#pyspark driver python
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
The total number of visits Tumblr.com received during January 2021 is 327 million.
Text
What are the languages supported by Apache Spark?
Hi,
Apache Spark is a versatile big data processing framework that supports several programming languages. Here are the main languages supported:

1. Scala: Scala is the primary language for Apache Spark and is used to develop Spark applications. Spark is written in Scala, and using Scala provides the best performance and access to all of Spark’s features. Scala’s functional programming capabilities align well with Spark’s design.
2. Java: Java is also supported by Apache Spark. It’s a common choice for developers who are familiar with the Java ecosystem. Spark’s Java API allows developers to build applications using Java, though it might be less concise compared to Scala.
3. Python: Python is widely used with Apache Spark through the PySpark API. PySpark allows developers to write Spark applications using Python, which is known for its simplicity and readability. Python’s extensive libraries make it a popular choice for data science and machine learning tasks.
4. R: Apache Spark provides support for R through the SparkR package. SparkR is designed for data analysis and statistical computing in R. It allows R users to harness Spark’s capabilities for big data processing and analytics.
5. SQL: Spark SQL is a component of Apache Spark that supports querying data using SQL. Users can run SQL queries directly on Spark data, and Spark SQL provides integration with BI tools and data sources through JDBC and ODBC drivers.
6. Others: While Scala, Java, Python, and R are the primary languages supported, Spark also has limited support for other languages through community contributions and extensions.
In summary, Apache Spark supports Scala, Java, Python, and R, making it accessible to a wide range of developers and data scientists. The support for SQL further enhances its capability to work with structured data and integrate with various data sources.
0 notes
Text
Essential Python Tools for Modern Data Science: A Comprehensive Overview

Python has established itself as a leading language in data science due to its simplicity and the extensive range of libraries and frameworks it offers. Here's a list of commonly used data science tools in Python:
Data Manipulation and Analysis:
pandas: A cornerstone library for data manipulation and analysis.
NumPy: Provides support for working with arrays and matrices, along with a large library of mathematical functions.
SciPy: Used for more advanced mathematical and statistical operations.
Data Visualization:
Matplotlib: A foundational plotting library.
Seaborn: Built on top of Matplotlib, it offers a higher level interface for creating visually pleasing statistical plots.
Plotly: Provides interactive graphing capabilities.
Bokeh: Designed for creating interactive visualizations for use in web browsers.
Machine Learning:
scikit-learn: A versatile library offering simple and efficient tools for data mining and data analysis.
Statsmodels: Used for estimating and testing statistical models.
TensorFlow and Keras: For deep learning and neural networks.
PyTorch: Another powerful library for deep learning.
Natural Language Processing:
NLTK (Natural Language Toolkit): Provides libraries for human language data processing.
spaCy: Industrial-strength natural language processing with pre-trained models for various languages.
Gensim: Used for topic modeling and similarity detection.
Big Data Processing:
PySpark: Python API for Apache Spark, which is a fast, in-memory data processing engine.
Web Scraping:
Beautiful Soup: Used for pulling data out of HTML and XML files.
Scrapy: An open-source and collaborative web crawling framework.
Requests: For making various types of HTTP requests.
Database Integration:
SQLAlchemy: A SQL toolkit and Object-Relational Mapping (ORM) library.
SQLite: A C-language library that offers a serverless, zero-configuration, transactional SQL database engine.
PyMongo: A Python driver for MongoDB.
Others:
Jupyter Notebook: An open-source web application that allows for the creation and sharing of documents containing live code, equations, visualizations, and narrative text.
Joblib: For saving and loading Python objects, useful when working with large datasets or models.
Scrapy: For web crawling and scraping.
The Python ecosystem for data science is vast, and the tools mentioned above are just the tip of the iceberg. Depending on the specific niche or requirement, data scientists might opt for more specialized tools. It's also worth noting that the Python data science community is active and continually innovating, leading to new tools and libraries emerging regularly.
