#pyspark python
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
In Q3 of 2020, 31% of US users access the Tumblr app daily.
Text
i just submitted three job applications with a resume that had a stupid typo in it so i think we're done for today ha ha haaa
#i mixed up two python libraries. i meant to say pyspark but i listed pytorch instead#why do all these stupid libraries have to start with py!!! i am using it IN PYTHON the py is not necessary#i know how to use both but i talked about it in the wrong context y'know#m.txt
4 notes
·
View notes
Text
Python built-in function round() not working in Databricks notebook
This is common issue that developers face while working on pyspark. This issue will happen if you import all functions pyspark. This issue will happen with several other built-in functions in python. There are several functions that shares the same name between the functions in python builtins and pyspark functions. Always be careful while doing the following import from pyspark.sql.functions…
#databricks functions conflict with python built-in functions#not a string or column:#python builtin function not working in databricks notebook#python function not working with pyspark#round() function not working for databricks Python#TypeError: Invalid argument
0 notes
Text
Python / PiSpark: Pivot on multiple rows
first… Let's create some data that needs pivoting. What is special about this data is that it has two columns (Product and Categories) in its granularity and that we want to pivot two values out (Amount and Quantity). # Make a dictionary list containing inventory data: data = [{"Product": 'Carrots', "Category": "Vegetable", "Quantity": 8, "Amount": 270}, {"Product": 'Broccoli', "Category":…
0 notes
Text
Python Training institute in Hyderabad
Best Python Training in Hyderabad by RS Trainings
Python is one of the most popular and versatile programming languages in the world, renowned for its simplicity, readability, and broad applicability across various domains like web development, data science, artificial intelligence, and more. If you're looking to learn Python or enhance your Python skills, RS Trainings offers the best Python training in Hyderabad, guided by industry IT experts. Recognized as the best place for better learning, RS Trainings is committed to delivering top-notch education that equips you with practical skills and knowledge.

Why Choose RS Trainings for Python?
1. Expert Instructors: Our Python training program is led by seasoned industry professionals who bring a wealth of experience and insights. They are adept at simplifying complex concepts and providing real-world examples to ensure you gain a deep understanding of Python.
2. Comprehensive Curriculum: The curriculum is meticulously designed to cover everything from the basics of Python to advanced topics. You'll learn about variables, data types, control structures, functions, modules, file handling, object-oriented programming, web development frameworks like Django and Flask, and data analysis libraries like Pandas and NumPy.
3. Hands-on Learning: We emphasize a practical approach to learning. Our training includes numerous hands-on exercises, coding assignments, and real-time projects that help you apply the concepts you learn in class, ensuring you gain practical experience.
4. Flexible Learning Options: RS Trainings offers both classroom and online training options to accommodate different learning preferences and schedules. Whether you are a working professional or a student, you can find a batch that fits your timetable.
5. Career Support: Beyond just training, we provide comprehensive career support, including resume building, interview preparation, and job placement assistance. Our aim is to help you smoothly transition into a successful career in Python programming.
Course Highlights:
Introduction to Python: Get an overview of Python and its applications, understanding why it is a preferred language for various domains.
Core Python Concepts: Dive into the core concepts, including variables, data types, control structures, loops, and functions.
Object-Oriented Programming: Learn about object-oriented programming in Python, covering classes, objects, inheritance, and polymorphism.
Web Development: Explore web development using popular frameworks like Django and Flask, and build your own web applications.
Data Analysis: Gain proficiency in data analysis using libraries like Pandas, NumPy, and Matplotlib.
Real-world Projects: Work on real-world projects that simulate industry scenarios, enhancing your practical skills and understanding.
Who Should Enroll?
Aspiring Programmers: Individuals looking to start a career in programming.
Software Developers: Developers wanting to add Python to their skill set.
Data Scientists and Analysts: Professionals aiming to leverage Python for data analysis and machine learning.
Web Developers: Web developers interested in using Python for backend development.
Students and Enthusiasts: Anyone with a passion for learning programming and Python.
Enroll Today!
Join RS Trainings, the best Python training institute in Hyderabad, and embark on a journey to master one of the most powerful programming languages. Our expert-led training, practical approach, and comprehensive support ensure you are well-prepared to excel in your career.
