhas built advanced fraud detection models that analyze transaction patterns in real-time. Spark’s distributed computing capabilities allow the system to identify suspicious activities instantly, reducing financial risks and improving user trust.
NASA: Accelerating Scientific Research
Beyond the corporate world, NASA leverages Apache Spark to process satellite imagery and climate data. With its in-memory computation and optimized execution models, Spark has revolutionized data analysis and processing. Its ability to handle petabytes of data efficiently enables data-driven decisions for space missions and environmental studies.
The Impact of Apache Spark on Modern Data Processing
These case studies demonstrate Apache Spark’s ability to tackle large-scale data challenges efficiently. From real-time analytics and fraud detection to scientific research and AI-driven applications, Spark continues to be the go-to solution for data-driven enterprises. As businesses increasingly rely on big data, Spark’s role in shaping the future of analytics and machine learning remains stronger than ever.
Scalability and Fault Tolerance for Enterprise Needs
Designed for scalability, Apache Spark runs on Hadoop YARN, Apache Mesos, and Kubernetes, and integrates seamlessly with cloud platforms like AWS, Azure, and Google Cloud. Its Resilient Distributed Dataset (RDD) architecture ensures fault tolerance by automatically recovering lost data, making it a reliable choice for mission-critical applications. Whether deployed on a single server or across thousands of nodes, Spark maintains its efficiency and robustness.
The Future of Big Data with Apache Spark
As data continues to grow exponentially, the need for fast, scalable, and intelligent processing solutions will only increase. Apache Spark’s continuous evolution, strong community support, and integration with cutting-edge technologies make it a key player in the future of big data. Whether in AI, machine learning, or real-time analytics, Spark’s capabilities position it as an indispensable tool for data-driven innovation.
DSC Next 2025: Exploring the Future of Data Science
Given Spark’s growing importance in big data and AI, events like DSC Next 2025 provide an opportunity to explore its latest advancements. Scheduled for May 7–9, 2025, in Amsterdam, the event will bring together data scientists, engineers, and AI experts to discuss cutting-edge innovations in big data analytics, machine learning, and cloud computing. With industry leaders sharing insights on Apache Spark’s role in scalable data processing, DSC Next 2025 is a must-attend for professionals looking to stay ahead in data science and AI.
0 notes
Text
Azure DevOps Certification: Your Ultimate Guide to Advancing Your IT Career
Azure DevOps Certification
With the growing need for efficient software development and deployment, DevOps has become a fundamental approach for IT professionals. Among the available certifications, Azure DevOps Certification is highly sought after, validating expertise in managing DevOps solutions on Microsoft Azure. This guide provides insights into the certification, its benefits, career opportunities, and preparation strategies.

Understanding Azure DevOps
Azure DevOps is a cloud-based service from Microsoft designed to facilitate collaboration between development and operations teams. It includes essential tools for:
Azure Repos – Source code management using Git repositories.
Azure Pipelines – Automating build and deployment processes.
Azure Test Plans – Enhancing software quality through automated testing.
Azure Artifacts – Managing dependencies effectively.
Azure Boards – Agile project tracking and planning.
Gaining expertise in these tools helps professionals streamline software development lifecycles.
Why Pursue Azure DevOps Certification?
Obtaining an Azure DevOps Certification offers multiple advantages, such as:
Expanded Job Prospects – Preferred by employers looking for skilled DevOps professionals.
Higher Earnings – Certified individuals often earn more than non-certified peers.
Global Recognition – A credential that validates proficiency in Azure DevOps practices.
Career Progression – Opens doors to senior roles like DevOps Engineer and Cloud Consultant.
Practical Knowledge – Helps professionals apply DevOps methodologies effectively in real-world scenarios.
Who Should Consider This Certification?
This certification benefits:
Software Developers
IT Administrators
Cloud Engineers
DevOps Professionals
System Architects
Anyone looking to Learn Azure DevOps and enhance their technical skill set will find this certification valuable.
Azure DevOps Certification Options
Microsoft offers several certifications focusing on DevOps practices:
1. AZ-400: Designing and Implementing Microsoft DevOps Solutions
This certification covers:
DevOps strategies and implementation
Continuous integration and deployment (CI/CD)
Infrastructure automation and monitoring
Security and compliance
2. Microsoft Certified: Azure Administrator Associate
Aimed at professionals handling Azure-based infrastructures, including:
Network and storage configurations
Virtual machine deployment
Identity and security management
3. Microsoft Certified: Azure Solutions Architect Expert
This certification is ideal for those designing cloud-based applications and managing Azure workloads efficiently.
