#pyspark python path
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Women make up for the other 50% of Tumblr’s audience.
Text
Big Data Analytics: Tools & Career Paths

In this digital era, data is being generated at an unimaginable speed. Social media interactions, online transactions, sensor readings, scientific inquiries-all contribute to an extremely high volume, velocity, and variety of information, synonymously referred to as Big Data. Impossible is a term that does not exist; then, how can we say that we have immense data that remains useless? It is where Big Data Analytics transforms huge volumes of unstructured and semi-structured data into actionable insights that spur decision-making processes, innovation, and growth.
It is roughly implied that Big Data Analytics should remain within the triangle of skills as a widely considered niche; in contrast, nowadays, it amounts to a must-have capability for any working professional across tech and business landscapes, leading to numerous career opportunities.
What Exactly Is Big Data Analytics?
This is the process of examining huge, varied data sets to uncover hidden patterns, customer preferences, market trends, and other useful information. The aim is to enable organizations to make better business decisions. It is different from regular data processing because it uses special tools and techniques that Big Data requires to confront the three Vs:
Volume: Masses of data.
Velocity: Data at high speed of generation and processing.
Variety: From diverse sources and in varying formats (!structured, semi-structured, unstructured).
Key Tools in Big Data Analytics
Having the skills to work with the right tools becomes imperative in mastering Big Data. Here are some of the most famous ones:
Hadoop Ecosystem: The core layer is an open-source framework for storing and processing large datasets across clusters of computers. Key components include:
HDFS (Hadoop Distributed File System): For storing data.
MapReduce: For processing data.
YARN: For resource-management purposes.
Hive, Pig, Sqoop: Higher-level data warehousing and transfer.
Apache Spark: Quite powerful and flexible open-source analytics engine for big data processing. It is much faster than MapReduce, especially for iterative algorithms, hence its popularity in real-time analytics, machine learning, and stream processing. Languages: Scala, Python (PySpark), Java, R.
NoSQL Databases: In contrast to traditional relational databases, NoSQL (Not only SQL) databases are structured to maintain unstructured and semic-structured data at scale. Examples include:
MongoDB: Document-oriented (e.g., for JSON-like data).
Cassandra: Column-oriented (e.g., for high-volume writes).
Neo4j: Graph DB (e.g., for data heavy with relationships).
Data Warehousing & ETL Tools: Tools for extracting, transforming, and loading (ETL) data from various sources into a data warehouse for analysis. Examples: Talend, Informatica. Cloud-based solutions such as AWS Redshift, Google BigQuery, and Azure Synapse Analytics are also greatly used.
Data Visualization Tools: Essential for presenting complex Big Data insights in an understandable and actionable format. Tools like Tableau, Power BI, and Qlik Sense are widely used for creating dashboards and reports.
Programming Languages: Python and R are the dominant languages for data manipulation, statistical analysis, and integrating with Big Data tools. Python's extensive libraries (Pandas, NumPy, Scikit-learn) make it particularly versatile.
Promising Career Paths in Big Data Analytics
As Big Data professionals in India was fast evolving, there were diverse professional roles that were offered with handsome perks:
Big Data Engineer: Designs, builds, and maintains the large-scale data processing systems and infrastructure.
Big Data Analyst: Work on big datasets, finding trends, patterns, and insights that big decisions can be made on.
Data Scientist: Utilize statistics, programming, and domain expertise to create predictive models and glean deep insights from data.
Machine Learning Engineer: Concentrates on the deployment and development of machine learning models on Big Data platforms.
Data Architect: Designs the entire data environment and strategy of an organization.
Launch Your Big Data Analytics Career
Some more Specialized Big Data Analytics course should be taken if you feel very much attracted to data and what it can do. Hence, many computer training institutes in Ahmedabad offer comprehensive courses covering these tools and concepts of Big Data Analytics, usually as a part of Data Science with Python or special training in AI and Machine Learning. Try to find those courses that offer real-time experience and projects along with industry mentoring, so as to help you compete for these much-demanded jobs.
When you are thoroughly trained in the Big Data Analytics tools and concepts, you can manipulate information for innovation and can be highly paid in the working future.
At TCCI, we don't just teach computers — we build careers. Join us and take the first step toward a brighter future.
Location: Bopal & Iskcon-Ambli in Ahmedabad, Gujarat
Call now on +91 9825618292
Visit Our Website: http://tccicomputercoaching.com/
0 notes
Text
Azure Data Engineering Training in Hyderabad
Master Data Engineering with Azure and PySpark at RS Trainings, Hyderabad
In today's data-driven world, the role of a data engineer has become more critical than ever. For those aspiring to excel in this field, mastering tools like Azure and PySpark is essential. If you're looking for the best place to gain comprehensive data engineering training in Hyderabad, RS Trainings stands out as the premier choice, guided by seasoned industry IT experts.

Why Data Engineering?
Data engineering forms the backbone of any data-centric organization. It involves the design, construction, and management of data architectures, pipelines, and systems. As businesses increasingly rely on big data for decision-making, the demand for skilled data engineers has skyrocketed. Proficiency in platforms like Azure and frameworks like PySpark is crucial for managing, transforming, and making sense of large datasets.
Azure for Data Engineering
Azure is Microsoft's cloud platform that offers a suite of services to build, deploy, and manage applications through Microsoft-managed data centers. For data engineers, Azure provides powerful tools such as:
Azure Data Factory: A cloud-based data integration service that allows you to create data-driven workflows for orchestrating and automating data movement and data transformation.
Azure Databricks: An Apache Spark-based analytics platform optimized for the Microsoft Azure cloud services platform, providing an interactive workspace for data engineers and data scientists to collaborate.
Azure Synapse Analytics: An integrated analytics service that accelerates time to insight across data warehouses and big data systems.
PySpark: The Engine for Big Data Processing
PySpark, the Python API for Apache Spark, is a powerful tool for big data processing. It allows you to leverage the scalability and efficiency of Apache Spark using Python, a language known for its simplicity and readability. PySpark is used for:
Data Ingestion: Efficiently bringing in data from various sources.
Data Cleaning and Transformation: Ensuring data quality and converting data into formats suitable for analysis.
Advanced Analytics: Implementing machine learning algorithms and performing complex data analyses.
Real-time Data Processing: Handling streaming data for immediate insights.
RS Trainings: Your Gateway to Expertise
RS Trainings in Hyderabad is the ideal destination for mastering data engineering with Azure and PySpark. Here’s why:
Industry-Experienced Trainers: Learn from IT experts who bring real-world experience and insights into the classroom, ensuring that you get practical, hands-on training.
Comprehensive Curriculum: The course covers all essential aspects of data engineering, from fundamental concepts to advanced techniques, including Azure Data Factory, Azure Databricks, and PySpark.
Hands-on Learning: Engage in extensive hands-on sessions and projects that simulate real-world scenarios, helping you build practical skills that are immediately applicable in the workplace.
State-of-the-Art Facilities: RS Trainings provides a conducive learning environment with the latest tools and technologies to ensure an immersive learning experience.
Career Support: Benefit from career guidance, resume building, and interview preparation sessions to help you transition smoothly into a data engineering role.
Why Choose RS Trainings?
Choosing RS Trainings means committing to a path of excellence in data engineering. The institute’s reputation for quality education, combined with the expertise of its instructors, makes it the go-to place for anyone serious about a career in data engineering. Whether you are a fresh graduate or an experienced professional looking to upskill, RS Trainings provides the resources, guidance, and support you need to succeed.
Embark on your data engineering journey with RS Trainings and equip yourself with the skills and knowledge to excel in the fast-evolving world of big data. Join us today and take the first step towards becoming a proficient data engineer with expertise in Azure and PySpark.
#data engineer training#data engineer online training#data engineer training in hyderabad#data engineer training institute in hyderabad#data engineer training with placement#azure data engineer online training#azure data engineering training in hyderabad#data engineering
0 notes
Text
From Beginner to Pro: The Best PySpark Courses Online from ScholarNest Technologies

Are you ready to embark on a journey from a PySpark novice to a seasoned pro? Look no further! ScholarNest Technologies brings you a comprehensive array of PySpark courses designed to cater to every skill level. Let's delve into the key aspects that make these courses stand out:
1. What is PySpark?
Gain a fundamental understanding of PySpark, the powerful Python library for Apache Spark. Uncover the architecture and explore its diverse applications in the world of big data.
