#programmable analog blocks
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr’s reach among the 26-to-35-year-olds in the US is 11%.
Text
information flow in transformers
In machine learning, the transformer architecture is a very commonly used type of neural network model. Many of the well-known neural nets introduced in the last few years use this architecture, including GPT-2, GPT-3, and GPT-4.
This post is about the way that computation is structured inside of a transformer.
Internally, these models pass information around in a constrained way that feels strange and limited at first glance.
Specifically, inside the "program" implemented by a transformer, each segment of "code" can only access a subset of the program's "state." If the program computes a value, and writes it into the state, that doesn't make value available to any block of code that might run after the write; instead, only some operations can access the value, while others are prohibited from seeing it.
This sounds vaguely like the kind of constraint that human programmers often put on themselves: "separation of concerns," "no global variables," "your function should only take the inputs it needs," that sort of thing.
However, the apparent analogy is misleading. The transformer constraints don't look much like anything that a human programmer would write, at least under normal circumstances. And the rationale behind them is very different from "modularity" or "separation of concerns."
(Domain experts know all about this already -- this is a pedagogical post for everyone else.)
1. setting the stage
For concreteness, let's think about a transformer that is a causal language model.
So, something like GPT-3, or the model that wrote text for @nostalgebraist-autoresponder.
Roughly speaking, this model's input is a sequence of words, like ["Fido", "is", "a", "dog"].
Since the model needs to know the order the words come in, we'll include an integer offset alongside each word, specifying the position of this element in the sequence. So, in full, our example input is
[ ("Fido", 0), ("is", 1), ("a", 2), ("dog", 3), ]
The model itself -- the neural network -- can be viewed as a single long function, which operates on a single element of the sequence. Its task is to output the next element.
Let's call the function f. If f does its job perfectly, then when applied to our example sequence, we will have
f("Fido", 0) = "is" f("is", 1) = "a" f("a", 2) = "dog"
(Note: I've omitted the index from the output type, since it's always obvious what the next index is. Also, in reality the output type is a probability distribution over words, not just a word; the goal is to put high probability on the next word. I'm ignoring this to simplify exposition.)
You may have noticed something: as written, this seems impossible!
Like, how is the function supposed to know that after ("a", 2), the next word is "dog"!? The word "a" could be followed by all sorts of things.
What makes "dog" likely, in this case, is the fact that we're talking about someone named "Fido."
That information isn't contained in ("a", 2). To do the right thing here, you need info from the whole sequence thus far -- from "Fido is a", as opposed to just "a".
How can f get this information, if its input is just a single word and an index?
This is possible because f isn't a pure function. The program has an internal state, which f can access and modify.
But f doesn't just have arbitrary read/write access to the state. Its access is constrained, in a very specific sort of way.
2. transformer-style programming
Let's get more specific about the program state.
The state consists of a series of distinct "memory regions" or "blocks," which have an order assigned to them.
Let's use the notation memory_i for these. The first block is memory_0, the second is memory_1, and so on.
In practice, a small transformer might have around 10 of these blocks, while a very large one might have 100 or more.
Each block contains a separate data-storage "cell" for each offset in the sequence.
For example, memory_0 contains a cell for position 0 ("Fido" in our example text), and a cell for position 1 ("is"), and so on. Meanwhile, memory_1 contains its own, distinct cells for each of these positions. And so does memory_2, etc.
So the overall layout looks like:
memory_0: [cell 0, cell 1, ...] memory_1: [cell 0, cell 1, ...] [...]
Our function f can interact with this program state. But it must do so in a way that conforms to a set of rules.
Here are the rules:
The function can only interact with the blocks by using a specific instruction.
This instruction is an "atomic write+read". It writes data to a block, then reads data from that block for f to use.
When the instruction writes data, it goes in the cell specified in the function offset argument. That is, the "i" in f(..., i).
When the instruction reads data, the data comes from all cells up to and including the offset argument.
The function must call the instruction exactly once for each block.
These calls must happen in order. For example, you can't do the call for memory_1 until you've done the one for memory_0.
Here's some pseudo-code, showing a generic computation of this kind:
f(x, i) { calculate some things using x and i; // next 2 lines are a single instruction write to memory_0 at position i; z0 = read from memory_0 at positions 0...i; calculate some things using x, i, and z0; // next 2 lines are a single instruction write to memory_1 at position i; z1 = read from memory_1 at positions 0...i; calculate some things using x, i, z0, and z1; [etc.] }
The rules impose a tradeoff between the amount of processing required to produce a value, and how early the value can be accessed within the function body.
Consider the moment when data is written to memory_0. This happens before anything is read (even from memory_0 itself).
So the data in memory_0 has been computed only on the basis of individual inputs like ("a," 2). It can't leverage any information about multiple words and how they relate to one another.
But just after the write to memory_0, there's a read from memory_0. This read pulls in data computed by f when it ran on all the earlier words in the sequence.
If we're processing ("a", 2) in our example, then this is the point where our code is first able to access facts like "the word 'Fido' appeared earlier in the text."
However, we still know less than we might prefer.
Recall that memory_0 gets written before anything gets read. The data living there only reflects what f knows before it can see all the other words, while it still only has access to the one word that appeared in its input.
The data we've just read does not contain a holistic, "fully processed" representation of the whole sequence so far ("Fido is a"). Instead, it contains:
a representation of ("Fido", 0) alone, computed in ignorance of the rest of the text
a representation of ("is", 1) alone, computed in ignorance of the rest of the text
a representation of ("a", 2) alone, computed in ignorance of the rest of the text
Now, once we get to memory_1, we will no longer face this problem. Stuff in memory_1 gets computed with the benefit of whatever was in memory_0. The step that computes it can "see all the words at once."
Nonetheless, the whole function is affected by a generalized version of the same quirk.
All else being equal, data stored in later blocks ought to be more useful. Suppose for instance that
memory_4 gets read/written 20% of the way through the function body, and
memory_16 gets read/written 80% of the way through the function body
Here, strictly more computation can be leveraged to produce the data in memory_16. Calculations which are simple enough to fit in the program, but too complex to fit in just 20% of the program, can be stored in memory_16 but not in memory_4.
All else being equal, then, we'd prefer to read from memory_16 rather than memory_4 if possible.
But in fact, we can only read from memory_16 once -- at a point 80% of the way through the code, when the read/write happens for that block.
The general picture looks like:
The early parts of the function can see and leverage what got computed earlier in the sequence -- by the same early parts of the function. This data is relatively "weak," since not much computation went into it. But, by the same token, we have plenty of time to further process it.
The late parts of the function can see and leverage what got computed earlier in the sequence -- by the same late parts of the function. This data is relatively "strong," since lots of computation went into it. But, by the same token, we don't have much time left to further process it.
3. why?
There are multiple ways you can "run" the program specified by f.
Here's one way, which is used when generating text, and which matches popular intuitions about how language models work:
First, we run f("Fido", 0) from start to end. The function returns "is." As a side effect, it populates cell 0 of every memory block.
Next, we run f("is", 1) from start to end. The function returns "a." As a side effect, it populates cell 1 of every memory block.
Etc.
If we're running the code like this, the constraints described earlier feel weird and pointlessly restrictive.
By the time we're running f("is", 1), we've already populated some data into every memory block, all the way up to memory_16 or whatever.
This data is already there, and contains lots of useful insights.
And yet, during the function call f("is", 1), we "forget about" this data -- only to progressively remember it again, block by block. The early parts of this call have only memory_0 to play with, and then memory_1, etc. Only at the end do we allow access to the juicy, extensively processed results that occupy the final blocks.
Why? Why not just let this call read memory_16 immediately, on the first line of code? The data is sitting there, ready to be used!
Why? Because the constraint enables a second way of running this program.
The second way is equivalent to the first, in the sense of producing the same outputs. But instead of processing one word at a time, it processes a whole sequence of words, in parallel.
Here's how it works:
In parallel, run f("Fido", 0) and f("is", 1) and f("a", 2), up until the first write+read instruction. You can do this because the functions are causally independent of one another, up to this point. We now have 3 copies of f, each at the same "line of code": the first write+read instruction.
Perform the write part of the instruction for all the copies, in parallel. This populates cells 0, 1 and 2 of memory_0.
Perform the read part of the instruction for all the copies, in parallel. Each copy of f receives some of the data just written to memory_0, covering offsets up to its own. For instance, f("is", 1) gets data from cells 0 and 1.
In parallel, continue running the 3 copies of f, covering the code between the first write+read instruction and the second.
Perform the second write. This populates cells 0, 1 and 2 of memory_1.
Perform the second read.
Repeat like this until done.
Observe that mode of operation only works if you have a complete input sequence ready before you run anything.
(You can't parallelize over later positions in the sequence if you don't know, yet, what words they contain.)
So, this won't work when the model is generating text, word by word.
But it will work if you have a bunch of texts, and you want to process those texts with the model, for the sake of updating the model so it does a better job of predicting them.
This is called "training," and it's how neural nets get made in the first place. In our programming analogy, it's how the code inside the function body gets written.
The fact that we can train in parallel over the sequence is a huge deal, and probably accounts for most (or even all) of the benefit that transformers have over earlier architectures like RNNs.
Accelerators like GPUs are really good at doing the kinds of calculations that happen inside neural nets, in parallel.
So if you can make your training process more parallel, you can effectively multiply the computing power available to it, for free. (I'm omitting many caveats here -- see this great post for details.)
Transformer training isn't maximally parallel. It's still sequential in one "dimension," namely the layers, which correspond to our write+read steps here. You can't parallelize those.
But it is, at least, parallel along some dimension, namely the sequence dimension.
The older RNN architecture, by contrast, was inherently sequential along both these dimensions. Training an RNN is, effectively, a nested for loop. But training a transformer is just a regular, single for loop.
4. tying it together
The "magical" thing about this setup is that both ways of running the model do the same thing. You are, literally, doing the same exact computation. The function can't tell whether it is being run one way or the other.
This is crucial, because we want the training process -- which uses the parallel mode -- to teach the model how to perform generation, which uses the sequential mode. Since both modes look the same from the model's perspective, this works.
This constraint -- that the code can run in parallel over the sequence, and that this must do the same thing as running it sequentially -- is the reason for everything else we noted above.
Earlier, we asked: why can't we allow later (in the sequence) invocations of f to read earlier data out of blocks like memory_16 immediately, on "the first line of code"?
And the answer is: because that would break parallelism. You'd have to run f("Fido", 0) all the way through before even starting to run f("is", 1).
By structuring the computation in this specific way, we provide the model with the benefits of recurrence -- writing things down at earlier positions, accessing them at later positions, and writing further things down which can be accessed even later -- while breaking the sequential dependencies that would ordinarily prevent a recurrent calculation from being executed in parallel.
In other words, we've found a way to create an iterative function that takes its own outputs as input -- and does so repeatedly, producing longer and longer outputs to be read off by its next invocation -- with the property that this iteration can be run in parallel.
We can run the first 10% of every iteration -- of f() and f(f()) and f(f(f())) and so on -- at the same time, before we know what will happen in the later stages of any iteration.
The call f(f()) uses all the information handed to it by f() -- eventually. But it cannot make any requests for information that would leave itself idling, waiting for f() to fully complete.
Whenever f(f()) needs a value computed by f(), it is always the value that f() -- running alongside f(f()), simultaneously -- has just written down, a mere moment ago.
No dead time, no idling, no waiting-for-the-other-guy-to-finish.
p.s.
The "memory blocks" here correspond to what are called "keys and values" in usual transformer lingo.
If you've heard the term "KV cache," it refers to the contents of the memory blocks during generation, when we're running in "sequential mode."
Usually, during generation, one keeps this state in memory and appends a new cell to each block whenever a new token is generated (and, as a result, the sequence gets longer by 1).
This is called "caching" to contrast it with the worse approach of throwing away the block contents after each generated token, and then re-generating them by running f on the whole sequence so far (not just the latest token). And then having to do that over and over, once per generated token.
#ai tag#is there some standard CS name for the thing i'm talking about here?#i feel like there should be#but i never heard people mention it#(or at least i've never heard people mention it in a way that made the connection with transformers clear)
313 notes
·
View notes
Text
One post gotta be the first
So, for me Reddit finally died. As a programmer who is generally in favour of making stuff available for as many people as possible, they did right by that for many years. Giving everyone who wanted that access to it was generous of them, and made it a very fun platform. Random bots everywhere, apps catered to whatever preference people had, even -dare I say it- the tiniest bit of the wild-west-internet that once existed. But they got to greedy, flew to close to the sun, whatever analogy you want to have for it. I don't fault them wanting to make money off that, hosting is expensive, but the way they lied to everyone, attacked the Apollo developer for outing their lies, "riding the storm until it died out", it was too much.
So now I'm here, hopelessly lost in land I only got glimpses of on r/tumblr. I don't even know why I write this. I doubt many people will read it, or even see it. It's my first Tumblr post, and it probably will be very rambly, incoherent, and missing any kind of red line. The shortest answer to "Why I wrote this?" is probably "Because some google doc in '#tumblr help'" told me to post stuff!".
And I'm bad at posting stuff. I never done it. In the olden days, when forums were all around, I was a lurker. I'd read about everything, posted when I actually had something relevant to say, and shut up otherwise. I was known within the communities, generally active in the adjacent msn/skype groups, but not on the main spam threads in the forum.
When the forums began to die out, I got on Reddit. My account is 11 years old now, I've been using it almost hourly over the last 6 years, and it has a grand total of 9 posts. There's a bit more comments in that, but it's probably basically nothing compared to the average comments per hour spend on other accounts.
Why do I tell this? Because I might change that here. I've been lurking around Tumblr for the last few weeks, and the interaction and people are way different than I'm used to. Honestly, it's refreshing, and nice to see. But entering a new environment, one has to adept.
And I've been stuck too long in my old habits! I am often hesitant to contribute to anything, because I never did. I don't write, because I never wrote. But having a new environment, new people, new interest around me makes me wanna try out new stuff. And who knows? Maybe I'll like it, maybe I'll find people who like what I write, and I'll have more stuff to interact with.
And maybe I don't. Maybe I'll feel too unsure, too self-conscious, to change my lurking habits. I'm fine with that. I got other places to interact about my passions. Most of them are through Discord-groups nowadays, others through the few still-existing actual forums out there, but they still exist.
That's my last thing. I don't know what I even write about. Some of my interest are too different from the usual Tumblr-niches to have any kind of following. While typing this I had a look at the "enlisted game" tag, which has a grand total of 1 active poster. I had some looks at the different Magic the Gathering tags, but (as I expected), most of the people in there are about more about the lore of the game than I do. That's fine, I got my spike-talking places, and I will probably lurk those tags anyway.
The one place I'll probably feel most comfortable is the Brandon Sanderson-aligned tags. I'll be there, maybe even contributing, once I finished the last books (or I find the appropriate tags to block, I probably gotta look into that).
That uncertainty makes me circle back to a point a made a few paragraphs ago. I can explore, I can try out new stuff. Maybe I'll try to add to some of the punk tags here, maybe I'll hop onto some of the computer science tags and see if I can wordvomit there, maybe I'll go to something completely new! I can go exploring again, discovering things I never saw before, and that makes me eager.
13 notes
·
View notes
Text
TDSP WEEKEND UPDATE
Chapter 5 is programmed, and we're getting ready to recruit some beta testers. The Captain is talking with one of the programmers to see how many we need. So far, we have one for testing the PC version. It feels like we're halfway done...
Because of this, The Captain is contemplating on getting the PDF walkthroughs ready. It will cure the writer's block she has of the scene she has to write about Bob's backstory and his powers.
Speaking of writing, she is starting to work in the newly written scene into the Charlie and Ollie routes. The scene for Charlie's route will need a little more tweaking since it will have more romance elements. After that, she will move on to the Bob scene. It's taking a little while for her to gather her thoughts on it because she has to make sure there are no unanswered questions that the players will have.
When she last spoke to a writing group that she belongs to, The Captain mentioned George RR Martin's analogy that there are 2 types of writers: Architects and Gardeners. The Captain and TDSP crew are pretty much gardeners. That's why it's taking us so long to write the story.

