#opencl
Text
AMD Ryzen 7 8700G APU Zen 4 & Polaris Wonders!

AMD Ryzen 7 8700G APU
The company formidable main processing unit (APU) with Zen 4 framework and Polaris designs, the AMD Ryzen 7 processor 8700G
The conclusions of the assessments for the Ryzen 5 processor from AMD 8600G had previously revealed this morning, and now some of the most recent measurements from the Ryzen 7 8700G APU graph G have been released made public. Among AMD’s Hawk A point generation of advanced processing units (APUs), the upcoming Ryzen 7 8700G APU will represent the top of the lineup of the The AM5 series desktops APU. That is going to have an identical blend of Zen 4 and RDNA 3 cores in a single monolithic package.
Featuring 16 MB of L3 memory cache and 8 megabytes of L2 cache, the aforementioned AMD Ryzen 7 8700G APU features a total of 8 CPU cores and a total of 16 threads built onto it. It is possible to quicken the clock to 5.10 GHz from its base frequency of 4.20 GHz. A Radeon 780M based on RDNA 3 with 12 compute units and a clock speed of 2.9 GHz is included in the integrated graphics processing unit (GPU). It is anticipated that future Hawk Point APUs would have support for 64GB DDR5 modules, which will allow for a maximum of 256GB of DRAM capacity to be used on the AM5 architecture.
The study ASUS TUF Extreme X670E-PLUS wireless internet chipset with 32GB of DDR5 4800 RAM was used for the performance tests that were carried out. Because of this design, it is anticipated that the performance would be somewhat reduced. The Hawk Point APUs and the AM5 platform are both compatible with faster memory modules, which may lead to improved performance. This is made possible by the greater bandwidth that is advantageous to the integrated graphics processing unit (iGPU).
The AMD Ryzen 7 8700G “Hawk Point” APU was able to reach a performance of 35,427 points in the Vulkan benchmark, while it earned 29,244 points in the OpenCL benchmark. With the Ryzen 5 8600G equipped with the Radeon 760M integrated graphics processing unit, this results in a 15% improvement in Vulkan and an 18% increase in OpenCL. The 760M integrated graphics processing unit (iGPU) has only 8 compute units, but the AMD 780M has 12 compute units.
In spite of the fact that the 760M integrated graphics processing unit (iGPU) has faster DDR5 6000 memory, performance does not seem to rise linearly whenever there are fifty percent more cores. It would seem that this is the maximum performance that the Radeon IGPs are capable of. The results of future testing, particularly those involving overclocking, will be fascinating. However, the Meteor Lake integrated graphics processing units (iGPUs) might be improved with better quality memory configurations (LPDDR5x).
With the debut of the AM5 “Hawk Point” APUs at the end of January, it is anticipated that the RDNA 3 chips would provide increased performance for the integrated graphics processing unit (iGPU). At AMD’s next CES 2024 event, it is anticipated that further details will be discussed and revealed.
Read more on Govindhtech.com
2 notes
·
View notes
Link
Microsoft recently added support for GPU Video Acceleration by building on top of the existing Mesa 3D D3D12 backend and integrating the VAAPI Mesa frontend. Several Linux media apps use the VAAPI interface to access hardware video acceleration when available, which can now be leveraged in WSLg. Read this article to know more about this feature.
0 notes
Text
LANGUAGE(ISH) PROPOSAL
A language that unifies C#, Rust, and CUDA/OpenCL.
Heres why:
C# is a featureful, rich language. There’s so much that the language provides, and so much you can do. It has interfaces, indexers, properties, abstracts, attributes, and more. Where it falls short, however, Rust picks it up. C# variables are not thread-safe by default, and nulls are allowed by default (although the `lock` keyword and `?` suffix do help). There is also no immutability or macros. Rust guarantees a lot with compile-time checking. You know that when a function returns an i32, you WILL get an i32. However, once you get into higher-level code, managing memory safely and efficiently can get painful, and multithreading is a whole other problem. Even if it is safe, Rust gets a bit too eager with it’s management. Having that link between infallible functionality and lenient, intricate structure is good. CUDA/OpenCL is pulled into this because they provide GPU interfacing, which is just nice to have. If you don’t want that, then it’s just C++, which has good memory access.
The ‘language’ part would kinda just be links between the three. FFI can be a problem. C# classes and Rust structs are both different, Rust handles strings differently than C# and C++ (lengthed vs null terminated), and there’s a bit of friction when interfacing between them. The language would simplify the process. You can have “rsstr” and “cstr” and switch between them, or you can just have “str” and convert to it’s native definition (&str, char*, string) when taken as a function parameter or passed through to a function. You can have a “csclass” that can be converted to a “struct” and back.
1 note
·
View note
Text
I think I figured out why GNU Backgammon's evaluations have been so stubbornly slow, even despite all of my rewriting, refactoring, and optimizing.
On a whim, I tried turning the "evaluation threads" counter in the options menu all the way down to 1 (from the two dozen or so I had it set at before)... yet the performance / evaluation time was completely identical. I dug a little deeper, and everything I've found thus far has confirmed my suspicion:
The evaluations are all being performed one at a time, in serial.
On one hand, really? Fucking REALLY? I get that this codebase has all the structure and maintainability of a mud puddle, and that the developers are volunteers, but this is egregious!
On the other hand, this will make improving the engine's performance yet further a much simpler task. No need to break out OpenCL if plain ol' threads aren't being properly utilized, heheh.
#backgammon#programming#txt#I might end up using OpenCL anyway#Imagine being able to get near-instant 6-ply and 7-ply analysis...!#XG's days are numbered
1 note
·
View note
Text
Opencl benchmark ucsd