2. Learning PySpark by Example:
Experience is the best teacher! Our courses focus on hands-on examples, allowing you to apply your theoretical knowledge to real-world scenarios. Learn by doing and enhance your problem-solving skills.
3. PySpark Certification:
Elevate your career with our PySpark certification programs. Validate your expertise and showcase your proficiency in handling big data tasks using PySpark.
4. Structured Learning Paths:
Whether you're a beginner or seeking advanced concepts, our courses offer structured learning paths. Progress at your own pace, mastering each skill before moving on to the next level.
5. Specialization in Big Data Engineering:
Our certification course on big data engineering with PySpark provides in-depth insights into the intricacies of handling vast datasets. Acquire the skills needed for a successful career in big data.
6. Integration with Databricks:
Explore the integration of PySpark with Databricks, a cloud-based big data platform. Understand how these technologies synergize to provide scalable and efficient solutions.
7. Expert Instruction:
Learn from the best! Our courses are crafted by top-rated data science instructors, ensuring that you receive expert guidance throughout your learning journey.
8. Online Convenience:
Enroll in our online PySpark courses and access a wealth of knowledge from the comfort of your home. Flexible schedules and convenient online platforms make learning a breeze.
Whether you're a data science enthusiast, a budding analyst, or an experienced professional looking to upskill, ScholarNest's PySpark courses offer a pathway to success. Master the skills, earn certifications, and unlock new opportunities in the world of big data engineering!
#big data#data engineering#data engineering certification#data engineering course#databricks data engineer certification#pyspark course#databricks courses online#best pyspark course online#pyspark online course#databricks learning#data engineering courses in bangalore#data engineering courses in india#azure databricks learning#pyspark training course#pyspark certification course
1 note
·
View note
Text
"The Fast and Furious: Exploring the Rapid Growth of Python in the Programming World"
The fastest growing and the most popular programming language in today’s programming world is Python. The word time, the word "Python" evoked images of a massive snake, but today, it's synonymous with a wildly popular programming language. According to the TIOBE Index, Python holds the prestigious position of being the fourth most popular programming language globally, and its meteoric rise shows no signs of slowing.

Python’s and Growing User Base:
Several factors contribute to Python's remarkable success. First and foremost is its widespread adoption in web development. Renowned companies such as Google, Facebook, Mozilla, Quora, and many others employ Python web frameworks, elevating its prominence in this domain. Another pivotal driver behind Python's rapid growth is its pivotal role in the realm of data science.
Another factor that takes Python to the next level programming language is its easy use in Data Science. Therefore, the language is steadily growing in demand in the last ten years. In 2018, it was found in a survey that the majority of developers are obtaining training for the language and started work as Python developers. Initially, Python was built to solve the code readability issues discovered in C and Java languages.
The Reason Behind the Popularity of Pythons:
●As per the record, the reason behind the demand for python is it is easy to use. The language is pretty simple and can be easily readable. The simplicity of the language makes Python a favorite programming language among developers. Moreover, Python is an efficient language.
●Today almost all the developers and big tech giants prefer Python for web development. Some famous web frameworks can be utilized for web development project requirements.
●Even high-level Python is being trained as coursework. So that student can get prepared for the upcoming pythons’ trends and achieve success in their careers.
Python's skyrocketing popularity and its path towards becoming the world's most popular programming language are indeed remarkable phenomena.
Several Key Factors Underpin This Incredible Rise:
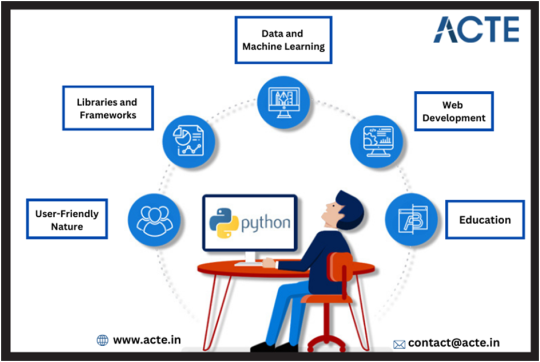
Python's User-Friendly Nature: Python stands out for its user-friendliness. Its simple, easily readable syntax appeals to both experienced developers and budding students. What's more, Python is highly efficient, allowing developers to accomplish more with fewer lines of code, making it a beloved choice.
A Supportive Python Community: Python has been around since 1990, providing ample time to foster a vibrant and supportive community. This strong support network empowers learners to expand their knowledge, contributing to Python's ever-increasing popularity. Abundant online resources, from official documentation to YouTube tutorials, make Python accessible to all.
Abundance of Libraries and Frameworks: Python's already widespread adoption has led to a wealth of libraries and frameworks developed by the community. These resources save developers time and effort, creating a virtuous cycle of popularity. Notable Python libraries include NumPy, SciPy, Django, BeautifulSoup, scikit-learn, and nltk.
Corporate Backing: Python's ascent is not solely a grassroots movement. Corporate support plays a significant role. Top companies like Google, Facebook, Mozilla, Amazon, and Quora have embraced Python for their products, with Google even offering guides and tutorials through its Python Class. This backing has been pivotal in Python's growth and success.
Python in Data and Machine Learning: Python plays a vital role in the hot trends of Big Data, Machine Learning, and Artificial Intelligence. It's widely used in research and development in these domains, and numerous Python tools like Scikit-Learn, Theano, and libraries such as Pandas and PySpark are instrumental.
Python in Web Development: Python's popularity extends to web development. It's an ideal choice for both learning and powering some of the world's most popular websites, including Spotify, Instagram, Pinterest, Mozilla, and Yelp. Python offers a range of web frameworks, from full-stack options like Django to microframeworks like Flask.
Python in Academics: The presence of Python in academic coursework is a testament to its significance. It's now a core requirement in many educational institutions, reflecting its crucial role in data science, machine learning, deep learning, and artificial intelligence. As more students learn Python, its future importance is assured.
Python's astonishing success is multifaceted and cannot be attributed to a single reason. Instead, it's the combined effect of the factors outlined above that paints a comprehensive picture of why Python has become such a pivotal and influential language in the world of programming.
If you're eager to improve your knowledge of Python, I strongly advise getting in touch with ACTE Technologies. They offer certification programs and the potential for job placements, ensuring a comprehensive learning experience. Their services are available both online and at physical locations. To commence your Python learning journey at ACTE Technologies, consider taking a methodical approach and explore the possibility of enrolling in one of their courses if it aligns with your interests.
0 notes
Text
The Ultimate Guide to Becoming an Azure Data Engineer

The Azure Data Engineer plays a critical role in today's data-driven business environment, where the amount of data produced is constantly increasing. These professionals are responsible for creating, managing, and optimizing the complex data infrastructure that organizations rely on. To embark on this career path successfully, you'll need to acquire a diverse set of skills. In this comprehensive guide, we'll provide you with an extensive roadmap to becoming an Azure Data Engineer.
1. Cloud Computing
Understanding cloud computing concepts is the first step on your journey to becoming an Azure Data Engineer. Start by exploring the definition of cloud computing, its advantages, and disadvantages. Delve into Azure's cloud computing services and grasp the importance of securing data in the cloud.
2. Programming Skills
To build efficient data processing pipelines and handle large datasets, you must acquire programming skills. While Python is highly recommended, you can also consider languages like Scala or Java. Here's what you should focus on:
Basic Python Skills: Begin with the basics, including Python's syntax, data types, loops, conditionals, and functions.
NumPy and Pandas: Explore NumPy for numerical computing and Pandas for data manipulation and analysis with tabular data.
Python Libraries for ETL and Data Analysis: Understand tools like Apache Airflow, PySpark, and SQLAlchemy for ETL pipelines and data analysis tasks.
3. Data Warehousing
Data warehousing is a cornerstone of data engineering. You should have a strong grasp of concepts like star and snowflake schemas, data loading into warehouses, partition management, and query optimization.
4. Data Modeling
Data modeling is the process of designing logical and physical data models for systems. To excel in this area:
Conceptual Modeling: Learn about entity-relationship diagrams and data dictionaries.