#wordsfromthecaptain#thedistantshoresproject#tdspupdate#charlie smith#oliver cochrane#edward mortemer#choices distant shores
15 notes
·
View notes
Text
Programming Techniques for PLC Controllers in Complex Industrial Processes
Introduction to PLC Controllers in Industrial Automation
Programmable Logic Controllers (PLCs) play a foundational role in industrial automation, offering precise, real-time control over machinery and systems. Their robust design and programming flexibility make them essential in complex industrial environments, from manufacturing lines and HVAC systems to chemical plants and packaging facilities. PLCs are capable of managing intricate, multi-step processes with minimal human intervention, improving productivity, consistency, and operational safety.
Structured Programming for Enhanced Flexibility
One of the core programming approaches in modern automation is structured programming. Built on the IEC 61131-3 standard, PLCs support multiple programming languages, including Ladder Diagram (LD), Function Block Diagram (FBD), and Structured Text (ST). These languages enable engineers to develop modular code—functions or routines that can be reused, tested independently, and scaled as needed.
Structured programming improves clarity, simplifies troubleshooting, and makes large automation projects more manageable. In applications where control logic must adapt to different conditions or production stages, this modular approach allows for flexible logic definition and efficient system updates.
Integration with Frequency Converters for Optimized Control
Modern industrial processes often rely on motors that must operate at variable speeds. By integrating PLC controllers with frequency converters, also known as inverters or VFDs (Variable Frequency Drives), engineers can fine-tune motor control based on real-time requirements. PLCs send commands to adjust speed, torque, or acceleration according to changing system loads, environmental conditions, or product flow.
This integration enhances process stability, reduces energy usage, and prevents unnecessary mechanical wear. For example, in HVAC systems or conveyor lines, the ability to ramp motors up or down smoothly reduces strain on both the equipment and power infrastructure.
Advanced Communication Protocols for Seamless System Integration
In large-scale automation networks, connectivity between components is crucial. PLCs must communicate with devices such as sensors, actuators, Human-Machine Interfaces (HMIs), and Supervisory Control and Data Acquisition (SCADA) systems. To enable this, modern PLCs support communication protocols like Modbus, CANopen, EtherCAT, and RS485.
These protocols facilitate real-time data exchange across systems, allowing centralized control, monitoring, and data logging. With seamless integration, operators can visualize process states, remotely adjust settings, or trigger maintenance alerts—all from a single interface. Communication-enabled PLCs also support cloud integration and IoT-based monitoring, making them a key part of Industry 4.0 environments.
Precision and Real-Time Responsiveness in Complex Applications
For high-speed or critical operations, real-time responsiveness is essential. PLCs are designed with fast scan cycles and deterministic logic execution, enabling them to react within milliseconds. This capability ensures that time-sensitive tasks—such as synchronizing a robotic arm, detecting faults on a packaging line, or managing pressure in a chemical reactor—are executed reliably and safely.
In addition to digital signals, PLCs also handle analog inputs and outputs, which are vital in processes that require precise measurement and control of variables like temperature, pressure, or flow rate. Their ability to manage these signals with minimal latency ensures that systems remain responsive under varying conditions.
Robust Design for Harsh Industrial Conditions
Industrial environments are often harsh, featuring high levels of dust, moisture, vibration, or electromagnetic interference. PLC controllers are engineered with rugged components and protective features to ensure long-term operation under these demanding conditions. Features such as reinforced casings, temperature-resistant electronics, and EMI shielding enable PLCs to maintain stable performance in environments where conventional computers or microcontrollers might fail.
This robustness minimizes unplanned downtime and reduces maintenance frequency, making PLCs a reliable choice for mission-critical systems.
Scalability for Expanding Automation Needs
As industrial operations evolve, the ability to scale control systems becomes a major advantage. PLCs are inherently modular—supporting expansion with additional I/O modules, communication interfaces, and memory capacity. Engineers can add new sensors, actuators, or logic routines without replacing the core controller.
This scalability ensures that a system can grow alongside the business. Whether upgrading machinery, increasing production capacity, or integrating new technologies, PLCs provide a future-ready solution that supports both current needs and long-term innovation.
Conclusion: Building Smarter Automation with Advanced PLC Programming
Advanced programming techniques for PLC controllers are essential for managing the increasing complexity of industrial automation. Structured, modular programming, real-time integration with motor drives, robust communication, and hardware designed for tough environments all contribute to highly responsive and efficient control systems.
By leveraging these programming practices, engineers can create scalable, reliable, and intelligent automation frameworks that reduce costs, improve safety, and optimize performance. As industry trends continue toward digitalization and smart manufacturing, the role of well-programmed PLC systems will only grow in significance—serving as the core intelligence behind the machines that drive modern industry.
0 notes
Text
youtube
How Israel is replicating Nazi starvation tactics | Soumaya Ghannoushi | MEE Opinion Middle East Eye / June 04, 2025 at 04:46AM / https://www.youtube.com/watch?v=ElifkCsKxW4 Time: 5:57 Soumaya Ghannoushi, writer and expert in Middle East politics, says that what is happening in Gaza is not merely starvation, but the deliberate breaking of a people. She describes a woman kneeling in the dust, clawing at the ground for scraps of flour. Around her, others bend too, not in prayer, but in desperation. This, she says, is not simply hunger. It is a calculated effort to push people beyond the limits of human endurance. This is what Gaza’s aid now looks like. Not distribution, but oppression. Not relief, but ritual debasement. The flour had been withheld for weeks, stockpiled, blocked, used as bait. Exhausted families walked for miles, past corpses and craters, to reach drop sites, only to find cages, soldiers, and drones. When they ran towards the food, they were shot. On 1 June, more than 30 Palestinians were massacred and over 170 wounded near an aid distribution point in Rafah, as Israeli forces opened fire on starving civilians. The drop was coordinated by the Gaza Humanitarian Foundation. Aid has become a trap. Hunger, a pretext for slaughter. Ghannoushi says that they have built a bureaucracy of starvation and called it a humanitarian foundation. She recalls the Nazi Hunger Plan, which deliberately starved millions. In the ghettos, food was weaponised, and access to bread and meat tightly controlled. Hunger was not a failure - it was policy. Under current plans, the average Palestinian in Gaza receives the same number of calories as Jews were given in the Warsaw Ghetto. This is not an analogy. It is arithmetic. She concludes that Israel is not content with crushing Palestinian bodies. It wants to crush their souls. And while the world looks away, a mother still kneels in the rubble, scraping at the ground to feed her children with flour dusted in dirt and drenched in blood. Catch MEE LIVE, our new biweekly live news programme, where we take a look at the news shaping our world through breaking coverage, expert analysis and hard-hitting interviews. MEE LIVE: Tuesday & Thursday | 12pm ET | 5pm BST | Join the conversation at [email protected] Support stories that matter. Join this channel to get access to perks: https://www.youtube.com/channel/UCR0fZh5SBxxMNYdg0VzRFkg/join Subscribe to our channel: http://ow.ly/AVlW30n1OWH Subscribe to MEE Telegram channel to stay up to date: https://t.me/MiddleEastEye_TG Middle East Eye Website: https://middleeasteye.net Follow us on TikTok: https://www.tiktok.com/@middleeasteye Follow us on Instagram: https://instagram.com/MiddleEastEye Like us on Facebook: https://facebook.com/MiddleEastEye Follow us on Twitter: https://twitter.com/MiddleEastEye
0 notes
Text
Kotlin: From Darkness to Dawn

Kotlin: From Darkness To Dawn
A Beginner’s Journey Through Code, Logic, and Light

