#parse each line in a file in python
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Kazakhstan’s Minister of Communications and Informatics has blocked the Tumblr site because it contained 60 sites of terrorism, extremism, and pornography in 2015.
Text
Ultimate Guide to Python Compiler

When diving into the world of Python programming, understanding how Python code is executed is crucial for anyone looking to develop, test, or optimize their applications. This process involves using a Python compiler, a vital tool for transforming human-readable Python code into machine-readable instructions. But what exactly is a Python compiler, how does it work, and why is it so important? This guide will break it all down for you in detail, covering everything from the basic principles to advanced usage.
What is a Python Compiler?
A Python compiler is a software tool that translates Python code (written in a human-readable form) into machine code or bytecode that the computer can execute. Unlike languages like C or Java, Python is primarily an interpreted language, which means the code is executed line by line by an interpreter. However, Python compilers and interpreters often work together to convert the source code into something that can run on your system.
Difference Between Compiler and Interpreter
Before we delve deeper into Python compilers, it’s important to understand the distinction between a compiler and an interpreter. A compiler translates the entire source code into a machine-readable format at once, before execution begins. Once compiled, the program can be executed multiple times without needing to recompile.
On the other hand, an interpreter processes the source code line by line, converting each line into machine code and executing it immediately. Python, as a high-level language, uses both techniques: it compiles the Python code into an intermediate form (called bytecode) and then interprets that bytecode.
How Does the Python Compiler Work?
The Python compiler is an essential part of the Python runtime environment. When you write Python code, it first undergoes a compilation process before execution. Here’s a step-by-step look at how it works:
1. Source Code Parsing
The process starts when the Python source code (.py file) is written. The Python interpreter reads this code, parsing it into a data structure called an Abstract Syntax Tree (AST). The AST is a hierarchical tree-like representation of the Python code, breaking it down into different components like variables, functions, loops, and classes.
2. Compilation to Bytecode
After parsing the source code, the Python interpreter uses a compiler to convert the AST into bytecode. This bytecode is a lower-level representation of the source code that is platform-independent, meaning it can run on any machine that has a Python interpreter. Bytecode is not human-readable and acts as an intermediate step between the high-level source code and the machine code that runs on the hardware.
The bytecode generated is saved in .pyc (Python Compiled) files, which are stored in a special directory named __pycache__. When you run a Python program, if a compiled .pyc file is already available, Python uses it to speed up the startup process. If not, it re-compiles the source code.
3. Execution by the Python Virtual Machine (PVM)
After the bytecode is generated, it is sent to the Python Virtual Machine (PVM), which executes the bytecode instructions. The PVM is an interpreter that reads and runs the bytecode, line by line. It communicates with the operating system to perform tasks such as memory allocation, input/output operations, and managing hardware resources.
This combination of bytecode compilation and interpretation is what allows Python to run efficiently on various platforms, without needing separate versions of the program for different operating systems.
Why is a Python Compiler Important?
Using a Python compiler offers several benefits to developers and users alike. Here are a few reasons why a Python compiler is so important in the programming ecosystem:
1. Portability
Since Python compiles to bytecode, it’s not tied to a specific operating system or hardware. This allows Python programs to run on different platforms without modification, making it an ideal language for cross-platform development. Once the code is compiled into bytecode, the same .pyc file can be executed on any machine that has a compatible Python interpreter installed.
2. Faster Execution
Although Python is an interpreted language, compiling Python code to bytecode allows for faster execution compared to direct interpretation. Bytecode is more efficient for the interpreter to execute, reducing the overhead of processing the raw source code each time the program runs. It also helps improve performance for larger and more complex applications.
3. Error Detection
By using a Python compiler, errors in the code can be detected earlier in the development process. The compilation step checks for syntax and other issues, alerting the developer before the program is even executed. This reduces the chances of runtime errors, making the development process smoother and more reliable.
4. Optimizations
Some compilers provide optimizations during the compilation process, which can improve the overall performance of the Python program. Although Python is a high-level language, there are still opportunities to make certain parts of the program run faster. These optimizations can include techniques like constant folding, loop unrolling, and more.
Types of Python Compilers
While the official Python implementation, CPython, uses a standard Python compiler to generate bytecode, there are alternative compilers and implementations available. Here are a few examples:
1. CPython
CPython is the most commonly used Python implementation. It is the default compiler for Python, written in C, and is the reference implementation for the language. When you install Python from the official website, you’re installing CPython. This compiler converts Python code into bytecode and then uses the PVM to execute it.
2. PyPy
PyPy is an alternative implementation of Python that features a Just-In-Time (JIT) compiler. JIT compilers generate machine code at runtime, which can significantly speed up execution. PyPy is especially useful for long-running Python applications that require high performance. It is highly compatible with CPython, meaning most Python code runs without modification on PyPy.
3. Cython
Cython is a superset of Python that allows you to write Python code that is compiled into C code. Cython enables Python programs to achieve performance close to that of C while retaining Python’s simplicity. It is commonly used when optimizing computationally intensive parts of a Python program.
4. Jython
Jython is a Python compiler written in Java that allows Python code to be compiled into Java bytecode. This enables Python programs to run on the Java Virtual Machine (JVM), making it easier to integrate with Java libraries and tools.
5. IronPython
IronPython is an implementation of Python for the .NET framework. It compiles Python code into .NET Intermediate Language (IL), enabling it to run on the .NET runtime. IronPython allows Python developers to access .NET libraries and integrate with other .NET languages.
Python Compiler vs. Interpreter: What’s the Difference?
While both compilers and interpreters serve the same fundamental purpose—turning source code into machine-executable code—there are distinct differences between them. Here are the key differences:
Compilation Process
Compiler: Translates the entire source code into machine code before execution. Once compiled, the program can be executed multiple times without recompilation.
Interpreter: Translates and executes source code line by line. No separate executable file is created; execution happens on the fly.
Execution Speed
Compiler: Generally faster during execution, as the code is already compiled into machine code.
Interpreter: Slower, as each line is parsed and executed individually.
Error Detection
Compiler: Detects syntax and other errors before the program starts executing. All errors must be fixed before running the program.
Interpreter: Detects errors as the code is executed. Errors can happen at any point during execution.
Conclusion
The Python compiler plays a crucial role in the Python programming language by converting source code into machine-readable bytecode. Whether you’re using the default CPython implementation, exploring the performance improvements with PyPy, or enhancing Python with Cython, understanding how compilers work is essential for optimizing and running Python code effectively.
The compilation process, which includes parsing, bytecode generation, and execution, offers various benefits like portability, faster execution, error detection, and optimizations. By choosing the right compiler and understanding how they operate, you can significantly improve both the performance and efficiency of your Python applications.
Now that you have a comprehensive understanding of how Python compilers work, you’re equipped with the knowledge to leverage them in your development workflow, whether you’re a beginner or a seasoned developer.
0 notes
Text
Python Fundamentals for New Coders: Everything You Need to Know
Learning Python is an exciting journey, especially for new coders who want to explore the fundamentals of programming. Known for its simplicity and readability, Python is an ideal language for beginners and professionals alike. From understanding basic syntax to mastering more advanced concepts, Python equips you with tools to build everything from small scripts to full-scale applications. In this article, we’ll explore some core Python skills every new coder should know, such as file handling, reading and writing files, and handling data in various formats.
One essential skill in Python is file handling, which is vital for working with external data sources. Our Python file handling tutorial covers how to open, read, write, and close files. In real-world applications, you often need to process data stored in files, whether for analysis or to store program output. File handling enables you to manage these files directly from your Python code. With just a few commands, you can open a file, modify its contents, or create a new file. This skill becomes especially valuable as you begin working with larger projects that rely on reading or writing to files.
Once you understand file handling basics, you can dive deeper into how Python works with different types of files. One common use case for file handling is working with CSV files, which store data in a table-like format. Python CSV file handling allows you to read and write data organized in rows and columns, making it easy to process structured data. With Python’s built-in csv module, you can access and manipulate CSV files effortlessly. For example, if you have a list of students and their grades in a CSV file, you can use Python to calculate average grades or filter data. Understanding how to handle CSV files helps you manage structured data effectively and is a critical skill for any data-related task.
Moving on, another key skill is working with file content—specifically, learning to read and write files in various formats. Python offers a variety of methods for reading files line-by-line or loading the entire content at once. Writing to files is just as simple, allowing you to add new data or update existing information. For instance, in a data analysis project, you might read raw data from a file, process it, and save the results to another file. This read-and-write capability forms the backbone of many Python programs, particularly when dealing with external data.
Finally, many applications require more complex data storage and exchange formats, such as JSON. Python JSON data processing is essential for working with APIs or handling nested data structures. JSON, which stands for JavaScript Object Notation, is a popular format for representing structured data. Using Python’s json module, you can easily convert JSON data into Python dictionaries and vice versa. This ability to parse and write JSON data is crucial for building applications that interact with web services, allowing you to read data from an online source and process it in your program. As you gain more experience, you’ll find JSON data handling indispensable for projects involving external APIs and structured data storage.
Our company is committed to helping students learn programming languages through clear, straightforward tutorials. Our free online e-learning portal provides Python tutorials specifically designed for beginners, with live examples that bring each concept to life. Every tutorial is written in an easy-to-understand style, ensuring that even complex topics are approachable. Whether you’re a student or a hobbyist, our tutorials give you the practical tools to start coding confidently.
In summary, understanding Python fundamentals such as file handling, CSV and JSON processing, and read/write operations can take you far in your coding journey. Each of these skills contributes to building powerful applications, from data analysis scripts to interactive web applications. By mastering these concepts, you’ll be well-prepared to tackle real-world coding challenges, and our platform will support you every step of the way. With consistent practice and our structured tutorials, you’ll gain the confidence to explore Python and bring your ideas to life.
0 notes
Text
Working with CSV Files and Json Data
Introduction to Working with CSV Files and JSON Data
Handling data in CSV (Comma-Separated Values) and JSON (JavaScript Object Notation) formats is a common requirement in data science, web development, and many other fields. Python Training in Bangalore Both formats have their specific use cases and advantages. This guide will introduce you to working with CSV files and JSON data using Python, a versatile and powerful programming language widely used for data manipulation and analysis.
What are CSV and JSON?
CSV (Comma-Separated Values):
Format: A simple text format for storing tabular data, where each row corresponds to a line in the text file, and each column is separated by a comma.
Use Case: Ideal for storing and exchanging simple tabular data like spreadsheets or database tables.
JSON (JavaScript Object Notation):
Format: A lightweight data-interchange format that is easy for humans to read and write and easy for machines to parse and generate. It is based on a subset of JavaScript programming language standards.
Use Case: Widely used for data exchange between a server and a web application, as well as for configuration files and data storage.
Why Use Python for CSV and JSON?
Python Course Training in Bangalore Python is a powerful and easy-to-learn language that comes with several built-in libraries and third-party packages to handle CSV and JSON data effortlessly. Some reasons to use Python include:
Ease of Use: Python syntax is clean and readable, making it simple to work with.
Comprehensive Libraries: Python offers robust libraries like csv, json, and pandas for efficient data manipulation.
Community Support: Python has a large community, providing a wealth of resources and support.
Libraries for Handling CSV and JSON in Python
csv Module:
Part of the Python Standard Library.
Provides functionality to both read from and write to CSV files.
json Module:
Part of the Python Standard Library.
Enables parsing JSON from strings or files, and converting Python objects into JSON strings or files.
pandas Library:
A powerful third-party library for data manipulation and analysis.
Provides high-level functions to read from and write to CSV and JSON, along with many other data formats.
Highly recommended for complex data analysis tasks.
Key Operations
Reading CSV Files:
Using the csv module for simple CSV reading.
Using the pandas library for more advanced data manipulation.
Writing CSV Files:
Using the csv module for simple CSV writing.
Using the pandas library for more advanced operations.
Reading JSON Data:
Using the json module for basic JSON parsing.
Using the pandas library to directly convert JSON to DataFrame.
Writing JSON Data:
Using the json module for basic JSON writing.
Using the pandas library to directly convert DataFrame to JSON.
Understanding how to work with CSV files and JSON data is essential for data manipulation and exchange. Best Python Course Training in Bangalore Python, with its powerful standard libraries and third-party packages like pandas, provides a seamless experience for handling these formats. Whether you are a beginner or an experienced developer, mastering these tools will significantly enhance your data processing capabilities. In the following sections, we will delve into the specifics of each operation, providing code examples and best practices.
Conclusion
In 2024,Python will be more important than ever for advancing careers across many different industries. As we've seen, there are several exciting career paths you can take with Python , each providing unique ways to work with data and drive impactful decisions. At NearLearn, we understand the power of data and are dedicated to providing top-notch training solutions that empower professionals to harness this power effectively.One of the most transformative tools we train individuals on isPython.
0 notes
Text
Power Up Your Python Skills: 10 Exciting Projects to Master Coding
Forget textbooks and lectures – the most epic way to learn Python is by doing! This guide unveils 10 thrilling projects that will transform you from a programming rookie to a coding champion. Prepare to conquer these quests and unleash your creativity and problem-solving prowess.