Logical Modeling: Explore concepts like normalization, denormalization, and object-oriented data modeling.
Physical Modeling: Understand how to implement data models in database management systems, including indexing and partitioning.
5. SQL Mastery
As an Azure Data Engineer, you'll work extensively with large datasets, necessitating a deep understanding of SQL.
SQL Basics: Start with an introduction to SQL, its uses, basic syntax, creating tables, and inserting and updating data.
Advanced SQL Concepts: Dive into advanced topics like joins, subqueries, aggregate functions, and indexing for query optimization.
SQL and Data Modeling: Comprehend data modeling principles, including normalization, indexing, and referential integrity.
6. Big Data Technologies
Familiarity with Big Data technologies is a must for handling and processing massive datasets.
Introduction to Big Data: Understand the definition and characteristics of big data.
Hadoop and Spark: Explore the architectures, components, and features of Hadoop and Spark. Master concepts like HDFS, MapReduce, RDDs, Spark SQL, and Spark Streaming.
Apache Hive: Learn about Hive, its HiveQL language for querying data, and the Hive Metastore.
Data Serialization and Deserialization: Grasp the concept of serialization and deserialization (SerDe) for working with data in Hive.
7. ETL (Extract, Transform, Load)
ETL is at the core of data engineering. You'll need to work with ETL tools like Azure Data Factory and write custom code for data extraction and transformation.
8. Azure Services
Azure offers a multitude of services crucial for Azure Data Engineers.
Azure Data Factory: Create data pipelines and master scheduling and monitoring.
Azure Synapse Analytics: Build data warehouses and marts, and use Synapse Studio for data exploration and analysis.
Azure Databricks: Create Spark clusters for data processing and machine learning, and utilize notebooks for data exploration.
Azure Analysis Services: Develop and deploy analytical models, integrating them with other Azure services.
Azure Stream Analytics: Process real-time data streams effectively.
Azure Data Lake Storage: Learn how to work with data lakes in Azure.
9. Data Analytics and Visualization Tools
Experience with data analytics and visualization tools like Power BI or Tableau is essential for creating engaging dashboards and reports that help stakeholders make data-driven decisions.
10. Interpersonal Skills
Interpersonal skills, including communication, problem-solving, and project management, are equally critical for success as an Azure Data Engineer. Collaboration with stakeholders and effective project management will be central to your role.
Conclusion
In conclusion, becoming an Azure Data Engineer requires a robust foundation in a wide range of skills, including SQL, data modeling, data warehousing, ETL, Azure services, programming, Big Data technologies, and communication skills. By mastering these areas, you'll be well-equipped to navigate the evolving data engineering landscape and contribute significantly to your organization's data-driven success.
Ready to Begin Your Journey as a Data Engineer?
If you're eager to dive into the world of data engineering and become a proficient Azure Data Engineer, there's no better time to start than now. To accelerate your learning and gain hands-on experience with the latest tools and technologies, we recommend enrolling in courses at Datavalley.
Why choose Datavalley?
At Datavalley, we are committed to equipping aspiring data engineers with the skills and knowledge needed to excel in this dynamic field. Our courses are designed by industry experts and instructors who bring real-world experience to the classroom. Here's what you can expect when you choose Datavalley:
Comprehensive Curriculum: Our courses cover everything from Python, SQL fundamentals to Snowflake advanced data engineering, cloud computing, Azure cloud services, ETL, Big Data foundations, Azure Services for DevOps, and DevOps tools.
Hands-On Learning: Our courses include practical exercises, projects, and labs that allow you to apply what you've learned in a real-world context.
Multiple Experts for Each Course: Modules are taught by multiple experts to provide you with a diverse understanding of the subject matter as well as the insights and industrial experiences that they have gained.
Flexible Learning Options: We provide flexible learning options to learn courses online to accommodate your schedule and preferences.
Project-Ready, Not Just Job-Ready: Our program prepares you to start working and carry out projects with confidence.
Certification: Upon completing our courses, you'll receive a certification that validates your skills and can boost your career prospects.
On-call Project Assistance After Landing Your Dream Job: Our experts will help you excel in your new role with up to 3 months of on-call project support.
The world of data engineering is waiting for talented individuals like you to make an impact. Whether you're looking to kickstart your career or advance in your current role, Datavalley's Data Engineer Masters Program can help you achieve your goals.
#datavalley#dataexperts#data engineering#dataexcellence#data engineering course#online data engineering course#data engineering training
0 notes
Text
How to change the python version in PySpark ?
How to change the python version in PySpark ?
To switch the python version in pyspark, set the following environment variables. I was working in an environment with Python2 and Python3. I had to use Python3 in pyspark where the spark was using Python 2 by default.

Python 2 was pointing to –> /usr/bin/python
Python 3 was pointing to –> /usr/bin/python3
To configure pyspark to use python 3, set the following environment variables.
View On WordPress
#how to set pyspark_python#how to set python path in pyspark#how to set python version for pyspark#how to update python in pyspark#pyspark#pyspark change python version#pyspark driver python#pyspark executor pythonpath#pyspark python#pyspark python path#switch python in pyspark
0 notes
Text
Price: [price_with_discount] (as of [price_update_date] - Details) [ad_1] Create distributed applications with clever design patterns to solve complex problemsKey FeaturesSet up and run distributed algorithms on a cluster using Dask and PySparkMaster skills to accurately implement concurrency in your codeGain practical experience of Python design patterns with real-world examplesBook DescriptionThis Learning Path shows you how to leverage the power of both native and third-party Python libraries for building robust and responsive applications. You will learn about profilers and reactive programming, concurrency and parallelism, as well as tools for making your apps quick and efficient. You will discover how to write code for parallel architectures using TensorFlow and Theano, and use a cluster of computers for large-scale computations using technologies such as Dask and PySpark. With the knowledge of how Python design patterns work, you will be able to clone objects, secure interfaces, dynamically choose algorithms, and accomplish much more in high performance computing.By the end of this Learning Path, you will have the skills and confidence to build engaging models that quickly offer efficient solutions to your problems.This Learning Path includes content from the following Packt products:Python High Performance - Second Edition by Gabriele LanaroMastering Concurrency in Python by Quan NguyenMastering Python Design Patterns by Sakis KasampalisWhat you will learnUse NumPy and pandas to import and manipulate datasetsAchieve native performance with Cython and NumbaWrite asynchronous code using asyncio and RxPyDesign highly scalable programs with application scaffoldingExplore abstract methods to maintain data consistencyClone objects using the prototype patternUse the adapter pattern to make incompatible interfaces compatibleEmploy the strategy pattern to dynamically choose an algorithmWho this book is forThis Learning Path is specially designed for Python developers who want to build high-performance applications and learn about single core and multi-core programming, distributed concurrency, and Python design patterns. Some experience with Python programming language will help you get the most out of this Learning Path. Publisher : Ingram short title (1 January 2019) Language : English Paperback : 672 pages ISBN-10 : 1838551212 ISBN-13 : 978-1838551216 Item Weight : 1 kg 130 g Dimensions : 19.05 x 3.86 x 23.5 cm Country of Origin : India [ad_2]
0 notes
Photo

These initiatives will have to be submitted and offered during the ExcelR Solutions module in the path of the tip of the program. Demand for skilled data scientists has witnessed an enormous development in latest years.
ExcelR Solutions offer data science certification courses that may allow you to achieve your data science certificates. Here data scientists need to design a system that mines often and produces knowledge units as variable adjustments in time and want prolonged knowledge cleaning, information mining, and analysis. To meet the project objective and analyze the results, knowledge models are developed based on what the scientist needs to attain.
This implies that Big Data has the potential to bring about monumental social and economic benefits. Strategic use of Big Data will form the key foundation of competitors, underpinning new waves of productiveness, progress, innovation, and consumer surplus. Firstly, introduction to Data Science, Python core and superior, and understood textual content and Data Analysis and Visualization with Python. Prime classes, a famed Data Science Institute in Andheri, supply high-quality skill-set improvement providers for school kids and corporates. Their vision is to make a national-level ability pool by making a giant number of youths prepared for growing industry needs in new-age innovations viz Data Science, AI, Machine Learning, Digital Marketing, Data Analytics, and Blockchain. Familiarity and ability to put in writing code in any programming language is a should.