Kotlin: From Darkness to Dawn is your ultimate guide to transforming from a complete beginner into a confident Kotlin programmer. Whether you're starting with zero knowledge or looking to strengthen your foundation, this book walks you step by step out of the confusion (“darkness”) and into clarity and skill (“dawn”).
This book doesn’t just teach Kotlin — it teaches how to think like a programmer.
Inside, you’ll explore the core building blocks of Kotlin in a simple, relatable way:
Variables – Learn how to store, update, and use data like a pro.
Data Types – Understand the difference between numbers, text, booleans, and more.
Conditional Statements – Master how to make decisions in your code using if, else if, and else.
Loops – Automate repetition with for and while loops — plus how to control them with break and continue.
Methods – Discover how to write reusable blocks of code, create clean programs, and break big problems into small solutions.
Through practical examples, real-world analogies, and hands-on exercises, Kotlin: From Darkness to Dawn turns confusion into clarity. It’s not just a programming book — it’s your personal journey into the world of code.
By Souhail Laghchim.
0 notes
Text
Effortless PLC Programming Using CODESYS at Servotech
Introduction
In today’s fast-paced industrial automation landscape, efficient and user-friendly PLC programming is crucial for optimizing processes and reducing downtime. Servotech, a leader in automation solutions, leverages CODESYS to simplify PLC programming, making it more accessible and streamlined. Whether you are an experienced engineer or a novice, programming with CODESYS at Servotech ensures effortless integration, flexibility, and efficiency.
What is CODESYS?
CODESYS (Controller Development System) is a software platform designed for industrial automation, providing an integrated development environment (IDE) for programming PLCs and other control devices. It supports multiple IEC 61131-3 programming languages, including:
Ladder Diagram (LD)
Structured Text (ST)
Function Block Diagram (FBD)
Instruction List (IL)
Sequential Function Chart (SFC)
Continuous Function Chart (CFC)
CODESYS is hardware-independent, allowing it to be used across various controllers, making it a versatile and scalable solution for industries.
Why Choose CODESYS for PLC Programming at Servotech?
1. User-Friendly Interface
CODESYS provides an intuitive and graphical environment, making PLC programming easier. Engineers at Servotech benefit from an integrated project tree, drag-and-drop functionality, and seamless code visualization, reducing programming complexity.
2. Hardware Independence
Unlike traditional PLC software, CODESYS is not tied to specific hardware. This means that Servotech can use a variety of controllers, reducing costs and increasing flexibility in automation solutions.
3. Multi-Language Support
The ability to switch between different IEC 61131-3 languages allows programmers to choose the best approach for their application, ensuring efficient code development.
4. Powerful Debugging and Simulation Tools
CODESYS includes a real-time debugging environment, simulation tools, and diagnostics, which enable Servotech engineers to test and refine PLC programs without deploying them directly on hardware.
5. Seamless Integration with HMI and SCADA
CODESYS supports Human Machine Interface (HMI) and Supervisory Control and Data Acquisition (SCADA) systems, allowing for comprehensive process control and monitoring.
Step-by-Step Guide to PLC Programming with CODESYS at Servotech
Step 1: Setting Up the CODESYS Environment
Install CODESYS IDE on a Windows-based system.
Configure the target PLC hardware (if applicable) or use a virtual PLC.
Step 2: Creating a New Project
Launch CODESYS and select New Project.
Choose the desired PLC type and programming language (LD, ST, FBD, etc.).
Step 3: Defining Inputs and Outputs (I/O)
Set up digital and analog inputs/outputs in the project tree.
Assign appropriate tags to sensors, actuators, and communication interfaces.
Step 4: Writing the PLC Logic
Use Ladder Logic (LD) for simple control processes.
Implement Function Block Diagram (FBD) for graphical logic representation.
Use Structured Text (ST) for complex calculations and conditions.
Step 5: Simulating and Debugging
Run offline simulation to verify logic and troubleshoot errors.
Utilize breakpoints and variable monitoring to optimize program execution.
Step 6: Deploying the Program
Download the finalized PLC program onto the Servotech automation system.
Test real-time performance and adjust parameters as needed.
Applications of CODESYS-Based PLC Programming at Servotech
1. Factory Automation
Assembly line automation
Conveyor belt control
Material handling systems
2. Process Control
Temperature and pressure regulation
Fluid flow monitoring
Batch processing in manufacturing
3. Building Automation
Smart lighting control
HVAC system automation
Security and access control
4. Renewable Energy Systems
Solar and wind energy management
Battery storage optimization
Grid integration solutions
Advantages of CODESYS at Servotech
Cost-Effective Development
CODESYS eliminates the need for expensive proprietary software, making it a cost-efficient solution for Servotech’s automation needs.
Scalability and Modularity
Servotech can use CODESYS across multiple projects, scaling from small automation tasks to large industrial control systems.
Community Support and Updates
With an active global community and regular updates, CODESYS remains up-to-date with the latest industrial trends, ensuring future-proof automation.
Conclusion
CODESYS has revolutionized PLC programming at Servotech, providing an effortless, cost-effective, and flexible automation solution. Its hardware independence, user-friendly interface, powerful debugging tools, and multi-language support make it the ideal choice for modern industrial applications. By adopting CODESYS, Servotech continues to lead the way in smart automation, delivering high-performance control solutions for diverse industries.
0 notes
Text
Price: [price_with_discount] (as of [price_update_date] - Details) [ad_1] Designing Software Synthesizer Plugins in C++ provides everything you need to know to start designing and writing your own synthesizer plugins, including theory and practical examples for all of the major synthesizer building blocks, from LFOs and EGs to PCM samples and morphing wavetables, along with complete synthesizer example projects. The book and accompanying SynthLab projects include scores of C++ objects and functions that implement the synthesizer building blocks as well as six synthesizer projects, ranging from virtual analog and physical modelling to wavetable morphing and wave-sequencing that demonstrate their use. You can start using the book immediately with the SynthLab-DM product, which allows you to compile and load mini-modules that resemble modular synth components without needing to maintain the complete synth project code. The C++ objects all run in a stand-alone mode, so you can incorporate them into your current projects or whip up a quick experiment. All six synth projects are fully documented, from the tiny SynthClock to the SynthEngine objects, allowing you to get the most from the book while working at a level that you feel comfortable with. This book is intended for music technology and engineering students, along with DIY audio programmers and anyone wanting to understand how synthesizers may be implemented in C++. Publisher : Focal Press; 2nd edition (17 June 2021); 01149344934 Language : English Paperback : 276 pages ISBN-10 : 0367510464 ISBN-13 : 978-0367510466 Item Weight : 562 g Dimensions : 19.1 x 1.75 x 23.5 cm Country of Origin : India Net Quantity : 1 Count Importer : CBS PUBLISHERS AND DSITRIBUTORS PVT LTD PHONE-01149344934 Packer : CBS PUBLISHERS AND DISTRIBUTORS PVT LTD Generic Name : books [ad_2]
0 notes
Text
Animated dolls playing dice on rollers! ’(thread 16^12 (article 0x25/?))

Mainline follow-up to this article:
Research dive
Getting inspired some for analog computing roots of the androids clades through those programmable wirebox, automatic card feeds & control panel stuff... as well as the whole of computation history.
Learnt about Pacific Cyber/Metrix (PCM for short) today, could get really handy as inspiration for 16^12 Angora hardware designs due to the tribble-based machines they made...
Anyways, back to the worldscape summary for 4524:
Civilizations
Shoshones
Poland
Morocco
Assyria
Mayas
Incas
Brazil
Babylon
Austria
Portugal
Korea
Carthage
Persia / Iran
Netherlands
Burgundy
Vietnam
Angola
Inuit
Sumer
Samoa
Scotland
Minoans
Mycenae
Hittites
Cree
Dene
Hungary
Ottoman Turks
Tatar Crimea
Blackfoot
Corsica
Moravia
Sinhala
Sami
Lithuania
Latvian
Songhay
Levantine (Yiddish?)
Nubia
Basque
Aremorici
Georgia
Armenia
Catalonia
Canton
Sweden
Czechia
Oman / Swahili
Major Religions
Pohakantenna (Shoshones, Blackfoot, Dene, Hurons)
Angakkunngurniq (Inuit)
Druidism / Al-Asnam (Aremorici)
Chalcedonian Ba'hai / Gnosticism / Arianism (Austria, Portugal, Brazil)
Hussitism (Poland, Moravia, Slovakia, Georgia)
Calvinism (Scotland, Burgundy)
Chaldeanism (Assyria, Morocco, Cree, Sumer, Babylon)
Tala-e-Fonua (Samoa, Sami, Canton, Czechia, Korea)
Daoism / Jainism (Chola / Sinhala, Vietnam)
Zoroastrianism (Iran, Minoans, Mycenae, Hittites)
Ibadiyya [Bantu + Ibadi Islam*] (Angola, Sweden)
Canaanism (Carthage, Netherlands)
"Kushite" Pesedjet (Nubia, Songhay)
Intiism (Incas, Coast Salish, Levant)
Tzolk'in (Mayas, Tatar / Crimea, Lithuania)
Contemporary trade blocks
Shoshone Union ("Hispanic"-tier cosmopolitan Americana-equivalent)
Inuit Assembly
Esperanto Pact as "Brazil" (industrious Burgundy, Scotland, Austria, Portugal... form under the Esperanto auxiliary language creole banner)
Nisian Conglomerate (Morocco + Assyria, collapses in 2000 and emulates soviet union history)
Polish Commonwealth
Samoan Trade Federation
Punic Confederation
Zapatista Authority (authoritarian "enlightened despotism" state turnt communal republic, history likewise to holy roman empire but revolutionary?)
0 notes
Text
How to Download Rounds (REAKTOR)

If you're looking to elevate your music production game with Native Instruments' ROUNDS, you've come to the right place. ROUNDS is a dynamic and versatile software instrument powered by REAKTOR or REAKTOR PLAYER, providing an exceptional range of sound capabilities. Whether you're a seasoned music producer or just starting, this tool will be an exciting addition to your creative workflow.
In this article, we’ll provide a comprehensive overview of ROUNDS and walk you through the process of downloading it from a trusted source.
At a Glance: ROUNDS
Product Type:
KOMPLETE Instrument
Compatibility:
Requires REAKTOR Player or REAKTOR version 5.9.2 or higher. Make sure your setup meets these requirements to ensure smooth performance and installation.
Number of Sounds:
233
Sound Categories:
ROUNDS offers a wide range of sound categories, including:
Bass
Lead
Pad
Soundscape
SFX
Melodic Sequence
Multitrack Sequence
Arpeggiator Presets
The presets are also prepared to work seamlessly with Komplete Kontrol’s onboard arpeggiator, making it an excellent fit for advanced sequencing and sound design.
Download Size:
Just 26 MB (Mac/PC), making it lightweight and easy to download.
Start Your Engines: Analog and Digital Synthesis
One of the defining features of ROUNDS is its dual-engine design, combining both analog and digital synthesis. Let’s break down what this means:
Analog Engine:
Inspired by the classic two-oscillator synthesizer, the analog engine delivers warm, harmonically-rich tones. Native Instruments has expertly captured the revered analog sound in a simple, no-fuss interface. You can design up to eight sounds per engine, giving you the flexibility to create and tweak the perfect tone for your project.
Digital Engine:
On the digital side, ROUNDS offers an FM engine with three oscillators and a 2-pole filter. The digital engine is capable of producing clean, sparkling tones as well as more metallic, dissonant sounds, all with superior note definition. This versatility makes ROUNDS an essential tool for sound designers and producers who want a wide sonic palette at their fingertips.
Performance Features
ROUNDS isn’t just about producing incredible sounds; it's also designed for live performance. Here’s a look at some key performance features:
Voice Programmer: Sequence up to eight independent sounds per engine, each with unique parameter settings, and switch between them in real-time.
Remote Octave Feature: Use your keyboard to trigger on/off assignments for sound blocks with white keys and toggle cells on black keys in real time.
Multi-Edit View: Simplify your workflow by editing one parameter across all sounds simultaneously.
Macro Assignments: Map up to eight macros and easily tweak sound parameters via your hardware, offering deep customization on the fly.
How to Download ROUNDS
If you’re excited about adding ROUNDS to your music production setup, you can download it easily by following the steps below:
Go to the Download Page: Visit the official download page at KalaPlugins. This ensures you're getting the genuine product from a trusted source.
Check System Requirements: Ensure you have REAKTOR Player or REAKTOR version 5.9.2 or higher installed. This is essential for ROUNDS to work correctly on your machine.
Download and Install: Click the download link and follow the installation instructions for your operating system (Mac or PC). The download size is just 26 MB, so it won’t take up much space on your hard drive.
Launch REAKTOR: Once installed, open REAKTOR or REAKTOR Player and load ROUNDS into your environment. From there, you can explore the 233 sounds and start designing your own unique patches.
Conclusion
ROUNDS is an innovative instrument that combines the best of analog and digital synthesis, offering vast creative possibilities for sound design, music production, and live performance. Download ROUNDS today and experience the full range of its capabilities! Visit KalaPlugins to get started.
0 notes
Text
New Kids On The Block 2024 Event Shirt
New Kids On The Block 2024 Event Shirt
A New Kids On The Block 2024 Event Shirt is that replacing one of these legacy systems is like “changing the tire on your car while it’s in motion.” But, that analogy really doesn’t describe the complexity of the problem at all. Imagine having to replace your car’s frame while it’s in motion. The corporation can’t take a year off to do this, it needs to continue down the highway without sputtering while you replace the framework that not only holds the wheels in place, but restrains the powertrain, protects the driver, holds the wires in place, and keeps the road from rattling everything apart. I witnessed several attempts to replace these systems. Each team was given a large budget and told to make it happen. Spirits of young programmers were dashed against the rocks again and again by these projects. They eagerly dove in, and documented all of the functions that are performed by the legacy. Then they began to build replacement systems that must run in parallel to the legacy. Until the project is completed, these replacements must pipe information into and out of the legacy while establishing an entirely new framework.