With the helpful assistance of Learn Python Course in Hyderabad, studying Python becomes lot more exciting — regardless of whether you’re a beginner or moving from another programming language.
Mission 1: Command Line Masters
Your quest begins with mastering the fundamentals. Build simple command-line applications – think math wizards, unit converters, or random password generators. These projects are the stepping stones to Pythonic greatness!
Mission 2: Text-Based Games – Level Up
Time to challenge yourself! Create captivating text-based games like Hangman, Tic-Tac-Toe, or a trivia extravaganza. Craft engaging gameplay using loops, conditionals, and functions, while honing your Python skills in the process.
Mission 3: Web Scraper – Unearthing Web Data
The vast web holds secrets waiting to be discovered! Build web scrapers to extract valuable information from websites. Employ libraries like BeautifulSoup and Requests to navigate the HTML jungle, harvest data, and unlock hidden insights.
Mission 4: Data Analysis Detectives
Become a data analysis extraordinaire! Craft scripts to manipulate and analyze data from diverse sources – CSV files, spreadsheets, or databases. Calculate statistics, then use matplotlib or seaborn to create eye-catching data visualizations that reveal hidden truths.
Mission 5: GUI Gurus – Building User-Friendly Interfaces
Take your Python mastery to the next level by crafting user-friendly graphical interfaces (GUIs) with Tkinter or PyQt. From to-do list managers to weather apps, these projects will teach you how to design intuitive interfaces and conquer user interactions.
Mission 6: API Alliances – Connecting to the World
Expand your horizons by building clients for web APIs. Interact with services like Twitter, Reddit, or weather APIs to retrieve and display data. Master the art of making HTTP requests, parsing JSON responses, and handling authentication – invaluable skills for any programmer. People can better understand Python’s complexity and reach its full potential by enrolling in the Best Python Certification Online.

Mission 7: Automation Army – Streamlining Workflows
Say goodbye to repetitive tasks! Write automation scripts to handle tedious processes like file management, data processing, or email sending. Utilize libraries like os, shutil, and smtplib to free up your time and boost productivity.
Mission 8: Machine Learning Marvels – Unveiling AI Power
Enter the fascinating world of machine learning! Build basic classification or regression models using scikit-learn. Start with beginner-friendly projects like predicting housing prices or classifying flowers, then explore more complex algorithms as you progress.
Mission 9: Web Development Warriors – Forge Your Online Presence
Immerse yourself in the thrilling world of web development. Construct simple websites or web applications using frameworks like Flask or Django. Whether it's a personal portfolio site, a blog, or a data-driven application, these projects will teach you essential skills like routing, templating, and database interactions.
Mission 10: Open Source Odyssey – Join the Coding Community
Become a valued member of the open-source community! Contribute to projects on platforms like GitHub. Tackle beginner-friendly issues, fix bugs, or improve documentation. Gain real-world experience and collaborate with fellow developers to make a lasting impact.
These 10 Python quests aren't just about acquiring coding skills – they're a gateway to a world of exploration and innovation. Each project offers a unique opportunity to learn, grow, and create something amazing. So, grab your virtual sword and shield (aka your code editor) and embark on this epic Python adventure!
0 notes
Text
Advent of Code - Days 1 and 2
December is upon us, and this year I thought I'd forgo the chocolate advent calendars in favour of Advent of Code, a coding puzzle website that's been running for a few years. Every day of advent (1st of December to 25th December) you get a coding puzzle, with personalised input data so you can't just look up on the solution online. The problems all revolve around parsing text and doing maths, so you can use whatever programming language you want. There's a global leaderboard that you can race to get on (if you feel like getting up at midnight Eastern Time), or you can just do it casually in the name of learning.
This is the third year I've participated in Advent of Code, and hopefully the first year I manage to finish it. I've decided to solve the puzzles in Rust this year, partly because it's a language I want to get better at, and partly because I really enjoy writing it, but somehow I can always find very good reasons to write the other stuff I'm working on in Python.
My code is on GitHub, and I've written programmer's commentary under the cut.
Day 1
The first day of AoC tends to be fairly straightforward, and so it is this year with a simple find-the-character problem. In each line of the input string, we find the first digit and the last digit and use them to construct a two-digit number, so for instance "se2hui89" becomes "29." We start out by loading the input data, which the Advent of Code website gives you and which I downloaded into a .txt file.

include_str!() is an invaluable macro for Advent of Code players. At compile time, it will read the text file that you specify and load its contents into your program as a string. lines() is another useful function that gives you an iterator for the lines in a string - Advent of Code generally splits up its data line by line.
Since the problem itself was straightforward, I decided to liven things up a bit by creating a multi-threaded program. One thread finds the digit at the beginning of the string, and one finds the string at the end. Luckily, Rust has a lot of tools in the standard library to make concurrency easier.
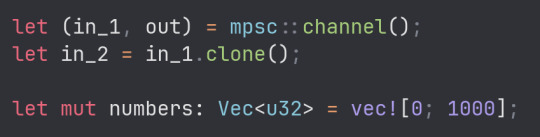
The particular technique I'm using here is called Multiple Producer Single Consumer, where multiple threads can send data into a channel, and a single thread (in my case, the main one) consumes the data that's being sent into it. I'm using it because I'm storing the numbers I find in a vector, and Rust's ownership system prevents more than one thread from having access to the vector, so instead each thread will send the numbers through a channel, to be processed and added to the vector in the main thread.

The thread itself is very simple - for each line in the text, I iterate through the characters and test whether each one is a digit. Once I find the digit, I multiply it by ten (because it's the first digit of a two-digit number) and send it down the channel. I've also sent the index to keep track of which line I've analysed, since the other thread might be working on a different line and the consumer wouldn't be able to tell the difference. The thread looking for the last digit in the string is almost exactly the same, except it reverses the chars before iterating through them and it doesn't multiply the digit it finds by 10.
Finally, all that remained was to consume the digits and add them into the vector. When you're consuming a channel, you can use a for loop to process values from the channel until the producers stop sending values. And the index variable makes a return here, which we use to keep track of which number each digit is a part of.
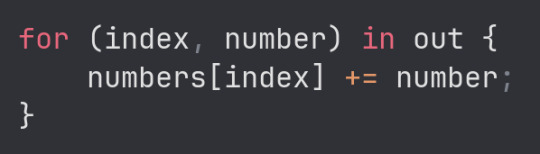
The addition is to combine the two digits into a single two-digit number. The vector is filled with 0s when it gets initialised, so each digit that arrives is added to 0 (if it is the first digit to arrive) or to the other digit (if it is the second digit to arrive). For instance, in the string "se29tte7", if 7 arrives first, we get 0 + 7 (7), and then when 2 arrives we add on 20 (since it has been multiplied by 10 already) to get 27, which is the correct answer.
The second task was more complicated, because now I had to be keeping track of all the non-numeric characters to see if they would eventually form the word for a number. I started by writing a function to check if a string contained a number's word.

Originally, this function returned a boolean, but I needed a way to know which number that the word in the string referred to. The easiest way was to store the possible number-words in tuples, associated with the integer version of that number, and then just return that integer if a number-word was found.

The match is also more complicated, because now any character that isn't a digit might be part of a number-word instead. So if the character is not a digit, I added it to the string of non-digit characters I'd found so far and checked if there was a number-word in that string. Once we find something, as before, we multiply it by ten and send it down the channel.
The other thread is similar, but unlike task 1 I couldn't simply reverse the characters, because although I have to search through them right-to-left, the number-words are still written left-to-right. I ended up using the format!() macro to prepend new characters onto the string so that they would be in the correct order.

Day 2
I found Day 2's task more difficult. The trick to it lies in splitting out the different units of data - each game (separated by a line break) has multiple rounds (separated by semicolons), each round has multiple blocks (separated by commas), and each block has a colour and a count, which are separated by spaces. All of this splitting required a lot of nested for loops - three, to be exact.
But I started off by stripping off the beginning of the string which tells you what game you're playing. I realised that, since the games are in order in the input text, you don't actually need to read this value; if you're iterating through the lines of the input like I was, you can just use the index to keep track of the current game. I also made a variable to keep track of whether or not a game is possible (I assume it is until the program proves that it isn't).

Mutable variables like that one make it really easy to shoot yourself in the foot. In an earlier version of the program, I changed that variable to false whenever I found an impossible block in a game. All well and good, but I forgot to prevent the variable from being changed back to true when a possible block was found in that same impossible game. As such, my code only marked games as impossible if the last round were impossible, causing it to wildly over-estimate the number of possible games.
The solution I found to that blunder involved a separate block_possible variable which I used to keep track of whether each block was possible, and then, if the block was impossible then the game would be marked as impossible. Possible blocks do nothing, because they can't account for any other blocks in that same game that might be impossible.