0 notes
Text
"The Fast and Furious: Exploring the Rapid Growth of Python in the Programming World"
The fastest growing and the most popular programming language in today’s programming world is Python. The word time, the word "Python" evoked images of a massive snake, but today, it's synonymous with a wildly popular programming language. According to the TIOBE Index, Python holds the prestigious position of being the fourth most popular programming language globally, and its meteoric rise shows no signs of slowing.

Python’s and Growing User Base:
Several factors contribute to Python's remarkable success. First and foremost is its widespread adoption in web development. Renowned companies such as Google, Facebook, Mozilla, Quora, and many others employ Python web frameworks, elevating its prominence in this domain. Another pivotal driver behind Python's rapid growth is its pivotal role in the realm of data science.
Another factor that takes Python to the next level programming language is its easy use in Data Science. Therefore, the language is steadily growing in demand in the last ten years. In 2018, it was found in a survey that the majority of developers are obtaining training for the language and started work as Python developers. Initially, Python was built to solve the code readability issues discovered in C and Java languages.
The Reason Behind the Popularity of Pythons:
●As per the record, the reason behind the demand for python is it is easy to use. The language is pretty simple and can be easily readable. The simplicity of the language makes Python a favorite programming language among developers. Moreover, Python is an efficient language.
●Today almost all the developers and big tech giants prefer Python for web development. Some famous web frameworks can be utilized for web development project requirements.
●Even high-level Python is being trained as coursework. So that student can get prepared for the upcoming pythons’ trends and achieve success in their careers.
Python's skyrocketing popularity and its path towards becoming the world's most popular programming language are indeed remarkable phenomena.
Several Key Factors Underpin This Incredible Rise:
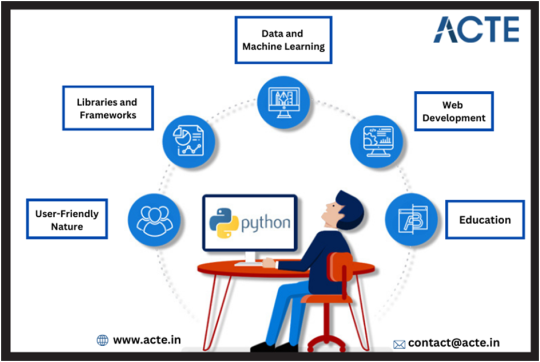
Python's User-Friendly Nature: Python stands out for its user-friendliness. Its simple, easily readable syntax appeals to both experienced developers and budding students. What's more, Python is highly efficient, allowing developers to accomplish more with fewer lines of code, making it a beloved choice.
A Supportive Python Community: Python has been around since 1990, providing ample time to foster a vibrant and supportive community. This strong support network empowers learners to expand their knowledge, contributing to Python's ever-increasing popularity. Abundant online resources, from official documentation to YouTube tutorials, make Python accessible to all.
Abundance of Libraries and Frameworks: Python's already widespread adoption has led to a wealth of libraries and frameworks developed by the community. These resources save developers time and effort, creating a virtuous cycle of popularity. Notable Python libraries include NumPy, SciPy, Django, BeautifulSoup, scikit-learn, and nltk.
Corporate Backing: Python's ascent is not solely a grassroots movement. Corporate support plays a significant role. Top companies like Google, Facebook, Mozilla, Amazon, and Quora have embraced Python for their products, with Google even offering guides and tutorials through its Python Class. This backing has been pivotal in Python's growth and success.
Python in Data and Machine Learning: Python plays a vital role in the hot trends of Big Data, Machine Learning, and Artificial Intelligence. It's widely used in research and development in these domains, and numerous Python tools like Scikit-Learn, Theano, and libraries such as Pandas and PySpark are instrumental.
Python in Web Development: Python's popularity extends to web development. It's an ideal choice for both learning and powering some of the world's most popular websites, including Spotify, Instagram, Pinterest, Mozilla, and Yelp. Python offers a range of web frameworks, from full-stack options like Django to microframeworks like Flask.