Career Opportunities with Azure DevOps Certification
Certified professionals can pursue roles such as:
DevOps Engineer – Specializing in automation and CI/CD.
Cloud Engineer – Focusing on cloud computing solutions.
Site Reliability Engineer (SRE) – Ensuring system stability and performance.
Azure Consultant – Assisting businesses in implementing Azure DevOps.
Automation Engineer – Enhancing software deployment processes through scripting.
These positions offer competitive salaries and significant career growth.
Key Skills Required for Azure DevOps Certification
Professionals preparing for the certification should have expertise in:
CI/CD Pipelines – Automating application delivery.
Infrastructure as Code (IaC) – Managing cloud environments through scripts.
Version Control Systems – Proficiency in Git and repository management.
Containerization – Understanding Docker and Kubernetes.
Security & Monitoring – Implementing best practices for secure deployments.
How to Prepare for the Azure DevOps Certification Exam?
1. Review the Exam Syllabus
The AZ-400 exam covers DevOps methodologies, security, infrastructure, and compliance. Understanding the objectives helps in creating a structured study plan.
2. Enroll in an Azure DevOps Course
Joining an Azure DevOps Advanced Course provides structured learning and hands-on experience. Platforms like Kodestree offer expert-led training, ensuring candidates are well-prepared.
3. Gain Hands-on Experience
Practical exposure is crucial. Setting up DevOps pipelines, managing cloud resources, and automating processes will enhance understanding and confidence.
4. Utilize Microsoft Learning Resources
Microsoft provides free documentation, learning paths, and virtual labs to help candidates prepare effectively.
5. Engage with DevOps Communities
Joining study groups, participating in discussions, and attending webinars keeps candidates updated with industry best practices.
Exam Cost and Preparation Duration
1. Cost
The AZ-400 certification exam costs approximately $165 USD, subject to location-based variations.
2. Preparation Timeline
Beginners: 3-6 months
Intermediate Professionals: 2-3 months
Experienced Engineers: 1-2 months
Azure DevOps vs AWS DevOps Certification

Best Training Options for Azure DevOps Certification
If you’re searching for the best DevOps Training Institute in Bangalore, consider Kodestree. They offer:
Hands-on projects and practical experience.
Placement assistance for job seekers.
Instructor-led Azure DevOps Training Online options for remote learners.
Other learning formats include:
Azure Online Courses for flexible self-paced study.
DevOps Coaching in Bangalore for structured classroom training.
DevOps Classes in Bangalore with personalized mentoring.
Tips for Successfully Passing the Exam
Study Microsoft’s official guides.
Attempt practice exams to identify weak areas.
Apply knowledge to real-world scenarios.
Keep up with the latest Azure DevOps updates.
Revise consistently before the exam day.
Conclusion
Azure DevOps Certification is a valuable credential for IT professionals aiming to specialize in DevOps methodologies and Azure-based cloud solutions. The increasing demand for DevOps expertise makes this certification an excellent career booster, leading to higher salaries and better job prospects.
For structured learning and expert guidance, explore Kodestree’s Azure DevOps Training Online and start your journey toward a rewarding career in DevOps today!
#Azure Devops Advanced Course#Azure Devops Certification#Azure Online Courses#Azure Devops Course#Devops Certification#Devops Classes In Bangalore
0 notes
Text
Top Site Reliability Engineering | SRE Online Training
Capacity Planning in SRE: Tools and Techniques

Capacity planning is one of the most critical aspects of Site Reliability Engineering (SRE). It ensures that systems are equipped to handle varying loads, scale appropriately, and perform efficiently, even under the most demanding conditions. Without adequate capacity planning, organizations risk performance degradation, outages, or even service disruptions when faced with traffic spikes or system failures. This article explores the tools and techniques for effective capacity planning in SRE.
What is Capacity Planning in SRE?