Visit our website or contact us to learn more about our Python training program, upcoming batches, and enrollment details. Elevate your programming skills with RS Trainings – the best place for better learning in Hyderabad!
#python training#python online training#python training in Hyderabad#python training institute in Hyderabad#python course online Hyderabad#pyspark course online
0 notes
Link
#BigData#DataLake#DeltaLake#DWH#ETL#PySpark#Python#Security#Spark#SQL#архитектура#безопасность#Большиеданные#обработкаданных
0 notes
Text
[Python] PySpark to M, SQL or Pandas
Hace tiempo escribí un artículo sobre como escribir en pandas algunos códigos de referencia de SQL o M (power query). Si bien en su momento fue de gran utilidad, lo cierto es que hoy existe otro lenguaje que representa un fuerte pie en el análisis de datos.
Spark se convirtió en el jugar principal para lectura de datos en Lakes. Aunque sea cierto que existe SparkSQL, no quise dejar de traer estas analogías de código entre PySpark, M, SQL y Pandas para quienes estén familiarizados con un lenguaje, puedan ver como realizar una acción con el otro.
Lo primero es ponernos de acuerdo en la lectura del post.
Power Query corre en capas. Cada linea llama a la anterior (que devuelve una tabla) generando esta perspectiva o visión en capas. Por ello cuando leamos en el código #“Paso anterior” hablamos de una tabla.
En Python, asumiremos a "df" como un pandas dataframe (pandas.DataFrame) ya cargado y a "spark_frame" a un frame de pyspark cargado (spark.read)
Conozcamos los ejemplos que serán listados en el siguiente orden: SQL, PySpark, Pandas, Power Query.
En SQL:
SELECT TOP 5 * FROM table
En PySpark
spark_frame.limit(5)
En Pandas:
df.head()
En Power Query:
Table.FirstN(#"Paso Anterior",5)
Contar filas
SELECT COUNT(*) FROM table1
spark_frame.count()
df.shape()
Table.RowCount(#"Paso Anterior")
Seleccionar filas
SELECT column1, column2 FROM table1
spark_frame.select("column1", "column2")
df[["column1", "column2"]]
#"Paso Anterior"[[Columna1],[Columna2]] O podría ser: Table.SelectColumns(#"Paso Anterior", {"Columna1", "Columna2"} )
Filtrar filas
SELECT column1, column2 FROM table1 WHERE column1 = 2
spark_frame.filter("column1 = 2") # OR spark_frame.filter(spark_frame['column1'] == 2)
df[['column1', 'column2']].loc[df['column1'] == 2]
Table.SelectRows(#"Paso Anterior", each [column1] == 2 )
Varios filtros de filas
SELECT * FROM table1 WHERE column1 > 1 AND column2 < 25
spark_frame.filter((spark_frame['column1'] > 1) & (spark_frame['column2'] < 25)) O con operadores OR y NOT spark_frame.filter((spark_frame['column1'] > 1) | ~(spark_frame['column2'] < 25))
df.loc[(df['column1'] > 1) & (df['column2'] < 25)] O con operadores OR y NOT df.loc[(df['column1'] > 1) | ~(df['column2'] < 25)]
Table.SelectRows(#"Paso Anterior", each [column1] > 1 and column2 < 25 ) O con operadores OR y NOT Table.SelectRows(#"Paso Anterior", each [column1] > 1 or not ([column1] < 25 ) )
Filtros con operadores complejos
SELECT * FROM table1 WHERE column1 BETWEEN 1 and 5 AND column2 IN (20,30,40,50) AND column3 LIKE '%arcelona%'
from pyspark.sql.functions import col spark_frame.filter( (col('column1').between(1, 5)) & (col('column2').isin(20, 30, 40, 50)) & (col('column3').like('%arcelona%')) ) # O spark_frame.where( (col('column1').between(1, 5)) & (col('column2').isin(20, 30, 40, 50)) & (col('column3').contains('arcelona')) )
df.loc[(df['colum1'].between(1,5)) & (df['column2'].isin([20,30,40,50])) & (df['column3'].str.contains('arcelona'))]
Table.SelectRows(#"Paso Anterior", each ([column1] > 1 and [column1] < 5) and List.Contains({20,30,40,50}, [column2]) and Text.Contains([column3], "arcelona") )
Join tables
SELECT t1.column1, t2.column1 FROM table1 t1 LEFT JOIN table2 t2 ON t1.column_id = t2.column_id
Sería correcto cambiar el alias de columnas de mismo nombre así:
spark_frame1.join(spark_frame2, spark_frame1["column_id"] == spark_frame2["column_id"], "left").select(spark_frame1["column1"].alias("column1_df1"), spark_frame2["column1"].alias("column1_df2"))
Hay dos funciones que pueden ayudarnos en este proceso merge y join.