Python in Academics: The presence of Python in academic coursework is a testament to its significance. It's now a core requirement in many educational institutions, reflecting its crucial role in data science, machine learning, deep learning, and artificial intelligence. As more students learn Python, its future importance is assured.
Python's astonishing success is multifaceted and cannot be attributed to a single reason. Instead, it's the combined effect of the factors outlined above that paints a comprehensive picture of why Python has become such a pivotal and influential language in the world of programming.
If you're eager to improve your knowledge of Python, I strongly advise getting in touch with ACTE Technologies. They offer certification programs and the potential for job placements, ensuring a comprehensive learning experience. Their services are available both online and at physical locations. To commence your Python learning journey at ACTE Technologies, consider taking a methodical approach and explore the possibility of enrolling in one of their courses if it aligns with your interests.
0 notes
Link
0 notes
Text
How to change the python version in PySpark ?
How to change the python version in PySpark ?
To switch the python version in pyspark, set the following environment variables. I was working in an environment with Python2 and Python3. I had to use Python3 in pyspark where the spark was using Python 2 by default.

Python 2 was pointing to –> /usr/bin/python
Python 3 was pointing to –> /usr/bin/python3
To configure pyspark to use python 3, set the following environment variables.
View On WordPress
#how to set pyspark_python#how to set python path in pyspark#how to set python version for pyspark#how to update python in pyspark#pyspark#pyspark change python version#pyspark driver python#pyspark executor pythonpath#pyspark python#pyspark python path#switch python in pyspark
0 notes
Text
300+ TOP PYSPARK Interview Questions and Answers
PYSPARK Interview Questions for freshers experienced :-
1. What is Pyspark? Pyspark is a bunch figuring structure which keeps running on a group of item equipment and performs information unification i.e., perusing and composing of wide assortment of information from different sources. In Spark, an undertaking is an activity that can be a guide task or a lessen task. Flash Context handles the execution of the activity and furthermore gives API’s in various dialects i.e., Scala, Java and Python to create applications and quicker execution when contrasted with MapReduce. 2. How is Spark not quite the same as MapReduce? Is Spark quicker than MapReduce? Truly, Spark is quicker than MapReduce. There are not many significant reasons why Spark is quicker than MapReduce and some of them are beneath: There is no tight coupling in Spark i.e., there is no compulsory principle that decrease must come after guide. Spark endeavors to keep the information “in-memory” however much as could be expected. In MapReduce, the halfway information will be put away in HDFS and subsequently sets aside longer effort to get the information from a source yet this isn’t the situation with Spark. 3. Clarify the Apache Spark Architecture. How to Run Spark applications? Apache Spark application contains two projects in particular a Driver program and Workers program. A group supervisor will be there in the middle of to communicate with these two bunch hubs. Sparkle Context will stay in contact with the laborer hubs with the assistance of Cluster Manager. Spark Context resembles an ace and Spark laborers resemble slaves. Workers contain the agents to run the activity. In the event that any conditions or contentions must be passed, at that point Spark Context will deal with that. RDD’s will dwell on the Spark Executors. You can likewise run Spark applications locally utilizing a string, and on the off chance that you need to exploit appropriated conditions you can take the assistance of S3, HDFS or some other stockpiling framework. 4. What is RDD? RDD represents Resilient Distributed Datasets (RDDs). In the event that you have enormous measure of information, and isn’t really put away in a solitary framework, every one of the information can be dispersed over every one of the hubs and one subset of information is called as a parcel which will be prepared by a specific assignment. RDD’s are exceptionally near information parts in MapReduce. 