Capacity planning in SRE refers to the process of ensuring a system has the right resources (computing, storage, networking, etc.) to meet the expected workload while maintaining reliability, performance, and cost efficiency. It involves anticipating future resource needs and preparing infrastructure accordingly, avoiding overprovisioning, under-provisioning, or resource contention. Site Reliability Engineering Training
Effective capacity planning allows SRE teams to design systems that are resilient, performant, and capable of scaling with demand, ensuring seamless user experiences during periods of high load.
Tools for Capacity Planning in SRE
Prometheus Prometheus is an open-source monitoring system that gathers time-series data, which makes it ideal for tracking resource usage and performance over time. By monitoring metrics like CPU usage, memory consumption, network I/O, and disk utilization, Prometheus helps SRE teams understand current system performance and identify potential capacity bottlenecks. It also provides alerting capabilities, enabling early detection of performance degradation before it impacts end-users.
Grafana Often used in conjunction with Prometheus, Grafana is a popular open-source visualization tool that turns metrics into insightful dashboards. By visualizing capacity-related metrics, Grafana helps SREs identify trends and patterns in resource utilization. This makes it easier to make data-driven decisions on scaling, resource allocation, and future capacity planning.
Kubernetes Metrics Server For teams leveraging Kubernetes, the Metrics Server provides crucial data on resource usage for containers and pods. It tracks memory and CPU utilization, which is essential for determining whether the system can handle the current load and where scaling may be required. This data is also crucial for auto-scaling decisions, making it an indispensable tool for teams that rely on Kubernetes.
AWS Cloud Watch (or Azure Monitor, GCP Stackdriver) Cloud-native services like AWS CloudWatch offer real-time metrics and logs related to resource usage, including compute instances, storage, and networking. These services provide valuable insights into the capacity health of cloud-based systems and can trigger automated actions such as scaling up resources, adding more instances, or redistributing workloads to maintain optimal performance. SRE Certification Course
New Relic is a comprehensive monitoring and performance management tool that provides deep insights into application performance, infrastructure health, and resource usage. With advanced analytics capabilities, New Relic helps SREs predict potential capacity issues and plan for scaling and resource adjustments. It’s particularly useful for applications with complex architectures.
Techniques for Effective Capacity Planning
Historical Data Analysis One of the most reliable methods for predicting future capacity needs is by examining historical data. By analyzing system performance over time, SREs can identify usage trends and potential spikes in resource demand. Patterns such as seasonality, traffic growth, and resource consumption during peak times can help forecast future requirements. For example, if traffic doubles during certain months, teams can plan to scale accordingly.
Load Testing and Stress Testing Load testing involves simulating various traffic loads to assess how well the system performs under varying conditions. Stress testing goes one step further by testing the system’s limits to identify the breaking point. By performing load and stress tests, SRE teams can determine the system’s capacity threshold and plan resources accordingly.
Capacity Forecasting Forecasting involves predicting future resource requirements based on expected growth in user demand, traffic, or data. SREs use models that account for expected business growth, infrastructure changes, or traffic spikes to anticipate capacity needs in the coming months or years. Tools like historical data, trend analysis, and machine learning models can help build accurate forecasts.
Auto-Scaling Auto-scaling is an essential technique for dynamically adjusting system capacity based on real-time traffic demands. Cloud services like AWS, GCP, and Azure offer auto-scaling features that automatically add or remove resources based on pre-configured policies. These systems enable a more efficient capacity plan by automatically scaling up during periods of high demand and scaling down during off-peak times. SRE Course Online
Proactive Alerting Monitoring tools like Prometheus and Cloud Watch offer alerting mechanisms to notify SREs of imminent capacity issues, such as resource exhaustion. By setting thresholds and alerts for CPU, memory, or disk usage, SRE teams can proactively address problems before they escalate, allowing for more timely capacity adjustments.
Conclusion
Capacity planning in SRE is a critical discipline that requires both proactive and reactive strategies. By leveraging the right tools, including Prometheus, Grafana, and cloud-native monitoring services, SRE teams can ensure that their systems are always ready to handle traffic spikes and maintain high levels of reliability and performance. Techniques like historical data analysis, load testing, forecasting, auto-scaling, and proactive alerting empower SREs to anticipate, plan for, and mitigate potential capacity challenges. When implemented effectively, capacity planning ensures that systems are both cost-efficient and resilient, delivering seamless user experiences even during periods of high demand.