Opencl benchmark ucsd how to#
Opencl benchmark ucsd full#
Opencl benchmark ucsd portable#
Opencl benchmark ucsd software#
This allows the science applications to manage the network as a first-class schedulable resource in a manner similar to instruments, compute, and storage.
Opencl benchmark ucsd software#
Intelligent orchestrator and software defined systems allow for more » custom tailoring of scalability and realtime responsiveness based on individual application and infrastructure operator requirements. An intent based interface allows applications to express their high-level service requirements. The SENSE system includes a model-based architecture, implementation, and deployment which enables end-to-end network service instantiation across administrative domains. The SENSE system allows National Labs and Universities to request and provision end-to-end intelligent network services for their application workflows leveraging Software Defined Network (SDN) capabilities. The Software-defined network for End-to-end Networked Science at Exascale (SENSE) research developed intelligent network services to accelerate scientific discovery in the era of big data driven by Exascale, cloud computing, machine learning and artificial intelligence. ROSE’s predefined DSL Building Blocks (for example the Fortran base language) are represented as abstract language plugins and DSL developers can use Rosebud to construct additional building blocks in the same way. These plugins implement a form of generalized DSL which includes both concrete languages used to write application source code and abstract languages used within the compilation process. The Rosebud framework is a cohesive interface allowing modular DSL plugins to be developed independently and then distributed and combined in HPC applications. The research explored in this project provided the more » expression of the Fortran grammar in SDF form for integration with the Rosebud DSL framework developed by Rice University. In the final year of the project, the Fortran parser was updated to comply with the complete 2018 standard, as specified in the ISO/IEC document, JTC 1/SC 22/WG 5/N2146.
Opencl benchmark ucsd full#
The developed Fortran parser incorporates the full Fortran 2008 standard with extensions from the more recent document, TS 29113, “Further Interoperability of Fortran with C,” (to be included in the Fortran 2018 standard). Primary partners in this effort were Rice University and Lawrence Livermore National Laboratory. The University of Oregon has produced a Fortran parser based on an SDF (Syntax Definition Formalism) grammar. This report provides a summary of the research and development work on the D-TEC project at Rice University.
Opencl benchmark ucsd how to#
D-TEC research and more » development work at Rice University focused on on three principal topics: understanding how to automate the tuning of code for complex architectures, research and development of the Rosebud DSL engine, and compiler technology to support complex execution platforms. Different aspects of the D-TEC research portfolio were the focus of work at each of the partner institutions in the multi-institutional project. As a result, developing a general toolkit for building domain-specific languages was a key goal for the D-TEC project. If leveraging domain specificity is the key to keep exascale software tractable, a corollary is that many different DSLs will be needed to encompass the full range of exascale computing applications moreover, a single application may well need to use several different DSLs in conjunction. Domain specificity is what makes these properties possible in a programming language. Two chief properties contribute: DSLs permit expression at a high level of abstraction so that a programmer’s intent is clear to a compiler and DSL implementations encapsulate human domain-specific optimization knowledge so that a compiler can be smart enough to achieve good results on specific hardware.
Opencl benchmark ucsd portable#
DSLs employ automated code transformation to shift the burden of delivering portable performance from application programmers to compilers. A multi-institutional project known as D-TEC (short for “Domain- specific Technology for Exascale Computing”) set out to explore technologies to support the construction of Domain Specific Languages (DSLs) to map application programs to exascale architectures.
0 notes
Text
Opencl benchmark mac