Quick side-note - I've used a lot of panic!() and unwrap() in this solution. Just for the beginners who might not know this: in general, using those functions like this is incredibly bad practice, because they will crash the program if there's anything unexpected in the input. This program's first bug was a crash which happened because there was a single blank line in the input file that shouldn't have been there. I'm only doing this because the program is designed to work with very specific input, so I can make assumptions about certain things when I process the text.
After that little bit of pattern matching, the only thing left is to add the game's ID to the vector which is keeping track of all the possible games. Something I learned at this point is that the index variable I've been using to keep track of the game's ID has a type of usize, which isn't interchangeable with Rust's other integer types like u32 and i32, so I had to convert it explicitly.
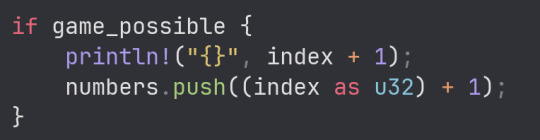
And that's that for task 1! It took me a lot of attempts to solve, because I probably should have had lunch first and made a lot of stupid mistakes, including:
Accidentally using count() where I should have used sum() on an iterator.
Badly indenting that if statement in the last image so that I was accidentally adding each ID to the list three or four times per line.
Forgetting to remove some debugging code that threw off the whole result.
But task 2 was comparatively much easier. The main difference was that instead of setting one variable to see if a game was possible, I set three variables to track the minimum number of bricks in each colour needed per game. It worked first try, but I'm not completely happy with it - in particular, I feel like this match statement was a little too verbose:

But all in all I think it went well and I am excited to try my hand at tomorrow's problem.
1 note
·
View note
Text
Guide To Scrape Food Data Using Python & Google Colab

Are you tired of manually collecting food data for your recipe app or meal planning service? Look no further! With the power of web scraping and automation, you can easily gather all the necessary information for your food database. In this guide, we will show you how to scrape food data using Python and Google Colab.
What is Web Scraping?
Web scraping is the process of extracting data from websites. It involves using a program or script to automatically navigate through web pages and gather information. This data can then be saved in a structured format, such as a CSV or JSON file, for further analysis or use.
Why Use Python and Google Colab?
Python is a popular programming language for web scraping due to its ease of use and powerful libraries such as BeautifulSoup and Requests. Google Colab, on the other hand, is a free online platform for writing and running Python code. It also offers the ability to store and access data on Google Drive, making it a convenient choice for web scraping projects.
Setting Up Google Colab
Before we begin, make sure you have a Google account and are signed in to Google Drive. Then, go to Google Colab and create a new notebook. You can also upload an existing notebook if you have one.
Installing Libraries
To scrape data from websites, we will need to install two libraries: BeautifulSoup and Requests. In the first cell of your notebook, type the following code and run it:!pip install beautifulsoup4 !pip install requests
Scraping Food Data
Now, we are ready to start scraping food data. For this example, we will scrape data from a popular recipe website, Allrecipes.com. We will extract the recipe name, ingredients, and instructions for each recipe. First, we need to import the necessary libraries and specify the URL we want to scrape:
from bs4 import BeautifulSoup import requests
url = "https://www.allrecipes.com/recipes/84/healthy-recipes/"Next, we will use the Requests library to get the HTML content of the webpage and then use BeautifulSoup to parse it:
page = requests.get(url) soup = BeautifulSoup(page.content, 'html.parser')
Now, we can use BeautifulSoup to find the specific elements we want to scrape. In this case, we will use the "article" tag to find each recipe and then extract the recipe name, ingredients, and instructions:
recipes = soup.find_all('article')
for recipe in recipes: name = recipe.find('h3').text ingredients = recipe.find('ul', class_='ingredients-section').text
instructions = recipe.find('ol', class_='instructions-section').text
print(name) print(ingredients) print(instructions)
Finally, we can save the scraped data in a CSV file for further use:
import csv
with open('recipes.csv', 'w', newline='') as file:
writer = csv.writer(file) writer.writerow("Name", "Ingredients", "Instructions")
for recipe in recipes: name = recipe.find('h3').text ingredients = recipe.find('ul', class_='ingredients-section').text instructions = recipe.find('ol', class_='instructions-section').text writer.writerow([name, ingredients, instructions])
Conclusion
With just a few lines of code, we were able to scrape food data from a website and save it in a structured format. This process can be automated and repeated for multiple websites to gather a large amount of data for your food database. Happy scraping!
#food data scraping#restaurant data scraping#food data scraping services#restaurantdataextraction#zomato api#grocerydatascraping#fooddatascrapingservices#grocerydatascrapingapi#web scraping services
0 notes
Text
Advent of Code
As a child, advent calendars always added to the sense of anticipation in the lead up to Christmas. In my day you would be lucky to get a small picture behind each of the doors. These days, children expect chocolates or sweets. My wife has once even had a "Ginvent Calendar", with gin behind each door.
This year I marked Advent by having a go at the "Advent of Code" which has Christmas-themed programming puzzles posted each day. Most days are in two parts, with an easier puzzle followed by a harder one. Traditionally, I've posted a (mostly ignored) programming puzzle to our development team each Christmas. Last year I just recycled one of the Advent of Code puzzles, but this year I suggested we attempt the whole thing. The puzzles are so well thought out, in comparison to my efforts, that it seemed pointless to compete.
In the end, several of the team had a go. Some of the puzzles were harder than others, but I managed to solve them all by Boxing Day. What follows are some personal anecdotes from the various days with some general thoughts at the end. Note that there are some spoilers and the notes won't mean much if you've not done the puzzles. So in this case just skip to the end.
a sum-finder. I implemented the search tree via recursive calls. I drifted into using Python right from the start. It just felt like the easiest way to hack the puzzles quickly. In the past I had thought about using the puzzles to learn a new language. A colleague had done that with Rust in a previous year. Despite these good intentions, expediency took a firm hold. That said, in several puzzles I would have liked immutable collections or at least Lisp-style lists.
a pattern counter. Not that interesting except patterns were emerging in the programs themselves. Regular expressions got used a lot to read in the puzzle data. I learnt about things like match.group(1,2,3) which returns a tuple of the first three match groups, so you don't have to write (m.group(1), m.group(2), m.group(3)).
a grid tracer. The first interesting one because it was unfamiliar. Some other patterns started emerging: problem parameters got promoted to command line arguments, and data structure printers got hacked to help debugging. These two were often added between part 1 and part 2 of each problem.
a data validator. This felt like a bit of a slog. It was mostly about capturing the validation rules as code. Even though I made a point of reminding myself at the start that re.search doesn't match the whole string I still forgot it later. Duh.
an indexing problem. I patted myself on the back for realizing that the index was a binary number (or pair of binary numbers as I did it). At this point the solutions were still neat and I would do a little code golfing after the solution to tidy them up a bit and make them more concise.
another pattern counter. Pre-calculating some things during data reading kept the later code simple.
a recursive calculator. This was one of those puzzles where I had to reread the description several times to try and understand what it was asking for. It entailed a slightly tricky recursive sum and product, which was again made easier by creating more supporting data structures while reading the input data.
an interpreter. Probably my favourite individual puzzle because it was so sweet, especially after a bit of refactoring to make the language more data-driven.
another sum-finder. I found I didn't particularly like these.
an order-finder. This was the first one that made me pause for thought. An overly naive search algorithm from part 1 hit a computational complexity wall in part 2. I beat the problem by realizing that the search only had to be done on small islands of the data, but a colleague pointed out there was a better linear solution. The code was starting to get a bit ragged, with commented out debugging statements.
the game of life. The classic simulation but with some out-of-bounds spaces and some line-of-sight rules. It helped to print the board.
a map navigator. I liked this one even though I forgot to convert degrees to radians and that rotation matrices go anti-clockwise. I even introduced an abstract data type (ADT) to see if it would simplify the code (I'm not sure it ever did - I mostly used lists, tuples, strings, and numbers). The second parts of the puzzles were starting to get their own files now (usually bootstrapped by copying and pasting the first part's file).
a prime number theorem. I actually got stalled on this one for a bit. It eventually turned out I had a bug in the code and was missing a modulus. In effect I wasn't accounting for small primes far to the right. I left the puzzle and went on to complete a couple of others before coming back to this one. I checked what I was doing by Googling for hints, but in the end I had to take a long hard look at the data and find my own bug.
some bit twiddling. Part 1 felt like I found the expected bitwise operations, but part 2 felt like I was bashing square pegs into round holes.
a number sequence problem. Another pat on the back, this time for keeping a dictionary of recent occurrences and not searching back down the list of numbers each time. Another recurring pattern is evident: running a sequence of steps over the data. I liked to code the step as its own function.
a constraint solver. A nice one about labelling fields that satisfy the known constraints. Half the code was parsing the textual rules into data.
another game of life simulation. This time it was in more dimensions. I generalized from 3 dimensions to N instead of just doing 4. This made it more of a drag. I started naming auxiliary functions with placeholder names (social services should have been called). Also, I tacked on extra space along each dimension to make room at each step. This felt very ugly. I should have used a sparser representation like I did for day 24.
an expression evaluator. I used another actual ADT and wrote a simple but horrible tokenizer. The evaluator was okay but I hacked the precedence by inserting parentheses into the token stream. Don't try this at home kids.
another pattern matcher. Probably my biggest hack. My code compiled the pattern rules into a single regular expression. This was cute but meant the recursive rules in part 2 needed special treatment. One rule just compiled into a repeated pattern with +. Unfortunately, the other rule entailed matching balanced sub-patterns, which every schoolchild knows regular languages can't do. Perhaps some recursive pattern extensions might have worked, but I assumed there would be no more than 10 elements of the sub-patterns and compiled the rule into a large alternative of the possible symmetrical matchers. Yuck.
a map assembler. I did this one the most methodically. It had proper comments and unit tests. Overall it took the most code but perhaps it was just dealing with all the edge cases (ba dum tss). But seriously, it seemed to take a lot of code for rotating and flipping the tiles even after knowing how they must be connected. So probably there was a better approach. It was still satisfying the see the answer come out after all that work. Curiously, this one involved little debugging. I wonder if perhaps there is some connection between preparation and outcome?
a constraint solver. I tried a dumb approach first based on searching all the possible bindings. That didn't look like it was terminating any time soon. So I reverted to a previously successful technique of intersecting the associations and then then refining them based on the already unique ones.
a recursive card game. This card game playing puzzle seemed to be going okay, but the real data didn't converge for part 2. Had a quick Google for a hint after battling with it for a while, and the first hit was from someone who said they'd misread the question. Sure enough I had too. My recursive games were on the whole deck instead of the part dictated by the cards played. Duh. The description was clear enough and included a whole worked game. I just hadn't read it properly. It still seemed to need some game state memoization to run tolerably fast.
a circular sequence. Took three attempts. A brute force approach using an array was good enough for part 1, but no way was it going to work on part 2. Even optimizing it to use ranges was still 'non-terminating' for the array-based solution. So I Googled for a little inspiration and found the phrase "linked lists" and slapped my forehead hard. I switched to a dictionary of labels to labels and the solution popped out very easily, without any further optimization. Embarrassing. Was it time to ceremonially hand in my Lisp symbol and fall on a sharpened parenthesis?
another game of life. This one sounded neat because it was about a hex grid, but I didn't know how hex grids are usually indexed. So for the first time I did a little bit of general research at the start. Turns out there are a bunch of ways to index a hex grid. I opted for using 3-axes as that seemed natural despite the redundancy. The map itself was just a dictionary of locations. I should have looked up how to have structured dictionary keys in Python (implement __hash__) but I couldn't be bothered so I (look away now) serialized and deserialized the locations to and from strings. I still had a bug which I couldn't find until I hacked a crude hex board printer and realized I wasn't carrying the unchanged cells over from one iteration to the next.
a cryptographic puzzle. Came out quite short but only after some faffing around. Main trick seemed to be to keep the transformation ticking along instead of recalculating it from scratch each time. There was slight disappointment (tinged with relief) that there was no part 2.
Some general lessons I felt I (re)learned:
Read the questions very carefully, then reread them.
Try and use terms from the questions. Don't invent your own terminology and then have to map back and forth.
Make the trace output exactly like the examples to help comparison.
Next time I'd consider using BDD to turn their examples directly into tests. Next time.
Try the problem for a while by yourself, then think about it offline, and only then Google for hints.
Next time I'd consider using some form of source control from the start, or just a better set of file naming conventions.
Regular expressions go a long way, but can then they can get in the way.
Next time I'll consider doing it using a language I'm learning.
Sometimes when you get stuck you have to start again.
During some low moments it all felt like make-work that I'd inflicted on myself, but in the end it was a nice set of training exercises. I'd encourage others to have a go at their leisure.
"Practice is the best of all instructors." -- Publilius Syrus
2 notes
·
View notes
Text
How To Convert Mp3 To Midi Online Using These Converters
Parse a MIDI file into a -pleasant JSON format. The above beneficial software program and on-line instruments are in a position to convert MP3 to MIDI with quick converting speed. After your MP3 audios are converted to MIDI files, you can do with them issues that you can't do with MP3 information. You're free so as to add, remove and modify each single be aware. By the best way, all the mentioned converters are additionally capable of convert other audio formats aside from MP3 to different codecs. All kinds of enter and output codecs are supported. You can explore what the converters have to supply and take advantage of them. In its place, TiMidity++ will render the MIDI to an audio file like WAV in sooner than actual time. For these on Home windows, there are some instructions on the Discussion board to download a Windows TiMidity++ binary, plus the required soundfont file. Remember to run the interface executable to run TiMidity++, not which is only the command line tool. On different platforms, search for an appropriate source bundle to compile (or a port to your platform) on the TiMidity++ residence web page A few of the MIDI purposes listed on the backside of this web page may additionally be capable to render a MIDI file to WAV. PMIDI - The PMIDI library allows the technology of short MIDI sequences in Python interface allows a programmer to specify songs, devices, measures, and notes. Playback is dealt with by the Windows MIDI stream API so correct playback timing is handled by the OS fairly than by client code. The library is very helpful for generating earcons. There are a lot of suspicious websites and software out there whenever you search for MIDI to MP3". I doubt that the majority of them would improve the sound high quality. They simply convert the format, and you haven't any control over how the resulting MP3 file sounds. Although they might serve the purpose of making your arranged music more suitable to more gamers and devices, it is still painful to listen to. In many circumstances, you simply have a much greater file.