df_joined = df1.merge(df2, left_on='lkey', right_on='rkey', how='left') df_joined = df1.join(df2, on='column_id', how='left')Luego seleccionamos dos columnas df_joined.loc[['column1_df1', 'column1_df2']]
En Power Query vamos a ir eligiendo una columna de antemano y luego añadiendo la segunda.
#"Origen" = #"Paso Anterior"[[column1_t1]] #"Paso Join" = Table.NestedJoin(#"Origen", {"column_t1_id"}, table2, {"column_t2_id"}, "Prefijo", JoinKind.LeftOuter) #"Expansion" = Table.ExpandTableColumn(#"Paso Join", "Prefijo", {"column1_t2"}, {"Prefijo_column1_t2"})
Group By
SELECT column1, count(*) FROM table1 GROUP BY column1
from pyspark.sql.functions import count spark_frame.groupBy("column1").agg(count("*").alias("count"))
df.groupby('column1')['column1'].count()
Table.Group(#"Paso Anterior", {"column1"}, {{"Alias de count", each Table.RowCount(_), type number}})
Filtrando un agrupado
SELECT store, sum(sales) FROM table1 GROUP BY store HAVING sum(sales) > 1000
from pyspark.sql.functions import sum as spark_sum spark_frame.groupBy("store").agg(spark_sum("sales").alias("total_sales")).filter("total_sales > 1000")
df_grouped = df.groupby('store')['sales'].sum() df_grouped.loc[df_grouped > 1000]
#”Grouping” = Table.Group(#"Paso Anterior", {"store"}, {{"Alias de sum", each List.Sum([sales]), type number}}) #"Final" = Table.SelectRows( #"Grouping" , each [Alias de sum] > 1000 )
Ordenar descendente por columna
SELECT * FROM table1 ORDER BY column1 DESC
spark_frame.orderBy("column1", ascending=False)
df.sort_values(by=['column1'], ascending=False)
Table.Sort(#"Paso Anterior",{{"column1", Order.Descending}})
Unir una tabla con otra de la misma característica
SELECT * FROM table1 UNION SELECT * FROM table2
spark_frame1.union(spark_frame2)
En Pandas tenemos dos opciones conocidas, la función append y concat.
df.append(df2) pd.concat([df1, df2])
Table.Combine({table1, table2})
Transformaciones
Las siguientes transformaciones son directamente entre PySpark, Pandas y Power Query puesto que no son tan comunes en un lenguaje de consulta como SQL. Puede que su resultado no sea idéntico pero si similar para el caso a resolver.
Analizar el contenido de una tabla
spark_frame.summary()
df.describe()
Table.Profile(#"Paso Anterior")
Chequear valores únicos de las columnas
spark_frame.groupBy("column1").count().show()
df.value_counts("columna1")
Table.Profile(#"Paso Anterior")[[Column],[DistinctCount]]
Generar Tabla de prueba con datos cargados a mano
spark_frame = spark.createDataFrame([(1, "Boris Yeltsin"), (2, "Mikhail Gorbachev")], inferSchema=True)
df = pd.DataFrame([[1,2],["Boris Yeltsin", "Mikhail Gorbachev"]], columns=["CustomerID", "Name"])
Table.FromRecords({[CustomerID = 1, Name = "Bob", Phone = "123-4567"]})
Quitar una columna
spark_frame.drop("column1")
df.drop(columns=['column1']) df.drop(['column1'], axis=1)
Table.RemoveColumns(#"Paso Anterior",{"column1"})
Aplicar transformaciones sobre una columna
spark_frame.withColumn("column1", col("column1") + 1)
df.apply(lambda x : x['column1'] + 1 , axis = 1)
Table.TransformColumns(#"Paso Anterior", {{"column1", each _ + 1, type number}})
Hemos terminado el largo camino de consultas y transformaciones que nos ayudarían a tener un mejor tiempo a puro código con PySpark, SQL, Pandas y Power Query para que conociendo uno sepamos usar el otro.