Opencl benchmark mac drivers#
Opencl benchmark mac update#
Opencl benchmark mac pro#
Single-precision Floating-point support (core)Ĭorrectly-rounded divide and sqrt operations Yesĭouble-precision Floating-point support (n/a) Half-precision Floating-point support (n/a) Preferred work group size multiple (kernel) 32 Platform Extensions cl_APPLE_SetMemObjectDestructor cl_APPLE_ContextLoggingFunctions cl_APPLE_clut cl_APPLE_query_kernel_names cl_APPLE_gl_sharing cl_khr_gl_event Memory.Total.: 5461 MB (limited to 512 MB allocatable in one block) Hashcat (v6.2.4) starting in backend information mode 1500, 900, 50, 60) fail in the same manner.įor now, the Homebrew formula is stuck at v6.1.1. Zsh: abort hashcat -benchmark -m 0 -D 1,2 -w 2
Opencl benchmark mac drivers#
* Device #1: Apple's OpenCL drivers (GPU) are known to be unreliable. : OpenCL Error : Failed to retrieve device information! Invalid enumerated value! Hashcat (v6.2.4) starting in benchmark mode Speed.#1.: 1739.1 MH/s (7.35ms) Accel:256 Loops:1024 Thr:256 Vec:1Īs of v6.2.0, it simply stops without output, even when built with DEBUG enabled: % export CL_LOG_ERRORS=stdout Hashcat (v6.1.1) starting in benchmark mode. That's a market Apple has zero interest in and more of a bother than the iPod touch market.The last version that the Apple Silicon (M1) platform ran the benchmark on was 6.1.1: % hashcat -benchmark -m 0 -D 1,2 -w 2 Microsoft, Intel and AMD beware! Apple's going to take a bite of your lunch on the top 20% of the PC market.Įxcluding of course PCMR types. Performance per Watt is very important to data centers too.
Opencl benchmark mac pro#
Once Apple releases iMac Pro(?) and Mac Pro with Apple Silicon I expect them to reintroduce Xserve. Wait for next year for power users like yourselves. If you're a regular on r/hardware then the M1 Macs are probably not for you. 10GbE port will be an option by next year. With the same number of ports as the Intel Macs sold today on. Are there enough budget Mac users with an eGPU that is more expensive than their Mac that nominally cost ~$1,000?Īll Macs will get Apple Silicon.
Opencl benchmark mac update#
I expect eGPU support to come with a future update to macOS Big Sur when higher-end Macs will sport Apple Silicon. Sorry pros you're far fewer than the mass market of users. So it is logical from management, financial and supply chain point of view to prioritize the ~80% of all Macs shipped. This has the greatest impact on the bottom line. In business, management often look at the largest cost center to prioritize over the 2nd highest or lower cost centers. The M1 chip limited by 16GB of RAM, the best in class iGPU whose performance is comparable to a GTX 1050 Ti and that allows battery life from 10 hours to 20 hours will have a future variant for higher-end Macs with more RAM, an iGPU that has better than GTX 1050 Ti performance and battery life of ~2x. So be patient the Mac you want to buy will get a higher-end Apple Silicon chip within ~7 months. These Macs represent ~80% of all Macs shipped. The M1 chip is designed to refresh the lowest-end Macs that Apple makes.
0 notes
Text
scarlets linux misadventures episode 1
attempting to install amd gpu drivers and opencl to edit videos
"why cant you find this package my little zenbook"
"you need to install these other 10 things first and then manually install the latest version of amdgpu-install directly from the repo because for some reason amd does not list the latest version that is for ubuntu 24 at all."
"and then it will work?"
👁️👄👁️
14 notes
·
View notes
Text
Introduction to RK3588
What is RK3588?
RK3588 is a universal SoC with ARM architecture, which integrates quad-core Cortex-A76 (large core) and quad-core Cortex-A55(small core). Equipped with G610 MP4 GPU, which can run complex graphics processing smoothly. Embedded 3D GPU makes RK3588 fully compatible with OpenGLES 1.1, 2.0 and 3.2, OpenCL up to 2.2 and Vulkan1.2. A special 2D hardware engine with MMU will maximize display performance and provide smooth operation. And a 6 TOPs NPU empowers various AI scenarios, providing possibilities for local offline AI computing in complex scenarios, complex video stream analysis, and other applications. Built-in a variety of powerful embedded hardware engines, support 8K@60fps H.265 and VP9 decoders, 8K@30fps H.264 decoders and 4K@60fps AV1 decoders; support 8K@30fps H.264 and H.265 encoder, high-quality JPEG encoder/decoder, dedicated image pre-processor and post-processor.
RK3588 also introduces a new generation of fully hardware-based ISP (Image Signal Processor) with a maximum of 48 million pixels, implementing many algorithm accelerators, such as HDR, 3A, LSC, 3DNR, 2DNR, sharpening, dehaze, fisheye correction, gamma Correction, etc., have a wide range of applications in graphics post-processing. RK3588 integrates Rockchip's new generation NPU, which can support INT4/INT8/INT16/FP16 hybrid computing. Its strong compatibility can easily convert network models based on a series of frameworks such as TensorFlow / MXNet / PyTorch / Caffe. RK3588 has a high-performance 4-channel external memory interface (LPDDR4/LPDDR4X/LPDDR5), capable of supporting demanding memory bandwidth.
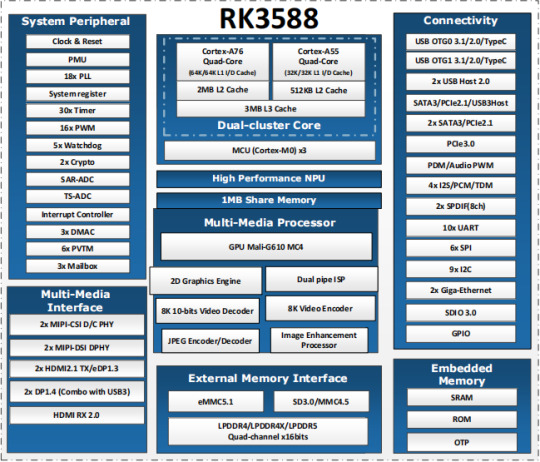
RK3588 Block Diagram
Advantages of RK3588?
Computing: RK3588 integrates quad-core Cortex-A76 and quad-core Cortex-A55, G610 MP4 graphics processor, and a separate NEON coprocessor. Integrating the third-generation NPU self-developed by Rockchip, computing power 6TOPS, which can meet the computing power requirements of most artificial intelligence models.
Vision: support multi-camera input, ISP3.0, high-quality audio;
Display: support multi-screen display, 8K high-quality, 3D display, etc.;
Video processing: support 8k video and multiple 4k codecs;
Communication: support multiple high-speed interfaces such as PCIe2.0 and PCIe3.0, USB3.0, and Gigabit Ethernet;
Operating system: Android 12 is supported. Linux and Ubuntu will be developed in succession;