Data Science Courses
This is specialized and customized training based mostly on your small business requirements. One devoted trainer for one learner, this is a superb method of studying to grasp the content in an easy means. ExcelR Solutions are main in 1-to-1 training, a lot of the learner prefers this for numerous benefits. It equips the individuals with all of the conceptual and technical data science skills required to resolve varied industries' business issues. The course is a mix of 3 courses, and the individuals get 3 certificates after completion of the whole syllabus.
Unlike earlier days, the industry values topic knowledge over certification. Working professionals from any business with prior coding knowledge or publicity to information-driven processes can join the course. If the profile doesn’t match the above criteria, they want to qualify for the Python basic check & TQ analysis check to take up the DS course. Technical students from Engineering, MCA, BCA, MTech, Ph.D., Medical, Statistics, Finance can join the course topic for preliminary screening same as for working professionals. Industries/Companies employ Data Scientists to assist them to gain insights in regards to the market and to raise their merchandise.
As a Business System Engineer at Nexon, I’m answerable for designing, creating, and maintaining functions software and integrations for internal solutions. We obtained to find out about this job opportunity through Professor Aditya Narvekar (Assistant Professor – Data Science, SP Jain). The interview was rigorous and targeted logical pondering, industrial information, and technical data. This online course by ExcelR Solutions is part of its MicroMasters program. Through this, you will acquire hands-on expertise utilizing PySpark inside the Jupyter notebooks environment.
They choose batches that are suitable to attain a certification and might quite select a fantastic institute. Data Science lessons in Andheri are provided by institutes like ExcelR to the aspirants that can be opted by professionals. Therefore, getting a Data Science certification assists them in achieving nice rankings in the hierarchy by which is a broad scope for the data scientist and opens many career courses. Aspirants can opt for Data Science training in Andheri at ExcelR since it is a potent group of tutors offering the most effective coaching experience. It has mechanically created a chance for a data scientist that has the power to drive this amount of data's value.
For More Details Contact Us ExcelR- Data Science, Data Analytics, Business Analytics Course Training Andheri Address: 301, Third Floor, Shree Padmini Building, Sanpada, Society, Teli Galli Cross Rd, above Star Health and Allied Insurance, Andheri East, Mumbai, Maharashtra 400069 Phone: 09108238354
Data Science Courses
0 notes
Text
Data Analyst Course in Delhi
The next lectures will move one step forwards and perform evaluation and visualizations on the records data that you’ve got ready. This program provides a preface to knowledge science and the kind of issues that can be handled utilizing the Pandas library. Follow the steps of installations and surroundings set up and learn to import records data from numerous sources. After this, you may be ready to organize, study, filter, and manipulate datasets. The concluding part talks about tips and tips, such as working with plots and shift capabilities. If you are looking ahead to a breakthrough into the info science business, then this Data analyst course in Delhi is a great place to take step one. Throughout the courses, you’ll gain an in-depth understanding of the process of analyzing giant datasets.

Quantitative thoughts, detail-oriented, process-oriented, and so on with the correct mix of people administration expertise are the qualities being matched to the profiles being dished out. So, individual competence meets proper training provider with proper method paves approach to illustrative careers in BA. The process of the extraction of data from a given pool of data is known as data analytics. A knowledge analyst extracts the knowledge through several methodologies like information cleansing, knowledge conversion, and information modeling. Your PMC will contact you every four weeks to debate your progress made to date, examine you’re understanding of your coaching modules, and support you with gathering evidence in your portfolio. These free online programs in data analysis will assist you to perceive issues that organizations face by exploring information in significant methods. With a strong understanding of data analysis, you’ll discover ways to organize, interpret, structure, and current knowledge, turning them into useful information necessary for making properly informed and environmentally friendly decisions. Students are given a public housing knowledge set and informed to classify each variable based on its measurement. There are multiple aspects and approaches with numerous techniques for the info evaluation. The knowledge analysis in statistics is typically divided into descriptive statistics, exploratory information analysis, and confirmatory knowledge analysis. There are many analyses that could be done through the preliminary data evaluation part. This is the primary course of knowledge evaluation where record matching, deduplication, and column segmentation are accomplished to clean the raw data from different sources. Imagine you had a clear, step-by-step path to follow to turn into a knowledge analyst. A SQL developer who earns the CCA Data Analyst course in Delhi provides certification demonstrates core analyst skills to load, rework, and mannequin Hadoop knowledge to define relationships and extract significant results from the uncooked output. It requires passing the CCA Data Analyst course Exam, a distant-proctored set of eight to 12 performance-based mostly, arms-on tasks on a CDH 5 cluster. Candidates have one hundred twenty minutes to implement a technical solution for every task. The lessons take place in the course of the weekends at the PES campus, electronic metropolis. This Program permits candidates to achieve an in-depth understanding of knowledge science and analytics techniques and tools which might be widely applied by firms. The course covers the instruments and skills desired by main firms in Data Science. Candidates shall be educated on numerous instruments and programming languages like Python, SQL, Tableau, Data Science, and Machine Learning. Participants within the course construct their knowledge via classroom lectures by the professional school and working on multiple challenging projects across numerous matters and functions in Data Science. BrainStation’s Data Science program, however, is intensive, full-time learning expertise, delivered in 12 weeks. Leading firms are hiring skilled IT professionals, making it one of the fastest-rising careers in the world. You get palms-on expertise in working with professional instruments such as R, Python, Tableau, SQL, Pig, Hive, Apache Spark & Storm, and much more. This diploma is meant to equip individuals with the survey and data skills to contribute to the coverage debates in South Africa and the world. Both the practical data abilities in addition to the theoretical understanding of the development and coverage context might be emphasized. PySpark Project-Get a handle on using Python with Spark through this hands-on data processing spark python tutorial. Dremio integrates with relational databases, Apache Hadoop, MongoDB, Amazon S3, ElasticSearch, and different data sources. Power BI is among the most popular Data Visualization device, and a Business Intelligence Tool. Power BI is a group of data connectors, apps, and software program providers, that are used to get data from totally different supplies, transform data, and produce stunning reports. The course is supposed to assist learners in research and choose up the tempo with the R programming language for carrying out numerous kinds of data analytics tasks. While the Pandas library is meant for carrying out real-world data analysis utilizing Python, NumPy specializes in machine learning tasks. The course can be the go-to choice for any beginner Python developer with a deep curiosity in knowledge analytics or data science. You’ll acquire the talents you want for managing, cleansing, abstracting, and aggregating information, and conducting a range of analytical research on that knowledge. You’ll acquire an excellent understanding of information constructions, database methods and procedures, and the range of analytical instruments used to undertake a range of various kinds of analysis. The qualification will help you acquire the talents you should work in a variety of roles, such as Data Analyst course in Delhi, Data Manager, Data Modeller, or Data Engineer. The software will assist data scientists and analysts in enhancing their productiveness via automated machine learning. Aggregate, filter, sort, and modify your dataset — and use tools like pivot tables to generate new insights about teams of records, corresponding to tendencies over a time period. Identify sources of error in your information, and discover ways to clear your dataset to minimize potential points. Join a lively neighborhood of over 3,000 college students, alumni, mentors, and career specialists, and get entry to exclusive events and webinars. Get to know how data can be utilized to solve enterprise issues with clever options. Claudia graduated from MIT in 2007 and has labored on knowledge-associated problems ever since, starting from automatically monitoring owls within the forest at the MIT Media Lab to being the second analyst at Airbnb. In her free time, she enjoys traveling to far-away places and has been to about 30 international locations. At ExcelR, the Data Analyst course in Delhi curriculum provides extensive knowledge of Data Collection, Extraction, Cleansing, Exploration, and Transformation with expert trainers having 10+ years of experience with 100% placement assistance. You can reach us at: Address M 130–131, Inside ABL WorkSpace, Second Floor, Connaught Cir, Connaught Place, New Delhi, Delhi 110001 Phone 919632156744 Map Url https://g.page/ExcelRDataScienceDelhi?share Base page link https://www.excelr.com/data-science-course-training Web site Url https://www.excelr.com/data-science-course-training-in-delhi
0 notes
Text
Tomorrow’s jobs require impressing a bot with quick thinking
Beth Pinsker, Reuters, May 1, 2018
NEW YORK (Reuters)--When Andrew Chamberlain started in his job four years ago in the research group at jobs website Glassdoor.com, he worked in a programming language called Stata. Then it was R. Then Python. Then PySpark.