5. What is the job of blend () and repartition () in Map Reduce? Both mix and repartition are utilized to change the quantity of segments in a RDD however Coalesce keeps away from full mix. On the off chance that you go from 1000 parcels to 100 segments, there won’t be a mix, rather every one of the 100 new segments will guarantee 10 of the present allotments and this does not require a mix. Repartition plays out a blend with mix. Repartition will result in the predefined number of parcels with the information dispersed utilizing a hash professional. 6. How would you determine the quantity of parcels while making a RDD? What are the capacities? You can determine the quantity of allotments while making a RDD either by utilizing the sc.textFile or by utilizing parallelize works as pursues: Val rdd = sc.parallelize(data,4) val information = sc.textFile(“path”,4) 7. What are activities and changes? Changes make new RDD’s from existing RDD and these changes are sluggish and won’t be executed until you call any activity. Example:: map(), channel(), flatMap(), and so forth., Activities will return consequences of a RDD. Example:: lessen(), tally(), gather(), and so on., 8. What is Lazy Evaluation? On the off chance that you make any RDD from a current RDD that is called as change and except if you consider an activity your RDD won’t be emerged the reason is Spark will defer the outcome until you truly need the outcome in light of the fact that there could be a few circumstances you have composed something and it turned out badly and again you need to address it in an intuitive manner it will expand the time and it will make un-essential postponements. Additionally, Spark improves the required figurings and takes clever choices which is beyond the realm of imagination with line by line code execution. Sparkle recoups from disappointments and moderate laborers. 9. Notice a few Transformations and Actions Changes map (), channel(), flatMap() Activities diminish(), tally(), gather() 10. What is the job of store() and continue()? At whatever point you need to store a RDD into memory with the end goal that the RDD will be utilized on different occasions or that RDD may have made after loads of complex preparing in those circumstances, you can exploit Cache or Persist. You can make a RDD to be continued utilizing the persevere() or store() works on it. The first occasion when it is processed in an activity, it will be kept in memory on the hubs. When you call persevere(), you can indicate that you need to store the RDD on the plate or in the memory or both. On the off chance that it is in-memory, regardless of whether it ought to be put away in serialized organization or de-serialized position, you can characterize every one of those things. reserve() resembles endure() work just, where the capacity level is set to memory as it were.

11. What are Accumulators? Collectors are the compose just factors which are introduced once and sent to the specialists. These specialists will refresh dependent on the rationale composed and sent back to the driver which will total or process dependent on the rationale. No one but driver can get to the collector’s esteem. For assignments, Accumulators are compose as it were. For instance, it is utilized to include the number blunders seen in RDD crosswise over laborers. 12. What are Broadcast Variables? Communicate Variables are the perused just shared factors. Assume, there is a lot of information which may must be utilized on various occasions in the laborers at various stages. 13. What are the enhancements that engineer can make while working with flash? Flash is memory serious, whatever you do it does in memory. Initially, you can alter to what extent flash will hold up before it times out on every one of the periods of information region information neigh borhood process nearby hub nearby rack neighborhood Any. Channel out information as ahead of schedule as could be allowed. For reserving, pick carefully from different capacity levels. Tune the quantity of parcels in sparkle. 14. What is Spark SQL? Flash SQL is a module for organized information handling where we exploit SQL questions running on the datasets. 15. What is a Data Frame? An information casing resembles a table, it got some named sections which composed into segments. You can make an information outline from a document or from tables in hive, outside databases SQL or NoSQL or existing RDD��s. It is practically equivalent to a table. 