FET3588-C SoM based on Rockchip RK3588
Forlinx FET3588-C SoM inherits all advantages of RK3588. The following introduces it from structure and hardware design.
1. Structure:
The SoM size is 50mm x 68mm, smaller than most RK3588 SoMs on market;
100pin ultra-thin connector is used to connect SoM and carrier board. The combined height of connectors is 1.5mm, which greatly reduces the thickness of SoM; four mounting holes with a diameter of 2.2mm are reserved at the four corners of SoM. The product is used in a vibration environment can install fixing screws to improve the reliability of product connections.

2. Hardware Design:
FET3568-C SoM uses 12V power supply. A higher power supply voltage can increase the upper limit of power supply and reduce line loss. Ensure that the Forlinx’s SoM can run stably for a long time at full load. The power supply adopts RK single PMIC solution, which supports dynamic frequency modulation.
FET3568-C SoM uses 4 pieces of 100pin connectors, with a total of 400 pins; all the functions that can be extracted from processor are all extracted, and ground loop pins of high-speed signal are sufficient, and power supply and loop pins are sufficient to ensure signal integrity and power integrity.
The default memory configuration of FET3568-C SoM supports 4GB/8GB (up to 32GB) LPDDR4/LPDDR4X-4266; default storage configuration supports 32GB/64GB (larger storage is optional) eMMC;
Each interface signal and power supply of SoM and carrier board have been strictly tested to ensure that the signal quality is good and the power wave is within specified range.
PCB layout: Forlinx uses top layer-GND-POWER-bottom layer to ensure the continuity and stability of signals.
RK3588 SoM hardware design Guide
FET3588-C SoM has integrated power supply and storage circuit in a small module. The required external circuit is very simple. A minimal system only needs power supply and startup configuration to run, as shown in the figure below:

The minimum system includes SoM power supply, system flashing circuit, and debugging serial port circuit. The minimum system schematic diagram can be found in "OK3588-C_Hardware Manual". However, in general, it is recommended to connect some external devices, such as debugging serial port, otherwise user cannot judge whether system is started. After completing these, on this basis, add the functions required by user according to default interface definition of RK3588 SoM provided by Forlinx.
RK3588 Carrier Board Hardware Design Guide
The interface resources derived from Forlinx embedded OK3588-C development board are very rich, which provides great convenience for customers' development and testing. Moreover, OK3588-C development board has passed rigorous tests and can provide stable performance support for customers' high-end applications.