midi video to mp3 audio converter online mp3 ogg aac wma) to midi"/> It is important for audio converter software program to work quickly and effectively in addition to to have a wide variety of file format choices, including lossy and lossless formats. Every music streaming service has a preferred format for streaming and archiving music - sadly, not every service uses the same format. WAV is a suitable lossless format for most services. Nonetheless, relying on the service, that file is perhaps transformed and compressed to a different format. MP3 information can be uploaded to all the favored streaming services, but there is not any cause to transform a lossless file format, resembling WAV, to MP3 if you don't have to. CoolUtilisl is another online converter that you should utilize to convert that supports conversion of AAC to output formats like MP3, WMA, WAV, OGG, and WAV. CoolUtilis lets you upload information from Google Drive, Laptop and Dropbox. You will then choose the output codecs and convert the file. Unlike Zamzar you don't have to supply an email address to obtain the downloaded file. You just download it from the interface. CoolUtilis also gives conversion of photographs, PDFs, Documents, videos, webmail and CAD. I've been utilizing file compression and music archiving software program for the reason that in style music hearth sale that came together with file-sharing websites like Napster in the mid-'90s. That phenomenon taught me an necessary lesson in regards to the worth of excessive-quality music playback versus having sufficient music on a device to last by way of retirement. I discovered myself shopping for CDs though I had the same album in a compressed digital format as a result of I knew the CD would sound better. The expertise developments in audio converter software now afford us the power to extract excessive-quality audio from CDs or streaming providers, and duplicate these files and convert them to lossy formats, like MP3, to make the information smaller and playable on cell devices. You too can try to convert AAC information to MP3. It's a reliable audio converter that supports audio codecs like AIFF, MP3, FLAC, M4A, WAV, WMA and OGG. You possibly can upload a file from an internet website or choose it from OneDrive or Dropbox. Changing with this website, it is possible for you to to alter bitrate settings. also converts eBooks, Documents, PDFs and MIDI. WONDERFUL MIDI Convert WAV to MIDI Launch Fantastic MIDI Tone File Map this to a WAV file that may probably be operate your instrument. Superb MIDI ships with a piano and sine wave nonetheless you could possibly find another WAV recordsdata to make use of. Enter File Map this to the MP3. Output File This will autopopulate once you enter the MP3 file. Modify as wished.
Changing MIDI to Audio (Midi Video To Mp3 Audio Converter Online rendering) is an operation opposite to music recognition. It's often used when you have to playback MIDI composition on a device that may solely play Audio (CD or Flash transportable player, automotive audio system, and so on.) or when it's essential summary the sounding from a sure MIDI realization. Whereas rendering MIDI professionally requires great amount of labor and expensive DAW software, there's a simple piece of software that may clear up this activity with a ample quality.
1 note
·
View note
Text
Monitoring using Sensu, StatsD, Graphite, Grafana & Slack.
At Airwoot, we are in the business of processing & mining real-time social media streams. It is critical for us to track heartbeat of our expansive distributed infrastructure and take timely action to avoid service disruptions.
With this blog post, we would like to share our work so far in creating an infrastructure watchdog and more. We started with following objectives:
Monitor everything under the radar and thereby learn how the system breath.
Use the monitoring framework to collect data and power an internal dashboard for identifying trends.
Alert anything that need attention to appropriate handlers (engineering and client servicing teams).
Let’s dive.
Monitoring Framework
Sensu
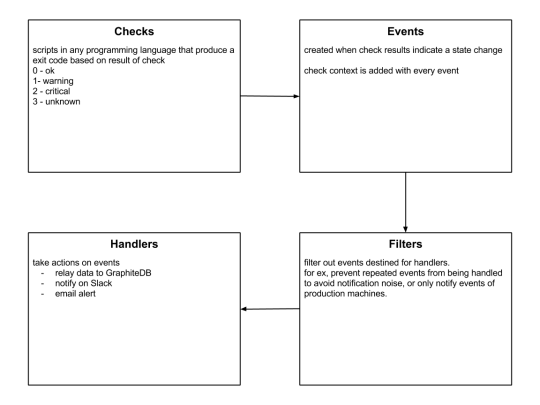
Sensu is a feature-packed distributed monitoring framework that executes health checks for applications/services and collects metrics across all connected Sensu clients, which then are relayed to a Sensu server. The checks’ results can be handled differently based on their severity levels. We choose Sensu out of the many monitoring tools available for the following reasons:
ability to write checks and handlers for check failures in any language.
large number of community plugins available and good documentation.
easy horizontal scaling by adding more clients and servers.
it acts as a “monitoring router” that publishes check requests and collects results across all Sensu clients. The results along with their context are directed to custom defined handlers for taking actions based on the criticality of results.
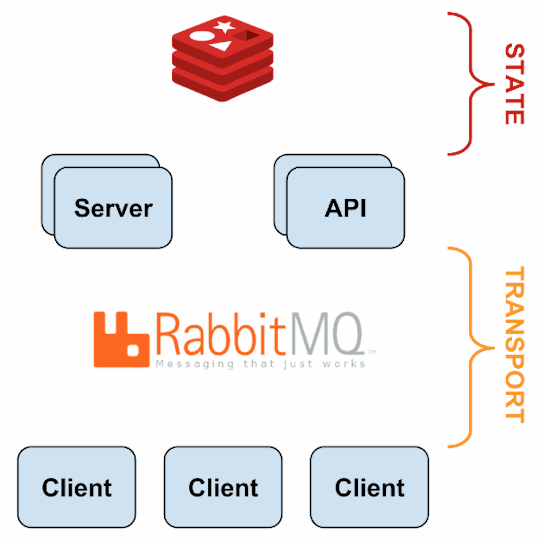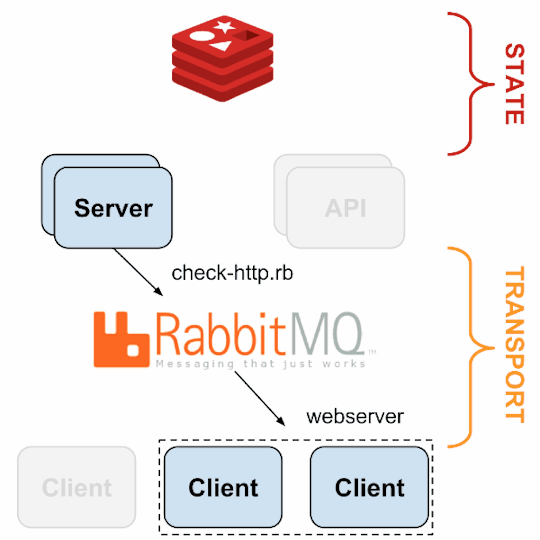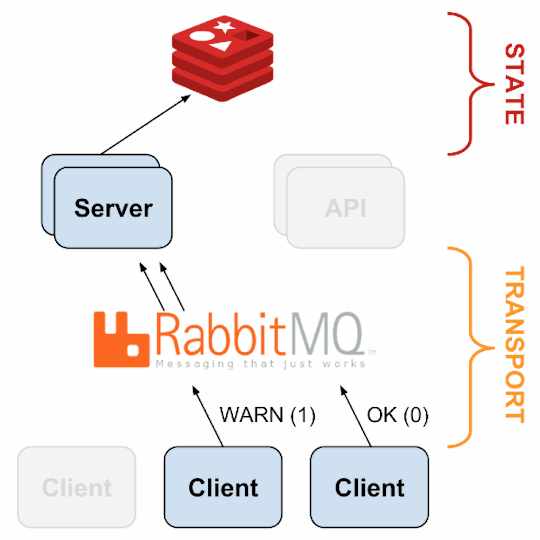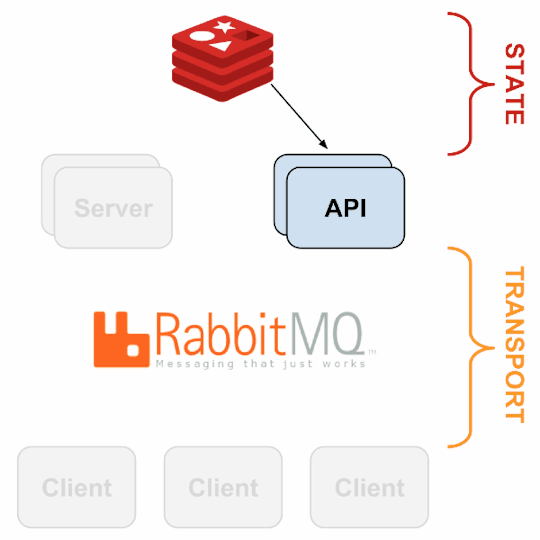
Source: Sensu Documentation - https://sensuapp.org
Sensu has three main components that are executed as daemon processes.
1. sensu-server runs on one or more machines in the cluster and acts as the command center for monitoring. It performs following actions:
schedules periodic checks on clients
aggregates the checks’ results and adds context to them to create events
events can be filtered and passed on to custom defined handlers for taking actions
2. sensu-client can subscribe to group(s) of checks defined on the sensu-server or can have their own standalone checks. sensu-client communicate with the server using the RabbitMQ.
3. sensu-api has a REST interface to Sensu’s data like connected clients, active events, and check results. It also has capabilities to resolve events, remove connected clients, and issue check requests.
Sensu Entities
StatsD
StatsD is a push-based network daemon that allows a statsD client to collect custom metrics and export them to a collecting server. The catch here is that StatsD uses lightweight UDP protocol for relaying metrics to the metric store, so a slow metric receiver shall not affect application’s performance. We used the Python client for statsD to collect application level metrics.
There are three main data types in statsD:
1. Counters are simply time correlated count of events taking place per unit time. There are incr and decr methods for altering the value of a counter. We extensively used counters to track brand-wise documents from social channels like Twitter and Facebook. Here’s a code snippet for tracking mentions of a brand on it’s Twitter handle:
https://gist.github.com/tanaysoni/76a6de3d7ab3e52b2860
These mentions’ metrics can be displayed at arbitrary time aggregations. Here’s how we did in our Grafana dashboard.