Visualpath is the Best Software Online Training Institute in Hyderabad. Avail complete Site Reliability Engineering (SRE) Training worldwide. You will get the best course at an affordable cost. For More Information Click Here
#SiteReliabilityEngineeringTraining#SRECourse#SiteReliabilityEngineeringOnlineTraining#SRETrainingOnline#SiteReliabilityEngineeringTraininginHyderabad#SREOnlineTraininginHyderabad#SRECoursesOnline#SRECertificationCourse
0 notes
Text
How to Start Your Career in Cloud Computing: A Beginner's Guide

Cloud computing has dramatically changed the IT landscape and offers thousands of opportunities for those who work in this fast-changing environment. Whether you are an individual looking to begin a career in cloud computing or a professional who is changing his or her career, this beginner's guide will help you to find your direction.
Why Should You Pursue a Career in Cloud Computing?
The cloud is the modern backbone of digital infrastructure. It ranges from start-ups to worldwide conglomerates, in which companies utilize the cloud as a platform for applications, storage, and even remote collaboration. According to recent industry reports, demand for professionals who work on cloud is high. Some roles in high demand are cloud engineers, architects, and DevOps specialists. Advantages of a Cloud Computing Career
High Demand: Organizations of all industries are embracing cloud technologies, and that is creating many job openings.
Lucrative Salaries: Cloud professionals can command competitive salaries because of the specialized skill set.
Career Growth: Opportunities abound for advancement up to senior engineering, architecture, and leadership positions.
Flexibility: Many of the roles provide remote work options, which provides work-life balance and location independence.
Step 1: Understand the Basics of Cloud Computing
Before getting into cloud certifications or courses, you would learn the basics first. Therefore, you will get to understand what exactly cloud computing is, its deployment models: public, private, hybrid, and service models: IaaS, PaaS, SaaS. Some of the main sources are YouTube tutorials, blogs, and introductory courses.
Key Concepts to Learn:
Cloud platforms like AWS, Azure, and Google Cloud
Virtualization and containerization
Networking and storage basics
Step 2: Enroll in a Cloud Computing and DevOps Course
You may find a structured cloud computing and DevOps course that can really expedite your learning curve. These are hands-on, so you would be building skills in real-life scenarios. Then, look for programs that will include projects like:
Setting up virtual machines and cloud environments
Deploying and managing containers with Docker and Kubernetes
Automating with tools like Jenkins, Terraform, and Ansible
When selecting a course, ensure that it covers the most popular cloud providers (AWS, Azure, Google Cloud) and the principles of DevOps. Add significant weight to your resume by obtaining certifications like AWS Certified Solutions Architect, Microsoft Azure Fundamentals, or Google Cloud Certified.
Step 3: Practical Experience
Theory alone won’t cut it. Employers look for hands-on experience in managing cloud environments. Use free-tier accounts on AWS, Azure, or Google Cloud to experiment with creating virtual machines, deploying web applications, and configuring networks. Participate in hackathons, contribute to open-source projects, or build a personal portfolio showcasing your cloud skills.
Step 4: Get Certified
Certifications validate your expertise and enhance your credibility. Depending on your interest and career goals, consider:
AWS Certified Solutions Architect-Associate
Microsoft Certified: Azure Administrator Associate
Google Cloud Professional Cloud Architect
Certified Kubernetes Administrator (CKA)
These certifications are known worldwide, and you will see these on your resume. This is proof that you know a specific kind of cloud technology well.
Step 5: Supplement Skills
Cloud computing also touches on DevOps, cybersecurity, and data analytics. You become a more versatile professional with additional skills. Try the following:
Programming: Become conversant in Python, Java, or Bash scripting.
DevOps Practices: Know your CI/CD pipelines and automation tools.
Security: Learn about cloud security principles to protect data.
Step 6: Network and Stay Updated
Join online communities, attend webinars, and participate in tech meetups to stay connected with industry trends. Follow thought leaders in cloud computing and DevOps on LinkedIn and Twitter. Staying updated ensures you remain competitive in this fast-evolving field.
Final Thoughts
It is relatively intimidating to be a beginner cloud computing professional in today's world of high-tech networking, but definitely doable in the right method. Start solid, take up a cloud computing and DevOps course, and practically experience it because practice makes more confident. Things are bright as far as opportunities are concerned; hence, determination and persistence create a rewarding avenue in this vast exciting domain called cloud.
0 notes