16. How might you associate Hive to Spark SQL? The principal significant thing is that you need to place hive-site.xml record in conf index of Spark. At that point with the assistance of Spark session object we can develop an information outline as, 17. What is GraphX? Ordinarily you need to process the information as charts, since you need to do some examination on it. It endeavors to perform Graph calculation in Spark in which information is available in documents or in RDD’s. GraphX is based on the highest point of Spark center, so it has got every one of the abilities of Apache Spark like adaptation to internal failure, scaling and there are numerous inbuilt chart calculations too. GraphX binds together ETL, exploratory investigation and iterative diagram calculation inside a solitary framework. You can see indistinguishable information from the two charts and accumulations, change and unite diagrams with RDD effectively and compose custom iterative calculations utilizing the pregel API. GraphX contends on execution with the quickest diagram frameworks while holding Spark’s adaptability, adaptation to internal failure and convenience. 18. What is PageRank Algorithm? One of the calculation in GraphX is PageRank calculation. Pagerank measures the significance of every vertex in a diagram accepting an edge from u to v speaks to a supports of v’s significance by u. For exmaple, in Twitter if a twitter client is trailed by numerous different clients, that specific will be positioned exceptionally. GraphX accompanies static and dynamic executions of pageRank as techniques on the pageRank object. 19. What is Spark Streaming? At whatever point there is information streaming constantly and you need to process the information as right on time as could reasonably be expected, all things considered you can exploit Spark Streaming. 20. What is Sliding Window? In Spark Streaming, you need to determine the clump interim. In any case, with Sliding Window, you can indicate what number of last clumps must be handled. In the beneath screen shot, you can see that you can indicate the clump interim and what number of bunches you need to process. 21. Clarify the key highlights of Apache Spark. Coming up next are the key highlights of Apache Spark: Polyglot Speed Multiple Format Support Lazy Evaluation Real Time Computation Hadoop Integration Machine Learning 22. What is YARN? Like Hadoop, YARN is one of the key highlights in Spark, giving a focal and asset the executives stage to convey adaptable activities over the bunch. YARN is a conveyed holder chief, as Mesos for instance, while Spark is an information preparing instrument. Sparkle can keep running on YARN, a similar way Hadoop Map Reduce can keep running on YARN. Running Spark on YARN requires a double dispersion of Spark as based on YARN support. 23. Do you have to introduce Spark on all hubs of YARN bunch? No, in light of the fact that Spark keeps running over YARN. Flash runs autonomously from its establishment. Sparkle has a few alternatives to utilize YARN when dispatching employments to the group, as opposed to its very own inherent supervisor, or Mesos. Further, there are a few arrangements to run YARN. They incorporate ace, convey mode, driver-memory, agent memory, agent centers, and line. 24. Name the parts of Spark Ecosystem. Spark Core: Base motor for huge scale parallel and disseminated information handling Spark Streaming: Used for handling constant spilling information Spark SQL: Integrates social handling with Spark’s useful programming API GraphX: Graphs and chart parallel calculation MLlib: Performs AI in Apache Spark 25. How is Streaming executed in Spark? Clarify with precedents. Sparkle Streaming is utilized for handling constant gushing information. Along these lines it is a helpful expansion deeply Spark API. It empowers high-throughput and shortcoming tolerant stream handling of live information streams. The crucial stream unit is DStream which is fundamentally a progression of RDDs (Resilient Distributed Datasets) to process the constant information. The information from various sources like Flume, HDFS is spilled lastly handled to document frameworks, live dashboards and databases. It is like bunch preparing as the information is partitioned into streams like clusters. 26. How is AI executed in Spark? MLlib is adaptable AI library given by Spark. It goes for making AI simple and adaptable with normal learning calculations and use cases like bunching, relapse separating, dimensional decrease, and alike. 27. What record frameworks does Spark support? The accompanying three document frameworks are upheld by Spark: Hadoop Distributed File System (HDFS). Local File framework. Amazon S3 28. What is Spark Executor? At the point when SparkContext associates with a group chief, it obtains an Executor on hubs in the bunch. Representatives are Spark forms that run controls and store the information on the laborer hub. The last assignments by SparkContext are moved to agents for their execution. 