0 notes
Text
Industrial Controls Market – Trends Forecast Till 2030
Industrial Controls Market analysis report figures out market landscape, brand awareness, latest trends, possible future issues, industry trends and customer behaviour so that the business can stand high in the crowd. It includes extensive research on the current conditions of the industry, potential of the market in the present and the future prospects from various angles. This Industrial Controls Market report comprises of data that can be pretty essential when it comes to dominating the market or making a mark in the Semiconductors & Electronics industry as a new emergent. To bestow clients with the best results, Industrial Controls Market research report is produced by using integrated approaches and latest technology.
Download Free Sample Report at: https://www.delvens.com/get-free-sample/industrial-controls-market

Industrial Controls Market by Type (Distributed Control System, Supervisory Control & Data Acquisition System, Manufacturing Execution System, Programmable Logic Controller (PLC), Product Lifecycle Management (PLM), Enterprise Resource Planning (ERP), Human Machine Interface (HMI) and Others), Component (Modular Terminal Blocks, Relays & Optocouplers, Surge Protectors, Marking Systems, Printing, Ferulles Cable Lugs, Handtools, Testers, Enclosure Products, PCB Connectors & Terminals, Heavy Duty Connectors, Analog Signal Conditioner, Electronic Housings, Power Supplies, Industrial Ethernet, and Remote IO), Application and End User (Automotive, Utility, Electronics & Semiconductors, Oil and Gas, Chemical and Petrochemical, Power, Life Sciences, Food and Beverage and Mining), and region (North America, Europe, Asia-Pacific, Middle East and Africa and South America), global opportunity analysis and Industry Forecast, 2023-2030. The global Industrial Controls market size was estimated at USD 140 billion in 2023 and is projected to reach USD 239.9354 billion in 2030 at a CAGR of 8% during the forecast period 2023-2030.
Industrial Controls Market Competitive Landscape:
ABB Ltd.
Emerson Electric Corporation
Honeywell International Incorporation
Kawasaki Robotics control system
Mitsubishi Electric Factory Automation
Omron Corporation
Rockwell Automation Inc.
Siemens AG
Schneider Electric SA
Yokogawa Electric Corporation
Endress+Hauser AG
General Electric
GLC Controls Inc.
Industrial Controls Market Recent Developments:
In July 2022, IBM acquired Databand.ai, a leading provider of data observability software that helps organizations fix issues with their data, including errors, pipeline failures, and poor quality, before it impacts their bottom line.
In July 2022, Sap acquired Askdata to strengthen its ability to help organizations take better-informed decisions by leveraging AI-driven natural language searches. Users are empowered to search, interact, and collaborate on live data to maximize business insights.
Make an Inquiry Before Buying at: https://www.delvens.com/Inquire-before-buying/industrial-controls-market
Industrial controls systems refer to various automation devices, machines and equipment used in industry. They are developed to better control and monitor industrial processes and automate tasks to increase efficiency and reliability while improving quality. These systems include a variety of controls systems such as supervisory control and data acquisition or SCADA, programmable logic controllers or PLCs, and distributed controls systems or DCS.
They can help automate processes, critical infrastructure or remote monitoring and management. They also help collect data from remote devices, monitor the operation of distributed factories, and perform automated electromechanical processes. Rapid adoption of cloud-based services and growing automation trends in industry are important factors for the global industry. Market dominance. Automation helps industries achieve better accuracy and quality while reducing costs.
Growth is driven by the demand for intelligent controls systems and automation in various industries, mass production in industry and the adoption of industrial controls systems in various end-uses such as automotive and mining, as well as increasing R&D investments. in the industrial control market. However, increasing cyber-attacks, lack of authentication procedures, lack of experienced professionals and awareness of industrial security solutions are restraining the growth of the industrial controls market. In addition, the deployment of a smart grid to protect critical infrastructure against cyber-attacks and cloud computing for industrial controls systems creates lucrative opportunities for the industrial surveillance market.
Scope of the Industrial Controls Market Report:
The Industrial Controls Market is segmented into various segments such as type, component, End user and region:
Based on type
Distributed control system (DCS)
Supervisory control & data acquisition system (SCADA)
Manufacturing execution system (MES)
Programmable Logic Controller (PLC)
Product Lifecycle Management (PLM)
Enterprise Resource Planning (ERP)
Human Machine Interface (HMI)
Others
Based on the component
Modular terminal blocks
Relays & optocouplers
Surge protectors
Marking systems
Printing
Ferulles cable lugs
Handtools
Testers
Enclosure products
PCB connectors and terminals
Heavy duty connectors
Analog signal conditioner
Electronic housings
Power supplies
Industrial ethernet
Remote IO
Based on the End user
Automotive
Utility
Electronics & semiconductors
Mining
Oil and Gas
Chemical and Petrochemical
Power
Life Sciences
Food and Beverage
Others
Based on Application
Automotive
Pharmaceutical
Oil & Gas
Electrical Power
Others
Based on Network
Fieldbus
Communication Router
Firewall
MODEMS
Remote Access Points
Based on region
Asia Pacific
North America
Europe
South America
Middle East & Africa
Industrial Controls Market Regional Analysis:
North America to Dominate the Market
North America is on the brink of the fourth industrial revolution. The data generated is used for high-volume production, while the data is integrated into various production systems throughout the supply chain. The region is also one of the world's largest automotive markets, with more than 13 major automotive manufacturers operating. The automobile industry was one of the largest income generators in the region. Due to significant adoption of industrial control systems and automation technologies in the automotive industry, the region offers a huge opportunity for market growth.
Several key vendors operating in the country are launching new upgrades to support the growth of smart factories along with the development of industrial control systems. Such technological development indicates regional growth in the studied market.
Direct Purchase of the Industrial Controls Market Research Report at: https://www.delvens.com/checkout/industrial-controls-market
Browse Related Reports:
12V Lithium-Ion Battery Market
Pressure Sensor Market
Industrial Valves Market
About Us:
Delvens is a strategic advisory and consulting company headquartered in New Delhi, India. The company holds expertise in providing syndicated research reports, customized research reports and consulting services. Delvens qualitative and quantitative data is highly utilized by each level from niche to major markets, serving more than 1K prominent companies by assuring to provide the information on country, regional and global business environment. We have a database for more than 45 industries in more than 115+ major countries globally.
Delvens database assists the clients by providing in-depth information in crucial business decisions. Delvens offers significant facts and figures across various industries namely Healthcare, IT & Telecom, Chemicals & Materials, Semiconductor & Electronics, Energy, Pharmaceutical, Consumer Goods & Services, Food & Beverages. Our company provides an exhaustive and comprehensive understanding of the business environment.
Contact Us:
UNIT NO. 2126, TOWER B,
21ST FLOOR ALPHATHUM
SECTOR 90 NOIDA 201305, IN
+44-20-3290-6466
#consulting company#strategic advisory firm#best market reports#trending reports#market analysis reports#syndicated reports#Industrial Controls Market#Industrial Controls
0 notes
Text
Industrial PLC Programming