“My dad was a commercial printer and did the same thing for 30 years. I have to continually stay on stuff,” said Chamberlain, who is now the chief economist for the site.
Chamberlain already has one of the jobs of the future--a perpetually changing, shifting universe of work that requires employees to be critical thinkers and fast on their feet. Even those training for a specific field, from plumbing to aerospace engineering, need to be nimble enough to constantly learn new technologies and apply their skills on the fly.
When companies recruit new workers, particularly for entry-level jobs, they are not necessarily looking for knowledge of certain software. They are looking for what most consider soft skills: problem solving, effective communication and leadership. They also want candidates who show a willingness to keep learning new skills.
“The human being’s role in the workplace is less to do repetitive things all the time and more to do the non-repetitive tasks that bring new kinds of value,” said Anthony Carnevale, director of the Georgetown Center on Education and the Workforce in the United States.
So while specializing in a specialized STEM (science, technology, engineering and mathematics) field can seem like an easy path to a lucrative first job, employers are telling colleges: You are producing engineers, but they do not have the skills we need.
It is “algorithmic thinking” rather than the algorithm itself that is relevant, said Carnevale.
Out in the field, Marie Artim is looking for potential. As vice president of talent acquisition for car rental firm Enterprise Holdings Inc, she sets out to hire about 8,500 young people every year for a management training program, an enormous undertaking that has her searching college campuses across the country.
Artim started in the training program herself, 26 years ago, as did the Enterprise chief executive, and that is how she gets the attention of young adults and their parents who scoff at a future of renting cars.
According to Artim, the biggest deficit in the millennial generation is autonomous decision-making. They are used to being structured and “syllabused,” she said.
To get students ready, some colleges, and even high schools, are working on building critical thinking skills.
For three weeks in January at the private Westminster Schools in Atlanta, Georgia, students either get jobs or go on trips, which gives them a better sense of what they might do in the future.
At Texas State University in San Marcos, meanwhile, students can take a marketable-skills master class series.
One key area hones in on case studies that companies are using increasingly to weed out prospects. This means being able to answer hypothetical questions based on a common scenario the employer faces, and showing leadership skills in those scenarios.
The career office at the university also focuses on interview skills. Today, that means teaching kids more than just writing an effective resume and showing up in smart clothes. They have to learn how to perform best on video and phone interviews, and how to navigate gamification and artificial intelligence bots that many companies are now using in the recruiting process.
Norma Guerra Gaier, director of career services at Texas State, said her son just recently got a job and not until the final step did he even have a phone interview.
“He had to solve a couple of problems on a tech system, and was graded on that. He didn’t even interface with a human being,” Guerra Gaier said.
When companies hire at great volume, they try to balance the technology and face-to-face interactions, said Heidi Soltis-Berner, evolving workforce talent leader at financial services firm Deloitte.
Increasingly, Soltis-Berner does not know exactly what those new hires will be doing when they arrive, other than what business division they will be serving.
“We build flexibility into that because we know each year there are new skills,” she said.
1 note
·
View note
Text
Everything you need to know about python programming language
In the fast-growing world, python has become one of the most highly popular programming languages. Numerous reasons are available to learn the Python programming language. The main reason behind this is that language is easy to learn and simple to use. Python works on distinct platforms like Mac, Raspberry Pi, Linux, and Windows, and more. Python developers write the code in very fewer lines whereas the complexity level is lower in python languages. The python for beginners sets a great path to achieve their goal in corporate fields. Here comes some of the top reasons to learn the python language.
Why do beginners need to learn python programming language conflicting with the other languages?
All the languages are useful at the time of developing the application but the only python is easier to understand than other languages. Here comes some of the following attributes
Python languages are performed by indentation using whitespaces. Indentation is used to define scopes like loops, classes, objects, etc. while other languages use curly brackets to fulfill this purpose.
Python languages are simple to read, the code is similar to the English language.
In other programming languages, the semicolon or parentheses are used while python uses a new line to finish the command.
Start your career by joining python courses as well as python for beginners tutorials which will help you to learn from the basics. Python tutorial increases your programming knowledge skills. There are a lot of professional developers who are offering training online for beginners from base to expert level.
Simple and easy to learn
Python is the simplest and easiest to learn because of its simple syntax and readability. While comparing the python language with other programming languages like c, C++ it is an easily understandable language. If you’re a beginner in learning programming languages, without any hesitation you can choose learning python language.
Python is used in data science
Python is a high-level language that is open, fast, friendly, and simple to learn. Python language can be run anywhere and interpreted with other languages. For scientific research, the data scientists and scholars were using the MATLAB language but in now, they are preferring to use python numerical engines such as NumPy and Pandas. What makes python language to be preferable tools when compared to other data science tools
Scalable
While comparing other data science tools, python is higher in scalability. It solves all the problems which can’t be solved by the other programming languages like Java. Nowadays many business sectors are moving towards python language, it establishes applications and tools instantly.
Visualization and graphics options
The developers find various options for performing visualization and graphics designs in python language. Even they can use their graphical layouts, charts, web-ready pots, etc.
Open to library functions
When you are using python language you can enjoy multiple libraries in machine learning and artificial intelligence. The most popular libraries it is using are Pytorch, sci-kit learns, seaborn, and Matpotlib.
Python scripting and automation
You can easily automate anything on python because it is an open-source scripting language. If you are a beginner in learning python language, you can easily learn it's basic and slowly able to write its scripts to automate the data. To get an execution write the code in scripts and check the error during the run time. Without any interruption, the python developers can run the code many times.
Python with big data
A lot of hassles of data are handled by python programming. You can use python for Hadoop hence it supports parallel computing functions. In python, there is a library function called Pydoop as well as you can write MapReduce to process the data present in the HDFS cluster. In big data, there is another library that is available such as Pyspark and Dask.
Python supports testing
Python languages are a powerful tool for authenticating the products and establishing ideas for enterprises. There are various built-in frameworks available in python that helps in debugging and rapid workflows. Its modules and tools like selenium and splinter work to make things easier. Python also supports cross-browser and cross-platform testing with frameworks like Robot and PyTest frameworks.
Python used in artificial intelligence
Python languages offer a lesser code while compared to the other programming language. Python is highly used in artificial intelligence. For advanced computing, the python has prebuilt libraries such as SciPy. Pybrain is used for machine learning, NumPy is used in scientific computation. These are the reasons python has been the best language used in AI.
Python is highly dynamic and it has the choice to choose the coding format whether in OOPs concepts or by scripting. Beginners can start using IDE to get a required code. The developers who are struggling with different algorithms can start using python language.
Web development
For developing websites python has an array of frameworks such as Django, Pylons, and Flask. Python languages play a major role in web development. Design your website by joining in python for beginners course where you will be guided with different frameworks and its function. The popular frameworks in python are characterized by stable and faster code. Webs scraping can be performed in python languages which means fetching details from other websites.
Advantages of learning a python programming language
Python languages are easy to read and simple to learn.
Beginners feel easy to learn the python programming language and they easily pick up the programming pace.
Python offers a greater programming environment as compared to other high-level languages.
In all major working sectors, python languages are applied.
Python works on big data and facilitates automation and data mining.
Python provides a development process to a greater extent with the help of extensive frameworks and libraries.
Python has a larger community so you can solve all your doubts with the help of professional developers online.
Python languages offer various job opportunities for job seekers.
Bottom-line
The above-given information shows the importance of learning python. Especially for beginners who are starting their careers in the corporate field can start their career by obtaining python courses. Where they can upstand in their job and can easily move to higher positions.
0 notes
Text
Install Apache Spark di Ubuntu
Pastikan beberapa package dibawah sudah terpasang di local machine terlebih dahulu:
Python
Java
Scala/SBT
Kalau semua sudah terpasang, download Spark di official website nya disini - saya menggunakan Spark 2.1 karena lebih stabil. Extract menggunakan tar -zxvf spark-2.1.2-bin-hadoop2.7.tgz. Pindahkan folder hasil extraksti, spark-2.1.2-bin-hadoop2.7, ke /opt di root.
mv spark-2.1.2-bin-hadoop2.7 /opt/spark21
dan sekarang Spark ada di folder spark21.