#spark#pyspark#python#pandas#sql#power query#powerquery#notebooks#ladataweb#data engineering#data wrangling#data cleansing
0 notes
Video
youtube
Part 2 Interview - Why Spark is often preferred over MapReduce
0 notes
Text
Greetings from Ashra Technologies we are hiring
#ashra#ashratechnologies#jobs#hiring#jobalert#jobsearch#jobhunt#recruiting#recruitingpost#experience#azure#azuredatabricks#azuresynapse#azuredatafactory#azurefunctions#logicapps#scala#apachespark#python#pyspark#sql#azuredevops#pune#chennai#hybrid#hybridwork#linkedin#linkedinprofessionals#linkedinlearning#linkedinads
0 notes
Text
Mastering PySpark: A Comprehensive Certification Course and Effective Training Methods
Are you eager to delve into the world of big data analytics and data processing? Look no further than PySpark, a powerful tool for efficiently handling large-scale data. In this article, we will explore the PySpark certification course and its training methods, providing you with the essential knowledge to master this transformative technology.
Understanding PySpark: Unveiling the Power of Big Data
PySpark is a Python library for Apache Spark, an open-source, distributed computing system designed for big data processing and analysis. It enables seamless integration with Python, allowing developers to leverage the vast capabilities of Spark using familiar Python programming paradigms. PySpark empowers data scientists and analysts to process vast amounts of data efficiently, making it an invaluable tool in today's data-driven landscape.
The PySpark Certification Course: A Pathway to Expertise
Enrolling in a PySpark certification course can be a game-changer for anyone looking to enhance their skills in big data analytics. These courses are meticulously designed to provide a comprehensive understanding of PySpark, covering its core concepts, advanced features, and practical applications. The curriculum typically includes:
Introduction to PySpark: Understanding the basics of PySpark, its architecture, and key components.
Data Processing with PySpark: Learning how to process and manipulate data using PySpark's powerful capabilities.
Machine Learning with PySpark: Exploring how PySpark facilitates machine learning tasks, allowing for predictive modeling and analysis.
Real-world Applications and Case Studies: Gaining hands-on experience through real-world projects and case studies.
Training Methods: Tailored for Success
The training methods employed in PySpark certification courses are designed to maximize learning and ensure participants grasp the concepts effectively. These methods include:
Interactive Lectures: Engaging lectures delivered by experienced instructors to explain complex concepts in an easily digestible manner.
Hands-on Labs and Projects: Practical exercises and projects to apply the learned knowledge in real-world scenarios, reinforcing understanding.
Collaborative Learning: Group discussions, teamwork, and peer interaction to foster a collaborative learning environment.
Regular Assessments: Periodic quizzes and assessments to evaluate progress and identify areas for improvement.
FAQs about PySpark Certification Course
1. What is PySpark?
PySpark is a Python library for Apache Spark, providing a seamless interface to integrate Python with the Spark framework for efficient big data processing.
2. Why should I opt for a PySpark certification course?
A PySpark certification course equips you with the skills needed to analyze large-scale data efficiently, making you highly valuable in the data analytics job market.
3. Are there any prerequisites for enrolling in a PySpark certification course?
While prior knowledge of Python can be beneficial, most PySpark certification courses start from the basics, making them accessible to beginners as well.
4. How long does a typical PySpark certification course last?
The duration of a PySpark certification course can vary, but it typically ranges from a few weeks to a few months, depending on the depth of the curriculum.
5. Can I access course materials and resources after completing the course?
Yes, many institutions provide access to course materials, resources, and alumni networks even after completing the course to support continued learning and networking.
6. Will I receive a certificate upon course completion?
Yes, upon successful completion of the PySpark certification course, you will be awarded a certificate, validating your proficiency in PySpark.
7. Is PySpark suitable for individuals without a background in data science?
Absolutely! PySpark courses are designed to accommodate individuals from diverse backgrounds, providing a structured learning path for beginners.
8. What career opportunities can a PySpark certification unlock?
A PySpark certification can open doors to various career opportunities, including data analyst, data engineer, machine learning engineer, and more, in industries dealing with big data.
In conclusion, mastering PySpark through a well-structured certification course can significantly enhance your career prospects in the ever-evolving field of big data analytics. Invest in your education, embrace the power of PySpark, and unlock a world of possibilities in the realm of data processing and analysis.