Introduction to Industrial PLC Programming
Industrial Programmable Logic Controllers (PLCs) play a pivotal role in automating processes across various industries. These programmable devices execute specific tasks in response to inputs and produce outputs, thereby controlling machinery and processes in manufacturing plants, factories, and other industrial settings.
Importance of PLC Programming in Industrial Automation
PLC programming is essential for streamlining operations, improving efficiency, and ensuring precision in industrial processes. By programming PLCs, engineers can automate repetitive tasks, monitor equipment performance, and implement complex control algorithms to optimize production.
Components of Industrial PLC Systems
Industrial PLC systems comprise hardware and software components. The hardware includes the PLC itself, along with input and output modules, sensors, actuators, and communication interfaces. The software encompasses programming tools, such as ladder logic editors, function block editors, and other programming languages.
PLC Hardware
The hardware components of a PLC system provide the physical interface between the control system and the machinery it controls. These components include the CPU (Central Processing Unit), memory modules, digital and analog input/output modules, power supply units, and communication modules.
PLC Software
PLC software enables engineers to develop and deploy control logic for industrial processes. Common programming languages used in PLC programming include ladder logic, function block diagrams, structured text, sequential function charts, and instruction lists.
Basic Concepts of PLC Programming
Understanding fundamental concepts is crucial for mastering PLC programming.
Input and Output (I/O) Modules
I/O modules serve as the interface between the PLC and external devices such as sensors, switches, actuators, and motors. Inputs receive signals from sensors or switches, while outputs send signals to actuators or motors to control their operation.
Ladder Logic Programming
Ladder logic is a graphical programming language commonly used in PLC programming. It represents logic functions and control sequences using rungs and contacts resembling electrical relay circuits.
Function Block Diagram (FBD)
Function block diagrams provide a visual representation of control logic using interconnected function blocks. Each block represents a specific function or operation, facilitating modular programming and code reuse.
Advanced PLC Programming Techniques
Beyond basic programming concepts, advanced techniques offer greater flexibility and scalability in PLC programming.
Sequential Function Chart (SFC)
SFC programming allows engineers to design complex control sequences using state-based logic. It breaks down processes into discrete steps or states, transitioning between them based on predefined conditions.
Structured Text (ST)
Structured text is a high-level programming language resembling Pascal or C, suitable for implementing complex algorithms and mathematical calculations in PLC programs.
Instruction List (IL)
Instruction list programming involves writing PLC programs using mnemonic codes corresponding to specific instructions executed by the PLC processor. It offers a low-level approach to programming and is commonly used for performance-critical applications.
Industrial Applications of PLC Programming
PLC programming finds extensive use in various industrial applications, including:
Manufacturing Automation: PLCs control assembly lines, robotic arms, conveyors, and other machinery in manufacturing plants to optimize production processes.
Process Control: PLCs regulate parameters such as temperature, pressure, flow rate, and level in industrial processes such as chemical manufacturing, water treatment, and HVAC systems.
Robotics: PLCs coordinate the motion and operation of industrial robots for tasks such as material handling, welding, painting, and assembly.
Challenges and Considerations in Industrial PLC Programming
While PLC programming offers numerous benefits, engineers must address several challenges and considerations:
Safety Concerns
Ensuring the safety of personnel and equipment is paramount in industrial automation. Engineers must implement appropriate safety measures and fail-safe mechanisms in PLC programs to prevent accidents and hazardous situations.
Maintenance and Troubleshooting
Regular maintenance and timely troubleshooting are essential for ensuring the reliability and efficiency of PLC systems. Engineers must possess strong troubleshooting skills and diagnostic capabilities to identify and rectify faults promptly.
Cybersecurity Risks
As industrial systems become increasingly interconnected and digitized, cybersecurity threats pose a significant concern. Protecting PLCs from unauthorized access, malware, and cyberattacks requires robust security measures and adherence to industry standards and best practices.
Future Trends in Industrial PLC Programming
The future of PLC programming is shaped by emerging technologies and trends that offer new opportunities and challenges:
Internet of Things (IoT) Integration
Integrating PLCs with IoT platforms enables real-time monitoring, remote access, and data analytics, enhancing operational efficiency and predictive maintenance capabilities.
Machine Learning and Artificial Intelligence
Applying machine learning algorithms and AI techniques to PLC programming enables adaptive control, anomaly detection, and predictive optimization, paving the way for autonomous industrial systems.
Conclusion
Industrial PLC programming plays a vital role in driving automation, efficiency, and innovation across diverse industries. By mastering PLC programming techniques and embracing emerging technologies, engineers can unlock new possibilities and propel industrial automation into the future. If you want to read more blogs related these type of topics so visit here👉PujaControls
#plc#automation#technology#software development#industrial automation#labviewsoftware#system integration#labview#plc automation#plc programming
1 note
·
View note
Text
Mamba Explained
New Post has been published on https://thedigitalinsider.com/mamba-explained/
Mamba Explained
The State Space Model taking on Transformers
Right now, AI is eating the world.
And by AI, I mean Transformers. Practically all the big breakthroughs in AI over the last few years are due to Transformers.
Mamba, however, is one of an alternative class of models called State Space Models (SSMs). Importantly, for the first time, Mamba promises similar performance (and crucially similar scaling laws) as the Transformer whilst being feasible at long sequence lengths (say 1 million tokens). To achieve this long context, the Mamba authors remove the “quadratic bottleneck” in the Attention Mechanism. Mamba also runs fast – like “up to 5x faster than Transformer fast”1.
Mamba performs similarly (or slightly better than) other Language Models on The Pile (source)
Gu and Dao, the Mamba authors write:
Mamba enjoys fast inference and linear scaling in sequence length, and its performance improves on real data up to million-length sequences. As a general sequence model backbone, Mamba achieves state-of-the-art performance across several modalities such as language, audio, and genomics. On language modelling, our Mamba-3B model outperforms Transformers of the same size and matches Transformers twice its size, both in pretraining and downstream evaluation.
Here we’ll discuss:
The advantages (and disadvantages) of Mamba (🐍) vs Transformers (🤖),
Analogies and intuitions for thinking about Mamba, and
What Mamba means for Interpretability, AI Safety and Applications.
Problems with Transformers – Maybe Attention Isn’t All You Need
We’re very much in the Transformer-era of history. ML used to be about detecting cats and dogs. Now, with Transformers, we’re generating human-like poetry, coding better than the median competitive programmer, and solving the protein folding problem.
But Transformers have one core problem. In a transformer, every token can look back at every previous token when making predictions. For this lookback, we cache detailed information about each token in the so-called KV cache.
When using the Attention Mechanism, information from all previous tokens can be passed to the current token
This pairwise communication means a forward pass is O(n²) time complexity in training (the dreaded quadratic bottleneck), and each new token generated autoregressively takes O(n) time. In other words, as the context size increases, the model gets slower.
To add insult to injury, storing this key-value (KV) cache requires O(n) space. Consequently, the dreaded CUDA out-of-memory (OOM) error becomes a significant threat as the memory footprint expands. If space were the only concern, we might consider adding more GPUs; however, with latency increasing quadratically, simply adding more compute might not be a viable solution.
On the margin, we can mitigate the quadratic bottleneck with techniques like Sliding Window Attention or clever CUDA optimisations like FlashAttention. But ultimately, for super long context windows (like a chatbot which remembers every conversation you’ve shared), we need a different approach.
Foundation Model Backbones
Fundamentally, all good ML architecture backbones have components for two important operations:
Communication between tokens
Computation within a token
The Transformer Block
In transformers, this is Attention (communication) and MLPs (computation). We improve transformers by optimising these two operations2.
We would like to substitute the Attention component3 with an alternative mechanism for facilitating inter-token communication. Specifically, Mamba employs a Control Theory-inspired State Space Model, or SSM, for Communication purposes while retaining Multilayer Perceptron (MLP)-style projections for Computation.
The Mamba Block
Like a Transformer made up of stacked transformer blocks, Mamba is made up of stacked Mamba blocks as above.
We would like to understand and motivate the choice of the SSM for sequence transformations.
Motivating Mamba – A Throwback to Temple Run
Imagine we’re building a Temple Run agent4. It chooses if the runner should move left or right at any time.
To successfully pick the correct direction, we need information about our surroundings. Let’s call the collection of relevant information the state. Here the state likely includes your current position and velocity, the position of the nearest obstacle, weather conditions, etc.
Claim 1: if you know the current state of the world and how the world is evolving, then you can use this to determine the direction to move.
Note that you don’t need to look at the whole screen all the time. You can figure out what will happen to most of the screen by noting that as you run, the obstacles move down the screen. You only need to look at the top of the screen to understand the new information and then simulate the rest.
This lends itself to a natural formulation. Let h be the hidden state, relevant knowledge about the world. Also let x be the input, the observation that you get each time. h’ then represents the derivative of the hidden state, i.e. how the state is evolving. We’re trying to predict y, the optimal next move (right or left).
Now, Claim 1 states that from the hidden state h, h’, and the new observation x, you can figure out y.
More concretely, h, the state, can be represented as a differential equation (Eq 1a):
$h’(t) = mathbfAh(t) + mathbfBx(t)$
Knowing h allows you to determine your next move y (Eq 1b):
$y(t) = mathbfCh(t) + mathbfDx(t)$
The system’s evolution is determined by its current state and newly acquired observations. A small new observation is enough, as the majority of the state can be inferred by applying known state dynamics to its previous state. That is, most of the screen isn’t new, it’s just a continuation of the previous state’s natural downward trajectory. A full understanding of the state would enable optimal selection of the subsequent action, denoted as y.
You can learn a lot about the system dynamics by observing the top of the screen. For instance, increased velocity of this upper section suggests an acceleration of the rest of the screen as well, so we can infer that the game is speeding up5. In this way, even if we start off knowing nothing about the game and only have limited observations, it becomes possible to gain a holistic understanding of the screen dynamics fairly rapidly.
What’s the State?
Here, state refers to the variables that, when combined with the input variables, fully determine the future system behaviour. In theory, once we have the state, there’s nothing else we need to know about the past to predict the future. With this choice of state, the system is converted to a Markov Decision Process. Ideally, the state is a fairly small amount of information which captures the essential properties of the system. That is, the state is a compression of the past6.
Discretisation – How To Deal With Living in a Quantised World
Okay, great! So, given some state and input observation, we have an autoregressive-style system to determine the next action. Amazing!
In practice though, there’s a little snag here. We’re modelling time as continuous. But in real life, we get new inputs and take new actions at discrete time steps7.
We would like to convert this continuous-time differential equation into a discrete-time difference equation. This conversion process is known as discretisation. Discretisation is a well-studied problem in the literature. Mamba uses the Zero-Order Hold (ZOH) discretisation8. To give an idea of what’s happening morally, consider a naive first-order approximation9.
From Equation 1a, we have
$h’(t) = mathbfAh(t) + mathbfBx(t)$
And for small ∆,
$h’(t) approx frach(t+Delta) – h(t)Delta$
by the definition of the derivative.
We let:
$h_t = h(t)$
and
$h_t+1 = h(t + Delta)$
and substitute into Equation 1a giving:
$h_t+1 – h_t approx Delta (mathbfAh_t + mathbfBx_t)$ $Rightarrow h_t+1 approx (I + Delta mathbfA)h_t + (Delta mathbfB)x_t$
Hence, after renaming the coefficients and relabelling indices, we have the discrete representations:
The Discretised Version of the SSM Equation
If you’ve ever looked at an RNN before10 and this feels familiar – trust your instincts:
We have some input x, which is combined with the previous hidden state by some transform to give the new hidden state. Then we use the hidden state to calculate the output at each time step.
Understanding the SSM Matrices
Now, we can interpret the A, B, C, D matrices more intuitively:
A is the transition state matrix. It shows how you transition the current state into the next state. It asks “How should I forget the less relevant parts of the state over time?”
B is mapping the new input into the state, asking “What part of my new input should I remember?”11
C is mapping the state to the output of the SSM. It asks, “How can I use the state to make a good next prediction?”12
D is how the new input passes through to the output. It’s a kind of modified skip connection that asks “How can I use the new input in my prediction?”
Visual Representation of The SSM Equations
Additionally, ∆ has a nice interpretation – it’s the step size, or what we might call the linger time or the dwell time. For large ∆, you focus more on that token; for small ∆, you skip past the token immediately and don’t include it much in the next state.
(source)
And that’s it! That’s the SSM, our ~drop-in replacement for Attention (Communication) in the Mamba block. The Computation in the Mamba architecture comes from regular linear projections, non-linearities, and local convolutions.
Okay great, that’s the theory – but does this work? Well…
Effectiveness vs Efficiency: Attention is Focus, Selectivity is Prioritisation
At WWDC ‘97, Steve Jobs famously noted that “focusing is about saying no”. Focus is ruthless prioritisation. It’s common to think about Attention positively as choosing what to notice. In the Steve Jobs sense, we might instead frame Attention negatively as choosing what to discard.
There’s a classic intuition pump in Machine Learning known as the Cocktail Party Problem13. Imagine a party with dozens of simultaneous loud conversations:
Question:
How do we recognise what one person is saying when others are talking at the same time?14
Answer:
The brain solves this problem by focusing your “attention” on a particular stimulus and hence drowning out all other sounds as much as possible.
Transformers use Dot-Product Attention to focus on the most relevant tokens. A big reason Attention is so great is that you have the potential to look back at everything that ever happened in its context. This is like photographic memory when done right.15
Transformers (🤖) are extremely effective. But they aren’t very efficient. They store everything from the past so that they can look back at tokens with theoretically perfect recall.
Traditional RNNs (🔁) are the opposite – they forget a lot, only recalling a small amount in their hidden state and discarding the rest. They are very efficient – their state is small. Yet they are less effective as discarded information cannot be recovered.
We’d like something closer to the Pareto frontier of the effectiveness/efficiency tradeoff. Something that’s more effective than traditional RNNs and more efficient than transformers.
The Mamba Architecture seems to offer a solution which pushes out the Pareto frontier of effectiveness/efficiency.
SSMs are as efficient as RNNs, but we might wonder how effective they are. After all, it seems like they would have a hard time discarding only unnecessary information and keeping everything relevant. If each token is being processed the same way, applying the same A and B matrices as if in a factory assembly line for tokens, there is no context-dependence. We would like the forgetting and remembering matrices (A and B respectively) to vary and dynamically adapt to inputs.
The Selection Mechanism
Selectivity allows each token to be transformed into the state in a way that is unique to its own needs. Selectivity is what takes us from vanilla SSM models (applying the same A (forgetting) and B (remembering) matrices to every input) to Mamba, the Selective State Space Model.
In regular SSMs, A, B, C and D are learned matrices – that is
$mathbfA = mathbfA_theta$ etc. (where θ represents the learned parameters)
With the Selection Mechanism in Mamba, A, B, C and D are also functions of x. That is $mathbfA = mathbfA_theta(x)$ etc; the matrices are context dependent rather than static.
Mamba (right) differs from traditional SSMs by allowing A,B,C matrices to be selective i.e. context dependent (source)
Making A and B functions of x allows us to get the best of both worlds:
We’re selective about what we include in the state, which improves effectiveness vs traditional SSMs.
Yet, since the state size is bounded, we improve on efficiency relative to the Transformer. We have O(1), not O(n) space and O(n) not O(n²) time requirements.
The Mamba paper authors write:
The efficiency vs. effectiveness tradeoff of sequence models is characterized by how well they compress their state: efficient models must have a small state, while effective models must have a state that contains all necessary information from the context. In turn, we propose that a fundamental principle for building sequence models is selectivity: or the context-aware ability to focus on or filter out inputs into a sequential state. In particular, a selection mechanism controls how information propagates or interacts along the sequence dimension.
Humans (mostly) don’t have photographic memory for everything they experience within a lifetime – or even within a day! There’s just way too much information to retain it all. Subconsciously, we select what to remember by choosing to forget, throwing away most information as we encounter it. Transformers (🤖) decide what to focus on at recall time. Humans (🧑) also decide what to throw away at memory-making time. Humans filter out information early and often.
If we had infinite capacity for memorisation, it’s clear the transformer approach is better than the human approach – it truly is more effective. But it’s less efficient – transformers have to store so much information about the past that might not be relevant. Transformers (🤖) only decide what’s relevant at recall time. The innovation of Mamba (🐍) is allowing the model better ways of forgetting earlier – it’s focusing by choosing what to discard using Selectivity, throwing away less relevant information at memory-making time16.
The Problems of Selectivity
Applying the Selection Mechanism does have its gotchas though. Non-selective SSMs (i.e. A,B not dependent on x) are fast to compute in training. This is because the component of
Yt which depends on xi can be expressed as a linear map, i.e. a single matrix that can be precomputed!
For example (ignoring the D component, the skip connection):
$$y_2 = mathbfCmathbfBx_2 + mathbfCmathbfAmathbfBx_1 + mathbfCmathbfAmathbfAmathbfBx_0$$
If we’re paying attention, we might spot something even better here – this expression can be written as a convolution. Hence we can apply the Fast Fourier Transform and the Convolution Theorem to compute this very efficiently on hardware as in Equation 3 below.
We can calculate Equation 2, the SSM equations, efficiently in the Convolutional Form, Equation 3.
Unfortunately, with the Selection Mechanism, we lose the convolutional form. Much attention is given to making Mamba efficient on modern GPU hardware using similar hardware optimisation tricks to Tri Dao’s Flash Attention17. With the hardware optimisations, Mamba is able to run faster than comparably sized Transformers.
Machine Learning for Political Economists – How Large Should The State Be?
The Mamba authors write, “the efficiency vs. effectiveness tradeoff of sequence models is characterised by how well they compress their state”. In other words, like in political economy18, the fundamental problem is how to manage the state.
🔁 Traditional RNNs are anarchic
They have a small, minimal state. The size of the state is bounded. The compression of state is poor.
🤖 Transformers are communist
They have a maximally large state. The “state” is just a cache of the entire history with no compression. Every context token is treated equally until recall time.
🐍Mamba has a compressed state
…but it’s selective about what goes in. Mamba says we can get away with a small state if the state is well focused and effective19.
Language Models and State Size
The upshot is that state representation is critical. A smaller state is more efficient; a larger state is more effective. The key is to selectively and dynamically compress data into the state. Mamba’s Selection Mechanism allows for context-dependent reasoning, focusing and ignoring. For both performance and interpretability, understanding the state seems to be very useful.
Information Flow in Transformer vs Mamba
How do Transformers know anything? At initialization, a transformer isn’t very smart. It learns in two ways:
Training data (Pretraining, SFT, RLHF etc)
In context-data
Training Data
Models learn from their training data. This is a kind of lossy compression of input data into the weights. We can think of the effect of pretraining data on the transformer kinda like the effect of your ancestor’s experiences on your genetics – you can’t recall their experiences, you just have vague instincts about them20.
In Context-Data
Transformers use their context as short-term memory, which they can recall with ~perfect fidelity. So we get In-Context Learning, e.g. using induction heads to solve the Indirect Object Identification task, or computing Linear Regression.
Retrieval
Note that Transformers don’t filter their context at all until recall time. So if we have a bunch of information we think might be useful to the Transformer, we filter it outside the Transformer (using Information Retrieval strategies) and then stuff the results into the prompt. This process is known as Retrieval Augmented Generation (RAG). RAG determines relevant information for the context window of a transformer. A human with the internet is kinda like a RAG system – you still have to know what to search but whatever you retrieve is as salient as short-term memory to you.
Information Flow for Mamba
Training Data acts similarly for Mamba. However, the lines are slightly blurred for in-context data and retrieval. In-context data for Mamba is compressed/filtered similar to retrieval data for transformers. This in-context data is also accessible for look-up like for transformers (although with somewhat lower fidelity).
Transformer context is to Mamba states what short-term is to long-term memory. Mamba doesn’t just have “RAM”, it has a hard drive21 22.
Swapping States as a New Prompting Paradigm
Currently, we often use RAG to give a transformer contextual information.
With Mamba-like models, you could instead imagine having a library of states created by running the model over specialised data. States could be shared kinda like LoRAs for image models.
For example, I could do inference on 20 physics textbooks and, say, 100 physics questions and answers. Then I have a state which I can give to you. Now you don’t need to add any few-shot examples; you just simply ask your question. The in-context learning is in the state.
In other words, you can drag and drop downloaded states into your model, like literal plug-in cartridges. And note that “training” a state doesn’t require any backprop. It’s more like a highly specialised one-pass fixed-size compression algorithm. This is unlimited in-context learning applied at inference time for zero-compute or latency23.
The structure of an effective LLM call goes from…
System Prompt
Preamble
Few shot-examples
Question
…for Transformers, to simply…
Inputted state (with problem context, initial instructions, textbooks, and few-shot examples)
Short question
…for Mamba.
This is cheaper and faster than few-shot prompting (as the state is infinitely reusable without inference cost). It’s also MUCH cheaper than finetuning and doesn’t require any gradient updates. We could imagine retrieving states in addition to context.
Mamba & Mechanistic Interpretability
Transformer interpretability typically involves:
understanding token relationships via attention,
understanding circuits, and
using Dictionary Learning for unfolding MLPs.
Most of the ablations that we would like to do for Mamba are still valid, but understanding token communication (1) is now more nuanced. All information moves between tokens via hidden states instead of the Attention Mechanism which can “teleport” information from one sequence position to another.
For understanding in-context learning (ICL) tasks with Mamba, we will look to intervene on the SSM state. A classic task in-context learning task is Indirect Object Identification in which a model has to finish a paragraph like:
Then, Shelby and Emma had a lot of fun at the school. [Shelby/Emma] gave an apple to [BLANK]
The model is expected to fill in the blank with the name that is not repeated in the paragraph. In the chart below we can see that information is passed from the [Shelby/Emma] position to the final position via the hidden state (see the two blue lines in the top chart).
Since it’s hypothesised that much of In-Context Learning in Transformers is downstream of more primitive sequence position operations (like Induction Heads), Mamba being able to complete this task suggests a more general In-Context Learning ability.
What’s Next for Mamba & SSMs?
Mamba-like models are likely to excel in scenarios requiring extremely long context and long-term memory. Examples include:
Processing DNA
Generating (or reasoning over) video
Writing novels
An illustrative example is agents with long-term goals.
Suppose you have an agent interacting with the world. Eventually, its experiences become too much for the context window of a transformer. The agent then has to compress or summarise its experiences into some more compact representation.
But how do you decide what information is the most useful as a summary? If the task is language, LLMs are actually fairly good at summaries – okay, yeah, you’ll lose some information, but the most important stuff can be retained.
However, for other disciplines, it might not be clear how to summarise. For example, what’s the best way to summarise a 2 hour movie?24. Could the model itself learn to do this naturally rather than a hacky workaround like trying to describe the aesthetics of the movie in text?
This is what Mamba allows. Actual long-term memory. A real state where the model learns to keep what’s important. Prediction is compression – learning what’s useful to predict what’s coming next inevitably leads to building a useful compression of the previous tokens.
The implications for Assistants are clear:
Your chatbot co-evolves with you. It remembers.
The film HER is looking better and better as time goes on 😳
Agents & AI Safety
One reason for positive updates in existential risk from AGI is Language Models. Previously, Deep-RL agents trained via self-play looked set to be the first AGIs. Language models are inherently much safer since they aren’t trained with long-term goals25.
The potential for long-term sequence reasoning here brings back the importance of agent-based AI safety. Few agent worries are relevant to Transformers with an 8k context window. Many are relevant to systems with impressive long-term memories and possible instrumental goals.
The Best Collab Since Taco Bell & KFC: 🤖 x 🐍
The Mamba authors show that there’s value in combining Mamba’s long context with the Transformer’s high fidelity over short sequences. For example, if you’re making long videos, you likely can’t fit a whole movie into a Transformer’s context for attention26. You could imagine having Attention look at the most recent frames for short-term fluidity and an SSM for long-term narrative consistency27.
This isn’t the end for Transformers. Their high effectiveness is exactly what’s needed for many tasks. But now Transformers aren’t the only option. Other architectures are genuinely feasible.
So we’re not in the post-Transformer era. But for the first time, we’re living in the post-only-Transformers era28. And this blows the possibilities wide open for sequence modelling with extreme context lengths and native long-term memory.
Two ML researchers, Sasha Rush (HuggingFace, Annotated Transformer, Cornell Professor) and Jonathan Frankle (Lottery Ticket Hypothesis, MosaicML, Harvard Professor), currently have a bet here.
Currently Transformers are far and away in the lead. With 3 years left, there’s now a research direction with a fighting chance.
All that remains to ask is: Is Attention All We Need?
1. see Figure 8 in the Mamba paper. 2. And scaling up with massive compute. 3. More specifically the scaled dot-product Attention popularised by Transformers 4. For people who don’t see Temple Run as the cultural cornerstone it is 🤣 Temple Run was an iPhone game from 2011 similar to Subway Surfer 5. Here we assume the environment is sufficiently smooth. 6. One pretty important constraint for this to be efficient is that we don’t allow the individual elements of the state vector to interact with each other directly. We’ll use a combination of the state dimensions to determine the output but we don’t e.g. allow the velocity of the runner and the direction of the closest obstacle (or whatever else was in our state) to directly interact. This helps with efficient computation and we achieve this practically by constraining A to be a diagonal matrix. 7. Concretely consider the case of Language Models – each token is a discrete step 8. ZOH also has nice properties for the initialisations – we want A_bar to be close to the identity so that the state can be mostly maintained from timestep to timestep if desired. ZOH gives A_bar as an exponential so any diagonal element initialisations close to zero give values close to 1 9. This is known as the Euler discretisation in the literature 10. It’s wild to note that some readers might not have, we’re so far into the age of Attention that RNNs have been forgotten! 11. B is like the Query (Q) matrix for Transformers. 12. C is like the Output (O) matrix for Transformers. 13. Non-alcoholic options also available! 14. Especially as all voices roughly occupy the same space on the audio frequency spectrum Intuitively this seems really hard! 15. Note that photographic memory doesn’t necessarily imply perfect inferences from that memory! 16. To be clear, if you have a short sequence, then a transformer should theoretically be a better approach. If you can store the whole context, then why not!? If you have enough memory for a high-resolution image, why compress it into a JPEG? But Mamba-style architectures are likely to hugely outperform with long-range sequences. 17. More details are available for engineers interested in CUDA programming – Tri’s talk, Mamba paper section 3.3.2, and the official CUDA code are good resources for understanding the Hardware-Aware Scan 18. or in Object Oriented Programming 19. Implications to actual Political Economy are left to the reader but maybe Gu and Dao accidentally solved politics!? 20. This isn’t a perfect analogy as human evolution follows a genetic algorithm rather than SGD. 21. Albeit a pretty weird hard drive at that – it morphs over time rather than being a fixed representation. 22. As a backronym, I’ve started calling the hidden_state the state space dimension (or selective state dimension) which shortens to SSD, a nice reminder for what this object represents – the long-term memory of the system. 23. I’m thinking about this similarly to the relationship between harmlessness finetuning and activation steering. State swapping, like activation steering, is an inference time intervention giving comparable results to its train time analogue. 24. This is a very non-trivial problem! How do human brains represent a movie internally? It’s not a series of the most salient frames, nor is it a text summary of the colours, nor is it a purely vibes-based summary if you can memorise some lines of the film. 25. They’re also safer since they inherently understand (though don’t necessarily embody) human values. It’s not all clear that how to teach an RL agent human morality. 26. Note that typically an image (i.e. a single frame) counts as >196 tokens, and movies are typically 24 fps so you’ll fill a 32k context window in 7 seconds 🤯 27. Another possibility that I’m excited about is applying optimisation pressure to the state itself as well as the output to have models that respect particular use cases. 28. This is slightly hyperbolic, the TS-Mixer for time series, Gradient Boosting Trees for tabular data and Graph Neural Networks for weather prediction exist and are currently used, but these aren’t at the core of AI
Author Bio
Kola Ayonrinde is a Research Scientist and Machine Learning Engineer with a flair for writing. He integrates technology and creativity, focusing on applying machine learning in innovative ways and exploring the societal impacts of tech advancements.
Acknowledgements
This post was originally posted on Kola’s personal blog.
Thanks to Gonçalo for reading an early draft, Jaden for the nnsight library used for the Interpretability analysis and Tessa for Mamba patching visualisations.Also see: Mamba paper, Mamba Python code, Annotated S4, Nathan Labenz podcast
Citation
For attribution in academic contexts or books, please cite this work as
Kola Ayonrinde, "Mamba Explained," The Gradient, 2024
@article{Ayonrinde2024mamba, author = Kola Ayonrinde, title = Mamba Explained, journal = The Gradient, year = 2024, howpublished = urlhttps://thegradient.pub/mamba-explained,
#2024#8K#AGI#ai#ai model#algorithm#amazing#amp#Analysis#apple#applications#approach#architecture#Art#Article#attention#attention mechanism#audio#Best Of#Blog#Blue#Books#Brain#brains#Building#cache#cats#chart#chatbot#code
0 notes
Text