In order to facilitate user's secondary development, Forlinx provides RK3588 hardware design guidelines to annotate the problems that may be encountered during design process of RK3588. We want to help users make the research and development process simpler and more efficient, and make customers' products smarter and more stable. Due to the large amount of content, only a few guidelines for interface design are listed here. For details, you can contact us online to obtain "OK3588-C_Hardware Manual" (Click to Inquiry)
1 note
·
View note
Photo

Banana Pi BPI-CM5 Pro: представлена альтернатива Raspberry Pi CM4 с ИИ-процессором Rockchip
В ассортименте Banana Pi, по сообщению ресурса CNX Software, появился вычислительный модуль BPI-CM5 Pro, предназначенный для построения устройств с ИИ-функциями. Новинка, выполненная на аппаратной платформе Rockchip, представляет собой альтернативу Raspberry Pi CM4. Изделие имеет размеры 55×40 мм. Применён процессор RK3576, который содержит по четыре ядра Cortex-A72 (2,2 ГГц) и Cortex-A53 (1,8 ГГц), а также графический блок Arm Mali-G52 MC3 с поддержкой OpenGL ES 1.1/2.0/3.2, OpenCL 2.0 и Vulkan 1.1. Встроенный нейропроцессорный узел облает ИИ-производительностью до 6 TOPS (INT8) и поддержкой INT4/INT8/INT16/BF16/TF32. Объём оперативной памяти LPDDR5 может составлять 8 или 16 Гбайт.
Подробнее на https://7ooo.ru/group/2024/09/09/424-banana-pi-bpi-cm5-pro-predstavlena-alternativa-raspberry-pi-cm4-s-ii-processorom-rockchip-grss-339657823.html
0 notes
Text
Game Changer Alert: AMD Ryzen 5 8600G Graphics Unleashed!

The Ryzen 5 8600G Graphics from AMD
AMD instead continues generating waves in the continually changing field of computing hardware by introducing the accessible Ryzen 5 8600G CPU, having an especially strong focus on the built-in graphic capabilities of the chip.
Geekbench 6 Benchmarks of the Ryzen 5 8600G
The benchmark results of AMD’s Ryzen 5 8600G have been recently leaked on Geekbench 6, which has shed light on the scores and provided a look into the graphics performance that is predicted for the chip.With scores of 30,770 points in Vulkan and 24,842 points in OpenCL, the Ryzen 5 8600G exhibits impressive performance when analyzed using the precise performance measures that are available in Geekbench 6.
An Outstanding Graphics Processor known as the Radeon 760M
a number of the biggest and most significant aspects of the Ryzen 5 8600G is the Radeon 760M integrated graphic processor, which has a speed of operation of 2.8GHz. Let’s get started take an additional look at the characteristics that truly set this graphics processor apart from others.A comparison of the Radeon 760M found in the 8600G to its mobile equivalents is revealed as investigate the variances that exist between the desktop and mobile versions of the graphics card.
In comparison to the GTX 1060 and Ryzen 5 8600G:
At the same time as the Ryzen 5 8600G gets test results comparable to those of the aged but still relevant desktop GTX 1060, comparisons with Nvidia’s GTX 1060 are becoming more prevalent.
AMD’s Integrated Graphics provide an advantage
The 8600G from AMD is notable for its outstanding performance, which is accompanied by a much reduced power consumption. This exemplifies the effectiveness of integrated graphics by showcasing its efficiency.
DDR5-6000 DIMMs: Performance of the 8600G
It is a purposeful decision that has a good influence on the overall performance of the 8600G because AMD combines it with two 16GB DDR5-6000 DIMMs. The following is done with the objective to boost the performance of the 8600G. This Ryzen 5 8600G is a tempting decision over gamers who want to play on a tighter budget.
The research AMD Ryzen 5 8600G shows up as an acceptable budget-friendly gameplay an approach especially to people who are upon a low economy. The machine’s gaming the parameters are equivalent to those of the GTX 1060.
Prospects for the Ryzen 8000G Lineup
AMD investigate the possible upgrades that might be made to the Ryzen 8000G portfolio, which hint to even more remarkable integrated graphics possibilities, in anticipation of future launches.
Ryzen 7 8700G: A Powerhouse That Has Been Rumored
There are rumors going around concerning the Ryzen 7 8700G, which may be influenced by the Radeon 780M in order to achieve a performance boost of around fifty percent. What possibilities does this have for gamers?
Things You can Expect at the Annual Consumer Computer Show in 2024
An increasing quantity of observers are predicting AMD to issue official comments and display the Ryzen 8000G series around the next upcoming Consumer Electronics Show (CES) in 2024.
Concluding Remarks:
A Gaming Solution That Is Friendly to Your Budget In conclusion, the Ryzen 5 8600G may be considered a great alternative for gamers who are concerned about their financial situation. It provides comparable performance without the need of a dedicated graphics processing unit (GPU).
Read more on Govindhtech.com
1 note
·
View note
Text
GPU AMD Radeon RX 8000 "RDNA 4" tem especificações vazadas
Por Vinicius Torres Oliveira