Tambahkan beberapa command dibawah ke dalam .bashrc.
export SPARK_HOME=/opt/spark21 export PATH=$SPARK_HOME/bin:$PATH export PYTHONPATH=$SPARK_HOME/libexec/python:$SPARK_HOME/libexec/python/build:$PYTHONPATH PYTHONPATH=$SPARK_HOME/python/lib/py4j-0.10.4-src.zip:$PYTHONPATH export PYTHONPATH=$SPARK_HOME/python:$SPARK_HOME/python/build:$PYTHONPATH
dan restart terminal.
Coba buka Python lewat terminal dan jalan kan, import pyspark. Apabila tidak gagal, selamat, PySpark sudah terinstall dan ter-integrasi dengan Python.
Referensi:
https://blog.sicara.com/get-started-pyspark-jupyter-guide-tutorial-ae2fe84f594f
https://stackoverflow.com/a/33513655
4 notes
·
View notes
Text
Clevertech: Python/Data Science [REMOTE]

Headquarters: Remote URL: https://www.clevertech.biz
Python/Data Science developer required to join a team project which uses social network data at scale. Please note that this is a senior-level role, we are currently only considering candidates that meet the requirements below.
Qualifications:
5+ years experience in a senior developer or architect role; ideally, you have delivered business-critical software to large enterprises
This role requires a statistical background with experience working with large databases
Experience working with Python packages such as PySpark and Pandas
Experience with AWS data-oriented products is required: AWS Glue, Athena, DynamoDB, S3, Lambda Functions
Experience with Databricks as part of an AWS Pipeline with Lambdas
Advanced knowledge of interfacing to Facebook, Instagram, Twitter, and Youtube social network APIs
Experience with NodeJS and ReactJS based web applications
Experience with Jenkins and Groovy-based imperative pipelines to orchestrate multiple processes during deployments
Experience and knowledge of advanced GraphQL topics such as schema stitching and federation
What you’ll do:
Gather influencer statistics, social engagement statistics for sentiment analysis
Collaborate in every stage of a product's lifecycle; from planning to delivery
Create clean, modern, testable, well-documented code
Communicate daily with clients to understand and deliver technical requirements
How We Work
Why do people join Clevertech? To make an impact. To grow themselves. To be surrounded by developers who they can learn from. We are truly excited to be creating waves in an industry under transformation.
True innovation comes from an exchange of knowledge across all of our teams. To put people on the path for success, we nurture a culture built on trust, collaboration, and personal growth. You will work in small feature-based cross-functional teams and be empowered to take ownership.
We make a point of constantly evolving our experience and skills. We value diverse perspectives and fostering personal growth by challenging everyone to push beyond our comfort level and try something new.
The result? We produce meaningful work
Want to learn more about Clevertech and the team? Check out clevertech.careers and our recent video highlighting an actual Clevertech Sr Developer's Story
To apply: https://www.clevertech.biz/careers/senior-python-developer/apply?ct_src=weworkremotely
from We Work Remotely: Remote jobs in design, programming, marketing and more https://ift.tt/34lmqSa from Work From Home YouTuber Job Board Blog https://ift.tt/37AYNr0
0 notes
Text
300+ TOP PYSPARK Interview Questions and Answers
PYSPARK Interview Questions for freshers experienced :-
1. What is Pyspark? Pyspark is a bunch figuring structure which keeps running on a group of item equipment and performs information unification i.e., perusing and composing of wide assortment of information from different sources. In Spark, an undertaking is an activity that can be a guide task or a lessen task. Flash Context handles the execution of the activity and furthermore gives API’s in various dialects i.e., Scala, Java and Python to create applications and quicker execution when contrasted with MapReduce. 2. How is Spark not quite the same as MapReduce? Is Spark quicker than MapReduce? Truly, Spark is quicker than MapReduce. There are not many significant reasons why Spark is quicker than MapReduce and some of them are beneath: There is no tight coupling in Spark i.e., there is no compulsory principle that decrease must come after guide. Spark endeavors to keep the information “in-memory” however much as could be expected. In MapReduce, the halfway information will be put away in HDFS and subsequently sets aside longer effort to get the information from a source yet this isn’t the situation with Spark. 3. Clarify the Apache Spark Architecture. How to Run Spark applications? Apache Spark application contains two projects in particular a Driver program and Workers program. A group supervisor will be there in the middle of to communicate with these two bunch hubs. Sparkle Context will stay in contact with the laborer hubs with the assistance of Cluster Manager. Spark Context resembles an ace and Spark laborers resemble slaves. Workers contain the agents to run the activity. In the event that any conditions or contentions must be passed, at that point Spark Context will deal with that. RDD’s will dwell on the Spark Executors. You can likewise run Spark applications locally utilizing a string, and on the off chance that you need to exploit appropriated conditions you can take the assistance of S3, HDFS or some other stockpiling framework. 4. What is RDD? RDD represents Resilient Distributed Datasets (RDDs). In the event that you have enormous measure of information, and isn’t really put away in a solitary framework, every one of the information can be dispersed over every one of the hubs and one subset of information is called as a parcel which will be prepared by a specific assignment. RDD’s are exceptionally near information parts in MapReduce. 5. What is the job of blend () and repartition () in Map Reduce? Both mix and repartition are utilized to change the quantity of segments in a RDD however Coalesce keeps away from full mix. On the off chance that you go from 1000 parcels to 100 segments, there won’t be a mix, rather every one of the 100 new segments will guarantee 10 of the present allotments and this does not require a mix. Repartition plays out a blend with mix. Repartition will result in the predefined number of parcels with the information dispersed utilizing a hash professional. 6. How would you determine the quantity of parcels while making a RDD? What are the capacities? You can determine the quantity of allotments while making a RDD either by utilizing the sc.textFile or by utilizing parallelize works as pursues: Val rdd = sc.parallelize(data,4) val information = sc.textFile(“path”,4) 7. What are activities and changes? Changes make new RDD’s from existing RDD and these changes are sluggish and won’t be executed until you call any activity. Example:: map(), channel(), flatMap(), and so forth., Activities will return consequences of a RDD. Example:: lessen(), tally(), gather(), and so on., 8. What is Lazy Evaluation? On the off chance that you make any RDD from a current RDD that is called as change and except if you consider an activity your RDD won’t be emerged the reason is Spark will defer the outcome until you truly need the outcome in light of the fact that there could be a few circumstances you have composed something and it turned out badly and again you need to address it in an intuitive manner it will expand the time and it will make un-essential postponements. Additionally, Spark improves the required figurings and takes clever choices which is beyond the realm of imagination with line by line code execution. Sparkle recoups from disappointments and moderate laborers. 9. Notice a few Transformations and Actions Changes map (), channel(), flatMap() Activities diminish(), tally(), gather() 10. What is the job of store() and continue()? At whatever point you need to store a RDD into memory with the end goal that the RDD will be utilized on different occasions or that RDD may have made after loads of complex preparing in those circumstances, you can exploit Cache or Persist. You can make a RDD to be continued utilizing the persevere() or store() works on it. The first occasion when it is processed in an activity, it will be kept in memory on the hubs. When you call persevere(), you can indicate that you need to store the RDD on the plate or in the memory or both. On the off chance that it is in-memory, regardless of whether it ought to be put away in serialized organization or de-serialized position, you can characterize every one of those things. reserve() resembles endure() work just, where the capacity level is set to memory as it were.