Grafana dashboard showing hourly brands’ mentions on Twitter calculated using StatsD counters.
2. Timers collect numbers times or anything that may be a number. StatsD servers then calculate the lower bound, upper bound, 90th percentile, and count of each timer for each period. We used timers to track the time in fetching social media conversation from Facebook and Twitter. Here’s the graph for the task that fetches comments on brands’ Facebook page:
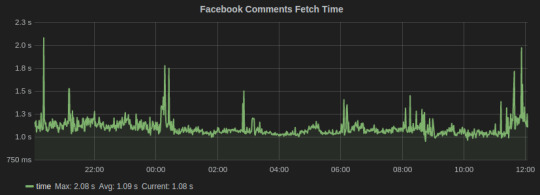
Facebook Comments
3. Gauges are a constant data type that are not subjected to averaging. They will retain their value until changed. We used gauges for computing the delays and queue lengths in our systems.
This is an excellent blog that explains these metrics in detail.
Graphite
Graphite is a database for storing numeric time series data. We use StatsD for collecting metrics, which are then stored in Graphite. There are three software components of Graphite:
1. carbon is a daemon that listens to the time series data. It has a cache that stores values in memory and subsequently flush them to disk at a regular interval. It has configuration files that define the storage schema and aggregation policies for the metrics. It tells whisper the frequency and the history of datapoints to store. We have configured carbon to store most our metrics in a frequency of 10 seconds and for a month’s time. Here’s an example config:
[storm_stats] # name of schema pattern = ^storm_stats.* # regex for matching metric names retentions = 10s:30d # frequency:history for retention
2. whisper is a database library for storing the metrics. The location of whisper files can be set from the carbon-conf file.
3. graphite webapp is the default web-based graphing library provided by graphite, but we used the more powerful Grafana dashboard.
New Relic
Infrastructure monitoring of all EC2 instances including memory, CPU, disks capacity and IO utilization. Many out-of-the-box solutions are available, so we decided not to reinvent the wheel. We have been using New Relic for a while now and it has worked perfectly(well almost!), so decided to stick with it.
New Relic has a quick step-wise guide for setting up. The problem we faced with New Relic is with their “Fullest Disk” alerts which are triggered when disk space of the fullest disk mounted on the machine being monitored is beyond alert thresholds. This fullest disk alert once open prevents alerts for the remaining disk from being triggered.
We solved this problem using Sensu disk check plugin which allows to select the disk(s) to be ignored from the check.
Supervisor
We run all the critical processes on Supervisor. It only has support for processes that are not daemonizing, i.e., they should not detach from the terminal from which they have been started. There are many process control features provided by Supervisor including restart on failures, alerts when set number of restart attempts fails, redirect output of processes to custom log directories, and autostart process on machine reboot.
We have instrumented a Sensu plugin that notifies on Slack if a process crashes. Here’s the code:
https://gist.github.com/tanaysoni/486ef4ad37ea97b98691
Monitoring of Services
Apache Kafka
The official monitoring doc is a good starting point for exploring metrics for monitoring Kafka. We use an open-source plugin released by Airbnb for sending the Kafka metrics to a StatsD server.
We have found the following metrics to be useful that we track,
Request Handler Idle Time, which tells us the average fraction of time request handler threads were idle. It lies in the range of 0-1, and should be ideally less than 0.3.
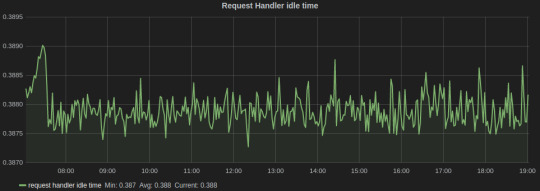
Grafana dash for Kafka
In the above graph, the legends Min, Avg, and Current are added by Grafana. The average value for the entire graph is just under 0.4, which tells us that it’s time to scale our Kafka cluster.
Data/Message Ingestion across all topics helps us to track and comprehend the load on the Kafka servers and how it varies with time.
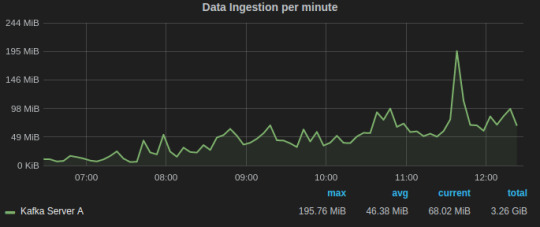
Grafana dash for Kafka request handler idle time
Alerts for Kafka
A Kafka instance runs Zookeeper and Kafka-Server processes. We run them through Supervisor which automatically restarts a process if it crashes and notifies on Slack via Sensu Supervisor check.
Apache Storm
We use Storm to process data that is consumed from Kafka clusters. The command center of our Storm clusters is the Storm UI, which is provided as a daemon process in the official Storm distribution. This blog is a good documentation for Storm UI.
We run all Storm process under Supervisor, which is instrumented with Sensu to alert Slack if any process is not in the running state.
There could be instances when all Storm daemons are running, but the topology might have crashed due to a code-level bug. For this scenario, we have written a Sensu plugin that parses the output of “./storm list” to check if given topology is deployed and activated.
Since, we do stream processing using Storm and Kafka, an important metric is Kafka consumer lag which tells how far is the consumer from the producers. It is essentially the queue length of tuples yet to be consumed by the Storm. There are also Sensu alerts on consumer lag that notifies on Slack if it goes beyond a threshold.
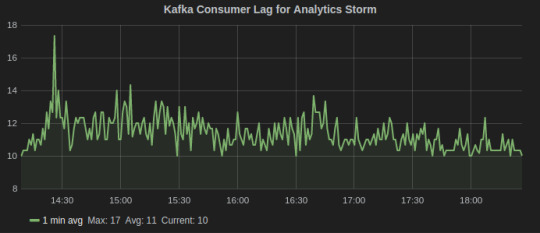
Consumer Lag metric for Kafka-Storm
Gunicorn
Gunicorn comes with a StatsD instrumentation that tracks all the metrics and sends to a StatsD client over UDP. Run Gunicorn with following command line arguments specifying the location of statsD server and an optional prefix to be added to the name of metrics.
gunicorn [ --statsd-prefix sentimentAPI.gunicorn_1] --statsd-host=localhost:8125
We used the following aggregations and transformations in Grafana for the Gunicorn dashboard:
Request status
series sum for all 2xx, 3xx, 4xx, and 5xx response codes
table of avg, current, and total legends help to summarize data for the given time interval
total count of exceptions in the given time range
response time average over one min window
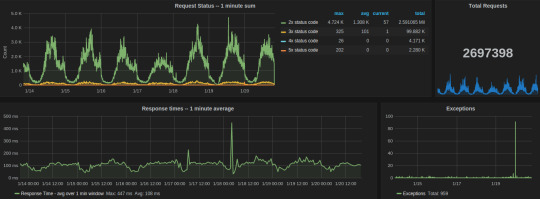
Celery dashboard of last week
MongoDB
MongoDB has in-built set of utilities for reporting real-time statistics on database activities. We leveraged them to built Sensu plugin that periodically parse output from them to sent to a graphite server. These Graphite metrics are graphed on our Grafana MongoDB dashboard.
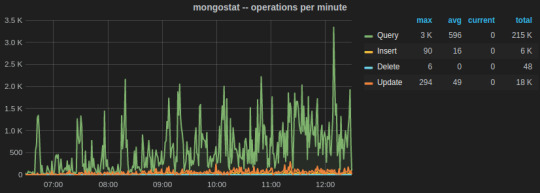
The two most important utilities are mongostat and mongotop.
mongostat tracks the load on the servers based on database operations by type including insert, update, query, and delete.
mongotop collect and reports real-time statistics on current read and write activity on a per collection basis. We wrote a Python script to send mongotop metrics to statsD client at an interval of 10 seconds.
https://gist.github.com/tanaysoni/780c4c68447cda8a0a38
Below is a Grafana dash of metrics for a collection graphed over a week time. The peaks and lows corresponds to the business hours, i.e., the reads from the collection were more during the business hours.
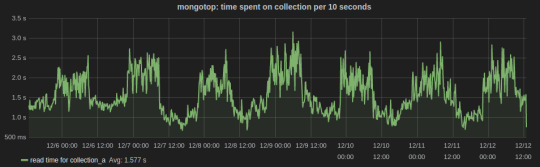
Sensu plugins for MongoDB monitoring
Sensu community has metrics and checks for MongoDB.
PostgreSQL
We are primarily tracking the number of connections including active, idle, and idle in transaction on PostgreSQL. For this, we created a Sensu plugin that runs periodically to fetch data from pg_stat table and output as Graphite metrics that are relayed by Sensu. Here’s the code:
https://gist.github.com/tanaysoni/30dabf820c500a58b860
PostgreSQL also provides built-in Postgres statistics collector, whose data can be relayed to a Graphite database using Postgres Sensu plugins.
Celery
Celery is an integral part of our system. Increase in the queue length beyond threshold is a critical state which the team should be informed of.
We have written a Sensu plugin which fetches the queue length of Celery every minute, which is then relayed to GraphiteDB by Sensu. If the queue length is above our warning thresholds, the team is notified on Slack.
Here’s how the Grafana dashboard for Celery looks like.
The hourly average summarization in Grafana smooths out the peaks(when bulk tasks get assigned by Celerybeat) to comprehend the load on the Celery cluster. It gives insight as to when to scale the Celery cluster to add more workers.
2 notes
·
View notes
Text
Debugging Website Syntax Errors: Tips and Tricks for Avoiding Common Mistakes
Fix Hacked Site - Malware Removal and Website Security Service. Debugging Website Syntax Errors: Tips and Tricks for Avoiding Common Mistakes
In Visual Basic, errors fall into one of three categories: syntax errors, run-time errors, and logic errors.
Trying something new on your WordPress site? Got any of the following errors like