A AMD submeteu uma de suas novas GPUs Radeon RX 8000 "RDNA 4" ao Geekbench, mostrando o que esperar das próximas placas de vídeo
Uma das GPUs AMD Radeon RX 8000 “RDNA 4” teve suas informações divulgadas no Geekbench, mostrando algumas de suas especificações e como ela se posicionará diante dos demais hardwares da linha.
Ela é descrita como “GFX1201”, o que confirma que o modelo específico usará o SKU Navi 48 – o maior dos dois dies Navi 4X. A placa de vídeo é listada com 28 unidades computacionais (UC) e, levando em conta que o RDNA 3 trazia um motor de sombreamento com unidades duplas, é possível que isso signifique que traga 56 UC no total.
Essa contagem de unidades computacionais da GPU AMD Radeon RX 8000 “RDNA 4” se mostraria entre dois modelos da fabricante – a RX 7700 XT, que foi lançada com 54 UC e a RX 7800 XT, modelo lançado com 60 UC.
Além disso, é listado que a placa de vídeo terá uma velocidade de clock configurada em 2,1 GHz – o que parece baixo em comparação às GPUs RDNA 3 (que atingem entre 2,5 a 2,6 GHz com facilidade), mas é importante ressaltar que esta pode ser apenas uma amostra, uma versão de testes que não representa o estado final do modelo.
Por fim, também é visto que a GPU AMD Radeon RX 8000 “RDNA 4” (GFX1201) é listada com 16 GB de VRAM – similar ao que é visto nas RX 7800 XT e RX 7900 GRE. Isto confirma que usará a interface de bus de 256-bit, mas apesar da informação não foi revelado o tipo de memória que foi utilizado – apesar de vazamentos sugerirem que usarão o GDDR6 em 18 Gbps.
O desempenho da GPU AMD Radeon RX 8000 “RDNA 4” não teve resultados tão positivos assim no benchmark OpenCL, mas como citamos anteriormente, como é uma versão prévia e o chip deve estar passando por testes apenas, isto provavelmente não representa o que será visto em seu lançamento em 2025.
É importante notar que, se os testes já estão ocorrendo com as amostras, a fabricante deve estar analisando os dados para os ajustes necessários – algo que sempre ocorre antes da chegada dos principais hardwares ao mercado e aos consumidores. Isso significa que seu lançamento – de fato – não está tão distante assim.
Possivelmente a AMD mostrará mais detalhes das suas GPUs Radeon RX 8000 “RDNA 4” durante a CES 2025. No entanto, a concorrência também está de olho no evento e as placas de vídeo da NVIDIA “GeForce RTX 50” também estão previstas para marcarem presença por lá.
0 notes
Text
coreldraw graphics suite crack

CorelDRAW® Graphics Suite is your fully-loaded professional design toolkit for delivering breathtaking vector illustration, layout, photo editing, and typography projects with total efficiency. A budget-friendly subscription provides incredible ongoing value with instant, guaranteed access to exclusive new features and Content, peak performance, and support for the latest technologies.
Illustrators and artists can combine their traditional art practices with CorelDRAW's state-of-the-art vector-illustration technology to create beautiful, sophisticated works of art.
CorelDRAW is a trusted name in engineering, manufacturing, and construction firms with precision tools for creating product and parts illustrations, diagrams, schematics, and other intricate visuals.
Includes Extra Content
CorelDRAWGraphicsSuite2022Extras-Fills
CorelDRAWGraphicsSuite2022Extras-Fonts-Fonts
CorelDRAWGraphicsSuite2022Extras-Images-Earth_and_Nature
CorelDRAWGraphicsSuite2022Extras-Images-Layout
CorelDRAWGraphicsSuite2022Extras-Images-Modern_Life
CorelDRAWGraphicsSuite2022Extras-Images-Transport
CorelDRAWGraphicsSuite2022Extras-Templates
Additional Content includes
7000 clip art, digital images, and vehicle templates
1000 high-resolution digital photos
Over 1000 TrueType and OpenType fonts
150 professional templates
Over 600 fountain, vector, and bitmap fills
System Requirements and Technical Details
Windows 11 or Windows 10 (Version 21H1 or later), 64-bit, with the latest Updates
Intel Core i3/5/7/9 or AMD Ryzen 3/5/7/9/Threadripper, EPYC
OpenCL 1.2-enabled video card with 3+ GB VRAM
8 GB RAM
5.5 GB hard disk space for application and installation files
Mouse, tablet, or multi-touch screen
1280 x 720 screen resolution at 100% (96 dpi)
DVD drive optional (for box installation);
Installation from DVD requires a download of up to 900 MB
http://getlourl.com/nvaz8
0 notes
Photo