11. What are Accumulators? Collectors are the compose just factors which are introduced once and sent to the specialists. These specialists will refresh dependent on the rationale composed and sent back to the driver which will total or process dependent on the rationale. No one but driver can get to the collector’s esteem. For assignments, Accumulators are compose as it were. For instance, it is utilized to include the number blunders seen in RDD crosswise over laborers. 12. What are Broadcast Variables? Communicate Variables are the perused just shared factors. Assume, there is a lot of information which may must be utilized on various occasions in the laborers at various stages. 13. What are the enhancements that engineer can make while working with flash? Flash is memory serious, whatever you do it does in memory. Initially, you can alter to what extent flash will hold up before it times out on every one of the periods of information region information neigh borhood process nearby hub nearby rack neighborhood Any. Channel out information as ahead of schedule as could be allowed. For reserving, pick carefully from different capacity levels. Tune the quantity of parcels in sparkle. 14. What is Spark SQL? Flash SQL is a module for organized information handling where we exploit SQL questions running on the datasets. 15. What is a Data Frame? An information casing resembles a table, it got some named sections which composed into segments. You can make an information outline from a document or from tables in hive, outside databases SQL or NoSQL or existing RDD’s. It is practically equivalent to a table. 16. How might you associate Hive to Spark SQL? The principal significant thing is that you need to place hive-site.xml record in conf index of Spark. At that point with the assistance of Spark session object we can develop an information outline as, 17. What is GraphX? Ordinarily you need to process the information as charts, since you need to do some examination on it. It endeavors to perform Graph calculation in Spark in which information is available in documents or in RDD’s. GraphX is based on the highest point of Spark center, so it has got every one of the abilities of Apache Spark like adaptation to internal failure, scaling and there are numerous inbuilt chart calculations too. GraphX binds together ETL, exploratory investigation and iterative diagram calculation inside a solitary framework. You can see indistinguishable information from the two charts and accumulations, change and unite diagrams with RDD effectively and compose custom iterative calculations utilizing the pregel API. GraphX contends on execution with the quickest diagram frameworks while holding Spark’s adaptability, adaptation to internal failure and convenience. 18. What is PageRank Algorithm? One of the calculation in GraphX is PageRank calculation. Pagerank measures the significance of every vertex in a diagram accepting an edge from u to v speaks to a supports of v’s significance by u. For exmaple, in Twitter if a twitter client is trailed by numerous different clients, that specific will be positioned exceptionally. GraphX accompanies static and dynamic executions of pageRank as techniques on the pageRank object. 19. What is Spark Streaming? At whatever point there is information streaming constantly and you need to process the information as right on time as could reasonably be expected, all things considered you can exploit Spark Streaming. 20. What is Sliding Window? In Spark Streaming, you need to determine the clump interim. In any case, with Sliding Window, you can indicate what number of last clumps must be handled. In the beneath screen shot, you can see that you can indicate the clump interim and what number of bunches you need to process. 21. Clarify the key highlights of Apache Spark. Coming up next are the key highlights of Apache Spark: Polyglot Speed Multiple Format Support Lazy Evaluation Real Time Computation Hadoop Integration Machine Learning 22. What is YARN? Like Hadoop, YARN is one of the key highlights in Spark, giving a focal and asset the executives stage to convey adaptable activities over the bunch. YARN is a conveyed holder chief, as Mesos for instance, while Spark is an information preparing instrument. Sparkle can keep running on YARN, a similar way Hadoop Map Reduce can keep running on YARN. Running Spark on YARN requires a double dispersion of Spark as based on YARN support. 23. Do you have to introduce Spark on all hubs of YARN bunch? No, in light of the fact that Spark keeps running over YARN. Flash runs autonomously from its establishment. Sparkle has a few alternatives to utilize YARN when dispatching employments to the group, as opposed to its very own inherent supervisor, or Mesos. Further, there are a few arrangements to run YARN. They incorporate ace, convey mode, driver-memory, agent memory, agent centers, and line. 24. Name the parts of Spark Ecosystem. Spark Core: Base motor for huge scale parallel and disseminated information handling Spark Streaming: Used for handling constant spilling information Spark SQL: Integrates social handling with Spark’s useful programming API GraphX: Graphs and chart parallel calculation MLlib: Performs AI in Apache Spark 25. How is Streaming executed in Spark? Clarify with precedents. Sparkle Streaming is utilized for handling constant gushing information. Along these lines it is a helpful expansion deeply Spark API. It empowers high-throughput and shortcoming tolerant stream handling of live information streams. The crucial stream unit is DStream which is fundamentally a progression of RDDs (Resilient Distributed Datasets) to process the constant information. The information from various sources like Flume, HDFS is spilled lastly handled to document frameworks, live dashboards and databases. It is like bunch preparing as the information is partitioned into streams like clusters. 26. How is AI executed in Spark? MLlib is adaptable AI library given by Spark. It goes for making AI simple and adaptable with normal learning calculations and use cases like bunching, relapse separating, dimensional decrease, and alike. 27. What record frameworks does Spark support? The accompanying three document frameworks are upheld by Spark: Hadoop Distributed File System (HDFS). Local File framework. Amazon S3 28. What is Spark Executor? At the point when SparkContext associates with a group chief, it obtains an Executor on hubs in the bunch. Representatives are Spark forms that run controls and store the information on the laborer hub. The last assignments by SparkContext are moved to agents for their execution. 29. Name kinds of Cluster Managers in Spark. The Spark system underpins three noteworthy sorts of Cluster Managers: Standalone: An essential administrator to set up a group. Apache Mesos: Generalized/regularly utilized group administrator, additionally runs Hadoop MapReduce and different applications. YARN: Responsible for asset the board in Hadoop. 30. Show some utilization situations where Spark beats Hadoop in preparing. Sensor Data Processing: Apache Spark’s “In-memory” figuring works best here, as information is recovered and joined from various sources. Real Time Processing: Spark is favored over Hadoop for constant questioning of information. for example Securities exchange Analysis, Banking, Healthcare, Telecommunications, and so on. Stream Processing: For preparing logs and identifying cheats in live streams for cautions, Apache Spark is the best arrangement. Big Data Processing: Spark runs upto multiple times quicker than Hadoop with regards to preparing medium and enormous estimated datasets. 31. By what method can Spark be associated with Apache Mesos? To associate Spark with Mesos: Configure the sparkle driver program to associate with Mesos. Spark paired bundle ought to be in an area open by Mesos. Install Apache Spark in a similar area as that of Apache Mesos and design the property ‘spark.mesos.executor.home’ to point to the area where it is introduced. 32. How is Spark SQL not the same as HQL and SQL? Flash SQL is a unique segment on the Spark Core motor that supports SQL and Hive Query Language without changing any sentence structure. It is conceivable to join SQL table and HQL table to Spark SQL. 33. What is ancestry in Spark? How adaptation to internal failure is accomplished in Spark utilizing Lineage Graph? At whatever point a progression of changes are performed on a RDD, they are not assessed promptly, however languidly. At the point when another RDD has been made from a current RDD every one of the conditions between the RDDs will be signed in a diagram. This chart is known as the ancestry diagram. Consider the underneath situation Ancestry chart of every one of these activities resembles: First RDD Second RDD (applying map) Third RDD (applying channel) Fourth RDD (applying check) This heredity diagram will be helpful on the off chance that if any of the segments of information is lost. Need to set spark.logLineage to consistent with empower the Rdd.toDebugString() gets empowered to print the chart logs. 34. What is the contrast between RDD , DataFrame and DataSets? RDD : It is the structure square of Spark. All Dataframes or Dataset is inside RDDs. It is lethargically assessed permanent gathering objects RDDS can be effectively reserved if a similar arrangement of information should be recomputed. DataFrame : Gives the construction see ( lines and segments ). It tends to be thought as a table in a database. Like RDD even dataframe is sluggishly assessed. It offers colossal execution due to a.) Custom Memory Management – Data is put away in off load memory in twofold arrangement .No refuse accumulation because of this. Optimized Execution Plan – Query plans are made utilizing Catalyst analyzer. DataFrame Limitations : Compile Time wellbeing , i.e no control of information is conceivable when the structure isn’t known. DataSet : Expansion of DataFrame DataSet Feautures – Provides best encoding component and not at all like information edges supports arrange time security. 