29. Name kinds of Cluster Managers in Spark. The Spark system underpins three noteworthy sorts of Cluster Managers: Standalone: An essential administrator to set up a group. Apache Mesos: Generalized/regularly utilized group administrator, additionally runs Hadoop MapReduce and different applications. YARN: Responsible for asset the board in Hadoop. 30. Show some utilization situations where Spark beats Hadoop in preparing. Sensor Data Processing: Apache Spark’s “In-memory” figuring works best here, as information is recovered and joined from various sources. Real Time Processing: Spark is favored over Hadoop for constant questioning of information. for example Securities exchange Analysis, Banking, Healthcare, Telecommunications, and so on. Stream Processing: For preparing logs and identifying cheats in live streams for cautions, Apache Spark is the best arrangement. Big Data Processing: Spark runs upto multiple times quicker than Hadoop with regards to preparing medium and enormous estimated datasets. 31. By what method can Spark be associated with Apache Mesos? To associate Spark with Mesos: Configure the sparkle driver program to associate with Mesos. Spark paired bundle ought to be in an area open by Mesos. Install Apache Spark in a similar area as that of Apache Mesos and design the property ‘spark.mesos.executor.home’ to point to the area where it is introduced. 32. How is Spark SQL not the same as HQL and SQL? Flash SQL is a unique segment on the Spark Core motor that supports SQL and Hive Query Language without changing any sentence structure. It is conceivable to join SQL table and HQL table to Spark SQL. 33. What is ancestry in Spark? How adaptation to internal failure is accomplished in Spark utilizing Lineage Graph? At whatever point a progression of changes are performed on a RDD, they are not assessed promptly, however languidly. At the point when another RDD has been made from a current RDD every one of the conditions between the RDDs will be signed in a diagram. This chart is known as the ancestry diagram. Consider the underneath situation Ancestry chart of every one of these activities resembles: First RDD Second RDD (applying map) Third RDD (applying channel) Fourth RDD (applying check) This heredity diagram will be helpful on the off chance that if any of the segments of information is lost. Need to set spark.logLineage to consistent with empower the Rdd.toDebugString() gets empowered to print the chart logs. 34. What is the contrast between RDD , DataFrame and DataSets? RDD : It is the structure square of Spark. All Dataframes or Dataset is inside RDDs. It is lethargically assessed permanent gathering objects RDDS can be effectively reserved if a similar arrangement of information should be recomputed. DataFrame : Gives the construction see ( lines and segments ). It tends to be thought as a table in a database. Like RDD even dataframe is sluggishly assessed. It offers colossal execution due to a.) Custom Memory Management – Data is put away in off load memory in twofold arrangement .No refuse accumulation because of this. Optimized Execution Plan – Query plans are made utilizing Catalyst analyzer. DataFrame Limitations : Compile Time wellbeing , i.e no control of information is conceivable when the structure isn’t known. DataSet : Expansion of DataFrame DataSet Feautures – Provides best encoding component and not at all like information edges supports arrange time security. 35. What is DStream? Discretized Stream (DStream) Apache Spark Discretized Stream is a gathering of RDDS in grouping . Essentially, it speaks to a flood of information or gathering of Rdds separated into little clusters. In addition, DStreams are based on Spark RDDs, Spark’s center information reflection. It likewise enables Streaming to flawlessly coordinate with some other Apache Spark segments. For example, Spark MLlib and Spark SQL. 36. What is the connection between Job, Task, Stage ? Errand An errand is a unit of work that is sent to the agent. Each stage has some assignment, one undertaking for every segment. The Same assignment is done over various segments of RDD. Occupation The activity is parallel calculation comprising of numerous undertakings that get produced in light of activities in Apache Spark. Stage Each activity gets isolated into littler arrangements of assignments considered stages that rely upon one another. Stages are named computational limits. All calculation is impossible in single stage. It is accomplished over numerous stages. 