AMD pulveriza la RTX 4090 de Nvidia en el popular benchmark Geekbench OpenCL, pero necesitarás una pequeña hipoteca para comprar la GPU más rápida jamás producida por AMD Introducido por primera vez a fina... https://ujjina.com/amd-pulveriza-la-rtx-4090-de-nvidia-en-el-popular-benchmark-geekbench-opencl-pero-necesitaras-una-pequena-hipoteca-para-comprar-la-gpu-mas-rapida-jamas-producida-por-amd/?feed_id=670113&_unique_id=66787199f223e
0 notes
Text

Như bạn đã thấy. Vì thiết kế vi mạch đòi hỏi sự rõ ràng trong cách thức lập luận về điều kiện để luồng dữ liệu chảy ở mức cao hơn rất nhiều so với công nghệ thông tin (thử nhằn cấu trúc dữ liệu và giải thuật đi ạ!) nên thách thức lớn nhất cho việc chuyển một triệu nhân sự từ ICT (Information and Communications Technology) sang ICD (Integrated Circuit Design) có lẽ là môi trường cho họ sinh sống và nghỉ ngơi sau giờ làm việc ạ. Và đây rõ ràng đây là điều bất khả trong tương lai gần bởi đó là số dân của một tỉnh trung bình nha. Haha :)))
Yepp. Có thể bạn cảm thấy buồn cười khi nghe việc nhiều bác sĩ thấy rất khó chịu vì ở đâu cũng có vi trùng nhưng đây là một triệu chứng trong hội chứng Rối loạn ám ảnh cưỡng chế (Obsessive-compulsive disorder - OCD). Có mã ICD10 là F42, ICD11 là 6B20, đây là một bệnh tâm căn được cho là nảy sinh từ sự lo lắng quá mức về sự thiếu vắng của một thao tác nào đó, như ở trường hợp bác sĩ là nguy cơ nhiễm trùng bệnh viện, nên rất có khả năng đây là một vấn đề sức khỏe chủ yếu ở những kỹ sư thiết kế vi mạch làm việc trong nước bởi sự vênh nhau chả hề nhẹ giữa cách họ nghĩ để làm với cách họ nghĩ để sống, ví dụ như một cái cần định nghĩa chi tiết còn một cái chả hề có luôn.
*Ngáp* Nếu thấy ngứa mắt với từ Apps trong Setting của Windows 11 thì bạn bị OCD rồi đấy. Nếu sửa thành Applications thì sẽ đỡ và bạn chả thể nào sửa được hay than phiền về điều này với Satya Nadella!!!
Ừ hứ. Kĩ sư cầu nối (Bridge System Engineer - BrSE) là người sẽ làm việc trực tiếp với khách hàng, kết nối và chịu trách nhiệm truyền đạt yêu cầu từ nội bộ khách hàng tới nhóm phát triển ở bên ngoài, đảm bảo hai bên hiểu nhau và hợp tác suôn sẻ, thuận lợi. Câu hỏi ở đây là nghiên cứu thị trường (cụ thể là khách hàng) và nghiên cứu khoa học giống và khác như thế nào? Có lấy cái này thay cái kia được chăng???
Yepp. Một dự án ICT hoàn chỉnh sẽ phải có các mục về phần cứng. Có điều đó hoặc là phần được thầu riêng hoặc là sử dụng tiếp các thiết bị có sẵn nên Software mới là phần trọng tâm khi làm kỹ sư cầu nối cho thị trường Nhật. Nó cũng đã gây khó khăn không ít cho đội vận hành khi họ vẫn đang xài đĩa mềm và chả muốn thay đổi. Huhu!
*Ngáp* "Trồng cây gì, nuôi con gì" là ví dụ minh họa cho Governance. Và để ra được đáp án thì cần cả nghiên cứu khoa học để biết cái gì thì sẽ thế nào lẫn nghiên cứu thị trường để làm rõ thế nào thì khách hàng chốt đơn. Nhưng theo mình, đây chỉ là điểm dễ thấy nhất thôi!
***
Ừ hứ. Lý thuyết mà nói thì GPU của Ivy Bridge đã đủ khả năng tăng tốc giải mã media dùng chuẩn nén VP8 (Tức là tệp ảnh đuôi webp và nhiều tệp phim đuôi webm, nói là nhiều vì thiết kế của định dạng tệp tin WebM còn cho phép nó chứa chuỗi hình được mã hóa theo kiểu VP9 và AV1. Trong đó VP9 được tối ưu cho nội dung có độ phân giải đến Full HD còn AV1 thì tốt hơn cho nội dung từ 2K trở lên) bởi S.o.C Atom Z3770 có tính năng này và có GPU thực ra là phiên bản cắt bớt đơn vị thực thi (Execution Units - EU) và xung nhịp của GPU có trong các chíp thế hệ ba cho máy tính để bàn và xách tay nên sự thiếu sót tính năng này chắc bởi vì chưa tích hợp chương trình điều khiển. Và do Intel đã ngừng việc phát triển chương trình điều khiển cho thế hệ chíp này nên ta sẽ cần đốt kha khá tiền để chứng minh năng lực giải quyết vấn đề thiếu điện (giảm tải CPU) ở quy mô toàn cầu này nha :D