35. What is DStream? Discretized Stream (DStream) Apache Spark Discretized Stream is a gathering of RDDS in grouping . Essentially, it speaks to a flood of information or gathering of Rdds separated into little clusters. In addition, DStreams are based on Spark RDDs, Spark’s center information reflection. It likewise enables Streaming to flawlessly coordinate with some other Apache Spark segments. For example, Spark MLlib and Spark SQL. 36. What is the connection between Job, Task, Stage ? Errand An errand is a unit of work that is sent to the agent. Each stage has some assignment, one undertaking for every segment. The Same assignment is done over various segments of RDD. Occupation The activity is parallel calculation comprising of numerous undertakings that get produced in light of activities in Apache Spark. Stage Each activity gets isolated into littler arrangements of assignments considered stages that rely upon one another. Stages are named computational limits. All calculation is impossible in single stage. It is accomplished over numerous stages. 37. Clarify quickly about the parts of Spark Architecture? Flash Driver: The Spark driver is the procedure running the sparkle setting . This driver is in charge of changing over the application to a guided diagram of individual strides to execute on the bunch. There is one driver for each application. 38. How might you limit information moves when working with Spark? The different manners by which information moves can be limited when working with Apache Spark are: Communicate and Accumilator factors 39. When running Spark applications, is it important to introduce Spark on every one of the hubs of YARN group? Flash need not be introduced when running a vocation under YARN or Mesos in light of the fact that Spark can execute over YARN or Mesos bunches without influencing any change to the group. 40. Which one will you decide for an undertaking – Hadoop MapReduce or Apache Spark? The response to this inquiry relies upon the given undertaking situation – as it is realized that Spark utilizes memory rather than system and plate I/O. In any case, Spark utilizes enormous measure of RAM and requires devoted machine to create viable outcomes. So the choice to utilize Hadoop or Spark changes powerfully with the necessities of the venture and spending plan of the association. 41. What is the distinction among continue() and store() endure () enables the client to determine the capacity level while reserve () utilizes the default stockpiling level. 42. What are the different dimensions of constancy in Apache Spark? Apache Spark naturally endures the mediator information from different mix tasks, anyway it is regularly proposed that clients call persevere () technique on the RDD on the off chance that they intend to reuse it. Sparkle has different tirelessness levels to store the RDDs on circle or in memory or as a mix of both with various replication levels. 43. What are the disservices of utilizing Apache Spark over Hadoop MapReduce? Apache Spark’s in-memory ability now and again comes a noteworthy barrier for cost effective preparing of huge information. Likewise, Spark has its own record the board framework and consequently should be incorporated with other cloud based information stages or apache hadoop. 44. What is the upside of Spark apathetic assessment? Apache Spark utilizes sluggish assessment all together the advantages: Apply Transformations tasks on RDD or “stacking information into RDD” isn’t executed quickly until it sees an activity. Changes on RDDs and putting away information in RDD are languidly assessed. Assets will be used in a superior manner if Spark utilizes sluggish assessment. Lazy assessment advances the plate and memory utilization in Spark. The activities are activated just when the information is required. It diminishes overhead. 45. What are advantages of Spark over MapReduce? Because of the accessibility of in-memory handling, Spark executes the preparing around 10 to multiple times quicker than Hadoop MapReduce while MapReduce utilizes diligence stockpiling for any of the information handling errands. Dissimilar to Hadoop, Spark gives inbuilt libraries to play out numerous errands from a similar center like cluster preparing, Steaming, Machine learning, Interactive SQL inquiries. Be that as it may, Hadoop just backings cluster handling. Hadoop is very plate subordinate while Spark advances reserving and in-memory information stockpiling. 46. How DAG functions in Spark? At the point when an Action is approached Spark RDD at an abnormal state, Spark presents the heredity chart to the DAG Scheduler. Activities are separated into phases of the errand in the DAG Scheduler. A phase contains errand dependent on the parcel of the info information. The DAG scheduler pipelines administrators together. It dispatches task through group chief. The conditions of stages are obscure to the errand scheduler.The Workers execute the undertaking on the slave. 47. What is the hugeness of Sliding Window task? Sliding Window controls transmission of information bundles between different PC systems. Sparkle Streaming library gives windowed calculations where the changes on RDDs are connected over a sliding window of information. At whatever point the window slides, the RDDs that fall inside the specific window are consolidated and worked upon to create new RDDs of the windowed DStream. 48. What are communicated and Accumilators? Communicate variable: On the off chance that we have an enormous dataset, rather than moving a duplicate of informational collection for each assignment, we can utilize a communicate variable which can be replicated to every hub at one timeand share similar information for each errand in that hub. Communicate variable assistance to give a huge informational collection to every hub. Collector: Flash capacities utilized factors characterized in the driver program and nearby replicated of factors will be produced. Aggregator are shared factors which help to refresh factors in parallel during execution and offer the outcomes from specialists to the driver. 49. What are activities ? An activity helps in bringing back the information from RDD to the nearby machine. An activity’s execution is the aftereffect of all recently made changes. lessen() is an activity that executes the capacity passed over and over until one esteem assuming left. take() move makes every one of the qualities from RDD to nearby hub. 50. Name kinds of Cluster Managers in Spark. The Spark system bolsters three noteworthy kinds of Cluster Managers: Independent : An essential administrator to set up a bunch. Apache Mesos : Summed up/ordinarily utilized group director, additionally runs Hadoop MapReduce and different applications. PYSPARK Questions and Answers Pdf Download Read the full article
0 notes
Text
Importance of Python and its Web Development in 2020
Welcome to the world of online course to learn python in Python Programming course. Are you the one who is looking forward to knowing the web development in Python? Or the one who is very keen to explore the Python with Examples that are available? Then you’ve landed on the Right path which provides the standard information of web development in online python course.
Python is an interpreted programming language, that is, it does not need to be preprocessed by a compiler, whose philosophy is that of a syntax that favors the writing of readable code.
It is also multi-paradigm, since it supports object orientation, functional programming (although to a lesser extent) and imperative programming. Not only that, but it also uses a dynamic and cross-platform typing.
Python as a scripting language
Python has always been a good ally of system administrators and operations teams, even replacing scripts written in bash. But it is not only limited to this, it is also a pioneer in the world of scraping and crawling, where we can obtain information from web pages in a very simple and fully automated way.
Some examples of libraries for testing are:
Unittest.
Pytest.
Robot.
Python in web development
One of the fields in which Python is also shining is in the development of web applications, mainly thanks to the use of frameworks such as Djando or Flask. And, despite the fact that there are already great programming languages for web applications (such as PHP), what makes Python so special is the possibility of offering a complete and quality framework that will allow us to create web applications in record time .
Big Data, Data Science and AI
If all of the above seems to you little, in recent years something has happened that has revolutionized and made Python more famous. And it is that the generalization of Big Data, Artificial Intelligence (or AI), with Machine Learning and Deep Learning, together with the emergence of data science, have created a totally revolutionized panorama which Python has known how to take advantage of , creating a multitude of new tools to be exploited and to interact with these advances.
Some examples of libraries to perform Big Data, Data Science or AI can be:
Pyspark.
Dask.
Pydoop.
Pandas
NumPy.
Keras.
TensorFlow.
We hope you understand sets in Python strings tutorial with examples. Get success in your career as a Python developer by being a part of the Prwatech, India’s leading Python training institute in Bangalore.
0 notes
Text
Python training in Chennai
Python Training in Chennai
iconGen IT Solutions is the best Python training in Chennai
Why we are the best in Python Training in Chennai?
Python is open-source general-purpose programming language. Now, Python is being used in Data Science by various organizations across the globe to harvest insights from their data and get a competitive edge. Python is best suited tool for Data Science & Machine learning Algorithms
At iconGen, we will provide the basics of Python training in Chennai and Advance concepts.. During the course our experts will impart training on various libraries available in Python viz Pandas, NumPy,Matplotlib etc
At iconGen, We believe that a practical, hands-on approach is the key to meaningful learning and skills advancement. With this in mind, we integrate real-life exercises and activities throughout our Python training in Chennai, with long-term retention of learning and development in mind.
Course Info
Course:Python Training In Chennai
Timings:90 Mts/Daily
Duration:30 Hours
Get Course
We are offering following courses:
Python training in Chennai
Python online training
Data Science with Python training
Data Science with Python online training
Machine Learning with Python training
Machine Learning with Python online training
PySpark training in Chennai
OUR TRAINING
Classroom Training
Online Training
Corporate Training
QUICK LINKS
Home
Course
Placement
Blog
Reach Us
iconGen offers Python Training in Chennai by python experts For complete syllabus : Click Course Curriculum / Fill Enquiry Form (or) Call us @ 99401 56760
0 notes