Sometimes, when making your own devices on microcontrollers, there is a need to display huge amounts of information on a display and to use a bigger screen for ease of perception. Unfortunately, there are no ready-made and budget-friendly solutions for this task on the market. LCD displays with the ability to connect to a microcontroller are usually tiny and pricy.
But at the same time, there is a wide selection of legacy LCD monitors with a VGA interface. Models with a diagonal of 15 to 19 inches can be purchased in perfect working condition for a very low price, or one can even get one for free. This especially applies to monitors with a 4:3 aspect ratio. In addition, such models are usually quite reliable.
Most older monitors only have a VGA connector for connecting to a computer. Sometimes there is an additional DVI port (on more expensive models). The HDMI connector is more common on modern devices.
Thus, with a probability close to 100%, we'll get just a VGA on an older monitor. In order to display an image on such a monitor, it is enough to work with only five signals: analog R (red), G (green), and B (blue), responsible for the brightness of each color component, as well as digital HS (horizontal sync) and VS (vertical sync), providing synchronization. Analogue signal levels should range from 0 to 0.7 V, where 0 V corresponds to no light at all and 0.7 V to maximum brightness. Digital signals HS and VS are short pulses with a TTL level of negative polarity. The timings of these signals can be found, for example, here: http://tinyvga.com/vga-timing/640x480@60Hz.
Typically, special controllers, or FPGAs, are used to generate video signals, and many FPGA development boards are already equipped with a VGA connector. However, FPGAs are often expensive and require many additional components. I was looking for a simpler and cheaper solution. As a result, the decision was made to use CPLD. CPLDs have fewer available logic gates (LEs) than FPGAs but are less expensive. For example, the MAX II Altera EPM240 development board is sold on Aliexpress: https://www.aliexpress.us/item/3256804686276488.html for only $8.12 (excluding shipping), and the kit even includes a programmer. The chips themselves can be purchased for $1.6–2.1 (for nice knockoffs).