37. Clarify quickly about the parts of Spark Architecture? Flash Driver: The Spark driver is the procedure running the sparkle setting . This driver is in charge of changing over the application to a guided diagram of individual strides to execute on the bunch. There is one driver for each application. 38. How might you limit information moves when working with Spark? The different manners by which information moves can be limited when working with Apache Spark are: Communicate and Accumilator factors 39. When running Spark applications, is it important to introduce Spark on every one of the hubs of YARN group? Flash need not be introduced when running a vocation under YARN or Mesos in light of the fact that Spark can execute over YARN or Mesos bunches without influencing any change to the group. 40. Which one will you decide for an undertaking – Hadoop MapReduce or Apache Spark? The response to this inquiry relies upon the given undertaking situation – as it is realized that Spark utilizes memory rather than system and plate I/O. In any case, Spark utilizes enormous measure of RAM and requires devoted machine to create viable outcomes. So the choice to utilize Hadoop or Spark changes powerfully with the necessities of the venture and spending plan of the association. 41. What is the distinction among continue() and store() endure () enables the client to determine the capacity level while reserve () utilizes the default stockpiling level. 42. What are the different dimensions of constancy in Apache Spark? Apache Spark naturally endures the mediator information from different mix tasks, anyway it is regularly proposed that clients call persevere () technique on the RDD on the off chance that they intend to reuse it. Sparkle has different tirelessness levels to store the RDDs on circle or in memory or as a mix of both with various replication levels. 43. What are the disservices of utilizing Apache Spark over Hadoop MapReduce? Apache Spark’s in-memory ability now and again comes a noteworthy barrier for cost effective preparing of huge information. Likewise, Spark has its own record the board framework and consequently should be incorporated with other cloud based information stages or apache hadoop. 44. What is the upside of Spark apathetic assessment? Apache Spark utilizes sluggish assessment all together the advantages: Apply Transformations tasks on RDD or “stacking information into RDD” isn’t executed quickly until it sees an activity. Changes on RDDs and putting away information in RDD are languidly assessed. Assets will be used in a superior manner if Spark utilizes sluggish assessment. Lazy assessment advances the plate and memory utilization in Spark. The activities are activated just when the information is required. It diminishes overhead. 45. What are advantages of Spark over MapReduce? Because of the accessibility of in-memory handling, Spark executes the preparing around 10 to multiple times quicker than Hadoop MapReduce while MapReduce utilizes diligence stockpiling for any of the information handling errands. Dissimilar to Hadoop, Spark gives inbuilt libraries to play out numerous errands from a similar center like cluster preparing, Steaming, Machine learning, Interactive SQL inquiries. Be that as it may, Hadoop just backings cluster handling. Hadoop is very plate subordinate while Spark advances reserving and in-memory information stockpiling. 46. How DAG functions in Spark? At the point when an Action is approached Spark RDD at an abnormal state, Spark presents the heredity chart to the DAG Scheduler. Activities are separated into phases of the errand in the DAG Scheduler. A phase contains errand dependent on the parcel of the info information. The DAG scheduler pipelines administrators together. It dispatches task through group chief. The conditions of stages are obscure to the errand scheduler.The Workers execute the undertaking on the slave. 47. What is the hugeness of Sliding Window task? Sliding Window controls transmission of information bundles between different PC systems. Sparkle Streaming library gives windowed calculations where the changes on RDDs are connected over a sliding window of information. At whatever point the window slides, the RDDs that fall inside the specific window are consolidated and worked upon to create new RDDs of the windowed DStream. 48. What are communicated and Accumilators? Communicate variable: On the off chance that we have an enormous dataset, rather than moving a duplicate of informational collection for each assignment, we can utilize a communicate variable which can be replicated to every hub at one timeand share similar information for each errand in that hub. Communicate variable assistance to give a huge informational collection to every hub. Collector: Flash capacities utilized factors characterized in the driver program and nearby replicated of factors will be produced. Aggregator are shared factors which help to refresh factors in parallel during execution and offer the outcomes from specialists to the driver. 