1 note
·
View note
Text

Kaara We are Hiring for the position of "Lead Data Engineer"
Exp:- 7+ Years Location:- Hyderabad (WFO) Notice:- 15 days
Required Skills:-
AWS Glue
AWS Lambda
Python & Pyspark
Snowflake
Interested Candidates Share your portfolio / CV to [email protected]
Reach us: www.kaaratech.com
#kaaratech#aws#python#pyspark#snowflake#technicaljobs#wearehiring#jobs#jobvacancy#hyderabadjobs#jobseekers#microsoft
0 notes
Text
English SDK for Apache Spark
Are you tired of dealing with complex code and confusing commands when working with Apache Spark? Well, get ready to say goodbye to all that hassle! The English SDK for Spark is here to save the day.

View On WordPress
#AI#Apache Spark#ChatGPT#code#Coding#compiler#Creative content#Data Frames#databricks apache spark#english#English SDK#generative AI#GPT-4#Large Language Model#LLM#OpenAI#pyspark#Python#SDK#Source code#Spark#Spark Session
0 notes
Text

Wielding Big Data Using PySpark
Introduction to PySpark
PySpark is the Python API for Apache Spark, a distributed computing framework designed to process large-scale data efficiently. It enables parallel data processing across multiple nodes, making it a powerful tool for handling massive datasets.
Why Use PySpark for Big Data?
Scalability: Works across clusters to process petabytes of data.
Speed: Uses in-memory computation to enhance performance.
Flexibility: Supports various data formats and integrates with other big data tools.
Ease of Use: Provides SQL-like querying and DataFrame operations for intuitive data handling.
Setting Up PySpark
To use PySpark, you need to install it and set up a Spark session. Once initialized, Spark allows users to read, process, and analyze large datasets.
Processing Data with PySpark
PySpark can handle different types of data sources such as CSV, JSON, Parquet, and databases. Once data is loaded, users can explore it by checking the schema, summary statistics, and unique values.
Common Data Processing Tasks
Viewing and summarizing datasets.
Handling missing values by dropping or replacing them.
Removing duplicate records.
Filtering, grouping, and sorting data for meaningful insights.
Transforming Data with PySpark
Data can be transformed using SQL-like queries or DataFrame operations. Users can:
Select specific columns for analysis.
Apply conditions to filter out unwanted records.
Group data to find patterns and trends.
Add new calculated columns based on existing data.
Optimizing Performance in PySpark
When working with big data, optimizing performance is crucial. Some strategies include:
Partitioning: Distributing data across multiple partitions for parallel processing.
Caching: Storing intermediate results in memory to speed up repeated computations.
Broadcast Joins: Optimizing joins by broadcasting smaller datasets to all nodes.
Machine Learning with PySpark
PySpark includes MLlib, a machine learning library for big data. It allows users to prepare data, apply machine learning models, and generate predictions. This is useful for tasks such as regression, classification, clustering, and recommendation systems.
Running PySpark on a Cluster
PySpark can run on a single machine or be deployed on a cluster using a distributed computing system like Hadoop YARN. This enables large-scale data processing with improved efficiency.
Conclusion
PySpark provides a powerful platform for handling big data efficiently. With its distributed computing capabilities, it allows users to clean, transform, and analyze large datasets while optimizing performance for scalability.
For Free Tutorials for Programming Languages Visit-https://www.tpointtech.com/
2 notes
·
View notes
Text
Can I use Python for big data analysis?
Yes, Python is a powerful tool for big data analysis. Here’s how Python handles large-scale data analysis:

Libraries for Big Data:
Pandas:
While primarily designed for smaller datasets, Pandas can handle larger datasets efficiently when used with tools like Dask or by optimizing memory usage..
NumPy:
Provides support for large, multi-dimensional arrays and matrices, along with a collection of mathematical functions to operate on these arrays.
Dask:
A parallel computing library that extends Pandas and NumPy to larger datasets. It allows you to scale Python code from a single machine to a distributed cluster
Distributed Computing:
PySpark:
The Python API for Apache Spark, which is designed for large-scale data processing. PySpark can handle big data by distributing tasks across a cluster of machines, making it suitable for large datasets and complex computations.