Plain text mode was chosen for implementation because it is easier for a slow microcontroller but at the same time quite informative. Some graphics elements can be implemented using pseudo-graphics symbols, as was often done in the days of DOS. The introduction of a graphics mode would require transferring a large amount of data from the microcontroller and additional efforts to create it, which is not always possible, especially for weak cores.
CPLD has a built-in Flash ROM (User Flash Memory block, UFM), which can be used as a character ROM. However, its capacity is very limited—only 8 kbit, or 1 KB. This amount of storage is only sufficient for characters with a resolution of 5×7 pixels, and only if we discard non-displayable, insignificant, and visually identical characters from the ASCII table. In addition, the use of UFM will require the use of logic gates (LE), of which there are already a few. Despite the attractiveness of this option, I had to abandon it and use an external ROM chip, which can be salvaged from an old motherboard. Choosing a microchip with a supply voltage of 3.3 V will eliminate problems with matching voltage levels for the CPLD. The capacity of such ROMs is quite large: 2, 4, or 8 Mbit, or at least 256 to 1024 KB, which allows one to store a large number of different fonts with a decent resolution of 8x16 pixels.

To store the screen image, you will also need a RAM chip. Let's estimate the approximate size required for this. If we plan on using an 8×16 pixel font on a screen with a resolution of 640×480 pixels, we will end up with 80 characters per line and 30 lines on the screen. Thus, saving the screen image will require 80 × 30 = 2400 bytes. This number is somewhat inconvenient because it is just slightly larger than the nearest power of two, 2048. The memory use in this case is inefficient—only 58%, since the next power of two is 4096. By the way, this is exactly why text mode with 80×25 symbols became popular since there are 5 fewer lines on the screen. In this case, only 2000 bytes of memory are needed, which easily fits into 2 KB.
However, modern memory chips have significant storage sizes, and saving memory is not so critical nowadays. Moreover, one can deliberately choose to waste memory in order to simplify the decryption logic and save CPLD logic elements. Then you will need at least 4096 bytes (2^12, 12 address bits), which can be divided as follows: 5 address bits are allocated to the row address on the screen (30 of 32 will be used) and 7 bits to the column or position address characters in the string (80 out of 128 will be used).
4096 bytes are required only for storing ASCII symbols. The same amount of memory will be taken by the symbol attribute page. Attributes must include character color (3 bits), background color (3 bits), underline, and blinking. So, a memory of at least 8 KB is required.
Of the most affordable options, the best one is static RAM (used as cache memory), also salvaged from old devices or motherboards. It should be noted that this memory can only operate at 5 V. However. If it is a CMOS-type memory, it can take 3.3 V, but this will require timing correction.
So, we got the following diagram:.
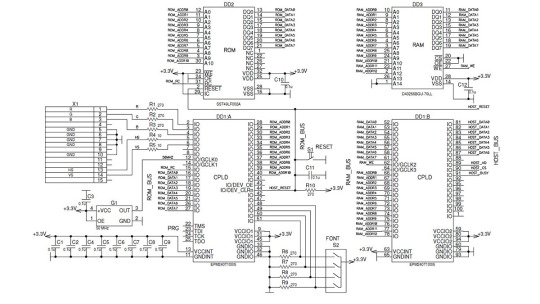
The circuit includes only three microchips and a minimum number of external components. Using the aforementioned Altera EPM240 development board as a base, all you need are ROM chips, RAM chips, and a DSUB header with five resistors. Connecting signals to the CPLD is just an approximation, since almost all of its pins are equivalent (with the exception of Global CLK, one of which requires connecting a signal from a clock generator). When the chip is repeatedly reprogrammed for a new device, almost all of its signals can be reassigned. Currently, the device is assembled on a breadboard and can be left aside.
The device communicates with the microcontroller via a parallel 8-bit interface (in the diagram, signals with the HOST prefix), which is logically almost identical to the widely used display interface on the 1602 and similar controllers. The only difference is the addition of a BUSY signal directed from the device to the microcontroller. Its necessity is due to the fact that access to the RAM chip is provided only during the backward sweep period. The rest of the time, the chip is busy (pun intended) executing CPLD logic. The BUSY signal also acts like an interrupt request (IRQ) function. When it's changed, the controller can automatically start writing to the screen buffer.
Interface description:
DATA[7:0] – eight bits of data, unidirectional port, intended exclusively for writing to the device
CS – chip select; 0 for chip is selected, 1 for chip is not selected. On the positive edge of the CS signal, the data is latched for writing.
AD – address/data, during a write operation: 0 – data is being transferred; 1 – address is being transferred.
BUSY – device busy state; 0 – free; 1 – busy. If the device is busy, the write operation to RAM is ignored. Writing is only possible to the address register.
RESET – device reset. 0 – reset; 1 – work. A hard reset can be used to turn off the screen immediately. When this signal is activated, the image output to the monitor stops. Resetting does not affect the contents of the RAM chip.
Writing data from the microcontroller to RAM is possible only during the backward sweep of the frame scan, when the RAM chip is not occupied by the CPLD logic. This time interval is 1.440 milliseconds. Despite the significant duration of this interval, when using slow microcontrollers, there may not be enough time to completely rewrite the entire memory space. For example, an AVR microcontroller, when operating at a frequency of 11.0592 MHz, is capable of recording only three full-screen lines with all the attributes. If one does not update the attributes (as is usually the case in real-life applications, attributes are written once when the program starts), then six full rows can be written in this time. Perhaps optimizing the code and rewriting it in assembly language can significantly speed up the process of updating data. Otherwise, it may take from 5 cycles (if updating only the data) to 15 cycles (if updating the attributes) to completely rewrite the screen. At 60 fps, it will take 1/12 to 1/4 of a second. Those who have ever worked on IBM PC/XT or IBM PC/AT computers with processor clock speeds around 4 to 12 MHz may notice the experience of refreshing the screen to be familiar.
If you don’t want to wait for the next vertical pulse and want to record all the data at once, you can use the RESET signal. When activated, the internal logic of the CPLD stops and is disconnected from the RAM chip, allowing the microcontroller to directly access the memory. Registers for working with RAM are not affected by the reset signal.
In general, the write operations are as follows: you need to wait until the BUSY signal becomes zero, then put the desired data on the data bus, set the data type (address or data) AD, and set the CS signal first to 0, then to 1. When this signal changes from 0 to 1, the data is stored in memory. During a vertical pulse, the RAM chip is directly connected to the microcontroller's HOST signals, so maintaining the timings during writes becomes the responsibility of the microcontroller. However, since static RAM is a fairly fast device and typically has timings significantly smaller than the maximum speed of an average microcontroller driving its I/O lines, this task is not difficult.
The RAM chip D43256BGU-70LL is connected to the CPLD's output pins, with the lines having a 'RAM' prefix on the diagram. These signals include an 8-bit bidirectional data bus and a 13-bit address bus. Of the control signals, only the WE signal is used. Since there is only one chip on the RAM bus and both buses (address and data) are completely under its control, the OE and CS signals are not used, equal 0, and connected to GND.
The SST49LF002A ROM chip is connected similarly (signals with the 'ROM' prefix), except that the data bus in this case is unidirectional. The OE and WE signals of this IC are also not used and are directly connected to 0 (GND) and 1 (VCC), respectively.
Jumpers are connected to the available CPLD pins to select the current font. Since the ROM chip is large enough, it allows one to store several different fonts, including national alphabets, and switch to them by installing jumpers.
The DSUB VGA port is connected to the CPLD using only 5 resistors. Resistors in the HS and VS circuits are primarily for protection and can be ditched. Resistors in circuits R, G, and B are selected in such a way that, together with the input resistance of the monitor (75 Ohms), they form a voltage divider that reduces the voltage at the monitor input to 0.7 V.
The power leads are shunted with ceramic capacitors, and the clock signal with a frequency of 50 MHz from a crystal is supplied to the GCLK0 pin. These parts were on the breadboard originally.
A resistor, a capacitor, and a button are connected to the RESET signal, forming it. However, if the signal is generated by a microcontroller, these components are redundant.
After creating the main part of the CPLD operating logic, it became clear that the number of logic elements (LEs) used was slightly over half of the available ones. In this regard, the idea arose to complexify the logic and add more features. First of all, the number of colors can be increased to 16 by adding three additional CPLD pins and three resistors. This won't significantly complicate the scheme, but it will add eight more colors. In this case, the RAM page with attributes will have to be completely devoted to color, and another page with attributes will have to be added, increasing the RAM address bus by 1 bit. In the second page of attributes, you can implement font selection, underlining, character and background flickering, and so on.
The new scheme looks similar to the previous one.
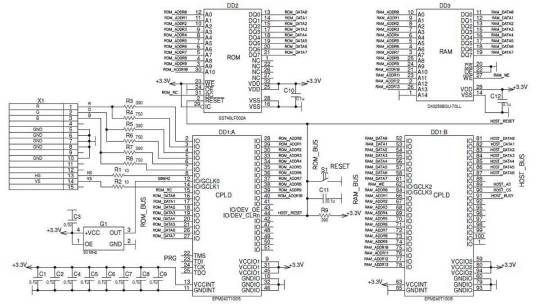
As the number of colors increases, the question is: which palette to choose? With only 8 colors, there is no such question; all colors are different combinations of the three primary colors: red, green, and blue (2^3 = 8). When there are more colors, different options are possible. For example, the 16-color EGA palette: https://moddingwiki.shikadi.net/wiki/EGA_Palette:
As can be seen from the presented palette, the 4th bit in the color number stands for brightness. However, the halves of the table are not evenly separated by brightness. The first half is set to 2/3 brightness (byte AAH = 170 = 2/3 × 256). In the second half, another 1/3 of brightness is added (byte 55H = 85 = 1/3 × 256), and the colors in this part are called "bright."
Interestingly, color No. 6 (yellow/brown) in this scheme deviates from the expected AAAA00 and is specifically set to AA5500. This was done to replace the unattractive, dirty yellow color with the more appealing brown. This is a known feature of EGA video cards and monitors. Some monitors took this into account, while others did not implement this feature in order to simplify the circuit. Some models added a BROWN ADJ knob so that the user could set the desired shade of that color. That is why the color in the table is indicated as yellow/brown.
Nonlinear separation by brightness level automatically leads to two shades of gray showing up: light gray and dark gray, which are widely used.
In the 16-color VGA palette: https://lospec.com/palette-list/microsoft-vga, the situation is slightly different: the colors are divided exactly in two halves by brightness (80H = 128 = 1/2 × 256):