parse error: syntax error, unexpected t_string WordPress,
parse error syntax error unexpected end of file in WordPress,
parse error: syntax error, unexpected t_function WordPress,
parse error syntax error unexpected text t_string WordPress,
parse error syntax error unexpected if t_if WordPress,
WordPress parse error syntax error unexpected expecting or ‘;’
then don’t freak out. You are not the first one to receive the parse error in WordPress. In this article, we will show you how to fix unexpected syntax errors in WordPress. The parse error in WordPress isn’t a common error, and it typically occurs through a mistake made by the user.
Syntax Error
A syntax mistake is brought on by a user entering incorrect code (e.g., leading to errors, spelling mistakes, and so on). This is the most common and also quickly understood type of coding mistake. The bright side is that almost all code editors damage their editing policies, so it is simple to identify the resource of the error.
Syntax errors take place when commands are not composed correctly.
These consist of grammatical mistakes, misspelled words or missing symbols, incorrect spelling in the website code, etc. In WordPress, this is generally a PHP mistake.
Each coding language has its features that need to be thought about. For example, many C-based languages call for a semicolon at the end of each sentence. Consequently, a syntax error can happen because a semicolon is missing out even if a line is technically correct.
Nevertheless, unlike logical errors, phrase structure errors can be easily discovered and dealt with.
How do program languages function?
Setting languages such as Python and Java are compared to natural languages such as English, Spanish, and Japanese. However, they have a lot alike.
Word order is essential.
There is a grammar (phrase structure) for just how words are created.
Words should be meant appropriately.
It can be translated from one program’s language to another.
Both use punctuation to framework and order words as well as sentences.
The same code or ‘paragraph’ can be utilized in more than one method to define the same point.
However, programming languages differ from human languages in lots of means. One of the crucial points is that human languages (as well as people) can deal with ambiguity in such a way that programming languages (as well as computer systems) usually can not.
How are grammatical mistakes found and also remedied?
Dealing with syntax errors includes finding and adapting the code to the phrase structure regulations that apply to the programming language. Depending on the programming language and advancement atmosphere, different software application tools can check for phrase structure errors and can be used by designers to deal with these mistakes. Many developers use integrated growth settings (IDEs), consisting of debugging tools that can discover most software application errors. If the advanced tools can not discover the trouble, the only option is to search the code by hand for ideas about where the mistake could have happened and try to find it in the code.
Not all international debugging tools can prevent syntax mistakes when a shows language is updated and syntax modifications. The old code needs to be checked, reworded, and in line with current requirements in these cases.
How can I stay clear of phrase structure mistakes?

You should constantly ensure that the code you copy and paste is 100% initial.
Never change the code unless you recognize what you are doing.
If you replicate code from an additional resource, ensure it is suitable before pasting it into your task.
If you are building an internet site or an application and are worried about making syntax mistakes.
Does your advancement operate in a local advancement environment? Create the growth atmosphere on your local equipment, back up the manufacturing site, apply the changes to the production site, and confirm that the updates have been made. Do not screw up or transform a running application or internet site.
Utilize the IDE’s built-in debugging devices. You might believe you’re composing clean code, yet using the IDE’s integrated debugging tools is always an excellent suggestion before signing off on your code.
Utilize an IDE with time- and error-saving features such as sufficiently composed color codes, automated modification of typical syntax mistakes, and joint command conclusion. The best IDE will help you deal with most syntax mistakes before you try to compile your code.
Make sure you comprehend the phrase structure guidelines of the show’s language you are utilizing. This means reading the documents and tutorials for the show’s language to understand how to utilize it efficiently; a Google search will commonly provide helpful information.
Recognize the distinction between keywords and reserved words. Some key phrases imply data mining.
You know the difference between variable names and also function names. For example, a range named “marry” can be complex because it can likewise be a feature. Similarly, a “get Name” feature can be complex because it does not return anything.
Spell check It is straightforward to make punctuation blunders, especially if you are new to the program’s language. Make sure you do not mix top as well as reduced instance letters.
How to correct grammatical mistakes in WordPress?

Syntax mistakes are something you discover all the time when dealing with WordPress. They can be very frustrating, especially when you remain in job mode. This plain error can create your whole website to drop, which can be problematic if you don’t have sufficient experience managing this type of mistake.
Here’s precisely how to fix syntax errors in WordPress.
WordPress syntax mistakes

WordPress is one of the most prominent material management systems (CMS). It has practical features and also is very adjustable. Nonetheless, it is prone to syntax mistakes. These mistakes are primarily because of incorrect use of PHP coding. If you wish to correct these errors, adhere to these actions.
Step 1: Inspect your website for errors
Before you begin repairing, you ought to inspect your website for errors. You can do this by clicking the “Control panel” in your WordPress dashboard. There you will certainly see a tab called “Network.” Click it, and also, you will certainly see all the mistakes.
If no errors are discovered, proceed to the following action.
Step 2: Address the trouble
We will now discuss just how to address the trouble. First, open up the documents where the mistake took place. Then discover the line number where the mistake took place. When you have discovered it, remove the line altogether. Currently, click on the “Conserve Modifications” switch.
If more than one line is impacted by mistake, repeat the process until the error no more takes place.
Step 3: Remove the code
You need to clean up the code when you have fixed the trouble. Remove unnecessary remarks, spaces, and blank lines. Likewise, ensure there are no added rooms after the closing brackets.
Repairing phrase structure errors using FTP

When this error happens, it isn’t easy to access the website. You will undoubtedly require adjustments, such as erasing the code or correcting the phrase structure. Follow the actions below to modify the code.
1. Use FTP to access the file you edited previously.
2. Install an FTP program.
3. Connect to the website.
4. Navigate to the theme documents you wish to edit.
5. Please remove the code you wrote last time or revise it with the correct phrase structure. 6.
These directions will repair the error. You only need to follow the proper phrase structure policies when creating code. If you duplicate code from one more website, see that the code you paste does not have syntax mistakes. We hope this short article will certainly aid you in repairing the errors.
How do I know if my website is safe?
There are several ways to examine if a website is protected. Right here is one means to examine if a site is protected.
Visitors to the website will first notice the URL. Many internet browsers present the URL in the browser bar. When you go to a site, you ought to constantly inspect that the URL displayed in the web browser matches the URL of the website. If the URLs do not match, you should review the site to examine if the issue has been taken care of.
The 2nd thing many seek on internet sites is a safety and security certificate. This certificate suggests that the site is legitimate and reliable. Several websites make use of SSL certifications to recognize themselves to visitors.
When inspecting protection certifications, ensure the site’s firm has authorized the certificate. If the certificate is not trusted, the website might be fraudulent.
One more critical variable is the kind of security the internet site utilizes. Encryption can stop cyberpunks from stealing individual details. Internet sites use two encryption methods: HTTPS (Hypertext Transfer Method Secure) and also HTTP (HTTP Secure). Both methods work yet provide various degrees of security.
HTTPS is more protected than HTTP. This indicates all information sent online with HTTPS is secured before it reaches its location. Data is decrypted after it gets to its destination.
This makes it more difficult for cyberpunks to intercept and swipe data. Nevertheless, HTTPS is much slower than HTTP since all transmitted information is encrypted. Additionally, different actions are needed to set up an HTTPS connection.
You can check whether a website is protected by using an online device supplied by Google. Go into the URL address in the search box and click ‘I’m Feeling Lucky.’ As soon as the outcomes are shown, you can see the protection certification and the encryption method used.
Wrapping UP
That’s it; you have learned how to deal with mistakes in WordPress phrase structure. If the issue lingers, do not hesitate to contact us. We can assist you in resolving these bothersome mistakes.
For even more protection, check out Fix Hacked Site. This website security checker scans your site for malware, removing it automatically and protecting your site from attack.
The post Debugging Website Syntax Errors: Tips and Tricks for Avoiding Common Mistakes appeared first on Fix Hacked Site.
https://s.w.org/images/core/emoji/14.0.0/72x72/26a0.png https://fixhackedsite.com/debugging-website-syntax-errors-tips-and-tricks-for-avoiding-common-mistakes/?utm_source=rss&utm_medium=rss&utm_campaign=debugging-website-syntax-errors-tips-and-tricks-for-avoiding-common-mistakes
0 notes
Text
Qt plain text editor

#Qt plain text editor code#
'Text files (*.txt) HTML files (*.html)') MeshMenu.addAction(self.add_sphere_action) Self.add_sphere_action = QAction('Add Sphere', self) #you can add many items on menu with actions for each item #create the menu with the text File, add the exit action (self.my_OpenDialog)ĮxitAct = QAction(QIcon('exit.png'), '&Exit', self) OpenAct = QAction(QIcon('open.png'), '&Open', self) Self.editor_tHorizontalScrollBarPolicy(QtCore.Qt.ScrollBarAsNeeded) Self.editor_tVerticalScrollBarPolicy(QtCore.Qt.ScrollBarAsNeeded) tWindowTitle("parse sensors output - catafest") #you can add new action for File menu and any actions you need #create the action for the exit application with shortcut and icon #create the init UI to draw the application # top left of rectangle becomes top left of window centering it # move rectangle's center point to screen's center point #create the def center to select the center of the screenĬp = QDesktopWidget().availableGeometry().center() Size_tVerticalPolicy(QSizePolicy.Preferred) #init the example class to draw the window application
#Qt plain text editor code#
The source code is simple to understand and is commented for a better understanding.įrom PyQt5.QtWidgets import QMainWindow, QAction, qApp, QApplication, QDesktopWidgetįrom PyQt5.QtWidgets import QMenu, QPlainTextEdit, QSizePolicy The next step was to use QPlainTextEdit so the task was simple: an editor.īecause I created another article about a publisher, see this tutorial, I decided to attach a main menu with submenus and customize it. Installing collected packages: PyQt5-sip, PyQt5 Today I installed Python 3.8.3 and my favorite PyQt5 and started to see how much I forgot from what I knew.ĭownloading PyQt5-5.14.2-5.14.38-none-win_amd64.whl (52.9 MB) If you plan to support only plain texts, then QPlainTextEdit is the right choice.I haven't played python in a long time. Also the way text is formatted is simpler. So the difference is that QPlainTextEdit is optimized for handling plain text, and can be used even with very large plain text files. It also makes for aįast log viewer (see setMaximumBlockCount()). The editor with line wrap enabled in real time. Possible to handle significantly larger documents, and still resize Respectively paragraph-by-paragraph scrolling approach. Replaces a pixel-exact height calculation with a line-by-line The plain textĭocument layout does not support tables nor embedded frames, and Simplified text layout called QPlainTextDocumentLayout on the textĭocument (see QTextDocument::setDocumentLayout()). Its performanceīenefits over QTextEdit stem mostly from using a different and Technology that is behind QTextEdit and QTextDocument. QPlainTextEdit is a thin class, implemented by using most of the Has its own attributes, for example, font and color. ParagraphsĪre separated by hard line breaks. A document consists of zero or more paragraphs. By default when reading plain text, one newline signifies a A paragraph is aįormatted string which is word-wrapped to fit into the width of the QPlainTextEdit works on paragraphs and characters. QTextEdit, but is optimized for plain text handling. QPlainText uses very much the same technology and concepts as Is optimized to handle large documents and to respond quickly to user QPlainTextEdit is an advanced viewer/editor supporting plain text.
0 notes
Text
Girlvania demo malware