49. What are activities ? An activity helps in bringing back the information from RDD to the nearby machine. An activity’s execution is the aftereffect of all recently made changes. lessen() is an activity that executes the capacity passed over and over until one esteem assuming left. take() move makes every one of the qualities from RDD to nearby hub. 50. Name kinds of Cluster Managers in Spark. The Spark system bolsters three noteworthy kinds of Cluster Managers: Independent : An essential administrator to set up a bunch. Apache Mesos : Summed up/ordinarily utilized group director, additionally runs Hadoop MapReduce and different applications. PYSPARK Questions and Answers Pdf Download Read the full article
0 notes
Link
Hadoop Spark Hive Big Data Admin Class Bootcamp Course NYC ##FreeCourse ##UdemyDiscount #Admin #Big #Bootcamp #Class #Data #Hadoop #Hive #NYC #Spark Hadoop Spark Hive Big Data Admin Class Bootcamp Course NYC Introduction Hadoop Big Data Course Introduction to the Course Top Ubuntu commands Understand NameNode, DataNode, YARN and Hadoop Infrastructure Hadoop Install Hadoop Installation & HDFS Commands Java based Mapreduce # Hadoop 2.7 / 2.8.4 Learn HDFS commands Setting up Java for mapreduce Intro to Cloudera Hadoop & studying Cloudera Certification SQL and NoSQL SQL, Hive and Pig Installation (RDBMS world and NoSQL world) More Hive and SQOOP (Cloudera – Sqoop and Hive on Cloudera. JDBC drivers. Pig Intro to NoSQL, MongoDB, Hbase Installation Understanding different databases Hive : Hive Partitions and Bucketing Hive External and Internal Tables Spark Scala Python Spark Installations and Commands Spark Scala Scala Sheets Hadoop Streaming Python Map Reduce PySpark – (Python – Basics). RDDs. Running Spark-shell and importing data from csv files PySpark – Running RDD Mid Term Projects Pull data from csv online and move to Hive using hive import Pull data from spark-shell and run map reduce for fox news first page Create Data in MySQL and using SQOOP move it to HDFS Using Jupyter Anaconda and Spark Context run count on file that has Fox news first page Save raw data using delimiter comma, space, tab and pipe and move that into spark-context and spark shell Broadcasting Data – stream of data Kafka Message Broadcasting Who this course is for: Carrier changes who would like to move to Big Data Hadoop Learners who want to learn Hadoop installations 👉 Activate Udemy Coupon 👈 Free Tutorials Udemy Review Real Discount Udemy Free Courses Udemy Coupon Udemy Francais Coupon Udemy gratuit Coursera and Edx ELearningFree Course Free Online Training Udemy Udemy Free Coupons Udemy Free Discount Coupons Udemy Online Course Udemy Online Training 100% FREE Udemy Discount Coupons https://www.couponudemy.com/blog/hadoop-spark-hive-big-data-admin-class-bootcamp-course-nyc/
0 notes
Text
PySpark: Java UDF Integration
#ICYDK: PySpark is the Spark API implementation using the Non-JVM language Python. Though developers utilize PySpark by implementing Python Code using Spark API’s (Python version of Spark API’s), internally, Spark uses data to be cached in JVM. The Python Driver Program has SparkContext, which uses Py4J, a specialized library for Python Java interoperability to launch JVM and create a JavaSparkContext. https://goo.gl/LdxSxk #DataIntegration #ML
0 notes
Link
0 notes
Text
PySpark: Java UDF Integration
#ICYMI: PySpark is the Spark API implementation using the Non-JVM language Python. Though developers utilize PySpark by implementing Python Code using Spark API’s (Python version of Spark API’s), internally, Spark uses data to be cached in JVM. The Python Driver Program has SparkContext, which uses Py4J, a specialized library for Python Java interoperability to launch JVM and create a JavaSparkContext. https://goo.gl/NdUXoo #DataIntegration #ML
0 notes
Text
PySpark: Java UDF Integration
PySpark is the Spark API implementation using the Non-JVM language Python. Though developers utilize PySpark by implementing Python Code using Spark API’s (Python version of Spark API’s), internally, Spark uses data to be cached in JVM. The Python Driver Program has SparkContext, which uses Py4J, a specialized library for Python Java interoperability to launch JVM and create a JavaSparkContext. https://goo.gl/Pa1iUz #DataIntegration #ML
0 notes