Dask:
Also provides distributed computing capabilities, allowing you to perform parallel computations on large datasets across multiple cores or nodes.
Data Storage and Access:
HDF5:
A file format and set of tools for managing complex data. Python’s h5py library provides an interface to read and write HDF5 files, which are suitable for large datasets.
Databases:
Python can interface with various big data databases like Apache Cassandra, MongoDB, and SQL-based systems. Libraries such as SQLAlchemy facilitate connections to relational databases.
Data Visualization:
Matplotlib, Seaborn, and Plotly: These libraries allow you to create visualizations of large datasets, though for extremely large datasets, tools designed for distributed environments might be more appropriate.
Machine Learning:
Scikit-learn:
While not specifically designed for big data, Scikit-learn can be used with tools like Dask to handle larger datasets.
TensorFlow and PyTorch:
These frameworks support large-scale machine learning and can be integrated with big data processing tools for training and deploying models on large datasets.
Python’s ecosystem includes a variety of tools and libraries that make it well-suited for big data analysis, providing flexibility and scalability to handle large volumes of data.
Drop the message to learn more….!
2 notes
·
View notes
Link
0 notes
Text
[Fabric] Dataflows Gen2 destino “archivos” - Opción 2
Continuamos con la problematica de una estructura lakehouse del estilo “medallón” (bronze, silver, gold) con Fabric, en la cual, la herramienta de integración de datos de mayor conectividad, Dataflow gen2, no permite la inserción en este apartado de nuestro sistema de archivos, sino que su destino es un spark catalog. ¿Cómo podemos utilizar la herramienta para armar un flujo limpio que tenga nuestros datos crudos en bronze?
Veamos una opción más pythonesca donde podamos realizar la integración de datos mediante dos contenidos de Fabric
Como repaso de la problemática, veamos un poco la comparativa de las características de las herramientas de integración de Data Factory dentro de Fabric (Feb 2024)
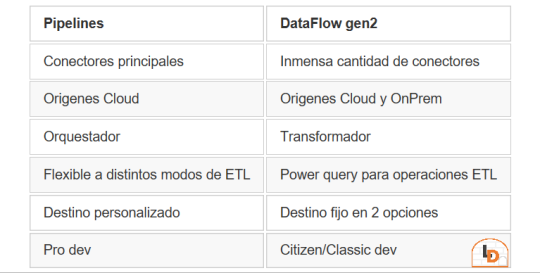
Si nuestro origen solo puede ser leído con Dataflows Gen2 y queremos iniciar nuestro proceso de datos en Raw o Bronze de Archivos de un Lakehouse, no podríamos dado el impedimento de delimitar el destino en la herramienta.
Para solucionarlo planteamos un punto medio de stage y un shortcut en un post anterior. Pueden leerlo para tener más cercanía y contexto con esa alternativa.
Ahora vamos a verlo de otro modo. El planteo bajo el cual llegamos a esta solución fue conociendo en más profundidad la herramienta. Conociendo que Dataflows Gen2 tiene la característica de generar por si mismo un StagingLakehouse, ¿por qué no usarlo?. Si no sabes de que hablo, podes leer todo sobre staging de lakehouse en este post.
Ejemplo práctico. Cree dos dataflows que lean datos con "Enable Staging" activado pero sin destino. Un dataflow tiene dos tablas (InternetSales y Producto) y otro tiene una tabla (Product). De esa forma pensaba aprovechar este stage automático sin necesidad de crear uno. Sin embargo, al conectarme me encontre con lo siguiente:
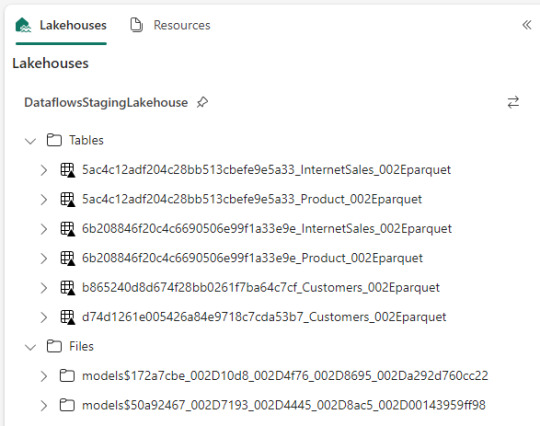
Dataflow gen2 por defecto genera snapshots de cada actualización. Los dataflows corrieron dos veces entonces hay 6 tablas. Por si fuera aún más dificil, ocurre que las tablas no tienen metadata. Sus columnas están expresadas como "column1, column2, column3,...". Si prestamos atención en "Files" tenemos dos models. Cada uno de ellos son jsons con toda la información de cada dataflow.