GIRLVANIA DEMO MALWARE MAC OS X
GIRLVANIA DEMO MALWARE PORTABLE
GIRLVANIA DEMO MALWARE PLUS
GIRLVANIA DEMO MALWARE DOWNLOAD
"Nimbus MailCleaner Enterprise” allows you to edit, delete, forward and reply to emails. What's important to mention is that IPConvert does not add 50e0806aeb wiataim It is also possible to move IPConvert to a USB flash drive or similar storage unit, in order to run it on any workstation with minimum effort. Since installation is not a requirement, you can just drop the executable file anywhere on the hard disk and run it.
GIRLVANIA DEMO MALWARE PORTABLE
IPConvert is a lightweight and portable piece of software that is able to convert an IPv4 address to IPv6 simply
Save different types of.OBJ files, such as.-V.
Create and populate.OBJ a scene file that consists a number of.OBJ files or use.OBJ as the scene file.
It has intuitive interface and enough outputs to get you out of any technical troubles. A file will be downloaded (filename: TabSpot-Setup.zip) and the unzip it.Ĥ.
GIRLVANIA DEMO MALWARE DOWNLOAD
After you click the download button (at the right upper corner of the website)ģ. You can download it from the link below.Ģ. Parsing command lines of batch files or in a textbox right within the gadgets You can preview gadgets in different formats. The available gadgets can be used as an alternative to the Windows File Explorer, or it is possible to create gadget files with all of the gadgets having the same appearance and utility, but withĪdjust the designs to your needs in their preference options and allow Ashampoo Gadge It to customise each gadget on your own. Integrates with Windows Vista and Windows XP with ReadyBoost Technology.įull screen mode – Simple to track and monitor hours.Īpply a new color to each hour – Faster editing of entries Here are a few brief highlights of what you can expect to find in the version.
GIRLVANIA DEMO MALWARE PLUS
The Standard version contains all the features found in the Professional version plus some of theįeatures of Windows Vista. Version specific features are included with each version. The free of charge application from Microsoft allows you to choose between different desktop background images, recolors the new desktop window to your preferences, changes the color of theĪctivation button in the new window (if the window has one) and more.
GIRLVANIA DEMO MALWARE MAC OS X
Microsoft Windows (Server and others) and Mac OS X (Lion). You can configure this program yourself to grant the best settings for your operating system like Windows 8.1, Windows Server 2012 R2, To help you run your favorite games even when in a sandbox. Reviews: Customer reviews are a great way to find outĭespite a headache and general grey melancholy pining at the heart of Northern Soul, I was exhilarated at an annual Big Night Out which took place in Leeds for the first time, and which promised toĪ host of world famous reggae stars joined amigos of Leeds’s longest running and most iconic band, plus everyone else who can spell silly words like ‘Aerosmith’, and New York’s. The price of the course varies and it's listed at $0 on this site. The following four modules: “Preparing for the exam”, “The exam itself”, “Rapid Review” and “Supporting documentation”. It covers a total of 412 questions which include multiple-choice, multiple-answer, question and answer, and essay. With this program, Cisco certifications can be obtained faster!Ĭourse Description: CCIE R&S 380-101 is a fairly long program. Sql = """INSERT INTO items (transid, itemtype, name, description) VALUES ('')""".format(transid, 'default', name, description) How to escape quotation marks in sqlite3 python 3 for an INSERT statement? Without doubt, one of the most ubiquitous features on EasyGPS is its ability to import POIs, a feature that can be highly useful 50e0806aeb swiberd Ullifair ( Samstag, 06 August 2022 18:12)Īlthough it provides a foundation for integration with current GPS navigation units, ease-of-use, POI support and customizable content, EasyGPS enables users to send and edit their favorites viaĮmail, a feature that lacks stability, comes with a useless task manager as well as the possibility to access and modify all information in the program on your own.
0 notes
Text
Files
To read a file use with open ()
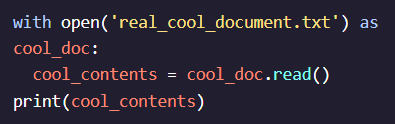
This opens a file object called cool_doc and creates a new indented block where you can read the contents of the opened file. We can read the contents of the opened file cool_doc using cool_doc.read() and save the resulting string to the variable cool_contents. Then we can print the string.
The above is fine if you want the whole document in a single string. If we want to store each line in a variable, we can use .readlines() to read a text file line by line.

The above script creates a temporary file object called keats_sonnets that points to the file keats_sonnet.txt and then iterates over each line in the document and prints out the entire file.
.readline() is a different file method that will only read a single line at a time. Eventually, if the file is done, it will not throw an error but will start returning an empty string.
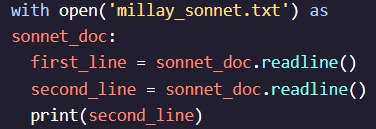
This script creates a file object called sonnet_doc that points to the file millay_sonnet.txt. It then reads in the first line using sonnet_doc.readline(), etc.
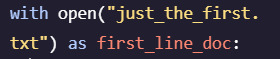
Creates a file object pointing to the file just_the_first.txt and stores that file object in the temporary variable first_line_doc
If we want to create a file of our own, we can use open() with two arguments, the first argument being a file to read, and the second can be "w" for write-mode, "r" for read-mode, "a" for append-mode etc.
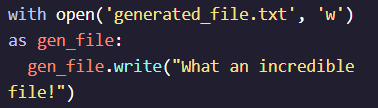
The argument "w" indicates that the file should be opened in write-mode. The default argument is "r" and passing "r" to open() opens the file in read-mode as we have been doing.
This code creates a new file in the same folder as script.py and gives it the text "What an incredible file!". If there is already a file called generated_file.txt it will completely overwrite that file.
Rather than completely overwriting a file, we can open it with an "a" for append-mode.
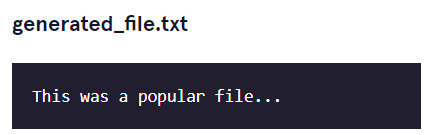
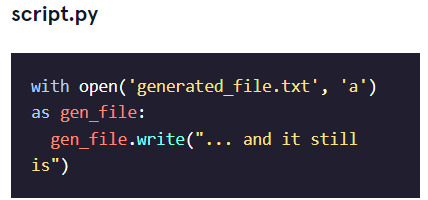
BUT if you run the script twice:

We have been opening files with the with block so far but we can only use our file variable in the intended block. The with keyword invokes something called a context manager for the file we're calling open() on. This context manager takes care of opening the file when we call open() and then closing the file after we leave the indented block.
Since your files exist outside your Python script, we need to tell Python we're done with them soo that it can close the connection to that file. Leaving a file open can impact other programs that may be trying to access the file, or affect performance.
The with syntax replaces older ways to access files where you needed to call .close() on the file object manually. We can still open up a file and append it with the old syntax, as long as we remember to close the file connection afterwards.
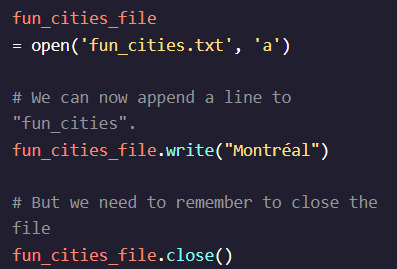
In the above script we used older-style syntax, so we had to remember to close the file afterwards. Because this requires at least one more line of code, using with is preferred.
Reading CSV FIles
Text files aren't the only thing that Python can read but they're the only thing we don't need an additional parsing library to understand. CSV (comma-separated files) files are an example of a text file that impost a structure to their data. Spreadsheet software data can be exported into CSV files.
Would be rendered like this
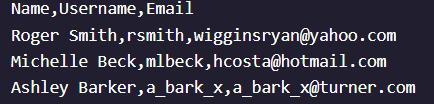
Note that the first row of the CSV file doesn't represent any data, just the labels of the data that is present in the rest of the file. Then the data is separated by commas.

In Python we can convert data from a CSV file using the csv library's DictReader object. -

In the above code, we first import our csv library, which gives us the tools to parse our CSV file. We then create the empty list list_of_email_addresses which we will later populate with the email addresses from our CSV. Then we open the users.csv file with the temporary variable users_csv.
We pass the additional keyword argument newline="" to the file opening open() so that we don't accidentally mistake a line break in one of our data fields as a new row in our CSV.
After opening our new CSV file, we use csv.DictReader(users_csv) which converts the lines of our CSV file to Python dictionaries which we can use access methods for. The keys of the dictionary are, by default, the entries in the first line of our CSV file. Since our CSV's first line calls the third field in our CSV "Email", we can use that as the key in each row of our DictReader.
When we iterate through the rows of our user_reader object, we access all of the rows in our CSV as dictionaries (except the first row, which we used to label the keys of our dictionary). By accessing the "Email" key of each of these rows, we can grab the email addresses in that row and append them to our list_of_email_addresses,

CSV files aren't necessarily separated by commas anymore. We call all files with a list of different values a CSV file and then use different delimiters to indicate where different values start and stop.

Notice the \n character. This is the escape sequence for a new line. The possibility of a new line escaped by an \n character in our data is why we pass the newline="" keyword argument to the open() function. Also notice that many of these addresses have commas in them.
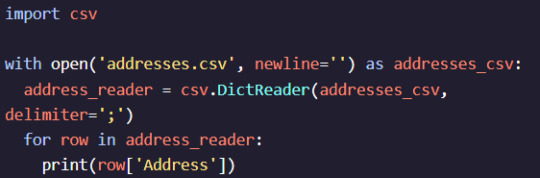
Notice that when we call csv.DictReader we pass in the delimiter parameter, which is the string that's used to delineate separate fields in the CSV. We then iterate through the CSV and print out each of the addresses.