Yepp. Ivy Bridge có hỗ trợ OpenCl (Open Computing Language) còn Sandy Bridge liền trước thì không và dù nhiều người đã viết chương trình giải mã VP8/VP9 bằng OpenCl nhưng hiện tại nó rất chậm khi chạy trên x86 nên chả còn ai quan tâm đến phương án này làm chi.
Ừ hứ. Intel có giới thiệu cách dùng Register-Transfer Level (RTL hay Cấp độ thanh ghi - chuyển đổi) để tối ưu mã lệnh OpenCl chạy trên FPGA và Google đã cung cấp miễn phí RTL của vi mạch giải mã VP8/VP9 cho bất kì công ty nào có nhu cầu thêm tính năng này vào sản phẩm thực tế. Nhưng hiệu năng của cách này trên GPU đến từ Intel hiện chưa đủ tốt nên việc phát minh lại cái bánh xe vẫn cần diễn ra :D
*Cho bạn nào chưa biết* Về cơ bản, RTL là sự thể hiện của mạch số dưới dạng luồng dữ liệu giữa các thanh ghi và các phép toán luận lý trên các tín hiệu mang dữ liệu đó. Tạo ra RTL hiện là bước đầu tiên để thiết kế vi mạch thuần số trước khi tái tạo nó bởi ngôn ngữ mô tả phần cứng như Verilog hay VHDL để máy tính tạo ra thiết kế mẫu ít trừu tượng hơn, tức làm hiện ra mối liên kết cụ thể giữa các linh kiện để tối ưu hoá bằng tay. Việc tối ưu hoá này rất mất thời gian nên đây là cơ hội cho các đơn vị bên ngoài khi giúp công ty thiết kế vi mạch có thể cắt giảm các chi phí kém ưu tiên như tiền cho cơ sở hạ tầng: Giá thuê văn phòng trung bình ở Âu Mỹ hiện đang gấp đôi giá thuê văn phòng hạng A ở Việt Nam (Và có nhiều nhân sự dưới chuẩn hơn)
***
Chả biết. Vì dùng nhân Linux tiêu chuẩn nên chắc không cần sửa đổi nhiều để chạy Tizen trên WSL 2 như Windows Subsystem for Android đã bị ngưng do thu chả bù chi. (Tencent đã xác nhận tiếp tục chi tiền cho dự án nhưng hên xui vì hiện chỉ dành cho mỗi thị trường Đại lục) Tức là cản trở lớn nhất hiện giờ để Microsoft Store có mặt trên các thiết bị di động chỉ là các bên liên quan có muốn triển khai hay không
Nhân tiện thì rất nhiều chuyên gia đã kêu gọi ngưng dùng QtWebkit vì quá nhiều lỗ hổng bảo mật không được vá. Và lý do để vẫn còn sử dụng thư viện này là vì lõi Chromium chả tối ưu bộ nhớ như Webkit2.
0 notes
Text
ME 766 : HW 3 solved
1. Create two matrices, A and B, each of size (N N). Write a CUDA or OpenCL (choice
is yours) for computing C = AB. Report the times taken for the codes. Vary the size of
the problem from N = 100 . . . 10000. Also report the specifications of the computer
you are running this on. Also specs of the GPU (if any).
2. Choose A and B to be same as HW 2.
3. Submit your code and a report.

View On WordPress
0 notes
Text
ME 766 : HW 3
1. Create two matrices, A and B, each of size (N N). Write a CUDA or OpenCL (choice
is yours) for computing C = AB. Report the times taken for the codes. Vary the size of
the problem from N = 100 . . . 10000. Also report the specifications of the computer
you are running this on. Also specs of the GPU (if any).
2. Choose A and B to be same as HW 2.
3. Submit your code and a report.

View On WordPress
0 notes
Last Seen Blogs

finalfantacee
Til Sea Swallows All

nerdyfox
anomalous

occasional-secco
pretty much an achive now :/

shahanasrecipes
Shahanas Recipes

slytherkingdae
SlytherKing