Muy buena información pero de shortcut difícilmente podríamos solucionarlo. Sin perder la curiosidad hablo con un Data Engineer para preguntarle más en detalle sobre la información que podemos encontrar de Tablas Delta, puesto que Fabric almacena Delta por defecto en "Tables". Ahi me compartió que podemos ver la última fecha de modificación con lo que podríamos conocer cual de esos snapshots es el más reciente para moverlo a Bronze o Raw con un Notebook. El desafío estaba. Leer la tabla delta más reciente, leer su metadata en los json de files y armar un spark dataframe para llevarlo a Bronze de nuestro lakehouse. Algo así:
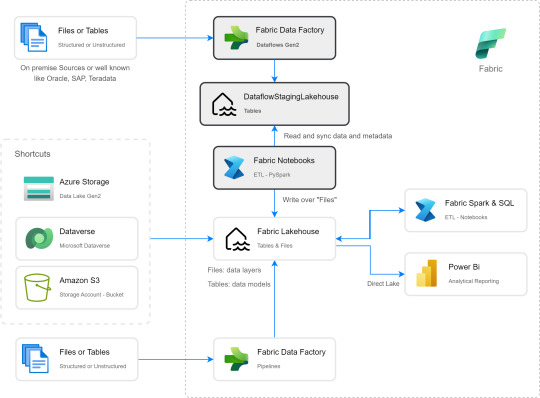
Si apreciamos las cajas con fondo gris, podremos ver el proceso. Primero tomar los datos con Dataflow Gen2 sin configurar destino asegurando tener "Enable Staging" activado. De esa forma llevamos los datos al punto intermedio. Luego construir un Notebook para leerlo, en mi caso el código está preparado para construir un Bronze de todas las tablas de un dataflow, es decir que sería un Notebook por cada Dataflow.
¿Qué encontraremos en el notebook?
Para no ir celda tras celda pegando imágenes, puede abrirlo de mi GitHub y seguir los pasos con el siguiente texto.
Trás importar las librerías haremos los siguientes pasos para conseguir nuestro objetivo.
1- Delimitar parámetros de Onelake origen y Onelake destino. Definir Dataflow a procesar.
Podemos tomar la dirección de los lake viendo las propiedades de carpetas cuando lo exploramos:

La dirección del dataflow esta delimitado en los archivos jsons dentro de la sección Files del StagingLakehouse. El parámetro sería más o menos así:
Files/models$50a92467_002D7193_002D4445_002D8ac5_002D00143959ff98/*.json
2- Armar una lista con nombre de los snapshots de tablas en Tables
3- Construimos una nueva lista con cada Tabla y su última fecha de modificación para conocer cual de los snapshots es el más reciente.
4- Creamos un pandas dataframe que tenga nombre de la tabla delta, el nombre semántico apropiado y la fecha de modificación
5- Buscamos la metadata (nombre de columnas) de cada Tabla puesto que, tal como mencioné antes, en sus logs delta no se encuentran.
6- Recorremos los nombre apropiados de tabla buscando su más reciente fecha para extraer el apropiado nombre del StagingLakehouse con su apropiada metadata y lo escribimos en destino.
Para más detalle cada línea de código esta documentada.
De esta forma llegaríamos a construir la arquitectura planteada arriba. Logramos así construir una integración de datos que nos permita conectarnos a orígenes SAP, Oracle, Teradata u otro onpremise que son clásicos y hoy Pipelines no puede, para continuar el flujo de llevarlos a Bronze/Raw de nuestra arquitectura medallón en un solo tramo. Dejamos así una arquitectura y paso del dato más limpio.
Por supuesto, esta solución tiene mucho potencial de mejora como por ejemplo no tener un notebook por dataflow, sino integrar de algún modo aún más la solución.
#dataflow#data integration#fabric#microsoft fabric#fabric tutorial#fabric tips#fabric training#data engineering#notebooks#python#pyspark#pandas
0 notes