There is also a noticeable outlier in this palette: light gray (С0С0С0), which should be black, duplicating an existing color. Additionally, this color swapped places with the dark gray color (808080). This was done intentionally to ensure compatibility between the VGA and EGA 16-color palettes, making them almost identical.
In our case, when the R, G, and B signals are generated in hardware using resistors, it is more convenient to use the EGA palette. So, it is necessary to make a software correction only for one color, No. 6. All other colors are generated automatically. Switching to the VGA palette would require not only a program change but also an additional group of resistors to be added to create the light gray color (C0C0C0). The resistors should be picked so that one group provides a brightness level of 1/3, the second is 2/3, and together they provide full brightness. By simple calculations using Ohm's law, we get the following values: 390 Ohms and 750 Ohms.
The signal generation logic for a static image like the one with test color bars is quite simple. However, if it is necessary to generate a dynamic image, the task becomes more complicated. It is necessary to organize a logical interface with RAM and ROM. At the same time, data exchange should occur not just quickly but lightning-fast! Let's first evaluate whether the selected chips can keep up with operating like this.
So, the resolution is 640x480. Pixel output frequency is 25 MHz (the standard specifies 25.175 MHz, but rounding to 25 MHz is acceptable since VGA, like many other analog standards, allows a significant spread of parameters). The frame refresh rate is 60 Hz (actually 59.5 Hz), and the line refresh rate is 31.46875 kHz (actually 31.25 kHz). Thus, the output time of one pixel is 40 ns, and the output time of an 8-bit character is 320 ns. During this time, the ASCII code of the character (one byte), the color code (one byte), and the attributes (one byte) should be read from RAM, and then, using the ASCII code as an address, we should read the bit mask of the character from ROM. Only then will the CPLD logic have all the necessary information to begin imaging.
According to the technical description (datasheet), for the selected D43256BGU-70LL chip, a full read cycle takes 70 ns. Considering the use of the chip at reduced voltage, the read cycle takes longer—let's say, 100 ns. Thus, in 320 ns, we will have enough time to read three bytes from RAM: ASCII code, color code, and character attributes. Great. The situation with ROM is more complicated: the address is written to it in two steps—in rows and columns—and, according to the manual, the read cycle takes 270 ns. Not the highest speed, but within the required 320 ns, even with time to spare.
The problem is that we can't start issuing the ROM address until we know at least the ASCII code, which takes 100 ns. This sums up to 370 ns. What saves us is the fact that each RAM or ROM read cycle individually fits within the allowed interval, and we can simply spend two additional cycles reading data. To add these two loops during data preparation, it is necessary to shift the character display area, creating an additional blanking area 2 characters wide at the beginning of the line and reducing the same area at the end of the line by 2 characters. This is quite simple to do: we simply shift the horizontal blanking pulse by 640 ns (accordingly, the horizontal sync pulse also shifts). From the monitor's point of view, there is no difference.
To better understand when and what to write and read, it is handy to create a timing diagram. At the beginning, all the timings were in my head, but creating a paper diagram and giving it another look allowed me to significantly optimize read cycles and even reduce the number of registers used.
The cycle begins by setting the RAM address of the ASCII character byte on the bus. After 80 ns, the requested byte appears on the RAM data bus, which is instantly used to generate the byte read address from the character generator ROM. At the 100 ns mark, we set the address of the symbol attributes byte to the RAM address bus. At 140 ns (60 ns after setting the address), we latch the first part of the ROM address. After another 60 ns, we set the second part of the address on the ROM address bus. At this point, there should be a byte of data on the RAM data bus with character attributes, where 5 bits correspond to the font and are included in the second part of the ROM address. The remaining 3 bits of data are stored in temporary register 2. After another 60 ns, we latch the second part of the ROM address. Data will appear on the ROM data bus 120 ns after this event, already during the second cycle. To prevent loop intersections, we write this data to temporary register 1 at 80 ns. And finally, at 300 ns, all the prepared data is written to the working registers. The character bitmask from temporary register 1 is copied into the rom_reg register, and the stored attribute bits are applied to the color byte that has been read at that time.
Thus, by the end of the second loop, all the data will be ready for outputting the symbol.
Writing data from the microcontroller to RAM is carried out as follows. We wait until the BUSY signal becomes zero, after which we set the starting addresses in the registers where data will be written. Typically, this is address 0, corresponding to the start of the data page, but a random address can also be chosen if only a few bytes need to be changed. Then we record the data. After each byte is written, the address is automatically incremented. When the edge of the screen is reached (the 80th character in a line), the address of the character position in the line is automatically reset to zero, and the line address is incremented by 1. After the entire page of data is written, the address is automatically adjusted to the attribute page entries and then the color page entries. After writing all three pages, the address is also automatically reset, and the process begins again with writing to the data page. Thus, the start address is set only once, and then only data is written. This saves a few microseconds on address setting and simplifies the code when all data can be transferred in one cycle.
Data format for writing data (AD=0):

The data page stores ASCII character codes.

The attributes page stores symbol attributes. The lower two bits are responsible for the hardware-driven blinking of a character or background, and the third bit is for the underline. The upper 5 bits select the font. Accordingly, you can display characters from different fonts mixed in any combination. 5 digits for selecting the font allow one to store 32 different fonts, which can include any symbols of national alphabets as well as tiles for displaying an image.

The color page contains the character color and the background color. Color can be anything from the 16-color palette.
There are three address registers. The choice of which particular one to write to is defined by the most significant bits of the data byte. If the most significant bit [7] is 0, then the position register in the row (column) is written. If it is 1, then the line number register (line) and RAM page number register (ASCII code, attributes, or color) are written. If the three most significant bits are equal to 1, then a special control register is written, bits [4] and [3] of which determine the position of the hardware-generated line when the underscore bit is turned on, and bits [2–0] are reserved for future settings.
Data format for writing address (AD = 1):
A register stores the position in a string.

The register stores the line number and page selection.

If you set an address outside the range of 0-79 for a column and 0-29 for a row, then data will begin to be written to the shadow memory area, which is not displayed on the screen. There is nothing wrong with this; after passing the address 127, the data will again be written to the visible area.
Internal CPLD registers (some):

The register contains the current horizontal scan position. It is clocked at a frequency of 50 MHz, which is two times the required 25 MHz, so the least significant bit (tact bit) is not used. Accordingly, bits 1 to 3 indicate the position within the character, and bits 4 to 10 indicate the position of the character in the string. When the value reaches 1600, the register is reset to zero, and the value in the vreg register is increased by 1.
The register contains the current vertical scan position. Clocked from the hreg register. Bits 0 to 3 indicate the line within the character, and bits 4 to 8 indicate the line on the screen. Bit 9 is not used. When the value reaches 525, the register is reset to zero.
The registers contain the current address value for accessing RAM (16 KB in total). The lower 7 bits are the character address in the line (column), then 5 bits are the line address, and 2 bits are the page address (ASCII code, attributes, or color). There are two of these registers: one for internal use by the CPLD logic, and the second is controlled externally by the microcontroller.
The ROM address register is written in two stages. It contains the character string address, the character's ASCII code, and the font address. These addresses are located in such a way that one can flash standard DOS *.fnt font files into the ROM without any additional processing, just one after another. You can combine several fonts into one file for firmware using any file editing program. Just make sure that the fonts have a resolution of 8x16.

Color output register. This register is connected directly to the CPLD pins, supplying the R, G, and B signals to the monitor. The lower 3 bits provide a signal with 2/3 of a brightness level (they must be connected to 390 Ohm resistors); the highest ones provide a signal with a brightness level of 1/3 (they must be connected to 750 Ohm resistors).
Photos to illustrate:



0 notes
Text
Ruby: From Darkness To Dawn

Ruby: From Darkness To Dawn
A Beginner’s Journey Through Code, Logic, and Light

Ruby: From Darkness to Dawn is your ultimate guide to transforming from a complete beginner into a confident Ruby programmer. Whether you're starting with zero knowledge or looking to strengthen your foundation, this book walks you step by step out of the confusion (“darkness”) and into clarity and skill (“dawn”).
This book doesn’t just teach Ruby — it teaches how to think like a programmer.
Inside, you’ll explore the core building blocks of Ruby in a simple, relatable way:
Variables – Learn how to store, update, and use data like a pro.
Data Types – Understand the difference between numbers, text, booleans, and more.
Conditional Statements – Master how to make decisions in your code using if, else if, and else.
Loops – Automate repetition with for and while loops — plus how to control them with break and continue.
Methods – Discover how to write reusable blocks of code, create clean programs, and break big problems into small solutions.
Through practical examples, real-world analogies, and hands-on exercises, Ruby: From Darkness to Dawn turns confusion into clarity. It’s not just a programming book — it’s your personal journey into the world of code.
By Souhail Laghchim.
0 notes