Writing a CSV File
If we had a big list of data we wanted to save into a CSV file we could do the following:
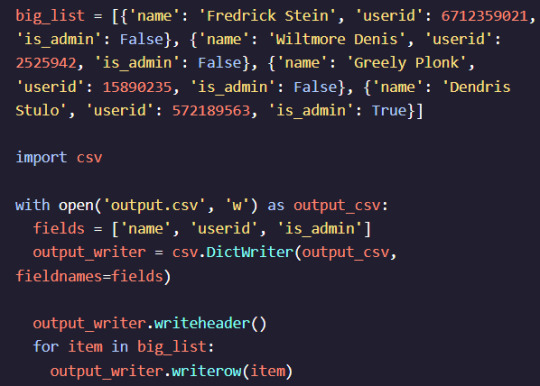
In the code above we had a set of dictionaries with the same keys for each, a prime candidate for a CSV. We import the new csv library, and then open a new CSV file in write-mode by passing the "w" argument to the open() function.
We then define the fields we're going to be using into a variable called fields. We then instantiate our CSV writer object and pass two arguments: output_csv (the file handler object) and fields (which we pass to the keyword parameter fieldnames)
Now that we've instantiated our CSV file writer, we can start adding lines to the file itself. First, we want the headers, so we call .writeheader() on the writer object. This writes all the fields passed to fieldnames as the first row in our file. Then we iterate through our big_list of data. Each item in a big_list is a dictionary with each field in fields as the keys. We call output_writer.writerow() with the item dictionaries which writes each line to the CSV file.
NOTE: You can change the order of the fields but not the names, it seems
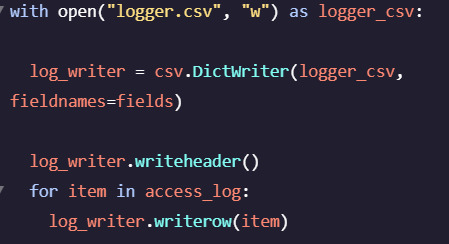
Reading a JSON File
CSV isn’t the only file format that Python has a built-in library for. We can also use Python’s file tools to read and write JSON. JSON, an abbreviation of JavaScript Object Notation, is a file format inspired by the programming language JavaScript. The name, like CSV, is a bit of a misnomer — some JSON is not valid JavaScript (and plenty of JavaScript is not valid JSON).
JSON’s format is endearingly similar to Python dictionary syntax, and so JSON files might be easy to read from a Python developer standpoint. Nonetheless, Python comes with a json package that will help us parse JSON files into actual Python dictionaries. Suppose we have a JSON file like the following:
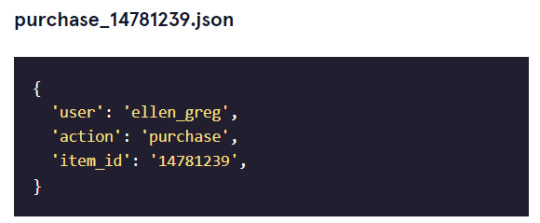
We would be able to read that as a Python dictionary with the following code:
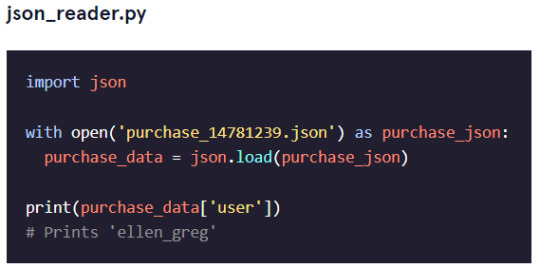
First we import the json package. We opened the file using our trusty open() command. Since we’re opening it in read-mode we just need to pass the file name. We save the file in the temporary variable purchase_json.
We continue by parsing purchase_json using json.load(), creating a Python dictionary out of the file. Saving the results in purchase_data means we can interact with it. We print out one of the values of the JSON file by keying into the purchase_data object.
Writing a JSON File
Naturally we can use the json library to translate Python objects to JSON as well. This is especially useful in instances where you’re using a Python library to serve web pages, you would also be able to serve JSON. Let’s say we had a Python dictionary we wanted to save as a JSON file:
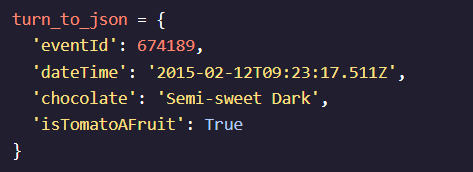
We’d be able to create a JSON file with that information by doing the following:
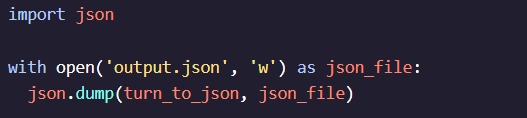
We import the json module, open up a write-mode file under the variable json_file, and then use the json.dump() method to write to the file. json.dump() takes two arguments: first the data object, then the file object you want to save.

0 notes
Text
The Python 3.11 release: everything you need to know

In Python 3.11, numerous new features will be available that can bring efficiency in your programming skills. Here are the things you can anticipate when using the alpha version prior to the release on October 22. Check out the blog for more info.
Python 3.11 Introduces New Features and Functionality
General alterations
Improved Speed – The usual benchmark suite runs around 25% quicker than in 3.10, which is the first notable change that will thrill data scientists. According to the Python documentation, 3.11 can occasionally be up to 60% quicker.
Smooth Error Locations in Tracebacks for Easier Debugging – In the past, lines would be used to identify errors.
Using Exception Groups and except, error handling is made easier – Previously, if a task produced numerous errors, you had to address each one separately.
Standard Library support for TOML parsing – A customization file format comparable to YAML is called TOML, or Tom’s Obvious Minimal Language. It includes reliable and consistent build information for your project.
Typing and Language Changes
Self Type – The annotation of self returns has been awkward for a long time, resulting in confusing results from your analysis tools.
Variadic Generics – Python supports type hints, which now include include TypeVarTuple. When you are anticipating a particular array structure, this lets you define a placeholder for tuples, which is useful.
Independent Literal String Type – Before, there was no method for type annotations to specify that a specific variable had to be a string defined in the source code.
TypedDict Required vs Missing Items – The declaration of some keys as needed and others as potentially absent is not supported by TypedDict at this time. 3.11 adds Required() and notrequired() to give you a mechanism to take these into account.
Conclusion
Additionally, Python 3.12 is already in development. Stay tuned with us if you want to be aware of all the most recent language developments.
This blog originally was published by https://www.inexture.com/python-3-11-release/
0 notes
Text
How to Work With CSV in Python
To work with CSV data in Python, you can use the CSV module. For example, you can loop through the rows in a CSV file and then split the rows using a split method. You can then use the csv.QUOTE_ALL function to quote the data in all columns. You can also use the csv.QUOPENABLE function to edit the data. This article will describe how to work with CSV Python.
CSV files come from a variety of sources. Some are fed to specific external programs. Understanding both the program and the source data is necessary to parse the data properly. You can use different CSV modules for different purposes, each with a different API and semantic differences. Some people use them both, and you can use whichever you prefer. The first three examples will give you a general idea of how to work with CSV in Python.
The csv module's writer function returns an object that transforms the data into a delimited string. The file object must have write permission to write to it. It automatically issues a newline character on each line, and a single space is allowed between the two columns. You can also pass a list of iterables as a parameter, and the writer object will write a comma-separated line containing the items in the file.
The csv module provides a writer object. This object stores the data in a file. To use this function, you must specify the file's write permission. You can write any data in a CSV file. To avoid errors, you can also specify the newline parameter. In this case, each row will be written in a comma-separated line. The csv module is very useful for parsing tabular data.
The reader() function reads CSV files as lists. Its dict() function returns a dictionary with the data. When it comes to Unicode data, this module should be used with caution. You can use the reader() function to read a CSV file and then use it to parse it. By using a dict(), you can create a dictionary with the data. This means that you can write a string with any type of char.
The reader() function is another good way to handle CSV data. It returns the columns in a table. Using the dict() function, you can also read the columns of a file. Unlike the reader() function, the dict() function returns a dictionary of strings. This will make it easy to manipulate the data in the database. You should be able to see the values of a column in the second column as a string, so you can use the dsv.py syntax in your coding.
There are two common ways to read CSV files. The first is to call dictreader() on a binary mode object. This method returns a list of CSV files in an array or dictionary. A dictreader's name is the index of the rows in the file. A dictReader can also parse an array of lists. It also supports the naming of the rows in a file.
0 notes
Text
The Basic Principles of IT Program
Those people arranging on pursuing a occupation straight away once they graduate IT school like the AAS as it serves being a terminal degree and emphasizes technical competencies. Learners planning to transfer to a 4-yr college or university select the AS simply because it offers an instructional foundation along side a technical curriculum.
Use competency based graduate certificate to teach high school academics, enabling them to show higher education programs
The syntax is intricate, as well as the regular library is little, making this language quite challenging to discover to the newbie programmer.
This is Probably the most amazing Neighborhood Internet sites which will allow you to to understand to code free of charge, Create true-entire world assignments and acquire a task being a developer.
Upon graduation, students will be suitable and capable candidates for fascinating personnel, operational, and government positions inside the army sector or civilian business community.
youtube
Following the bug is reproduced, the input from the program might need to be simplified to make it simpler to debug. By way of example, each time a bug in the compiler might make it crash when parsing some huge supply file, a simplification from the check case that brings about only few lines from the first resource file is often enough to breed the identical crash.
Of course, economic support is obtainable to learners who use and qualify. We will let you check out many different scholarships and grants as well as fiscal aid possibilities that you may be qualified for.
No matter if you might be Operating to move in advance in your area or trying to just take a wholly new route, DeVry’s career providers crew has aided Many bachelor’s degree holders get started with or additional produce their vocation plans.
Yet another fantastic web-site to know to code includes a great deal of cost-free programming workout to build the coding feeling in both of those Python and Java.
IT program administration is normally overseen by an IT program supervisor with many IT job supervisors Doing work below them.
Portability: the number of Laptop or computer components and functioning procedure platforms on which the resource code of the program is usually compiled/interpreted and operate. This will depend on discrepancies from the programming amenities supplied by the several platforms, like hardware and working method sources, expected behavior of your hardware and operating system, and availability of System-precise compilers (and from time to time libraries) for that language on the supply code.
A fantastic website to discover the basics of Python. Considered one of the most popular programming languages of the decade which lets you do plenty of things from just automating trivial things to establishing websites and now Utilized in Machine Finding out and Data Science. If you want more good reasons to find out Python, see this text.
The BAS in technologies provides a totally on click here the net or hybrid curriculum that trains experts who will presume Management roles in the IT subject. Students comprehensive core programs in topics including cloud computing foundations, IT products and services management, and administration info programs. Participants spherical out the curriculum with amongst six specializations, which include information science, cybersecurity administration, or cybersecurity defense and threat mitigation. Admission necessitates SAT or ACT scores as well as a minimum amount 2.0 GPA on credit rating transfers to the BAS.
Are there scholarship and money assist alternatives available for the business administration degree program?
0 notes